
Explaining Neural Networks Using Attentive Knowledge Distillation



Abstract
1. Introduction
- We propose a knowledge distillation method that transforms the black-box target model into the corresponding surrogate network. The proposed knowledge distillation provides enriched information at various levels to be integrated into a saliency map for the model prediction.
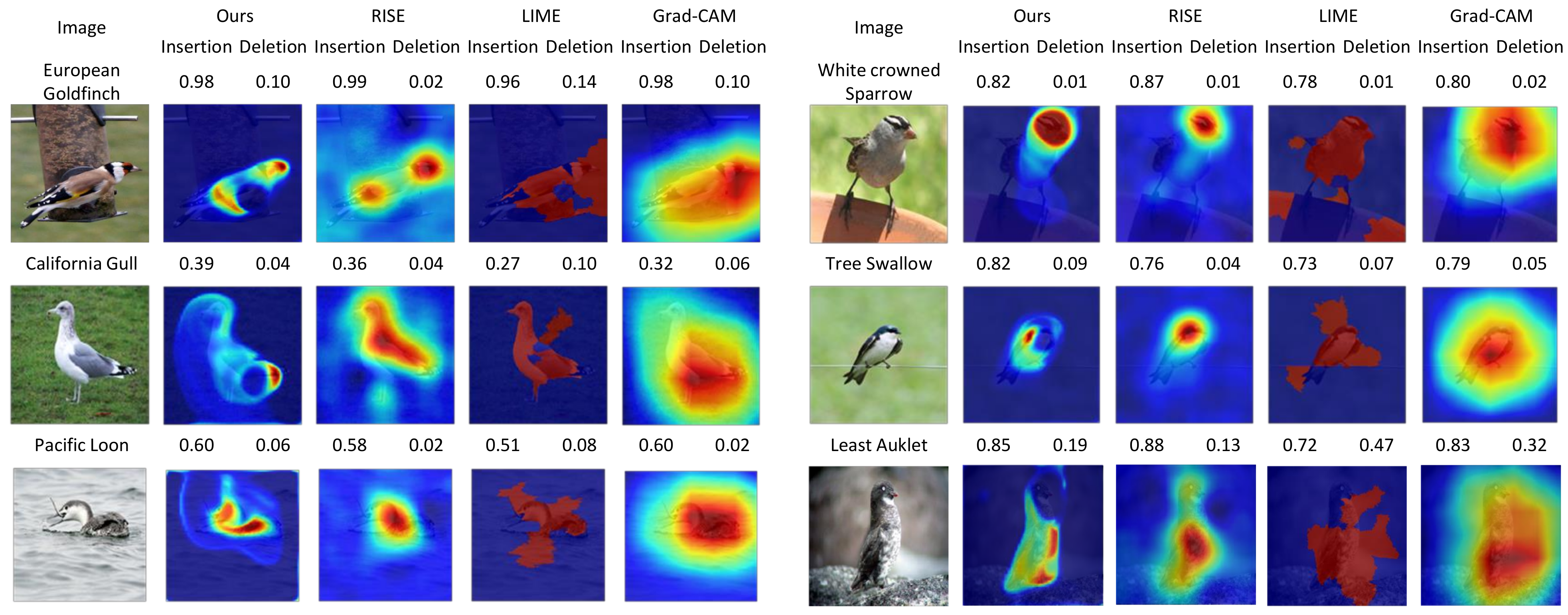
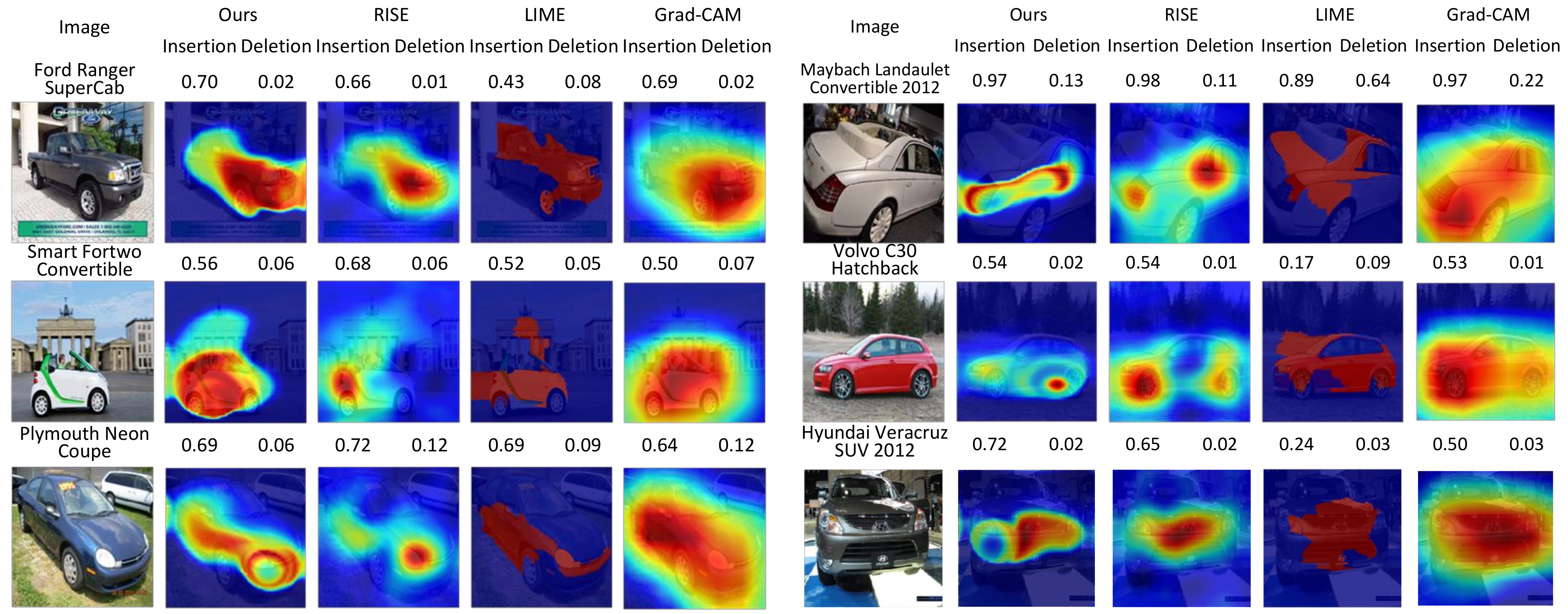
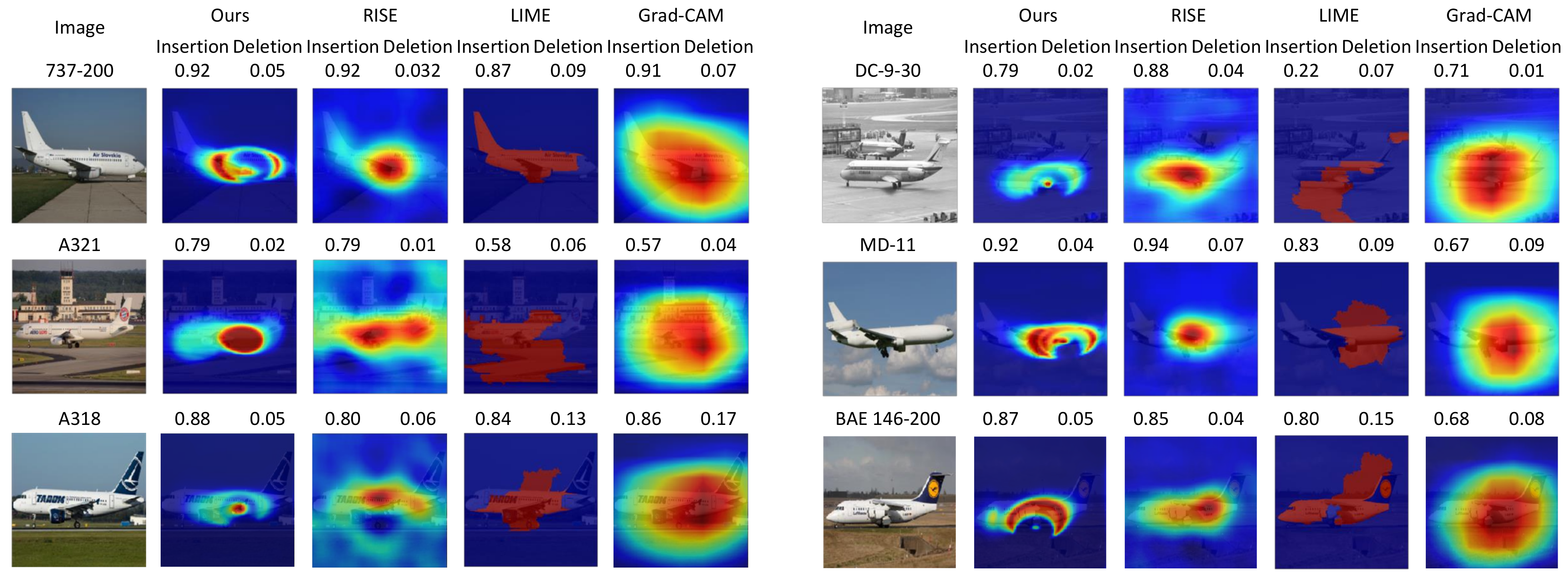
- As a result, the proposed method creates a fine-grained saliency map compared to those of the existing methods. Experiments demonstrate that fusing the multi-level information is beneficial, especially in a fined-grained classification task.
- The proposed method requires no individual learning for the input once the corresponding surrogate networks are trained using the knowledge distillation. Generating a saliency map is done at the inference speed of the surrogate networks, which is significantly faster than the learning-based methods while providing comparable explanations both quantitatively and qualitatively.
2. Related Work
2.1. Learning-by-Perturbation Methods
2.2. Activation Map-Based Methods
2.3. Gradient-Based Methods
3. Proposed Method
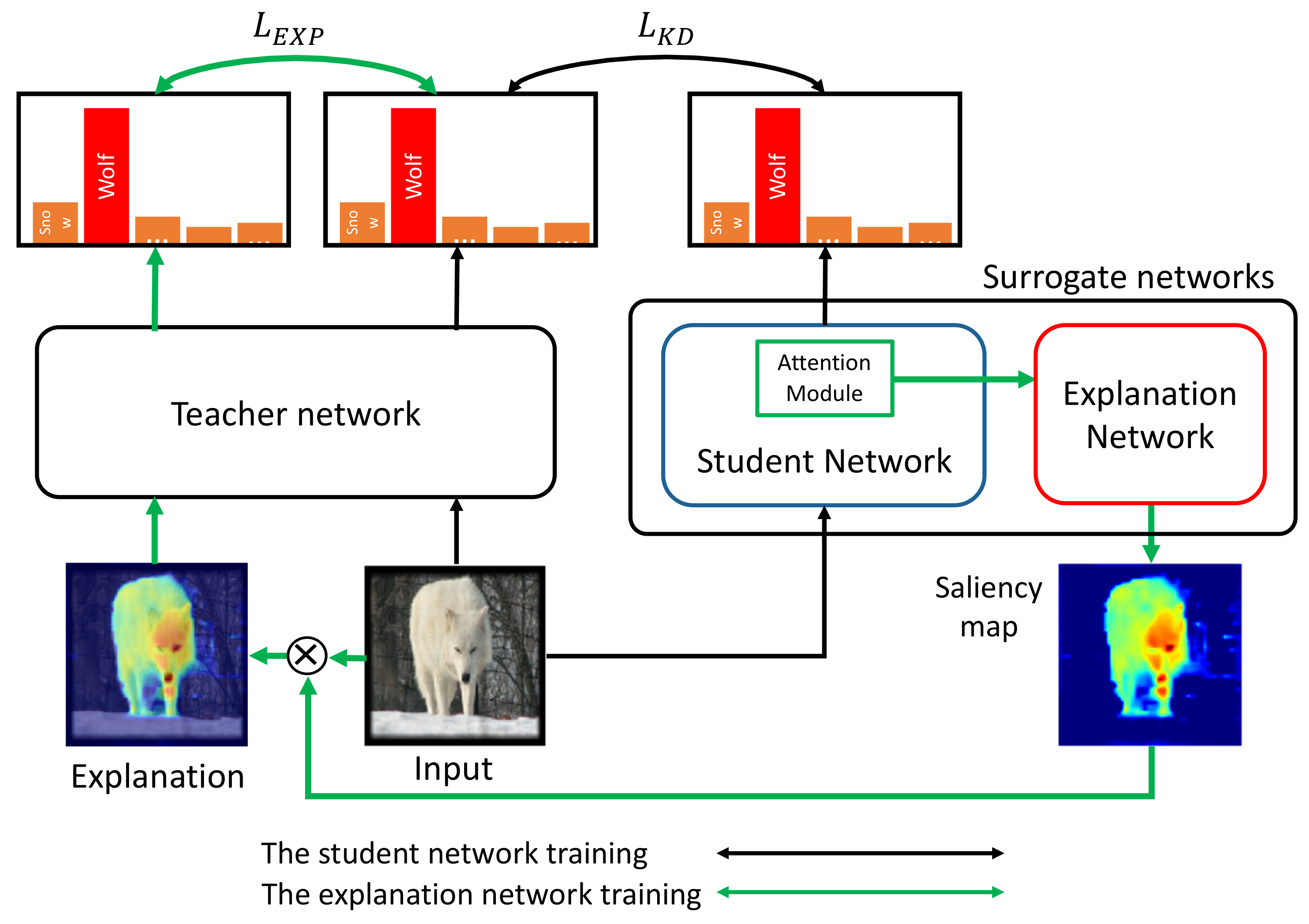
3.1. Problem Formulation and Overview
3.2. An Attentive Surrogate Network Learning Using Knowledge Distillation
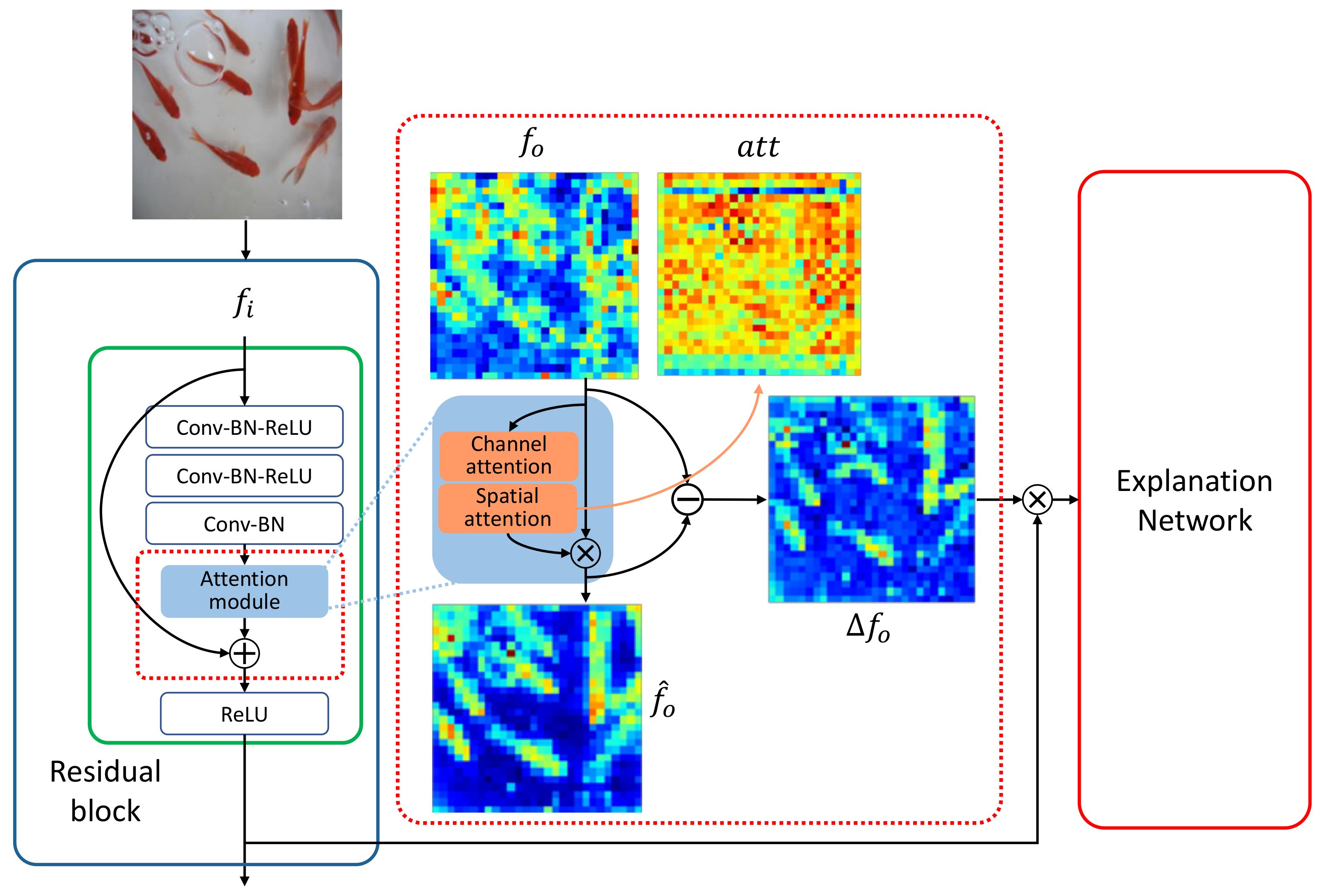
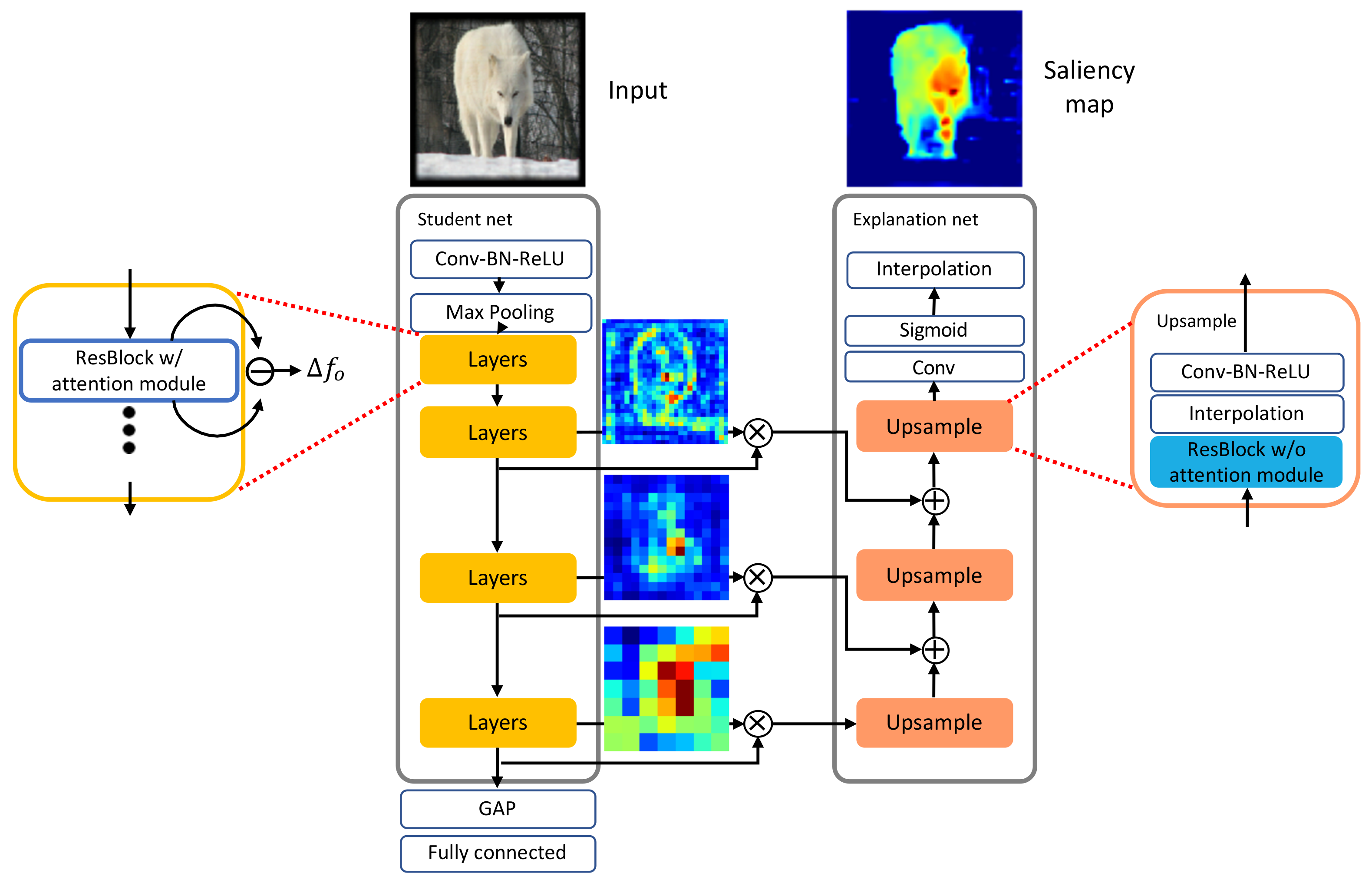
3.3. Attention-Based Student Network
3.4. Explanation Network
4. Experiments
- How do saliency maps generated by the proposed method retrieve the class score that is predicted by the target network for a given input?
- How is the proposed method advantageous over existing explanation methods? In other words, how fast does the proposed method process images? Additionally, are there any downstream tasks that the proposed method performs favorably as compared to the previous methods?
4.1. Experimental Setups
4.2. Quantitative Evaluations
4.2.1. Evaluation Methods
4.2.2. Evaluation Results
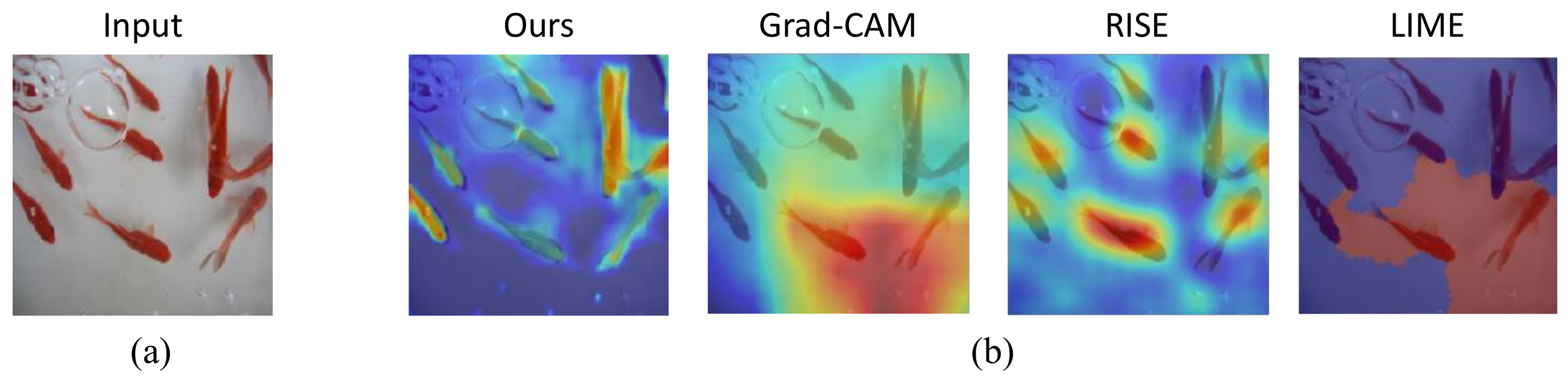
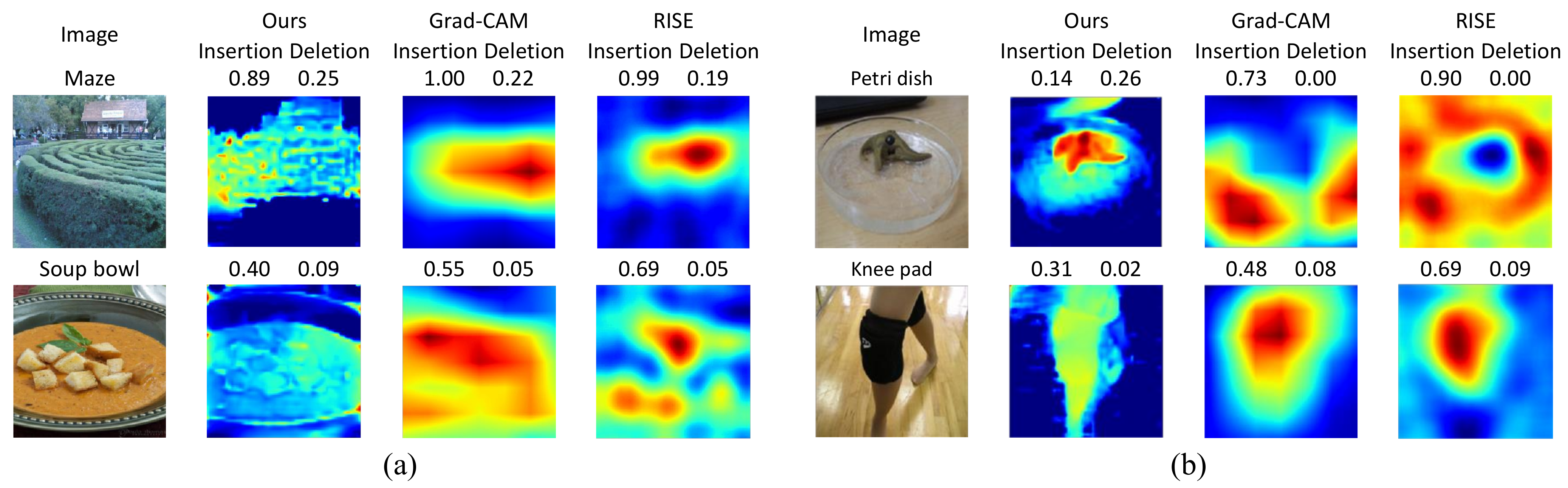
4.3. Qualitative Evaluations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A
| Algorithm A1 Calculating the insertion score. |
| Input: Image I, visual explanation E of I, model M, # of pixel batch n, |
| filter size of Gaussian kernel k, standard deviation of Gaussian kernel |
| Output: Insertion score s of E for I |
| 1: funtion |
| 2: predicted class of I by M |
| 3: |
| 4: |
| 5: |
| 6: while do |
| 7: position of xth important pixels in |
| 8: |
| 9: |
| 10: |
| 11: end while |
| 12: |
| 13: end function |
| Algorithm A2 Calculating the deletion score. |
| Input: Image I, visual explanation E of I, model M, # of pixel batch n |
| Output: Deletion score s of E for I |
| 1: funtion |
| 2: predicted class of I by M |
| 3: |
| 4: |
| 5: |
| 6: while do |
| 7: position of xth important pixels in |
| 8: |
| 9: |
| 10: |
| 11: end while |
| 12: |
| 13: end function |
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Petsiuk, V.; Das, A.; Saenko, K. Rise: Randomized input sampling for explanation of black-box models. arXiv, 2018; arXiv:1806.07421. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Seo, D.; Oh, K.; Oh, I.S. Regional multi-scale approach for visually pleasing explanations of deep neural networks. IEEE Access 2019, 8, 8572–8582. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv, 2013; arXiv:1312.6034. [Google Scholar]
- Wagner, J.; Kohler, J.M.; Gindele, T.; Hetzel, L.; Wiedemer, J.T.; Behnke, S. Interpretable and fine-grained visual explanations for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9097–9107. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, Germany, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv, 2015; arXiv:1503.02531. [Google Scholar]
- Dabkowski, P.; Gal, Y. Real time image saliency for black box classifiers. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6967–6976. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, 2018; arXiv:1810.04805. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Lei, Y.; Dong, X.; Tian, Z.; Liu, Y.; Tian, S.; Wang, T.; Jiang, X.; Patel, P.; Jani, A.B.; Mao, H.; et al. CT prostate segmentation based on synthetic MRI-aided deep attention fully convolution network. Med. Phys. 2020, 47, 530–540. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv, 2013; arXiv:1306.5151. [Google Scholar]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 87. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Classes | Training Set | # Images Validation Set | Test Set |
|---|---|---|---|---|
| ImageNet [28] | 1000 | 1,281,167 | 48,238 | - |
| CUB-200 2011 [29] | 200 | 5994 | - | 5794 |
| Cars [30] | 196 | 8144 | - | 8041 |
| Aircraft variant [31] | 100 | |||
| Aircraft family [31] | 70 | 3334 | 3333 | 3333 |
| Aircraft manufacturer [31] | 30 | 0 | 0 | 0 |
| Dataset | ImageNet | CUB-200 | Cars | Aircraft V | Aircraft F | Aircraft M |
|---|---|---|---|---|---|---|
| Target network () | 0.7615 | 0.8172 | 0.8956 | 0.8402 | 0.9200 | 0.9394 |
| Student network () | 0.7371 | 0.84 | 0.8834 | 0.8483 | 0.9600 | 0.9512 |
| Speed (fps) | Mean Pixel Intensity of a Saliency Map | |
|---|---|---|
| Normal inference | 83.3 | 1.0 |
| Ours | 24.4 | 0.189 |
| RISE [9] | 0.03 | 0.347 |
| Grad-CAM [11] | 34.8 | 0.421 |
| ImageNet | CUB-200 | Cars | Aircraft V | Aircraft F | Aircraft M | ||
|---|---|---|---|---|---|---|---|
| Ours | ins | 0.7049 | 0.7136 | 0.7260 | 0.6910 | 0.7808 | 0.8240 |
| del | 0.1211 | 0.0757 | 0.0699 | 0.0746 | 0.1045 | 0.1635 | |
| Ours | ins | 0.6517 | 0.6895 | 0.7152 | 0.6894 | 0.7726 | 0.8145 |
| del | 0.1211 | 0.0659 | 0.0780 | 0.0714 | 0.0978 | 0.1704 | |
| RISE [9] | ins | 0.7335 | 0.7461 | 0.7720 | 0.7248 | 0.8026 | 0.8475 |
| del | 0.1077 | 0.0588 | 0.0658 | 0.0569 | 0.0762 | 0.1383 | |
| LIME [10] | ins | 0.6940 | 0.6531 | 0.6447 | 0.5647 | 0.6532 | 0.7091 |
| del | 0.1217 | 0.1287 | 0.1345 | 0.1508 | 0.1935 | 0.3009 | |
| Grad-CAM [11] | ins | 0.6785 | 0.6982 | 0.7197 | 0.6742 | 0.7480 | 0.8011 |
| del | 0.1253 | 0.0805 | 0.0798 | 0.0740 | 0.1049 | 0.1735 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.; Kim, S. Explaining Neural Networks Using Attentive Knowledge Distillation. Sensors 2021, 21, 1280. https://doi.org/10.3390/s21041280
Lee H, Kim S. Explaining Neural Networks Using Attentive Knowledge Distillation. Sensors. 2021; 21(4):1280. https://doi.org/10.3390/s21041280
Chicago/Turabian StyleLee, Hyeonseok, and Sungchan Kim. 2021. "Explaining Neural Networks Using Attentive Knowledge Distillation" Sensors 21, no. 4: 1280. https://doi.org/10.3390/s21041280
APA StyleLee, H., & Kim, S. (2021). Explaining Neural Networks Using Attentive Knowledge Distillation. Sensors, 21(4), 1280. https://doi.org/10.3390/s21041280