
New Position Candidate Identification via Clustering toward an Extensible On-Body Smartphone Localization System



Abstract
1. Introduction
- A data-driven method that finds an optimal parameter value for clustering is heuristically developed, which does not need to specify the number of clusters in advance, yet it uses a dataset to train the position classification component. An evaluation shows that the proposed approach is comparable to existing methods that specify the number of clusters in advance and that estimate the number of clusters on-the-fly. The re-trained classifier performs well with high accuracy, i.e., an accuracy of more than 0.94.
- A condition that determines the time of performing a new position candidate identification process is presented as a result of experiments varying the number of samples and the breakdown of the samples of new class candidates. The estimated minimum time to collect a sufficient number of samples is appropriate, i.e., 5–12 min. in three datasets used in the evaluation, enough to be implemented in daily use.
- By integrating the design principles that are presented in this work with those already known in our previous work, a complete picture of the incremental position addition framework during walking is presented.
2. Related Work
2.1. Usefulness of On-Body Smartphone Position Recognition
2.2. On-Body Device Position Recognition
2.3. Application of Machine Learning Techniques to Inertial Sensor Signals
3. Incremental Position Addition Framework
3.1. Overview
3.2. Our Previous Work and the Scope of This Article
4. Designing a New Position Candidate Identification Component
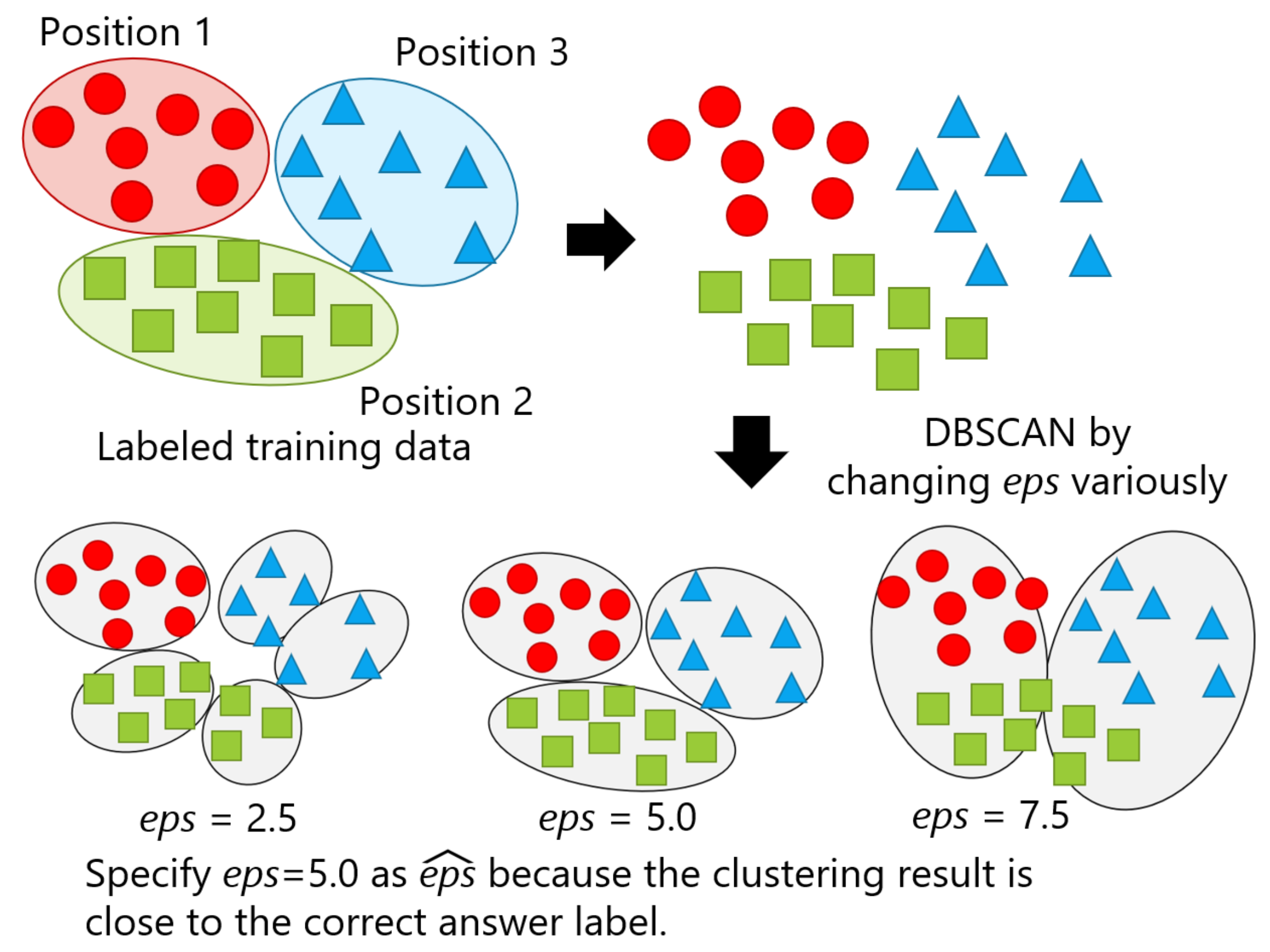
4.1. Finding an Optimal Value of eps
4.1.1. Parameters Used for Evaluating the Appropriateness of eps
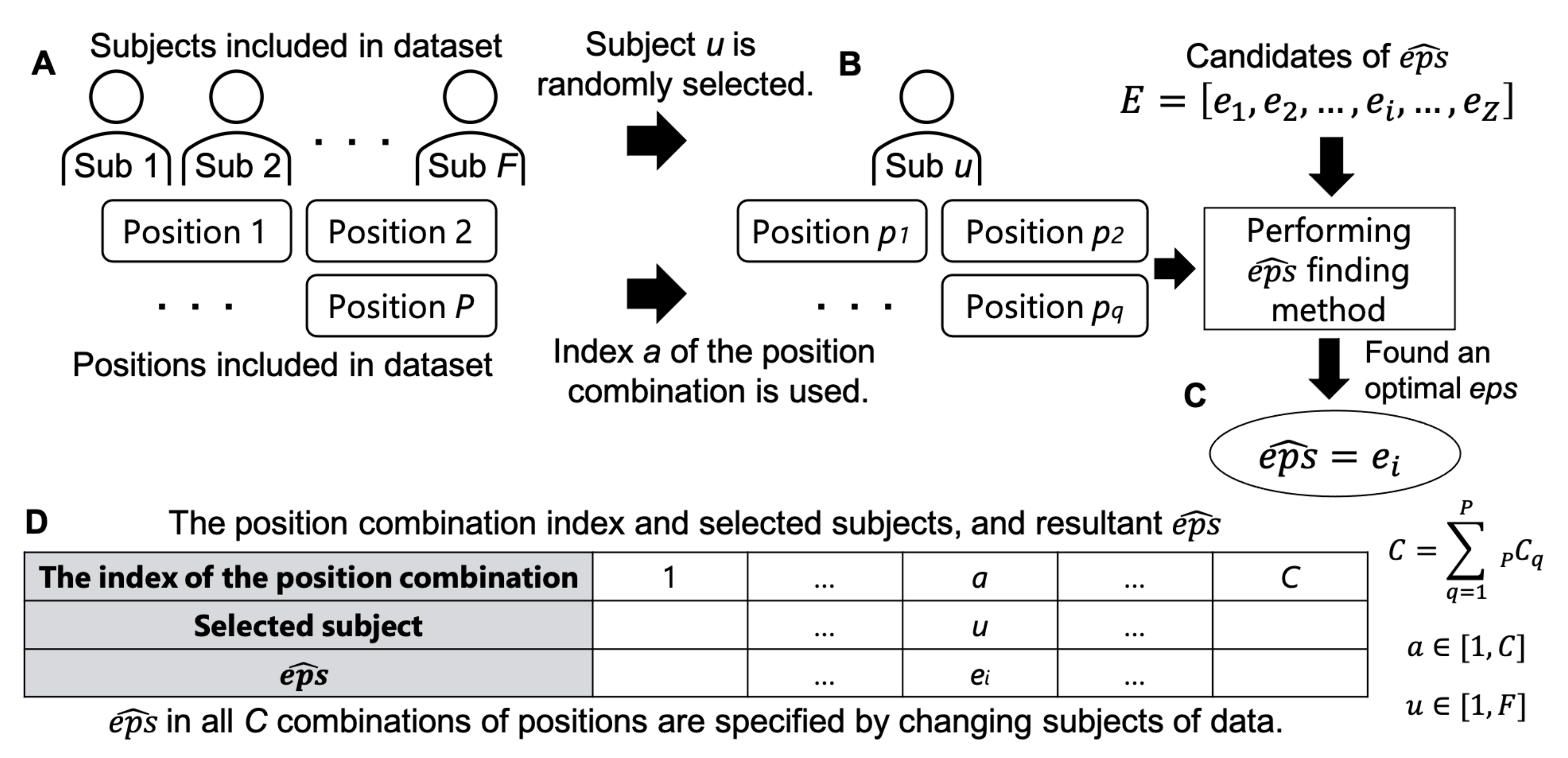
4.1.2. Finding an Optimal for Hyperparameter Tuning
- Step 1:
- Perform DBSCAN on the training data of one person by giving each of the Z eps in a specific candidate of eps and calculate , , , and .
- Step 2:
- Exclude eps whose is more than the threshold value ().
- Step 3:
- Exclude eps whose is below the threshold ().
- Step 4:
- Exclude eps whose is above the threshold ().
- Step 5:
- Specify the eps with the maximum from the remaining set of eps as .
4.2. Experiment: Effectiveness of the Proposed Search Method
4.2.1. Searching Optimal
4.2.2. Evaluation on Clustering Performance Using Optimal
4.2.3. Datasets
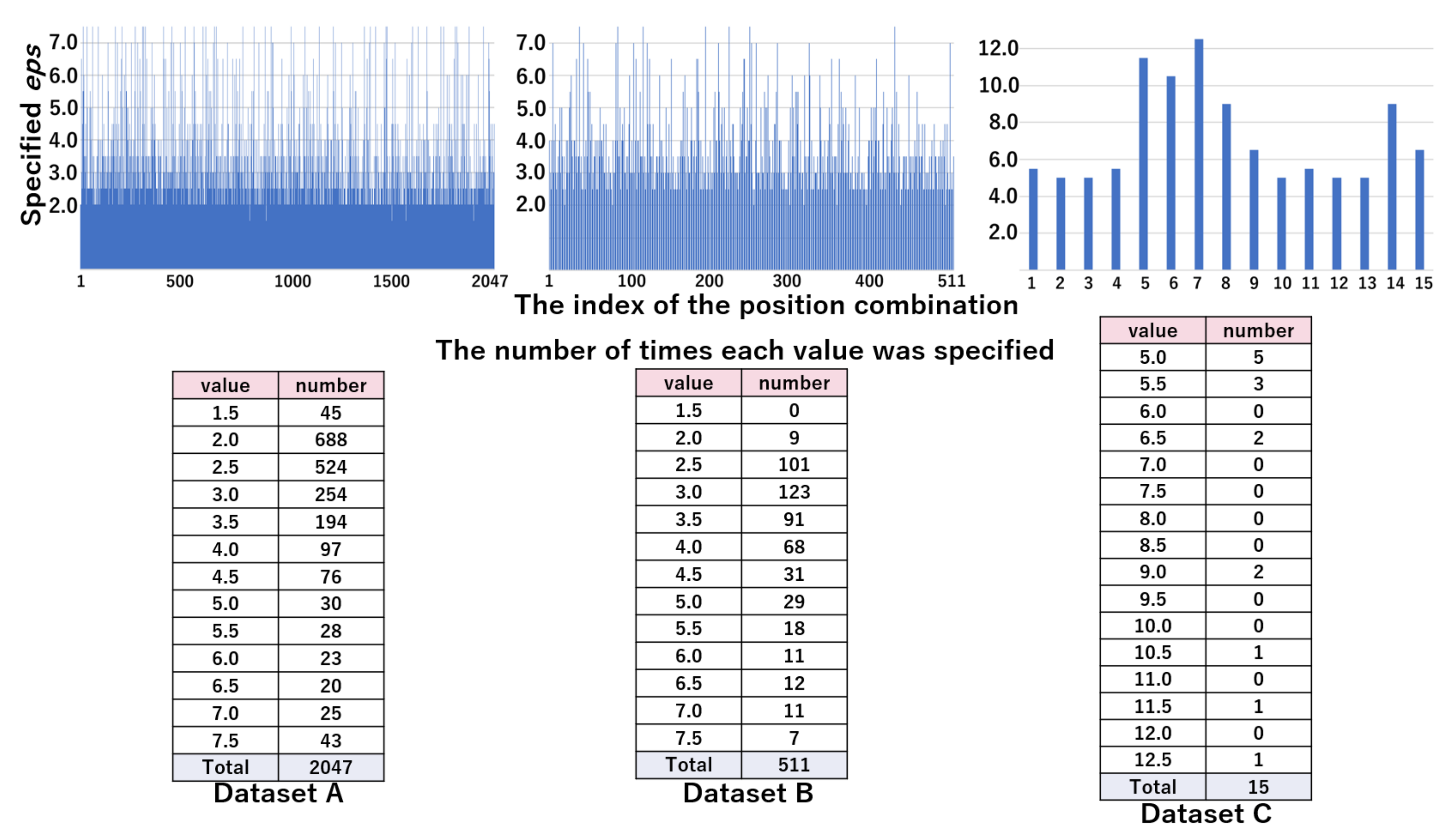
4.2.4. Analysis of Searching Optimal eps
4.2.5. Results of the Clustering Performance
4.3. Discussion
5. Timing of New Position Candidate Identification
5.1. Overview
5.2. Experiment: Impact of the Number of Samples on the New Position Candidate Identification Process Performance
5.2.1. Method
5.2.2. Results
5.3. Experiment: Impact of the Breakdown of Positions on the New Position Candidate Identification Process Performance
5.3.1. Method
5.3.2. Results
5.4. Discussion
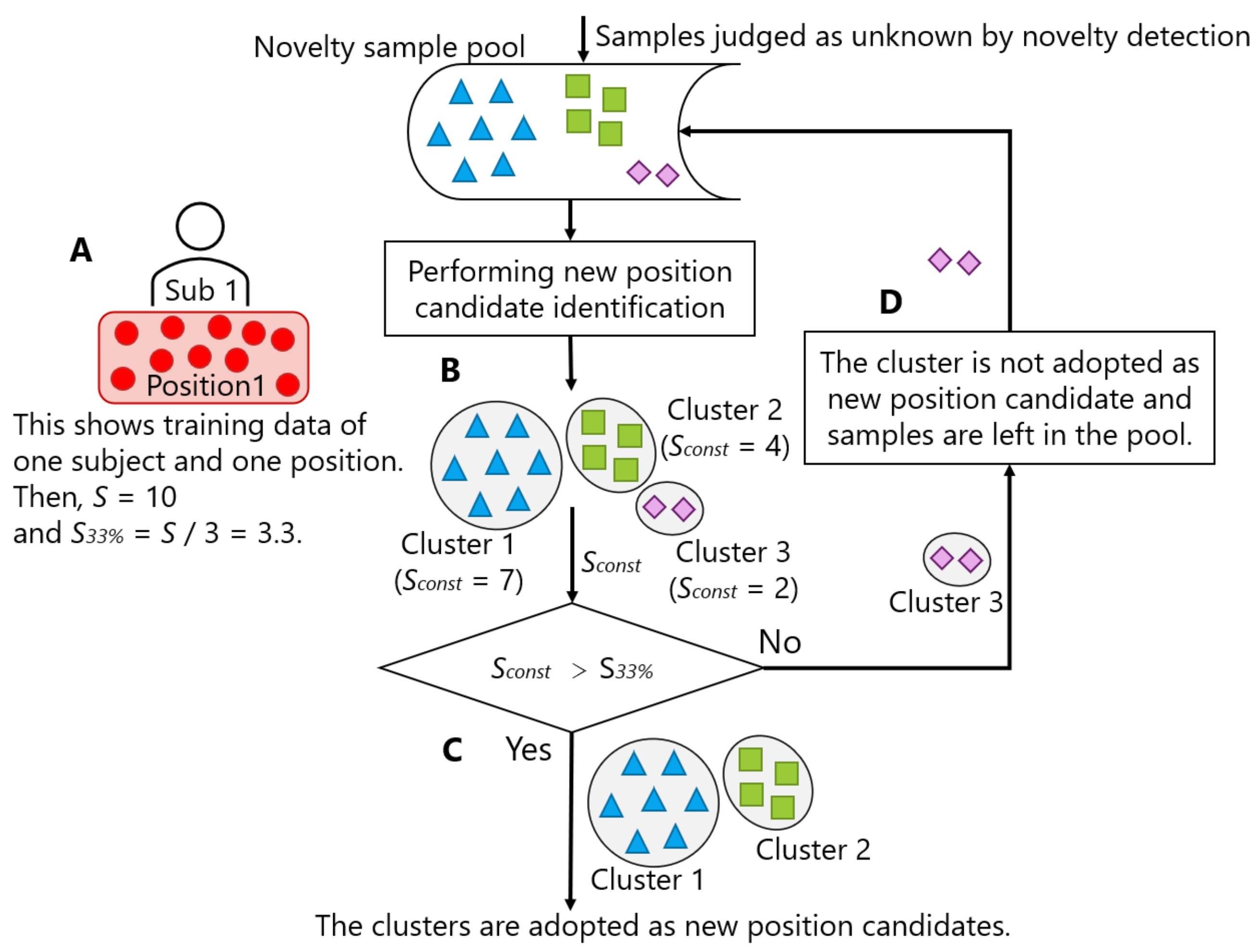
- The new position candidate identification process can be periodically invoked to check whether at least 33% of the data for each new class candidate relative to the number of original training data are stored. If the condition is satisfied, the result is adopted; otherwise, the samples remain stored in the novelty sample pool for future use.
6. Conclusions and Future Work
- When compared to a method that estimates the number of clusters (i.e., X-means), the proposed method performed clustering closer to the ideal number of positions.
- The proposed method showed a comparable level of FMI and Acc, as compared to a method that specifies the number of clusters in advance (i.e., k-means).
- The identification process can be invoked if at least 33% of the data for each new class candidate relative to the number of original training data are stored.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, Y.; Chipchase, J.; Ichikawa, F. A Cross Culture Study on Phone Carrying and Physical Personalization. In Usability and Internationalization. HCI and Culture; Aykin, N., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 483–492. [Google Scholar]
- Fujinami, K. Smartphone-based environmental sensing using device location as metadata. Int. J. Smart Sens. Intell. Syst. 2016, 9, 2257–2275. [Google Scholar] [CrossRef]
- Exler, A.; Dinse, C.; Günes, Z.; Hammoud, N.; Mattes, S.; Beigl, M. Investigating the perceptibility different notification types on smartphones depending on the smartphone position. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 970–976. [Google Scholar]
- Fujinami, K.; Saeki, T.; Li, Y.; Ishikawa, T.; Jimbo, T.; Nagase, D.; Sato, K. Fine-grained Accelerometer-based Smartphone Carrying States Recognition during Walking. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Shi, Y.; Shi, Y.; Liu, J. A Rotation Based Method for Detecting On-Body Positions of Mobile Devices. In Proceedings of the 13th International Conference on Ubiquitous Computing, UbiComp ’11, Beijing, China, 17–21 September 2011; pp. 559–560. [Google Scholar] [CrossRef]
- Bieshaar, M. Where is my Device?—Detecting the Smart Device’s Wearing Location in the Context of Active Safety for Vulnerable Road Users. arXiv 2018, arXiv:1803.02097. [Google Scholar]
- Saito, M.; Fujinami, K. Evaluation of Novelty Detection Methods in On-Body Smartphone Localization Problem. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019. [Google Scholar] [CrossRef]
- Maisonneuve, N.; Stevens, M.; Niessen, M.E.; Steels, L. NoiseTube: Measuring and mapping noise pollution with mobile phones. In Information Technologies in Environmental Engineering; Athanasiadis, I.N., Rizzoli, A.E., Mitkas, P.A., Gómez, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 215–228. [Google Scholar]
- Miyaki, T.; Rekimoto, J. Sensonomy: EnvisioningFolksonomic Urban Sensing. In Proceedings of the UbiComp 2008 Workshop Programs, Seoul, Korea, 21 September–24 September 2008; pp. 187–190. [Google Scholar]
- Lockhart, J.; Weiss, G. The Benefits of Personalized Smartphone-Based Activity Recognition Models. Proc. SIAM Int. Conf. Data Min. 2014. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M.; Alsanad, A.; Savaglio, C. A body sensor data fusion and deep recurrent neural network-based behavior recognition approach for robust healthcare. Inf. Fusion 2020, 55, 105–115. [Google Scholar] [CrossRef]
- Albert, M.; Kording, K.; Herrmann, M.; Jayaraman, A. Fall classification by machine learning using mobile phones. PLoS ONE 2012, 7. [Google Scholar] [CrossRef] [PubMed]
- Coskun, D.; Incel, O.; Ozgovde, A. Phone position/placement detection using accelerometer: Impact on activity recognition. In Proceedings of the 2015 IEEE 10th International Conference on Intelligent Sensors, Sensor Networks and Information Processing, ISSNIP 2015, Singapore, 7–9 April 2015. [Google Scholar] [CrossRef]
- Alanezi, K.; Mishra, S. Design, implementation and evaluation of a smartphone position discovery service for accurate context sensing. Comput. Electr. Eng. 2015, 44, 307–323. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–18 March 2016. [Google Scholar] [CrossRef]
- Kunze, K.; Lukowicz, P.; Junker, H.; Tröster, G. Where Am i: Recognizing on-Body Positions of Wearable Sensors. In Proceedings of the First International Conference on Location- and Context-Awareness, LoCA’05, Oberpfaffenhofen, Germany, 12–13 May 2005; pp. 264–275. [Google Scholar]
- Vahdatpour, A.; Amini, N.; Sarrafzadeh, M. On-body device localization for health and medical monitoring applications. In Proceedings of the 2011 IEEE International Conference on Pervasive Computing and Communications (PerCom), Seattle, WA, USA, 21–25 March 2011; pp. 37–44. [Google Scholar] [CrossRef]
- Wiese, J.; Saponas, T.S.; Brush, A.B. Phoneprioception: Enabling Mobile Phones to Infer Where They Are Kept. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’13, Paris, France, 27 April–2 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 2157–2166. [Google Scholar] [CrossRef]
- Weenk, D.; van Beijnum, B.; Baten, C.; Hermens, H.; Veltink, P. Automatic identification of inertial sensor placement on human body segments during walking. J. Neuroeng. Rehabil. 2013, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed]
- Hoseinitabatabaei, S.A.; Gluhak, A.; Tafazolli, R. Towards a position and orientation independent approach for pervasive observation of user direction with mobile phones. Pervasive Mob. Comput. 2015, 17, 23–42. [Google Scholar] [CrossRef]
- Diaconita, I.; Reinhardt, A.; Christin, D.; Rensing, C. Inferring Smartphone Positions Based on Collecting the Environment’s Response to Vibration Motor Actuation. In Proceedings of the 11th ACM Symposium on QoS and Security for Wireless and Mobile Networks—Q2SWinet ‘15, Cancun, Mexico, 2–6 November 2015. [Google Scholar]
- Fujinami, K. On-Body Smartphone Localization with an Accelerometer. Information 2016, 7, 21. [Google Scholar] [CrossRef]
- Yang, R.; Wang, B. PACP: A Position-Independent Activity Recognition Method Using Smartphone Sensors. Information 2016, 7, 72. [Google Scholar] [CrossRef]
- Shi, D.; Wang, R.; Wu, Y.; Mo, X.; Wei, J. A Novel Orientation- and Location-Independent Activity Recognition Method. Pers. Ubiquitous Comput. 2017, 21, 427–441. [Google Scholar] [CrossRef]
- Hasegawa, T.; Hirahashi, S.; Koshino, M. Determining Smartphone’s Placement Through Material Detection, Using Multiple Features Produced in Sound Echoes. IEEE Access 2017, 5, 5331–5339. [Google Scholar] [CrossRef]
- Sang, V.N.T.; Yano, S.; Kondo, T. On-body sensor positions hierarchical classification. Sensors 2018, 18, 3612. [Google Scholar] [CrossRef]
- Chen, S.; Park, W.; Yang, J.; Wagner, D. Inferring Phone Location State. In Proceedings of the 2018 14th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Limassol, Cyprus, 15–17 October 2018; pp. 42–47. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Q.; Ji, X.; Wang, S.; Feng, M.; Sun, Y. Multimode Pedestrian Dead Reckoning Gait Detection Algorithm Based on Identification of Pedestrian Phone Carrying Position. Mob. Inf. Syst. 2019, 2019. [Google Scholar] [CrossRef]
- Li, Q.; Shin, S.; Hong, C.P.; Kim, S.D. On-body wearable device localization with a fast and memory efficient SVM-kNN using GPUs. Pattern Recognit. Lett. 2020, 139, 128–138. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-Label Classification: An Overview. Int. J. Data Warehous. Min. 2009, 3, 1–13. [Google Scholar] [CrossRef]
- Miljković, D. Review of novelty detection methods. In Proceedings of the 33rd International Convention MIPRO, Opatija, Croatia, 24–28 May 2010; pp. 593–598. [Google Scholar]
- Hassani, M.; Seidl, T. Using internal evaluation measures to validate the quality of diverse stream clustering algorithms. Vietnam. J. Comput. Sci. 2016, 4. [Google Scholar] [CrossRef]
- Yin, J.; Yang, Q.; Pan, J.J. Sensor-Based Abnormal Human-Activity Detection. IEEE Trans. Knowl. Data Eng. 2008, 20, 1082–1090. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, X.; Sun, Y.; Ping, G.; Zhao, G.; Li, Z. Smartphone-based patients’ activity recognition by using a self-learning scheme for medical monitoring. J. Med Syst. 2016, 40, 140. [Google Scholar] [CrossRef]
- Yang, J.; Wang, S.; Chen, N.; Chen, X.; Shi, P. Wearable accelerometer based extendable activity recognition system. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 3641–3647. [Google Scholar] [CrossRef]
- Trabelsi, D.; Mohammed, S.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. An Unsupervised Approach for Automatic Activity Recognition Based on Hidden Markov Model Regression. IEEE Trans. Autom. Sci. Eng. 2013, 10, 829–835. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, Z.Q.; Zhu, H.; Fu, Y.; Xiong, H.; Yang, J. Learning Adaptive Embedding Considering Incremental Class. arXiv 2020, arXiv:2008.13351. [Google Scholar]
- Schölkopf, B.; Williamson, R.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support Vector Method for Novelty Detection. In Proceedings of the 12th International Conference on Neural Information Processing Systems, NIPS’99, Cambridge, MA, USA, 29 November–4 December 1999; pp. 582–588. [Google Scholar]
- Breunig, M.; Kriegel, H.P.; Ng, R.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on MANAGEMENT of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Liu, F.T.; Ting, K.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Saito, M.; Fujinami, K. Unknown On-Body Device Position Detection Based on Ensemble Novelty Detection. Sens. Mater. 2020, 32, 27–40. [Google Scholar] [CrossRef]
- Saito, M.; Fujinami, K. New Class Candidate Generation applied to On-Body Smartphone Localization. In Activity and Behavior Computing. Smart Innovation, Systems and Technologies; Ahad, M.A.R., Inoue, S., Roggen, D., Fujinami, K., Eds.; Springer: Singapore, 2021; Volume 204, pp. 81–98. [Google Scholar]
- Saito, M.; Fujinami, K. Applicability of DBSCAN in Identifying the Candidates of New Position in On-Body Smartphone Localization Problem. In Proceedings of the 2020 IEEE Global Conference on Consumer Electronics (GCCE2020), Kobe, Japan, 13–16 October 2020. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Statistics; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Pelleg, D.; Moore, A. X-means: Extending K-means with Efficient Estimation of the Number of Clusters. Mach. Learn. 2002, 1, 727–734. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Bholowalia, P.; Kumar, A. EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Van Craenendonck, T.; Blockeel, H. Using internal validity measures to compare clustering algorithms. Benelearn Poster Present. 2015. Available online: https://core.ac.uk/download/pdf/34638775.pdf (accessed on 10 February 2021).
- Campello, R.J.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y.; Han, J.; Wang, J. A framework for clustering evolving data streams. In Proceedings 2003 VLDB Conference; Morgan Kaufmann: Berlin, Germany, 2003; pp. 81–92. [Google Scholar]
- Mojena, R. Hierarchical grouping methods and stopping rules: An evaluation. Comput. J. 1977, 20, 359–363. [Google Scholar] [CrossRef]
- Fowlkes, E.B.; Mallows, C.L. A Method for Comparing Two Hierarchical Clusterings. J. Am. Stat. Assoc. 1983, 78, 553–569. [Google Scholar] [CrossRef]
- Syarif, I.; Prugel-Bennett, A.; Wills, G. SVM parameter optimization using grid search and genetic algorithm to improve classification performance. Telkomnika 2016, 14, 1502. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fujinami, K.; Vu, T.T.; Sato, K. A Framework for Human-Centric Personalization of Context Recognition Models on Mobile Devices. In Proceedings of the 2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 885–888. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Position |
|---|---|
| Kunze et al. [16] | Wrist, head, trouser left pocket, and chest pocket |
| Shi et al. [5] | Chest pocket, front/back trouser pocket, and hand |
| Vahdatpour et al. [17] | Upper arm, forearm, waist, shin, thigh, and head |
| Wiese et al. [18] | Pocket, bag, hand, and away from human |
| Weenk et al. [19] | Pelvis, sternum, head, shoulder, upper arm, forearm, hand, upper/lower leg, and foot |
| Shoaib et al. [20] | Trouser pocket, arm, wrist, and belt |
| Coskun et al. [13] | Pocket, bag, and hand |
| Alanezi et al. [14] | Jacket pocket, front/back trouser pocket, desk, and hand (calling, watching the screen in the portrait direction, and swinging during walking) |
| Hoseinitabatabaei et al. [21] | Front trouser pocket, shoulder bag, hand, and belt |
| Diaconita et al. [22] | Pocket, bag, hand, and desk (facing the ceiling and facing the surface of the desk) |
| Sztyler et al. [15] | Head, chest, upper arm, waist, forearm, thigh, and shin |
| Fujinami [23] | Neck (hanging), chest pocket, jacket pocket, front/back trouser pocket, and bag (backpack, hand bag, shoulder bag, and messenger bag) |
| Yang et al. [24] | Jacket pocket, trouser pocket, bag, and hand |
| Fujinami et al. [4] | Neck (hanging), chest pocket, jacket pocket, front/back trouser pocket, bag (backpack, hand bag, and shoulder bag), and hand (calling, watching the screen in the portrait direction, and swinging during walking) |
| Shi et al. [25] | Chest pocket, front trouser pocket, jacket pocket, and hand |
| Hasegawa et al. [26] | Bag, trouser pocket, cushion, towel, rubber, copper, wood, hand, and phone stand |
| Bieshaar [6] | Jacket pocket, front/back trouser pocket, and backpack |
| Sang et al. [27] | Arm, hand, and thigh |
| Chen et al. [28] | Backpack, pocket, bag, and hand |
| Guo et al. [29] | Backpack, flat, and hand (calling and swinging during walking) |
| Li et al. [30] | Calf, thigh, upper/lower arm, and back |
| Dataset | # Person | Position | Candidates (Pattern NF) | ||
|---|---|---|---|---|---|
| A [4] | 70 | 50 Hz | 256 | Neck (hanging), chest pocket, jacket pocket, front/back trouser pocket, bag (backpack, hand bag, and shoulder bag), and hand (calling, watching the screen in the portrait direction, and swinging during walking) | 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, and 7.5 |
| B [23] | 20 | 25 Hz | 256 | Neck (hanging), chest pocket, jacket pocket, front/back trouser pocket, and bag (backpack, hand bag, shoulder bag, and messenger bag) | 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0, and 7.5 |
| C [20] | 10 | 50 Hz | 100 | Trouser pocket, arm, wrist, and belt | 5.0, 5.5, 6.0, 6.5, 7.0, 7.5, 8.0, 8.5, 9.0, 9.5, 10.0, 10.5, 11.0, 11.5, 12.0, and 12.5 |
| DBSCAN (WC Pattern) | DBSCAN (NF Pattern) | DBSCAN () | X-Means | k-Means | |
|---|---|---|---|---|---|
| 0.004 | 0.007 | 0.969 | - | - | |
| +0.58 | +1.10 | - | +5.56 | - | |
| 0.932 | 0.935 | - | - | 0.954 | |
| 0.984 | 0.988 | - | - | 0.987 |
| DBSCAN (WC Pattern) | DBSCAN (NF Pattern) | DBSCAN () | X-Means | k-Means | |
|---|---|---|---|---|---|
| 0.002 | 0.003 | 0.998 | - | - | |
| +0.34 | +0.54 | - | +6.54 | - | |
| 0.915 | 0.922 | - | - | 0.947 | |
| 0.927 | 0.940 | - | - | 0.969 |
| DBSCAN (WC Pattern) | DBSCAN (NF Pattern) | DBSCAN () | X-Means | k-Means | |
|---|---|---|---|---|---|
| 0.001 | 0.007 | 0.999 | - | - | |
| - | +3.37 | - | |||
| 0.861 | 0.865 | - | - | 0.841 | |
| 0.975 | 0.977 | - | - | 0.997 |
| Dataset A | Dataset B | Dataset C | |
|---|---|---|---|
| WC pattern | −0.10 | −0.20 | −0.07 |
| NF pattern | −0.08 | −0.14 | 0.07 |
| 100% | 66% | 33% | 10% | |
|---|---|---|---|---|
| Dataset A | 0.99 | 0.98 | 0.94 | 0.35 |
| Dataset B | 0.93 | 0.92 | 0.82 | 0.16 |
| Dataset C | 0.98 | 0.98 | 0.97 | 0.65 |
| 100% | 66% | 33% | 10% | |
|---|---|---|---|---|
| Dataset A | +1.10 | +0.19 | ||
| Dataset B | +0.54 | |||
| Dataset C | +0.07 |
| 100% | 100% | 100% | 100% | 66% | 66% | 66% | 33% | 33% | 10% | |
|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 66% | 33% | 10% | 66% | 33% | 10% | 33% | 10% | 10% | |
| Dataset A | 0.99 | 0.99 | 0.99 | 0.93 | 0.99 | 0.99 | 0.81 | 0.93 | 0.43 | 0.01 |
| Dataset B | 0.98 | 0.97 | 0.96 | 0.86 | 0.96 | 0.95 | 0.81 | 0.91 | 0.23 | 0.01 |
| Dataset C | 0.99 | 0.99 | 0.99 | 0.97 | 0.99 | 0.99 | 0.98 | 0.99 | 0.94 | 0.80 |
| 100% | 100% | 100% | 100% | 66% | 66% | 66% | 33% | 33% | 10% | |
|---|---|---|---|---|---|---|---|---|---|---|
| 100% | 66% | 33% | 10% | 66% | 33% | 10% | 33% | 10% | 10% | |
| Dataset A | +0.52 | +0.28 | +0.07 | |||||||
| Dataset B | +0.39 | +0.31 | +0.13 | +0.09 | ||||||
| Dataset C | +0.17 | +0.08 | +0.16 | +0.17 | +0.23 | +0.04 | +0.08 |
| Dataset A | Dataset B | Dataset C | |
|---|---|---|---|
| The time per sample () | 5.12 s | 10.24 s | 2 s |
| Number of persons (F) | 70 | 20 | 10 |
| Number of positions (P) | 11 | 9 | 4 |
| Number of all samples included in dataset () | 145,661 | 34,962 | 22,450 |
| Sample per person per position (S) | approx. 189 | approx. 194 | approx. 561 |
| Sample of 33% () | approx. 63 | approx. 65 | approx. 187 |
| Time to satisfy the timing condition () | approx. 323 s | approx. 666 s | approx. 374 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saito, M.; Fujinami, K. New Position Candidate Identification via Clustering toward an Extensible On-Body Smartphone Localization System. Sensors 2021, 21, 1276. https://doi.org/10.3390/s21041276
Saito M, Fujinami K. New Position Candidate Identification via Clustering toward an Extensible On-Body Smartphone Localization System. Sensors. 2021; 21(4):1276. https://doi.org/10.3390/s21041276
Chicago/Turabian StyleSaito, Mitsuaki, and Kaori Fujinami. 2021. "New Position Candidate Identification via Clustering toward an Extensible On-Body Smartphone Localization System" Sensors 21, no. 4: 1276. https://doi.org/10.3390/s21041276
APA StyleSaito, M., & Fujinami, K. (2021). New Position Candidate Identification via Clustering toward an Extensible On-Body Smartphone Localization System. Sensors, 21(4), 1276. https://doi.org/10.3390/s21041276