
A Multi-Level Feature Fusion Network for Remote Sensing Image Segmentation


Abstract
1. Introduction
1.1. Related Works
1.2. Contributions of MFNet
- (1)
- By focusing on the uneven size of the target object in the remote sensing image, a multi-level feature fusion network is proposed to extract the features, and it retains the information of the small objects as much as possible. In addition, it improves the recognition result of the small objects.
- (2)
- For the feature fusion module at the different levels, we proposed a cross-type feature fusion module, which can make the feature fusion module have effective semantic information and spatial texture information. In addition, it facilitates information exchange for the different features.
- (3)
- The proposed remote sensing image network model can have good target extraction and segmentation results in the urbanization remote sensing images. We significantly improved the segmentation results on the Vaihingen and Potsdam datasets.
- (4)
- The proposed multi-level feature fusion framework is a basic feature extraction framework that can be applied to the other remote sensing image deep learning tasks. At the same time, the cross-type feature fusion module is an embedding module that can be widely used to perform feature fusion.
2. Methodology
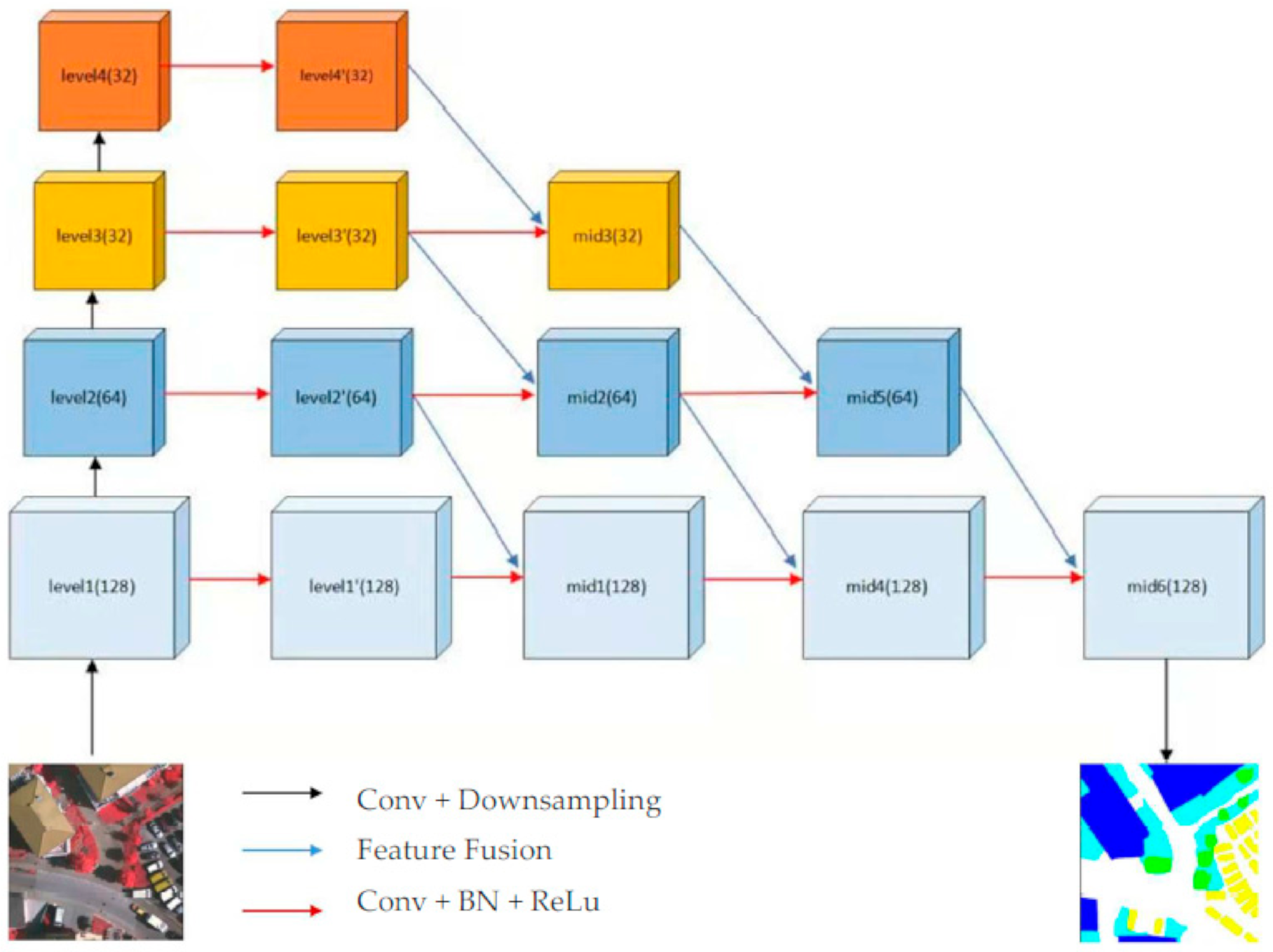
2.1. Multi-Level Feature Fusion Network
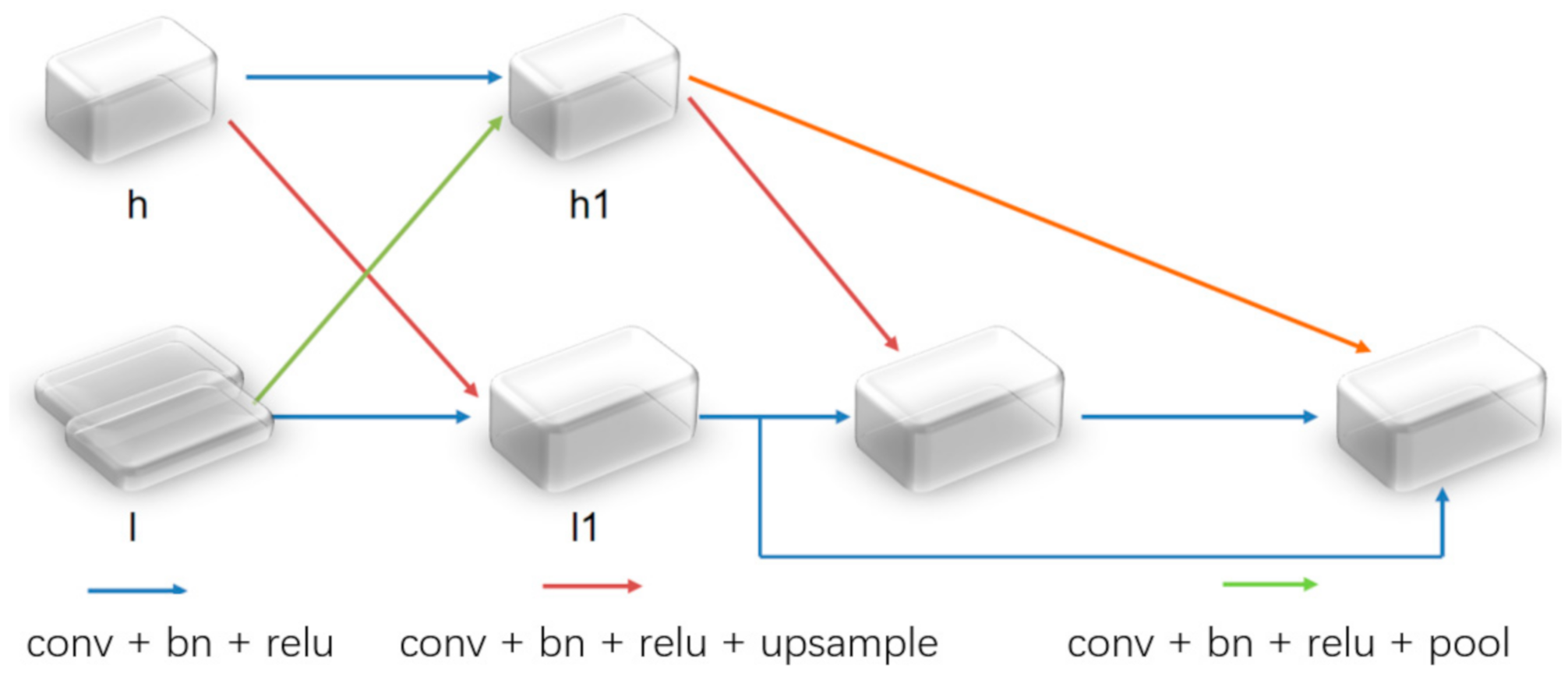
2.2. Cross-Type Feature Fusion Module
3. Results
3.1. Dataset
3.1.1. Vaihingen Dataset and Potsdam Dataset Introduction
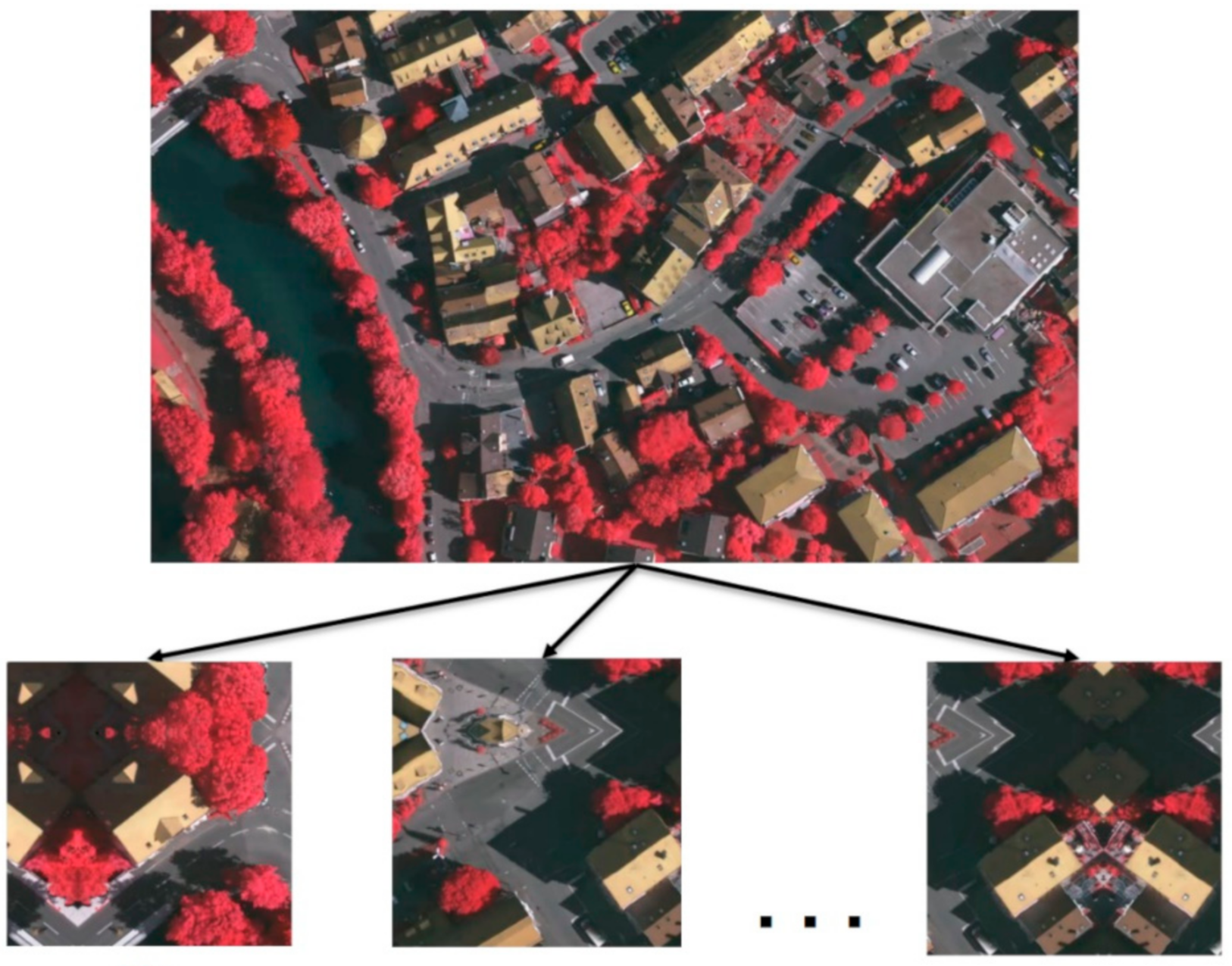
3.1.2. Dataset Crop Method
3.1.3. Data Augmentation Method
3.2. Experiment Evaluation Metrics
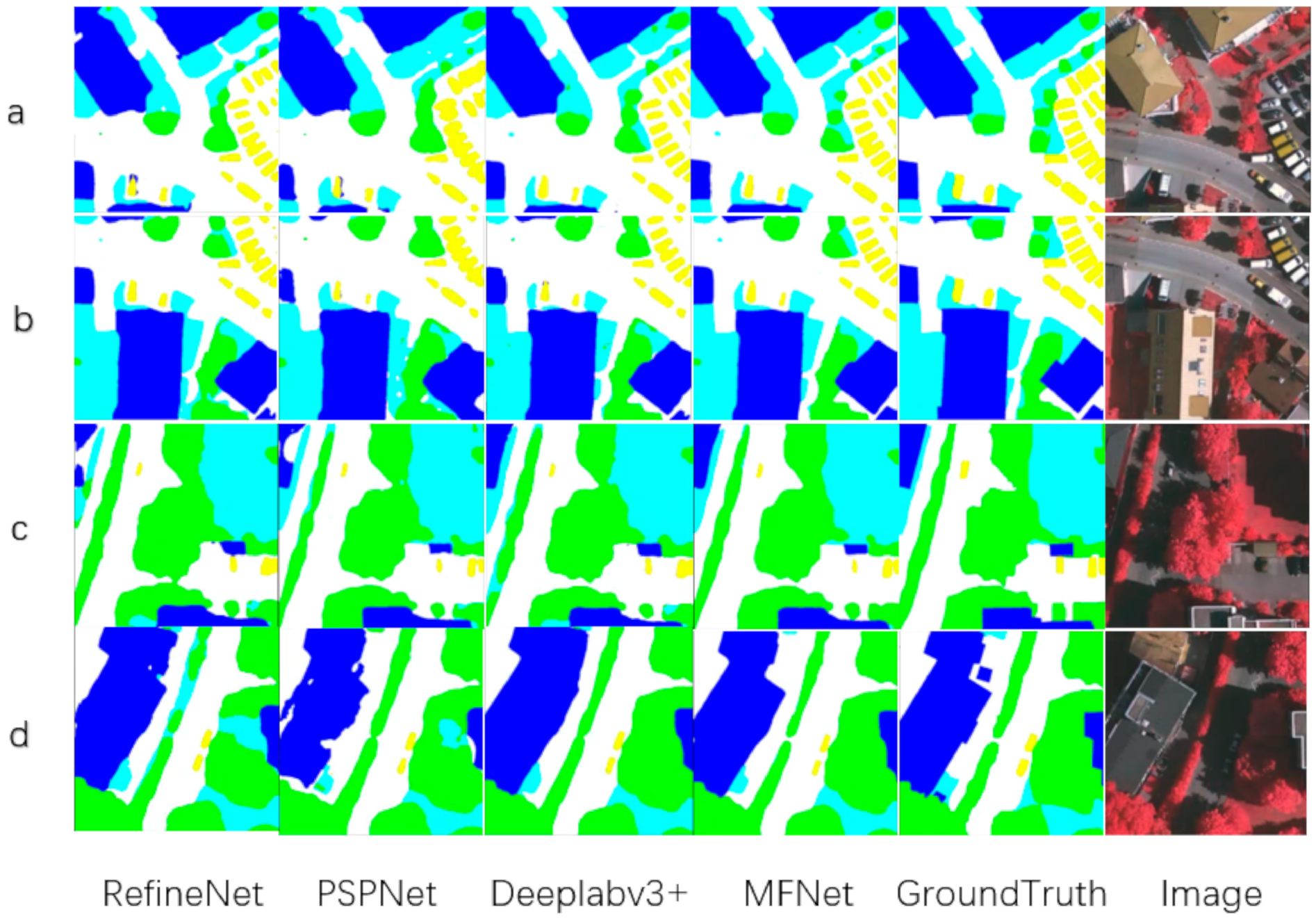
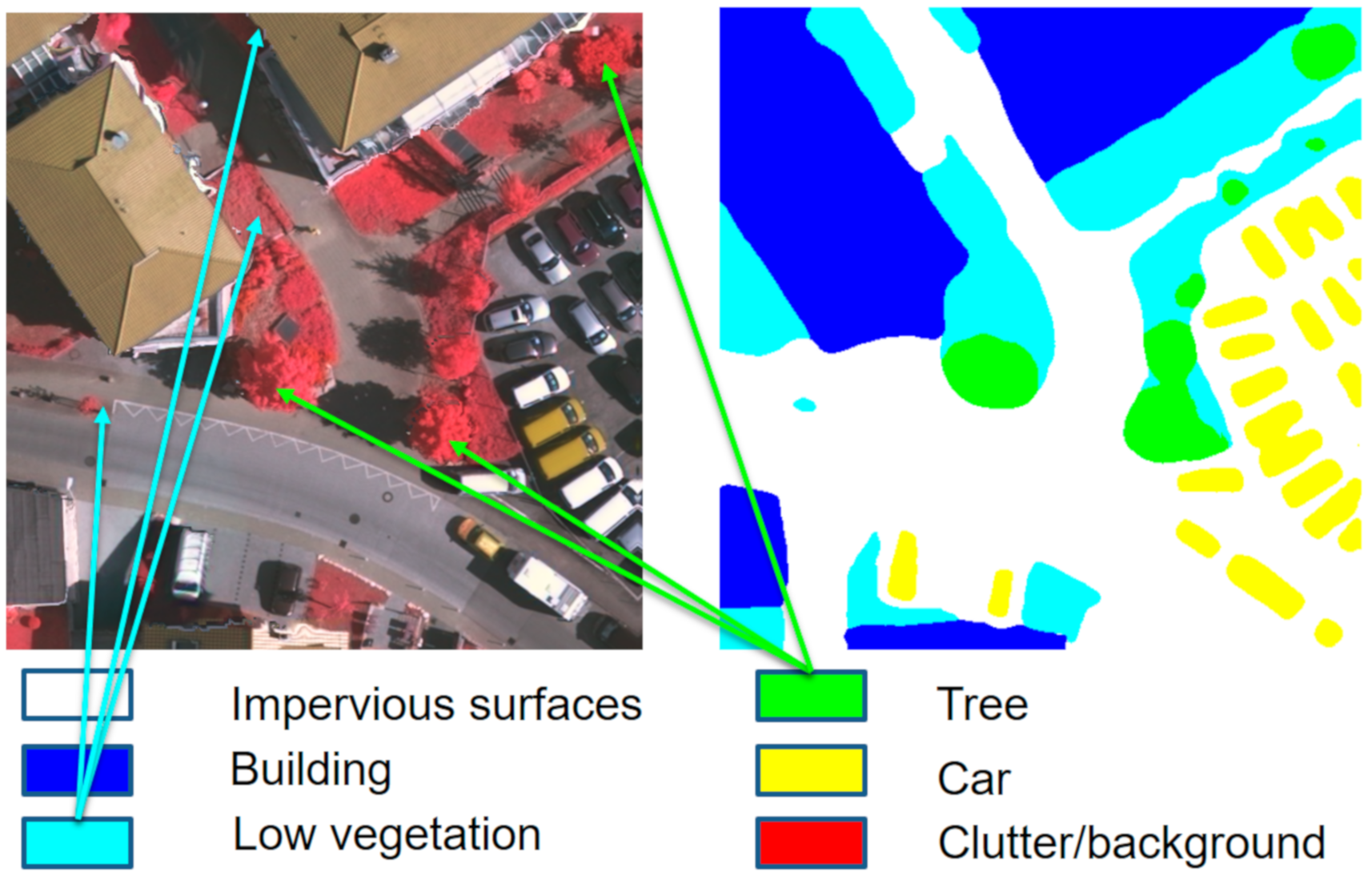
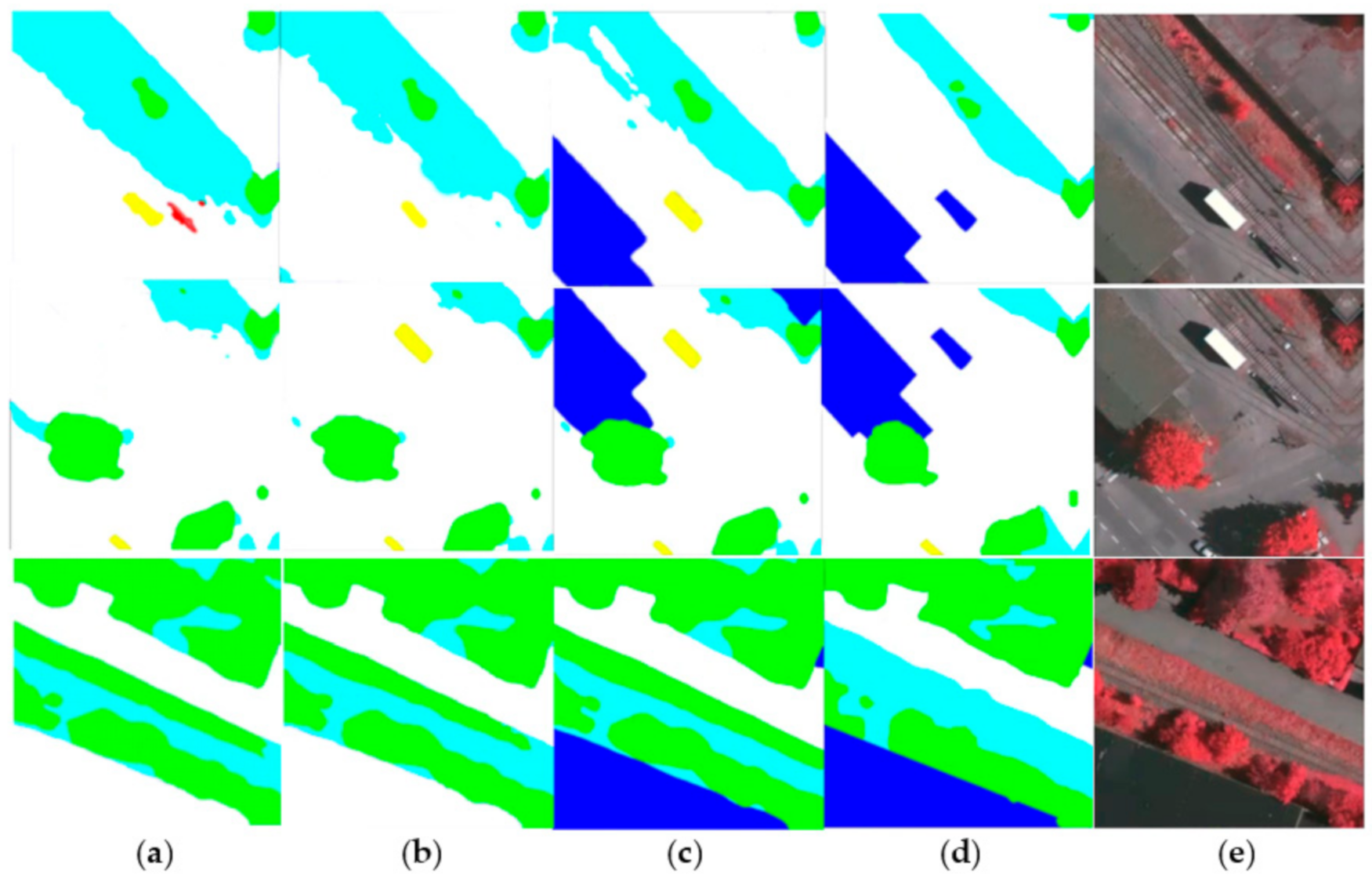
3.3. Results and Visualization in the Vaihingen dataset
3.4. Results and Visualization in the Potsdam Dataset
4. Discussion
4.1. Target Scale Difference
4.2. Ablation Study in the Vaihingen Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road Segmentation for Remote Sensing Images using Adversarial Spatial Pyramid Networks. arXiv 2020, arXiv:2008.04021. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Scene parsing with multiscale feature learning, purity trees, and optimal covers. arXiv 2012, arXiv:1202.2160. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Park, S.J.; Hong, K.S.; Lee, S. Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar]
- Mei, Q.; Gül, M. Multi-level feature fusion in densely connected deep-learning architecture and depth-first search for crack segmentation on images collected with smartphones. Struct. Health Monit. 2020, 19. [Google Scholar] [CrossRef]
- Zhang, B.; Li, W.; Hui, Y.; Liu, J.; Guan, Y. MFENet: Multi-level feature enhancement network for real-time semantic segmentation. Neurocomputing 2020, 393, 54–65. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Ding, H.; Jiang, X.; Liu, A.Q.; Thalmann, N.M.; Wang, G. Boundary-aware feature propagation for scene segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6819–6829. [Google Scholar]
- Hatamizadeh, A.; Terzopoulos, D.; Myronenko, A. End-to-end boundary aware networks for medical image segmentation. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2019; pp. 187–194. [Google Scholar]
- Hayder, Z.; He, X.; Salzmann, M. Boundary-aware instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5696–5704. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters--improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-Scale Semantic Segmentation and Spatial Relationship Recognition of Remote Sensing Images Based on an Attention Model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Markus, G. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); University of Twente: Enschede, The Netherlands, 2015. [Google Scholar]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic segmentation of aerial images with shuffling convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Lin, J.; Jing, W.; Song, H. SAN: Scale-Aware Network for Semantic Segmentation of High-Resolution Aerial Images. arXiv 2019, arXiv:1907.03089. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive Tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Niu, R. HMANet: Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. arXiv 2020, arXiv:2001.02870. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Accuracy (%) |
|---|---|---|
| FCN | VGG-16 | 82.39 |
| SegNet | VGG-16 | 83.64 |
| Edeeper-SCNN [26] | ResNet-50 | 85.78 |
| SANet [27] | ResNet-101 | 86.47 |
| EncNet | ResNet-101 | 86.63 |
| RefineNet | ResNet-50 | 89.41 |
| PSPNet | ResNet-50 | 89.50 |
| UNet | ResNet-50 | 89.83 |
| V-FuseNet [28] | * | 90.04 |
| Deeplabv3plus | ResNet-50 | 91.14 |
| MFNet | ResNet-50 [29] | 91.34 |
| Method | IoU (%) | Mean IoU | Mean F1 | Overall Accuracy | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | ||||
| RefineNet | 79.47 | 86.05 | 66.03 | 76.24 | 58.65 | 73.29 | 85.57 | 89.41 |
| PSPNet | 82.14 | 87.12 | 66.69 | 74.57 | 56.87 | 73.48 | 85.82 | 89.50 |
| Deeplabv3+ | 83.77 | 89.92 | 67.93 | 78.67 | 62.46 | 76.55 | 87.90 | 91.14 |
| MFNet (CFM&DSM) | 84.37 | 90.15 | 68.04 | 79.21 | 63.49 | 77.05 | 88.24 | 91.47 |
| Method | Backbone | Accuracy (%) |
|---|---|---|
| FCN | VGG-16 | 82.39 |
| TreeUNet [30] | * | 90.65 |
| CCNet [31] | ResNet-50 | 90.87 |
| HMANet [32] | * | 92.21 |
| MFNet | ResNet-50 | 91.65 |
| Method | Iou (%) | Mean Iou | Mean F1 | Overall Acc. | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | ||||
| Source FCN | 77.28 | 84.25 | 63.81 | 74.46 | 57.97 | 71.55 | 83.65 | 87.12 |
| MFNet | 84.14 | 88.04 | 67.48 | 78.39 | 64.13 | 76.44 | 87.85 | 91.22 |
| MFNet(CFM) | 84.37 | 90.15 | 68.04 | 79.21 | 63.49 | 77.05 | 88.24 | 91.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, S.; Chen, Z. A Multi-Level Feature Fusion Network for Remote Sensing Image Segmentation. Sensors 2021, 21, 1267. https://doi.org/10.3390/s21041267
Dong S, Chen Z. A Multi-Level Feature Fusion Network for Remote Sensing Image Segmentation. Sensors. 2021; 21(4):1267. https://doi.org/10.3390/s21041267
Chicago/Turabian StyleDong, Sijun, and Zhengchao Chen. 2021. "A Multi-Level Feature Fusion Network for Remote Sensing Image Segmentation" Sensors 21, no. 4: 1267. https://doi.org/10.3390/s21041267
APA StyleDong, S., & Chen, Z. (2021). A Multi-Level Feature Fusion Network for Remote Sensing Image Segmentation. Sensors, 21(4), 1267. https://doi.org/10.3390/s21041267