
Deep Convolutional and LSTM Networks on Multi-Channel Time Series Data for Gait Phase Recognition


Abstract
1. Introduction
2. Materials and Methods
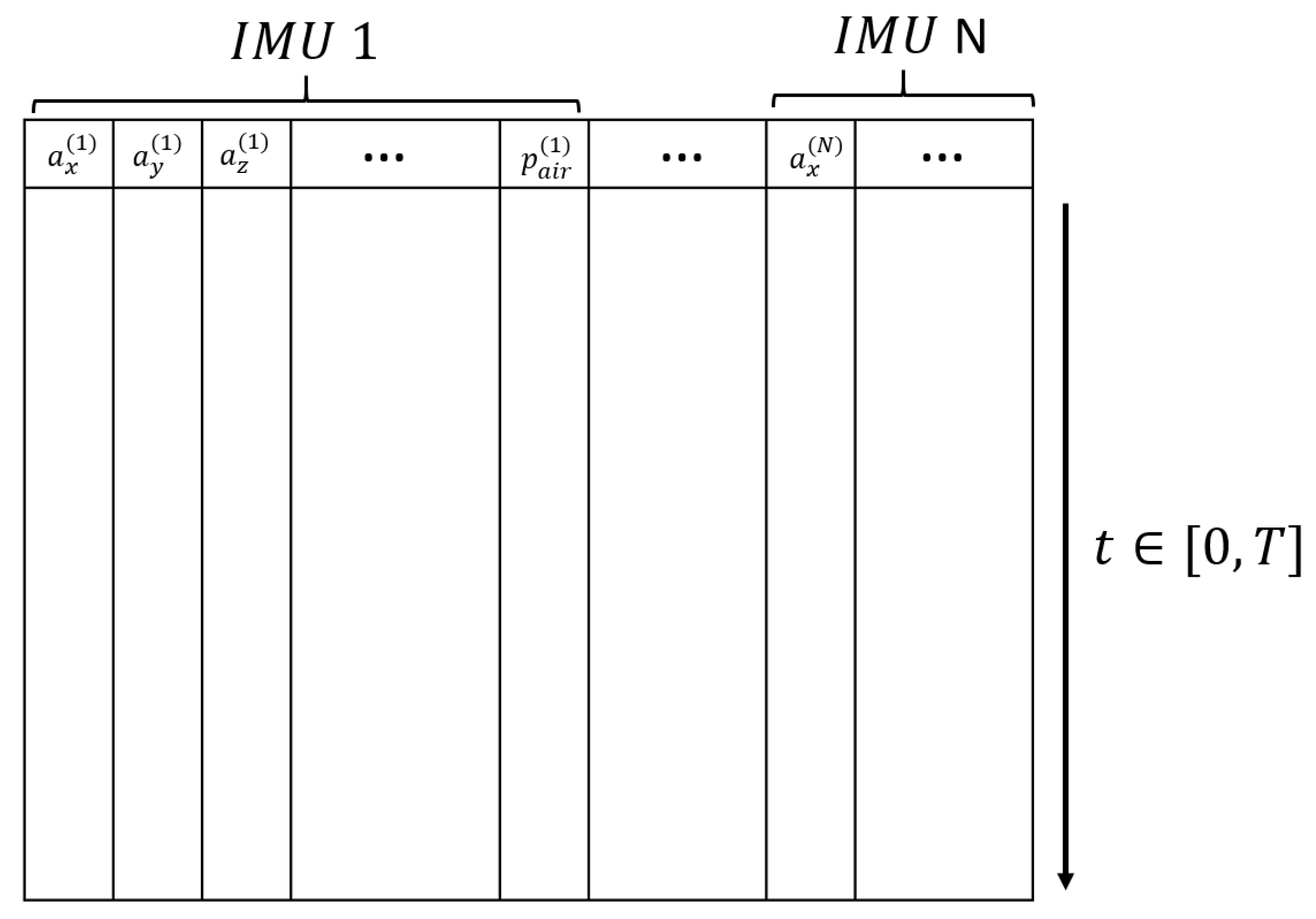
2.1. Inertial Measurement Units and Sensor Setup
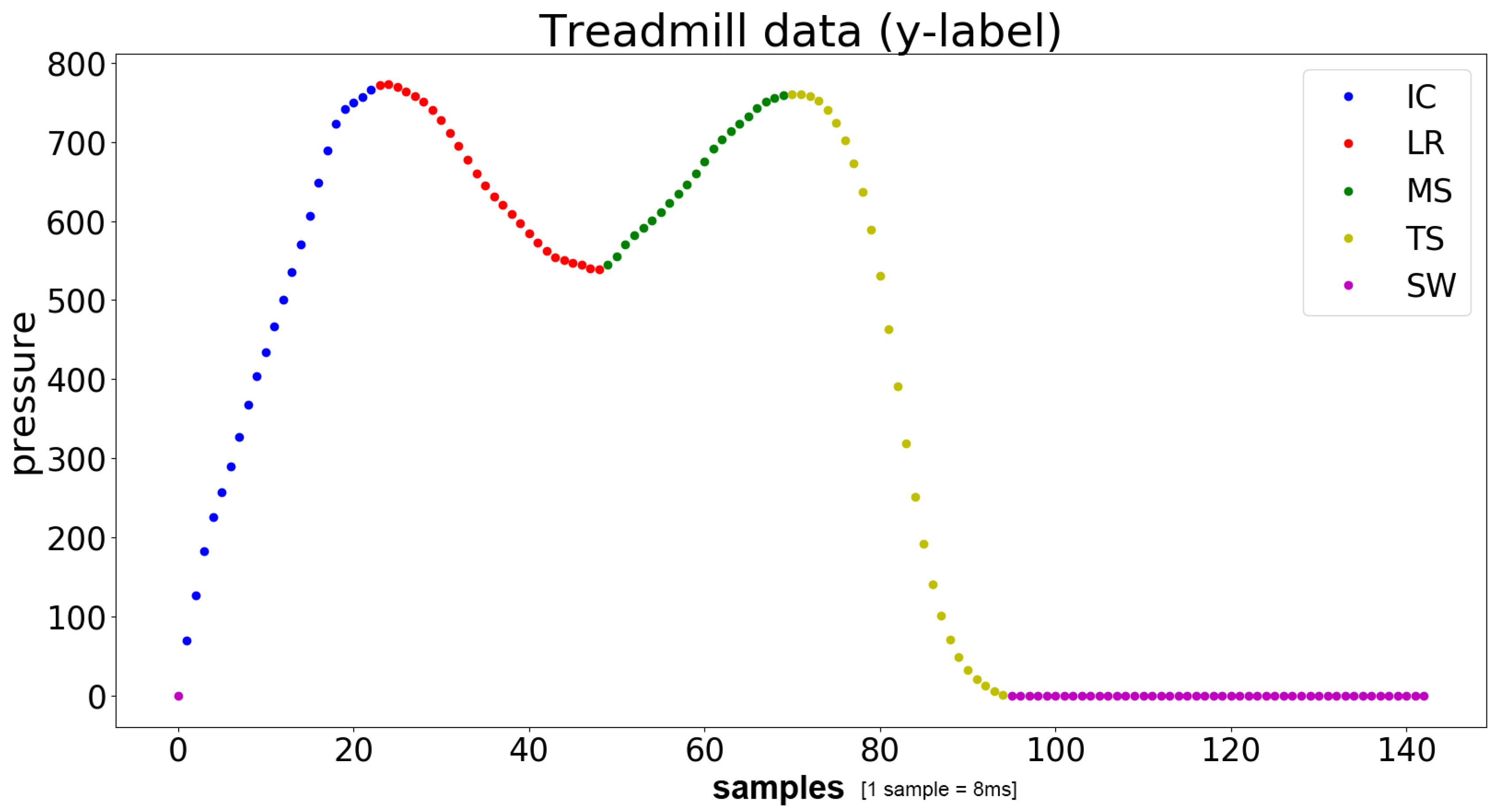
2.2. Label Generation
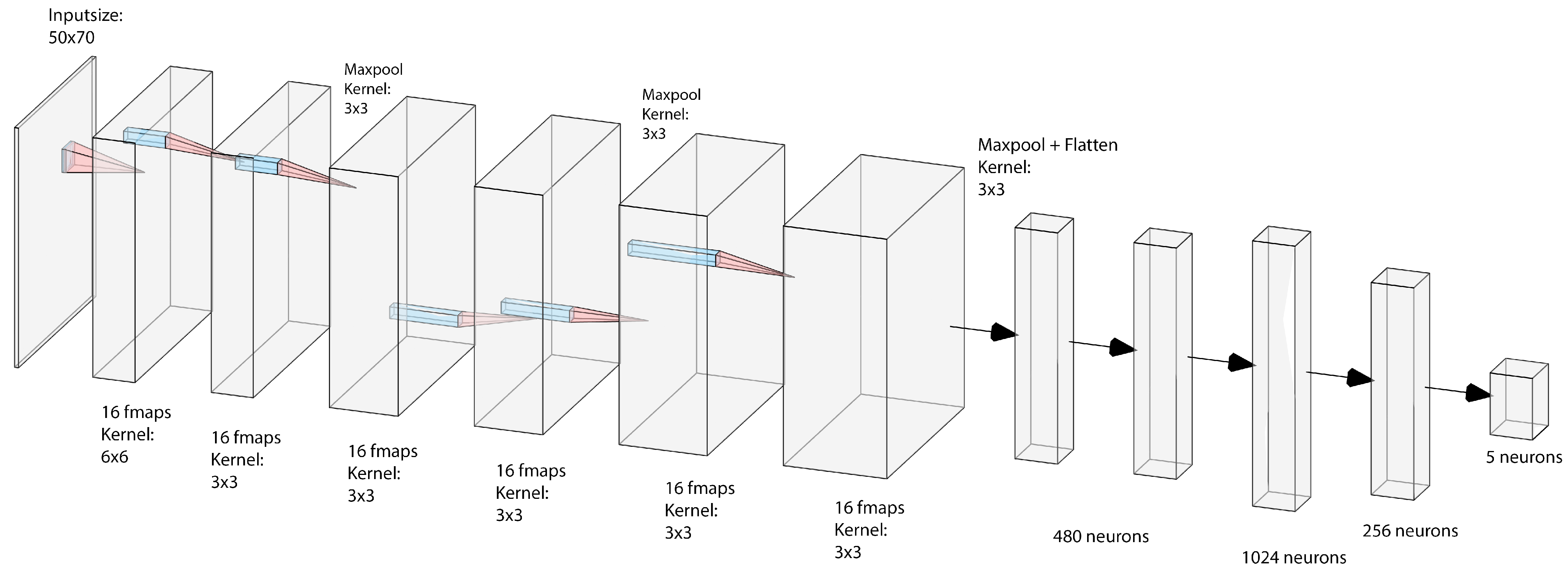
2.3. Deep Neural Network Architecture
2.4. Training the Model
2.5. Hyperparameter Optimization
2.6. Feature Importance and Channel Order
2.7. Network Certainty
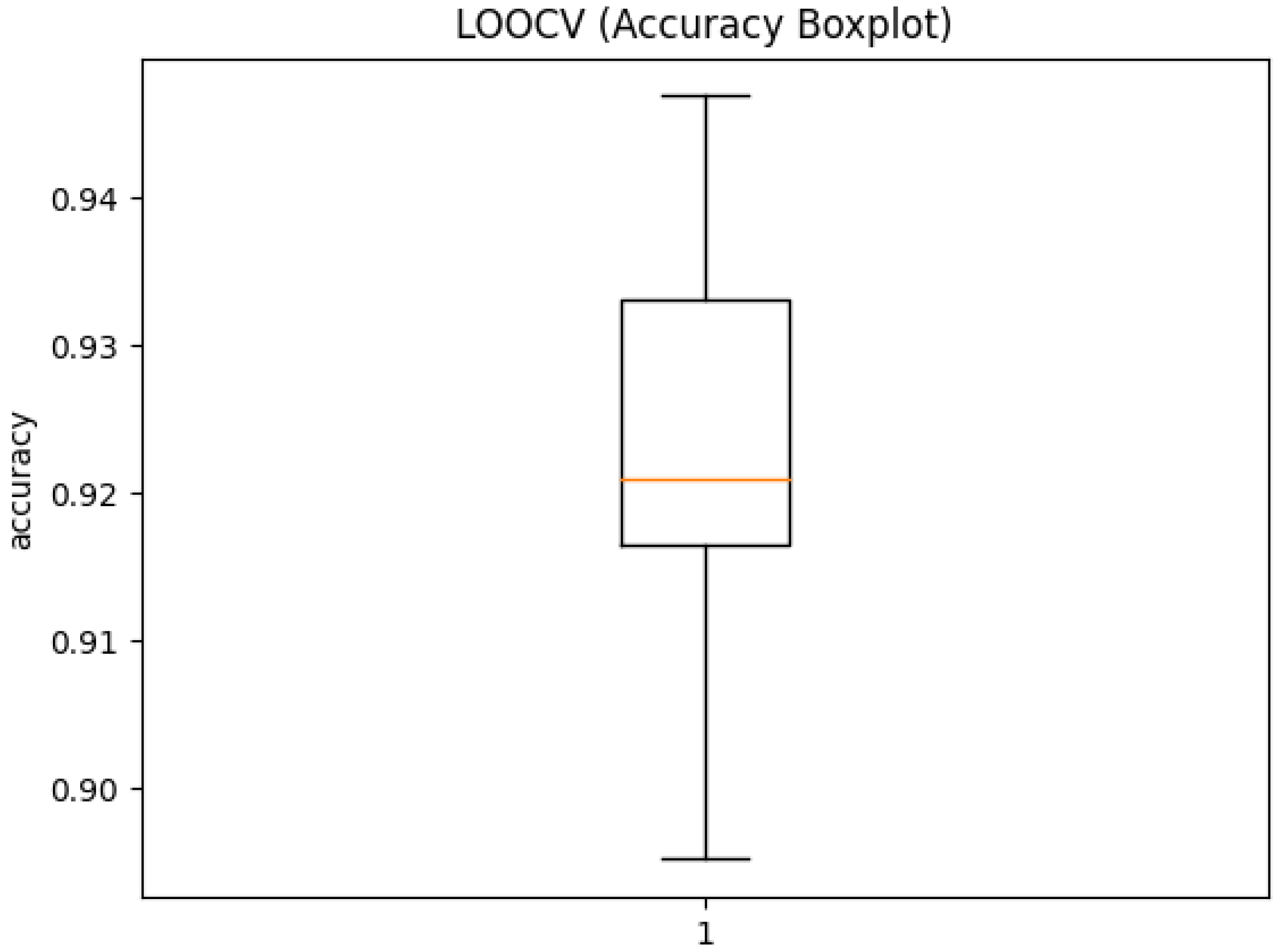
3. Results
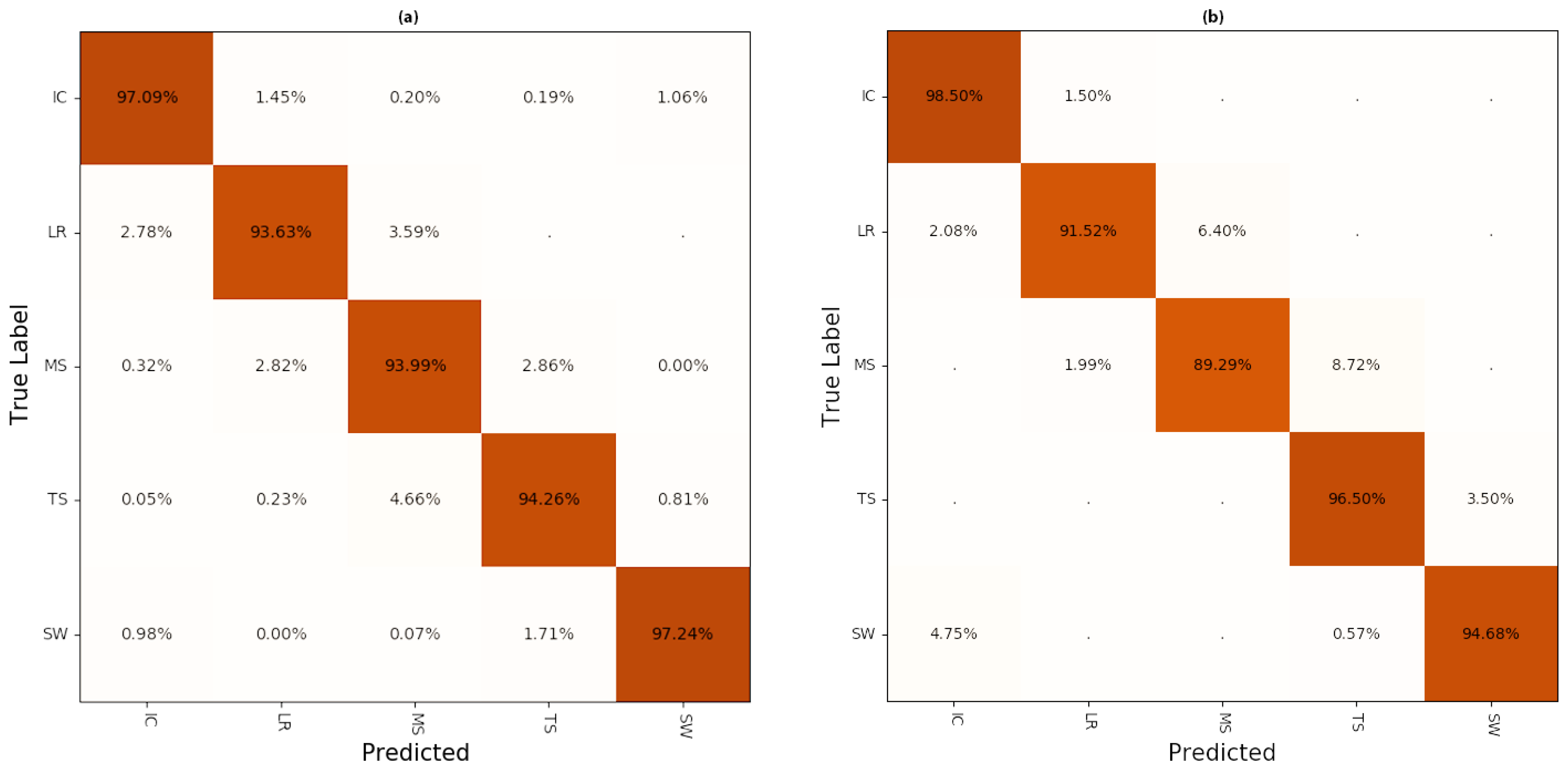
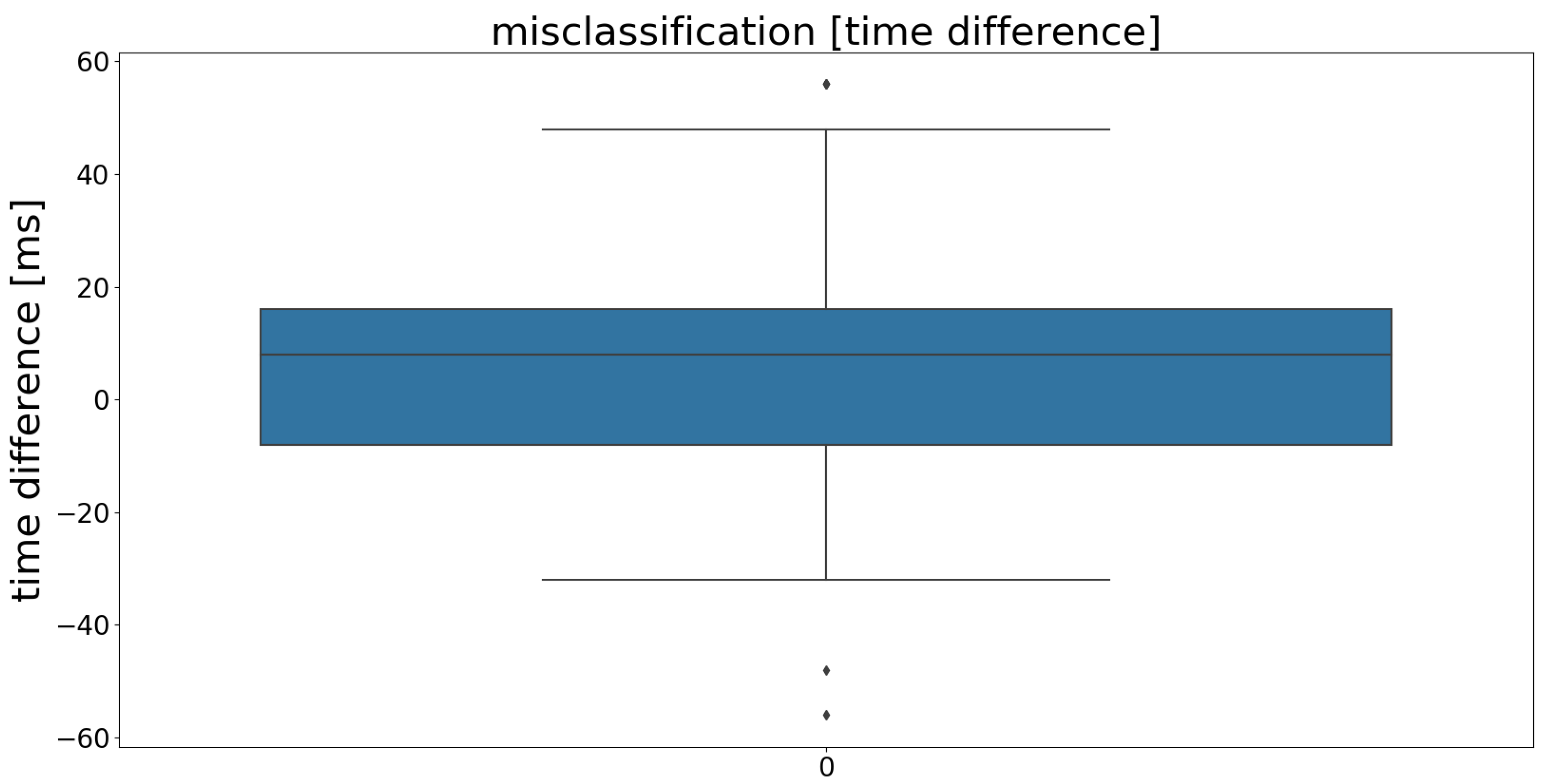
3.1. Misclassification
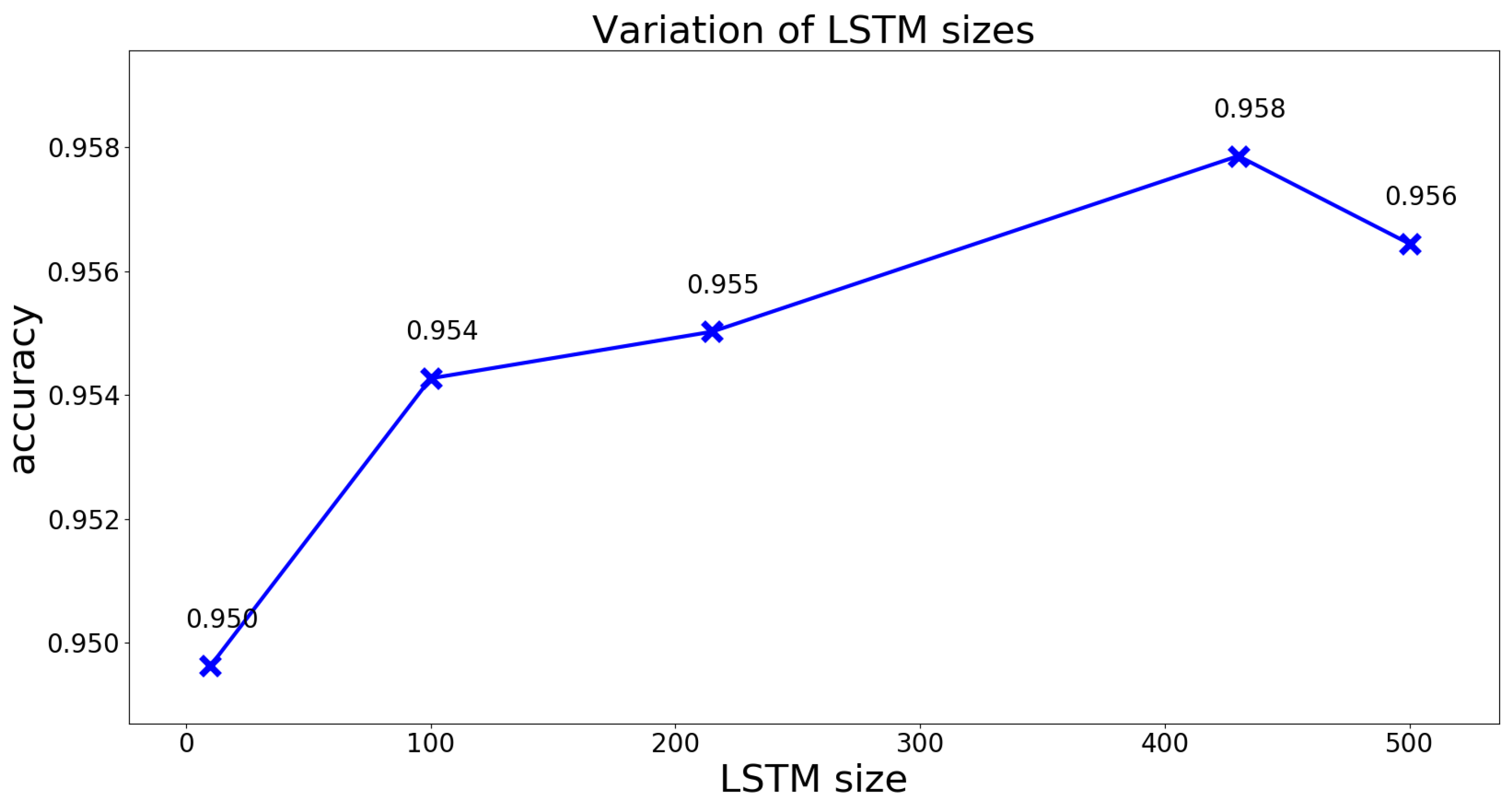
3.2. Hyperparameter Optimization
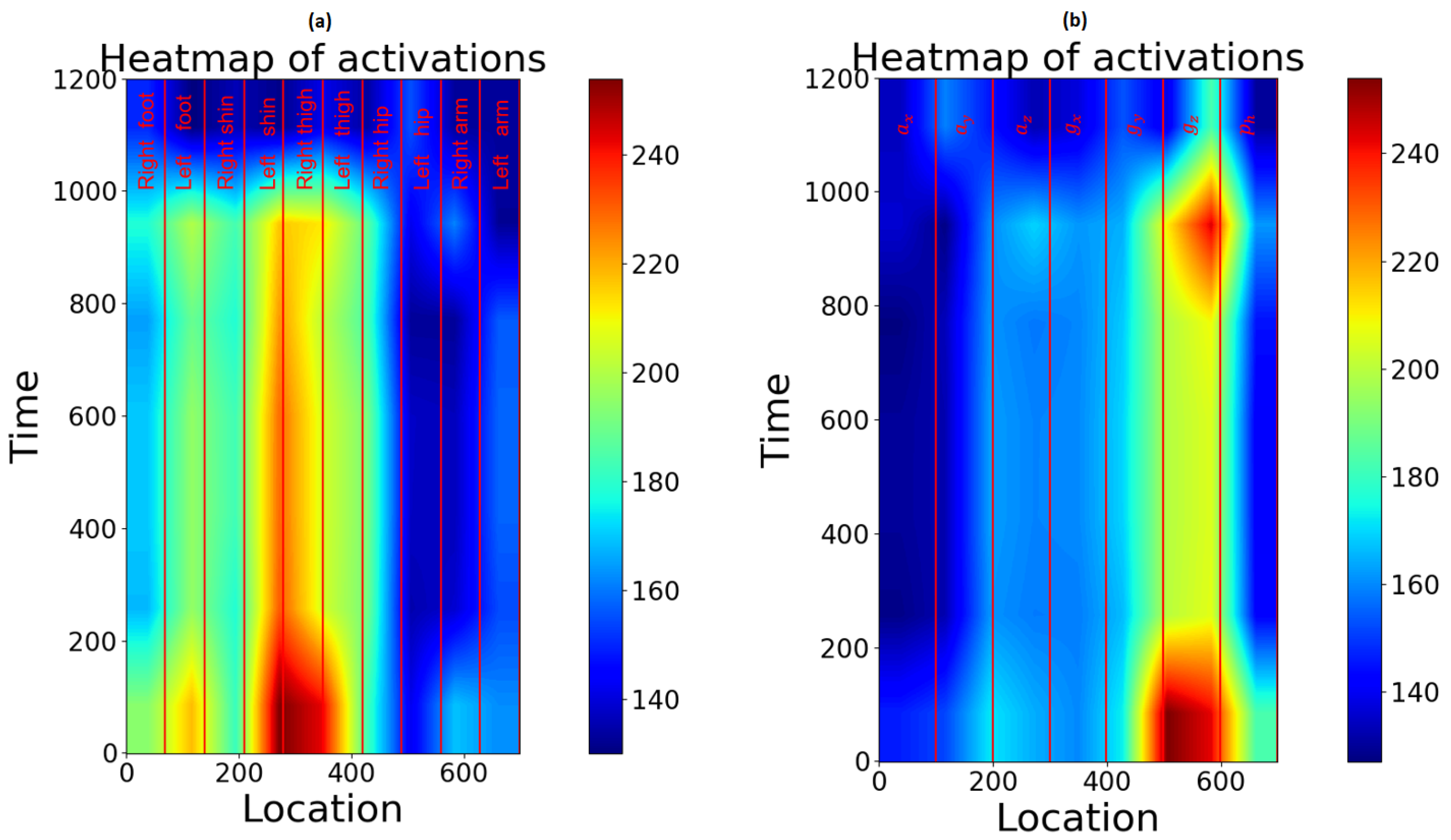
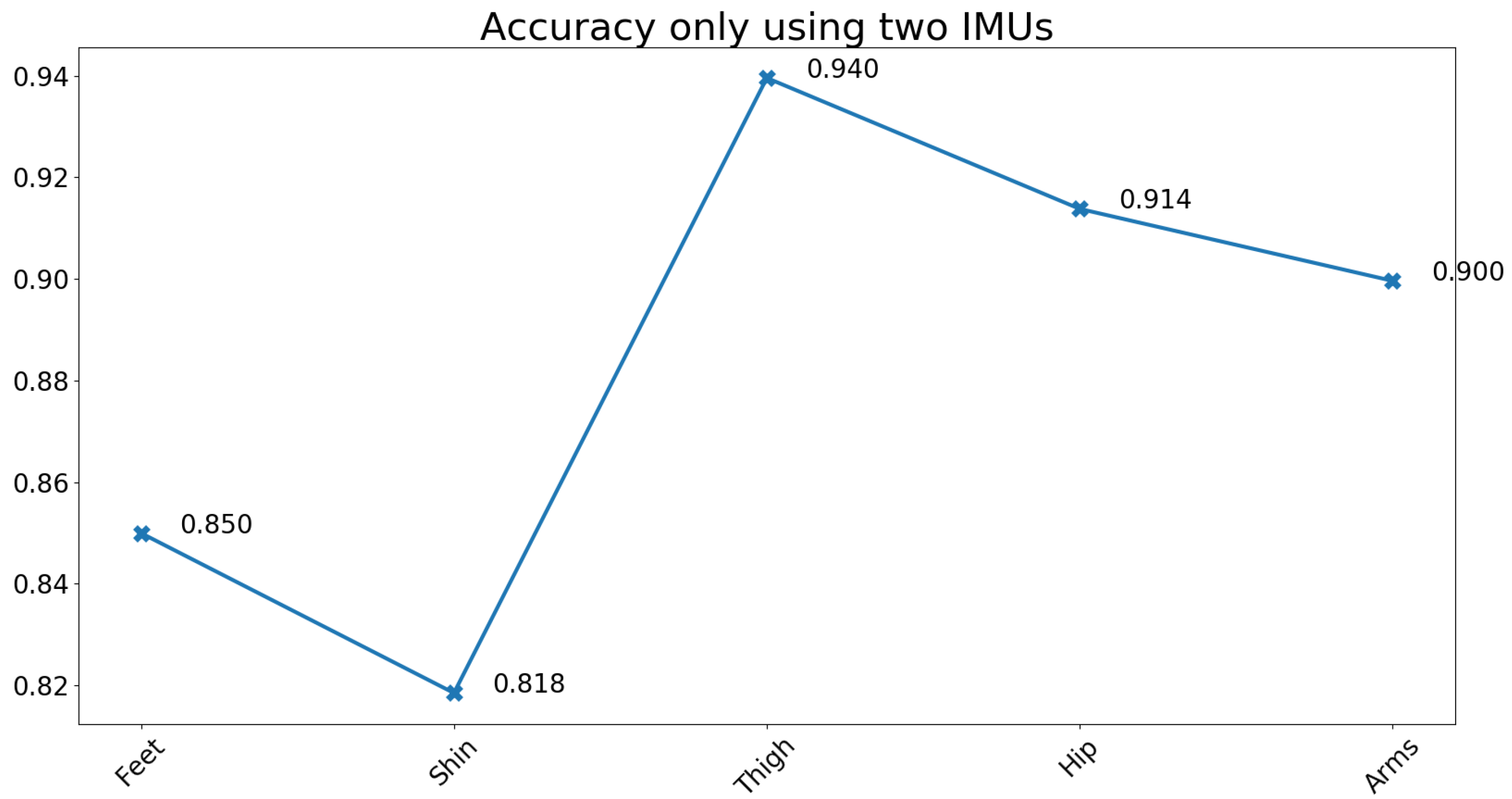
3.3. Feature Importance and Channel Order
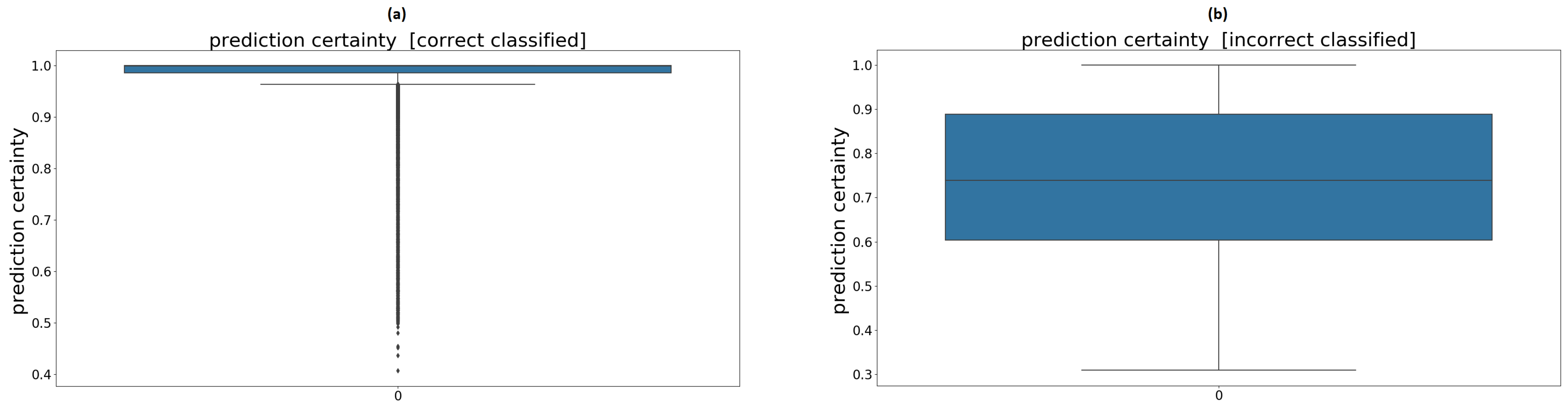
3.4. Network Certainty
4. Discussion
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Y.; Bruijn, S.; Lin, J.; Meijer, O.; Wu, W.; Abbasi-Bafghi, H.; Lin, X.; Van Dieen, J. Gait adaptations in low back pain patients with lumbar disc herniation: Trunk coordination and arm swing. Eur. Spine J. 2010, 20, 491–499. [Google Scholar] [CrossRef]
- Mueske, N.M.; Ounpuu, S.; Ryan, D.D.; Healy, B.S.; Thomson, J.; Choi, P.; Wren, T.A. Impact of gait analysis on pathology identification and surgical recommendations in children with spina bifida. Gait Posture 2019, 67, 12–132. [Google Scholar] [CrossRef]
- Verghese, J.; LeValley, A.; Hall, C.; Katz, M.; Ambrose, A.; Lipton, R. Epidemiology of Gait Disorders in Community-Residing Older Adults. J. Am. Geriatr. Soc. 2006, 54, 255–261. [Google Scholar] [CrossRef]
- Buke, A.; Gaoli, F.; Yongcai, W.; Lei, S.; Zhiqi, Y. Healthcare algorithms by wearable inertial sensors: A survey. China Commun. 2015, 12, 1–12. [Google Scholar] [CrossRef]
- Mannini, A.; Sabatini, A.M. Gait phase detection and discrimination between walking-jogging activities using hidden Markov models applied to foot motion data from a gyroscope. Gait Posture 2012, 36, 657–661. [Google Scholar] [CrossRef]
- Taborri, J.; Rossi, S.; Palermo, E.; Patanè, F.; Cappa, P. A Novel HMM Distributed Classifier for the Detection of Gait Phases by Means of a Wearable Inertial Sensor Network. Sensors 2014, 14, 16212–16234. [Google Scholar] [CrossRef]
- Nguyen, M.D.; Mun, K.; Jung, D.; Han, J.; Park, M.; Kim, J.; Kim, J. IMU-based Spectrogram Approach with Deep Convolutional Neural Networks for Gait Classification. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 4–6 January 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Goršič, M.; Kamnik, R.; Ambrožič, L.; Vitiello, N.; Lefeber, D.; Pasquini, G.; Munih, M. Online Phase Detection Using Wearable Sensors for Walking with a Robotic Prosthesis. Sensors 2014, 14, 2776–2794. [Google Scholar] [CrossRef] [PubMed]
- Zebin, T.; Peek, N.; Casson, A.; Sperrin, M. Human activity recognition from inertial sensor time-series using batch normalized deep LSTM recurrent networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar] [CrossRef]
- Vaith, A.; Taetz, B.; Bleser, G. Uncertainty based active learning with deep neural networks for inertial gait analysis. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Moya Rueda, F.; Grzeszick, R.; Fink, G.; Feldhorst, S.; Hompel, M. Convolutional Neural Networks for Human Activity Recognition Using Body-Worn Sensors. Informatics 2018, 5, 26. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Wang, Y.; Zhao, Y.; Wang, Q.; Shen, C.; Li, Q. Deep Learning Based Gait Recognition Using Smartphones in the Wild. arXiv 2018, arXiv:abs/1811.00338. [Google Scholar]
- Martinez-Hernandez, U.; Solis, A.R.; Dehghani, A. Recognition of Walking Activity and Prediction of Gait Periods with a CNN and First-Order MC Strategy. In Proceedings of the 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 897–902. [Google Scholar]
- Jeon, H.; Kim, S.L.; Kim, S.; Lee, D. Fast Wearable Sensor–Based Foot–Ground Contact Phase Classification Using a Convolutional Neural Network with Sliding-Window Label Overlapping. Sensors 2020, 20, 4996. [Google Scholar] [CrossRef]
- Coviello, G.; Avitabile, G.; Florio, A. A Synchronized Multi-Unit Wireless Platform for Long-Term Activity Monitoring. Electronics 2020, 9, 1118. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network. arXiv 2018, arXiv:abs/1808.03314. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; Curran Associates Inc.: Red Hook, NY, USA, 3–8 December 2012; pp. 1097–1105.
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS’10), Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. arXiv 2017, arXiv:abs/1706.04599. [Google Scholar]
- Berrar, D. Cross-Validation; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Subject (Left Out) | Accuracy |
|---|---|
| subject 1 | 0.9218 |
| subject 2 | 0.9469 |
| subject 3 | 0.9204 |
| subject 4 | 0.9428 |
| subject 5 | 0.9451 |
| subject 6 | 0.9209 |
| subject 7 | 0.9161 |
| subject 8 | 0.9020 |
| subject 9 | 0.8952 |
| subject 10 | 0.9168 |
| subject 11 | 0.9234 |
| Accepted Offset to the True Class | 0 Time Frames | 1 Time Frame | 2 Time Frames | 3 Time Frames |
|---|---|---|---|---|
| (0 ms) | (8 ms) | (16 ms) | (24 ms) | |
| accuracy | 0.9353 | 0.9422 | 0.9740 | 0.9907 |
| Threshold 0.8 | Threshold 0.9 | |
|---|---|---|
| accuracy (certainty > threshold) | 0.9790 | 0.9880 |
| unknown samples (amount) | 2408 | 3866 |
| correct → unknown (amount) | 1544 | 2757 |
| misclassified → unknown (amount) | 864 | 1109 |
| unknown samples (% of all samples) | 0.0882 | 0.1416 |
| correct → unknown (% of all correct samples) | 0.05969 | 0.1066 |
| misclassified → unknown (% of all false samples) | 0.6017 | 0.7723 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kreuzer, D.; Munz, M. Deep Convolutional and LSTM Networks on Multi-Channel Time Series Data for Gait Phase Recognition. Sensors 2021, 21, 789. https://doi.org/10.3390/s21030789
Kreuzer D, Munz M. Deep Convolutional and LSTM Networks on Multi-Channel Time Series Data for Gait Phase Recognition. Sensors. 2021; 21(3):789. https://doi.org/10.3390/s21030789
Chicago/Turabian StyleKreuzer, David, and Michael Munz. 2021. "Deep Convolutional and LSTM Networks on Multi-Channel Time Series Data for Gait Phase Recognition" Sensors 21, no. 3: 789. https://doi.org/10.3390/s21030789
APA StyleKreuzer, D., & Munz, M. (2021). Deep Convolutional and LSTM Networks on Multi-Channel Time Series Data for Gait Phase Recognition. Sensors, 21(3), 789. https://doi.org/10.3390/s21030789