1. Introduction
Intelligent transportation systems aim to improve traffic efficiency, safety, and driver comfort in various situations [
1,
2,
3]. As an essential element of intelligent transportation systems, intelligent vehicles have potentials to help traffic participants make effective decisions for driving safely and efficiently. Most driver assistance systems are developed to ensure and improve driving safety in specific critical environments [
1], which requires a clear and comprehensive understanding of driving behavior to achieve a high level of intelligence [
4]. An accurate driving behavior prediction can leave sufficient time for driver assistance systems to deliver a warning to the driver or for autonomous systems to directly take over the vehicle to ensure traffic safety [
1]. Many researchers focus on driving behavior prediction regarding elements, such as motion, gaze behavior, and intention [
5,
6,
7,
8]. Ref. [
9] proposed a new evolving fuzzy systems method based on adaptive fuzzy pattern classification for the detecting the lane-change intention of a driver. Ref. [
10] applied non-linear polynomial regression and recurrent hidden semi-Markov model to realize the recognition of driver lane-change intention. Here, we focus on predicting driving behaviors such as lateral and longitudinal behaviors. Some mature model-based methods have been used for prediction such as dynamic Bayesian networks, support vector machine, and hidden Markov models [
11,
12,
13,
14]. For example, Kumagai presents a driving behavior prediction method based on dynamic Bayesian networks and shows good prediction results for stop behavior [
15]. A prediction approach based on a dynamic Bayesian network is proposed for lane-change maneuvers and also shows good accuracy [
16]. Ref. [
17] develops a prediction method for lane-change maneuver of the vehicle ahead by using a hidden Markov model, and result shows that the model can achieve a high accuracy rate. However, model-based methods cannot adapt to the infinite complexity of driving behaviors.
Fortunately, the data-driven methods, such as artificial neural networks (ANNs), have been widely used for driving behavior prediction because of their flexible structures and powerful capability to describe non-linearity [
18,
19,
20,
21]. For instance, ref. [
19] used three variables (safe speed, workload, and yaw rate) as the inputs to predict a safe speed in curve negotiation based on a two-layer back propagation (BP) neural network. In addition, the ANNs were also used to predict upcoming lane change behavior by considering three phases including lane change intention, preparation, and action [
20]. Although significant achievements have been made, the existing ANN-based methods, such as BP and Radial Basis Function (RBF) neural network showed a limited accuracy in driving behavior learning and prediction because of their shallow architecture and manually-selected features [
19,
22,
23].
The advanced on-board sensors allow obtaining plentiful data, which enables some data-hungry techniques to be practicable such as deep learning. Deep learning has attracted full attention because of its capability to automatically and genuinely extract features [
24,
25,
26,
27]. Many recent works on driving behavior prediction are primarily based on the image or video data from cameras [
28,
29,
30,
31]. For instance, researchers of [
1,
32] used raw images and human driving videos from camera to predict different driver actions including steering and braking/acceleration based on a recurrent neural network (RNN). Ref. [
33] exploited a convolutional neural network (CNN) to extract features in a scene understanding subsystem for decision-making with considering the features from images. Ref. [
34] proposed a novel method to predict lane-change maneuvers in highway scenarios by using deep learning and visual representations of the traffic scene. Additionally, some scholars studied driving behavior using mobile-based signals, for example, ref. [
35,
36,
37]. However, the majority research above relied on image data rather than focused on the deep end-to-end network based on the data from on-board sensors for driving behavior prediction. CNN is also widely used in a wide range of image-related research work due to its powerful convolution structure in image feature extraction and recognition. It is suitable for dealing with 2-D data such as image data, but not suitable for working on the data obtained from on-board sensors [
38].
Some existing works used the real-time and historical data collected from on-board sensors to predict driving behaviors [
39]. For example, ref. [
26] took road geometry, historical traffic information, and driver specific speed as inputs of a deep network stacked autoencoder to predict current vehicle speed. Based on the historical sensory data collected from natural driving, the structural RNN can predict the forthcoming lane-change behaviors of surrounding vehicles in 1∼3 s ahead [
27]. Ref. [
40] proposed a new model to predict the lane-change maneuvers by considering the historical information and neighbor vehicles’ information. Driving behavior prediction should be not only based on the understanding of traffic information but also based on the learning of driving control behavior of human drivers to realize a high level of intelligence. However, the research above did not take both human driver actions and environmental behaviors into consideration to predict the future behavior of the ego vehicle.
Although the deep learning models can extract more features than shallow ones, the above existing methods only separately predict longitudinal and lateral behaviors. For example, ref. [
26] focuses on the longitudinal while [
27] focuses on lane change behavior. Ref. [
1] predicted lane change, steering, acceleration, and braking, but the predictions of longitudinal and lateral behaviors are conducted regardless of their mutual relationship. Among all deep learning methods, the deep belief network (DBN) is relatively effective [
41], and most of the applications based on DBN were classification [
42]. Then, researchers applied DBN into traffic flow prediction [
43]. For example, ref. [
41] predicted the traffic flow using DBN with multitask learning, which proves the deep model can achieve much high prediction accuracy for traffic flow. Considering the ability of DBN to encode network with multiple layers and avoid over-fitting and local minimum [
26,
41,
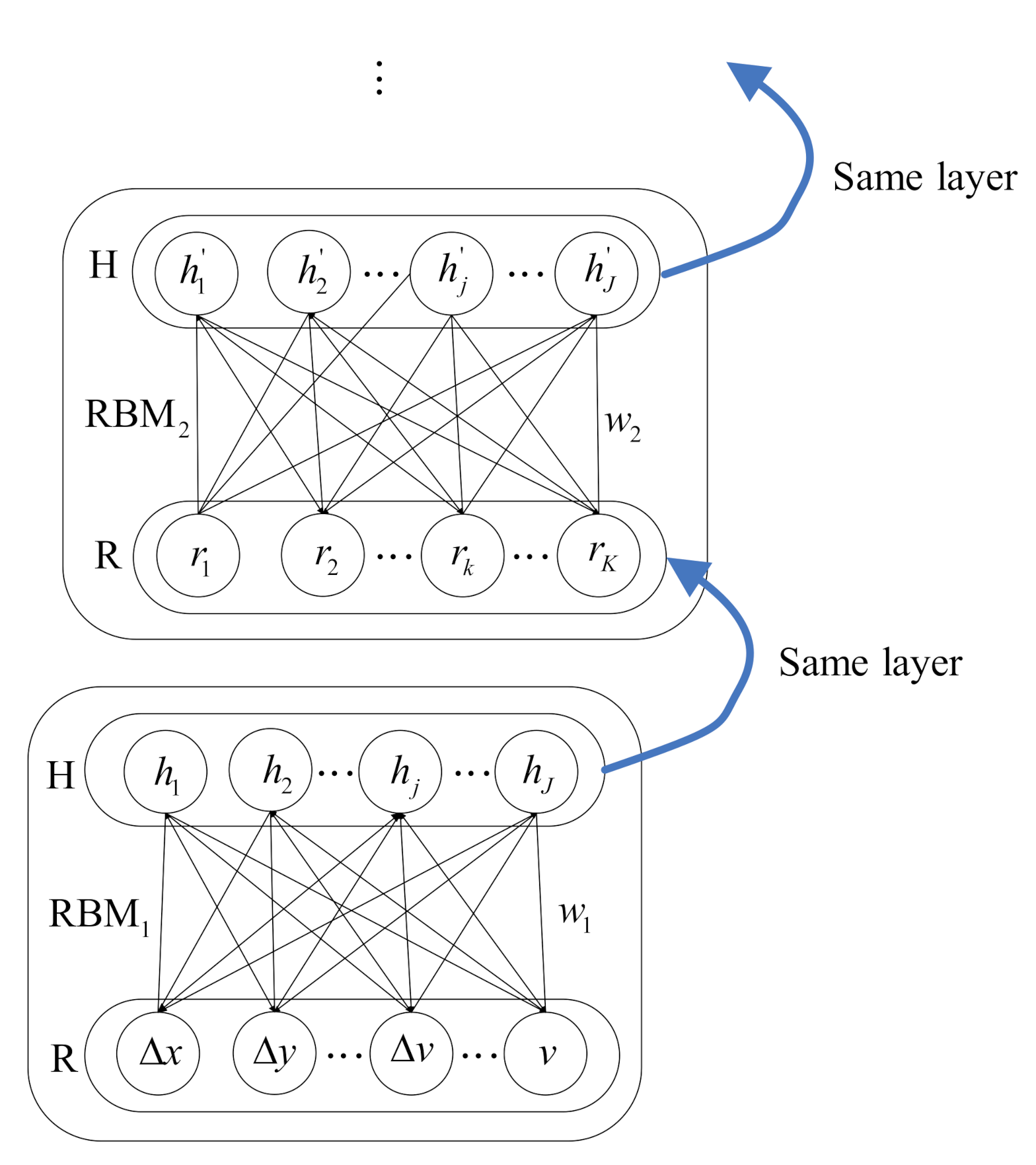
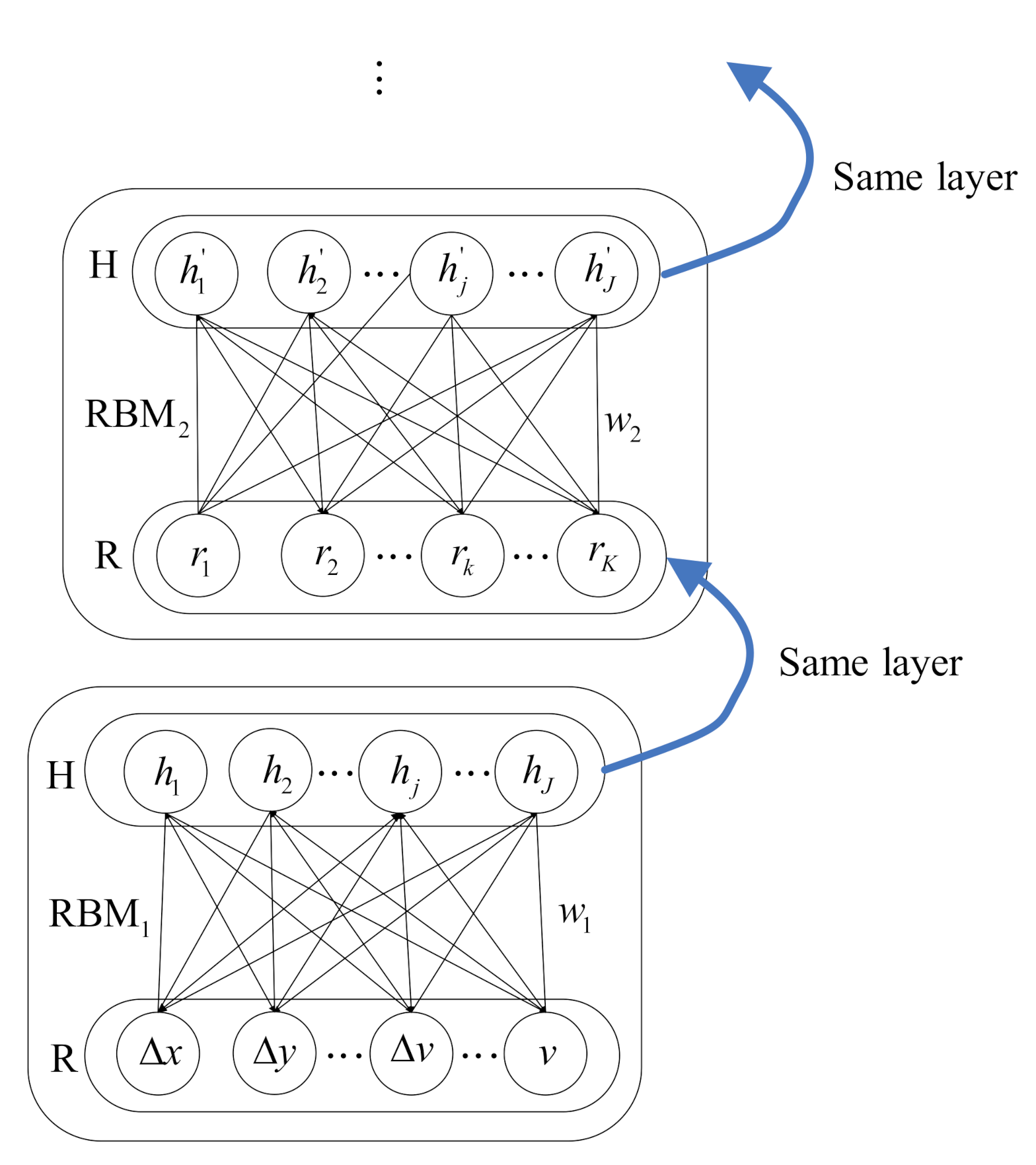
44], this paper attempts to develop a deep structure to predict longitudinal and lateral driving behaviors simultaneously.
In addition, the driving action implemented by the driver does depend on the states of surrounding vehicles. However, the future states of surrounding vehicles are unavailable when predicting the driver’s forthcoming behavior of the ego vehicle. Therefore, most behavior prediction methods are based on historical data without considering the future states of surrounding vehicles [
1,
32,
33]. In this paper, we predict future states of surrounding vehicles by utilizing corresponding historical states. Then, we predict the future maneuver of the ego vehicle based on predicted states of surrounding vehicles and historical multi-sensor data including the states of surrounding vehicles, the ego vehicle, and driver control.
Tackling the problem of behavior prediction can simplify the problem of trajectory prediction and contribute to the decision-making of the vehicle [
27]. From this perspective, this paper demonstrates that the deep learning model based on DBN can extract features to predict and understand the driving behavior and then utilizes the DBN to predict the lateral and longitudinal behaviors of an ego vehicle.
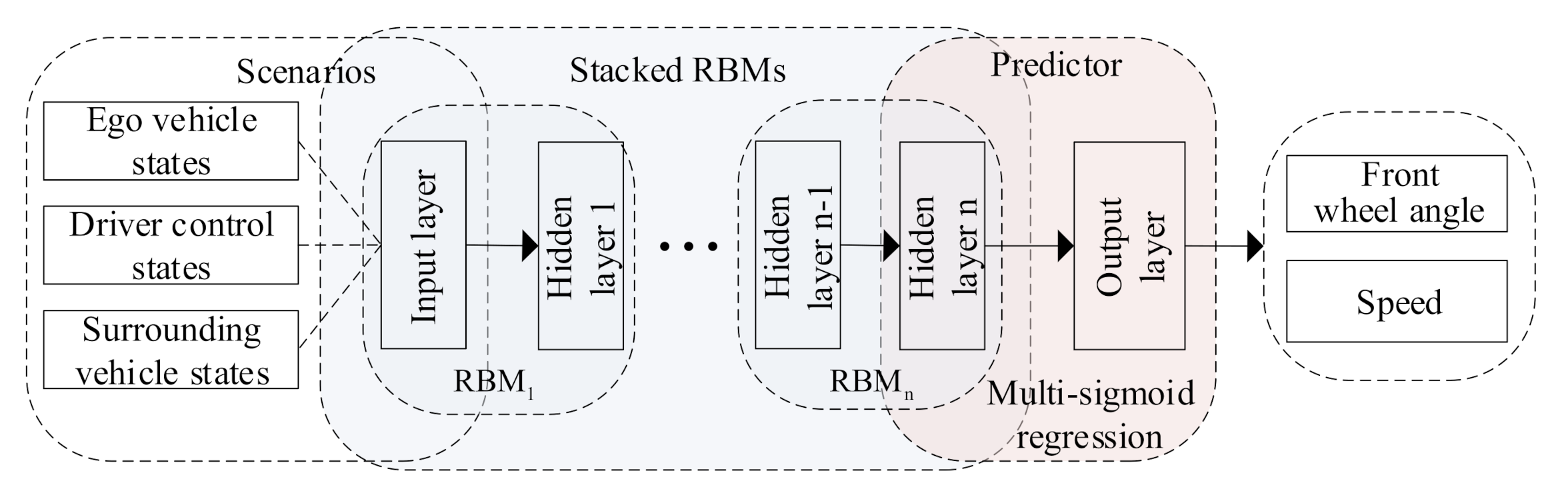
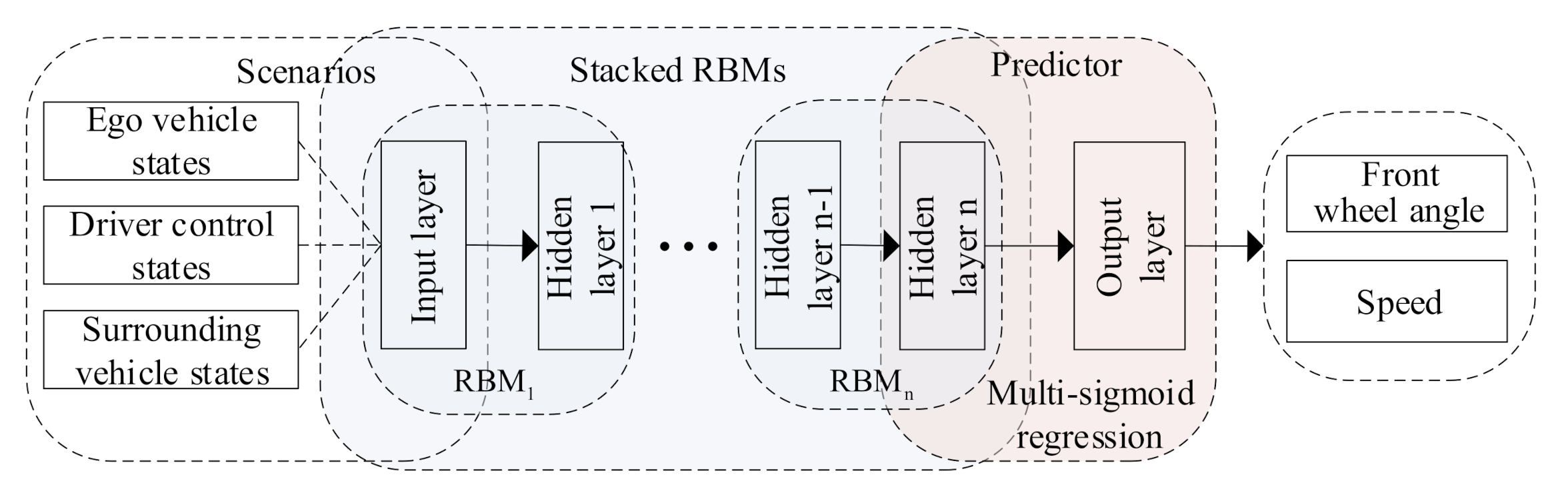
Figure 1 illustrates our proposed driving behavior prediction system, which consists of four modules: data acquisition, data preprocessing, DBN prediction, and result analysis. The main contributions of this paper are in three-fold:
Developing a general prediction system, which allows us to consider real-world data including states of surrounding vehicles and the ego vehicle and the driver’s control inputs simultaneously to predict the driving behavior in an end-to-end way;
Proposing a systematic testing method to obtain optimal parameters of the prediction model;
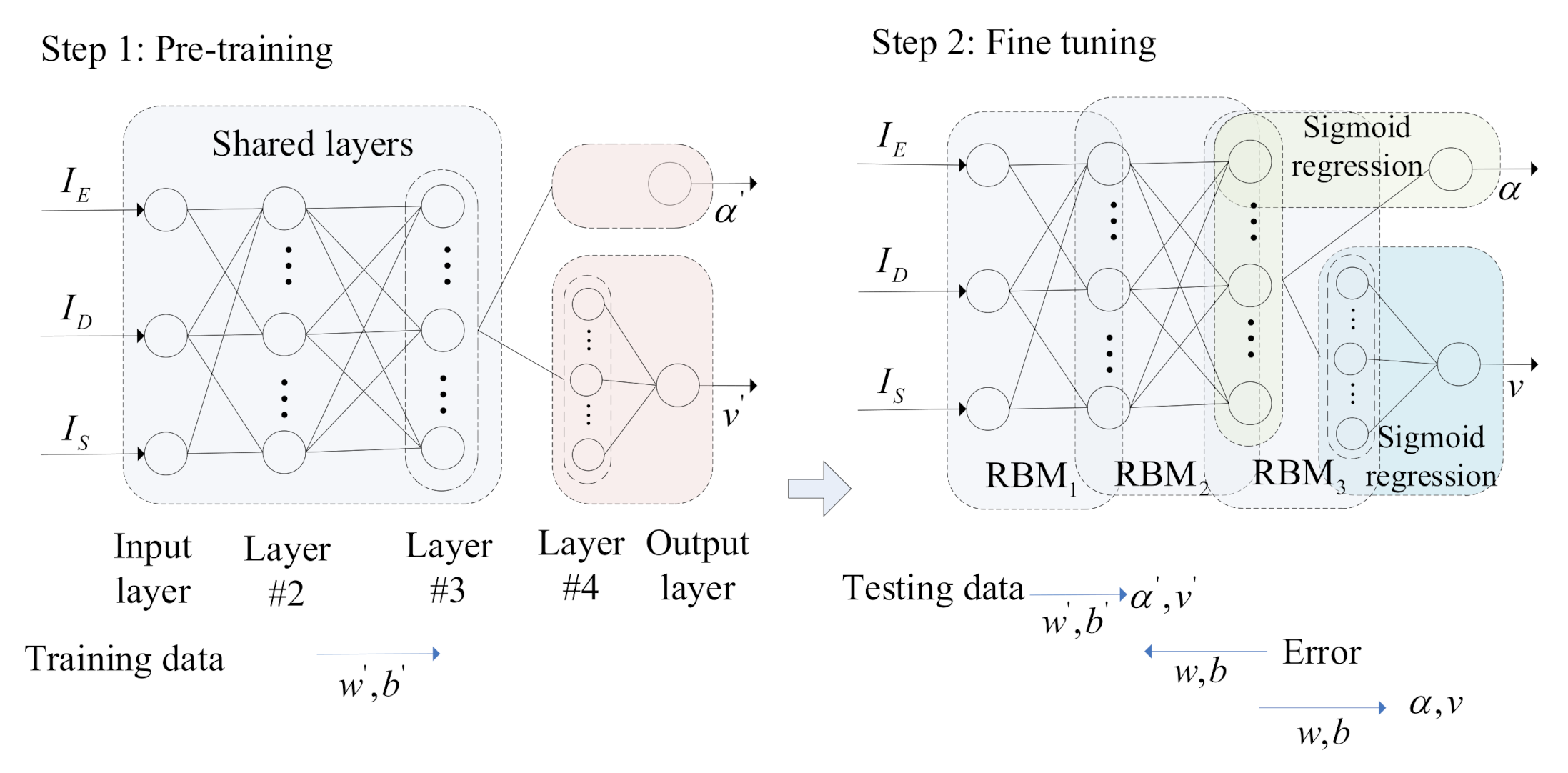
Proposing an MSR-DBN prediction model with a multi-target sigmoid regression layer to realize coupled optimization for lateral and longitudinal behavior prediction.
Figure 1.
Proposed driving behavior prediction system.
Figure 1.
Proposed driving behavior prediction system.
The remainder of the paper is organized as follows.
Section 2 presents the DBN prediction architecture and proposes the MSR-DBN prediction model.
Section 3 presents the data collection and data pre-training for the experiment.
Section 4 shows the experiment process of determining the optimal structure of our proposed model. Then, the prediction results based on MSR-DBN and comparison results are analyzed.
Section 5 gives further discussion and conclusion.
5. Discussion
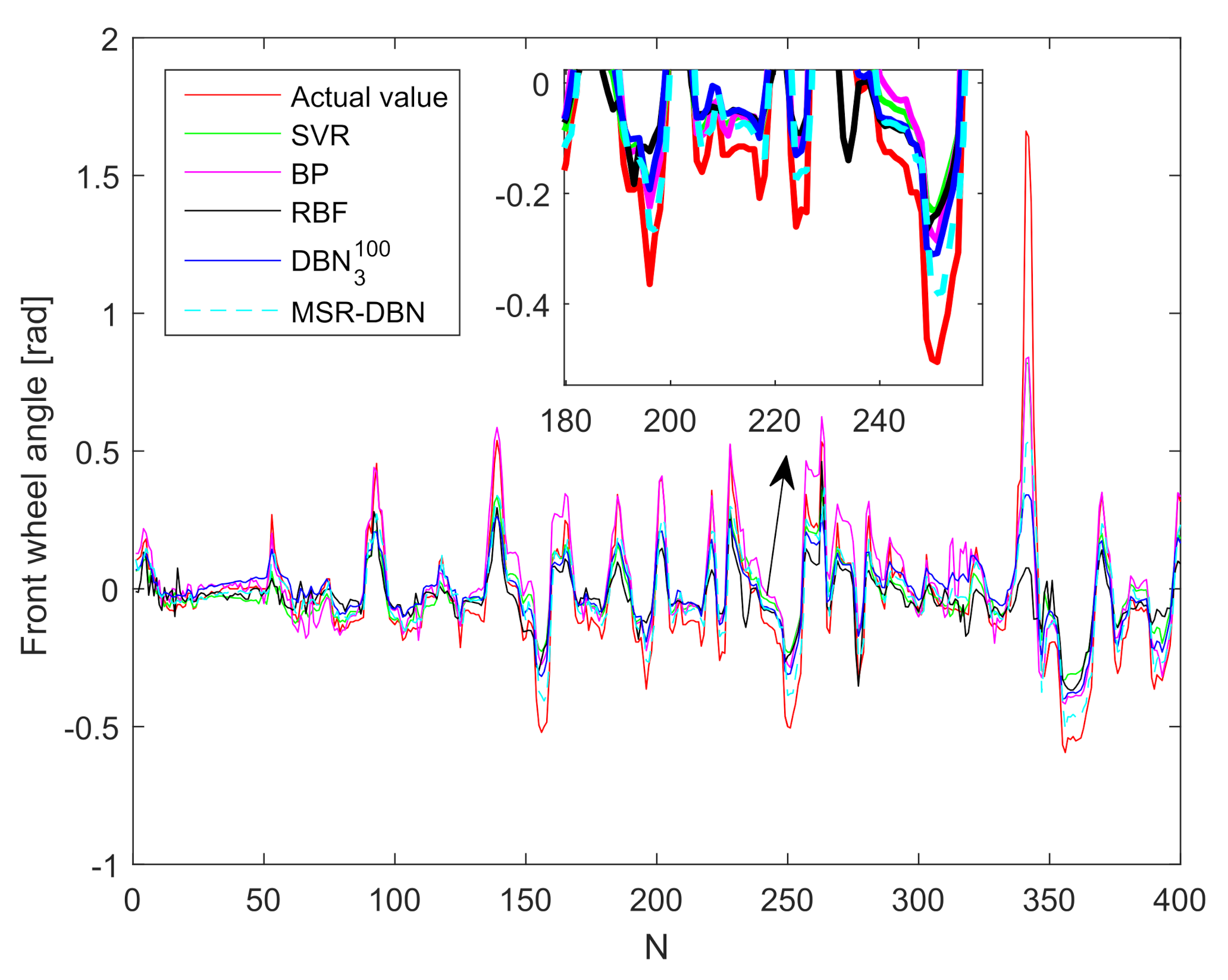
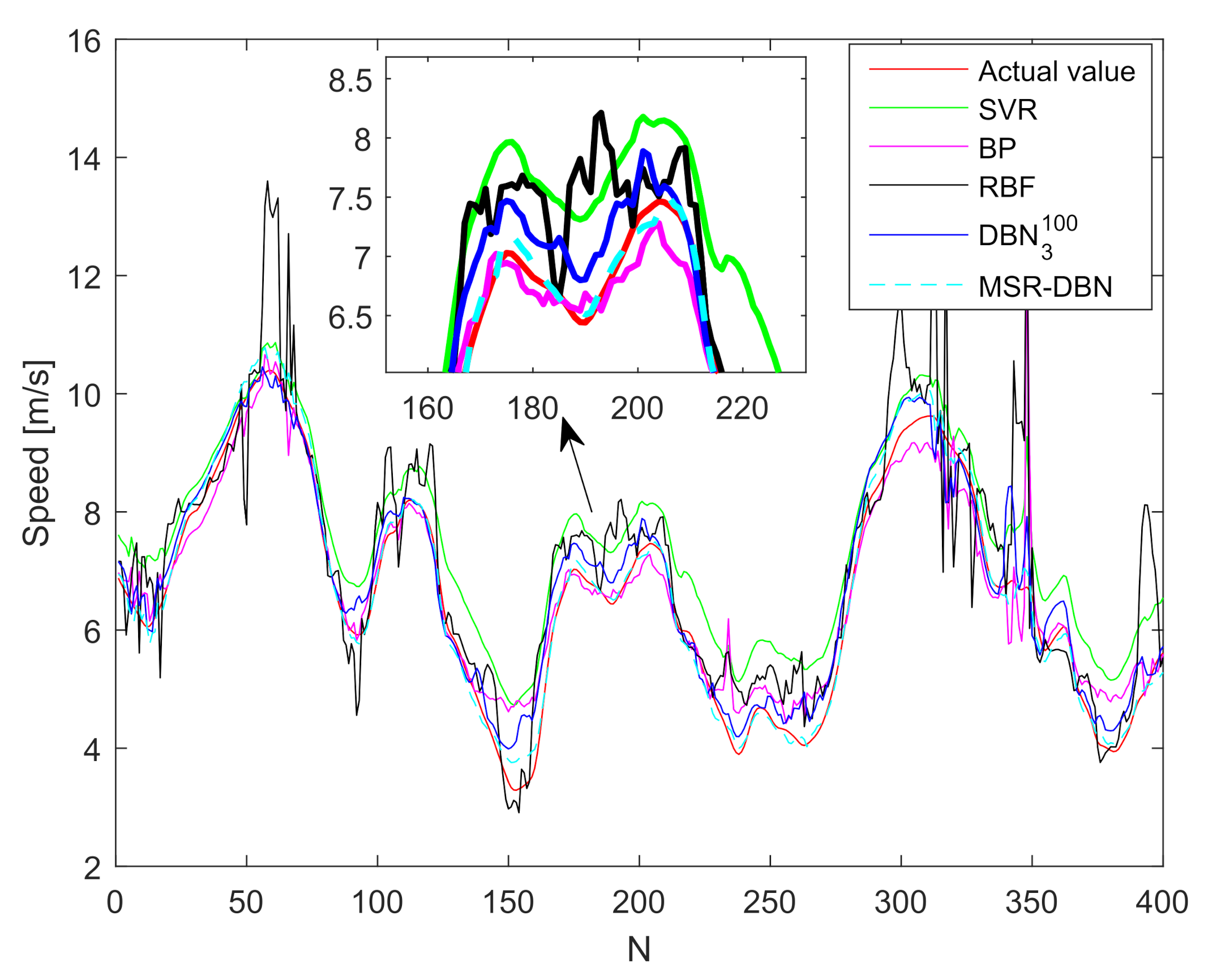
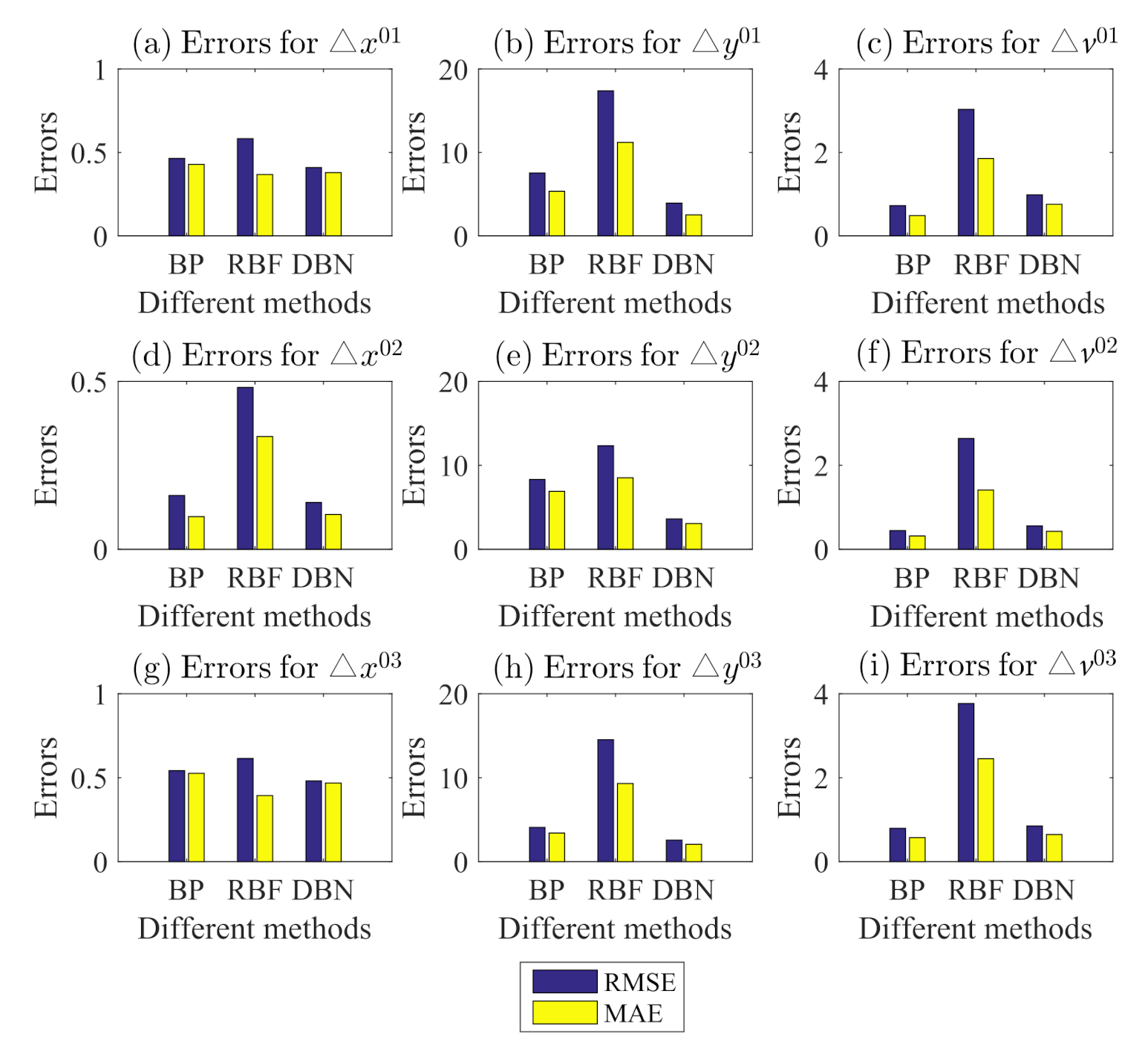
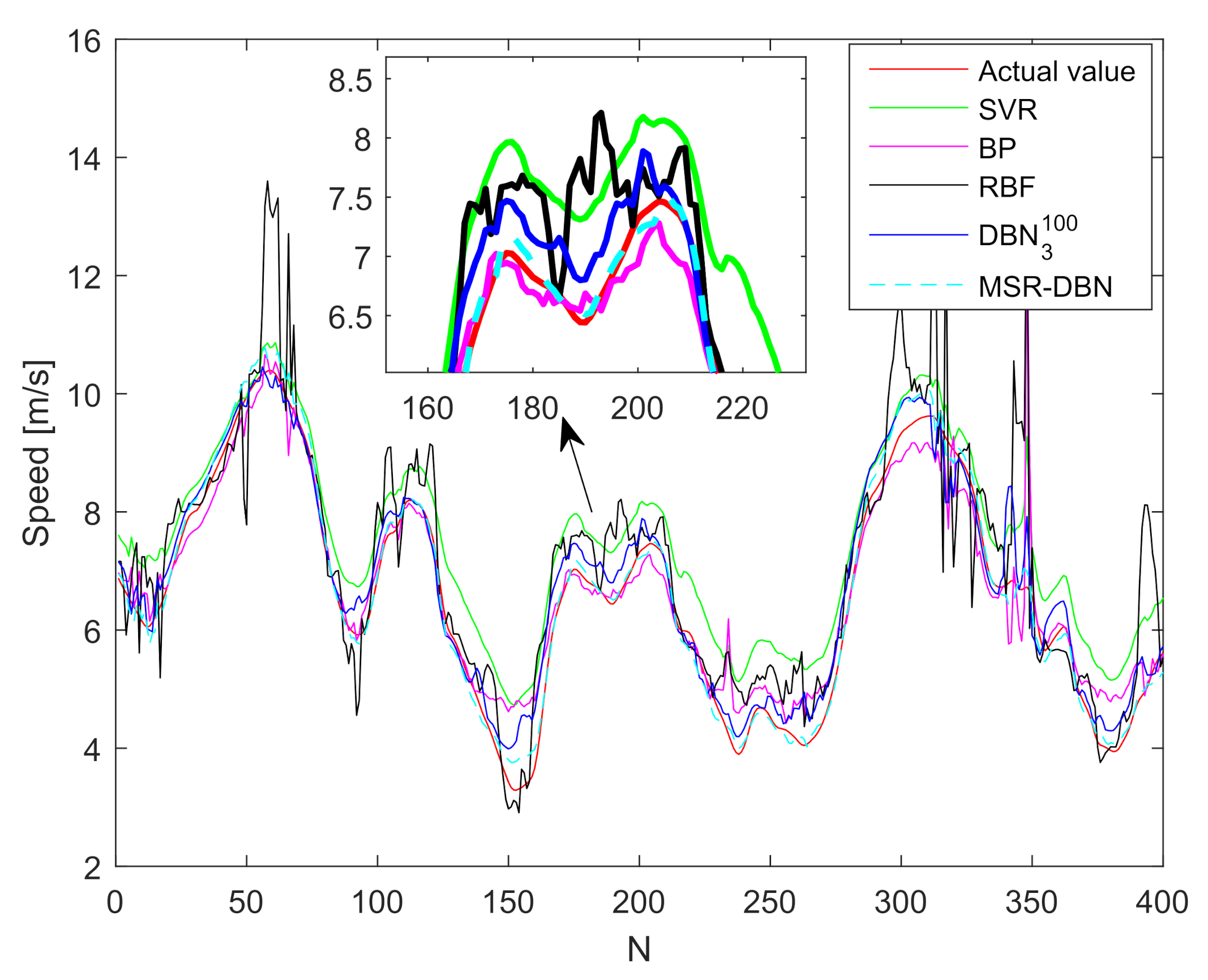
This paper presented a driving behavior prediction system with four sub-systems, data acquisition, data preprocessing, DBN prediction, and result analysis. This system can utilize multi-resource data including states of the ego vehicle, states of driver control, and states of surrounding vehicles. In addition, we used a systematic testing method obtaining an optimal DBN structure and then developed a new DBN (called MSR-DBN, consisting of two sub-networks) by integrating a multi-target sigmoid regression to predict the longitudinal and lateral driving behavior simultaneously. A series of comparison results demonstrate that our proposed MSR-DBN can reduce the prediction errors of the speed and front wheel angle with more stable performance and higher accuracy for driving behavior.
Although our proposed MSR-DBN shows promising results, there still exist some work to improve further prediction performance, such as increasing more data. Additionally, more complex predictions will be conducted in the near future such as real-time behavior prediction, specific behavior prediction in different scenarios, and interaction behavior prediction.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}