
A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method



Abstract
:1. Introduction
2. The Construction of the Dataset
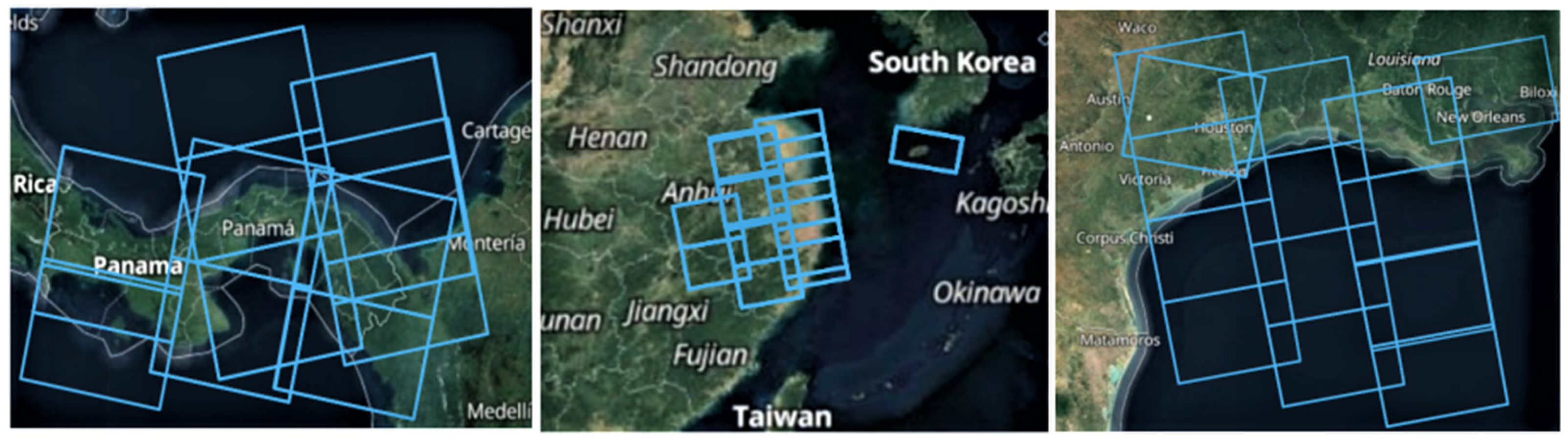
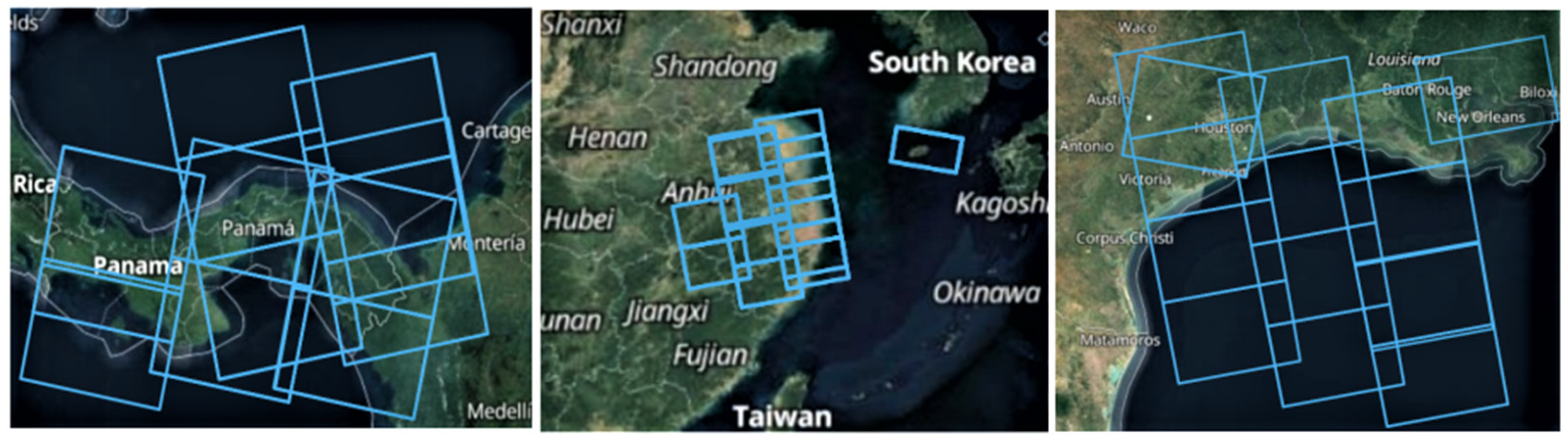
2.1. The Original SAR Imageries
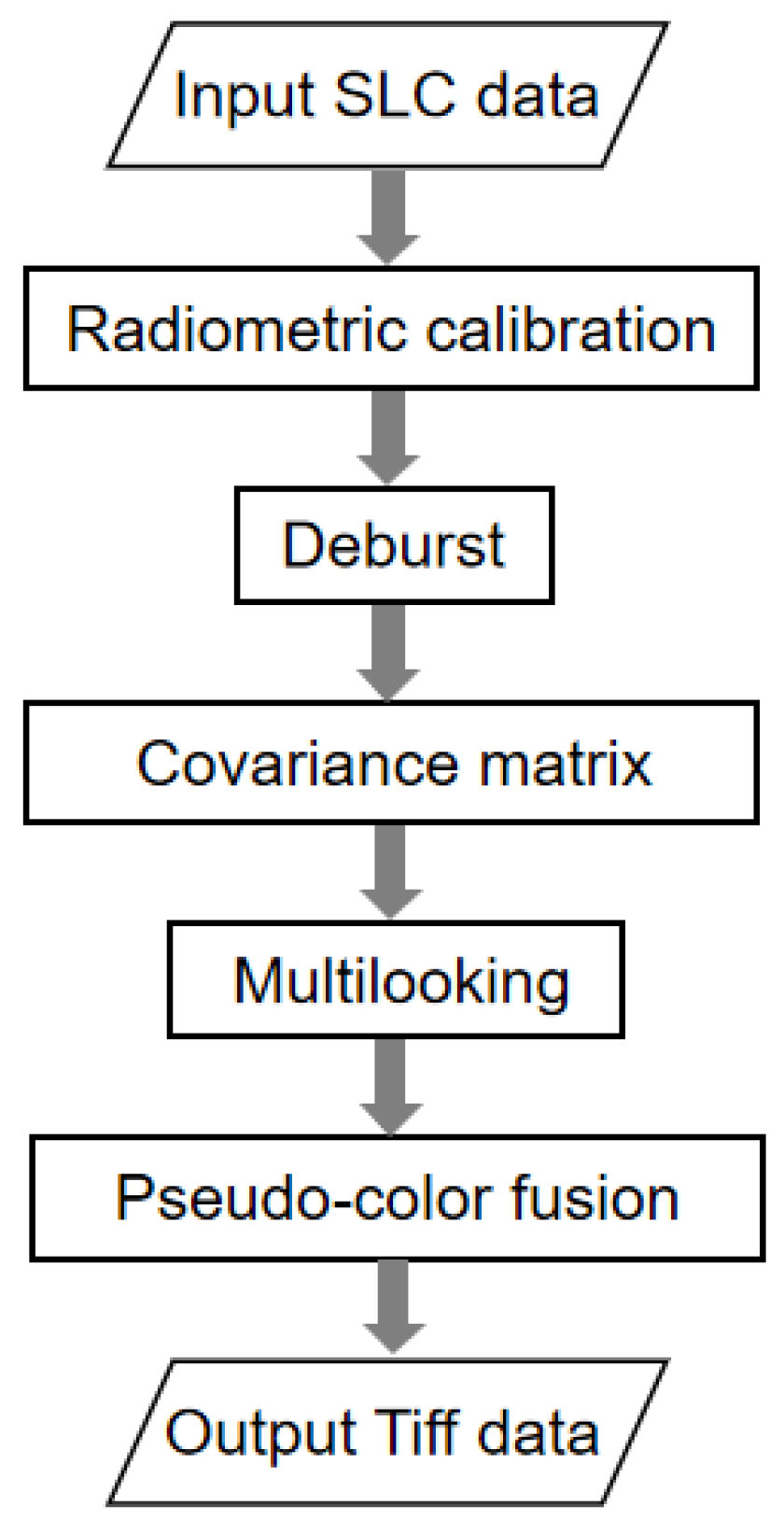
2.2. Preprocessing for SAR Imageries
2.3. Data Format
2.4. Strategy for Labeling the Dataset
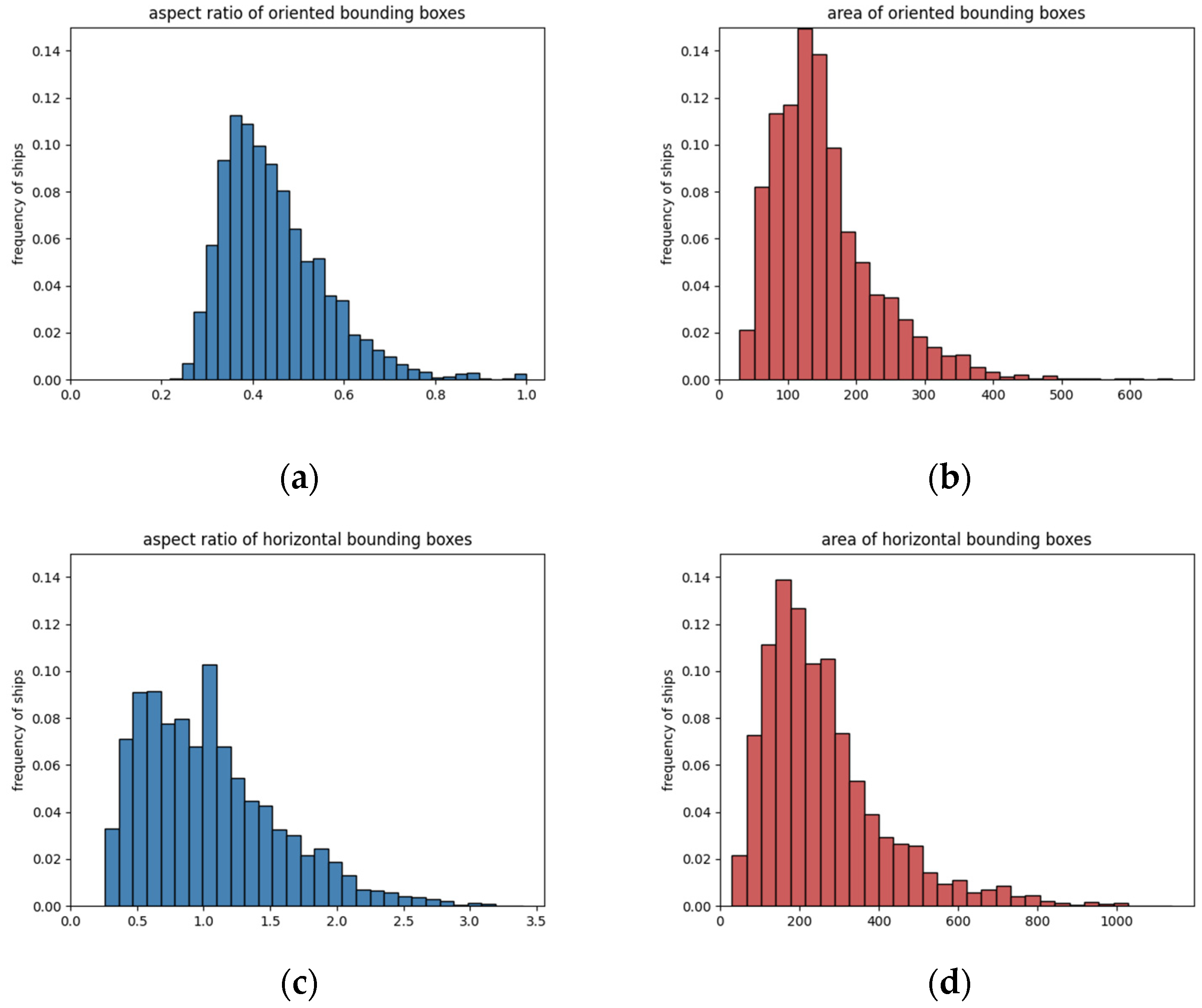
2.5. Properties Analysis
3. Detection Benchmarks of Supervised Approaches
3.1. Benchmark Networks
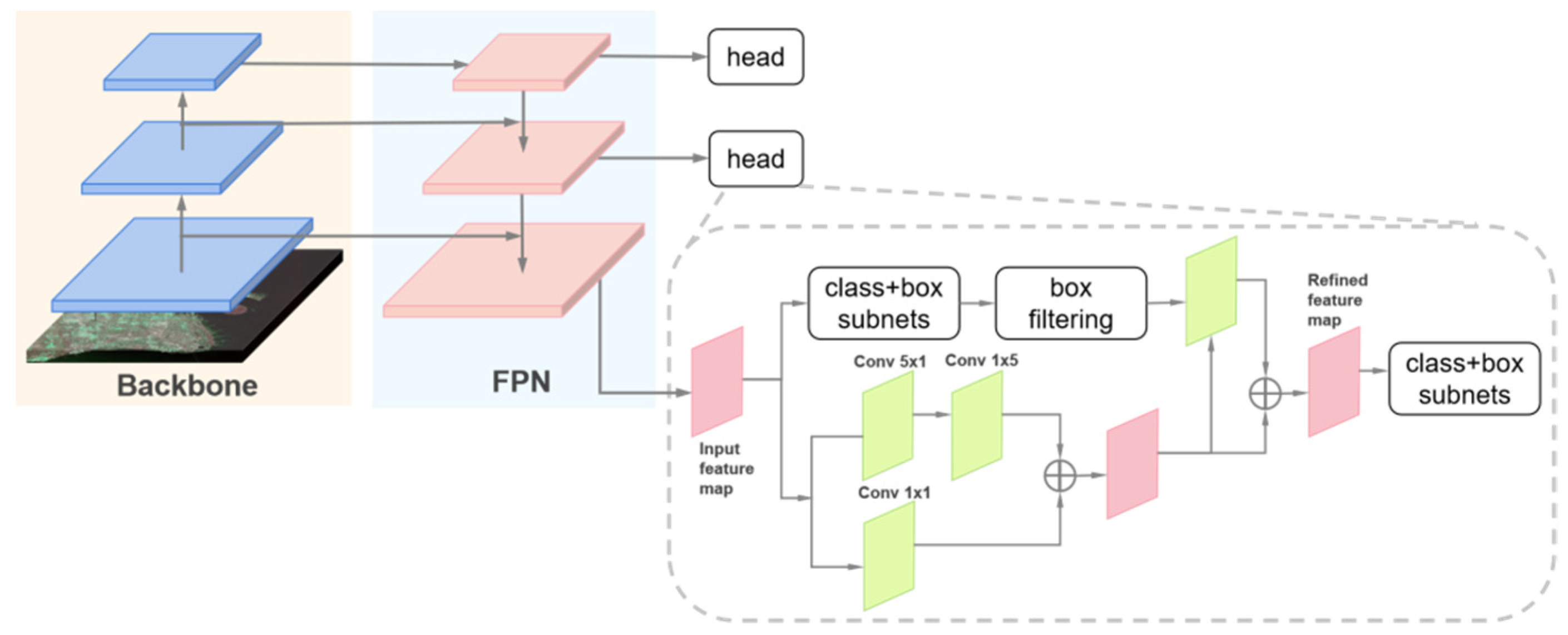
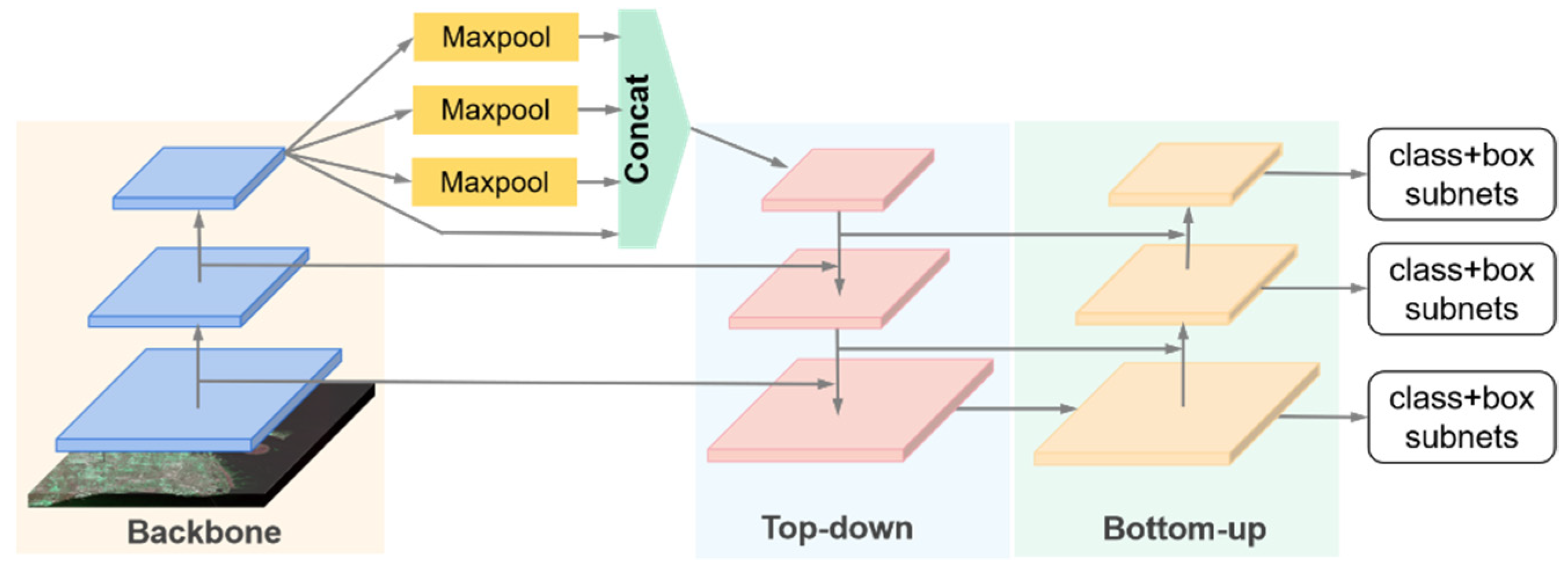
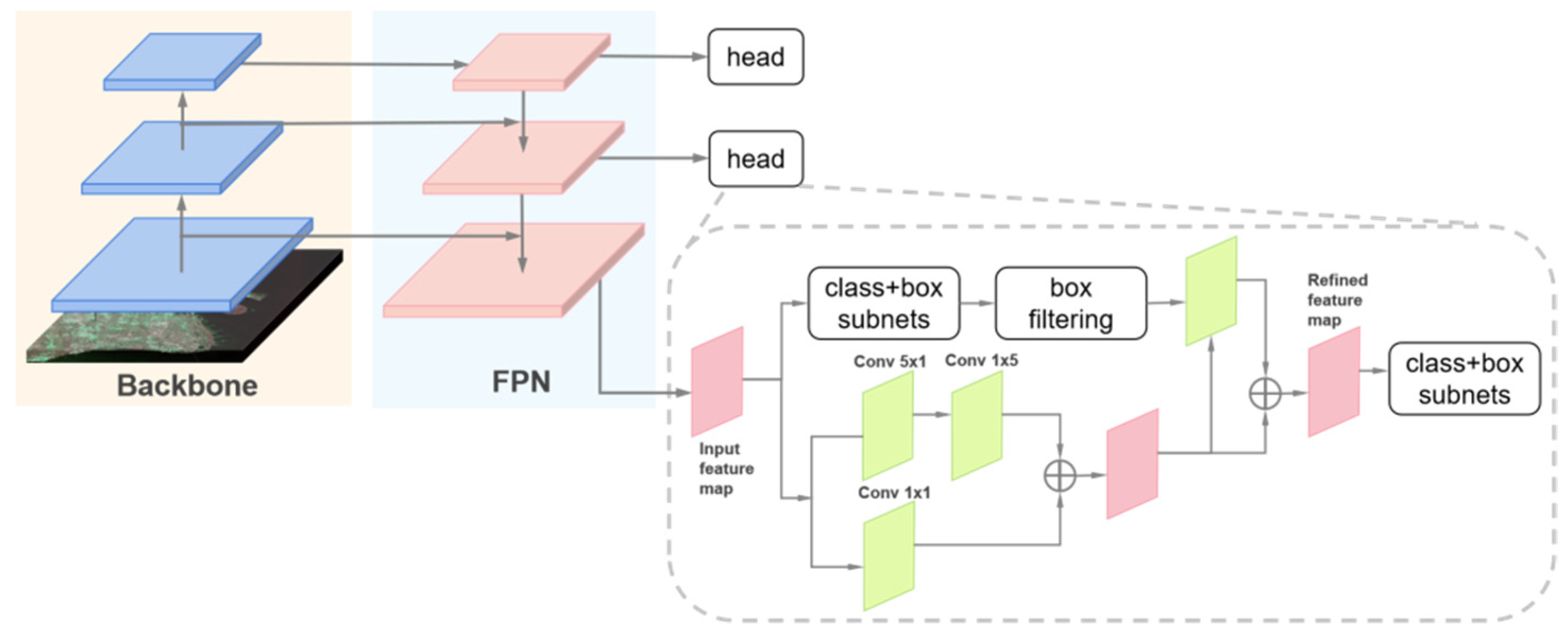
3.1.1. R3Det
3.1.2. YOLOv4
3.2. Implementation Details
3.3. Experimental Results
4. A Weakly Supervised Method
4.1. Motivation
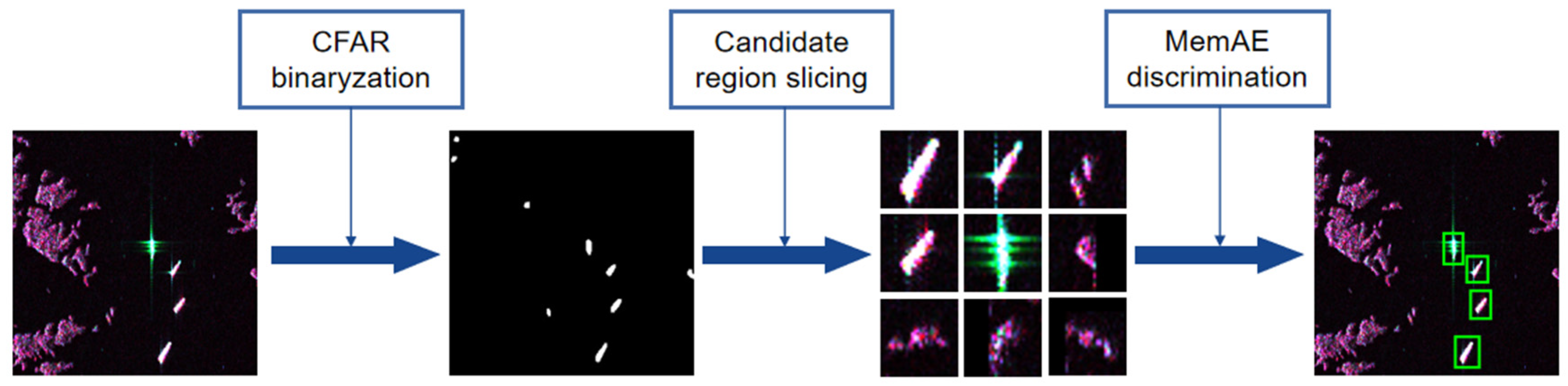
4.2. Overall Scheme of Proposed Method
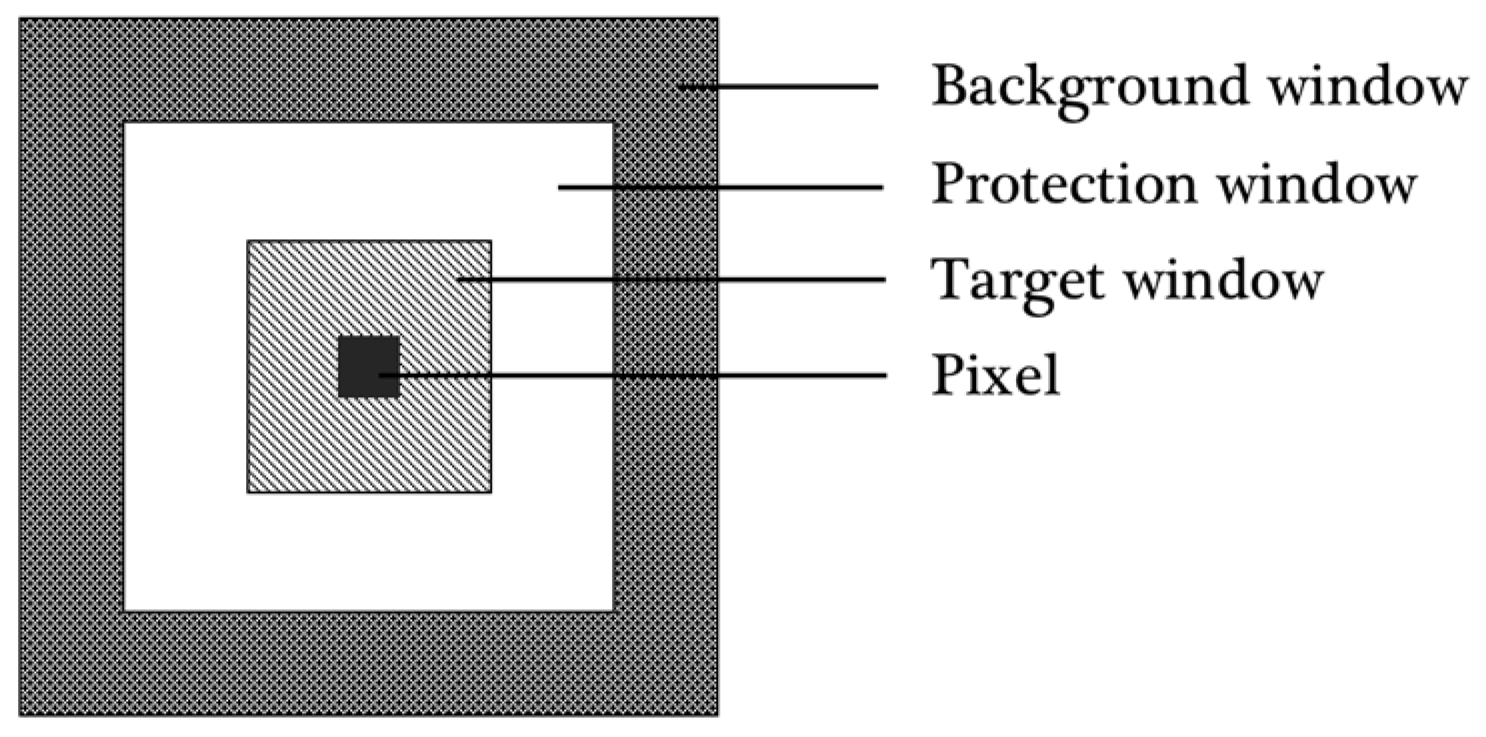
4.3. Two-Parameter Constant False Alarm Rate
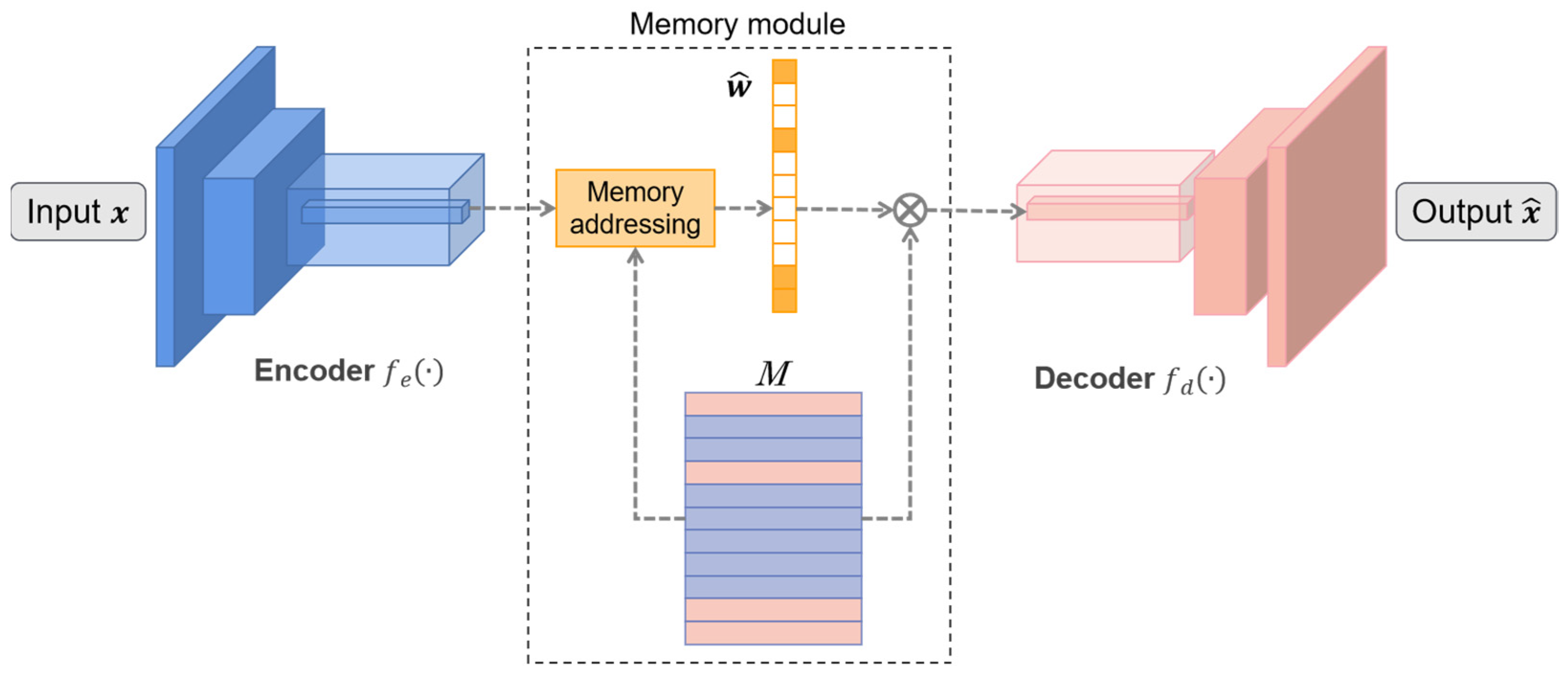
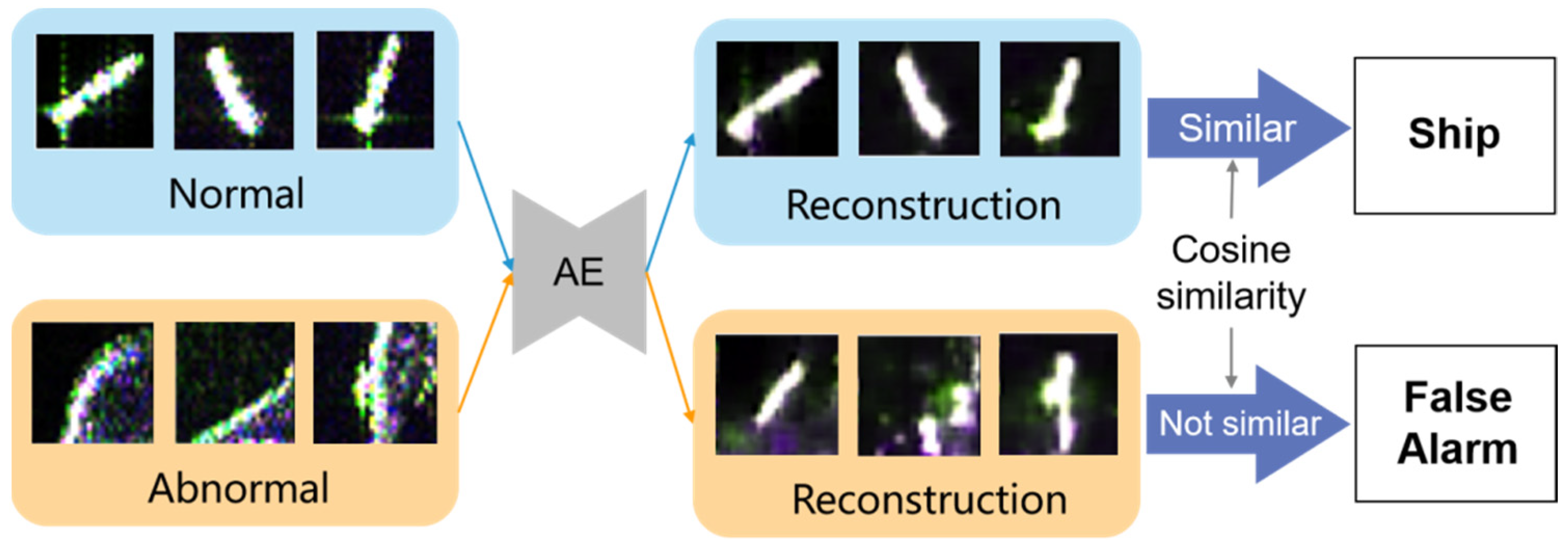
4.4. Memory-Augmented Deep Autoencoder
4.5. Implementation Details
4.5.1. Slicing
4.5.2. Training
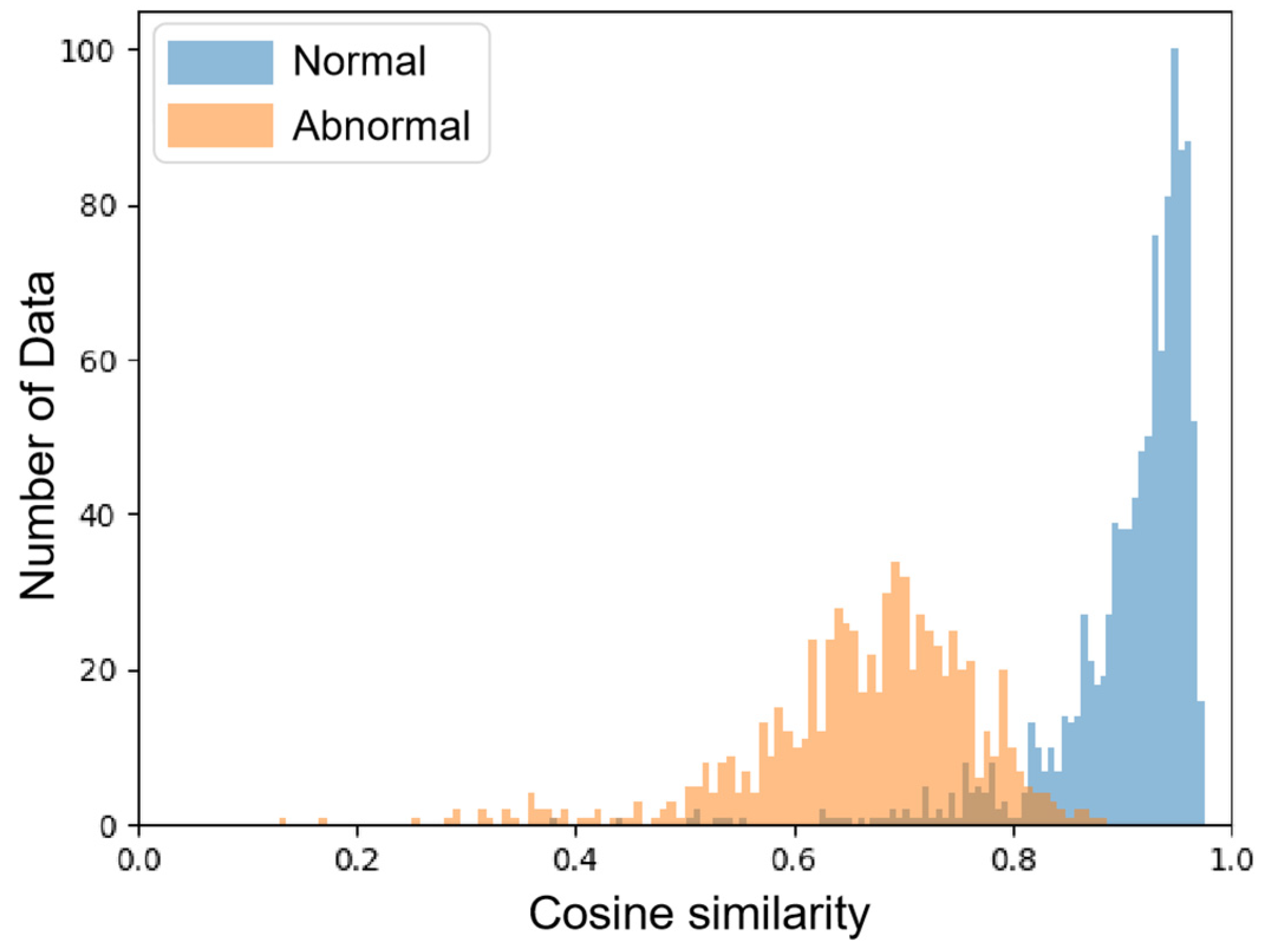
4.5.3. Threshold Selecting
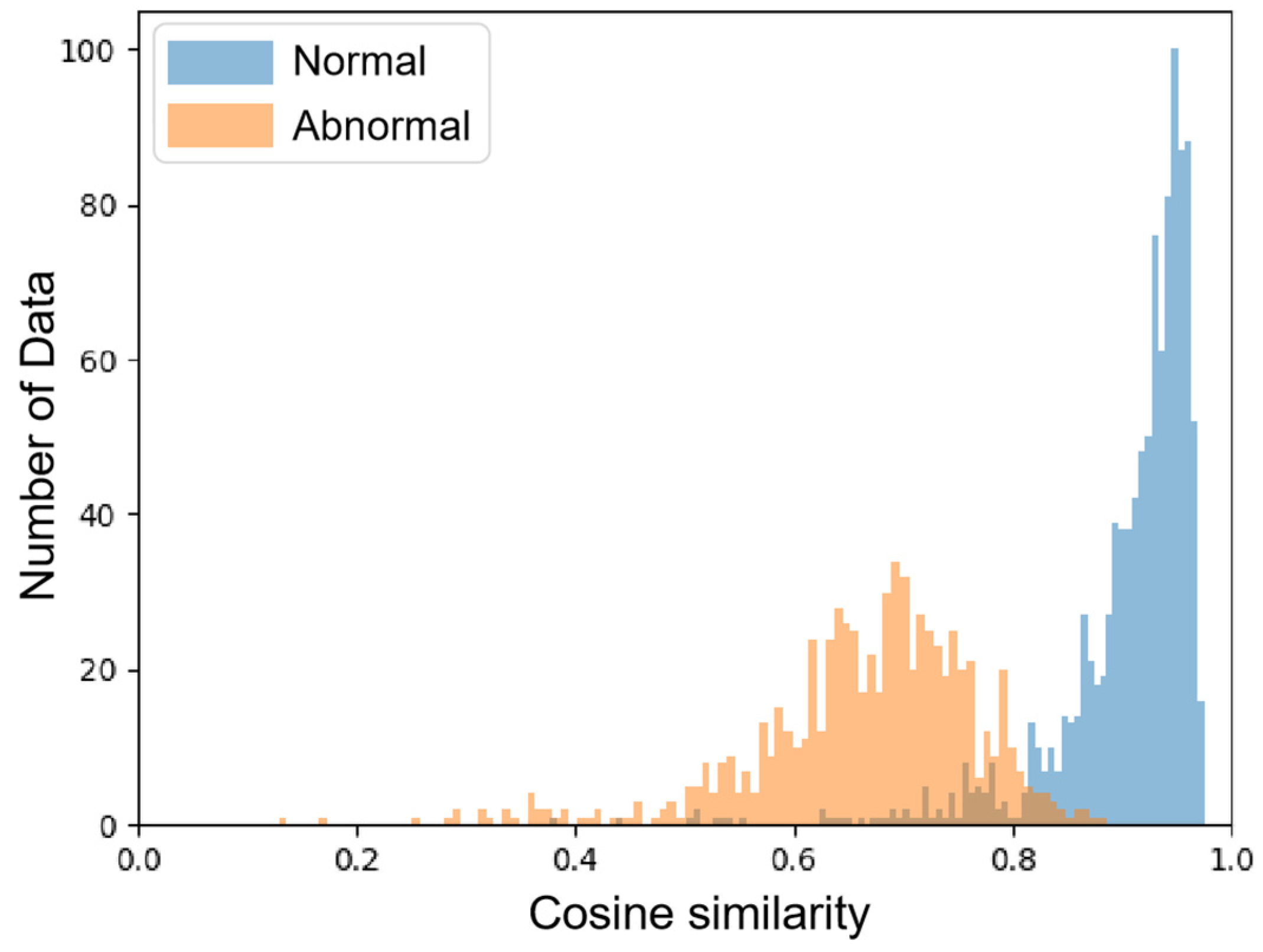
4.6. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kanjir, U.; Greidanus, H.; Ostir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, W. Review of Target Detection in SAR Image Based on CNN. J. Ordnance Equip. Eng. 2021, 42, 15–21. [Google Scholar]
- Rosen, P.A.; Hensley, S.; Joughin, I.R.; Li, F.K.; Madsen, S.N.; Rodriguez, E.; Goldstein, R.M. Synthetic aperture radar interferometry—Invited paper. Proc. IEEE 2000, 88, 333–382. [Google Scholar] [CrossRef]
- Tang, M.; Lin, T.; Wen, G. Overview of ship detection methods in remote sensing image. Appl. Res. Comput. 2011, 28, 29–36. [Google Scholar]
- Li, X.F.; Liu, B.; Zheng, G.; Ren, Y.B.; Zhang, S.S.; Liu, Y.J.; Gao, L.; Liu, Y.H.; Zhang, B.; Wang, F. Deep-learning-based information mining from ocean remote-sensing imagery. Natl. Sci. Rev. 2020, 7, 1584–1605. [Google Scholar] [CrossRef]
- Hou, X.; Jin, G.; Tan, L. Survey of Ship Detection in SAR Images Based on Deep Learning. Laser Optoelectron. Prog. 2021, 58, 53–64. [Google Scholar]
- Liu, T.; Yang, Z.; Jiang, Y.; Gao, G. Review of Ship Detection in Polarimetric Synthetic Aperture Imagery. J. Radars 2021, 10, 1–19. [Google Scholar]
- Li, C.; Yu, Z.; Chen, J. Overview of Techniques for Improving High-resolution Spaceborne SAR Imaging and Image Quality. J. Radars 2019, 8, 717–731. [Google Scholar]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Fan, C.; Meng, J. Discussion on Application of Polarimetric Synthetic Aperture Radar in Marine Surveillance. J. Radars 2016, 5, 596–606. [Google Scholar]
- Margarit, G.; Mallorqui, J.J.; Fortuny-Guasch, J.; Lopez-Martinez, C. Phenomenological Vessel Scattering Study Based on Simulated Inverse SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1212–1223. [Google Scholar] [CrossRef]
- Huynen, J.R. Physical Reality of Radar Targets. In Proceedings of the Conference on Radar Polarimetry, San Diego, CA, USA, 23–24 July 1992; pp. 86–96. [Google Scholar]
- Poelman, A.J.; Guy, J.R.F. Polarization information utilization in primary radar—An introduction and up-date to activities at SHAPE Technical Centre. Inverse Methods Electromagnetic Imaging. 1985, 1, 521–572. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloneyb, C. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. J. Appl. Remote Sens. 2013, 7, 071598. [Google Scholar] [CrossRef] [Green Version]
- Cui, X.; Su, Y.; Chen, S. Polarimetric SAR Ship Detection Based on Polarimetric Rotation Domain Features and Superpixel Technique. J. Radars 2021, 10, 35–48. [Google Scholar]
- Tao, Z.; Zhen, Y.; Xiong, H.; Sensing, R. PolSAR Ship Detection Based on the Polarimetric Covariance Difference Matrix. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3348–3359. [Google Scholar]
- Novak, L.M.; Hesse, S.R. On the performance of order-statistics CFAR detectors. In Proceedings of the 25th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 4–6 November 1991; pp. 835–840. [Google Scholar]
- Ai, J.-Q.; Qi, X.-Y.; Yu, W.-D. Improved Two Parameter CFAR Ship Detection Algorithm in SAR Images. J. Electron. Inf. Technol. 2009, 31, 2881–2885. [Google Scholar]
- Jin, R.J.; Zhou, W.; Yin, J.J.; Yang, J. CFAR Line Detector for Polarimetric SAR Images Using Wilks’ Test Statistic. IEEE Geosci. Remote Sens. Lett. 2016, 13, 711–715. [Google Scholar] [CrossRef]
- Dai, H.; Du, L.; Wang, Y.; Wang, Z.C. A Modified CFAR Algorithm Based on Object Proposals for Ship Target Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1925–1929. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Y.L.; Yang, J. Ship Detection Using Polarization Cross-Entropy. IEEE Geosci. Remote Sens. Lett. 2009, 6, 723–727. [Google Scholar] [CrossRef]
- Sugimoto, M.; Ouchi, K.; Nakamura, Y. On the novel use of model-based decomposition in SAR polarimetry for target detection on the sea. Remote Sens. Lett. 2013, 4, 843–852. [Google Scholar] [CrossRef]
- Yin, J.J.; Yang, J.; Xie, C.H.; Zhang, Q.J.; Li, Y.; Qi, Y.L. An Improved Generalized Optimization of Polarimetric Contrast Enhancement and Its Application to Ship Detection. IEICE Trans. Commun. 2013, E96B, 2005–2013. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path Aggregation Network for Instance Segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, C.Y.; Liao, H.; Wu, Y.H.; Chen, P.Y.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhu, C.C.; Zheng, Y.T.; Luu, K.; Savvides, M. CMS-RCNN: Contextual Multi-Scale Region-Based CNN for Unconstrained Face Detection. In Deep Learning for Biometrics; Advances in Computer Vision and Pattern Recognition; Bhanu, B., Kumar, A., Eds.; Springer: Cham, Switzerland, 2017; pp. 57–79. [Google Scholar]
- Kang, M.; Ji, K.F.; Leng, X.G.; Lin, Z. Contextual Region-Based Convolutional Neural Network with Multilayer Fusion for SAR Ship Detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Chen, G.W.; Pan, Z.X.; Lei, B.; An, Q.Z. Inshore ship detection in sar images based on deep neural Networks. In Proceedings of the 38th IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 25–28. [Google Scholar]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the SAR in Big Data Era: Models, Methods & Applications, Beijing, China, 13–14 November 2017. [Google Scholar]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W.; Sensing, R. OpenSARShip: A Dataset Dedicated to Sentinel-1 Ship Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 195–208. [Google Scholar] [CrossRef]
- Wei, S.J.; Zeng, X.F.; Qu, Q.Z.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Dellaventura, A.; Schettini, R.; Int Assoc Pattern, R. Computer-aided color coding for data display. In Proceedings of the Conference C: Image, Speech, and Signal Analysis, at the 11th IAPR International Conference on Pattern Recognition, The Hague, The Netherlands, 30 August–3 September 1992; pp. 29–32. [Google Scholar]
- Wang, Z.W.; Li, S.Z.; Lv, Y.P.; Yang, K.T. Remote Sensing Image Enhancement Based on Orthogonal Wavelet Transformation Analysis and Pseudo-color Processing. Int. J. Comput. Intell. Syst. 2010, 3, 745–753. [Google Scholar]
- Zhou, X.D.; Zhang, C.H.; Li, S. A perceptive uniform pseudo-color coding method of SAR images. In Proceedings of the CIE International Conference on Radar, Shanghai, China, 16–19 October 2006; pp. 1327–1330. [Google Scholar]
- Uhlmann, S.; Kiranyaz, S. Integrating Color Features in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2197–2216. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Xia, J.L.; Tan, X.H.; Zhou, X.C.; Wang, T. PolSAR Image Classification via Learned Superpixels and QCNN Integrating Color Features. Remote Sens. 2019, 11, 1831. [Google Scholar] [CrossRef] [Green Version]
- Zuo, Y.X.; Guo, J.Y.; Zhang, Y.T.; Lei, B.; Hu, Y.X.; Wang, M.Z. A Deep Vector Quantization Clustering Method for Polarimetric SAR Images. Remote Sens. 2021, 13, 2127. [Google Scholar] [CrossRef]
- Yang, G.; Zhao, W.; Duan, F.; Zhao, W. The Extraction of Buildings in Towns and Villages from Digital Aerial Images Based on Texture Enhancement. Remote Sens. Land Resour. 2010, 22, 51–55. [Google Scholar]
- Fan, Q.C.; Chen, F.; Cheng, M.; Lou, S.L.; Xiao, R.L.; Zhang, B.; Wang, C.; Li, J. Ship Detection Using a Fully Convolutional Network with Compact Polarimetric SAR Images. Remote Sens. 2019, 11, 2171. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Lin, Y.; Hong, W. Research on Multi-Aspect SAR Images Target Recognition Using Deep Learning. J. Signal Process. 2018, 34, 513–522. [Google Scholar]
- A Dual-Polarimetric SAR Ship Detection Dataset. Available online: https://github.com/liyiniiecas/A_Dual-polarimetric_SAR_Ship_Detection_Dataset (accessed on 4 November 2021).
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- NASA’s Earthdata Search. Available online: https://search.earthdata.nasa.gov/search (accessed on 1 March 2021).
- ESA-Step Science Toolbox Explotiation Platform. Available online: http://step.esa.int/main/toolboxes/sentinel-1-toolbox (accessed on 8 May 2021).
- Wang, J.; Xing, L.; Pan, J.; Dong, L.; Yang, D.; Wang, Y. Application Study on the Target Decomposition Method of Dual-polarization SAR. Remote Sens. Inf. 2013, 28, 106. [Google Scholar]
- Schmitt, M.; Stilla, U. Adaptive multilooking of airborne ka-band multi-baseline InSAR data of urban areas. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany, 22–27 July 2012; pp. 7401–7404. [Google Scholar]
- Feng, Z.C.; Liu, X.L.; Pei, B.Z. Pseudo-color Coding Method for High-dynamic Single-polarization SAR Images. In Proceedings of the 9th International Conference on Graphic and Image Processing (ICGIP), Ocean Univ China, Acad Exchange Ctr, Qingdao, China, 14–16 October 2017. [Google Scholar]
- RoLabelImg. Available online: https://github.com/cgvict/roLabelImg (accessed on 12 April 2021).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Xu, J.; Zuo, Y.; Xia, B.; Xia, X.G.; Peng, Y.N.; Wang, Y.L. Ground Moving Target Signal Analysis in Complex Image Domain for Multichannel SAR. IEEE Trans. Geosci. Remote Sens. 2012, 50, 538–552. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Wang, C.; Zhang, H.; Dong, Y.B.; Wei, S.S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef] [Green Version]
- An, Q.Z.; Pan, Z.X.; Liu, L.; You, H.J. DRBox-v2: An Improved Detector with Rotatable Boxes for Target Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.C.; Feng, Z.M.; He, T.; Assoc Advancement Artificial, I. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2020, arXiv:1908.05612. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.B.; Datcu, M.; Pelillo, M.; Zhang, L.P. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, Z.K.; Yuan, L.; Weng, L.B.; Yang, Y.P. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.J.; et al. ICDAR 2015 Competition on Robust Reading. In Proceedings of the 13th IAPR International Conference on Document Analysis and Recognition (ICDAR), Nancy, France, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Shen, F.; Zeng, G. Weighted Residuals for Very Deep Networks. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2017. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W.; Assoc Advancement Artificial, I. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Otsu, N. Threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Imaging Mode | Resolution Rg. × Az.(m) | Swath (km) | Polarization Modes | Incident Angle (°) | Product Type | Number of Images |
|---|---|---|---|---|---|---|---|
| Sentinel-1 | IW | 2.3 × 14.0 | 250 | VV + VH | 29.1~46.0 | SLC | 50 |
| Method/Dataset | Backbone | Precision | Recall | AP0.5 | AP0.5:0.95 | |
|---|---|---|---|---|---|---|
| R3Det | VV | ResNet-50 + FPN | 0.936 | 0.893 | 0.888 | 0.304 |
| VH | 0.942 | 0.877 | 0.887 | 0.334 | ||
| Pseudo-color | 0.957 | 0.921 | 0.902 | 0.405 | ||
| VV | ResNet-101 + FPN | 0.943 | 0.913 | 0.899 | 0.440 | |
| VH | 0.946 | 0.903 | 0.896 | 0.446 | ||
| Pseudo-color | 0.962 | 0.915 | 0.902 | 0.475 | ||
| Method/Dataset | Backbone | Precision | Recall | AP0.5 | AP0.5:0.95 | |
|---|---|---|---|---|---|---|
| YOLOv4 | VV | CSPDarknet53 | 0.944 | 0.923 | 0.924 | 0.579 |
| VH | 0.948 | 0.922 | 0.922 | 0.551 | ||
| Pseudo-color | 0.958 | 0.933 | 0.938 | 0.585 | ||
| Layer Name | Output Size | Kernel Size | Stride |
|---|---|---|---|
| Input | 28 × 28 | - | - |
| Conv_1 | 14 × 14 | 3 × 3, 16 | 2 |
| Conv_2 | 7 × 7 | 3 × 3, 32 | 2 |
| Conv_3 | 4 × 4 | 3 × 3, 64 | 2 |
| Dconv_1 | 7 × 7 | 3 × 3, 32 | 2 |
| Dconv_2 | 14 × 14 | 3 × 3, 16 | 2 |
| Dconv_3 | 28 × 28 | 3 × 3, 3 | 2 |
| Method | Precision | Recall |
|---|---|---|
| CFAR | 0.773 | 0.966 |
| Ours | 0.926 | 0.923 |
| Method | P | R | AP | Params | FLOPs | Speed |
|---|---|---|---|---|---|---|
| EfficientDet-D0 | 0.918 | 0.887 | 0.911 | 3.9 M | 2.5 B | 366 ms |
| YOLOv4-tiny | 0.933 | 0.924 | 0.926 | 5.9 M | 3.4 B | 176 ms |
| MobileNetV3 + SSD | 0.874 | 0.843 | 0.837 | 2.7 M | 420 M | 64 ms |
| Ours | 0.926 | 0.923 | 0.925 | 1.5 M | 1.4 M | 82 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Li, Y.; Pan, Z. A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method. Sensors 2021, 21, 8478. https://doi.org/10.3390/s21248478
Hu Y, Li Y, Pan Z. A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method. Sensors. 2021; 21(24):8478. https://doi.org/10.3390/s21248478
Chicago/Turabian StyleHu, Yuxin, Yini Li, and Zongxu Pan. 2021. "A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method" Sensors 21, no. 24: 8478. https://doi.org/10.3390/s21248478
APA StyleHu, Y., Li, Y., & Pan, Z. (2021). A Dual-Polarimetric SAR Ship Detection Dataset and a Memory-Augmented Autoencoder-Based Detection Method. Sensors, 21(24), 8478. https://doi.org/10.3390/s21248478