5.1. Experimental Settings
Dataset. To demonstrate the effectiveness of our proposed method, we evaluated the proposed method on multiple datasets such as CIFAR-10, CIFAR-100, TinyImageNet-200, and VOC 2007/2012 datasets [
14,
29,
30]. The CIFAR-10, CIFAR-100, and TinyImageNet-200 dataset are used for evaluating classification performance, and the VOC 2007/2012 datasets are used for evaluating object detection performance. The CIFAR-10 and CIFAR-100 each comprise 50 K training images and 10 K test images, and each image has the same size as
. The numbers of classes in CIFAR-10 and CIFAR-100 are 10 and 100, respectively. TinyImageNet-200, which is a smaller dataset than the original ImageNet dataset [
14] with fewer image classes (e.g., 200), comprises 100 K training images and 10 K test images, and each image has the same size as
. VOC 2007/2012 dataset contains 20 object categories, and we used 16 K and
K images for train and test, respectively.The summary of dataset is shown in
Table 3 below.
Implementation. Our code was implemented using PyTorch [
31] for the classification task and Detectron2 [
32] for the detection. The experiments were conducted on a Quadro RTX 8000 GPUs for classification tasks and four A100 GPUs for object detection tasks.
Parameter Settings for Classification Task. We used PreActResNet-18, PreActResNet-50, and PreActResNet-101 as baseline architectures for classification experiments [
33]. The number means the number of layers of the architecture. (e.g., PreActResNet-50 means the architecture has 50 layers.) The number of parameters for each model are 11 M, 24 M, and 43 M, respectively. We trained the models for 300 epochs.
On the CIFAR [
29] datasets, the initial learning rate was
, and the learning rate was multiplied by 0.1 at 150 and 225 epochs. On the TinyImageNet-200 [
34], the initial learning rate was the same as for CIFAR, but it was multiplied by 0.1 at 75, 150, and 225 epochs. The mini-batch size was set to 64 and 128 for CIFAR and TinyImageNet-200, respectively. Stochastic gradient descent was used with a momentum of
and weight decay of
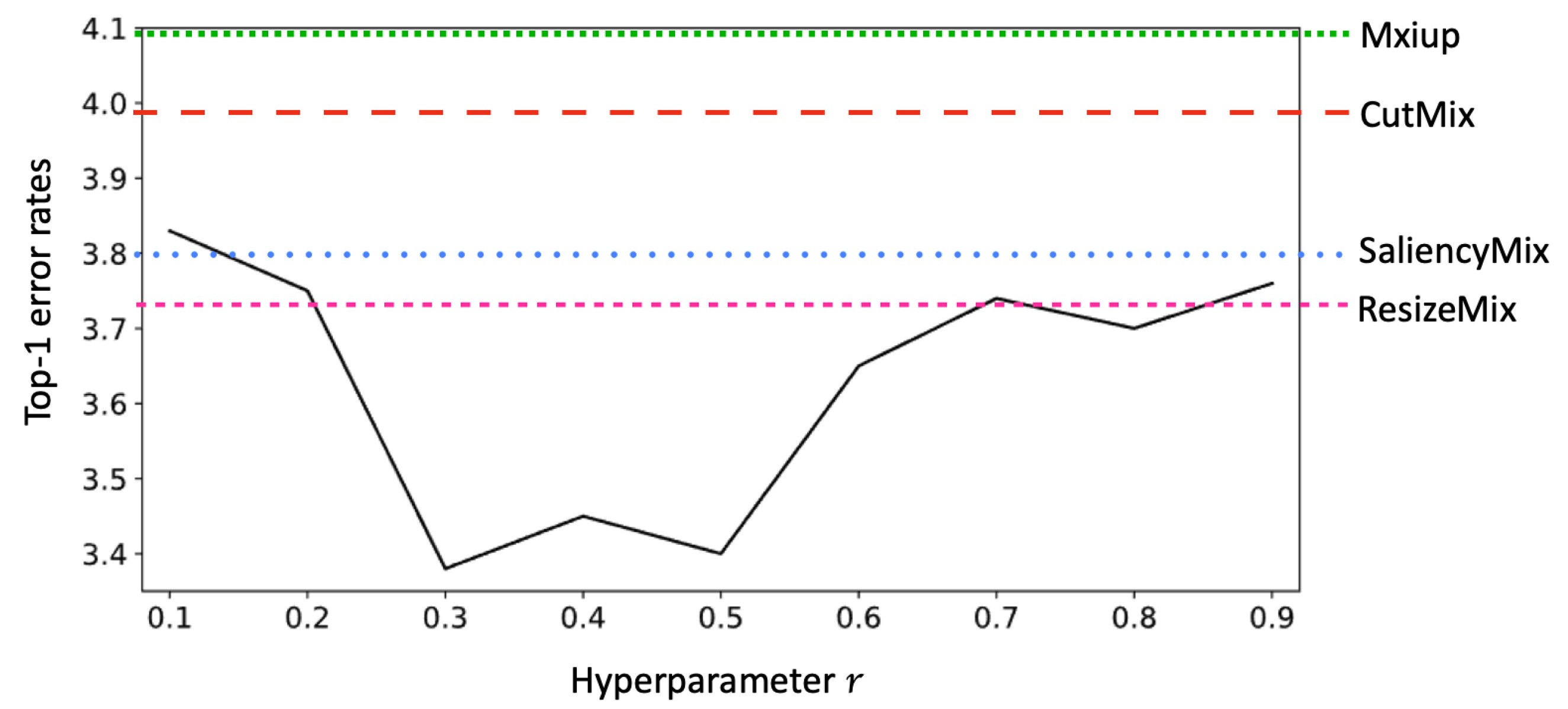
. The size of the saliency map that passed average pooling was
and
for CIFAR and TinyImageNet-200, respectively. The patch size of
and
were set according to
.
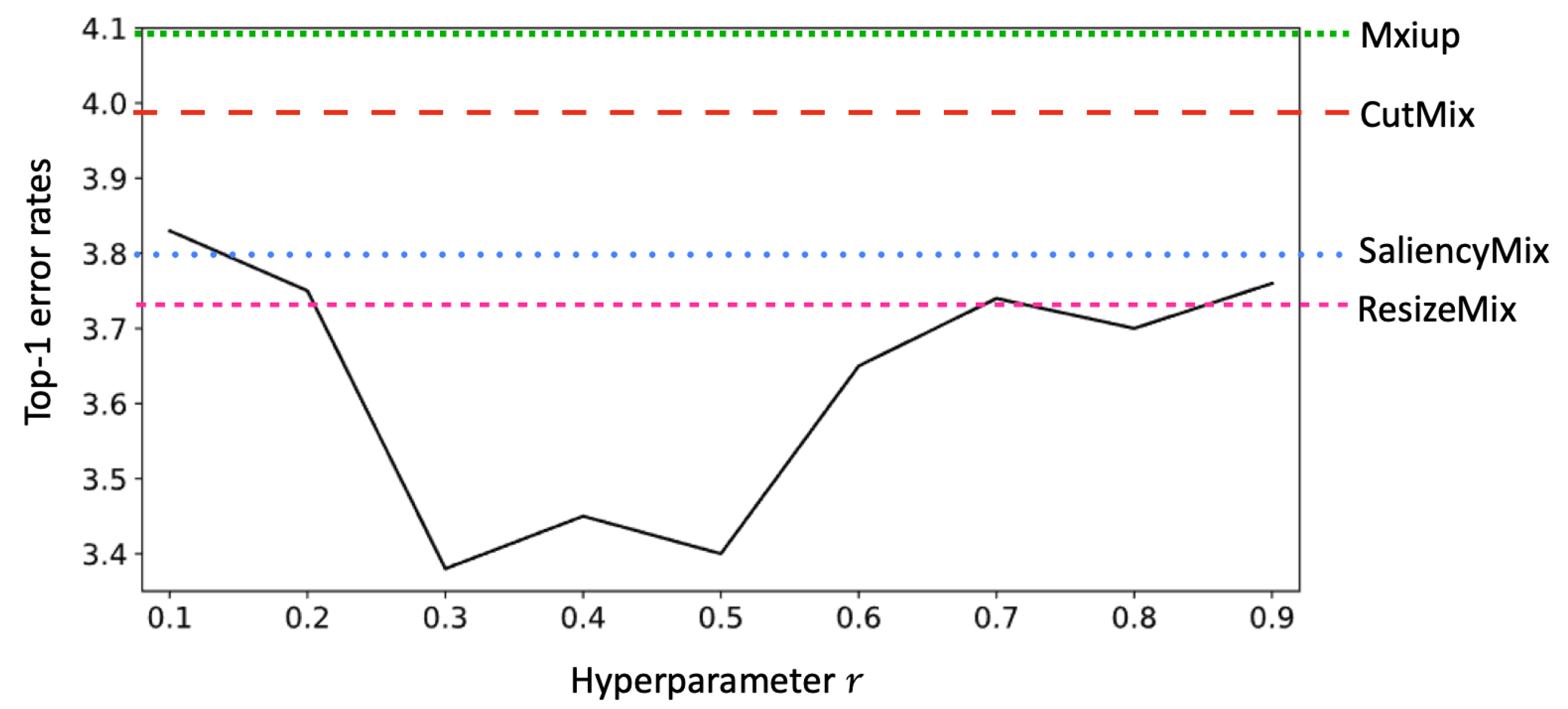
The parameter values for each data augmentation method were set as the default values used in their corresponding studies [
16,
18,
19,
22]. Cutout uses regional dropout, and its mask size is set to
ratio of the input image size. Mixup, CutMix, and SaliencyMix use the same beta distribution as a ratio to mix two images. In ResizeMix,
and
to determine the image patch size were set to
and
, respectively. For geometric data augmentation, random resized crop, random horizontal flip and normalization were used for the CIFAR dataset, and additional color jittering and brightness were used for TinyImageNet-200.
Parameter Settings for Detection Task. For the object detection task, ResNet architecture with 50 layers was used. We trained the ResNet on the TinyImageNet-200 dataset, and the experimental setting is the same as the TinyImageNet-200 experiment for classification tasks. We transferred it to the detection task of VOC 2007/2012 datasets. Parameters for batch size, learning rate, and training iterations were set to 8, 0.02 and 24 k, respectively. The learning rate was multiplied by 0.1 at 18 k and 22 k iterations.
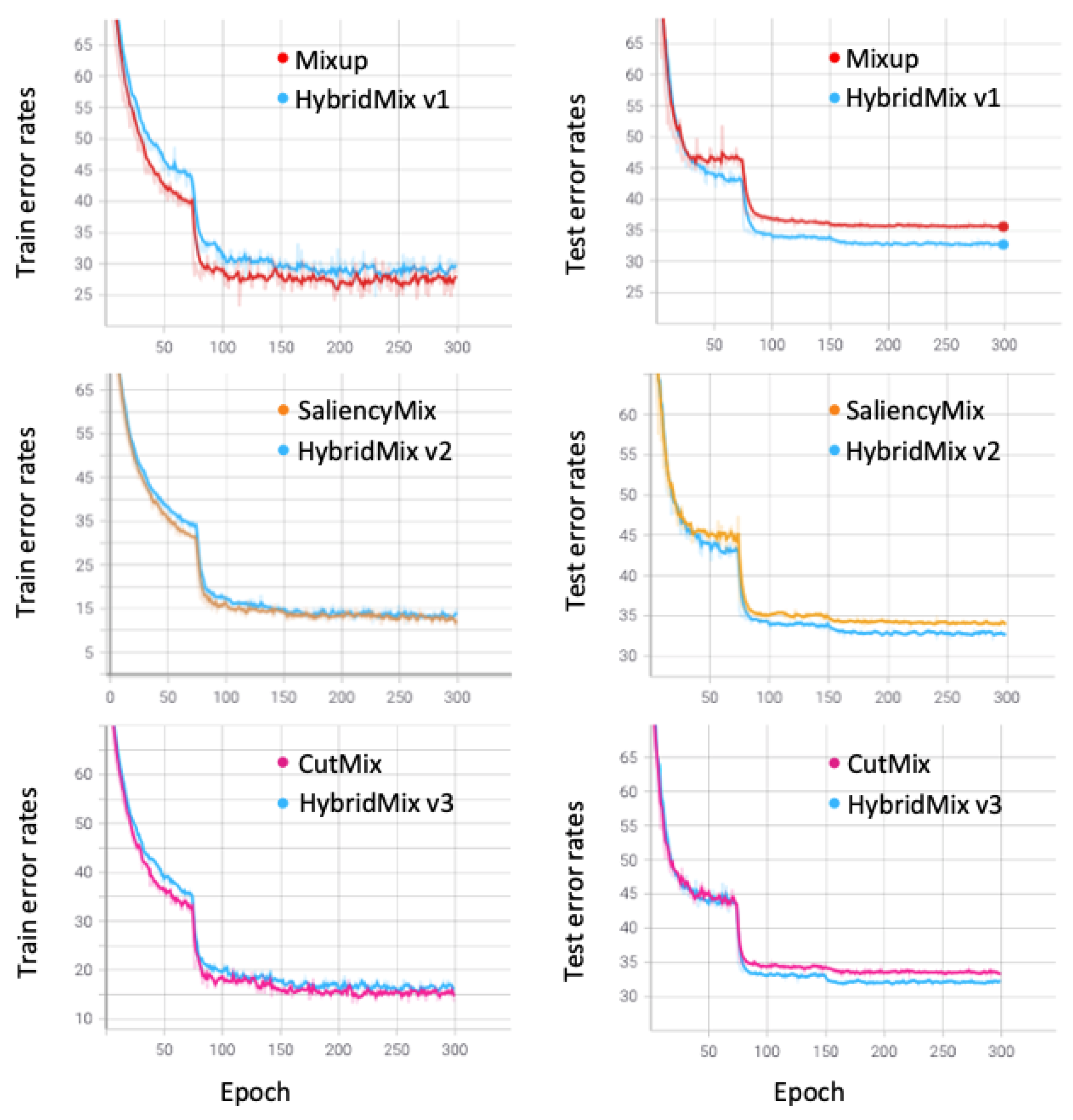
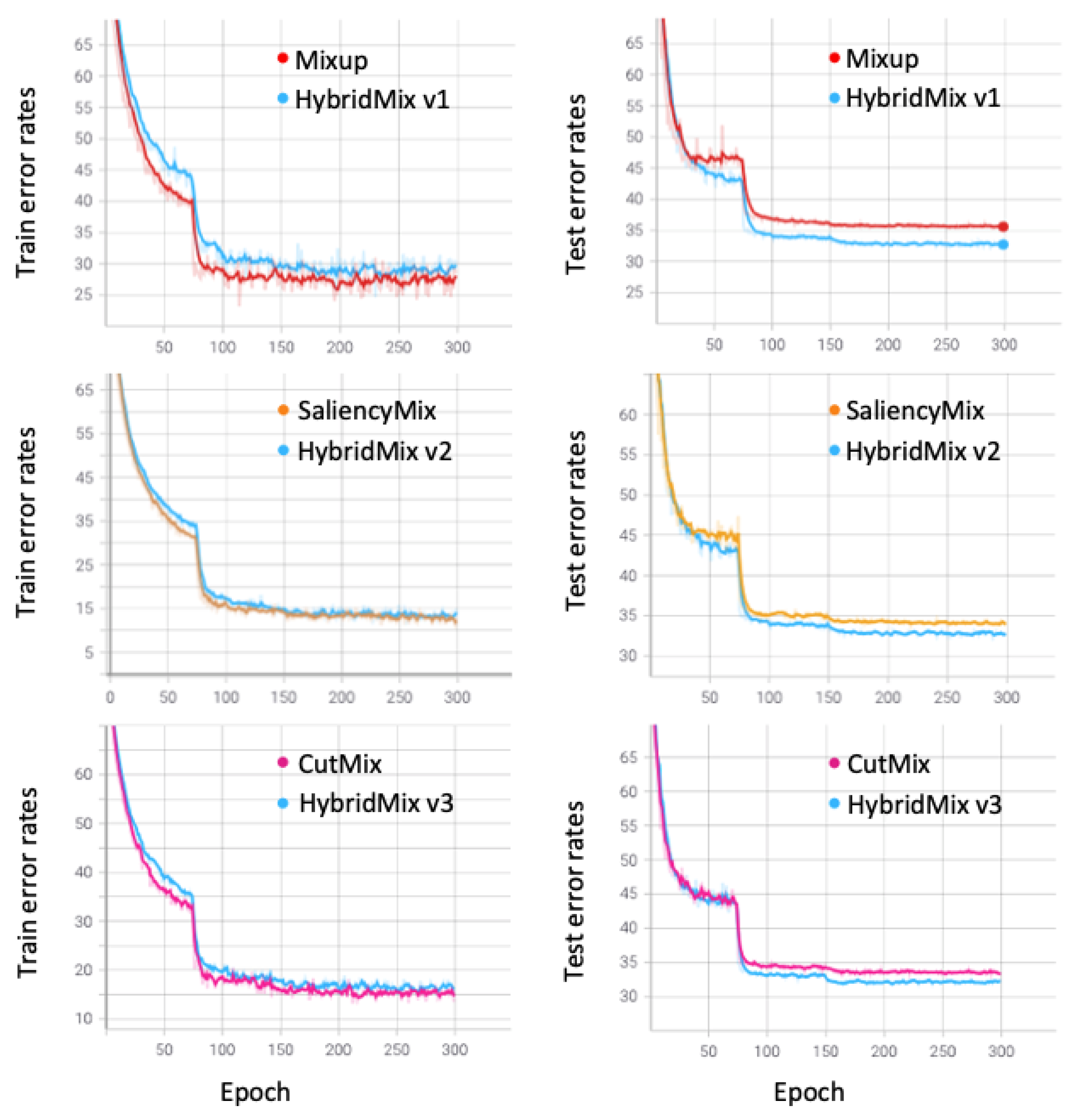
5.2. CIFAR-10/100 Classification
The experimental results are shown in
Table 4 and
Table 5. We measured the Top-1 error rates to compare with the competing methods. HybridMix v1, HybridMix v2, and HybridMix v3 outperform state-of-the-art data augmentation approaches, such as Mixup, SaliencyMix, and CutMix. Particularly, HybridMix v3 achieved
%,
% and
% error rates, respectively, when using PreActResNet-18, 50, and 101 models on the CIFAR-10 dataset. It reduced
%,
%, and
% error rates, respectively, compared to the baseline and showed
%,
%, and
% performance improvements compared to CutMix. It also showed better performance than most recently proposed techniques such as SaliencyMix and ResizeMix.
On the CIFAR-100 dataset, our method also achieves performance improvements at all depths of the model, as shown in
Table 5. The state-of-the-art on PreActResNet-18 was an error rate of
% achieved by SaliencyMix. HybridMix v2 outperformed with an error rate of
%. Additionally, we conducted additional experiments using the same parameter settings in the PuzzleMix paper [
21]. HybridMix v1, v2, and v3 achieved
%,
%, and
% error rates, respectively, leading to
% performance improvements using HybridMix v3 compared to PuzzleMix.
We also conduct additional experiments using other architectures. PyramidNet-110 [
35] and RegNet-200M [
36] were used, and the number of parameters are
and
million, respectively. The experimental settings for PyramidNet-110 are the same as the CutMix paper [
19]. Furthermore, the settings for RegNet-200M were adopted from the source code (
https://github.com/yhhhli/RegNet-Pytorch, accessed on 1 August 2021).
As a results, HybridMix v3 achieved
% and
% using PyramidNet-110 and RegNet-200M, respectively. Especially, HybridMix v3 significantly reduces the error rates compared to the RegNet-200M baseline model (
, Baseline VS
, HybridMix v3), as shown in
Table 6.
5.3. TinyImageNet-200 Classification
Table 7 depicts the experimental results on the TinyImageNet-200 dataset. The largest performance improvement was achieved with PreActResNet-101, which is the deepest architecture. This is an improvement of
% from the baseline and
% from CutMix using HybridMix v3. Similarly, HybridMix v1 and HybridMix v2 showed
% and
% performance improvements over Mixup and SaliencyMix, respectively.
Similar to the experiment on CIFAR-100 dataset, we also compared to PuzzleMix using the same settings in the PuzzleMix paper. HybridMix v1, v2, and v3 recorded %, %, and %, respectively. These are 1%, %, and % performance improvements over Puzzle Mix.
5.4. Transferring to Object Detection Task
We used the ResNet50 model trained with HybridMix v1, v2, and v3 as the backbone of Faster R-CNN [
37]. Data augmentation techniques were used only to train the backbone, ResNet50. ResNet50 models are pre-trained on the TinyImageNet-200 dataset and used the pre-trained models as backbone networks for Faster R-CNN. The Faster R-CNN was fine-tuned on VOC 2007/2012 training data. To confirm the effect of HybridMix on object detection, ResNet models were independently trained using other two images-based augmentation approaches, such as Mixup, SaliencyMix, CutMix, and ResizeMix [
18,
19,
20,
22]. We used mean average precision (mAP) as the evaluation metric.
and
mean mAP were calculated at IoU = 0.5 and IoU = 0.75, respectively.
Table 8 shows the object detection experimental results on VOC 2007/2012 dataset. HybridMix-trained backbone network showed
%,
%, and
% performance improvements in terms of
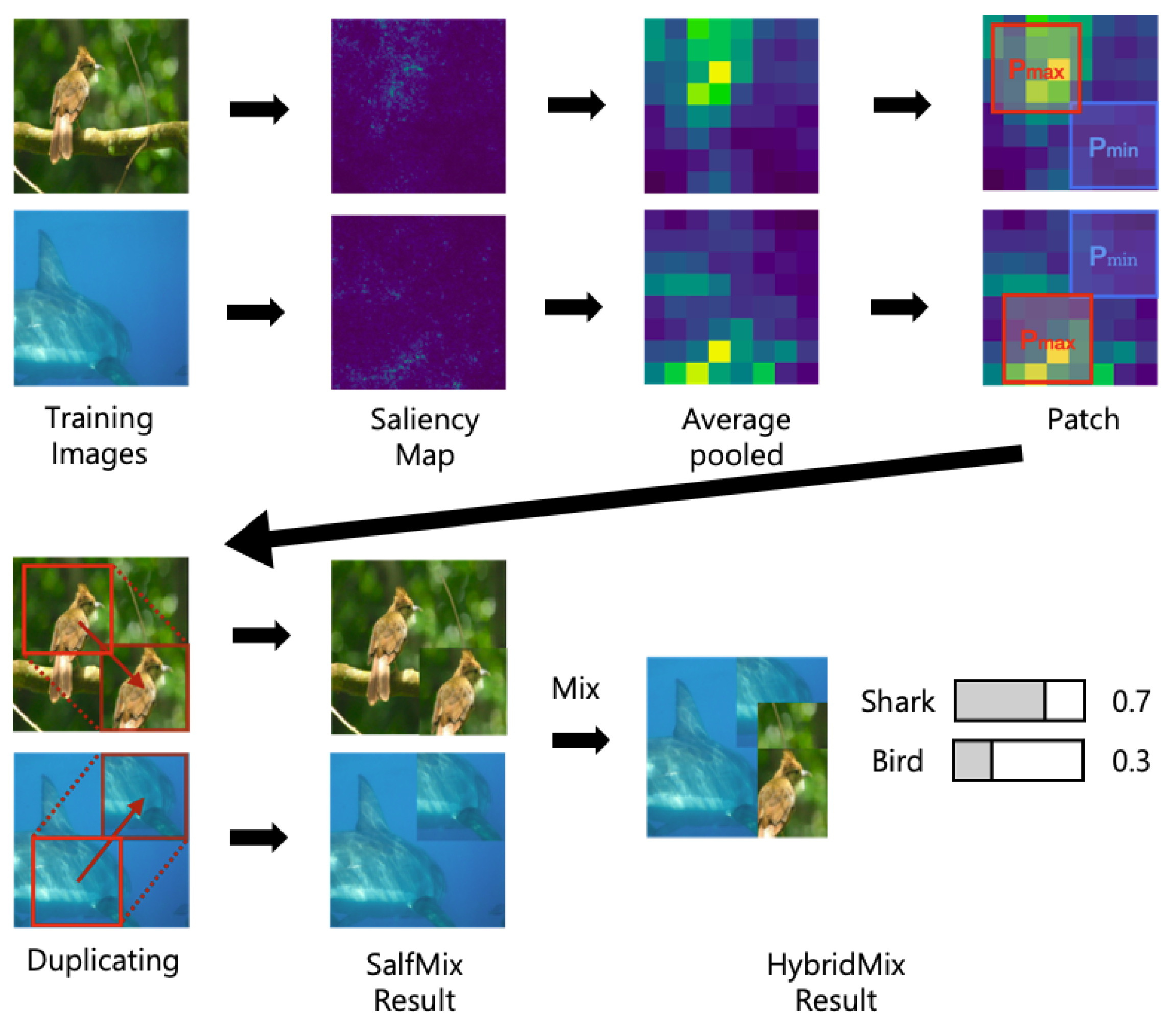
, compared to the baseline, respectively. Each version of HybridMix also showed performance improvements over other two images-based data augmentations. HybridMix v3 which is a combination of CutMix and SalfMix led to
% performance improvement over CutMix, and it has the best performance in terms of
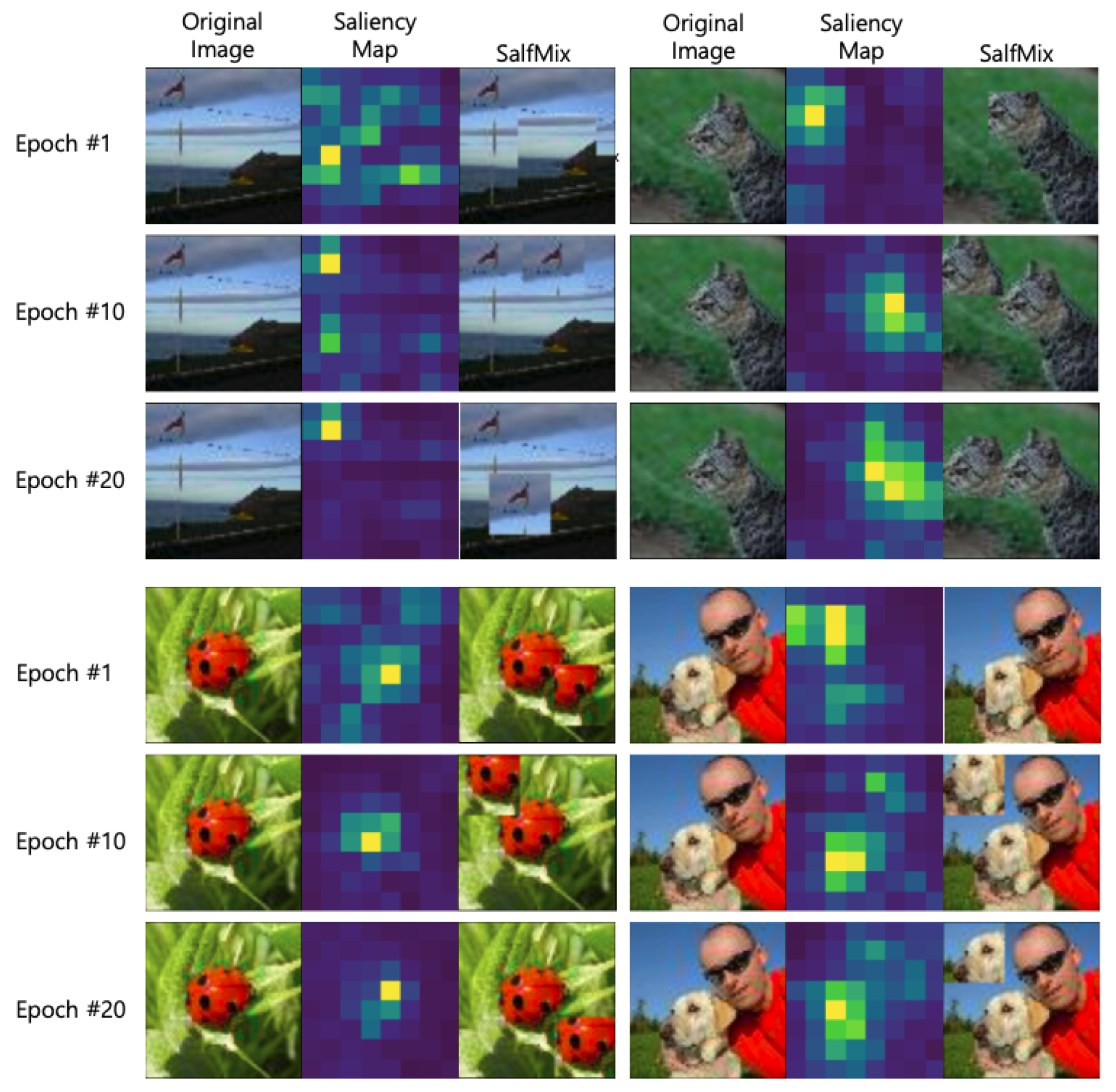
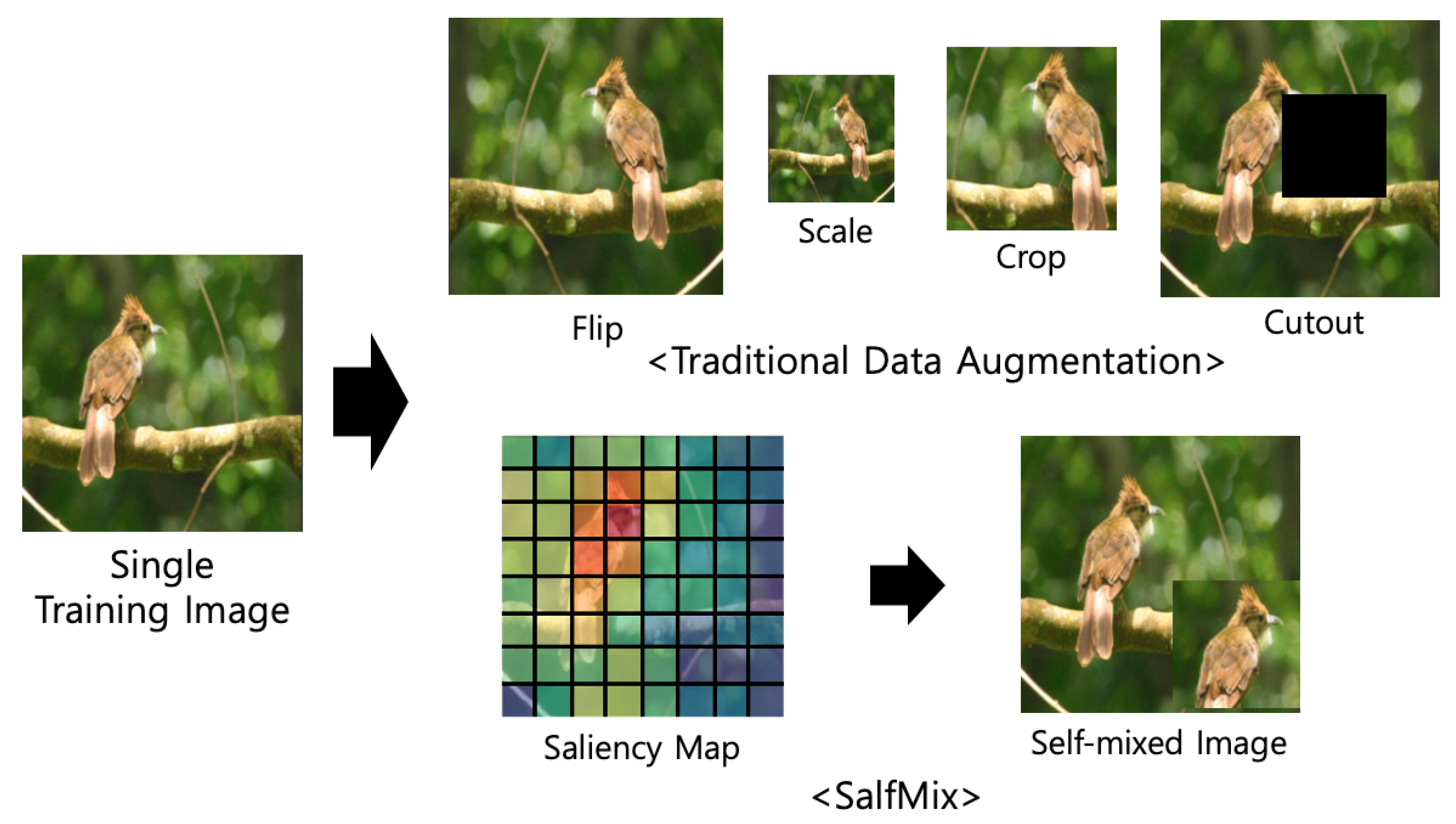
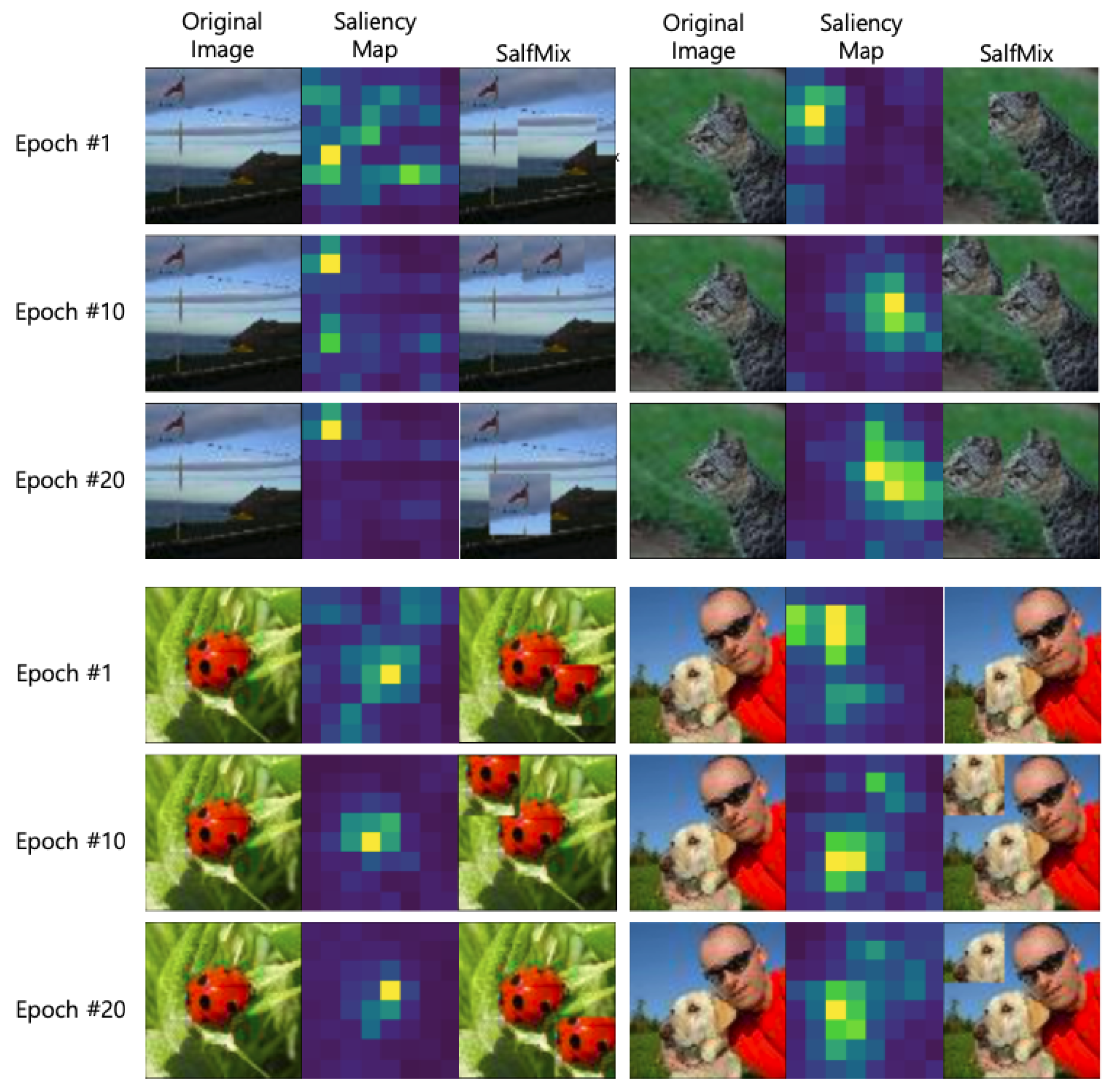
. Compared to the Cutout-trained model, the SalfMix-trained model showed a
% performance improvement in terms of
. This means that copying and pasting in a single image is effective for improving the object detection accuracies.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}