
A Novel, Low Computational Complexity, Parallel Swarm Algorithm for Application in Low-Energy Devices


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. State-of-the-Art Study
2.1. Application Abilities of the PSO Algorithm
2.2. Optimization Aspects of the PSO Algorithm
2.3. Block Generating Random Values
2.4. Development of Deterministic PSO Algorithms
2.5. Solutions for Inverse Square Root Operation
3. An Overview of a Conventional PSO Algorithm
- position—position of a particle in search space;
- velocity—speed of a given particle;
- —personal best value found so far by a given agent and its position; and
- —global best value found so far by any agent in the swarm and its position.
3.1. Computation of the Fitness Function
3.2. Updating Personal Best Values
3.3. Updating Global Best Value
3.4. Updating Particle Velocities
3.4.1. Inertial Component
3.4.2. Cognitive Component
3.4.3. Social Component
3.5. Updating Particle Positions
- —position of a given particle in a given iteration;
- —velocity of a given particle in a given iteration;
- , , , , —parameters that play the role of the weights.
3.6. Final Step—Terminating the Optimization Process
4. Materials and Methods
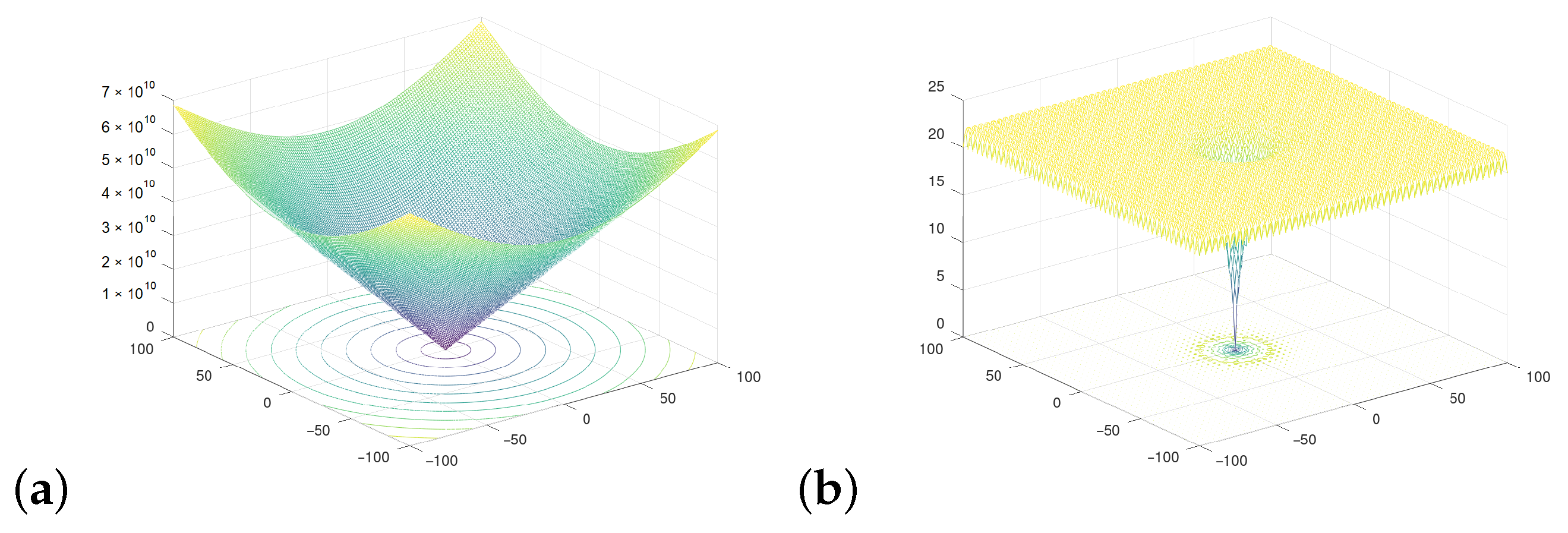
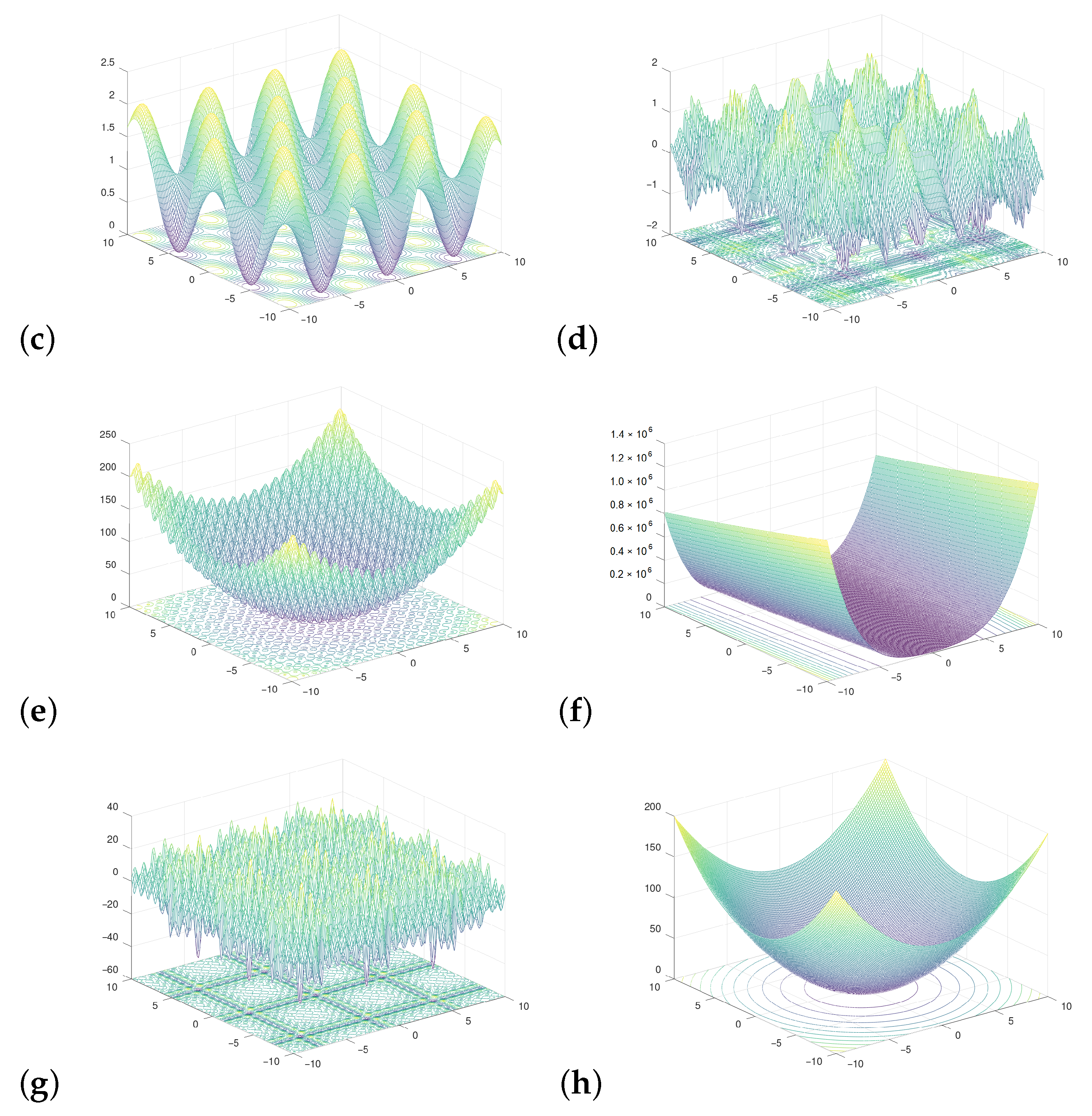
4.1. Materials/Tools
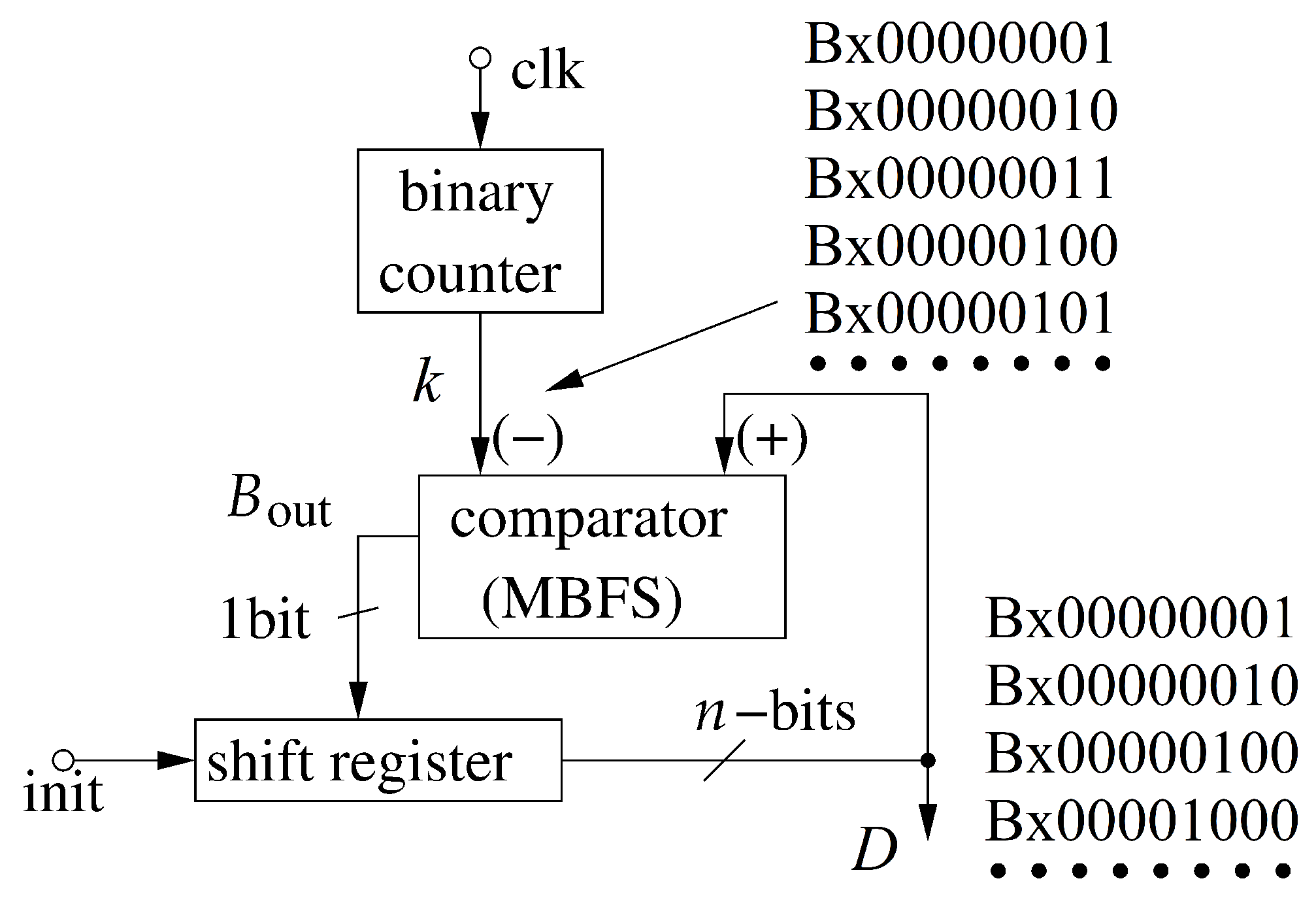
4.2. Methods—Proposed Algorithms
4.3. Proposed Modifications of Coefficients
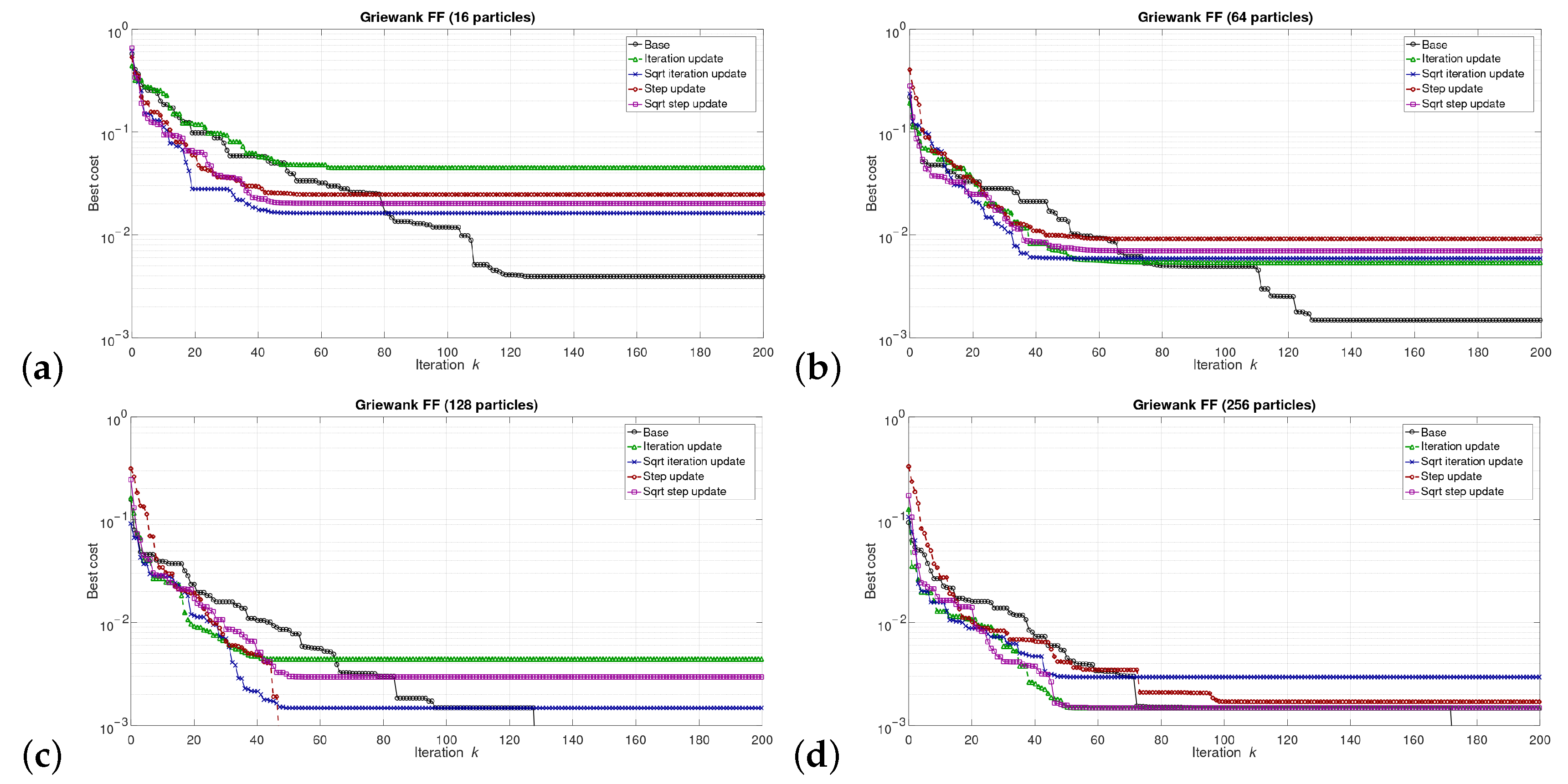
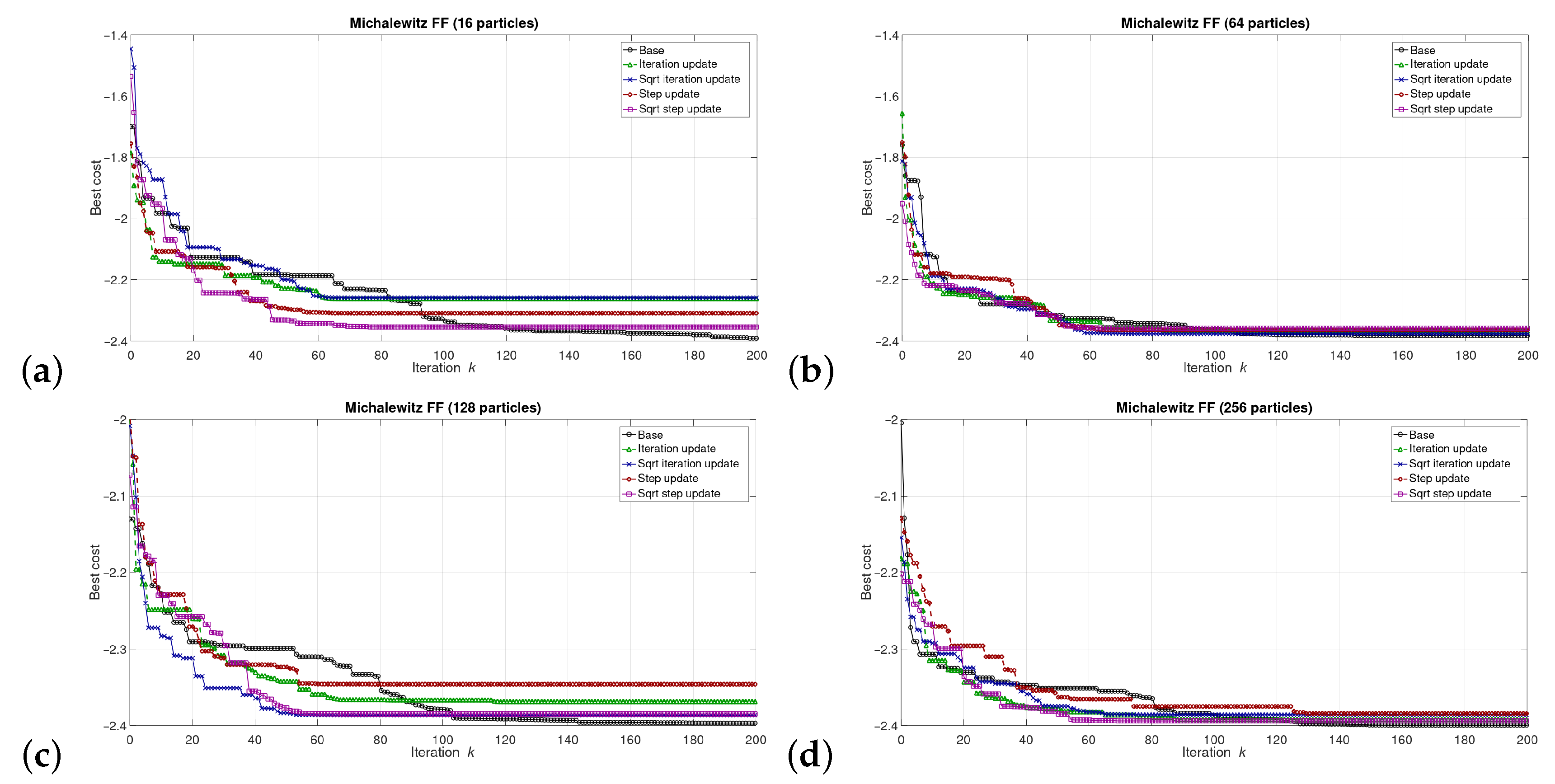
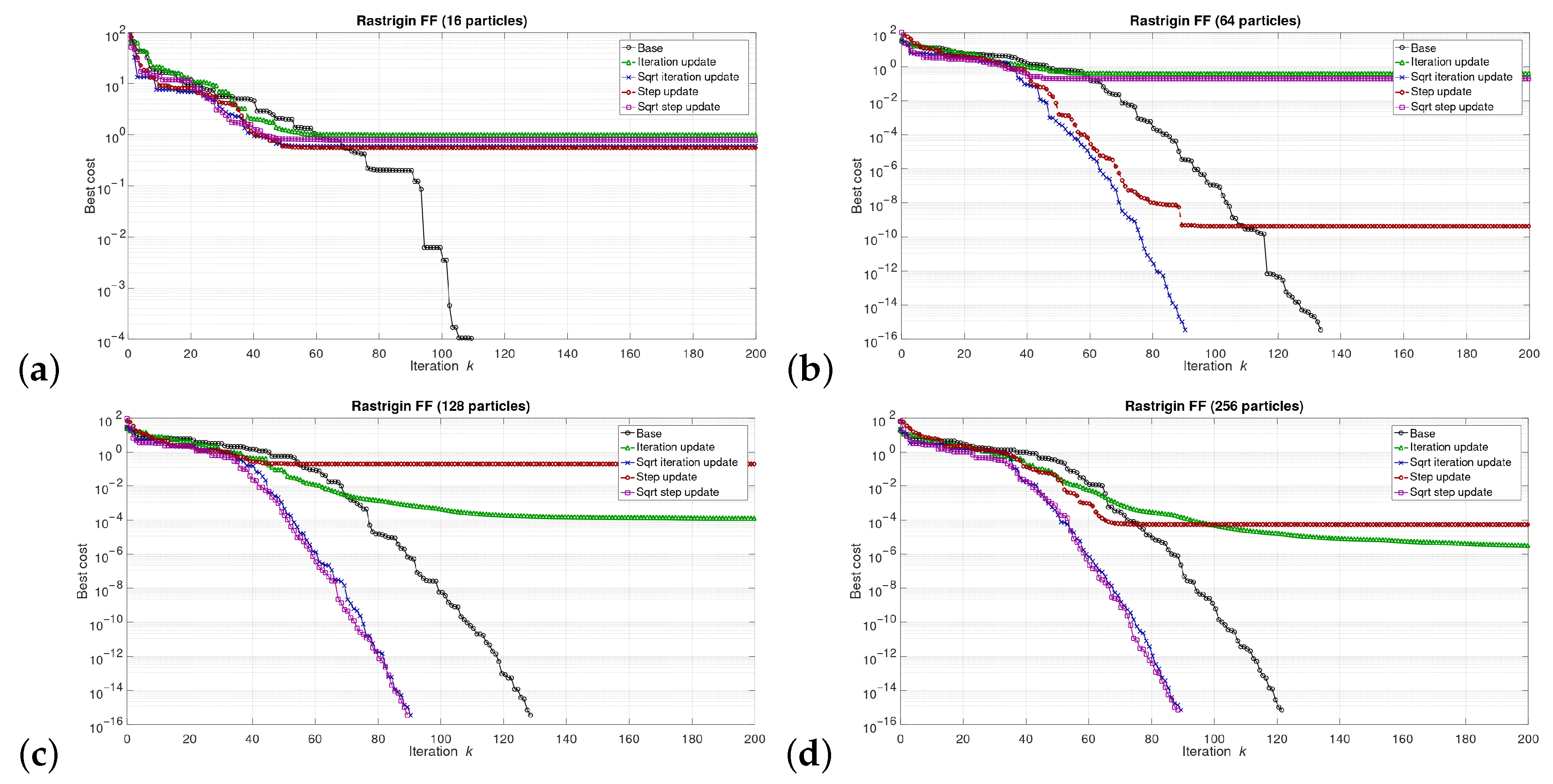
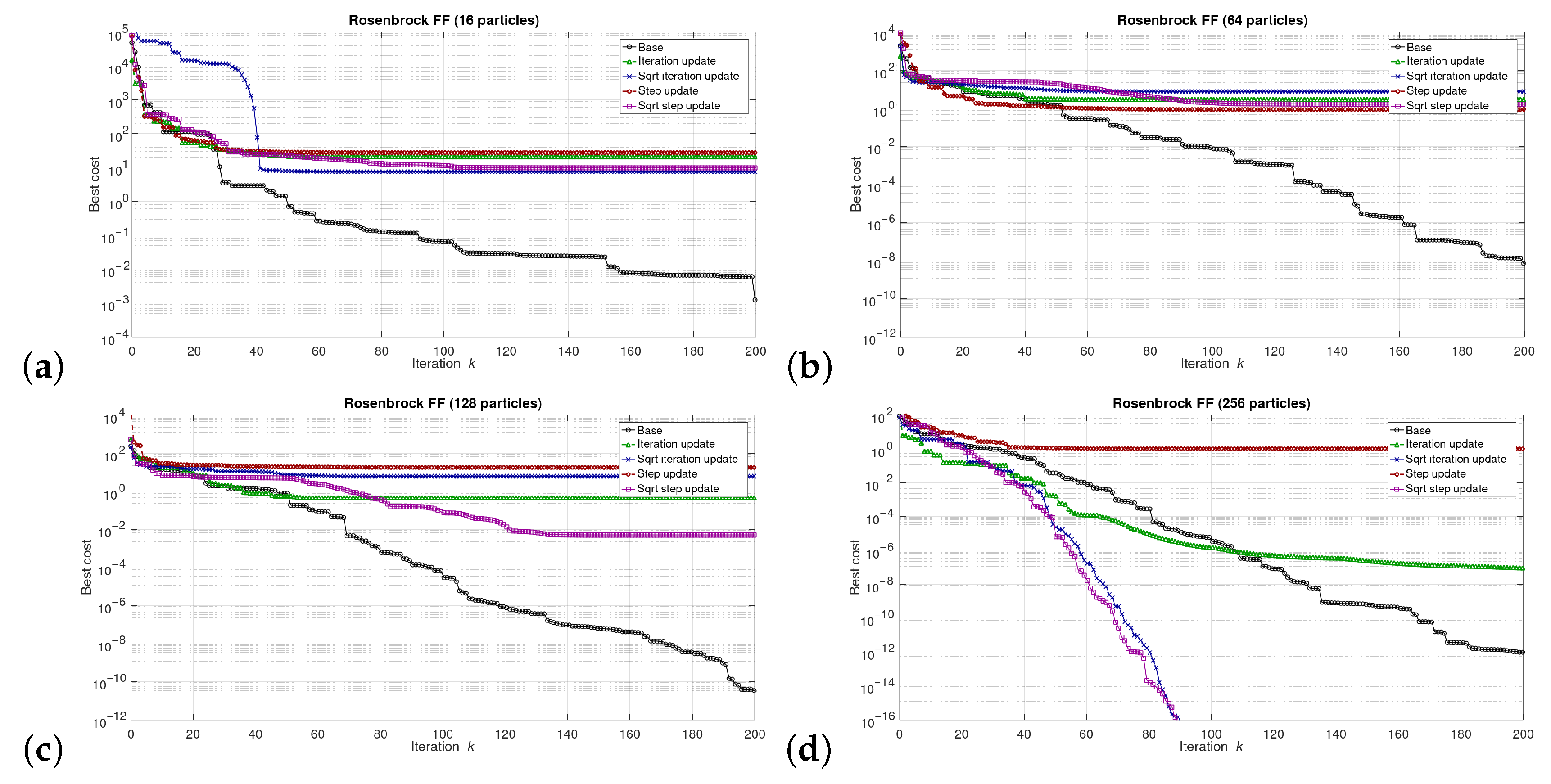
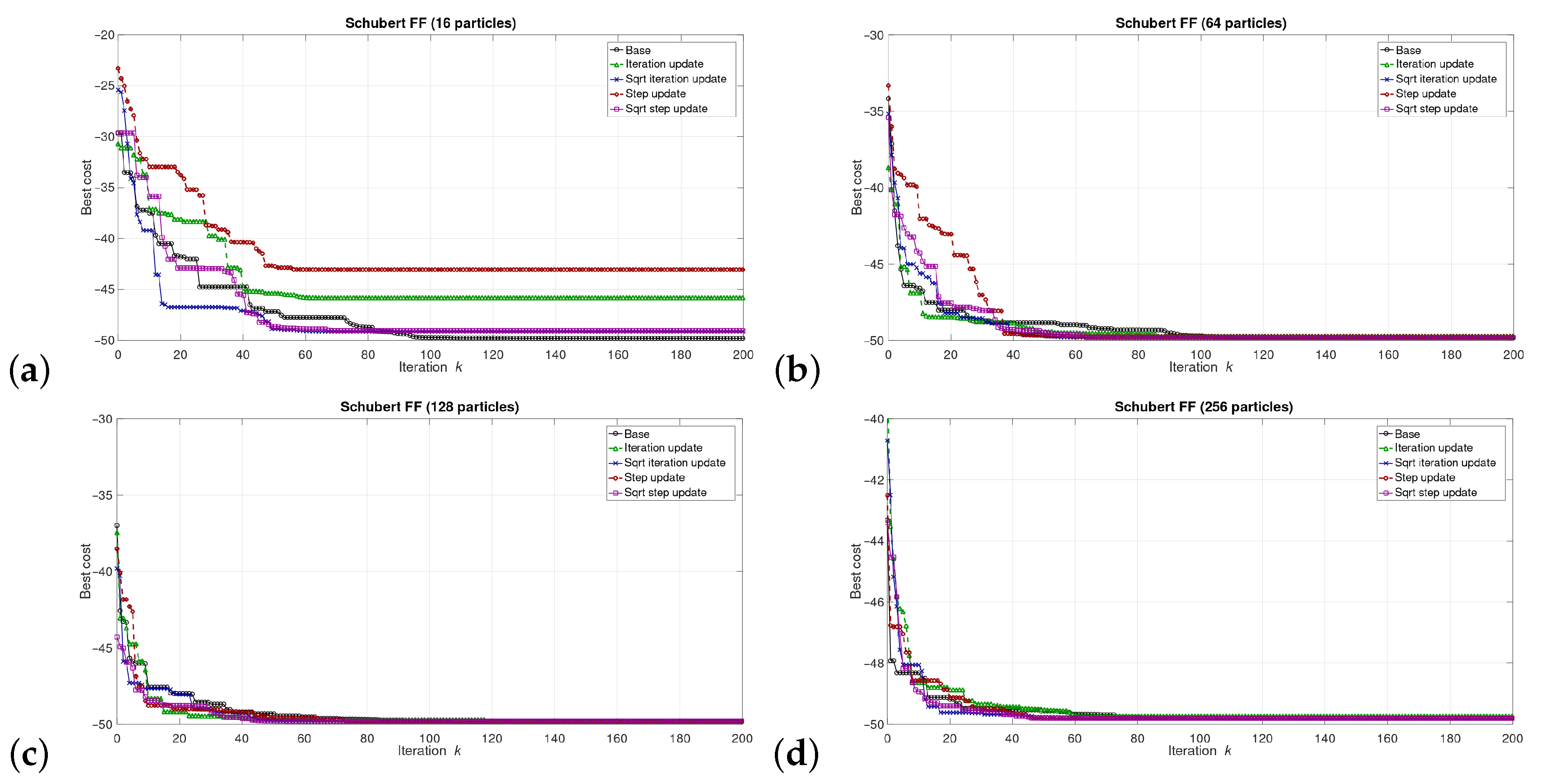
5. Results
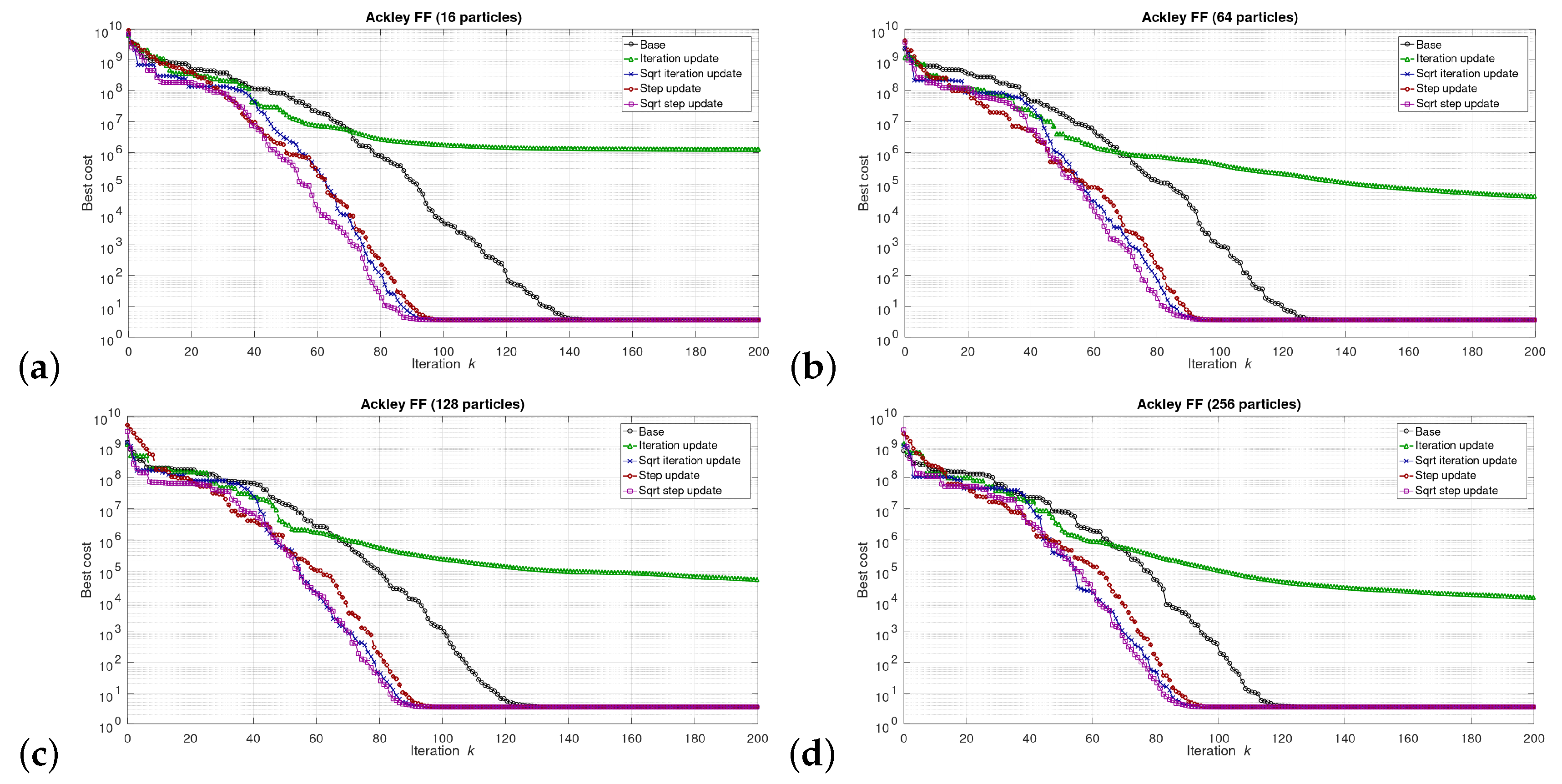
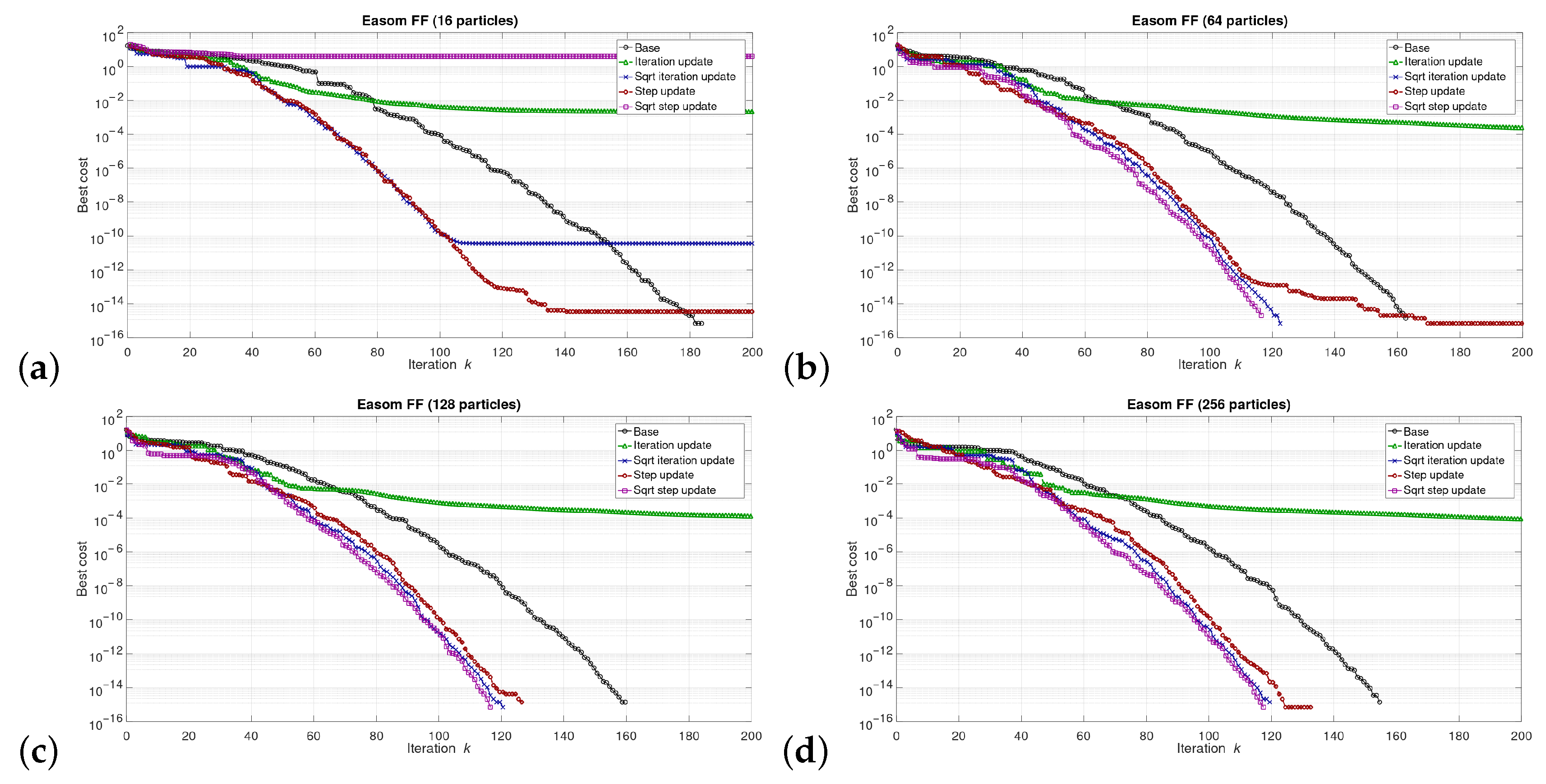
5.1. Results at the Software/Model Level
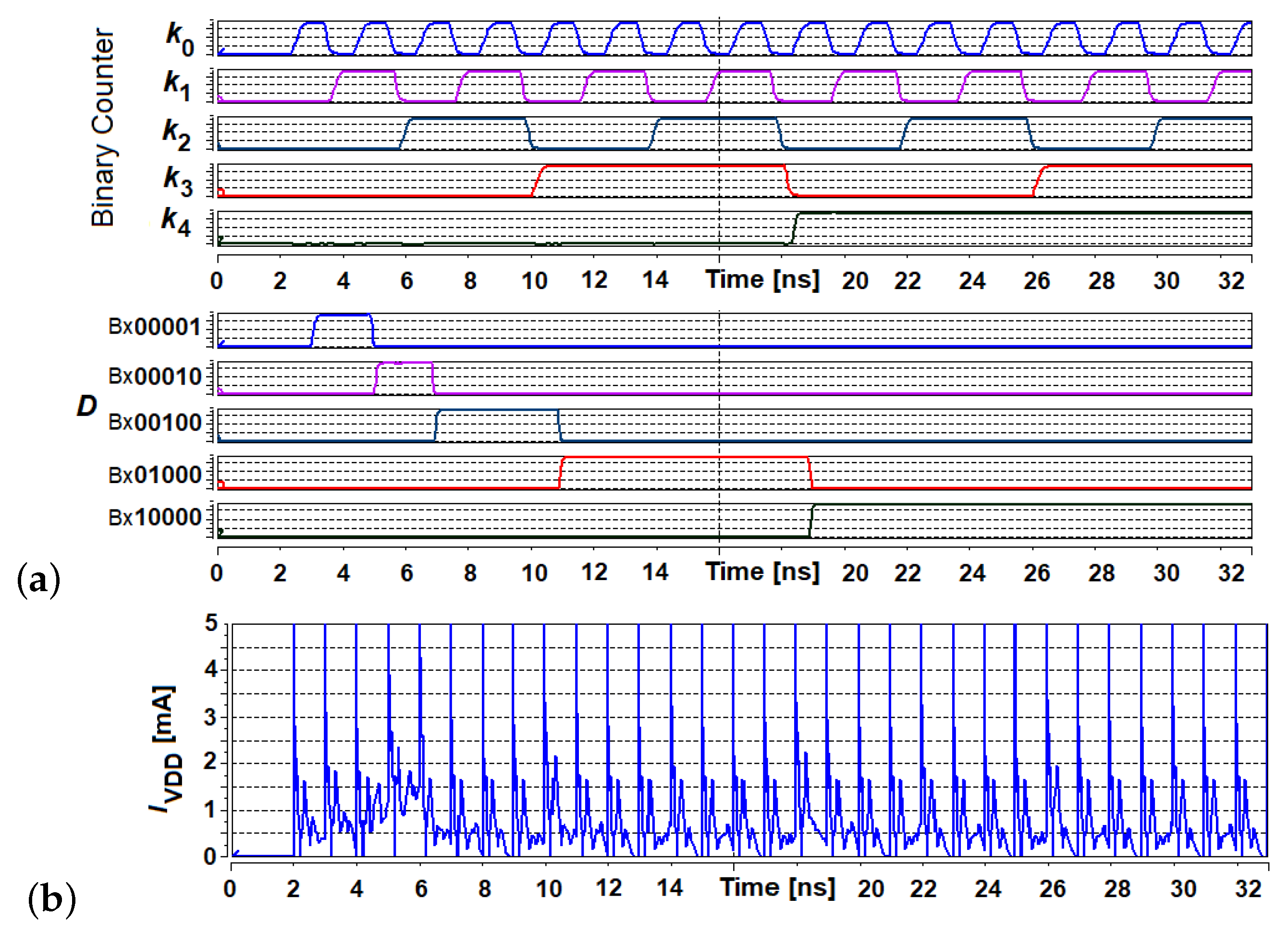
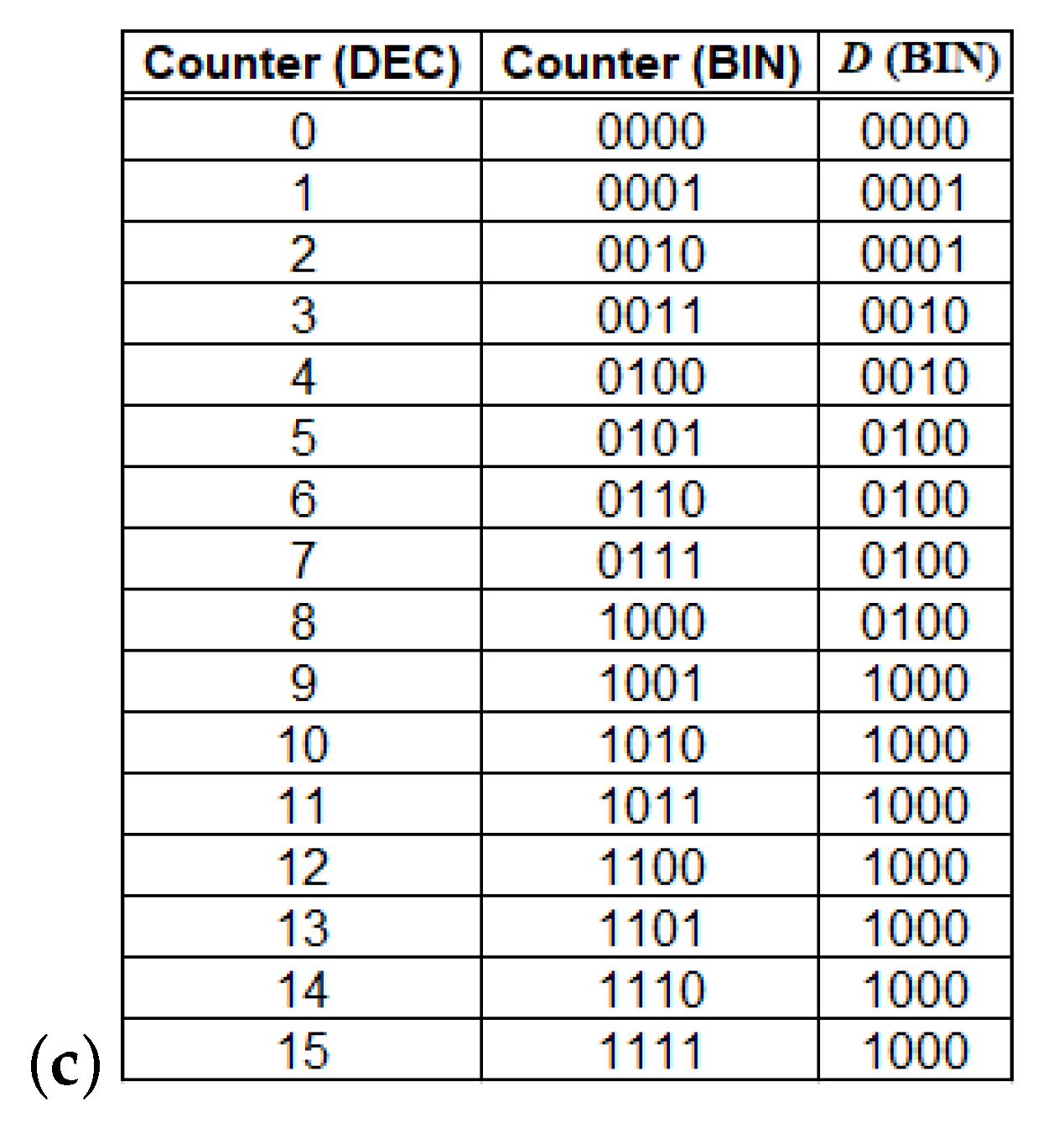
5.2. Results at the Hardware Level
6. Discussion
6.1. Software Level Results
6.2. Hardware Level Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 1BFA | 1-bit full adders |
| 1BFS | 1-bit full subtractor |
| ABC | Artificial Bee Colony |
| ACO | Ant Colony Optimization |
| BA | Bat Algorithm |
| BFO | Bacterial Foraging Optimization |
| DFF | D-flip flops |
| FF | Fitness Function |
| LUT | Look-Up-Table |
| MBFA | multi-bit Full Adder |
| MBFS | Multi-bit Full Subtractor |
| MSB | Most Significant Bit |
| PSO | Particle Swarm Optimization |
| SVM | Support Vector Machine |
References
- Basnet, A.; Shakya, S.; Thapa, M. Power and capacity optimization for wireless sensor network (WSN). In Proceedings of the International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 434–439. [Google Scholar]
- Iqbal, M.; Naeem, M.; Anpalagan, A.; Ahmed, A.; Azam, M. Wireless Sensor Network Optimization: Multi-Objective Paradigm. Sensors 2015, 15, 17572–17620. [Google Scholar] [CrossRef] [PubMed]
- Długosz, R.; Fischer, G. Low Chip Area, Low Power Dissipation, Programmable, Current Mode, 10-bits, SAR ADC Implemented in the CMOS 130 nm Technology. In Proceedings of the International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Gdynia, Poland, 25–27 June 2015. [Google Scholar]
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Bereketli, A.; Akan, O. Communication coverage in wireless passive sensor networks. IEEE Commun. Lett. 2009, 13, 133–135. [Google Scholar] [CrossRef]
- Długosz, R.; Kolasa, M.; Pedrycz, W.; Szulc, M. Parallel Programmable Asynchronous Neighborhood Mechanism for Kohonen SOM Implemented in CMOS Technology. IEEE Trans. Neural Netw. 2011, 22, 2091–2104. [Google Scholar] [CrossRef]
- Banach, M.; Długosz, R.; Talaśka, T.; Pauk, J. Hardware Efficient Solutions for Wireless Air Pollution Sensors Dedicated to Dense Urban Areas. Remote Sens. 2020, 12, 776. [Google Scholar] [CrossRef] [Green Version]
- Inan, O.; Giovangrandi, L.; Kovacs, G. Robust neural-networkbased classification of premature ventricular contractions using wavelet transform and timing interval features. IEEE Trans. Biomed. Eng. 2006, 53, 2507–2515. [Google Scholar] [CrossRef]
- He, L.; Hou, W.; Zhen, X.; Peng, C. Recognition of ECG patterns using artificial neural network. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications, Jinan, China, 16–18 October 2006; Volume 2, pp. 477–481. [Google Scholar]
- Talaśka, T.; Kolasa, M.; Długosz, R. Parallel Asynchronous Winner Selection Circuit for Hardware Implemented Self-Organizing Maps. In Proceedings of the 24th International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Gdynia, Poland, 21–23 June 2018. [Google Scholar]
- Banach, M.; Talaśka, T.; Dalecki, J.; Długosz, R. New Technologies for Smart Cities—High Resolution Air Pollution Maps Based on Intelligent Sensors. In Concurrency and Computation: Practice and Experience; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Perry, L. IoT and Edge Computing for Architects—Implementing Edge and IoT Systems from Sensors to Clouds with Communication Systems, Analytics, and Security, 2nd ed.; Packt Publishing: Birmingham, UK, 2020. [Google Scholar]
- Raponi, S.; Caprolu, M.; Di Pietro, R. Intrusion Detection at the Network Edge: Solutions, Limitations, and Future Directions. In Proceedings of the 3rd International Conference Edge Computing, EDGE 2019, San Diego, CA, USA, 25–30 June 2019. [Google Scholar]
- Li, X.; Zhu, L.; Chu, X.; Fu, H. Edge Computing-Enabled Wireless Sensor Networks for Multiple Data Collection Tasks in Smart Agriculture. J. Sens. 2020, 2020, 4398061. [Google Scholar] [CrossRef]
- Pushpan, S.; Velusamy, B. Fuzzy-Based Dynamic Time Slot Allocation for Wireless Body Area Networks. Sensors 2019, 19, 2112. [Google Scholar] [CrossRef] [Green Version]
- Banach, M.; Długosz, R. Method to Improve the Determination of a Position of a Roadside Unit, Road-Side Unit and System to Provide Position Information. U.S. Patent US10924888 (B2), 16 February 2021. [Google Scholar]
- Dorigo, M.; Stützle, T. Ant Colony OptimizationAnt Colony Optimization; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2012, 42, 21–57. [Google Scholar] [CrossRef]
- Yang, X.S. A New Metaheuristic Bat-Inspired Algorithm. In Nature Inspired Cooperative Strategies for Optimization; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Passino, K.M. Bacterial Foraging optimization. Int. J. Swarm Intell. Res. 2010, 1, 1–16. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks 1995, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Kim, Y.-G.; Sun, B.-Q.; Kim, P.; Jo, M.-B.; Ri, T.-H.; Pak, G.-H. A study on optimal operation of gate-controlled reservoir system for flood control based on PSO algorithm combined with rearrangement method of partial solution groups. J. Hydrol. 2021, 593, 125783. [Google Scholar] [CrossRef]
- Nilesh, K.; Ritu, T.; Joydip, D. Particle swarm optimization and feature selection for intrusion detection system. Sādhanā 2020, 45, 1–4. [Google Scholar]
- Gao, L.; Ye, M.; Wu, C. Cancer Classification Based on Support Vector Machine Optimized by Particle Swarm Optimization and Artificial Bee Colony. Molecules 2017, 22, 2086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boser, B.; Guyon, I.; Vapnik, V. A training algorithm for optimal margin classifiers, In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992.
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambrigde, UK, 2001. [Google Scholar]
- Zhang, Y.; Agarwal, P.; Bhatnagar, V.; Balochian, S.; Yan, J. Swarm Intelligence and Its Applications. Sci. World J. 2013, 2013, 528069. [Google Scholar] [CrossRef] [PubMed]
- Zamani-Gargari, M.; Nazari-Heris, M.; Mohammadi-Ivatloo, B. MChapter 30—Application of Particle Swarm Optimization Algorithm in Power System Problems. In Handbook of Neural Computation; Academic Press: Cambridge, MA, USA, 2017; pp. 571–579. [Google Scholar]
- Babazadeh, A.; Poorzahedy, H.; Nikoosokhan, S. Application of particle swarm optimization to transportation network design problem. J. King Saud Univ. Sci. 2011, 23, 293–300. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.; Dutta, D.; Choudhury, K. Training Artificial Neural Network using Particle Swarm Optimization Algorithm. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 23, 430–434. [Google Scholar]
- Shi, Y.; Eberhart, R.C. Empirical study of particle swarm optimization. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1945–1950. [Google Scholar]
- Ren, M.; Huang, X.; Zhu, X.; Shao, L. Optimized PSO algorithm based on the simplicial algorithm of fixed point theory. Appl. Intell. 2020, 50, 2009–2024. [Google Scholar] [CrossRef]
- Jiang, Y.; Hu, T.; Huang, C.; Wu, X. An improved particle swarm optimization algorithm. Appl. Math. Comput. 2007, 193, 231–239. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R.C. Parameter selection in particle swarm optimization. In Proceedings of the Evolutionary Programming, VII (EP98), San Diego, CA, USA, 25–27 March 1998; pp. 591–600. [Google Scholar]
- Eberhart, R.C.; Shi, Y. Comparing inertia weights and constriction factors in particle swarm optimization. In Proceedings of the 2000 Congress on Evolutionary Computation, San Francisco, CA, USA, 10–12 July 2000; pp. 84–88. [Google Scholar]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. In Soft Computing; Springer: Berlin/Heidelberg, Germany, 2018; Volume 22, pp. 387–408. [Google Scholar]
- Tewolde, G.S.; Hanna, D.M.; Haskell, R.E. A modular and efficient hardware architecture for particle swarm optimization algorithm. Microprocess. Microsyst. 2012, 36, 289–302. [Google Scholar] [CrossRef]
- Tewolde, G.S.; Hanna, D.M.; Haskell, R.E. Multi-swarm parallel PSO: Hardware implementation. In Proceedings of the 2009 IEEE Swarm Intelligence Symposium, Nashville, TN, USA, 30 March–2 April 2009; pp. 60–66. [Google Scholar]
- Suresh, V.B. On-Chip True Random Number Generation in Nanometer CMOS; University of Massachusetts Amherst: Amherst, MA, USA, 2012. [Google Scholar]
- Stanchieri, G.D.P.; De Marcellis, A.; Palange, E.; Faccio, M. A true random number generator architecture based on a reduced number of FPGA primitives. AEU Int. J. Electron. Commun. 2019, 105, 15–23. [Google Scholar] [CrossRef]
- Cherkaoui, A.; Fischer, V.; Aubert, A.; Fesquet, L. A Self-timed Ring Based True Random Number Generator. In Proceedings of the 2013 IEEE 19th International Symposium on Asynchronous Circuits and Systems, Santa Monica, CA, USA, 19–22 May 2013. [Google Scholar]
- Bucci, M.; Germani, L.; Luzzi, R.; Tommasino, P.; Trifiletti, A.; Varanonuovo, M. A high-speed IC random-number source for SmartCard microcontrollers. IEEE Trans. Circuits Syst. Fundam. Theory Appl. 2003, 50, 1373–1380. [Google Scholar] [CrossRef]
- Petrie, C.S.; Connelly, J.A. A Noise-Based IC Random Number Generator for Applications in Cryptography. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 2000, 47, 615–621. [Google Scholar] [CrossRef]
- Zhou, S.H.; Zhang, W.; Wu, N.J. An ultra-low power CMOS random number generator. Solid-State Electron. 2008, 52, 233–238. [Google Scholar] [CrossRef]
- Tavas, V.; Demirkol, A.S.; Ozoguz, S.; Kilinc, S.; Toker, A.; Zeki, A. An IC Random Number Generator Based on Chaos. In Proceedings of the 2010 International Conference on Applied Electronics, Kyoto, Japan, 1–3 August 2010. [Google Scholar]
- Jin’no, K. A Novel Deterministic Particle Swarm Optimization System. J. Signal Process. 2009, 13, 507–513. [Google Scholar]
- Tsujimoto, T.; Shindo, T.; Jin’no, K. The Neighborhood of Canonical Deterministic PSO. In Proceedings of the 2011 IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011. [Google Scholar]
- Jin’no, K.; Shindo, T. Analysis of dynamical characteristic of canonical deterministic PSO. In Proceedings of the IEEE Congress of Evolutionary Computation (CEC), Barcelona, Spain, 18–23 July 2013. [Google Scholar]
- Jin’no, K.; Shindo, T.; Kurihara, T.; Hiraguri, T.; Yoshino, H. Canonical Deterministic Particle Swarm Optimization to Sustain Global Search. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014. [Google Scholar]
- Kohinata, K.; Kurihara, T.; Shindo, T.; Jin’no, K. A novel deterministic multi-agent solving method. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015. [Google Scholar]
- Ishaque, K.; Salam, Z. A Deterministic Particle Swarm Optimization Maximum Power Point Tracker for Photovoltaic System Under Partial Shading Condition. IEEE Trans. Ind. Electron. 2013, 60, 3195–3206. [Google Scholar] [CrossRef]
- Popa, C.R. Synthesis of Computational Structures for Analog Signal Processing; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Nag, A.; Paily, R.P. Low power squaring and square root circuits using subthreshold MOS transistors. In Proceedings of the 2009 International Conference on Emerging Trends in Electronic and Photonic Devices & Systems, Sabzevar, Iran, 22–24 December 2009; pp. 96–99. [Google Scholar]
- Analog Device, Low Cost Analog Multiplier, AD633, Datasheet. Available online: https://www.analog.com/media/en/technical-documentation/data-sheets/AD633.pdf (accessed on 9 December 2021).
- Sakul, C. A CMOS Square-Rooting Circuits. In Proceedings of the International Technical Conference on Circuits/Systems, Computers and Communications, (ITC-CSCC 2008), Shimonoseki City, Japan, 6–9 July 2008. [Google Scholar]
- Hasnat, A.; Bhattacharyya, T.; Dey, A.; Halder, S.; Bhattacharjee, D. A fast FPGA based architecture for computation of square root and Inverse Square Root. In Proceedings of the 2017 Devices for Integrated Circuit (DevIC), Kalyani, Nadia, 23–24 March 2017; pp. 383–387. [Google Scholar]
- Parrilla, L.; Lloris, A.; Castillo, E.; García, A. Table-free Seed Generation for Hardware Newton–Raphson Square Root and Inverse Square Root Implementations in IoT Devices. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Ercegovac, M.D.; Lang, T.; Muller, J.; Tisserand, A. Reciprocation, square root, inverse square root, and some elementary functions using small multipliers. IEEE Trans. Comput. 2000, 49, 628–637. [Google Scholar] [CrossRef] [Green Version]
- Wong, W.F.; Goto, E. Fast Evaluation of the Elementary Functions in Single Precision. IEEE Trans. Comput. 1995, 44, 453–457. [Google Scholar] [CrossRef]
- Ito, M.; Takagi, N.; Yajima, S. Efficient Initial Approximation and Fast Converging Methods for Division and Square Root. In Proceedings of the 12th Symposium on Computer Arithmetic, Bath, UK, 19–21 July 1995; pp. 2–9. [Google Scholar]
- Acharya, D.; Goel, S.; Asthana, R.; Bhardwaj, A. A Novel Fitness Function in Genetic Programming to Handle Unbalanced Emotion Recognition Data. Pattern Recognit. Lett. 2020, 133, 272–279. [Google Scholar] [CrossRef]
- Malhotra, R.; Khanna, M. Dynamic selection of fitness function for software change prediction using Particle Swarm Optimization. Inf. Softw. Technol. 2019, 112, 51–67. [Google Scholar] [CrossRef]
- Liu, D.; Jinling, D.; Xiaohua, C. A Genetic Algorithm Based on a New Fitness Function for Constrained Optimization Problem. In Proceedings of the 2011 Seventh International Conference on Computational Intelligence and Security, Sanya, China, 3–4 December 2011; pp. 6–9. [Google Scholar]
- Chen, Q.; Worden, K.; Peng, P.; Leung, A.Y.T. Genetic algorithm with an improved fitness function for (N)ARX modelling. Mech. Syst. Signal Process. 2007, 21, 994–1007. [Google Scholar] [CrossRef]
- Cao, J.; Cui, H.; Shi, H.; Jiao, L. Big Data: A Parallel Particle Swarm Optimization-Back-Propagation Neural Network Algorithm Based on MapReduce. PLoS ONE 2016, 11, e0157551. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Zhang, Q.; Quande, Q. Big Data Analytics with Swarm Intelligence. Ind. Manag. Data Syst. 2016, 116, 646–666. [Google Scholar] [CrossRef]
- Rajewski, M.; Długosz, Z.; Długosz, R.; Talaśka, T. Modified Particle Swarm Optimization Algorithm Facilitating its Hardware Implementation. In Proceedings of the 26th International Conference Mixed Design of Integrated Circuits and Systems (MIXDES), Łódź, Poland, 23–25 June 2020. [Google Scholar]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Długosz, Z.; Rajewski, M.; Długosz, R.; Talaśka, T. A Novel, Low Computational Complexity, Parallel Swarm Algorithm for Application in Low-Energy Devices. Sensors 2021, 21, 8449. https://doi.org/10.3390/s21248449
Długosz Z, Rajewski M, Długosz R, Talaśka T. A Novel, Low Computational Complexity, Parallel Swarm Algorithm for Application in Low-Energy Devices. Sensors. 2021; 21(24):8449. https://doi.org/10.3390/s21248449
Chicago/Turabian StyleDługosz, Zofia, Michał Rajewski, Rafał Długosz, and Tomasz Talaśka. 2021. "A Novel, Low Computational Complexity, Parallel Swarm Algorithm for Application in Low-Energy Devices" Sensors 21, no. 24: 8449. https://doi.org/10.3390/s21248449
APA StyleDługosz, Z., Rajewski, M., Długosz, R., & Talaśka, T. (2021). A Novel, Low Computational Complexity, Parallel Swarm Algorithm for Application in Low-Energy Devices. Sensors, 21(24), 8449. https://doi.org/10.3390/s21248449