
Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation



Abstract
1. Introduction
2. Related Works
3. Materials and Methodology
3.1. Materials
About OpenPose
- Deep learning bases the estimation of pose on variations of Convolutional Neural Networks (CNN). These architectures have a strong mathematical basis on which these models are built:
- Apply ReLu (REctified Linear Unit): the rectifier function is applied to increase the non-linearity in the CNN.
- Group: It is based in spatial invariance, a concept in which the location of an object in an image does not affect the ability of the neural network to detect its specific characteristics. Thus, the clustering allows CNN to detect features in multiple images regardless of the lighting difference in the pictures and the different angles of the images.
- Flattening: Once the grouped featured map is obtained, the next step is to flatten it. The flattening involves transforming the entire grouped feature map matrix into a single column which is then fed to the neural network for processing.
- Full connection: After flattening, the flattened feature map is passed through a network neuronal. This step is made up of the input layer, the fully connected layer, and the output layer. The output layer is where the predicted classes are provided. The final values produced by the neural network do not usually add up to one. However, it is important that these values are reduced to numbers between zero and one, which represent the probability of each class. This is the role of the Softmax function.All these steps can be represented by the following diagram in Figure 1.
3.2. Methodology
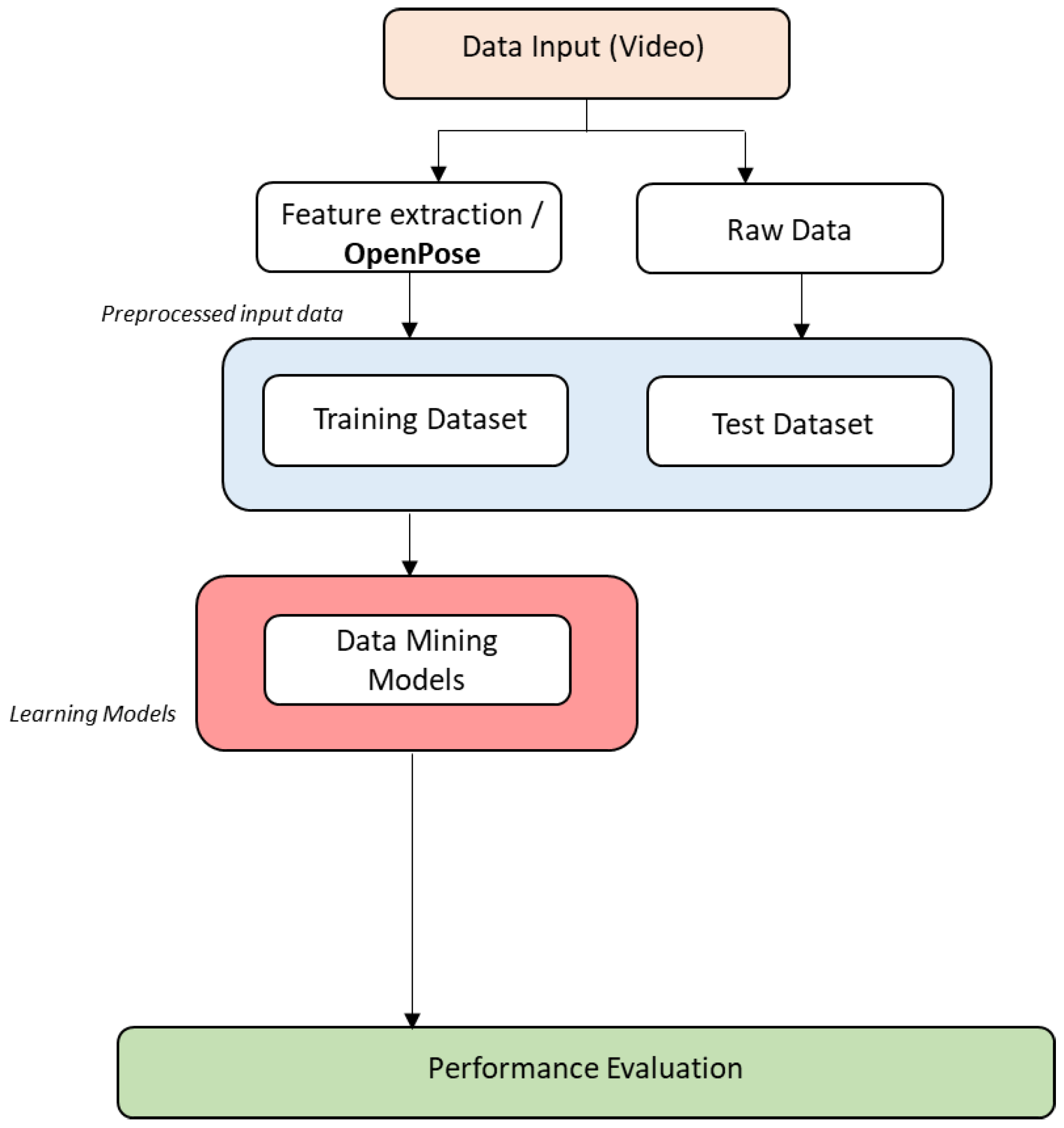
- Acquisition of data input: Record the movements to create the dataset to be used in the experiment, and later to test it.
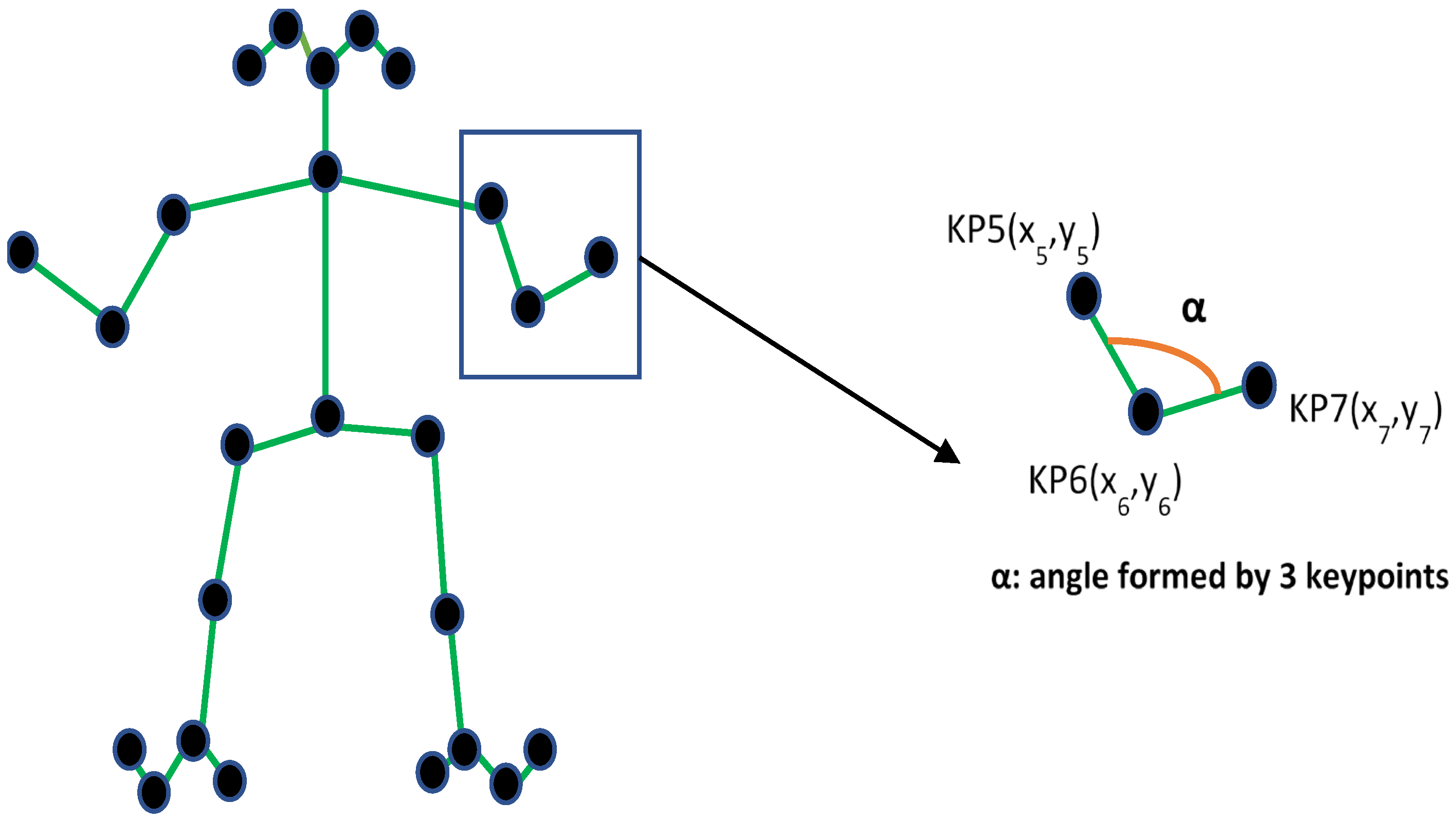
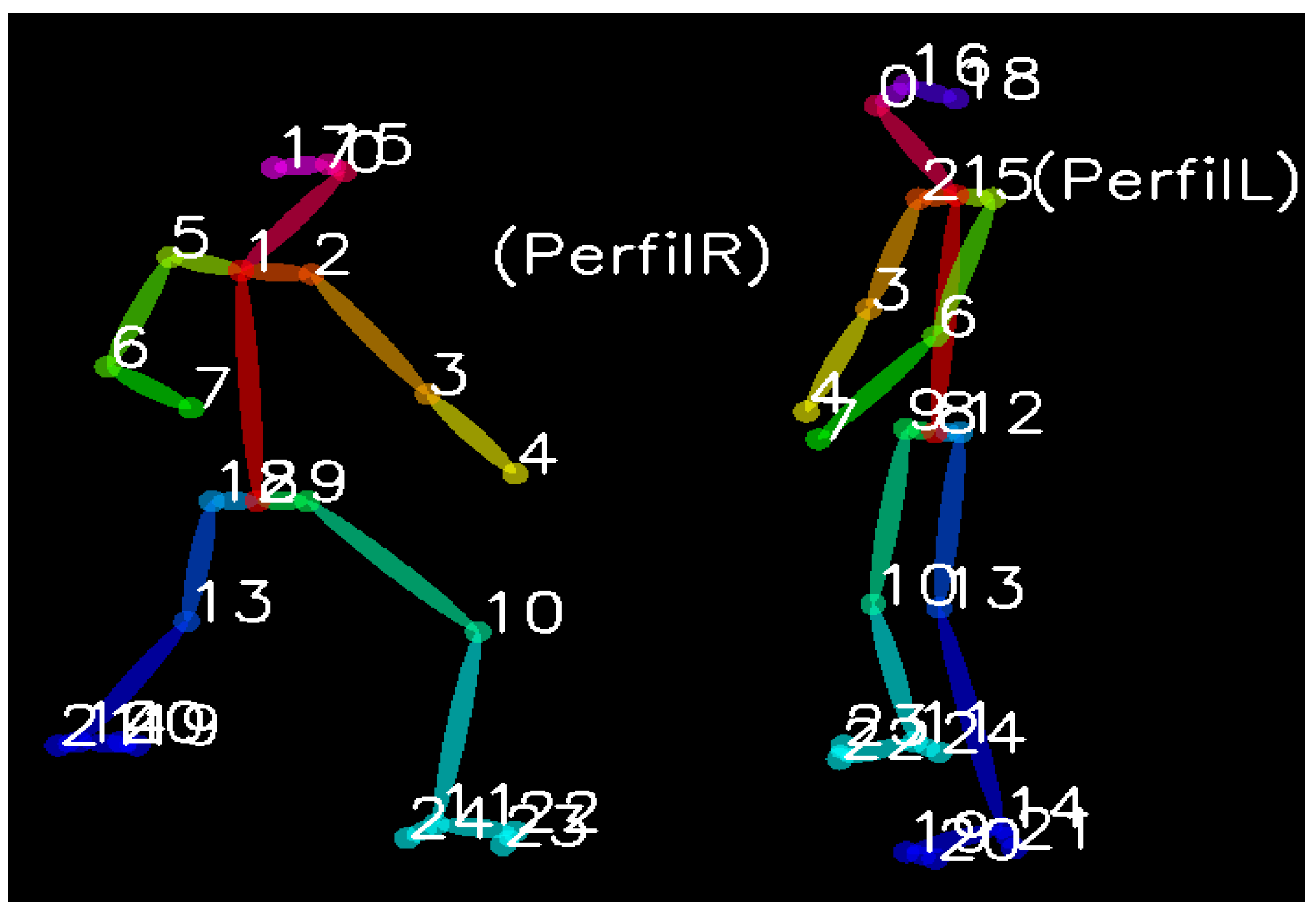
- Feature extraction: Applying the OpenPose algorithm to the dataset to group anatomical positions of the body (called keypoints) into triplets to calculate the angle, which allow generating a pre-processed input data file for algorithm training (see Figures 3 and 4). OpenPose allows to have the 2D position of each point (x, y). Thus, by having the coordinates of three consecutive points, the angle formed by those three with respect to the central one is calculated. An example is provided next.
- Train a movement classifier: With the pre-processed data from point 2, train data mining algorithms to classify and identify the movements. Several data mining algorithms can be used for the classification in the current work generating the corresponding learning models (see below). For the evaluation of the classification performance, 10-fold cross validation is proposed, following [105,106,107].
- Test the movement classifier: Apply the trained classifier to the non-preprocessed input (raw data) with the movements performed by the karateka.
- Evaluate the performance of the classifiers: Compare the results obtained by each algorithm in the classification process with usual machine learning classification metrics, currently those offered by Weka: (i) true positive rate, (ii) false positive rate, (iii) precision (number of true positives that are actually positive compared to the total number of predicted positive values), (iv) recall (number of true positives that the model has classified based on the total number of positive values), (v) F-measure (metric that combines precision and recall), (vi) MMC (Mahalanobis Metric for Clustering: minimizes the distances between similarly labeled inputs while maximizing the distances between differently labeled inputs), ROC area (area under the Receiver Operating Curve: used for classification problems and represents the percentage of true positives against the ratio of false positives), and PRC area (Precision Recall Curve: a plot of precision vs. recall for all potential cut-offs for a test).
3.3. Computational Cost
- pxStreamReadCamServer: receives MxN pixels image compressed in JPEG: (640 * 480) = O(ni) to decompress
- receiveArrayOfDouble: receives 26 double (angle) = 26 = K2
- stampMatOnJLabel: display image on a Jlabel =~ K1
- wrapperClassifier.prediceClase: deduce position of the angles, 26 * num layers = 26 ∗ 16 = K3
- Cost: O(ni) + K2 = 26 => 1 (one) + K3 = 26 ∗ 16 => 16 == O(ni) + K;
- Full cost per frame for one person: 2 ∗ O(ni) + K;
- Full cost per frame for more than one person: O(N^2) + 2 ∗ O(ni) + K;
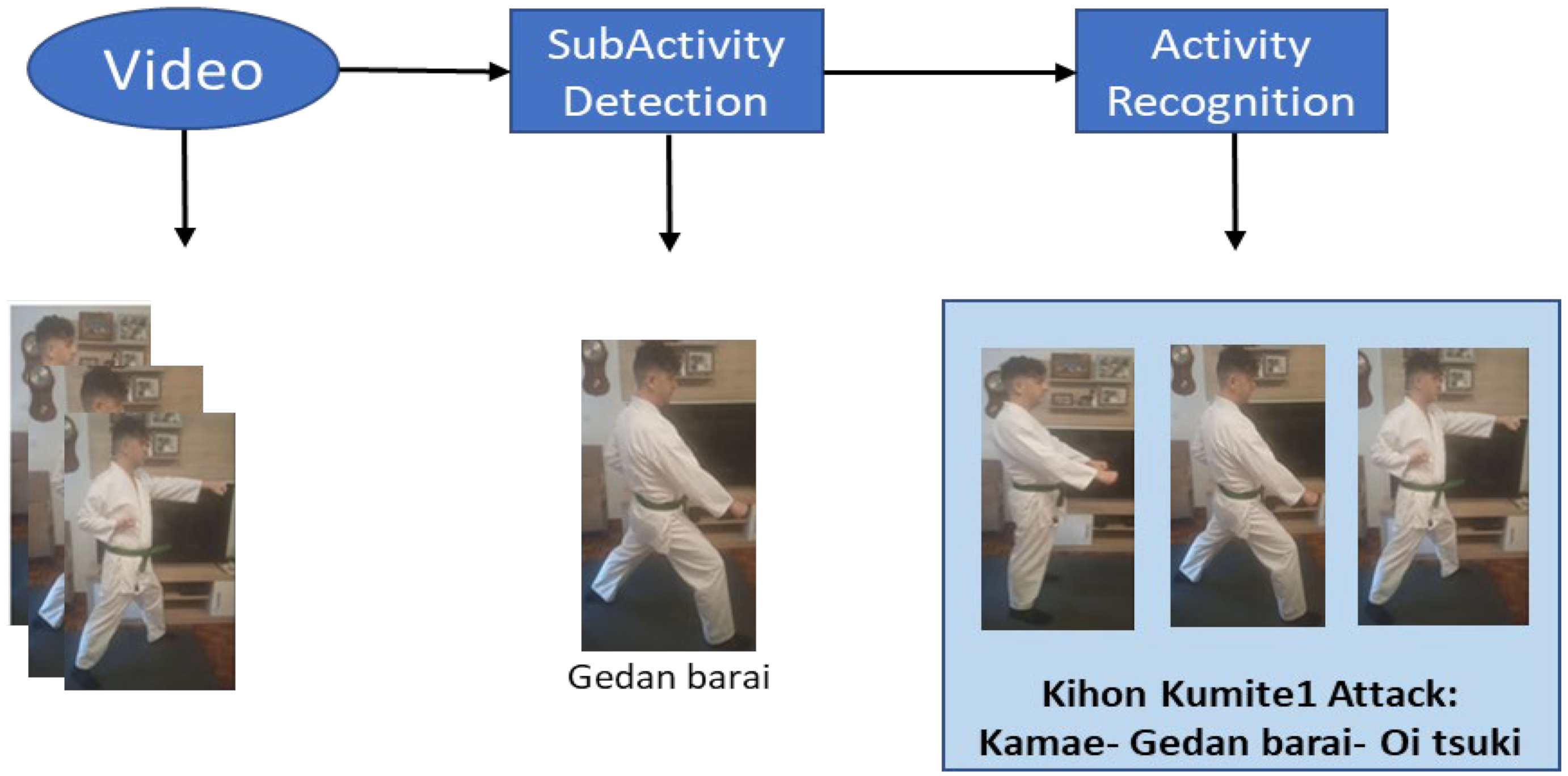
4. Dataset Construction
4.1. Defining the Dataset Inputs
4.2. Preparing the Dataset
4.3. Implemented Application to Obtain the Dataset
5. Analysis and Results
Network Hyperparameters
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 1–28. [Google Scholar] [CrossRef]
- Yang, Y.; Saleemi, I.; Shah, M. Discovering motion primitives for unsupervised grouping and one-shot learning of human actions, gestures, and expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1635–1648. [Google Scholar] [CrossRef] [PubMed]
- Ni, B.; Moulin, P.; Yang, X.; Yan, S. Motion Part Regularization: Improving Action Recognition via Trajectory Group Selection. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2015, 3698–3706. [Google Scholar] [CrossRef]
- Patron-Perez, A.; Marszalek, M.; Reid, I.; Zisserman, A. Structured learning of human interactions in TV shows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2441–2453. [Google Scholar] [CrossRef]
- Li, J.H.; Tian, L.; Wang, H.; An, Y.; Wang, K.; Yu, L. Segmentation and Recognition of Basic and Transitional Activities for Continuous Physical Human Activity. IEEE Access 2019, 7, 42565–42576. [Google Scholar] [CrossRef]
- Martinez, H.P.; Yannakakis, G.N.; Hallam, J. Don’t classify ratings of affect; Rank Them! IEEE Trans. Affect. Comput. 2014, 5, 314–326. [Google Scholar] [CrossRef]
- Lan, T.; Sigal, L.; Mori, G. Social roles in hierarchical models for human activity recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1354–1361. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Marinho, L.B.; de Souza Junior, A.H.; Filho, P.P.R. A new approach to human activity recognition using machine learning techniques. Adv. Intell. Syst. Comput. 2017, 557, 529–538. [Google Scholar] [CrossRef]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable Computing: Accelerometers’ Data Classification of Body Postures and Movements. Lect. Notes Comput. Sci. 2012, 7589, 52–61. [Google Scholar] [CrossRef]
- Masum, A.K.M.; Jannat, S.; Bahadur, E.H.; Alam, M.G.R.; Khan, S.I.; Alam, M.R. Human Activity Recognition Using Smartphone Sensors: A Dense Neural Network Approach. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology, 2019, ICASERT 2019, Dhaka, Bangladesh, 3–5 May 2019; 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Bhuiyan, R.A.; Ahmed, N.; Amiruzzaman, M.; Islam, M.R. A robust feature extraction model for human activity characterization using 3-axis accelerometer and gyroscope data. Sensors 2020, 20, 6990. [Google Scholar] [CrossRef]
- Sekiguchi, R.; Abe, K.; Shogo, S.; Kumano, M.; Asakura, D.; Okabe, R.; Kariya, T.; Kawakatsu, M. Phased Human Activity Recognition based on GPS. In Proceedings of the UbiComp/ISWC 2021—Adjunct Proceedings of the 2021 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2021 ACM International Symposium on Wearable Computers, New York, NY, USA, 21–26 September 2021; pp. 396–400. [Google Scholar] [CrossRef]
- Zhang, Z.; Poslad, S. Improved use of foot force sensors and mobile phone GPS for mobility activity recognition. IEEE Sens. J. 2014, 14, 4340–4347. [Google Scholar] [CrossRef]
- Ulyanov, S.S.; Tuchin, V.V. Pulse-wave monitoring by means of focused laser beams scattered by skin surface and membranes. Static Dyn. Light Scatt. Med. Biol. 1993, 1884, 160. [Google Scholar] [CrossRef]
- Pan, S.; Mirshekari, M.; Fagert, J.; Ramirez, C.G.; Chung, A.J.; Hu, C.C.; Shen, J.P.; Zhang, P.; Noh, H.Y. Characterizing human activity induced impulse and slip-pulse excitations through structural vibration. J. Sound Vib. 2018, 414, 61–80. [Google Scholar] [CrossRef]
- Zhang, M.; Sawchuk, A.A. A preliminary study of sensing appliance usage for human activity recognition using mobile magnetometer. In Proceedings of the UbiComp ’12—Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 745–748. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B. Human activity recognition using inertial/magnetic sensor units. Lect. Notes Comput. Sci. 2010, 6219 LNCS, 38–51. [Google Scholar] [CrossRef]
- Hoang, M.L.; Carratù, M.; Paciello, V.; Pietrosanto, A. Body temperature—Indoor condition monitor and activity recognition by mems accelerometer based on IoT-alert system for people in quarantine due to COVID-19. Sensors 2021, 21, 2313. [Google Scholar] [CrossRef]
- Santos, O.C. Artificial Intelligence in Psychomotor Learning: Modeling Human Motion from Inertial Sensor Data. World Sci. 2019, 28, 1940006. [Google Scholar] [CrossRef]
- Nandakumar, N.; Manzoor, K.; Agarwal, S.; Pillai, J.J.; Gujar, S.K.; Sair, H.I.; Venkataraman, A. Automated eloquent cortex localization in brain tumor patients using multi-task graph neural networks. Med. Image Anal. 2021, 74, 102203. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Cai, Q. Human Motion Analysis: A Review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv 2011, 43, 43. [Google Scholar] [CrossRef]
- Prati, A.; Shan, C.; Wang, K.I.K. Sensors, vision and networks: From video surveillance to activity recognition and health monitoring. J. Ambient Intell. Smart Environ. 2019, 11, 5–22. [Google Scholar] [CrossRef]
- Roitberg, A.; Somani, N.; Perzylo, A.; Rickert, M.; Knoll, A. Multimodal human activity recognition for industrial manufacturing processes in robotic workcells. In Proceedings of the ICMI 2015—Proceedings of the 2015 ACM International Conference Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 259–266. [Google Scholar] [CrossRef]
- Piyathilaka, L.; Kodagoda, S. Human Activity Recognition for Domestic Robots. In Field and Service Robotics; Springer: Cham, Switzerland, 2015; Volume 105, pp. 395–408. [Google Scholar] [CrossRef]
- Osmani, V.; Balasubramaniam, S.; Botvich, D. Human activity recognition in pervasive health-care: Supporting efficient remote collaboration. J. Netw. Comput. Appl. 2008, 31, 628–655. [Google Scholar] [CrossRef]
- Subasi, A.; Radhwan, M.; Kurdi, R.; Khateeb, K. IoT based mobile healthcare system for human activity recognition. In Proceedings of the 15th Learning & Technology Conference (L & T 2018), Jeddah, Saudi Arabia, 25–26 February 2018; pp. 29–34. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Rashid, O.; Al-Hamadi, A.; Michaelis, B. A framework for the integration of gesture and posture recognition using HMM and SVM. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems ICIS, Shanghai, China, 20–22 November 2009; pp. 572–577. [Google Scholar] [CrossRef]
- Chu, W.C.C.; Shih, C.; Chou, W.Y.; Ahamed, S.I.; Hsiung, P.A. Artificial Intelligence of Things in Sports Science: Weight Training as an Example. Computer 2019, 52, 52–61. [Google Scholar] [CrossRef]
- Zalluhoglu, C.; Ikizler-Cinbis, N. Collective Sports: A multi-task dataset for collective activity recognition. Image Vis. Comput. 2020, 94, 103870. [Google Scholar] [CrossRef]
- Kautz, T.; Groh, B.H.; Eskofier, B.M. Sensor fusion for multi-player activity recognition in game sports. KDD Work. Large-Scale Sport. Anal. 2015, pp. 1–4. Available online: https://www5.informatik.uni-erlangen.de/Forschung/Publikationen/2015/Kautz15-SFF.pdf (accessed on 2 December 2021).
- Sharma, A.; Al-Dala’In, T.; Alsadoon, G.; Alwan, A. Use of wearable technologies for analysis of activity recognition for sports. In Proceedings of the CITISIA 2020—IEEE Conference on Innovative Technologies in Intelligent Systems and Industrial Applications, Sydney, Australia, 25–27 November 2020; Available online: https://doi.org/10.1109/CITISIA50690.2020.9371779 (accessed on 20 November 2021). [CrossRef]
- Camomilla, V.; Bergamini, E.; Fantozzi, S.; Vannozzi, G. Trends Supporting the In-Field Use of Wearable Inertial Sensors for Sport Performance Evaluation: A Systematic Review. Sensors 2018, 18, 873. [Google Scholar] [CrossRef]
- Xia, K.; Wang, H.; Xu, M.; Li, Z.; He, S.; Tang, Y. Racquet sports recognition using a hybrid clustering model learned from integrated wearable sensor. Sensors 2020, 20, 1638. [Google Scholar] [CrossRef]
- Wickramasinghe, I. Naive Bayes approach to predict the winner of an ODI cricket game. J. Sport. Anal. 2020, 6, 75–84. [Google Scholar] [CrossRef]
- Jaser, E.; Christmas, W.; Kittler, J. Temporal post-processing of decision tree outputs for sports video categorisation. Lect. Notes Comput. Sci. 2004, 3138, 495–503. [Google Scholar] [CrossRef]
- Sadlier, D.A.; O’Connor, N.E. Event detection in field sports video using audio-visual features and a support vector machine. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 1225–1233. [Google Scholar] [CrossRef]
- Nurwanto, F.; Ardiyanto, I.; Wibirama, S. Light sport exercise detection based on smartwatch and smartphone using k-Nearest Neighbor and Dynamic Time Warping algorithm. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016. [Google Scholar] [CrossRef]
- Hoettinger, H.; Mally, F.; Sabo, A. Activity Recognition in Surfing—A Comparative Study between Hidden Markov Model and Support Vector Machine. Procedia Eng. 2016, 147, 912–917. [Google Scholar] [CrossRef]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. Shot classification of field sports videos using AlexNet Convolutional Neural Network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef]
- Neagu, L.M.; Rigaud, E.; Travadel, S.; Dascalu, M.; Rughinis, R.V. Intelligent tutoring systems for psychomotor training—A systematic literature review. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; pp. 335–341. [Google Scholar]
- Casas-Ortiz, A.; Santos, O.C. Intelligent systems for psychomotor learning. In Handbook of Artificial Intelligence in Education; du Boulay, B., Mitrovic, A., Yacef, K., Eds.; Edward Edgar Publishing: Northampton, MA, USA, 2022; In progress. [Google Scholar]
- Santos, O.C. Training the Body: The Potential of AIED to Support Personalized Motor Skills Learning. Int. J. Artif. Intell. Educ. 2016, 26, 730–755. [Google Scholar] [CrossRef]
- Santos, O.C.; Boticario, J.G.; Van Rosmalen, P. The Full Life Cycle of Adaptation in aLFanet eLearning Environment. 2004. Available online: https://tc.computer.org/tclt/wp-content/uploads/sites/5/2016/12/learn_tech_october2004.pdf (accessed on 27 November 2021).
- Casas-Ortiz, A.; Santos, O.C. KSAS: A Mobile App with Neural Networks to Guide the Learning of Motor Skills. In Proceedings of the XIX Conference of the Spanish Association for the Artificial Intelligence (CAEPIA 20/21). Competition on Mobile Apps with A.I. Techniques, Malaga, Spain, 22–24 September 2021; Available online: https://caepia20-21.uma.es/inicio_files/caepia20-21-actas.pdf (accessed on 27 November 2021).
- Echeverria, J.; Santos, O.C. KUMITRON: Artificial intelligence system to monitor karate fights that synchronize aerial images with physiological and inertial signals. In Proceedings of the IUI ’21 Companion International Conference on Intelligent User Interfaces, College Station, TX, USA, 13–17 April 2021; pp. 37–39. [Google Scholar] [CrossRef]
- Echeverria, J.; Santos, O.C. KUMITRON: A Multimodal Psychomotor Intelligent Learning System to Provide Personalized Support when Training Karate Combats. MAIEd’21 Workshop. The First International Workshop on Multimodal Artificial Intelligence in Education. 2021. Available online: http://ceur-ws.org/Vol-2902/paper7.pdf (accessed on 27 September 2021).
- Echeverria, J.; Santos, O.C. Punch Anticipation in a Karate Combat with Computer Vision. In Proceedings of the UMAP 21—Adjunct 29th ACM Conference on User Modeling, Adaptation and Personalization, Utrecht, The Netherlands, 12–25 June 2021; pp. 61–67. [Google Scholar] [CrossRef]
- Santos, O.C. Psychomotor Learning in Martial Arts: An opportunity for User Modeling, Adaptation and Personalization. In Proceedings of the UMAP 2017—Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, New York, NY, USA, 9–12 July 2017; pp. 89–92. [Google Scholar] [CrossRef]
- Santos, O.C.; Corbi, A. Can Aikido Help with the Comprehension of Physics? A First Step towards the Design of Intelligent Psychomotor Systems for STEAM Kinesthetic Learning Scenarios. IEEE Access 2019, 7, 176458–176469. [Google Scholar] [CrossRef]
- Funakoshi, G. My Way of Life, 1st ed; Kodansha International Ltd.: San Francisco, CA, USA, 1975. [Google Scholar]
- World Karate Federation. Karate Competition Rules. 2020. Available online: https://www.wkf.net/pdf/WKF_Competition%20Rules_2020_EN.pdf (accessed on 27 November 2021).
- Hachaj, T.; Ogiela, M.R. Application of Hidden Markov Models and Gesture Description Language classifiers to Oyama karate techniques recognition. In Proceedings of the 2015 9th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, IMIS 2015, Santa Catarina, Brazil, 8–10 July 2015; pp. 160–165. [Google Scholar] [CrossRef]
- Yıldız, S. Relationship Between Functional Movement Screen and Some Athletic Abilities in Karate Athletes. J. Educ. Train. Stud. 2018, 6, 66. [Google Scholar] [CrossRef]
- Hachaj, T.; Ogiela, M.R.; Koptyra, K. Application of assistive computer vision methods to Oyama karate techniques recognition. Symmetry 2015, 7, 1670–1698. [Google Scholar] [CrossRef]
- Santos, O.C. Beyond Cognitive and Affective Issues: Designing Smart Learning Environments for Psychomotor Personalized Learning; Learning, Design, and Technology; Spector, M., Lockee, B., Childress, M., Eds.; Springer: New York, NY, USA, 2016; pp. 1–24. Available online: https://link.springer.com/referenceworkentry/10.1007%2F978-3-319-17727-4_8-1 (accessed on 27 November 2021).
- Zhang, F.; Zhu, X.; Ye, M. Fast human pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3512–3521. [Google Scholar] [CrossRef]
- Piccardi, M.; Jan, T. Recent advances in computer vision. Ind. Phys. 2003, 9, 18–21. [Google Scholar]
- Chen, X.; Pang, A.; Yang, W.; Ma, Y.; Xu, L.; Yu, J. SportsCap: Monocular 3D Human Motion Capture and Fine-Grained Understanding in Challenging Sports Videos. Int. J. Comput. Vis. 2021, 129, 2846–2864. [Google Scholar] [CrossRef]
- Shingade, A.; Ghotkar, A. Animation of 3D Human Model Using Markerless Motion Capture Applied To Sports. Int. J. Comput. Graph. Animat. 2014, 4, 27–39. [Google Scholar] [CrossRef]
- Bridgeman, L.; Volino, M.; Guillemaut, J.Y.; Hilton, A. Multi-person 3D pose estimation and tracking in sports. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 2487–2496. [Google Scholar] [CrossRef]
- Xiaojie, S.; Qilei, L.; Tao, Y.; Weidong, G.; Newman, L. Mocap data editing via movement notations. In Proceedings of the Ninth International Conference on Computer Aided Design and Computer Graphics (CAD-CG’05), Hong Kong, China, 7–10 December 2005; pp. 463–468. [Google Scholar] [CrossRef]
- Thành, N.T.; Hùng, L.V.; Công, P.T. An Evaluation of Pose Estimation in Video of Traditional Martial Arts Presentation. J. Res. Dev. Inf. Commun. Technol. 2019, 2019, 114–126. [Google Scholar] [CrossRef][Green Version]
- Mohd Jelani, N.A.; Zulkifli, A.N.; Ismail, S.; Yusoff, M.F. A Review of Virtual Reality and Motion Capture in Martial Arts Training. Int. J. Interact. Digit. Media 2020, 5, 22–25. Available online: http://repo.uum.edu.my/26996/ (accessed on 20 November 2021).
- Zhang, W.; Liu, Z.; Zhou, L.; Leung, H.; Chan, A.B. Martial Arts, Dancing and Sports dataset: A challenging stereo and multi-view dataset for 3D human pose estimation. Image Vis. Comput. 2017, 61, 22–39. [Google Scholar] [CrossRef]
- Kaharuddin, M.Z.; Khairu Razak, S.B.; Kushairi, M.I.; Abd Rahman, M.S.; An, W.C.; Ngali, Z.; Siswanto, W.A.; Salleh, S.M.; Yusup, E.M. Biomechanics Analysis of Combat Sport (Silat) by Using Motion Capture System. IOP Conf. Ser. Mater. Sci. Eng. 2017, 166, 12028. [Google Scholar] [CrossRef]
- Petri, K.; Emmermacher, P.; Danneberg, M.; Masik, S.; Eckardt, F.; Weichelt, S.; Bandow, N.; Witte, K. Training using virtual reality improves response behavior in karate kumite. Sport. Eng. 2019, 22, 2. [Google Scholar] [CrossRef]
- Toyama, K.; Krumm, J.; Brumitt, B.; Meyers, B. Wallflower: Principles and practice of background maintenance. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 255–261. [Google Scholar] [CrossRef]
- Takala, T.M.; Hirao, Y.; Morikawa, H.; Kawai, T. Martial Arts Training in Virtual Reality with Full-body Tracking and Physically Simulated Opponents. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Atlanta, GA, USA, 22–26 March 2020; p. 858. [Google Scholar] [CrossRef]
- Hämäläinen, P.; Ilmonen, T.; Höysniemi, J.; Lindholm, M.; Nykänen, A. Martial arts in artificial reality. In Proceedings of the CHI 2005 Technology, Safety, Community: Conference Proceedings—Conference on Human Factors in Computing Systems, Safety, Portland, OR, USA, 2–7 April 2005; pp. 781–790. [Google Scholar] [CrossRef]
- Corbi, A.; Santos, O.C.; Burgos, D. Intelligent Framework for Learning Physics with Aikido (Martial Art) and Registered Sensors. Sensors 2019, 19, 3681. [Google Scholar] [CrossRef]
- Cowie, M.; Dyson, R. A Short History of Karate. 2016, p. 156. Available online: www.kenkyoha.com (accessed on 1 December 2021). [CrossRef]
- Hariri, S.; Sadeghi, H. Biomechanical Analysis of Mawashi-Geri in Technique in Karate: Review Article. Int. J. Sport Stud. Heal. 2018, 1–8, in press. [Google Scholar] [CrossRef]
- Witte, K.; Emmermacher, P.; Langenbeck, N.; Perl, J. Visualized movement patterns and their analysis to classify similarities-demonstrated by the karate kick Mae-geri. Kinesiology 2012, 44, 155–165. [Google Scholar]
- Hachaj, T.; Piekarczyk, M.; Ogiela, M.R. Human actions analysis: Templates generation, matching and visualization applied to motion capture of highly-skilled karate athletes. Sensors 2017, 17, 2590. [Google Scholar] [CrossRef]
- Labintsev, A.; Khasanshin, I.; Balashov, D.; Bocharov, M.; Bublikov, K. Recognition punches in karate using acceleration sensors and convolution neural networks. IEEE Access 2021, 9, 138106–138119. [Google Scholar] [CrossRef]
- Kolykhalova, K.; Camurri, A.; Volpe, G.; Sanguineti, M.; Puppo, E.; Niewiadomski, R. A multimodal dataset for the analysis of movement qualities in karate martial art. In Proceedings of the 2015 7th International Conference on Intelligent Technologies for Interactive Entertainment, INTETAIN 2015, Torino, Italy, 10–12 June 2015; pp. 74–78. [Google Scholar] [CrossRef]
- Goethel, M.F.; Ervilha, U.F.; Moreira, P.V.S.; de Paula Silva, V.; Bendillati, A.R.; Cardozo, A.C.; Gonçalves, M. Coordinative intra-segment indicators of karate performance. Arch. Budo 2019, 15, 203–211. [Google Scholar]
- Petri, K.; Bandow, N.; Masik, S.; Witte, K. Improvement of Early Recognition of Attacks in Karate Kumite Due to Training in Virtual Reality. J. Sport Area 2019, 4, 294–308. [Google Scholar] [CrossRef]
- Gupta, V. Pose Detection Comparison: WrnchAI vs OpenPose. 2019. Available online: https://learnopencv.com/pose-detection-comparison-wrnchai-vs-openpose/ (accessed on 2 December 2021).
- Eivindsen, J.E. Human Pose Estimation Assisted Fitness Technique Evaluation System. Master’s Thesis, NTNU, Norweigian University of Science and Technology, Trondheim, Norway, 2020. Available online: https://ntnuopen.ntnu.no/ntnu-xmlui/handle/11250/2777528?locale-attribute=en (accessed on 2 December 2021).
- Carissimi, N.; Rota, P.; Beyan, C.; Murino, V. Filling the gaps: Predicting missing joints of human poses using denoising autoencoders. Lect. Notes Comput. Sci. 2019, 11130 LNCS, 364–379. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Available online: http://human-pose.mpi-inf.mpg.de/ (accessed on 2 December 2021).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Park, H.J.; Baek, J.W.; Kim, J.H. Imagery based Parametric Classification of Correct and Incorrect Motion for Push-up Counter Using OpenPose. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1389–1394. [Google Scholar] [CrossRef]
- Rosique, F.; Losilla, F.; Navarro, P.J. Applying Vision-Based Pose Estimation in a Telerehabilitation Application. Appl. Sci. 2021, 11, 9132. [Google Scholar] [CrossRef]
- Chen, W.; Jiang, Z.; Guo, H.; Ni, X. Fall Detection Based on Key Points of Human-Skeleton Using OpenPose. Symmetry 2020, 12, 744. Available online: https://www.mdpi.com/2073-8994/12/5/744 (accessed on 24 June 2021). [CrossRef]
- Yunus, A.P.; Shirai, N.C.; Morita, K.; Wakabayashi, T. Human Motion Prediction by 2D Human Pose Estimation using OpenPose. 2020. Available online: https://easychair.org/publications/preprint/8P4x (accessed on 2 December 2021).
- Lin, C.B.; Dong, Z.; Kuan, W.K.; Huang, Y.F. A framework for fall detection based on OpenPose skeleton and LSTM/GRU models. Appl. Sci. 2021, 11, 329. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, J.; Wu, P.; Qi, Y. Application Development of Dance Pose Recognition Based on Embedded Artificial Intelligence Equipment. J. Phys. Conf. Ser. 2021, 1757, 012011. [Google Scholar] [CrossRef]
- Xing, J.; Zhang, J.; Xue, C. Multi person pose estimation based on improved openpose model. IOP Conf. Ser. Mater. Sci. Eng. 2020, 768, 072071. [Google Scholar] [CrossRef]
- Bajireanu, R.; Pereira, J.A.R.; Veiga, R.J.M.; Sardo, J.D.P.; Cardoso, P.J.S.; Lam, R.; Rodrigues, J.M.F. Mobile human shape superimposi-tion: An initial approach using OpenPose. Int. J. Comput. 2018, 3, 1–8. Available online: http://www.iaras.org/iaras/journals/ijc (accessed on 22 May 2021).
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.; Schiele, B. DeepCut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–26 June 2014; pp. 2155–2162. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. 2014. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2014/html/Toshev_DeepPose_Human_Pose_2014_CVPR_paper.html (accessed on 12 June 2021).
- Güler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation in the Wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Xiao, G.; Lu, W. Joint COCO and Mapillary Workshop at ICCV 2019: COCO Keypoint Detection Challenge Track. 2019. Available online: http://cocodataset.org/files/keypoints_2019_reports/ByteDanceHRNet.pdf (accessed on 25 August 2021).
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the 2015 International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar] [CrossRef]
- Zhu, L. Computer Vision-Driven Evaluation System for Assisted Decision-Making in Sports Training Lijin. Wirel. Commun. Mob. Comput. 2021, 2021, 1–7. [Google Scholar] [CrossRef]
- Berrar, D. Cross-validation. Encycl. Bioinforma. Comput. Biol. ABC Bioinforma. 2018, 1–3, 542–545. [Google Scholar] [CrossRef]
- Rodríguez, J.D.; Pérez, A.; Lozano, J.A. Sensitivity Analysis of k-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable Accuracy Estimates from k-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
- Wang, P.; Cai, R.; Yang, S. News video classification using multimodal classifiers and text-biased combination strategies. Qinghua Daxue Xuebao J. Tsinghua Univ. 2005, 45, 475–478. [Google Scholar]
- Yang, J.; Yan, R.; Hauptmann, A.G. Adapting SVM classifiers to data with shifted distributions. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 69–74. [Google Scholar] [CrossRef]
- Yin, P.; Criminisi, A.; Winn, J.; Essa, I. Tree-based classifiers for bilayer video segmentation. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Sivic, J.; Everingham, M.; Zisserman, A. Who are you?—Learning person specific classifiers from video. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1145–1152. [Google Scholar] [CrossRef]
- Mia, M.R.; Mia, M.J.; Majumder, A.; Supriya, S.; Habib, M.T. Computer vision based local fruit recognition. Int. J. Eng. Adv. Technol. 2019, 9, 2810–2820. [Google Scholar] [CrossRef]
- Ponti, M.A.; Ribeiro, L.S.F.; Nazare, T.S.; Bui, T.; Collomosse, J. Everything You Wanted to Know about Deep Learning for Computer Vision but Were Afraid to Ask. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images Tutorials (SIBGRAPI-T), Niteroi, Brazil, 17–18 October 2017; pp. 17–41. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Islam, S.M.S.; Rahman, S.; Rahman, M.M.; Dey, E.K.; Shoyaib, M. Application of deep learning to computer vision: A comprehensive study. In Proceedings of the 5th International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; pp. 592–597. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, Y.; Li, Q.; Jin, S.; Li, F. The application of deep learning in computer vision. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 6522–6527. [Google Scholar] [CrossRef]
- Van Dao, D.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Van Phong, T.; Ly, H.B.; Le, T.T.; Trinh, P.T.; et al. A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. Catena 2020, 188, 104451. [Google Scholar] [CrossRef]
- Grekow, J. Music emotion recognition using recurrent neural networks and pretrained models. J. Intell. Inf. Syst. 2021, 1–16. [Google Scholar] [CrossRef]
- Li, T.; Fong, S.; Siu, S.W.; Yang, X.-S.; Liu, L.-S.; Mohammed, S. White learning methodology: A case study of cancer-related disease factors analysis in real-time PACS environment. Comput. Methods Programs Biomed. 2020, 197, 105724. [Google Scholar] [CrossRef]
- Vanam, M.K.; Amirali Jiwani, B.; Swathi, A.; Madhavi, V. High performance machine learning and data science based implementation using Weka. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Ramírez, I.; Cuesta-Infante, A.; Schiavi, E.; Pantrigo, J.J. Bayesian capsule networks for 3D human pose estimation from single 2D images. Neurocomputing 2020, 379, 64–73. [Google Scholar] [CrossRef]
- Wang, Y.-K.; Cheng, K.-Y. A Two-Stage Bayesian Network Method for 3D Human Pose Estimation from Monocular Image Sequences. EURASIP J. Adv. Signal Process. 2010, 2010, 16. [Google Scholar] [CrossRef]
- Lehrmann, A.M.; Gehler, P.V.; Nowozin, S. A Non-parametric Bayesian Network Prior of Human Pose. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar] [CrossRef]
- Wang, Y.; Li, J.; Zhang, Y.; Sinnott, R.O. Identifying lameness in horses through deep learning. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Gwangju, Korea, 22–26 March 2021; pp. 976–985. [Google Scholar] [CrossRef]
- Park, J.H.K.Y.-S. A Kidnapping Detection Using Human Pose Estimation in Intelligent Video Surveillance Systems. J. Korea Soc. Comput. Inf. 2018, 23, 9–16. [Google Scholar] [CrossRef]
- Elteren, T.; van Zant, T. Real-Time Human Pose and Gesture Recognition for Autonomous Robots Using a Single Structured Light 3D-Scanner. Intell. Environ. Workshops 2012, 213–220. [Google Scholar] [CrossRef]
- Szczuko, P. Deep neural networks for human pose estimation from a very low resolution depth image. Multimed. Tools Appl. 2019, 78, 29357–29377. [Google Scholar] [CrossRef]
- Park, S.; Hwang, J.; Kwak, N. 3D human pose estimation using convolutional neural networks with 2D pose information. Lect. Notes Comput. Sci. 2016, 9915 LNCS, 156–169. [Google Scholar] [CrossRef]
- Rahmad, N.A.; Amir As’ari, M.; Ghazali, N.F.; Shahar, N.; Anis, N.; Sufri, J. A Survey of Video Based Action Recognition in Sports. Indones. J. Electr. Eng. Comput. Sci. 2018, 11, 987–993. [Google Scholar] [CrossRef]
- Kanazawa, H. Karate Fighting Techniques: The Complete Kumite. 2013. Available online: https://www.amazon.es/Karate-Fighting-Techniques-Complete-Kumite/dp/1568365160 (accessed on 30 July 2021).
- Chaabène, H.; Hachana, Y.; Franchini, E.; Mkaouer, B.; Chamari, T. Physical and Physiological Profile of Elite Karate Athletes. Sport. Med. 2012, 42, 829–843. [Google Scholar]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F. Leyton-Brown, K. Auto-WEKA: Automatic Model Selection and Hyperparameter Optimization in WEKA. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 81–95. [Google Scholar] [CrossRef]
- Deotale, D.; Verma, M.; Suresh, P. Human Activity Recognition in Untrimmed Video using Deep Learning for Sports Domain. SSRN Electron. J. 2021, 596–607. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, K.; Su, H.; Ji, Q. Bayesian graph convolution LSTM for skeleton based action recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6881–6891. [Google Scholar] [CrossRef]
- Santos, O.C.; Boticario, J.G. Practical guidelines for designing and evaluating educationally oriented recommendations. Comput. Educ. 2015, 81, 354–374. [Google Scholar] [CrossRef]
- Santos, O.C.; Uria-Rivas, R.; Rodriguez-Sanchez, M.C.; Boticario, J.G. An Open Sensing and Acting Platform for Context-Aware Affective Support in Ambient Intelligent Educational Settings. IEEE Sens. J. 2016, 16, 3865–3874. [Google Scholar] [CrossRef]
- Santos, O.C. Toward personalized vibrotactile support when learning motor skills. Algorithms 2017, 10, 15. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pose Estimation Algorithms | Description |
|---|---|
| AlphaPose (https://github.com/MVIG-SJTU/AlphaPose, accessed on 28 November 2021) | Presented in 2016 [95], it is an algorithm that allows estimating the pose of one or more individuals. It is the first open source system that has reached the following records: 80+ mAP (82.1 mAP) on MPII dataset and 70+ mAP (72.3 mAP) on COCO dataset. This means that the algorithm is more precise in detecting keypoints in comparison with others. AlphaPose is free to use and distribute as long as it is not used for commercial purposes. |
| DeepCut (https://github.com/eldar/deepcut, accessed on 28 November 2021) | System developed in 2016 [96] presented as a multi-person computer vision system, with deeper, stronger and faster features compared to the state of the art at that time. It works bottom-up for image treatment. The way of working is to detect the people who are in an image to later predict the joint locations. It can be applied to both images and video of sports such as baseball, athletics or soccer. |
| Deep Pose (https://github.com/mitmul/deeppose, accessed on 28 November 2021) | An algorithm presented in 2014 [97] that estimates the human pose using Deep Neural Networks (DNN). To do this, a regression based on DNN is performed to estimate the joints. In challenges of precision in the classification of images [98], DeepPose obtained better results than the rest of the works, becoming a benchmark of that moment. |
| DensePose (https://github.com/facebookresearch/DensePose, accessed on 28 November 2021) | It is an algorithm developed in 2018 by members of Facebook [99] that maps the pixels of the human body in 2D to turn it into a 3D surface that covers the human body. It serves one or more individuals. It is being used to determine the surface of the human body for different purposes such as trying on virtually an article of clothing on the avatar created for oneself. |
| High Resolution Net (HRNet) (https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation, accessed on 28 November 2021) | Neural network architecture for the estimation of human pose developed in 2019 by Microsoft [100]. It is also used for semantic segmentation and object detection. Despite being a relatively new model, it is becoming a benchmark in the field of computer vision algorithms. It has been the winner in several computer vision tournaments, for example in ICCV2019 [101]. It is a useful architecture to implement in the postural analysis of televised events since it makes high-resolution estimates of postures. |
| OpenPose (https://github.com/CMU-Perceptual-Computing-Lab/openpose, accessed on 28 November 2021) | Computer vision algorithm for the estimation of pose in real time of several people in 2D developed in 2017 [102]. It has undergone functionalities extensions, and currently allows to be used in 3D, hand point detection, face detection, and work with Unity. The OpenPose API allows obtaining the image from various devices: recorded video, streaming video, webcam, etc. Other hardware is also supported, such as CUDA GPUs, OpenCL GPUs, and CPU-only devices. |
| PoseNet (https://github.com/tensorflow/tfjs-models/tree/master/posenet, accessed on 28 November 2021) | It is a pose estimator for a single person or several people, offering 17 keypoints with which to model the human body. It was developed in 2015 [103]. At first, it was aimed at lightweight devices such as mobile phones or browsers, although today it has advanced and improved performance. |
| WrnchAI (https://go.hingehealth.com/wrnch, accessed on 28 November 2021) | WrnchAI is a human deposit estimation algorithm developed by a company based in Canada in 2014 and released only under license. It can be used for one or several individuals making use of the low latency engine, being a system compatible with all types of video. Due to its commercial use, we could not find any scientific paper describing it. |
| OpenPose Features | |
|---|---|
| Main functionality (with a plain camera) | Detection of keypoints of several people in real time 2D. Body/foot keypoint estimate of 15, 18 or 25 keypoints, including 6 foot keypoints. Execution time invariable with respect to the number of people detected. Handheld keypoint estimate of 2 × 21 keypoints. The execution time depends on the number of people detected. Estimation of keypoints of faces of 70 keypoints. The execution time depends on the number of people detected. |
| Real-time single-person 3D keypoint detection | 3D triangulation of multiple unique views. Synchronization of Flir cameras managed. Compatible with Flir/Point Gray cameras. |
| Calibration Toolbox | Estimation of the distortion, intrinsic and extrinsic parameters of the camera. |
| Input | Image, Video, Webcam, Flir/Point Gray, IP Camera, and support for adding your own custom input source (e.g., depth camera). |
| Output | Basic image + keypoint display/save (PNG, JPG, AVI...), keypoint save (JSON, XML, YML...), keypoints as array class and support to add your own code custom output (e.g., some fancy user interface). |
| Characteristics | Machine Learning | Deep Learning |
|---|---|---|
| Data Requirement | Small/Medium | Large |
| Accuracy | High accuracy | Medium accuracy |
| Preprocessing phase | Needed | Not needed |
| Training time | Short time | Takes longer time |
| Interpretability | From easy (tree, logistic) to difficult (SVM) | From difficult to impossible |
| Hardware requirement | Trains on CPU | Requires GPU |
| KIHON-KUMITE (multi-step combat) | IPPON KIHON KUMITE: One-step conventional assault. |
| SAMBON KIHON KUMITE: Three-step conventional assault. | |
| GOHON KIHON KUMITE: Five-step conventional assault. | |
| KUMITE | JYU IPPON KUMITE: Free and flexible assault one step away. It can have different work types: (i) announcing height and type of attack, (ii) announcing height, (iii) announcing type of attack, and (iv) unannounced. |
| URA IPPON KUMITE (Kaisho Ippon Kumite): Unconventional one-step assault. In this type of work one of the karatekas (acting as uke) performs the attack and the other (as tori) defends it and counterattacks the uke who defends the counterattack by the tori and ends up counterattacking. There are three working types: (i) announcing the attack and with the pre-established counterattack, (ii) announcing the attack and with the free counterattack, and (iii) unannounced. | |
| JIYU KUMITE: Free and flexible combat. | |
| SHIAI KUMITE: Regulated combat for competition. |
| Attack | Defense | ||
|---|---|---|---|
| 1 | Kamae | 1 | Kamae |
| 1 | Gedan Barai | 2 | Soto Uke |
| 3 | Oi Tsuki | 3 | Gyaku Tsuki |
| Class | Color | Number of Dataset Inputs |
|---|---|---|
| Attack01: “Kamae” | Blue | 1801 |
| Attack02: “Gedan Barai” | Red | 1548 |
| Attack03: “Oi Tsuki” | Cyan | 1805 |
| Defense01: “Kamae” | Dark green | 3643 |
| Defense02: “Soto Uke” | Pink | 1721 |
| Defense03: “Gyaku Tsuki” | Light green | 3627 |
| J48 | BayesNet | MLP | DeepLearning4J | |
|---|---|---|---|---|
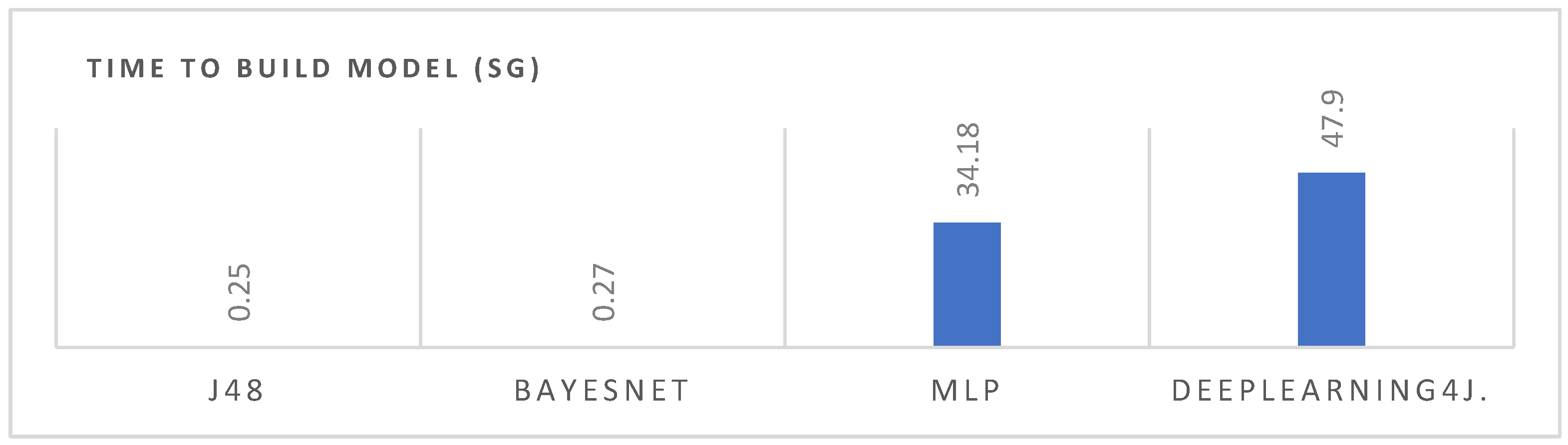
| Time to build model (seg) | 0.5 | 0.27 | 34.18 | 47.9 |
| Correctly Classified Instances | 14139 | 14137 | 14138 | 14142 |
| % Correct | 99.9576 | 99.9434 | 99.9505 | 99.9788 |
| Incorrectly Classified Instances | 6 | 8 | 7 | 3 |
| % Incorrect | 0.0424 | 0.0566 | 0.0495 | 0.0212 |
| Kappa statistic | 0.9995 | 0.9993 | 0.9994 | 0.9997 |
| Mean absolute error | 0.0001 | 0.0002 | 0.0006 | 0.0001 |
| Root mean squared error | 0.0119 | 0.0137 | 0.0118 | 0.0074 |
| Relative absolute error | 0.0539 | 0.0702 | 0.2148 | 0.0521 |
| Root relative squared error% | 3.2416 | 3.7228 | 3.2134 | 2.0249 |
| Total number of Instances | 14145 | 14145 | 14145 | 14145 |
| Algorithm | TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area |
|---|---|---|---|---|---|---|---|---|
| BayesNet | 1.000 | 0.000 | 0.999 | 0.999 | 0.999 | 0.999 | 1.000 | 1.000 |
| J48 | 1.000 | 0.000 | 1.000 | 1.000 | 0.999 | 0.999 | 1.000 | 0.999 |
| MLP | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 0.999 | 1.000 | 1.000 |
| DeepLearning4J | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area | Class | |
|---|---|---|---|---|---|---|---|---|---|
| 1.000 | 0.000 | 0.999 | 1.000 | 0.999 | 0.999 | 1.000 | 1.000 | Attack01 | |
| 1.000 | 0.000 | 0.996 | 1.000 | 0.998 | 0.998 | 1.000 | 0.999 | Attack02 | |
| 0.996 | 0.000 | 1.000 | 0.996 | 0.998 | 0.997 | 1.000 | 1.000 | Attack03 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense01 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense02 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense03 | |
| Avg. | 1.000 | 0.000 | 0.999 | 0.999 | 0.999 | 0.999 | 1.000 | 1.000 |
| TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area | Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0.999 | 0.000 | 0.998 | 0.999 | 0.999 | 0.998 | 0.999 | 0.997 | Attack01 | |
| 0.998 | 0.000 | 0.999 | 0.998 | 0.998 | 0.998 | 0.999 | 0.997 | Attack02 | |
| 0.999 | 0.000 | 1.000 | 0.999 | 1.000 | 1.000 | 1.000 | 1.000 | Attack03 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense01 | |
| 1.000 | 0.000 | 0.999 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | Defense02 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense03 | |
| Avg. | 1.000 | 0.000 | 1.000 | 1.000 | 0.999 | 0.999 | 1.000 | 0.999 |
| TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area | Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0.999 | 0.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 1.000 | Attack01 | |
| 0.997 | 0.000 | 0.998 | 0.997 | 0.998 | 0.997 | 1.000 | 1.000 | Attack02 | |
| 0.999 | 0.000 | 0.999 | 0.999 | 0.999 | 0.999 | 1.000 | 1.000 | Attack03 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense01 | |
| 1.000 | 0.000 | 0.999 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | Defense02 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense03 | |
| Avg. | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 0.999 | 1.000 | 1.000 |
| TP Rate | FP Rate | Precision | Recall | F-Measure | MCC | ROC Area | PRC Area | Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0.999 | 0.000 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 1.000 | Attack01 | |
| 0.999 | 0.000 | 1.000 | 0.999 | 0.999 | 0.999 | 1.000 | 1.000 | Attack02 | |
| 1.000 | 0.000 | 0.999 | 1.000 | 0.999 | 0.999 | 1.000 | 1.000 | Attack03 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense01 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | Defense02 | |
| 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | Defense03 | |
| Avg. | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Network Hyperparameters | |
|---|---|
| BayesNet | weka.classifiers.bayes.BayesNet -D -Q weka.classifiers.bayes.net.search.local.K2 -- -P 1 -S BAYES -E Weka.classifiers.bayes.net.estimate.SimpleEstimator -- -A 0.5 |
| J48 | weka.classifiers.trees.J48 -C 0.25 -M 2 |
| MLP | weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a |
| DeepLearning4j | weka.dl4j.inference.Dl4jCNNExplorer -custom-model “weka.dl4j.inference.CustomModelSetup -channels 3 -height 224 -width 224 -model-file C:\\Users\\Johni\\wekafiles\\packages” -decoder “weka.dl4j.inference.ModelOutputDecoder -builtIn IMAGENET -classMapFile C:\\Users\\Johni\\wekafiles\\packages” -saliency-map “weka.dl4j.interpretability.WekaScoreCAM -bs 1 -normalize -output C:\\Users\\Johni\\wekafiles\\packages -target-classes -1” -zooModel “weka.dl4j.zoo.Dl4jResNet50 -channelsLast false -pretrained IMAGENET” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Echeverria, J.; Santos, O.C. Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation. Sensors 2021, 21, 8378. https://doi.org/10.3390/s21248378
Echeverria J, Santos OC. Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation. Sensors. 2021; 21(24):8378. https://doi.org/10.3390/s21248378
Chicago/Turabian StyleEcheverria, Jon, and Olga C. Santos. 2021. "Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation" Sensors 21, no. 24: 8378. https://doi.org/10.3390/s21248378
APA StyleEcheverria, J., & Santos, O. C. (2021). Toward Modeling Psychomotor Performance in Karate Combats Using Computer Vision Pose Estimation. Sensors, 21(24), 8378. https://doi.org/10.3390/s21248378