
FedVoting: A Cross-Silo Boosting Tree Construction Method for Privacy-Preserving Long-Term Human Mobility Prediction


Abstract
:1. Introduction
2. Related Work
3. Preliminaries
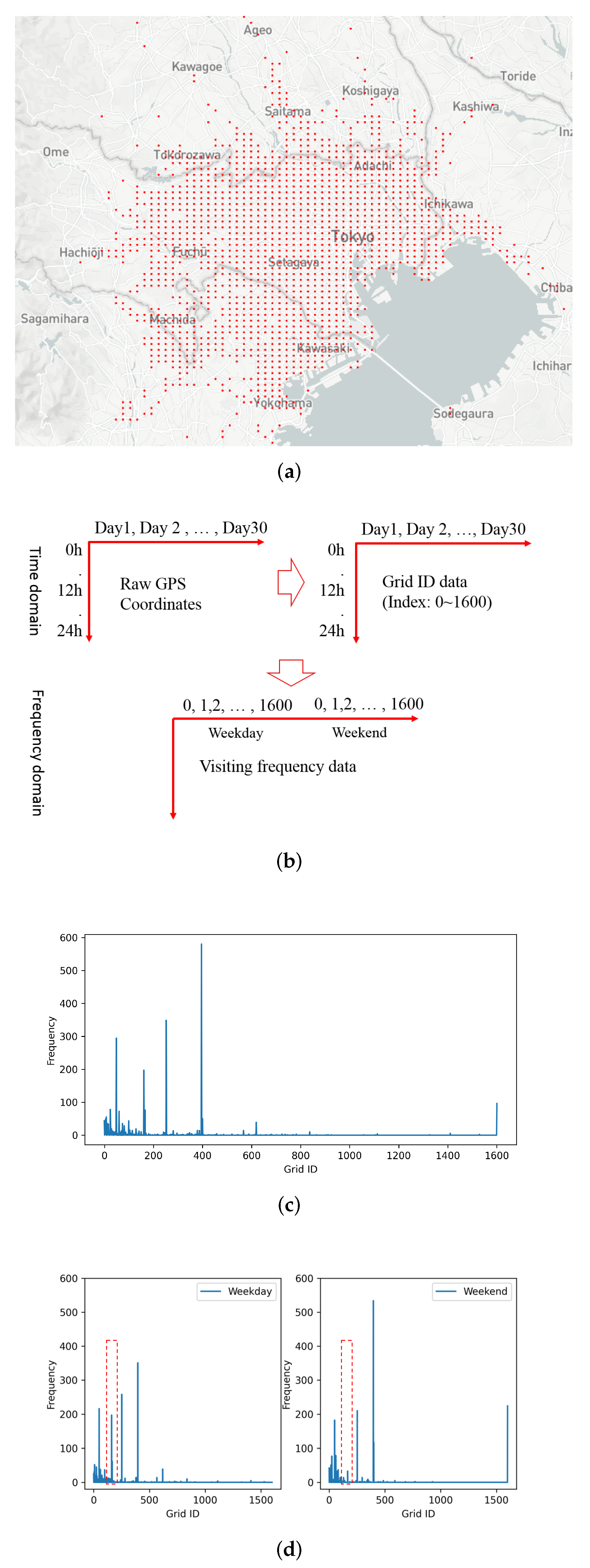
4. Travel-Frequency Pattern PRE-PROCESSING
5. Long-Term Human Mobility Prediction
5.1. Base Model Selection
5.2. Heterogeneous Privacy Protection with Differential Privacy (DP)
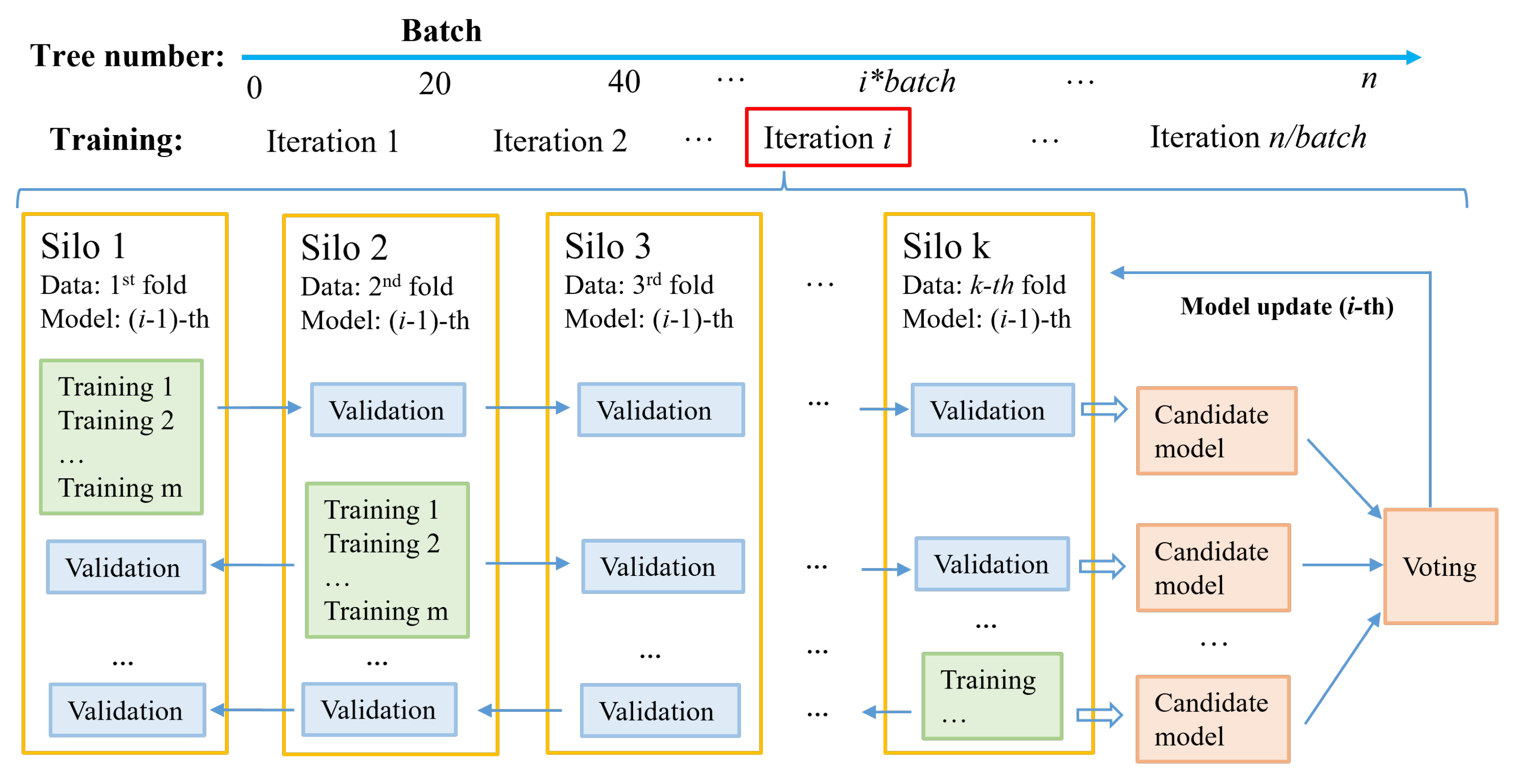
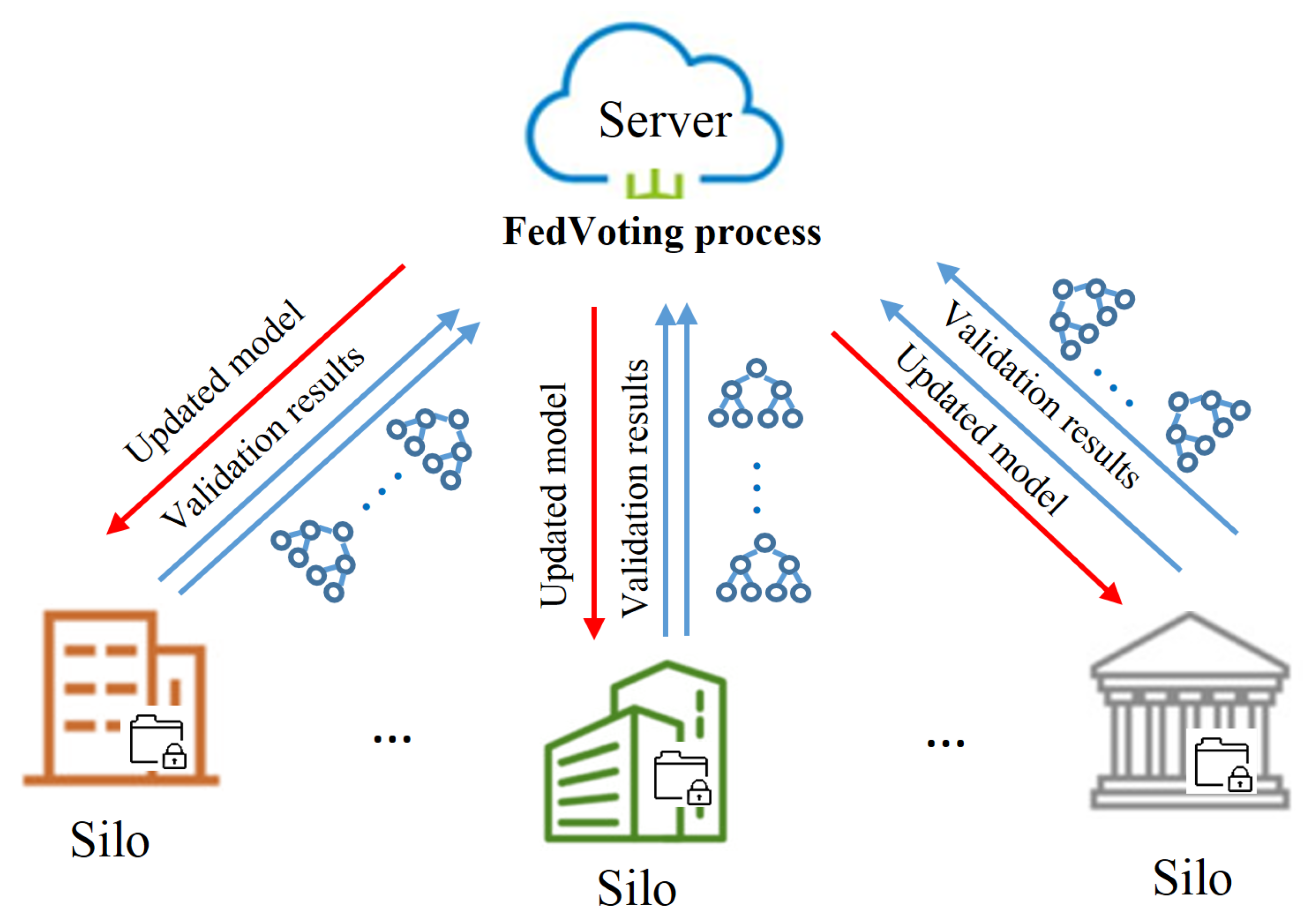
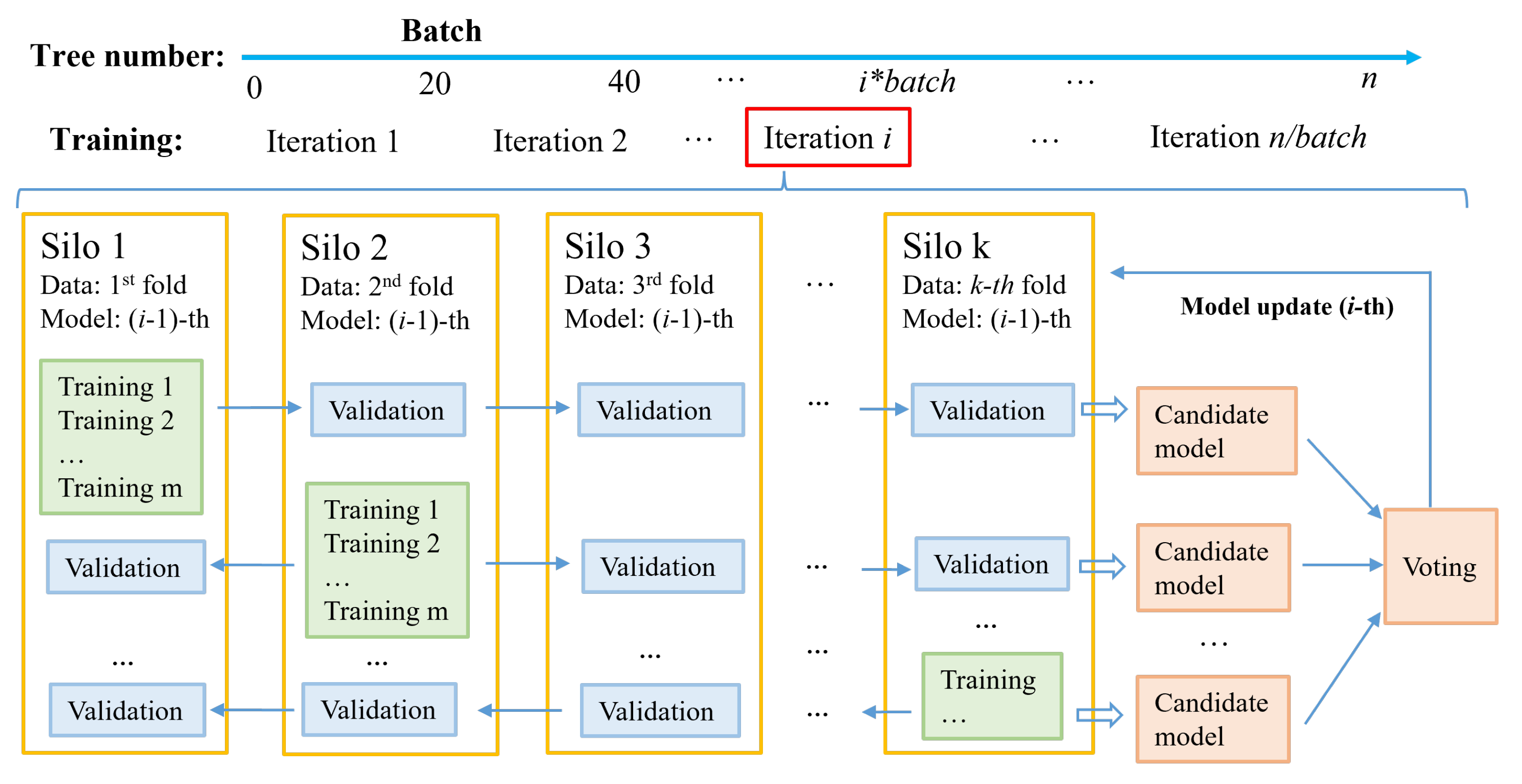
5.3. FedVoting Process to Construct Federated GBDT Model
| Algorithm 1: The FedVoting process among silos in one iteration. |
 |
6. Experimental Results
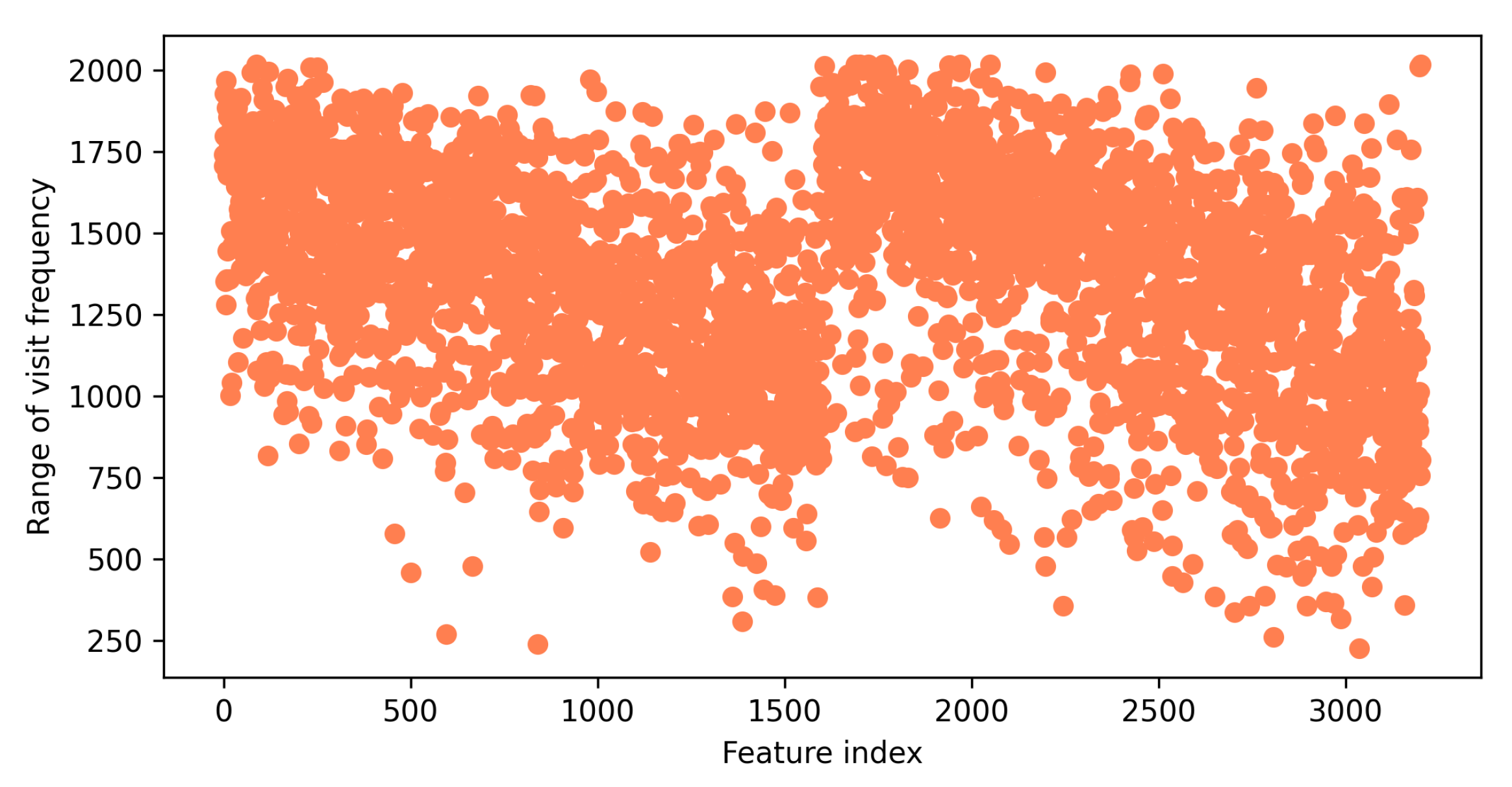
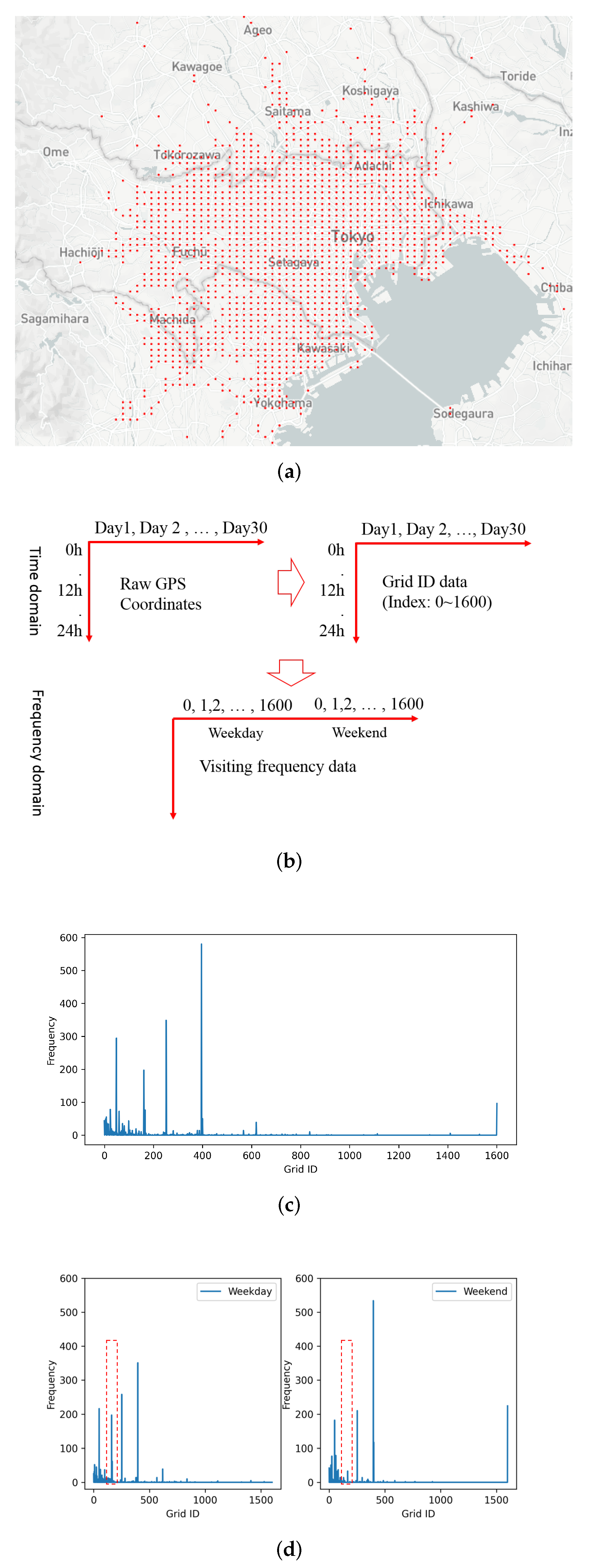
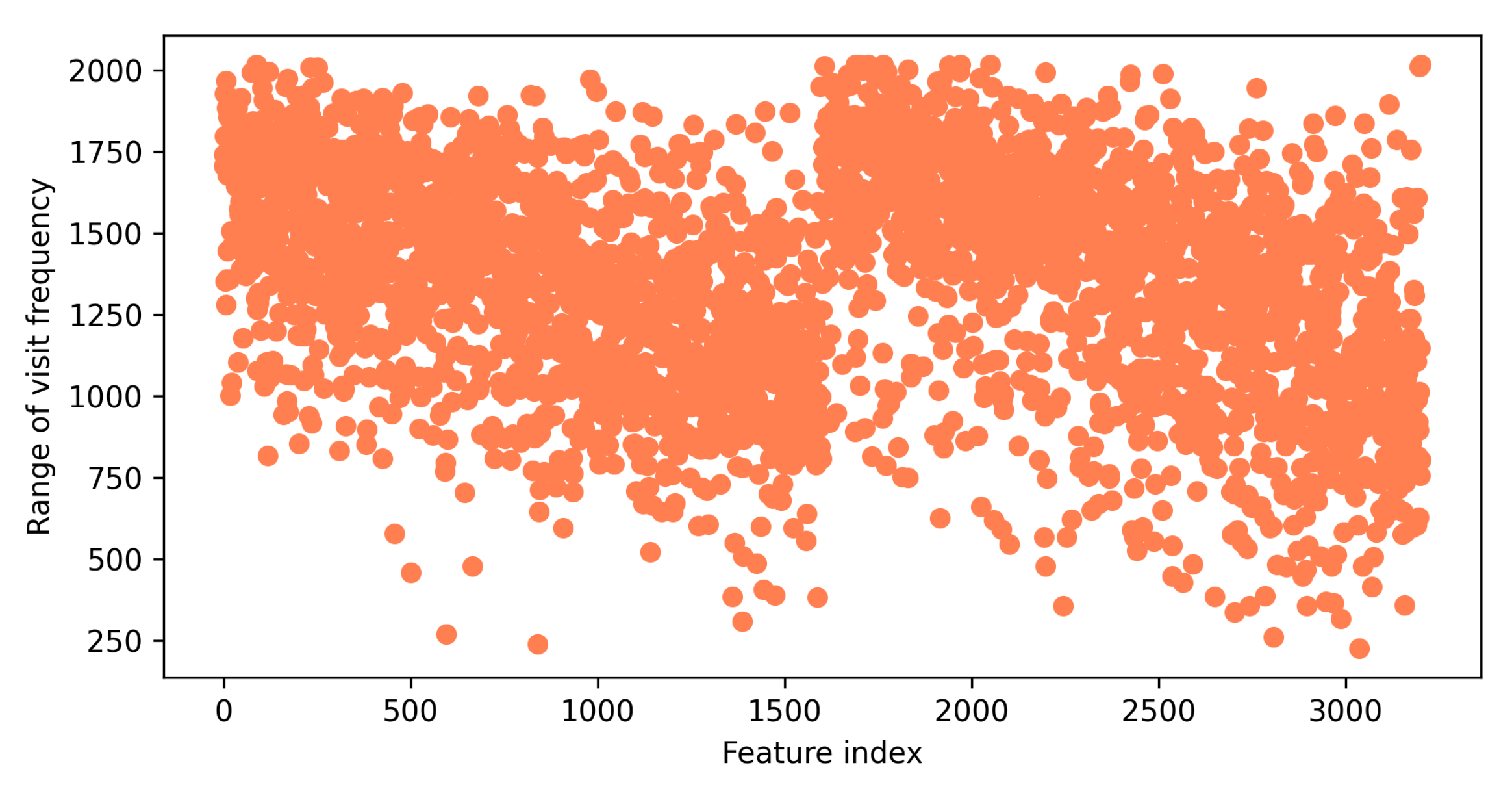
6.1. Data
6.2. Experiments’ Setup
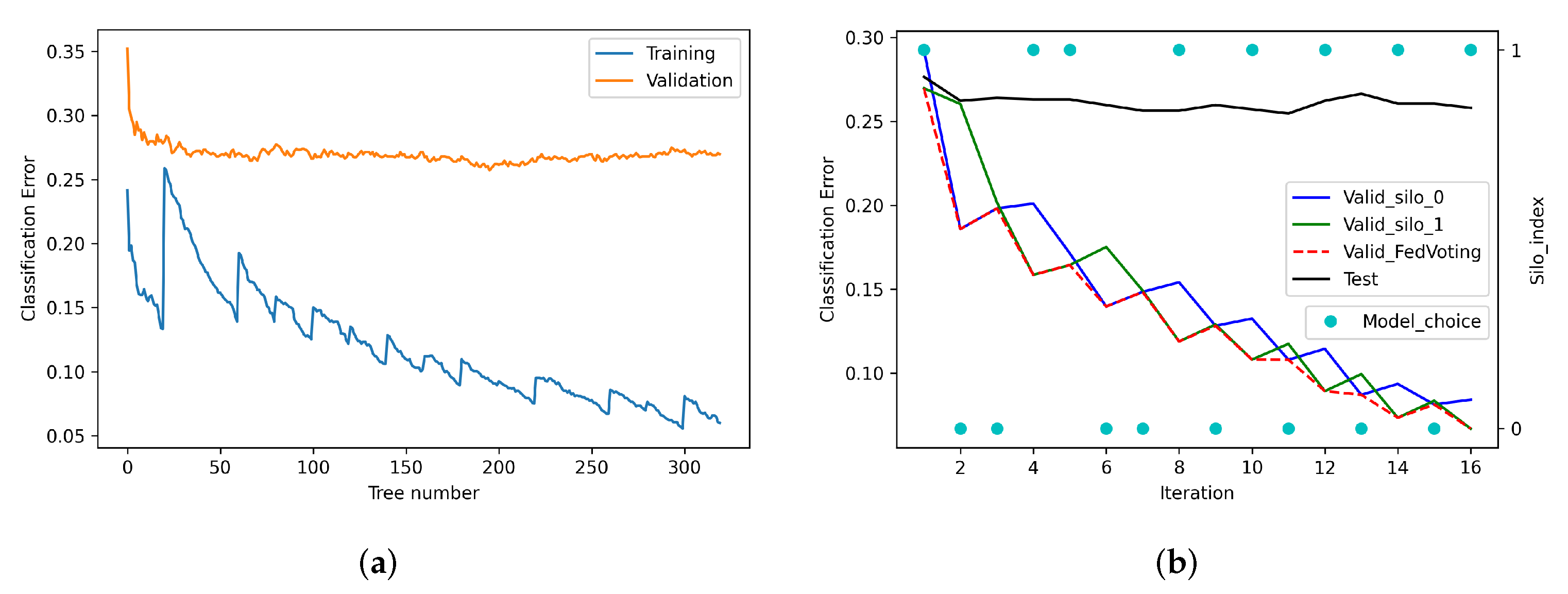
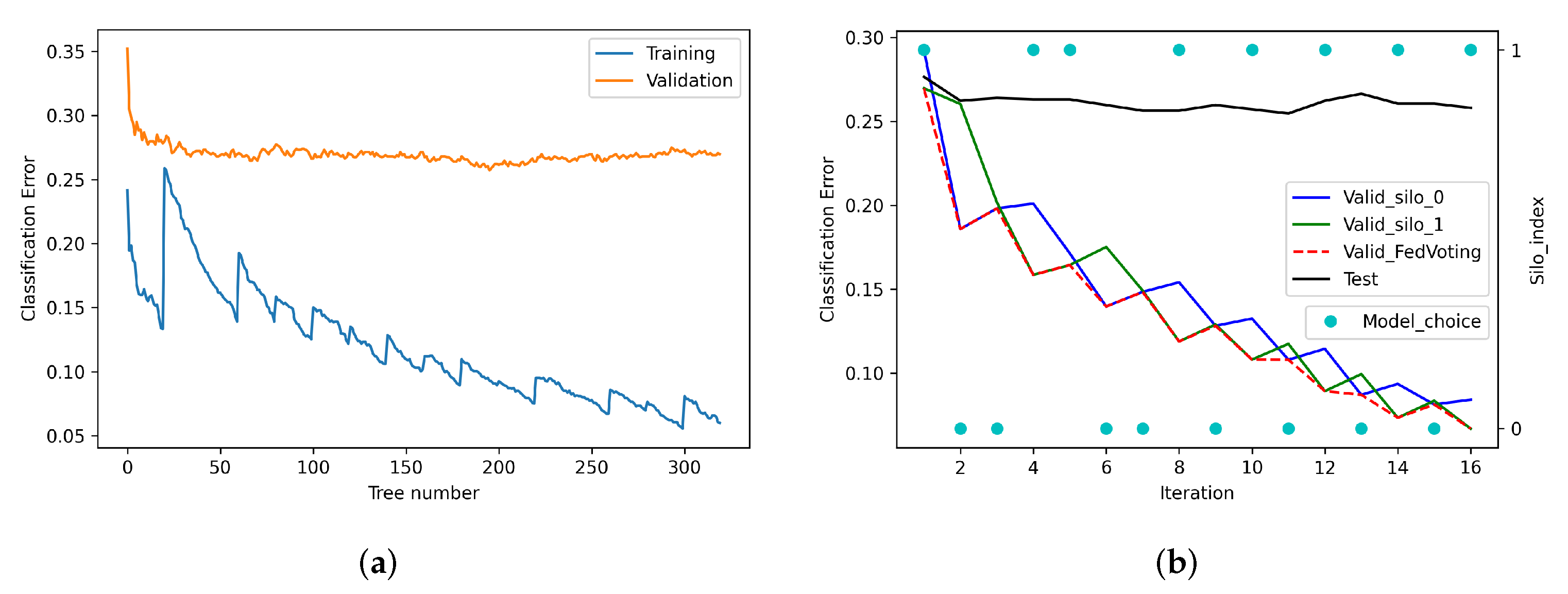
6.3. Analysis of the Training Process
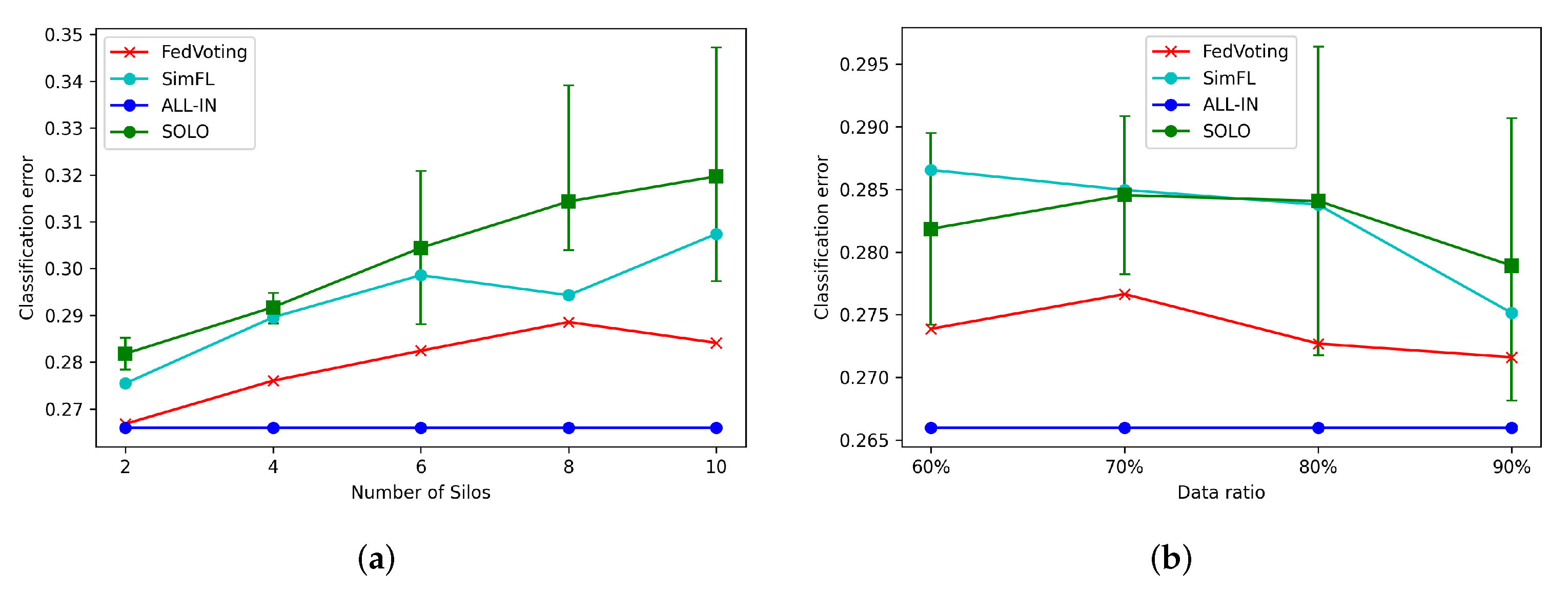
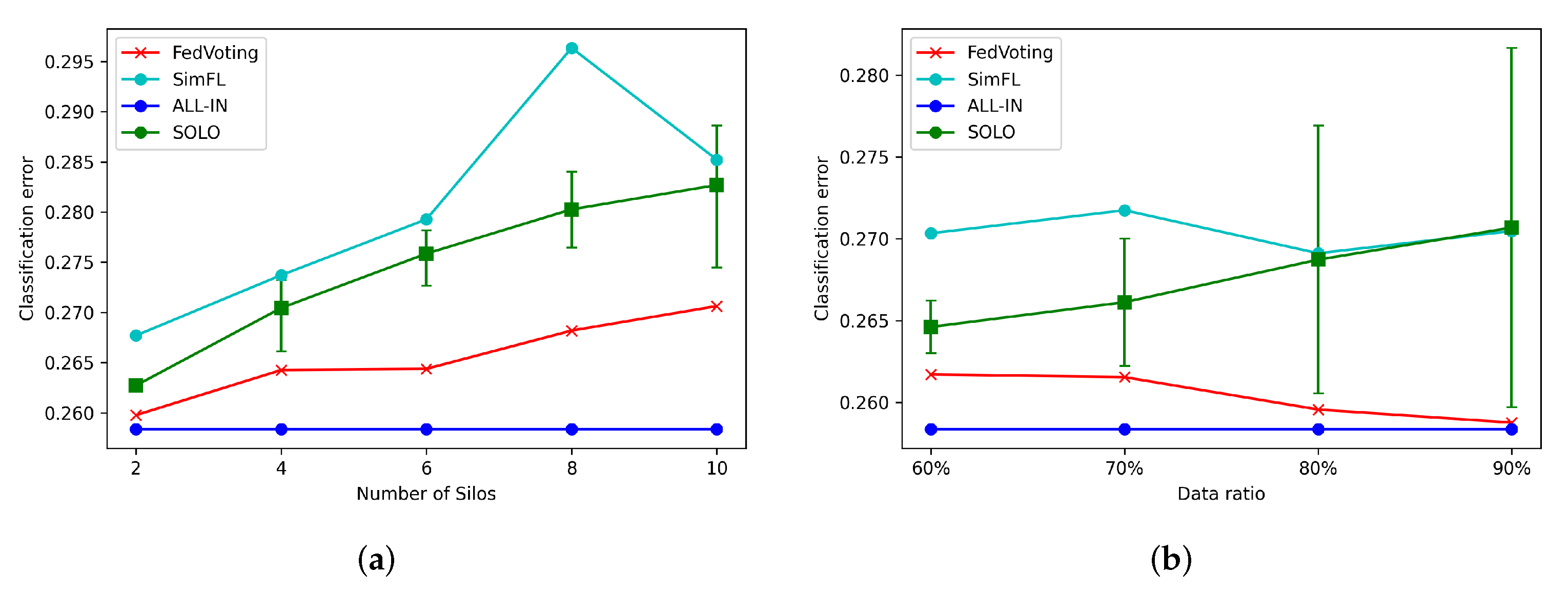
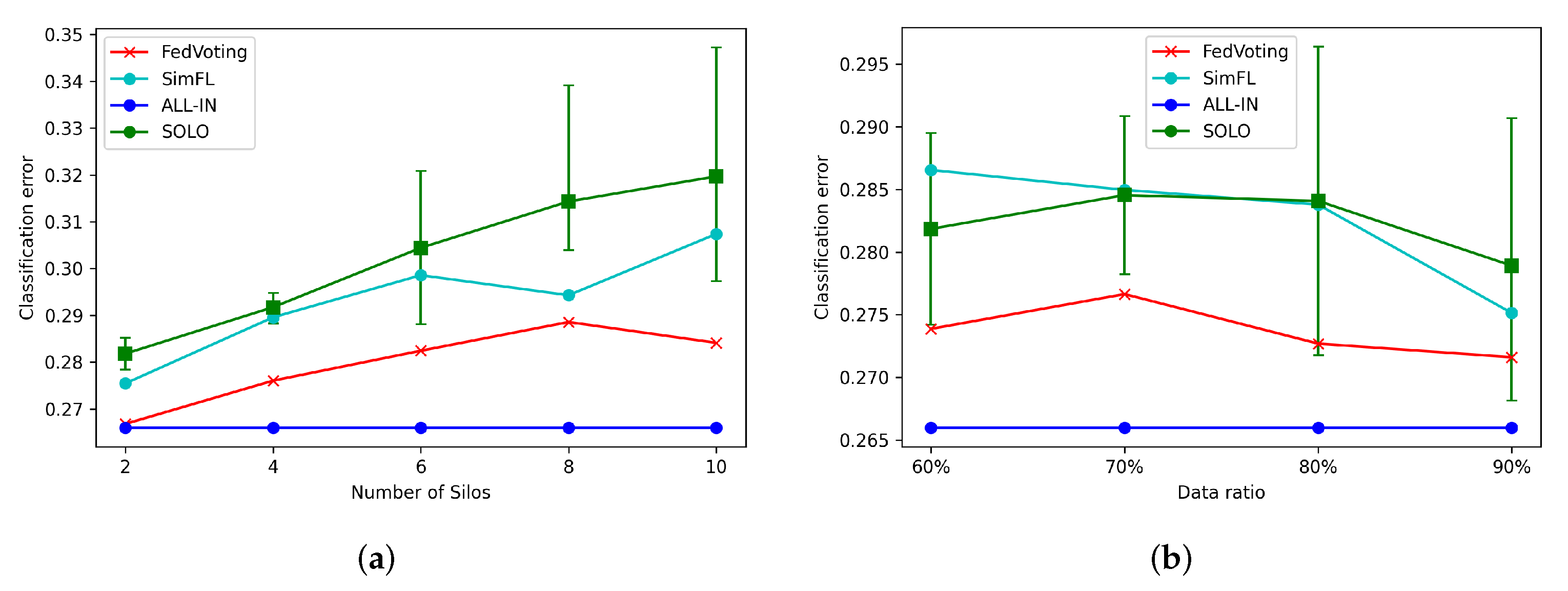
6.4. Long-Term Prediction of Special Event Attendance
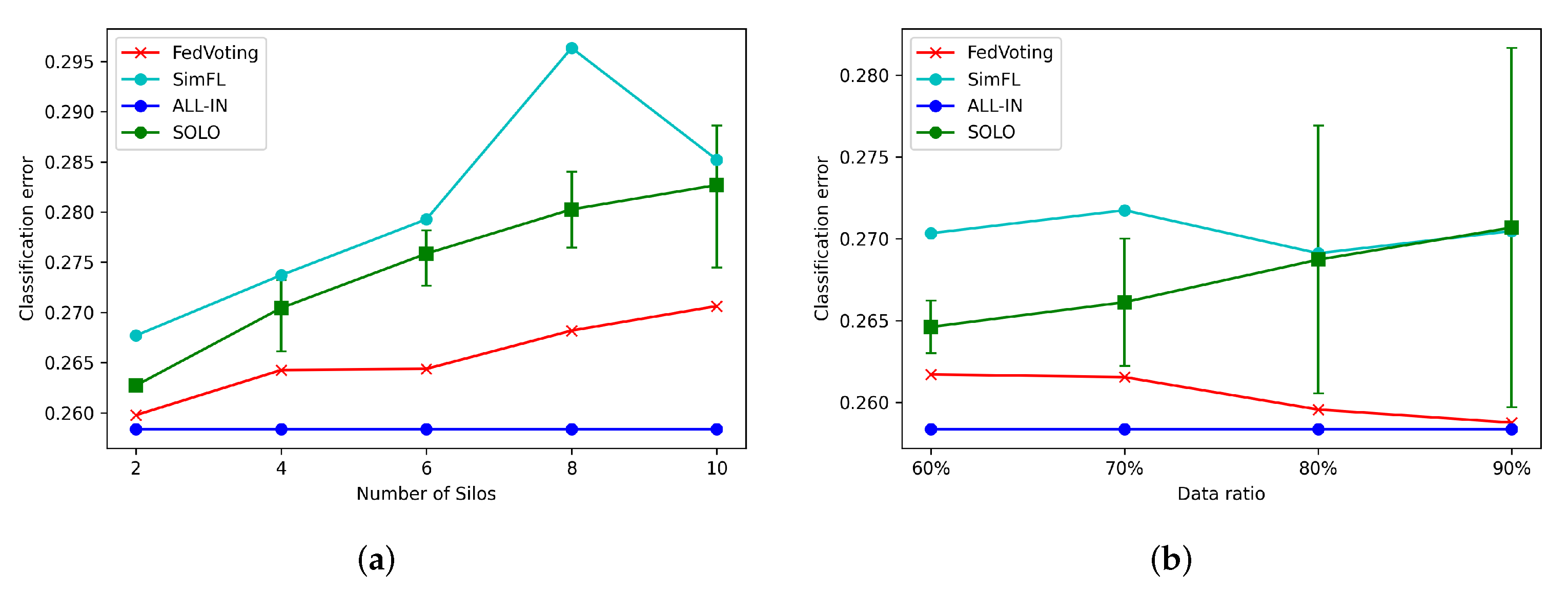
6.5. Long-Term Prediction of POI Visit
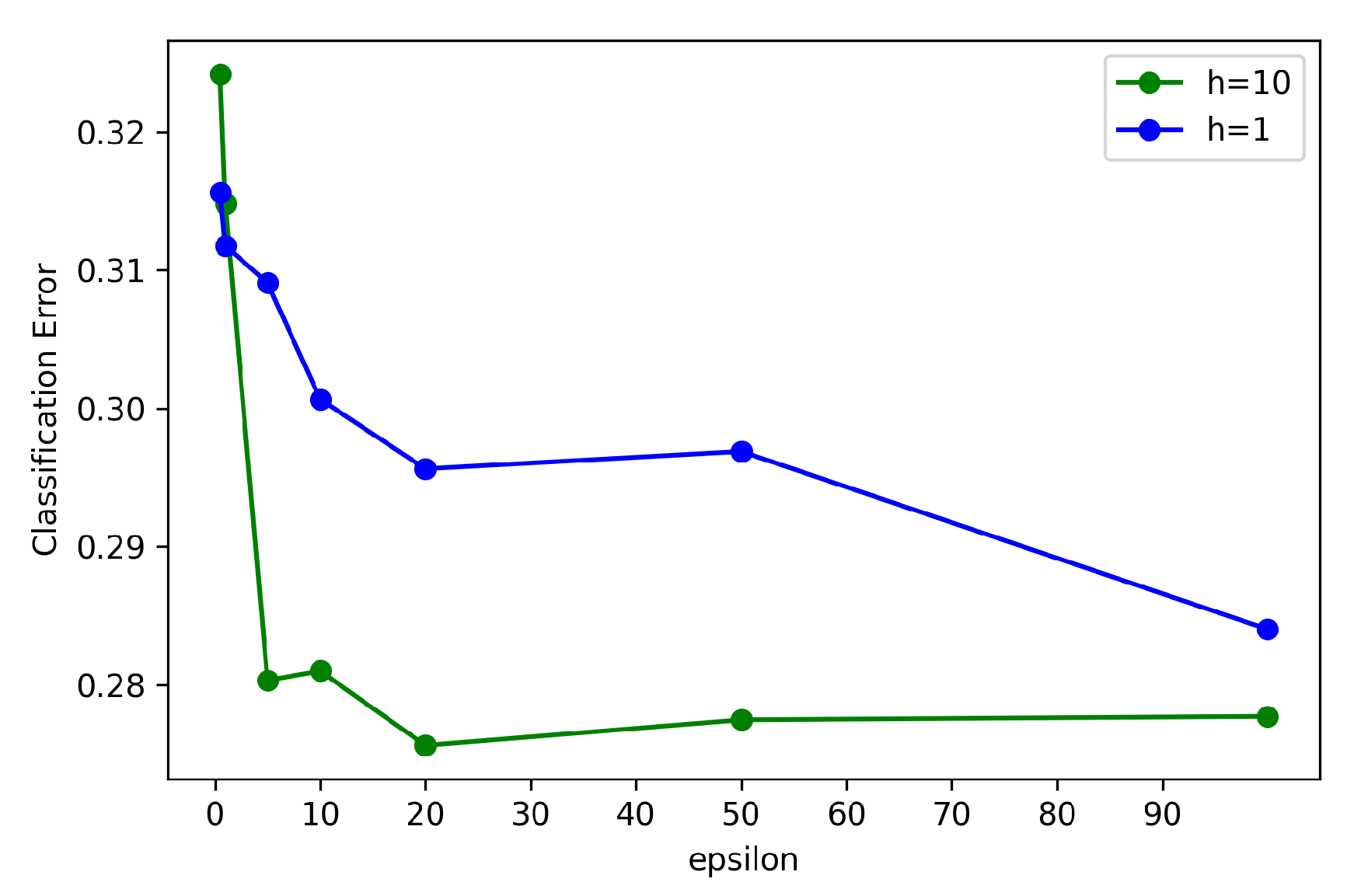
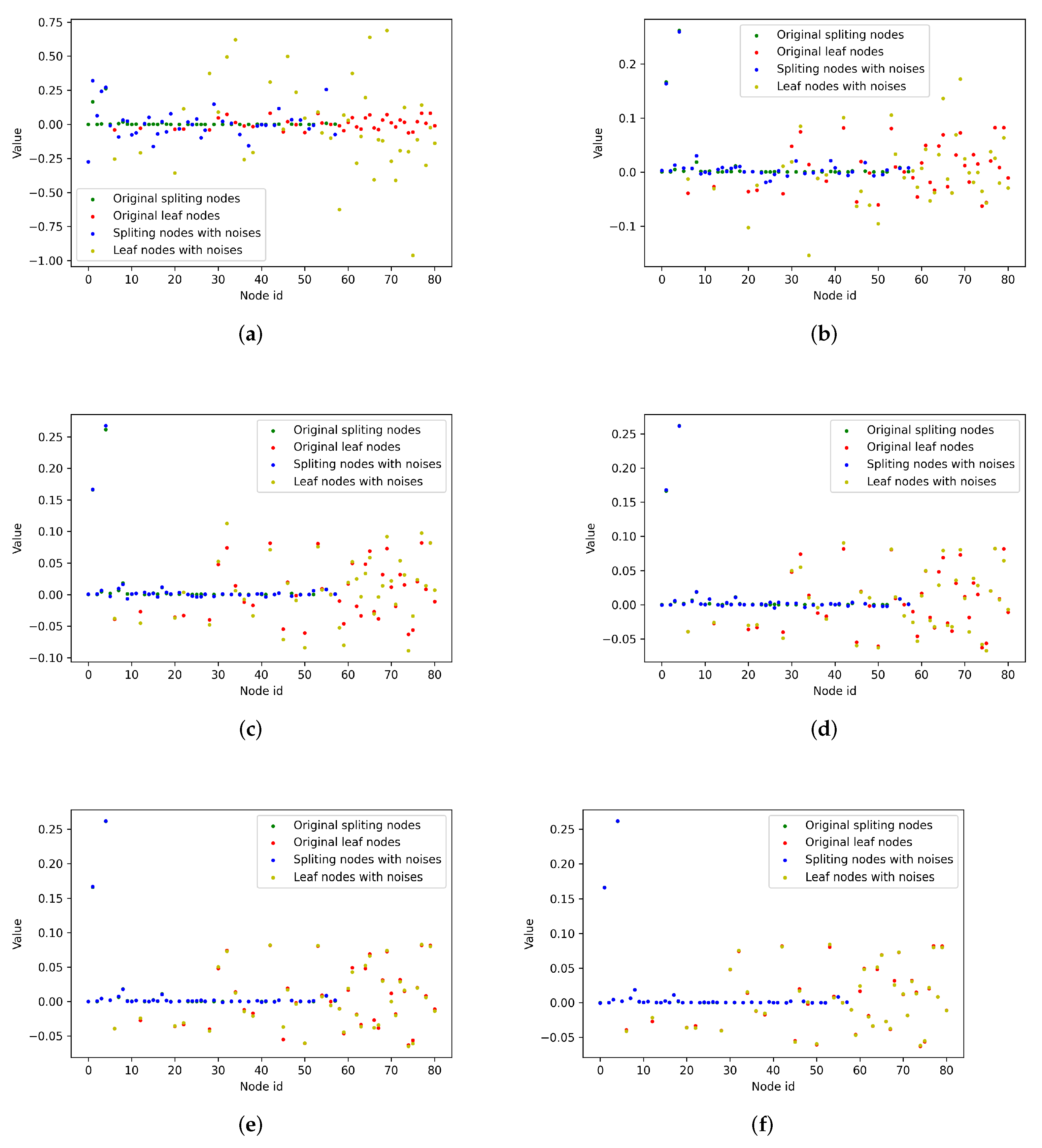
6.6. Privacy-Protection Analysis
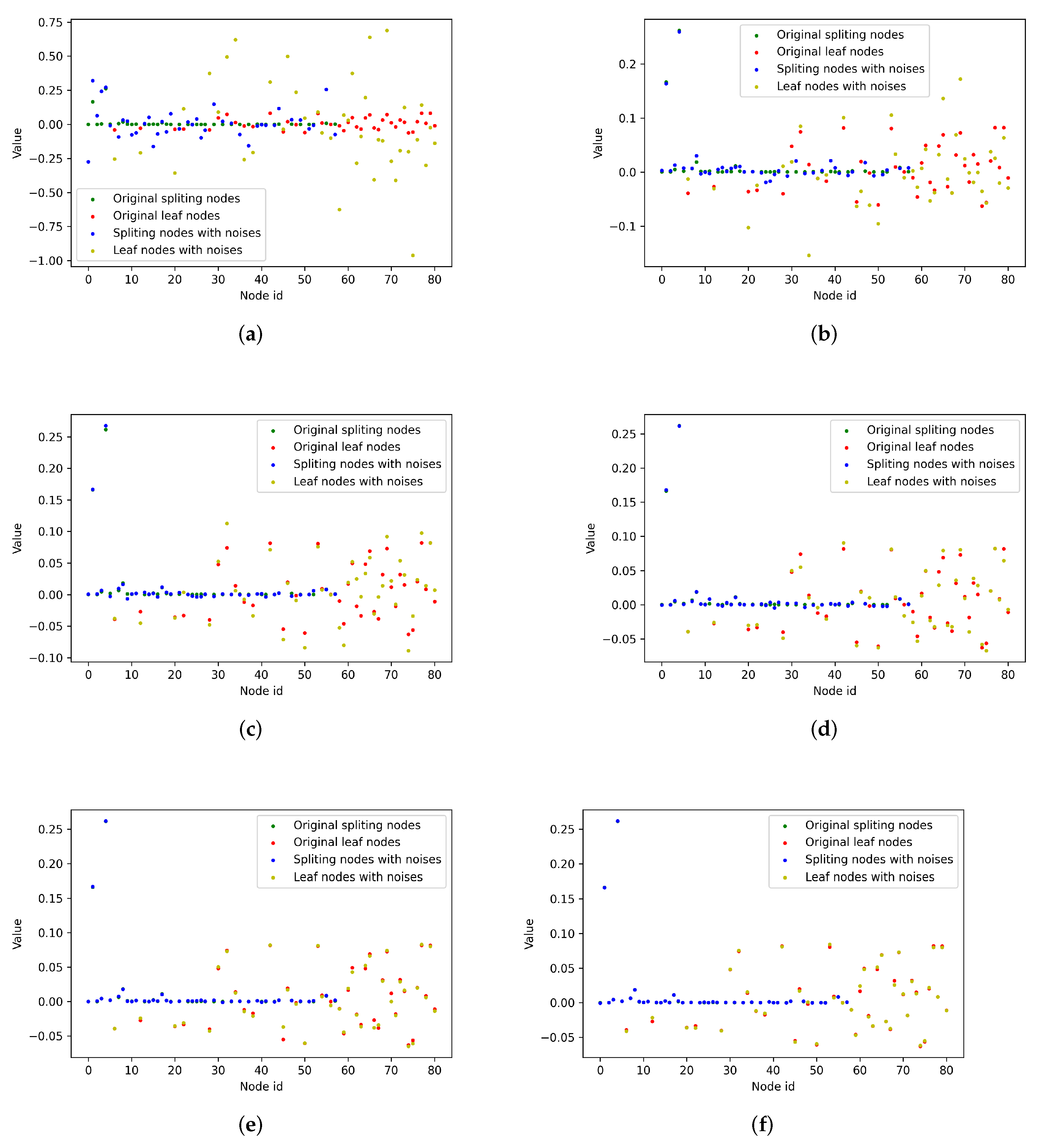
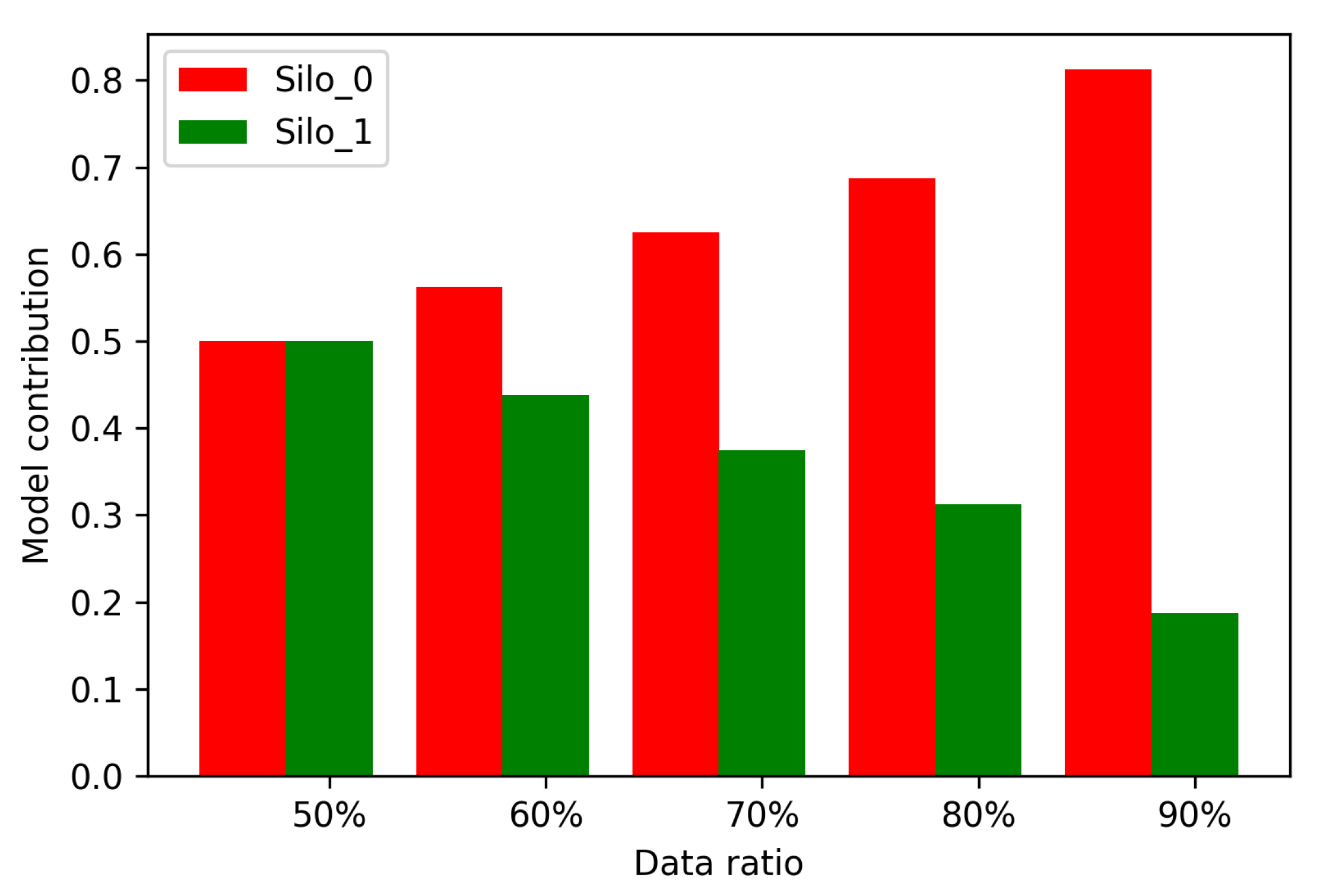
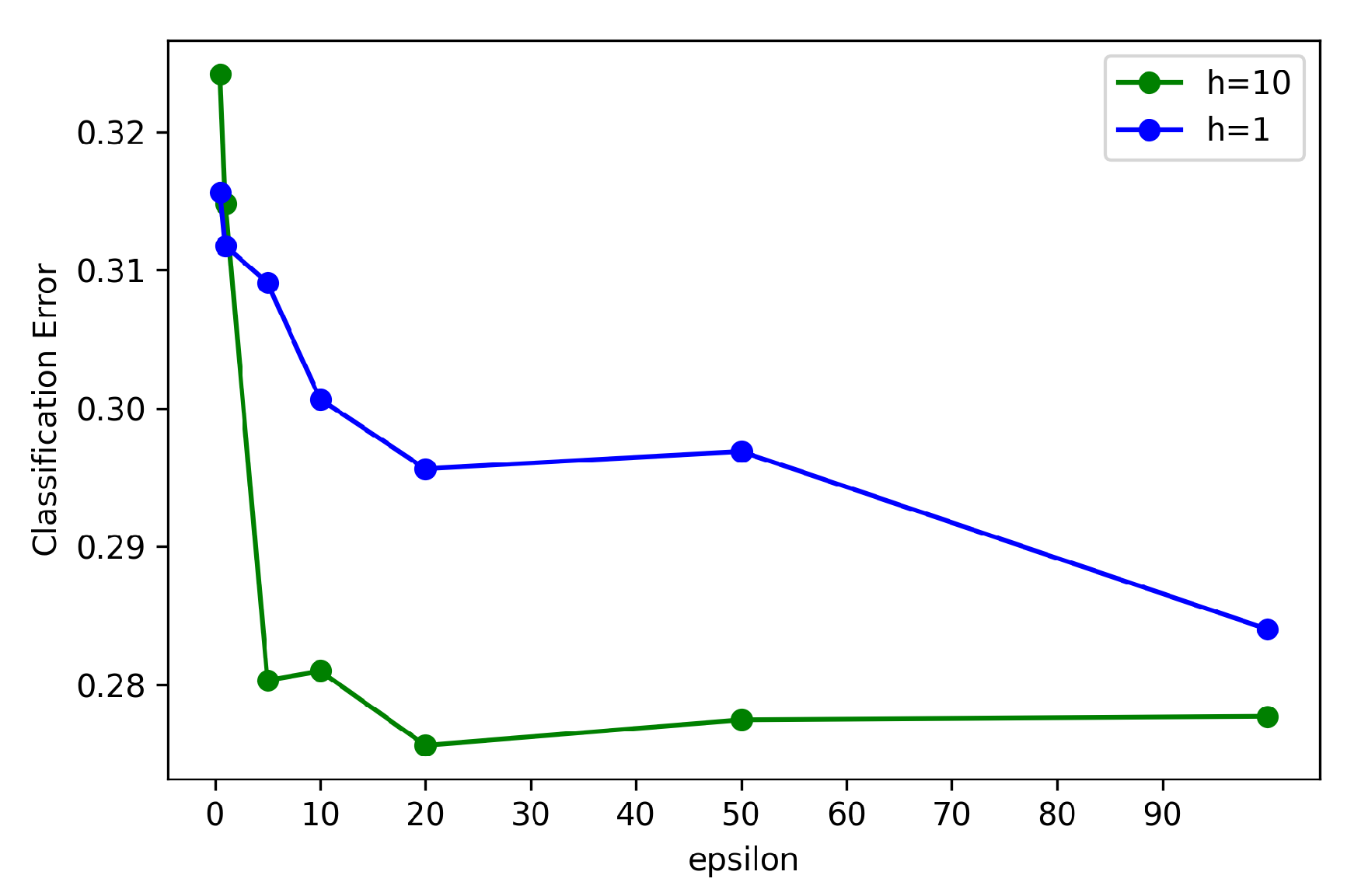
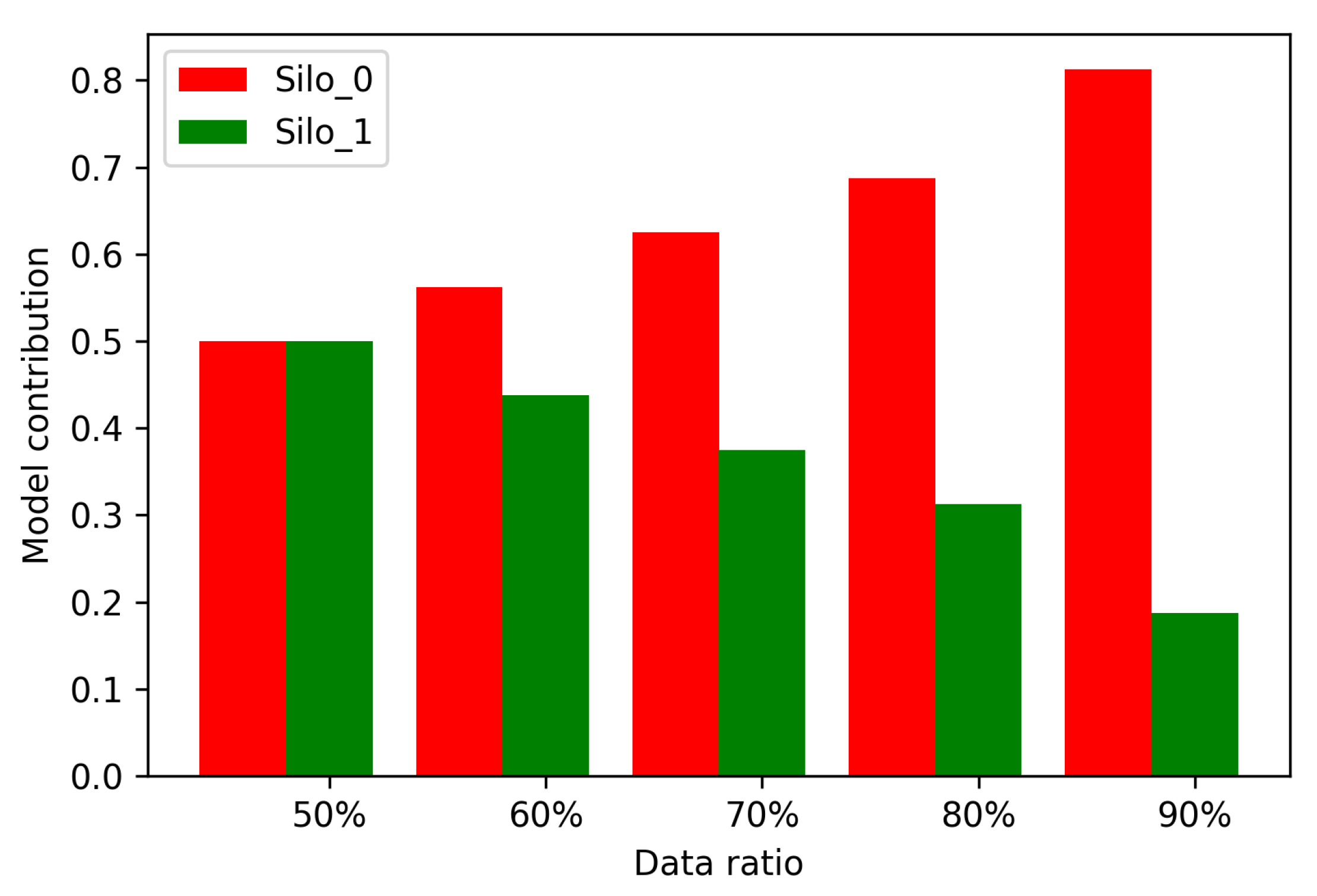
6.7. Motivation Mechanism Analysis
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Fan, Z.; Song, X.; Shibasaki, R.; Adachi, R. CityMomentum: An online approach for crowd behavior prediction at a citywide level. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 559–569. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhao, L.; Ni, L.; Hu, S.; Chen, Y.; Zhou, P.; Xiao, F.; Wu, L. Inprivate digging: Enabling tree-based distributed data mining with differential privacy. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 2087–2095. [Google Scholar]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting privately: Privacy-preserving federated extreme boosting for mobile crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Practical Federated Gradient Boosting Decision Trees. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4642–4649. [Google Scholar]
- Kuang, W.; An, S.; Jiang, H. Detecting traffic anomalies in urban areas using taxi GPS data. Math. Probl. Eng. 2015, 2015, 809582. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, C.; Yuan, N.J.; Song, R.; Xie, X.; Ma, Q. Understanding People Lifestyles: Construction of Urban Movement Knowledge Graph from GPS Trajectory. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3616–3623. [Google Scholar]
- Wang, L.; Yu, Z.; Yang, D.; Ma, H.; Sheng, H. Efficiently targeted billboard advertising using crowdsensing vehicle trajectory data. IEEE Trans. Ind. Informat. 2019, 16, 1058–1066. [Google Scholar] [CrossRef]
- Guillén-Pérez, A.; Baños, M.D.C. A WiFi-based method to count and locate pedestrians in urban traffic scenarios. In Proceedings of the 2018 14th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Limassol, Cyprus, 15–17 October 2018; pp. 123–130. [Google Scholar]
- Michau, G.; Nantes, A.; Bhaskar, A.; Chung, E.; Abry, P.; Borgnat, P. Bluetooth data in an urban context: Retrieving vehicle trajectories. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2377–2386. [Google Scholar] [CrossRef]
- Silva, T.H.; Viana, A.C.; Benevenuto, F.; Villas, L.; Salles, J.; Loureiro, A.; Quercia, D. Urban computing leveraging location-based social network data: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, D.; Yang, D.; Lim, B.Y.; Han, X.; Ma, X. Sparse mobile crowdsensing with differential and distortion location privacy. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2735–2749. [Google Scholar] [CrossRef]
- Du, R.; Yu, Z.; Mei, T.; Wang, Z.; Wang, Z.; Guo, B. Predicting activity attendance in event-based social networks: Content, context and social influence. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 425–434. [Google Scholar]
- Zhang, J.; Jiang, W.; Zhang, J.; Wu, J.; Wang, G. Exploring weather data to predict activity attendance in event-based social network: From the organizer’s view. ACM Trans. Web (TWEB) 2021, 15, 1–25. [Google Scholar] [CrossRef]
- Yu, Z.; Xu, H.; Yang, Z.; Guo, B. Personalized travel package with multi-point-of-interest recommendation based on crowdsourced user footprints. IEEE Trans. Hum.-Mach. Syst. 2015, 46, 151–158. [Google Scholar] [CrossRef]
- Feng, S.; Cong, G.; An, B.; Chee, Y.M. Poi2vec: Geographical latent representation for predicting future visitors. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Do, T.M.T.; Dousse, O.; Miettinen, M.; Gatica-Perez, D. A probabilistic kernel method for human mobility prediction with smartphones. Pervasive Mob. Comput. 2015, 20, 13–28. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Fankhauser, B.; Rosso, P.; Cudre-Mauroux, P. Location Prediction over Sparse User Mobility Traces Using RNNs: Flashback in Hidden States. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, Yokohama, Japan, 11–17 July 2020; pp. 2184–2190. [Google Scholar]
- Xu, F.; Lin, Z.; Xia, T.; Guo, D.; Li, Y. Sume: Semantic-enhanced urban mobility network embedding for user demographic inference. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–25. [Google Scholar] [CrossRef]
- Jiang, R.; Song, X.; Fan, Z.; Xia, T.; Chen, Q.; Miyazawa, S.; Shibasaki, R. Deepurbanmomentum: An online deep-learning system for short-term urban mobility prediction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Fan, Z.; Song, X.; Jiang, R.; Chen, Q.; Shibasaki, R. Decentralized Attention-based Personalized Human Mobility Prediction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–26. [Google Scholar] [CrossRef]
- Qiao, Y.; Si, Z.; Zhang, Y.; Abdesslem, F.B.; Zhang, X.; Yang, J. A hybrid Markov-based model for human mobility prediction. Neurocomputing 2018, 278, 99–109. [Google Scholar] [CrossRef]
- Jain, P.; Gyanchandani, M.; Khare, N. Big data privacy: A technological perspective and review. J. Big Data 2016, 3, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.K.; Bhushan, B.; Khamparia, A.; Astya, P.N.; Debnath, N.C. Blockchain Technology for Data Privacy Management; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Liu, Y.; Kang, Y.; Xing, C.; Chen, T.; Yang, Q. A secure federated transfer learning framework. IEEE Intell. Syst. 2020, 35, 70–82. [Google Scholar] [CrossRef]
- Cheng, K.; Fan, T.; Jin, Y.; Liu, Y.; Chen, T.; Yang, Q. Secureboost: A lossless federated learning framework. arXiv 2019, arXiv:1901.08755. [Google Scholar] [CrossRef]
- Xu, R.; Baracaldo, N.; Zhou, Y.; Anwar, A.; Ludwig, H. Hybridalpha: An efficient approach for privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 13–23. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Luo, J.; Wu, X.; Luo, Y.; Huang, A.; Huang, Y.; Liu, Y.; Yang, Q. Real-world image datasets for federated learning. arXiv 2019, arXiv:1910.11089. [Google Scholar]
- Sharma, S.; Xing, C.; Liu, Y.; Kang, Y. Secure and efficient federated transfer learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2569–2576. [Google Scholar]
- Feng, J.; Rong, C.; Sun, F.; Guo, D.; Li, Y. PMF: A privacy-preserving human mobility prediction framework via federated learning. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Li, A.; Wang, S.; Li, W.; Liu, S.; Zhang, S. Predicting Human Mobility with Federated Learning. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020; pp. 441–444. [Google Scholar]
- Agency, A.M. Standard Grid Square and Grid Square Code Used for the Statistics. Standard Grid Square Code. 1973. Available online: https://www.stat.go.jp/english/data/mesh/02.html (accessed on 8 November 2021).
- Fletcher, S.; Islam, M.Z. Decision tree classification with differential privacy: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- da Rosa, J.H.; Barbosa, J.L.; Ribeiro, G.D. ORACON: An adaptive model for context prediction. Expert Syst. Appl. 2016, 45, 56–70. [Google Scholar] [CrossRef]
- Lee, S.; Lee, K.C. Context-prediction performance by a dynamic bayesian network: Emphasis on location prediction in ubiquitous decision support environment. Expert Syst. Appl. 2012, 39, 4908–4914. [Google Scholar] [CrossRef]
- Filippetto, A.S.; Lima, R.; Barbosa, J.L.V. A risk prediction model for software project management based on similarity analysis of context histories. Inf. Softw. Technol. 2021, 131, 106497. [Google Scholar] [CrossRef]
- Ballings, M.; Van den Poel, D.; Hespeels, N.; Gryp, R. Evaluating multiple classifiers for stock price direction prediction. Expert Syst. Appl. 2015, 42, 7046–7056. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Base Model | GBDT | Random Forest | SVM (Linear) | SVM (Sigmoid) | MLP | FM |
|---|---|---|---|---|---|---|
| Accuracy | 0.7305 | 0.7195 | 0.65462 | 0.62269 | 0.60705 | 0.6397 |
| Event | Date | Number of Positive Instances | Number of Negative Instances |
|---|---|---|---|
| Attending Comiket | 8.10∼8.12, 2012 | 1965 | 77,952 (2000) |
| Visiting Disneyland | Total August, 2012 | 9680 | 80,850 (10,000) |
| Model | Classification Errors | |||
|---|---|---|---|---|
| Min | Average | Max | ||
| ALL_IN | 0.26387 | 0.2695 | 0.27815 | |
| SOLO | Silo 1 | 0.28571 | 0.29311 | 0.30672 |
| Silo 2 | 0.28487 | 0.29478 | 0.30588 | |
| Silo 3 | 0.28319 | 0.28823 | 0.29495 | |
| Silo 4 | 0.27647 | 0.29084 | 0.29916 | |
| FedVoting | 0.26387 | 0.27605 | 0.28571 | |
| SimFL | 0.27647 | 0.28958 | 0.3 | |
| Model | Classification Errors | |||
|---|---|---|---|---|
| Min | Average | Max | ||
| ALL_IN | 0.25559 | 0.25837 | 0.26118 | |
| SOLO | Silo 1 | 0.27473 | 0.27680 | 0.27981 |
| Silo 2 | 0.26762 | 0.27265 | 0.27558 | |
| Silo 3 | 0.27236 | 0.27476 | 0.27642 | |
| Silo 4 | 0.27473 | 0.27798 | 0.28083 | |
| Silo 5 | 0.27575 | 0.27818 | 0.28167 | |
| Silo 6 | 0.271 | 0.27476 | 0.27727 | |
| FedVoting | 0.26236 | 0.26438 | 0.26634 | |
| SimFL | 0.27575 | 0.27927 | 0.28421 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Fan, Z.; Song, X.; Shibasaki, R. FedVoting: A Cross-Silo Boosting Tree Construction Method for Privacy-Preserving Long-Term Human Mobility Prediction. Sensors 2021, 21, 8282. https://doi.org/10.3390/s21248282
Liu Y, Fan Z, Song X, Shibasaki R. FedVoting: A Cross-Silo Boosting Tree Construction Method for Privacy-Preserving Long-Term Human Mobility Prediction. Sensors. 2021; 21(24):8282. https://doi.org/10.3390/s21248282
Chicago/Turabian StyleLiu, Yinghao, Zipei Fan, Xuan Song, and Ryosuke Shibasaki. 2021. "FedVoting: A Cross-Silo Boosting Tree Construction Method for Privacy-Preserving Long-Term Human Mobility Prediction" Sensors 21, no. 24: 8282. https://doi.org/10.3390/s21248282
APA StyleLiu, Y., Fan, Z., Song, X., & Shibasaki, R. (2021). FedVoting: A Cross-Silo Boosting Tree Construction Method for Privacy-Preserving Long-Term Human Mobility Prediction. Sensors, 21(24), 8282. https://doi.org/10.3390/s21248282