
Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning


Abstract
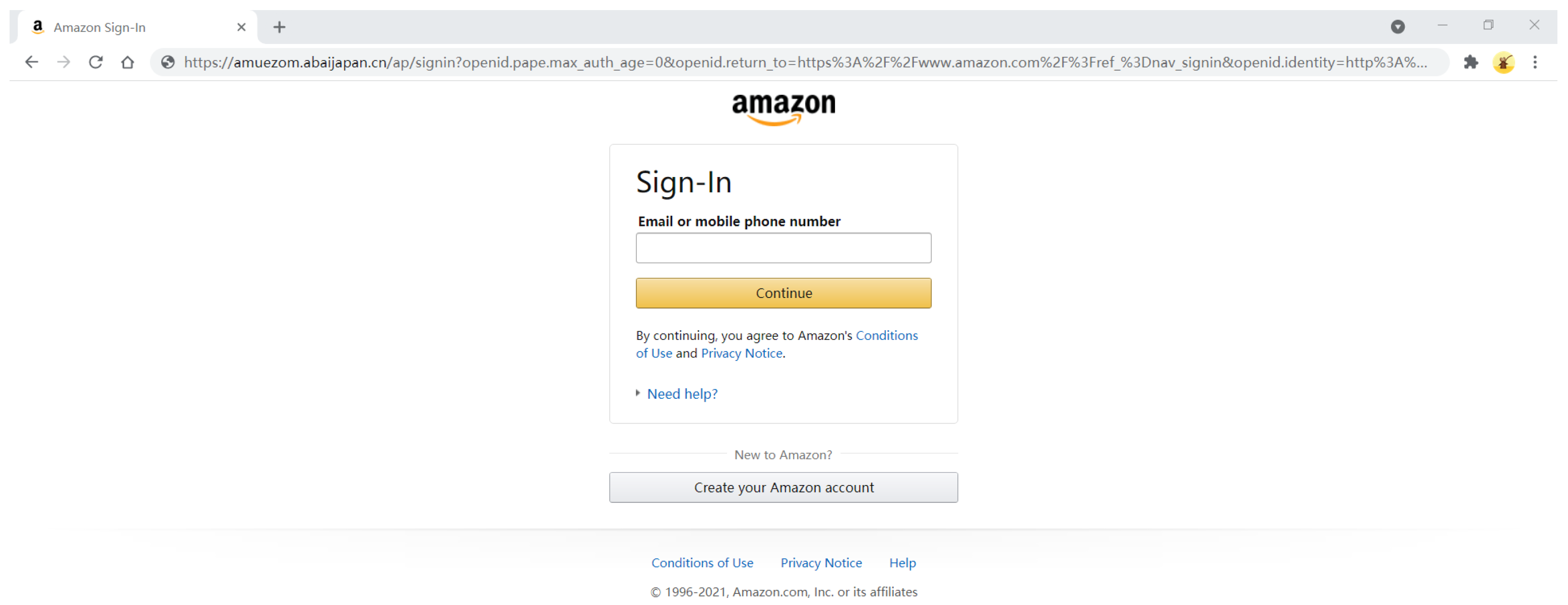
:1. Introduction
- Strong generalization ability: The proposed method has strong generalization ability. The multi-level features used by the proposed method obtain better generalization ability and check-side accuracy. The low-level features in the hidden layer are common and similar for different but related distributed datasets or tasks; these are combined with the low-latitude features in the hidden layer.
- Third-party service independence: The proposed method relies only on website URL features for detection, without extracting third-party features, such as page rank, search engine index, web traffic measurement, and domain age, which can improve the efficiency of detection and reduce the detection time.
- Independence of cybersecurity experts: Reduced required expert function engineering, the deep neural network CNN model proposed in this paper can automatically extract URL features without the need for experts.
- Language-independent: The approach proposed in this paper is effective for the detection of websites with content in various languages using character-level features.
- This paper proposes a phishing website detection technique based on integrated learning and deep learning with fast and accurate detection of phishing websites using only URL features.
- We built a real dataset by crawling 22,491 phishing URLs from phishtank and 24,719 legitimate URLs from Alex and conducted experiments on the dataset.
- The phishing website detection process based on ensemble learning and deep learning is described, and the constructed dataset is extensively experimented. The results of the experiments indicate that our proposed method shows good performance in terms of accuracy and false positive rate.
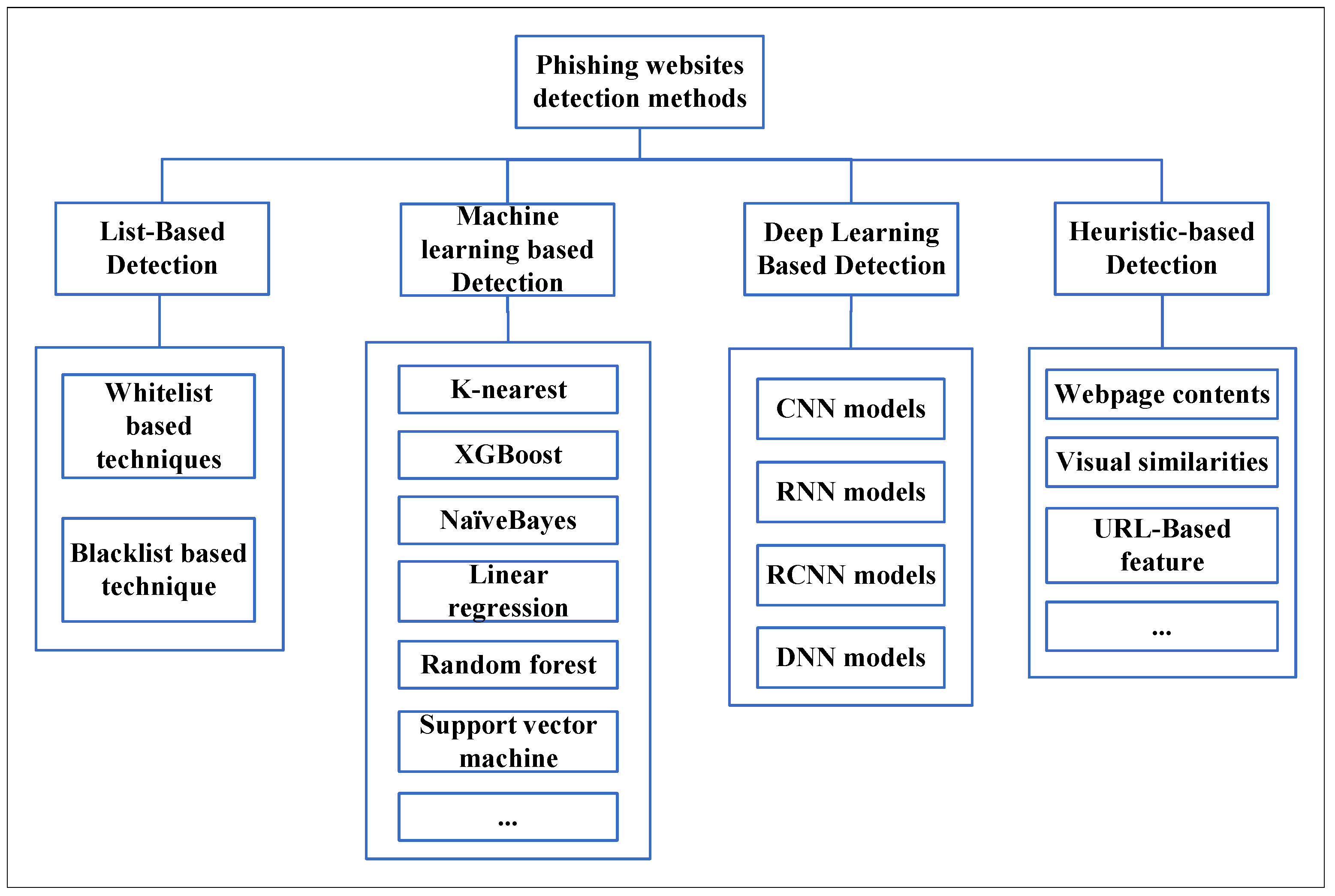
2. Literature Review
- 1.
- Black and whitelist
- 2.
- Heuristic
- 3.
- Visual Similarity
- 4.
- Machine Learning
3. Proposed Method
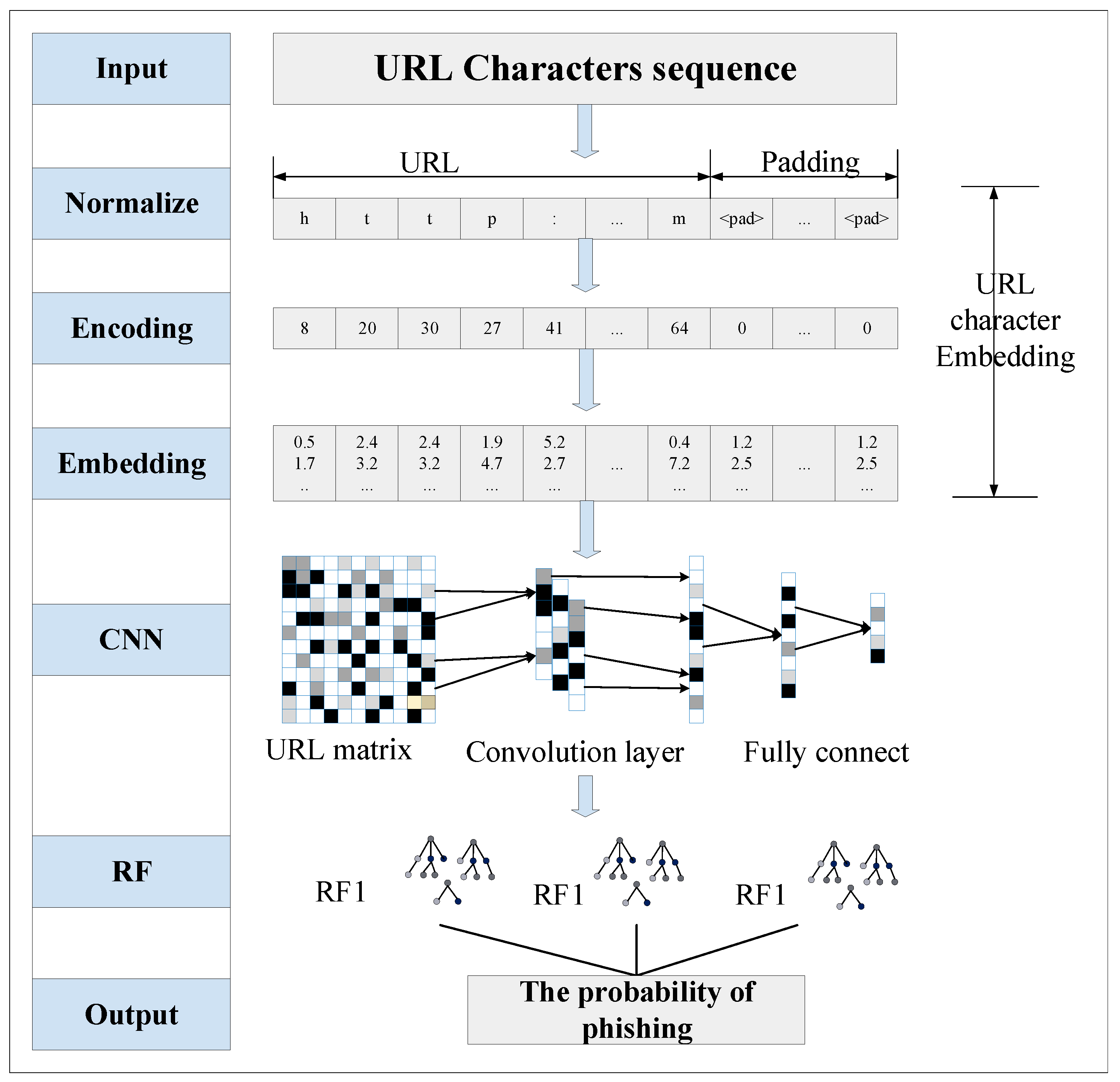
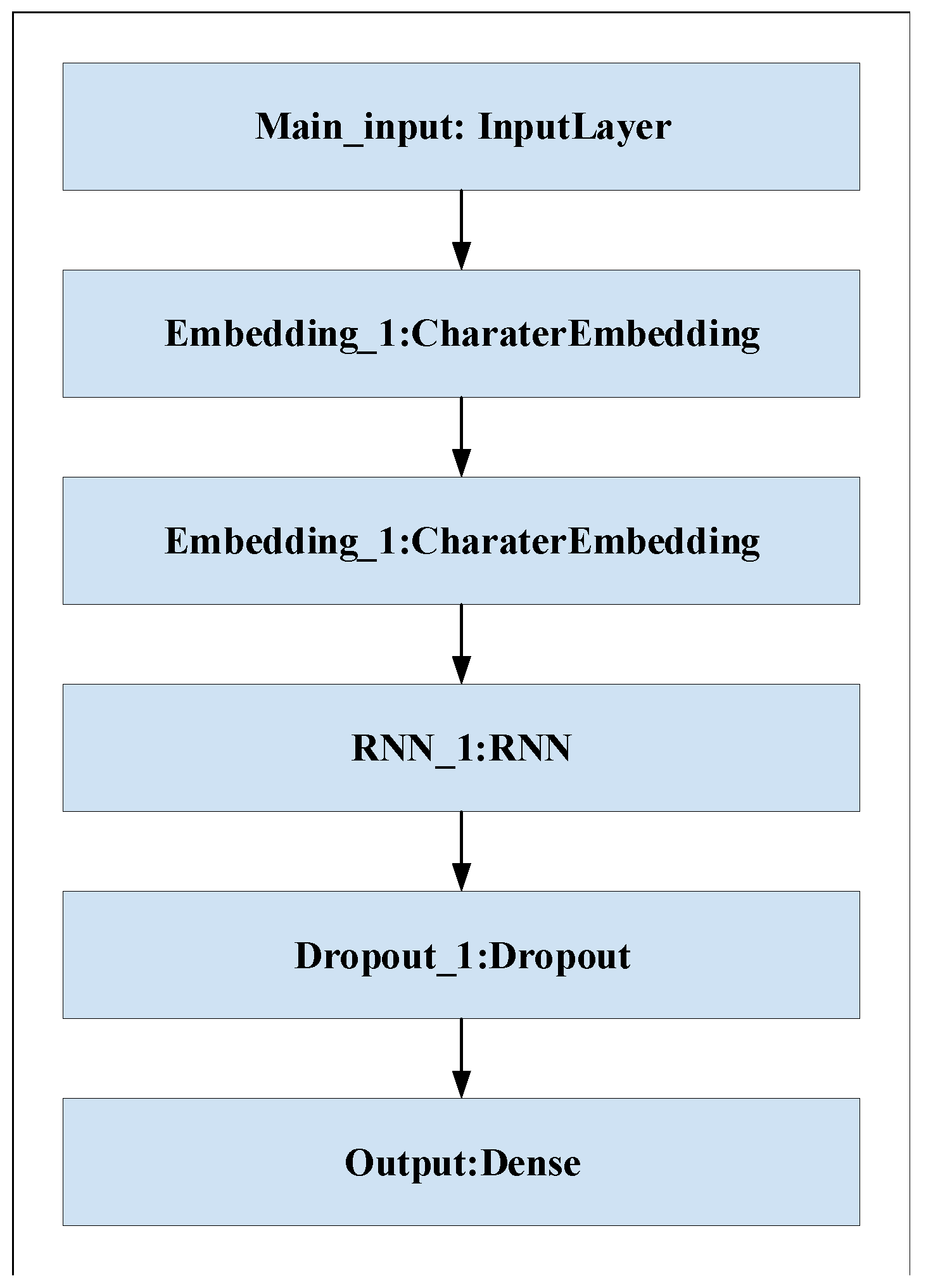
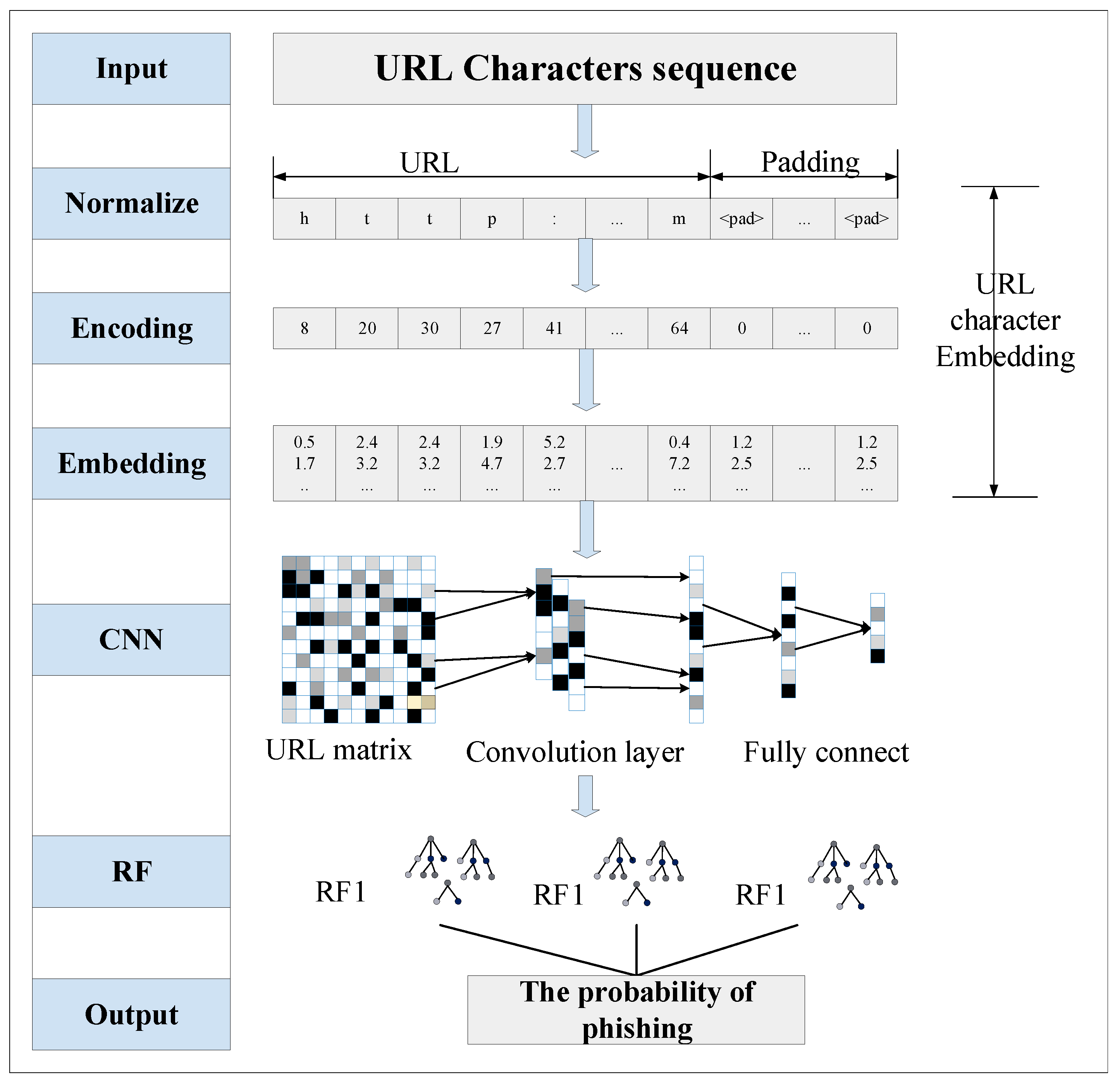
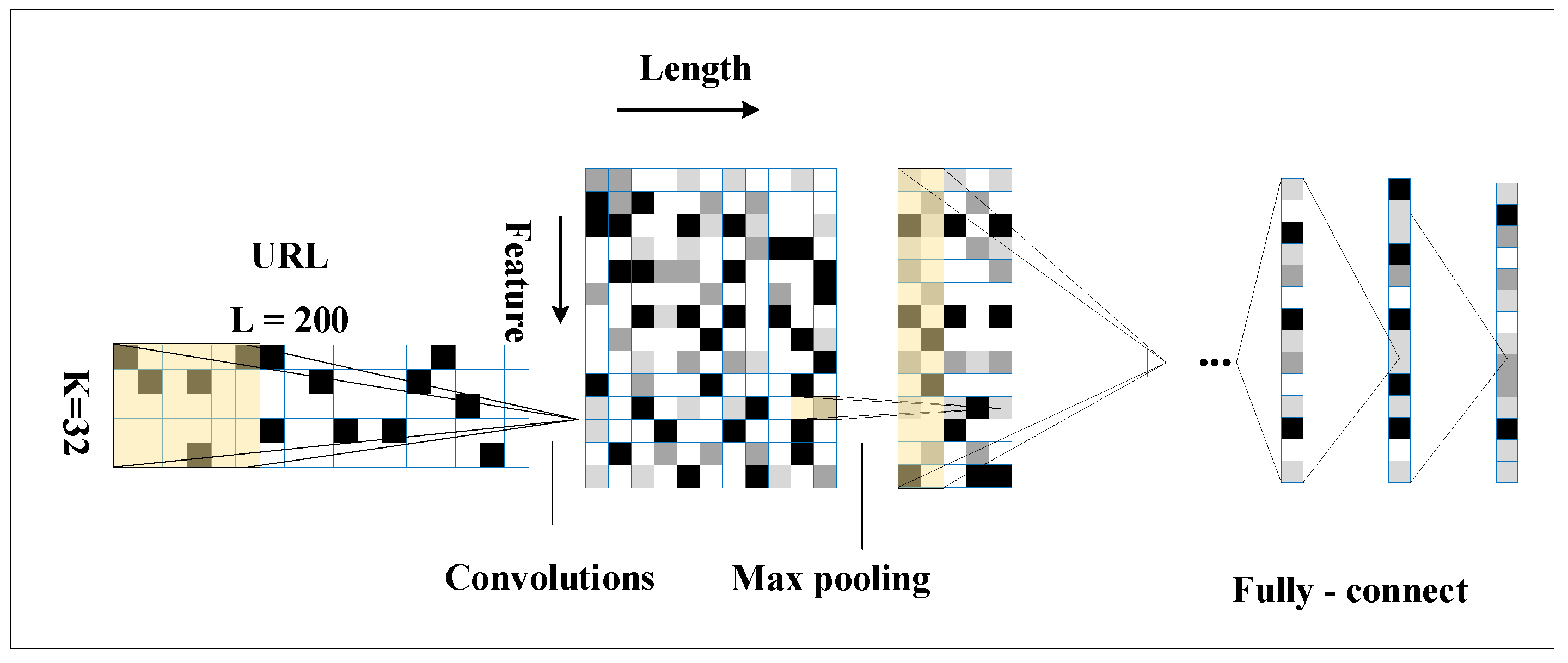
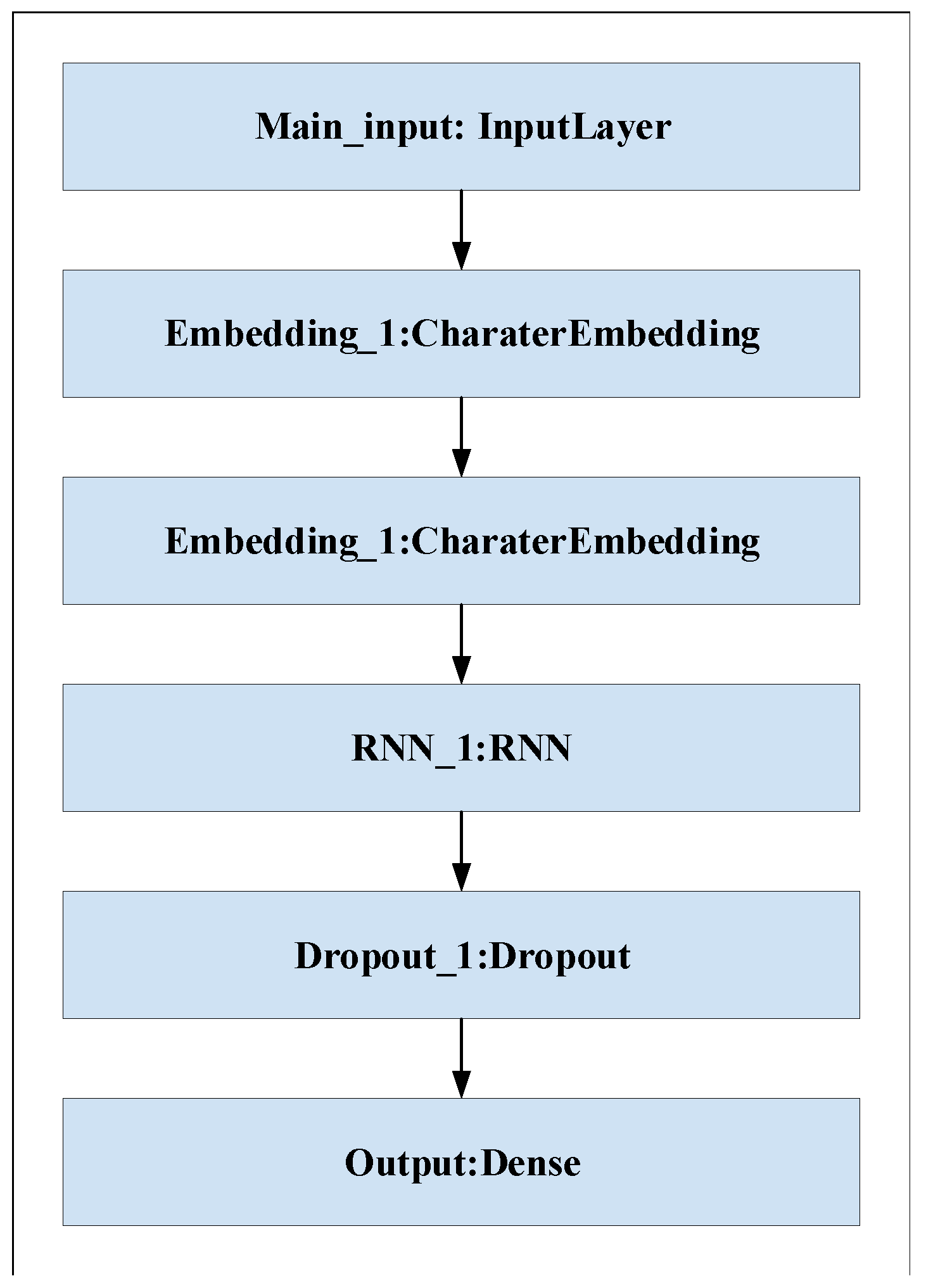
3.1. URL Character Embedding
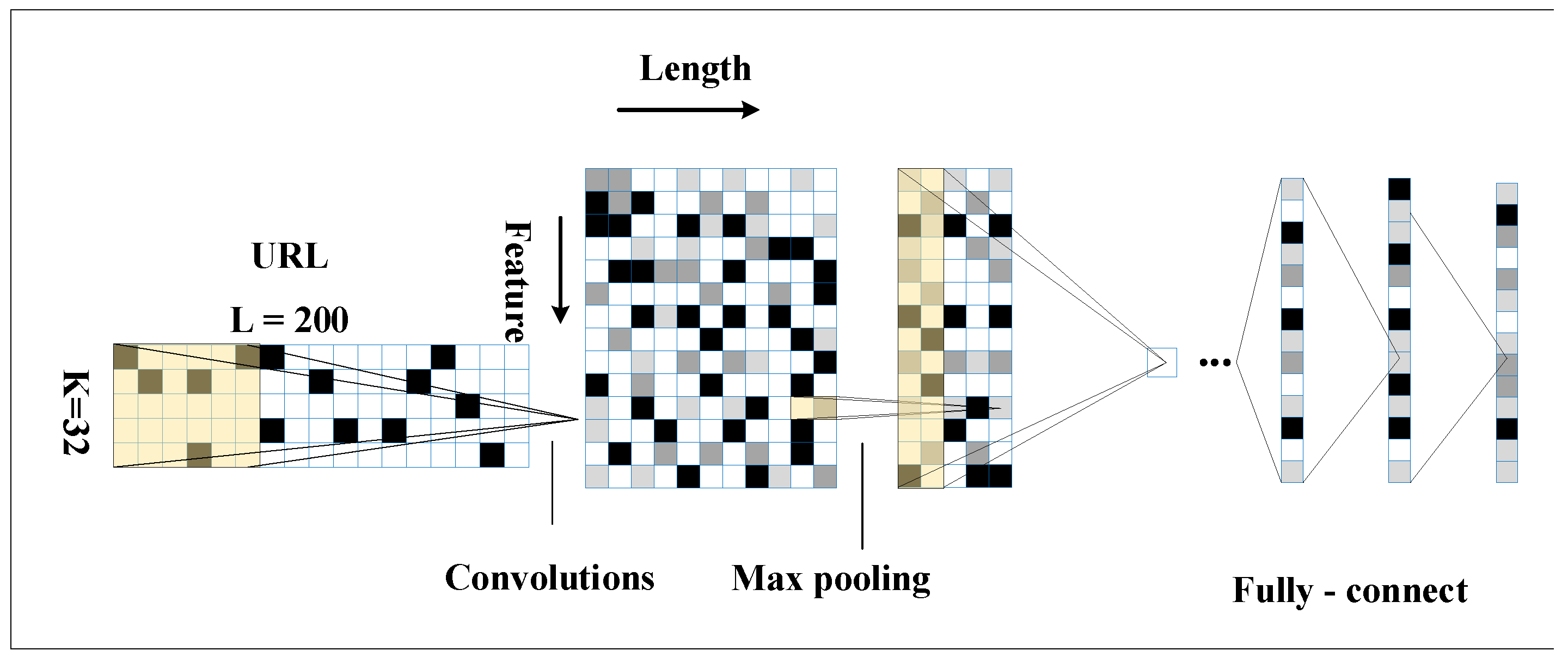
3.2. Designing an Improved CNN
| Algorithm 1 Extract Multiplyer Features (EMF-CNN) | |
Input: The training dataset , The testing dataset , , . Output: Multiplyer features F1, F2, F3. | |
| 1: | t = size of sliding step, = threshold value of loss function , T = num of sliding-window, , |
| 2: | , , , |
| 3: | For i in l do |
| 4: | |
| 5: | |
| 6: | |
| 7: | end for |
| 8: | |
| 9: | For j in B do |
| 10: | For i in D do |
| 11: | end for |
| 12: | end for |
| 13: | For n in B do |
| 14: | For t in M do |
| 15: | |
| 16: | end for |
| 17: | end for |
| 18: | |
| 19: | |
| 20: | while |
| 21: | |
| 22: | end while |
| 23: | |
| 24: | return |
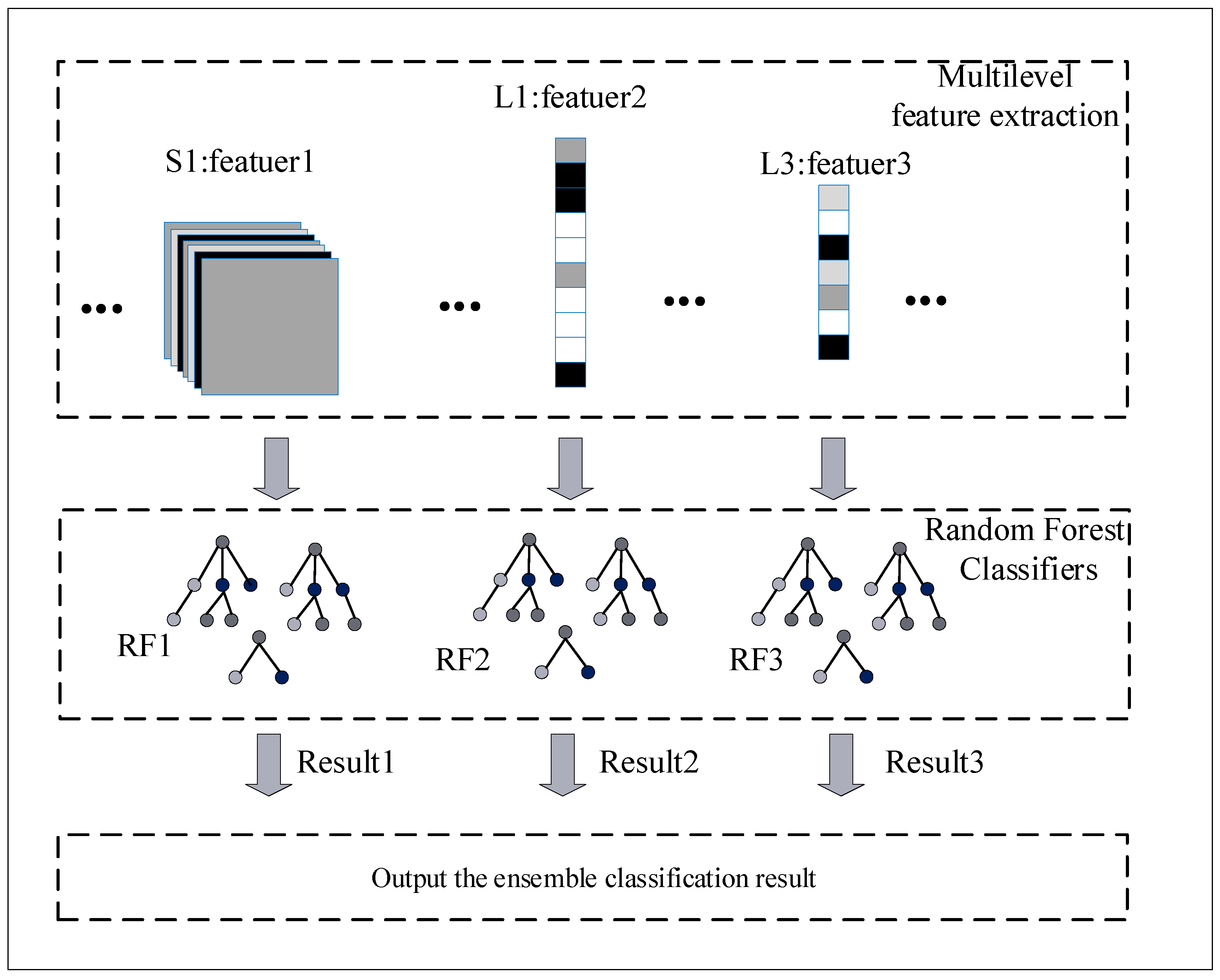
3.3. Ensemble Classification
| Algorithm 2 General procedure of proposed method | |
Input: Set of URLs Output:The probality of phishing | |
| 1: | , , , |
| 2: | For j in M do |
| 3: | , , |
| 4: | |
| 5: | , , |
| 6: | end for |
| 7: | |
| 8: | return |
4. Experimentation and Result Analysis
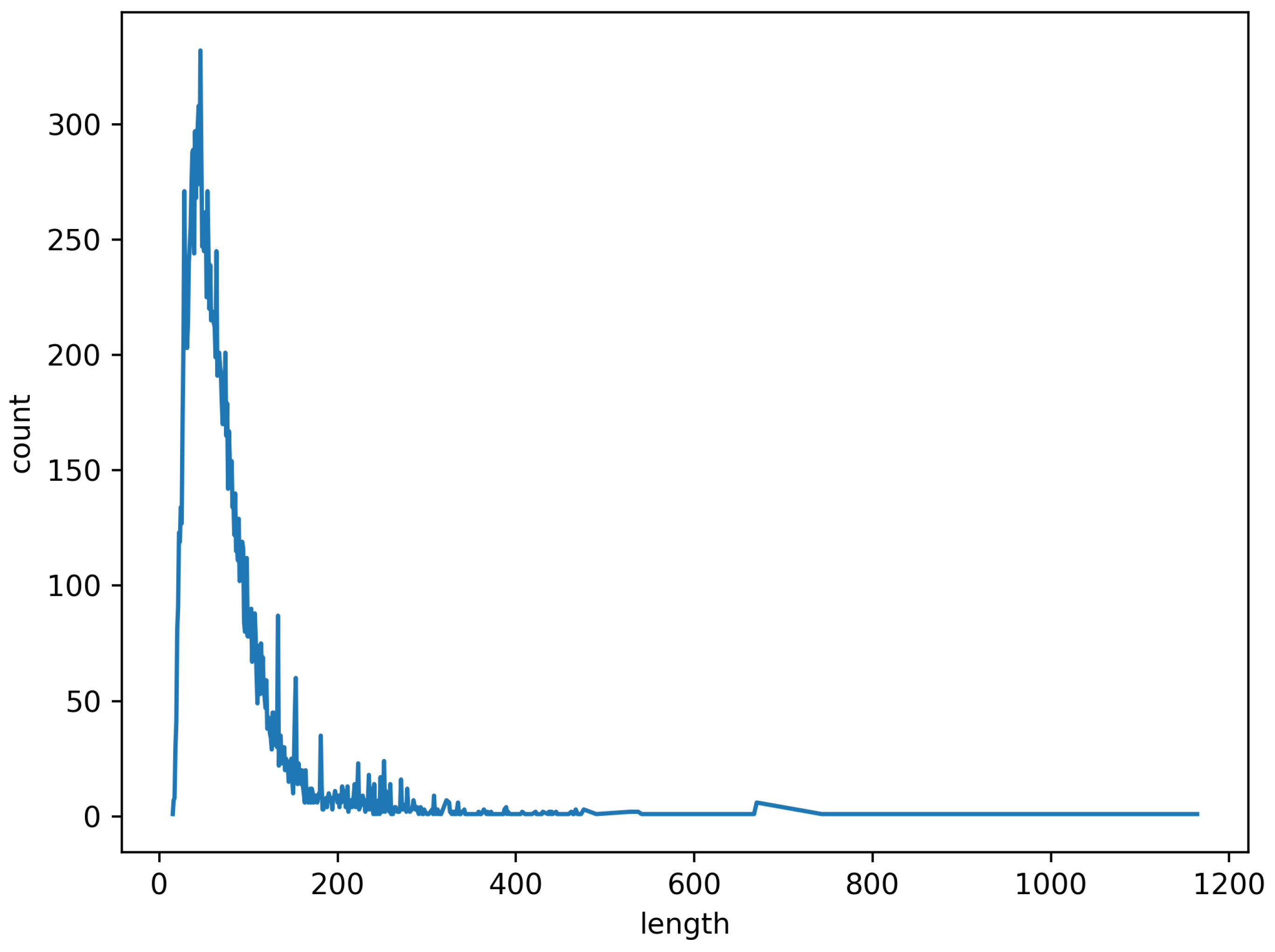
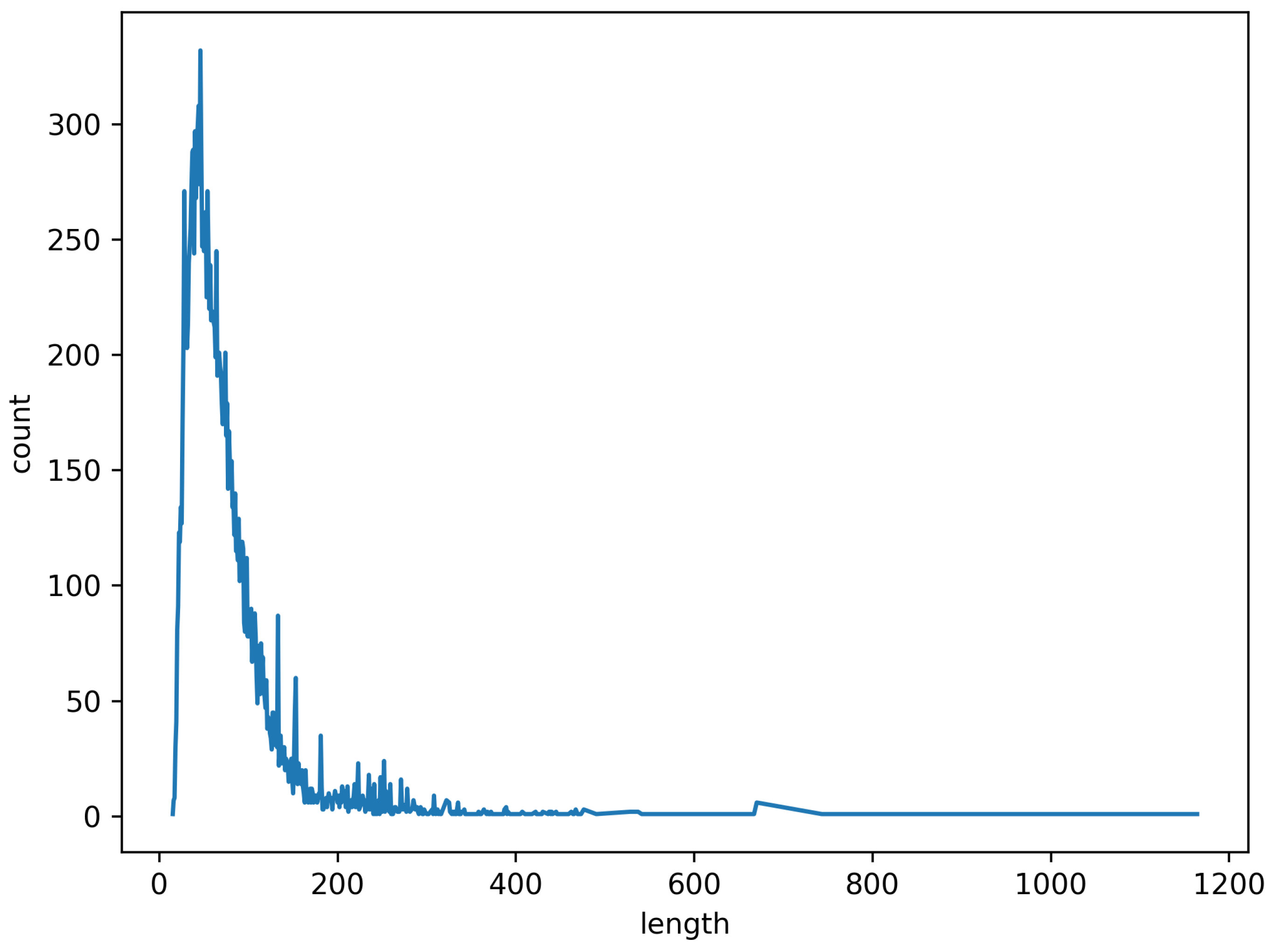
4.1. Dataset
4.2. Experimental Setup
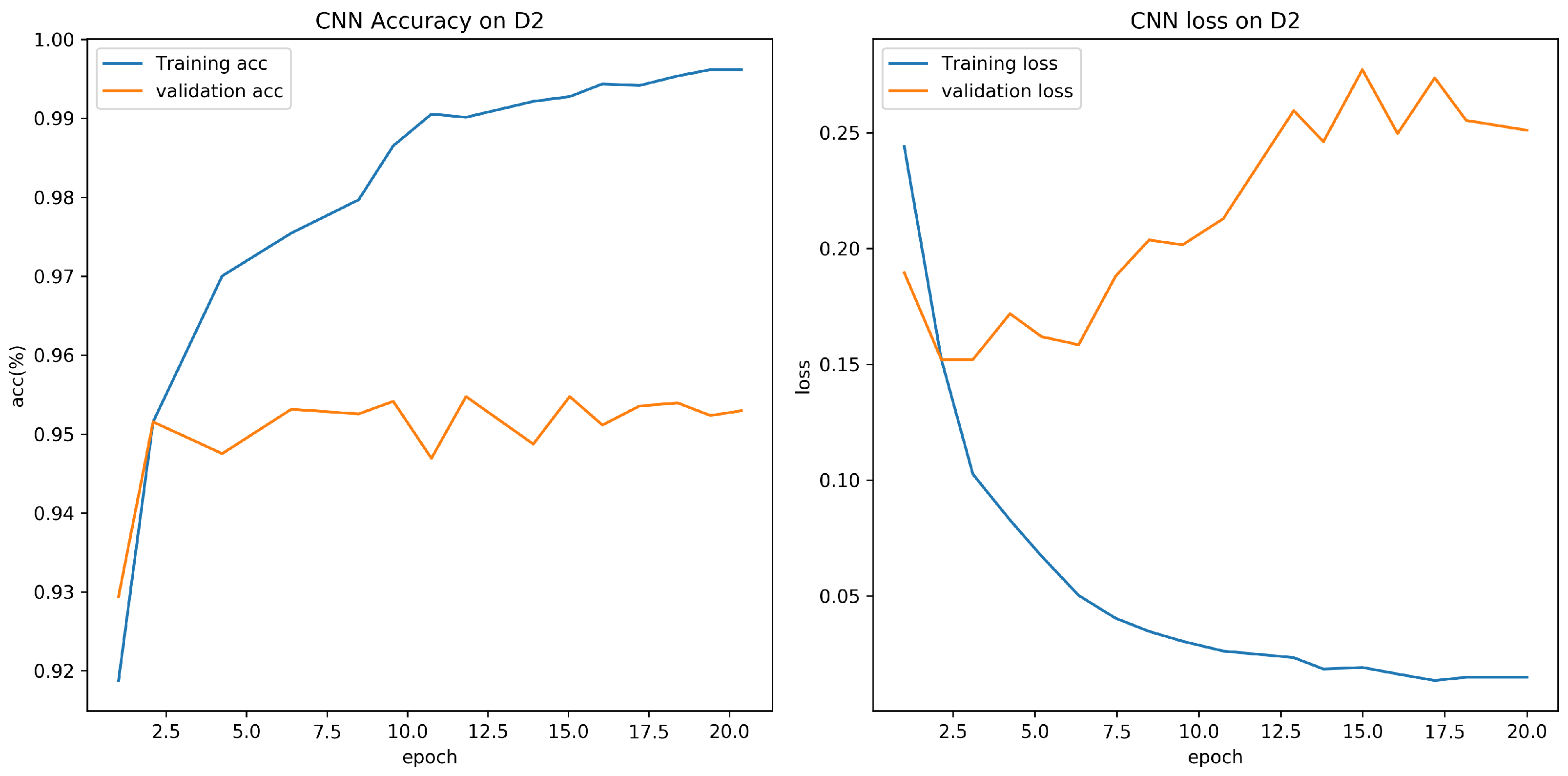
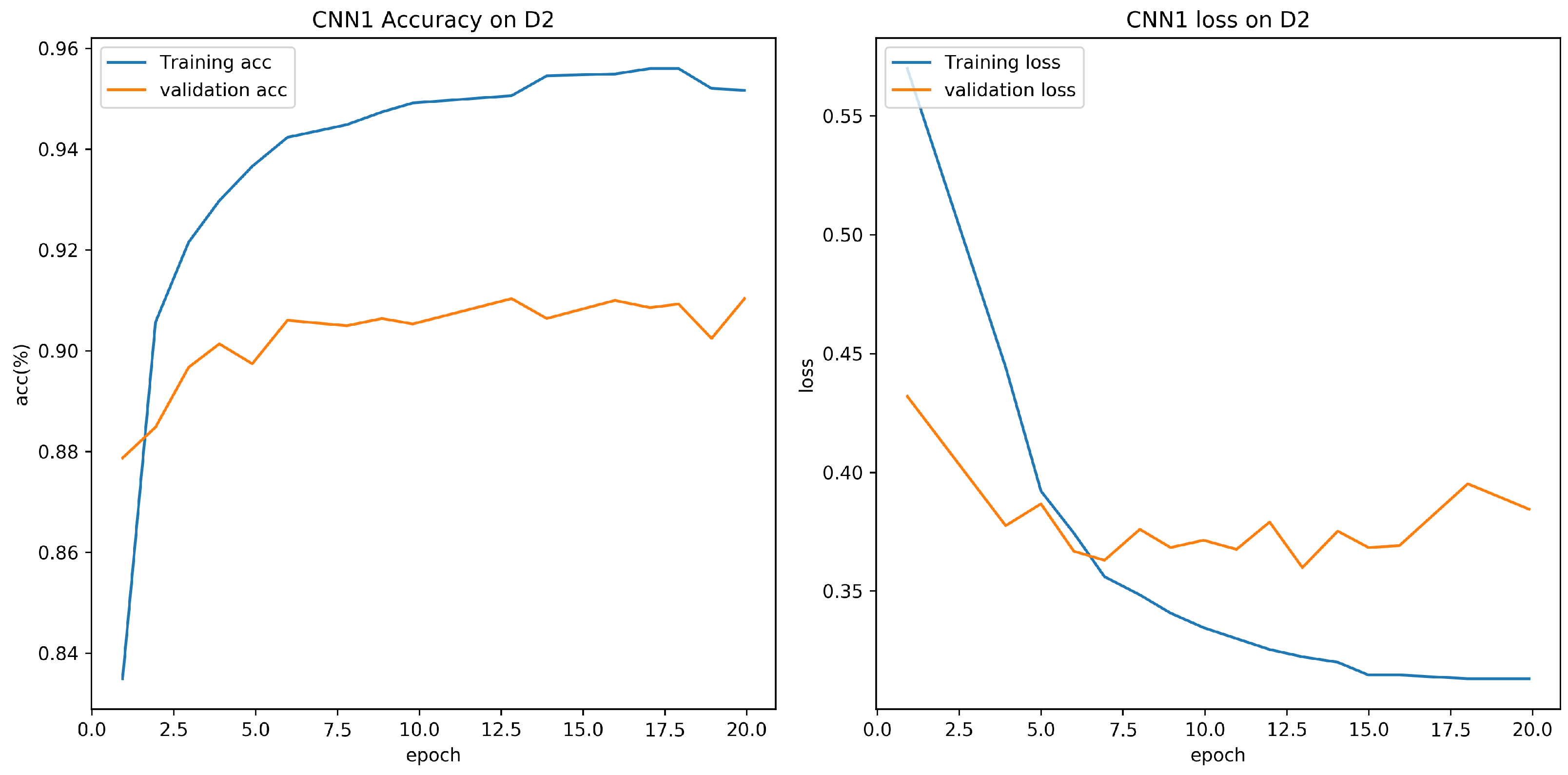
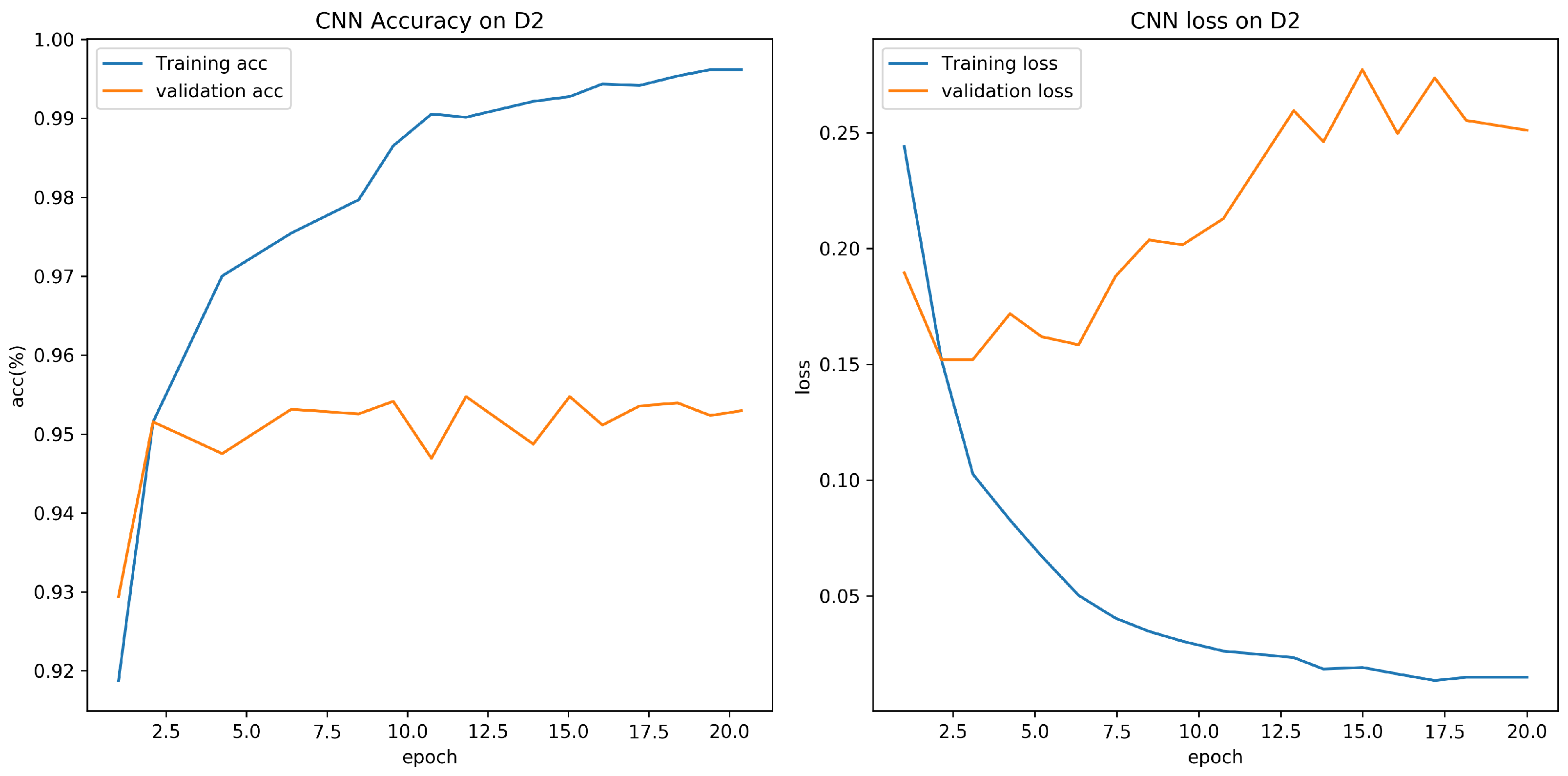
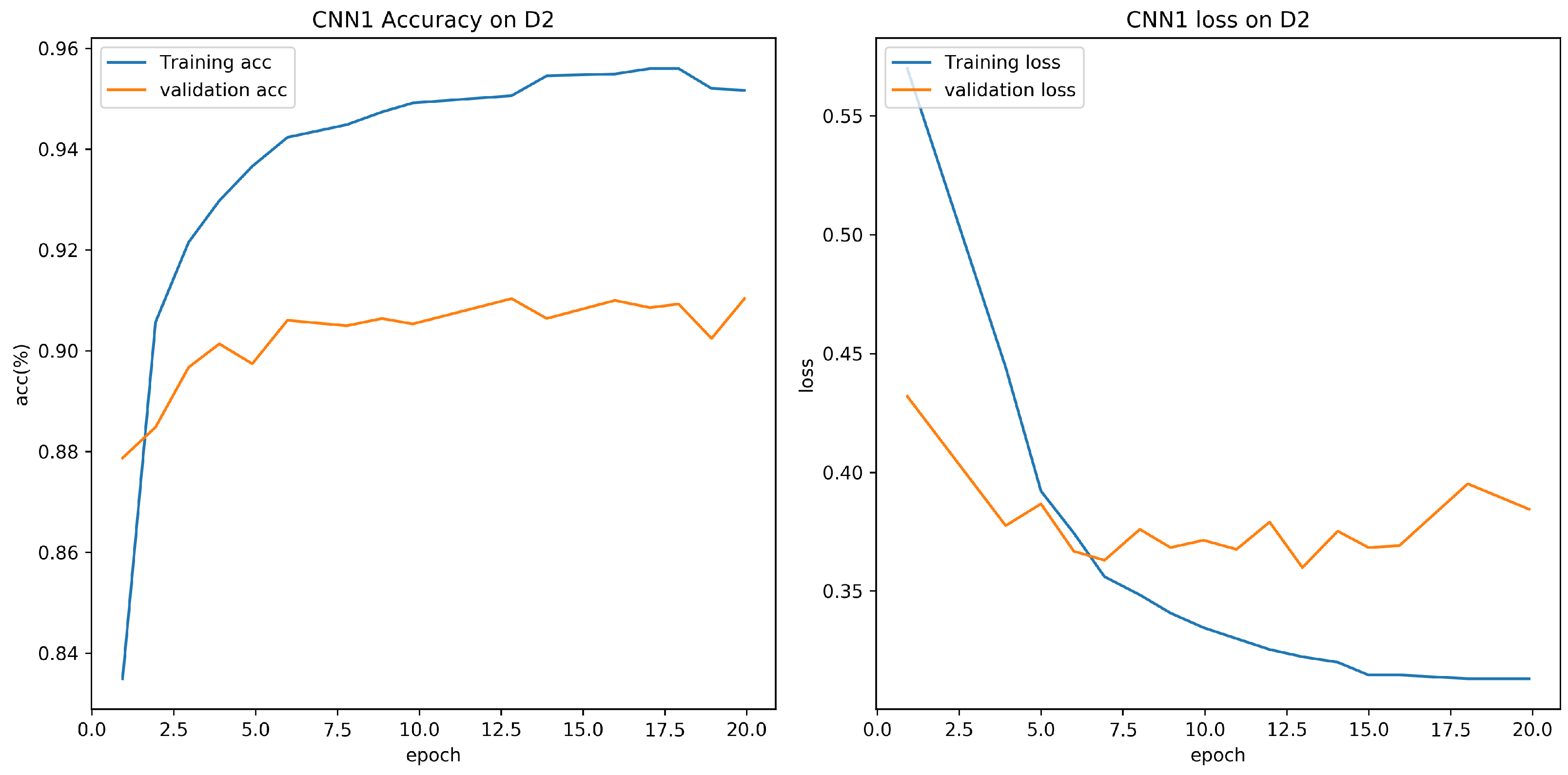
4.3. Evaluation on D1 with Different CNN Models
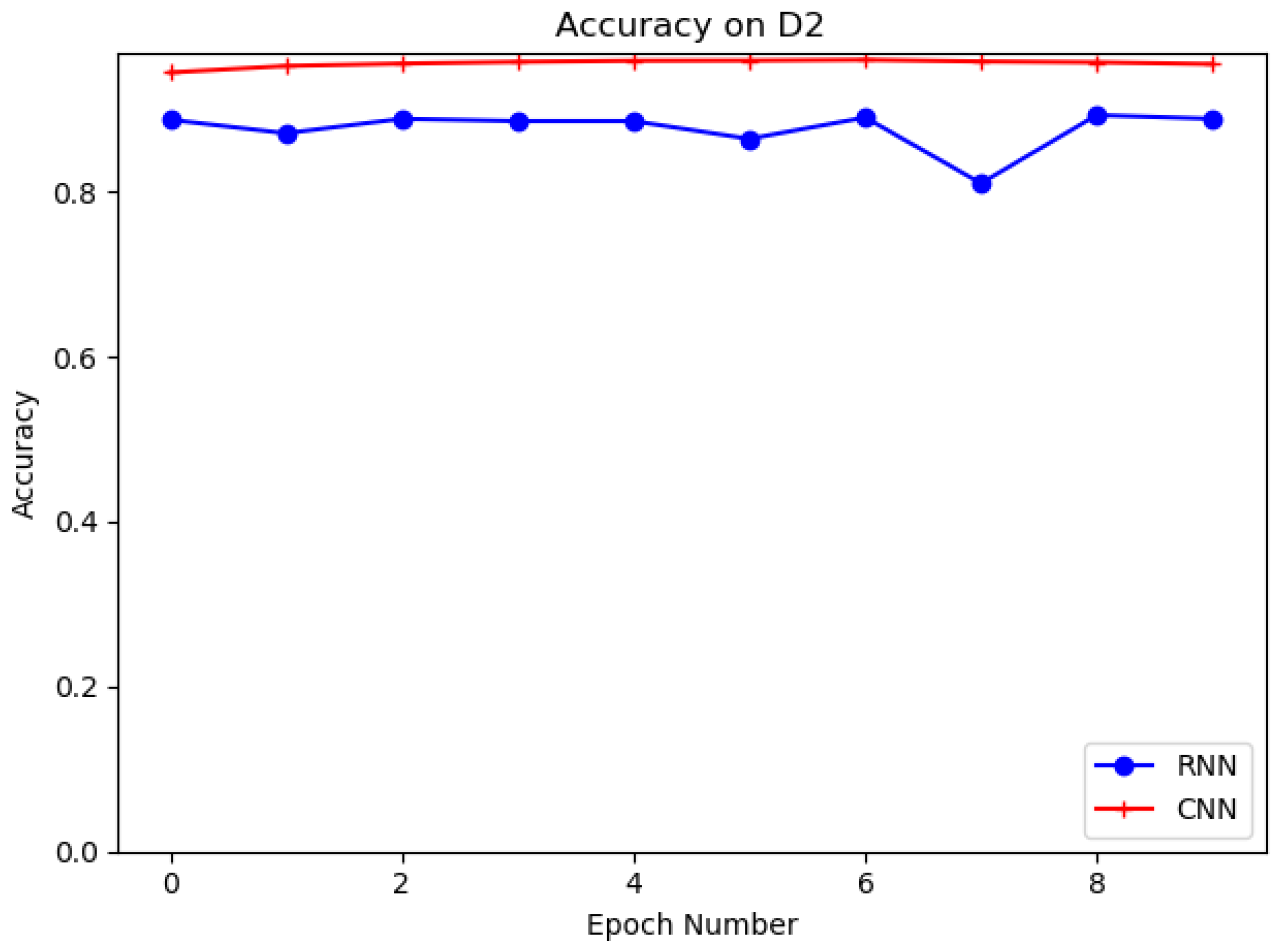
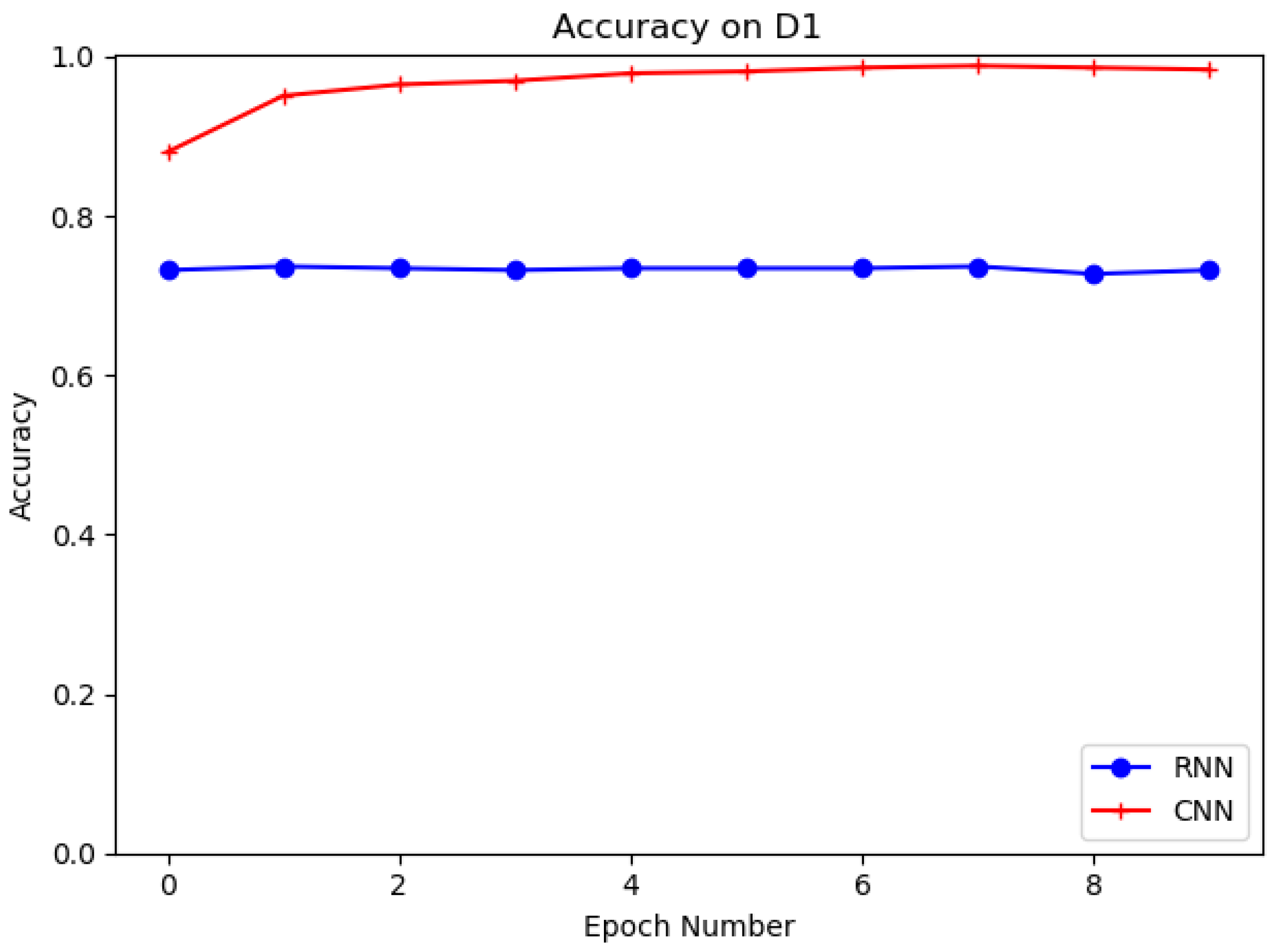
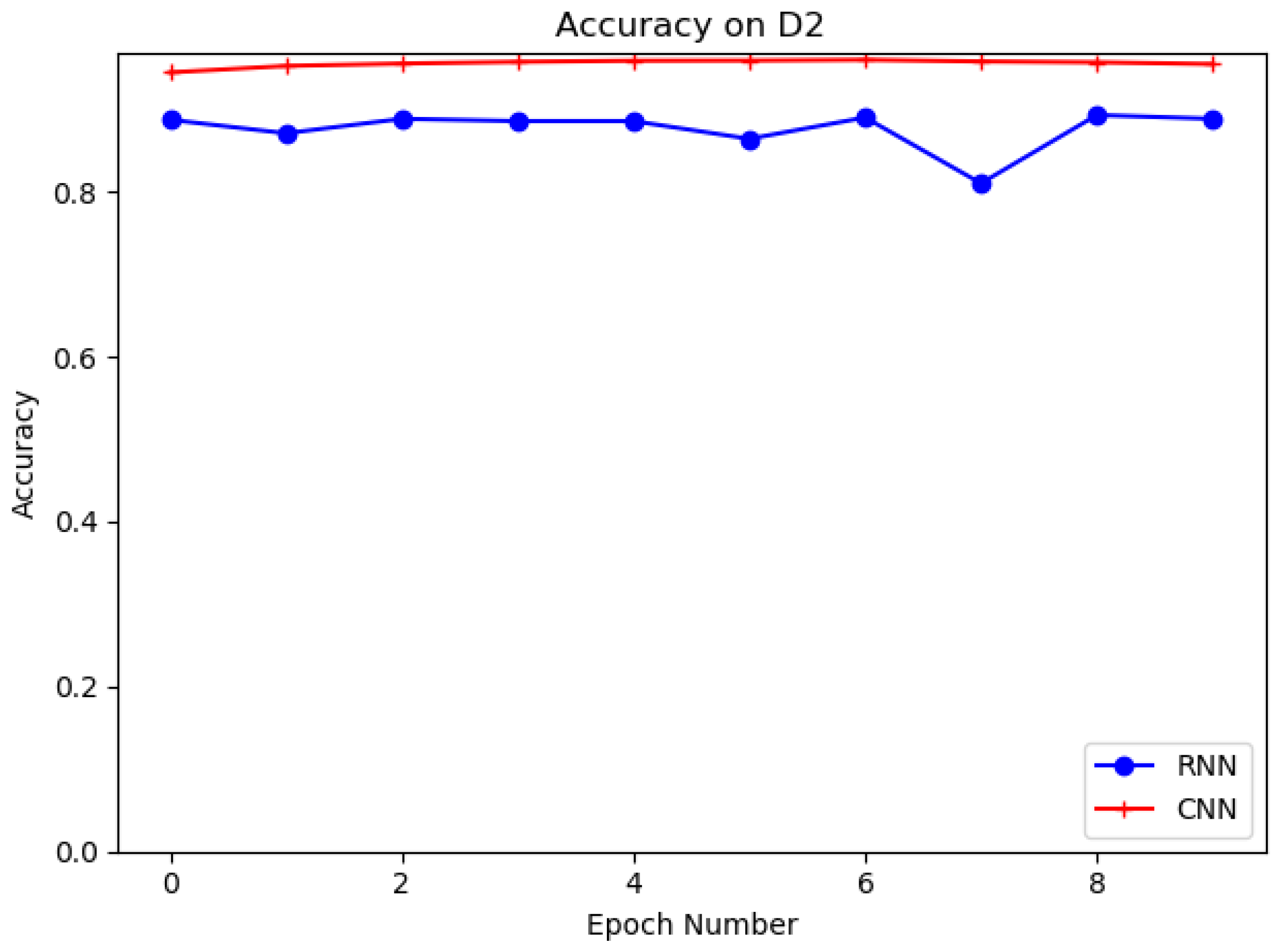
4.4. Evaluation on D1, D2 with RNN and CNN
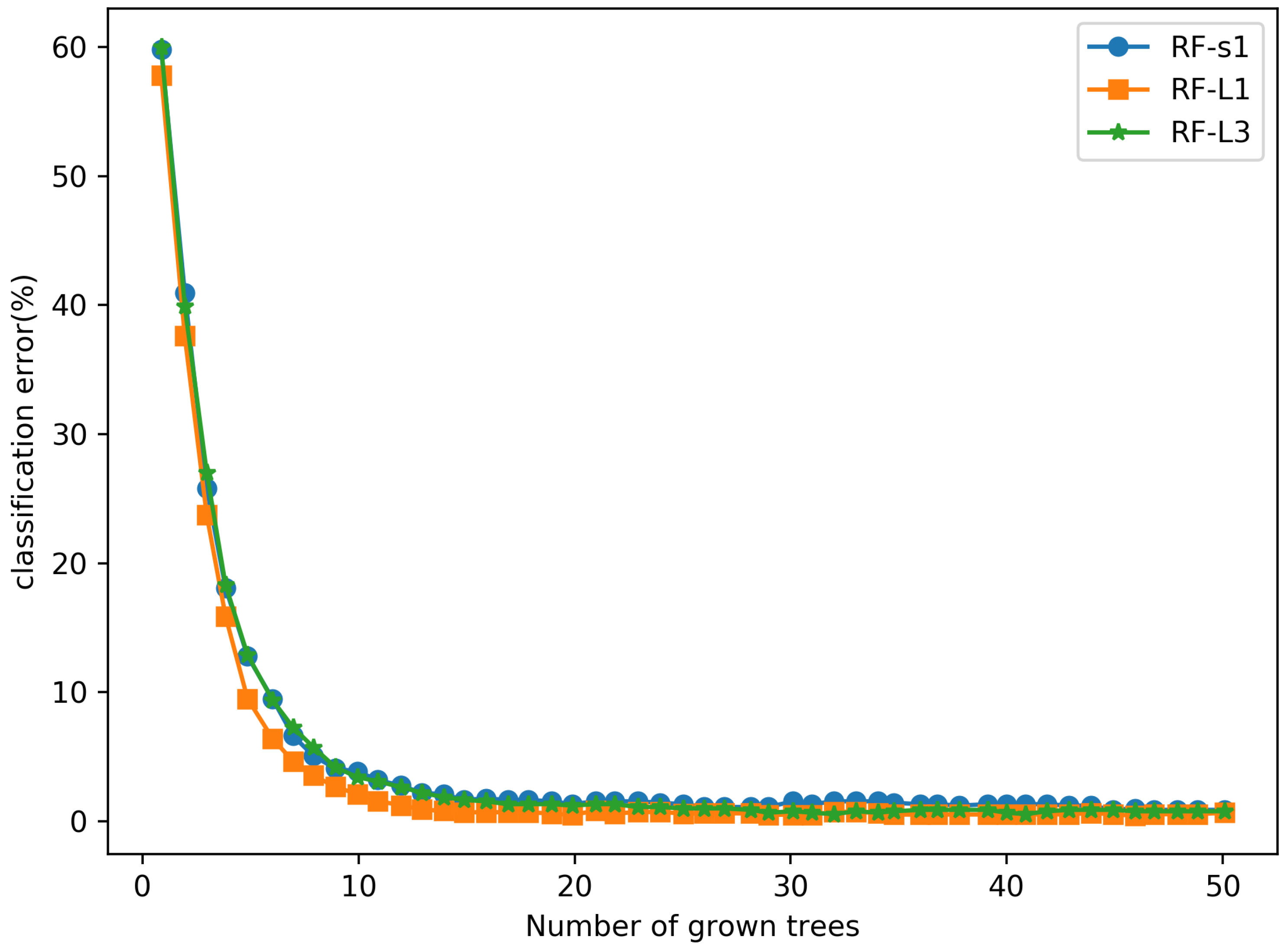
4.5. Evaluation on D1 with Different Classifier
4.6. Comparison of Proposed Model with Existing Baselines
5. Conclusions and Future Work
- (1)
- Character embedding of URLs is performed to convert URLs into normalized matrices, containing much important phishing website classification information in the URL characters. This information helps classify phishing websites. URLs are transformed into uniform signals by the character embedding technique, more suitable for CNN networks’ input.
- (2)
- Automatic phishing web feature extractor using CNN. The CNN model is pre-trained using the converted URL data to optimize and improve the CNN model parameters. The pre-trained model can extract multi-level features from the URL data. The extracted multi-level features contain sensitive information that can classify phishing websites and provide knowledge for phishing website classification.
- (3)
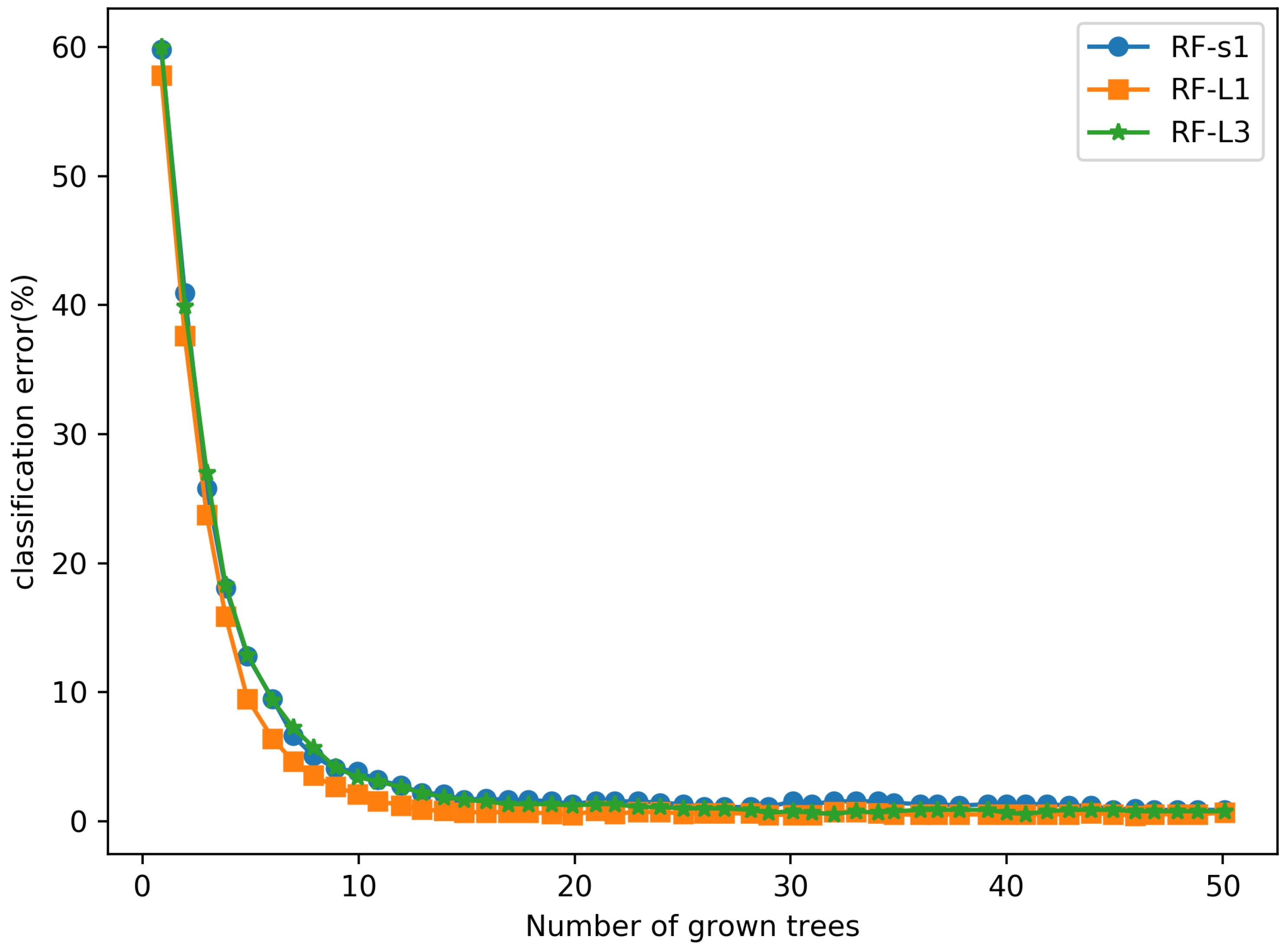
- Using multiple RF classifiers and a winner-take-all strategy improves the model’s accuracy and generalization. Extracting multi-level features for low latitude can be used to classify phishing websites. The RF classifier is trained using the extracted features of each layer, outputting the results of each RF, and, finally, choosing the one with the best results, improving the classification results.
- (4)
- The proposed method in this paper is validated by the dataset from PhishTank and Alex. A 99.35% correct classification rate of phishing websites was obtained on the dataset. Experiments were conducted on the test set and training set, and the experimental results proved that the proposed method has good generalization ability and is useful in practical applications.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Phishing Activity Trends Report: 4rd Quarter 2020. Anti-Phishing Work. Group. Retrieved April 2021, 30, 2020.
- FBI. 2019 Internet Crime Report Released-FBI. Available online: https://www.fbi.gov/news/stories/2019-internet-crime-report-released-021120. (accessed on 11 February 2020).
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Tutorial and critical analysis of phishing websites methods. Comput. Sci. Rev. 2015, 17, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Almomani, A.; Wan, T.C.; Altaher, A.; Manasrah, A.; ALmomani, E.; Anbar, M.; ALomari, E.; Ramadass, S. Evolving fuzzy neural network for phishing emails detection. J. Comput. Sci. 2012, 8, 1099. [Google Scholar]
- Prakash, P.; Kumar, M.; Kompella, R.R.; Gupta, M. Phishnet: Predictive blacklisting to detect phishing attacks. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–5. [Google Scholar]
- Zhang, J.; Porras, P.A.; Ullrich, J. Highly Predictive Blacklisting. In Proceedings of the USENIX Security Symposium, San Jose, CA, USA, 28 July–1 August 2008; pp. 107–122. [Google Scholar]
- Cao, Y.; Han, W.; Le, Y. Anti-phishing based on automated individual white-list. In Proceedings of the 4th ACM Workshop on Digital Identity Management, Alexandria, VA, USA, 31 October 2008; pp. 51–60. [Google Scholar]
- Srinivasa Rao, R.; Pais, A.R. Detecting phishing websites using automation of human behavior. In Proceedings of the 3rd ACM Workshop on Cyber-Physical System Security, Abu Dhabi, United Arab Emirates, 2–4 April 2017; pp. 33–42. [Google Scholar]
- Rao, R.S.; Ali, S.T. Phishshield: A desktop application to detect phishing webpages through heuristic approach. Procedia Comput. Sci. 2015, 54, 147–156. [Google Scholar] [CrossRef] [Green Version]
- Joshi, Y.; Saklikar, S.; Das, D.; Saha, S. PhishGuard: A browser plug-in for protection from phishing. In Proceedings of the 2008 2nd International Conference on Internet Multimedia Services Architecture and Applications, Las Vegas, NV, USA, 14–17 July 2008; pp. 1–6. [Google Scholar]
- Teraguchi, N.C.R.L.Y.; Mitchell, J.C. Client-side defense against web-based identity theft. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 5 February 2004; pp. 5–18. [Google Scholar]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Rao, R.S.; Pais, A.R. Detection of phishing websites using an efficient feature-based machine learning framework. Neural Comput. Appl. 2019, 31, 3851–3873. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Xiang, G.; Hong, J.; Rose, C.P.; Cranor, L. Cantina+ a feature-rich machine learning framework for detecting phishing web sites. ACM Trans. Inf. Syst. Secur. 2011, 14, 1–28. [Google Scholar] [CrossRef]
- Huh, J.H.; Kim, H. Phishing detection with popular search engines: Simple and effective. In Proceedings of the International Symposium on Foundations and Practice of Security, Paris, France, 12–13 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 194–207. [Google Scholar]
- Whittaker, C.; Ryner, B.; Nazif, M. Large-scale automatic classification of phishing pages. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2010, San Diego, CA, USA, 28 February–3 March 2010. [Google Scholar]
- Miyamoto, D.; Hazeyama, H.; Kadobayashi, Y. An evaluation of machine learning-based methods for detection of phishing sites. In Proceedings of the International Conference on Neural Information Processing, Vancouver, BC, Canada, 8–11 December 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 539–546. [Google Scholar]
- Zhang, Y.; Hong, J.I.; Cranor, L.F. Cantina: A content-based approach to detecting phishing web sites. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 639–648. [Google Scholar]
- Pan, Y.; Ding, X. Anomaly based web phishing page detection. In Proceedings of the 2006 22nd Annual Computer Security Applications Conference (ACSAC’06), Miami Beach, FL, USA, 11–15 December 2006; pp. 381–392. [Google Scholar]
- Bouvrie, J. Notes on Convolutional Neural Networks. Neural Nets 2006. Available online: http://cogprints.org/5869/ (accessed on 22 October 2021).
- Somesha, M.; Pais, A.R.; Rao, R.S.; Rathour, V.S. Efficient deep learning techniques for the detection of phishing websites. Sādhanā 2020, 45, 1–18. [Google Scholar] [CrossRef]
- Parra, G.D.L.T.; Rad, P.; Choo, K.K.R.; Beebe, N. Detecting Internet of Things attacks using distributed deep learning. J. Netw. Comput. Appl. 2020, 163, 102662. [Google Scholar] [CrossRef]
- Aljofey, A.; Jiang, Q.; Qu, Q.; Huang, M.; Niyigena, J.P. An effective phishing detection model based on character level convolutional neural network from URL. Electronics 2020, 9, 1514. [Google Scholar] [CrossRef]
- Vrbančič, G.; Fister Jr, I.; Podgorelec, V. Datasets for phishing websites detection. Data Brief 2020, 33, 106438. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhang, F.; Luo, X.; Zhang, S. Pdrcnn: Precise phishing detection with recurrent convolutional neural networks. Secur. Commun. Networks 2019, 2019, 2595794. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B. Comparative analysis of features based machine learning approaches for phishing detection. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 2125–2130. [Google Scholar]
- Lee, L.H.; Lee, K.C.; Chen, H.H.; Tseng, Y.H. Poster: Proactive blacklist update for anti-phishing. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1448–1450. [Google Scholar]
- Aburrous, M.; Hossain, M.A.; Dahal, K.; Thabtah, F. Experimental case studies for investigating e-banking phishing techniques and attack strategies. Cogn. Comput. 2010, 2, 242–253. [Google Scholar] [CrossRef] [Green Version]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based associative classification data mining. Expert Syst. Appl. 2014, 41, 5948–5959. [Google Scholar] [CrossRef]
- Hadi, W.; Aburub, F.; Alhawari, S. A new fast associative classification algorithm for detecting phishing websites. Appl. Soft Comput. 2016, 48, 729–734. [Google Scholar] [CrossRef]
- Mao, J.; Tian, W.; Li, P.; Wei, T.; Liang, Z. Phishing-alarm: Robust and efficient phishing detection via page component similarity. IEEE Access 2017, 5, 17020–17030. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, R.; Divakaran, D.M.; Ng, J.Y.; Chan, Q.Z.; Lu, Y.; Si, Y.; Zhang, F.; Dong, J.S. Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages. In Proceedings of the 30th {USENIX} Security Symposium ({USENIX} Security 21), Virtual Event, 11–13 August 2021. [Google Scholar]
- Zouina, M.; Outtaj, B. A novel lightweight URL phishing detection system using SVM and similarity index. Hum. Centric Comput. Inf. Sci. 2017, 7, 1–13. [Google Scholar] [CrossRef]
- Toolan, F.; Carthy, J. Feature selection for spam and phishing detection. In Proceedings of the 2010 eCrime Researchers Summit, Dallas, TX, USA, 18–20 October 2010; pp. 1–12. [Google Scholar]
- Zhu, E.; Chen, Y.; Ye, C.; Li, X.; Liu, F. OFS-NN: An effective phishing websites detection model based on optimal feature selection and neural network. IEEE Access 2019, 7, 73271–73284. [Google Scholar] [CrossRef]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Predicting phishing websites based on self-structuring neural network. Neural Comput. Appl. 2014, 25, 443–458. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unique Characters |
|---|
| abcdefghijklmnopqrstuvwxyz |
| ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| -:;.!?/[] ()@=+ # $ % & { } _ ^ - <>|\ |
| 0123456789 |
| Unrecognizable |
| Padding |
| Date Name | Legitimate URL | Source | Phishing URLS | Source | Total |
|---|---|---|---|---|---|
| DATA1 | 24,719 | ALEXA | 22,491 | PhishTank | 47,210 |
| DATA2 | 43,189 | Yandex | 40,668 | PhishTank | 83,857 |
| Layer Name | Configuration | Kernel/Pooling Size |
|---|---|---|
| Input | 32 × 200 | |
| C1 | 256@196 × 1 | 256@5 × 32 |
| S2 | 256@1 | 256@196 × 1 |
| L3 | 512 | |
| L4 | 256 | |
| L5 | 128 | |
| FC6 | 128 | |
| Output | 2 |
| Layer Name | Configuration | Kernel/Pooling Size |
|---|---|---|
| Input | 95 × 95 | |
| C1 | 32@6 × 6 | 32@3 × 3 |
| C2 | 6@3 × 3 | 6@2 × 2 |
| C3 | 16@5 × 5 | 16@2 × 2 |
| C4 | 120@5 × 5 | |
| FC5 | 84 | |
| Output | 2 |
| Sets | Model | Accuracy for DATA1 (%) | F1 (%) | Precision (%) | Recall (%) | AUC (%) |
|---|---|---|---|---|---|---|
| D1 | CNN | 95.73 | 95.53 | 95.96 | 95.11 | 95.37 |
| CNN1 | 90.34 | 89.96 | 90.87 | 88.06 | 90.23 |
| Sets | Model | Accuracy for DATA1 (%) | F1 (%) | Precision (%) | Recall (%) | AUC (%) |
|---|---|---|---|---|---|---|
| D1 | CNN | 95.73 | 95.53 | 95.96 | 95.11 | 95.37 |
| RNN | 72.32 | 71.76 | 73.85 | 69.79 | 72.18 | |
| D2 | CNN | 94.45 | 94.30 | 94.85 | 93.37 | 94.21 |
| RNN | 88.75 | 88.53 | 89.56 | 87.53 | 88.46 |
| Model | Feature | Accuracy for DATA1 (%) | F1 (%) | Precision (%) | Recall (%) | AUC (%) |
|---|---|---|---|---|---|---|
| MNB | CNN + MNB1 | 79.28 | 77.46 | 74.77 | 80.36 | 79.11 |
| CNN + MNB2 | 79.23 | 78.93 | 81.68 | 76.36 | 79.05 | |
| CNN + MNB3 | 79.24 | 78.67 | 80.39 | 77.03 | 79.31 | |
| CNN + MNB | 79.28 | 77.46 | 74.77 | 80.36 | 79.11 | |
| LR | CNN + LR1 | 86.33 | 85.85 | 87.08 | 84.65 | 86.16 |
| CNN + LR2 | 86.29 | 86.01 | 88.48 | 83.67 | 86.21 | |
| CNN + LR3 | 86.21 | 85.92 | 87.15 | 84.73 | 86.33 | |
| CNN + LR | 86.33 | 85.85 | 87.08 | 84.65 | 86.16 | |
| XGB | CNN + XGB1 | 89.27 | 88.68 | 88.28 | 89.08 | 89.26 |
| CNN + XGB2 | 89.31 | 89.29 | 88.90 | 87.92 | 89.30 | |
| CNN + XGB3 | 89.12 | 88.31 | 86.29 | 90.42 | 89.32 | |
| CNN + XGB | 89.31 | 89.29 | 88.90 | 87.92 | 89.30 | |
| RF | CNN + RF1 | 99.25 | 99.25 | 99.15 | 99.11 | 99.24 |
| CNN + RF2 | 99.35 | 99.34 | 99.52 | 99.21 | 99.34 | |
| CNN + RF3 | 99.27 | 99.26 | 99.14 | 99.06 | 99.27 | |
| CNN + RF | 99.35 | 99.34 | 99.52 | 99.21 | 99.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, R.; Zheng, K.; Wu, B.; Wu, C.; Wang, X. Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors 2021, 21, 8281. https://doi.org/10.3390/s21248281
Yang R, Zheng K, Wu B, Wu C, Wang X. Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors. 2021; 21(24):8281. https://doi.org/10.3390/s21248281
Chicago/Turabian StyleYang, Rundong, Kangfeng Zheng, Bin Wu, Chunhua Wu, and Xiujuan Wang. 2021. "Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning" Sensors 21, no. 24: 8281. https://doi.org/10.3390/s21248281
APA StyleYang, R., Zheng, K., Wu, B., Wu, C., & Wang, X. (2021). Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors, 21(24), 8281. https://doi.org/10.3390/s21248281