1. Introduction
Technologies such as network function virtualization (NFV) [
1] and multi-access edge computing (MEC) play a key role in the realization of 5G and beyond networks. NFV decouples the network functions’ (NFs) logic from proprietary hardware and runs them as software applications on general-purpose hardware [
2]. This technology is expected to not only reduce capital expenditure (CAPEX) and operational expenditure (OPEX), but also improve business agility by introducing new ways to design, orchestrate, deploy, and manage network services (NSs). Additionally, MEC [
3] brings computing, storage, and networking resources closer to the users.
The placement of applications and NFs, such as user plane functions (UPFs), at the network edge, provides significant improvements in the end-to-end (E2E) response time and bandwidth consumption, thus reducing the occurrence of bottlenecks in the network backhaul [
4]. However, the application of optimized placement strategies along with the use of acceleration solutions is required to meet stringent 5G requirements for ultra-high bandwidth and ultra-low latency (e.g., high throughput with 1–10 Gbps and less than 1 ms response time in the data plane). A common approach to boost UPF performance is to integrate the UPF software networking elements with hardware-assisted network interface controllers (NICs), such as field-programmable gate arrays (FPGAs) [
5]. An example of this is the solution design presented in [
5], where UPF performance achieved more than 200 Gbps throughput with an average latency of 70 microseconds. This approach nevertheless restricts the number of available candidates for the deployment of UPFs due to their dependency on hardware capabilities (e.g., availability of FPGA-NICs). To overcome this limitation, edge applications and NFs can make use of hardware capabilities or virtualized accelerators available in remote locations (e.g., the cloud). However, the latter may produce network overheads, which may affect bandwidth-bounded applications [
6]. In this context, the combination of UPFs and virtualized traffic accelerator capabilities at the edge [
7] could help to reduce bandwidth congestion, packet loss and latency.
Despite this potential solution, the deployment of virtual network functions (VNFs) at the edge poses several challenges due to the fact that they are more sensitive to traffic variations and the limited resources of the MEC nodes [
8]. When the allocated resources are insufficient to meet the requested demands, the user’s perceived quality of service (QoS) degrades [
9]. In contrast, if the assigned resources are over-provisioned, the service-associated costs increase. To make efficient use of MEC resources while providing the high QoS that characterizes 5G networks and lowering the service provisioning cost, the dynamic placement readjustment of VNFs along with the scaling of their assigned resources (e.g., number of instances or capacity) based on their workloads or user’s traffic demands is imperative.
The virtualization of some traditional NFs such as traffic accelerators or firewalls, which can be deployed in a bump-in-the-wire (BITW) manner to avoid altering the communication endpoints, would bring about extra difficulties. No modification in the packet headers is allowed when redirecting traffic to guarantee the standard functionality of a service (e.g., avoid service interruption) due to their transparent deployment. Scaling out BITW VNFs may cause occasional loops in the network and subsequent problems (e.g., slow and irregular connections and system failures). Additionally, bidirectional flow affinity during the flows’ lifetime may also be required.
Most of the literature addressing the problem of load balancing (LB) and auto-scaling of VNF clusters [
10,
11] neglects the aforementioned use case scenario and its particularities. To the best of our knowledge, we are the first to tackle the problem of dynamic auto-scaling and load balancing of transparent VNFs while ensuring bidirectional flow affinity. In this regard, the key contributions of this paper can be summarized as follows:
The design, implementation, and evaluation of a solution to make load balancing and auto-scaling decisions to manage a cluster of transparent VNFs.
The proposed solution can not only distribute traffic according to the selected LB strategy but also guarantee bidirectional flow affinity without packet modification.
An auto-scaling strategy is presented to manage the size of a transparent VNF cluster.
The testbed of the proposed strategy in this research utilized real hardware unlike most works on this topic, which use simulation tools (e.g., Mininet) to assess the performances of their proposed strategies.
The remainder of this paper is organized as follows.
Section 2 introduces some works related to the load balancing and auto-scaling of VNFs.
Section 3 gives some background on technologies, such as Open Source MANO and software-defined networking (SDN). In
Section 4, a solution is proposed for traffic distribution and the auto-scaling of a cluster of transparent VNFs is presented, and
Section 5 validates its effectiveness. Finally,
Section 6 concludes our work and presents future work directions.
3. Background
This section presents some background on NFV management and orchestrators, SDN, and OpenFlow switches. These elements are fundamental pillars for our solution implementation.
3.1. Open Source MANO
NFV is considered a key enabler technology for addressing the stringent requirements of 5G and beyond networks [
24,
25,
26]. Its agility and flexibility to manage network resources and services support carriers in deploying a variety of verticals with different requirements while reducing costs. In this vein, the ETSI NFV Management and Orchestration (MANO) framework [
27] provides a standard architecture, used as a reference by vendors and open source MANO projects for the monitoring and provisioning of VNFs [
28]. The group of open source MANO includes several projects such as Open Network Automation Platform (ONAP) [
29], Open Source MANO (OSM) [
30], Open Baton [
31], and Cloudify [
32]. Of these projects, ONAP and OSM are the most prominent ones in both academic and industry sectors since big operators such as AT&T and Telefonica support their development [
33].
This paper adopts OSM as the NFV orchestrator (NFVO) and virtual network function manager (VNFM). It is responsible for the deployment of NSs and VNFs and monitoring the life-cycle management of VNFs. The selection of OSM was based on its maturity, performance, and comprehensive utilization [
33]. Another criterion for this selection was its modular architecture formed by several elements, including Resource Orchestrator (RO), Lifecycle Management (LCM), Policy Manager (POL), and Monitoring (MON). Thus, our implementation could obtain information related to NSs and their associated metrics by directly communicating with the modules in charge of managing this information (i.e., RO and MON modules).
3.2. Software-Defined Networking
Along with the NFV paradigm, SDN is recognized as a crucial pillar in the development of 5G and beyond networks to fulfill their network requirements [
24,
25,
26]. The SDN architecture is composed of three layers: application, control, and data [
34]. The control plane is formed by the controller, which manages all the devices (e.g., routers and switches) in the data plane in a unified manner. Additionally, network applications, used by the controller, are implemented and executed in the application layer. One of SDN’s main features is the control and user plane separation (CUPS). The CUPS guarantees that the resources of each plane can be scaled independently. It also allows the placement of the user plane functions closer to users, thereby reducing network response times and bandwidth consumption. Moreover, the separation of these two planes allows the direct programmability of network policies, thus ensuring simplicity and versatility in networking configurations [
34]. Additionally, SDN offers new methods to flexibly instantiate NFs and services while reducing expenses and boosting performance. For instance, it allows the support for new protocols and the ability to adapt network resources and topology to changes in the configuration and placement of NFs and services [
35,
36].
The SDN concept is applied in a wide variety of solutions in which the controller is a key element in the control operations. In this regard, the architectural deployment of the controllers is crucial to guarantee that the performance of the overall network is adequate. Specifically, from an architectural point of view, SDN controllers can be classified into two groups: centralized and distributed. The centralized architecture is formed by a unique controller for the sake of simplicity. However, this design represents a bottleneck in the network and has scalability limitations when the network traffic increases. By contrast, a distributed architecture improves network scalability, flexibility, and reliability. For instance, this architecture avoids having a single point of failure since when one of its distributed controllers fails, another(s) can assume its functions and devices. Therefore, this design is more resilient to different kinds of disruptions. Furthermore, with the programmability of SDN, this process can be automated and configured according to the design and requirements of the network. Thus, the distributed architecture is capable of responding and adapting to new requirements and conditions.
3.3. OpenFlow Switches
An OFS consists of one or more flow tables and a group table, which perform packet lookup and forwarding, and one or more OpenFlow channels to communicate with an external controller. The switch communicates with the controller, and the controller manages the switch via the OpenFlow protocol [
37]. The controller can add, update, and delete flow entries from the switch flow tables through the OF protocol. A flow entry is formed by several fields such as match, counters, actions, and priority. Specifically, the match field allows the creation of flow entries according to various match criteria. For instance, it may be configured to match various packet header fields (e.g., source/destination IP/MAC/ports, protocol, VLAN ID), packet ingress port, or metadata value.
When a flow arrives at an OFS it verifies, in its flow tables, if there is already a defined rule that matches the incoming flow. If such a rule exists, then the specified actions are executed. A wide variety of instructions can be applied to flow entries, such as packet forwarding (e.g., forward packet to a port) and packet modification. In the case of several rules matching the flow description, the rule with the highest priority order is applied. In contrast, if no match is found in any flow tables, the switch can be configured to send the packet to its assigned controller or drop it.
3.4. Flow Affinity
Utilizing flow affinity implies that packets belonging to the same flow will undergo similar treatments along their paths (e.g., processed by the same set of network functions) [
38,
39]. In this study, we define bidirectional flow affinity as the property of processing packets associated with a specific flow by the same network function, in both directions of their data path (i.e., uplink and downlink). Traffic flows are identified by five parameters from the packet headers: source IP, destination IP, protocol, source port, and destination port. These parameters form a five-tuple, and by combining them, different hashing methods can be defined. The three most popular combinations are: source-destination IP, source-destination IP + protocol, and source-destination IP + source-destination port + protocol.
4. Solution Proposal
In this section, after a brief overview of the problem of interest, the proposed solution for the management (i.e., balancing and horizontal auto-scaling) of a cluster of transparent VNFs is presented.
4.1. Problem Description
Network operators are virtualizing their physical network functions to align with new services requirements imposed by 5G networks and beyond. These NFs can be grouped into different categories according to their characteristics (i.e., by network functionalities and connectivity, network security, and network performance). Many of the NFs associated with network performance (e.g., traffic shaping, rate limiting, and traffic accelerators) are usually transparently placed between the access and internet network providers. In other words, they do not have a forwarding IP since they are placed as BITW functions and, thus, work in layer 2 of the OSI model. The virtualization of NFs offers flexibility for the management of network resources since NFs can be scaled as their processed traffic changes. Existing MANO frameworks (e.g., OSM) offer some scaling policies to automatically adjust VNF capacity to traffic demands. However, the scale-out policy of MANO frameworks is characterized by the placement of new deployed functions in the same subnetwork as the original ones. Moreover, they do not allow for the modification of previously launched NSs, for instance, the adding of new VNF instances or subnetworks. These limitations cause severe problems in the network when scaling transparent functions since network loops may appear.
Load balancers are crucial to avoid overload and guarantee efficient traffic distribution to the pool members when more than one instance of a given type is deployed and forms a cluster. Additionally, load balancers enhance the availability and reliability of the network service by redirecting incoming requests to only healthy VNFs. Well-known MANO frameworks, such as OSM and ONAP, lack native load-balancing services. Thereby, they rely on specific virtual functions (e.g., HAProxy [
40]) that need to be deployed along with the pool members to provide this feature. However, this solution requires the assignment of a virtual IP to the load balancer to redirect all the incoming traffic to it. The latter is recommended when the pool entities are a final service or the destination of the incoming traffic. Otherwise, an extra function may need to be inserted in the flow path to modify the header packets to reach their final destination. A similar shortcoming has been found in virtual infrastructure management (VIM) technologies, such as OpenStack. Though these technologies provide load-balancing services (i.e., Octavia which is based on a neutron load-balancing mechanism (load balance as a service, LBaaS)), they are also aimed at final services.
Moreover, some VNF types, such as firewalls and intrusion detection systems, require that the same instance process all the fragments of a given flow during the flow lifetime. Other VNF types (e.g., TCP traffic accelerators) may need to ensure bidirectional flow affinity to work properly.
Under these circumstances, designing a mechanism for the efficient management of transparent VNF clusters is critical. The envisioned solution must be able to dynamically scale cluster resources, balance the flow traffic between transparent VNFs, ensure bidirectional flow affinity, and avoid packet modifications and extra processing.
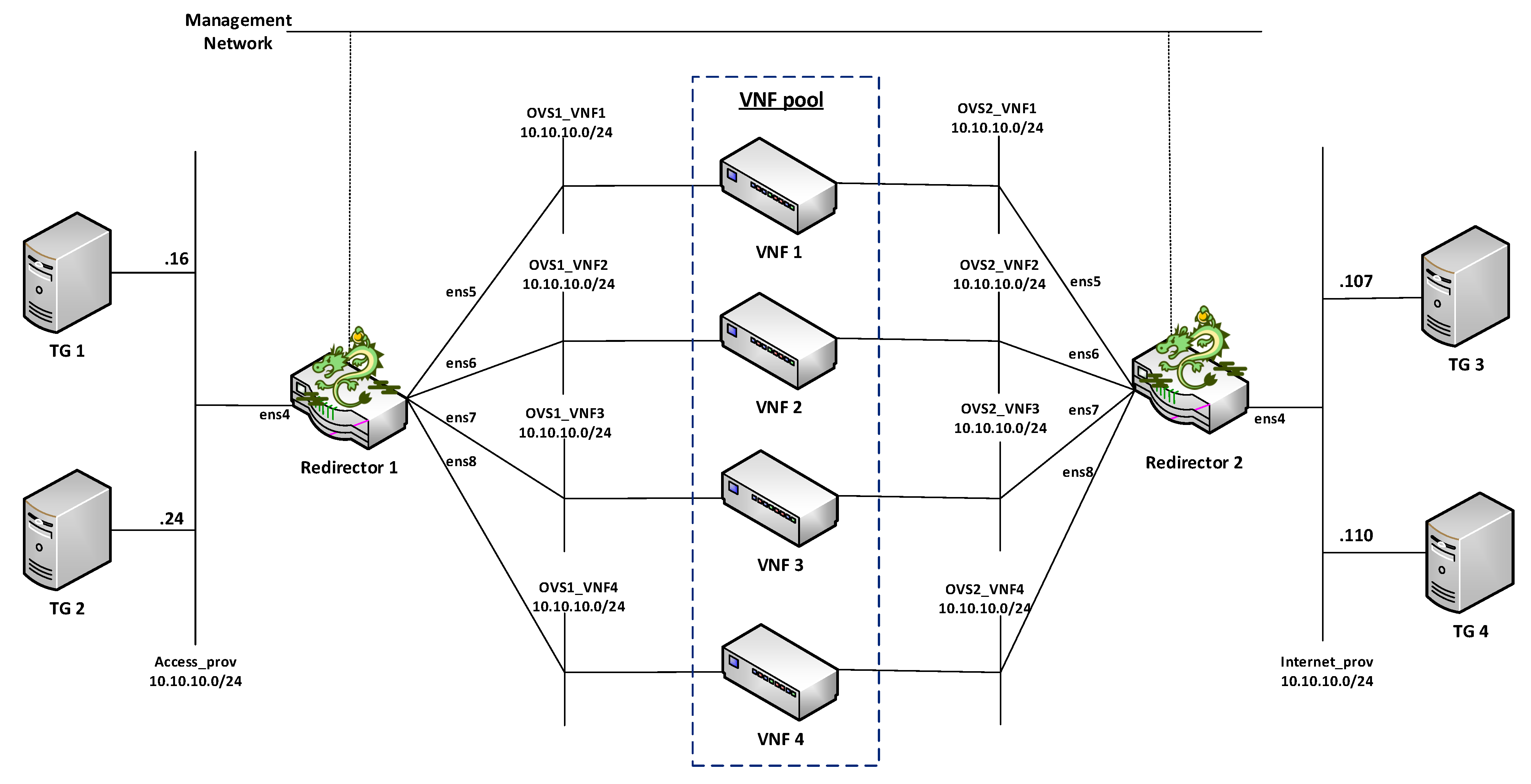
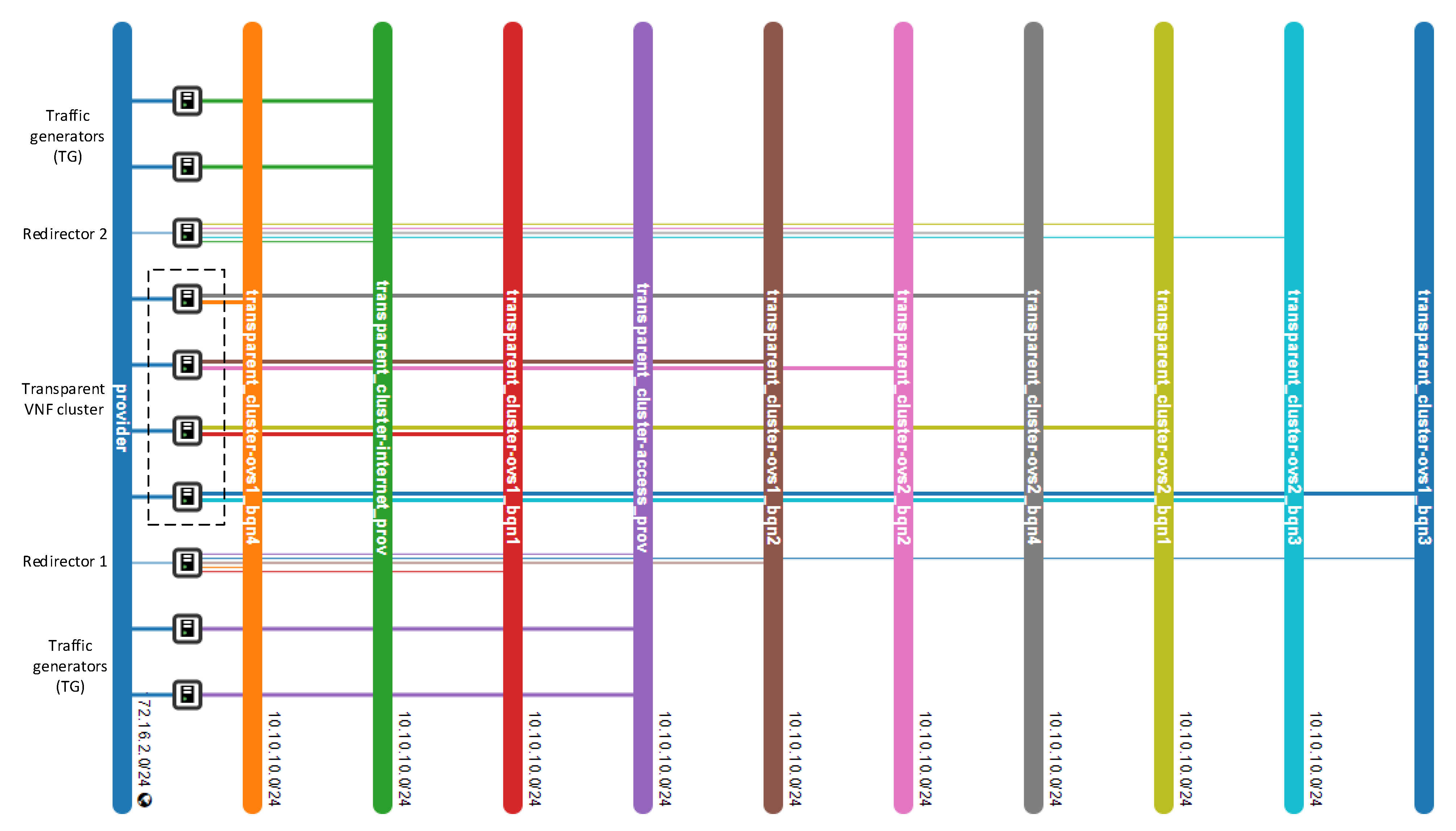
4.2. Design Architecture and Implementation
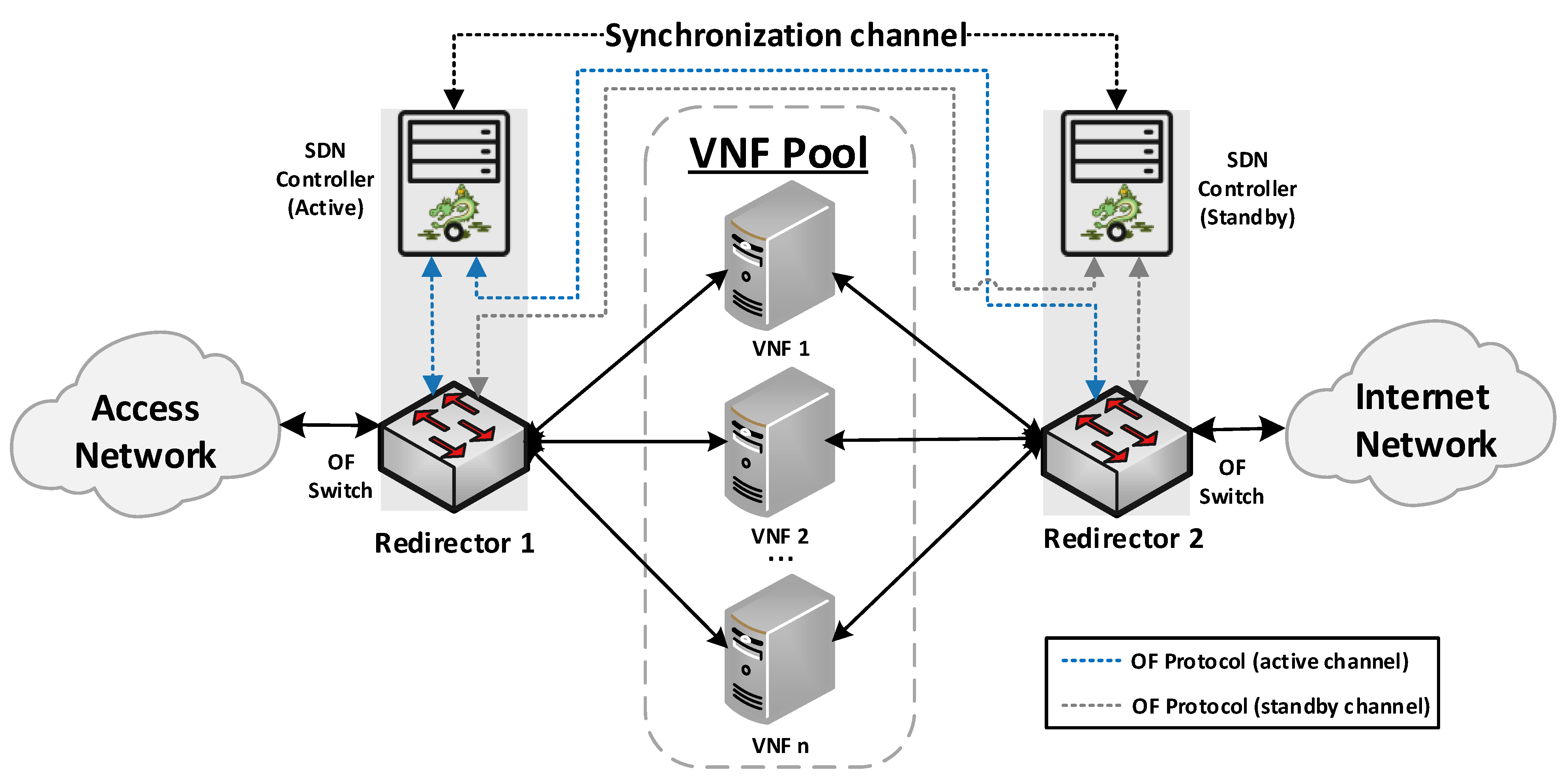
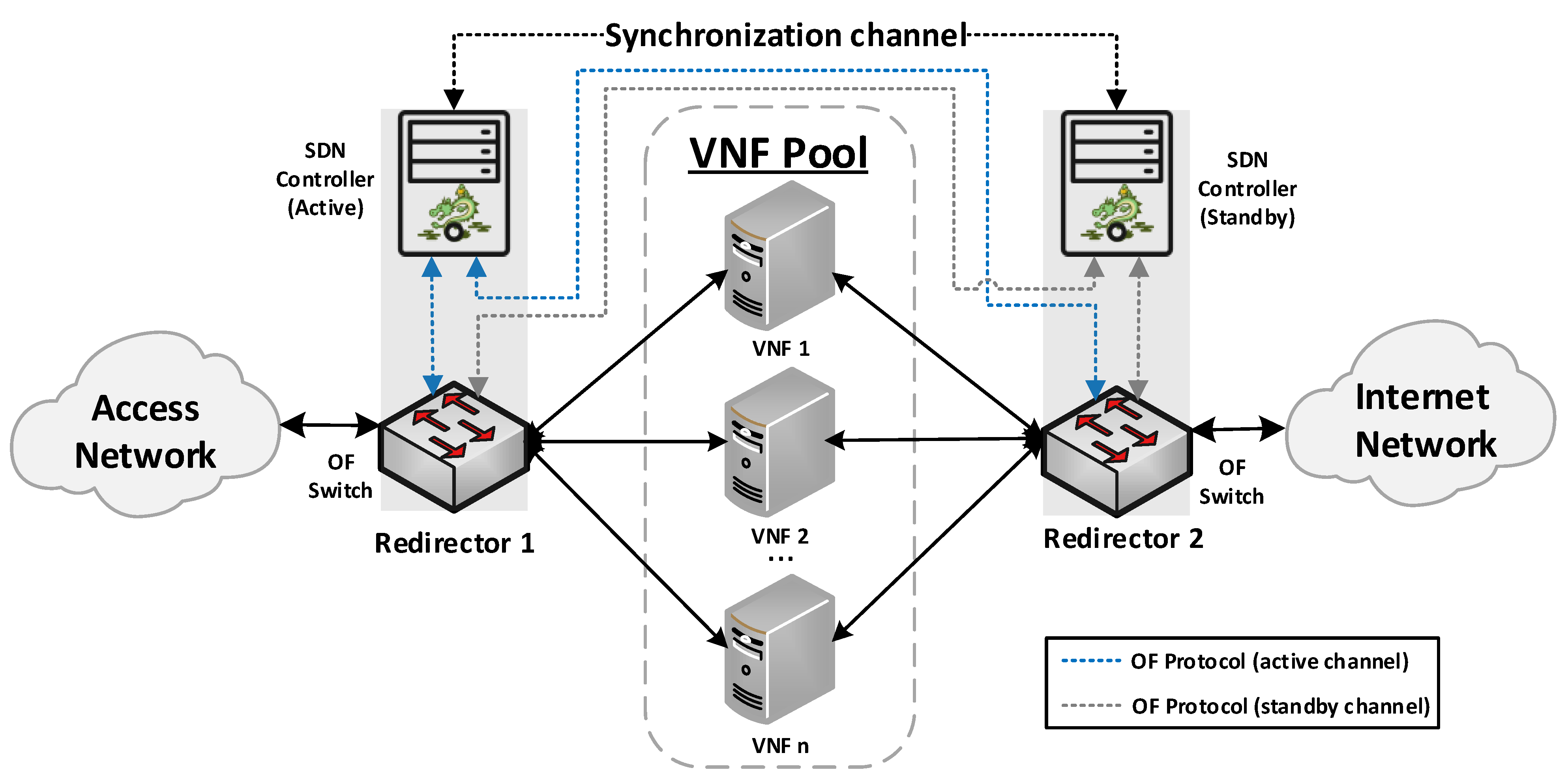
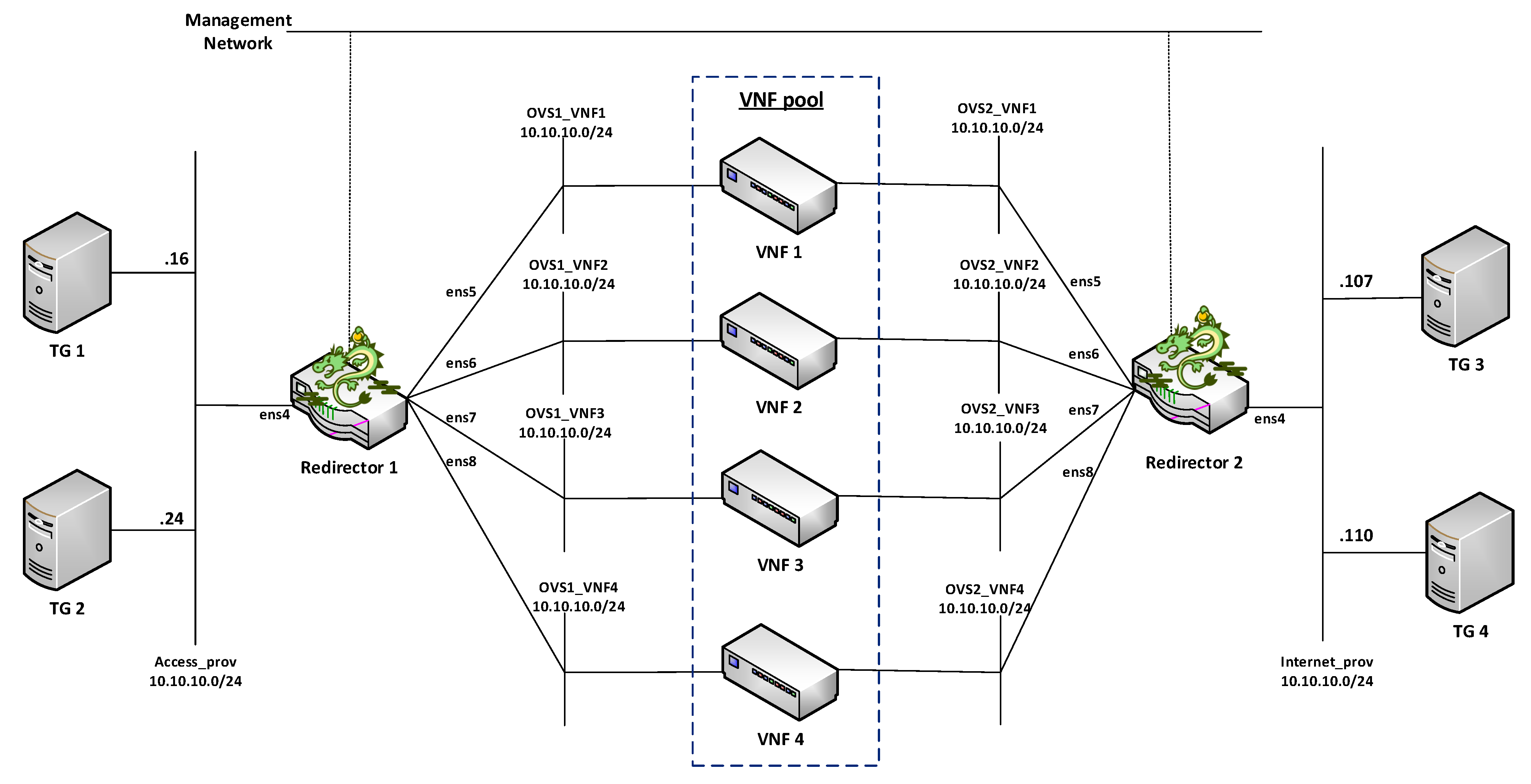
Our proposed solution for the management of transparent clusters is formed by two redirector VNFs, one at each side of the cluster. The reason for placing redirector functions on both sides of the cluster (uplink and downlink directions) is to ensure the bidirectional flow affinity requirement (see
Section 4.2.3). Each VNF redirector consists of an OFS and an SDN controller mainly responsible for load-balancing aspects. The SDN controllers work in an active-standby configuration. The active controller replicates the network information to the standby one by using the data distribution service (DDS) method described in [
41]. Since the DDS method is based on the publish/subscribe paradigm, the active controller will publish the discovered nodes and configured flows through a data stream also known as a topic. Specifically, the used topic is composed of seven fields: Identifier, NodeId, Port, SourceNode, SourceNodePort, DestinationNode, and DestinationNodePort. Using the identifier field, the active controller announces whether it will send a node or a flow. In the case of the standby controller, it will be subscribed to the used topic, thus receiving the network information. This approach avoids the network discovery phase of the standby controller in the case of a failure in the active controller, thus reducing the service downtime and improving the fault tolerance of the system. The master controller is placed facing the access network to reduce response time, since most traffic requests originate in the uplink direction. The use of two SDN controllers is not strictly necessary, but it is highly recommended to improve the robustness of the solution.
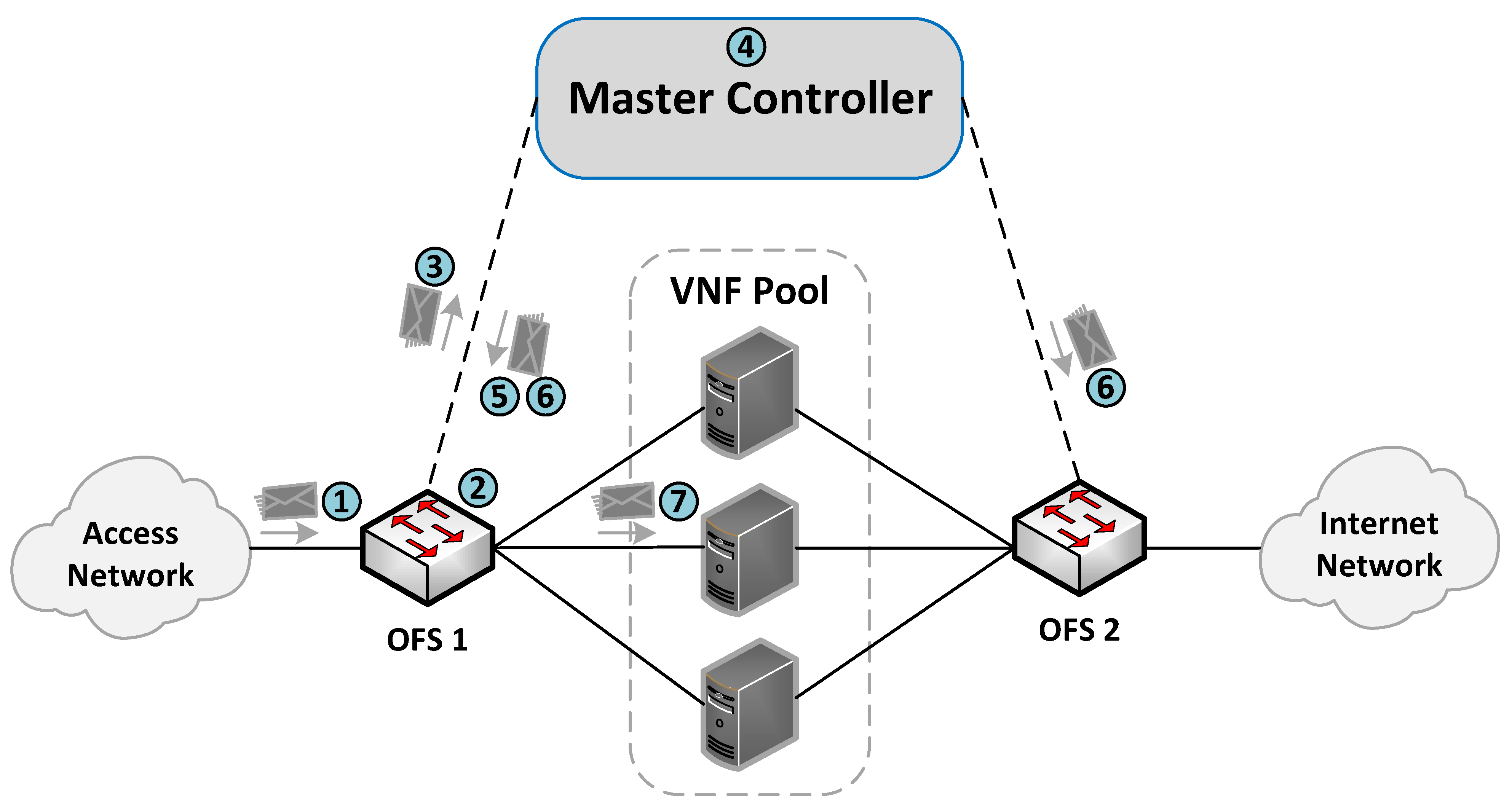
Figure 1 provides a general overview of the proposed design as well as the interconnection mode among the solution elements.
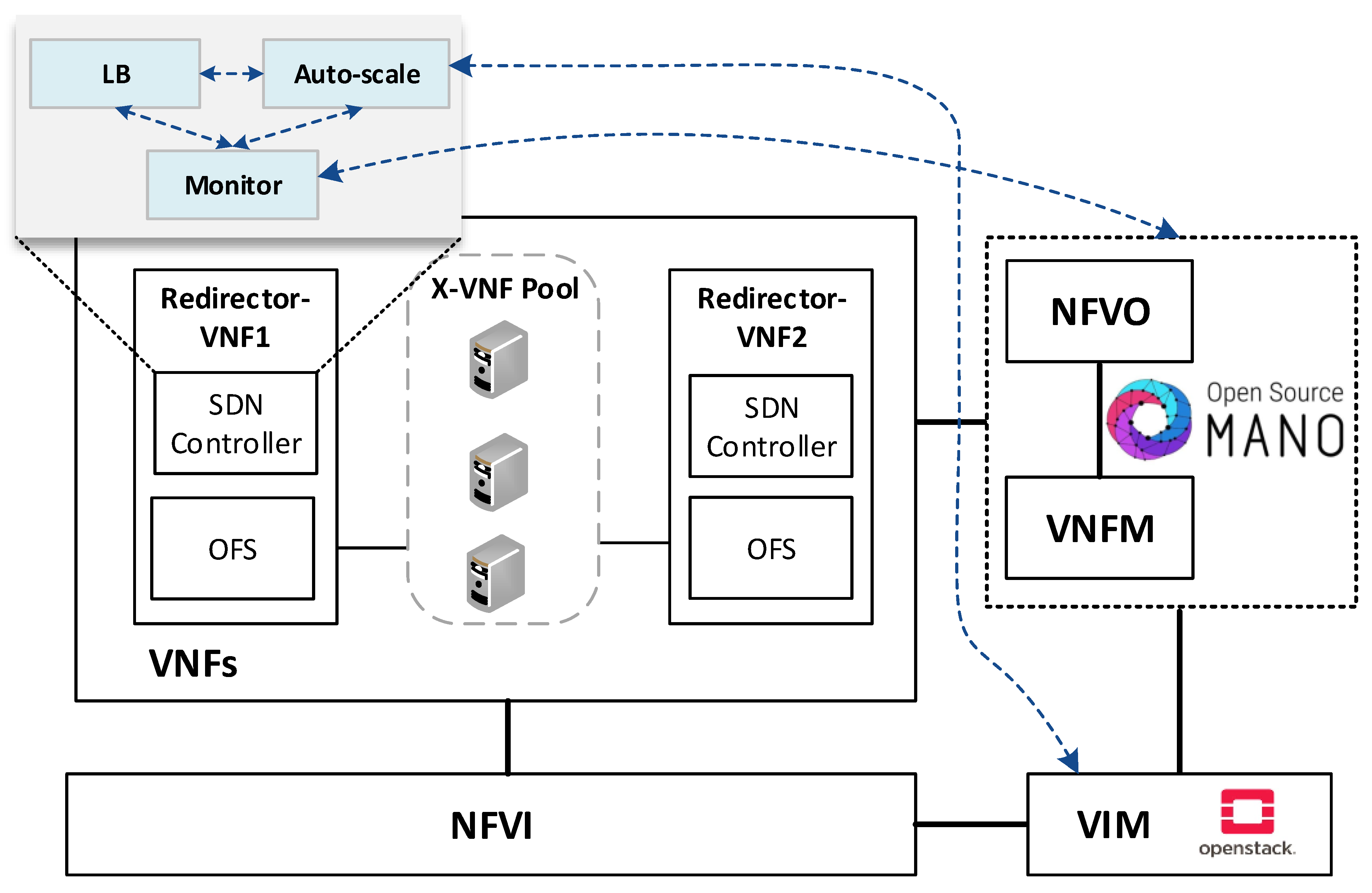
The envisioned VNF redirector application has a modular design, where each module performs a specific function (i.e., monitoring, auto-scaling, and load balancing). The logic of these functions runs on top of the SDN controllers, as shown in
Figure 2. The monitoring module is in charge of checking the status of VNF instances as well as periodically collecting metrics. This information is used as input by the load balancing and auto-scaling blocks to perform their logic. The auto-scaling module is in charge of managing the cluster size. Specifically, it triggers scale-in and scale-out actions based on the status and load of the pool members. Furthermore, the load-balancing module is the core of the redirector application. It is responsible for selecting the VNF instance to which a traffic request will be assigned for its processing. The selection of a VNF instance depends on the specified load-balancing strategy (e.g., least loaded CPU) and the status and capacity of the cluster’s members. Each instance belonging to the VNF cluster is associated with a unique port in the OF switches. To simplify the solution complexity, a mirror configuration, in which the same port in both switches is selected, is recommended.
To improve the VNF redirector performance and allow faster packet processing in the load-balancing module, our design exploits the parallel processing capacity of multi-cores along with a multi-threaded technique, thus avoiding delay in its procedure due to the performance of other modules. The following subsections provide more insights into the operation mode of the VNF redirector’s modules.
4.2.1. Monitoring Module
Transparent VNFs are not compatible with well-known health monitor methods, such as PING, TLS-HELLO, UDP-CONNECT, and TCP-CONNECT, since they all require that their queries be directed to an IP address. A workaround could be the use of the management network to send the messages associated with one of these health methods. However, this implies additional load in the VNF cluster. To resolve this shortcoming, our solution uses information already available to other components (i.e., VNFM). The VNFM monitors the health status and performance (e.g., CPU and memory utilization) of VNF instances and network services to manage their life cycles. In the OSM MANO, its monitoring module has a feature (mon-collector) to collect the specified metrics in the VNF descriptors. The mon-collector polls the VIM, where the VNFs are deployed, to gather the desired metrics and stores them in its Prometheus time-series database (TSDB). To make this information available to the redirector application, our solution implements the monitoring module. This module communicates with the Prometheus TSDB and gathers VNF status and metrics. In this manner, the LB can be aware of the healthy and unhealthy instances and their available resources. This approach solves the limitation mentioned above and avoids overloading the cluster with frequent health polling through the management network.
This monitor module also gathers information about the deployed NS configuration, for instance, the ID of the virtual deployment units (VDUs) that constitute the transparent cluster and their subnetworks. These data are used to match the VDUs with the OVS switch interfaces to which they are connected. These interfaces are discovered upon the OFS registration on the SDN controllers. In this way, the monitor module helps the redirector application to discover the network topology.
Additionally, when the monitoring module detects an unhealthy instance, it communicates the LB to trigger a flow rule updating process. Then, the LB module uses a method to delete the OF rules associated with the unhealthy instance in the switches table. This is achieved by sending a delete flow message to the OF switches, which instructs them to delete the flow rules that contain the specified port (i.e, the one connected with the unhealthy instance). With this action, the monitoring module avoids network disruption because another healthy transparent VNF can be selected by the LB to process the incoming traffic.
4.2.2. Auto-Scaling Module
The automatic scaling of transparent VNFs imposes several challenges to loop avoidance. For instance, when more than one transparent VNF is deployed in the same subnet, loops appear given that they act as a "wire" in the network. Thus, transparent VNFs should be deployed on different subnets to avoid network loops and redirect flows to a specific transparent instance since they do not dispose of routing information. However, the current MANO frameworks do not allow us to specify different subnets when executing auto-scaling policies or to add new VNF instances and subnetworks to already instantiated NSs. Therefore, we diverge from the assumption that the VNF cluster has been already dimensioned to resolve these challenges. In other words, the cluster is launched with all its members, and each VNF instance connects with one interface in the OFS. It should be noted that the OFS interfaces also need to be dimensioned according to the pool size. However, to save energy and computing resources, only the minimum required number of instances remains active, and the rest are on standby. Thus, the main aim of the scaling module is not to create or remove instances, but to manage their status (i.e., activate or deactivate them). To this end, the auto-scaling module needs to interact with the VIM. The OpenStack VIM, for instance, through its Nova service [
42], offers several options to manage VNFs such as stop or start, suspend or resume, shelve or unshelve, pause or unpause and resize. It should be further noted that each of these options has a different impact on the resource utilization of the system as well as the VNF activation time.
For the implementation of the auto-scaling logic, the following parameters need to be defined.
Scaling metric: the metric to be monitored (e.g., CPU or memory) and upon which scaling actions will be taken;
Aggregation type: refers to how the scaling metric is gathered (e.g., average or maximum values);
|VNF|_max: maximum number of active instances in the cluster;
|VNF|_min: minimum number of active instances in the cluster;
Thresholds: upper and lower bounds of the selected metric upon which scale-out or scale-in actions are triggered, respectively;
Threshold time: a minimum amount of time in seconds during which the state of the scaling metric with regard to the threshold values must sustain to trigger a scaling event. Different threshold times can be defined for scale-in and scale-out actions;
Cooldown time: the minimum amount of time that the system must wait after triggering an event before activating another.
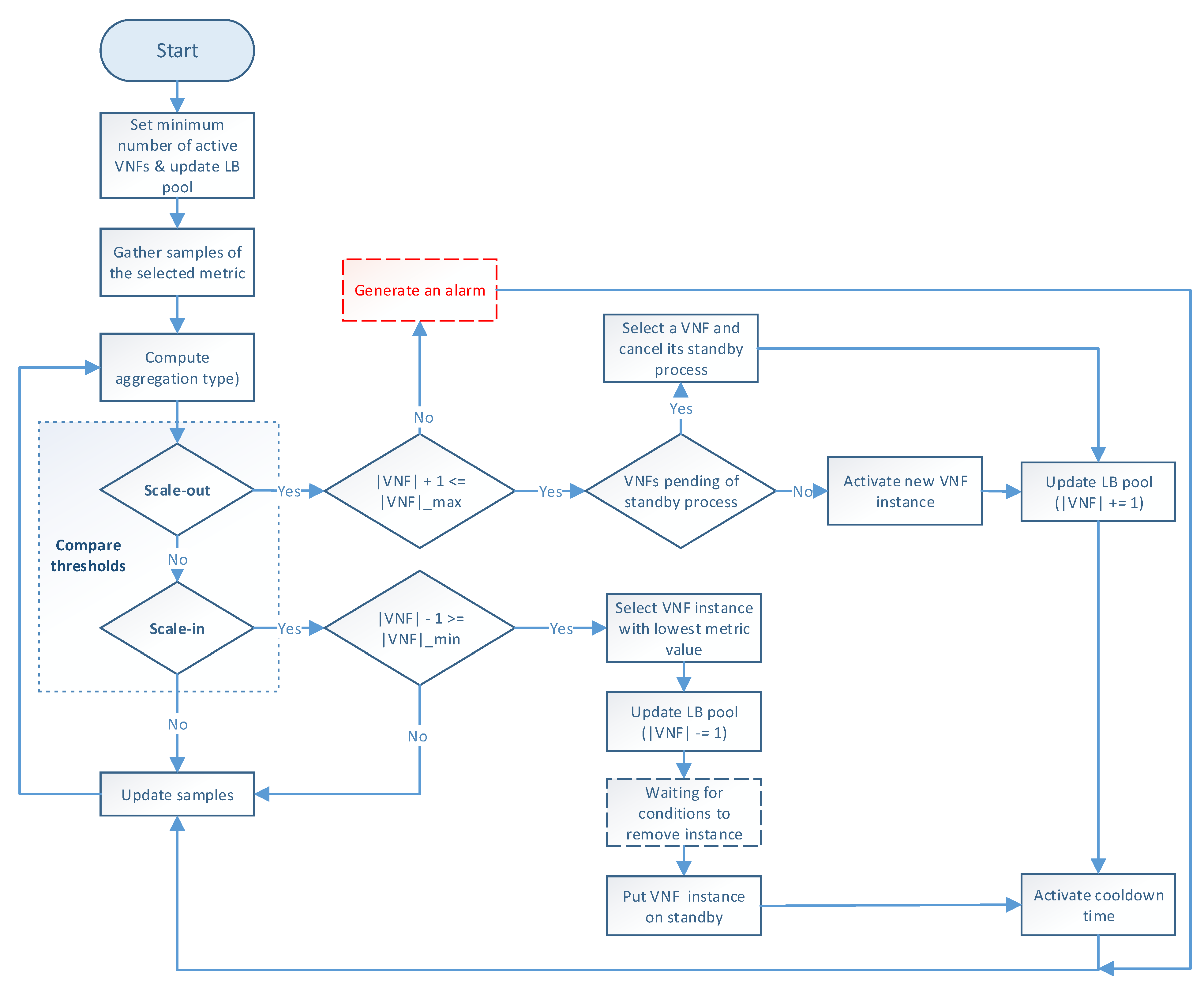
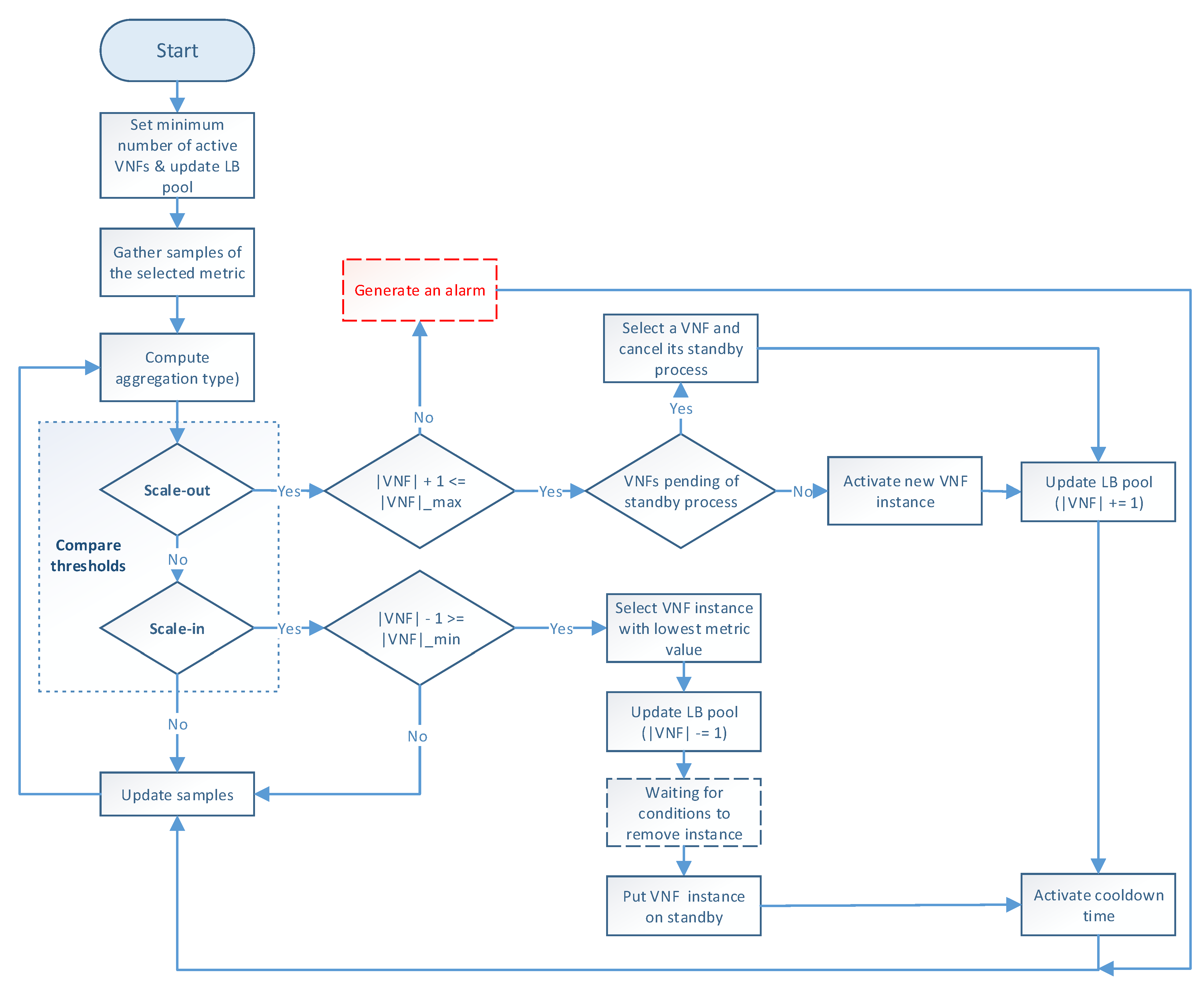
The auto-scaling logic runs during the system lifetime and updates the scaling metric values at each time instance.
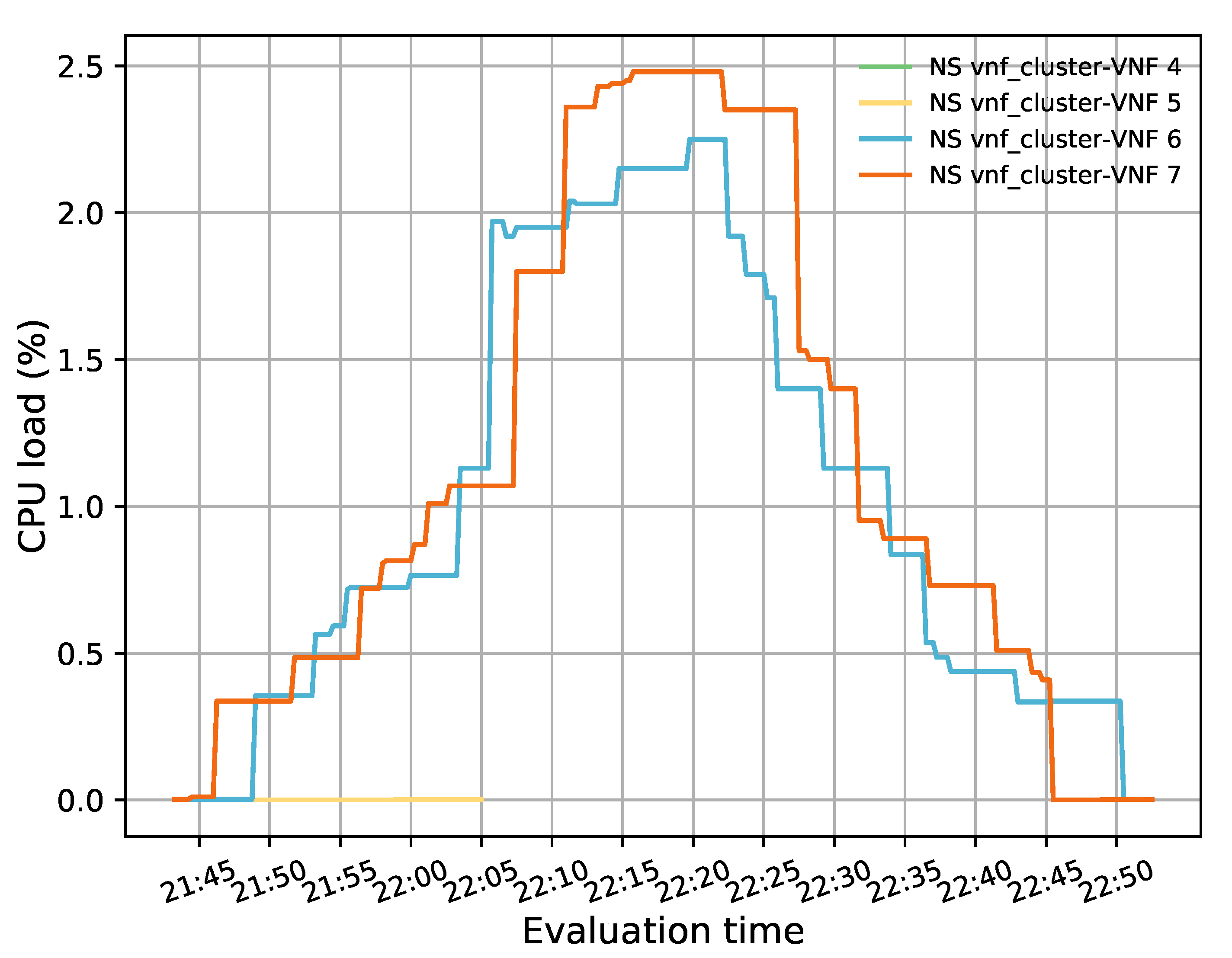
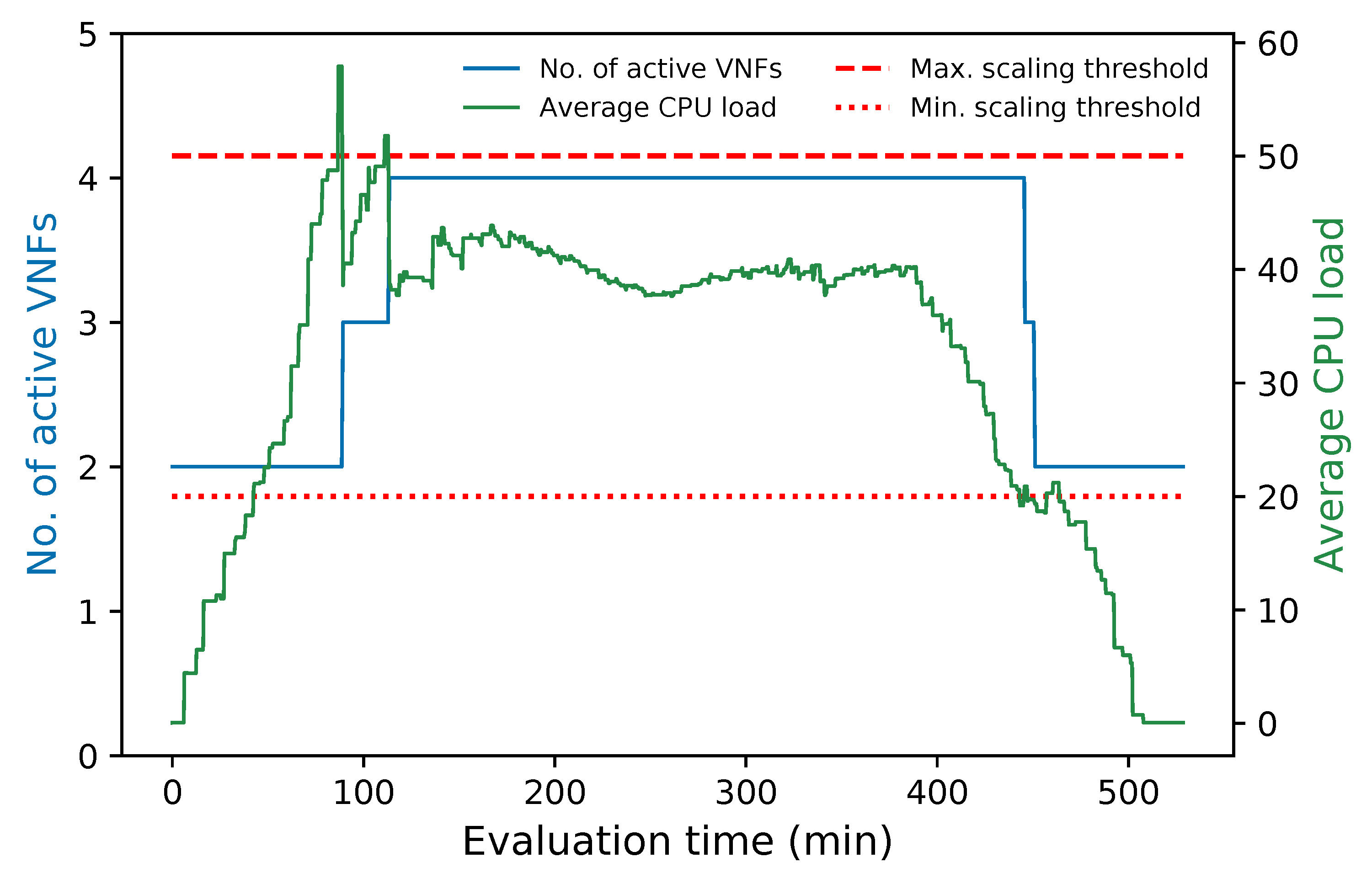
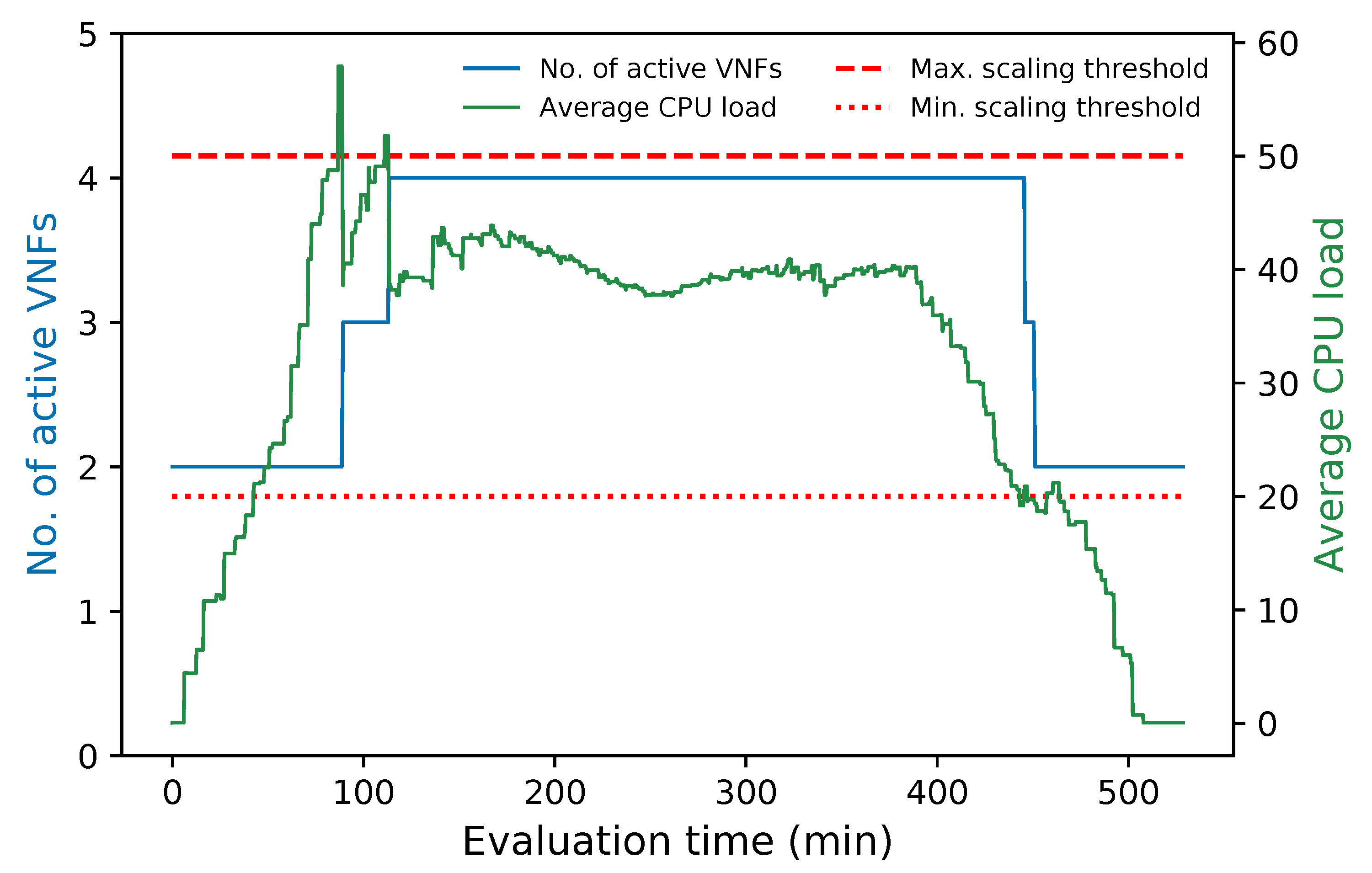
Figure 3 illustrates the programming logic of the auto-scaling block. It starts by setting the minimum number of active members and exposing this updated information to the LB block. Next, it proceeds to collect samples of the specified metric until completing a threshold time, for which communication with the monitor block is required, and computing its aggregation type with regard to the set of active members in the VNF pool. Afterward, the auto-scaling conditions are verified by comparing the obtained value with the maximum and minimum thresholds. If one of these conditions is met, the effect of its respective scaling action on the number of active instances is verified before proceeding with the activation or deactivation of a VNF instance. The latter helps to maintain the number of active instances between the established values. If the scaling action implies the violation of any of these thresholds, the scaling procedure is discarded, and the system continues gathering samples. Additionally, when the scaling procedure is omitted because the maximum number of active instances has been reached, an alarm can be activated to notify the system administrator that further actions need to be taken. Otherwise, new instances can be started, or existent ones deactivated depending on the triggered condition. According to the VNF service type, a waiting time may be required before putting an active instance on standby to prevent service degradation. In the case of scale-out actions, existing VNFs waiting to change their status to standby are selected instead of activating new ones, thus canceling their associated standby process. After each scaling decision, the set of available VNF instances is reported to the LB. It must be noted that this set is immediately updated for scale-in actions to avoid the assignment of new flows to a VNF instance in a standby process. Finally, a cooldown timer is activated to prevent unnecessary scaling actions caused by possible system instability, and the set of gathered samples is updated.
4.2.3. Load Balancing Module
There are two ways for maintaining flow affinity when load balancing traffic. One approach uses a dedicated load-balancing algorithm based on an IP hashing method. The other uses a stick table in memory along with a non-deterministic LB algorithm (e.g., round-robin or least connections). The use of the load-balancing algorithm approach is suitable as long as the number of involved instances does not change. Otherwise, more complex techniques, such as consistent hashing, need to be implemented to diminish the effects of variations in the number of instances on the flow affinity mapping. This method is recommended for load-balancing applications that do not require synchronization among LBs but still use the same hashing function. The second approach requires a global view of the system or synchronization among the LBs to ensure bidirectional affinity. The advantage of this approach is that no session is redirected when a new instance is added to the cluster. Our solution is based on the second technique since flow affinity is guaranteed upon flow entries registered in the OFS tables. Moreover, our solution does not require any exchange of information between the LBs (i.e., switch tables). The reason is that the flow entries associated with a given flow are simultaneously created in both switches by their master controller, which has a global view of the cluster. A drawback of working with flow tables is that flow waiting time may increase with significant traffic. Nevertheless, this effect can be diminished by implementing an efficient mechanism to manage switch tables [
43,
44].
Additionally, old flow entries belonging to expired flows can be removed to avoid overloaded flow tables. Using the idle_timeout field in OF FLOW_MOD messages is highly recommended in this process. This parameter allows you to specify a time interval that the switch can use to remove idle flow entries when no packet has matched within the given number of seconds. For this process to be completed successfully, the OFS must keep track of the arrival time of the last packet associated with the flow.
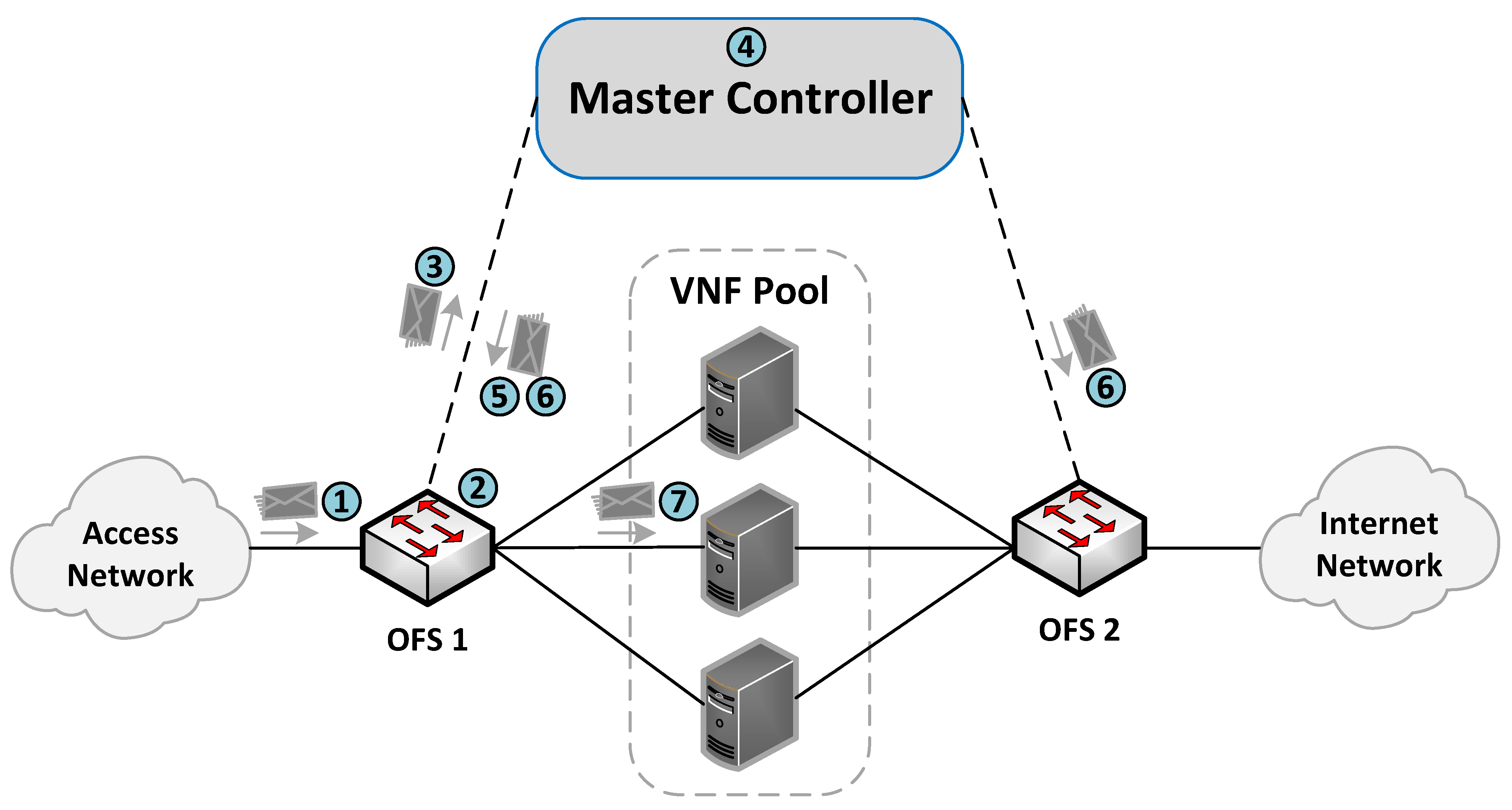
The communication process between the OFSs and the master controller for the flow rules creation is described in
Figure 4. More specifically, when an incoming flow arrives at an OFS (step 1), the switch searches in its flow tables the existence of a rule matching the flow (step 2). If there is a match, the switch applies the actions associated with the flow (step 7). Otherwise, the switch sends the packet to its assigned master controller through an OF PACKET_IN message (step 3). The controller is responsible for extracting the header packet information and determining the actions that need to be applied to the flow (step 4).
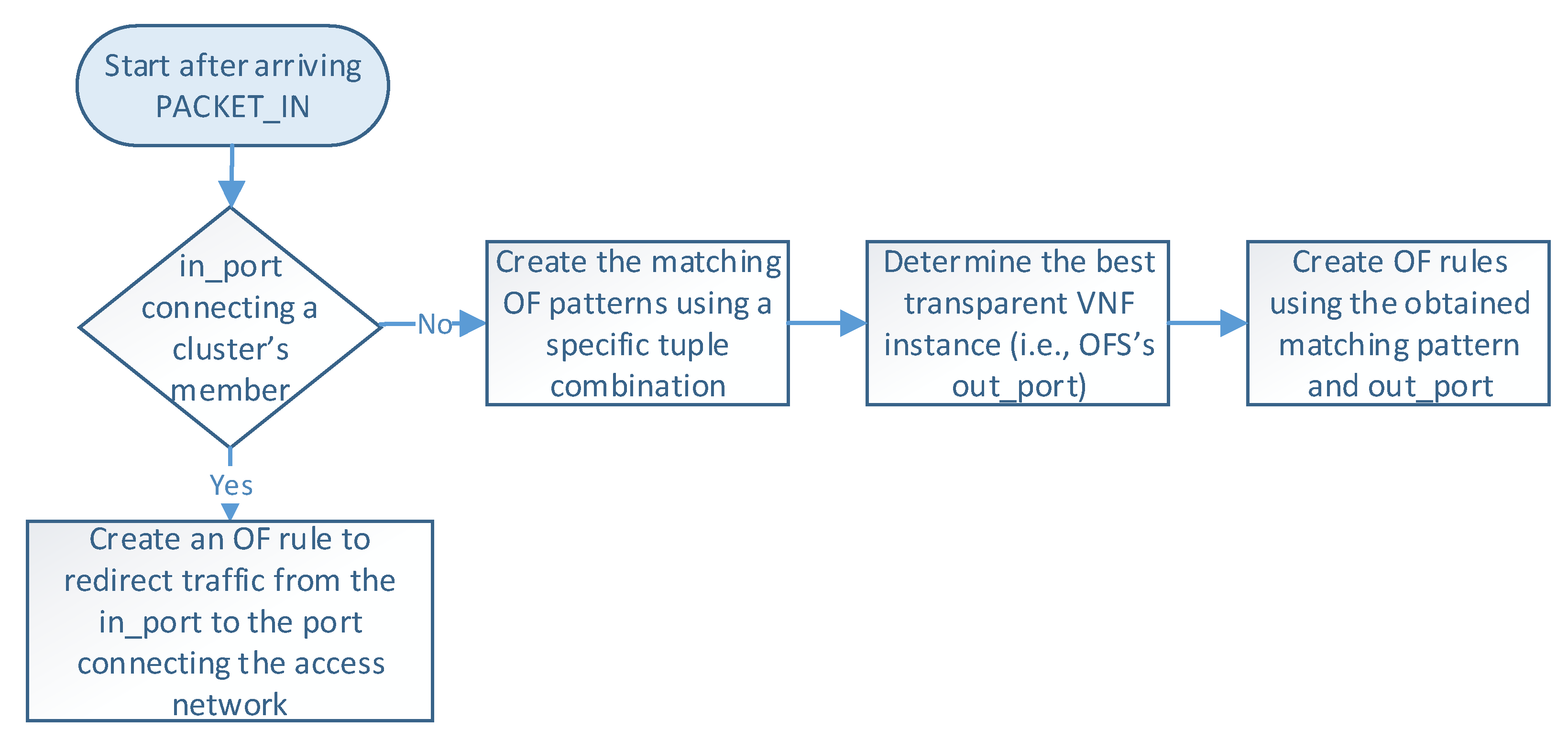
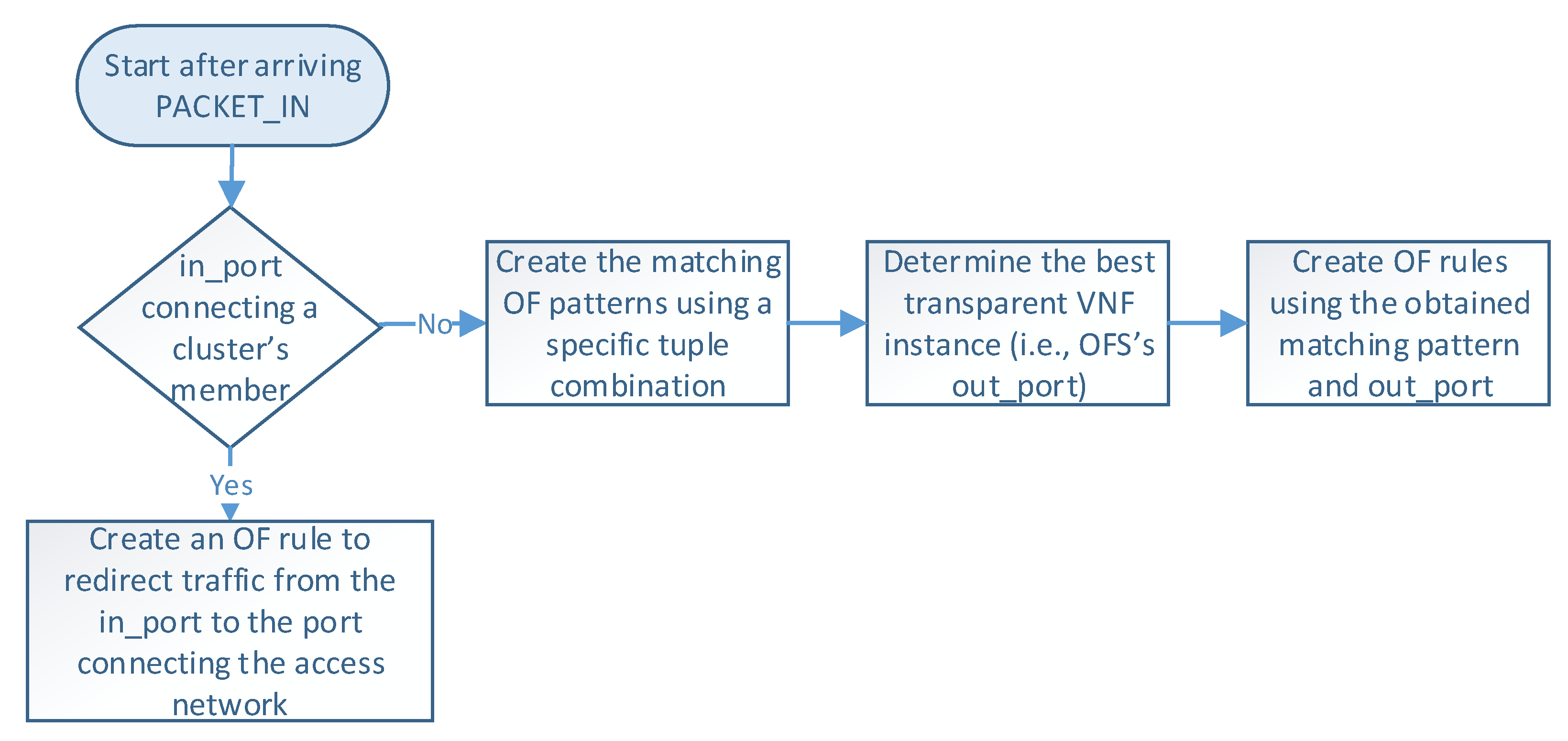
Figure 5 describes the logic executed in the SDN controller when it receives a PACKET_IN message (i.e., step 4 in
Figure 4). The controller begins by reading the packet information (e.g., headers and OFS’s in_port), which determines how the flow is processed. At this step, there are two possible options according to the packet’s in_port in the OFS. More specifically, when OFS’s in_port connects with a cluster member, an OF rule is configured to redirect the flow traffic from the cluster member port to the one connecting the access provider network. This rule is created only once during the operation phase unless specified in the idle_timeout field. On the other hand, if the in_port is the one connecting the access provider network, the controller configures actions based on the packet’s header information. In the last case, the load-balancing module creates an OF matching pattern using a specific tuple combination (e.g., source IP, destination IP, protocol, source port, destination port). Several treatments can be defined according to the different tuple combinations and the values of their parameters. For instance, flows matching a given protocol type or source IP can be configured to be processed by a specific cluster member by default. In contrast, other flows may require the selection of an appropriate VNF instance for their processing. Afterward, this module determines the switch’s out_port by selecting the best VNF instance according to the specified load-balancing strategy. Then, the controller creates an OF rule with the selected matching pattern and the obtained out_port. Please note that each transparent VNF instance connects to a specific switch’s port.
Once the controller has determined the OF rule, it sends an OF PACKET_OUT message and a FLOW_MOD message to the switch that sent the OF PACKET_IN (steps 5 and 6). These steps instruct the switch to send the packet through the selected port and configure the specified rule in its table. Similarly, a reverse OF rule is proactively configured in the opposite switch by swapping the source and destination fields in the matching pattern and specifying the same action (i.e., OFS’s out_port). In this manner, our load-balancing module ensures bidirectional flow affinity by simultaneously creating flow entries in both switches.
Currently, the load-balancing module has available three load-balancing strategies: random, round-robin, and least loaded [
14,
45]. The random approach is the simplest one since the controller only needs to be aware of the active members in the pool. This information is used by the controller to randomly choose a VNF instance to redirect incoming flows. Round-robin is one of the most popular load-balancing algorithms due to its simplicity. It distributes incoming traffic requests by sequentially selecting an active pool member to process the incoming traffic. Thus, each time that a new PACKET_IN arrives at the main controller, a different member is selected. Once all the members have been analyzed, it starts rotating again by selecting the first active VNF in the list. Finally, the least loaded algorithm is based on the load utilization (e.g., CPU or memory) of the active VNF members. These data are obtained from the monitoring block and used to select the active instance with minimum load to process new flows.
6. Conclusions
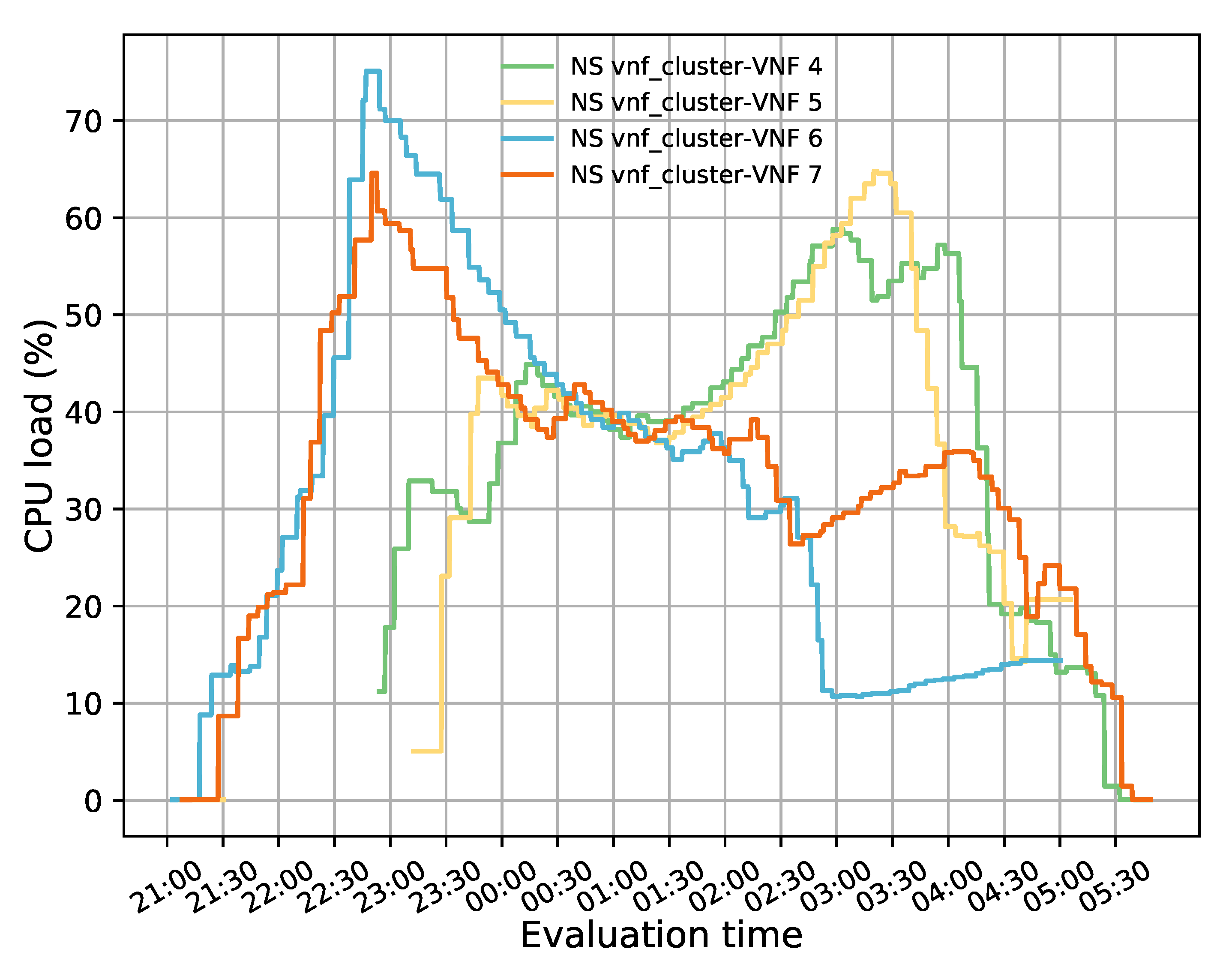
In this paper, we have proposed an SDN-based solution to manage a cluster of transparent VNFs dynamically. Specifically, our solution implements a modular application that runs on an SDN controller to perform load-balancing and auto-scaling decisions. The load-balancing block guarantees bidirectional flow affinity without packet modification by simultaneously configuring OpenFlow rules in the switches comprising the proposed solution. Most of the reviewed literature on this topic conducted experiments by using simulation tools such as Mininet. In contrast, our solution was implemented in a real environment using two well-known frameworks, OSM and OpenStack.
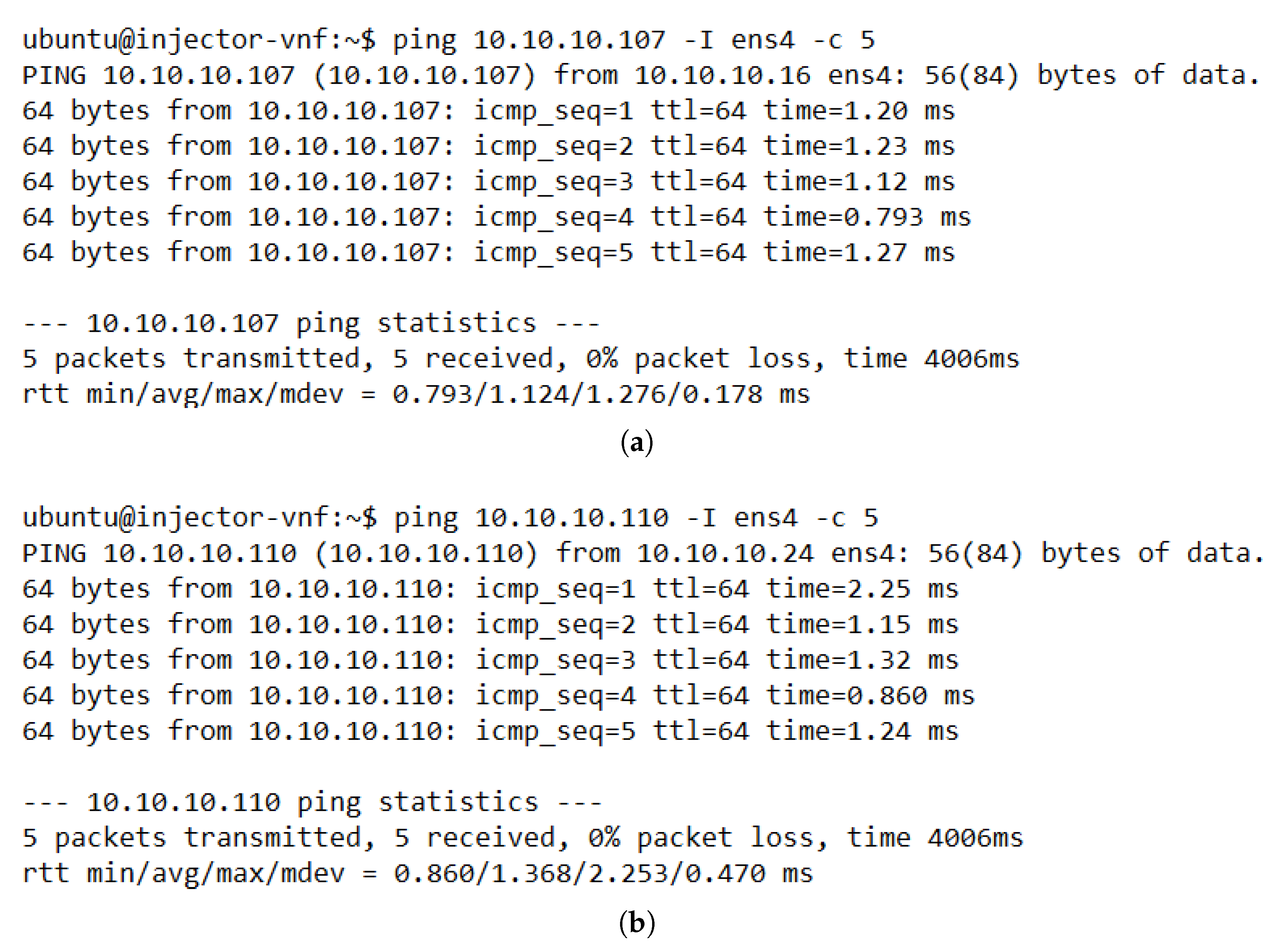
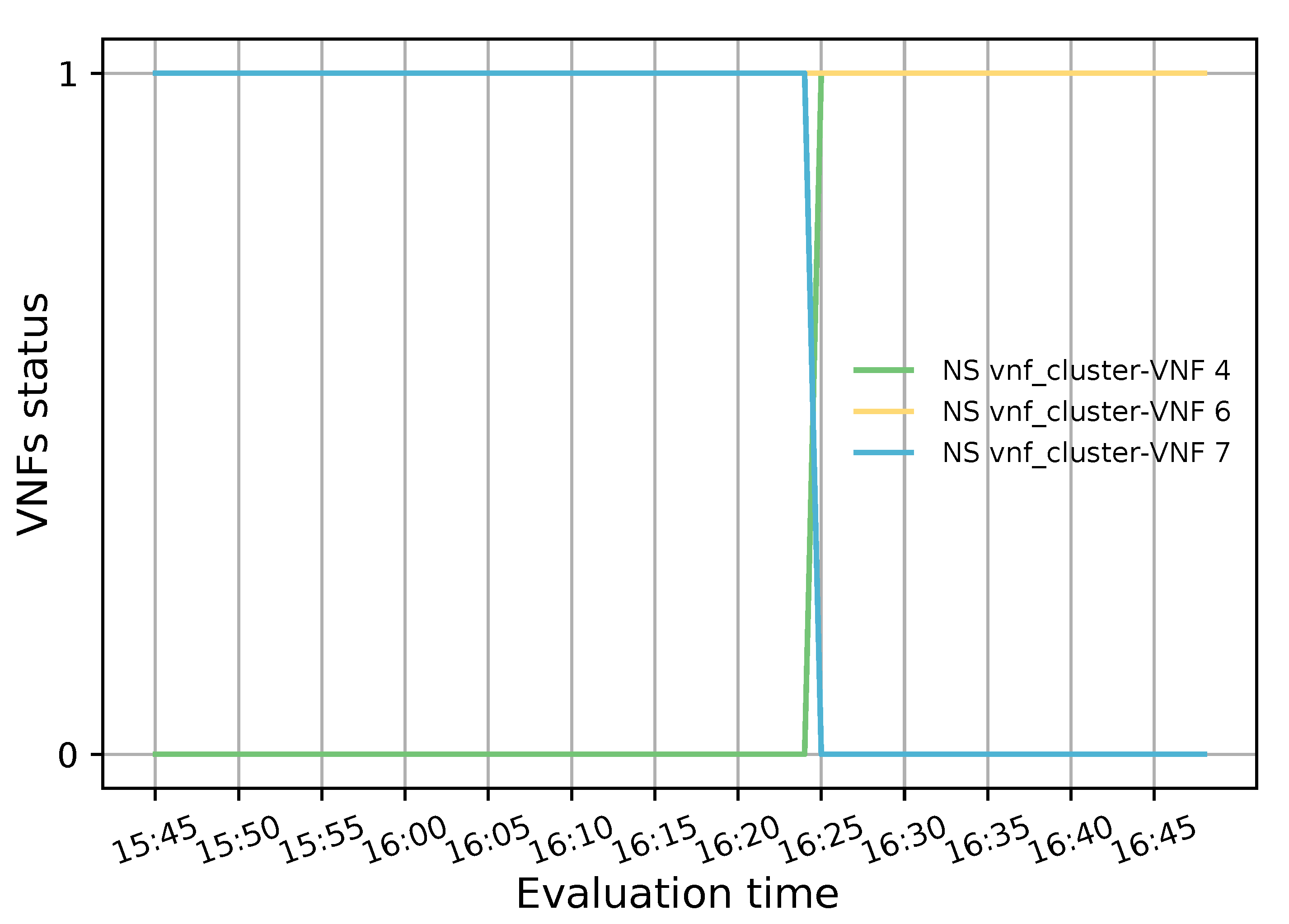
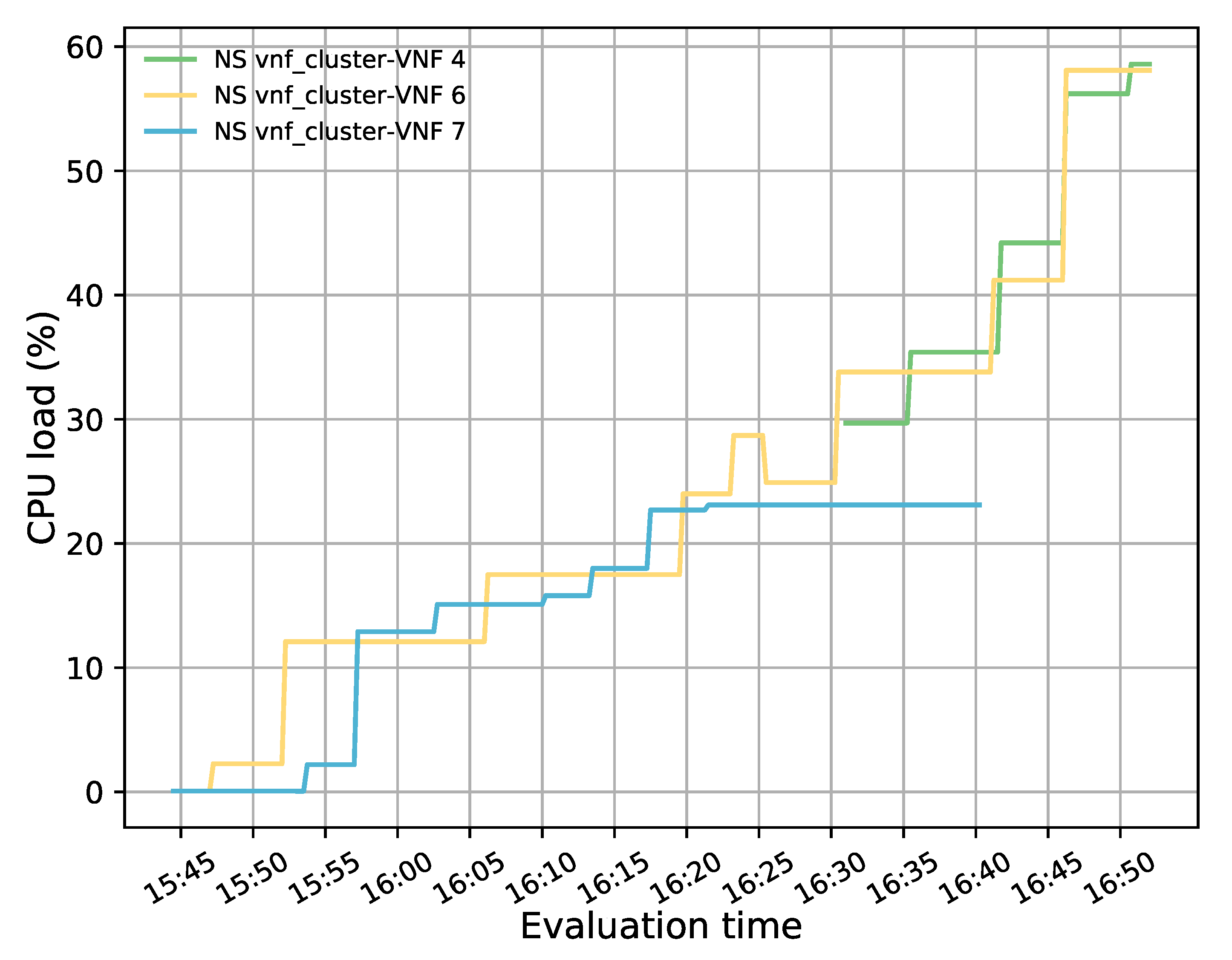
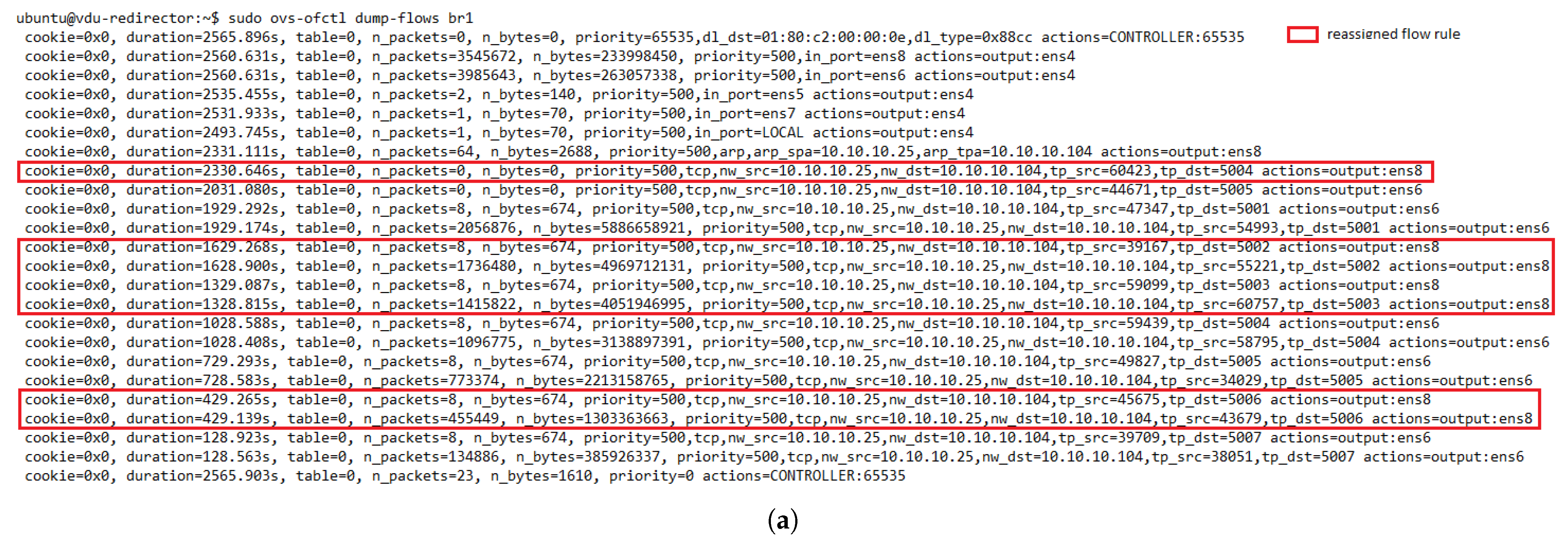
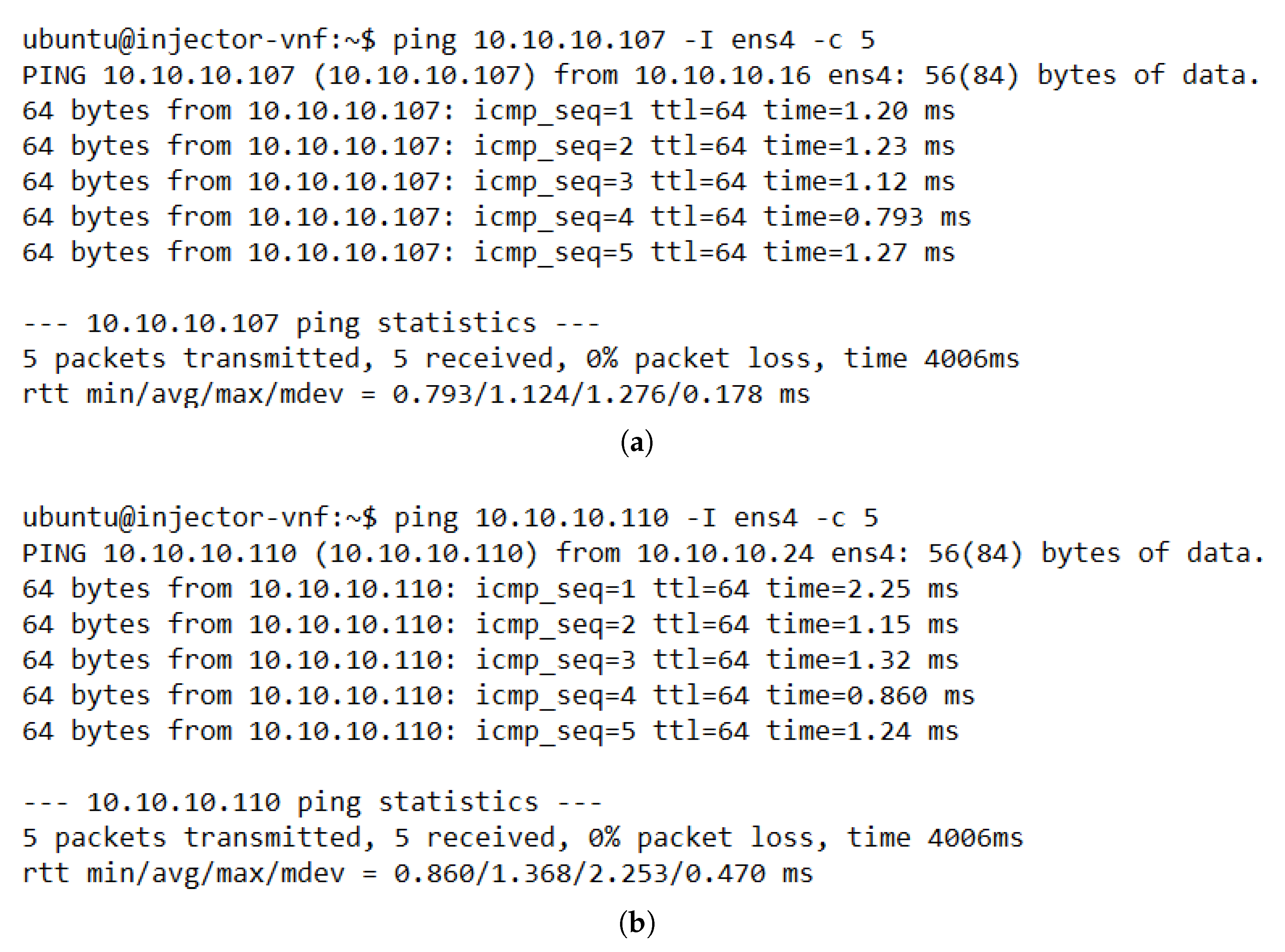
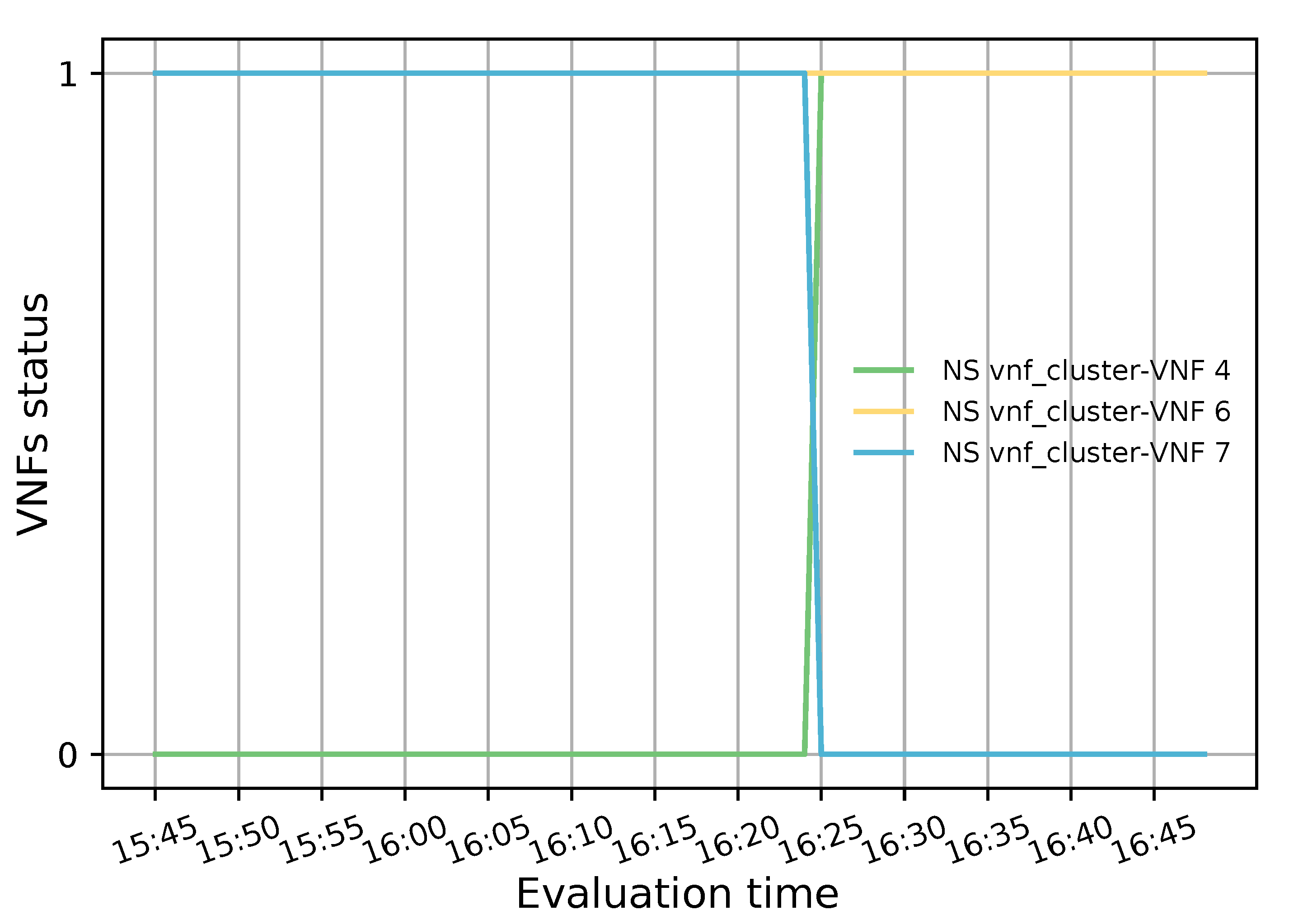
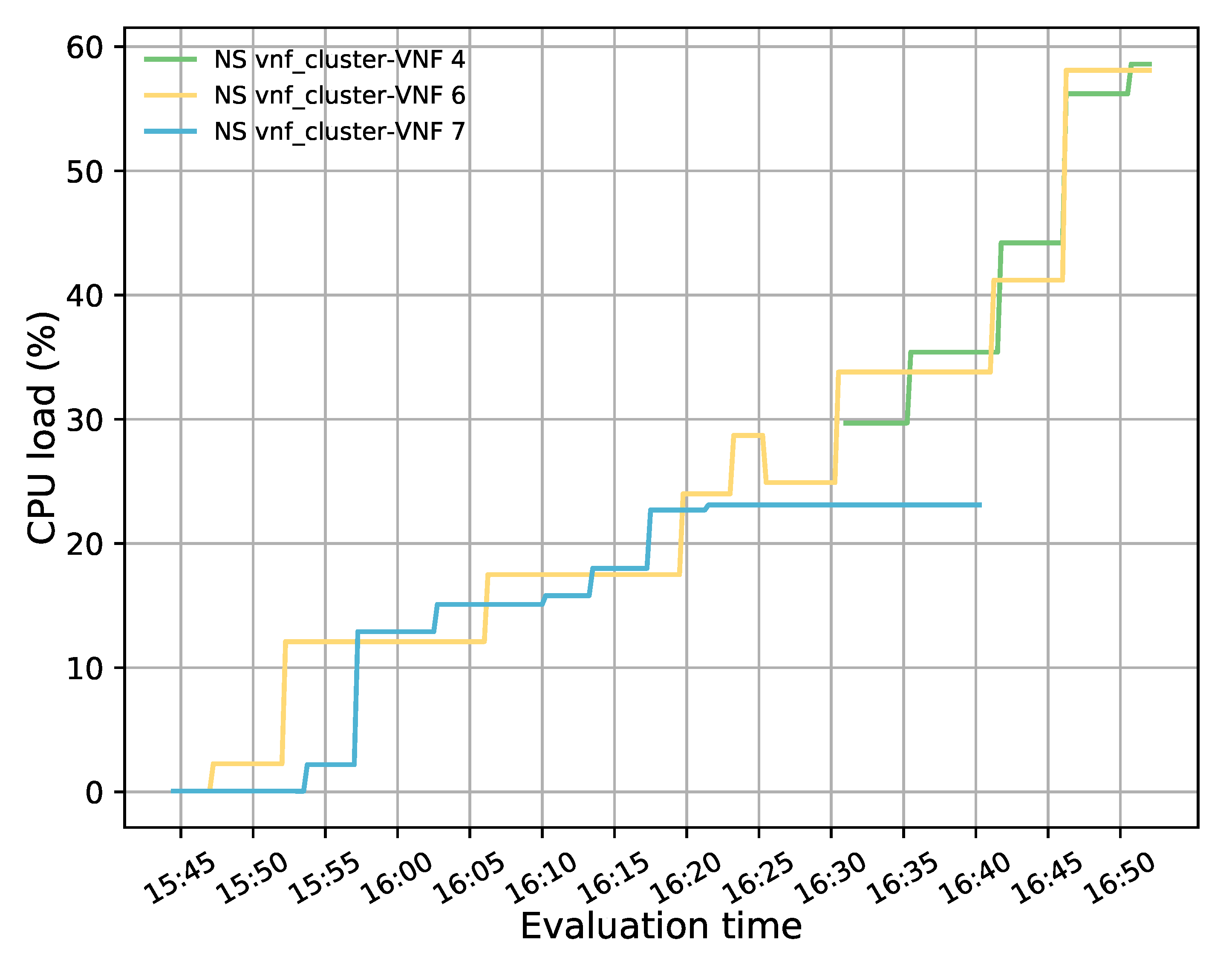
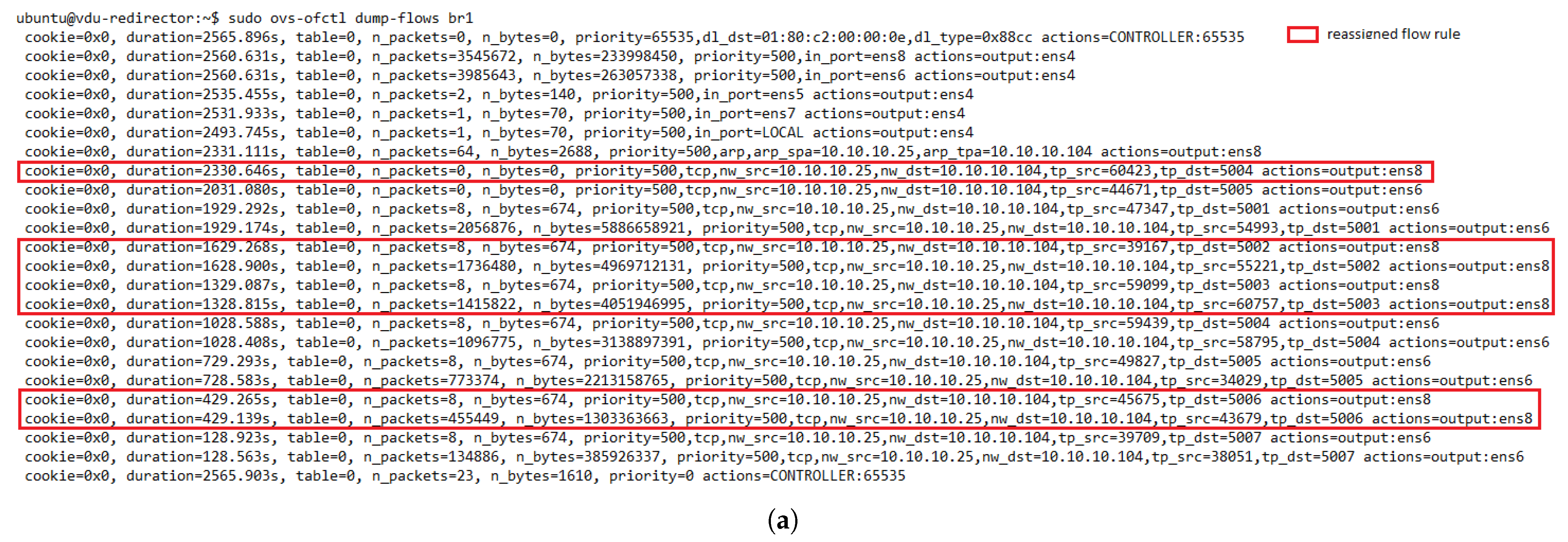
The evaluation results validated the feasibility of the proposed solution. The solution was shown to successfully redirect E2E traffic through the transparent cluster without losing any packets. Additionally, its bidirectional flow affinity capability was demonstrated by comparing the switches tables and finding each pair of source-destination addresses attached to the same port. Likewise, the effectiveness of the load-balancing and auto-scaling mechanisms was demonstrated through different experiments. Moreover, the monitoring module’s performance was evaluated through a health test in which we could notice the activation of a new instance to meet the minimum number of active members in the cluster after detecting a failed member.
Future work directions for this topic include designing strategies based on traffic forecasting. These strategies could enable scaling and load-balancing decisions to adapt to dynamic variations in traffic proactively. Furthermore, we intend to implement and test the performance of the proposed solutions in other VIM (e.g., Kubernetes) and MANO technologies to evaluate and compare their performance and extend the evaluation scenario (network service topology and SFC).


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}