
OBET: On-the-Fly Byte-Level Error Tracking for Correcting and Detecting Faults in Unreliable DRAM Systems


Abstract
:1. Introduction
- We propose an OBET architecture that provides runtime byte-level error tracking without additional DRAM input and output pins. OBET achieves this by exploiting a small number of pins that are not used during data transfers.
- We develop a memory fault management scheme based on our OBET architecture, where permanent fault pages are efficiently diagnosed and retired. Our proposed scheme targets both soft and hard failures, such as those caused by cosmic rays in scaled DRAM technologies.
- In OBET, the overhead of scrub operations, which are required to prevent DRAM error accumulation, is significantly reduced. This allows us to efficiently regulate the probability of multiple-bit errors in a word, for which rank-ECC cannot provide correction.
2. Preliminary Background
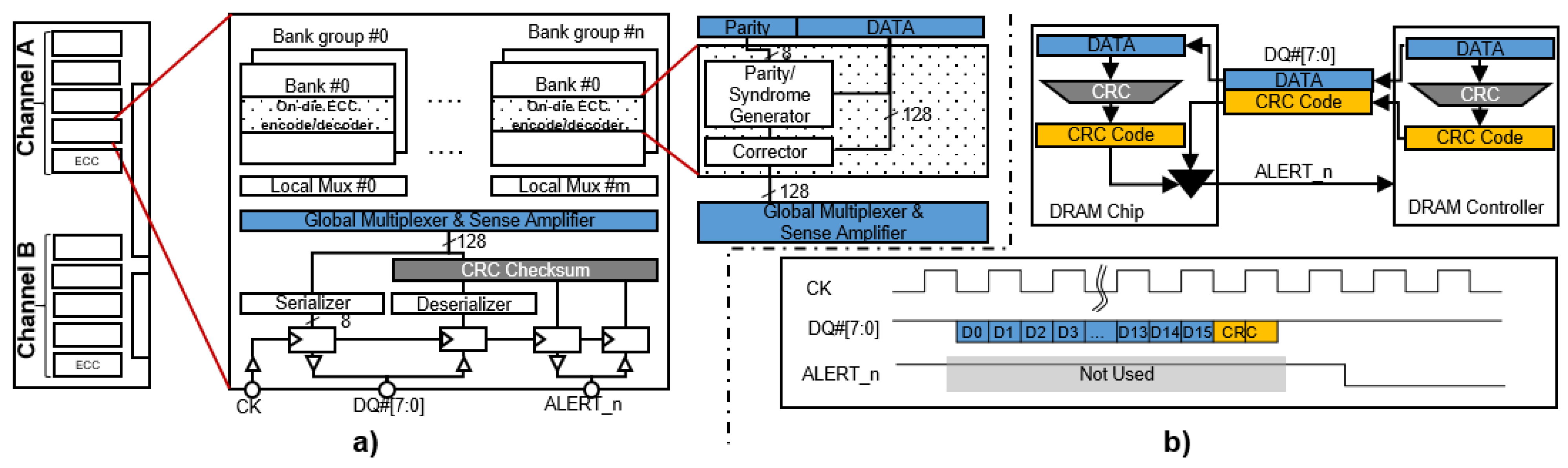
2.1. DRAM Organization and Operation
2.2. Read-Modify-Write
2.3. Function of ALERT_n Pin
2.4. DRAM Faults
2.5. DDR5 ECC Transparency and Scrubbing
3. Modern DRAM Issues and Motivation
3.1. Technology Scaling and Cosmic Rays
3.2. Row Hammering
3.3. State-of-the-Art Works Related to the On-Die ECC
3.4. Motivation
- DRAM is the most frequently failing component in hardware failures [28].
- The amount of required DRAM continues to grow, while technology scaling causes more errors. Short retention times, cosmic ray effects, and row hammering attacks have become severe issues in modern DRAM.
- In the DDR5 architecture, errors that occur in DRAM are silently masked by the on-die ECC. Because errors are not corrected, it is difficult to diagnose and study their behavior. It is necessary to expose the error information to the system.
- State-of-the-art works are still inefficient on DDR5.
4. OBET Architecture
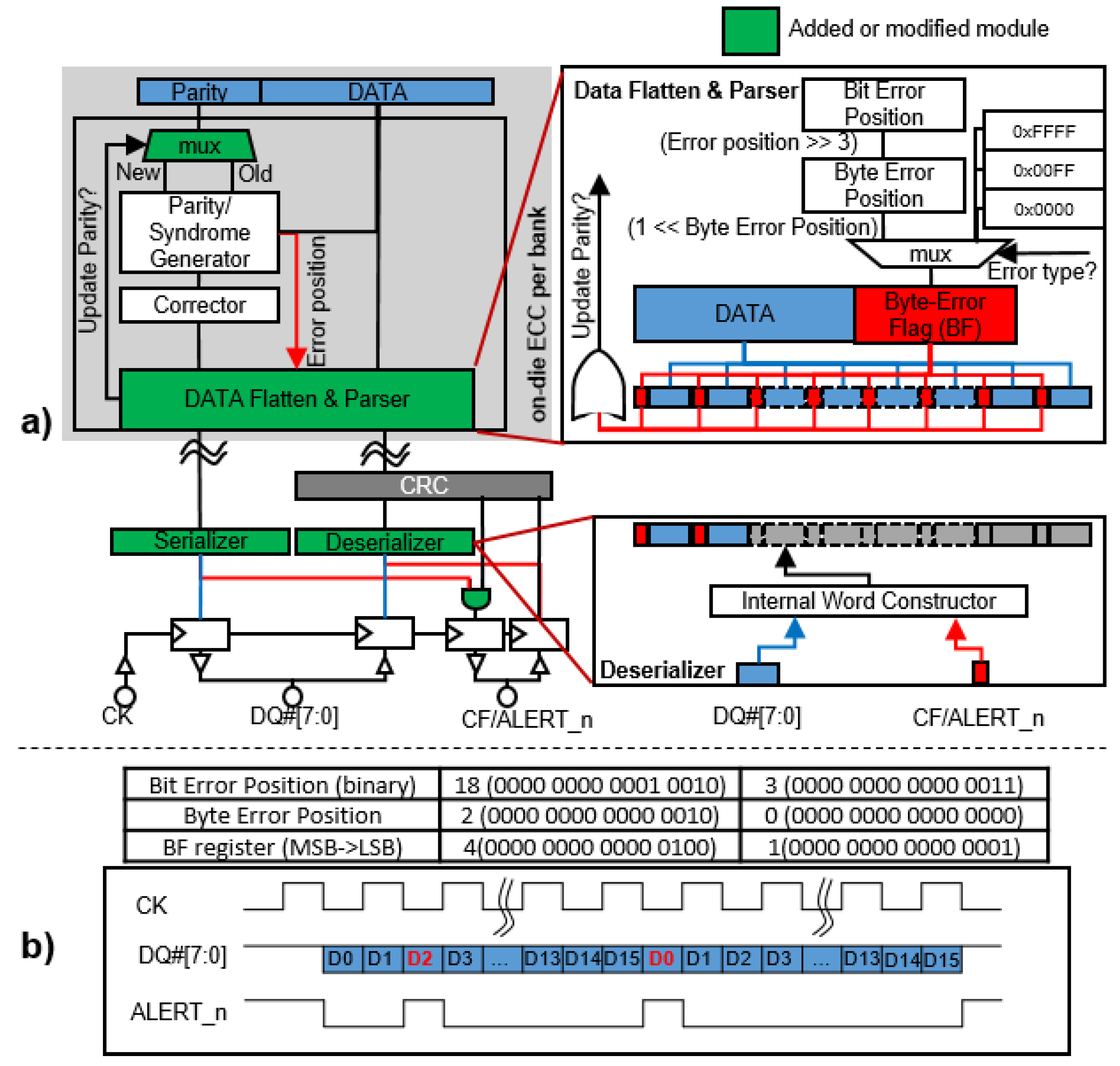
4.1. System Overview
4.2. DRAM Architecture for OBET
4.2.1. Generating a Byte-Error Flag
4.2.2. On-the-Fly Byte-Level Error Tracking
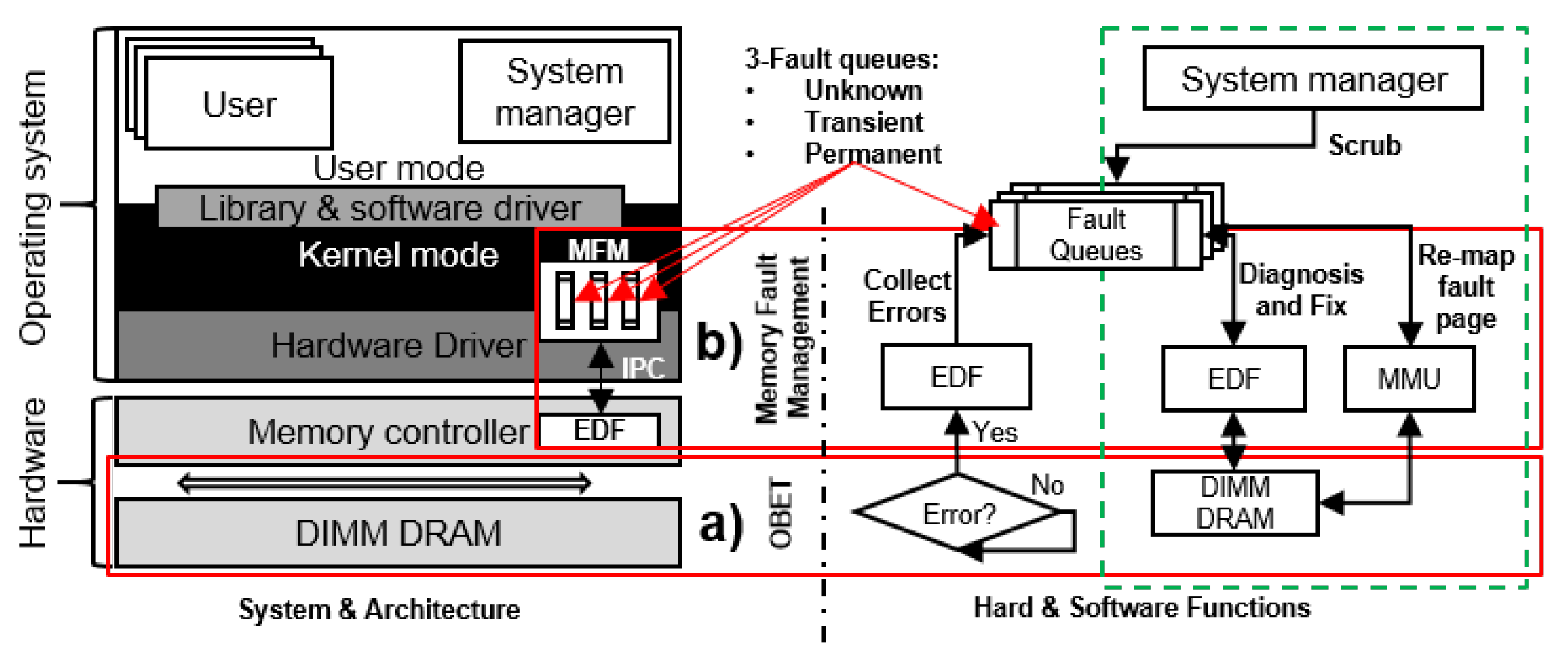
5. Memory Fault Management (MFM)
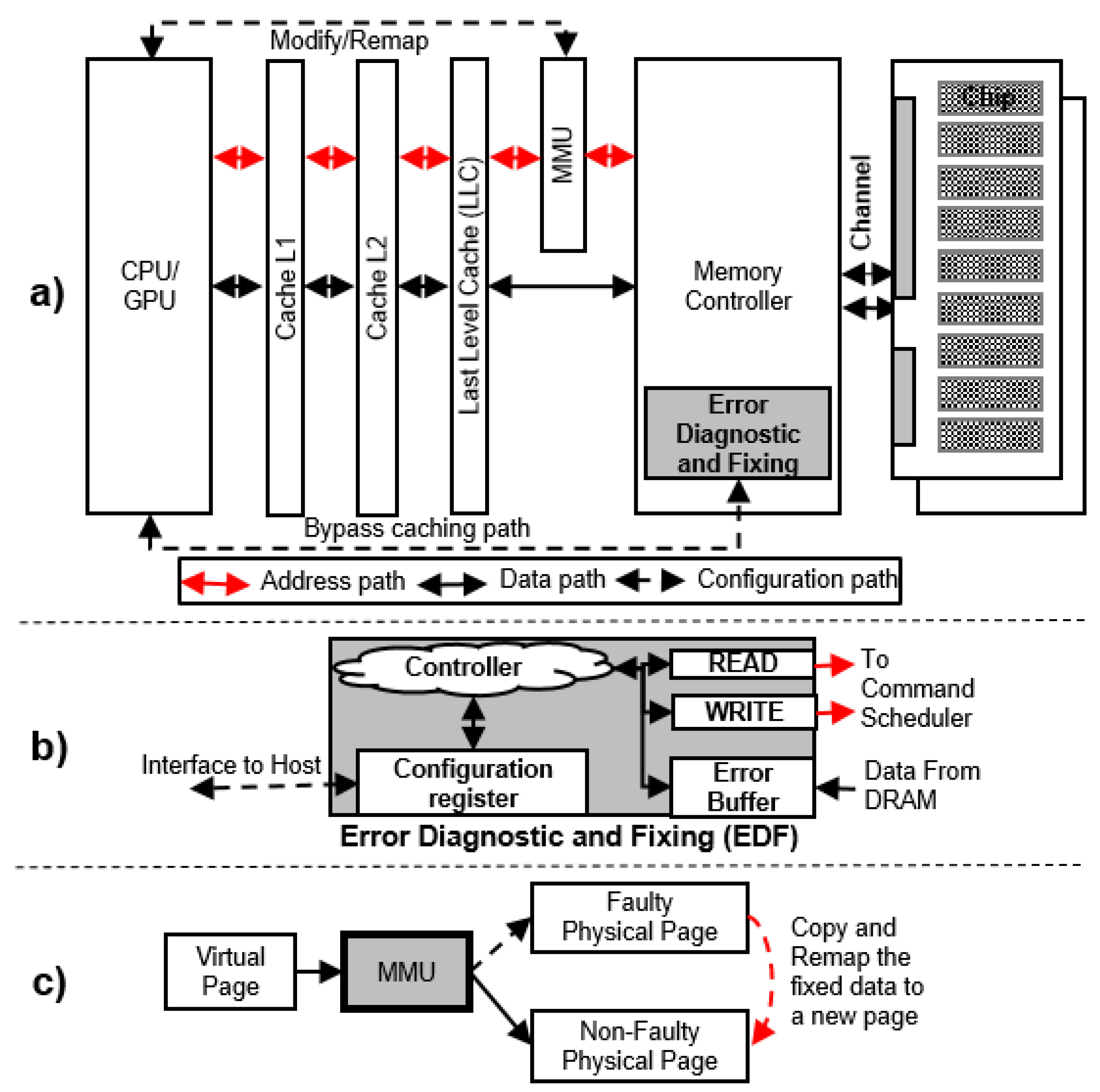
5.1. Error Diagnostic and Fixing (EDF) Module
5.2. Operation of the MFM Module
5.2.1. Collecting Errors
| Algorithm 1 Collecting the error position from EDF to OS |
|
5.2.2. Error Diagnostic and Repair Procedure
- When the BF is , we consider that the corresponding DRAM word has intermittent faults sent to the permanent fault queue. This is because, in the previous read, errors are reported from this DRAM word; however, no errors are found at this reading.
- When the BF is , it is clear that a multiple-bit error is detected and uncorrected, namely, DUE, by on-die ECCs. The DRAM word to cause the multiple-bit error is not categorized as transient or permanent. We only report the occurrence of multiple-bit errors to both the OS and the memory controller, handled by a rank-level ECC or other system-level techniques.
- When the BF has a single bit raised, regarded as default, or is , we assume that the corresponding DRAM word has a single-bit fault in data or parity, respectively. Then, we call the function to handle single-bit faults; the corresponding algorithms are discussed as follows.
- For the single-bit transient error, the read-out data are the same as the write-back data with no BF bits raised.
- For the single-bit permanent error, the read-out data are the same as the write-back data with one BF bit raised.
- For the miscorrection due to multiple-bit errors, the read-out data are different from the write-back data after the writing back, since a new error bit is created by on-die ECCs, which aim to correct wrong bit locations.
- For miscorrection due to multiple-bit errors, the read-out data are the same as the write-back data, while a notification of DUE is sent via BF.
- For miscorrection due to multiple-bit errors, the read-out data are the same as the write-back data with no BFs raised.
| Algorithm 2 Diagnostic and repair of faults from the OS |
|
| Algorithm 3 Data/parity error correction |
|
5.2.3. Remapping a Permanent Faulty Page
6. Evaluation
6.1. Multiple Types of OBET-Based Protection
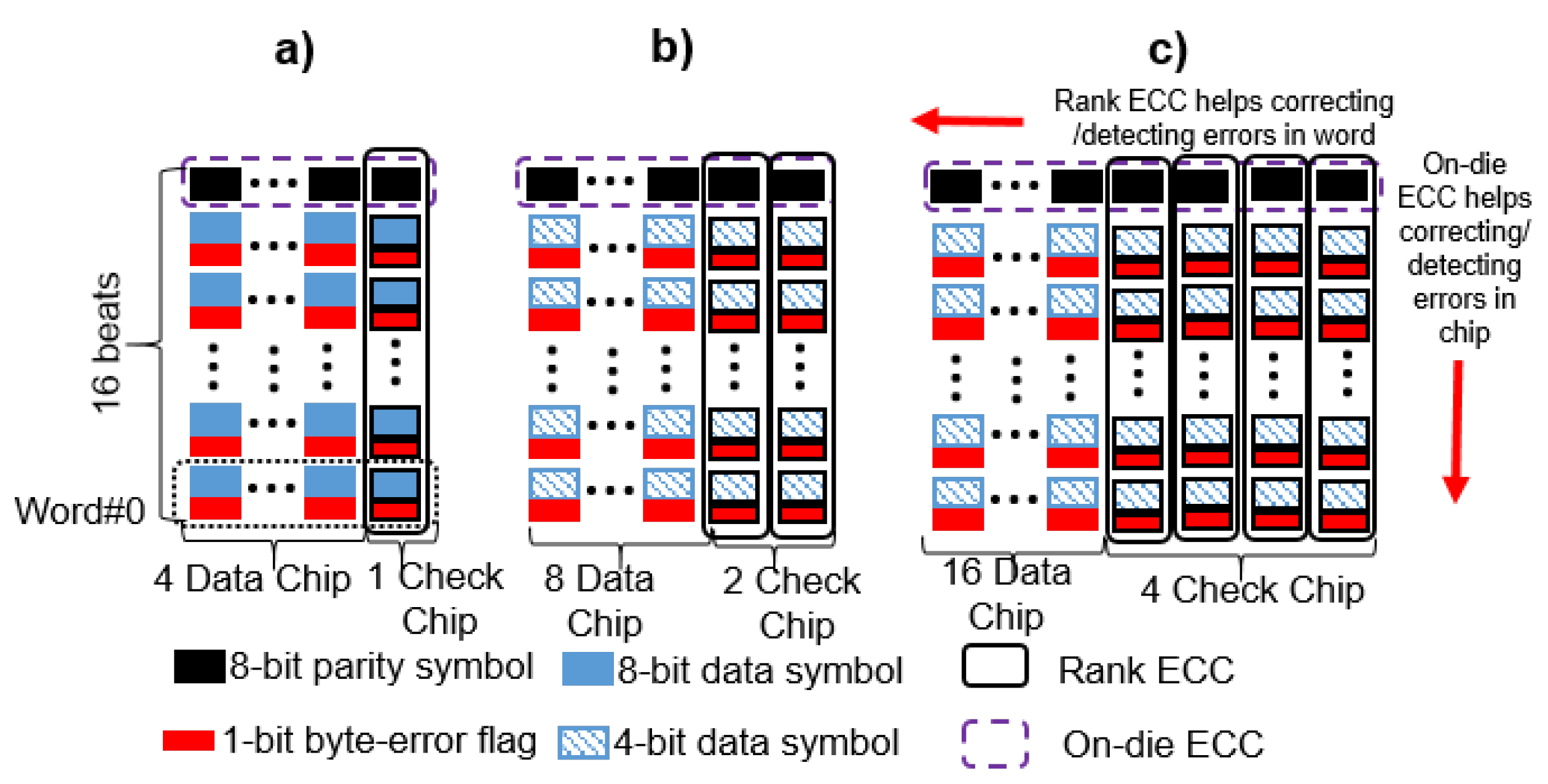
6.1.1. SECDED
6.1.2. Chipkill-Correct
6.1.3. Merging the Alert_n Pin in a DIMM
6.2. Methodology
6.3. Evaluation Results
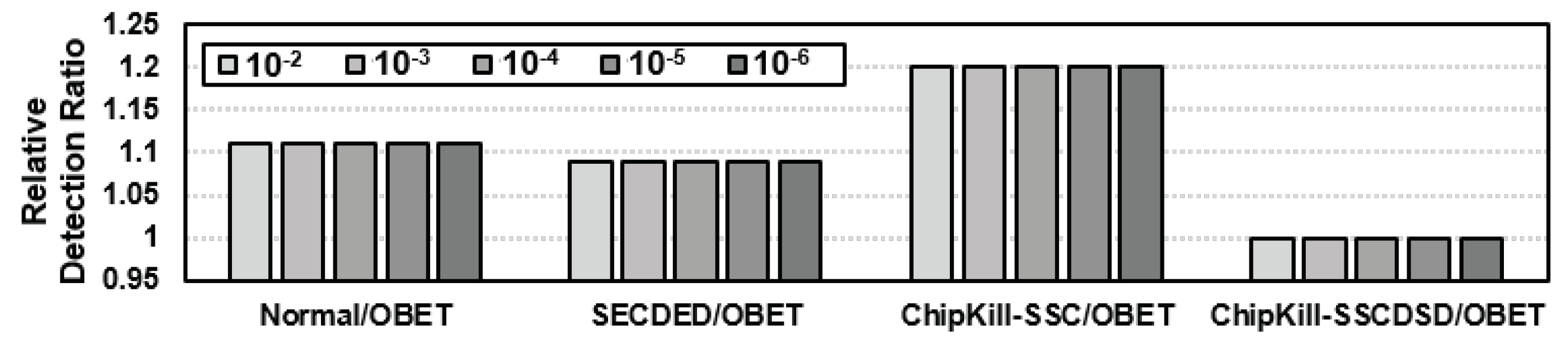
6.3.1. Enhanced Error Detection
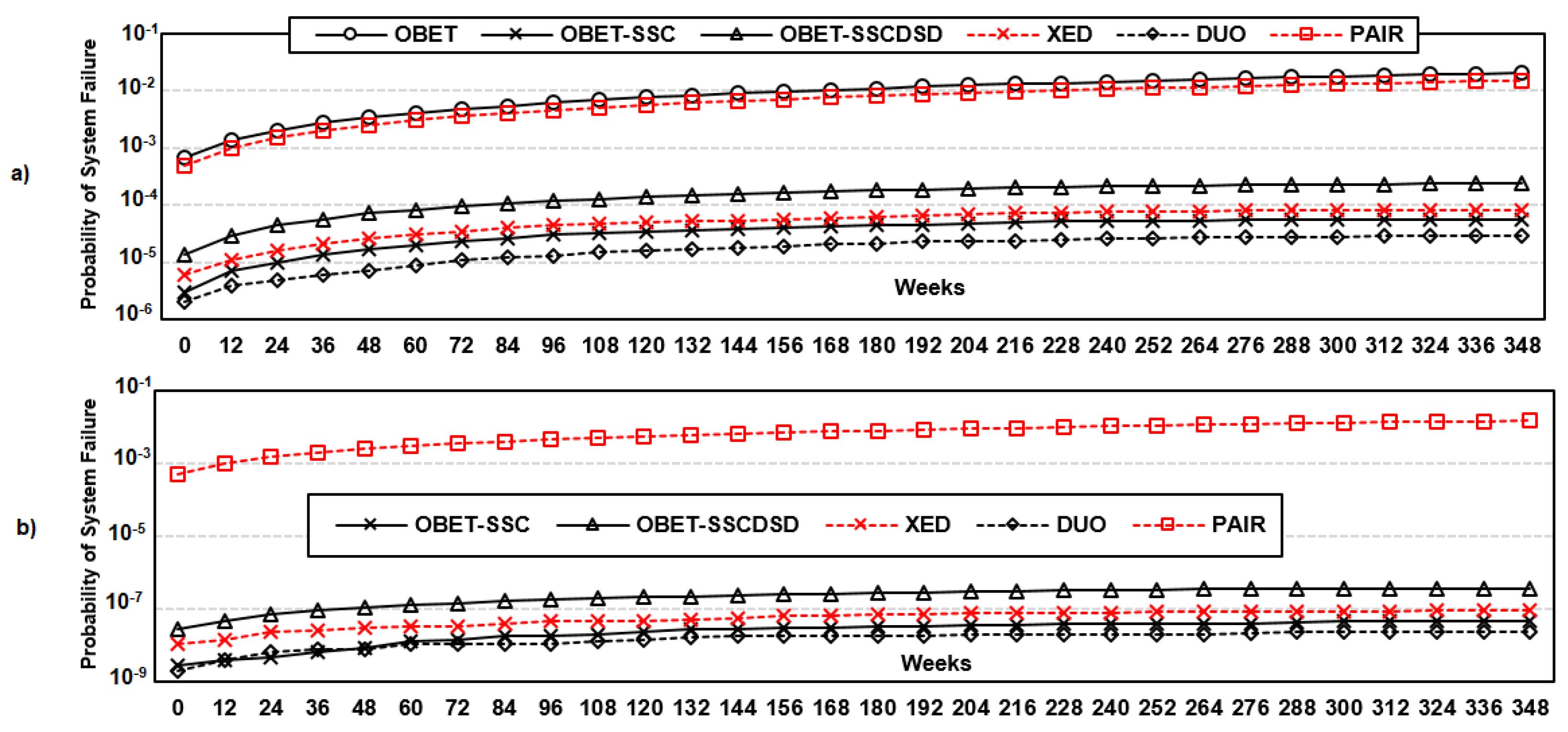
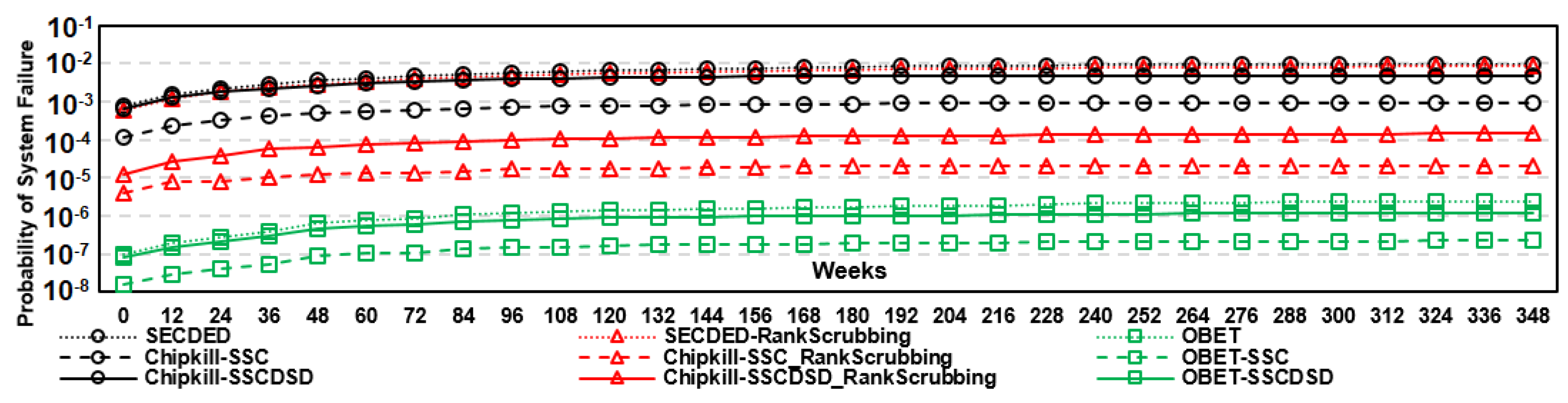
6.3.2. Reliability Comparison with State-of-the-Art Works
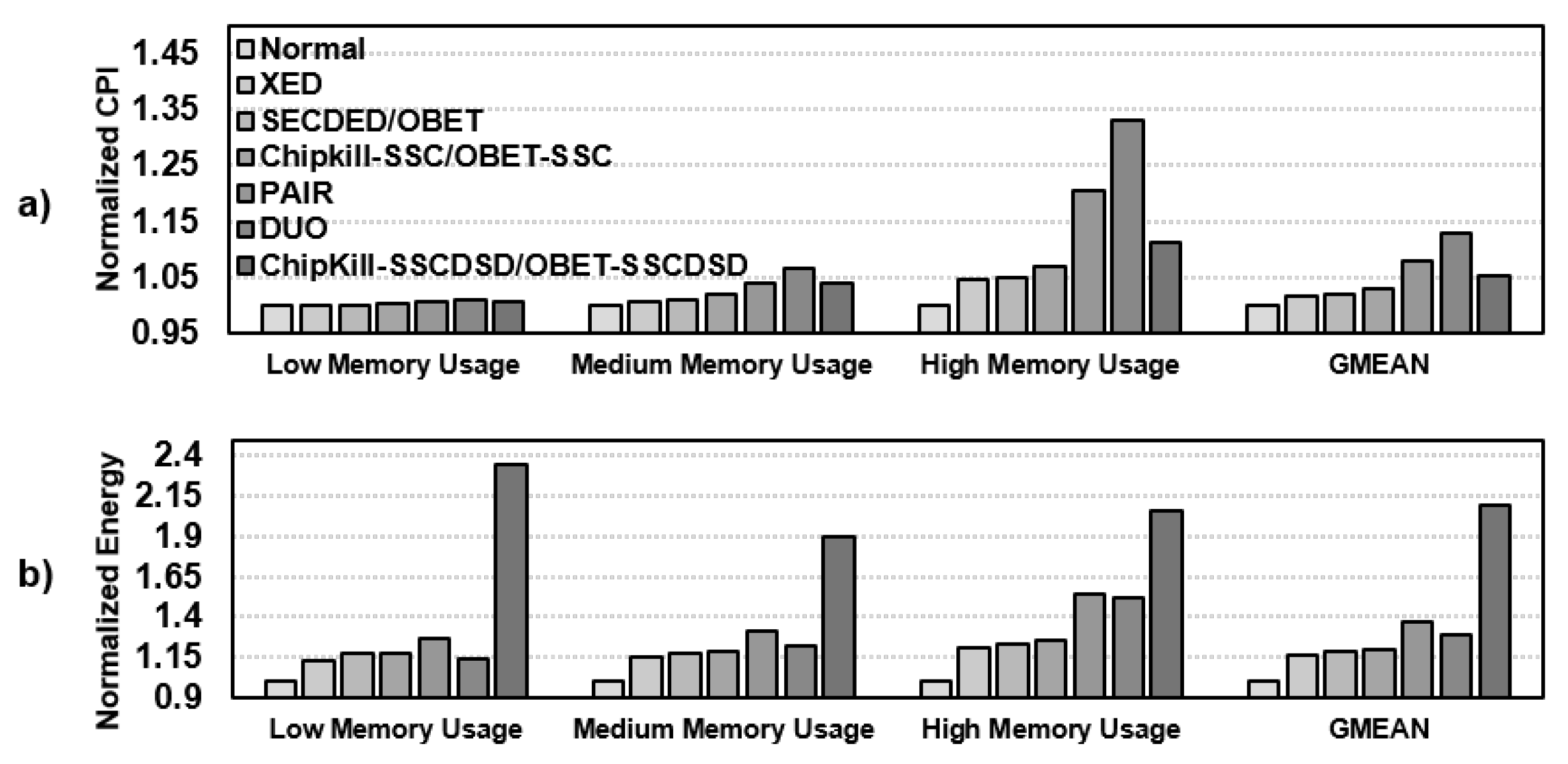
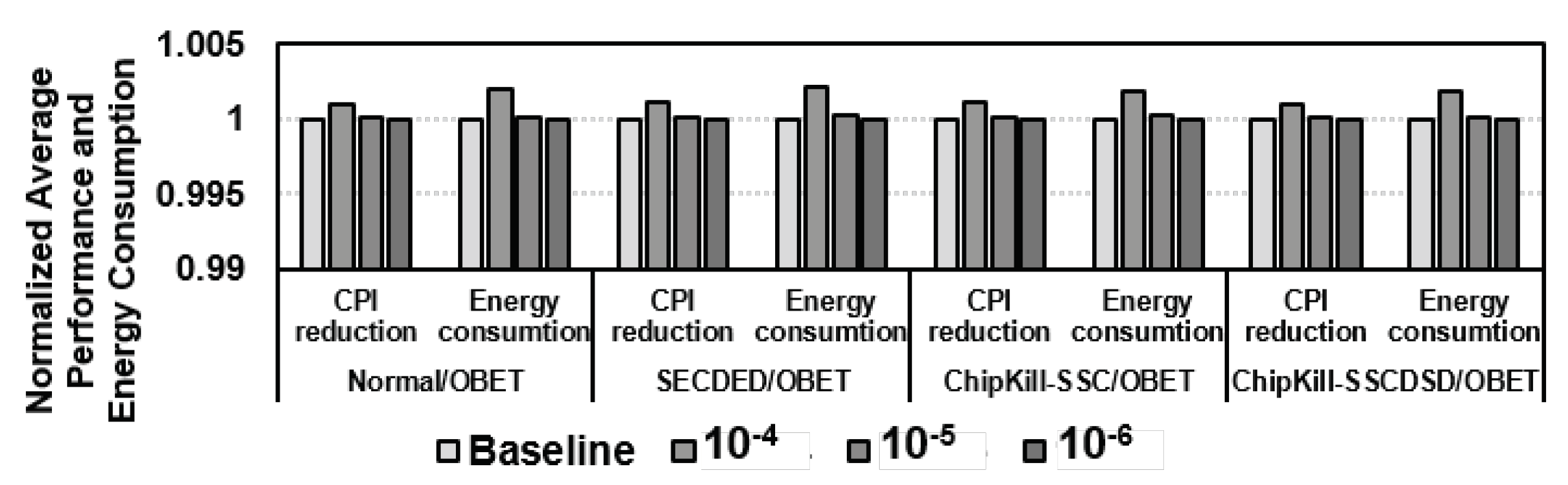
6.3.3. Performance and Energy Consumption Comparison
7. Efficient OBET-Based Scrubbing
7.1. OBET Scrubbing
| Algorithm 4 OBET-scrubbing |
|
7.2. Eliminating Errors with OBET Scrubbing
7.3. On-the-Fly Error Correction with OBET
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Kim, Y.; Daly, R.; Kim, J.; Fallin, C.; Lee, J.H.; Lee, D.; Wilkerson, C.; Lai, K.; Mutlu, O. Flipping bits in memory without accessing them: An experimental study of DRAM disturbance errors. ACM Sigarch Comput. Archit. News 2014, 42, 361–372. [Google Scholar] [CrossRef]
- Aweke, Z.B.; Yitbarek, S.F.; Qiao, R.; Das, R.; Hicks, M.; Oren, Y.; Austin, T. ANVIL: Software-based protection against next-generation rowhammer attacks. ACM Sigplan Not. 2016, 51, 743–755. [Google Scholar] [CrossRef]
- Brasser, F.; Davi, L.; Gens, D.; Liebchen, C.; Sadeghi, A.R. CAn’t touch this: Software-only mitigation against Rowhammer attacks targeting kernel memory. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 117–130. [Google Scholar]
- Satoh, S.; Tosaka, Y.; Wender, S. Geometric effect of multiple-bit soft errors induced by cosmic ray neutrons on DRAM’s. IEEE Electron Device Lett. 2000, 21, 310–312. [Google Scholar] [CrossRef]
- Ziegler, J.F.; Nelson, M.E.; Shell, J.D.; Peterson, R.J.; Gelderloos, C.J.; Muhlfeld, H.P.; Montrose, C.J. Cosmic ray soft error rates of 16-Mb DRAM memory chips. IEEE J. -Solid-State Circuits 1998, 33, 246–252. [Google Scholar] [CrossRef]
- Yan, A.; Chen, Y.; Hu, Y.; Zhou, J.; Ni, T.; Cui, J.; Girard, P.; Wen, X. Novel Speed-and-Power-Optimized SRAM Cell Designs With Enhanced Self-Recoverability From Single-and Double-Node Upsets. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 4684–4695. [Google Scholar] [CrossRef]
- Yan, A.; Fan, Z.; Ding, L.; Cui, J.; Huang, Z.; Wang, Q.; Zheng, H.; Girard, P.; Wen, X. Cost-Effective and Highly Reliable Circuit Components Design for Safety-Critical Applications. IEEE Trans. Aerosp. Electron. Syst. 2021, in press. [Google Scholar] [CrossRef]
- Yan, A.; Lai, C.; Zhang, Y.; Cui, J.; Huang, Z.; Song, J.; Guo, J.; Wen, X. Novel low cost, double-and-triple-node-upset-tolerant latch designs for nano-scale CMOS. IEEE Trans. Emerg. Top. Comput. 2018, 9, 520–533. [Google Scholar] [CrossRef] [Green Version]
- Shah, A.P.; Waltl, M. Bias temperature instability aware and soft error tolerant radiation hardened 10T SRAM cell. Electronics 2020, 9, 256. [Google Scholar] [CrossRef] [Green Version]
- Yan, A.; Hu, Y.; Cui, J.; Chen, Z.; Huang, Z.; Ni, T.; Girard, P.; Wen, X. Information Assurance Through Redundant Design: A Novel TNU Error-Resilient Latch for Harsh Radiation Environment. IEEE Trans. Comput. 2020, 69, 789–799. [Google Scholar] [CrossRef]
- Jiang, J.; Zhu, W.; Xiao, J.; Zou, S. A novel high-performance low-cost double-upset tolerant latch design. Electronics 2018, 7, 247. [Google Scholar] [CrossRef] [Green Version]
- IBM. Chipkill Memory. Available online: http://ps-2.kev009.com/pccbbs/pc_servers/chipkilf.pdf (accessed on 5 November 2021).
- Park, S.K. Technology scaling challenge and future prospects of DRAM and NAND flash memory. In Proceedings of the 2015 IEEE International Memory Workshop (IMW), Monterey, CA, USA, 17–20 May 2015; pp. 1–4. [Google Scholar]
- Hwang, A.A.; Stefanovici, I.A.; Schroeder, B. Cosmic rays don’t strike twice: Understanding the nature of DRAM errors and the implications for system design. ACM Sigplan Not. 2012, 47, 111–122. [Google Scholar] [CrossRef]
- O’Gorman, T.J. The effect of cosmic rays on the soft error rate of a DRAM at ground level. IEEE Trans. Electron Devices 1994, 41, 553–557. [Google Scholar] [CrossRef]
- McKee, W.; McAdams, H.; Smith, E.; McPherson, J.; Janzen, J.; Ondrusek, J.; Hyslop, A.; Russell, D.; Coy, R.; Bergman, D.; et al. Cosmic ray neutron induced upsets as a major contributor to the soft error rate of current and future generation DRAMs. In Proceedings of the International Reliability Physics Symposium, Dallas, TX, USA, 30 April–2 May 1996; pp. 1–6. [Google Scholar]
- JEDEC. JESD209-4. 2015. Available online: https://www.jedec.org/document_search?search_api_views_fulltext=JESD209-4 (accessed on 5 November 2021).
- JEDEC. DDR5 SDRAM Standard. 2020. Available online: https://www.jedec.org/standards-documents/docs/jesd79-5a (accessed on 5 November 2021).
- Nair, P.J.; Sridharan, V.; Qureshi, M.K. XED: Exposing on-die error detection information for strong memory reliability. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 341–353. [Google Scholar]
- Gong, S.L.; Kim, J.; Lym, S.; Sullivan, M.; David, H.; Erez, M. Duo: Exposing on-chip redundancy to rank-level ecc for high reliability. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 683–695. [Google Scholar]
- Cha, S.; Seongil, O.; Shin, H.; Hwang, S.; Park, K.; Jang, S.J.; Choi, J.S.; Jin, G.Y.; Son, Y.H.; Cho, H.; et al. Defect analysis and cost-effective resilience architecture for future DRAM devices. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 61–72. [Google Scholar]
- Oh, T.Y.; Chung, H.; Park, J.Y.; Lee, K.W.; Oh, S.; Doo, S.Y.; Kim, H.J.; Lee, C.; Kim, H.R.; Lee, J.H.; et al. A 3.2 gbps/pin 8 gbit 1.0 v lpddr4 sdram with integrated ecc engine for sub-1 v dram core operation. IEEE J. Solid State Circuits 2014, 50, 178–190. [Google Scholar] [CrossRef]
- Lee, C.J.; Narasiman, V.; Ebrahimi, E.; Mutlu, O.; Patt, Y.N. DRAM-Aware Last-Level Cache Writeback: Reducing Write-Caused Interference in Memory Systems; HPS Technical Report, TR-HPS-2010-002; Carnegie Mellon University: Pittsburgh, PA, USA, 2010. [Google Scholar]
- Stuecheli, J.; Kaseridis, D.; Daly, D.; Hunter, H.C.; John, L.K. The virtual write queue: Coordinating DRAM and last-level cache policies. ACM Sigarch Comput. Archit. News 2010, 38, 72–82. [Google Scholar] [CrossRef]
- JEDEC. DDR4 SDRAM Standard. 2012. Available online: https://www.jedec.org/document_search?search_api_views_fulltext=JESD79-4D (accessed on 5 November 2021).
- Sridharan, V.; DeBardeleben, N.; Blanchard, S.; Ferreira, K.B.; Stearley, J.; Shalf, J.; Gurumurthi, S. Memory errors in modern systems: The good, the bad, and the ugly. ACM Sigarch Comput. Archit. News 2015, 43, 297–310. [Google Scholar] [CrossRef]
- Sridharan, V.; Liberty, D. A study of DRAM failures in the field. In Proceedings of the SC’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1–11. [Google Scholar]
- Murphy, B. Automating software failure reporting. Queue 2004, 2, 42–48. [Google Scholar] [CrossRef] [Green Version]
- Frigo, P.; Vannacc, E.; Hassan, H.; Van Der Veen, V.; Mutlu, O.; Giuffrida, C.; Bos, H.; Razavi, K. TRRespass: Exploiting the many sides of target row refresh. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 747–762. [Google Scholar]
- Kim, J.S.; Patel, M.; Yağlıkçı, A.G.; Hassan, H.; Azizi, R.; Orosa, L.; Mutlu, O. Revisiting rowhammer: An experimental analysis of modern dram devices and mitigation techniques. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 638–651. [Google Scholar]
- Luza, L.M.; Söderström, D.; Puchner, H.; Alía, R.G.; Letiche, M.; Cazzaniga, C.; Bosio, A.; Dilillo, L. Neutron-induced effects on a self-refresh DRAM. Microelectron. Reliab. 2022, 128, 114406. [Google Scholar] [CrossRef]
- Patel, M.; Kim, J.S.; Shahroodi, T.; Hassan, H.; Mutlu, O. Bit-exact ecc recovery (BEER): Determining DRAM on-die ECC functions by exploiting DRAM data retention characteristics. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 282–297. [Google Scholar]
- Son, Y.H.; Lee, S.; Seongil, O.; Kwon, S.; Kim, N.S.; Ahn, J.H. CiDRA: A cache-inspired DRAM resilience architecture. In Proceedings of the 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), Burlingame, CA, USA, 7–11 February 2015; pp. 502–513. [Google Scholar]
- Udipi, A.N.; Muralimanohar, N.; Balsubramonian, R.; Davis, A.; Jouppi, N.P. LOT-ECC: Localized and tiered reliability mechanisms for commodity memory systems. In Proceedings of the 2012 39th Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 9–13 June 2012; pp. 285–296. [Google Scholar]
- Jeong, S.; Kang, S.; Yang, J.S. PAIR: Pin-aligned In-DRAM ECC architecture using expandability of Reed-Solomon code. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Kleen, A. Mcelog: Memory error handling in user space. In Proceedings of the International Linux System Technology Conference (Linux Kongress), Nuremberg (Nürnberg), Germany, 21–24 September 2010. [Google Scholar]
- MICRON. DDR5 16GB Die Datasheet. 2021. Available online: https://media-www.micron.com/-/media/client/global/documents/products/data-sheet/dram/ddr5/16gb_ddr5_sdram_diereva.pdf (accessed on 5 November 2021).
- Schechter, S.; Loh, G.H.; Strauss, K.; Burger, D. Use ECP, not ECC, for hard failures in resistive memories. ACM Sigarch Comput. Archit. News 2010, 38, 141–152. [Google Scholar] [CrossRef]
- Tang, D.; Carruthers, P.; Totari, Z.; Shapiro, M.W. Assessment of the effect of memory page retirement on system RAS against hardware faults. In Proceedings of the International Conference on Dependable Systems and Networks (DSN’06), Philadelphia, PA, USA, 25–28 June 2006; pp. 365–370. [Google Scholar]
- Hsiao, M.Y. A class of optimal minimum odd-weight-column SEC-DED codes. IBM J. Res. Dev. 1970, 14, 395–401. [Google Scholar] [CrossRef]
- BIOS and Kernel Developer’s Guide for AMD NPT Family 0Fh Processors Publication. July 2007. Available online: https://www.amd.com/system/files/TechDocs/32559.pdf (accessed on 5 November 2021).
- Kamat, S.J.; Riley, M.W. Determination of reliability using event-based Monte Carlo simulation. IEEE Trans. Reliab. 1975, 24, 73–75. [Google Scholar] [CrossRef]
- Nair, P.J.; Roberts, D.A.; Qureshi, M.K. Faultsim: A fast, configurable memory-reliability simulator for conventional and 3d-stacked systems. ACM Trans. Archit. Code Optim. (TACO) 2015, 12, 1–24. [Google Scholar]
- Henning, J. Standard Performance Evaluation Corporation (SPEC). 2006. Available online: https://www.spec.org/cpu2006/ (accessed on 5 November 2021).
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. ACM Sigarch Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Intel. Intel D1649N. Available online: https://www.intel.com/content/www/us/en/products/sku/193696/intel-xeon-d1649n-processor-12m-cache-2-30ghz/specifications.html (accessed on 5 November 2021).
- Jagtap, R.; Jung, M.; Elsasser, W.; Weis, C.; Hansson, A.; Wehn, N. Integrating DRAM power-down modes in gem5 and quantifying their impact. In Proceedings of the International Symposium on Memory Systems, Washington, DC, USA, 2 October 2017; pp. 86–95. [Google Scholar]
- Xilinx. Xilinx Logic Core Reed-Solomon Decoder 9.0. Available online: https://www.xilinx.com/support/documentation/ip_documentation/rs_decoder/v9_0/pg107-rs-decoder.pdf (accessed on 5 November 2021).
- Xilinx. Xilinx Logic Core Reed-Solomon Encoder 9.0. Available online: https://www.xilinx.com/support/documentation/ip_documentation/rs_encoder/v9_0/pg025_rs_encoder.pdf (accessed on 5 November 2021).
- MICRON. DDR4 Power Calculation. 2011. Available online: https://www.micron.com/-/media/client/global/documents/products/technical-note/dram/tn4007_ddr4_power_calculation.pdf (accessed on 5 November 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DRAM Conf. | DDR5 Correction Schemes | Num. of Data/Parity Chip | Check Code | Latency Cycles (ns@3200 MHz) | OBET- Scrubbing |
|---|---|---|---|---|---|
| X8 | SECDED | 4/1 | SEC+SECDED | 1.5 ns | |
| OBET | 4/1 | SEC+SECDED | 1.5 ns | X | |
| XED [19] | 4/1 | XOR | 0.5 ns | ||
| X4 | SECDED | 8/2 | SEC+SECDED | 1.5 ns | |
| OBET | 8/2 | SEC+SECDED | 1.5 ns | X | |
| XED [19] | 8/1 | XOR | 0.5 ns | ||
| DUO [20] | 8/1 | RS(76,64,8) | 217(67.81 ns) | ||
| PAIR [35] | 8/2 | RS(40,32,8) | 123(38.43 ns) | ||
| Chipkill-SSC | 8/2 | RS(10,8,4) | 35(10.94 ns) | ||
| OBET-SSC | 8/2 | RS(10,8,4) | 35(10.94 ns) | X | |
| Chipkill-SSCDSD | 16/4 | RS(20,16,8) | 61(19.06 ns) | ||
| OBET-SSCDSD | 16/4 | RS(20,16,8) | 61(19.06 ns) | X |
| Failure Mode | Failure Rate (FIT) | |
|---|---|---|
| Transient | Permanent | |
| Single-bit | 14.2 | 18.6 |
| Single-word | 1.4 | 0.3 |
| Single-column | 1.4 | 5.6 |
| Single-row | 0.2 | 8.2 |
| Single-bank | 0.8 | 10.0 |
| Multiple-bank | 0.3 | 1.4 |
| Multiple-rank | 0.9 | 2.8 |
| CPU | Intel D-1649N x8-3 Ghz |
|---|---|
| System configuration | System bus: 1 GHz |
| L1-I/L1-D: 32 kB|L2: 256 kB|L3: 12 MB | |
| 64-byte cache line—2/8/16-ways | |
| DRAM DDR5 | 16 Gb DDR5_DIMM_×4 |
| Clock/data rate: 1600 MHz/3200 Mbps/pin | |
| 2 channels/ FRFCFS scheduler | |
| Timing models: JEDEC79-5 [18] | |
| Energy models: GEM5 | |
| ECC latency(ns) | Table 1 |
| Benchmark | Low: perlbench, hmmer, libquant, |
| namd, omnetpp, tonto, povray, sjeng | |
| Medium: gamess, gromac, sphinx3, | |
| wrf, astar, zuesmp, calculix, leslie3d | |
| High: gcc, bzip2, bwaves, milc, | |
| gobmk, lbm, mcf |
| Scrubbing Mode | Sequence | Note |
|---|---|---|
| DDR5 ECS mode | ACT→RD→WR→PRE | All codewords |
| OBET scrubbing | ACT→RD→PRE | No error codewords |
| ACT→RD→WR→RD→PRE | Transient errors only | |
| ACT→RD→WR→RD→64(RD) →ACT→64(WR)→PRE→PRE | Permanent errors only |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.-T.; Ho, N.-M.; Wong, W.-F.; Chang, I.-J. OBET: On-the-Fly Byte-Level Error Tracking for Correcting and Detecting Faults in Unreliable DRAM Systems. Sensors 2021, 21, 8271. https://doi.org/10.3390/s21248271
Nguyen D-T, Ho N-M, Wong W-F, Chang I-J. OBET: On-the-Fly Byte-Level Error Tracking for Correcting and Detecting Faults in Unreliable DRAM Systems. Sensors. 2021; 21(24):8271. https://doi.org/10.3390/s21248271
Chicago/Turabian StyleNguyen, Duy-Thanh, Nhut-Minh Ho, Weng-Fai Wong, and Ik-Joon Chang. 2021. "OBET: On-the-Fly Byte-Level Error Tracking for Correcting and Detecting Faults in Unreliable DRAM Systems" Sensors 21, no. 24: 8271. https://doi.org/10.3390/s21248271
APA StyleNguyen, D.-T., Ho, N.-M., Wong, W.-F., & Chang, I.-J. (2021). OBET: On-the-Fly Byte-Level Error Tracking for Correcting and Detecting Faults in Unreliable DRAM Systems. Sensors, 21(24), 8271. https://doi.org/10.3390/s21248271