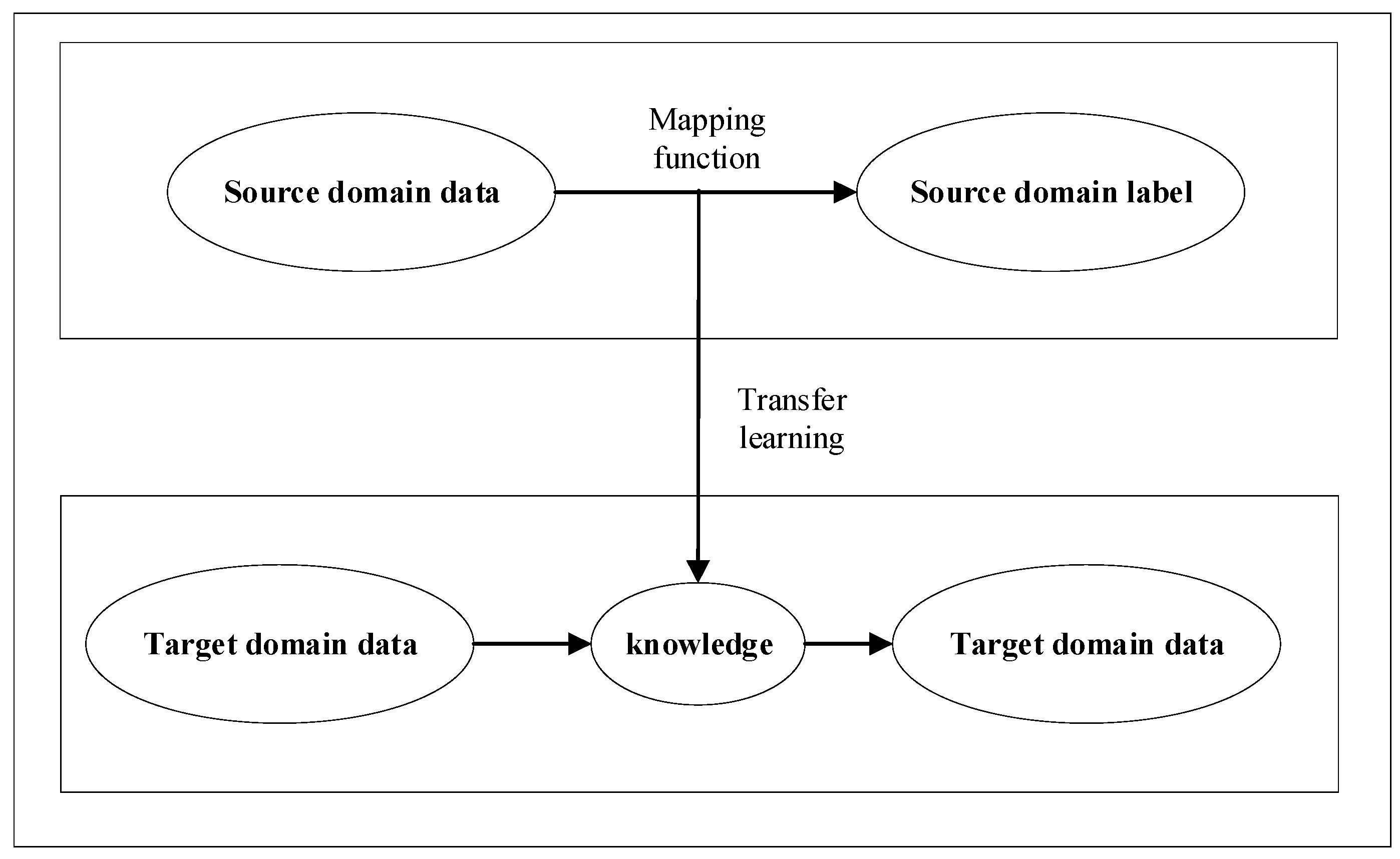
In order to evaluate the effectiveness of the proposed method, this paper conducts experiments on two rotating machinery failure data sets. We explain that the content mainly has the following two parts: the model transfer method FFCNN-SVM, which evaluates the transfer of the source domain model to the target domain model, and the evaluation of the deep CNN model based on knowledge transfer.
4.1. Case One
(1) Data set description and description of some parameters
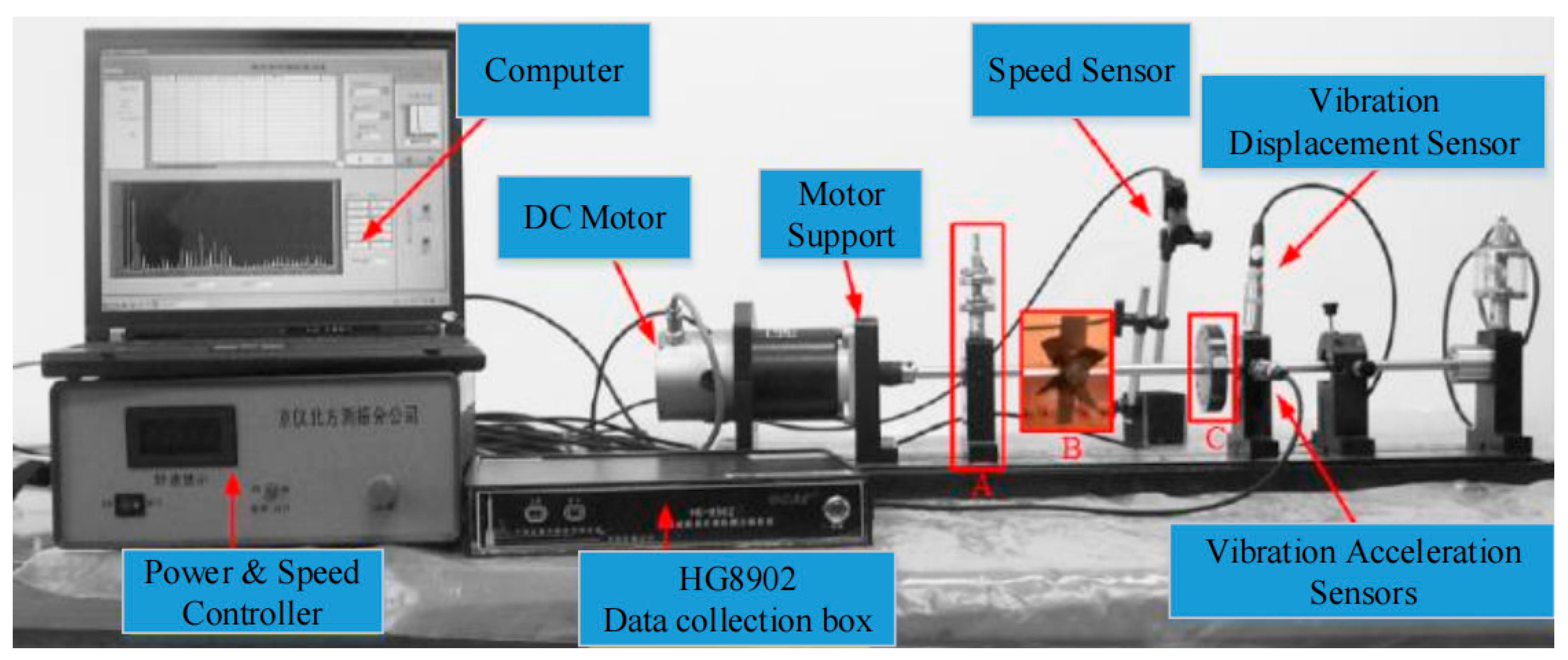
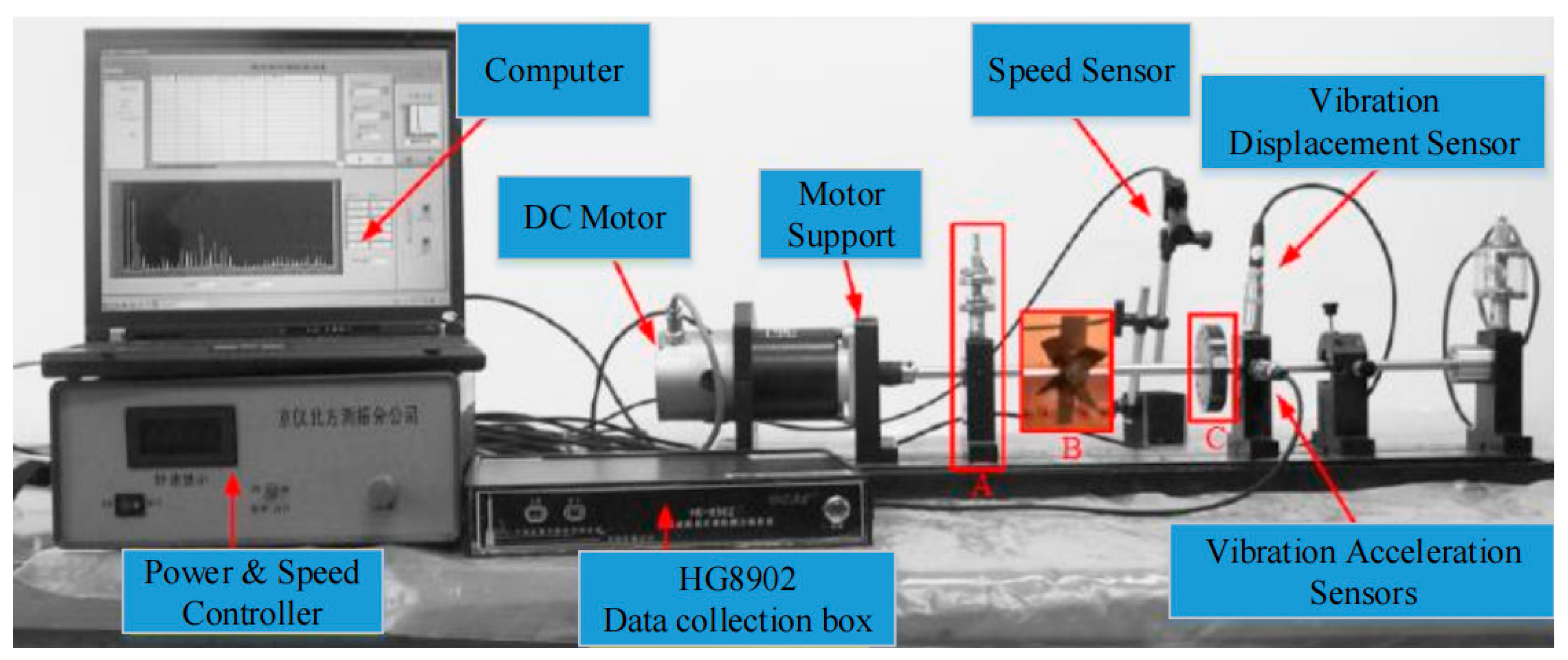
The rotating machinery fault diagnosis data sets we use are all from the ZHS-2 multifunctional motor platform shown in
Figure 5. All signals are collected by the HG8902 data collection box in
Figure 5. In this case, the data set has seven types of faults: Rotor Unbalance I, Rotor Unbalance III, Rotor Unbalance V, Rotor Unbalance VII, Pan Page Break, Pedestal Looseness, and the Normal condition. The four faults of rotor unbalance are simulated by installing different numbers of screws at the position shown in
Figure 5C. The Pan Page Break fault is simulated by installing a page breaker on the drum at the position of
Figure 5B. Pedestal Looseness is simulated by loosening the base bolts at the position of
Figure 5A.
During this experiment, the acquisition time of each sample lasts for 8 s, and there were 8 sensors with different positions, each of which recorded 10,240 data points. A total of 300 samples were collected for each fault type and the normal conditions.
In addition, in order to illustrate the difference between the source domain and the target domain, we divided 2100 samples into two parts. Among them, the Pan Page Break, Pedestal Looseness, Rotor Unbalance I, and the Normal condition are combined, 1200 samples constitute the original data set of the source domain, and Rotor Unbalance III, Rotor Unbalance V, Rotor Unbalance VII, and normal state total 1200 samples constitute the original data set of the target domain. In the target domain, in order to illustrate the small sample status, the training sample capacity of the target domain is 2% of the total data set sample capacity of the target domain, a total of 24, and among these, 24 training samples and test samples are allocated according to 2:1. The remaining 1176 samples together constitute the target domain’s unlabeled sample set. The details are shown in
Table 1.
Among them, the parameters of STFT are set as follows: For the window function, we choose a Hamming window with a length of 256, and its overlap size is 128. After STFT, the original signal of 10,240 sampling points can be turned into a two-dimensional spectrogram with a size of 32 × 128. There are eight sensors to collect waveform signals, so after STFT, the input size of the convolutional neural network is 32 × 128 × 8
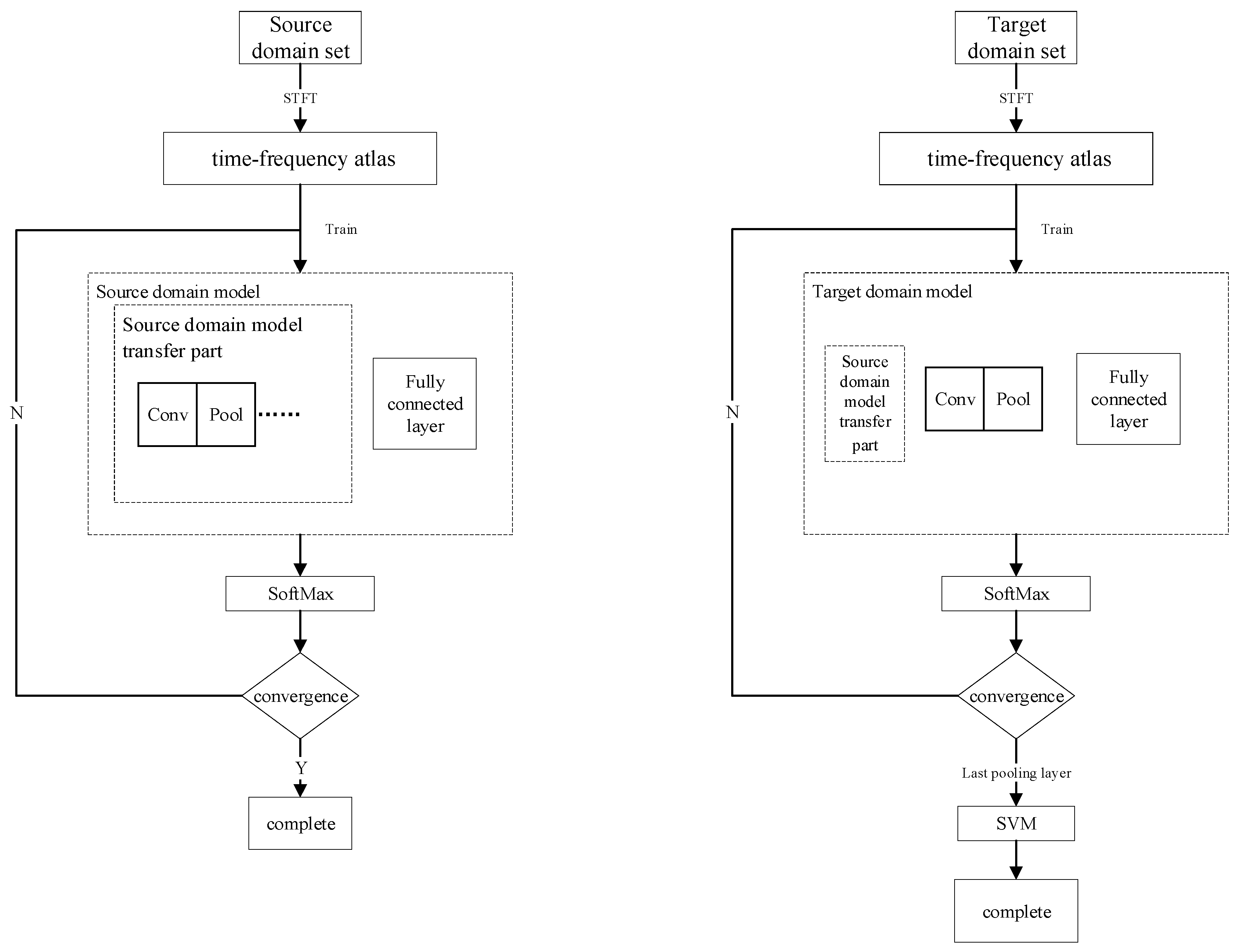
(2) Model transfer method FFCNN-SVM based on feature fusion
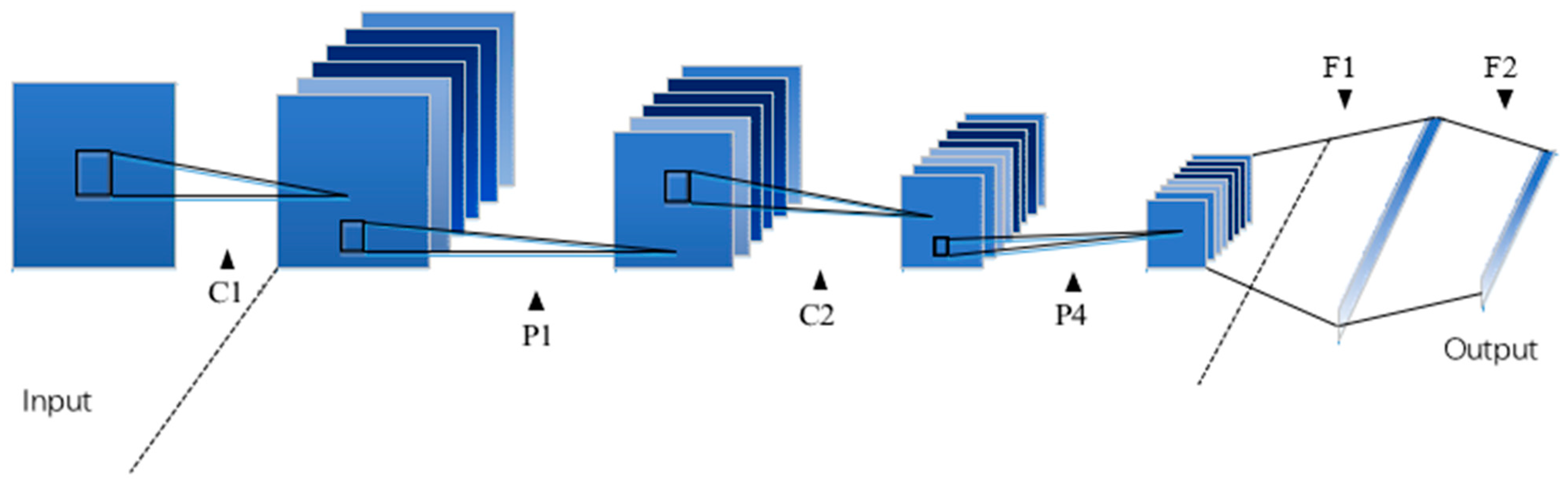
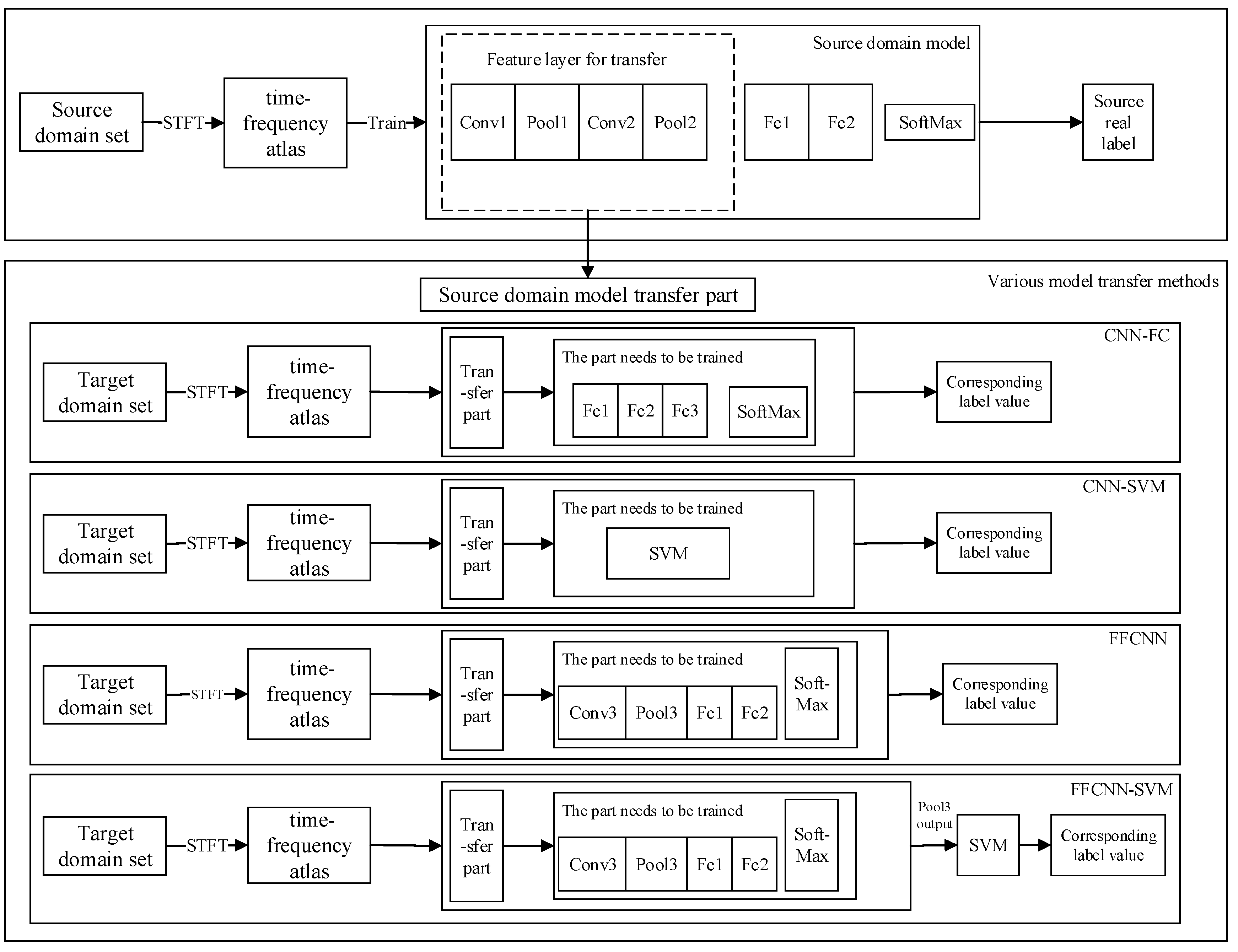
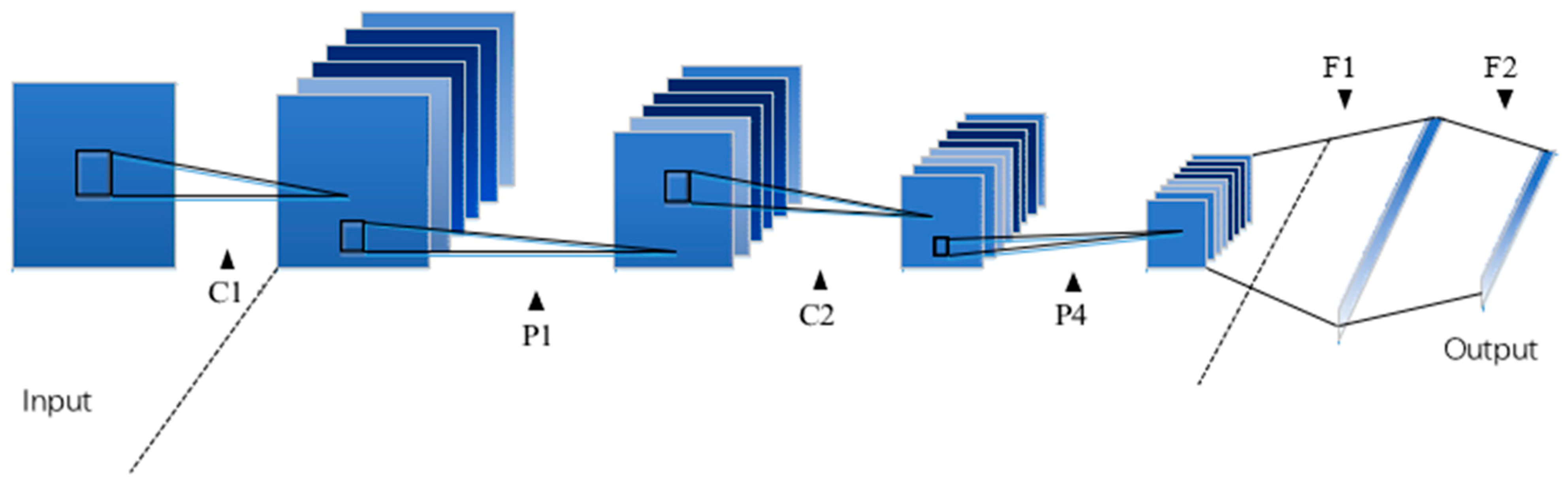
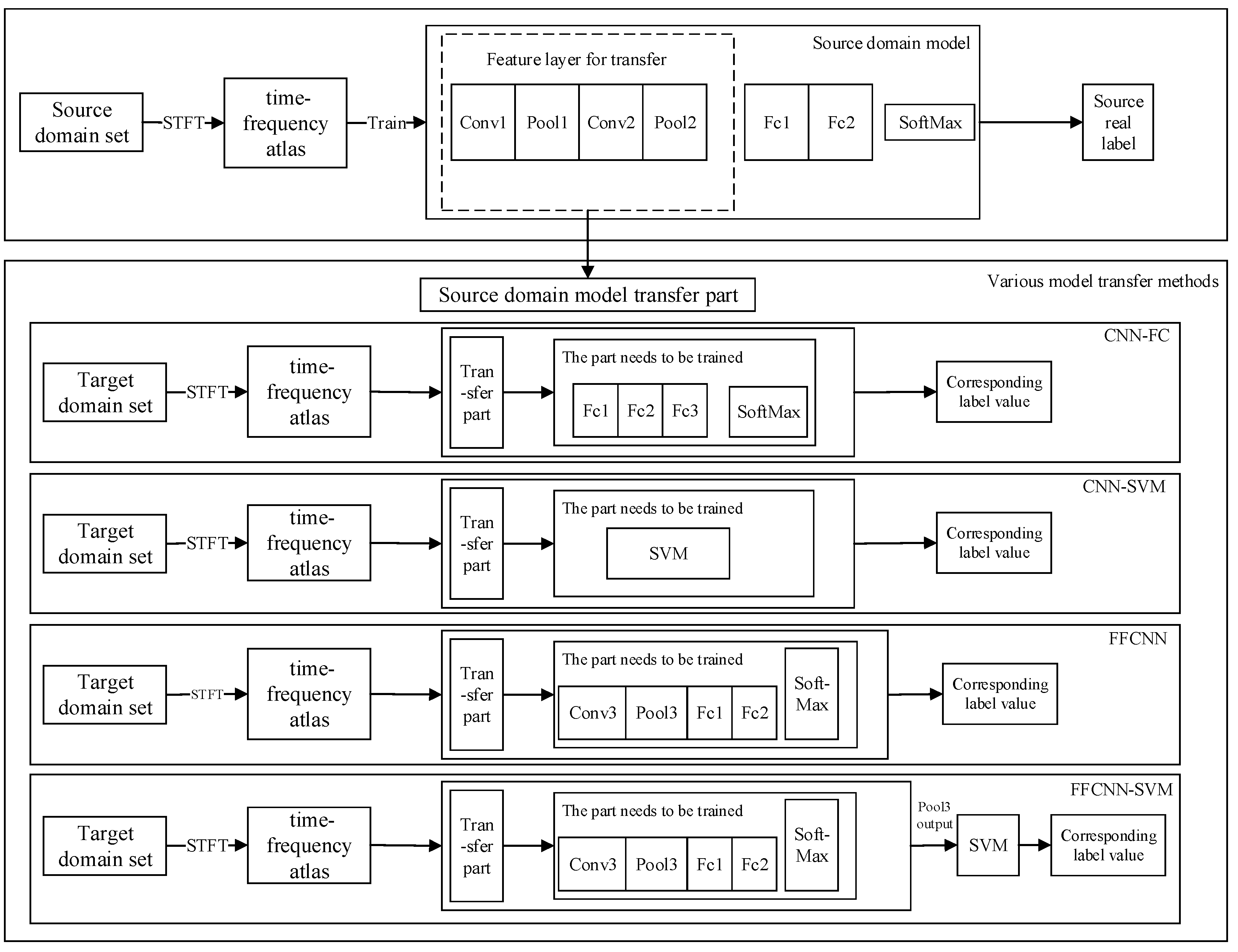
There are many ways to transfer models from the source domain to the target domain. The following will introduce the CNN-FC model transfer method, CNN-SVM model transfer method, FFCNN model transfer method, and FFCNN-SVM model transfer method. The flowchart of various model transfer methods is shown in
Figure 6.
In the simulation process of the FFCNN-SVM experiment, two types of CNN models with different levels of complexity were formed for the preliminary models of the source domain and the target domain. The specific network structure is shown in
Table 2.
Each of the mentioned CNN models has undergone 10,000 iterations with a batch size of 256, and the initial learning rate is set as 0.01. In the iterative process, the learning rate is reduced by 90% every 2500 iterations. The momentum and the decay parameter are set to 0.9 and 5 × 10−6.
After the preliminary model of the target domain is trained, the convolutional layer and pooling layer of the target domain also extract the sample features of the target domain based on the source domain features. After the initial model training converges, connect its final maximum pooling layer to the SVM classifier. Re-input the target domain training set to the model to train the SVM.
In order to compare the FFCNN-SVM method with other model transfer methods and verify in different methods, we compare with the traditional SVM training method used in the target domain, as well as the CNN-FC method, FFCNN, and CNN-SVM method. The schematic diagram of the above several transfer learning methods is shown in
Figure 6. The correct rate of the target domain test set is used as an index to evaluate the ability of model transfer, which is defined as follows:
Here,
is the number of samples that belong to the
category and are predicted to the
category.
is the number of categories.
Table 3 shows the classification accuracy of different methods in this experiment.
It can be seen from
Table 3 that the shallow model using FFCNN-SVM can make a very high fault diagnosis accuracy rate when there is only a small number of training data in the target domain. Therefore, this method is used as a shallow model of the target domain for subsequent marking of a large number of unlabeled samples.
(3) Knowledge-transferring for deep CNN
After pseudo-labeling a large number of unlabeled samples by the FFCNN-SVM model, we combine this part of the sample with the training samples of the target domain to form an ATS. After having the ATS, we already have the conditions to establish our own deep learning framework for the target domain. On this basis, we constructed a CNN, as shown in
Table 4.
Then, use ATS as the training set of the new CNN model. Realize the knowledge transfer of the shallow model. After the new CNN converges, its accuracy on the target domain test set is shown in
Table 5. We can see that the accuracy of the CNN trained with ATS on the same test set is much higher than that of the CNN trained with the original training set of the target domain. This means that the CNN trained by ATS has learned more discriminative characteristics of the fault.
This experimental conclusion shows that our newly constructed CNN has fully adapted to the target domain and can make good fault diagnosis and modification.
4.2. Case Two
(1) Data set description and description of some parameters
The roller bearing data sets we use are all from the public datasets of Case Western Reserve University (CRWU) [
37,
38].
Figure 7 shows the test platform of CRWU. In this case, we used the data with a motor load of 1 horsepower and eight types of faults as our data set: Ball Defect I, Ball Defect II, Ball Defect III, Inner Race Defect I, Inner Race Defect II, Inner Race Defect III, Outer Race Defect I, and Outer Race Defect II. During this experiment, there were three sensors with different positions, each of which recorded 400 data points. A total of 300 samples were collected for each fault type and the normal conditions, and a total of 2400 samples are collected.
To illustrate the transfer effect of the source domain to the target domain, the source domain data set is Ball Defect I, Ball Defect II, Inner Race Defect I, Inner Race Defect II; the target domain data set is Ball Defect III, Inner Race Defect III, Outer Race Defect I, Outer Race Defect II. The details are shown in
Table 6.
Among them, the parameters of STFT are set as follows: For the window function, we choose a Hamming window with a length of 16, and its overlap size is 8. After STFT, the original signal of 40 sampling points can be turned into a two-dimensional spectrogram with a size of 8 × 64. There are three sensors to collect waveform signals, so after STFT, the input size of the convolutional neural network is 8 × 64 × 3.
(2) Model transfer method FFCNN-SVM based on feature fusion
In the process of model transfer from the source domain to the target domain, various transfer methods are shown in
Figure 6 of Case 1. The model structure of the source domain model and the target domain preliminary model is shown in
Table 7.
Table 8 shows the classification accuracy of different methods in this experiment.
It can be seen from
Table 8 that the shallow model using FFCNN-SVM can make a very high fault diagnosis accuracy rate when there is only a small number of training data in the target domain. Therefore, this method is used as a shallow model of the target domain for subsequent marking of a large number of unlabeled samples in the target domain.
(3) Knowledge-transferring for deep CNN
Through the FFCNN-SVM model, a large number of unlabeled data sets in the target domain can be labeled. Then, this part of the data set with pseudo-labels is combined with the training set to form an ATS. After having the ATS, we already have the conditions to establish our own deep learning frame-work for the target domain. On this basis, we build a deep CNN structure to get the final high-accuracy fault diagnosis model. The results of the fault diagnosis experiment on the test tags can be seen in
Table 9.
This experimental conclusion shows that our newly constructed CNN has fully adapted to the target domain and can make good fault diagnosis and modification.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}