
Swin-HSTPS: Research on Target Detection Algorithms for Multi-Source High-Resolution Remote Sensing Images


Abstract
:1. Introduction
2. Related Work
3. Target Detection Algorithm Optimization
3.1. Model Construction
3.2. Incorporate MixUp Hybrid Enhancement Algorithm
3.3. Join PReLU Activation Function
3.4. Evaluation Index of Detection Algorithm
4. Results and Discussion
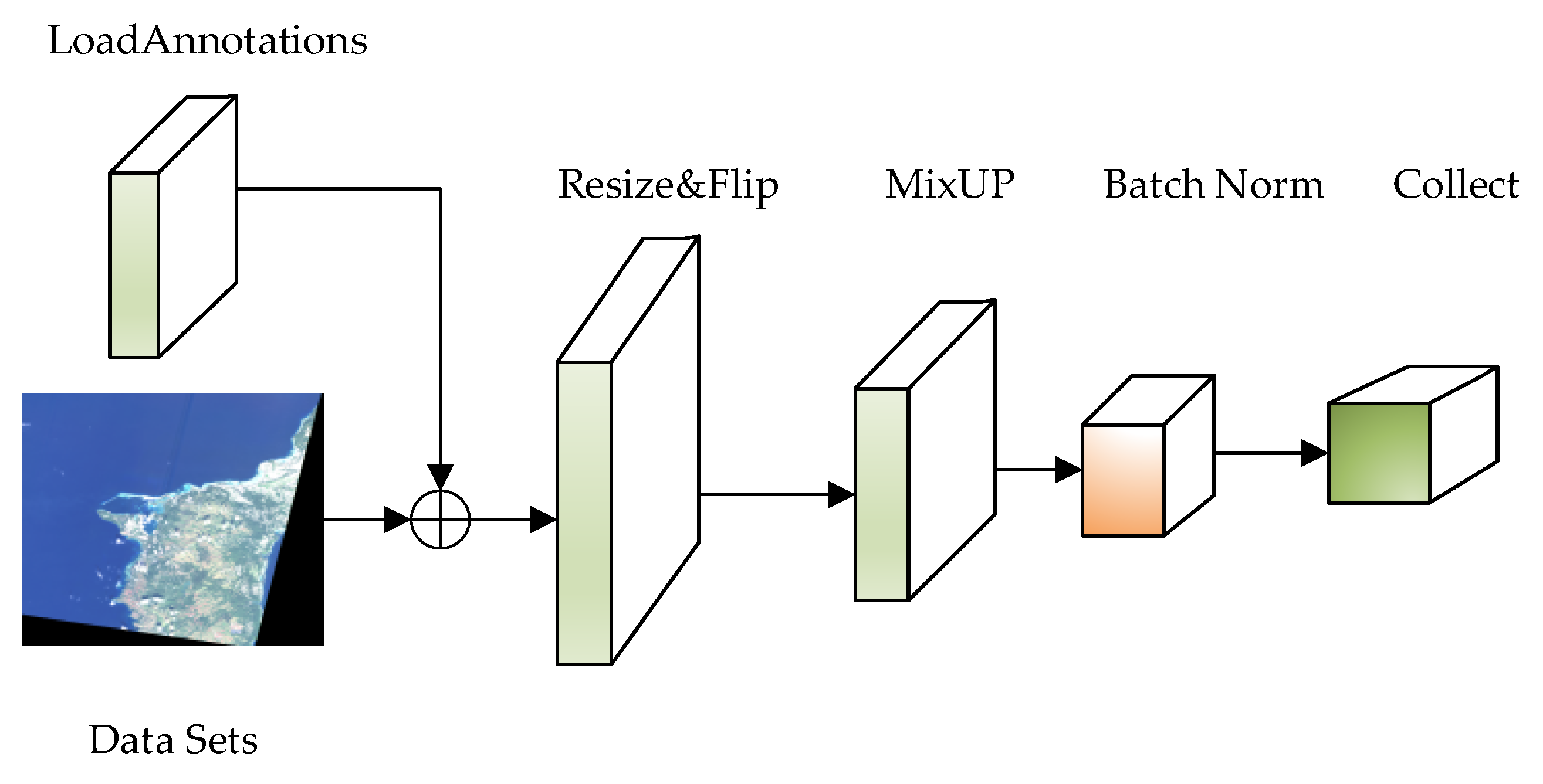
4.1. Data Sets and Processing
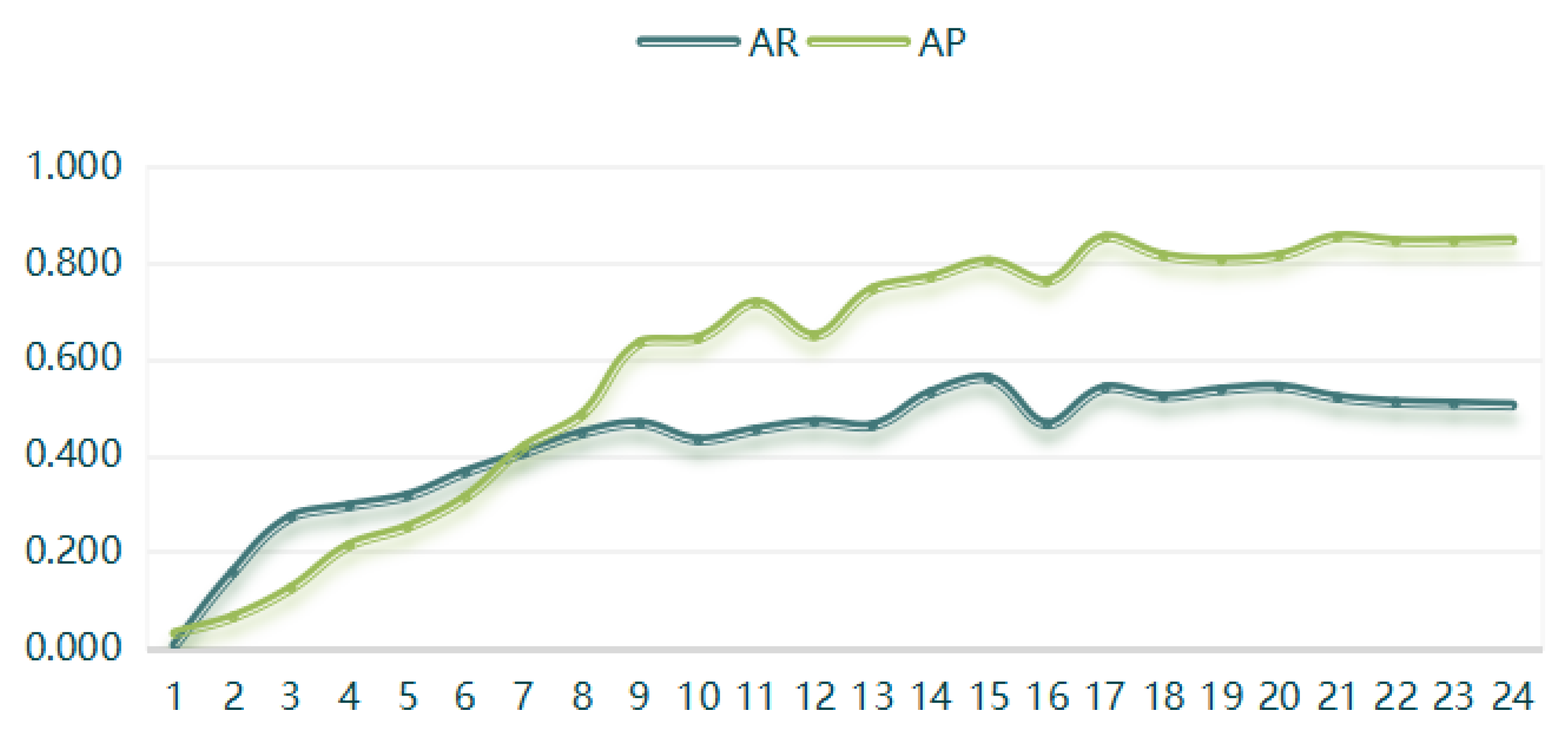
4.2. Model Training Results
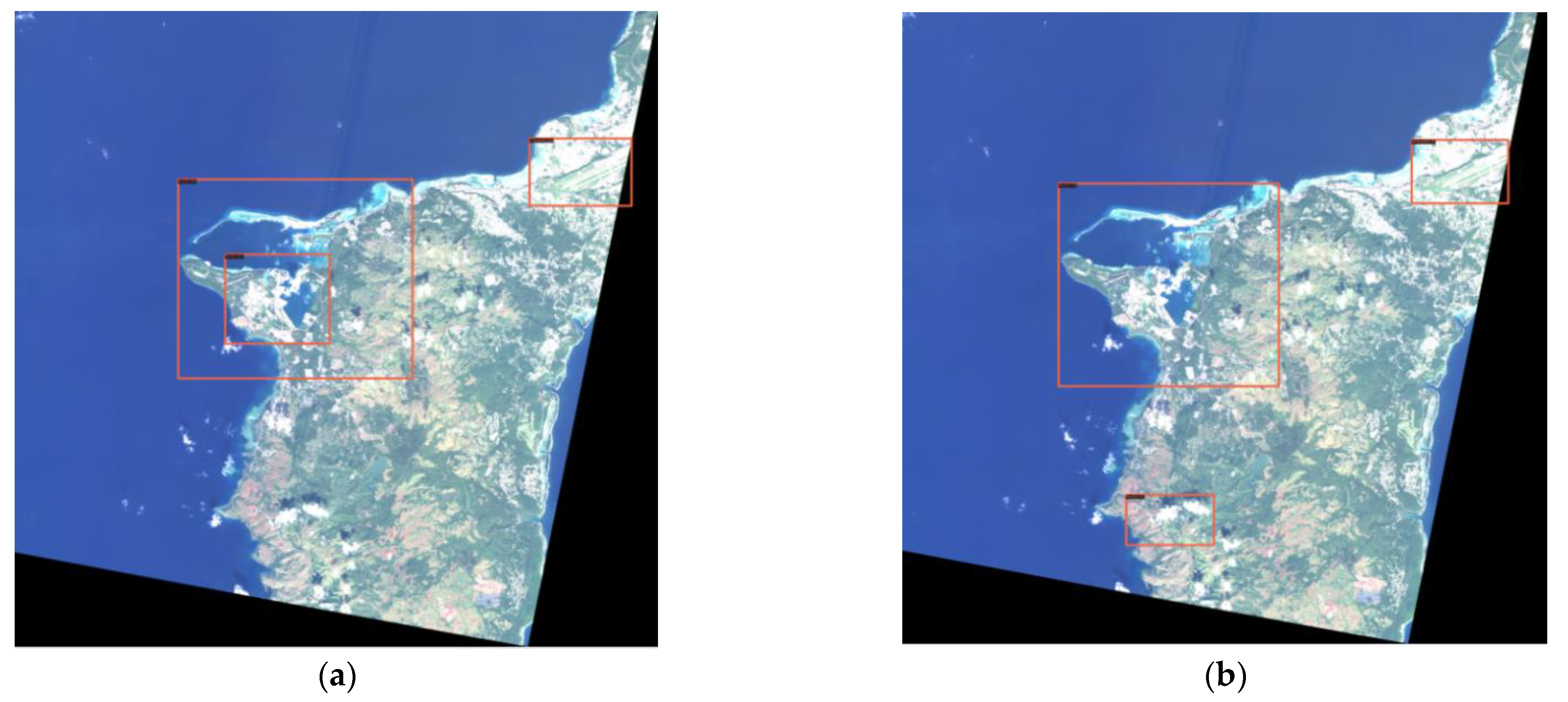
4.3. Model Prediction Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- CHAIHL. Research on Port Target in Remote Sensing Images Based on Knowledge; University of Electronic Science and Technology of China: Chengdu, China, 2015. [Google Scholar]
- Yuan, M.Y.; Jiang, T.; Wang, X. Aircraft target detection in remote sensing image based on improved YOLOv3 algorithm. J. Geomat. Sci. Technol. 2019, 36, 614–619. [Google Scholar]
- Tian, T.; Li, C.; Xu, J.; Ma, J. Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors 2018, 18, 904. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Zhang, L.; Shi, W.; Liu, Y. Airport Extraction via Complementary Saliency Analysis and Saliency-Oriented Active Contour Model. IEEE Geoence Remote. Sens. Lett. 2018, 15, 1085–1089. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.; Liu, Y.; Jin, L.; Xie, Z. DeRPN: Taking a further step toward more general object detection. arXiv 2018, arXiv:1811.06700. [Google Scholar] [CrossRef] [Green Version]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Confer-ence on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv Prepr. 2021, arXiv:2103.14030. [Google Scholar]
- Chen, K.; Wang, J.; Pang., J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv Prepr. 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification CVPR. Available online: https://openaccess.thecvf.com/content_iccv_2015/html/He_Delving_Deep_into_ICCV_2015_paper.html (accessed on 7 September 2021).
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. MixUP: Beyond Empirical Risk Minimization. arXiv Prepr. 2017, arXiv:1710.09412. [Google Scholar]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic r-cnn: Towards high quality object detection via dynamic training. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; Volume 12360, pp. 260–275. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. IEEE 2016, 3, 5. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable {detr}: Deformable transformers for end-to-end object detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021; p. 3. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. arXiv Prepr. 2021, arXiv:2101.11986. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv Prepr. 2020, arXiv:2004.10934. [Google Scholar]
- Girshick, R. Fast R-CNN. Comput. Vis. Found 2015, 1440–1448. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. arXiv Prepr. 2020, arXiv:2011.12450. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. IEEE Comput. Soc. 2013, 3, 5. [Google Scholar]
- Chu, X.; Zhang, B.; Tian, Z.; Wei, X.; Xia, H. Do we really need explicit position encodings for vision transformers? arXiv Prepr. 2021, arXiv:2102.10882. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. arXiv 2019, arXiv:1906.05909. [Google Scholar]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. arXiv Prepr. 2021, arXiv:2101.11605. [Google Scholar]
- Tay, Y.; Dehghani, M.; Abnar, S.; Shen, Y.; Bahri, D.; Pham, P.; Rao, J.; Yang, L.; Ruder, S.; Metzler, D. Long range arena: A benchmark for efficient transformers. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; et al. Unilmv2: Pseudo-masked language models for unified language model pretraining. In Proceedings of the International Con-ference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 642–652. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Nonlocal networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv Prepr. 2015, arXiv:1505.00853. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll´ar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Labellmg. Available online: https://github.com/tzutalin/labelImg (accessed on 7 September 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (α, β) | Image Size | ||
|---|---|---|---|
| (5, 1) | 2242 | 67.1 | 26.6 |
| (2, 5) | 2242 | 74.6 | 46.9 |
| (1, 3) | 2242 | 63 | 35 |
| (0.5, 0.5) | 2242 | 85.3 | 49.3 |
| (2, 2) | 2242 | 80.3 | 45.7 |
| Image Size | |||
|---|---|---|---|
| 0 | 2242 | 66.2 | 32.6 |
| 0.25 | 2242 | 76.3 | 41.8 |
| 0.4 | 2242 | 78.0 | 42.0 |
| 0.45 | 2242 | 85.3 | 49.3 |
| 0.5 | 2242 | 74.7 | 41.8 |
| 0.6 | 2242 | 72.5 | 41.6 |
| Model | Image Size | #Param. | FLOPs | ||
|---|---|---|---|---|---|
| R-CNN | 2242 | 126.65 M | 467.76 G | 58.3 | 40.4 |
| Swin Transformer | 2242 | 135.778 M | 814.719 G | 77.1 | 47.5 |
| Swin-HSTPS | 2242 | 135.778 M | 814.727 G | 85.3 | 49.3 |
| YOLOv5 | 2242 | - | - | 66.67 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, K.; Ouyang, J.; Hu, B. Swin-HSTPS: Research on Target Detection Algorithms for Multi-Source High-Resolution Remote Sensing Images. Sensors 2021, 21, 8113. https://doi.org/10.3390/s21238113
Fang K, Ouyang J, Hu B. Swin-HSTPS: Research on Target Detection Algorithms for Multi-Source High-Resolution Remote Sensing Images. Sensors. 2021; 21(23):8113. https://doi.org/10.3390/s21238113
Chicago/Turabian StyleFang, Kun, Jianquan Ouyang, and Buwei Hu. 2021. "Swin-HSTPS: Research on Target Detection Algorithms for Multi-Source High-Resolution Remote Sensing Images" Sensors 21, no. 23: 8113. https://doi.org/10.3390/s21238113
APA StyleFang, K., Ouyang, J., & Hu, B. (2021). Swin-HSTPS: Research on Target Detection Algorithms for Multi-Source High-Resolution Remote Sensing Images. Sensors, 21(23), 8113. https://doi.org/10.3390/s21238113