
Convolution-Based Encoding of Depth Images for Transfer Learning in RGB-D Scene Classification


Abstract
:1. Introduction
2. Related Work
2.1. Scene Classification Using Features Extracted
2.2. Scene Classification Using Neural Networks
2.3. Scene Recognition Using RGB-D Images
2.4. Class Balancing
3. Benchmark Dataset
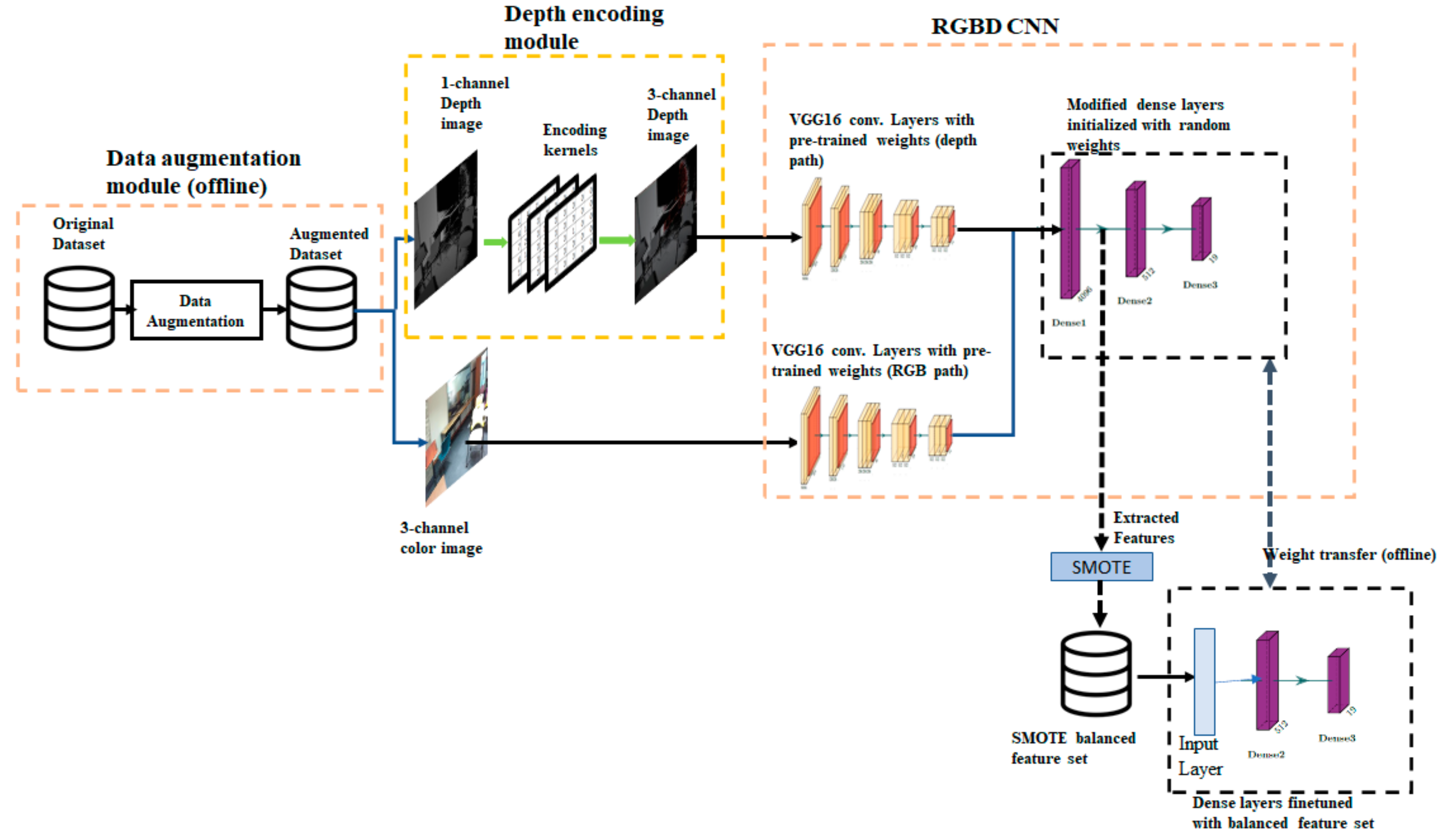
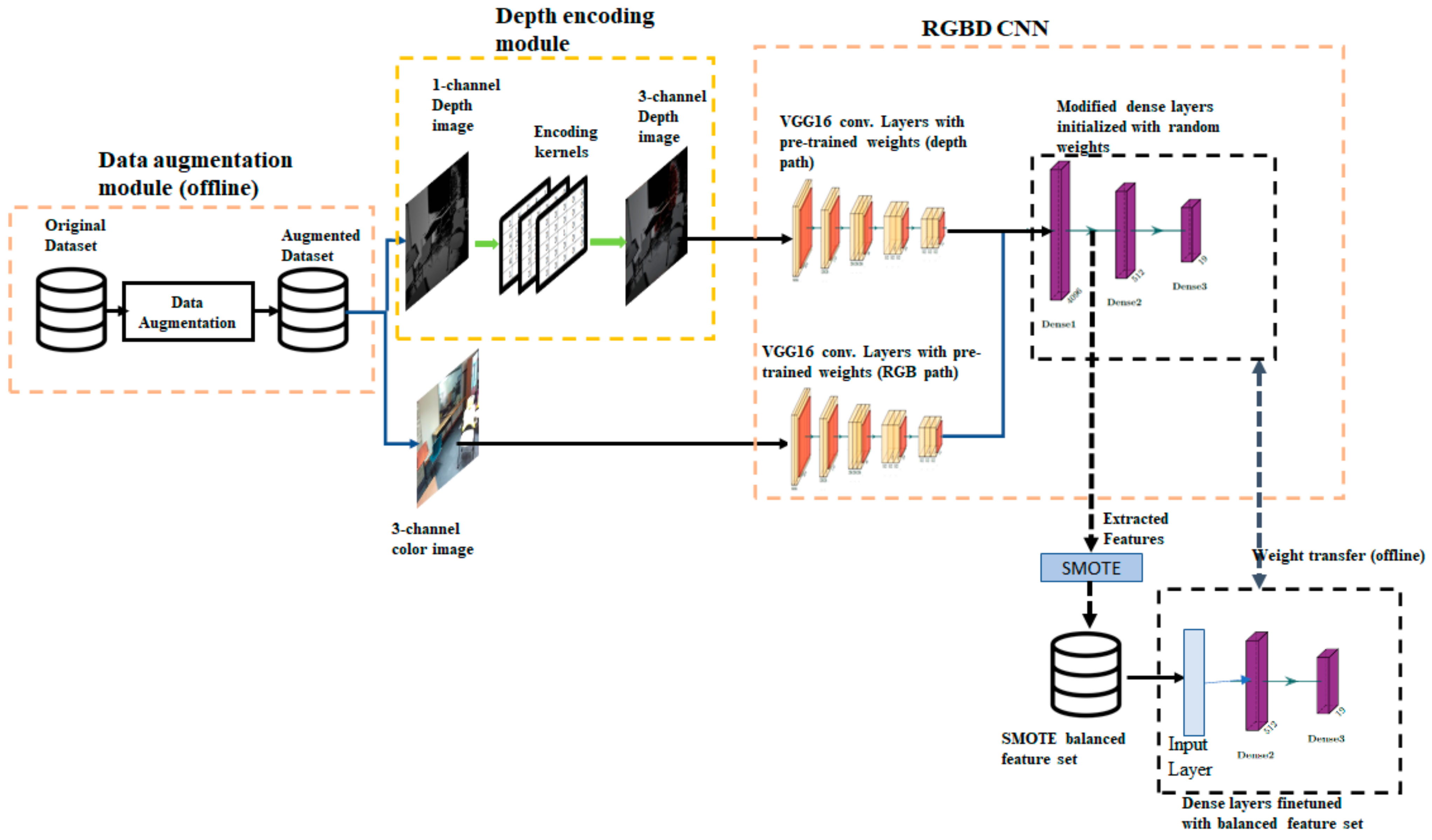
4. Architecture of the Proposed Method
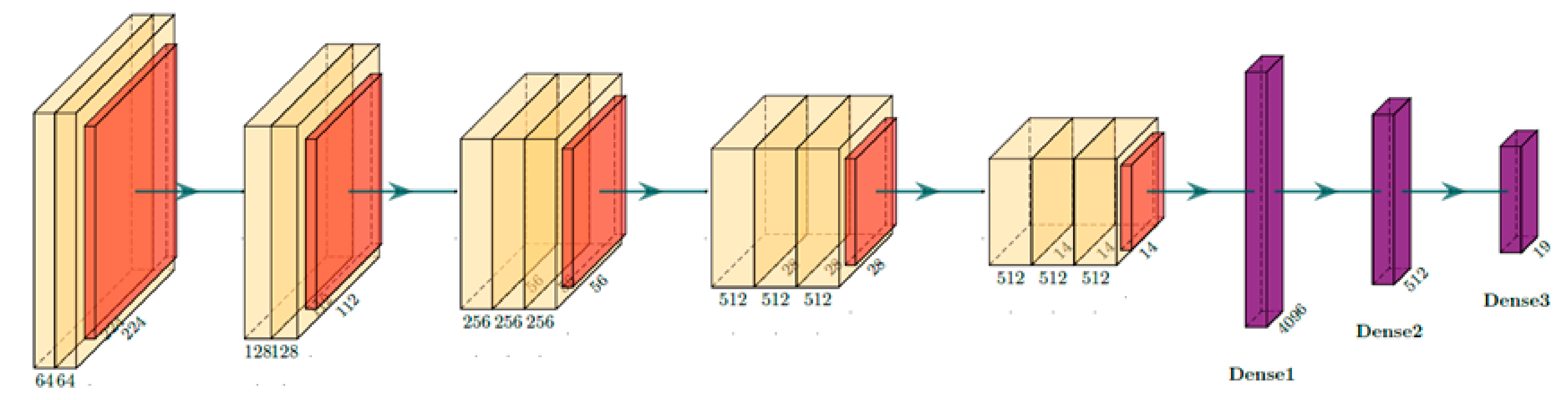
4.1. VGG Convolutional Network
Network with Two Convolutional Paths
4.2. Data Augmentation Module
Data Augmentation Method
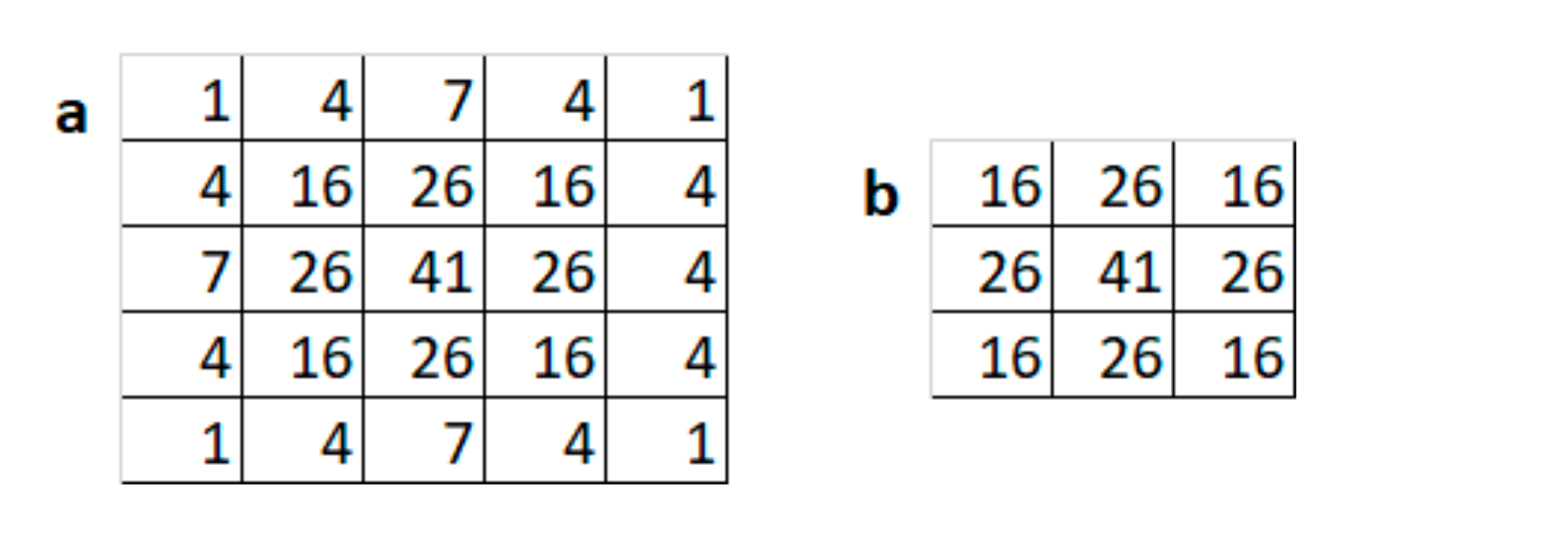
4.3. Depth Encoding Module
Implementing Encoding Filters Using a Convolutional Layer
4.4. SMOTE Oversampling and Fine-Tuning of Dense Layers
- Step 1.
- Train RGBD CNN using the augmented training set.
- Step 2.
- Using the trained network, extract a feature vector for each sample in the training set to create a feature dataset.
- Step 3.
- Apply SMOTE oversampling on the feature dataset to create a balanced feature set.
- Step 4.
- Create a new neural network consisting of only dense layers matching the dense layers of RGBD CNN. Copy the weights from the trained RGBD CNN to the new network.
- Step 5.
- Train the newly created network using the balance feature set.
- Step 6.
- Copy the weights from the new network to the dense layers of the trained RGBD CNN.
5. Experimental Setup
5.1. Dataset for Training and Validation
5.2. Ablation Study on VGG16-PlacesNet Configurations for Transfer Learning
5.3. Implementation of the Depth Encoding Module
6. Experimental Results and Analysis
- RGBD CNN with HHA: This set of experiments used the benchmark dataset without data augmentation. Depth images were encoded using HHA encoding. Hence the CBE encoding module was not used and the three channel HHA encoded images are given as input to the first layer of RGBD CNN
- RGBD CNN with HHA + DA: This set of experiments used a setup similar to the one in setup 1. However, the training dataset with data augmentation was used for training.
- RGBD CNN with CBE: RGBD CNN with added CBE layer was used in this setup. Dataset without data augmentation was used for training.
- RGBD CNN with CBE + DA: Network architecture in this setup is similar to the one in setup 3, i.e., RGBD CNN with added CBE layer. Dataset with data augmentation was used for training
- RGBD CNN with CBE + DA + SMOTE: This setup used RGBD CNN with added CBE layer and data augmentation and class balancing using SMOTE.
6.1. Experimental Results with Data Augmentation and Convolution-Based Encoding
6.1.1. Data Augmentation
6.1.2. Convolution-Based Encoding
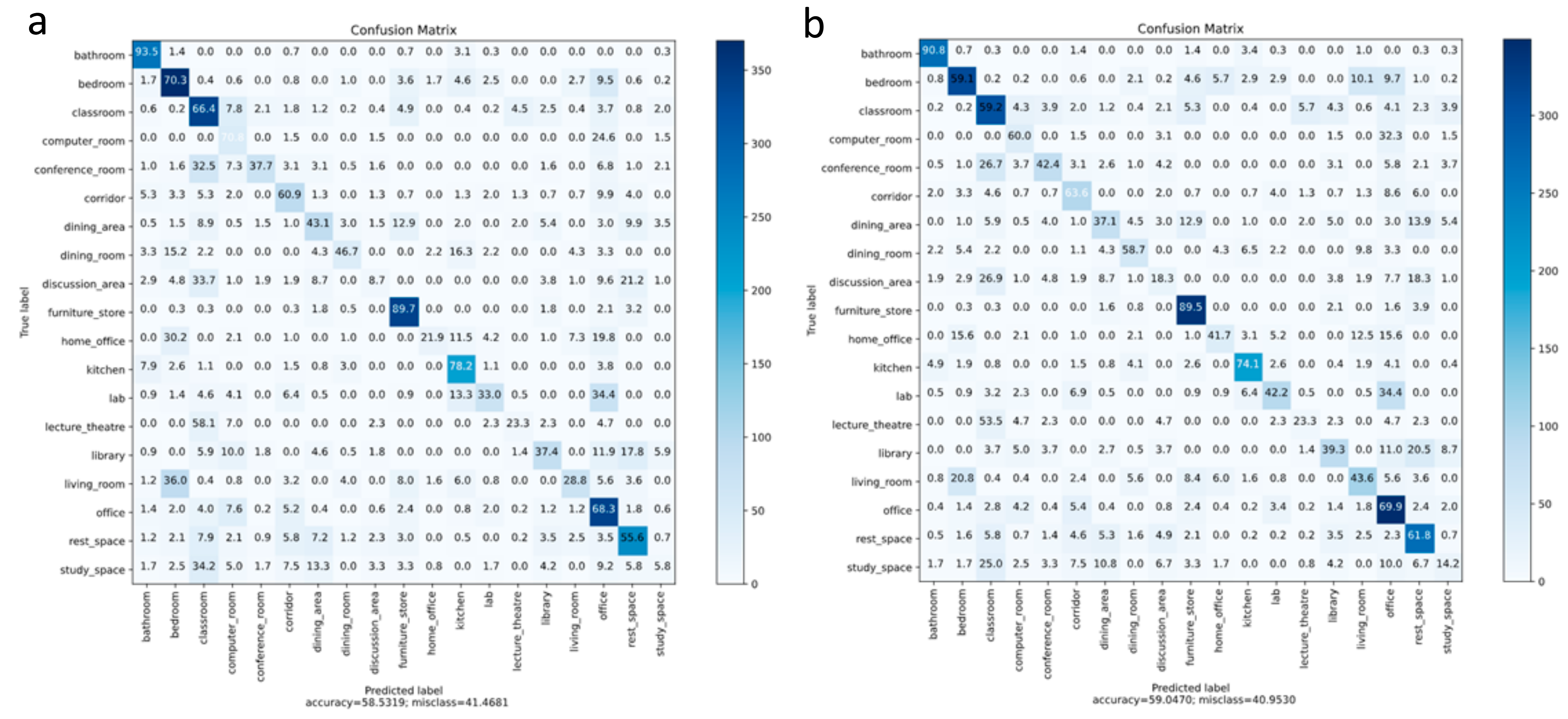
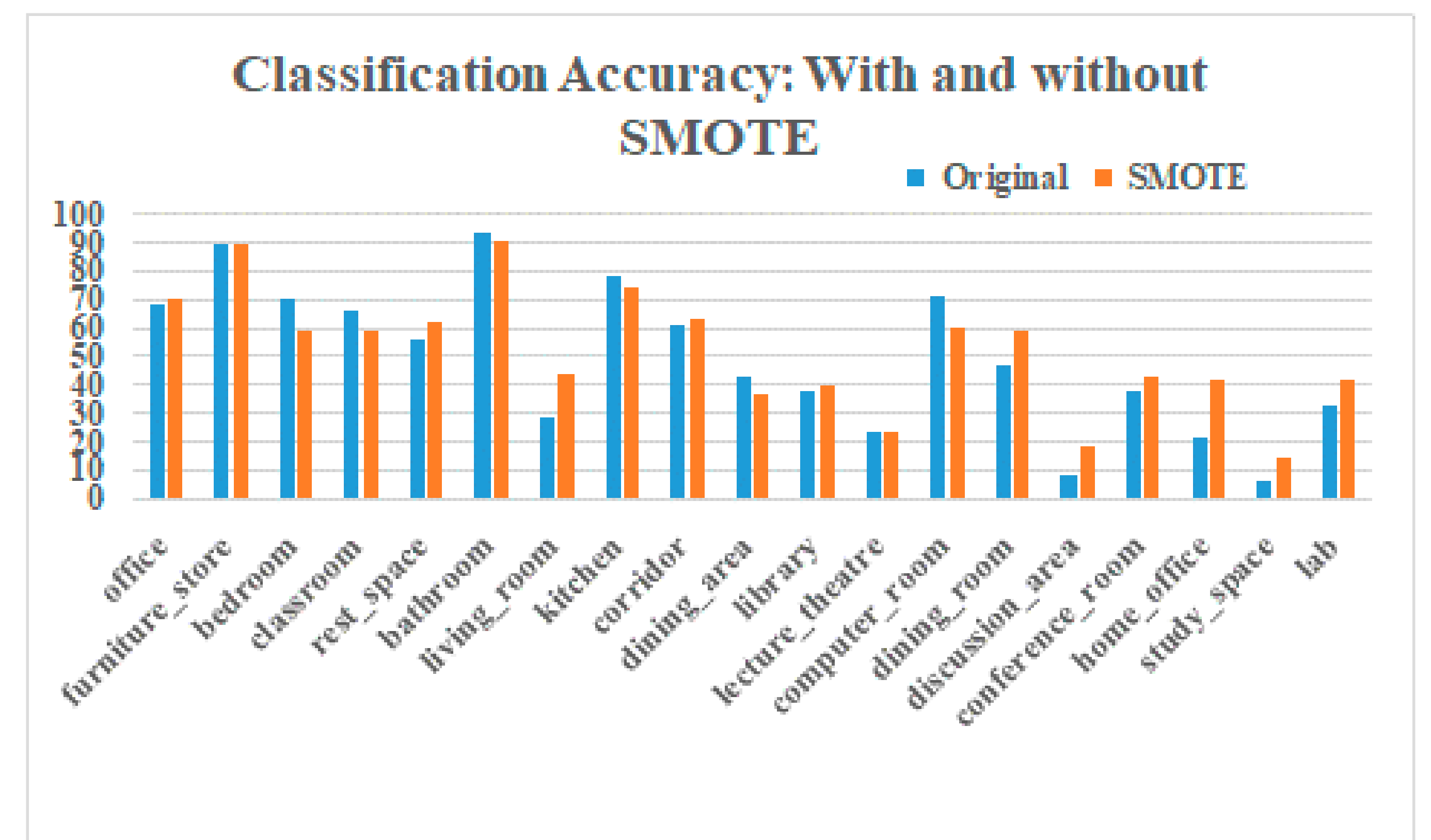
6.2. Experimental Results with Oversampling
6.3. Comparison with Existing Methods
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Breuer, T.; Macedo, G.R.G.; Hartanto, R.; Hochgeschwender, N.; Holz, D.; Hegger, F.; Jin, Z.; Müller, C.; Paulus, J.; Reckhaus, M.; et al. Johnny: An Autonomous Service Robot for Domestic Environments. J. Intell. Robot. Syst. 2012, 66, 245–272. [Google Scholar] [CrossRef]
- Goher, K.M.; Mansouri, N.; Fadlallah, S.O. Assessment of personal care and medical robots from older adults’ perspective. Robot. Biomim. 2017, 4, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gopalapillai, R.; Gupta, D. Object Boundary Identification using Two-phase Incremental Clustering. Procedia Comput. Sci. 2020, 171, 235–243. [Google Scholar] [CrossRef]
- Gopalapillai, R.; Gupta, D.; Sudarshan, T.S.B. Experimentation and Analysis of Time Series Data for Rescue Robotics. In Recent Advances in Intelligent Informatics; Advances in Intelligent Systems and Computing; Thampi, S., Abraham, A., Pal, S., Rodriguez, J., Eds.; Springer: Cham, Switzerland, 2014; Volume 235, pp. 443–453. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Romero-González, C.; Martínez-Gómez, J.; García-Varea, I.; Rodríguez-Ruiz, L. On robot indoor scene classification based on descriptor quality and efficiency. Expert. Syst. Appl. 2017, 79, 181–193. [Google Scholar] [CrossRef]
- Gopalapillai, R.; Gupta, D.; Sudarshan, T.S.B. Pattern identification of robotic environments using machine learning techniques. Procedia Comput. Sci. 2017, 115, 63–71. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kam, M.; Xiaoxun, Z.; Kalata, P. Sensor fusion for mobile robot navigation. Proc. IEEE 1997, 85, 108–119. [Google Scholar] [CrossRef]
- Mimouna, A.; Alouani, I.; Ben Khalifa, A.; El Hillali, Y.; Taleb-Ahmed, A.; Menhaj, A.; Ouahabi, A.; Ben Amara, N.E. OLIMP: A Heterogeneous Multimodal Dataset for Advanced Environment Perception. Electronics 2020, 9, 560. [Google Scholar] [CrossRef] [Green Version]
- Radhakrishnan, G.; Gupta, D.; Abhishek, R.; Ajith, A.; Tsb, S. Analysis of multimodal time series data of robotic environment. In Proceedings of the 12th International Conference on Intelligent Systems Design and Applications (ISDA), Kochi, India, 27–29 November 2012; pp. 734–739. [Google Scholar]
- De Silva, V.; Roche, J.; Kondoz, A. Robust fusion of LiDAR and wide-angle camera data for autonomous mobile robots. Sensors 2018, 18, 2730. [Google Scholar] [CrossRef] [Green Version]
- Gopalapillai, R.; Gupta, D.; Sudarshan, T.S.B. Robotic sensor data analysis using stream data mining techniques. Int. J. Eng. Technol. 2018, 7, 3967–3973. [Google Scholar]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; pp. 1150–1157. [Google Scholar]
- Johnson, A.; Hebert, M. Using spin images for efficient object recognition in cluttered 3D scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelop. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Wu, J.; Rehg, J.M. CENTRIST: A Visual Descriptor for Scene Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 33, 1489–1501. [Google Scholar]
- Xie, L.; Lee, F.; Liu, L.; Kotani, K.; Chen, Q. Scene recognition: A comprehensive survey. Pattern Recognit. 2020, 102, 107205. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Li, G.; Ji, Z.; Chang, Y.; Li, S.; Qu, X.; Cao, D. ML-ANet: A Transfer Learning Approach Using Adaptation Network for Multi-label Image Classification in Autonomous Driving. Chin. J. Mech. Eng. 2021, 34, 78. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl. Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- Bai, S. Growing random forest on deep convolutional neural networks for scene categorization. Expert Syst. Appl. 2017, 71, 279–287. [Google Scholar] [CrossRef]
- Damodaran, N.; Sowmya, V.; Govind, D.; Soman, K.P. Single-plane scene classification using deep convolution features. In Soft Computing and Signal Processing; Springer: Singapore, 2019; pp. 743–752. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Computer Vision—ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Eitel, A.J.; Springenberg, T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef] [Green Version]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Computer Vision—ECCV 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 345–360. [Google Scholar]
- Zhu, H.; Weibel, J.; Lu, S. Discriminative multi-modal feature fusion for RGBD indoor scene recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2969–2976. [Google Scholar]
- Liao, Y.; Kodagoda, S.; Wang, Y.; Shi, L.; Liu, Y. Understand scene categories by objects: A semantic regularized scene classifier using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), New York, NY, USA, 16–21 May 2016; pp. 2318–2325. [Google Scholar]
- Li, Y.; Zhang, J.; Cheng, Y.; Huang, K.; Tan, T. DF2Net: Discriminative feature learning and fusion network for rgb-d indoor scene classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7041–7048. [Google Scholar]
- Song, X.; Jiang, S.; Herranz, L.; Chen, C. Learning effective RGB-D representations for scene recognition. IEEE Trans. Image Process. 2019, 28, 980–993. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.; Yuan, Y.; Wang, Q. RGB-D Scene recognition via spatial-related multi-modal feature learning. IEEE Access 2019, 7, 106739–106747. [Google Scholar] [CrossRef]
- Xiong, Z.; Yuan, Y.; Wang, Q. ASK: Adaptively selecting key local features for RGB-D scene recognition. IEEE Trans. Image Process. 2021, 30, 2722–2733. [Google Scholar] [CrossRef]
- Fooladgar, F.; Kasaei, S. A survey on indoor RGB-D semantic segmentation: From hand-crafted features to deep convolutional neural networks. Multimed. Tools Appl. 2020, 79, 4499–4524. [Google Scholar] [CrossRef]
- Du, D.; Wang, L.; Wang, H.; Zhao, K.; Wu, G. Translate-to-recognize networks for RGB-D scene recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 11836–11845. [Google Scholar]
- Ayub, A.; Wagner, A.R. Centroid Based Concept Learning for RGB-D Indoor Scene Classification. In Proceedings of the British Machine Vision Conference (BMVC), Virtual Event, UK, 7–10 September 2020. [Google Scholar]
- Yuan, Y.; Xiong, Z.; Wang, Q. ACM: Adaptive Cross-Modal Graph Convolutional Neural Networks for RGB-D Scene Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9176–9184. [Google Scholar]
- Naseer, M.; Khan, S.; Porikli, F. Indoor scene understanding in 2.5/3D for autonomous agents: A survey. IEEE Access 2018, 7, 1859–1887. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Lee, Y.; Jeon, M. Imbalanced image classification with complement cross entropy. Pattern Recognit. Lett. 2021, 151, 33–40. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, X.; Ma, Y.; Yang, Q.; Wang, C.; Liu, H.; Qi, Q. Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sens. 2020, 12, 3547. [Google Scholar] [CrossRef]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Janoch, A.; Karayev, S.; Jia, Y.; Barron, J.T.; Fritz, M.; Saenko, K.; Darrell, T. A category-level 3-d object dataset: Putting the kinect to work. In Proceedings of the ICCV Workshop on Consumer Depth Cameras for Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. SUN3D: A database of big spaces reconstructed using SfM and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl. No. | Class Label | Numbers of Images |
|---|---|---|
| 1 | bathroom | 624 |
| 2 | bedroom | 1084 |
| 3 | classroom | 1023 |
| 4 | computer_room | 179 |
| 5 | conference_room | 290 |
| 6 | corridor | 373 |
| 7 | dining_area | 397 |
| 8 | dining_room | 200 |
| 9 | discussion_area | 201 |
| 10 | furniture_store | 965 |
| 11 | home_office | 169 |
| 12 | kitchen | 498 |
| 13 | lab | 258 |
| 14 | lecture_theatre | 176 |
| 15 | library | 381 |
| 16 | living_room | 524 |
| 17 | office | 1046 |
| 18 | rest_space | 924 |
| 19 | study_space | 192 |
| Network Configuration | Classification Accuracy | |
|---|---|---|
| Without DA | With DA | |
| RGBD CNN with HHA | 54.7% | 57.3 |
| RGBD CNN with CBE | 55.07% | 58.3 |
| RGBD CNN with CBE + SMOTE | 59.05% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gopalapillai, R.; Gupta, D.; Zakariah, M.; Alotaibi, Y.A. Convolution-Based Encoding of Depth Images for Transfer Learning in RGB-D Scene Classification. Sensors 2021, 21, 7950. https://doi.org/10.3390/s21237950
Gopalapillai R, Gupta D, Zakariah M, Alotaibi YA. Convolution-Based Encoding of Depth Images for Transfer Learning in RGB-D Scene Classification. Sensors. 2021; 21(23):7950. https://doi.org/10.3390/s21237950
Chicago/Turabian StyleGopalapillai, Radhakrishnan, Deepa Gupta, Mohammed Zakariah, and Yousef Ajami Alotaibi. 2021. "Convolution-Based Encoding of Depth Images for Transfer Learning in RGB-D Scene Classification" Sensors 21, no. 23: 7950. https://doi.org/10.3390/s21237950
APA StyleGopalapillai, R., Gupta, D., Zakariah, M., & Alotaibi, Y. A. (2021). Convolution-Based Encoding of Depth Images for Transfer Learning in RGB-D Scene Classification. Sensors, 21(23), 7950. https://doi.org/10.3390/s21237950