
One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention


Abstract
:1. Introduction
2. Related Work
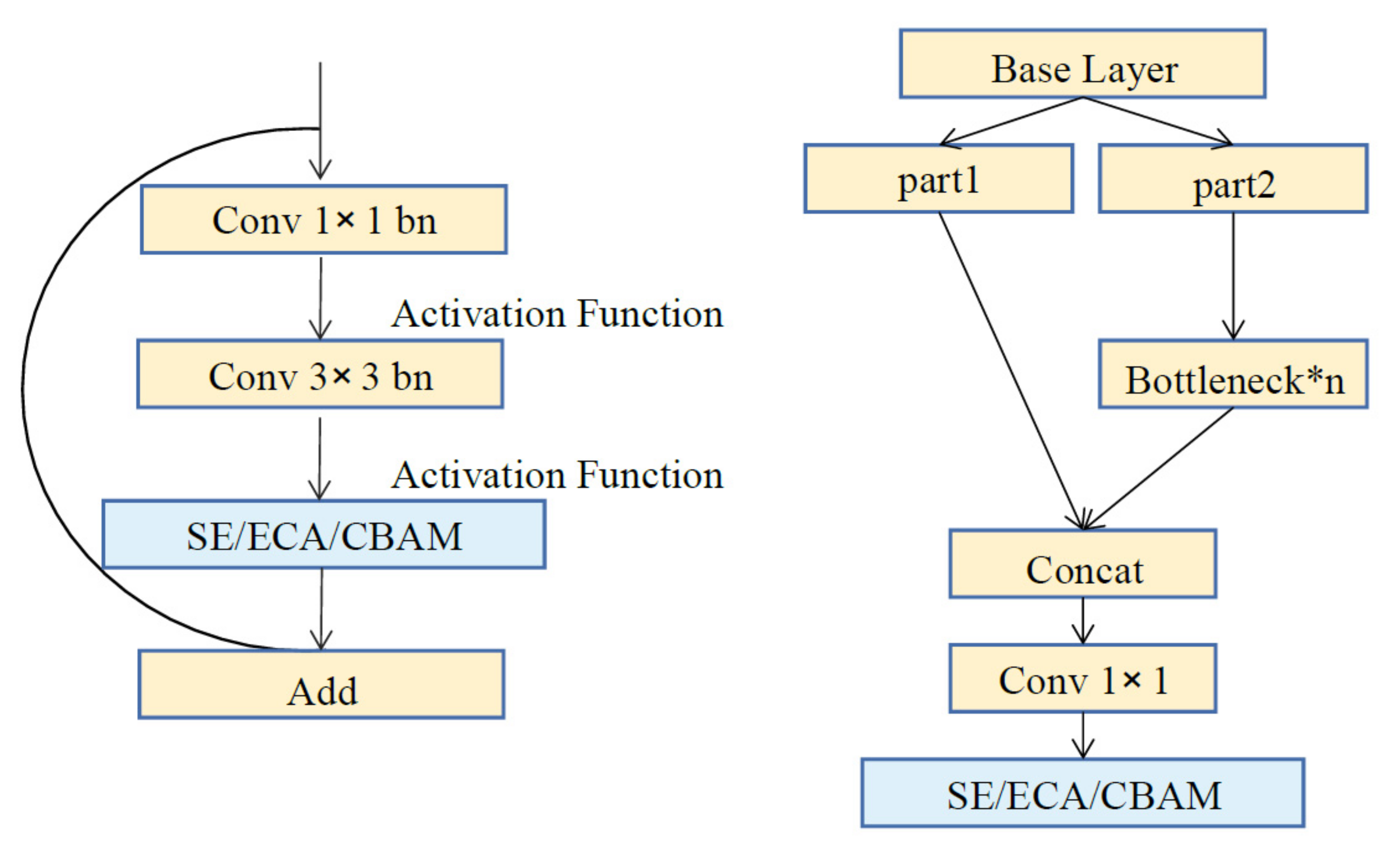
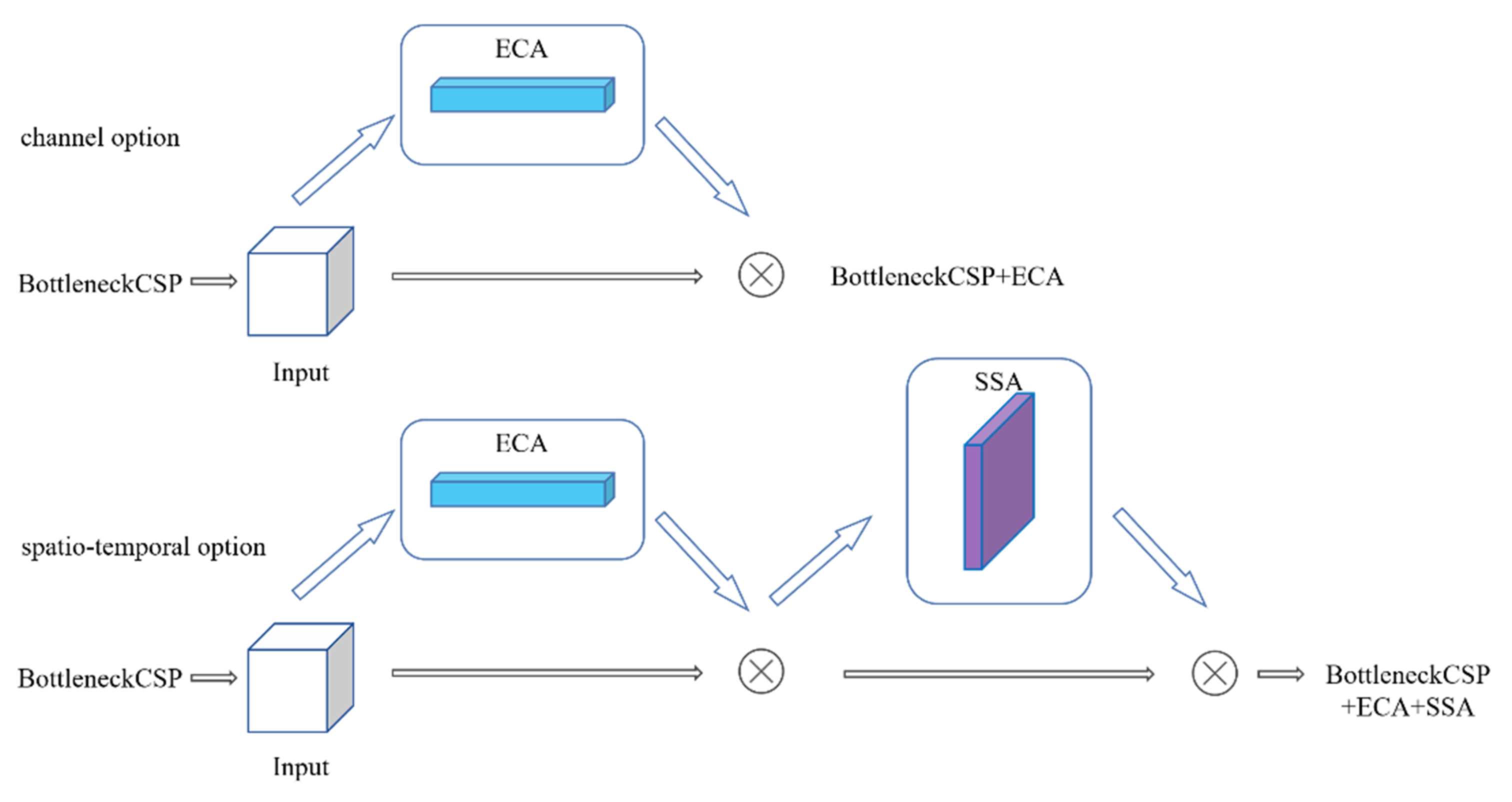
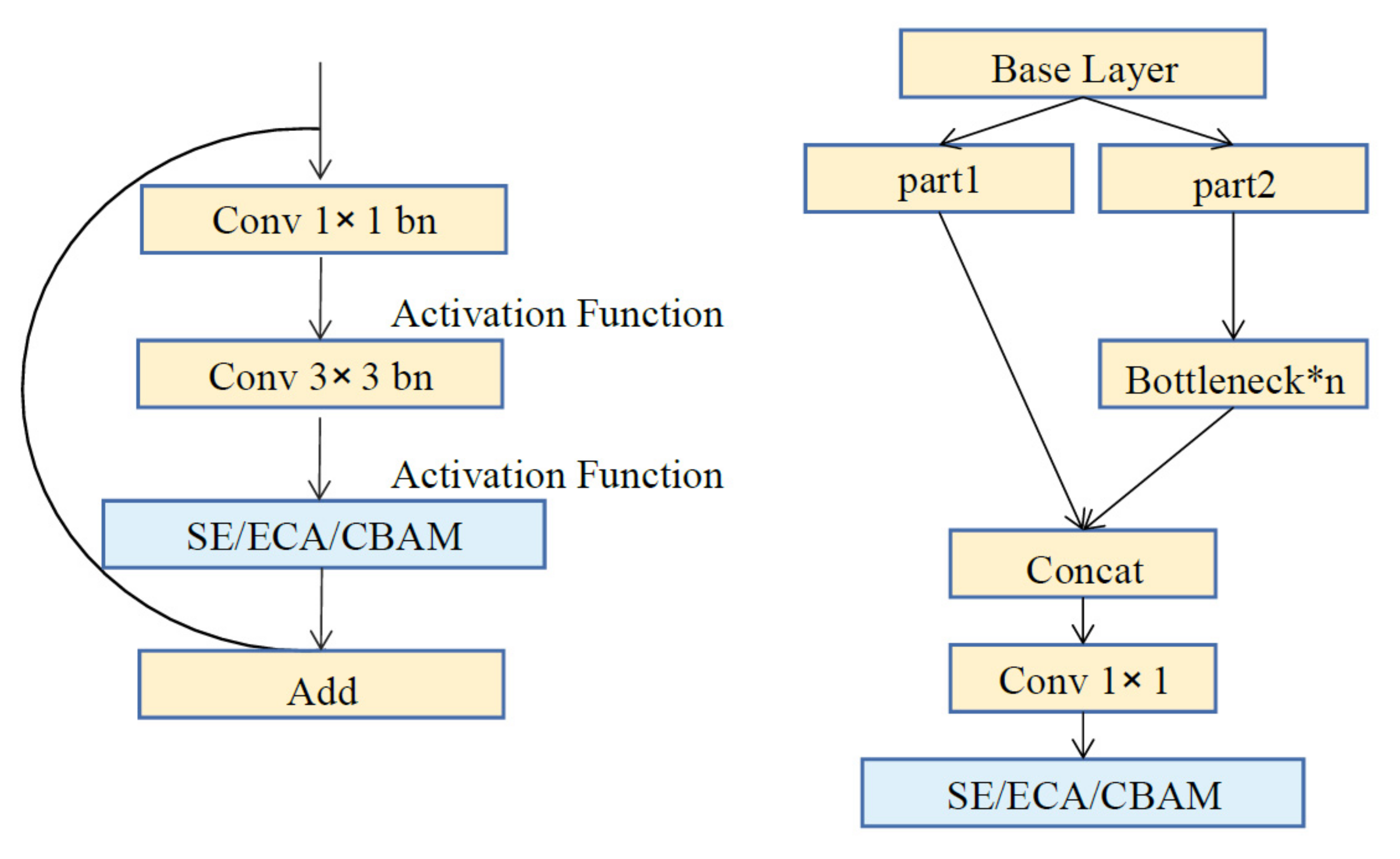
3. Proposed Method
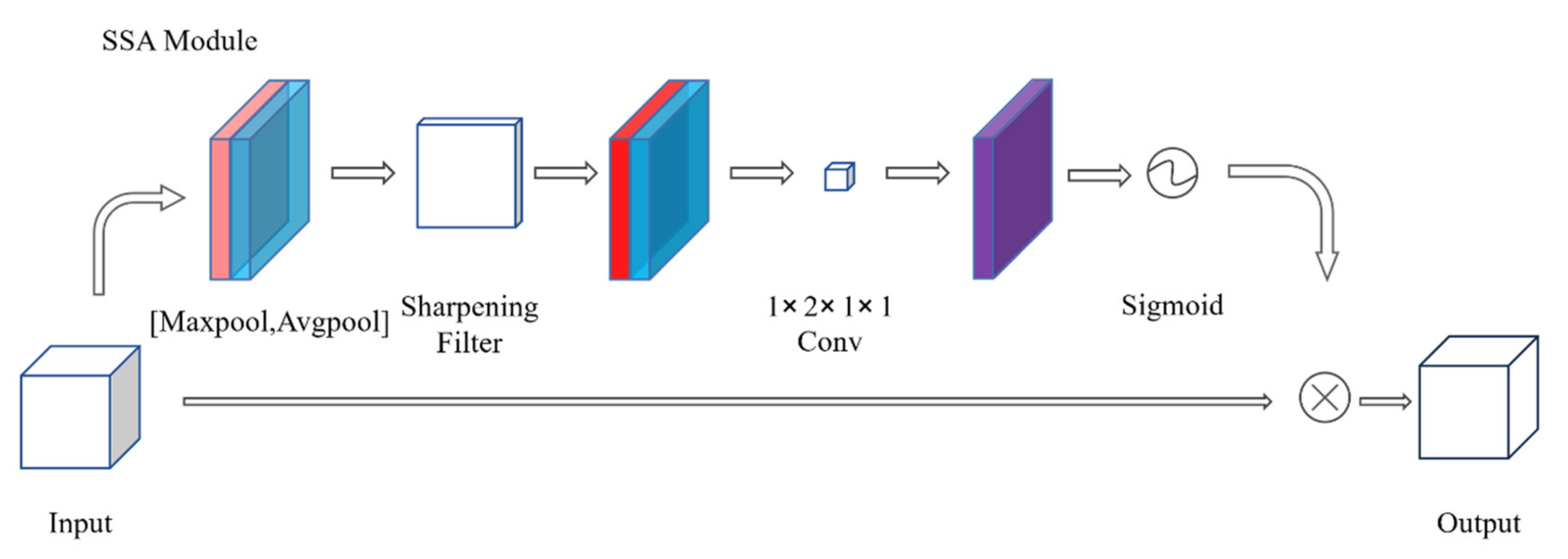
3.1. Spatial Attention Module
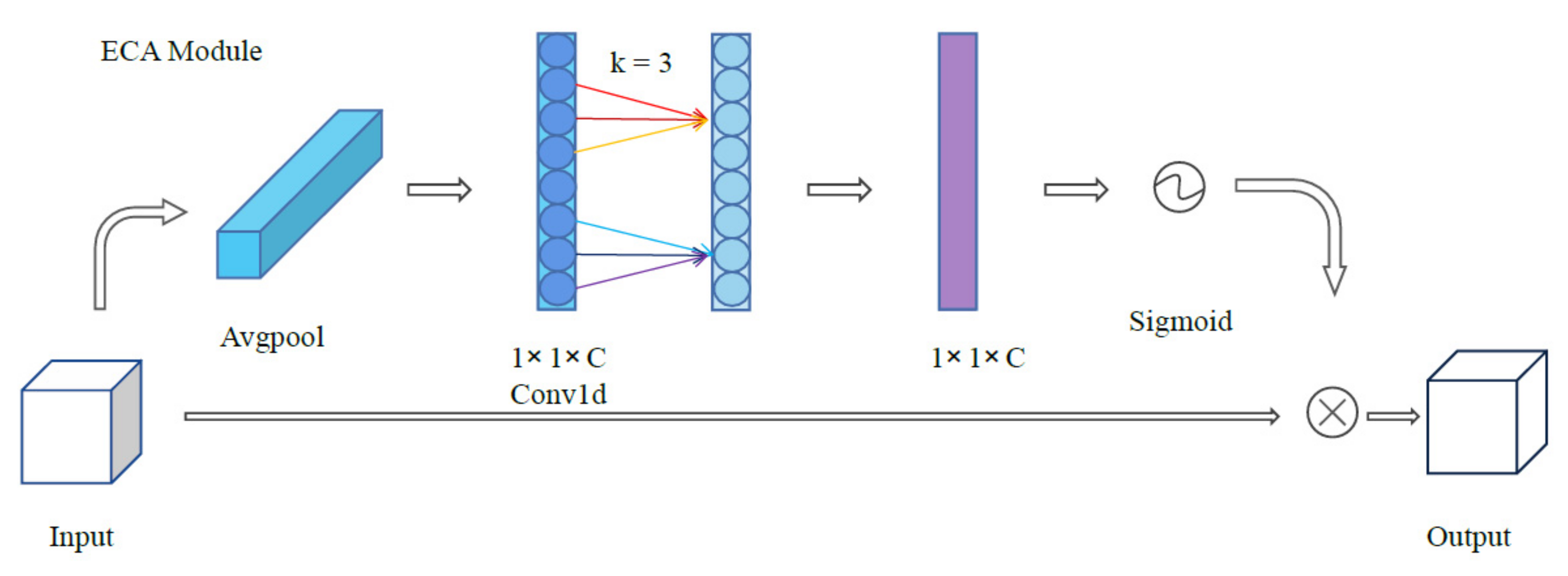
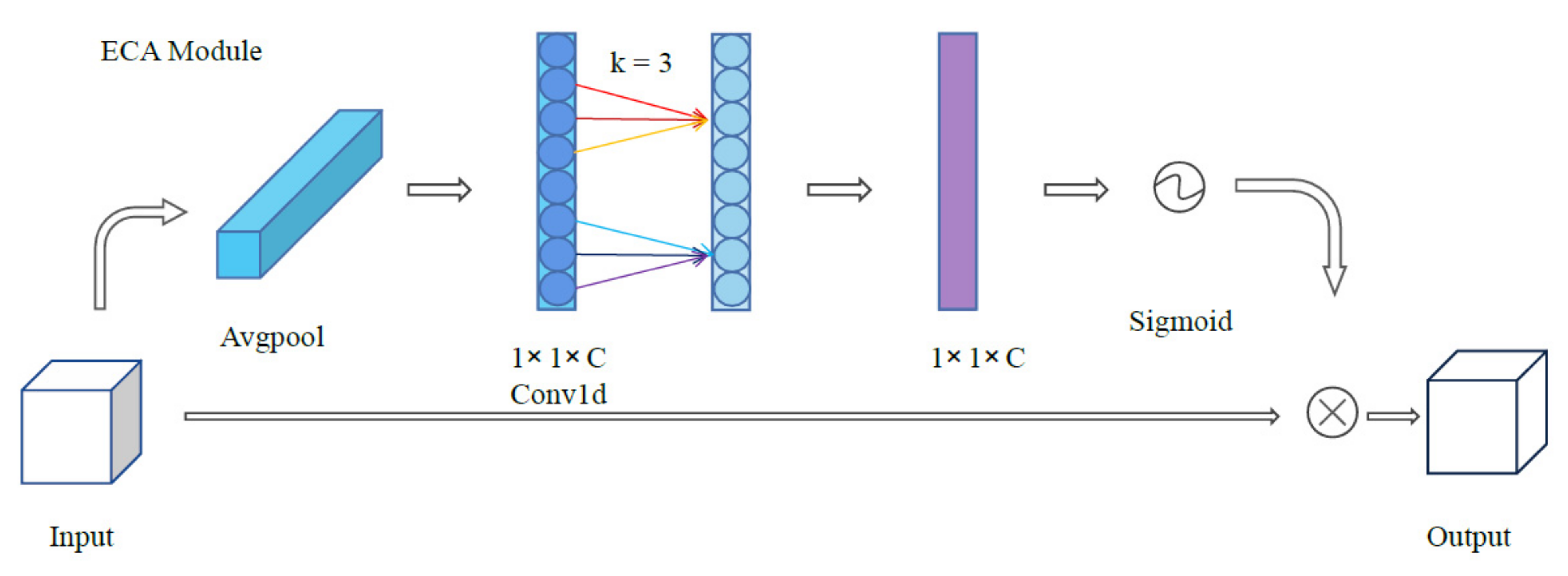
3.2. Channel Attention Module
4. Experiments
4.1. Object Detection Test on VOC2012 Dataset
4.1.1. Comparison Using Different Fusion Methods and Different Attention Mechanisms
4.1.2. Comparison Using Different Structures of Spatio-Temporal Sharpening Attention Mechanism
4.1.3. Comparison Using Different Edge Operators
4.1.4. Comparison Using Different Methods of Extraction
4.2. Object Detection on MS COCO2017 Dataset
4.2.1. Model Changes for YOLOv3-Tiny
4.2.2. Comparison of mAP, Speed and Weight
4.2.3. Detection Results of YOLOv5s with SSAM on COCO2017 Dataset
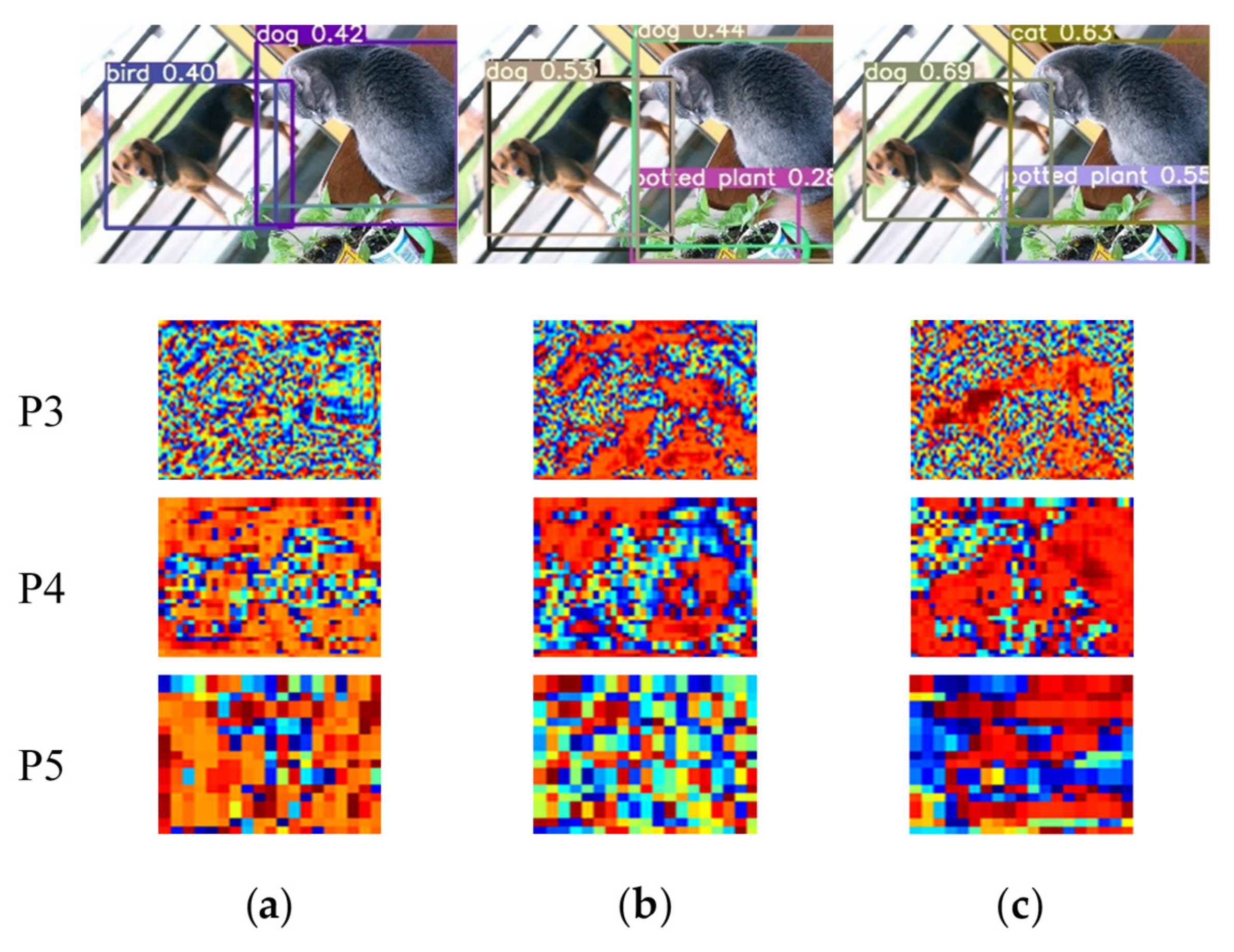
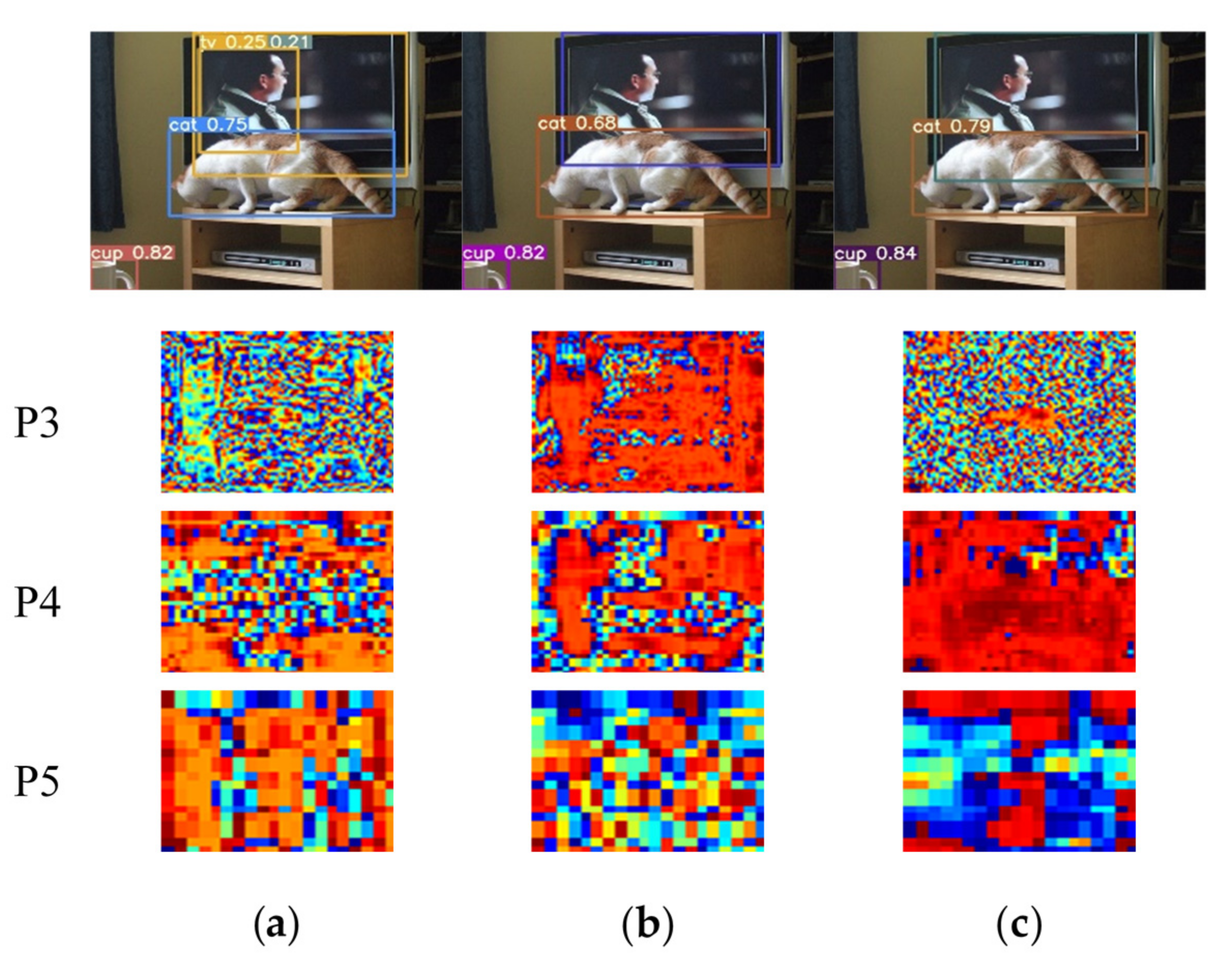
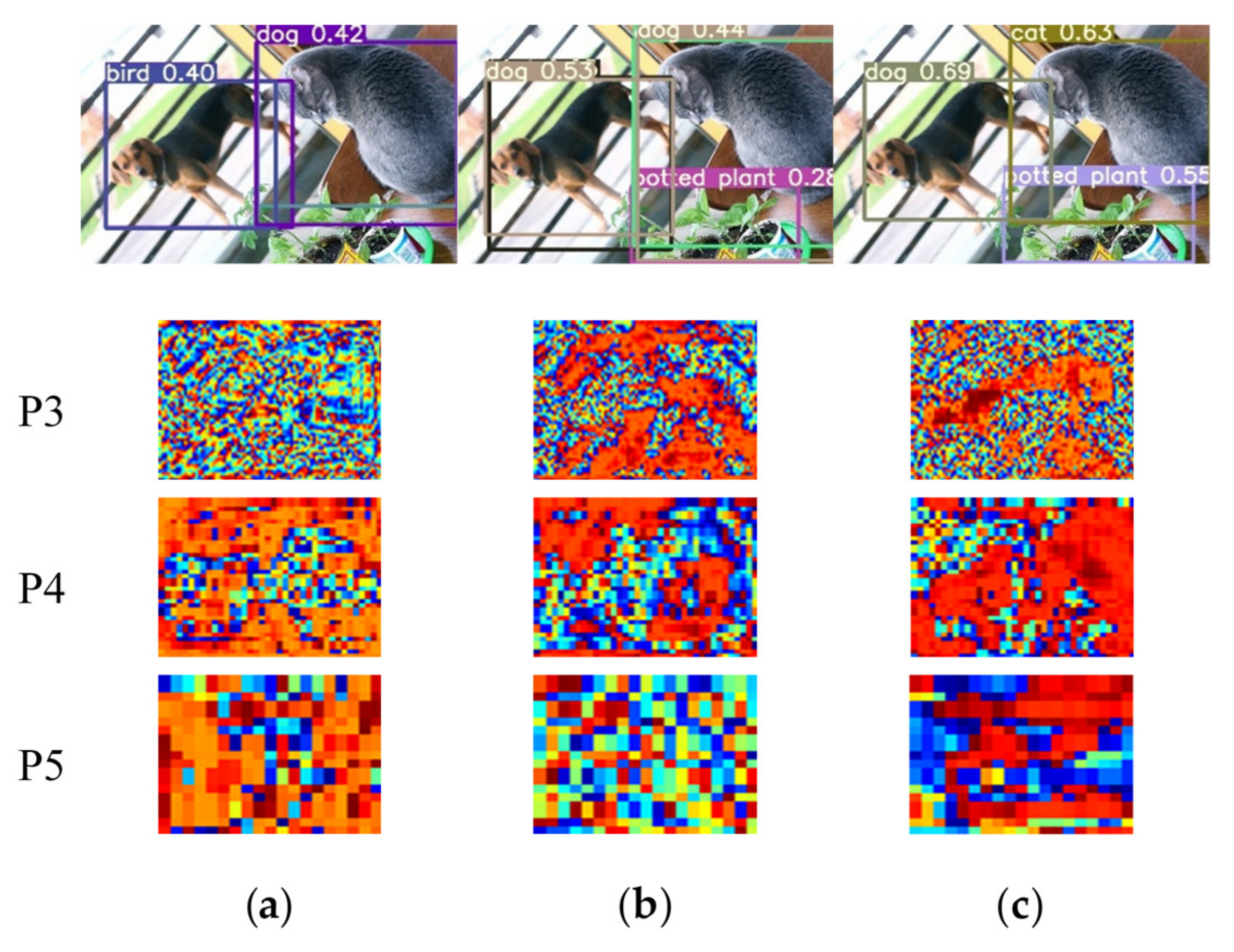
4.2.4. Visualization of YOLOv5s with SSAM on COCO2017 Dataset
4.2.5. How to Plug into Other Light-Weight Detectors
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Zhang, G. Survey of object detection algorithms for deep convolutional neural networks. Comput. Eng. Appl. 2020, 56, 12–23. [Google Scholar]
- Liu, J.M.; Meng, W.H. Review on Single-Stage Object Detection Algorithm Based on Deep Learning. Aero Weapon. 2020, 27, 44–53. [Google Scholar]
- Lu, J.; He, J.X.; Li, Z.; Zhou, Y.R. A survey of target detection based on deep learning. Electron. Opt. Control. 2020, 27, 56–63. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Duan, K.W.; Bai, S.; Xie, L.X.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6568–6577. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. arXiv 2017, arXiv:1612.08242. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.H.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 4–9 December 2016; pp. 379–387. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, Q.L.; Gao, Z.L.; Xie, J.T.; Zuo, W.M.; Li, P.H. Global Gated Mixture of Second-order Pooling for Improving Deep Convolutional Neural Networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Cao, Y.; Xu, J.R.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Ding, X.H.; Guo, Y.C.; Ding, G.G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 29 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.N.; Girshick, R.; Dollar, P.; Tu, Z.W.; He, K.M. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | AP50 | AP50:95 |
|---|---|---|
| YOLOv5s | 59.9% | 35.5% |
| YOLOv5s+SE (left) | 59.3% | 34.9% |
| YOLOv5s+SE (right) | 60.5% | 35.9% |
| YOLOv5s+ECA (left) | 59.4% | 35.1% |
| YOLOv5s+ECA (right) | 61.1% | 36.0% |
| YOLOv5s+CBAM (left) | 58.9% | 34.5% |
| YOLOv5s+CBAM (right) | 59.2% | 34.8% |
| Description | Backbone | Neck | Head | AP50 | AP50:95 |
|---|---|---|---|---|---|
| YOLOv5s | No | No | No | 59.9% | 35.5% |
| YOLOv5s+ECA | No | No | ECA | 60.7% | 35.9% |
| YOLOv5s+SSA | No | No | SSA | 60.4% | 35.7% |
| YOLOv5s+SSAM | No | No | ECA+SSA | 60.7% | 35.7% |
| YOLOv5s+SE | SE | SE | SE | 60.5% | 35.9% |
| YOLOv5s+CBAM | CBAM | CBAM | CBAM | 59.2% | 34.8% |
| YOLOv5s+ECA | ECA | ECA | ECA | 61.1% | 36.0% |
| YOLOv5s+[ECA+SAM] | ECA | ECA | ECA+SAM | 59.5% | 35.1% |
| YOLOv5s+SSAM | SSA+ECA | SSA+ECA | SSA | False | False |
| YOLOv5s+SSAM | SSA+ECA | SSA+ECA | SSA+ECA | False | False |
| YOLOv5s+SSAM | ECA | SSA+ECA | SSA+ECA | 61.4% | 36.1% |
| YOLOv5s+SSAM | ECA | ECA | SSA+ECA | 62.2% | 36.8% |
| YOLOv5s+SSAM | ECA | ECA | ECA+SSA | 62.3% | 37.1% |
| YOLOv5s+SSAM | ECA | ECA | ECA+NSA | 59.6% | 35.0% |
| YOLOv5s+SSAM | ECA | ECA | SSA | 60.6% | 35.9% |
| Description | Laplace 3 × 3 | Laplace 5 × 5 | Sobel 3 × 3 | AP50 | AP50:95 |
|---|---|---|---|---|---|
| YOLOv5s | 59.9% | 35.5% | |||
| YOLOv5s+SSAM | √ | 61.4% | 36.4% | ||
| YOLOv5s+SSAM | √ | 62.3% | 37.1% | ||
| YOLOv5s+SSAM | √ | 61.8% | 36.5% |
| Description | Maxpool | Avgpool | Max and Avgpool | AP50 | AP50:95 |
|---|---|---|---|---|---|
| YOLOv5s | 59.9% | 35.5% | |||
| YOLOv5s+SSAM | √ | 61.3% | 36.3% | ||
| YOLOv5s+SSAM | √ | 60.9% | 36.0% | ||
| YOLOv5s+SSAM | √ | 62.3% | 37.1% |
| Description | AP50 | AP75 | AP50:95 | FPS | Gflops | Parameters | Weights |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 55.6% | 39.0% | 36.8% | 455 | 17.0 | 7,276,605 | 14.11 m |
| YOLOv5s+SE | 56.0% | 40.1% | 36.8% | 416 | 17.1 | 7,371,325 | 14.30 m |
| YOLOv5s+SE+SSA | 56.9% | 39.8% | 36.9% | 416 | 17.1 | 7,371,406 | 14.31 m |
| YOLOv5s+ECA | 56.7% | 40.2% | 37.0% | 435 | 17.1 | 7,276,629 | 14.12 m |
| YOLOv5s+ECA+SSA | 57.6% | 40.9% | 37.7% | 435 | 17.1 | 7,276,710 | 14.13 m |
| Description | AP50 | AP75 | AP50:95 | FPS | Gflops | Parameters | Weights |
|---|---|---|---|---|---|---|---|
| YOLOv3-tiny | 34.9% | 15.8% | 17.6% | 667 | 13.3 | 8,852,366 | 16.94 m |
| YOLOv3-tiny+SE | 35.7% | 16.4% | 18.1% | 588 | 13.4 | 8,969,742 | 17.18 m |
| YOLOv3-tiny+SE+SSA | 36.0% | 16.8% | 18.3% | 588 | 13.4 | 8,969,796 | 17.19 m |
| YOLOv3-tiny+ECA | 35.6% | 16.4% | 18.0% | 625 | 13.3 | 8,885,155 | 17.01 m |
| YOLOv3-tiny+ECA+SSA | 35.8% | 16.5% | 18.2% | 625 | 13.3 | 8,885,209 | 17.02 m |
| Description | APsmall | APmedium | APlarge |
|---|---|---|---|
| YOLOv5s | 21.1% | 41.9% | 45.5% |
| YOLOv5s+SE | 20.9% | 42.1% | 46.5% |
| YOLOv5s+SE+SSA | 21.7% | 42.0% | 46.6% |
| YOLOv5s+ECA | 20.5% | 42.4% | 47.1% |
| YOLOv5s+ECA+SSA | 23.1% | 43.2% | 47.8% |
| Description | APsmall | APmedium | APlarge |
|---|---|---|---|
| YOLOv3-tiny | 9.6% | 22.2% | 22.1% |
| YOLOv3-tiny+SE | 9.8% | 22.6% | 22.8% |
| YOLOv3-tiny+SE+SSA | 10.4% | 23.0% | 22.6% |
| YOLOv3-tiny+ECA | 9.8% | 22.6% | 22.9% |
| YOLOv3-tiny+ECA+SSA | 10.1% | 22.5% | 23.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, M.; Chen, M.; Peng, D.; Guo, Y.; Chen, H. One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention. Sensors 2021, 21, 7949. https://doi.org/10.3390/s21237949
Xue M, Chen M, Peng D, Guo Y, Chen H. One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention. Sensors. 2021; 21(23):7949. https://doi.org/10.3390/s21237949
Chicago/Turabian StyleXue, Mengfan, Minghao Chen, Dongliang Peng, Yunfei Guo, and Huajie Chen. 2021. "One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention" Sensors 21, no. 23: 7949. https://doi.org/10.3390/s21237949
APA StyleXue, M., Chen, M., Peng, D., Guo, Y., & Chen, H. (2021). One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention. Sensors, 21(23), 7949. https://doi.org/10.3390/s21237949