
A Hierarchical Feature Extraction Network for Fast Scene Segmentation


Abstract
:1. Introduction
- (1)
- We propose a lightweight architecture with an encoder-decoder framework to extract hierarchical features from the input image;
- (2)
- An efficient encoder is proposed with inverted residual bottleneck modules to extracts global context information. A decoder is developed to aggregate multi-level hierarchical features, which effectively recovers spatial characteristics;
- (3)
2. Related Works
3. Description of Algorithm
3.1. Problem Formulation
3.2. Network Architecture
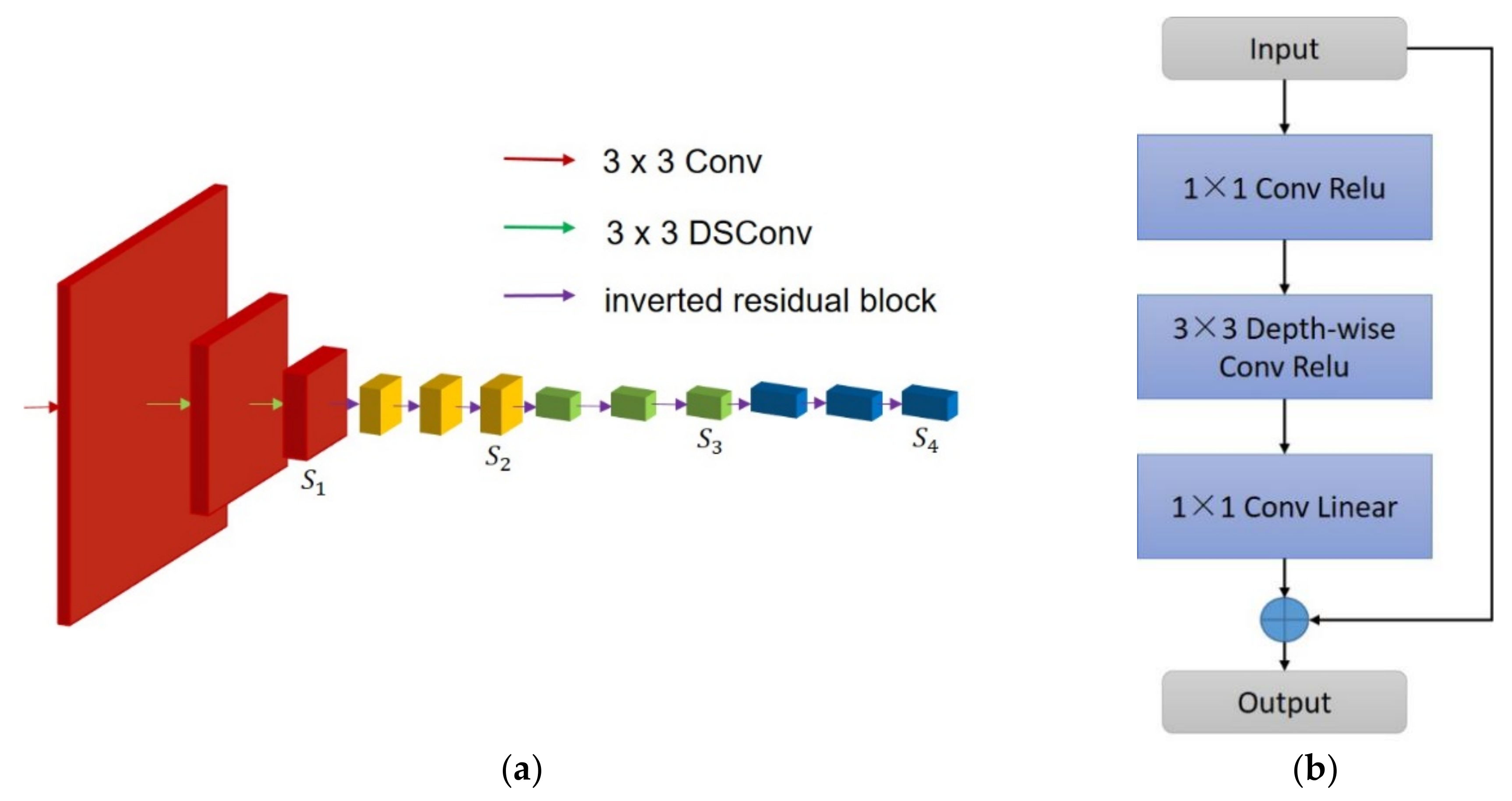
3.2.1. Encoder
| Algorithm 1: Encoder |
| Input: RBG Image I 1: I is propagated through a Conv2D and two DSConvs →; 2: for (i = 2; i <= 4; i++) 3: propagates through 3 Inverted Residual blocks respectively → ; Output |
3.2.2. Decoder
| Algorithm 2: Decoder |
| Input: Hierarchical Features 1: propagates through a 1 × 1 Conv →; 2: for (i = 3; i >=1; i−−) 3: propagates through a 1 × 1 Conv → ; 4: while (size of = size of ) 5: perform bilinear up-sampling operation with a factor of 2 on ; 6: perform element-wise summation: →; 7: up-sample to the same size then perform element-wise summation; 8: The combined features map propagates through PPM; 9: Perform up-sampling and Conv2D → final label map Output: Prediction Label Map |
4. Experiment and Analysis
4.1. Datasets
4.1.1. Cityscapes
4.1.2. Camvid
4.2. Implementation Details
4.2.1. Cityscapes
4.2.2. Camvid
4.3. Measurement
4.3.1. Computational Complexity
- (1)
- Giga floating-point operations per second (GFLOPs):GFLOPs indicates the number of multiply-add operations required to evaluate the model.
- (2)
- Number of processed frames per second (FPS):FPS refers to the processing time on a particular hardware platform.
- (3)
- Millions of parameters:The number of parameters directly represent the scale of the network.
4.3.2. Accuracy
4.4. Qualitative Analysis of Segmentation Results
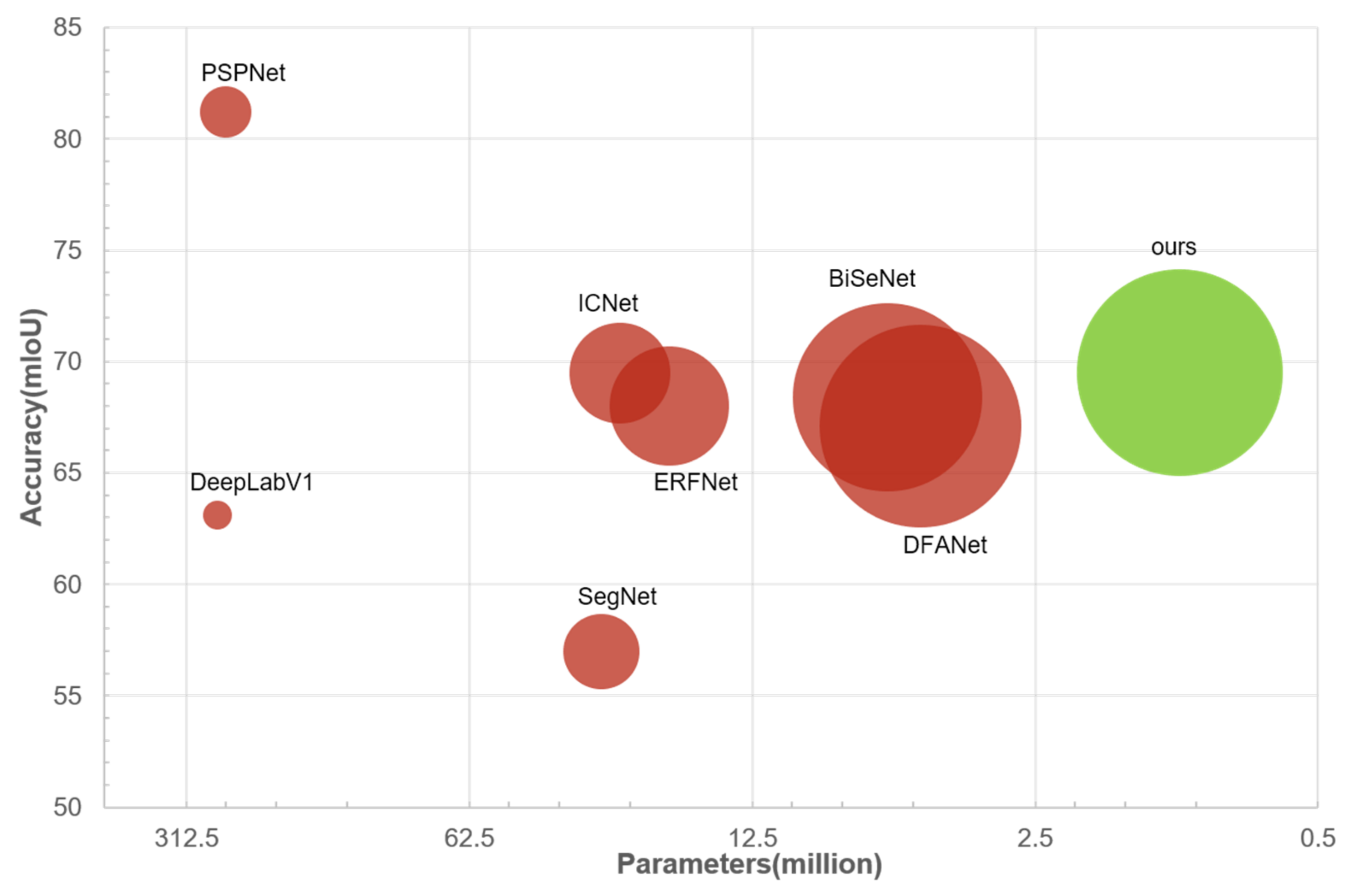
4.5. Quantitative Analysis of Speed vs Accuracy
4.5.1. Cityscapes
4.5.2. Camvid
4.6. Ablation Study
4.6.1. Encoder
4.6.2. Decoder
- (1)
- The multi-level pyramid pooling module; and
- (2)
- The feature aggregation module based on DSConv layers.
4.7. Testing on Lower Input Resolution
4.8. Segmentation Results on Other Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, W.; Zheng, N.; Zheng, R.; Zhao, X.B.; Wang, A. Digital Image Semantic Segmentation Algorithms: A Survey. J. Inf. Hiding Multim. Signal Process 2019, 10, 196–211. [Google Scholar]
- Ulku, I.; Akagunduz, E. A Survey on Deep Learning-based Architectures for Semantic Segmentation on 2D images. arXiv 2019, arXiv:1912.10230. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Marseille, France, 12–18 October 2008; pp. 44–57. [Google Scholar]
- Fu, C.; Hu, P.; Dong, C.; Mertz, C.; Dolan, J.M. Camera-Based Semantic Enhanced Vehicle Segmentation for Planar LIDAR. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3805–3810. [Google Scholar]
- Wang, J.; Yang, K.; Hu, W.; Wang, K. An Environmental Perception and Navigational Assistance System for Visually Impaired Persons Based on Semantic Stixels and Sound Interaction. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1921–1926. [Google Scholar]
- Feng, D.; Haase-Schuetz, C.; Rosenbaum, L.; Hertlein, H.; Duffhauss, F.; Gläser, C.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Berrio, J.S.; Worrall, S.; Nebot, E. Automated Evaluation of Semantic Segmentation Robustness for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1951–1963. [Google Scholar] [CrossRef]
- Wang, X.; Ma, H.; You, S. Deep clustering for weakly-supervised semantic segmentation in autonomous driving scenes. Neurocomputing 2020, 381, 20–28. [Google Scholar] [CrossRef]
- Azizpour, M.; Da Roza, F.; Bajcinca, N. End-to-End Autonomous Driving Controller Using Semantic Segmentation and Variational Autoencoder. In Proceedings of the 2020 7th International Conference on Control, Decision and Information Technologies (CoDIT), Prague, Czech Republic, 29 June–2 July 2020; Volume 1, pp. 1075–1080. [Google Scholar]
- Valenzuela, A.; Arellano, C.; Tapia, J. An Efficient Dense Network for Semantic Segmentation of Eyes Images Captured with Virtual Reality Lens. In Proceedings of the 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 26–29 November 2019; pp. 28–34. [Google Scholar]
- Ramirez, P.Z.; Paternesi, C.; Gregorio, D.D.; Stefano, L.D. Shooting Labels: 3D Semantic Labeling by Virtual Reality. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Utrecht, The Netherlands, 14–18 December 2020; pp. 99–106. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convoluional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking Bottleneck Structure for Efficient Mobile Network Design. In Lecture Notes in Computer Science; Springer: Singapore, 2020; pp. 680–697. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6245. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Seg-mentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2015, arXiv:1412.7062. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9514–9523. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2020, arXiv:1908.07919. [Google Scholar] [CrossRef] [Green Version]
- Mazzini, D. Guided Upsampling Network for Real-Time Semantic Segmentation. arXiv 2018, arXiv:1807.07466. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-SCNN: Fast Semantic Segmentation Network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1251–1258. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Poudel, R.P.; Bonde, U.D.; Liwicki, S.; Zach, C. ContextNet: Exploring Context and Detail for Semantic Segmentati-on in Real-time. arXiv 2018, arXiv:1805.04554. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Huang, Y.; Xu, H. Fully convolutional network with attention modules for semantic segmentation. Signal Image Video Process. 2021, 15, 1031–1039. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the Lecture Notes in Computer Science), Munich, Germany, 8–14 September 2018; pp. 561–580. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Wang, D.; Li, N.; Zhou, Y.; Mu, J. Bilateral attention network for semantic segmentation. IET Image Process. 2021, 15, 1607–1616. [Google Scholar] [CrossRef]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Semantic Image Segmentation via Deep Parsing Network. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1377–1385. [Google Scholar]
- Audebert, N.; Boulch, A.; Saux, B.L.; Lefèvre, S. Distance transform regression for spatially-aware deep semantic segmentation. Comput. Vis. Image Underst. 2019, 189, 102809. [Google Scholar] [CrossRef] [Green Version]
- Alhaija, H.A.; Mustikovela, S.K.; Mescheder, L.M.; Geiger, A.; Rother, C. Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes. Int. J. Comput. Vis. 2018, 126, 961–972. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Block | exp | Ch | n | s |
|---|---|---|---|---|---|
| 1024 × 2048 × 3 | Conv2D | - | 32 | 1 | 2 |
| 512 × 1024 × 32 | DSConv | - | 48 | 1 | 2 |
| 256 × 512 × 48 | DSConv | - | 64 | 1 | 2 |
| 128 × 256 × 64 | bottleneck | 6 | 64 | 3 | 2 |
| 64 × 128 × 64 | bottleneck | 6 | 96 | 3 | 2 |
| 32 × 64 × 96 | bottleneck | 6 | 128 | 3 | 1 |
| Model | Resolution | GFLOPs | Params (M) | mIoU (%) | Speed (FPS) | GPU | |
|---|---|---|---|---|---|---|---|
| Val | Test | ||||||
| PSPNet [16] | 713 × 713 | 412.2 | 250.8 | - | 81.2 | 0.78 | TitanX |
| BiANet [40] | - | - | - | 66.6 | - | - | |
| DeepLab [21] | 1024 × 512 | 457.8 | 262.1 | - | 63.1 | 0.25 | TitanX |
| FCN+PPAM+SAM [36] | 224 × 224 | 38.7 | 42.4 | 66.5 | - | - | |
| SegNet [17] | 640 × 360 | 286 | 29.5 | - | 57 | 16.7 | TitanX |
| ENet [37] | 640 × 360 | 3.8 | 0.4 | 57 | 135.4 | TitanX | |
| ICNet [22] | 2048 × 1024 | 270 | 26.5 | - | 69.5 | 30.3 | TitanX M |
| ESPNet [38] | 1024 × 512 | 13 | 0.4 | - | 60.3 | 113 | TitanX |
| ERFNet [39] | 1024 × 512 | 27.7 | 20 | 70 | 68 | 41.7 | TitanX M |
| Fast-SCNN [29] | 2048 × 1024 | - | 1.1 | 68.6 | 68 | 123.5 | TitanX |
| DFANet B [24] | 1024 × 1024 | 2.1 | 4.8 | - | 67.1 | 120 | TitanX |
| BiSeNet [19] | 1536 × 768 | 14.8 | 5.8 | 69 | 68.4 | 105.8 | GTX 1080Ti |
| Ours | 2048 × 1024 | 5.45 | 1.1 | 71.5 | 69.5 | 112 | RTX 2080Ti |
| Model | mIoU (%) | Speed (FPS) | GPU |
|---|---|---|---|
| DeepLab [21] | 61.6 | 4.9 | TitanX |
| SegNet [17] | 46.4 | 46 | TitanX |
| ENet [37] | 51.3 | - | |
| DPN [41] | 60.1 | 1.2 | TitanX |
| SDT [42] | 61.6 | - | |
| BiSeNet [19] | 65.6 | - | |
| DFANet A [24] | 64.7 | 120 | TitanX |
| DFANet B [24] | 59.3 | 160 | TitanX |
| Ours | 66.1 | 147 | RTX 2080Ti |
| Encoder | mIoU (%) | Params(M) | GFLOPs |
|---|---|---|---|
| ResNet-50 [18] | 76.5 | 28.72 | 367.44 |
| ResNet-18 [18] | 72.3 | 11.31 | 89.24 |
| MobileNetV2 [32] | 69.8 | 1.89 | 67.02 |
| Xception [31] | 67.5 | 1.99 | 53.67 |
| Ours | 71.5 | 1.1 | 5.45 |
| Encoder | mIoU (%) | GFLOPs |
|---|---|---|
| Ours | 71.5 | 5.45 |
| Double | 68.1 | 16.58 |
| Half | 62.9 | 1.71 |
| Decoder | mIoU (%) | Params (M) | GFLOPs |
|---|---|---|---|
| Ours | 71.5 | 1.1 | 5.45 |
| Without ppm | 69.7 | 1.1 | 5.41 |
| With Conv | 71.7 | 1.4 | 8.87 |
| Resolution | GFLOPs | mIoU (%) |
|---|---|---|
| 2048 × 1024 | 5.45 | 71.5 |
| 1024 × 512 | 1.36 | 61.8 |
| 512 × 256 | 0.34 | 47.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, L.; Zhang, Y. A Hierarchical Feature Extraction Network for Fast Scene Segmentation. Sensors 2021, 21, 7730. https://doi.org/10.3390/s21227730
Miao L, Zhang Y. A Hierarchical Feature Extraction Network for Fast Scene Segmentation. Sensors. 2021; 21(22):7730. https://doi.org/10.3390/s21227730
Chicago/Turabian StyleMiao, Liu, and Yi Zhang. 2021. "A Hierarchical Feature Extraction Network for Fast Scene Segmentation" Sensors 21, no. 22: 7730. https://doi.org/10.3390/s21227730
APA StyleMiao, L., & Zhang, Y. (2021). A Hierarchical Feature Extraction Network for Fast Scene Segmentation. Sensors, 21(22), 7730. https://doi.org/10.3390/s21227730