1. Introduction
New paradigms such as the Internet of things, Industry 4.0, health monitoring, assisted living and physical and environmental conditions monitoring, among other applications, have been introduced due to the increased reliability, improved autonomy and low-cost trend of sensor networks which enable the market growth for both military and civil applications. Data fusion techniques can be applied to find solutions in several challenges that must be addressed when designing new applications or techniques for sensor networks. Connectivity and network topology in ad hoc and sensor networks change dynamically due to variations in the propagation conditions and mobility, [
1]. At the same time, in nowadays network scenarios, position location awareness becomes more relevant in order to achieve network goals such as fast routing, efficient resource management, sensor energy harvesting and reliable deployment of location-aware services. Besides GPS and other GNSS systems meant to provide three-dimensional geolocation for outdoor applications, most existing positioning techniques deal with planar location environments that are not sufficiently suitable for many applications. Although GPS has been in place for many years for several uses, its availability and accuracy are insufficient for indoor applications and other compromised scenarios such as tunnels, mines and high-vegetation environments. Furthermore, in sensor networks, range-based location techniques might not be reliable due to range-noisy estimations obtained from complex physical environments. In real scenarios, sensors might fail, burn power batteries or be under different sources of interference; so, it is required to design alternative estimation methods to address these random restrictions.
Therefore, data fusion-based techniques represent a crucial alternative for multiple network applications, such as localization. Note that, in sensor positioning, data fusion can be understood as the set of techniques or methods that process or combine data from several sensors in order to obtain a better location estimation of a node of interest [
2,
3]. Therefore, alternative 3D localization schemes are necessary for applications such as emergency call services in urban and metropolitan environments, museum guides, warehouse stock management, industrial plant monitoring and assisted living, among many others [
4].
In the literature, we can find range-based and range-free sensor localization techniques, most of them designed for 2D scenarios. Basically, range-based localization techniques are focused on the improvement of the estimated distances (through TOA, DTOA and RSSI) between anchor nodes (ANs) and the node to locate or node of interest, [
5]. Then, available ANs perform classical trilateration and the centroid of the intersected areas is selected as the final location estimation of the node of interest. Some of these proposals use Kalman filters and/or modifications of the Kalman filter in order to improve estimated distances [
6,
7,
8] and thus the location estimation. Others have focused on the improvement of the centroid calculation of intersected areas, while some authors have proposed some variations such as the weighted centroid calculation [
9].
One of the first range-based 3D localization techniques was proposed in [
6], where they introduced a method based on two stages. During the first stage, nodes with known locations estimate distances based on the received signal strength indicator (RSSI) to a mobile location-assistant (LA) such as an aircraft, a balloon, a robot, a vehicle, etc. Then, each location-unaware sensor discovers its position by observing the moving, location-aware LA nodes. In the second stage, the location-unaware sensor nodes use an unscented Kalman filter for self-localization. This technique reports the requirement of a high number of known location anchor nodes in order to achieve moderate position errors. For instance, it is reported that, in low complexity scenarios with 200 sensor nodes deployed in a 1000 × 1000 × 100 feet space, they require 5% of anchor nodes in order to achieve position errors of around 11 feet for flat terrains. As they evaluate more complex scenarios, the accuracy is degraded to positioning errors of about 100 feet. Although this method does not rely on network density and topology, its performance depends on the observation of mobile devices that might not be available in some hostile scenarios; additionally, its performance degrades as the terrain complexity increases.
Another popular range-based approach was introduced in [
7] for sensor node localization in planar scenarios, using a multidimensional scaling (MDS) technique. An extrapolated concept for 3D scenarios is presented in [
10], where the authors propose an MDS-MAP-based localization technique where they calculate the shortest distances between every pair of nodes, then they apply classical multidimensional scaling to the distance matrix. Finally, the relative map with relative location for each node is obtained. In order to transform the relative map into a global map, at least four anchor nodes are needed. The main limitation of this algorithm is a strong dependency on the input information for the distance matrix and the high dependency on the network connectivity. The reported performance of the proposed algorithm considers a scenario with 100 nodes in a 100
r × 100
r × 100
r (
r is the unit length distance) space, varying connectivity. The position error reported is of about 12%
R (
R is the maximum transmission range) with high connectivity and a high number of anchors (10 anchors).
For comparison purposes, we can observe that the two algorithms just discussed in the previous paragraphs require at least 10 ANs to be implemented, while our proposed algorithm can be implemented using only three ANs. In terms of accuracy, the purpose of this paper is not to find a direct comparison between the worst analyzed cases. However, we achieve position errors of around 10%
rmax (
rmax is the maximum transmission range) using only three ANs, while, in [
6], the authors achieve an accuracy of around 45%
rmax and, in [
7], the authors achieve 12%
rmax for the worst analyzed cases.
In [
11], the authors present a range-based (RSSI estimations) sequence localization algorithm where they construct a 3D Voronoi diagram, which is used to divide the operational scenario depending on known location nodes. Then, they formulate a rank sequence table of estimated location nodes (virtual beacons) based on the previous partition. RSSI estimations between nodes are used to correct the measured distances and to fix the location sequence of unknown nodes. The location error is normalized to the transmission range
r0, achieving a location error of around 0.12
r0 for eight ANs.
In range-free localization methods, the distance between ANs and the node of interest is based on the hop count criterion; therefore, the position estimation of the node does not depend on the accuracy of the estimated distances between anchor nodes and the node to locate. Most of the range-free localization methods base their approaches on the assumption that the Euclidean distance between nodes is proportional to the number of hops in the connecting route. Then, a heuristic method to estimate the coordinates of the node of interest is applied. In [
12], the authors propose a range-free approach, where a position location (PL) method suitable for 3D environments is introduced. This method is based on the convenient deployment of access points (APs) or anchor nodes and on the discretization of the network space. They base distance estimation on the hop count criterion on a Manhattan scenario, [
13]. A set of algebraic relations is defined for the node’s coordinates based on the distances from the APs to the node of interest. In addition, a maximum a posteriori probability (MAP) criterion is used to improve the estimated distances and performance of the algebraic method. They deploy from 300 to 600 nodes in a 10
l × 10
l × 10
l space (
l = Manhattan step) and achieve localization errors of about 0.83
rmax (where
rmax is the maximum transmission range), which can be considered a good result for the free range/multihop scenarios analyzed.
Comparing the proposed method against the last 3D positioning methods summarized, we achieve an improvement of around 15.6% for similar scenarios, using 4 ANs, 600 deployed nodes and hop count as distance estimation criterion.
In this paper, we propose a novel localization technique named Recursive Localization (RL) algorithm, suitable for 3D sensor node positioning. In the proposed RL algorithm, the initial node of interest’s coordinates are estimated by classical trilateration techniques, after a reference plane is constructed based on the locations of only three available ANs. Then, the recently located node nj becomes a new anchor node and one of the original ANs is now considered to be a node of interest to be located. Since the actual locations of the ANs are known, we obtain the difference between the AN’s estimated location using nj and the AN’s true location by least squares. Finally, we use this difference (called recursive correcting vector, or CV) to recalculate the location of the node of interest nj. The algorithm is explained in detail in the following sections. Note that, when more than three ANs are available, we can take advantage of having several reference planes to improve the first location estimation of nj (this is the starting point of the RL). Note that observations are prone to impairments due to either the error in distance estimations, anchor node movements or the absence of direct connectivity from sensor nodes to ANs, rendering in ad hoc routes that may depart from a line of sight (LOS) trajectory. The performance of the proposed methodology is assessed for both LOS and multihop scenarios. Different scenarios are analyzed, where several network factors are modified, such as the number of ANs, their relative positions, the number of possible reference planes and the maximal transmission range, as well as the node densities for multi-hop scenarios. The performance in a noisy environment is considered. The proposed RL algorithm provides a significant improvement of the location accuracy for all the scenarios analyzed, without the need of additional information or processing for distance estimation improvement with a very low number of ANs.
In
Table 1, we summarize the characteristics of the main positioning methods described above in order to clarify the differences between the state of the art and the proposed method. We see further that the proposed RL algorithm can be used under both the range-based or free-range-based approach.
In [
14], the authors formulate a taxonomy for localization algorithms’ classification. They also present a study of different main localization algorithms along with their improved versions. The challenges and research approaches of localization in sensor networks emerging applications are also discussed.
In
Section 2, we introduce the scenario used for position location with the description of the Recursive Localization algorithm.
Section 3 contains the simulation results showing the performance as several parameters are varied and, in
Section 4, the conclusions are discussed.
2. Positioning System
In a basic network set up, we want to determine the location of a node in a defined 3D scenario. The node is considered to be able to establish direct or multihop routes to several ANs that provide global connectivity. The reachability of the node of interest to at least three anchor nodes,
AN1,
AN2 and
AN3, with corresponding known coordinates (
xk,
yk,
zk),
k = 1, 2, 3, is assumed. Note that the node to be located can be a radio source associated to a sensor with initial unknown location; this is a feasible scenario, as, in some cases, sensors may be deployed without precise location information. Anchor nodes are notified to perform distance estimations to the node of interest. This information is sent to the node so that it can estimate its own location. Any of three ANs (
ANk,
ANl, or
ANn) with original coordinates (
xko,
yko,
zko), (
xlo,
ylo,
zlo) and (
xno,
yno,
zno), respectively, can be selected to define the original reference plane
Pokln so that coordinates (
xjo,
yjo,
zjo) of the node to be located
nj can be expressed with respect to the reference plane. For instance, see the plane
Po123 defined by
AN1,
AN2 and
AN3 in
Figure 1a forming a reference for the location of node
nj.
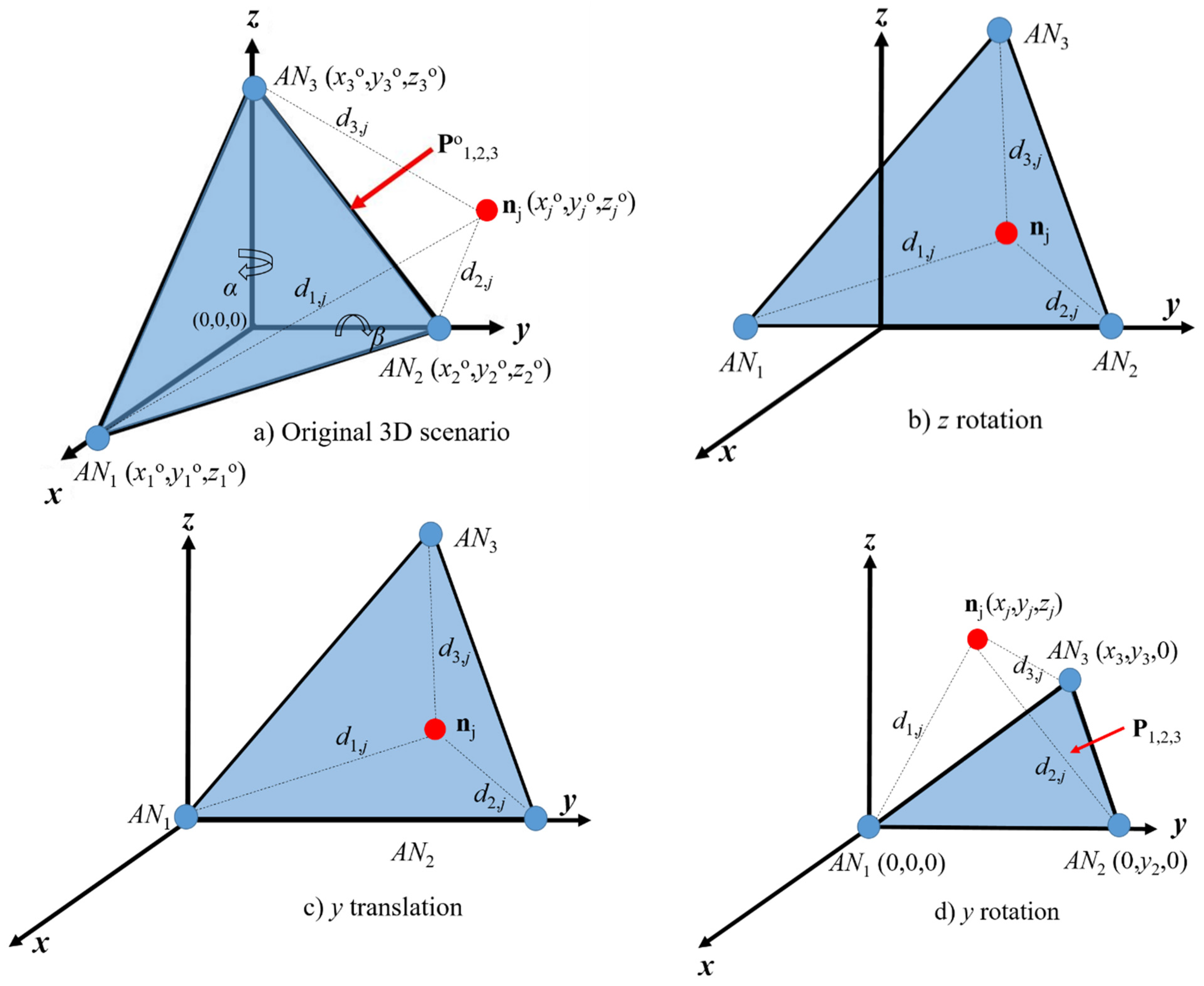
As illustrated in
Figure 1, the location estimation of the node of interest, calculated by anchor nodes that define the reference plane (
Figure 1a), is relative to the rotated/translated anchor’s coordinates (
Figure 1d). Note that, after rotation/translation, the coordinates of node
AN1 are (0, 0, 0); therefore, in order to obtain the scenario illustrated in
Figure 1b,c, a rotation by angles
α and
β is performed in the
z- and
y-axis, respectively. Therefore, the coordinates (
xj,
yj,
zj) of node
nj with respect to plane
P123 can be obtained from the following distance relationships:
where we denote the true separation distance between node
nj and
ANk as
dk,j and this is unaltered after plane rotation/translation. Thus, after the algebraic handling and in a noise free scenario, the coordinates (
xj,
yj,
zj) can be expressed as
For the scenario illustrated in
Figure 1, the coordinates (
xj,
yj,
zj) can be translated back to the original coordinate system (
xjo,
yjo,
zjo), so that node
nj is meant (after the rotation in
y- and
z-axis) to be located at
where
α and
β are the rotation angles illustrated in
Figure 1a. This process can be conducted for any other combination of ANs. Note that, in real environments, physical as well as propagation impairments render in noisy distance estimations from ANs to the node of interest. These impairments are quantified by using an additive noise model for estimation distances. Thus, let us define the estimated distance between
ANk and the node of interest
nj as
d’
k,j =
dk,j +
Ek,j, where we assume that
Ek,j is exponentially distributed with parameter
λ (
Ek,j~exp(λ)), that is proportional to the true distance
dk,j from the
ANk to node
nj. With these distances estimated, the coordinates of the node of interest are not those obtained in a noise-free scenario and they are noisy coordinates (
x’
j,
y’
j,
z’
j) obtained by using the same equation set (2), but with distances given by
d’
k,j,
k = 1, 2, 3. In the following section, we introduce the RL algorithm, where the coordinates of the node of interest are recursively recalculated and where we express (
x’
ln,
y’
ln,
z’
ln) as the
n-th calculation of the node of interest’s location coordinates. For the RL algorithm, the coordinates (
x’
j,
y’
j,
z’
j) obtained using Equation set (2) with
d’
k,j are defined as (
x’
jn,
y’
jn,
z’
jn) for
n = 1.
2.1. Recursive Localization (RL) Data Fusion Algorithm
As noted before, the estimated distances
d’
k,j may be corrupted, resulting in impaired coordinate calculations. In this section, we explain the data fusion-based Recursive Localization (RL) algorithm. This algorithm is based on the ANs’ known locations and on the first location estimation (
x’
j1,
y’
j1,
zj1) of the node of interest
nj, as follows. Let us consider a scenario with three available ANs,
AN1,
AN2 and
AN3, where we can estimate the location of a node of interest
nj, (
x’
jn,
y’
jn,
z jn), relative to plane
Pklm (e.g.,
P123), based on a set of estimated distances
d’
k,j (e.g.,
k = 1, 2, 3) as those in Equation set (2). Note that the super index of the coordinates (
x’
jn,
y’
jn,
zjn) starts with
n = 2 for the first time that the recursive algorithm recalculates the location of
nj and it continues for values of
n > 2 for the subsequent calculations. Once the coordinates (
x’
ln,
y’
ln,
z’
ln) are calculated, node
nj becomes an anchor node
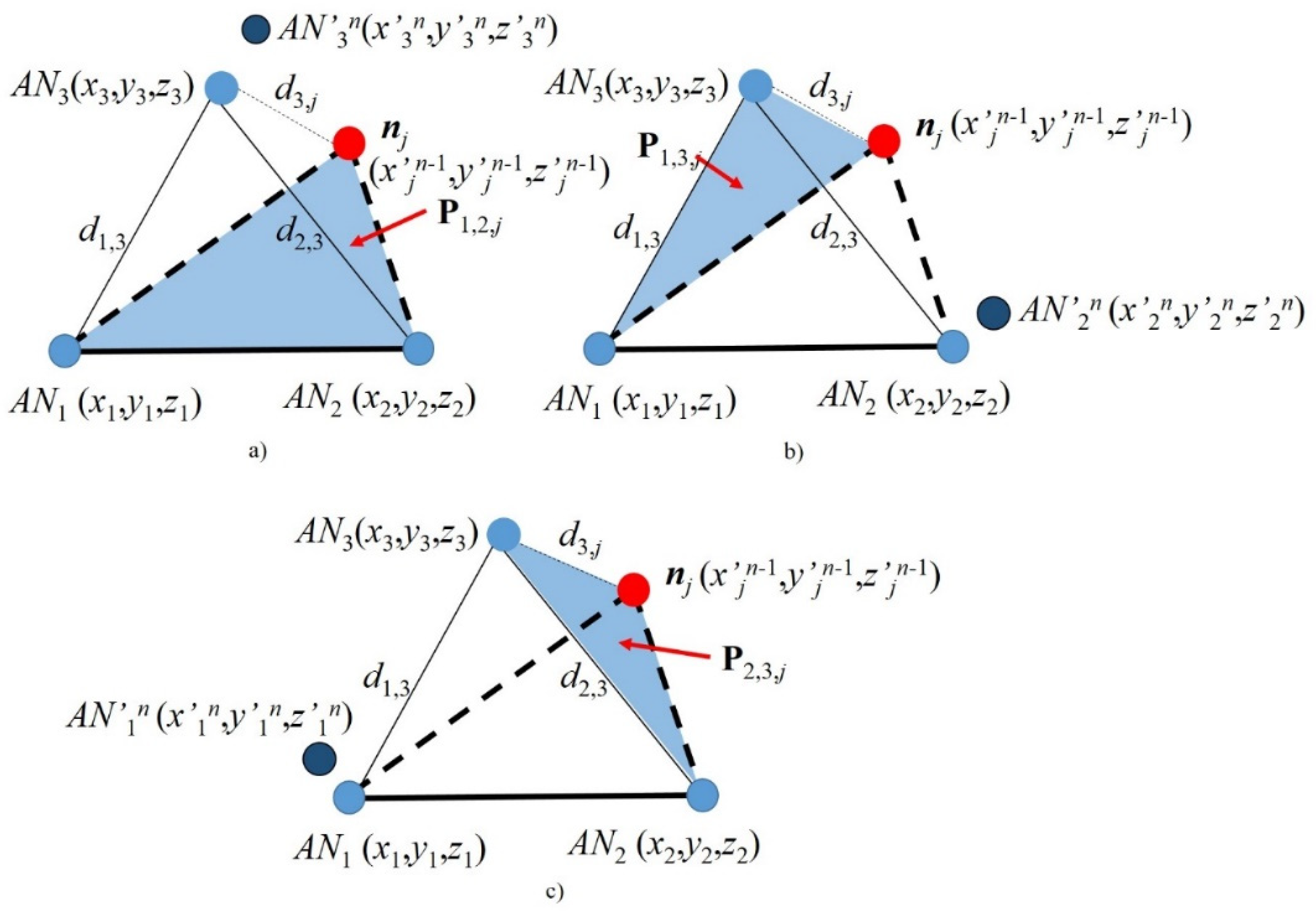
ANj and three new different planes of reference,
P12j,
P13j and
P23j, can be generated by rotation, as shown in
Figure 2. Note that, in each of these new planes, one of the original anchor nodes is disregarded, i.e.,
AN3 is not part of plane
P12j; we call this the extra anchor node. Then, the RL data fusion algorithm is as follows:
The extra anchor node
ANk (e.g.,
AN3 for reference plane
P12j, see
Figure 2a) performs self-localization (i.e., calculates the coordinates of
AN’
kn, namely,
x’
kn,
y’
kn,
z’
kn) based on the two noise-free distances with the other two original ANs (e.g.,
d13 and
d23, if
AN3 is self-locating) and one noisy distance (e.g.,
d’
3,j, if
AN3 is self-locating) with the estimated location of the new anchor node
nj. For instance, if
AN3 is self-locating,
x3′
n,
y3′
n and
z3′
n are calculated based on the distances
d1,3,
d2,3 and
d’
3,j and on the previous found coordinates (
x’
jn−1,
y’
jn−1,
z’
jn−1), using Equation set (2). Let us recall that
n − 1 = 1 for the first recursion.
The location error is defined as the Euclidean distance between the true position of
ANk (
xk,
yk,
zk) and the current
n-th estimate of
AN’
kn (
x’
kn,
y’
kn,
z’
kn), i.e.,
- 3.
Then, we formulate the recursive correcting vector CVk, which is used to re-calculate the node of interest coordinates, based on the difference between the estimated and the true position of ANk. This is calculated as CVkn = [cxkn = |x’kn − xk|, cykn = |y’kn − yk|, czkn = |z’kn − zk|] (e.g., CV3n = [cx3n = |x’3n − x3|, cy3n = |y’3n − y3|, cz3n = |z’3n − z3|]).
- 4.
Then, to find a local minimum of
nj coordinates, we calculate a new estimate of the coordinates (
x’
jn,
y’
jn,
z’
jn) of node
nj by applying
CVk as follows:
where
n is the number of the current coordinate calculation in the RL algorithm.
- 5.
Distances involved in equation set (2) are used again to re-calculate the location (
x’
kn,
y’
kn,
z’
kn) of anchor
AN’
kn; this process (steps 1–4) is repeated until a local minimum is found, that is, when the current error calculation
ekn is larger than the previous error
ekn−1. If this criterion is not met, the recursive algorithm continues until |
ekn −
ek−1n−1| < ξ, or when an unfeasible location is found, in order to proceed with the next step. Note that we are assuming that the node of interest is located at the first octant, as illustrated in
Figure 1d.
- 6.
Finally, the coordinates (x’jn, y’jn, z’jn) calculated in the last iteration are considered as the final location estimation of nj.
Please note that the convergence condition of the RL algorithm is defined in step 5. Simulations over different ξ in the range from 0.10ek−1n−1 to 0.30ek−1n−1 were performed and results showed a similar behavior.
In addition, note that the RL algorithm does not rely on the knowledge of the true position of nj. Let us recall that the local minimum as well as the threshold error ξ (step 5) are formulated based on successive calculations of the estimated locations of ANk. Note that the correcting factor is used to correct the position estimation of nj (step 4) and this new position is used to repeat steps 1–4 until the local minimum is found or the threshold error is reached (step 5).
In order to provide a better understanding of the complete localization process, we provide the following points of the execution of the algorithm:
Calculate the initial location estimation (x’j1, y’j1, z’j1) of nj using Equation set (2).
Then, node nj now becomes an anchor node.
Next, obtain the reference planes P12j, P13j and P23j using the new anchor node nj.
Then, follow steps 1–6 of the RL algorithm.
This algorithm can be implemented using a single extra anchor node AN or using the three ANs as extra anchor nodes and averaging the final nj location, which we call mean RL. We anticipate that using all the ANs involved might improve the nj location estimation.
Let us recall that the reference planes illustrated in
Figure 2 are obtained by rotation and translation of the original plane by applying Equation set (3). Finally, when the location estimation of anchor
AN’
kn (
x’
kn,
y’
kn,
z’
kn) is obtained, it can be transformed by translation/rotation to the original reference plane in order to calculate the corresponding recursive
CV.
2.2. Reference Plane Redundancy
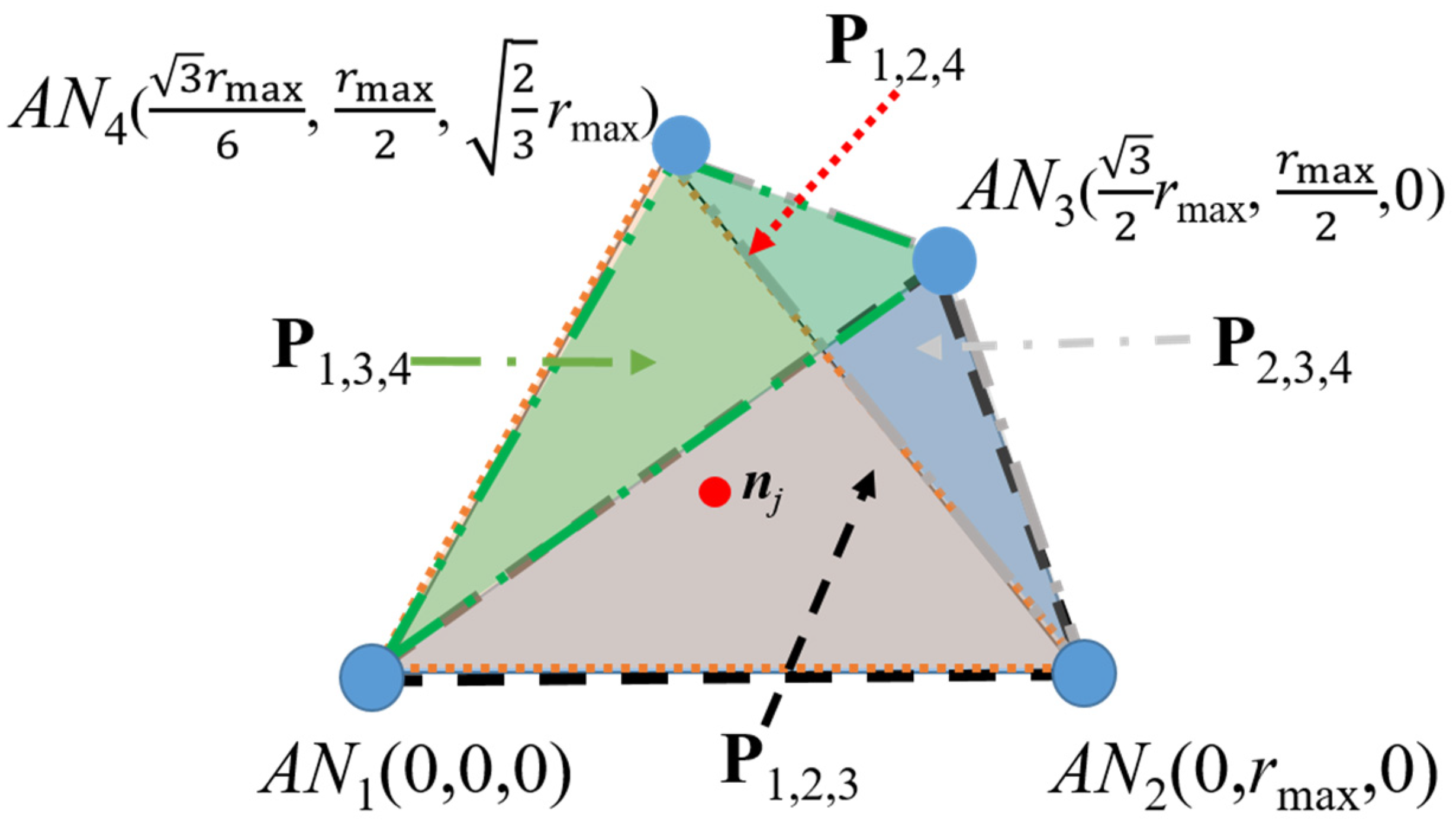
Note that, if more ANs are available, then we can obtain alternative planes that can be used for the location estimation of
nj and this may improve the first
nj location estimation (
x’
j1,
y’
j1,
z’
j1) used in the first step of the RL algorithm. The number of different planes that we can select to be used in the algorithm is given by the number of combinations
NC3, where
N is the number of available ANs. Thus, for
N = 4, four different sets of three ANs are obtained; therefore, four different calculations of coordinates (
xj,
yj,
zj) are possible (see
Figure 3). In a noise-free environment, these four sets of equations lead to the same location estimation result. However, in practice, the estimated distances
d’
k,j are obtained from field strength or delay measurements and are impaired by different propagation phenomena or routing strategies. All these impairments render in different coordinate calculations that can be averaged to smooth out the difference. In [
15], the authors proposed a PL method for a different 2D scenario based on a set of equations similar to those in (1); however, they did not take advantage of anchor point redundancy as we do in this paper. They related the equations in (1) by subtracting them and arranging terms in a matrix form, solving for a 2D scenario.
3. Simulations and Results
Note that, for scenarios as those illustrated in
Figure 1, the ANs’ locations can be arbitrarily set. In order to assess the performance of the proposed 3D PL technique and without loss of generality, we define the working operational space where three ANs are located at the corners of an equilateral triangle
AN1 (0,0,0),
AN2(
x2 =
rmax,0,0) and
AN3 (
x3 =
rmax/2,0), where
rmax is the maximal transmission range. For cases when four ANs are available, let us define a scenario such as that illustrated in
Figure 3, where the ANs’ locations are placed at the corners of a regular tetrahedron. Therefore, for simulation purposes and without loss of generality, the ANs’ locations are set as
AN1 (0,0,0),
AN2 (0,
rmax,0),
AN3 (
,
,0) and
AN4 (
,
,
).
Let us recall that we expect to have a distance estimation noise derived from signal propagation impairments. In the following, we present the results of the mean squared Euclidean distance error ε between the estimated and true locations, normalized to rmax, i.e., ε/rmax. The normalization allows us to observe the error as a proportion of the reachability radius and to see if, for a larger value of rmax, this proportion does not change. This normalized location error is shown for an additive observation error Ek,j of the true separation between ANk and the node to be located, nj. Let us recall that Ek,j is exponentially distributed with parameter λ and proportional to the true distance dk,j from ANk to node nj, Ek,j~exp(λ) ∗ dk,j. This is the observed distance d’k,j from ANk to nj and can be expressed as d’k,j = dk,j + Ek,j. The simulations were conducted for a random location of node nj and the maximum coverage radius was initially set to rmax = 10 m.
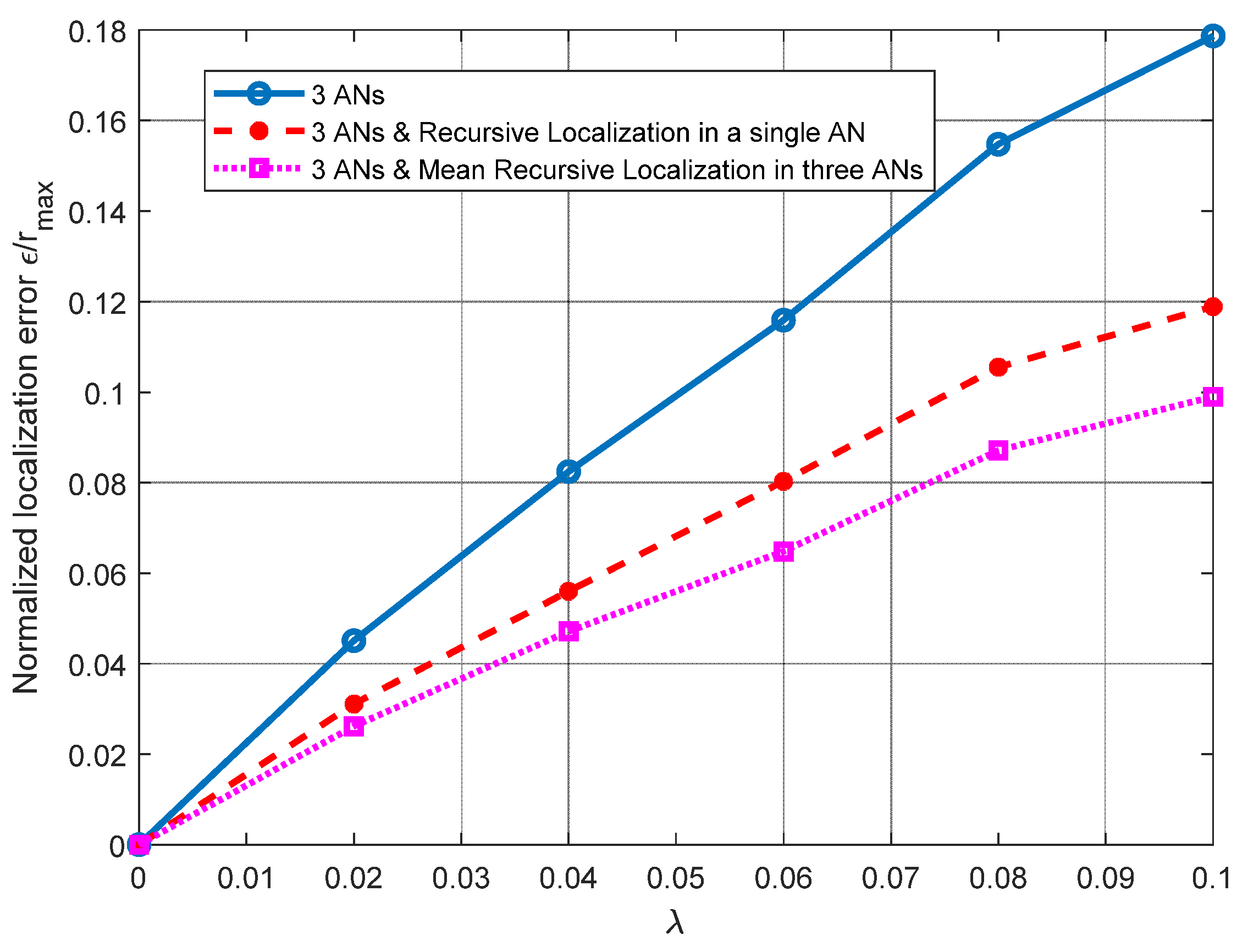
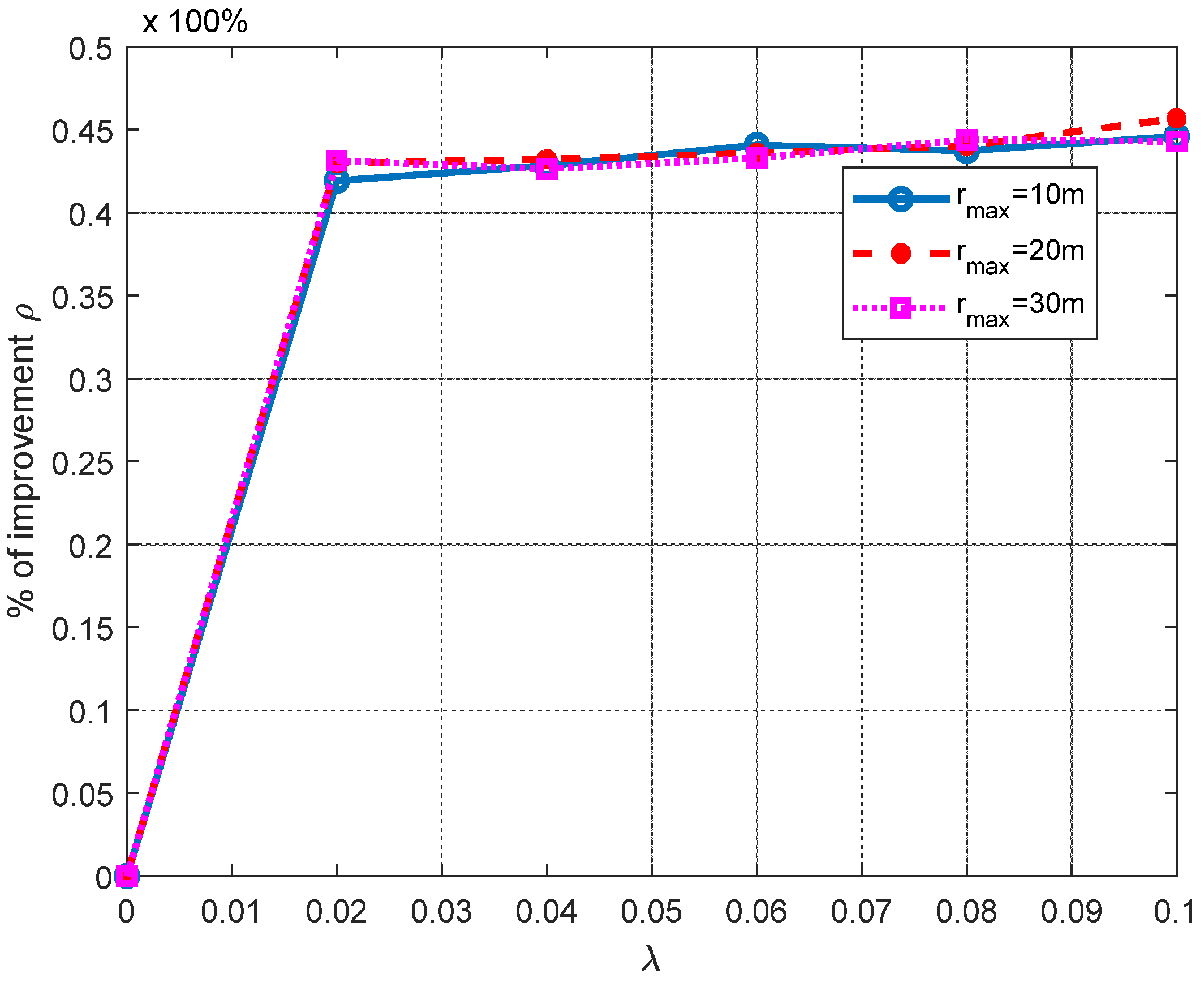
For the results shown in
Figure 4, a line of sight (LOS) from the ANs to node
nj is considered, to observe how having noisy distance estimations may affect the performance of the PL 3D technique. In this figure, the results of the normalized Euclidean error
ɛ/
rmax are presented as a function of the parameter
λ of the random variable—let us recall that
Ek,j~exp(
λ) ∗
dk,j. Please note that both the mean and the variance of the exponential random variable of the error are related to
λ (i.e., E[
Ek,j] = 1/
λ, Var[
Ek,j] = 1/
λ2). Please note that, as
λ increases, so does the error dispersion. In the context of distance estimation, this means that we evaluate distance errors with high variability. We select
λ from 0 to 0.1, to provide a high error dispersion. This simulation presents the results when using a single plane (three ANs available) and when single and mean RL are introduced on the node’s coordinates calculation. As noted in
Figure 4, the RL algorithm achieves significant improvements, of about 30% and 40%, when using one AN and three ANs, respectively.
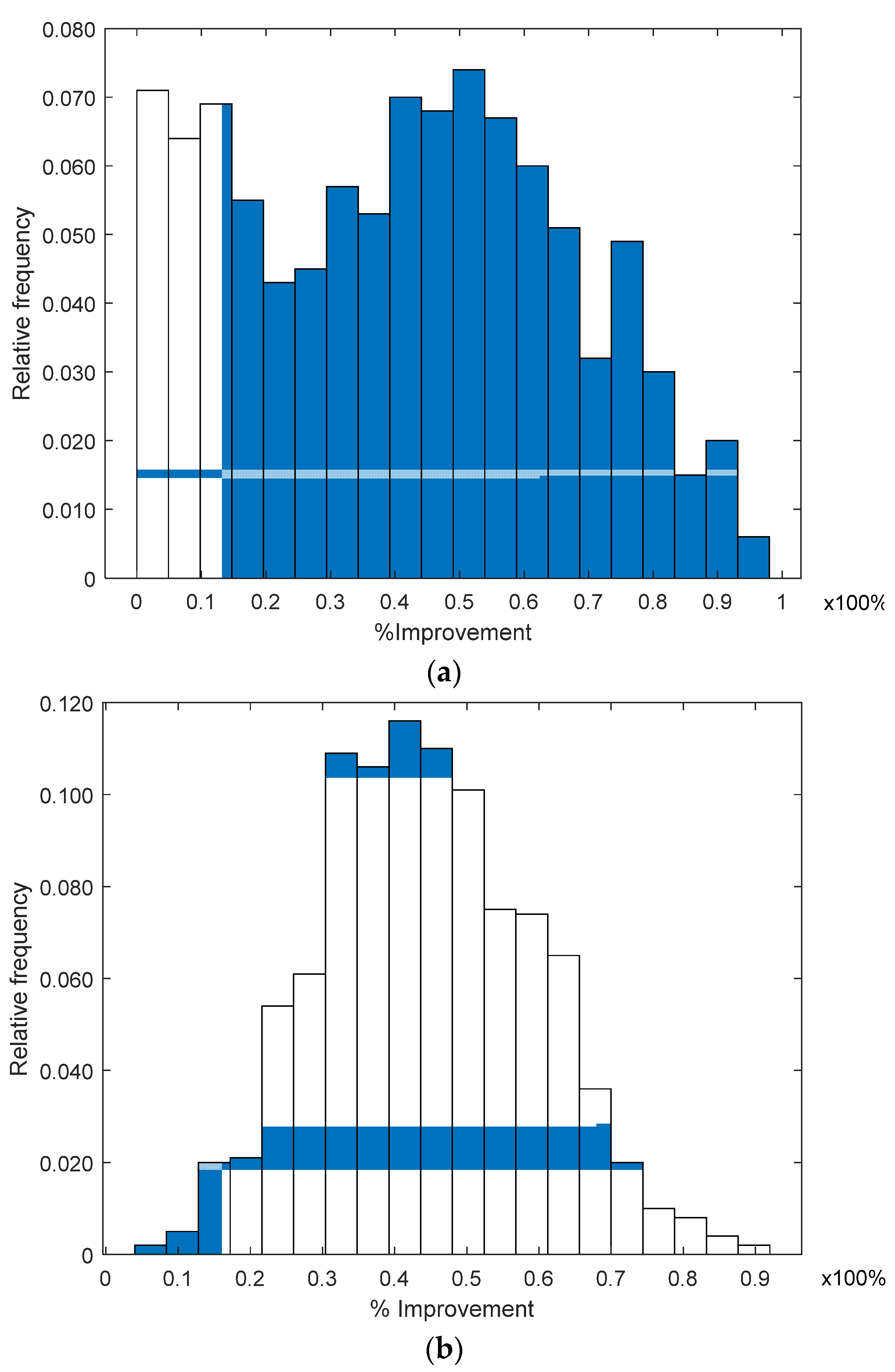
In
Figure 5, we present a histogram of the percentage of improvement obtained with the RL algorithm over the location estimation using a single plane for
λ = 0.1 and for 1000 analyzed cases. The improvement percentage
ρ is defined as
ρ =
, where
is the Euclidean distance error using a single plane and
is the Euclidean distance error using the RL algorithm, between the estimated and the true node location. In
Figure 5, we observe that the RL algorithm provides a significant improvement in all the analyzed cases, because all the values of
ρ in
Figure 5 are non-negative. The histograms show that the probability density function changes as more ANs are considered on the RL algorithm, concentrating improved values of
ρ around the mean (see
Figure 5b). Note that the improvement percentage
ρ pdf for the mean RL (three involved ANs) is different from that of the
ρ pdf using one AN. For the mean RL,
ρ seems to have a normal pdf with a mean of around
ρ = 50% and approximately 94.7% of the analyzed cases presented an improvement from
ρ = 20% to
ρ = 80%. When we take the average (mean RL) of the three ANs’ correction vectors, it is possible that the correction vector associated with a single AN is compensated by the other two estimations, providing a better behavior and avoiding any possible bias.
In
Figure 6, additional planes are considered (four ANs) for (
x’
j,
y’
j,
z’
j) calculation and it can be observed that, by using additional planes, we achieve better results than those shown in
Figure 4, where only a single plane (three ANs) is used. Note that we can perform recursive localization in a single AN or in the three ANs on the working plane and take the average of the three estimations (mean RL). This can be performed on a single plane or on several planes.
Moreover, it can be seen how the use of the RL algorithm in a single plane provides better results than using multiple reference planes alone. As it can be observed in
Figure 4, the proposed RL method provides significant improvements in both scenarios. These improvements can also be increased when the mean RL is used in the four ANs involved—an improvement of about 26% over the results obtained using the RL algorithm on a single plane. As in the scenario analyzed in
Figure 4, in this analysis, we can observe how the RL algorithm achieves significant improvements (single and mean) for all the cases analyzed (
σ).
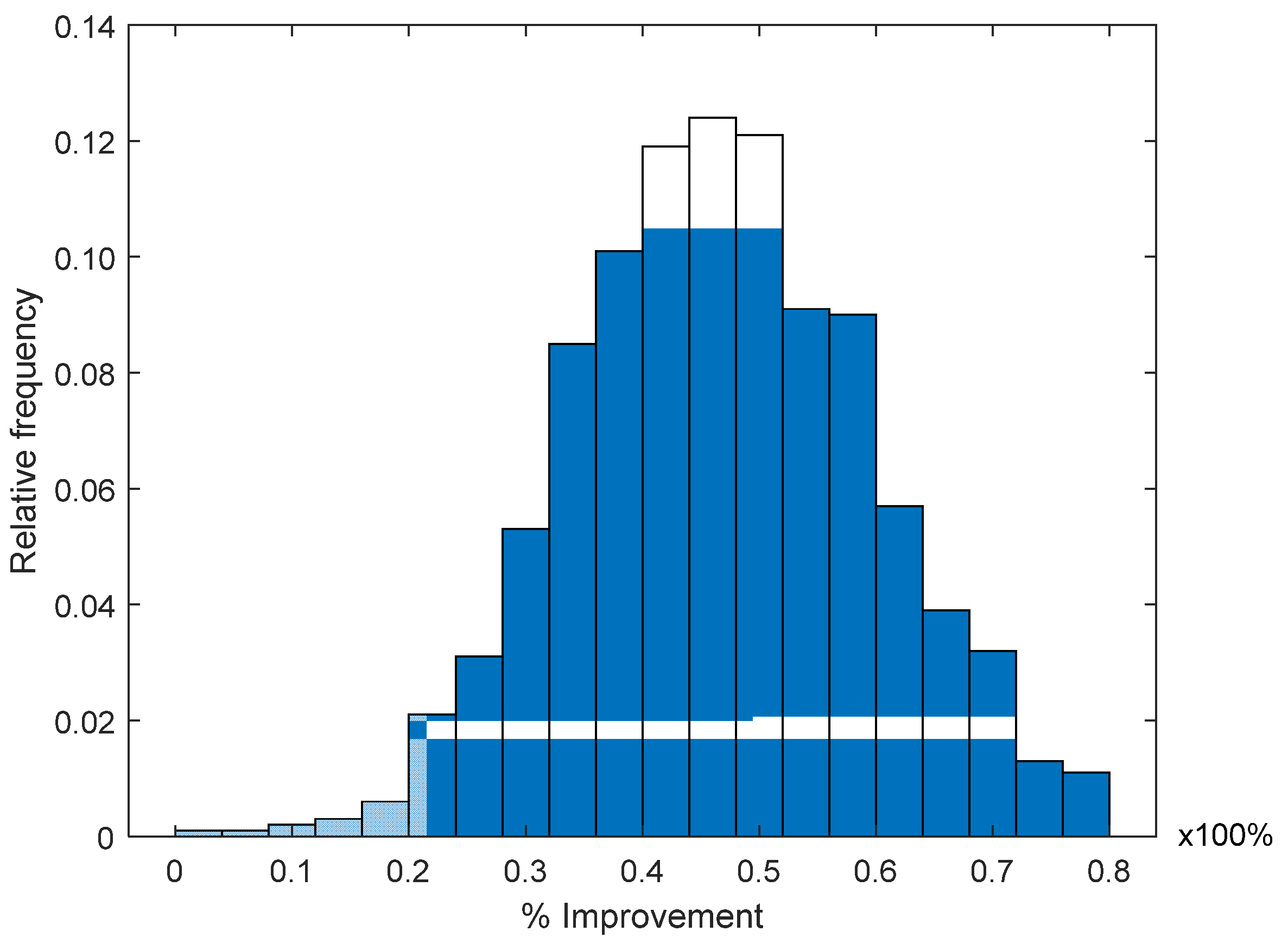
In
Figure 7, we present the histogram of the improvement percentage
ρ, obtained using the RL algorithm in the four ANs involved and averaging recursive vectors in order to obtain the final location estimation for
nj. In this figure, we can observe that, as more ANs are considered in the RL algorithm, the pdf of the improvement
ρ is more concentrated around the mean. For this evaluation,
ρ seems to have a normal pdf with a mean of around
ρ = 50% and approximately 99% of the analyzed cases presented an improvement from
ρ = 20% to
ρ = 80%.
In
Figure 8, we analyze the RL performance based on the improvement percentage
ρ using the mean RL in three ANs, for the scenario illustrated in
Figure 1b, where three ANs are located at the corners of an equilateral triangle,
AN1 (0,0,0),
AN2 (
x2 =
rmax,0,0) and
AN3 (
x3 =
,
rmax/2,0), and
rmax is increased gradually. In this figure, we can observe a very desirable behavior, as the RL performance is not degraded as the operational space is increased.
Now, we evaluate the improvement
ρ given by the RL algorithm when three ANs are available and for different locations of
AN2 and
AN3. Note that, by changing the position of these ANs defining the reference plane as that in
Figure 9, we obtain all the possible shapes for the triangle on the reference plane. The evaluation network scenario is generalized by modifying the coordinates of
AN2 and
AN3, as illustrated in
Figure 9.
The deployment of
AN2 is modified by adding to
x2 and
y2 random variables ±ζ
2x and ±ζ
2y respectively, while
z2 is kept without alteration. The same modification is conducted for the coordinates of
AN3. Let us recall that plane normalization by translation/rotation was carried out as explained before; therefore, we can consider that all the ANs are in
z = 0. So, let us define the distances ζ
ix and ζ
iy (
i = 1, 2, 3) as two uniformly distributed variables, defined in the ranges [0 ζ
x] and [0 ζ
y], respectively. (See axis-
x in
Figure 10.) This is performed in order to generalize the results given by the RL algorithm. In
Figure 10, we can observe that, for increments below the 30% of
rmax (ζ
x = 1, ζ
y = 1), the accuracy improvement
ρ is not severely degraded, as
ρ only decreases by approximately 11%.
For multihop scenarios, a direct link from the ANs to the node to locate may not be available. In
Figure 11, we analyze the performance of the localization technique using three ANs as in
Figure 1, over multihop scenarios in a defined cube with side
l =
rmax. The shortest route from
ANi to a node
nj, is referred to as
Ri,j and is obtained by Dijkstra’s algorithm, considering a homogenous reachability radius
rmax = 3 m for all nodes in the network. For this analysis, the distance
dij from
ADi to node
nj, is approximated by the hop count in the route linking the ANs to
nj. In
Figure 11, we analyze the RL algorithm performance over a multihop route scenario for a different number of nodes
η in the operational space. In this analysis, we can see that, as the number of nodes in the network grows, the distance error given by the single plane (three ANs) equations using the mean RL in three ANs tends to decrease. This can be explained by the fact that, when the number of nodes increases, the network connectivity improves and better routes may be obtained. Let us recall that, in this evaluation, distance estimation is based on the hop count method. Note that the improvement achieved by the RL algorithm is always above approximately 30%.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}