
A Clustering Method of Case-Involved News by Combining Topic Network and Multi-Head Attention Mechanism


Abstract
:1. Introduction
2. Related Work
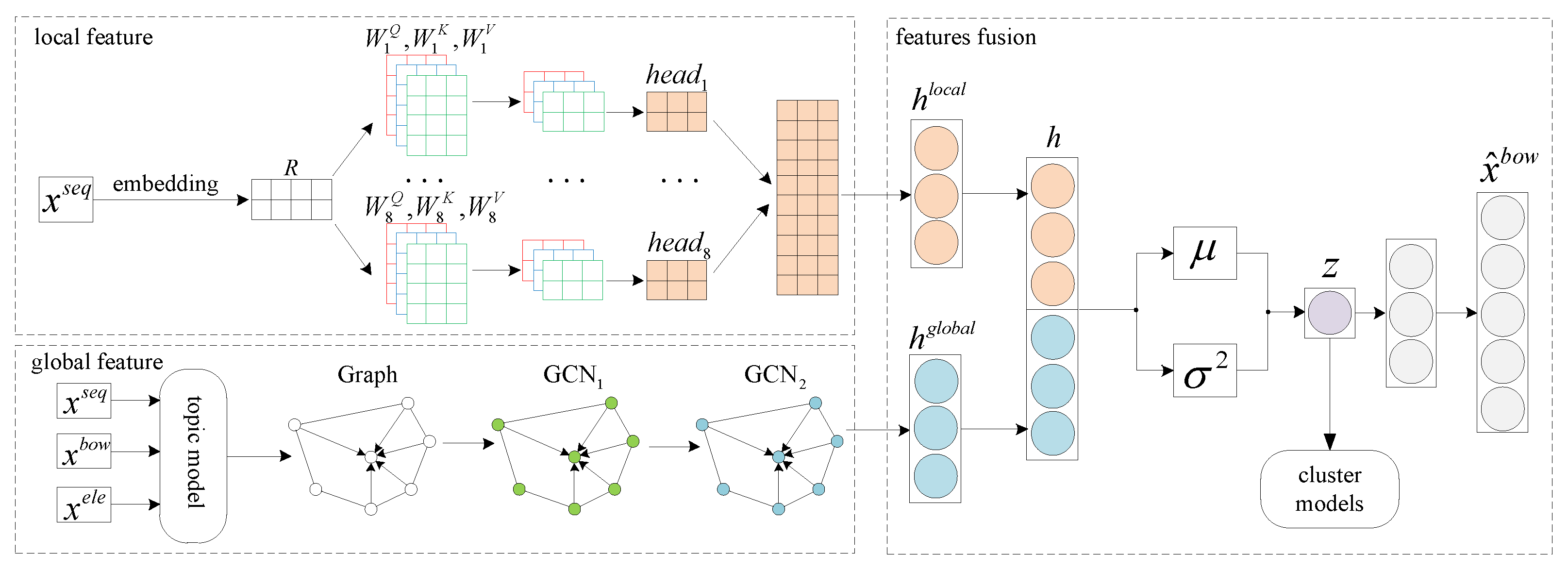
3. Method
3.1. Local Feature Extraction
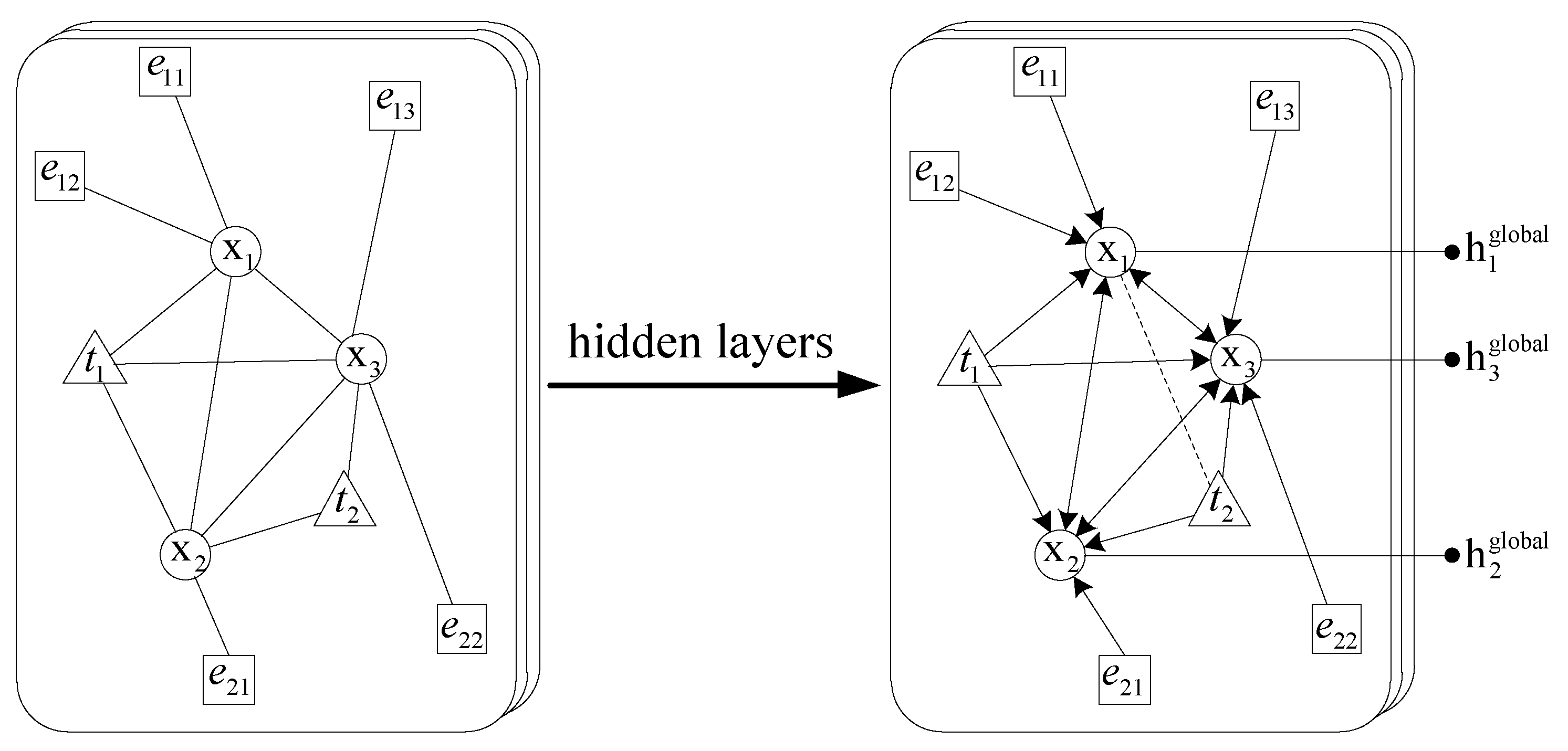
3.2. Global Feature Extraction
3.3. Features Fusion
- pre-training. The extracted local features and global features are concatenated as the input of the variational auto-encoder, and Equation (23) is taken as the optimization target for iterative training. After the pre-training, the latent representations of the news can be preliminarily obtained.
- fine-tuning. Firstly, we use the K-means model to initialize the cluster center on the basis of step 1, and then the clustering loss is calculated according to Equations (24)–(26). Finally, the loss function is defined as:where is the weight which balances the above two losses. The purpose of this step is to add clustering signals in the training process so as to obtain the latent representations of case-involved news that is more suitable for clustering.
4. Experiment
4.1. Dataset
4.2. Baseline Models
- K-means [3]: A classical clustering method based on raw data;
- AE [18]: It is a two-stage deep clustering algorithm which performs K-means on the representations learned by autoencoder;
- DEC [19]: It is a deep clustering method which designs a clustering objective to guide the learning of the data representations;
- DCN [20]: This method adds the objective function of Kmeans algorithm to AE;
- IDEC [26]: This method adds a reconstruction loss to DEC, so as to learn better representation;
- N2D [27]: It is a unsupervised method which carries out manifold learning on the basis of raw data and auto-encoder;
- SDCN [22]: This method integrates the data representation obtained from the encoder and the structural information extracted from the graph convolution network, and designs a dual self-supervised clustering guidance method.
4.3. Experiment Details
- Experimental environment: In this paper, we implement the experiments in python3.6.5, pytorch1.6.0 [28] on a NVIDIA TESLA T4.
- Corpus processing: For the corpus, we construct a vocabulary with size of 29,651 by selecting words with a frequency greater than three and removing stop words. For each news, we add the [CLS] flag at the beginning of each news as the starting flag, and the model uses this flag to extract the local feature. Otherwise, we intercept the part with the length of more than 100, and use the [pad] flag to pad the news with the length of less than 100 which is conducive to using the mask mechanism to eliminate invalid information. The adjacency matrix is constructed by the method described in Section 3.2, which is a sparse matrix containing news nodes, case element nodes and topic nodes, the information contained in it can be extracted by GCN model.
- Hyperparameters: For local feature, we use the multi-head attention mechanism, and the number of head is 8 and the dimension of hidden layser is 512. For global feature, we set the number of topic number to 15, and the dimension numbers of the 2-layer GCN model are 2000 and 512. For training process, we use the optimizer Adam [29] with learning rate of , and the number of dropout is set to . Some parameters, such as latent representation dimension and loss balance weight, will be compared with different values in the experimental part.
- Baseline models: For baseline models, K-means model is used for clustering, which is also the choice of the all original papers. For text representation, we chose to use the one-hot vector processed by L2 regularization, the reason for this choice is that we found that the effect of the original one-hot vector without processing is not as good as that after L2 regularization. Otherwise, we set the output dimension of AE to 20, and other parameters followed the settings of the original papers.
- Training steps: In the training phase, word sequence and adjacency matrix are used as inputs to the model, through multi-head attention mechanism and GCN model, model can extract the local and global features of the news. By concatenating the two features, the model obtains the input of the variational auto-encoder, then the VAE model will reconstruct the analog data, and the goal of reconstruction is the BoW (bag of word) representation of news. Finally, the method described in the last part of Section 3.3 is used to adjust the parameters, so as to obtain the representation with the best clustering effect.
4.4. Metrics
- Accuracymeasures the consistency between the true group label and the clustering group label. It is defined as follows:where is an indicator function, transforms the clustering label to its group label by the Hungarian algorithm [30].
- Normalized Mutual Information [31]is a popular metric used for evaluating clustering tasks. It is defined as follows:where is mutual information which measures the information gain to the true partition after knowing the clustering result, is entropy and the denominator is used to normalize the mutual information to be in the range of [0, 1]. When we partition the news perfectly, score is 1.
- Average Rand Index [32]is defined as follows:where is the expectation of the Rand index (RI), which can be calculated as shown in Equation (31). has a value between 0 and 1, with 0 indicating that the two data clusterings do not agree on any pair of points and 1 indicating that the data clusterings are exactly the same.where is defined as follows:
- -
- a: the number of pairs of news that are in the same cluster in y and in the same cluster in c;
- -
- b: the number of pairs of news that are in the different clusters in y and in the different clusters in c;
- -
- c: the number of pairs of news that are in the same cluster in y and in the different clusters in c
- -
- d: the number of pairs of news that are in the different clusters in y and in the same cluster in c
5. Analysis of Results
5.1. Analysis of Clustering Results
5.2. Analysis of Latent Representation in Different Dimensions
5.3. Analysis of Balance Weight
5.4. Analysis of Different Features
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Rusu, D.; Hodson, J.; Kimball, A. Unsupervised techniques for extracting and clustering complex events in news. In Proceedings of the Second Workshop on EVENTS: Definition, Detection, Coreference, and Representation, Baltimore, MD, USA, 22–27 June 2014; pp. 26–34. [Google Scholar]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A survey of clustering with deep learning: From the perspective of network architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Capó, M.; Pérez, A.; Lozano, J.A. An efficient approximation to the K-means clustering for massive data. Knowl.-Based Syst. 2017, 117, 56–69. [Google Scholar] [CrossRef] [Green Version]
- Kumar, J.; Shao, J.; Uddin, S.; Ali, W. An online semantic-enhanced Dirichlet model for short text stream clustering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 766–776. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need, In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Gupta, P.; Chaudhary, Y.; Buettner, F.; Schütze, H. Document informed neural autoregressive topic models with distributional prior. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6505–6512. [Google Scholar]
- Mousa, A.; Schuller, B. Contextual bidirectional long short-term memory recurrent neural network language models: A generative approach to sentiment analysis. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 1023–1032. [Google Scholar]
- Vu, N.T.; Gupta, P.; Adel, H.; Schütze, H. Bi-directional recurrent neural network with ranking loss for spoken language understanding. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2017; pp. 6060–6064. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.; Blei, D.M. Topic modeling in embedding spaces. Trans. Assoc. Comput. Linguist. 2020, 8, 439–453. [Google Scholar] [CrossRef]
- Bianchi, F.; Terragni, S.; Hovy, D. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv 2020, arXiv:2004.03974. [Google Scholar]
- Srivastava, A.; Sutton, C. Autoencoding variational inference for topic models. arXiv 2017, arXiv:1703.01488. [Google Scholar]
- Song, C.; Liu, F.; Huang, Y.; Wang, L.; Tan, T. Auto-encoder based data clustering. In Proceedings of the Iberoamerican Congress on Pattern Recognition, Havana, Cuba, 20–23 November 2013; pp. 117–124. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Yang, B.; Fu, X.; Sidiropoulos, N.D.; Hong, M. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3861–3870. [Google Scholar]
- Wang, C.; Pan, S.; Hu, R.; Long, G.; Jiang, J.; Zhang, C. Attributed graph clustering: A deep attentional embedding approach. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3670–3676. [Google Scholar]
- Bo, D.; Wang, X.; Shi, C.; Zhu, M.; Lu, E.; Cui, P. Structural deep clustering network. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 1400–1410. [Google Scholar]
- Chiu, B.; Sahu, S.K.; Thomas, D.; Sengupta, N.; Mahdy, M. Autoencoding Keyword Correlation Graph for Document Clustering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3974–3981. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Han, P.; Gao, S.; Yu, Z.; Huang, Y.; Guo, J. Case-involved Public Opinion News Summarization with Case Elements Guidance. J. Chin. Inf. Process. 2020, 34, 56–63. [Google Scholar]
- Guo, X.; Gao, L.; Liu, X.; Yin, J. Improved Deep Embedded Clustering with Local Structure Preservation. In Proceedings of the IJCAI’17, Melbourne, Australia, 19–25 August 2017; pp. 1753–1759. [Google Scholar]
- McConville, R.; Santos-Rodriguez, R.; Piechocki, R.J.; Craddock, I. N2d:(not too) deep clustering via clustering the local manifold of an autoencoded embedding. arXiv 2019, arXiv:1908.05968. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.Y.; Song, Y.; Bai, H.; Lin, C.J.; Chang, E.Y. Parallel spectral clustering in distributed systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 568–586. [Google Scholar] [CrossRef] [PubMed]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 15 | 12,468 | 1598 | 500 | 29,651 | 446 | 146 |
| Model | ACC | NMI | ARI |
|---|---|---|---|
| KM | 0.6416 | 0.6692 | 0.5067 |
| AE+KM | 0.7271 | 0.7393 | 0.6239 |
| DEC | 0.7765 | 0.7487 | 0.6945 |
| DCN | 0.7994 | 0.7786 | 0.7112 |
| IDEC | 0.8186 | 0.7902 | 0.7456 |
| N2D | 0.8466 | 0.8209 | 0.7819 |
| SDCN | 0.9014 | 0.8684 | 0.8368 |
| Ours | 0.9451 | 0.9011 | 0.9014 |
| Model | Feature Compression | Clustering Optimization | Correlation | Context |
|---|---|---|---|---|
| KM | - | - | - | - |
| AE+KM | ✓ | - | - | - |
| DEC | ✓ | ✓ | - | - |
| DCN | ✓ | ✓ | - | - |
| IDEC | ✓ | ✓ | - | - |
| N2D | ✓ | - | - | - |
| SDCN | ✓ | ✓ | ✓ | - |
| Ours | ✓ | ✓ | ✓ | ✓ |
| Dimension | ACC | NMI | ARI |
|---|---|---|---|
| 10 | 0.9000 | 0.8940 | 0.8776 |
| 20 | 0.9451 | 0.9011 | 0.9014 |
| 32 | 0.9339 | 0.9058 | 0.8975 |
| 64 | 0.8880 | 0.8736 | 0.8509 |
| 128 | 0.8586 | 0.8483 | 0.8227 |
| λ | ACC | NMI | ARI |
|---|---|---|---|
| 0.0 | 0.9287 | 0.8785 | 0.8696 |
| 0.1 | 0.9261 | 0.8743 | 0.8612 |
| 0.3 | 0.9301 | 0.8796 | 0.8741 |
| 0.5 | 0.9347 | 0.8858 | 0.8821 |
| 0.7 | 0.9451 | 0.9011 | 0.9014 |
| 0.9 | 0.9394 | 0.8929 | 0.8913 |
| 1.0 | 0.9354 | 0.8897 | 0.8794 |
| Feature | ACC | NMI | ARI |
|---|---|---|---|
| topic information | 0.7495 | 0.7179 | 0.6408 |
| local feature | 0.8587 | 0.8333 | 0.8267 |
| global feature | 0.8829 | 0.8658 | 0.8428 |
| feature fusion | 0.9451 | 0.9011 | 0.9014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, C.; Liang, H.; Yu, Z.; Huang, Y.; Guo, J. A Clustering Method of Case-Involved News by Combining Topic Network and Multi-Head Attention Mechanism. Sensors 2021, 21, 7501. https://doi.org/10.3390/s21227501
Mao C, Liang H, Yu Z, Huang Y, Guo J. A Clustering Method of Case-Involved News by Combining Topic Network and Multi-Head Attention Mechanism. Sensors. 2021; 21(22):7501. https://doi.org/10.3390/s21227501
Chicago/Turabian StyleMao, Cunli, Haoyuan Liang, Zhengtao Yu, Yuxin Huang, and Junjun Guo. 2021. "A Clustering Method of Case-Involved News by Combining Topic Network and Multi-Head Attention Mechanism" Sensors 21, no. 22: 7501. https://doi.org/10.3390/s21227501
APA StyleMao, C., Liang, H., Yu, Z., Huang, Y., & Guo, J. (2021). A Clustering Method of Case-Involved News by Combining Topic Network and Multi-Head Attention Mechanism. Sensors, 21(22), 7501. https://doi.org/10.3390/s21227501