
Small Object Detection in Traffic Scenes Based on YOLO-MXANet

Abstract
:1. Introduction
2. Baseline and YOLO-MXANet Algorithm
2.1. YOLOv3 Baseline Algorithm
2.2. YOLO-MXANet Algorithm
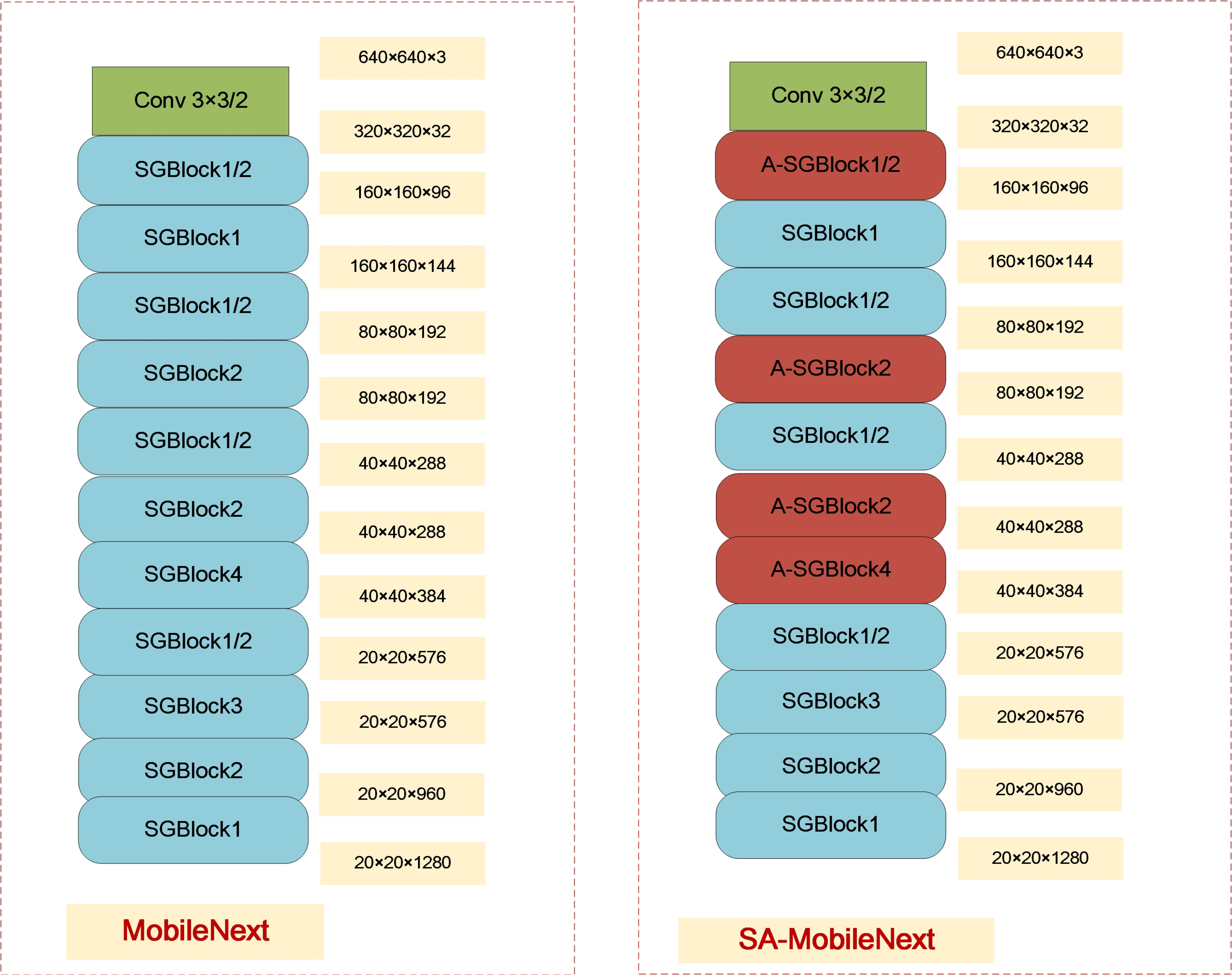
2.2.1. SA-MobileNeXt
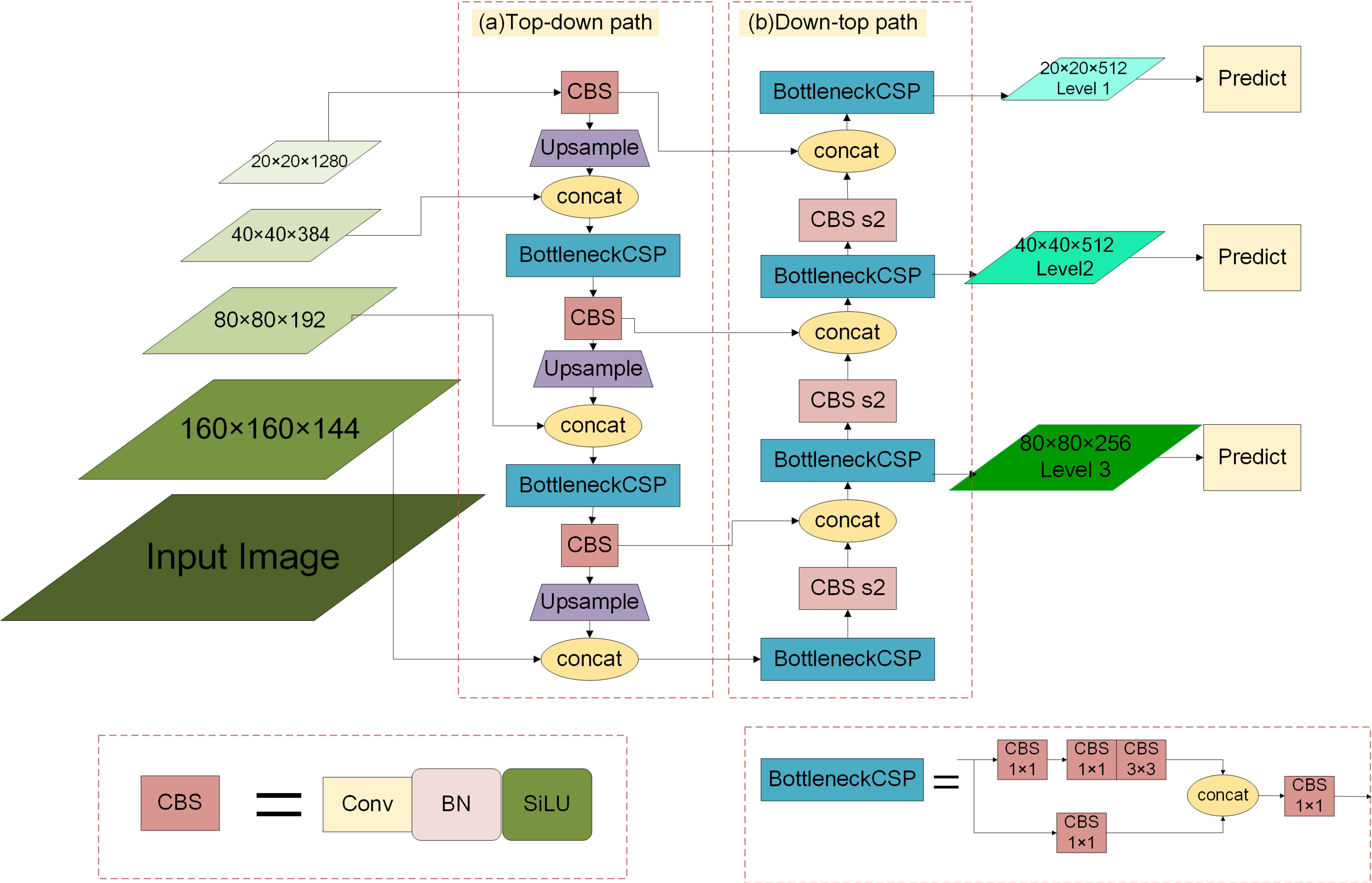
2.2.2. Multi-Scale Feature Enhancement Fusion Network
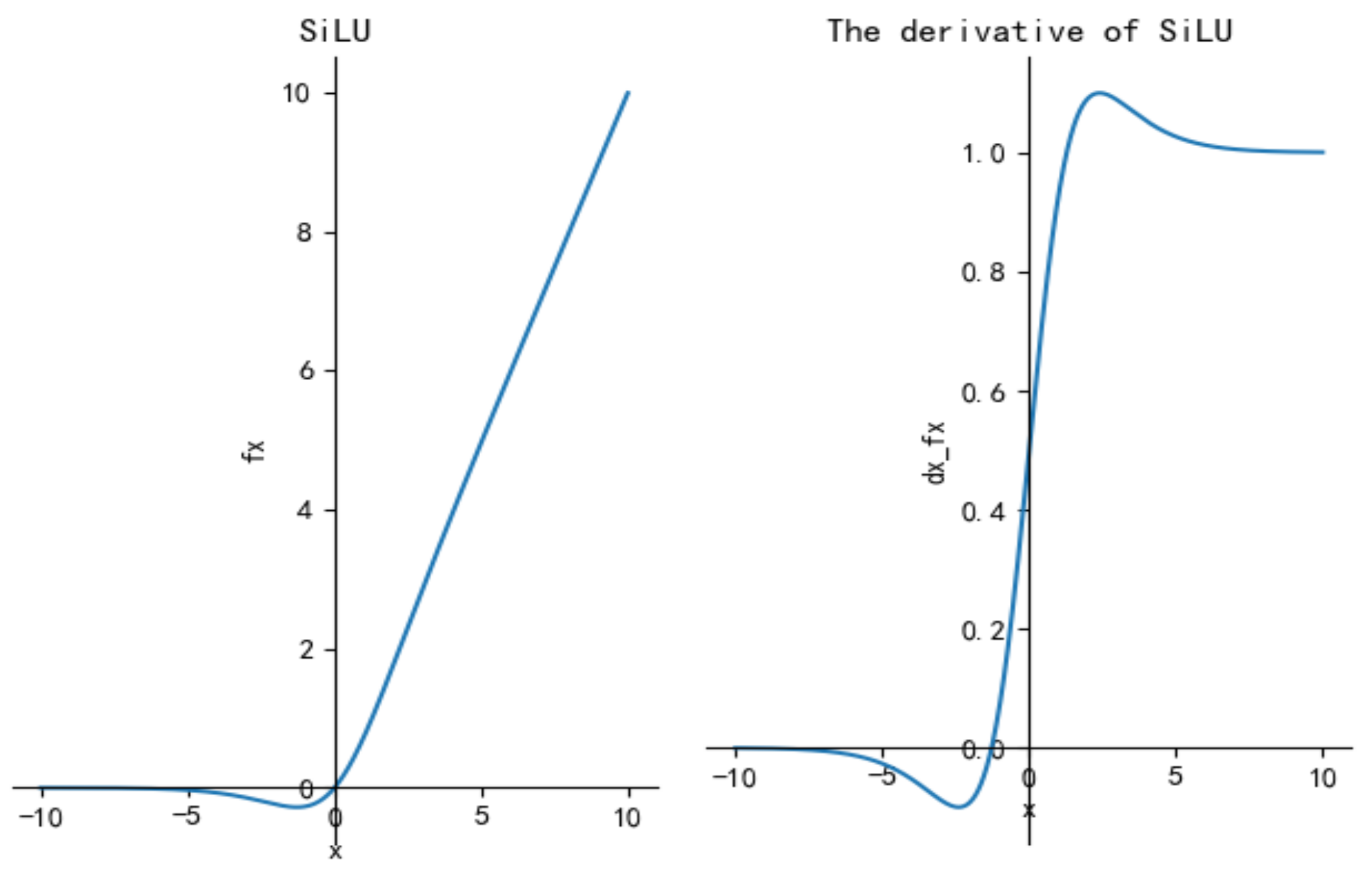
2.2.3. SiLU Activation Function
2.2.4. Data Enhancement
2.2.5. Loss Function
3. Experimental Results and Analysis
3.1. Ablation Learning on the KITTI Dataset
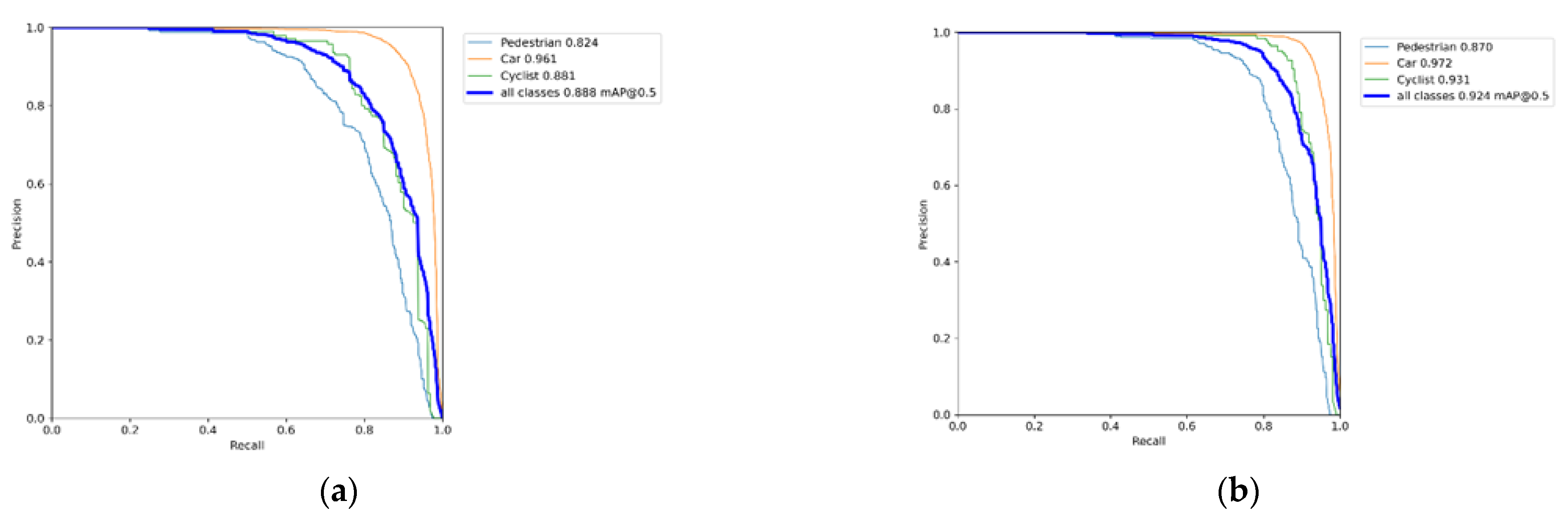
3.2. Comparison Experiments with Other Algorithms on the KITTI Dataset
3.3. Comparison Experiments with Other Algorithms on the CCTSDB Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrelland, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y. SSD: Single shot multi box detector. In Proceedings of the Europe Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.C.; Berg, A. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. Available online: https://arxiv.org/abs/1701.06659 (accessed on 23 January 2017).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767v1. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhu, C.; He, Y.H.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Que, L.; Zhang, T.; Guo, H.; Jia, C.; Gong, Y.; Chang, L.; Zhou, J. A Lightweight Pedestrian Detection Engine with Two-StageLow-Complexity Detection Network and Adaptive Region Focusing Technique. Sensors 2021, 21, 5851. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Liu, Q. Scale-sensitive feature reassembly network for pedestrian detection. Sensors 2021, 21, 4189. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Gong, X.; Ouyang, H. Improvement of Tiny YOLOv3 object detection. Opt. Precis. Eng. 2020, 28, 988–995. [Google Scholar]
- Guo, F.; Zhang, Y.; Tang, J.; Li, W. YOLOv3-A: A traffic sign detection network based on attention mechanism. J. Commun. 2021, 42, 87–99. [Google Scholar]
- Liu, C.; Wang, Q.; Bi, X. Research on Multi-target and Small-scale Vehicle Target Detection Method. Control Decis. 2021, 36, 2707–2712. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2110–2118. [Google Scholar]
- Wang, H.; Wang, J.; Bai, K.; Sun, Y. Centered Multi-Task Generative Adversarial Network for Small Object Detection. Sensors 2021, 21, 5194. [Google Scholar] [CrossRef]
- Bosquet, B.; Mucientes, M.; Brea, V. STDnet-ST: Spatio-temporal ConvNet for small object detection. Pattern Recognit. 2021, 116, 107929. [Google Scholar] [CrossRef]
- Lian, J.; Yin, Y.; Li, L.; Wang, Z.; Zhou, Y. Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors 2021, 21, 3031. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zhang, X.; Tu, D.; Wang, Y. Small object detection using deep convolutional networks: Applied to garbage detection system. J. Electron. Imaging 2021, 30, 043013. [Google Scholar] [CrossRef]
- Liu, C.; Li, S.; Chang, F.; Wang, Y. Machine Vision Based Traffic Sign Detection Methods: Review, Analyses and Perspectives. IEEE Access 2019, 7, 86578–86596. [Google Scholar] [CrossRef]
- Chen, R.-C.; Saravanarajan, V.S.; Hung, H.-T. Monitoring the behaviours of pet cat based on YOLO model and raspberry Pi. Int. J. Appl. Sci. Eng. 2021, 18, 1–12. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. arXiv 2020, arXiv:2005.03572. [Google Scholar]
- Daquan, Z.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking Bottleneck Structure for Efficient Mobile Network Design. arXiv 2020, arXiv:2007.02269. Available online: https://arxiv.org/abs/2007.02269 (accessed on 27 November 2020).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 23 April 2020).
- Zhang, H.; Gisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. Available online: https://arxiv.org/abs/1710.09412 (accessed on 27 April 2018).
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Glasgow, UK, 23–28 August 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honoluu, HI, USA, 22–25 July 2017; pp. 2117–2125. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. Available online: https://arxiv.org/abs/1704.04861 (accessed on 17 April 2017).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetv3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, H.; Zheng, H.; Sun, J. ShuffleNetv2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. Available online: https://arxiv.org/abs/1807.11164 (accessed on 30 July 2018).
- Landola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. Available online: https://arxiv.org/abs/1602.07360 (accessed on 4 November 2016).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. Available online: https://arxiv.org/abs/2103.02907 (accessed on 4 March 2021).
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Jiang, X.; Hartomo, K.D. Yolo V4 for Advanced Traffic Sign Recognition With Synthetic Training Data Generated by Various GAN. IEEE Access 2019, 7, 97228–97242. [Google Scholar]
- Cheng, R.; He, X.; Zheng, Z.; Wang, Z. Multi-Scale Safety Helmet Detection Based on SAS-YOLOv3-Tiny. Appl. Sci. 2021, 11, 3652. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over Union: A metric and a loss for bounding box regression. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. Available online: https://arxiv.org/abs/1911.08287 (accessed on 9 March 2020). [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Method | P | R | F1 | mAP 0.5 | SpeedGPU/ms | Params | GFLOPS |
|---|---|---|---|---|---|---|---|---|
| A | YOLOv3 | 0.923 | 0.765 | 0.837 | 0.888 | 3.5 | 61,508,200 | 154.9 |
| B | A CIoU | 0.930 | 0.799 | 0.860 | 0.911 | 3.5 | 61,508,200 | 154.9 |
| C | B MobileNeXt | 0.857 | 0.772 | 0.812 | 0.865 | 2.4 | 22,927,784 | 43.4 |
| D | C DA | 0.882 | 0.806 | 0.842 | 0.897 | 2.4 | 22,927,784 | 43.4 |
| E | D PAN 4s BC | 0.876 | 0.846 | 0.861 | 0.905 | 2.5 | 13,870,888 | 37.0 |
| F | E SiLU | 0.941 | 0.822 | 0.877 | 0.916 | 2.5 | 13,870,888 | 37.0 |
| G | F A-MobileNeXt | 0.943 | 0.818 | 0.876 | 0.922 | 2.9 | 13,987,271 | 37.1 |
| H | G SA-MobileNeXt | 0.930 | 0.844 | 0.885 | 0.924 | 2.9 | 13,874,564 | 37.0 |
| Indicator | P | R | F1 | mAP 0.5 | Params (M) |
|---|---|---|---|---|---|
| Algorithm | |||||
| YOLOv3 | 0.923 | 0.765 | 0.837 | 0.888 | 61.5 |
| YOLOv3-SPP | 0.923 | 0.783 | 0.847 | 0.894 | 62.6 |
| YOLOv5s | 0.922 | 0.781 | 0.846 | 0.889 | 7 |
| YOLOv5m | 0.899 | 0.862 | 0.880 | 0.923 | 21.1 |
| YOLOv3-tiny | 0.763 | 0.598 | 0.670 | 0.692 | 8.7 |
| YOLOv4-tiny | 0.589 | 0.761 | 0.663 | 0.762 | 5.9 |
| YOLO-MXANet | 0.930 | 0.844 | 0.885 | 0.924 | 13.8 |
| Indicator | P | R | F1 | mAP 0.5 |
|---|---|---|---|---|
| Algorithm | ||||
| YOLOv3 | 0.910 | 0.894 | 0.902 | 0.928 |
| YOLOv3-SPP | 0.929 | 0.877 | 0.902 | 0.937 |
| YOLOv5m | 0.968 | 0.939 | 0.953 | 0.966 |
| YOLOv3-tiny | 0.911 | 0.873 | 0.892 | 0.905 |
| YOLOv4-tiny | 0.795 | 0.964 | 0.871 | 0.951 |
| YOLO-MXAet | 0.930 | 0.967 | 0.948 | 0.973 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, X.; Cheng, R.; Zheng, Z.; Wang, Z. Small Object Detection in Traffic Scenes Based on YOLO-MXANet. Sensors 2021, 21, 7422. https://doi.org/10.3390/s21217422
He X, Cheng R, Zheng Z, Wang Z. Small Object Detection in Traffic Scenes Based on YOLO-MXANet. Sensors. 2021; 21(21):7422. https://doi.org/10.3390/s21217422
Chicago/Turabian StyleHe, Xiaowei, Rao Cheng, Zhonglong Zheng, and Zeji Wang. 2021. "Small Object Detection in Traffic Scenes Based on YOLO-MXANet" Sensors 21, no. 21: 7422. https://doi.org/10.3390/s21217422
APA StyleHe, X., Cheng, R., Zheng, Z., & Wang, Z. (2021). Small Object Detection in Traffic Scenes Based on YOLO-MXANet. Sensors, 21(21), 7422. https://doi.org/10.3390/s21217422