
Deepfake Detection Using the Rate of Change between Frames Based on Computer Vision


Abstract
:1. Introduction
2. Related Works
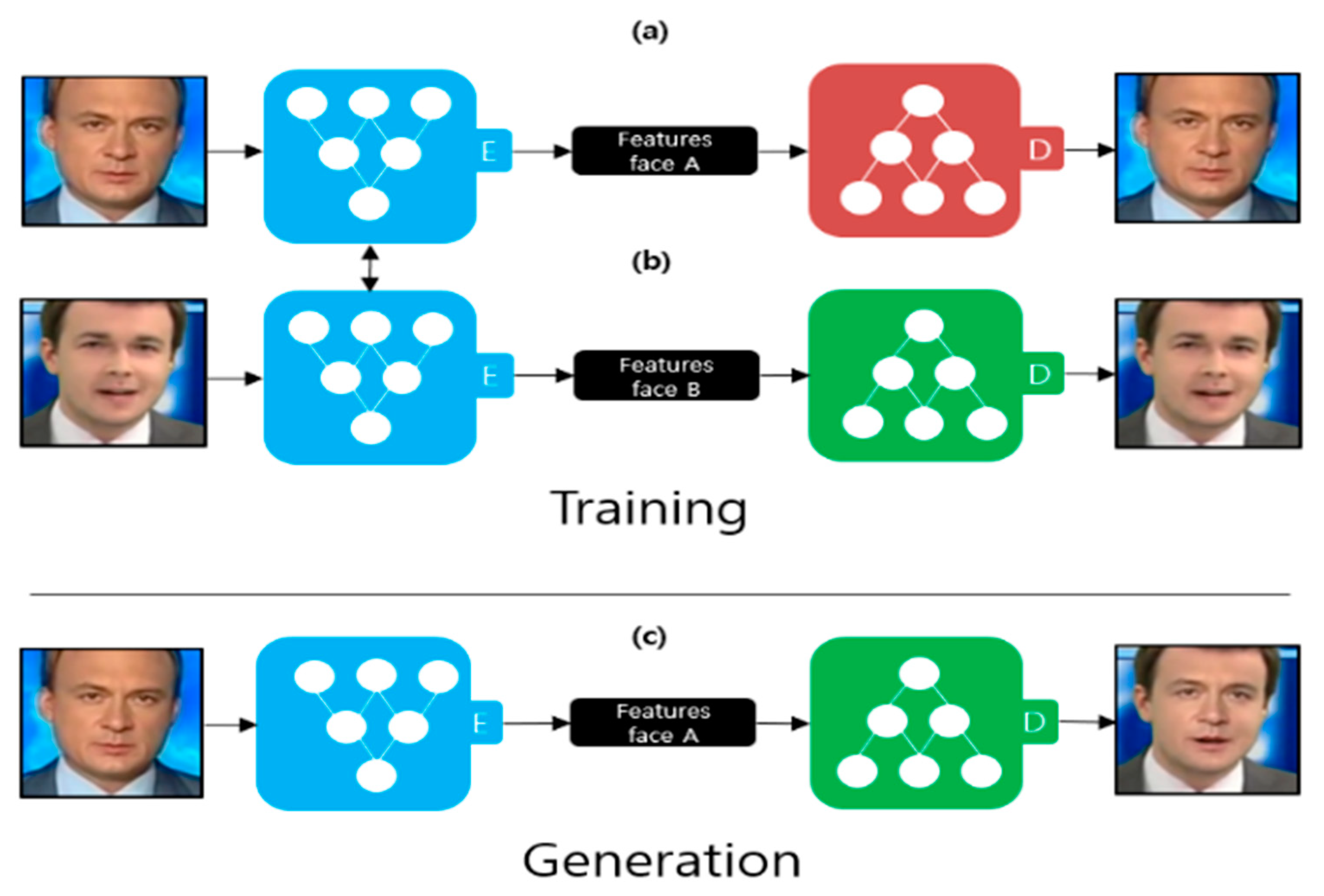
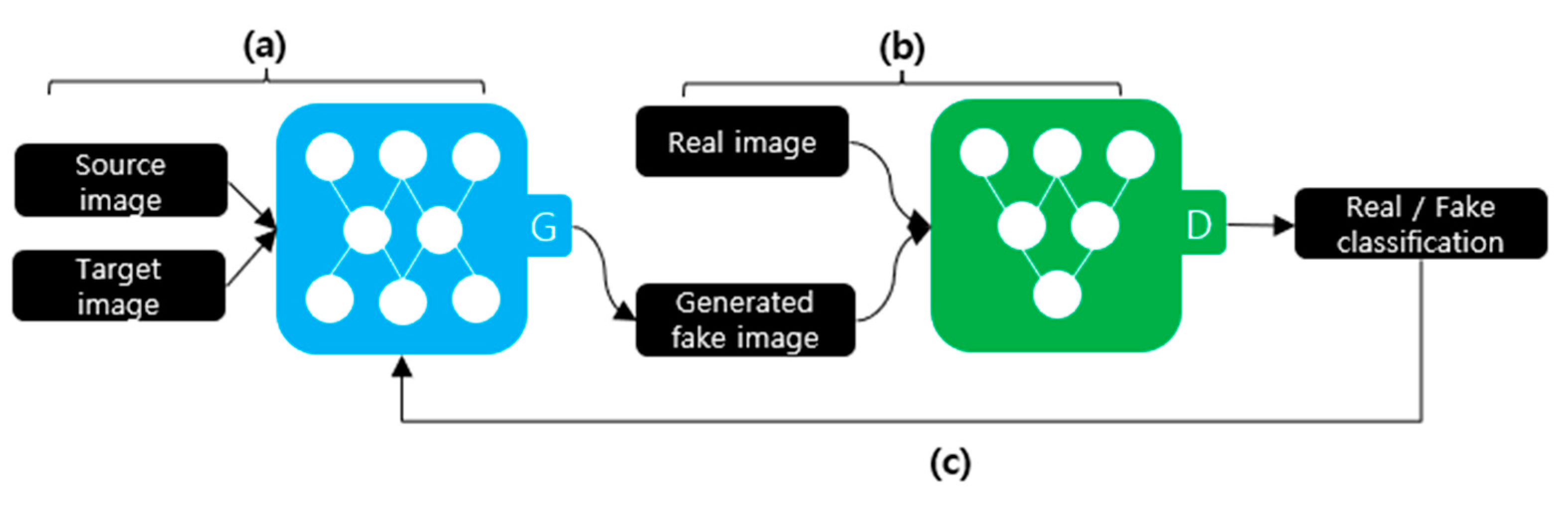
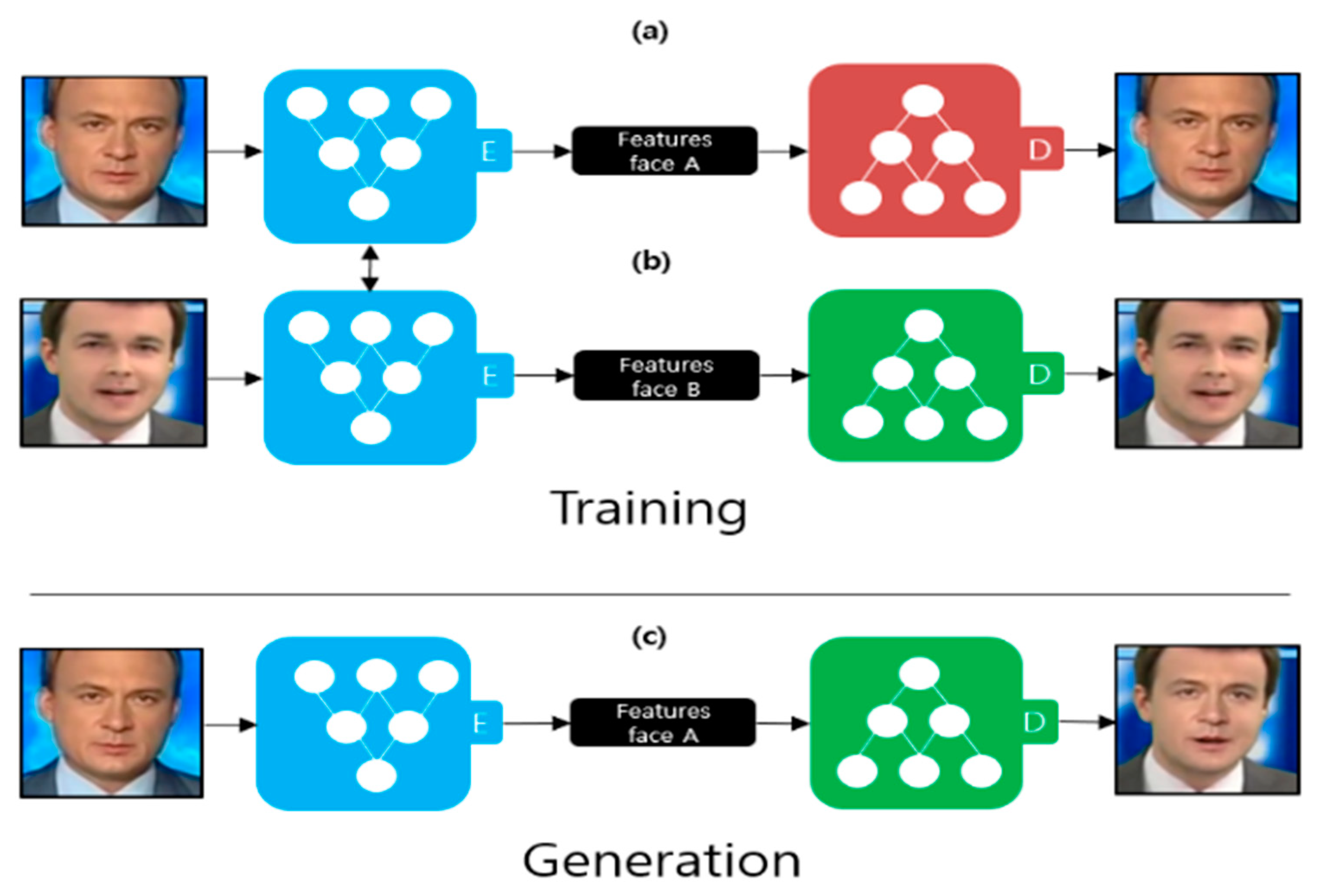
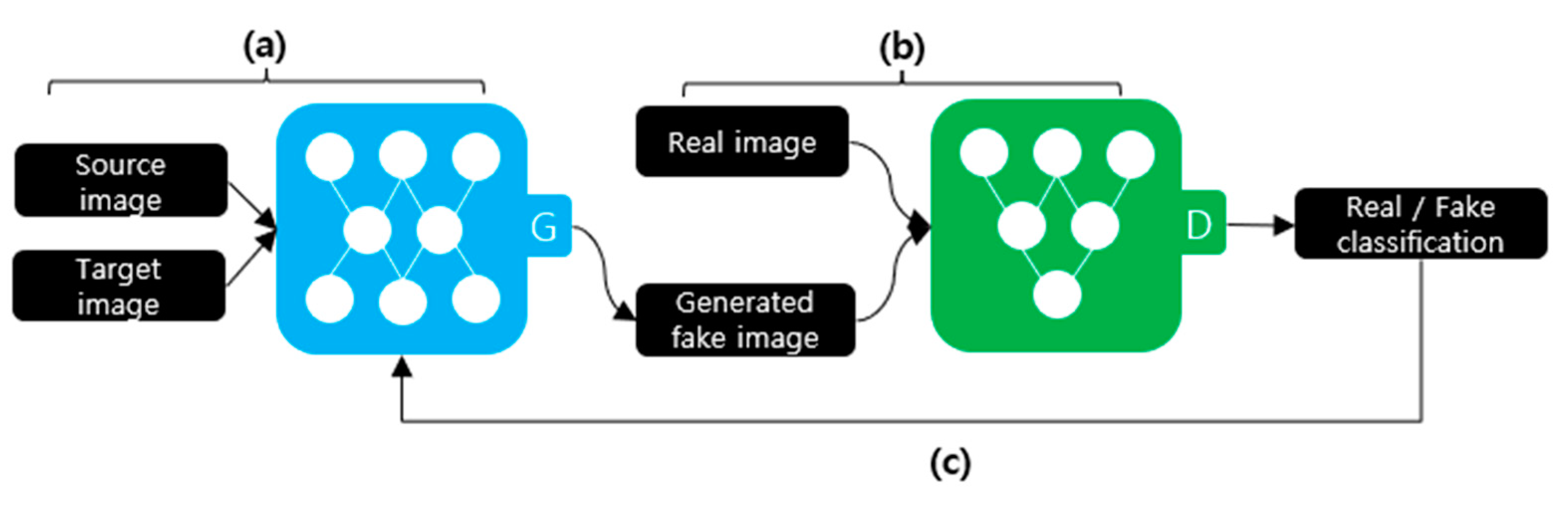
2.1. Deepfake Creation
2.2. Deepfake Detections
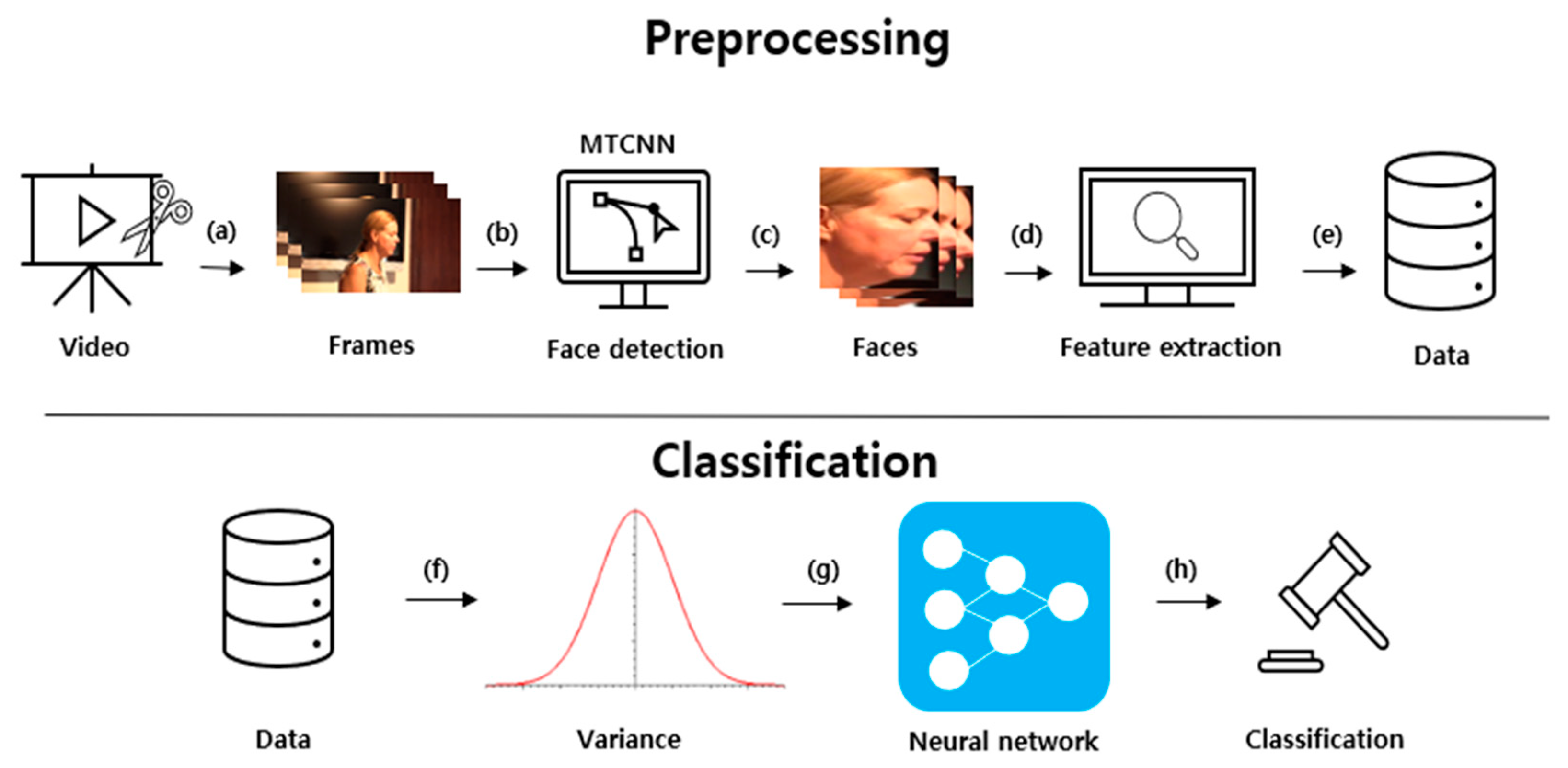
3. Proposed System
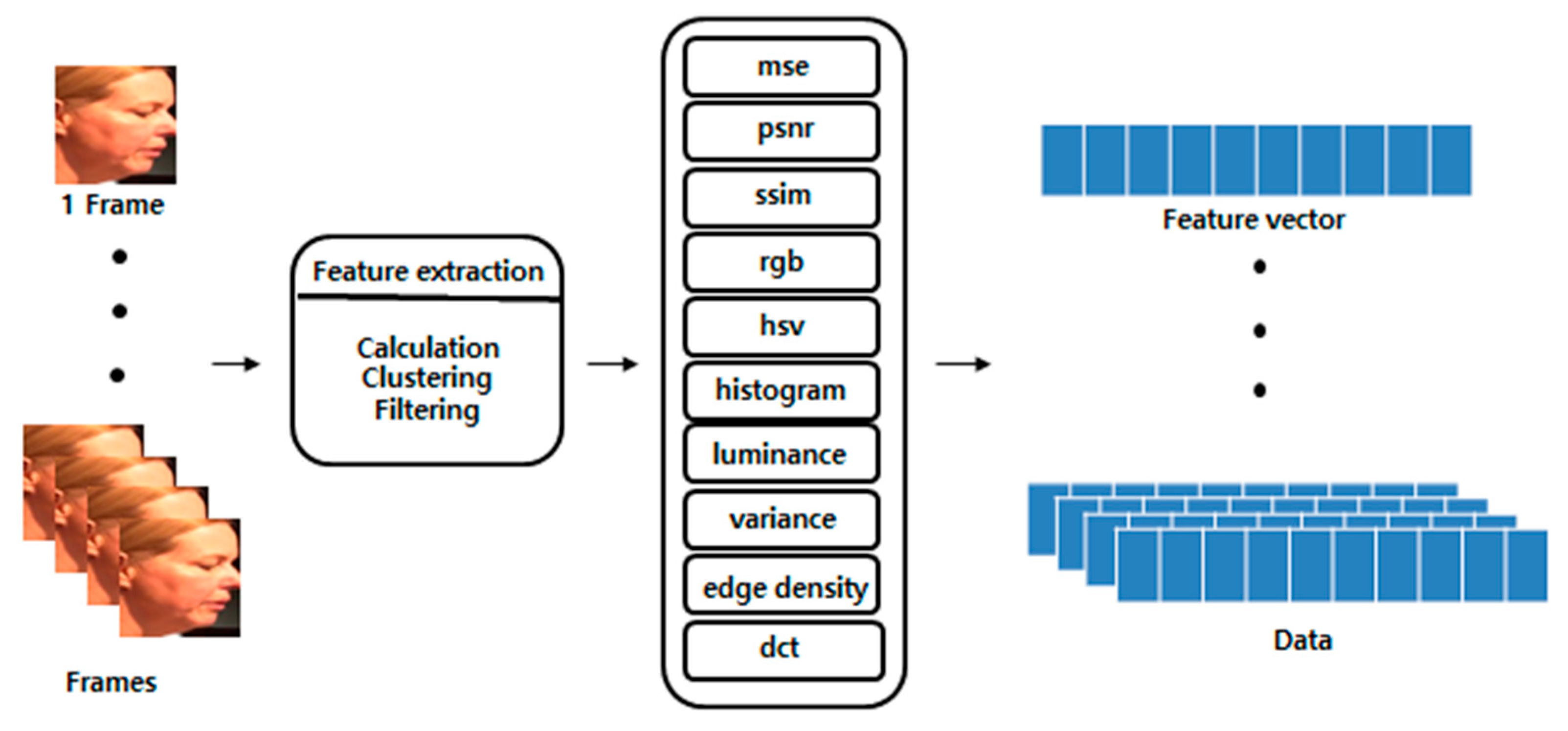
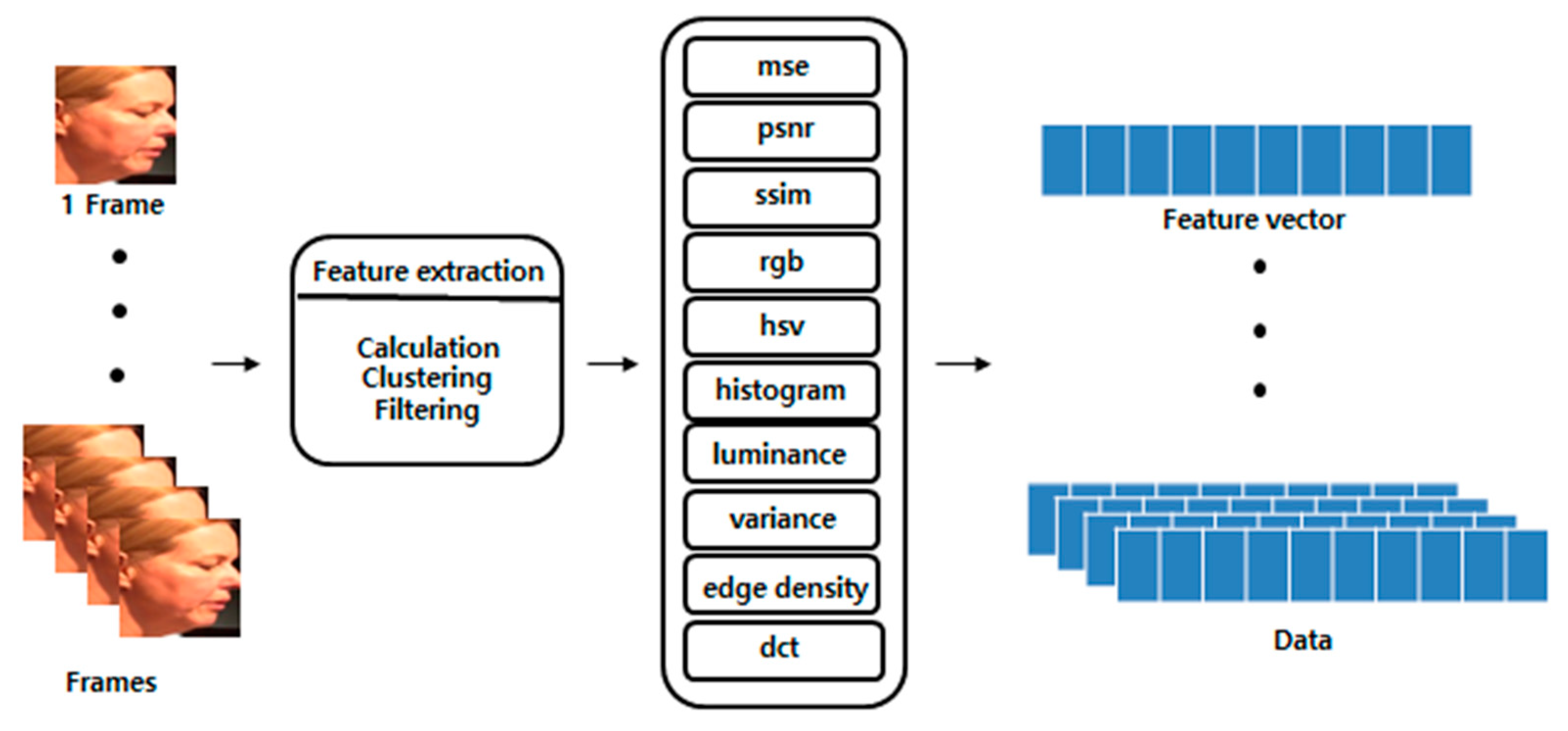
3.1. Preprocessing
3.2. Classification
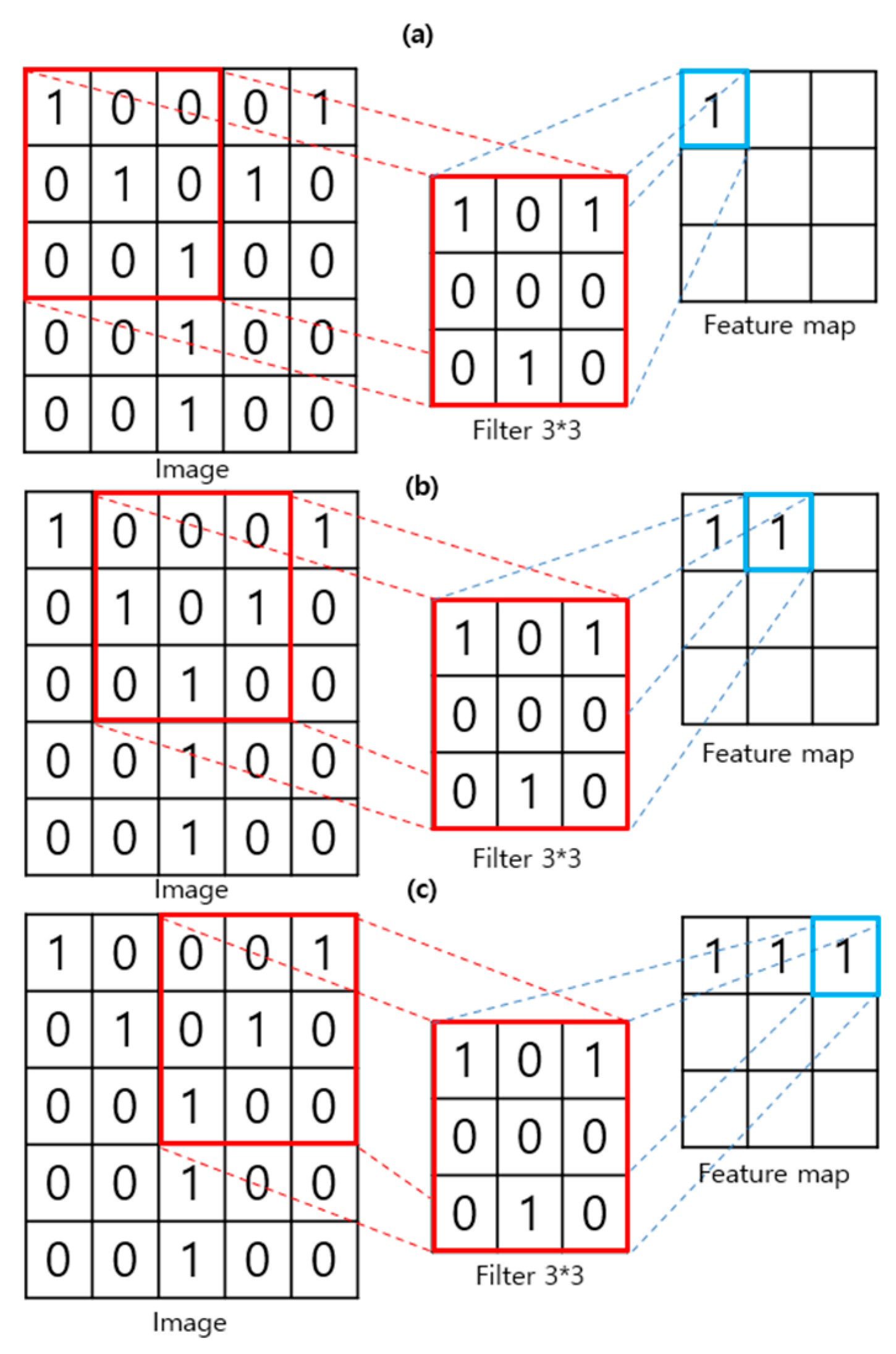
3.3. Modeling
4. Performance Evaluation
4.1. Dataset
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ruben, T.; Ruben, V.R.; Julian, F.; Aythami, M.; Javier, O.G. DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection. arXiv 2020, arXiv:2001.00179. [Google Scholar]
- Faceswap. Available online: https://faceswap.dev (accessed on 3 May 2021).
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. MesoNet: A Compact Facial Video Forgery Detection Network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake Video Detection Using Recurrent Neural Networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos by Detecting Face Warping Artifacts. arXiv 2019, arXiv:1811.00656. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing Deep Fakes Using Inconsistent Head Poses. arXiv 2018, arXiv:1811.00661. [Google Scholar]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2814–2822. [Google Scholar]
- Grm, K.; Štruc, V.; Artiges, A.; Caron, M.; Ekenel, H.K. Strengths and weaknesses of deep learning models for face recognition against image degradations. IET Biom. 2018, 7, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.; Shen, L.; Sun, K.; Qiu, G. Deep Feature Consistent Variational Autoencoder. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1133–1141. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Roy, P.; Ghosh, S.; Bhattacharya, S.; Pal, U. Effects of Degradations on Deep Neural Network Architectures. arXiv 2019, arXiv:1807.10108. [Google Scholar]
- Deepfake Detection Challenge|Kaggle. Available online: https://www.kaggle.com/c/deepfake-detection-challenge (accessed on 3 May 2021).
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multi-task cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- OpenCV. Available online: https://opencv.org/ (accessed on 3 May 2021).
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. arXiv 2019, arXiv:1901.08971. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26–26 August 2004; pp. 32–36. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Key Features | Architecture | Published |
|---|---|---|---|
| Microscopic analyses [3] | Mesoscopic properties of images | MesoNet (based on CNN) | 2018 |
| Temporal inconsistencies [4] | Frame level temporal features | CNN + LSTM | 2018 |
| Eye blinking [5] | Temporal patterns of eye blinking | CNN + LSTM | 2018 |
| Face warping [6] | Inconsistencies in warped face and surrounding area | VGG16, ResNet50 (based on CNN) | 2019 |
| Discrepancy [7] | Temporal discrepancies across frames | CNN + RNN | 2019 |
| Spoken phoneme mismatches [8] | Mismatches between the dynamics of the mouth shape | CNN | 2020 |
| Attribute | Explanation |
|---|---|
| mse | The average squared difference between the estimated values and the actual value |
| psnr | The ratio between the maximum possible power of a signal and the power of corrupting noise |
| ssim | The perceived quality of digital television and cinematic pictures |
| rgb | The percentage of each red, green, and blue color of the image |
| hsv | The percentage of each hue, saturation, and value of the image |
| histogram | The histogram plots the number of pixels in the image with a particular brightness or tonal value |
| luminance | The mean of the total brightness of the image |
| variance | Image variance of the image |
| edge_density | The ratio of edge pixels to the total pixels of in the image |
| dct | DCT bias of the image |
| Count | Accuracy |
|---|---|
| 5 | 90.78% |
| 10 | 92.33% |
| 20 | 95.22% |
| 30 | 86.67% |
| 50 | 76.67% |
| Optimizer | # Hidden Layers | Loss | Accuracy |
|---|---|---|---|
| SGD | 3 | 0.5560 | 67.83 |
| 5 | 0.4146 | 78.26 | |
| 8 | 0.3439 | 81.74% | |
| AdaGrad | 3 | 0.6577 | 60.43% |
| 5 | 0.6672 | 55.22% | |
| 8 | 0.6494 | 62.83 | |
| Adam | 3 | 0.1608 | 94.35% |
| 5 | 0.0722 | 97.39% | |
| 8 | 0.1120 | 94.78% |
| CPU | AMD Ryzen 7 3800X 8-Core Processor |
|---|---|
| RAM | 32 GB DDR4 |
| GPU | Nvidia GeForce GTX 1660 Ti |
| VRAM | 6 GB GDDR6 |
| Face2face | FaceSwap | DFDC | |
|---|---|---|---|
| Proposed model | 97.39% | 95.65% | 96.55% |
| Mesonet | 93.21% | 95.32% | 77.71% |
| SVM | 54.24% | 53.46% | 52.91% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.; Kim, M. Deepfake Detection Using the Rate of Change between Frames Based on Computer Vision. Sensors 2021, 21, 7367. https://doi.org/10.3390/s21217367
Lee G, Kim M. Deepfake Detection Using the Rate of Change between Frames Based on Computer Vision. Sensors. 2021; 21(21):7367. https://doi.org/10.3390/s21217367
Chicago/Turabian StyleLee, Gihun, and Mihui Kim. 2021. "Deepfake Detection Using the Rate of Change between Frames Based on Computer Vision" Sensors 21, no. 21: 7367. https://doi.org/10.3390/s21217367
APA StyleLee, G., & Kim, M. (2021). Deepfake Detection Using the Rate of Change between Frames Based on Computer Vision. Sensors, 21(21), 7367. https://doi.org/10.3390/s21217367