
A Manycore Vision Processor for Real-Time Smart Cameras †

 ,
,  and
and
Abstract
1. Introduction
2. Related Work
IP/CV Systems
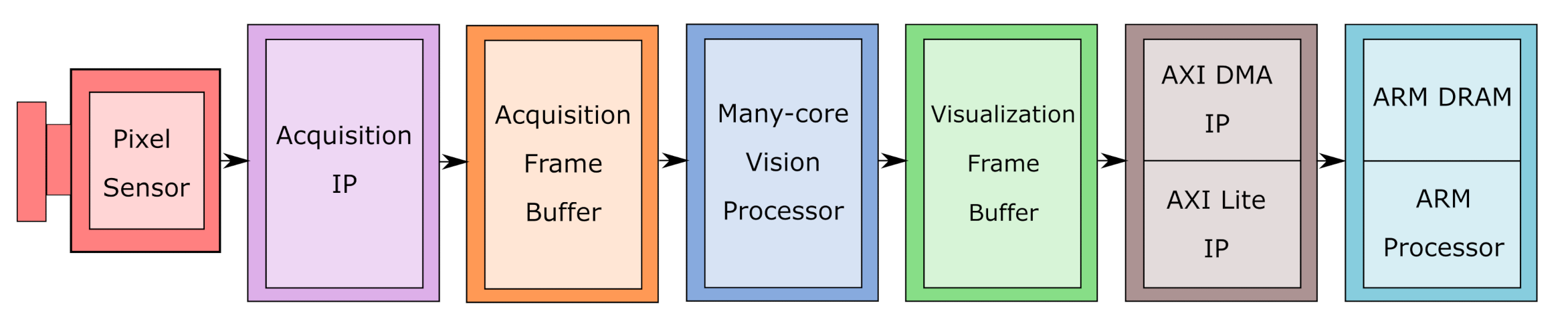
3. The HW/SW Platform
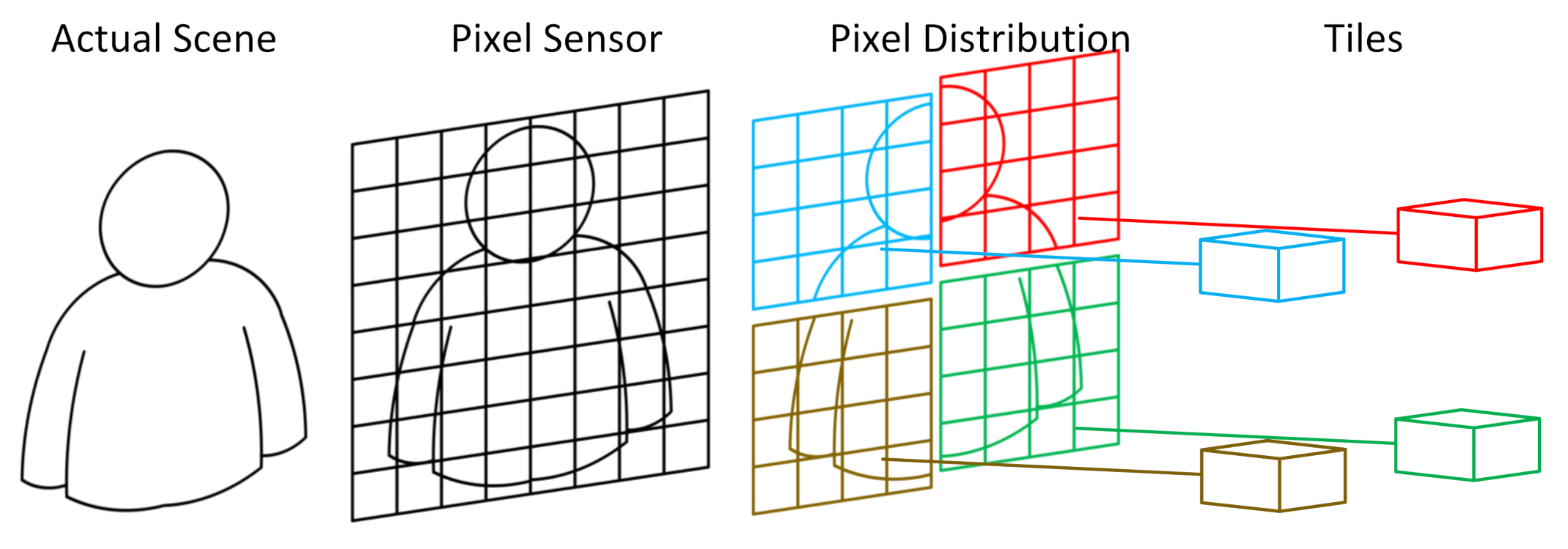
3.1. Pixel Sensor
3.2. Acquisition IP and Acquisition Frame Buffer
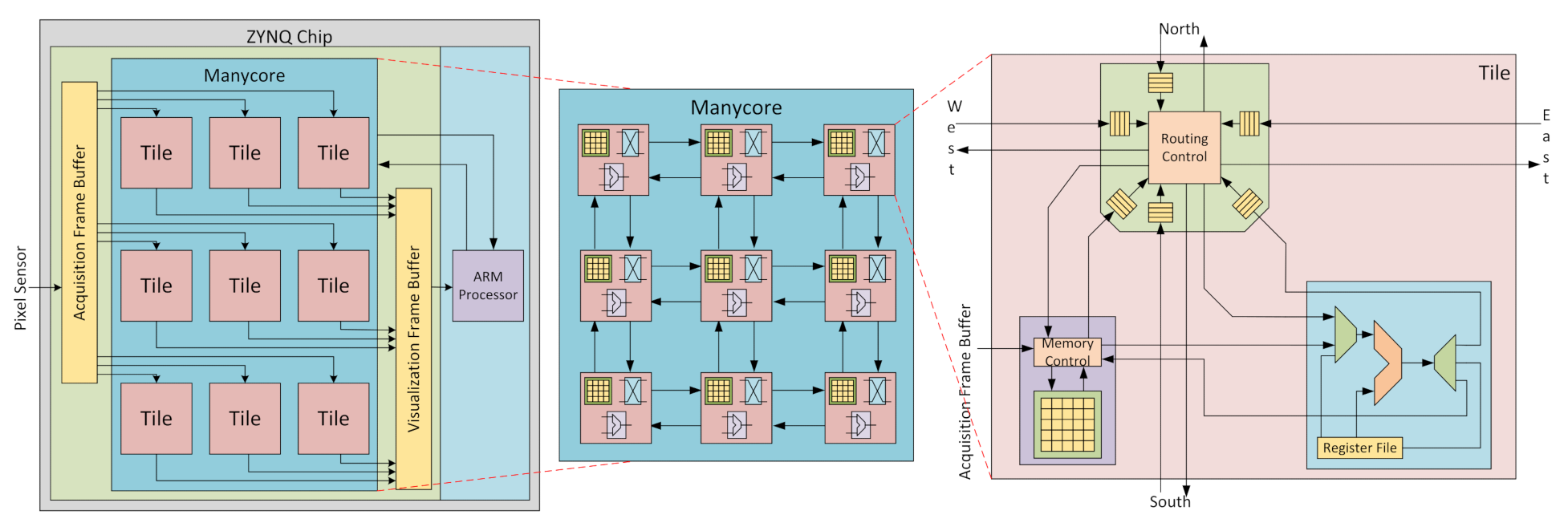
3.3. Manycore Vision Processor
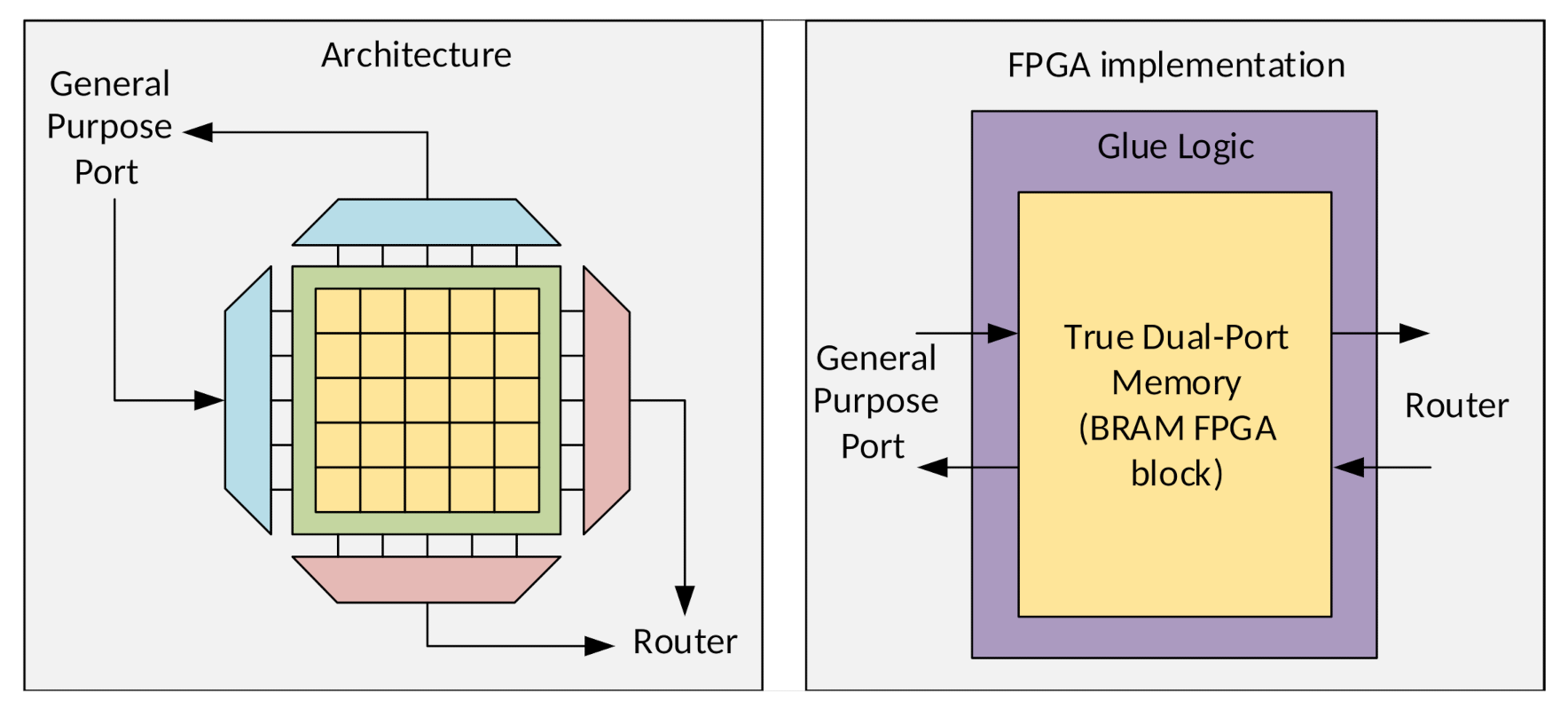
3.3.1. Pixel Memory
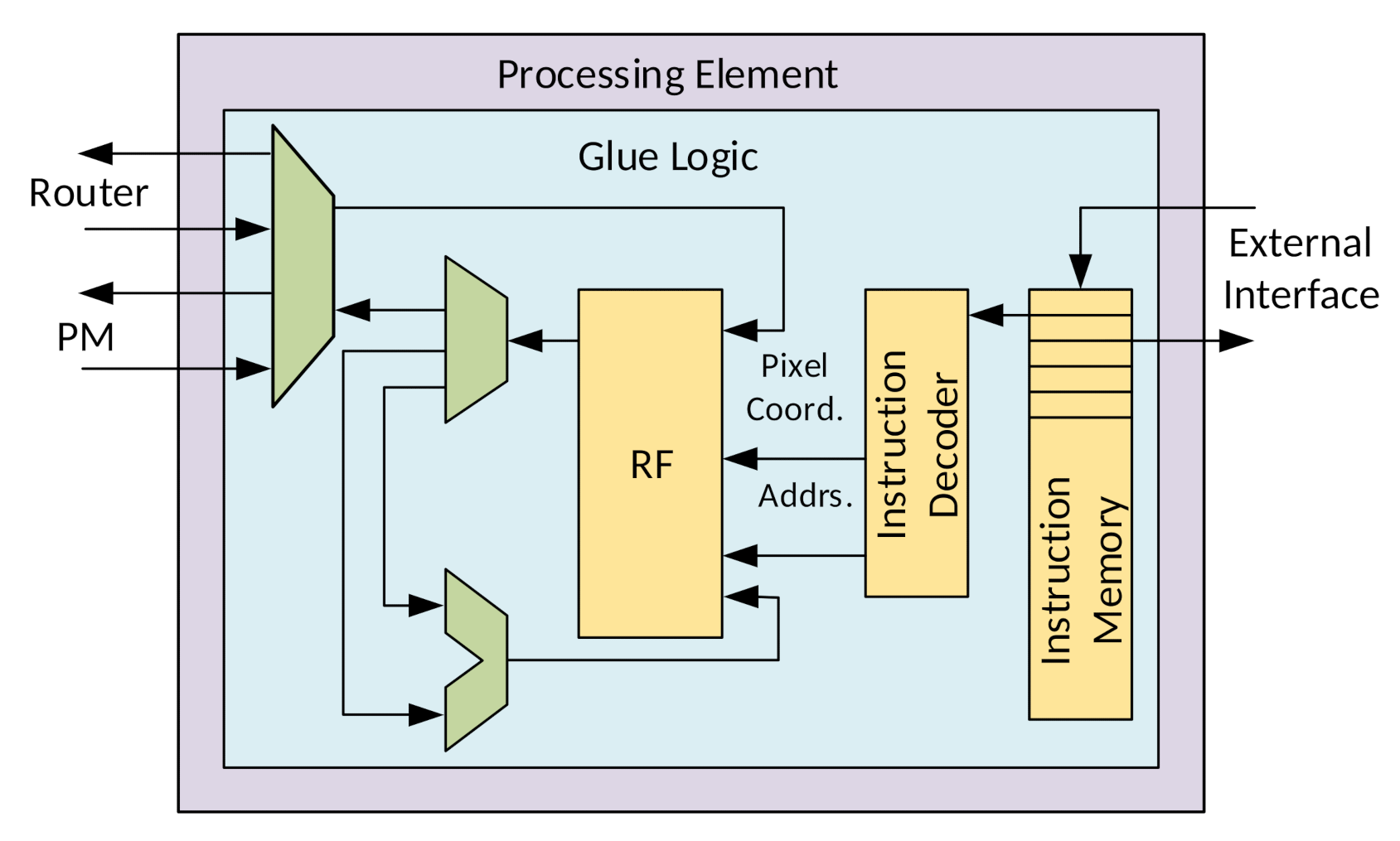
3.3.2. Processing Element
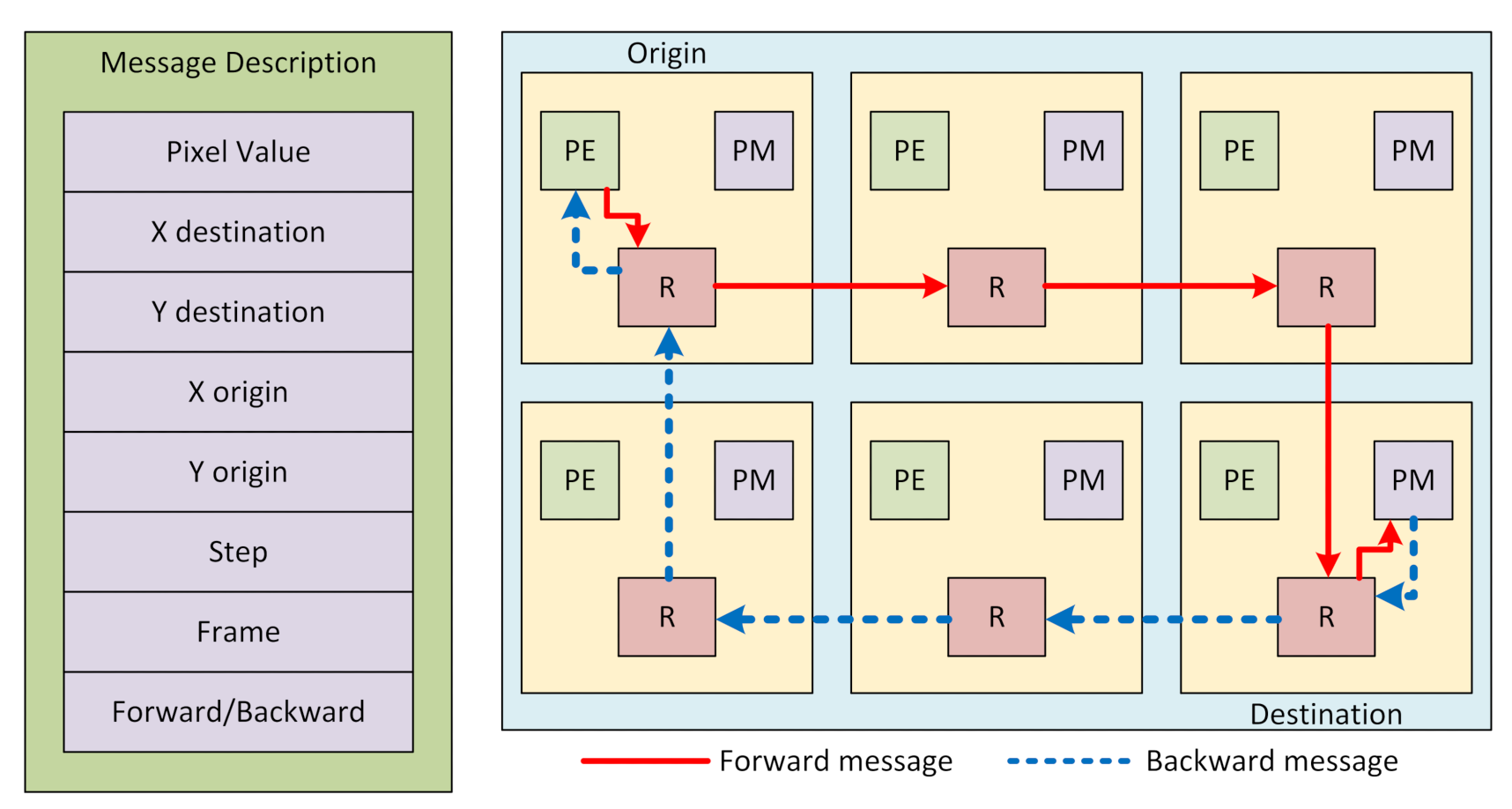
3.3.3. Router
3.4. Visualization Frame Buffer
3.5. AXI Direct Memory Access IP
3.6. ARM Processor
4. Application Domain Analysis
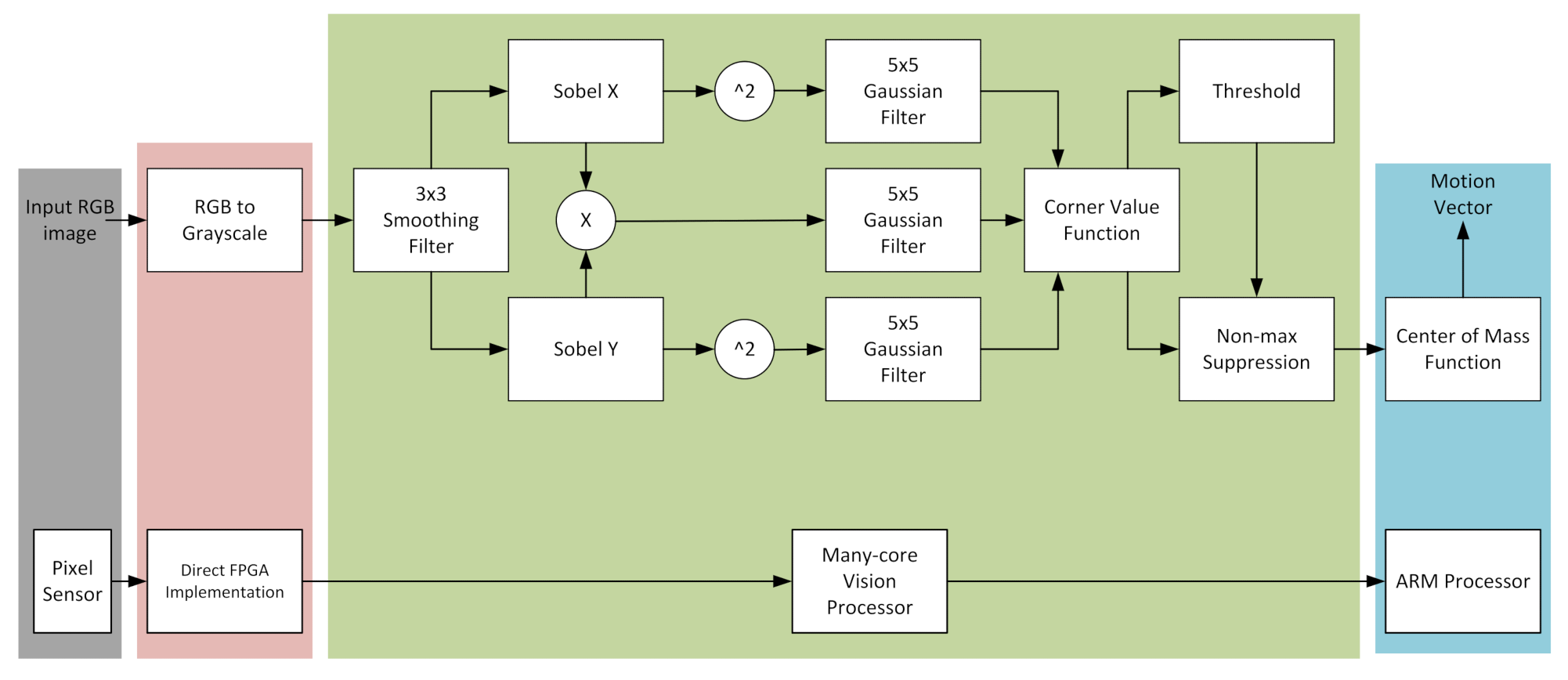
4.1. Harris Corner Detector
4.2. Motion Estimation
5. Results and Analysis
5.1. Resource Usage
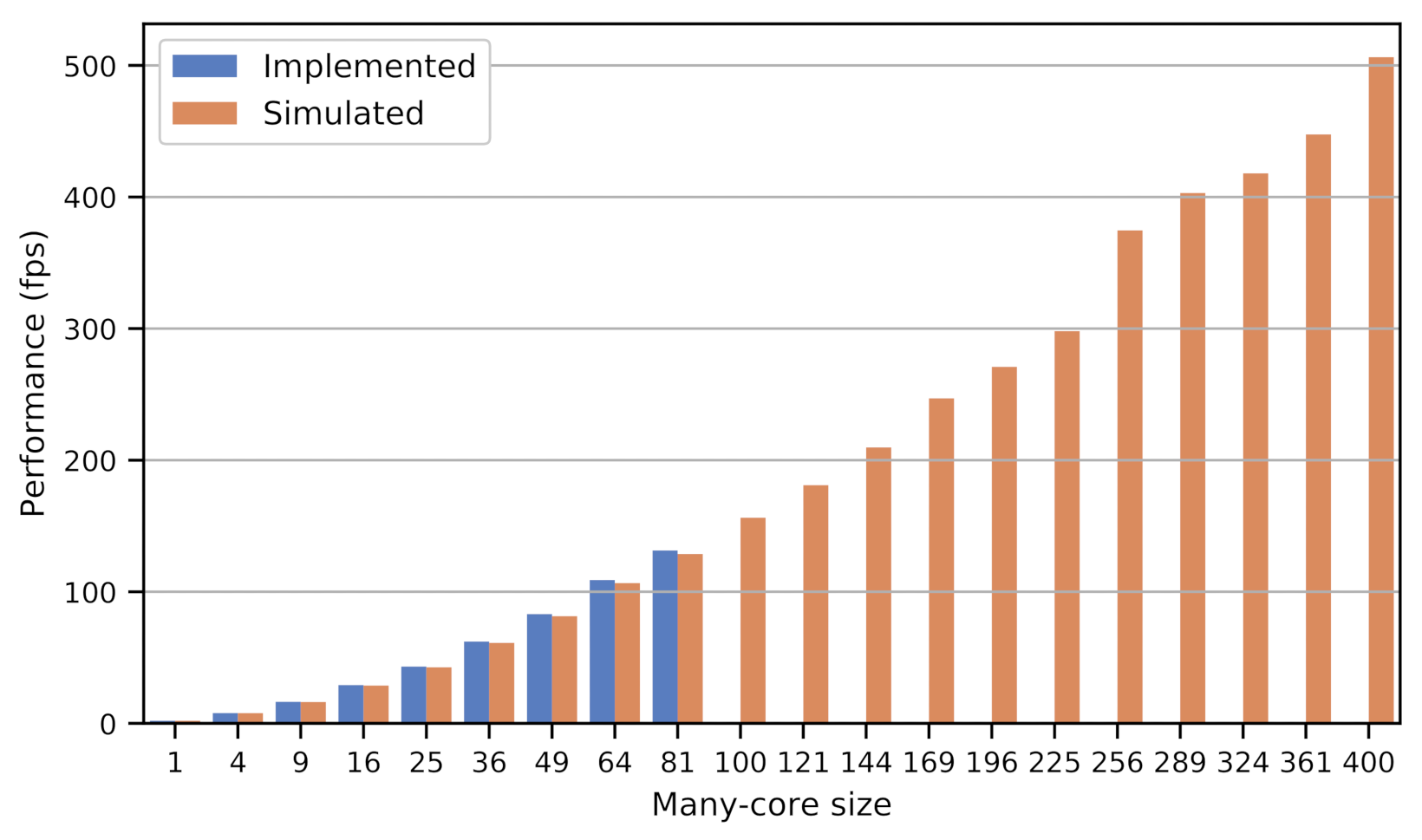
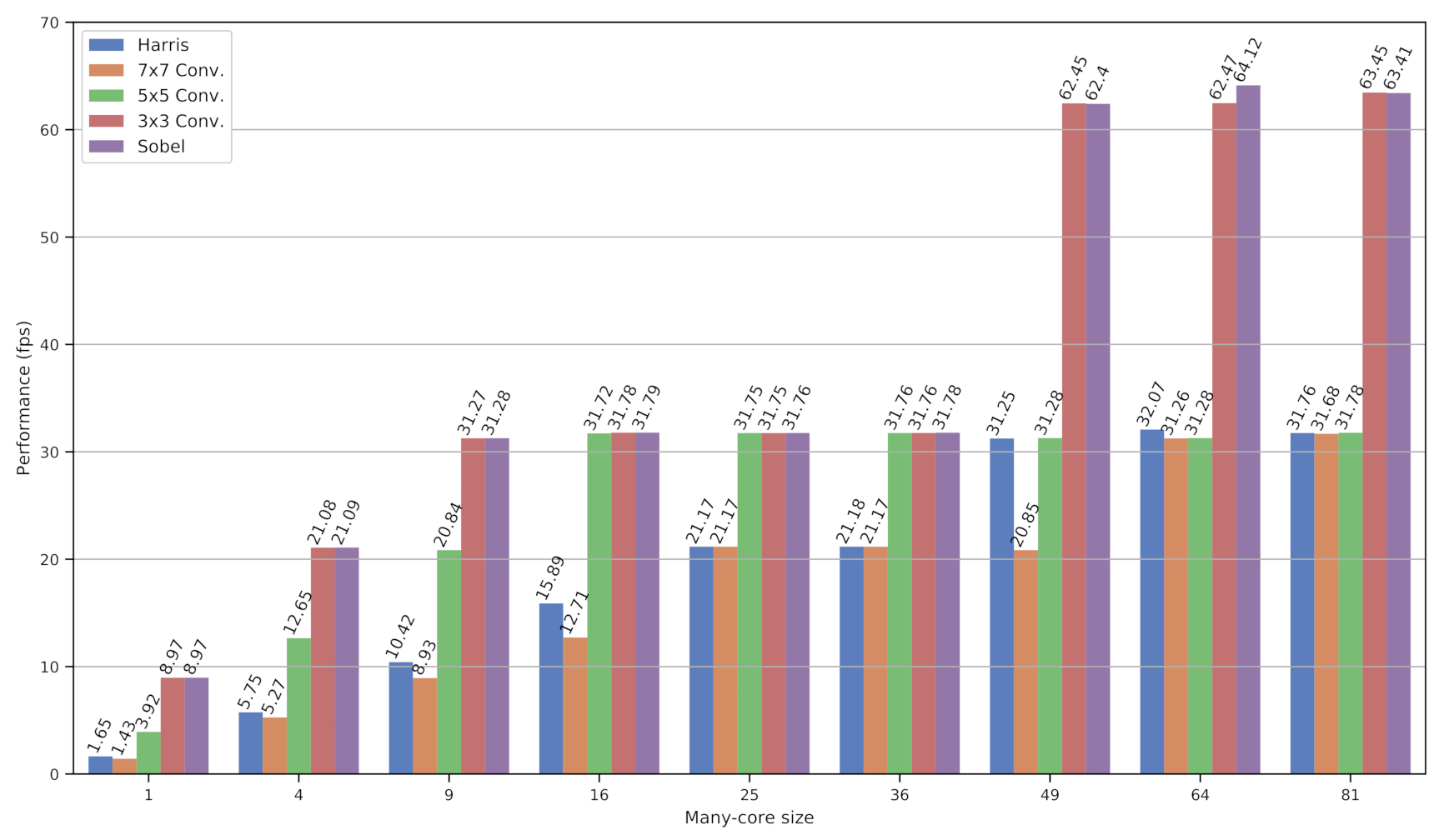
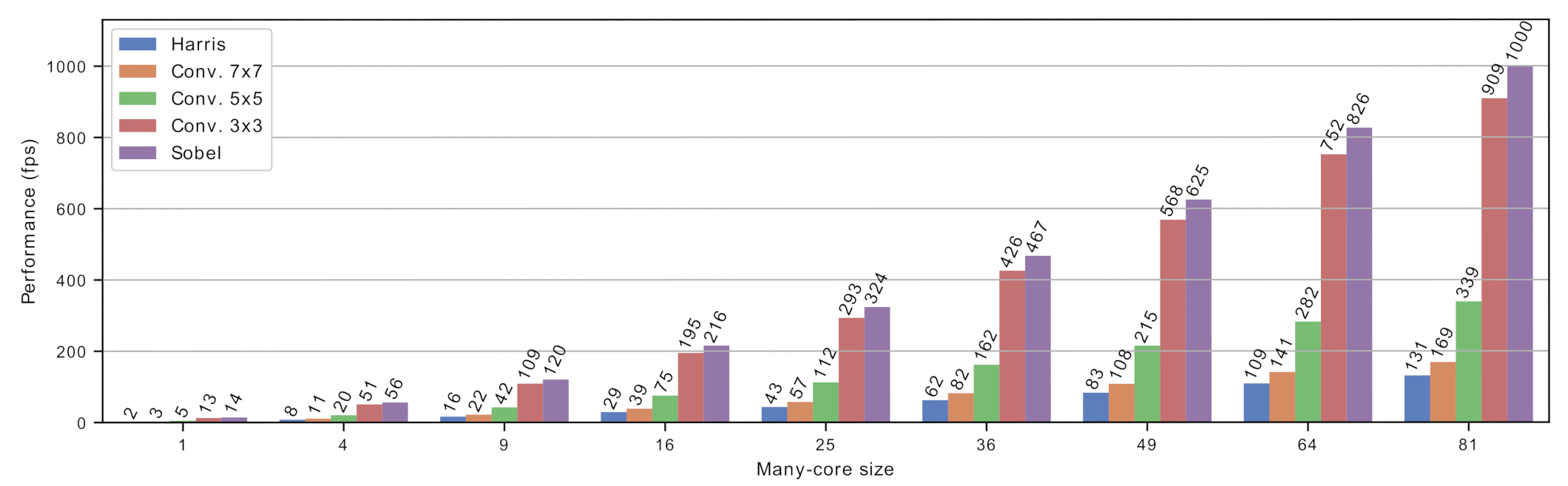
5.2. Performance Evaluation
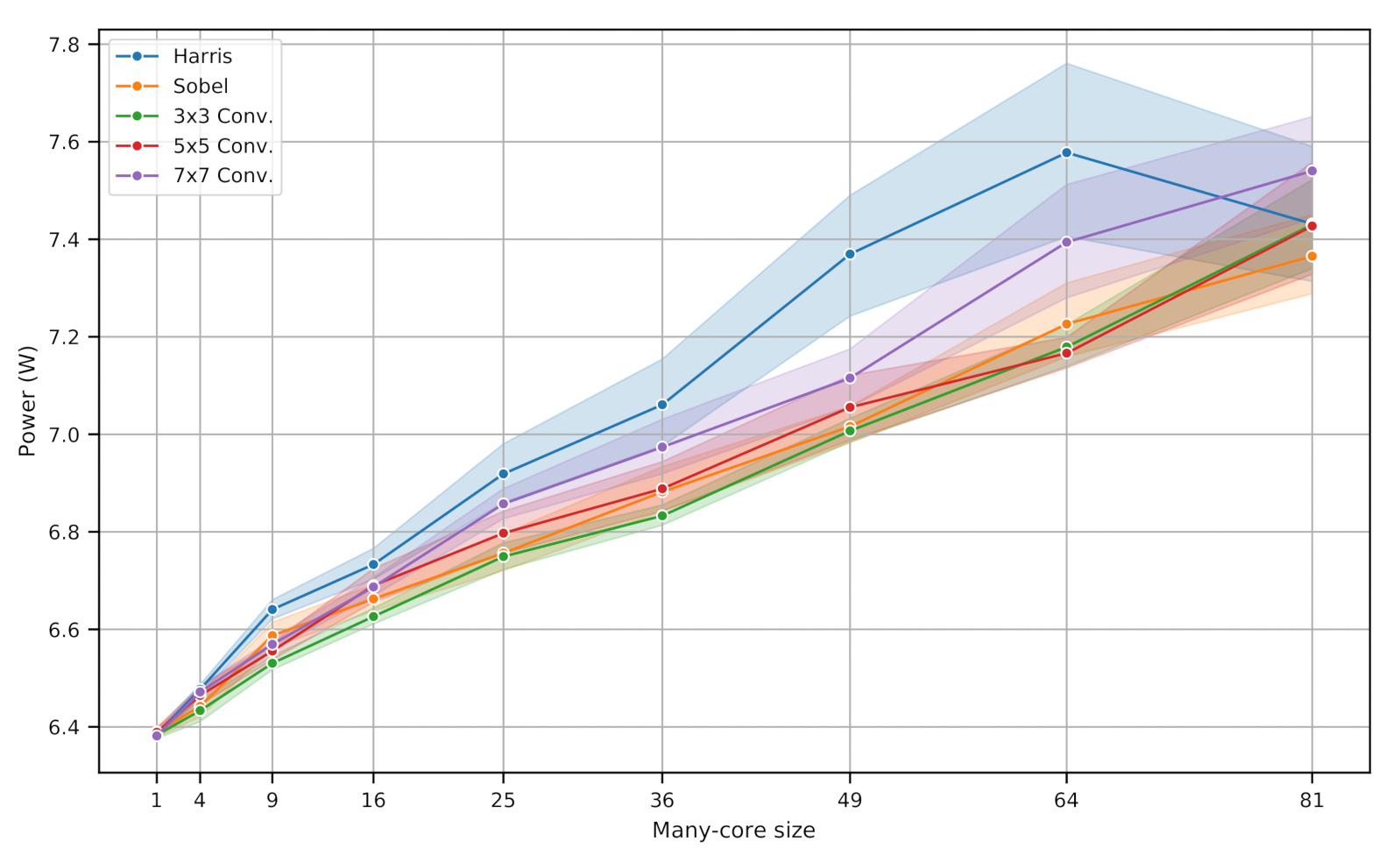
5.3. Power Consumption
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yudi, J.; Llanos, C.H.; Huebner, M. System-level design space identification for Many-Core Vision Processors. Microprocess. Microsyst. 2017, 52, 2–22. [Google Scholar] [CrossRef]
- Schmitz, J.A.; Gharzai, M.K.; Balkır, S.; Hoffman, M.W.; White, D.J.; Schemm, N. A 1000 frames/s vision chip using scalable pixel-neighborhood-level parallel processing. IEEE J. Solid State Circuits 2016, 52, 556–568. [Google Scholar] [CrossRef]
- Kehtarnavaz, N.; Gamadia, M. Real-time image and video processing: From research to reality. Synth. Lect. Image Video Multimed. Process. 2006, 2, 1–108. [Google Scholar] [CrossRef]
- Silva, B.A.; Lima, A.M.; Yudi, J. A manycore vision processor architecture for embedded applications. In Proceedings of the 2020 X Brazilian Symposium on Computing Systems Engineering (SBESC), Florianopolis, Brazil, 24–27 November 2020; pp. 1–8. [Google Scholar]
- Mori, J.Y.; Llanos, C.H.; Berger, P.A. Kernel analysis for architecture design trade off in convolution-based image filtering. In Proceedings of the 2012 25th Symposium on Integrated Circuits and Systems Design (SBCCI), Brasilia, Brazil, 30 August–2 September 2012; pp. 1–6. [Google Scholar]
- Kadi, M.A.; Janssen, B.; Yudi, J.; Huebner, M. General-Purpose Computing with Soft GPUs on FPGAs. ACM Trans. Reconfigurable Technol. Syst. 2018, 11, 1–22. [Google Scholar] [CrossRef]
- Hoozemans, J.; de Jong, R.; van der Vlugt, S.; Straten, J.V.; Elango, U.K.; Al-Ars, Z. Frame-based Programming, Stream-Based Processing for Medical Image Processing Applications. J. Signal Process. Syst. 2019, 91, 47–59. [Google Scholar] [CrossRef] [PubMed]
- Joshi, J.; Bade, S.; Batra, P.; Adyanthaya, R. Real Time Image Processing System using Packet Based on Chip Communication . In Proceedings of the National Conference on Communications, Kanpur, India, 26–28 January 2007. [Google Scholar]
- Joshi, J.; Karandikar, K.; Bade, S.; Bodke, M.; Adyanthaya, R.; Ahirwal, B. Multi-core image processing system using network on chip interconnect. In Proceedings of the 2007 50th Midwest Symposium on Circuits and Systems, Montreal, QC, Canada, 5–8 August 2007; pp. 1257–1260. [Google Scholar]
- Fresse, V.; Aubert, A.; Bochard, N. A predictive NoC architecture for vision systems dedicated to image analysis. Eurasip J. Embed. Syst. 2007, 2007, 1–13. [Google Scholar] [CrossRef][Green Version]
- Saponara, S.; Fanucci, L.; Petri, E. A multi-processor NoC-based architecture for real-time image/video enhancement. J. Real-Time Image Process. 2013, 8, 111–125. [Google Scholar] [CrossRef]
- Ross, J.A.; Richie, D.A.; Park, S.J. Implementing Image Processing Algorithms for the Epiphany Many-Core Coprocessor with Threaded MPI. In Proceedings of the 2015 IEEE High Performance Extreme Computing Conference, Waltham, MA, USA, 15–17 September 2015. [Google Scholar]
- Kadi, M.A. FGPU: A Flexible Soft GPU Architecture for General Purpose Computing on FPGAs. Ph.D. Thesis, Ruhr-University Bochum, Bochum, Germany, 2018. [Google Scholar]
- Lee, S.H.; Yang, C.S. A real time object recognition and counting system for smart industrial camera sensor. IEEE Sens. J. 2017, 17, 2516–2523. [Google Scholar] [CrossRef]
- Ali, K.M.; Atitallah, R.B.; Hanafi, S.; Dekeyser, J.L. A generic pixel distribution architecture for parallel video processing. In Proceedings of the 2014 International Conference on ReConFigurable Computing and FPGAs (ReConFig14), Cancun, Mexico, 8–10 December 2014. [Google Scholar]
- Khalil, K.; Eldash, O.; Kumar, A.; Bayoumi, M. A speed and energy focused framework for dynamic hardware reconfiguration. In Proceedings of the 2019 32nd IEEE International System-on-Chip Conference (SOCC), Singapore, 3 September 2019; pp. 388–393. [Google Scholar]
- Mori, J.Y.; Llanos, C.H.; Hüebner, M. A framework to the design and programming of many-core focal-plane vision processors. In Proceedings of the 2015 IEEE 13th International Conference on Embedded and Ubiquitous Computing, Porto, Portugal, 21–23 October 2015. [Google Scholar]
- Mori, J.Y.; Hübner, M. Multi-level parallelism analysis and system-level simulation for many-core Vision processor design. In Proceedings of the 2016 5th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 12–16 June 2016; pp. 90–95. [Google Scholar]
- Rettkowski, J.; Göhringer, D. SDMPSoC: Software-Defined MPSoC for FPGAs. J. Signal Process. Syst. 2019, 92, 1187–1196. [Google Scholar] [CrossRef]
- Suriano, L.; Arrestier, F.; Rodríguez, A.; Heulot, J.; Desnos, K.; Pelcat, M.; de la Torre, E. DAMHSE: Programming heterogeneous MPSoCs with hardware acceleration using dataflow-based design space exploration and automated rapid prototyping. Microprocess. Microsyst. 2019, 71, 102882. [Google Scholar] [CrossRef]
- da Silva, B.A. A Manycore Vision Processor Architecture for Embedded Applications. Master’s Thesis, University of Brasilia, Brasilia, Brazil, 2021. [Google Scholar]
- Xilinx. HW-Z1-ZCU104 Evaluation Board (XCZU7EV-2FFVC1156)—Schematic; v1.0-rev01; Xilinx Inc.: San Jose, CA, USA, 2018. [Google Scholar]
- OminiVision. OV7670/OV7171 CMOS VGA (640x480) Camera Chip with OmniPixel Technology; Omnivision Technologies: Santa Clara, CA, USA, 2005. [Google Scholar]
- Kendri, D. FPGA Camera System. 2019. Available online: https://www.hackster.io/dhq/fpga-camera-system-14d6ea (accessed on 21 October 2020).
- Xilinx. Vivado Design Suite User Guide—Synthesis; Xilinx Inc.: San Jose, CA, USA, 2020. [Google Scholar]
- Xilinx. AXI DMA v7.1—LogiCORE IP Product Guide; Xilinx Inc.: San Jose, CA, USA, 2019. [Google Scholar]
- Tkg, Inc. Khronos Releases OpenVX 1.3 Open Standard for Cross-Platform Vision and Machine Intelligence Acceleration. 2019. Available online: https://www.khronos.org/news/press/khronos-releases-openvx-1.3-open-standard-for-cross-platform-vision-and-machine-intelligence-acceleration (accessed on 5 December 2020).
- Burger, W.; Burge, M. Digital Image Processing: An Algorithmic Introduction Using Java; Texts in Computer Science; Springer: London, UK, 2016. [Google Scholar]
- Chahuara, H.; Rodríguez, P. Real-time corner detection on mobile platforms using cuda. In Proceedings of the 2018 IEEE XXV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Lima, Peru, 8–10 August 2018; pp. 1–4. [Google Scholar]
- Hosseini, F.; Fijany, A.; Fontaine, J.G. Highly Parallel Implementation of Harris Corner Detector on CSX SIMD Architecture. In Euro-Par 2010 Parallel Processing Workshops; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Sousa, É.R.; Tanase, A.; Hannig, F.; Teich, J. Accuracy and performance analysis of harris corner computation on tightly-coupled processor arrays. In Proceedings of the 2013 Conference on Design and Architectures for Signal and Image Processing, Cagliari, Italy, 8–10 October 2013; pp. 88–95. [Google Scholar]
- Aydogdu, M.F.; Demirci, M.F.; Kasnakoglu, C. Pipelining Harris corner detection with a tiny FPGA for a mobile robot. In Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 2177–2184. [Google Scholar]
- Liu, S.; Lyu, C.; Liu, Y.; Zhou, W.; Jiang, X.; Li, P.; Chen, H.; Li, Y. Real-time implementation of harris corner detection system based on fpga. In Proceedings of the 2017 IEEE International Conference on Real-time Computing and Robotics (RCAR), Okinawa, Japan, 14–18 July 2017; pp. 339–343. [Google Scholar]
- Amaricai, A.; Gavriliu, C.E.; Boncalo, O. An FPGA sliding window-based architecture Harris corner detector. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–4. [Google Scholar]
- Possa, P.R.; Mahmoudi, S.A.; Harb, N.; Valderrama, C.; Manneback, P. A multi-resolution FPGA-based architecture for real-time edge and corner detection. IEEE Trans. Comput. 2013, 63, 2376–2388. [Google Scholar] [CrossRef]
- Bleijerveld, B. Harris and FAST Corner Detection on the NVIDIA Jetson TX2 Using OpenCV. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2019. [Google Scholar]
- Xilinx. ZCU104 Evaluation Board v1.1—User Guide; Xilinx Inc.: San Jose, CA, USA, 2018. [Google Scholar]
- International Rectifier. PowIR-USB005 User Guide; Infineon Technologies AG: Neubiberg, Germany, 2014. [Google Scholar]
- Waskon, M. Seaborn Lineplot (Seaborn.Lineplot). 2020. Available online: http://seaborn.pydata.org/generated/seaborn.lineplot.html (accessed on 23 January 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | PE Type | Communication | Application Agnostic | Main Feature |
|---|---|---|---|---|
| [7] | VLIW | NoC | yes | FPGA overlay architecture to explore PS-PL |
| [8,9] | Heterogeneous | NoC | no | Early NoC proposal for IP/CV applications |
| [10] | Heterogeneous | NoC | no | Multiple Processing Units in asynchronous NoC |
| [12] | RISC | NoC | yes | Proprietary MPSoC and use of MPI model |
| [6] | Soft-GPU | Bus | yes | FPGA overlay resources optimization, use of soft-GPUs |
| [14] | GPU | Bus | yes | Achieve real-time object recognition with GPU/CPU combination |
| [1] | RISC | NoC | yes | Spatial parallelism exploration achieves high performance scaling |
| [19] | RISC | NoC | yes | HLS synthesis tool for a heterogeneous system built for FPGAs |
| [20] | Heterogeneous | Bus | no | Method to explore HW/SW design choices with few user interaction |
| Our work | RISC | NoC | yes | Overlay architecture that explores spatial parallelism with region-based processing |
| OpenVX Function | Classification |
|---|---|
| Canny Edge Detector, Fast Corners, Gaussian Image Pyramid, Histogram of Oriented Gradients, Harris Corners, Hough Lines Probabilistic, Laplacian Image Pyramid, Optical Flow Pyramid, Reconstruction from a Laplacian Image Pyramid, Equalize Histogram | composition of different types |
| Mean and Standard Deviation, Min, Max Location, Tensor Add, Tensor Convert Bit-Depth, Tensor Matrix Multiply, Tensor Multiply, Tensor Subtract, Tensor Table LookUp, Tensor Transpose, Control Flow, Data Object Copy, Histogram of Oriented Gradients, LBP descriptors | non direct image operation |
| Absolute Difference, Arithmetic Addition, Arithmetic Subtraction, Bitwise AND, Bitwise Exclusive OR, Bitwise Inclusive OR, Bitwise NOT, Channel Combine, Channel Extract, Color Convert, Convert Bit Depth, Magnitude, Phase, Pixel-wise Multiplication, Remap, Table Lookup, Thresholding, Weighted Average | Pixel to Pixel |
| Bilateral Filter, Box Filter, Custom Convolution, Dilate Image, Erode Image, Gaussian Filter, Integral Image, Match Template, Max, Median Filter, Min, Non Linear Filter, Non-Maxima Suppression, Sobel 3 × 3 | Region to Pixel |
| Scale Image, Warp Affine, Warp Perspective | Region to Region |
| Device | 1 Tile | 4 Tiles | 9 Tiles | 16 Tiles | |
| PL Max. Freq. (MHz) | - | 134.77 | 128.85 | 122.80 | 122.88 |
| LUT | 230,400 | 9841 | 16,057 | 26,117 | 39,765 |
| LUTRAM | 101,760 | 789 | 1557 | 2837 | 4629 |
| FF | 460,800 | 9733 | 15,219 | 24,164 | 36,843 |
| BRAM | 312 | 195 | 197 | 198 | 205 |
| URAM | 96 | 1 | 4 | 9 | 16 |
| DSP Blocks | 1728 | 6 | 18 | 38 | 66 |
| 25 Tiles | 36 Tiles | 49 Tiles | 64 Tiles | 81 Tiles | |
| PL Max. Freq. (MHz) | 120.61 | 122.01 | 122.56 | 122.70 | 111.42 |
| LUT | 56,837 | 80,944 | 110,941 | 141,772 | 178,582 |
| LUTRAM | 6933 | 9749 | 13,077 | 16,917 | 21,269 |
| FF | 53,240 | 73,421 | 97,350 | 124,997 | 156,400 |
| BRAM | 195 | 219 | 234 | 237 | 207 |
| URAM | 25 | 36 | 49 | 64 | 81 |
| DSP Blocks | 102 | 146 | 198 | 258 | 326 |
| Reference | Architecture | Cycles/Pixel | Application Agnostic? |
|---|---|---|---|
| [20] 2019 * | MPSoC-FPGA | 1.06 | no |
| Our (impl.) | MPSoC-FPGA | 1.52 | yes |
| [12] 2015 | MPSoC-ASIC | 2.67 | yes |
| [19] 2019 | MPSoC-FPGA | 64.13 | yes |
| Reference | Architecture | Cycles/Pixel | Application Agnostic? |
|---|---|---|---|
| [35] 2014 ** | FPGA | 1.00 | no |
| [34] 2014 | FPGA | 1.00 | no |
| [31] 2013 | FPGA | 1.36 | yes |
| [33] 2017 ** | FPGA | 2.11 | no |
| Ours (sim.) | MPSoC-FPGA | 3.02 | yes |
| [32] 2013 ** | FPGA | 3.03 | no |
| [30] 2010 | SIMD ASIC | 3.42 | yes |
| [12] 2015 | MPSoC-ASIC | 7.07 | yes |
| [29] 2018 * | Embedded GPU | 7.19 | yes |
| Ours (impl.) | MPSoC-FPGA | 11.61 | yes |
| Architecture | Algorithm | Image Resolution | Time Per Frame | fps | freq. (MHz) | Pixels/s | Cycles Per Pixel |
|---|---|---|---|---|---|---|---|
| MCVP-64 (64 PEs) | Convolution 5 × 5 | 256 × 256 | 3.55 | 282 | 100 | 18,481,152 | 5.411 |
| FGPU-8 (64 PEs) [6] | Sharpen 5 × 5 | 512 × 512 | 6.1 | 16.4 | 250 | 4,299,162 | 58.150 |
| MCVP-81 (81 PEs) | HCD | 256 × 256 | 9.17 | 109 | 100 | 7,143,424 | 14 |
| NVidia Jetson TX2 [36] (256 cores) | HCD | 640 × 480 | 26 | 38 | 854 | 11,673,600 | 73.156 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, B.A.d.; Lima, A.M.; Arias-Garcia, J.; Huebner, M.; Yudi, J. A Manycore Vision Processor for Real-Time Smart Cameras. Sensors 2021, 21, 7137. https://doi.org/10.3390/s21217137
Silva BAd, Lima AM, Arias-Garcia J, Huebner M, Yudi J. A Manycore Vision Processor for Real-Time Smart Cameras. Sensors. 2021; 21(21):7137. https://doi.org/10.3390/s21217137
Chicago/Turabian StyleSilva, Bruno A. da, Arthur M. Lima, Janier Arias-Garcia, Michael Huebner, and Jones Yudi. 2021. "A Manycore Vision Processor for Real-Time Smart Cameras" Sensors 21, no. 21: 7137. https://doi.org/10.3390/s21217137
APA StyleSilva, B. A. d., Lima, A. M., Arias-Garcia, J., Huebner, M., & Yudi, J. (2021). A Manycore Vision Processor for Real-Time Smart Cameras. Sensors, 21(21), 7137. https://doi.org/10.3390/s21217137