
DisCaaS: Micro Behavior Analysis on Discussion by Camera as a Sensor

 ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
- RH1: A 360 degree camera can recognize multiple participants’ micro-behavior in a small size meeting;
- RH2: Meetings can be recorded at any place, and the dataset can be mixed even if the collected place is different;
- RH3: Our camera as a sensor method can be utilized to evaluate not only offline meetings but also online meetings.
2. Related Work
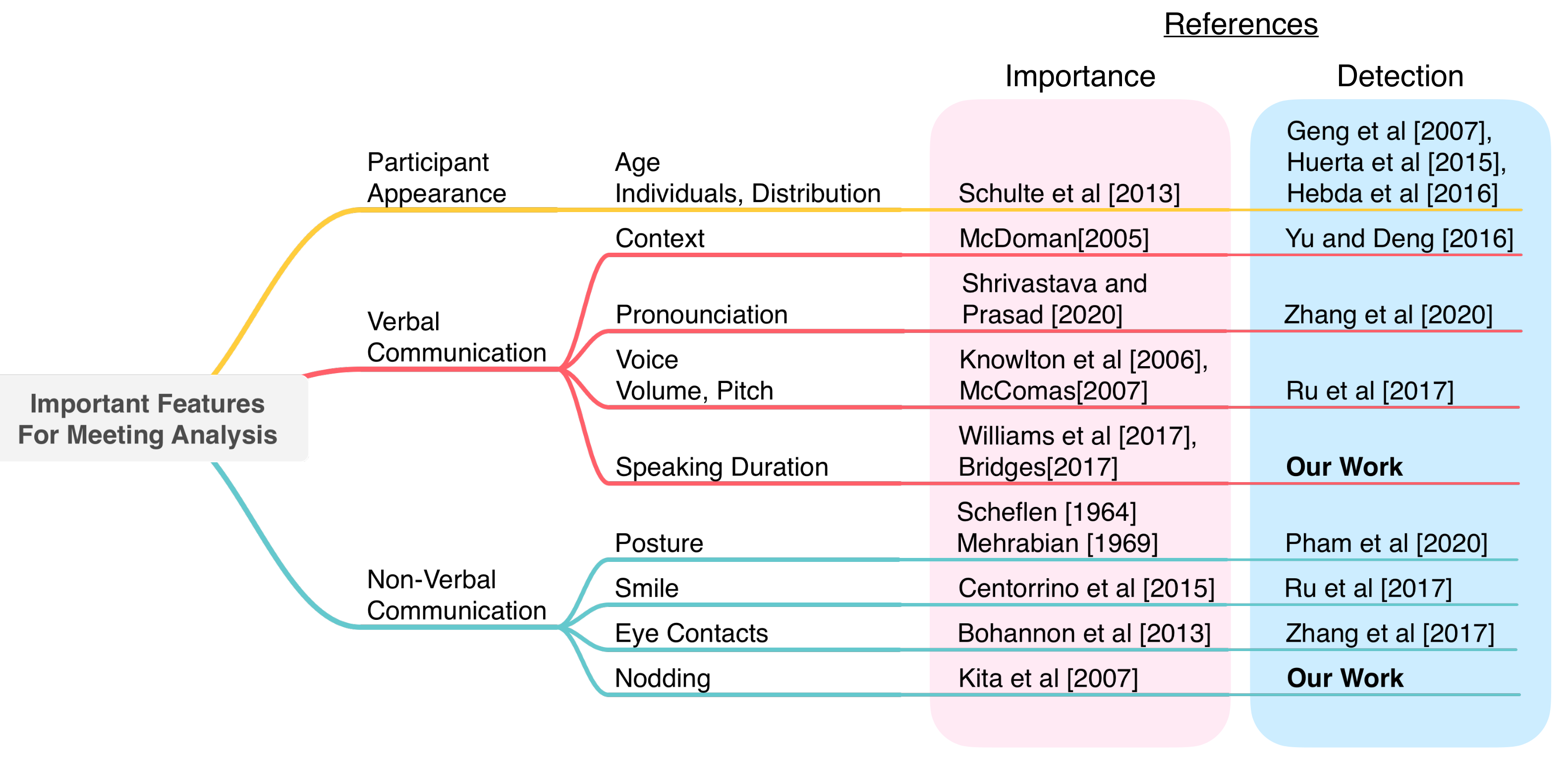
2.1. Participant Appearance
2.2. Verbal Communication
2.3. Nonverbal Communication
3. Proposed Method
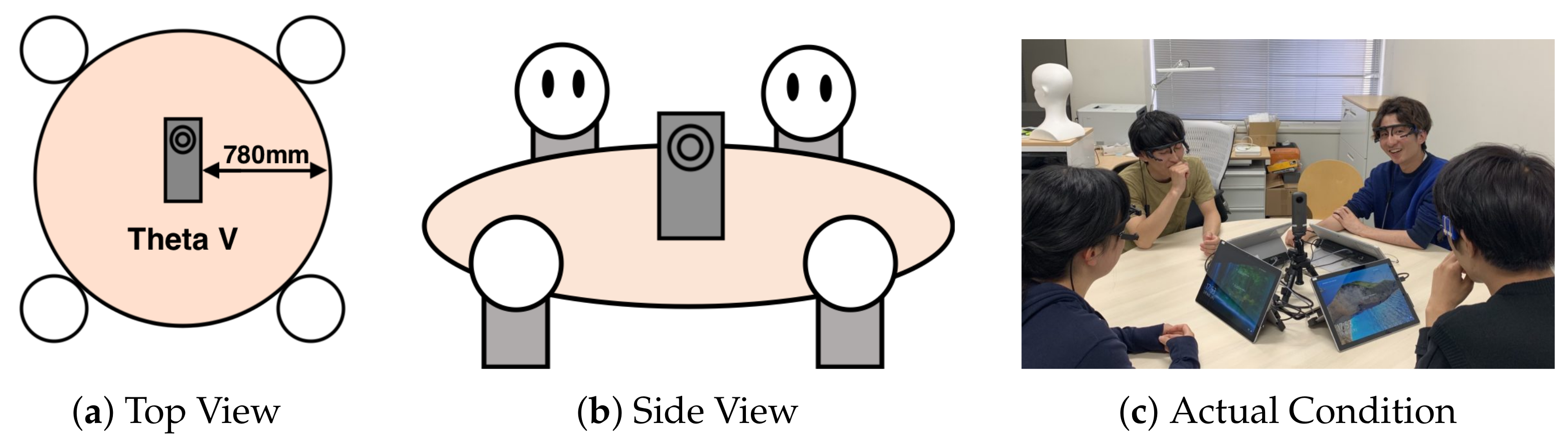
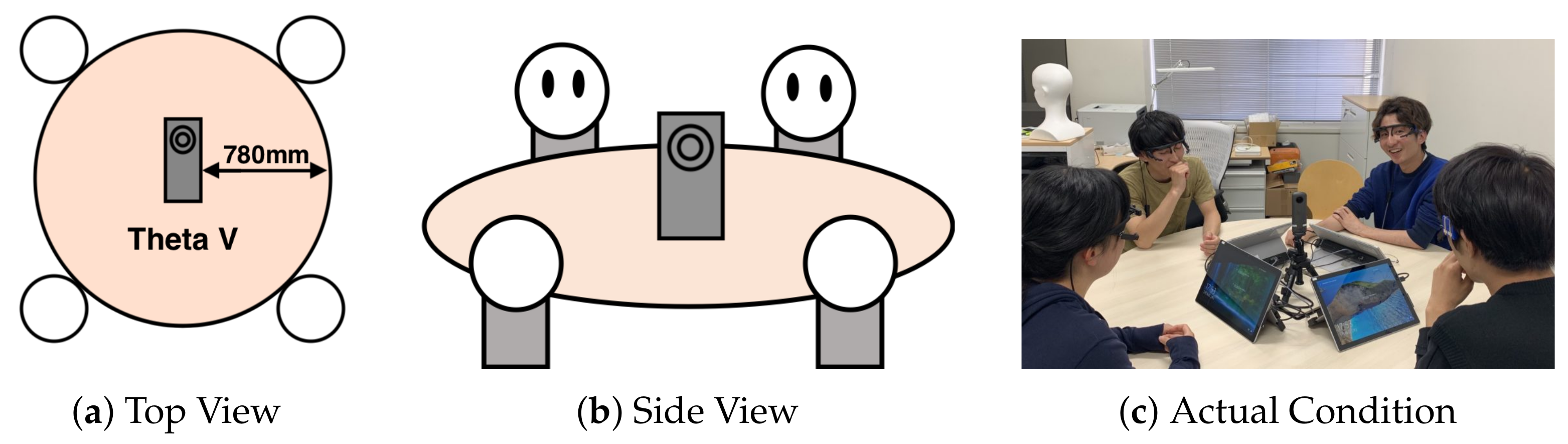
3.1. Offline Meeting Data Recording
3.2. Online Meeting Data Recording
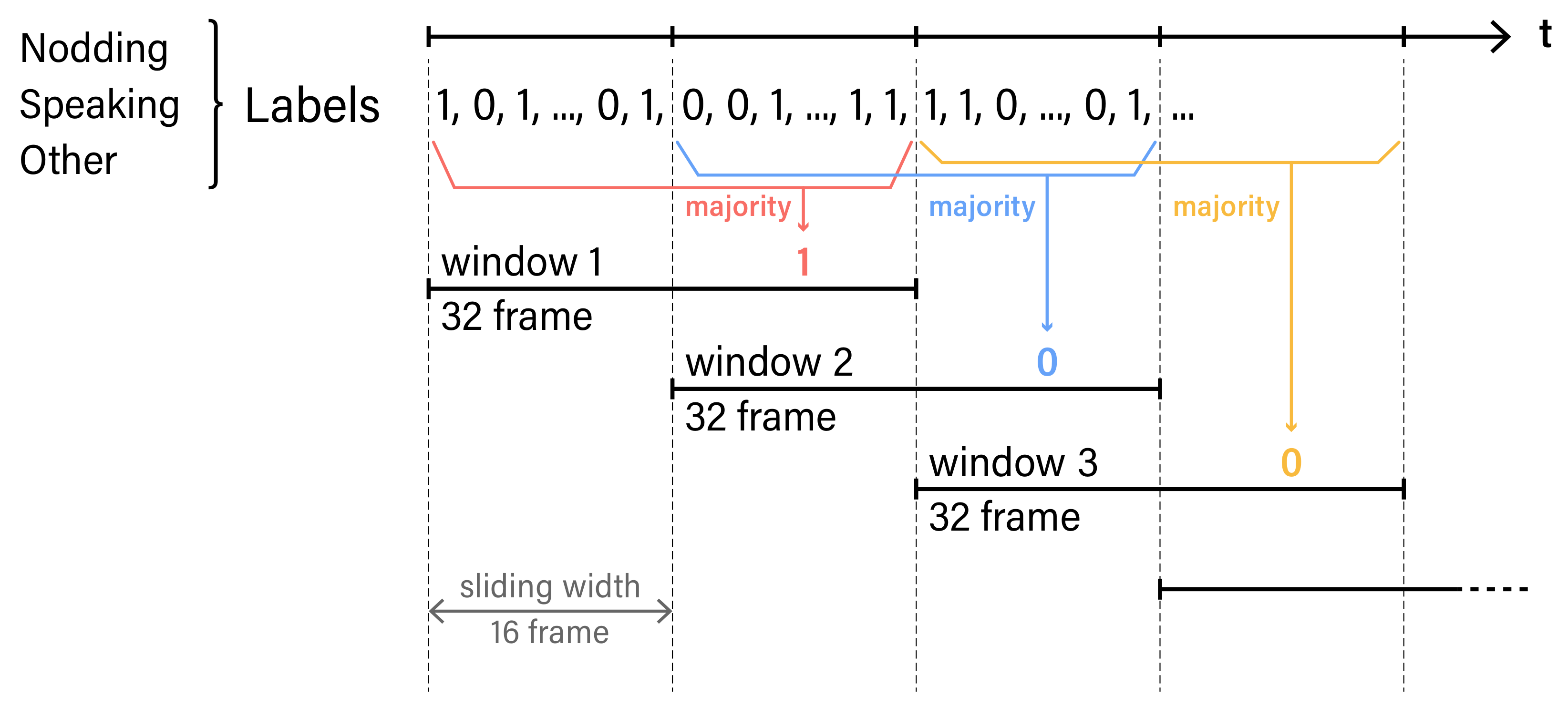
3.3. Annotation of Micro-Behaviours
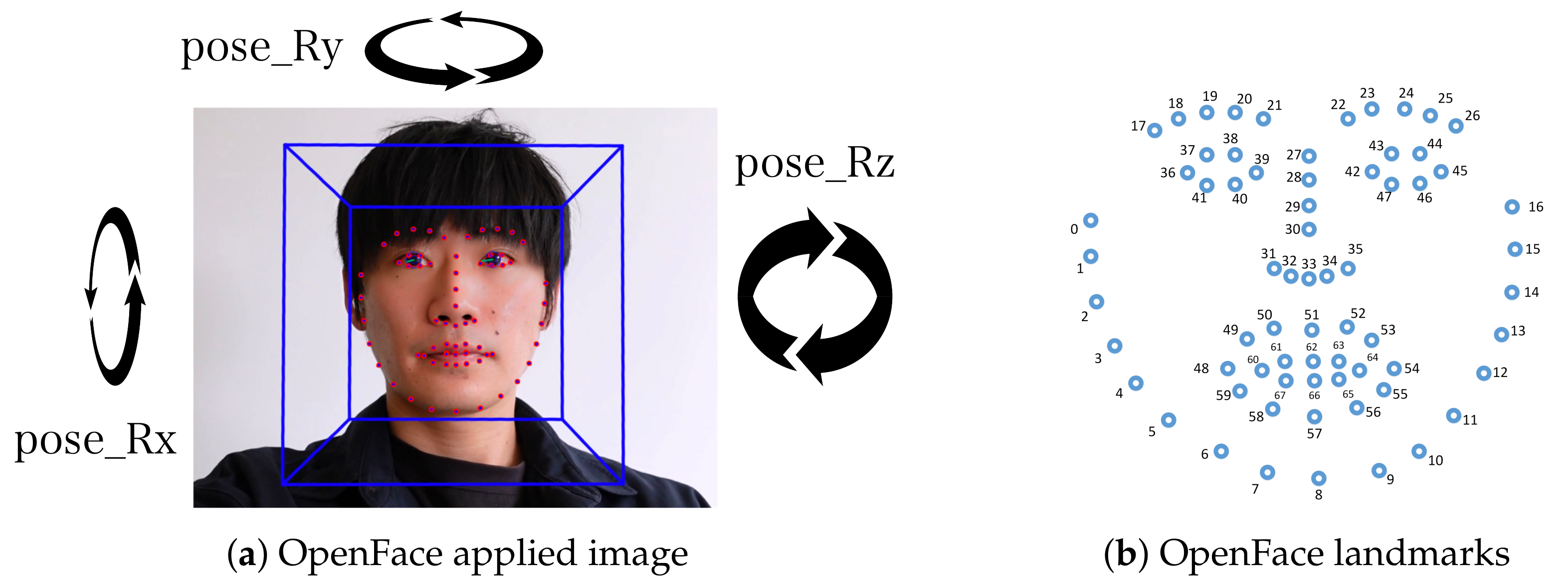
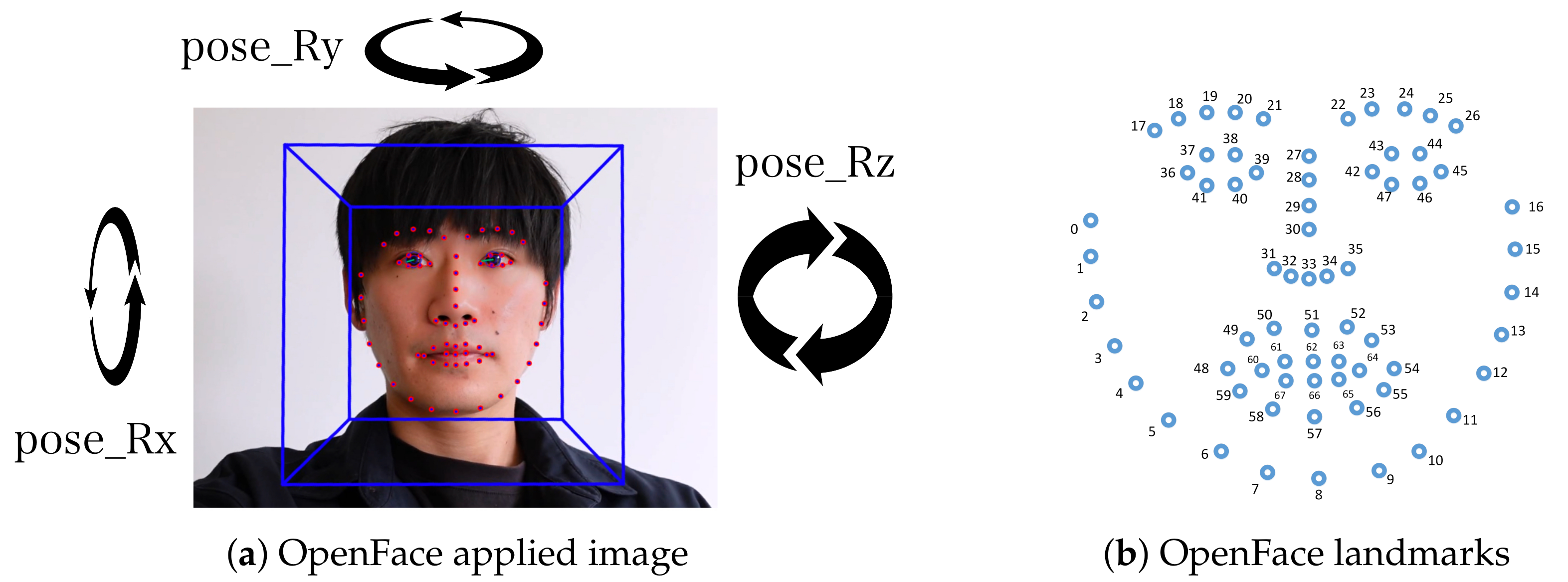
3.4. Extracting Head Rotations and Facial Points from Raw Video Frames Using OpenFace
3.5. Extracting Features from the Head Rotations and Facial Points
3.6. Classification
4. Experiment
4.1. Offline Meeting Dataset A
4.2. Offline Meeting Dataset B
4.3. Online Meeting Dataset
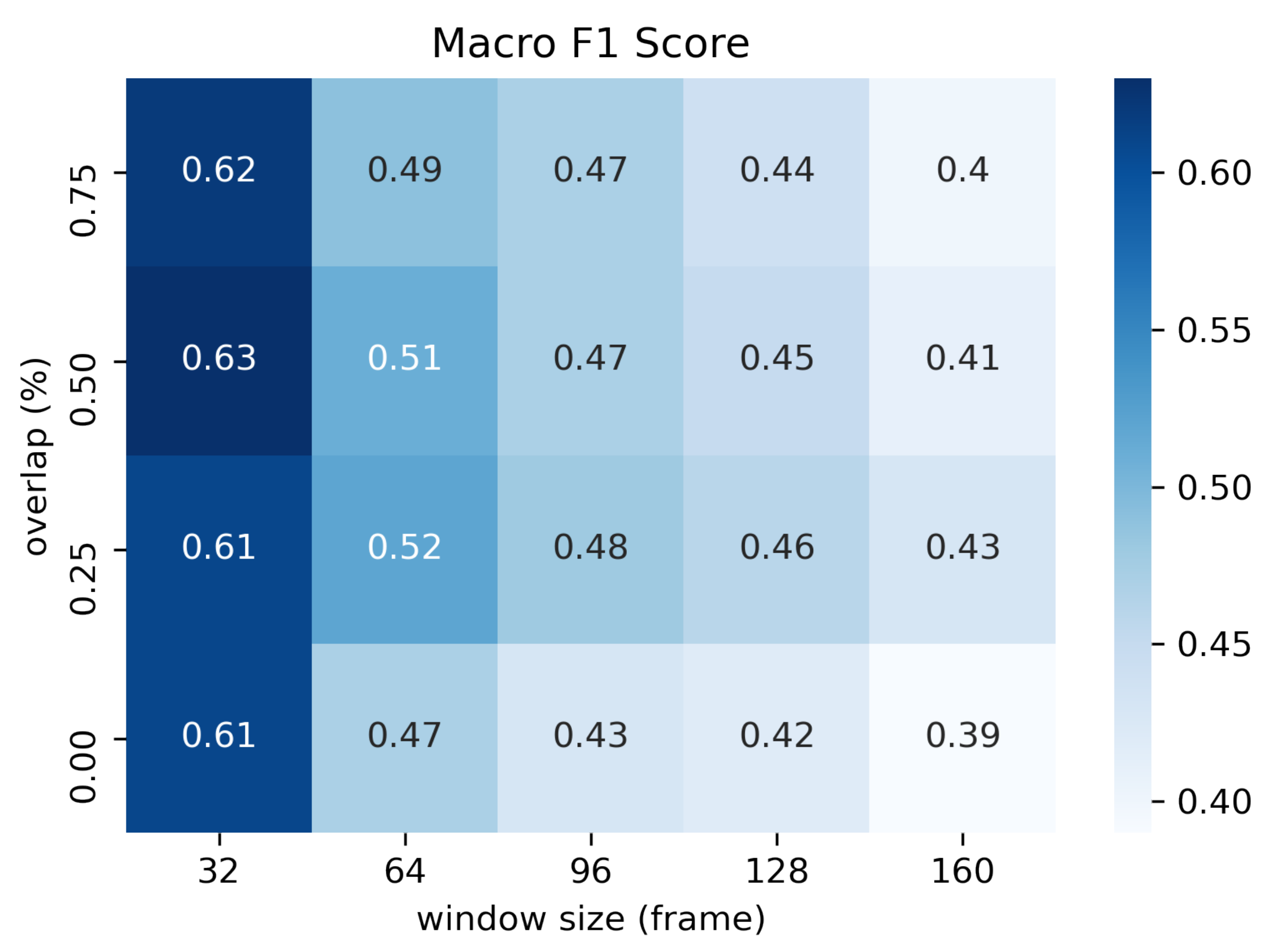
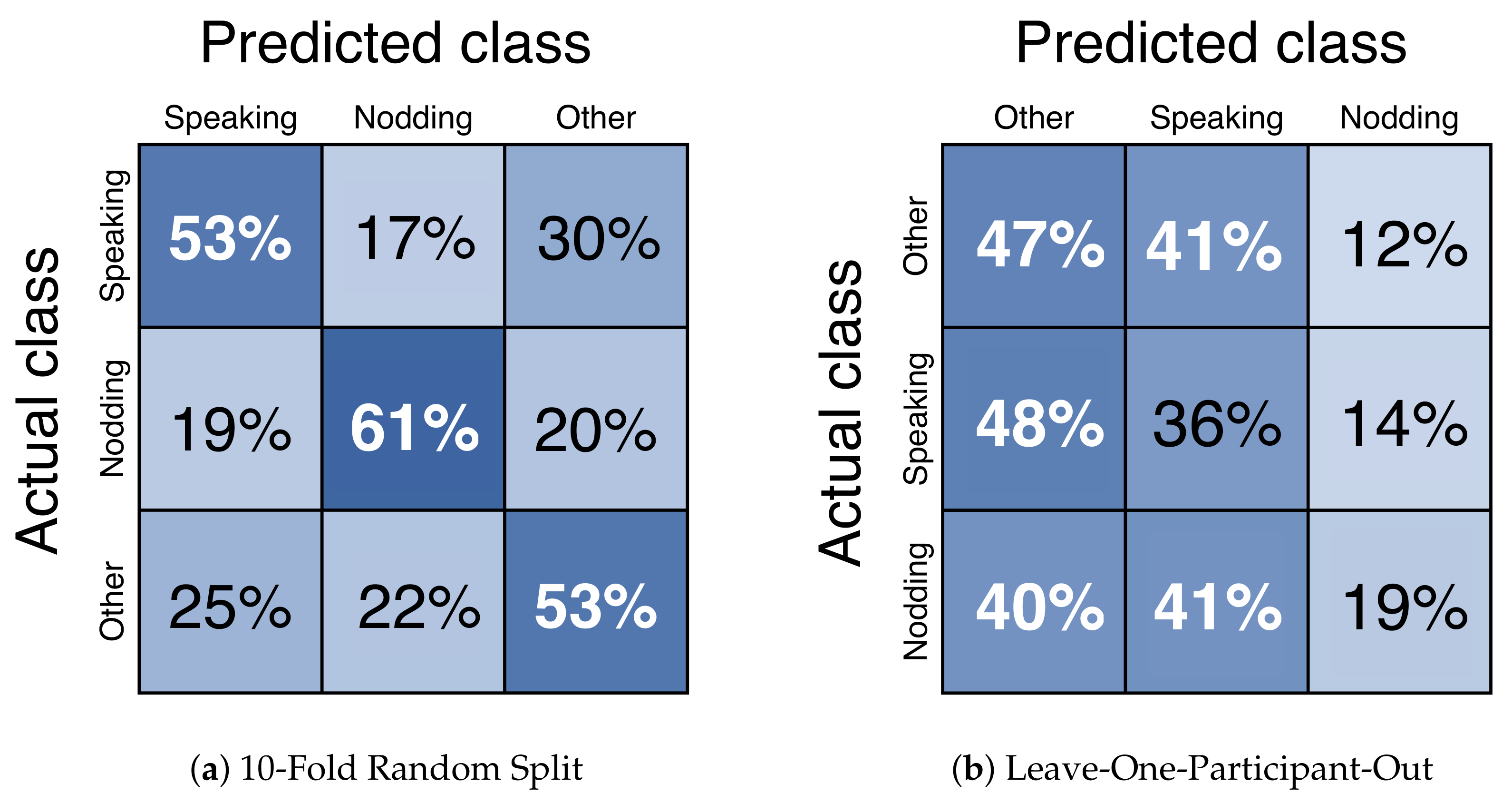
4.4. Evaluation Protocol
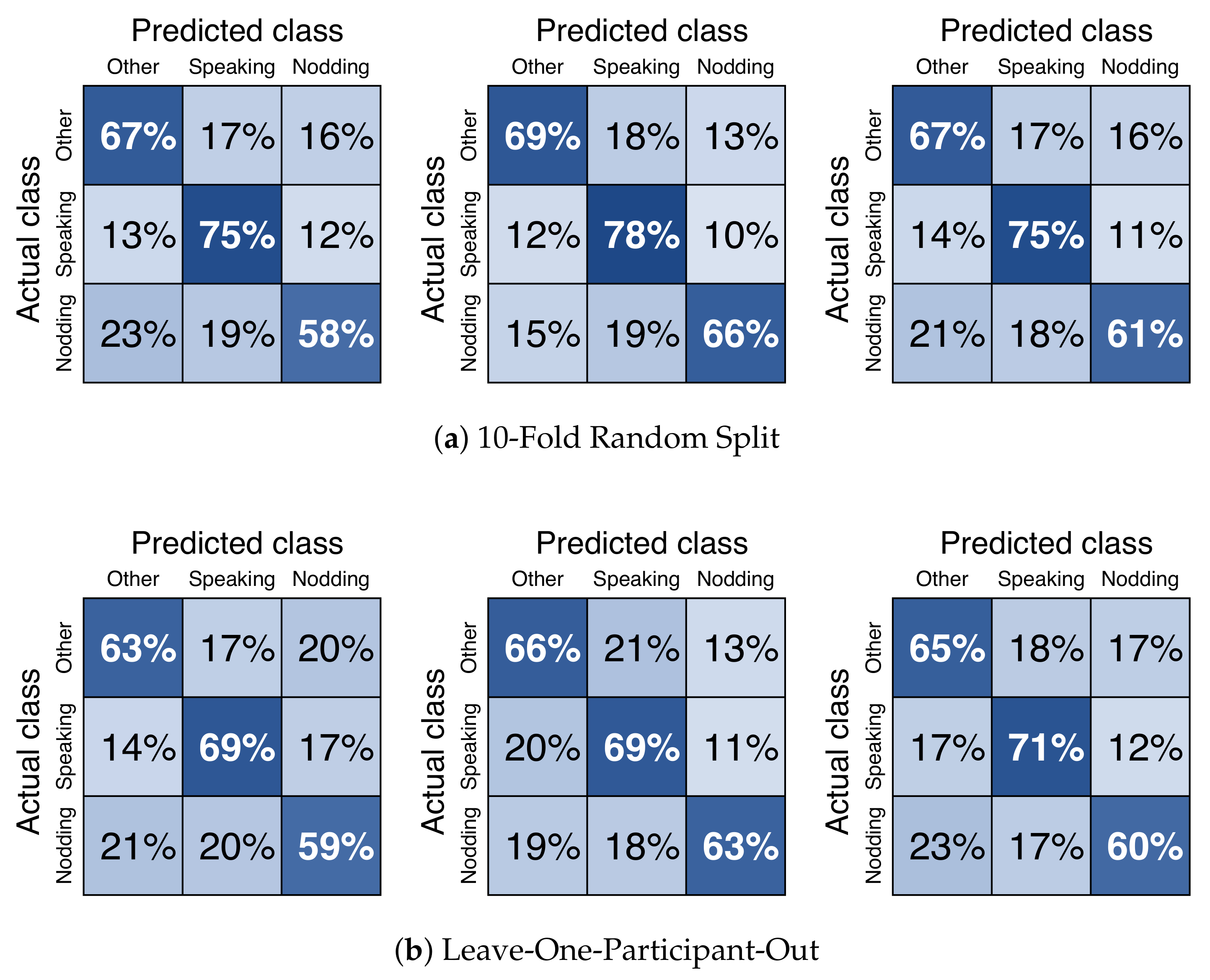
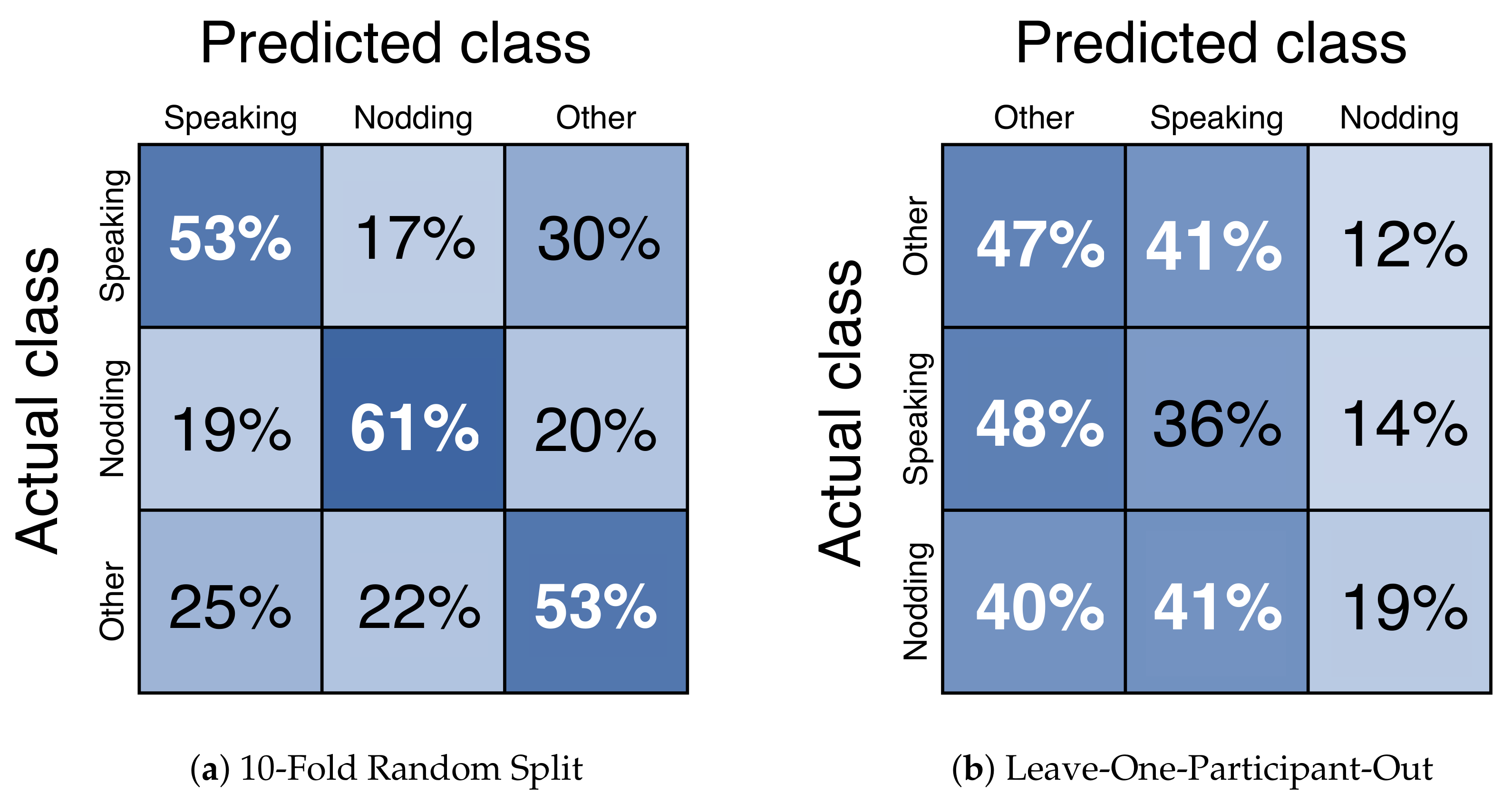
4.5. Results
5. Discussion
5.1. Can a 360 Degree Camera Recognize Multiple Participants Micro-Behaviour in a Meeting?
5.2. Can (and Should) We Extend the Dataset by Adding Data Recorded in Other Places?
5.3. Can Our “Camera as a Sensor” Method Cover Both Offline and Online Meetings?
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Allen, J.; Rogelberg, S.; Scott, J.C. Mind Your Meetings: Improve Your Organization’s Effectiveness One Meeting at a Time. Qual. Prog. 2008, 41, 48–53. [Google Scholar]
- Rogelberg, S.; Scott, C.; Kello, J.E. The Science and Fiction of Meetings. MIT Sloan Manag. Rev. 2007, 48, 18–21. [Google Scholar]
- Romano, N.C.; Nunamaker, J.F. Meeting analysis: Findings from research and practice. In Proceedings of the 34th Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 3–6 January 2001; p. 13. [Google Scholar] [CrossRef]
- Poel, M.; Poppe, R.; Nijholt, A. Meeting behavior detection in smart environments: Nonverbal cues that help to obtain natural interaction. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Sprain, L.; Boromisza-Habashi, D. Meetings: A cultural perspective. J. Multicult. Discourses 2012, 7, 179–189. [Google Scholar] [CrossRef]
- Lehmann-Willenbrock, N.; Allen, J.A.; Meinecke, A.L. Observing culture: Differences in US-American and German team meeting behaviors. Group Process. Intergroup Relations 2014, 17, 252–271. [Google Scholar] [CrossRef] [Green Version]
- Mroz, J.E.; Allen, J.A.; Verhoeven, D.C.; Shuffler, M.L. Do We Really Need Another Meeting? The Science of Workplace Meetings. Curr. Dir. Psychol. Sci. 2018, 27, 484–491. [Google Scholar] [CrossRef] [Green Version]
- Lübstorf, S.; Lehmann-Willenbrock, N. Are Meetings Really Just Another Stressor? The Relevance of Team Meetings for Individual Well-Being. In Research on Managing Groups and Teams; Emerald Publishing Limited: Bingley, UK, 2020; pp. 47–69. [Google Scholar] [CrossRef]
- Schulte, E.M.; Lehmann-Willenbrock, N.; Kauffeld, S. Age, forgiveness, and meeting behavior: A multilevel study. J. Manag. Psychol. 2013. [Google Scholar] [CrossRef]
- McDorman, T. Implementing existing tools: Turning words into actions–Decision-making processes of regional fisheries management organisations (RFMOs). Int. J. Mar. Coast. Law 2005, 20, 423–457. [Google Scholar] [CrossRef]
- Shrivastava, S.; Prasad, V. TECHNIQUES TO COMMUNICATE IN VIRTUAL MEETINGS AMIDST THE NEW NORMAL…A CONSIDERATION!!! Wutan Huatan Jisuan Jishu 2020, 16, 73–92. [Google Scholar]
- Knowlton, G.E.; Larkin, K.T. The influence of voice volume, pitch, and speech rate on progressive relaxation training: Application of methods from speech pathology and audiology. Appl. Psychophysiol. Biofeedback 2006, 31, 173–185. [Google Scholar] [CrossRef] [PubMed]
- McComas, K.A.; Trumbo, C.W.; Besley, J.C. Public meetings about suspected cancer clusters: The impact of voice, interactional justice, and risk perception on attendees’ attitudes in six communities. J. Health Commun. 2007, 12, 527–549. [Google Scholar] [CrossRef]
- Williams, J. Women at Work; Emerald Publishing Limited: Bingley, UK, 2017. [Google Scholar]
- Bridges, J. Gendering metapragmatics in online discourse: “Mansplaining man gonna mansplain…”. Discourse Context Media 2017, 20, 94–102. [Google Scholar] [CrossRef]
- Scheflen, A.E. The significance of posture in communication systems. Psychiatry 1964, 27, 316–331. [Google Scholar] [CrossRef]
- Mehrabian, A. Significance of posture and position in the communication of attitude and status relationships. Psychol. Bull. 1969, 71, 359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Centorrino, S.; Djemai, E.; Hopfensitz, A.; Milinski, M.; Seabright, P. Honest signaling in trust interactions: Smiles rated as genuine induce trust and signal higher earning opportunities. Evol. Hum. Behav. 2015, 36, 8–16. [Google Scholar] [CrossRef]
- Bohannon, L.S.; Herbert, A.M.; Pelz, J.B.; Rantanen, E.M. Eye contact and video-mediated communication: A review. Displays 2013, 34, 177–185. [Google Scholar] [CrossRef]
- Kita, S.; Ide, S. Nodding, aizuchi, and final particles in Japanese conversation: How conversation reflects the ideology of communication and social relationships. J. Pragmat. 2007, 39, 1242–1254. [Google Scholar] [CrossRef]
- Karremans, J.C.; Van Lange, P.A. Forgiveness in personal relationships: Its malleability and powerful consequences. Eur. Rev. Soc. Psychol. 2008, 19, 202–241. [Google Scholar] [CrossRef]
- Kauffeld, S.; Lehmann-Willenbrock, N. Meetings matter: Effects of team meetings on team and organizational success. Small Group Res. 2012, 43, 130–158. [Google Scholar] [CrossRef]
- Geng, X.; Zhou, Z.H.; Smith-Miles, K. Automatic age estimation based on facial aging patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2234–2240. [Google Scholar] [CrossRef] [Green Version]
- The FG-NET Aging Database. Available online: https://yanweifu.github.io/FG_NET_data/ (accessed on 24 August 2021).
- Ricanek, K.; Tesafaye, T. Morph: A longitudinal image database of normal adult age-progression. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; IEEE: New York, NY, USA, 2006; pp. 341–345. [Google Scholar]
- Edwards, G.J.; Lanitis, A.; Taylor, C.J.; Cootes, T.F. Statistical models of face images—Improving specificity. Image Vis. Comput. 1998, 16, 203–211. [Google Scholar] [CrossRef] [Green Version]
- Huerta, I.; Fernández, C.; Segura, C.; Hernando, J.; Prati, A. A deep analysis on age estimation. Pattern Recognit. Lett. 2015, 68, 239–249. [Google Scholar] [CrossRef] [Green Version]
- Hebda, B.; Kryjak, T. A compact deep convolutional neural network architecture for video based age and gender estimation. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; IEEE: New York, NY, USA, 2016; pp. 787–790. [Google Scholar]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhang, L.; Zhao, Z.; Ma, C.; Shan, L.; Sun, H.; Jiang, L.; Deng, S.; Gao, C. End-to-end automatic pronunciation error detection based on improved hybrid ctc/attention architecture. Sensors 2020, 20, 1809. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Li, V.; Barbosa, H.; Ghoshal, G.; Hoque, M.E. Semi-automated 8 collaborative online training module for improving communication skills. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Janin, A.; Baron, D.; Edwards, J.; Ellis, D.; Gelbart, D.; Morgan, N.; Peskin, B.; Pfau, T.; Shriberg, E.; Stolcke, A.; et al. The ICSI Meeting Corpus. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’03), Hong Kong, China, 6–10 April 2003; Volume 1, p. I. [Google Scholar] [CrossRef]
- Carletta, J.; Ashby, S.; Bourban, S.; Flynn, M.; Guillemot, M.; Hain, T.; Kadlec, J.; Karaiskos, V.; Kraaij, W.; Kronenthal, M.; et al. The AMI Meeting Corpus: A Pre-Announcement. In Proceedings of the Second International Conference on Machine Learning for Multimodal Interaction, Edinburgh, UK, 11–13 July 2005; MLMI’05. Springer: Berlin/Heidelberg, Germany, 2005; pp. 28–39. [Google Scholar] [CrossRef] [Green Version]
- Riedhammer, K.; Favre, B.; Hakkani-Tür, D. Long story short—Global unsupervised models for keyphrase based meeting summarization. Speech Commun. 2010, 52, 801–815. [Google Scholar] [CrossRef] [Green Version]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Velastin, S.A.; Zegers, P. A unified deep framework for joint 3d pose estimation and action recognition from a single rgb camera. Sensors 2020, 20, 1825. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sugano, Y.; Bulling, A. Everyday Eye Contact Detection Using Unsupervised Gaze Target Discovery. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, Quebec City, QC, Canada, October 22–25 2017; UIST’17. Association for Computing Machinery: New York, NY, USA, 2017; pp. 193–203. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W. The Repertoire of Nonverbal Behavior: Categories, Origins, Usage, and Coding. Semiotica 1969, 1, 49–98. [Google Scholar] [CrossRef]
- Morency, L.P.; Sidner, C.; Lee, C.; Darrell, T. Head gestures for perceptual interfaces: The role of context in improving recognition. Artif. Intell. 2007, 171, 568–585. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Yu, Z.; Aoyama, H.; Ozeki, M.; Nakamura, Y. Capture, recognition, and visualization of human semantic interactions in meetings. In Proceedings of the 2010 IEEE International Conference on Pervasive Computing and Communications (PerCom), Mannheim, Germany, 29 March–2 April 2010; pp. 107–115. [Google Scholar]
- Ohnishi, A.; Murao, K.; Terada, T.; Tsukamoto, M. A method for structuring meeting logs using wearable sensors. Internet Things 2019, 140–152. [Google Scholar] [CrossRef]
- Ricoh Company, L. Product|RICOH THETA V. 2017. Available online: https://theta360.com/de/about/theta/v.html (accessed on 24 August 2021).
- Google Inc., G. Product|GOOGLE MEET. Available online: https://meet.google.com/ (accessed on 24 August 2021).
- Archive, T.L. ELAN. 2002. Available online: https://archive.mpi.nl/tla/elan (accessed on 24 August 2021).
- Tadas Baltrušaitis, P.R.; Morency, L.P. OpenFace: An open source facial behavior analysis toolkit. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Nakamura, Y.; Matsuda, Y.; Arakawa, Y.; Yasumoto, K. WaistonBelt X: A Belt-Type Wearable Device with Sensing and Intervention Toward Health Behavior Change. Sensors 2019, 19, 4600. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soneda, Y.; Matsuda, Y.; Arakawa, Y.; Yasumoto, K. M3B Corpus: Multi-Modal Meeting Behavior Corpus for Group Meeting Assessment. In UbiComp/ISWC ’19 Adjunct, Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers; Association for Computing Machinery: New York, NY, USA, 2019; pp. 825–834. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Description | Formulation | Type |
|---|---|---|---|
| mean (s) | Arithmetic mean | T,F | |
| std (s) | Standard deviation | T,F | |
| mad (s) | Median absolute deviation | T,F | |
| max (s) | Largest values in array | T,F | |
| min (s) | Smallest value in array | T,F | |
| energy (s) | Average sum of the square | T,F | |
| sma (,,) | Signal magnitude area | T,F | |
| entropy (s) | Signal Entropy | T,F | |
| iqr (s) | Interquartile range | T,F | |
| autorregresion (s) | Fourth order Burg Autoregression coefficients | T | |
| correlation (,) | Pearson Correlation coefficient | T | |
| angle (,,,v) | Angle between signal mean and vector | T | |
| range (s) | Distance of the smallest and largest value | T | |
| rms (s) | Root square means | T | |
| skewness (s) | Frequency signal Skewness | F | |
| kurtosis (s) | Frequency signal Kurtosis | F | |
| maxFreqInd (s) | Largest frequency component | F | |
| meanFreq (s) | Frequency signal weighted average | F | |
| energyBand (s,a,b) | Spectral energy of a frequency band (a, b) | F | |
| psd (s) | Power spectral density | F |
| (a) 10-Fold Random Split | ||||
|---|---|---|---|---|
| Dataset | Label | Precision | Recall | F1-Score |
| A | nodding | |||
| speaking | ||||
| macro ave. | ||||
| B | nodding | |||
| speaking | ||||
| macro ave. | ||||
| A + B | nodding | |||
| speaking | ||||
| macro ave. | ||||
| (b) Leave-One-Participant-Out | ||||
| Dataset | Label | Precision | Recall | F1-Score |
| A | nodding | |||
| speaking | ||||
| macro ave. | ||||
| B | nodding | |||
| speaking | ||||
| macro ave. | ||||
| A + B | nodding | |||
| speaking | ||||
| macro ave. |
| (a) 10-Fold Random Split | |||
|---|---|---|---|
| Label | Precision | Recall | F1-Score |
| nodding | |||
| speaking | |||
| macro ave. | |||
| (b) Leave-One-Participant-Out | |||
| Label | Precision | Recall | F1-Score |
| nodding | |||
| speaking | |||
| macro ave. | |||
| (a) Offline Meeting | ||||
|---|---|---|---|---|
| Rank | Function | Component | Type | Weight |
| 1 | iqr | distance between facial point 62 and 66 | frequency | 0.046 |
| 2 | iqr | pose_Rx | frequency | 0.040 |
| 3 | std | distance between facial point 62 and 66 | time | 0.039 |
| 4 | ARCoeff-2 | distance between facial point 62 and 66 | time | 0.038 |
| 5 | ARCoeff-1 | pose_Rx | time | 0.037 |
| (b) Online Meeting | ||||
| Rank | Function | Component | Type | Weight |
| 1 | entropy | pose_Rx | time | 0.033 |
| 2 | mean | pose_Rx | time | 0.031 |
| 3 | ARCoeff-3 | distance between facial point 62 and 66 | time | 0.030 |
| 4 | min | pose_Rx | time | 0.029 |
| 5 | Skewness-1 | pose_Rx | frequency | 0.027 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watanabe, K.; Soneda, Y.; Matsuda, Y.; Nakamura, Y.; Arakawa, Y.; Dengel, A.; Ishimaru, S. DisCaaS: Micro Behavior Analysis on Discussion by Camera as a Sensor. Sensors 2021, 21, 5719. https://doi.org/10.3390/s21175719
Watanabe K, Soneda Y, Matsuda Y, Nakamura Y, Arakawa Y, Dengel A, Ishimaru S. DisCaaS: Micro Behavior Analysis on Discussion by Camera as a Sensor. Sensors. 2021; 21(17):5719. https://doi.org/10.3390/s21175719
Chicago/Turabian StyleWatanabe, Ko, Yusuke Soneda, Yuki Matsuda, Yugo Nakamura, Yutaka Arakawa, Andreas Dengel, and Shoya Ishimaru. 2021. "DisCaaS: Micro Behavior Analysis on Discussion by Camera as a Sensor" Sensors 21, no. 17: 5719. https://doi.org/10.3390/s21175719
APA StyleWatanabe, K., Soneda, Y., Matsuda, Y., Nakamura, Y., Arakawa, Y., Dengel, A., & Ishimaru, S. (2021). DisCaaS: Micro Behavior Analysis on Discussion by Camera as a Sensor. Sensors, 21(17), 5719. https://doi.org/10.3390/s21175719