1. Introduction
RGB-depth (RGB-D) cameras are widely used for 3D modeling [
1,
2,
3,
4] and human pose estimation [
5] due to their ability to acquire depth images in real time. RGB-D cameras provide color images aligned to the depth images, so each pixel location in a color–depth image pair is recorded with the 3D coordinates of a point and its RGB data. The 6D data enable the modeling of texture as well as structure.
To reconstruct the entire 3D structure of an object, one can use a single RGB-D camera to acquire an RGB-D video, moving the camera around the object [
1,
2]. If the object is dynamic, one can use a synchronized multiview RGB-D camera system [
3,
4]. In both cases, estimating the 3D rigid transformation across point clouds is the key problem to solve to obtain a single merged point cloud. If the frame rate of the RGB-D video is high, the identity transformation can be regarded as the initial estimate [
1]. For the multiview system, either extrinsic calibration [
6,
7] or global registration algorithms [
8,
9,
10,
11] can be employed.
The remaining errors in the transformations are effectively reduced by the Iterative Closest Point (ICP) algorithm [
12,
13,
14] and its variants [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26]. The ICP algorithm registers a source point cloud to a reference point cloud by repeatedly alternating steps of correspondence search and cost minimization. The correspondence search step transforms all source points to the reference frame using the current pose and then finds from the reference point cloud the closest point to each transformed source point. The point pairs whose point-to-point distance is shorter than a threshold are regarded as correspondences. The cost minimization step estimates the refined pose by minimizing a cost constructed from the correspondences.
The ICP variants [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26] have improved the original algorithm by solving different problems, such as disambiguation of the correspondence search [
15,
21,
24,
26], defining a better cost function [
13,
16,
17,
18,
19,
20,
22,
23,
25,
26], and searching for a better optimization method [
16,
17,
18,
19,
25]. Even with accurate poses, the registration accuracy is limited by the random and systematic depth measurement errors of the RGB-D cameras [
27]. The depth errors also lead to the poor visual quality of the merged point cloud. Reducing the errors in the earliest stage of the pipeline can wipe out the local structure, which is essential for the correspondence search. For this reason, depth-error reduction is often the last stage of the pipeline [
8,
26].
Simple postprocessing on the merged point cloud filters each 3D point using its neighbors [
28]. If the poses are inaccurate, only the neighbors from the same fragment tend to have large weights. In this case, the accuracy of individual point clouds can be improved; however, corresponding points across point clouds may not mix to produce a seamlessly merged point cloud. On the other hand, the cost functions of the ICP algorithm and its variants are designed to minimize the distance between corresponding points across point clouds. Thus, the registration can become more accurate by minimizing the cost further. A recent study showed that the cost of an ICP algorithm can be minimized further by refining the measured depth values instead of the pose parameters [
26]. However, the depth-update equation derived from the cost function tends to be numerically unstable, so a postprocessing step is needed to restrict the range of the output depth values. In addition, the points outside of the overlapping surfaces between point clouds are not covered by the cost function, so the depth errors of those points are not reduced by minimizing the cost function. As a solution, a regularization method is applied at the final step.
In this paper, we present a new cost function that is not only stable to minimize but also applied to all source points, irrespective of their corresponding points in the reference point cloud. We provide the reasoning for the unstable case of using the point-to-plane distance [
26], where a 3D point-to-point vector is projected onto the surface-normal direction. To prevent the unstable case, our cost function is built on an adaptive combination of two different projected distances instead of a single projected distance.
Another contribution of this paper is that we consider the problem of registering a source point cloud to the union of the source and reference point clouds. The source points without their closest points in the reference point cloud will have their closest points within the source point cloud as long as the distance threshold permits. This extension allows all points to be processed in a unified filtering framework. Unlike the filtering approach in [
28], the closest points are independently collected from the source and reference point clouds, and the effect of each set of closest points is controlled with a single parameter in our approach. Thus, we can control the mixing across point clouds.
The experimental results in this paper show that our proposed method prevents the unstable case, reduces the registration error, and provides high-quality merged point clouds. The results also show that the intra-point-cloud closest points are effective not only for reducing the depth errors but also for improving numerical stability.
The remainder of this paper is structured as follows. The following section provides a summary of existing methods. Our proposed method is presented in
Section 3. The experimental results are provided in
Section 4. Finally,
Section 5 concludes the paper.
2. Related Work
Kinect sensors are among the most widely used RGB-D cameras, which rely on either the structured light-pattern projection or the Time-of-Flight technology [
29]. Irrespective of the technology, the standard deviation of the random depth errors increases with the depth of the subject. For the structured light-pattern projection technology, the standard deviation approximately increases with the squared depth of the subject [
29]. For the Time-of-Flight technology, the standard deviation increases with the inverse of the amplitude of the received infrared light signal [
30]. The RGB-D cameras used in our work are based on the structured light-pattern projection as in Kinect v1 sensors, sharing similar depth-error characteristics.
For the global registration of point clouds, geometric invariants are used to establish pose hypotheses [
8,
9], or histogram features [
31] are used to establish candidate matches [
11]. The global registration algorithms typically find solutions by minimizing cost functions, for which robust, fast, and accurate optimization is crucial. The RANSAC algorithm [
32] is used in [
8], and smart indexing data organization is used for the acceleration [
9] of the optimization [
8]. In [
11], the graduated nonconvexity algorithm is applied only to the candidate matches for fast and accurate global registration of the point clouds.
The original ICP algorithm [
12] has room for improvement, and many local registration algorithms [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26] have been proposed by addressing different problems of the original algorithm. Setting the threshold appropriately in the correspondence-search step is important to collect sufficient correspondences while rejecting outliers. The threshold can be determined by using data statistics [
14]. Alternatively, the effect of the outliers can be weakened by using a robust loss function [
18] or a cost function based on sparsity-inducing norms [
23].
If the initial pose is inaccurate, the correspondence-search step based only on the 3D distance is prone to error. To improve the correspondence search, the color distance between points can be used as an auxiliary measure, extending the 3D search to a 4D or 6D search [
15,
21,
24,
26].
If the density of the point clouds is low or the initial pose is inaccurate, finding one-to-one correspondence is neither exact nor accurate. From this point of view, probabilistic approaches [
16,
17,
19] allow a source point to match all points in the reference point cloud, assigning matching probabilities to all the correspondences. The annealing schedule of the matching probability distribution allows all the correspondences to be equally probable at the beginning of the iterations and preserves only dominant one-to-one correspondences at the end of the iterations [
16,
17]. To reduce the computational complexity of the probabilistic approaches, a coarse-to-fine scheme [
25] can be used or the probabilities can be assigned only to the
K-closest points [
26], which can be efficiently obtained using a
KD tree [
33].
The original ICP algorithm relies on a cost function, which is the sum of squared point-to-point distances [
12]. Chen and Medioni proposed to use a different cost function based on point-to-plane distances [
13]. To compute the point-to-plane distance between a source point and a reference point, the difference vector between the points is projected onto the surface-normal vector of the reference point. The projected distance is equivalent to a Mahalanobis distance induced by a
matrix, which is the outer product of the surface-normal vector. Segal et al. [
20] show that point-to-plane and plane-to-plane distances can be represented by Mahalanobis distances. The Mahalanobis distance can also be used to reflect the anisotropic, inhomogeneous localization error of the measured points [
22]. Park et al. [
25] use a cost function based on both color and depth differences between two point clouds.
Deformable ICP algorithms change the individual point locations as well as the pose of the source point cloud [
34,
35,
36]. The algorithms assume that the object is deformable or articulated. In contrast, we assume that the multiview system is synchronous, so the object is assumed to be rigid across point clouds.
Our proposed method can be regarded as the unification of depth-error reduction [
30,
37] and point cloud registration [
26]. Depth-error reduction algorithms refine measured depth values using the neighborhood within a depth image [
30,
37]. The Iterative
K Closet Point (IKCP) algorithm [
26] refines measured depth values using the
K-closest points across point clouds. Our proposed method exploits the advantage of using the closest points from both source and reference point clouds.
Our method is similar to the bilateral filter for point clouds [
28] in that it changes the 3D position of a point using its neighbors. However, our method has several differences from the bilateral filter. One difference is the direction of change of the 3D point. Each point moves along the surface-normal direction in the bilateral filter, whereas in our method, it moves along the ray direction so that the changed 3D point position matches the original pixel location in the depth image. Another difference is that our method uses color information, unlike the bilateral filter.
3. Proposed Method
In this section, we first review the Iterative
K Closest Point (IKCP) algorithm [
26] and then present our proposed method addressing the problems of the IKCP algorithm.
Let us denote the source and reference point cloud by
and
, respectively, where
and
. We assume that the 3D rigid transformation from a source point
to its corresponding reference point
has been given by the registration pipeline. The transformation is represented by a
rotation matrix
and a translation vector
:
Defining
as
, a residual vector
can be computed as
. The IKCP algorithm for depth refinement aims at minimizing the following cost function.
where
In Equation (
3),
is the index set of the
K-closest points to
. The
K-closest points are searched for from
with a constraint that requires
to be less than a threshold
. Thus, the cardinality of
can be less than
K according to the magnitude of
and the setting of
.
is the weight of the correspondence between
and
, which is defined to decrease with the color-depth 6D difference between the two points. Finally,
is a
matrix determined by the type of the distance. For example,
if the distance type is point-to-plane, where
is the surface-normal vector of
. For the point-to-point distance,
is simply the
identity matrix.
By regarding the depth
of
as a variable and
and
as fixed variables, Choi et al. [
26] derived the following updated equation for minimizing
E:
where
is the normalized image coordinates of
satisfying
.
Denoting
by
, the update equation can become numerically unstable if
is nearly in the null space of
. In [
26], to improve the numerical stability,
is defined as
, where
is a small positive number. However, adding
to
does not completely prevent unwanted large changes in depth values, so Choi et al. [
26] rely on a postprocessing step that restricts large changes.
In the IKCP algorithm, such a numerically unstable case occurs when the ray direction of a source point is nearly orthogonal to the dominant surface-normal direction of the
K-closest points in the reference point cloud, as illustrated in
Figure 1. As the source point is allowed to move only in the ray direction, the point-to-plane distance is difficult to decrease in such a case.
Let us assume that
is very large for a certain reference point. Denoting the index of the point by
, the dominant surface-normal direction is
, and the matrix
is approximately
. Assuming that the ray direction
is nearly orthogonal to
, Equation (
4) is approximately
According to our assumption, the absolute value of
is very small; however,
may not be negligible. Thus, with a small value of
, the absolute value of
may become non-negligible compared to the denominator, causing the computation of Equation (
4) to be numerically unstable.
An easy method for increasing the numerical stability is simply to use the point-to-point distance. In this case, Equation (
4) is simplified to
where
has been removed.
We propose an adaptive method that exploits the fact that the direction
, whose dot product with
is never zero, is
itself or its non-zero multiple. For our new definition of
, let us define
as
We define
as a linear combination of
and
:
where
is the coefficient of
.
To avoid the numerical instability,
needs to be small if
is nearly orthogonal to
. To fulfill this requirement, we define
as
where
is the cosine of the angle
between
and
. Thus,
is
, and
is
or
.
With our new definition of
, if
is nearly orthogonal to
, Equation (
4) is approximated by
which is equivalent to Equation (
6) based on the point-to-point distance.
On the other hand, if
is nearly parallel with
, Equation (
4) is approximated by
which is purely based on the point-to-plane distance.
If
has no point satisfying
, Equation (
4) is not constructed for such
without valid closest points. To attract such points to those refined by valid closest points, Choi et al. [
26] use a regularization method that moves the source points as rigidly as possible toward the reference points. As the cost function has been designed to preserve the original structure of
, the depth measurement error in
is hardly reduced by the method if the overlap between
and
is small.
To treat every source point uniformly, we can regard as the reference point cloud instead of , where denotes the duplicate of . Assuming that the distance between neighboring points in is shorter than , is not an empty set for all i. In this case, however, most of the K-closest points will tend to be selected from . Such closest points hardly contribute to reducing the distance between and . To avoid this problem, we select two sets of K-closest points from and independently.
With the two sets of closest points, our cost function is defined as
where
and
are the index sets of the
K-closest points to
and
in
and
, respectively. We note that
as the transformation from
to its duplicate
is the identity transformation.
A positive constant
controls the effect of the
K-closest points from
. As we want their effect to be small if
is not an empty set, a reasonable choice of
is a small positive number, such as 0.01. We investigate the effect of
by varying its value from 0.01 to 1 in
Section 4.
Assuming that all points in
are fixed, we can derive the closed-form solution that minimizes Equation (
12). Equation (
13) is the consequent update equation with the two sets of
K-closest points.
The proposed method can be extended to a set of
point clouds by iteratively registering a point cloud to the union of the point clouds. Choi et al. [
26] proposed an algorithm for the extension, and Algorithm 1 shows the algorithm with a slight modification to use Equation (
13). In Algorithm 1,
is the transformed
to the reference frame using the pose parameters
and
.
is the number of cycles of depth-filtering operations. We set
to two throughout this paper, as in [
26]. This setting allows every point, except for those in
, to be filtered twice. The points in
are filtered once under this setting.
| Algorithm 1: Multiview depth refinement algorithm. |
![Sensors 21 07023 i001]() |
4. Results
This section provides experimental results. For a comparison to previous work, we use the synthetic and real-world datasets of Choi et al. [
26]. We provide quantitative results using the synthetic dataset and qualitative results using the real-world dataset.
The synthetic multiview RGB-D dataset [
26] was constructed by rendering graphics models of the pose-varying human model dataset [
38]. Twenty mesh models of different poses were sampled from a male (models 0–199) and a female (models 6800–6999) appearance, respectively. The number of views is twelve (
), and the distance to the models ranges from 1.5 m to 3 m. The 0th and 6th views are the closest, and the 3rd and 9th views are the farthest. The standard deviation of depth noise is approximately in proportion to the squared depth values [
29], and such realistic noise was added to the rendered depth images. The standard deviation of the noise ranges from 0.5 cm to 2.2 cm. The 3rd and 9th depth images suffer from the highest noise level, while the 0th and 6th depth images suffer from the lowest noise level. The ground-truth camera pose parameters are provided with the dataset. Thus, we can compare the registered output depth images to the registered ground-truth depth images with no pose error.
Figure 2 shows sample RGB-D images from the synthetic dataset.
We compare the proposed method to three existing methods [
26,
28,
39] and two extreme variants of the proposed method. We implemented the bilateral filter for point clouds [
28], which is referred to as the
Bilateral filter. We applied the guided image filter [
39] to point cloud filtering, which is referred to as the
Guided filter. The guided image filter has shown high performance not only in image filtering but also in cost volume filtering for stereo matching [
40]. In our implementation, the parameters of the two filters were set similarly to ours. For example, the maximum number of neighbors was set to 10 with the same threshold
= 4 cm. If the number of neighbors was less than 5, then at least five neighbors were used. As the filters were applied to the union of all multiview point clouds, this setting gave the filters approximately the same number of neighbors as the proposed method, which found a maximum of five closest points from the source and reference point clouds, respectively. The filters were applied twice so that each point would be filtered twice as in our method. On the other hand, we used the results of Choi et al. reported in [
26] without re-implementation.
Our proposed Algorithm 1 is referred to as
Filter adaptive.
Filter p2p is a variant of
Filter adaptive, where only point-to-point distances are used.
Filter p2l is another variant, where only point-to-plane distances are used. The two variants are obtained by fixing
in Equation (
8) to either 0 or 1. With the results of these variants, we can understand the effect of the proposed adaptive cost function.
4.1. Results on the Synthetic Dataset
The synthetic data set provides perturbed pose parameters, where five different rotational and translational perturbations were applied to the ground-truth rotation matrices and translation vectors with rotation angles of
to
and translation lengths of 5 cm to 25 cm, respectively. Regarding the perturbed pose parameters as the outputs of the inaccurate calibration or global registration, the IKCP algorithm for pose refinement [
26] was applied to reduce the registration error. To simulate a practical use case of the proposed method, the output pose parameters of the local pose refinement algorithm and the noisy depth images were used as input in this section, unless otherwise mentioned. The registration method of merging noisy point clouds with the estimated pose parameters is referred to as
initial.
The accuracy was measured by computing the RMSE between a filtered source point cloud and its corresponding ground-truth source point cloud:
where
s, ranging from 0 to
L, is the index of the source point cloud.
and
are the ground-truth pose parameters of the
sth view, while
and
are the estimated pose parameters by the local pose refinement algorithm.
is the
ith 3D point from the
sth ground-truth depth image, while
is its corresponding filtered 3D point.
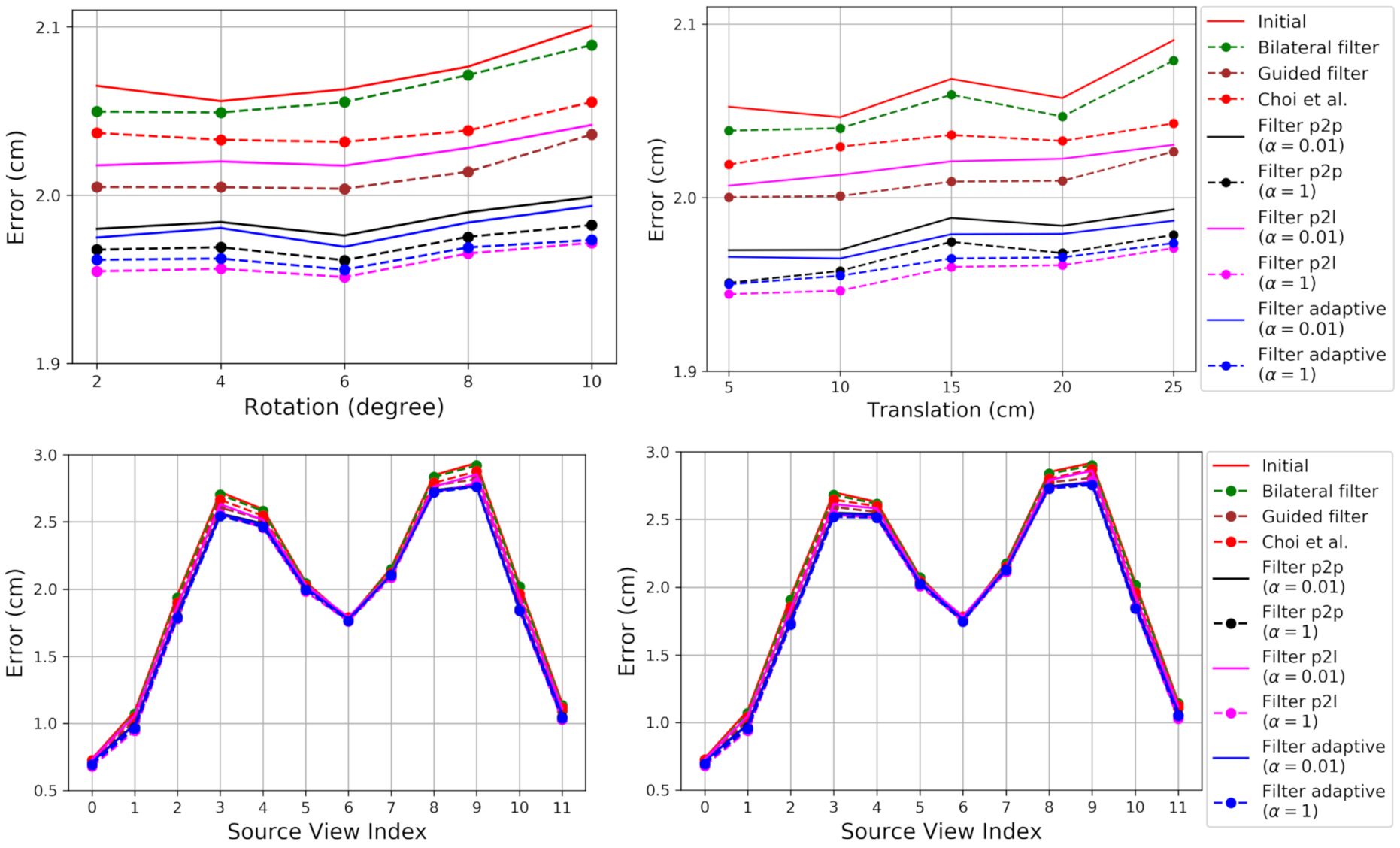
Figure 3 shows the RMSE. The proposed method and its variants consistently result in lower errors than the existing methods [
26,
28,
39], except for
Filter p2l with
. One of the differences of the proposed
Filters from the method of Choi et al. is the closest points within source point clouds, which are used for intra-point-cloud filtering. The reduced noise by the intra-point-cloud filtering is one of the contributions to the reduced RMSE.
Figure 3 shows that the proposed method is more effective for the views with more noise, showing larger performance gaps from
Initial.
The RMSE with is consistently lower than with . A large denotes more intra-point-cloud filtering and relatively less inter-point-cloud filtering. The intra-point-cloud filtering is not affected by the error in the estimated pose. Thus, a large can provide better results in the presence of a pose error.
If the multiview system has been calibrated accurately, one can expect low pose error. To compare the performances in the absence of pose errors, we applied the methods to the point clouds in their ground-truth poses.
Figure 4 shows the results.
Filter p2p and
Filter adaptive show consistent results, irrespective of the choice of
. It is interesting to notice that
Filter p2l with
provides better results than
Guided filter. We conjecture that this is due to the fact that the inter-point-cloud closest points are now more accurate neighbors for filtering. However,
Filter p2l still shows worse results with
than with
.
Filter p2l suffers from the instability problem addressed in this paper. A source point and its intra-point-cloud closest points tend to have similar ray directions and surface-normal directions. An RGB-D camera cannot measure the depth of a surface whose normal direction is orthogonal to its ray direction, so the normal directions are difficult to make orthogonal to the ray directions as long as the depth measurements exist. Thus, the stability of Equation (
13) for
Filter p2l increases with
, reducing the RMSE.
Figure 5 shows merged point clouds obtained by different depth refinement methods. The results were obtained from the inputs with 25 cm perturbation levels. The qualitative results are consistent with the quantitative results in
Figure 3.
Filters with
show the best results with greatly reduced noise.
Filter p2l with
shows the worst result among
Filters.
The running time of the proposed Algorithm 1 is reported in
Table 1. The running time was measured on a computer running Ubuntu 18.01 with an AMD Ryzen Threadripper 1920X 12-core processor and 128 GB of RAM. In
Table 1, all the algorithms are based on our unoptimized Python implementation. Therefore, the running times are appropriate only for relative comparison. Among the
Filters,
Filter p2p is the most efficient and
Filter adaptive is the most demanding. As
Filter adaptive computes two different kinds of projection matrices, it requires more computation time. The intra-point-cloud closest point search can be conducted only once, assuming that they do not change in the whole process. This assumption can reduce the computation time. However, our current implementation does not rely on the assumption. The running times of
Bilateral filter and
Guided filter are approximately half of that of
Filter p2p. This is mainly due to the fact that the proposed method conducts the
KD tree search once more for each filtering.
4.2. Results on the Real-World Dataset
In this section, we describe the application of the proposed method to the real-world dataset [
26]. The dataset is composed of eight RGB-D images, as shown in
Figure 6. The dataset was captured under accurate calibration, and the extrinsic parameters were further refined by the local pose refinement method [
26]. Thus, we can expect that the error in the estimated pose will be less than that of the synthetic dataset. Since the dataset was not captured with accurate laser scanners, an exact quantitative evaluation is not available.
Figure 7 shows merged point clouds obtained using different depth refinement methods. The best method for the results is subjective. If we focus on the stripe patterns on the back,
Filter p2l with
and Choi et al. [
26] show the best results.
Filters with
do not improve the stripe pattern of
Initial as much as those with
. The visual quality of a merged point cloud highly relies on the distance between similarly colored points across point clouds. The small
increases the effect of the inter-point-cloud filtering, so the inter-point-cloud distance is reduced. In addition, with the accurate pose parameters,
provides quantitatively equivalent results to
, except for
Filter p2l, as shown in
Figure 4.
In contrast, if we focus on the artifacts near the outer thighs,
Filter p2l with
shows the worst result. The errors caused by the numerical instability are reduced by increasing
, as discussed in
Section 4.1. However, neither the postprocessing method of Choi et al. [
26] nor the intra-point-cloud filtering of
Filter p2l completely removes the errors. In contrast,
Filter adaptive suffers less from the outer thigh errors than
Filter p2l, showing the effectiveness of the adaptive combination of the projected distances.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}