
Infrastructure as Software in Micro Clouds at the Edge



Abstract
:1. Introduction
- Simplify the deployment of geo-distributed infrastructure, allowing dynamical formation and management of disposable μCs, closer to the users.
- The possibility for application developers to venture into the “infrastructure programming”, allowing infrastructure to be managed in a similar way as the software is.
- Build numerous μCs designed for failure using automated tools where no μCs are irreplaceable—“treating μCs as cattle, not pets”.
2. Related Work
2.1. Infrastructure Management
2.2. Nodes Organization at the Edge
2.3. Advanced Infrastructure Tools
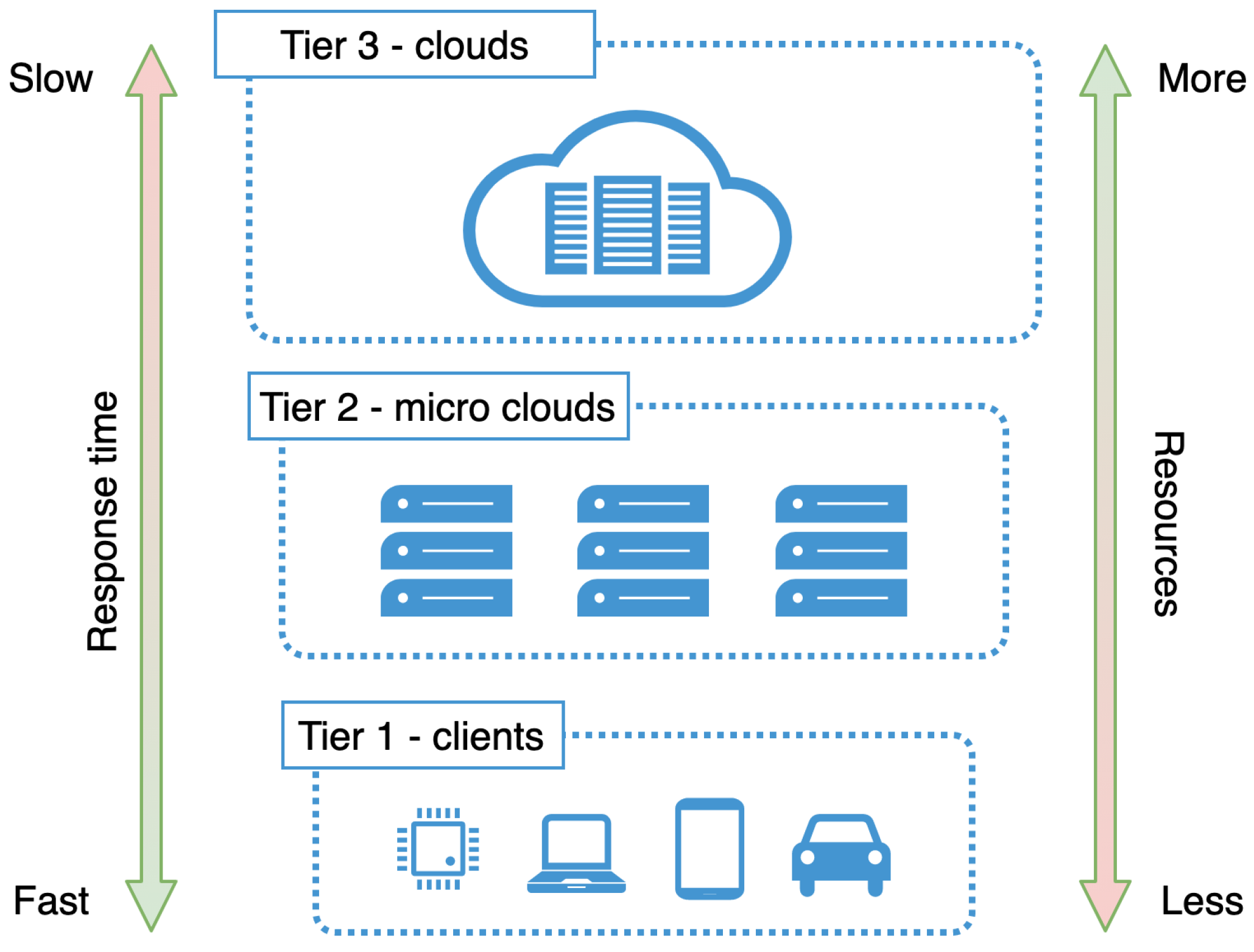
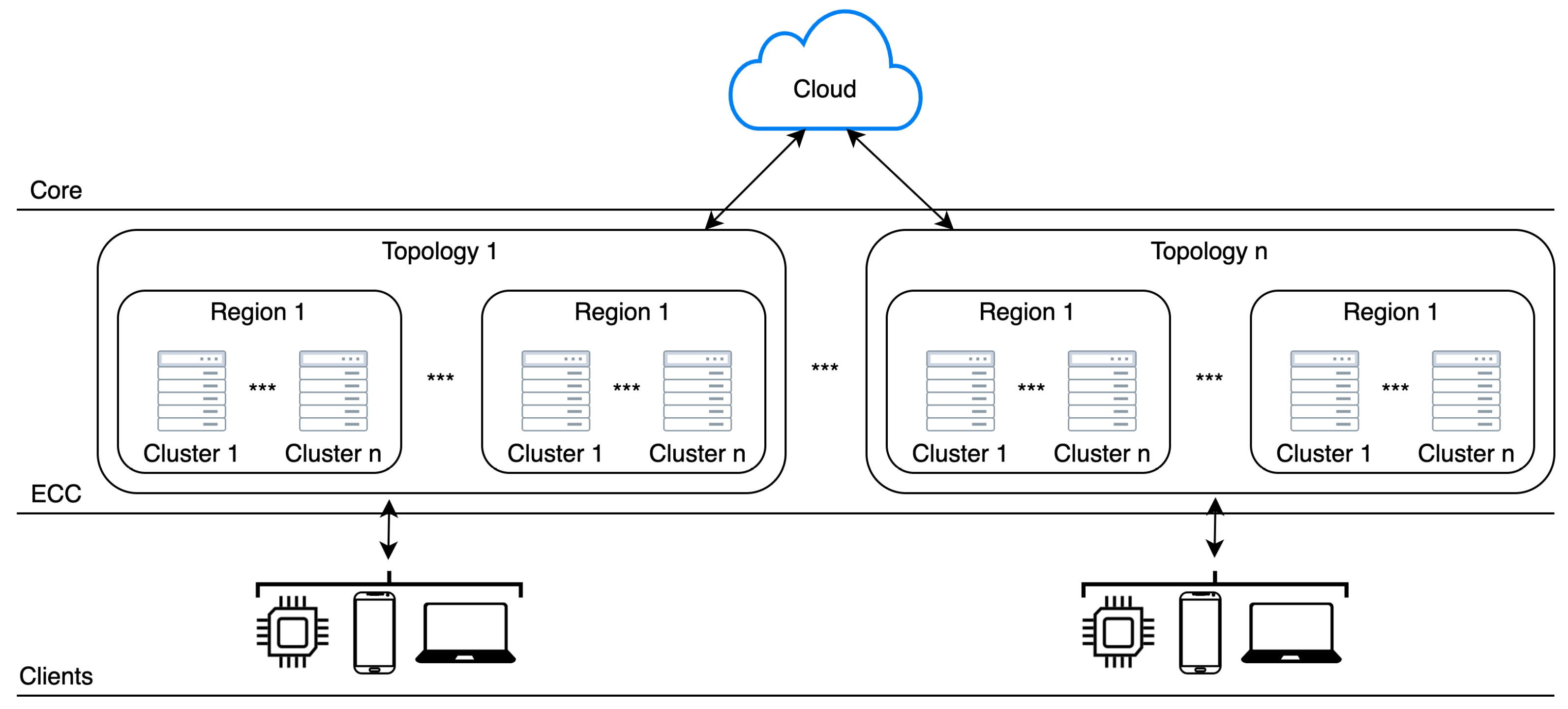
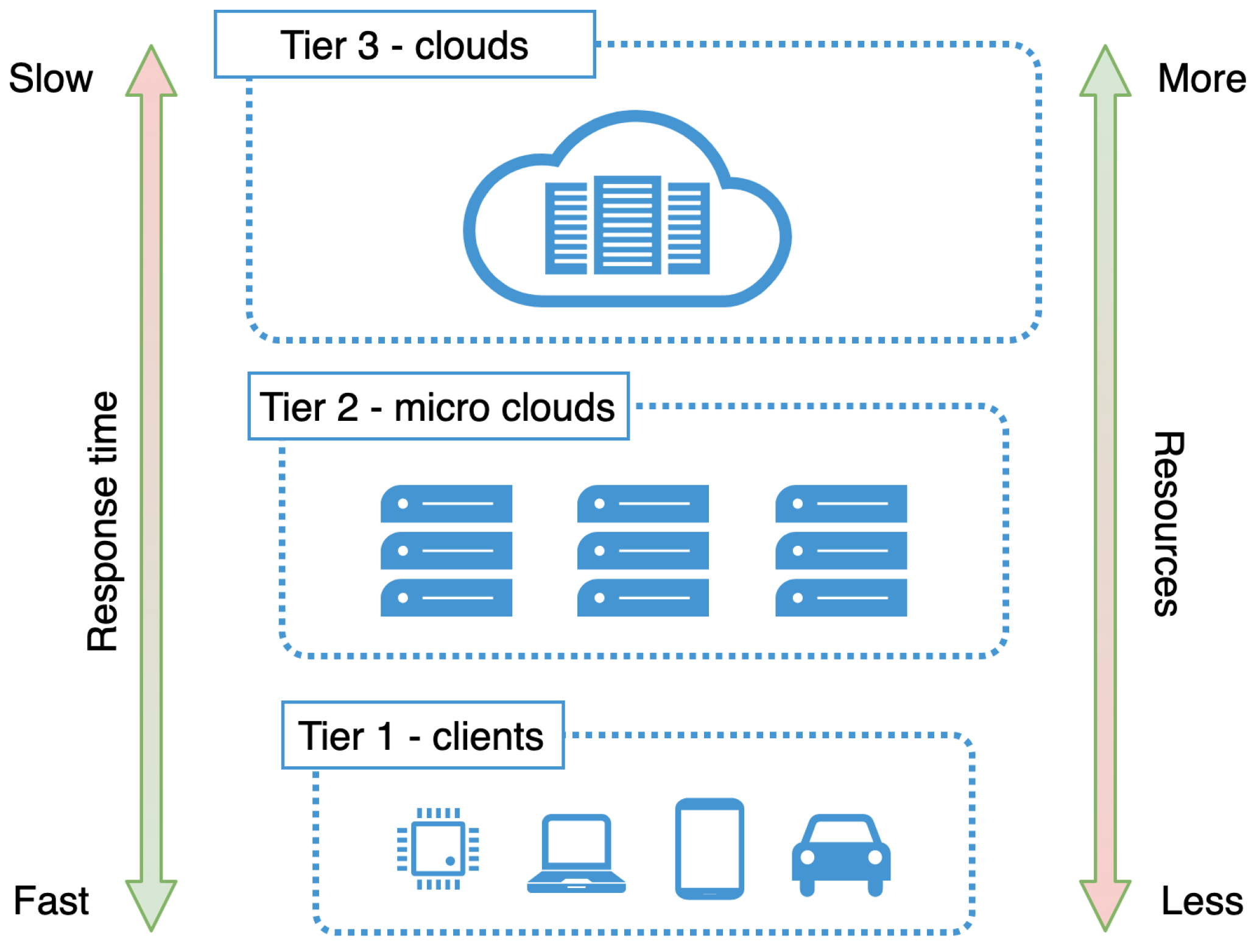
3. Micro Clouds at the Edge
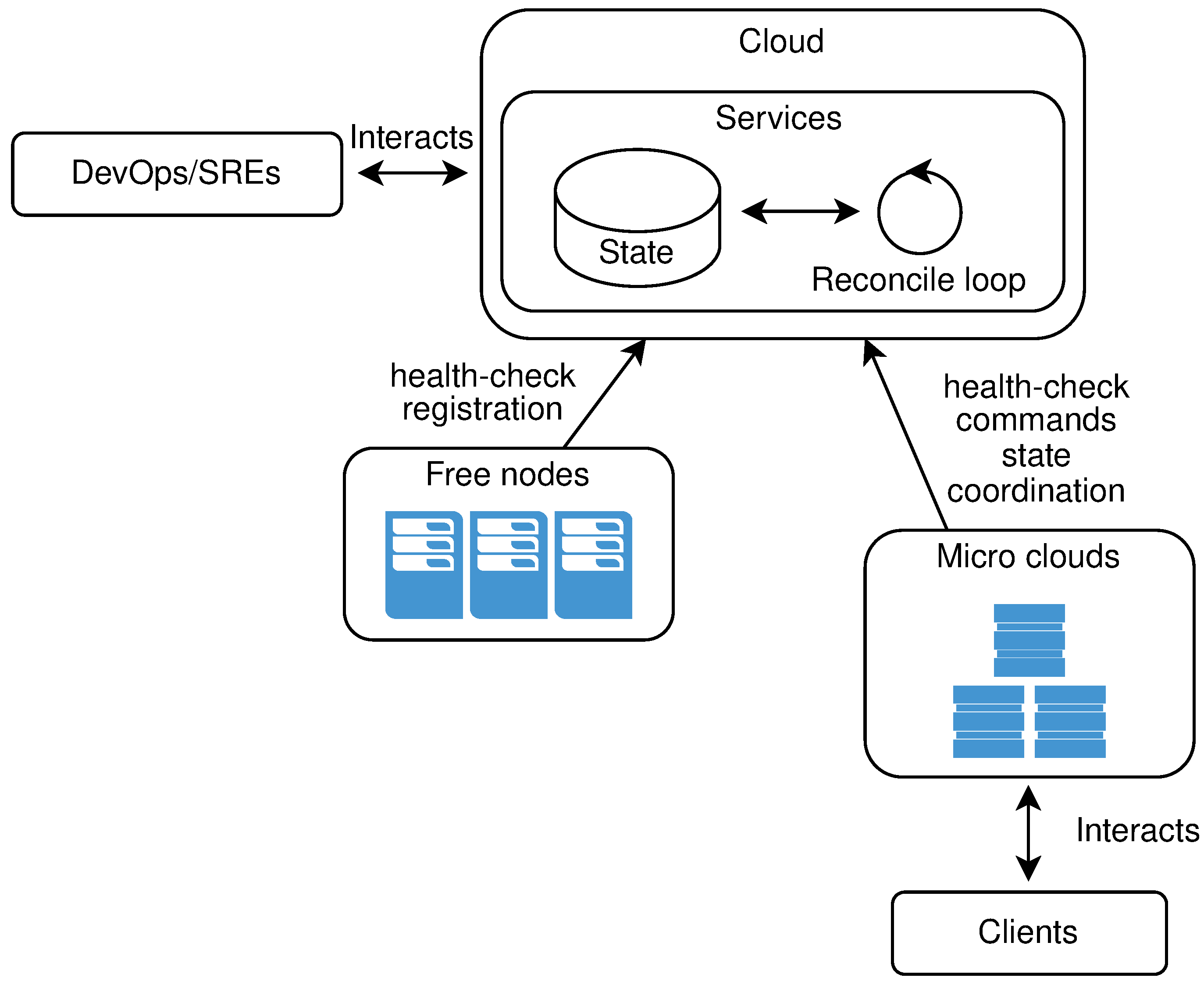
3.1. High Level Micro Cloud Infrastructure
3.2. Conceptual Model of Micro Clouds
- a node must run an operating system with a usable file system;
- a node must be able to run some isolation engine for applications, for example, containers or unikernels [38];
- a node must have available resources for utilization so that applications can be run or data stored;
- a node must have internet connection;
- a node must provide a list of attributes in the form of a list of key-value pairs—labels.
- Application resources like CPUs, GPUs, storage, network quotas, etc. if the user is submitting a new application into the cluster. For this type of task, virtualization will simplify resource management, and it will allow running applications over heterogeneous infrastructures;
- Infrastructure resources, if a user is creating a new clustered infrastructure. For this type of task, the user must specify what nodes are desired to be part of that cluster. Users can create dedicated clusters (e.g., processing, storage, etc.), or create clusters that can accept various types of tasks. Depending on the cluster type, nodes with different resources (e.g., CPUs, GPUs, storage, network. etc) can be targeted, forming a pool of available resources. This can be done by using some desired selector values that every node can have attached in the form of key-value pairs;
- Various configurations, The same system could be used for various configurations of nodes and clusters remotely. The model is easy to extend by just adding the new worker that will do a specific task when that kind of file is submitted to the system.
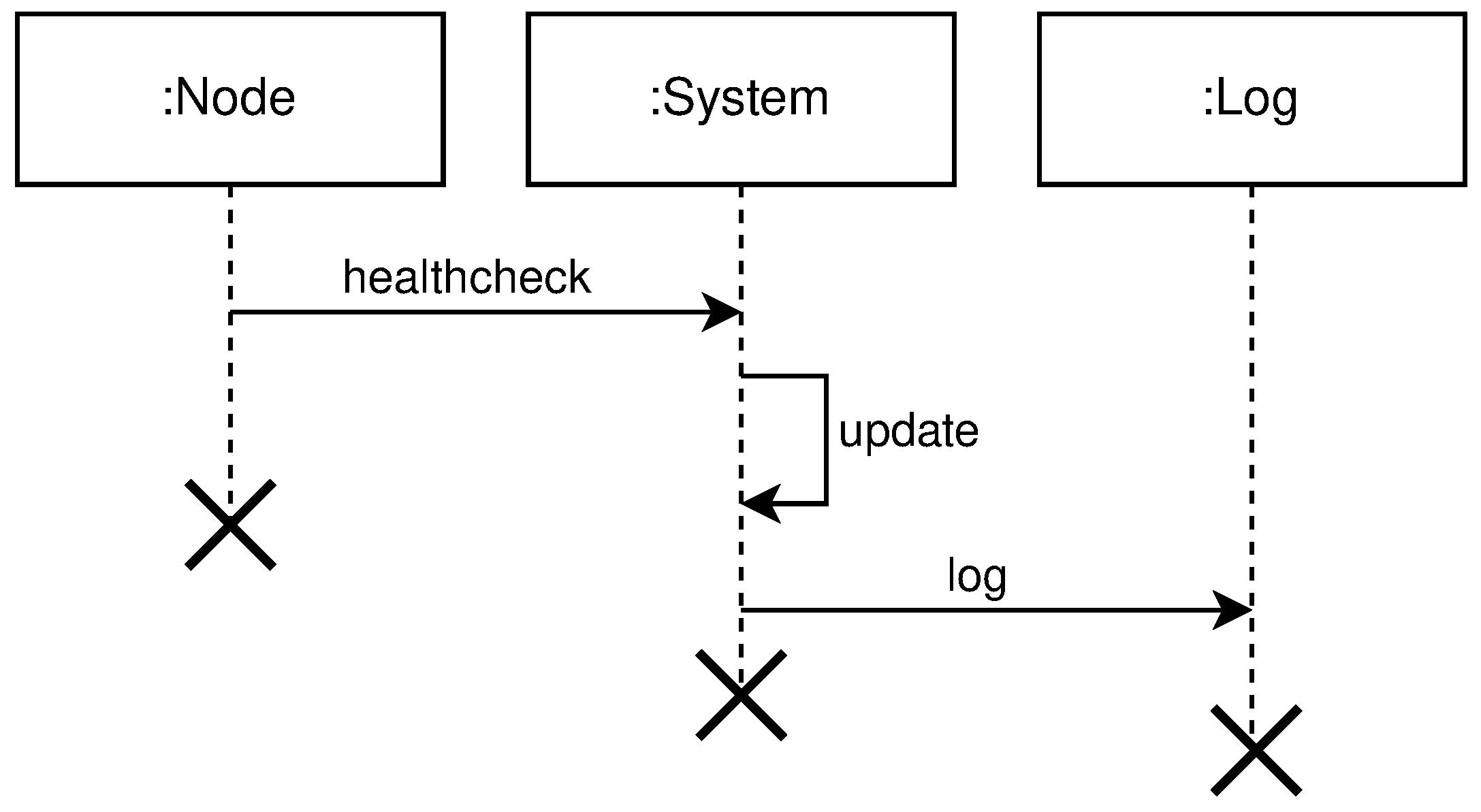
- query free nodes for the purpose to create clusters, regions, and topologies. This operation involves the following entities: User, System, and Log. The user submits a selector that is a list of key-value pairs to the system. These values represent desired properties of the nodes the user is searching for. After receiving the selector list, the system will query its local register to compare selector with labels for every registered node in the system not used in some cluster—free nodes. The system will log all interactions with the user. Figure 6 shows the high level communication for query operation;
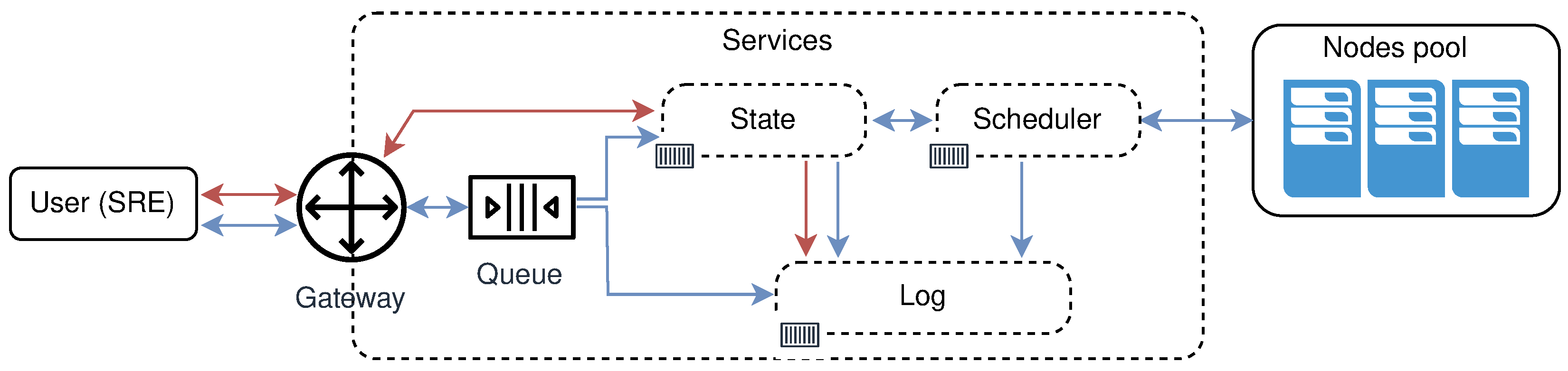
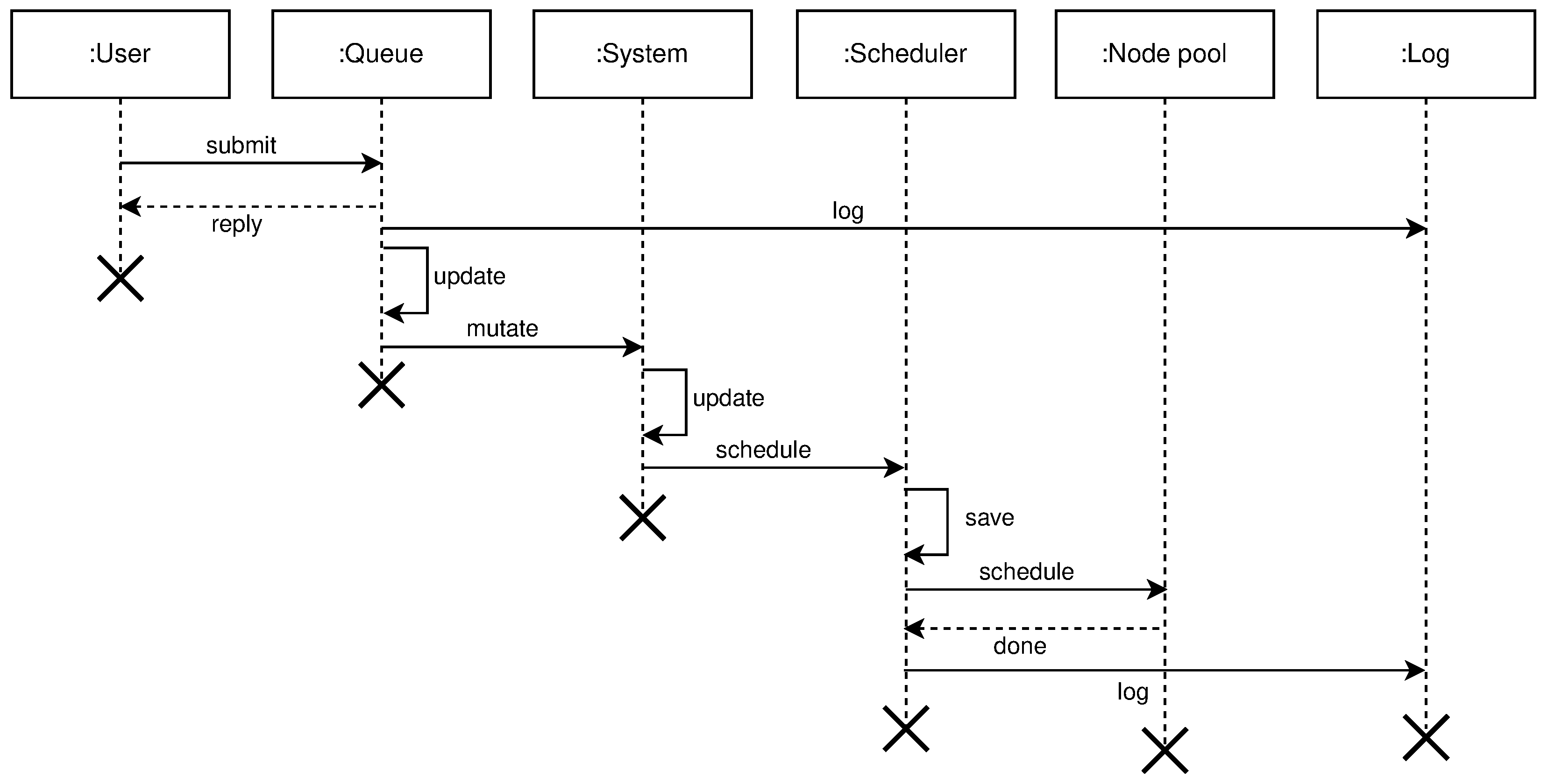
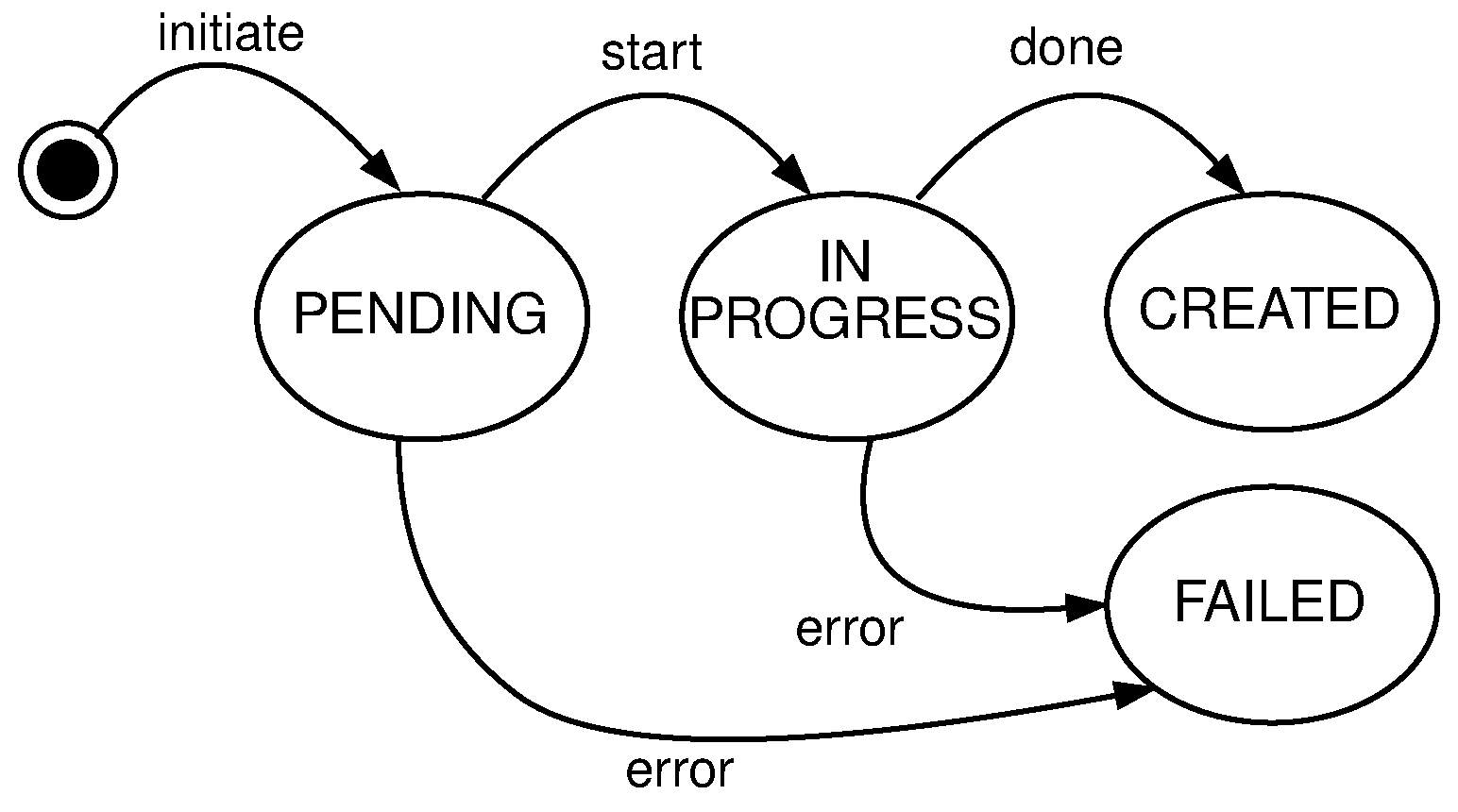
- mutate or creation of new clusters, regions, and topologies from the existing pool of free nodes (resources). Mutate operation requires following entities: User, Queue, System, Scheduler, Node Pool, and Log. The user submits a description file containing an infrastructure set up—a new infrastructure configuration. The queue accepts this new state and replies with an acceptance message to the user. The queue is drained at some configurable time t, to prevent overflow of the system, and it sends the mutate message to the system. The system accepts the mutate message, reserves nodes, and creates a new infrastructure configuration. When data is successfully stored, the system will schedule a new execution task, a new infrastructure to be physically set up. The scheduler executes the task and informs the node pool that needs to be part of the same cluster to start the membership protocol. When the membership protocol is done, the message is sent to both scheduler and the system. The system receives the health-check messages and properties of the cluster. The scheduler receives the done message, to signal that the scheduled task is done. Figure 7 shows the high level communication for mutate operation;When a user submits the cluster formation message, the system will accept the message and register the task with PENDING state. If the system cannot proceed further, for whatever reason (e.g., no available resources or nodes, etc.) the task is finished, and it goes to FAILED state, and this concludes the transaction. Otherwise, if there are no errors, and the system can proceed with the cluster formation protocol, the task will go to IN PROGRESS state.In this state, the system needs to save newly formed cluster information, prepare metrics service, add watchers for the cluster nodes health-check, etc. This operation spans multiple services, creating sub-transactions. The task state will prevent the users from applying other tasks, configurations, and actions on a not yet formed cluster. We can always invoke the rollback mechanism if any error happens during this process. Other options would be to try to fix the occurred issue with some of the retry strategies.If there are no errors, the cluster formation transaction finishes, changing the task state to CREATED. If there are errors during this process, the cluster formation transaction ends without creating the cluster. The task will go again to FAILED state, and this concludes the transaction. Figure 8 shows state diagram changes for the newly submitted task.
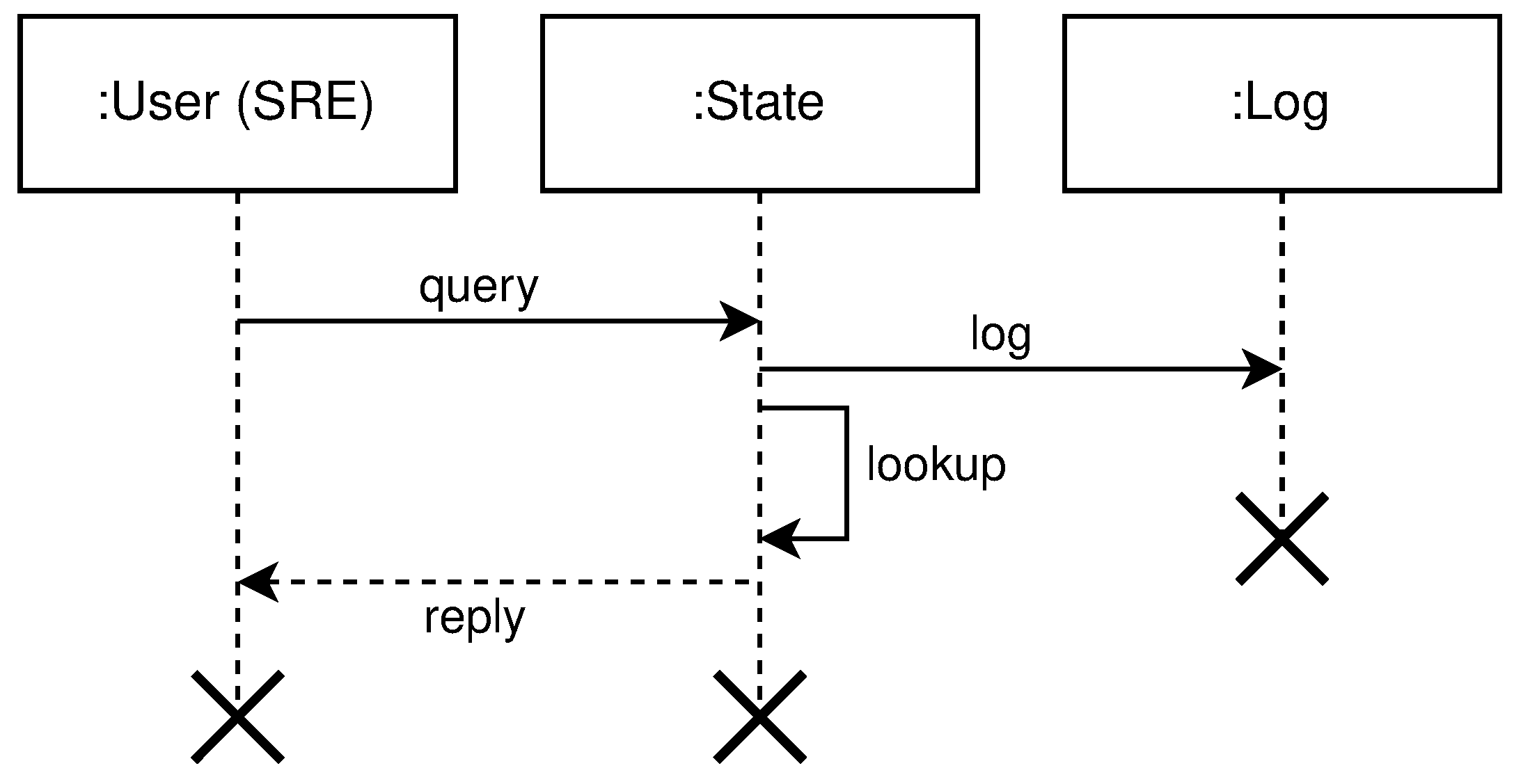
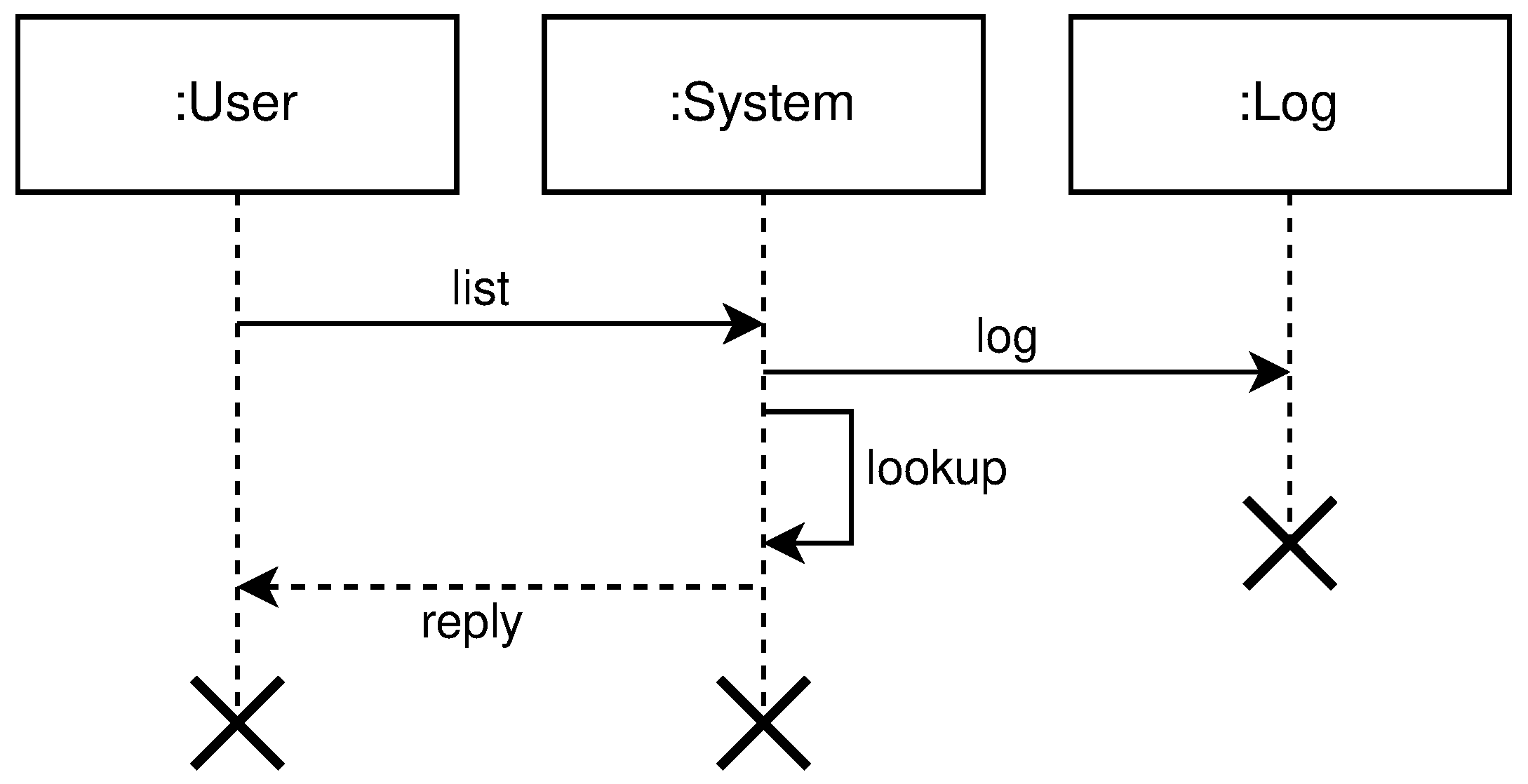
- list shows details about various parameters (e.g., nodes in clusters, regions, topologies, resource utilization, running applications, etc.). The entities involved in list operation are: User, System, and Log. The user submits what cluster/region/topology he wants details. The system will do a lookup on its state based on the query provided by the user. If such a record exists, it will show details about it (e.g., number of nodes per cluster, clusters per region, regions per topology, utilization, running applications, logs, etc.). All user interactions with the system will be logged. Figure 9 shows the high level communication for list operation;
3.3. User Data in Micro Clouds
- when a user moves to another place (e.g., from city to city, country to country), does the user data follow the user somehow, or should it be stationary? The decision should be on developers, users, and μC providers to decide—it depends on the service and type of data. The model anticipates different policies applied to the μC for every individual user or group of users—data plan. For example, if a user goes to another location and requests are served from another μC, the model can use a traditional cloud to locate the requested data. We can transfer requested data to the μC that is serving that request. The process is similar to the content delivery networks on the edge [23]. To minimize the network pressure, transfers should be only the requested data. An alternative option would be to use the traditional cloud as a backbone to serve user data if he moves to another location.
- how long should the user data be present in the μC, assuming that μCs need to serve many users, and they have limited resources. The model we propose relies on different policies applied to the user’s data. Depending on where the size of the μC lies in the specter given by Equation (1), μC providers and developers may offer different policies—time to live (TTL) [40] how long to store the data similar to the leases mechanism in cache systems [41].
4. Deployment Properties
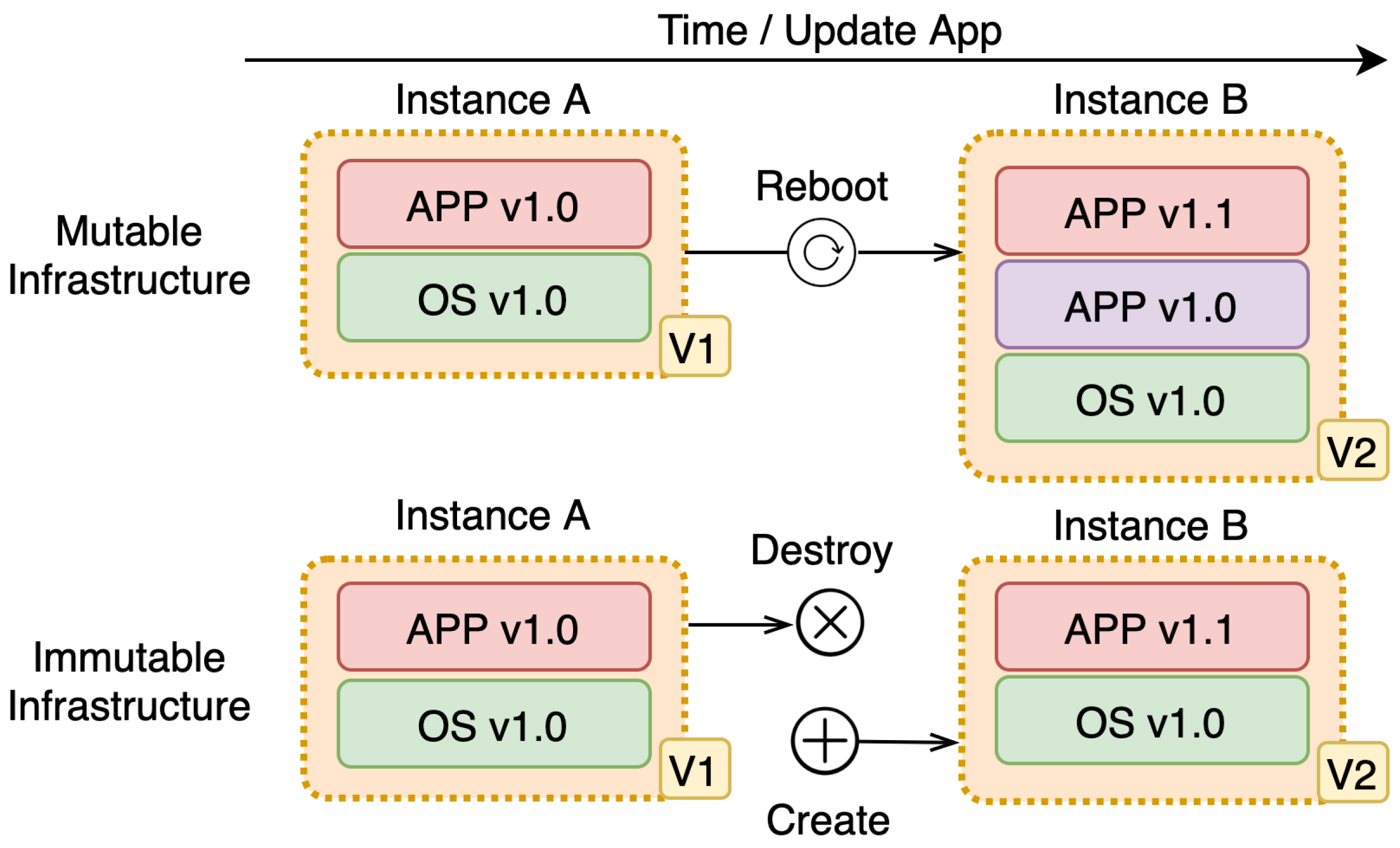
4.1. Deployment Models
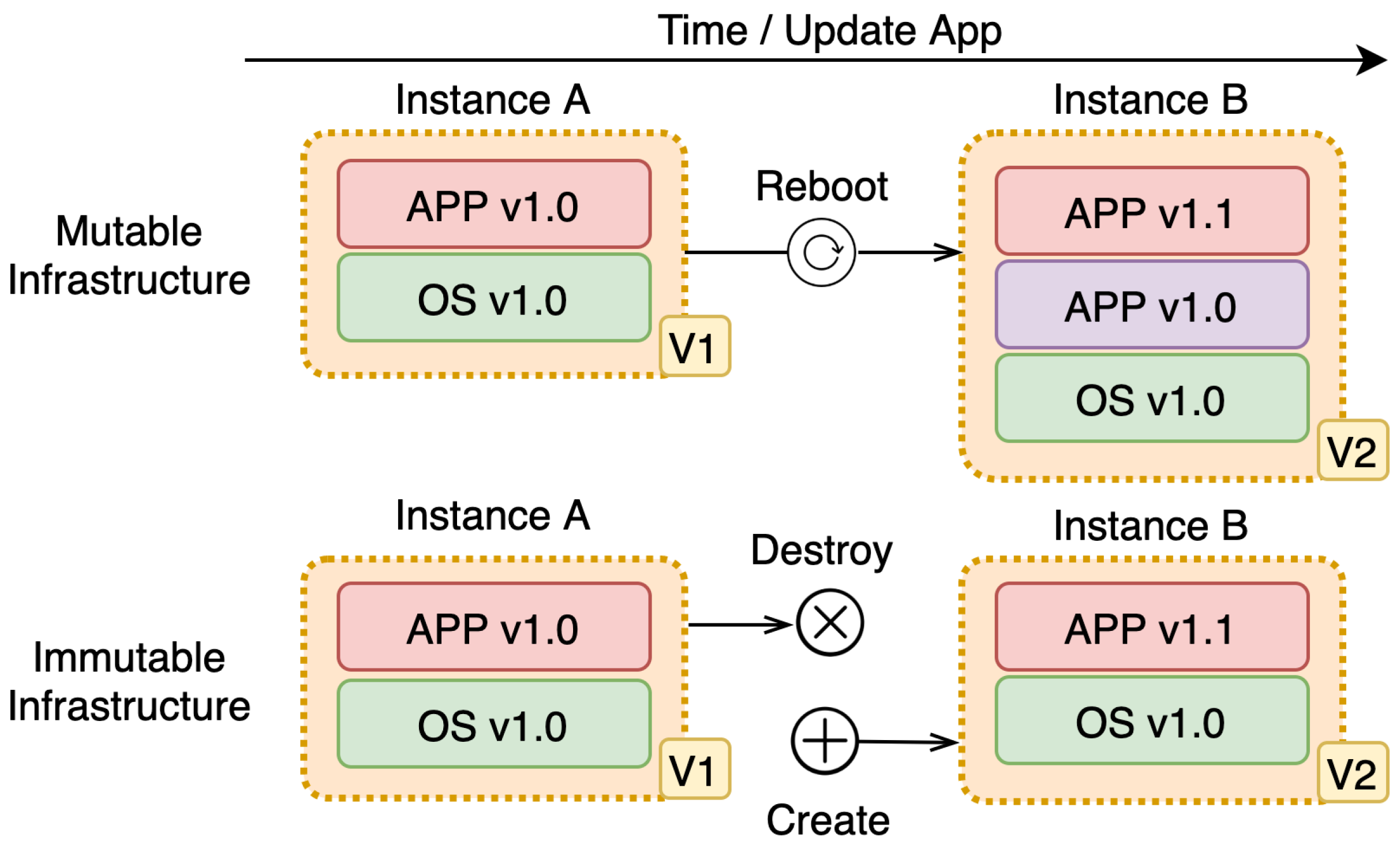
- A mutable deployment model is a model where changes are in place. In place, change means the existing infrastructure or applications get updated or changed during an update. This strategy is prone to leaving the system in an inconsistent state due to:
- −
- increased risk, because in-place change may not finish, which puts infrastructure or the application in a possible bad state. This is especially a problem if there are a lot of services and multiple copies of the same service because the same request may produce a different outcome. The possibility that the system is not available is a lot higher;
- −
- high complexity, this is a direct implication of the previous feature. Since the change might not get fully done, it cannot be guaranteed that the infrastructure or application is transitioned from one version to another — change is not discrete, but continues since we might end up in some state in between where we are now and where we want to be.
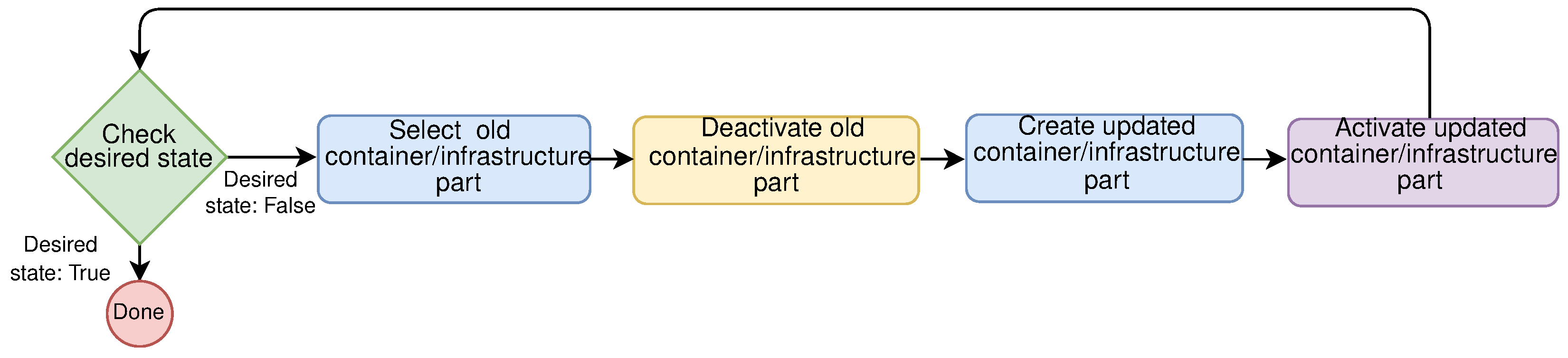
- An immutable deployment model is a model where no in-place changes on existing infrastructure or application are done whatsoever. In this model, the previous version is replaced completely with a new version that is updated or changed compared to the previous version. The previous version gets discarded in favor of the new version. When compared to the previous model, immutable deployment model:
- −
- has less risk, since the existing infrastructure or the application is not changed, but a new one is started and the previous one is shut down. This is important especially in distributed systems (DS) where everything can fail at any time;
- −
- has less complexity than the mutable deployment model. This is a direct implication of the previous feature since the previous version is shut down and fully replaced with the new one. This is a discrete version change and atomic deployment with deferring deployments with fast rollback and recovery processes;
- −
- requires more resources [43], since both versions must be present on the node for this process to be done. The second problem is the data that the application has generated should not be lost. The problem is solved by externalizing the data. We should not rely on local storage but store that data elsewhere, especially when the parts of the system are volatile and changed often. The key advantage of this approach is avoiding downtime experienced by the end-user when new features are released.
- Blue-Green deployment, this strategy requires two separate environments: (1) Blue current running version, and (2) Green is the new version that needs to be deployed. When there is satisfaction that the green version is working properly, the traffic can be gradually rerouted from the old environment to the new one, for example by modifying the Domain Name System (DNS). This strategy offers near-zero downtime;
- A canary update is a strategy where a small subset of requests is directed to the new version—the canary, and the rest of them are directed to an old version. If the change is satisfactory, the number of requests can be increased, and it should be monitored how the service is working with increasing load, if there are errors, etc.;
- Rolling update strategy updates large environments, a few nodes at the time. The setup is similar to blue-green deployment, but here there is a single environment. With this strategy, the new version gradually replaces the old one. If for whatever reason the new version is not working properly on the larger number of nodes, rolling back to the previous version can always be done.
4.2. Deployment Roles
- Site Reliability Engineers (SREs) are responsible for availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning [50]. It is a software engineering role and needs to have an understanding of the fundamentals of computing [51], applied to the infrastructure and operations problems.
4.3. Proof of Concept
5. Proposed Model Case Study
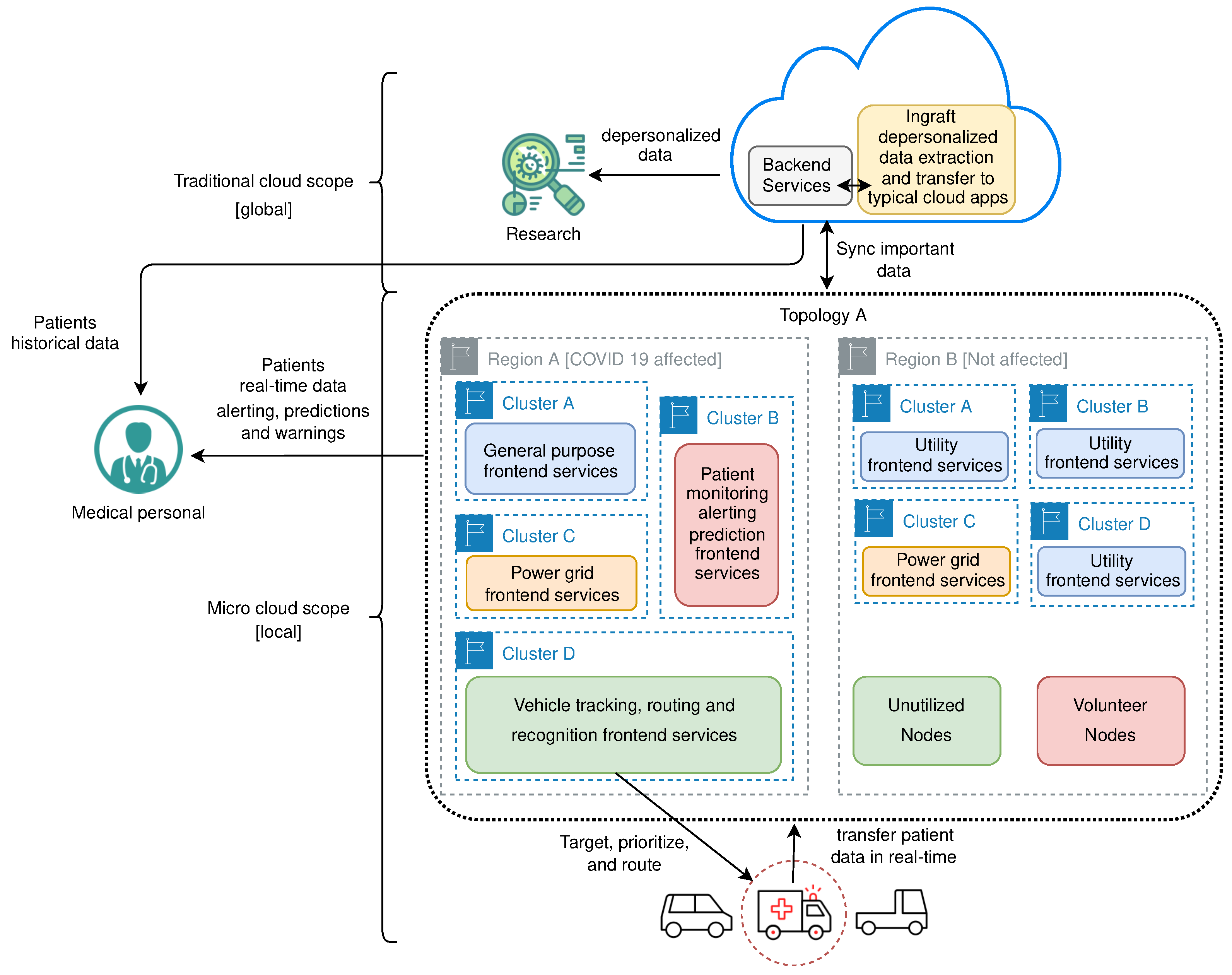
5.1. COVID-19 Area Traffic Control
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DS | Distributed systems |
| CC | Cloud computing |
| ECC | Edge-centric computing |
| IaC | Infrastructure as code |
| IaS | Infrastructure as software |
| IoT | Internet of things |
| DC | Data center |
| DNS | Domain Name System |
| DSL | Domain-specific language |
| SRE | Site Reliability Engineer |
| VM | Virtual machine |
| OS | Operating system |
| μDC | Micro data center |
| μC | Micro cloud |
| μCc | Micro cloud cluster |
| IaaS | Infrastructure as a service |
References
- Ronan-Alexandre, C.; Marie, D.; Adrien, L. Geo-Distribute Cloud Applications at the Edge. In EURO-PAR 2021—27th International European Conference on Parallel and Distributed Computing; HAL-Inria: Lisbon, Portugal, 2021; pp. 1–14. [Google Scholar]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Jha, D.N.; Ranjan, R. Osmosis: The Osmotic Computing Platform for Microelements in the Cloud, Edge, and Internet of Things. Computer 2019, 52, 14–26. [Google Scholar] [CrossRef]
- Elliot, S. DevOps and the Cost of Downtime: Fortune 1000 Best Practice Metrics Quantified. Technical Report. Available online: https://kapost-files-prod.s3.amazonaws.com/published/54ef73ef2592468e25000438/idc-devops-and-the-cost-of-downtime-fortune-1000-best-practice-metrics-quantified.pdf (accessed on 25 August 2021).
- Preimesberger, C. Unplanned IT Downtime Can Cost 5K USD Per Minute. Technical Report. Available online: https://www.eweek.com/networking/unplanned-it-downtime-can-cost-5k-per-minute-report/ (accessed on 25 August 2021).
- Phelps, D.; Milne, K. Leveraging IT Controls to Improve IT Operating Performance; Technical Report; The Institute of Internal Auditors Research Foundation: Lake Mary, FL, USA, 2008. [Google Scholar]
- Forrester Research Inc. Safeguard Business Reliability with an Intelligent Incident Resolution Strategy. Technical Report. Available online: https://www.chef.io/docs/default-source/legacy/the-forrester-wave-configuration-management-software-for-infrastructure-automation-2017.pdf (accessed on 28 June 2021).
- Brian, F.; Nicole, F.; Klaas-Jan, S.; Jez, H.; Brian, D. Infrastructure Is Software Too! SSRN Electron. J. 2015. [Google Scholar] [CrossRef]
- Leon, O. Software Processes Are Software Too, Revisited: An Invited Talk on the Most Influential Paper of ICSE 9. In Proceedings of the 19th International Conference on Software Engineering; ICSE ’97; Association for Computing Machinery: New York, NY, USA, 1997; pp. 540–548. [Google Scholar] [CrossRef] [Green Version]
- Torkura, K.A.; Sukmana, M.I.H.; Cheng, F.; Meinel, C. Continuous auditing and threat detection in multi-cloud infrastructure. Comput. Secur. 2021, 102, 102124. [Google Scholar] [CrossRef]
- Forsgren, N.; Humble, J.; Kim, G. Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations; IT Revolution Press: Portland, OR, USA, 2018. [Google Scholar]
- Lwakatare, L.E.; Kuvaja, P.; Oivo, M. Dimensions of DevOps. In Proceedings of the Agile Processes, in Software Engineering, and Extreme Programming—16th International Conference, Helsinki, Finland, 25–29 May 2015; Lassenius, C., Dingsøyr, T., Paasivaara, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 212, pp. 212–217. [Google Scholar] [CrossRef]
- Ryden, M.; Oh, K.; Chandra, A.; Weissman, J.B. Nebula: Distributed Edge Cloud for Data Intensive Computing. In Proceedings of the 2014 IEEE International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 57–66. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A. Augmenting computing capabilities at the edge by jointly exploiting mobile devices: A survey. Future Gener. Comput. Syst. 2018, 88, 644–662. [Google Scholar] [CrossRef]
- Satyanarayanan, M. The Emergence of Edge Computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Jararweh, Y.; Doulat, A.; AlQudah, O.; Ahmed, E.; Al-Ayyoub, M.; Benkhelifa, E. The future of mobile cloud computing: Integrating cloudlets and Mobile Edge Computing. In Proceedings of the 23rd International Conference on Telecommunications, ICT 2016, Thessaloniki, Greece, 16–18 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Satyanarayanan, M.; Bahl, P.; Cáceres, R.; Davies, N. The Case for VM-Based Cloudlets in Mobile Computing. IEEE Pervasive Comput. 2009, 8, 14–23. [Google Scholar] [CrossRef]
- Rahman, A.; Mahdavi-Hezaveh, R.; Williams, L.A. A systematic mapping study of infrastructure as code research. Inf. Softw. Technol. 2019, 108, 65–77. [Google Scholar] [CrossRef]
- Andrade, P.; Tim, B.; Eldik, J.; Gavin, M.; Panzer-Steindel, B.; Santos, M.; Schwickerath, U. Review of CERN Data Centre Infrastructure. J. Phys. Conf. Ser. 2012, 396, 042002. [Google Scholar] [CrossRef] [Green Version]
- Miloš, S.; Ivan, P.; Jovana, D.; Goran, S.; Branko, M. Towards Edge Computing as a Service: Dynamic Formation of the Micro Data-Centers. IEEE Access 2021, 9, 114468–114484. [Google Scholar] [CrossRef]
- Wurster, M.; Breitenbücher, U.; Falkenthal, M.; Krieger, C.; Leymann, F.; Saatkamp, K.; Soldani, J. The essential deployment metamodel: A systematic review of deploymentautomation technologies. SICS Softw.-Intensive Cyber Phys. Syst. 2020, 35, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Greenberg, A.G.; Hamilton, J.R.; Maltz, D.A.; Patel, P. The cost of a cloud: Research problems in data center networks. Comput. Commun. Rev. 2009, 39, 68–73. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Kurniawan, I.; Febiansyah, H.; Kwon, J. Cost-Effective Content Delivery Networks Using Clouds and Nano Data Centers; Springer: Berlin/Heidelberg, Germany, 2014; Volume 280, pp. 417–424. [Google Scholar] [CrossRef]
- Forestiero, A.; Mastroianni, C.; Meo, M.; Papuzzo, G.; Sheikhalishahi, M. Hierarchical Approach for Green Workload Management in Distributed Data Centers. In Proceedings of the Euro-Par 2014: Parallel Processing Workshops—Euro-Par 2014 International Workshops, Porto, Portugal, 25–26 August 2014; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8805, pp. 323–334. [Google Scholar] [CrossRef]
- Lèbre, A.; Pastor, J.; Simonet, A.; Desprez, F. Revising OpenStack to Operate Fog/Edge Computing Infrastructures. In Proceedings of the 2017 IEEE International Conference on Cloud Engineering, IC2E 2017, Vancouver, BC, Canada, 4–7 April 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 138–148. [Google Scholar] [CrossRef] [Green Version]
- Vogels, W. A head in the clouds the power of infrastructure as a service. In Proceedings of the 1st Workshop on Cloud Computing and Applications, Stanford, CA, USA, 23 April 2008. [Google Scholar]
- de Souza, F.R.; Miers, C.C.; Fiorese, A.; de Assunção, M.D.; Koslovski, G.P. QVIA-SDN: Towards QoS-Aware Virtual Infrastructure Allocation on SDN-based Clouds. J. Grid Comput. 2019, 17, 447–472. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, J.R. An Architecture for Modular Data Centers. In Proceedings of the CIDR 2007, Third Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 7–10 January 2007; pp. 306–313. Available online: www.cidrdb.org (accessed on 25 August 2021).
- Stoica, I.; Shenker, S. From cloud computing to sky computing. In Proceedings of the HotOS ’21: Workshop on Hot Topics in Operating Systems, Ann Arbor, MI, USA, 1–3 June 2021; Angel, S., Kasikci, B., Kohler, E., Eds.; ACM: New York, NY, USA, 2021; pp. 26–32. [Google Scholar] [CrossRef]
- Artac, M.; Borovsak, T.; Nitto, E.D.; Guerriero, M.; Tamburri, D.A. DevOps: Introducing infrastructure-as-code. In Proceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, 20–28 May 2017; Uchitel, S., Orso, A., Robillard, M.P., Eds.; IEEE Computer Society: Washington, DC, USA, 2017; pp. 497–498. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Q.; Shi, W. Edge Computing: A Primer; Springer Briefs in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Guo, Z.; Fox, G.C.; Zhou, M. Investigation of Data Locality in MapReduce. In Proceedings of the 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGrid 2012, Ottawa, ON, Canada, 13–16 May 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 419–426. [Google Scholar] [CrossRef] [Green Version]
- Tian, X.; Zhu, J.; Xu, T.; Li, Y. Mobility-Included DNN Partition Offloading from Mobile Devices to Edge Clouds. Sensors 2021, 21, 229. [Google Scholar] [CrossRef]
- Cheung, A.; Crooks, N.; Hellerstein, J.M.; Milano, M. New Directions in Cloud Programming. In Proceedings of the 11th Conference on Innovative Data Systems Research, CIDR 2021, Virtual Event, 11–15 January 2021. [Google Scholar]
- Herbst, N.R.; Kounev, S.; Reussner, R.H. Elasticity in Cloud Computing: What It Is, and What It Is Not. In Proceedings of the 10th International Conference on Autonomic Computing, ICAC’13, San Jose, CA, USA, 26–28 June 2013; Kephart, J.O., Pu, C., Zhu, X., Eds.; USENIX Association: Berkeley, CA, USA, 2013; pp. 23–27. [Google Scholar]
- Li, W.; Lemieux, Y.; Gao, J.; Zhao, Z.; Han, Y. Service Mesh: Challenges, State of the Art, and Future Research Opportunities. In Proceedings of the 13th IEEE International Conference on Service-Oriented System Engineering, SOSE 2019, San Francisco, CA, USA, 4–9 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Marko, L. Kubernetes in Action; Manning Publications: Shelter Island, NY, USA, 2018. [Google Scholar]
- Chen, S.; Mengchu, Z. Evolving Container to Unikernel for Edge Computing and Applications in Process Industry. Processes 2021, 9, 351. [Google Scholar] [CrossRef]
- Rossi, F.; Cardellini, V.; Presti, F.L.; Nardelli, M. Geo-distributed efficient deployment of containers with Kubernetes. Comput. Commun. 2020, 159, 161–174. [Google Scholar] [CrossRef]
- Cohen, E.; Halperin, E.; Kaplan, H. Performance aspects of distributed caches using TTL-based consistency. Theor. Comput. Sci. 2005, 331, 73–96. [Google Scholar] [CrossRef] [Green Version]
- Gray, C.G.; Cheriton, D.R. Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. In Proceedings of the Twelfth ACM Symposium on Operating System Principles, SOSP 1989, The Wigwam, Litchfield Park, AZ, USA, 3–6 December 1989; Andrews, G.R., Ed.; ACM: New York, NY, USA, 1989; pp. 202–210. [Google Scholar] [CrossRef] [Green Version]
- Mikkelsen, A.; Grønli, T.; Kazman, R. Immutable Infrastructure Calls for Immutable Architecture. In Proceedings of the 52nd Hawaii International Conference on System Sciences, HICSS 2019, Grand Wailea, Maui, HI, USA, 8–11 January 2019; pp. 1–9. [Google Scholar]
- Helland, P. Immutability changes everything. Commun. ACM 2016, 59, 64–70. [Google Scholar] [CrossRef]
- Perry, M. The Art of Immutable Architecture: Theory and Practice of Data Management in Distributed Systems; Apress: New York, NY, USA, 2020. [Google Scholar]
- Wolski, A.; Laiho, K. Rolling Upgrades for Continuous Services. In Proceedings of the Service Availability, First International Service Availability Symposium, ISAS 2004, Munich, Germany, 13–14 May 2004; Malek, M., Reitenspieß, M., Kaiser, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3335, pp. 175–189. [Google Scholar] [CrossRef]
- de Guzmán, P.C.; Gorostiaga, F.; Sánchez, C. i2kit: A Tool for Immutable Infrastructure Deployments based on Lightweight Virtual Machines specialized to run Containers. arXiv 2018, arXiv:1802.10375. [Google Scholar]
- Nicholas, A.; Lipika, D.; Daniel, P. Continuous Automotive Software Updates through Container Image Layers. Electronics 2021, 10, 739. [Google Scholar] [CrossRef]
- Leite, L.A.F.; Rocha, C.; Kon, F.; Milojicic, D.S.; Meirelles, P. A Survey of DevOps Concepts and Challenges. ACM Comput. Surv. 2020, 52, 127:1–127:35. [Google Scholar] [CrossRef] [Green Version]
- Jabbari, R.; Ali, N.B.; Petersen, K.; Tanveer, B. What is DevOps?: A Systematic Mapping Study on Definitions and Practices. In Proceedings of the Scientific Workshop Proceedings of XP2016, Edinburgh, UK, 24 May 2016; ACM: New York, NY, USA, 2016; p. 12. [Google Scholar] [CrossRef]
- Beyer, B.; Jones, C.; Petoff, J.; Murphy, N. Site Reliability Engineering: How Google Runs Production Systems; O’Reilly Media, Incorporated: Sebastopol, CA, USA, 2016. [Google Scholar]
- Jones, C.; Underwood, T.; Nukala, S. Hiring Site Reliability Engineers. 2015. Available online: https://research.google/pubs/pub45302/ (accessed on 25 August 2021).
- Beyer, B.; Murphy, N.R.; Fong-Jones, L.; Underwood, T.; Nolan, L.; Rensin, D.K. How SRE relates to DevOps. 2018. Available online: https://www.oreilly.com/library/view/how-sre-relates/9781492030645/ (accessed on 25 August 2021).
- Davidovic, S. Incident Metrics in SRE; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2021. [Google Scholar]
- Das, A.; Gupta, I.; Motivala, A. SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol. In Proceedings of the 2002 International Conference on Dependable Systems and Networks (DSN 2002), Bethesda, MD, USA, 23–26 June 2002; IEEE Computer Society: Washington, DC, USA, 2002; pp. 303–312. [Google Scholar] [CrossRef]
- Huang, X.; Ansari, N. Content Caching and Distribution at Wireless Mobile Edge. IEEE Trans. Cloud Comput. 2020, 1. [Google Scholar] [CrossRef]
- Baccarelli, E.; Naranjo, P.G.V.; Scarpiniti, M.; Shojafar, M.; Abawajy, J.H. Fog of Everything: Energy-Efficient Networked Computing Architectures, Research Challenges, and a Case Study. IEEE Access 2017, 5, 9882–9910. [Google Scholar] [CrossRef]
- Guo, H.; Rui, L.; Gao, Z. A zone-based content pre-caching strategy in vehicular edge networks. Future Gener. Comput. Syst. 2020, 106, 22–33. [Google Scholar] [CrossRef]
- Jeon, Y.J.; Kang, S.J. Wearable Sleepcare Kit: Analysis and Prevention of Sleep Apnea Symptoms in Real-Time. IEEE Access 2019, 7, 60634–60649. [Google Scholar] [CrossRef]
- Al-Khafajiy, M.; Baker, T.; Chalmers, C.; Asim, M.; Kolivand, H.; Fahim, M.; Waraich, A. Remote health monitoring of elderly through wearable sensors. Multim. Tools Appl. 2019, 78, 24681–24706. [Google Scholar] [CrossRef] [Green Version]
- Chiarini, G.; Ray, P.; Akter, S.; Masella, C.; Ganz, A. mHealth Technologies for Chronic Diseases and Elders: A Systematic Review. IEEE J. Sel. Areas Commun. 2013, 31, 6–18. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute/Cloud Type | Traditional Cloud | Micro Cloud |
|---|---|---|
| Logical | Cloud Provider | Topology |
| Region | ||
| Physical | Region | Cluster |
| Zone |
| Feature | DevOps | SREs |
|---|---|---|
| Task | Scaling, uptime, robustness | Development pipeline |
| Essence | Practices and metrics | Mindset and culture |
| Team structure | Wide range of roles: QA, developers, SREs etc. | SREs with operations and development skills |
| Focus | Development and delivery continuity | System availability and reliability |
| Goal | Bridge the gap between development and operation | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simić, M.; Sladić, G.; Zarić, M.; Markoski, B. Infrastructure as Software in Micro Clouds at the Edge. Sensors 2021, 21, 7001. https://doi.org/10.3390/s21217001
Simić M, Sladić G, Zarić M, Markoski B. Infrastructure as Software in Micro Clouds at the Edge. Sensors. 2021; 21(21):7001. https://doi.org/10.3390/s21217001
Chicago/Turabian StyleSimić, Miloš, Goran Sladić, Miroslav Zarić, and Branko Markoski. 2021. "Infrastructure as Software in Micro Clouds at the Edge" Sensors 21, no. 21: 7001. https://doi.org/10.3390/s21217001
APA StyleSimić, M., Sladić, G., Zarić, M., & Markoski, B. (2021). Infrastructure as Software in Micro Clouds at the Edge. Sensors, 21(21), 7001. https://doi.org/10.3390/s21217001