
A Novel EMG-Based Hand Gesture Recognition Framework Based on Multivariate Variational Mode Decomposition



Abstract
:1. Introduction
2. Related Algorithm
2.1. Relabel
2.2. Multivariate Variational Mode Decomposition
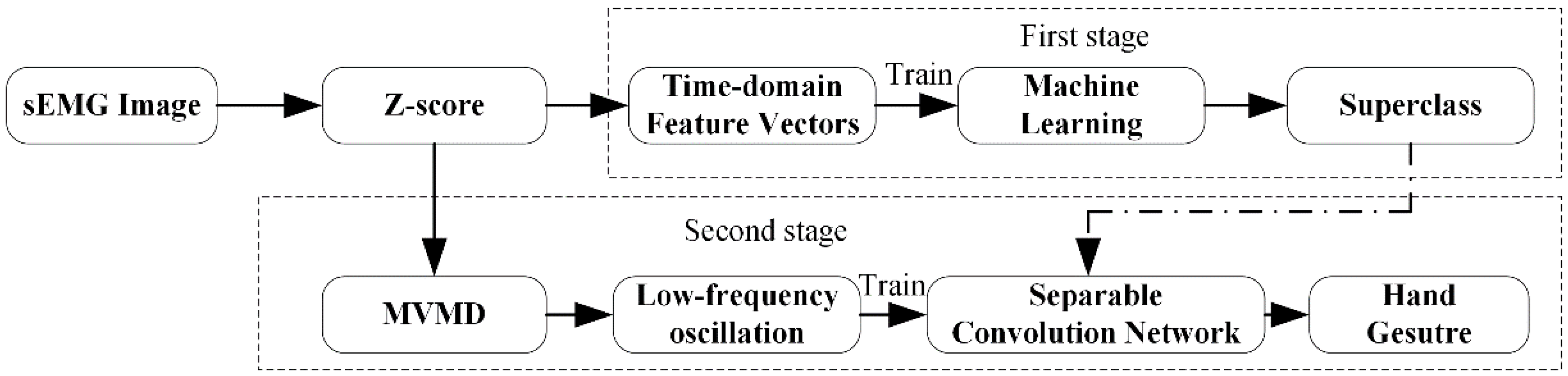
3. Proposed Framework
3.1. The Data Flow in the Proposed Framework
3.2. The Classifier on the First Stage
3.3. The Classifier on the Second Stage
- (i)
- The first step involves depth-wise convolution. Regarding the input data as composed of N channel data, we carried out single-channel convolution and then stacked them together again. This step resizes the data without changing the number of channels. The number of parameters trained is as (k × k × c).
- (ii)
- The second step involves pointwise convolution. The characteristic image obtained by (i) is applied with the standard convolution twice. The convolution kernel size is 1 × 1, and the filter number of convolution kernels is the same as the channel number of the previous layer. The parameters trained can be calculated as 1*1*c*N. In comparison to the standard convolution, the parameter ratio of separable two-dimensional convolution can be reduced. The parameter ratio of separable two-dimensional convolution and standard convolution can be summarized as (11). In this experiment, the total parameters drop about 1/3, which is beneficial in a lightweight and real-time performance.
4. Dataset and Experiment Method
4.1. Dataset Description
4.2. Experiment Method
5. Result and Discussion
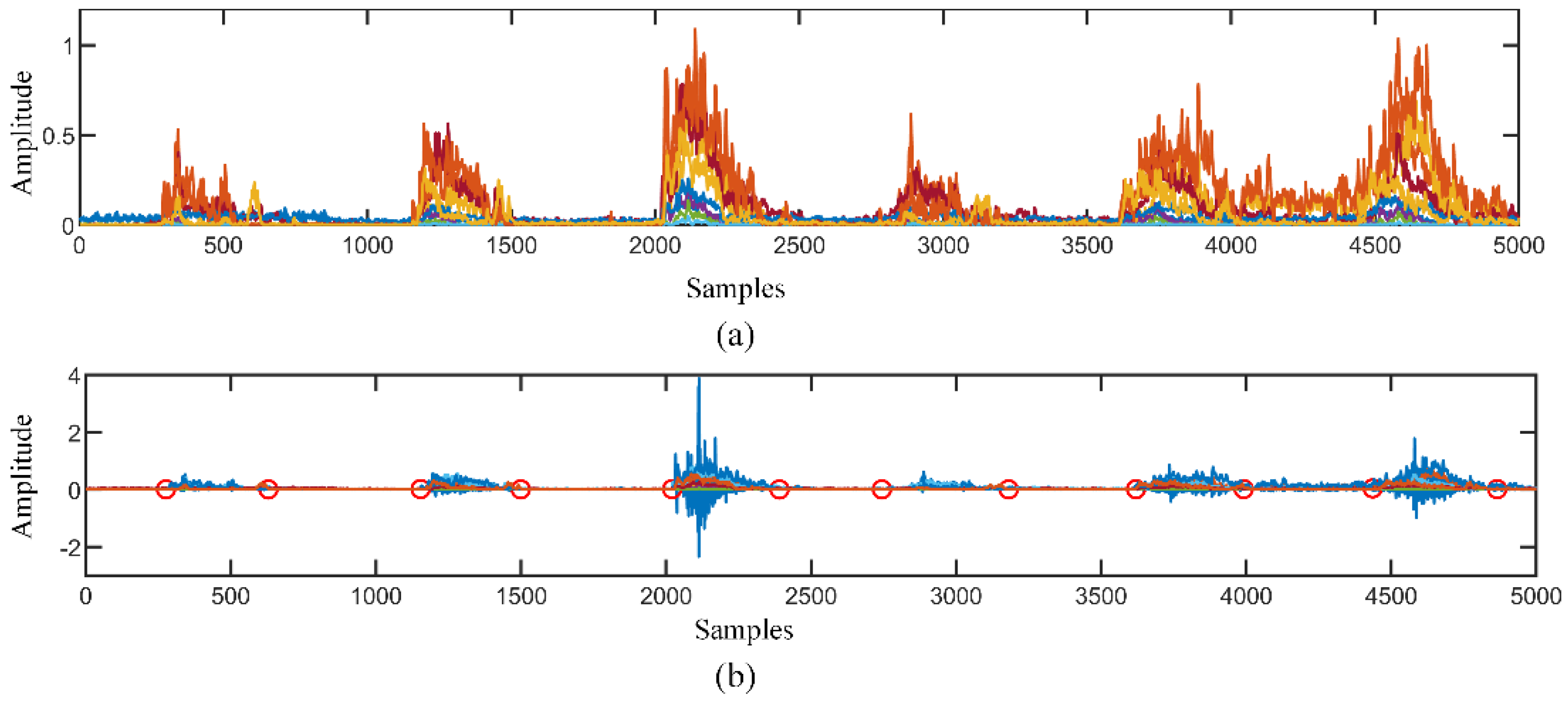
5.1. Relabel the Signal
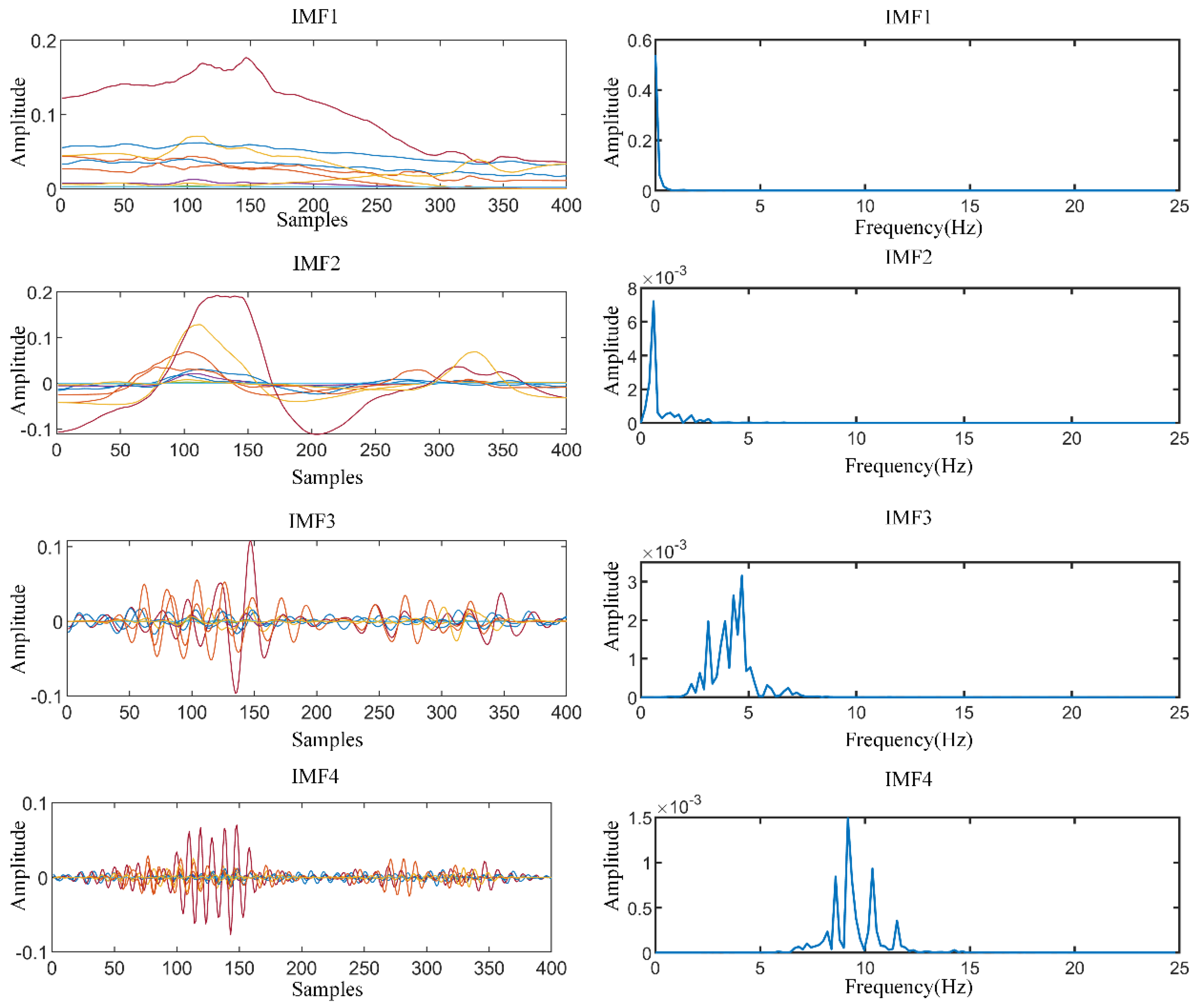
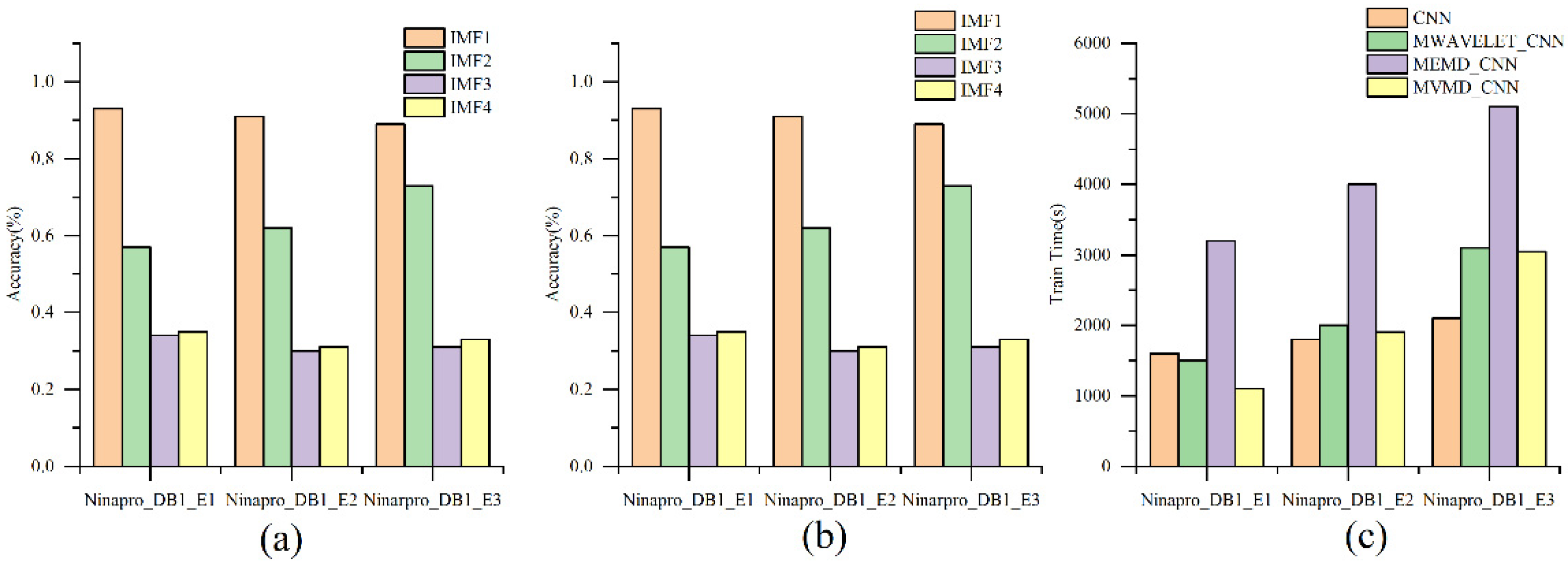
5.2. Analysis sEMG by MVMD
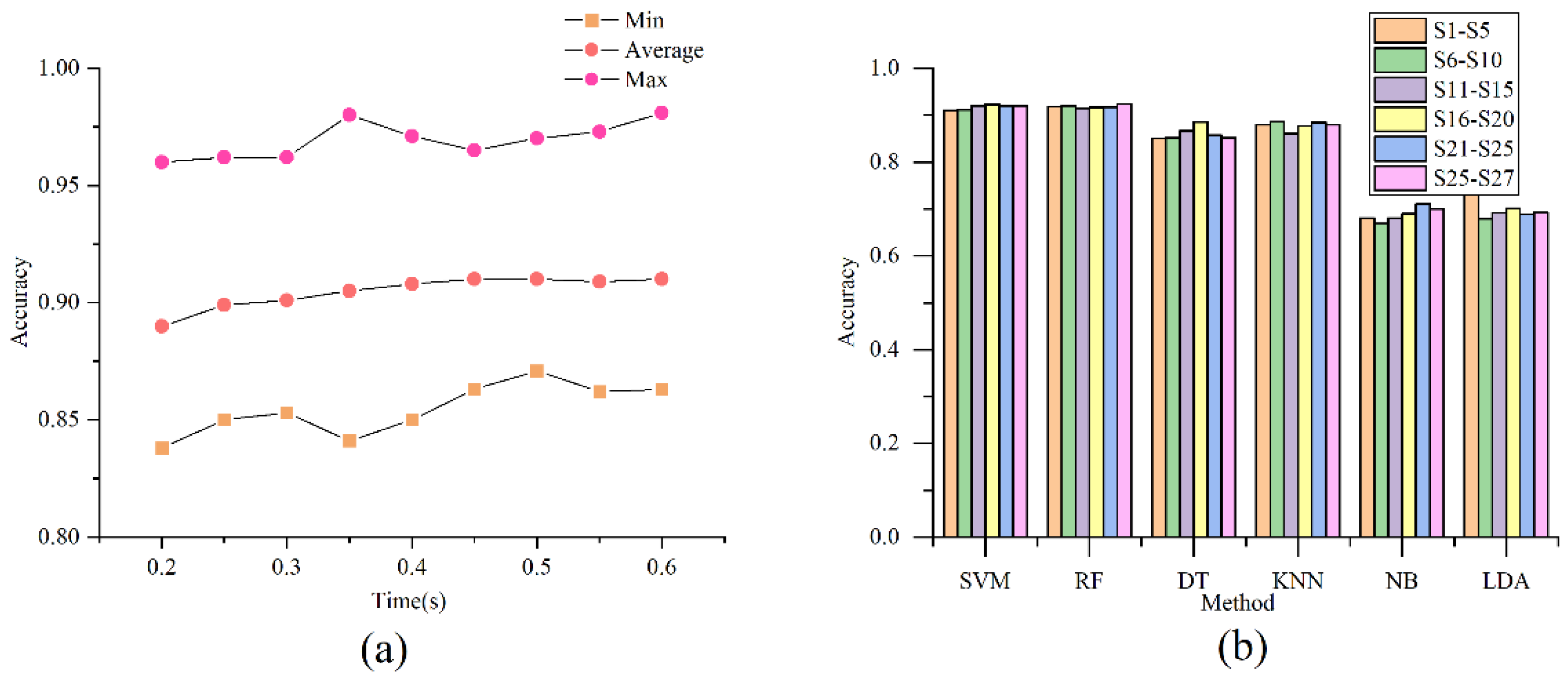
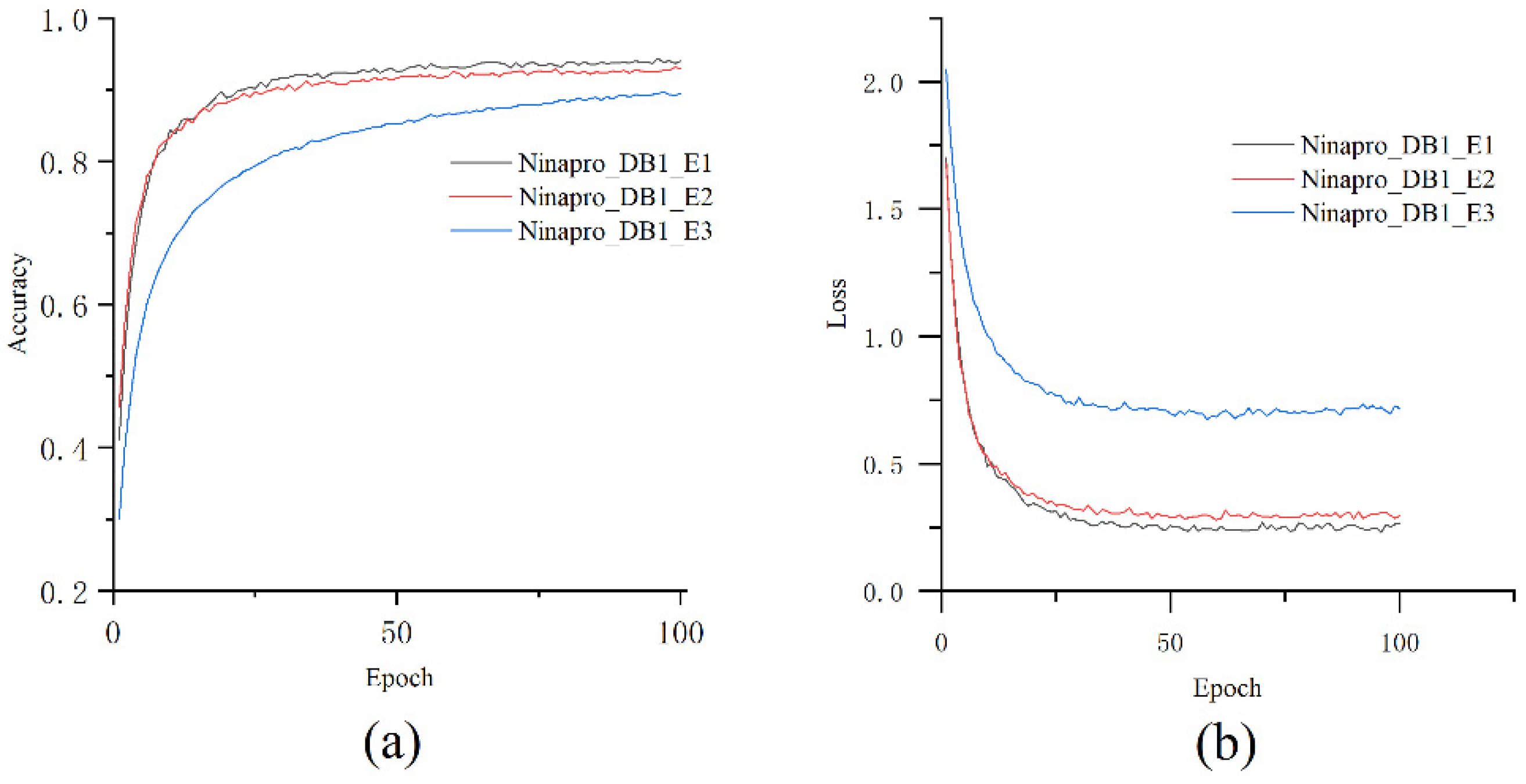
5.3. Train the Model on the First Stage
5.4. Train the Model on the Second Stage
- (1)
- CNN: set the sEMG image as the input to train CNN.
- (2)
- MWAVELET_CNN: decompose the sEMG image by wavelet 4-level into 3D-image, and then train the CNN model with the 3-D image.
- (3)
- MEMD_CNN: decompose the sEMG image by MEMD into 3D-image, and then train the CNN model with the 3-D image.
- (4)
- MVMD_CNN: decompose the sEMG image by MVMD into 3D-image, and then train the CNN model with the 3-D image.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cannan, J.; Hu, H. Human-Machine Interaction (HMI): A Survey; Technical Report: CES-508; School of Computer Science & Electronic Engineering University of Essex: Essex, UK, 2011; pp. 1–16. [Google Scholar]
- Zhang, Y.; Chen, Y.; Yu, H.; Yang, X.; Lu, W. Learning Effective Spatialoral Features for sEMG Armband-Based Gesture Recognition. IEEE Internet Things J. 2020, 7, 6979–6992. [Google Scholar] [CrossRef]
- Kumar, H.; Honrao, V.; Patil, S.; Shetty, P. Gesture Controlled Robot using Image Processing. Int. J. Adv. Res. Artif. Intell. 2013, 2. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Tian, Z.; Zhou, M. Latern: Dynamic Continuous Hand Gesture Recognition Using FMCW Radar Sensor. IEEE Sens. J. 2018, 18, 3278–3289. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Harras, K.A.; Youssef, M. WiGest demo: A ubiquitous WiFi-based gesture recognition system. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; pp. 17–18. [Google Scholar] [CrossRef]
- Sathiyanarayanan, M.; Rajan, S. MYO Armband for physiotherapy healthcare: A case study using gesture recognition application. In Proceedings of the 2016 8th International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 5–10 January 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Jiang, S.; Lv, B.; Guo, W.; Zhang, C.; Wang, H.; Sheng, X.; Shull, P.B. Feasibility of wrist-worn, real-time hand, and surface gesture recognition via sEMG and IMU Sensing. IEEE Trans. Ind. Inform. 2018, 14, 3376–3385. [Google Scholar] [CrossRef]
- Huang, J.; Lin, S.; Wang, N.; Dai, G.; Xie, Y.; Zhou, J. TSE-CNN: A Two-Stage End-to-End CNN for Human Activity Recognition. IEEE J. Biomed. Health Inform. 2020, 24, 292–299. [Google Scholar] [CrossRef]
- Kim, M.; Cho, J.; Lee, S.; Jung, Y. Imu sensor-based hand gesture recognition for human-machine interfaces. Sensors 2019, 19, 3827. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kundu, A.S.; Mazumder, O.; Lenka, P.K.; Bhaumik, S. Hand Gesture Recognition Based Omnidirectional Wheelchair Control Using IMU and EMG Sensors. J. Intell. Robot. Syst. Theory Appl. 2018, 91, 529–541. [Google Scholar] [CrossRef]
- Wu, J.; Li, X.; Liu, W.; Wang, Z.J. SEMG Signal Processing Methods: A Review. J. Phys. Conf. Ser. 2019, 1237, 032008. [Google Scholar] [CrossRef]
- Toledo-Pérez, D.C.; Martínez-Prado, M.A.; Gómez-Loenzo, R.A.; Paredes-García, W.J.; Rodríguez-Reséndiz, J. A study of movement classification of the lower limb based on up to 4-EMG channels. Electronics 2019, 8, 259. [Google Scholar] [CrossRef] [Green Version]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Intelligent Human-Computer Interaction Based on Surface EMG Gesture Recognition. IEEE Access 2019, 7, 61378–61387. [Google Scholar] [CrossRef]
- Ma, S.; Lv, B.; Lin, C.; Sheng, X.; Zhu, X. EMG Signal Filtering Based on Variational Mode Decomposition and Sub-Band Thresholding. IEEE J. Biomed. Health Inform. 2021, 25, 47–58. [Google Scholar] [CrossRef]
- Raurale, S.A.; McAllister, J.; Del Rincon, J.M. Real-Time Embedded EMG Signal Analysis for Wrist-Hand Pose Identification. IEEE Trans. Signal Process. 2020, 68, 2713–2723. [Google Scholar] [CrossRef]
- Zhang, Z.; Tang, Y.; Zhao, S.; Zhang, X. Real-time surface EMG pattern recognition for hand gestures based on support vector machine. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1258–1262. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, X.; Qian, J. Classification of finger movements for prosthesis control with surface electromyography. Sens. Mater. 2020, 32, 1523–1532. [Google Scholar] [CrossRef]
- Ortiz-Echeverri, C.J.; Salazar-Colores, S.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A new approach for motor imagery classification based on sorted blind source separation, continuous wavelet transform, and convolutional neural network. Sensors 2019, 19, 4541. [Google Scholar] [CrossRef] [Green Version]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Sanchez-Reyes, L.M.; Rodriguez-Resendiz, J.; Avecilla-Ramirez, G.N.; Garcia-Gomar, M.L.; Robles-Ocampo, J.B. Impact of EEG Parameters Detecting Dementia Diseases: A Systematic Review. IEEE Access 2021, 9, 78060–78074. [Google Scholar] [CrossRef]
- Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A.; Jauregui-Correa, J.C. Support Vector Machine-based EMG signal classification techniques: A review. Appl. Sci. 2019, 9, 4402. [Google Scholar] [CrossRef] [Green Version]
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 36571. [Google Scholar] [CrossRef] [PubMed]
- Smruthy, A.; Suchetha, M. Real-Time Classification of Healthy and Apnea Subjects Using ECG Signals with Variational Mode Decomposition. IEEE Sens. J. 2017, 17, 3092–3099. [Google Scholar] [CrossRef]
- Ur Rehman, N.; Park, C.; Huang, N.E.; Mandic, D.P. EMD via MEMD: Multivariate Noise-Aided Computation of Standard EMD. Adv. Adapt. Data Anal. 2013, 5, 1350007. [Google Scholar] [CrossRef] [Green Version]
- Rehman, N.U.; Aftab, H. Multivariate Variational Mode Decomposition. IEEE Trans. Signal Process. 2019, 67, 6039–6052. [Google Scholar] [CrossRef] [Green Version]
- Dragomiretskiy, K.; Zosso, D. Two-dimensional variational mode decomposition. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2015, 8932, 197–208. [Google Scholar] [CrossRef]
- Illankoon, P.; Tretten, P.; Kumar, U. Modelling human cognition of abnormal machine behaviour. Hum.-Intell. Syst. Integr. 2019, 1, 3–26. [Google Scholar] [CrossRef] [Green Version]
- Chandra, N.; Vaidya, H.; Ghosh, J.K. Human cognition based framework for detecting roads from remote sensing images. Geocarto Int. 2020, 1–20. [Google Scholar] [CrossRef]
- Shanmuganathan, V.; Yesudhas, H.R.; Khan, M.S.; Khari, M.; Gandomi, A.H. R-CNN and wavelet feature extraction for hand gesture recognition with EMG signals. Neural Comput. Appl. 2020, 32, 16723–16736. [Google Scholar] [CrossRef]
- Asif, A.R.; Waris, A.; Gilani, S.O.; Jamil, M.; Ashraf, H.; Shafique, M.; Niazi, I.K. Performance evaluation of convolutional neural network for hand gesture recognition using EMG. Sensors 2020, 20, 1642. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shaker, A.M.; Tantawi, M.; Shedeed, H.A.; Tolba, M.F. Generalization of Convolutional Neural Networks for ECG Classification Using Generative Adversarial Networks. IEEE Access 2020, 8, 35592–35605. [Google Scholar] [CrossRef]
- Luo, J.; Liu, C.; Yang, C. Estimation of EMG-Based force using a neural-network-based approach. IEEE Access 2019, 7, 64856–64865. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1, 140053. [Google Scholar] [CrossRef] [Green Version]
- Ning, Y.; Zhu, X.; Zhu, S.; Zhang, Y. Surface EMG decomposition based on K-means clustering and convolution kernel compensation. IEEE J. Biomed. Health Inform. 2015, 19, 471–477. [Google Scholar] [CrossRef] [Green Version]
- Lobov, S.; Krilova, N.; Kastalskiy, I.; Kazantsev, V.; Makarov, V.A. Latent factors limiting the performance of sEMG-interfaces. Sensors 2018, 18, 1122. [Google Scholar] [CrossRef] [Green Version]
- Tsinganos, P.; Cornelis, B.; Cornelis, J.; Jansen, B.; Skodras, A. Improved Gesture Recognition Based on sEMG Signals and TCN. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1169–1173. [Google Scholar] [CrossRef]
- Bai, L.; Zhao, Y.; Huang, X. A CNN Accelerator on FPGA Using Depthwise Separable Convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef] [Green Version]
- Atzori, M.; Gijsberts, A.; Kuzborskij, I.; Elsig, S.; Hager, A.G.M.; Deriaz, O.; Castellini, C.; Müller, H.; Caputo, B. Characterization of a benchmark database for myoelectric movement classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 73–83. [Google Scholar] [CrossRef]
- Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Geng, W. Surface EMG-based inter-session gesture recognition enhanced by deep domain adaptation. Sensors 2017, 17, 458. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | DESC | Equation |
|---|---|---|
| RMS | Root mean square | |
| MAV | Mean absolute value | |
| WL | Wavelength | |
| ZC | Zero crossing | |
| SSC | Slope sign change | |
| DASDV | Difference absolute standard deviation value | |
| WA | Willison amplitude | |
| VAR | Variance |
| Layer | Size | Channel | Para_1 | Para_2 |
|---|---|---|---|---|
| Input | (30,10,1) | 1 | 0 | 0 |
| Convolution1 | (3,3) | 32 | 1184 | 73 |
| Dropout | - | - | - | - |
| Convolution2 | (3,3) | 64 | 18,496 | 2400 |
| Maxooling1 | (2,2) | 64 | - | - |
| Convolution3 | (3,3) | 128 | 73,856 | 8896 |
| Zeropadding | (0,1) | 128 | - | - |
| Maxpooling2 | (2,2) | 128 | - | - |
| Flatten | - | - | - | - |
| Dropout | - | - | - | - |
| Dense | 128 | - | 344,192 | 344,192 |
| Softmax | 12 | - | 1548 | 1548 |
| Subjects | RMS | MAV | WL | ZC | SSC | DASDV | WA | VAR | RMS + MAV + DASDV |
|---|---|---|---|---|---|---|---|---|---|
| S1-S5 | 85.77 | 86.99 | 85.59 | 47.99 | 65.69 | 85.57 | 65.69 | 78.93 | 90.84 |
| S6-S10 | 89.17 | 90.08 | 88.20 | 47.12 | 70.45 | 87.08 | 71.25 | 81.50 | 93.05 |
| S11-S15 | 86.50 | 87.33 | 83.39 | 46.81 | 63.87 | 82.87 | 62.43 | 76.22 | 91.02 |
| S16-S20 | 82.63 | 84.01 | 82.57 | 47.39 | 61.26 | 81.92 | 60.80 | 75.75 | 90.24 |
| S21-S25 | 87.97 | 87.92 | 86.00 | 43.69 | 63.88 | 84.89 | 61.33 | 79.22 | 90.77 |
| S26-S27 | 87.78 | 87.16 | 87.13 | 44.65 | 70.46 | 85.47 | 63.97 | 80.15 | 92.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Xu, M.; Yang, X.; Yang, R.; Chen, Y. A Novel EMG-Based Hand Gesture Recognition Framework Based on Multivariate Variational Mode Decomposition. Sensors 2021, 21, 7002. https://doi.org/10.3390/s21217002
Yang K, Xu M, Yang X, Yang R, Chen Y. A Novel EMG-Based Hand Gesture Recognition Framework Based on Multivariate Variational Mode Decomposition. Sensors. 2021; 21(21):7002. https://doi.org/10.3390/s21217002
Chicago/Turabian StyleYang, Kun, Manjin Xu, Xiaotong Yang, Runhuai Yang, and Yueming Chen. 2021. "A Novel EMG-Based Hand Gesture Recognition Framework Based on Multivariate Variational Mode Decomposition" Sensors 21, no. 21: 7002. https://doi.org/10.3390/s21217002
APA StyleYang, K., Xu, M., Yang, X., Yang, R., & Chen, Y. (2021). A Novel EMG-Based Hand Gesture Recognition Framework Based on Multivariate Variational Mode Decomposition. Sensors, 21(21), 7002. https://doi.org/10.3390/s21217002