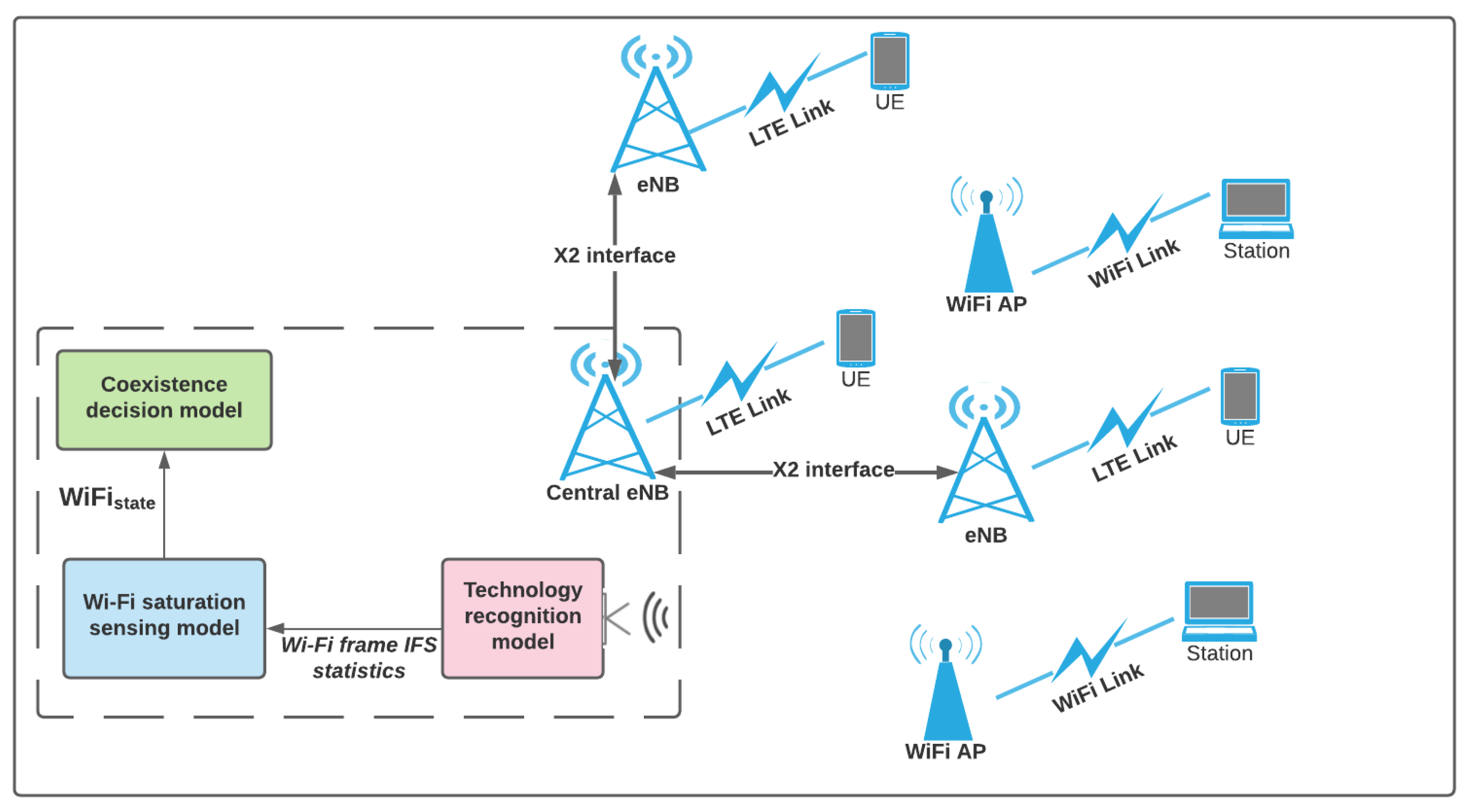
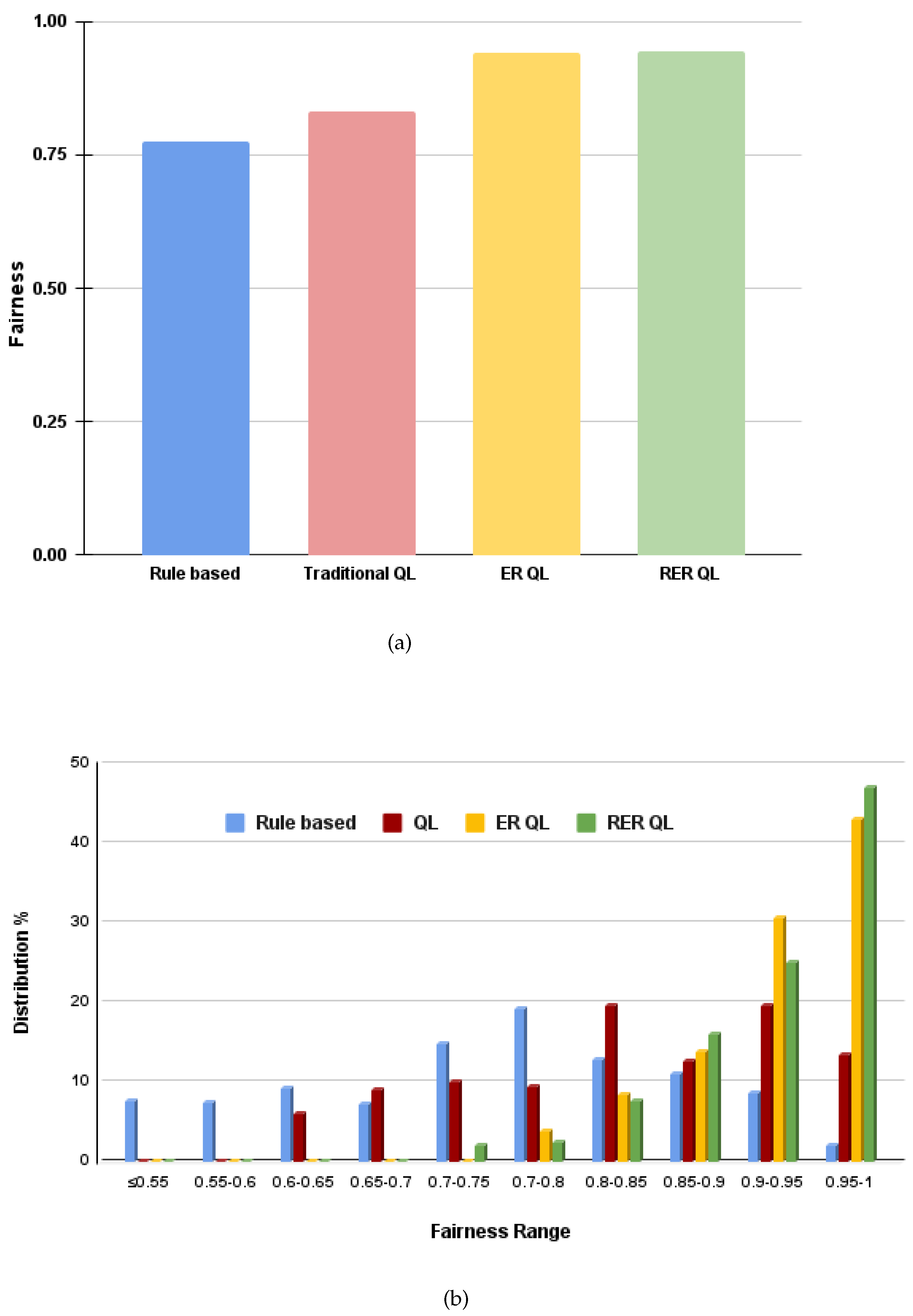
The ultimate goal of this article is to propose a WiFi saturation based fair and efficient coexistence scheme for uncoordinated LTE and WiFi networks. In this section, we formulate and describe coexistence schemes for non-coordinated coexistence solutions. For comparison and validation purposes, we formulated simple rule based and classical Q-learning coexistence schemes. These coexistence schemes are formulated in such a way that they can be utilized for uncoordinated LTE-U and Wi-Fi networks. For this reason, the first two subsections of this section describe a simple rule based adaptive coexistence scheme and Q-learning based coexistence scheme for uncoordinated LTE-U and WiFi networks. The proposed ER and RER based Q-learning coexistence schemes are described in the last two subsections of this section.
5.1. Rule Based Coexistence Scheme
In this subsection, we describe a rule-based coexistence scheme that is used to determine the number of LTE blank subframes (
) that lead to the highest fairness and spectrum efficiency. This rule based coexistence scheme is formulated for comparison purposes. The main goal of the algorithm is to select a
value based on
LTEState and
WiFiState. The
WiFiState represents WiFi state which can be either saturated (
WS) or unsaturated (
WU).
represents the state of LTE which is determined based on
and
. The algorithm uses possible states of LTE shown in
Table 2. When blank subframes are introduced in the LTE frame, the LTE throughput decreases proportionally [
30]. Hence, the 10 states in
Table 2 are used to represent all the possible range of throughput levels.
Algorithm 1 shows the steps of the proposed rule-based coexistence scheme. Initially, 50% of the LTE subframes are set as blank ensuring equal spectrum share for both technologies. Then, the fairness of this action is evaluated. We consider the action as 100% if the LTE network achieves sufficient throughput (L10) and the WiFi network is unsaturated. We also consider the action as 100% if and the WiFi network is saturated when the technologies are set to share the spectrum equally with 50% blank subframes. On the other hand, if the action is not , the value of Nb is adjusted based on LTE and WiFi states. If the WiFi network is saturated and the LTE network achieves sufficient throughput (L10), the number of blank LTE subframes is increased so that WiFi gets more spectrum thereby leading to better fairness. Contrarily, if the WiFi network is unsaturated and the LTE network does not achieve sufficient throughput, i.e., the number of blank subframes are reduced to achieve better fairness. represents the number of actions executed until the best action. This process has to be repeated periodically to adapt to the traffic dynamics of the co-located networks.
5.2. Q-Learning Based Coexistence Scheme
Reinforcement Learning (RL) is an area of machine learning where an agent learns from its interaction with the environment. Q-learning is a type of reinforcement learning algorithm that implements dynamic programming and Monte Carlo concepts to solve sequential decision-making problems in the form of Markov Decision Processes (MDP) [
37]. In MDP, the agent interacts with the environment and makes decisions based on the environment states. The agent chooses actions and the environment on the other hand is used to update the responses to these actions in the form of observations or new situations. The agent aims to maximize the cumulative reward of taking an action in a particular state by learning a policy
from trial and error in the environment. In the process of learning iteration, the agent initially observes the current state
s on the environment. The agent then selects the corresponding action
a according to the policy
and it receives the reward value
R from the environment. After the action is taken on the environment the state changes to
. Finally, the optimal policy
is updated based on the current state and the reward value [
37].
| Algorithm 1: Rule based coexistence scheme |
![Sensors 21 06977 i001]() |
In the Q-learning process, the agent balances between exploration and exploitation while it tries to find an optimal strategy in the selection of action a after observing the current state s of the environment. In the exploration case, the agent selects an action randomly, expecting that the random action will lead to a higher cumulative reward in the next iterations. On the contrary, in the exploitation process, an action is selected based on the latest expected optimal policy. Generally, during exploitation, the agent uses the experience from already investigated actions and selects the optimal action based on them, while during exploration, the agent investigates and experiences new actions. -greedy policy is a policy used to balance exploration and exploitation by using a decision value . The decision value is selected in the range and it is used to decide whether the agent will explore or exploit in every step. The agent uses exploration and exploitation with a probability of and , respectively.
Algorithm 2 shows how Q-learning can be used for optimally selecting the number of blank subframes (Nb), aiming at maximizing fairness and the aggregated throughput of LTE and WiFi networks. The procedures show how the agent selects an optimal value of Nb based on LTE throughput status and WiFi saturation status. The algorithm also shows how exploration and exploitation are balanced by an adjustable value of . Initially, the is set to a value close to 1 so that the agent starts with a higher probability of exploration so that it quickly explores different states. After number of iterations, the value of is reduced by a factor of , until a minimum value of is reached.
The key elements of the Q-learning process for optimal Nb selection can be described as follows:
Agent: eNB, we assume the LTE-U eNBs belong to the same operator which cooperates together.
State: The state at time is determined by the status of the environment after an action a is taken at time t. The statuses of the WiFi and the LTE networks are used to represent the state after a frame configuration of LTE is selected.
The new state
can be represented as:
WiFiState can be saturated (
WS) or unsaturated (
WU).
LTEState represents the state of LTE which is determined based on LTE target throughput and LTE obtained throughput. The state of the WiFi network is represented by its saturation status which is determined based on our previous work [
8]. On the other hand, the state of the LTE network is determined by the
LTEobtained and
LTETarget throughput. The possible states of
LTE are shown in
Table 2.
Nb is the number of blank LTE subframes in a single frame. The state-space
S includes all combination of
WiFiState,
LTEState, and
Nb values.
Action: The action a at time t represents the selection of number of blank LTE subframes.
Reward: LTE network is required to attain the highest possible throughput by accessing the spectrum while maintaining fairness with WiFi. However, the performance of the WiFi can not be directly accessed by the agent as our goal is to propose a coexistence scheme that does not require signaling exchanges between the WiFi AP and LTE eNB. For this reason, we consider the CNN-based WiFi network saturation sensing model to determine the status of the co-located WiFi. The reward value for action
a taken at a state
s is computed based on the newly achieved state
as follows:
where
Nb is the number of blank LTE subframes and
is used based on the values in
Table 2.
is 1 if WiFi state is
WU and 0.5 if WiFi state is
WS. The value of
increases as the
LTEObtained gets close to
LTETarget. Similarly, the value of
is higher when the WiFi network is unsaturated. Equation (
2) shows that the maximum reward is obtained when LTE gets the highest possible throughput range (state
L10) and WiFi is unsaturated (
WU). Similarly, the highest reward can be achieved if both technologies are spectrum hungry while both technologies are given equal spectrum share, i.e., if LTE is not at state
L10 and WiFi is at state
WS while
Nb = 5. Otherwise, the reward function depends on the values of
,
, and
Nb. As
Nb increases, LTE gets a lower spectrum share and hence the value of
decreases. On the other hand, as
Nb increases, there is a higher probability that the WiFi gets sufficient spectrum to attain unsaturated state leading to
= 1. Generally, the values of
and
are selected such that an action with a higher aggregated throughput and fairness leads to a higher reward value.
5.3. Experience Replay Based Q-Learning
The traffic load of wireless networks is mostly dynamic. In such a dynamic environment state–action pairs are not consistent over time. This makes predicting future rewards more complex. For this reason, the Q-learning algorithm is mostly applied in stationary environments where state-action pairs are consistent. However, this problem can be solved by using Experience Replay (ER). ER is an approach used to minimize action–state pair oscillation. This is achieved by storing a large number of past experiences. A single stored experience is represented by a combination of the current state, action, reward, and next state (
). In traditional Q-learning, the Q-table is updated based on the single latest experience. However, Q-table values are updated by taking a random portion of the buffered experiences in case of experience replay-based Q-learning [
9].
| Algorithm 2: Q-learning based algorithm for dynamic selection of Nb |
![Sensors 21 06977 i002]() |
In ER-based Q-learning, number of experiences are recorded as a single batch from the experience buffer. The batch size remains fixed as newly recorded experiences keep pushing the oldest experience out of the list. The use of such an experience record enables the agent to learn more from important individual experiences, i.e., some important experiences can be used multiple times to achieve faster convergence. The importance of the reward can be defined based on different criterion such as it corresponding reward or time of occurrence. The experience record also helps to recall rare occurrences and harmful correlations. For this reason, ER is a promising approach to achieve an optimal policy from fewer experiences. Hence, we propose an ER-based Q-learning solution for LTE and WiFi network coexistence.
The agent, action, and state elements of ER-based Q-learning are similar to the traditional Q-learning based solution described in
Section 5.2. In traditional Q-learning, we can only estimate the reward value of a given action based on the current state
s and the new state
after the action is taken. However, this equation only shows how good the action is in this state but with the knowledge of a single experience, we can not determine if the action is the best action among all the possible actions. For this reason, we propose ER based Q-learning solution to cope with the dynamic nature of the traffic load of the LTE and WiFi networks. For the dynamic traffic environment, we need to record the experiences by taking all possible actions for each traffic load combination and these observed experiences can be used to determine which action is the best. For each experience, a fairness factor (
) is included to indicate the fairness level in the experience. In other words,
value is selected in such a way that its value increases with the fairness level of the action.
is generated using the following equation:
where
Nb is the number of blank LTE subframes and
is used based on the values in
Table 2.
is 1 if WiFi state is
WU and 0.5 if WiFi state is
WS. The fairness factor equation shown in Equation (
3) is set in such a way that its value increases as the two technologies utilize a fair share of the spectrum. As far as the WiFi the network is unsaturated,
WU the fairness factor value increases when the LTE network’s obtained throughput increases. In the equation, the LTE network obtained throughput is reflected by the value of
. On the other hand, when the WiFi network gets saturated, the value of the fairness factor depends on the LTE obtained throughput (reflected by
) and
Nb. Generally, the equation leads to highest fairness factor value if
L10 and WiFi is at state
WU are obtained at a given action. However, if both LTE and WiFi networks have a higher traffic load, these
L10 and
WU state can not be achieved simultaneously in all possible actions. For this case, the highest fairness factor is obtained when both technologies share the spectrum equally, i.e.,
Nb = 5.
In case of experience replay based Q-learning, all possible actions are observed for each given traffic load. All actions are recorded with their corresponding
WiFistate and
LTEstate. The value of
is then computed based on the LTE and WiFi states and the corresponding reward values are computed using:
The reward function presented in Equation (
4) leads to the highest value when an action taken has the maximum possible fairness factor
value as compared to all the other possible actions recorded as experiences. Without the use of an experience record, it is not possible to determine if a given action is the best action as compared to other possible actions. For this reason, the value of
can not be used in the classical Q-learning reward function. In a dynamic environment, the best action can only be certainly determined after observing and recording all the possible actions. This is the reason behind proposing an ER based Q-learning solution for the LTE-U and WiFi network coexistence problem in a dynamic environment.
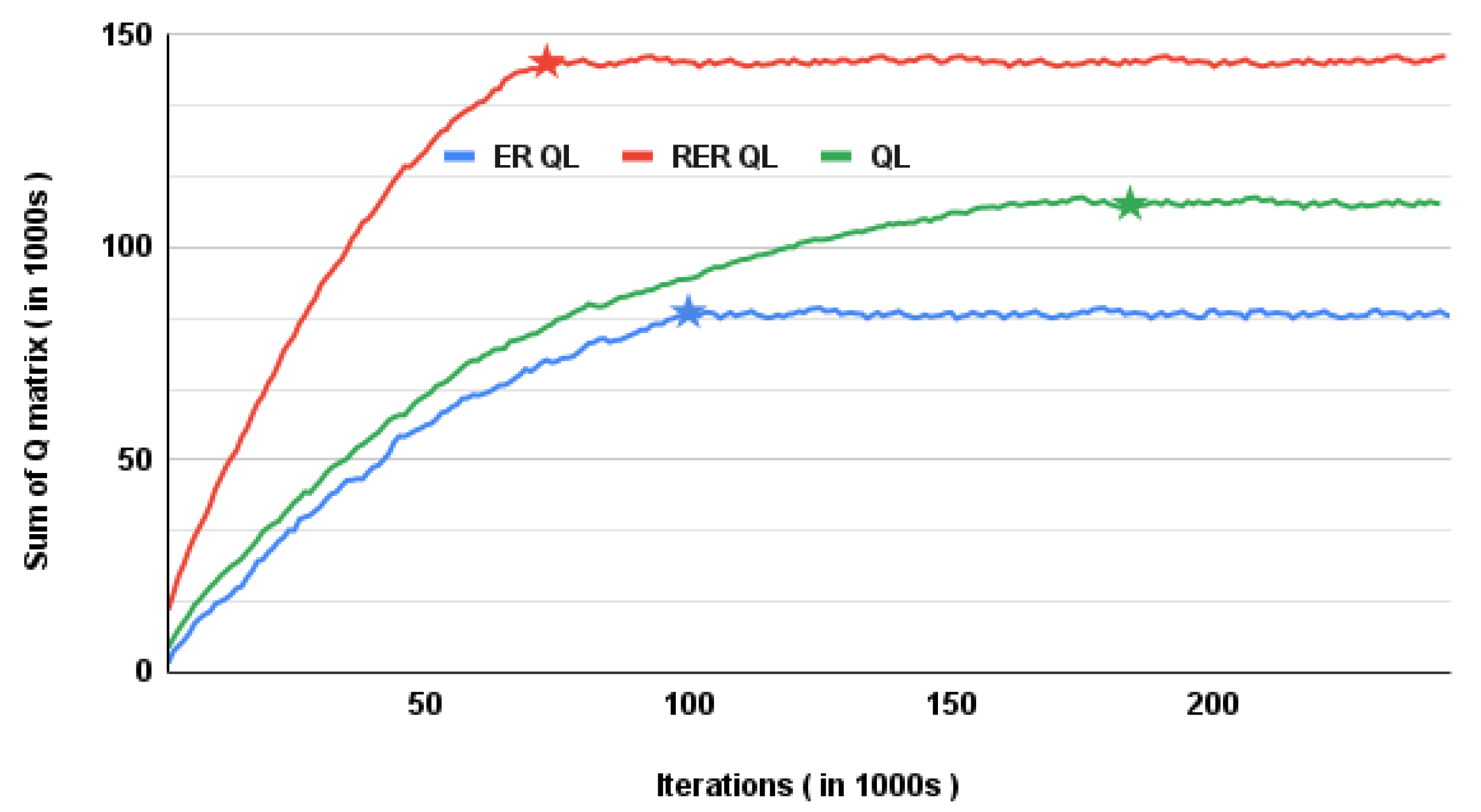
Algorithm 3 shows how the ER based Q-learning can be used to predict an optimal policy . The procedures show how recorded experiences are used to update the Q-network. The dynamic behavior of the environment is represented by generating random traffic load on the LTE and WiFi network. For a given fixed traffic load all possible actions are taken and values are recorded in for every action. Once the values of are stored for all actions, the reward values are computed and the values stored to for every action a. These values are then stored to until the number of experiences reaches . Once experiences are recorded, each stored element is used to update the Q-network based on the procedures mentioned in Algorithm 2. This whole process is repeated until the Q-matrix converges.
5.4. Reward Selective Experience Replay Based Q-Learning
We have seen that the ER-based Q-learning solution stores experience
for all actions until the number of experiences reaches
. After recording
experiences, each stored element
is used to update the Q-network using the steps described in Algorithm 3. In most circumstances, it is not recommended to use every experience in the database, so we must specify some sort of selection process. For this reason, we also investigate RER based Q-learning strategy in which we keep only the
best experiences with the highest attained reward in each action. In other words, the reward for each action is calculated using Equation (
4), and the corresponding experience is used to update the Q-matrix values if the acquired reward is 100.
In the RER based Q-learning, the main procedures used to update the Q-table are similar to the procedures used in ER based Q-learning scheme depicted in Algorithm 3. The difference between ER based Q-learning scheme and RER based Q-learning scheme is, in ER based Q-learning scheme every recorded experience is used to update the Q-table while RER based Q-learning scheme updates the Q-table based on experiences with best reward value. This reward based experience record update is adopted from [
9].
| Algorithm 3: ER Q-learning based algorithm for dynamic selection of Nb |
![Sensors 21 06977 i003]() |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}