
Multi-Agent Systems in Fog–Cloud Computing for Critical Healthcare Task Management Model (CHTM) Used for ECG Monitoring

 ,
, 
 ,
,  and
and 
Abstract
:1. Introduction
- Proper management of critical tasks by the CHTM model;
- Effective prioritization of irregular tasks;
- Effective task scheduling for the critical patient situation;
- Balanced network workload at global and local levels by calculating the global and local workload cost. Moreover, the cooperation of nodes and sharing of resources with adjacent nodes is enabled by utilizing a multi-agent system, in which four types of agents are used;
- Our model provides three levels of processing: PAs, FNAs, and cloud. Besides, our model provides two levels of control: master personal agents and master fog bodes.
2. Related Work
3. Motivation Scenario
- Lessening the delay in the application loop (latency);
- Using the fog devices resources efficiently (processor, RAM, energy, etc.);
- Reducing the use of the network.
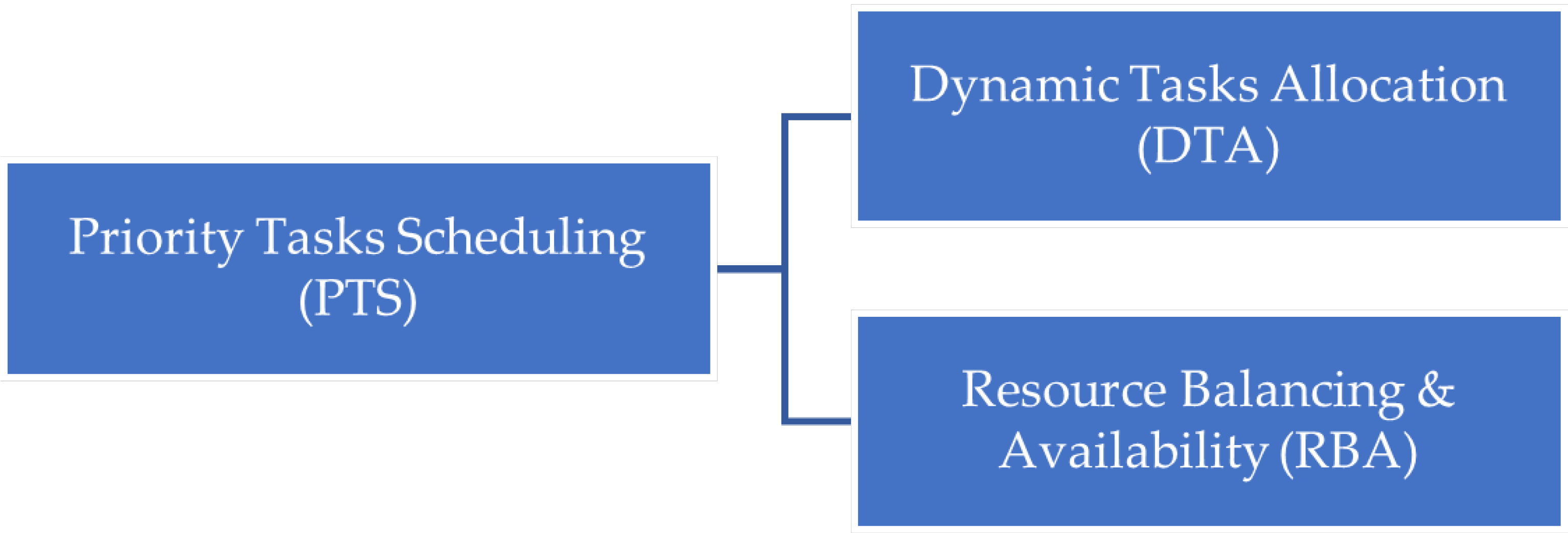
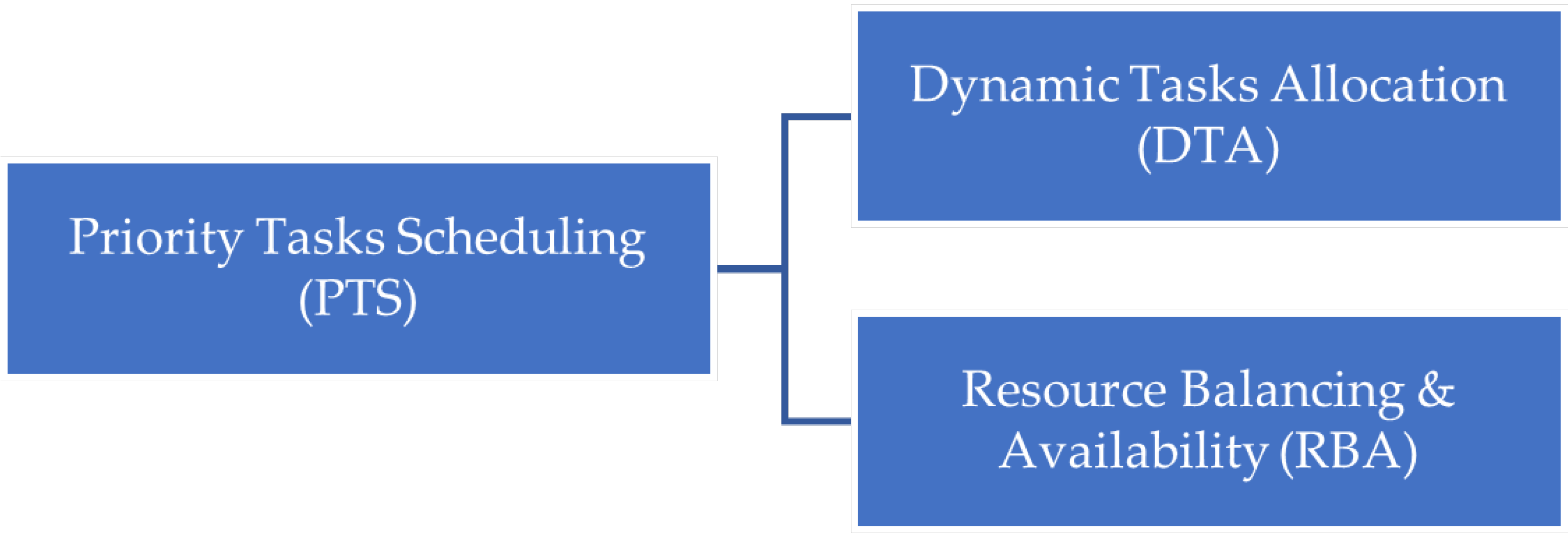
3.1. Priority Task Scheduling (PTS)
- Determine the task criticality;
- Decide the size of the incoming task;
- Comparison: the priority is determined utilizing patient history, considering whether the size is equivalent to that of another task;
- Sort: considering the priority and sorting the tasks;
- Update the reference value.
3.2. Dynamic Tasks Allocation (DTA)
3.3. Load Balancing and Availability (LBA)
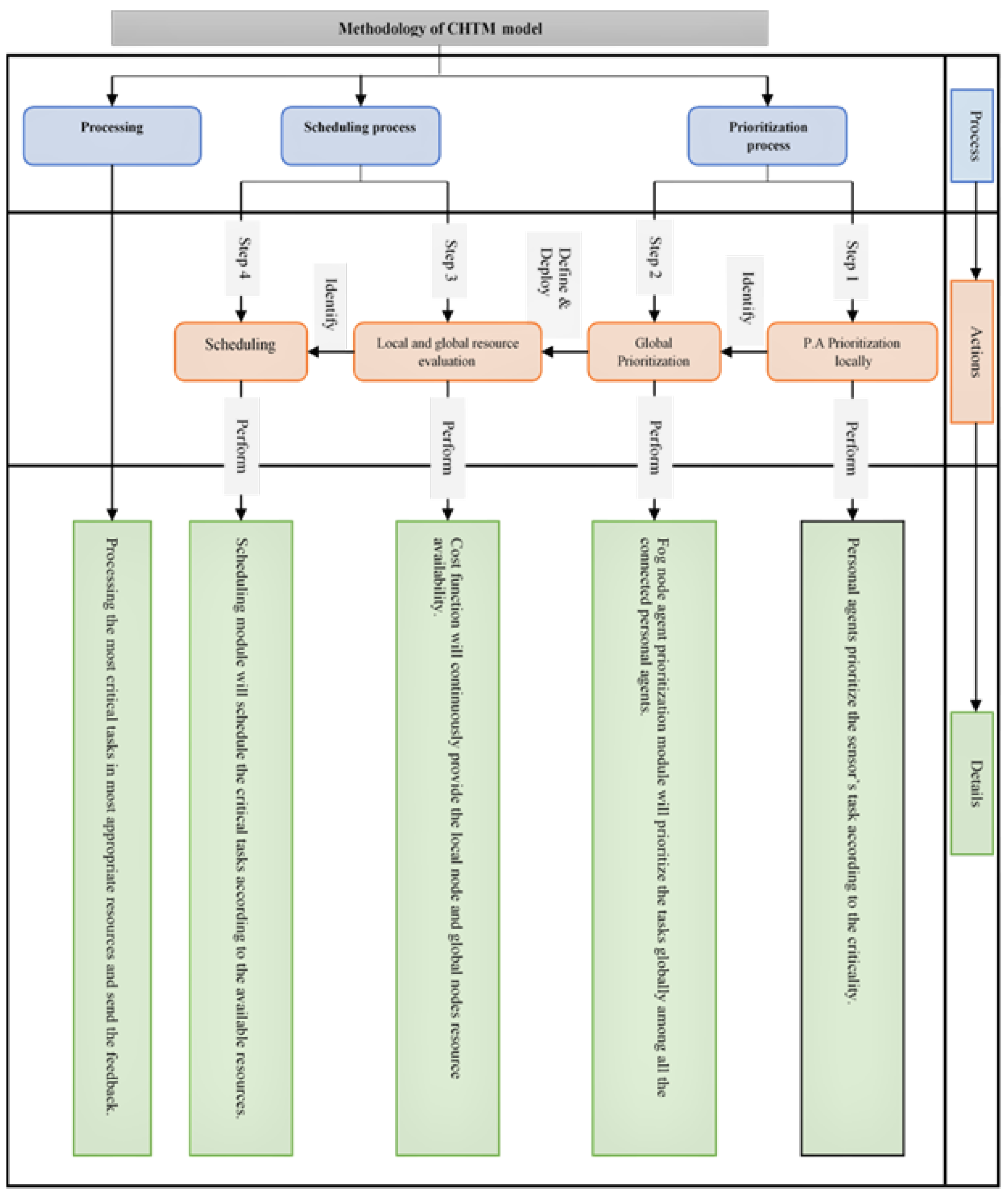
4. Methodology
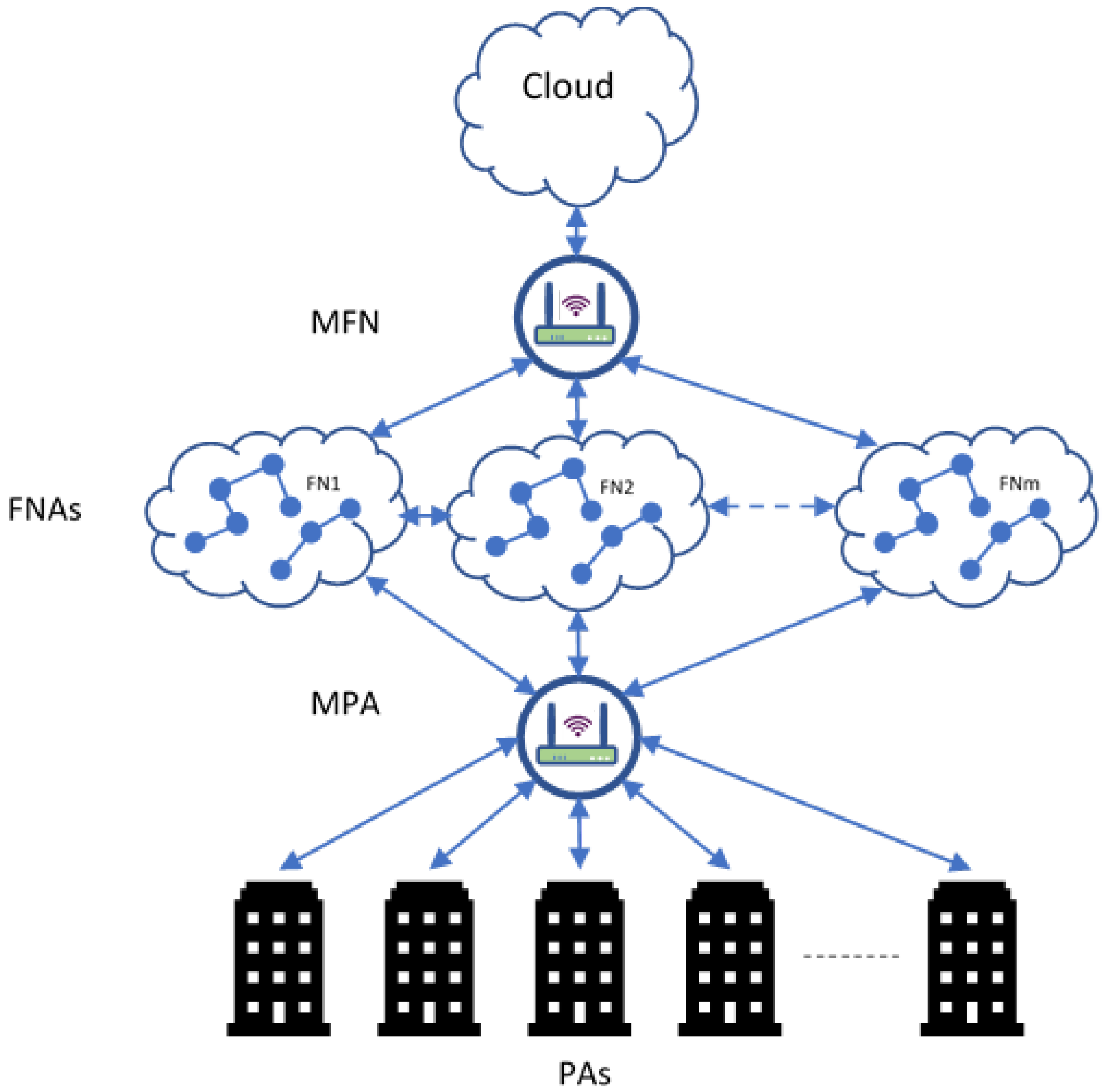
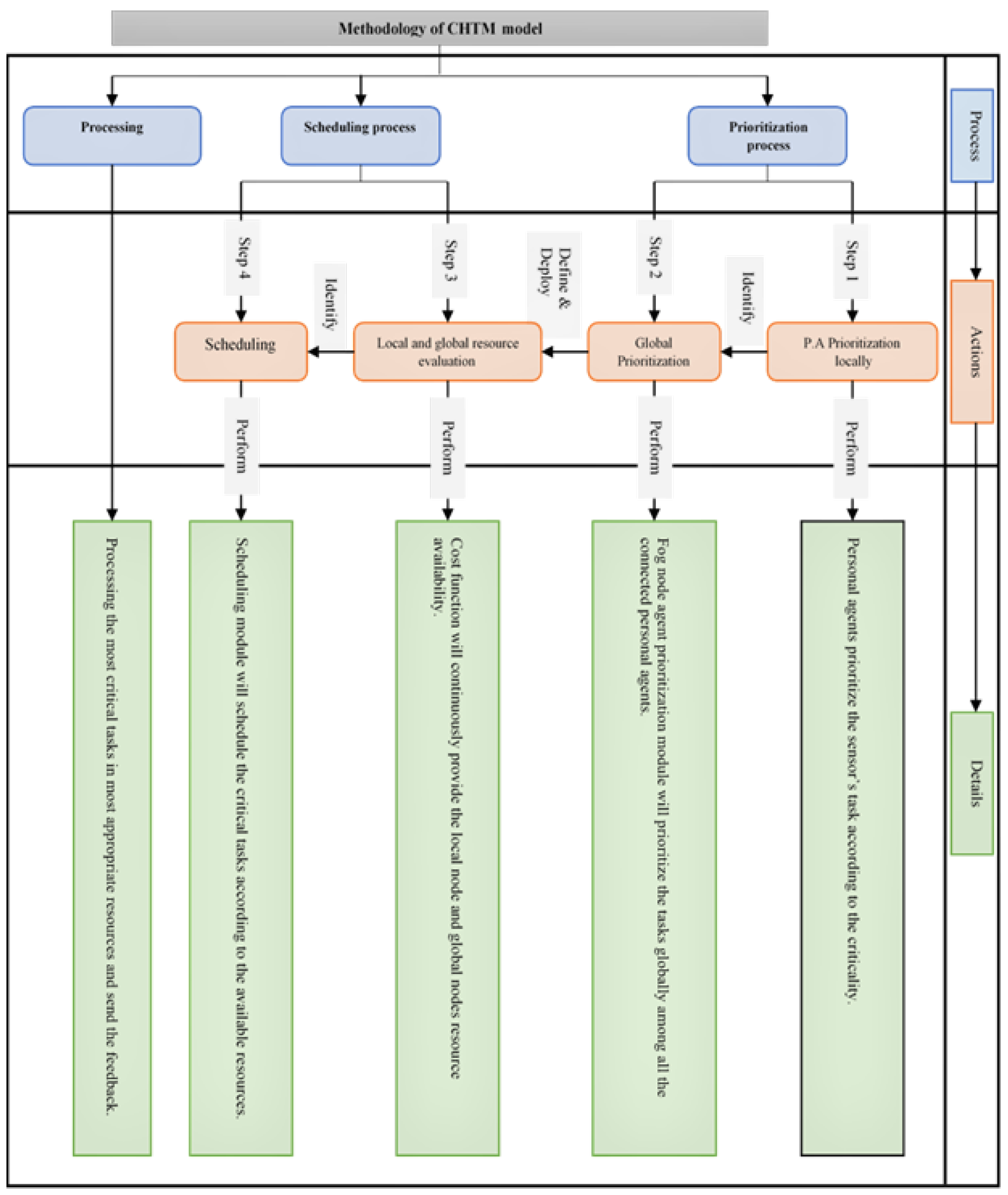
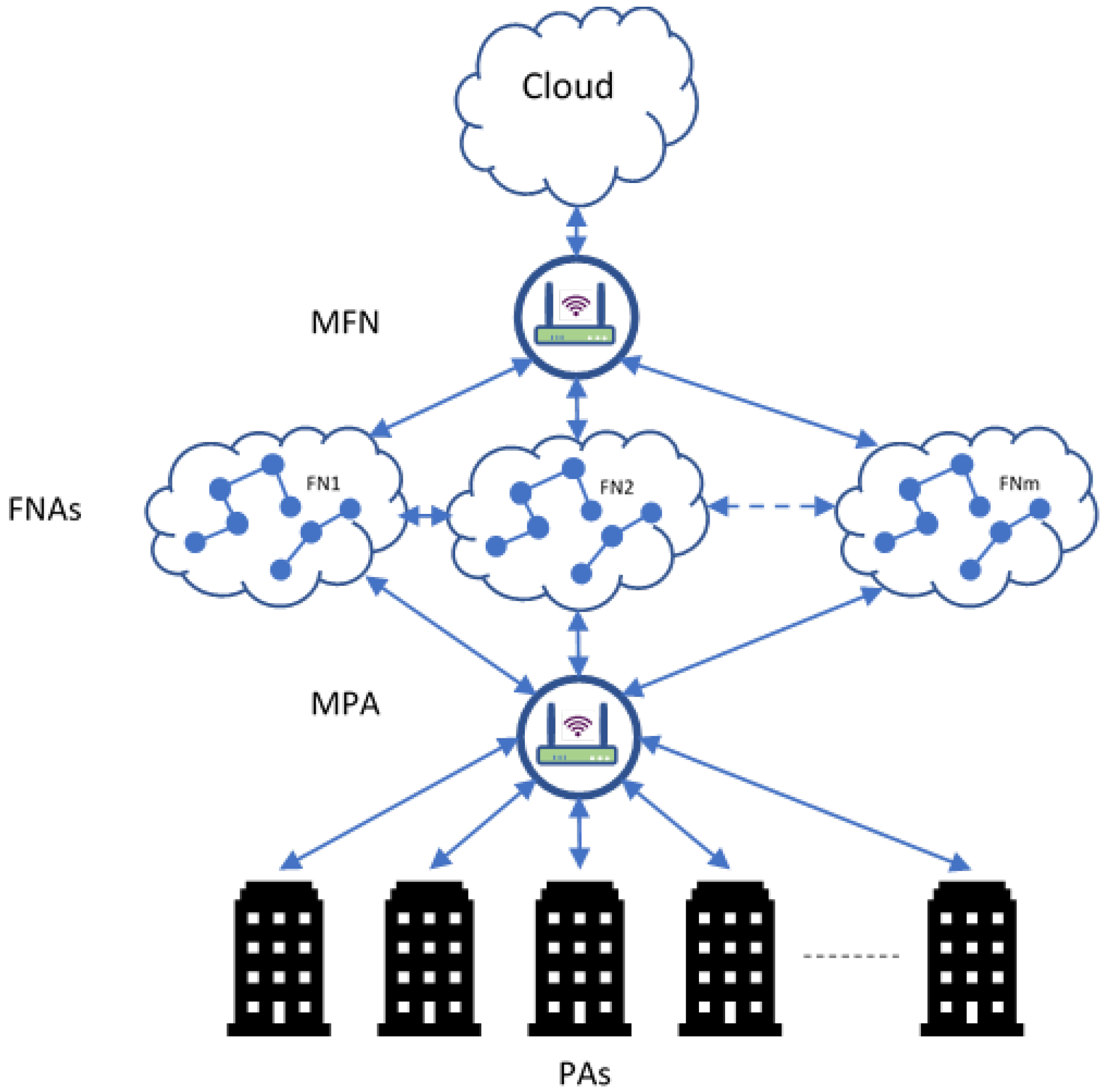
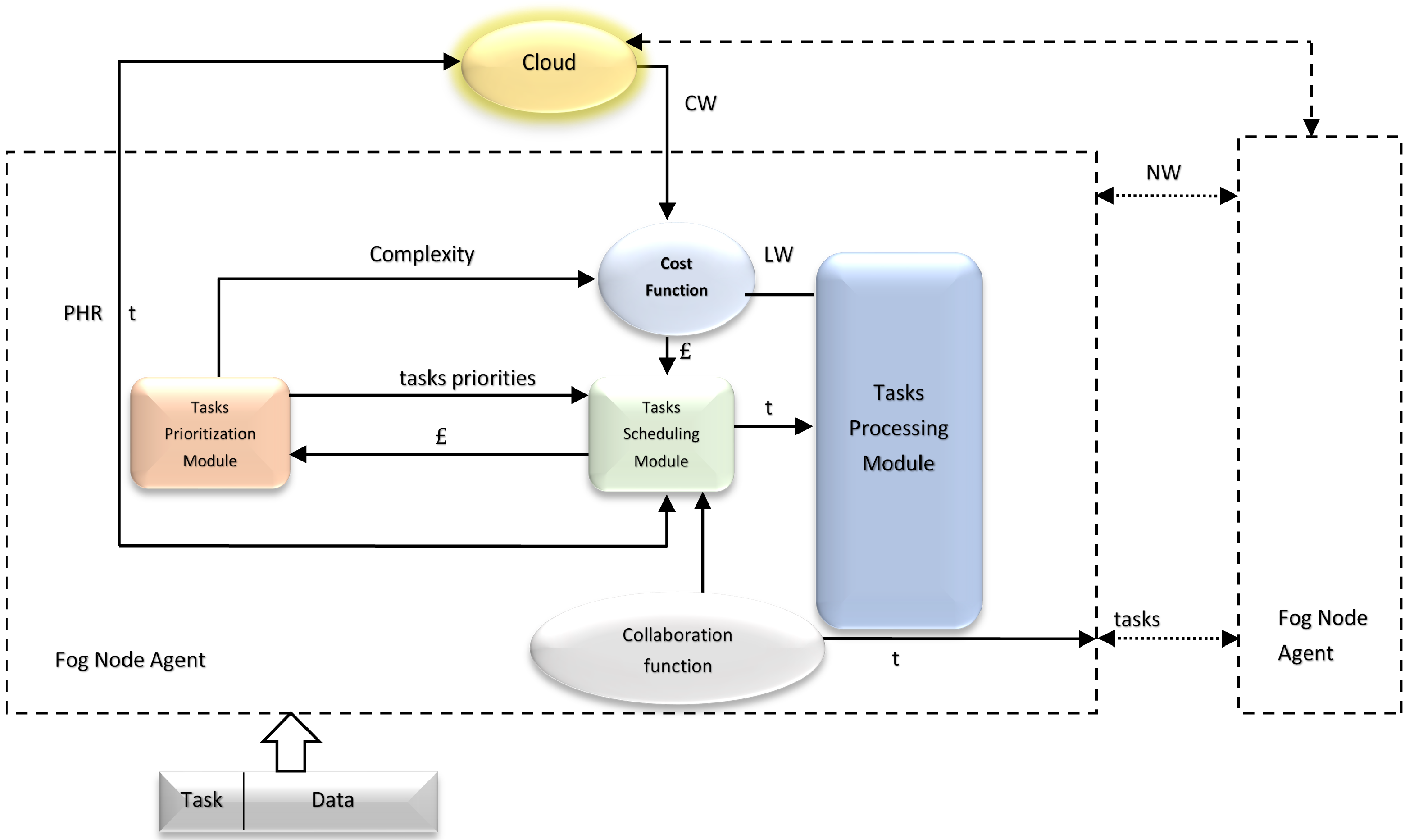
4.1. CHTM Model Architecture
4.1.1. CHTM Algorithm Steps
| Algorithm 1: CHTM Algorithms. |
 |
4.1.2. Low Level: Personal Agents (PA)
4.1.3. Intermediate Level: Fog Node Agents (FNAs)
4.1.4. High Level: Master Fog Node Agent (MFNA)
5. Results
- Examine the network usage;
- Examine the average response time for critical tasks;
- Measure the average network delay;
- Calculate the average energy consumption;
- Find the instance cost.
5.1. Experimental Configuration
5.2. Network Usage
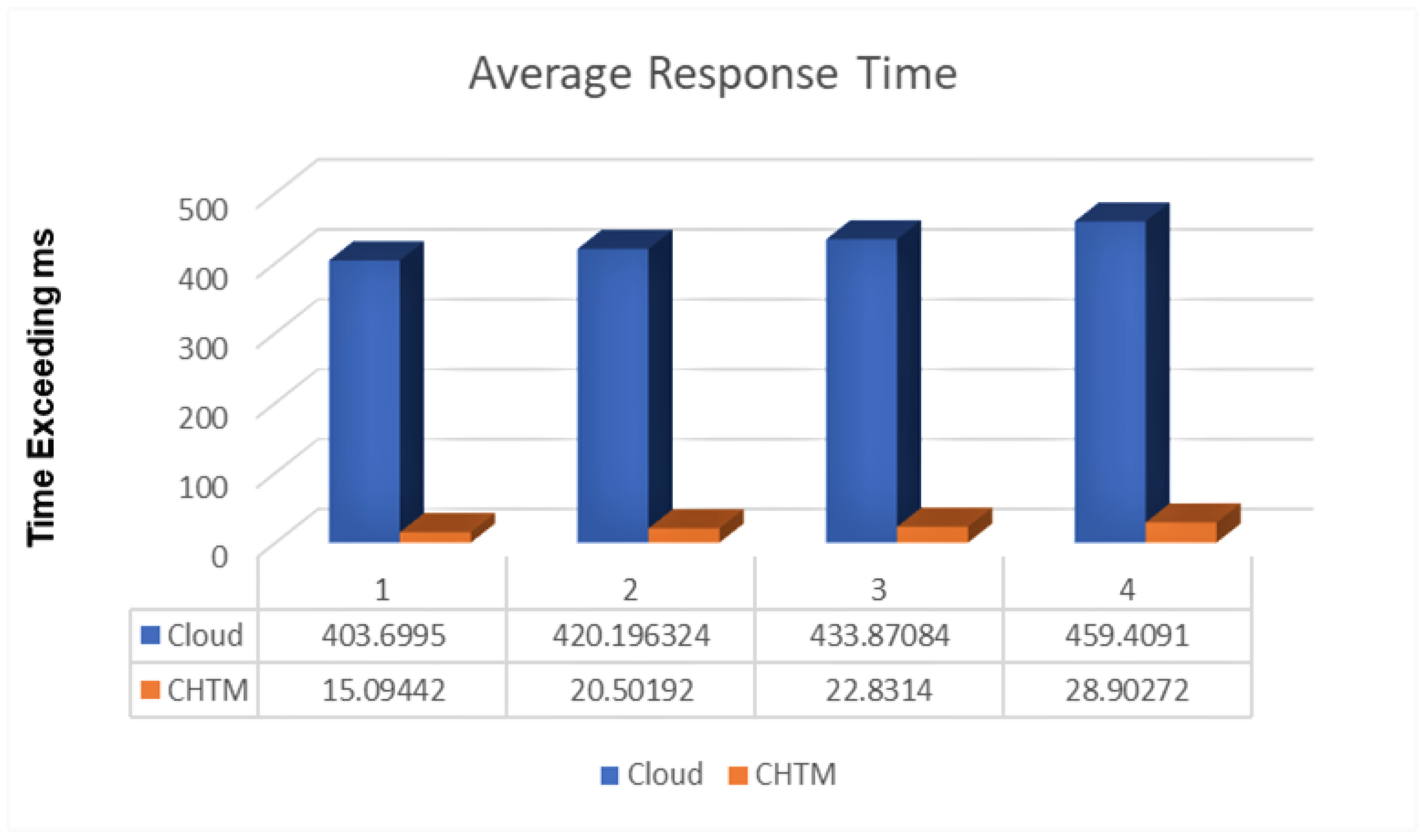
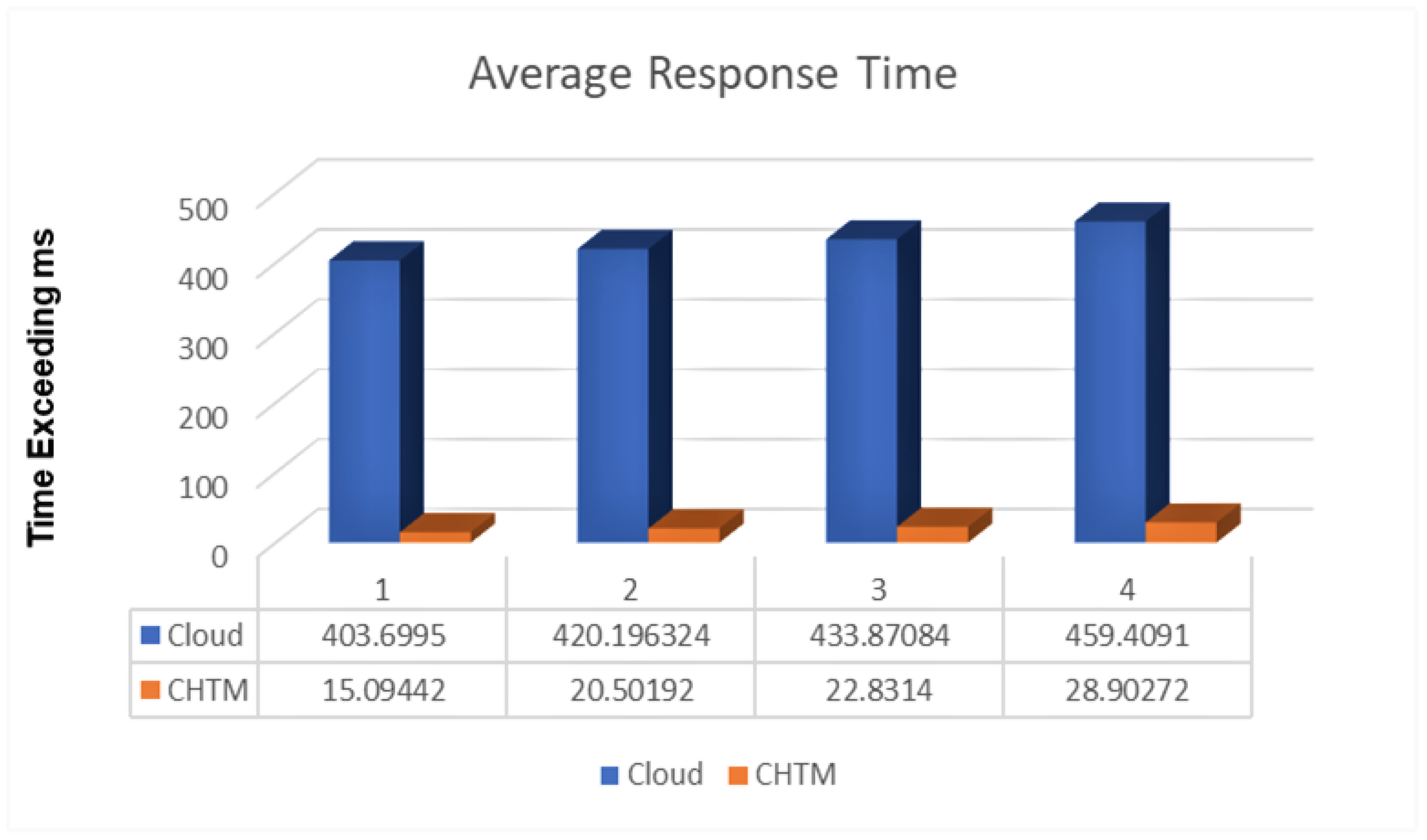
5.3. Response Time
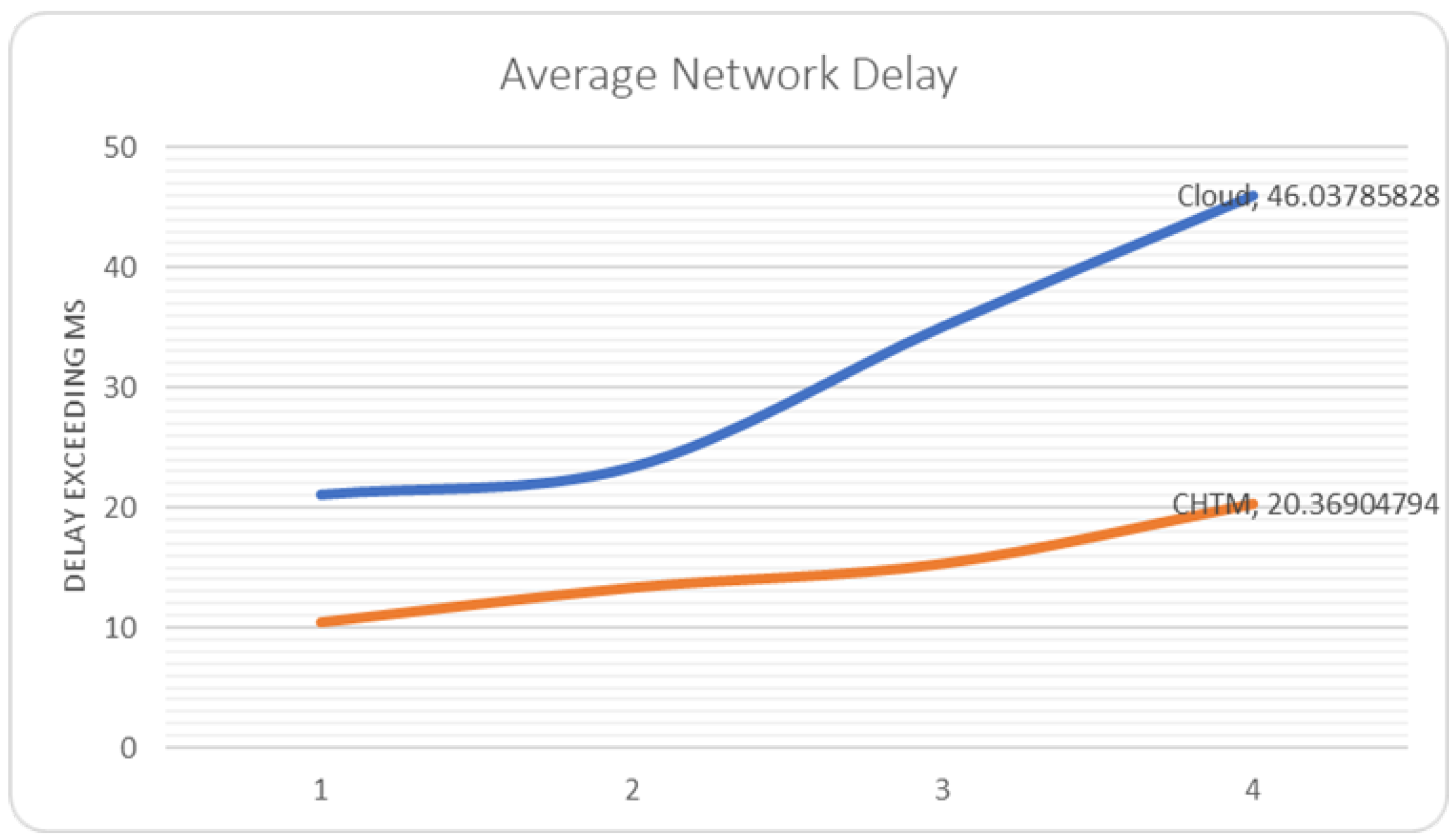
5.4. Network Delay
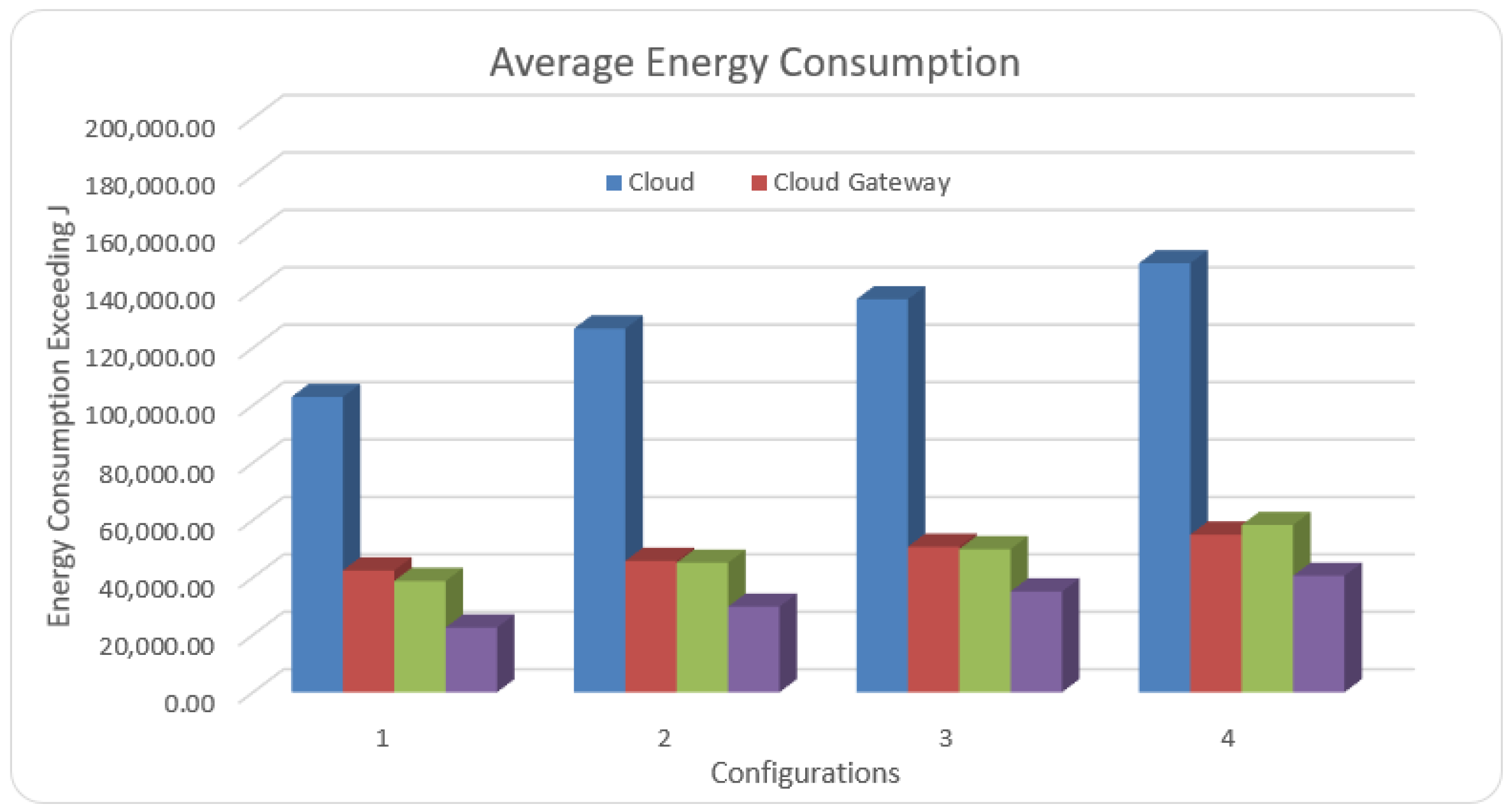
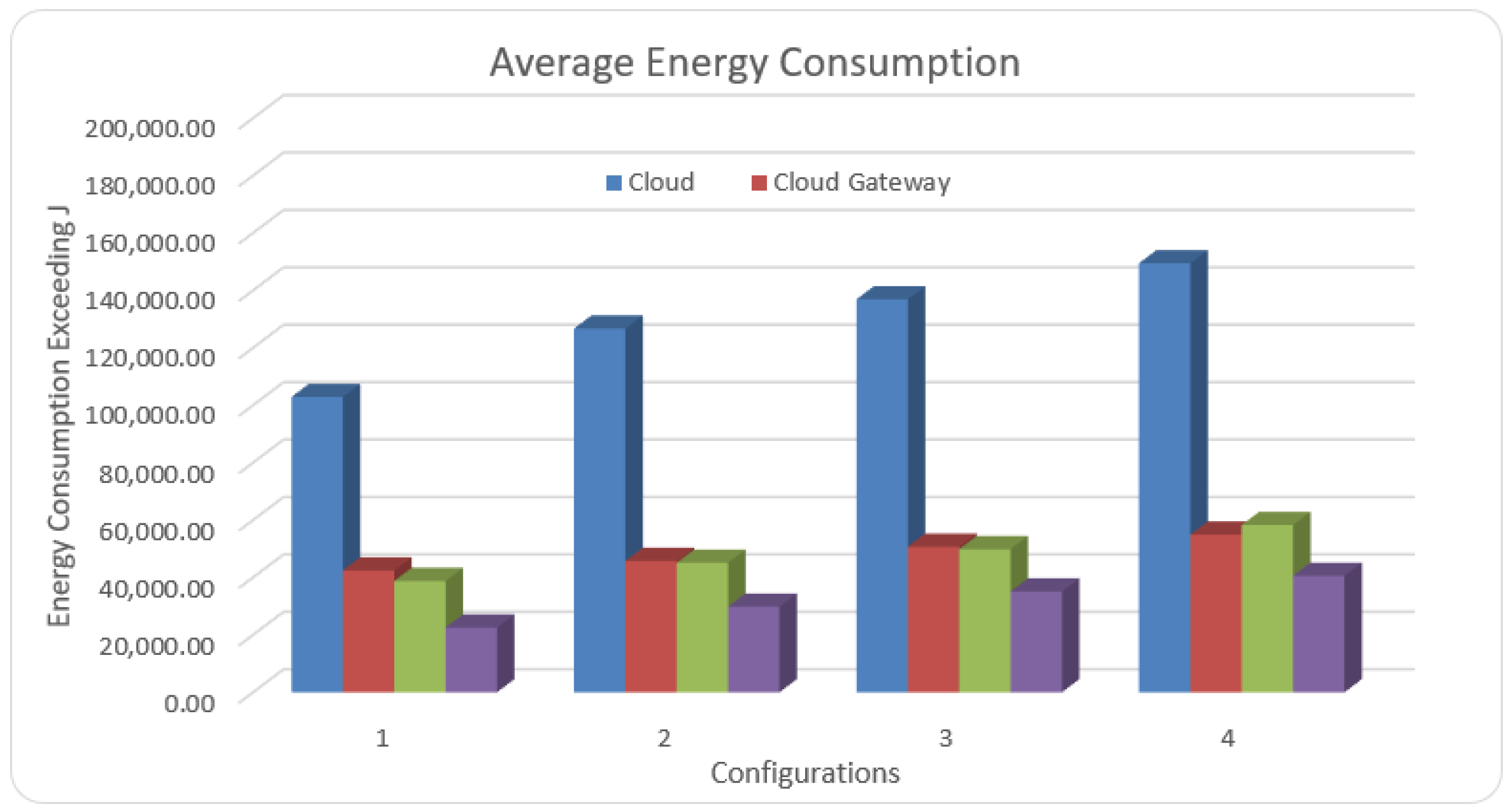
5.5. Energy Consumption
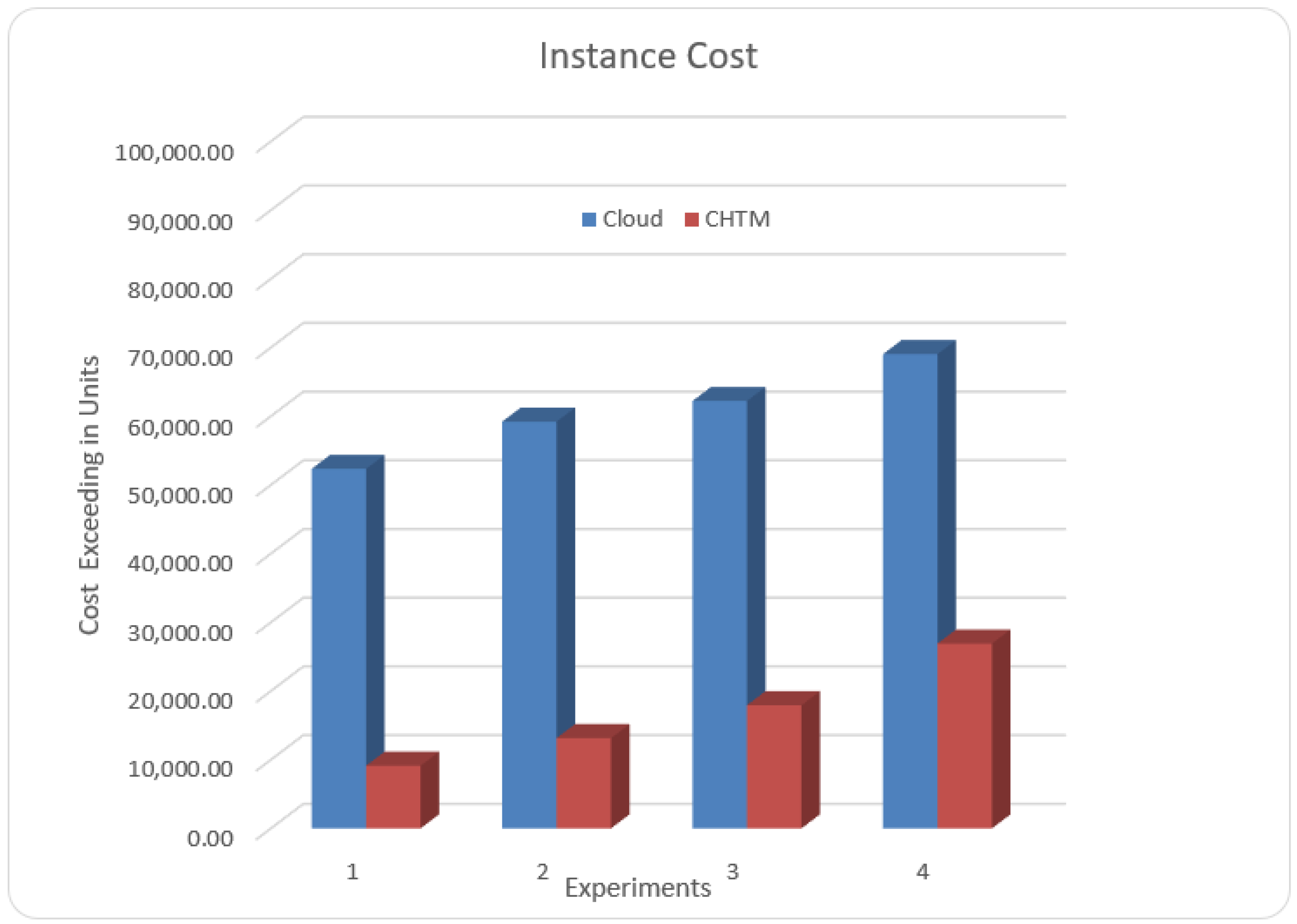
5.6. Cost
6. Comparison with State of the Art-Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mutlag, A.A.; Abd Ghani, M.K.; Arunkumar, N.A.; Mohammed, M.A.; Mohd, O. Enabling technologies for fog computing in healthcare IoT systems. Future Gener. Comput. Syst. 2019, 90, 62–78. [Google Scholar] [CrossRef]
- Lahoura, V.; Singh, H.; Aggarwal, A.; Sharma, B.; Mohammed, M.A.; Damaševičius, R.; Kadry, S.; Cengiz, K. Cloud computing-based framework for breast cancer diagnosis using extreme learning machine. Diagnostics 2021, 11, 241. [Google Scholar] [CrossRef]
- Tuli, S.; Basumatary, N.; Gill, S.S.; Kahani, M.; Arya, R.C.; Wander, G.S.; Buyya, R. HealthFog: An ensemble deep learning based Smart Healthcare System for Automatic Diagnosis of Heart Diseases in integrated IoT and fog computing environments. Future Gener. Comput. Syst. 2020, 104, 187–200. [Google Scholar] [CrossRef] [Green Version]
- Abdulkareem, K.H.; Mohammed, M.A.; Gunasekaran, S.S.; Al-Mhiqani, M.N.; Mutlag, A.A.; Mostafa, S.A.; Ali, N.S.; Ibrahim, D.A. A review of Fog computing and machine learning: Concepts, applications, challenges, and open issues. IEEE Access 2019, 7, 153123–153140. [Google Scholar] [CrossRef]
- Jin, Q.; Lin, R.; Zou, H.; Yang, F. A distributed fog computing architecture supporting multiple migrating mode. In Proceedings of the 2018 5th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2018 4th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Shanghai, China, 22–24 June 2018; pp. 218–223. [Google Scholar]
- Mahmud, R.; Ramamohanarao, K.; Buyya, R. Application management in fog computing environments: A taxonomy, review and future directions. ACM Comput. Surv. (CSUR) 2020, 53, 1–43. [Google Scholar] [CrossRef]
- Hong, H.K.; Park, S.S.; Song, S.K.; Youn, H.Y. A priority-based message scheduling scheme for multi-agent system dynamically, adapting to the environment change. In Proceedings of the 2009 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Zhangjiajie, China, 10–11 October 2009; pp. 191–196. [Google Scholar]
- Guo, S.; Qi, Y.; Jin, Y.; Li, W.; Qiu, X.; Meng, L. Endogenous Trusted DRL-Based Service Function Chain Orchestration for IoT. IEEE Trans. Comput. 2021. [Google Scholar] [CrossRef]
- Song, F.; Ai, Z.; Zhang, H.; You, I.; Li, S. Smart Collaborative Balancing for Dependable Network Components in Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2020, 17, 6916–6924. [Google Scholar] [CrossRef]
- Yoon, Y.S.; Ko, H.; Han, S.; Youn, H.Y. Priority-based message scheduling for the multi-agent system in ubiquitous environment. In Proceedings of the 2007 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology-Workshops, Silicon Valley, CA, USA, 5–12 November 2007; pp. 395–398. [Google Scholar]
- Mohammed, M.A.; Abdulkareem, K.H.; Al-Waisy, A.S.; Mostafa, S.A.; Al-Fahdawi, S.; Dinar, A.M.; Alhakami, W.; Abdullah, B.; Al-Mhiqani, M.N.; Alhakami, H.; et al. Benchmarking methodology for selection of optimal COVID-19 diagnostic model based on entropy and TOPSIS methods. IEEE Access 2020, 8, 99115–99131. [Google Scholar] [CrossRef]
- Mostafa, S.A.; Gunasekaran, S.S.; Mustapha, A.; Mohammed, M.A.; Abduallah, W.M. Modelling an adjustable autonomous multi-agent internet of things system for elderly smart home. In International Conference on Applied Human Factors and Ergonomics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 301–311. [Google Scholar]
- Herrera, M.; Pérez-Hernández, M.; Kumar Parlikad, A.; Izquierdo, J. Multi-agent systems and complex networks: Review and applications in systems engineering. Processes 2020, 8, 312. [Google Scholar] [CrossRef] [Green Version]
- Hussain, A.; Bui, V.H.; Kim, H.M. An effort-based reward approach for allocating load shedding amount in networked microgrids using multiagent system. IEEE Trans. Ind. Inform. 2019, 16, 2268–2279. [Google Scholar] [CrossRef]
- Rao, P.T.; Rao, S.K.; Manikanta, G.; Kumar, S.R. Distinguishing normal and abnormal ECG signal. Indian J. Sci. Technol. 2016, 9, 1–5. [Google Scholar]
- Auluck, N.; Rana, O.; Nepal, S.; Jones, A.; Singh, A. Scheduling real time security aware tasks in fog networks. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Ni, L.; Zhang, J.; Jiang, C.; Yan, C.; Yu, K. Resource allocation strategy in fog computing based on priced timed petri nets. Ieee Internet Things J. 2017, 4, 1216–1228. [Google Scholar] [CrossRef]
- Wan, J.; Chen, B.; Wang, S.; Xia, M.; Li, D.; Liu, C. Fog computing for energy-aware load balancing and scheduling in smart factory. IEEE Trans. Ind. Inform. 2018, 14, 4548–4556. [Google Scholar] [CrossRef]
- Choudhari, T.; Moh, M.; Moh, T.S. Prioritized task scheduling in fog computing. In Proceedings of the ACMSE 2018 Conference, Richmond, Kentucky, 29–31 March 2018; pp. 1–8. [Google Scholar]
- Fellir, F.; El Attar, A.; Nafil, K.; Chung, L. A multi-Agent based model for task scheduling in cloud-fog computing platform. In Proceedings of the 2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 2–5 February 2020; pp. 377–382. [Google Scholar]
- Jamil, B.; Shojafar, M.; Ahmed, I.; Ullah, A.; Munir, K.; Ijaz, H. A job scheduling algorithm for delay and performance optimization in fog computing. Concurr. Comput. Pract. Exp. 2020, 32, e5581. [Google Scholar] [CrossRef]
- Mass, J.; Chang, C.; Srirama, S.N. Edge Process Management: A case study on adaptive task scheduling in mobile IoT. Internet Things 2019, 6, 100051. [Google Scholar] [CrossRef]
- Kolomvatsos, K.; Anagnostopoulos, C. Multi-criteria optimal task allocation at the edge. Future Gener. Comput. Syst. 2019, 93, 358–372. [Google Scholar] [CrossRef] [Green Version]
- Al-Khafajiy, M.; Baker, T.; Al-Libawy, H.; Maamar, Z.; Aloqaily, M.; Jararweh, Y. Improving fog computing performance via fog-2-fog collaboration. Future Gener. Comput. Syst. 2019, 100, 266–280. [Google Scholar] [CrossRef]
- Mutlag, A.A.; Khanapi Abd Ghani, M.; Mohammed, M.A.; Maashi, M.S.; Mohd, O.; Mostafa, S.A.; Abdulkareem, K.H.; Marques, G.; de la Torre Díez, I. MAFC: Multi-agent fog computing model for healthcare critical tasks management. Sensors 2020, 20, 1853. [Google Scholar] [CrossRef] [Green Version]
- D’Aniello, G.; De Falco, M.; Mastrandrea, N. Designing a multi-agent system architecture for managing distributed operations within cloud manufacturing. Evol. Intell. 2020, 16, 1–8. [Google Scholar] [CrossRef]
- Blake, C. UCI Repository of Machine Learning Databases. 1998. Available online: http://www.ics.uci.edu/~{}mlearn/MLRepository.html (accessed on 20 May 2021).
- Mutlag, A.A.; Ghani, M.K.A.; Mohammed, M.A. A Healthcare Resource Management Optimization Framework for ECG Biomedical Sensors. In Efficient Data Handling for Massive Internet of Medical Things; Springer: Berlin/Heidelberg, Germany, 2021; pp. 229–244. [Google Scholar]
- Podder, A.K.; Al Bukhari, A.; Islam, S.; Mia, S.; Mohammed, M.A.; Kumar, N.M.; Cengiz, K.; Abdulkareem, K.H. IoT based smart agrotech system for verification of Urban farming parameters. Microprocess. Microsyst. 2021, 82, 104025. [Google Scholar] [CrossRef]
- Abdulkareem, K.H.; Mohammed, M.A.; Salim, A.; Arif, M.; Geman, O.; Gupta, D.; Khanna, A. Realizing an effective COVID-19 diagnosis system based on machine learning and IOT in smart hospital environment. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Approach | Fog–Cloud Interoperability | Priority Scheduling | MAS | Resource Sharing | Dynamic Tasks Al |
|---|---|---|---|---|---|---|
| [18] | RT-SANE (Re al-Time Security Aware scheduling on the Network Edge) | ✕ | ✓ | ✓ | ✕ | ✕ |
| [19] | A strategy of re source allocation of computing fog depending on Priced Timed Petri nets (PTPN) | ✕ | ✓ | ✕ | ✓ | ✕ |
| [20] | Energy-aware Load Balancing and Scheduling (ELBS) method | ✕ | ✓ | ✓ | ✕ | ✕ |
| [20] | Task scheduling algorithm in the layer of fog de pending on levels of priority | ✓ | ✓ | ✕ | ✓ | ✕ |
| [21] | Critical Healthcare Task Manage ment Model (CHTM) | ✓ | ✓ | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mutlag, A.A.; Ghani, M.K.A.; Mohammed, M.A.; Lakhan, A.; Mohd, O.; Abdulkareem, K.H.; Garcia-Zapirain, B. Multi-Agent Systems in Fog–Cloud Computing for Critical Healthcare Task Management Model (CHTM) Used for ECG Monitoring. Sensors 2021, 21, 6923. https://doi.org/10.3390/s21206923
Mutlag AA, Ghani MKA, Mohammed MA, Lakhan A, Mohd O, Abdulkareem KH, Garcia-Zapirain B. Multi-Agent Systems in Fog–Cloud Computing for Critical Healthcare Task Management Model (CHTM) Used for ECG Monitoring. Sensors. 2021; 21(20):6923. https://doi.org/10.3390/s21206923
Chicago/Turabian StyleMutlag, Ammar Awad, Mohd Khanapi Abd Ghani, Mazin Abed Mohammed, Abdullah Lakhan, Othman Mohd, Karrar Hameed Abdulkareem, and Begonya Garcia-Zapirain. 2021. "Multi-Agent Systems in Fog–Cloud Computing for Critical Healthcare Task Management Model (CHTM) Used for ECG Monitoring" Sensors 21, no. 20: 6923. https://doi.org/10.3390/s21206923
APA StyleMutlag, A. A., Ghani, M. K. A., Mohammed, M. A., Lakhan, A., Mohd, O., Abdulkareem, K. H., & Garcia-Zapirain, B. (2021). Multi-Agent Systems in Fog–Cloud Computing for Critical Healthcare Task Management Model (CHTM) Used for ECG Monitoring. Sensors, 21(20), 6923. https://doi.org/10.3390/s21206923