4.1. Datasets
In order to verify the superiority of the proposed model, we utilized real-world examples in two datasets below, instead of using synthetic ones.
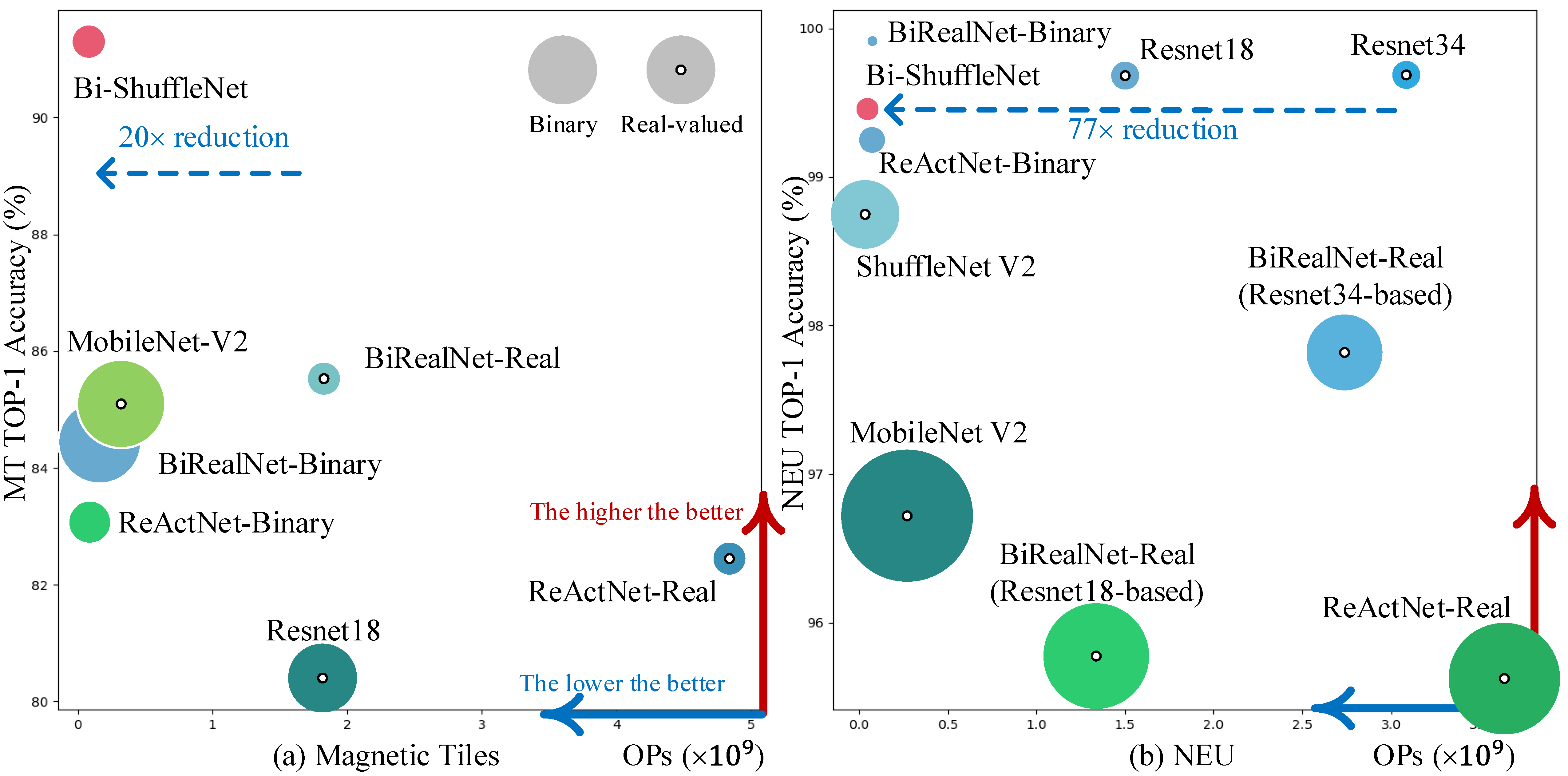
Magnetic Tile (MT) [
9] provides 472 surface defect images, with 6 classes for classification. Due to the scarcity of the data, we augmented the randomly split training set by rotation (0°, 90°, 180°, and 270°) and horizontal flipping, leading to a training set 8× larger than the unaugmented training set. Though most of the images in MT contain a certain type of rain-streak-like noise and severe vignette effect in the corner, we still gave up any crop operation, which was applied in [
11] to ensure the most relevant defective regions exist in patches.
The NEU Surface Defect Database [
43] is composed of 300 photographs per class and 6 classes (rolled-in scale, patches, crazing, pitted surface, inclusion, scratches) in total with defects whose size is 200 × 200 for classification; for segmentation, [
43] do not provide pixel-wise labels, but bounding box annotations. Only for patch defects did we obtain pixel-wise ground truth from [
11,
12]. For patch defects, there were roughly 22.9% of pixels labeled as defects, while the other 77.1% were labeled as non-defects. Messy backgrounds with a low signal-to-noise ratio (SNR) make it a more challenging task.
There is no formal data split for training, validation, and test sets in either dataset; therefore, we randomly partitioned them in a 7:1:2 fashion. All the performance results reported in the paper were calculated in 5 independent splits on average for credibility, if not specified.
4.2. Experimental Details
The training was conducted on the training set initially, and the trained parameters with the highest validation accuracy across all iterations were adopted for testing. All the binary networks were trained in two rounds because of RSign, RPReLU, and RSiLU in proposed networks, as in [
34]. At the first stage, we trained the learnable variables of RSign, RPReLU, or RSiLU with real-valued weight parameters from scratch. Then, at the second stage, binary networks were initialized by the weights learnt in the first stage, and fine-tuned with weights in the binary version. It is worth noting that, at both stages, the backpropagation was guided by cross-entropy loss between the binary network output and the ground truth. Other details are given below.
Coarse-grained task: In terms of Magnetic Tile, for all real-valued networks, the batch size was set as 32, training for 200 epochs with the Adam optimizer; the loss calculation is based on Tversky Loss [
44], which is widely applied in defect detection and lesion attribute segmentation, due to its strength in data imbalances. The initial learning rate was
, and was adjusted by the One Circle method [
45] during training.
As for NEU, for transferred Resnet18, Resnet34, and MobileNet V2, we employed the Adam optimizer and set the learning rate as when training on the target dataset. For the real version of ReActNet and BiRealNet, we also applied the Adam optimizer, but set the learning rate to . All the hyperparameters above were selected by both experience and grid search to avoid the training process falling into under-fitted or over-fitted situations.
In terms of all the 1-bit CNNs, the learning rate was decayed with the cosine annealing strategy and warm-up was applied for the first 5 epochs. The initial learning rates were
and
, respectively, in step 1 and step 2. In the first round of 1-bit CNN training, only learnable parameters in RSign and the activation function are optimized in priority, while both parameters and weights in 1-bit convolutions are optimized together in the second round, thus, a larger learning rate is required to accelerate. The Adam optimizer was also selected as it can normally prevent the training of 1-bit CNNs falling into the situation of local minima [
46], compared with other optimizers.
Fine-grained task: For the unaugmented NEU dataset, images were rotated by a random degree in [0°, 90°, 180°, 270°], and flipped horizontally or not at a 50/50 probability in the data pre-processing step. For the original full-precision U-Net, the batch size was set as 32, training for 200 epochs with the Adam optimizer. The learning rate was set as and loss was calculated by the Tversky method. As for the proposed U-BiNet, at both training steps, we used the Adam optimizer for 200 epochs with batch size as 8 and learning rate as . Taking the smaller batch size and learning rate than that of U-Net into account, we intended to ensure that the training of sensitive binary parameters in U-BiNet was stable and avoid overfitting.
4.4. Ablation Study
We conducted ablation experiments to classify each component’s exclusive contribution and the collaborative contribution of each unique combination towards the overall performance.
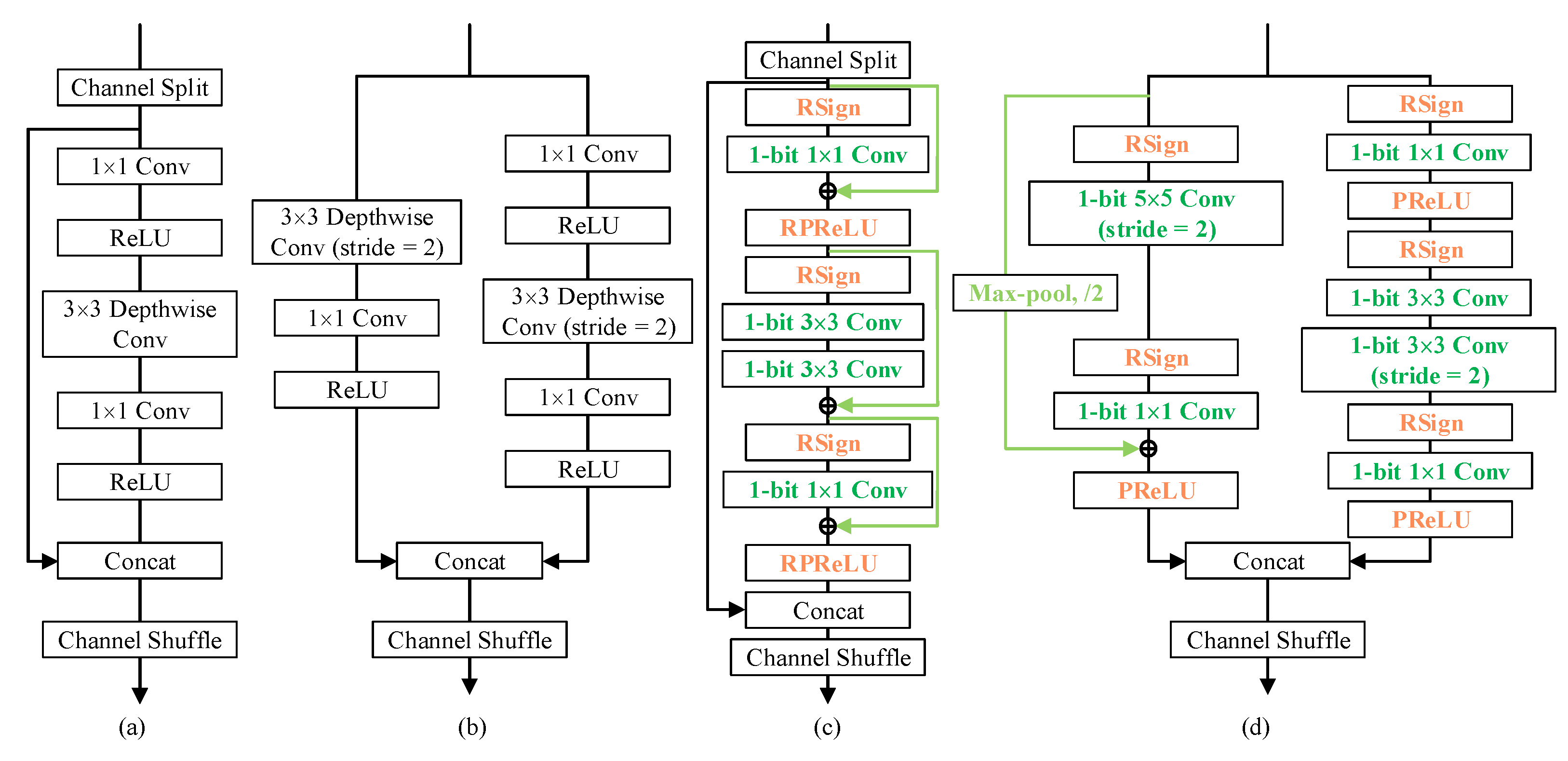
Initially, we analyzed the individual effects of the following modifications on the binarized ShuffleNet V2 0.5× at the very beginning. The abbreviations of modifications used in this section are as below:
: The baseline model, where RSign and RPReLU are introduced in Shufflenet V2 0.5× while all convolutions in the repeated units are replaced with 1-bit convolutions.
: Add shortcuts in the right branch of the basic unit.
: Add shortcuts in the left branch of the down-sampling unit.
: Reset the kernel size of the 1-bit convolution layer that substitutes the depthwise convolution layer in the left branch of the down-sampling unit. In addition, denotes 2 consecutive convolution layers on the left branch to obtain the same receptive field as a single convolution layer.
: Reset the kernel size of the 1-bit convolution layer that substitutes the depthwise convolution layer in the right branch of both basic and down-sampling units. Similarly, denotes 2 consecutive convolution layers on right branch.
: Reset the kernel size of the first vanilla convolution layer in Bi-ShuffleNet.
: Substitute the average pooling with max pooling in the shortcut in the down-sampling unit.
Experiments were carried out on Magnetic Tile and NEU datasets, as shown in
Table 5 and
Table 6, respectively, where we found that those proposed modifications are independent and can contribute collectively towards improving the overall accuracy. Besides, we can also draw some conclusions, which are beneficial for the design of networks in defect detection and construction of binary networks.
As for defect detection tasks, these turn out to be more efficient when enlarging the kernel size of convolution layers, no matter whether in building units (i.e.,
and
) or ahead of basic units (i.e.,
). When extending
to 5, the accuracy increases by 3.05% (II and III in
Table 6) and 7.75% (III and IV in
Table 5), respectively, in NEU and MT, without hurting stability. When
grows from 3 to 9, the accuracy jumps by 0.22% (III and VI in
Table 6) and 10% (VI and VIII in
Table 5) in NEU and MT, with comparable stability. When decomposing the 5 × 5 convolution into 2 consecutive 3 × 3 convolutions, considerable improvements can also be seen in IX, X, and XI in
Table 5, which is expected as they can enhance the nonlinear representation capacity [
51]. In addition, max pooling does function in downsampling when shortcuts are introduced in defect detectors. The intermediate networks with max pooling in shortcuts witness a growth of 0.95% (III and IV in
Table 6) and 2.25% (V and VI in
Table 5) in NEU and MT, and at most a 2× stability enhancement.
In terms of the design of a 1-bit CNN, real-valued shortcuts are of great importance for the contribution to the final accuracy. Intrinsically, a shortcut inspires the potential of the deep network by avoiding accuracy degradation [
52]. Besides, as shown in
Figure 2c,d, the shortcut normally connects the previous real-valued activations after activation functions to the later output of binary convolution; thus, it preserves the intermediate real-valued activations as much as possible, facilitating the network to approach the representation of networks in full precision, which is difficult and constantly pursued in the field of network binarization [
53,
54]. As verified in the tables, after adding shortcuts in basic and down-sampling units, the network beat the baselines by an obvious margin of 4.45% (I and II in
Table 6) and 15.72% (I and III in
Table 5) in NEU and MT datasets, respectively, with better stability and negligible extra computational cost.
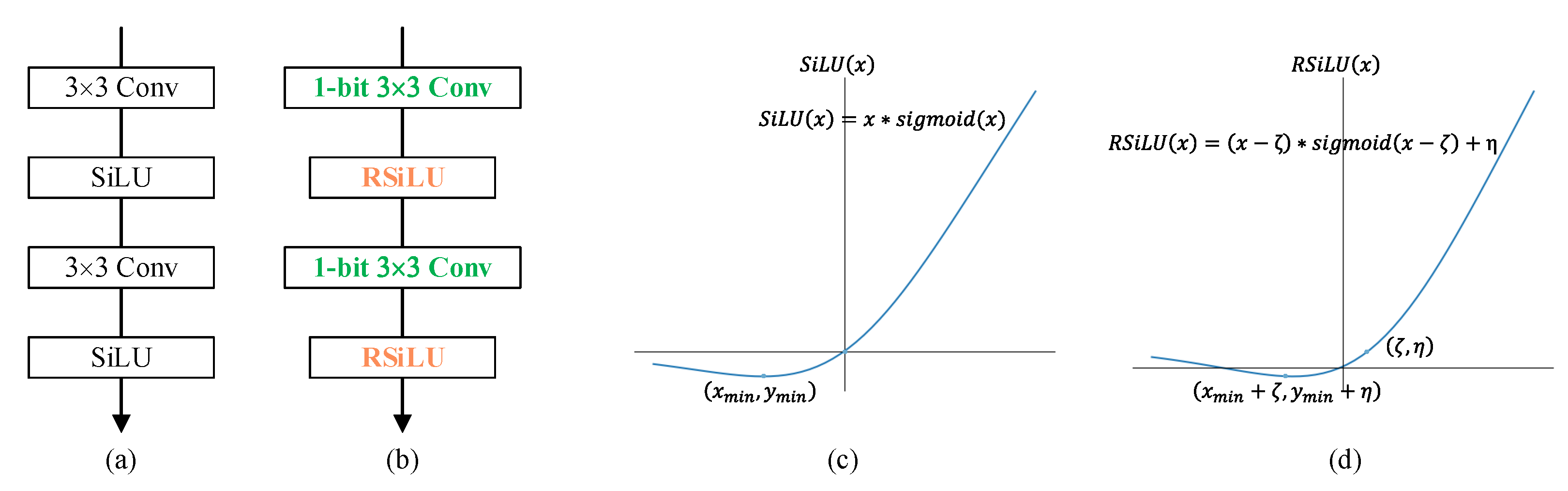
The effectiveness of RSiLU in U-BiNet is also demonstrated in
Table 7. In NEU Patches, U-BiNet with RSiLU shows overwhelming performance in each indicator. However, in MT, U-BiNet without RSiLU possesses relatively high FNR and MAE, but lower FPR, which demonstrates that it is prone to producing pseudo-results. Therefore, a logical deduction is that the addition of learnable variables on binary activations to explicitly shift activation distribution is simple yet helpful.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}