
Optimizing 3D Convolution Kernels on Stereo Matching for Resource Efficient Computations


Abstract
:1. Introduction
- A throughout discussion about optimizing already established 3D convolution kernels on stereo matching algorithms;
- A network design guideline when optimizing 3D convolution kernels on stereo matching algorithms for accurate disparity estimation and less computational complexity;
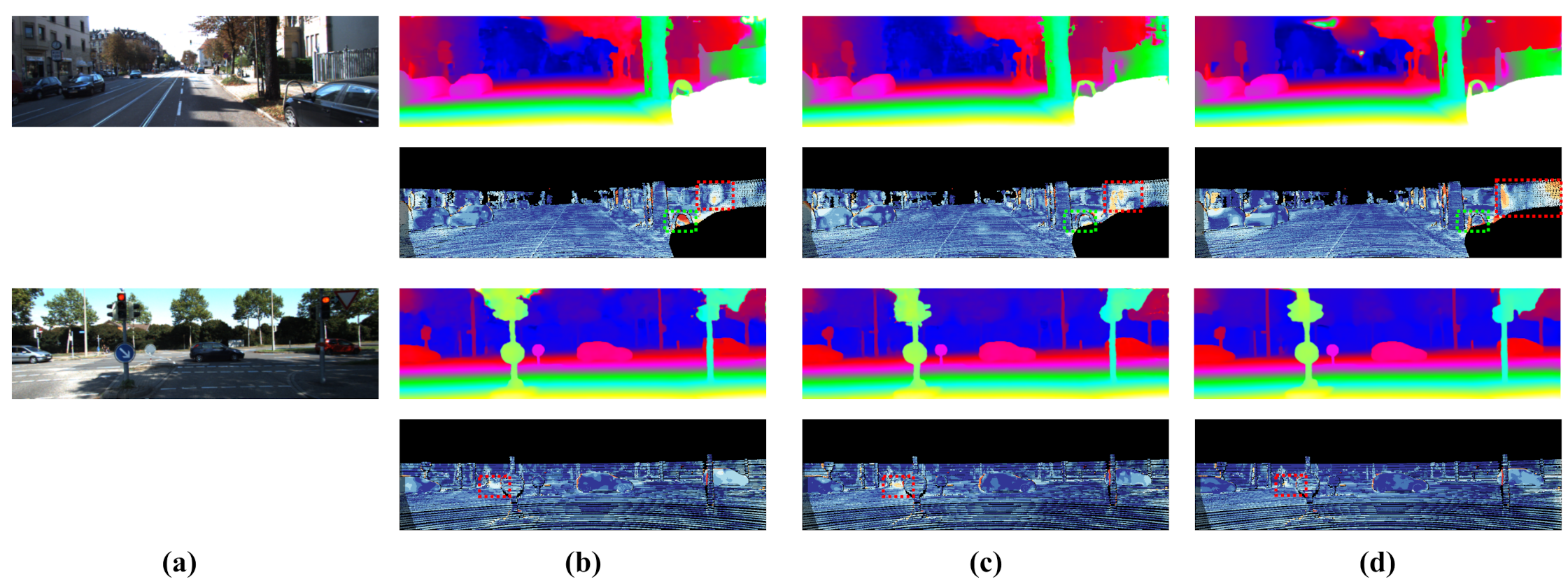
- By following the guideline above and without changing the architecture, our model performs comparable results to modern stereo matching algorithms with significantly less computational complexity.
2. Related Works
2.1. Kernel-Based Methods
2.2. Stereo Matching
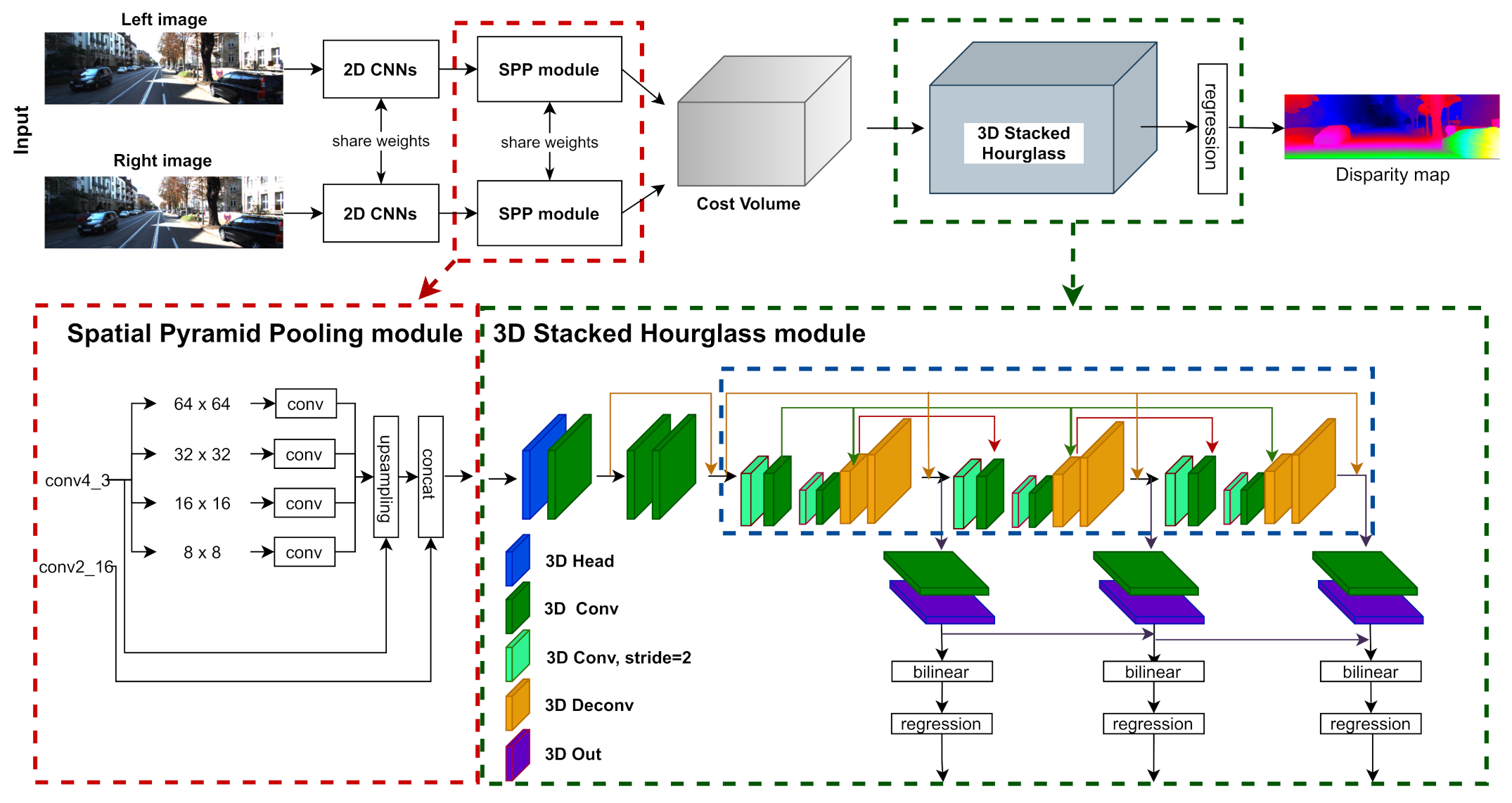
3. Network Architecture
3.1. PSMNet
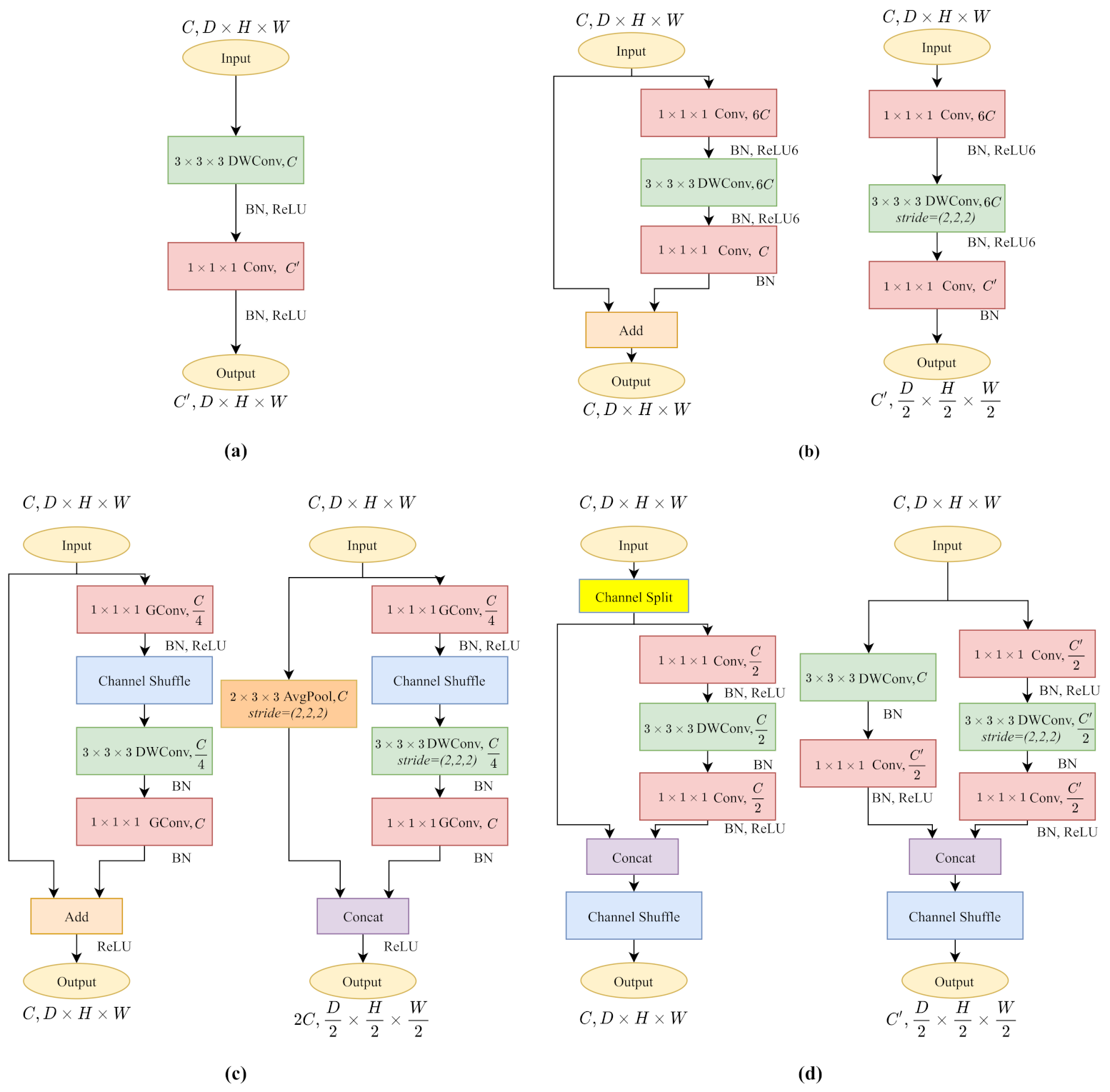
3.2. Architecture of 3D Convolution Kernels
3.2.1. 3D MobileNetV1
3.2.2. 3D MobileNetV2
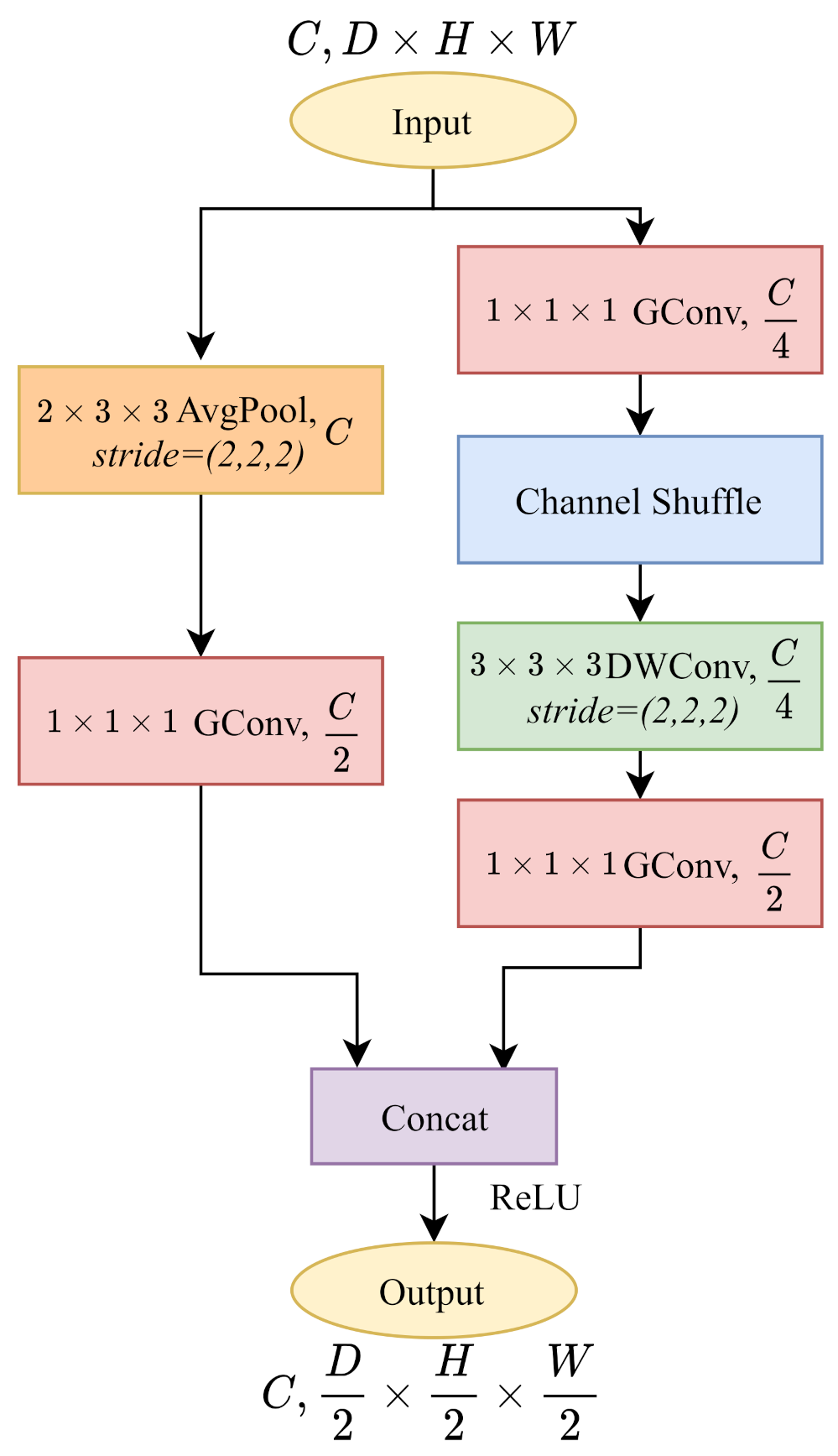
3.2.3. 3D ShuffleNetV1
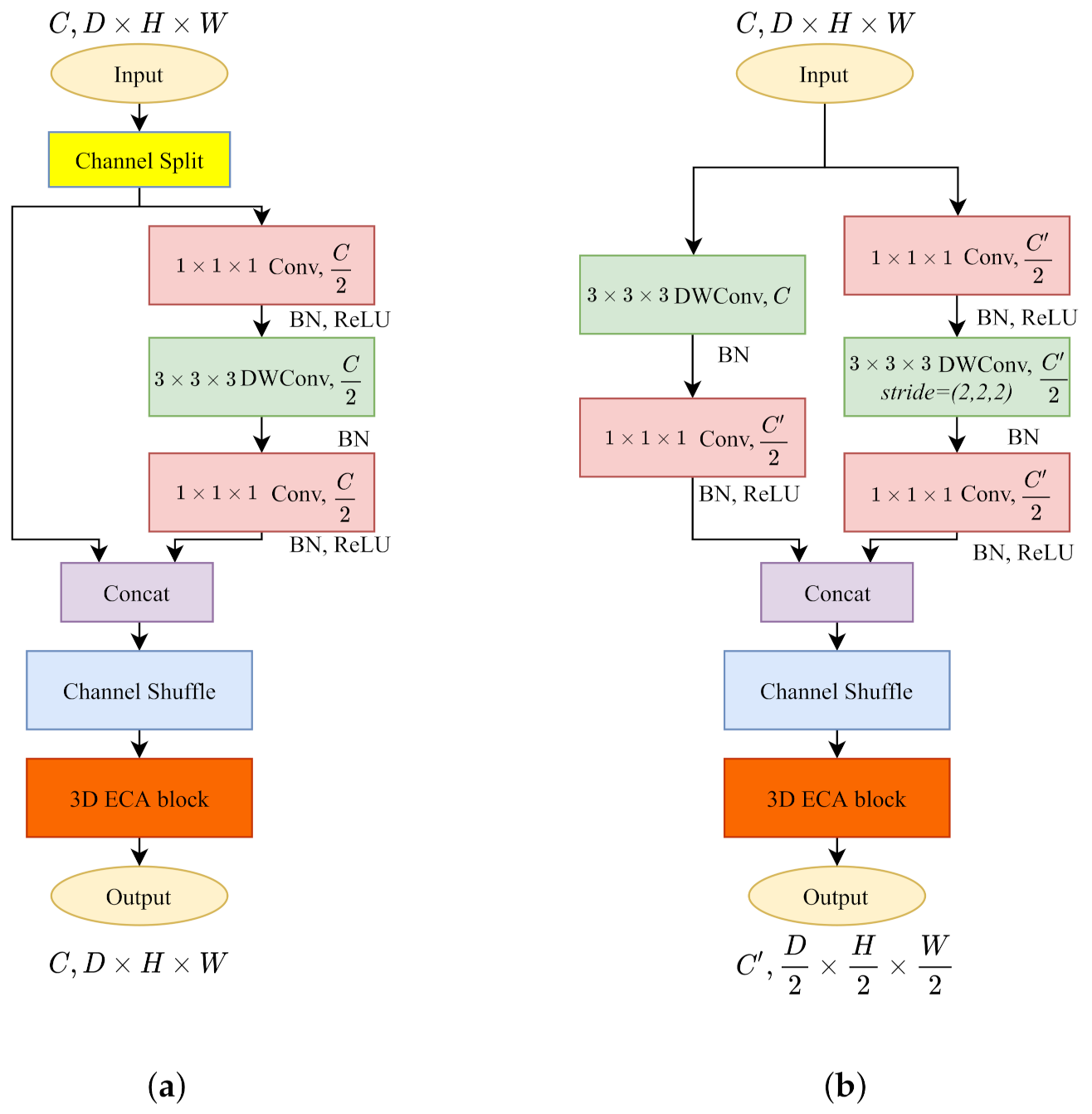
3.2.4. 3D ShuffleNetV2
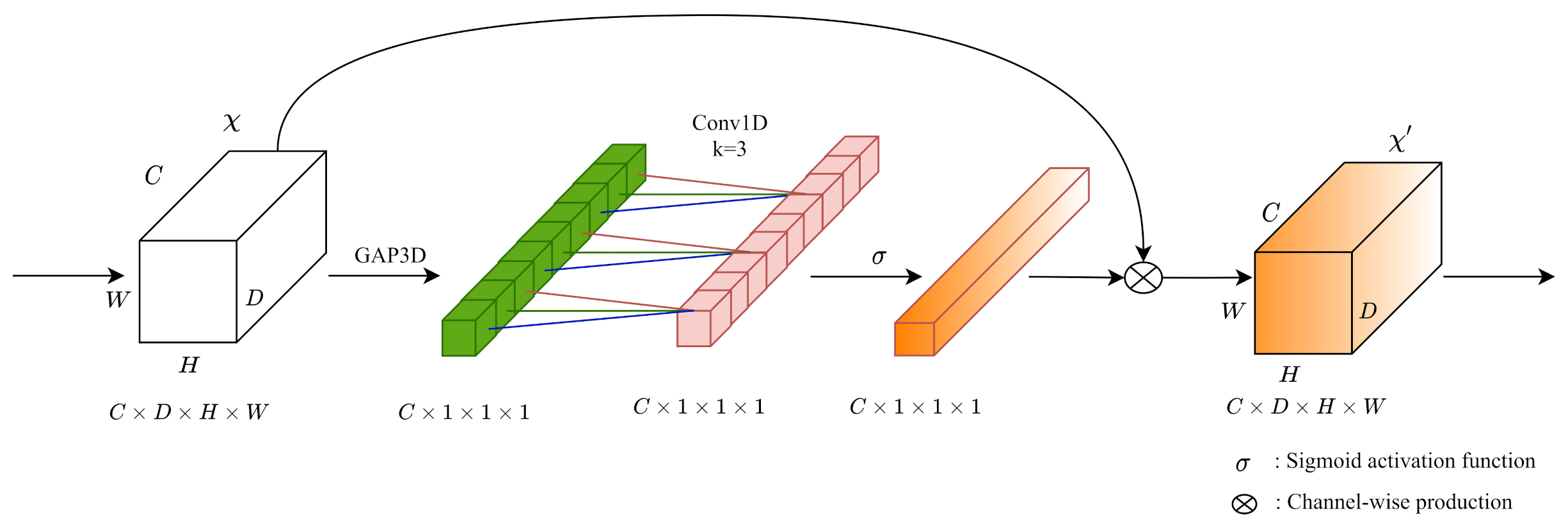
3.2.5. 3D ECA Blocks
4. Computational Complexity Matrics
- Parameters are the number of trainable neurons in the designed convolutional neural network;
- Multiply-Add operations(MAdd) describe the accumulated operations when training neural networks. [41] explain the calculation of floating point operations (FLOPs). MAdd is approximately half of FLOPs;
- Memory Access Cost (MAC) is the amount of allocating computational resource during the training process;
- Model Size shows the storage size of all trained parameters.
5. Network Design Pipline
5.1. Implementation
5.1.1. Dataset and Evaluation Metrics
- Scene Flow is a large scale dataset with synthetic stereo images. It contains 35,454 training and 4370 testing image pairs with resolutions. We report the end-point-error (EPE) for evaluations, where EPE shows the average disparity error in pixels;
- KITTI 2015 contains real street scenes taken by driving a car. It includes 200 training image pairs with ground truth disparity maps collected by LiDAR and 200 other test image pairs without ground truth disparity. The size of the training and test images is . We repot D1-all metrics as the official leaderboard.
5.1.2. Implementation Details
5.2. Optimize 3D Convolution Kernels in PSMNet
5.2.1. 3D Head
5.2.2. 3D Convoltion Layers
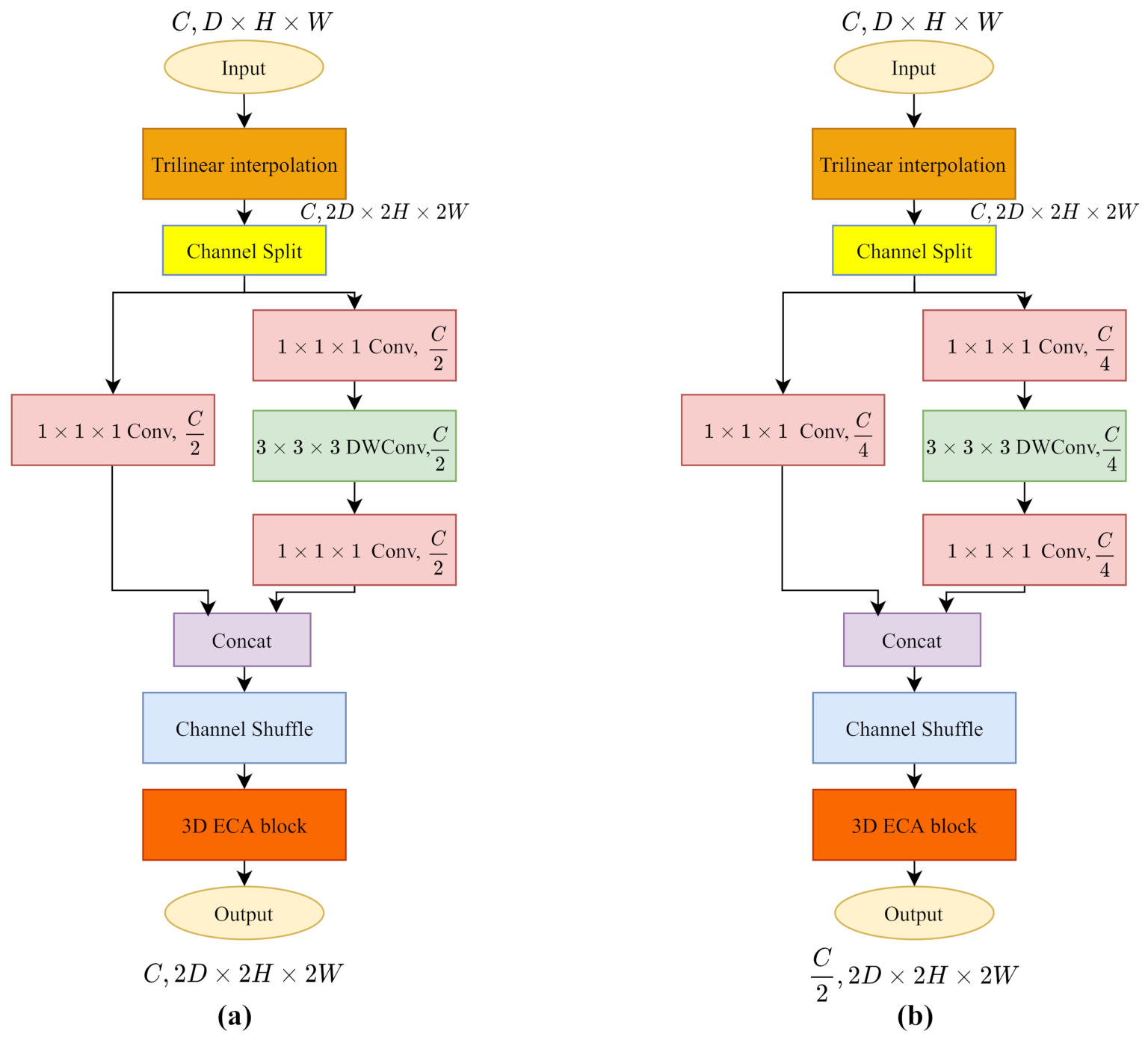
5.2.3. 3D Deconvoltion Layers
5.2.4. 3D Out
5.2.5. Network Design Overview
6. Benchmark Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. 10-Fold Cross Validation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | All (%) | Noc (%) | Loss | 3-Pixel Error in | ||||
|---|---|---|---|---|---|---|---|---|
| D1-Bg | D1-Fg | D1-All | D1-Bg | D1-Fg | D1-All | Training Set | ||
| Cross Validation | 2.03 | 4.89 | 2.51 | 1.86 | 4.53 | 2.30 | 0.291 | 0.707 |
| 10-fold Cross Validation | 1.94 | 4.76 | 2.41 | 1.75 | 4.42 | 2.22 | 0.314 | 0.747 |
Appendix B. 3D ECA-ShuffleNetV2 Blocks
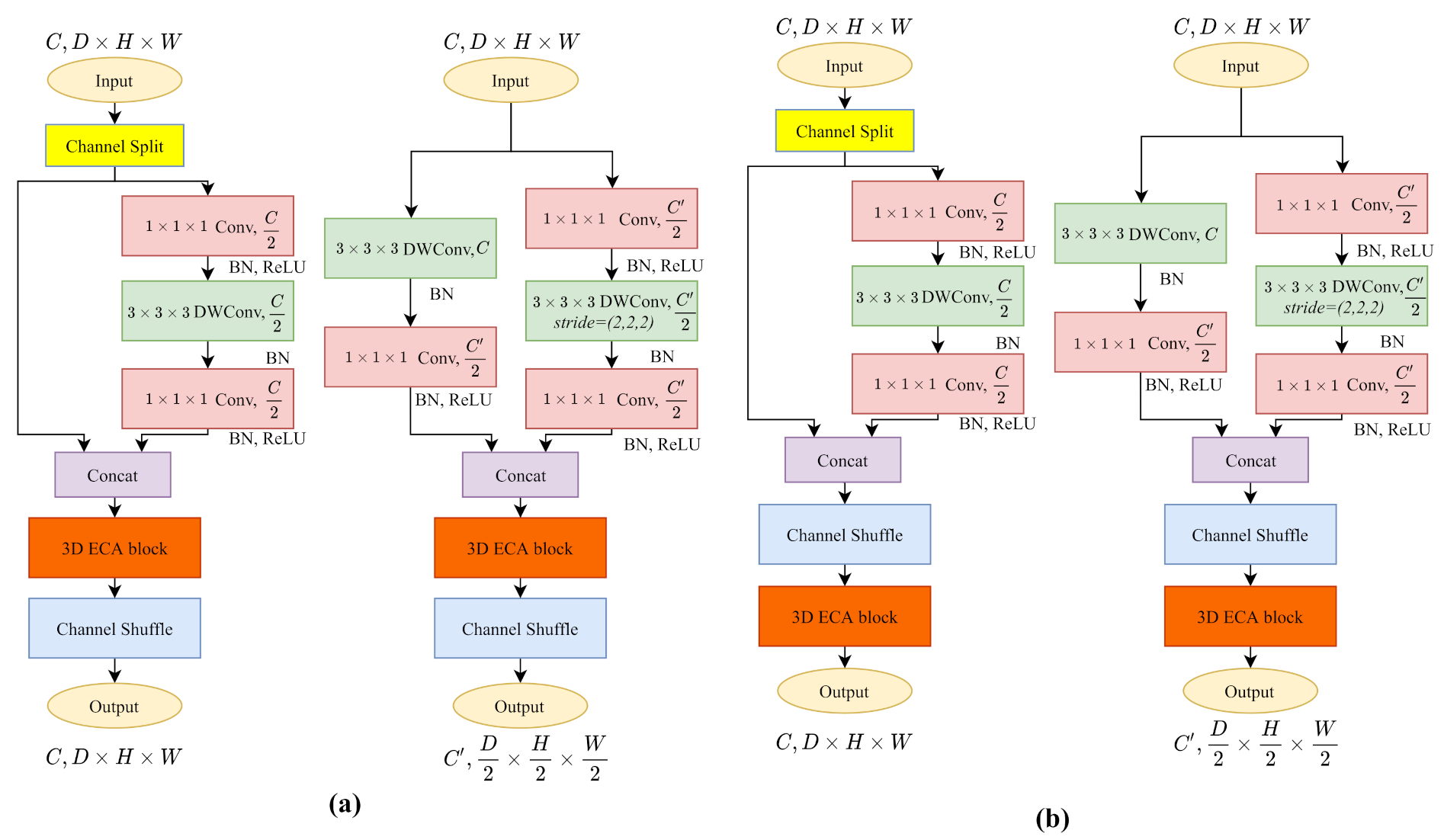
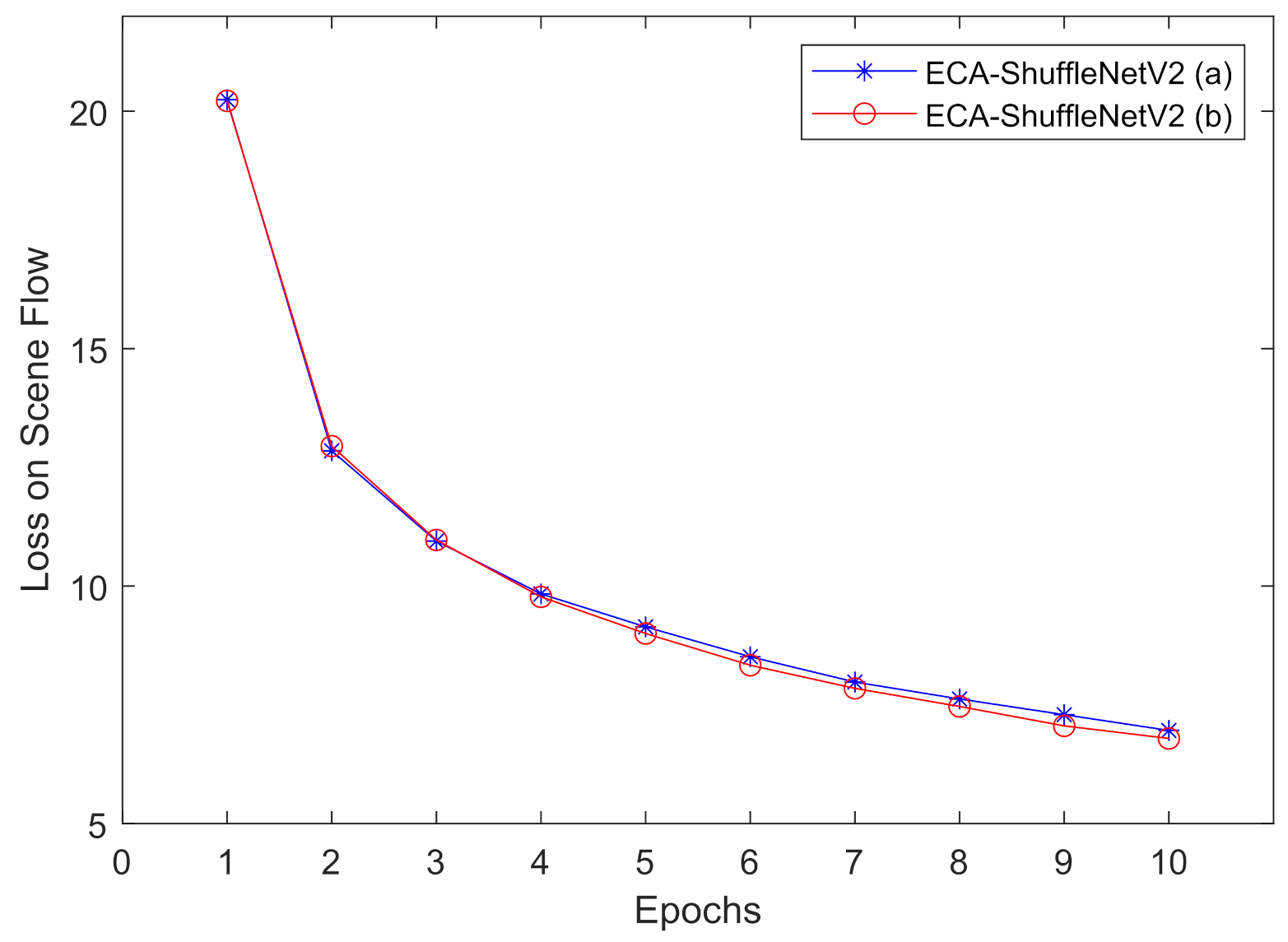
Appendix C. Parameterize Model Details on Optimizing 3D Convolution Kernels
| Method | Basline | M_V1 | M_V2 | S_V1 | S_V2 | +M_V1_Head | +ECA | +Transposed S_V2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) | Para(M) | MAdd(G) |
| 2D CNNs | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 | 3.340 | 58.191 |
| 3DConv0 | 0.055 | 21.781 | 0.055 | 21.781 | 0.055 | 21.781 | 0.055 | 21.781 | 0.055 | 21.781 | 0.004 | 1.560 | 0.004 | 1.573 | 0.004 | 1.573 |
| 3DConv1 | 0.083 | 32.716 | 0.006 | 2.378 | 0.006 | 2.416 | 0.001 | 0.566 | 0.003 | 1.265 | 0.003 | 1.265 | 0.003 | 1.302 | 0.003 | 1.302 |
| 3DStack1_1 | 0.055 | 2.727 | 0.003 | 0.153 | 0.008 | 1.183 | 0.001 | 0.117 | 0.005 | 0.642 | 0.005 | 0.642 | 0.005 | 0.645 | 0.005 | 0.645 |
| 3DStack2_1 | 0.111 | 5.442 | 0.006 | 0.299 | 0.020 | 1.019 | 0.001 | 0.060 | 0.003 | 0.156 | 0.003 | 0.156 | 0.003 | 0.159 | 0.003 | 0.159 |
| 3DStack3_1 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.496 | 0.002 | 0.026 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 |
| 3DStack4_1 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.127 | 0.001 | 0.007 | 0.003 | 0.019 | 0.003 | 0.019 | 0.003 | 0.020 | 0.003 | 0.020 |
| 3DStack5_1 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.422 | 0.003 | 0.159 |
| 3DStack6_1 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.002 | 0.755 |
| 3DStack1_2 | 0.055 | 2.727 | 0.003 | 0.153 | 0.008 | 1.183 | 0.001 | 0.117 | 0.005 | 0.642 | 0.005 | 0.642 | 0.005 | 0.645 | 0.005 | 0.645 |
| 3DStack2_2 | 0.111 | 5.442 | 0.006 | 0.299 | 0.020 | 1.019 | 0.001 | 0.060 | 0.003 | 0.156 | 0.003 | 0.156 | 0.003 | 0.159 | 0.003 | 0.159 |
| 3DStack3_2 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.496 | 0.002 | 0.026 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 |
| 3DStack4_2 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.127 | 0.001 | 0.007 | 0.003 | 0.019 | 0.003 | 0.019 | 0.003 | 0.020 | 0.003 | 0.020 |
| 3DStack5_2 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.422 | 0.003 | 0.159 |
| 3DStack6_2 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.002 | 0.755 |
| 3DStack1_3 | 0.055 | 2.727 | 0.003 | 0.153 | 0.008 | 1.183 | 0.001 | 0.117 | 0.005 | 0.642 | 0.005 | 0.642 | 0.005 | 0.645 | 0.005 | 0.645 |
| 3DStack2_3 | 0.111 | 5.442 | 0.006 | 0.299 | 0.020 | 1.019 | 0.001 | 0.060 | 0.003 | 0.156 | 0.003 | 0.156 | 0.003 | 0.159 | 0.003 | 0.159 |
| 3DStack3_3 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.496 | 0.002 | 0.026 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 | 0.008 | 0.143 |
| 3DStack4_3 | 0.111 | 0.681 | 0.006 | 0.037 | 0.020 | 0.127 | 0.001 | 0.007 | 0.003 | 0.019 | 0.003 | 0.019 | 0.003 | 0.020 | 0.003 | 0.020 |
| 3DStack5_3 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.442 | 0.111 | 5.422 | 0.003 | 0.159 |
| 3DStack6_3 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.055 | 21.768 | 0.002 | 0.755 |
| Out1_1 | 0.028 | 10.91 | 0.002 | 0.793 | 0.002 | 0.805 | 0.0004 | 0.189 | 0.001 | 0.422 | 0.001 | 0.422 | 0.001 | 0.434 | 0.001 | 0.434 |
| Out2_1 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 |
| Out1_2 | 0.028 | 10.91 | 0.002 | 0.793 | 0.002 | 0.805 | 0.0004 | 0.189 | 0.001 | 0.422 | 0.001 | 0.422 | 0.001 | 0.434 | 0.001 | 0.434 |
| Out2_2 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 |
| Out1_3 | 0.028 | 10.91 | 0.002 | 0.793 | 0.002 | 0.805 | 0.0004 | 0.189 | 0.001 | 0.422 | 0.001 | 0.422 | 0.001 | 0.434 | 0.001 | 0.434 |
| Out2_3 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 | 0.001 | 0.340 |
| 3D CNNs | 1.887 | 198.470 | 0.631 | 110.766 | 0.772 | 117.737 | 0.571 | 106.194 | 0.619 | 109.842 | 0.568 | 89.621 | 0.568 | 89.728 | 0.085 | 10.840 |
| Full Model | 5.227 | 256.661 | 3.971 | 168.957 | 4.112 | 175.928 | 3.912 | 164.385 | 3.959 | 168.033 | 3.908 | 147.812 | 3.908 | 147.919 | 3.425 | 69.031 |
References
- Zenati, N.; Zerhouni, N. Dense Stereo Matching with Application to Augmented Reality. In Proceedings of the IEEE International Conference on Signal Processing and Communications, Dubai, United Arab Emirates, 24–27 November 2007; pp. 1503–1506. [Google Scholar] [CrossRef]
- Noh, Z.; S, M.; Pan, Z. A Review on Augmented Reality for Virtual Heritage System. In Proceedings of the Springer International Conference on Technologies for E-Learning and Digital Entertainment, Banff, AB, Canada, 9–11 August 2009; Volume 5670. [Google Scholar] [CrossRef]
- Häne, C.; Sattler, T.; Pollefeys, M. Obstacle detection for self-driving cars using only monocular cameras and wheel odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5101–5108. [Google Scholar]
- Nalpantidis, L.; Sirakoulis, G.C.; Gasteratos, A. Review of stereo matching algorithms for 3D vision. In Proceedings of the 16th International Symposium on Measurement and Control in Robotic, Warsaw, Poland, 21–23 June 2007. [Google Scholar]
- Samadi, M.; Othman, M.F. A New Fast and Robust Stereo Matching Algorithm for Robotic Systems. In Proceedings of the 9th International Conference on Computing and InformationTechnology (IC2IT2013), Bangkok, Thailand, 9–10 May 2013. [Google Scholar]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Scharstein, D.; Szeliski, R. A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Zhang, L.; Seitz, S.M. Estimating optimal parameters for MRF stereo from a single image pair. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2007, 29, 331–342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scharstein, D.; Pal, C. Learning Conditional Random Fields for Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Haeusler, R.; Nair, R.; Kondermann, D. Ensemble Learning for Confidence Measures in Stereo Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 305–312. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Chang, J.-R.; Chen, Y.-S. Pyramid Stereo Matching Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Desig. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhou, K.; Meng, X.; Cheng, B. Review of Stereo Matching Algorithms Based on Deep Learning. Computational Intelligence and Neuroscience 2020, 2020, 8562323. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3273–3282. [Google Scholar]
- Khamis, S.; Fanello, S.; Rhemann, C.; Kowdle, A.; Valentin, J.; Izadi, S. StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 573–590. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. GA-Net: Guided Aggregation Net for End-To-End Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 185–194. [Google Scholar]
- Zhu, C.; Chang, Y. Hierarchical Guided-Image-Filtering for Efficient Stereo Matching. Appl. Sci. 2019, 15, 3122. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Chen, Y.; Bai, X.; Yu, S.; Yu, K.; Li, Z.; Yang, K. Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12926–12934. [Google Scholar]
- Duggal, S.; Wang, S.; Ma, W.; Hu, R.; Urtasun, R. DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 4384–4393. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing. Acm Trans. Graph. (Proc. Siggraph) 2009, 28, 24. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, J. AANet: Adaptive Aggregation Network for Efficient Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1959–1968. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2495–2504. [Google Scholar]
- Shen, Z.; Dai, Y.; Rao, Z. CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13906–13915. [Google Scholar]
- Wei, M.; Zhu, M.; Wu, Y.; Sun, J.; Wang, J.; Liu, C. A Fast Stereo Matching Network with Multi-Cross Attention. Sensors 2021, 18, 6016. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Gu, J.; Li, J.; Yu, X. A stereo matching algorithm based on the improved PSMNet. PLoS ONE 2021, 25, e0251657. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Cheng, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 1706, arXiv:1706.05587. [Google Scholar]
- Jia, X.; Chen, W.; Liang, Z.; Luo, X.; Wu, M.; Li, C.; He, Y.; Tan, Y.; Huang, L. A Joint 2D-3D Complementary Network for Stereo Matching. Sensors 2021, 21, 1430. [Google Scholar] [CrossRef] [PubMed]
- Vasileiadis, M.; Bouganis, C.-S.; Stavropoulos, G.; Tzovaras, D. Optimising 3D-CNN Design towards Human Pose Estimation on Low Power Devices. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource Efficient Inference. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–17. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Ng, A.Y. Preventing “overfitting” of cross-validation data. Machine Learning. In Proceedings of the International Conference on Machine Learning (ICML), Nashville, TN, USA, 8–12 July 1997; pp. 245–253. [Google Scholar]
- Tosi, F.; Liao, Y.; Schmitt, C.; Geiger, A. SMD-Nets: Stereo Mixture Density Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), virtual, 19–25 June 2021; pp. 8942–8952. [Google Scholar]
- Yee, K.; Chakrabarti, A. Fast Deep Stereo with 2D Convolutional Processing of Cost Signatures. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 183–191. [Google Scholar]
- Qin, Z.; Zhang, Z.; Li, D.; Zhang, Y.; Peng, Y. Diagonalwise Refactorization: An Efficient Training Method for Depthwise Convolutions. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Lu, G.; Zhang, W.; Wang, Z. Optimizing Depthwise Separable Convolution Operations on GPUs. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 70–87. [Google Scholar] [CrossRef]
| Name | Main Feature | Targeting Part |
|---|---|---|
| GwcNet [24] | Performs a group-wise correlation to generate | Cost volume aggregation & |
| a multi-feature cost volume. | Cost volume regularization | |
| StereoNet [25] | Utilizes more downsampling to form a low-resolution cost volume, | 2D Siamese CNNs & |
| which lead a great improvement in speed. | Cost volume regularization | |
| GANet [26] | Introduces a semi-global guided aggregation layer and | Cost volume regularization |
| a local guided aggregation layer | ||
| for replacing 3D convolution layer in 3D encoder-decoder. | ||
| Zhu et al. [27] | Apply edge-preserving guided-Image-filtering (GIF) at | Cost volume regularization |
| different resolutions on multi-scale stereo matching. | ||
| AcfNet [28] | Includes the ground truth cost volume and | Cost volume regularization |
| confidence map for intermediate supervision. | ||
| DeepPruner [29] | Aggregates a sparse cost volume | Cost volume aggregation |
| with a differentiable PatchMatch [30] module. | ||
| AANet [31] | Presents a intra-scale aggregation module | Cost volume regularization |
| for replacing 3D convolution layer & cross-scale aggregation for | ||
| integrating multi-scale cost volume. | ||
| CSN [32] & CFNet [33] | Implements the architecture in a coarse-to-fine manner. | Cost volume aggregation & |
| Cost volume regularization | ||
| Wei et al. [34] | Improve StereoNet[25] with edge-guided refinement & | 2D Siamese CNNs & |
| multi-cross attention module on multi-level cost volumes. | Cost volume regularization | |
| Huang et al. [35] | Implement ResNetXt [36] and Atrous Spatial Pyramid Pooling | 2D Siamese CNNs |
| (ASSP) [37] on 2D CNNs. | ||
| JDCNet [38] | Use the 2D stereo encoder-decoder to generate a disparity range | 2D Siamese CNNs & |
| for guiding 3D aggregation network. | Cost volume aggregation |
| 2D Part: Feature Extraction | 3D Part: Cost Volume Optimization | ||||
|---|---|---|---|---|---|
| Layer Name | Setting | Output Dimension | Layer Name | Setting | Output Dimension |
| Stereo input | - | Concat left and right feature maps | - | ||
| 2D CNNs | 3D Stacked Hourglass module | ||||
| Conv0_x | 3DConv0(3D Head) | , 32 | |||
| Conv1_x | 3DConv1(3D Conv) | ||||
| Conv2_x | 3DStack1_x(3D Conv, ) | ||||
| Conv3_x | 3DStack2_x(3D Conv) | ||||
| Conv4_x | 3DStack3_x(3D Conv, ) | ||||
| Spatial Pyramid Pooling (SPP) module | 3DStack4_x(3D Conv) | ||||
| Branch_1 | , 128, Avg_pooling | 3DStack5_x(3D Deconv) | ConvTranspose3d | ||
| , 32, Conv | |||||
| Upsample, Biliner interpolation | |||||
| Branch_2 | , 128, Avg_pooling | 3DStack6_x(3D Deconv) | ConvTranspose3d | ||
| , 32, Conv | |||||
| Upsample, Biliner interpolation | |||||
| Branch_3 | , 128, Avg_pooling | Out1_x(3D Conv) | |||
| , 32, Conv | |||||
| Upsample, Biliner interpolation | |||||
| Branch_4 | , 128, Avg_pooling | Out2_x(3D Out) | |||
| , 32, Conv | |||||
| Upsample, Biliner interpolation | |||||
| Concat[Conv2_16,Conv4_3,Branch_1,Branch_2,Branch_3,Branch_4] | Upsampling | Trilinear interpolation | |||
| Fusion | , 128 | - | Disparity regression | ||
| , 32, | |||||
| 3D Conv Kernel | EPE | D1-All | Parameters (Millon) | MAdd (Gb) | MAC (Mb) | Model Size (Mb) |
|---|---|---|---|---|---|---|
| 3D Convolution Layers | ||||||
| Baseline(re-implemented) | 1.123 | 2.41 | 5.23 | 256.66 | 3895 | 21.1 |
| MobileNetV1 | 1.252 | 2.68 | 3.97 | 168.96 | 5421 | 16.2 |
| MobileNetV2* | 1.215 | 2.60 | 4.11 | 175.93 | 6097 | 16.8 |
| ShuffleNetV1 | 1.295 | 2.88 | 3.91 | 164.39 | 4651 | 16.0 |
| ShuffleNetV2 | 1.241 | 2.62 | 3.96 | 168.03 | 5071 | 16.2 |
| 3D Head | ||||||
| 3D CNN | 1.241 | 2.62 | 3.96 | 168.03 | 5071 | 16.2 |
| MobileNetV1 (Head) | 1.233 | 2.61 | 3.91 | 147.81 | 5411 | 16.0 |
| 3D ECA Blocks | ||||||
| Without ECA Blocks | 1.233 | 2.61 | 3.91 | 147.81 | 5411 | 16.0 |
| ECA Blocks | 1.160 | 2.50 | 3.91 | 147.92 | 5835 | 16.0 |
| 3D Deconvoltion Layers | ||||||
| 3D Transposed CNN | 1.160 | 2.50 | 3.91 | 147.92 | 5835 | 16.0 |
| Transposed ShuffleNetV2 | 1.124 | 2.43 | 3.43 | 69.03 | 6771 | 14.1 |
| Method | Ours | Baseline [16] | GC-Net [11] | GANet [26] | DeepPruner-Best [29] | DispNetC [42] | StereoNet [25] | JDCNet [38] |
|---|---|---|---|---|---|---|---|---|
| EPE | 0.91 | 1.09 | 2.51 | 0.84 | 0.86 | 1.68 | 1.10 | 0.83 |
| Method | All (%) | Noc (%) | Runtime(s) | MAdd (G) | ||||
|---|---|---|---|---|---|---|---|---|
| D1-Bg | D1-Fg | D1-All | D1-Bg | D1-Fg | D1-All | |||
| Baseline [12] | 1.86 | 4.62 | 2.32 | 1.71 | 4.31 | 2.14 | 0.41 | 256.66 |
| PSMNet-lite (Ours) | 1.91 | 4.56 | 2.35 | 1.75 | 4.06 | 2.13 | 0.63 | 69.03 |
| MC-CNN [6] | 2.89 | 8.88 | 3.89 | 2.48 | 7.64 | 3.33 | 67 | - |
| GC-Net [11] | 2.21 | 6.16 | 2.87 | 2.02 | 5.58 | 2.61 | 0.9 | 733.36 |
| GwcNet [24] | 1.74 | 3.93 | 2.11 | 1.61 | 3.49 | 1.92 | 0.32 | 247.6 |
| DeepPruner-Fast [29] | 1.87 | 3.56 | 2.15 | 1.71 | 3.18 | 1.95 | 0.18 | - |
| GANet-15 [26] | 1.55 | 3.82 | 1.93 | 1.40 | 3.37 | 1.73 | 0.36 | - |
| CSN [32] | 1.59 | 4.03 | 2.00 | 1.43 | 3.55 | 1.78 | 0.6 | - |
| SMD-Net [45] | 1.69 | 4.01 | 2.08 | 1.54 | 3.70 | 1.89 | 0.41 | - |
| StereoNet [25] | 4.30 | 7.45 | 4.83 | - | - | - | 0.015 | 47.08 |
| DispNetC [42] | 4.32 | 4.41 | 4.34 | 4.11 | 3.72 | 4.05 | 0.03 | - |
| DeepPruner-Best [29] | 2.32 | 3.91 | 2.59 | 2.13 | 3.43 | 2.35 | 0.06 | - |
| AANet [31] | 1.99 | 5.39 | 2.55 | 1.80 | 4.93 | 2.32 | 0.062 | - |
| Fast DS-CS [46] | 2.83 | 4.31 | 3.08 | 2.53 | 3.74 | 2.73 | 0.02 | - |
| JDCNet [38] | 1.91 | 4.47 | 2.33 | 1.73 | 3.86 | 2.08 | 0.079 | - |
| Method | MobileNetV1 | MobileNetV2 | ShuffleNetV1 | ShuffleNetV2 | + MobileNetV1 | + ECA Blocks | + Transposed |
|---|---|---|---|---|---|---|---|
| Head | ShuffleNetV2 | ||||||
| Runtime (s) | 0.48 | 0.53 | 0.35 | 0.40 | 0.41 | 0.60 | 0.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Ma, D.; Yamane, S. Optimizing 3D Convolution Kernels on Stereo Matching for Resource Efficient Computations. Sensors 2021, 21, 6808. https://doi.org/10.3390/s21206808
Xiao J, Ma D, Yamane S. Optimizing 3D Convolution Kernels on Stereo Matching for Resource Efficient Computations. Sensors. 2021; 21(20):6808. https://doi.org/10.3390/s21206808
Chicago/Turabian StyleXiao, Jianqiang, Dianbo Ma, and Satoshi Yamane. 2021. "Optimizing 3D Convolution Kernels on Stereo Matching for Resource Efficient Computations" Sensors 21, no. 20: 6808. https://doi.org/10.3390/s21206808
APA StyleXiao, J., Ma, D., & Yamane, S. (2021). Optimizing 3D Convolution Kernels on Stereo Matching for Resource Efficient Computations. Sensors, 21(20), 6808. https://doi.org/10.3390/s21206808