GO-DEVS: Storage and Retrieval System for DEVS Models Using Graph and Ontology Representation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Introduction of an Ontology to DEVS Models: To effectively reuse DEVS models developed by other developers, models should be understood in common. To do that, we introduce an ontology to DEVS models.
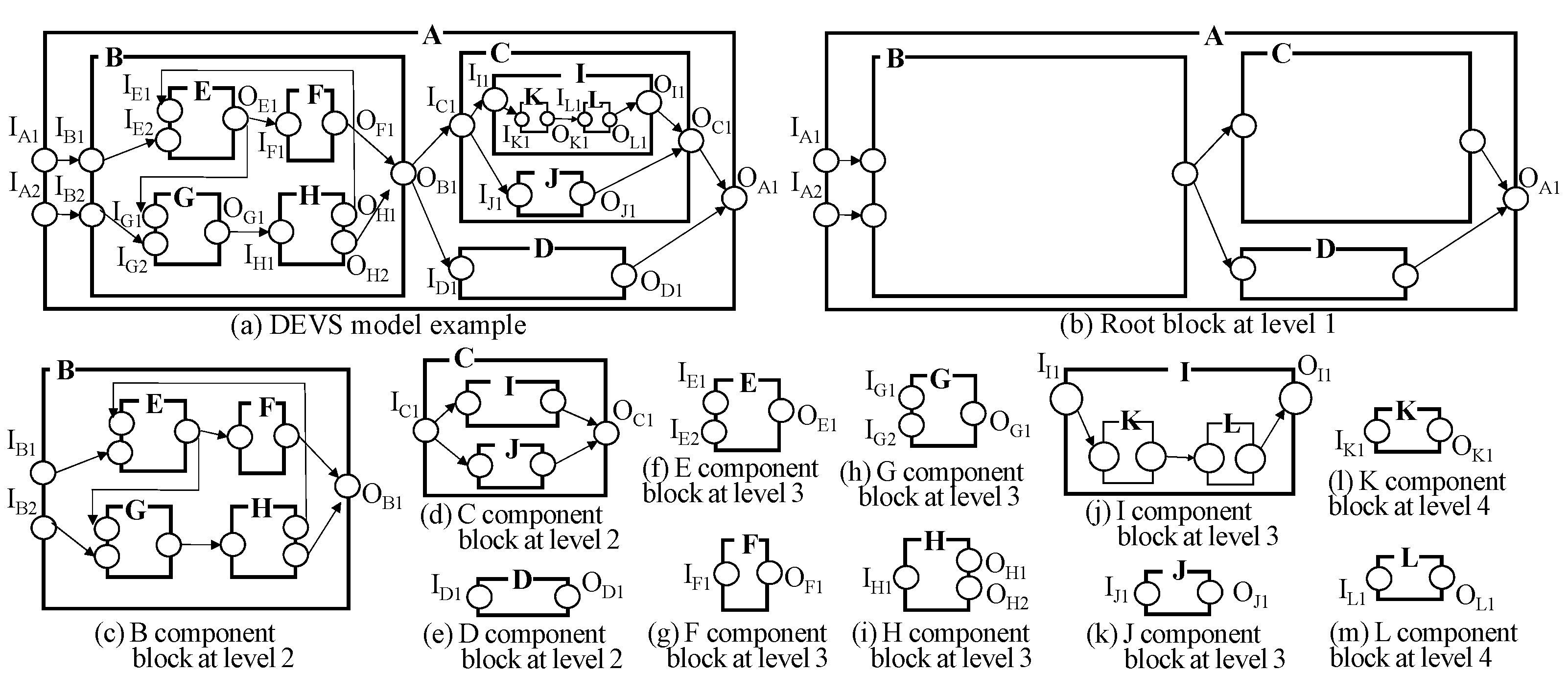
- Transformation of a DEVS Model into Graph Representation: To support the efficient model retrieval, we need to represent DEVS models effectively because they show a complicated pattern and are not easy to handle. To relieve the complexity of DEVS model structures, we propose a method to represent them by the set of graphs with meta information.
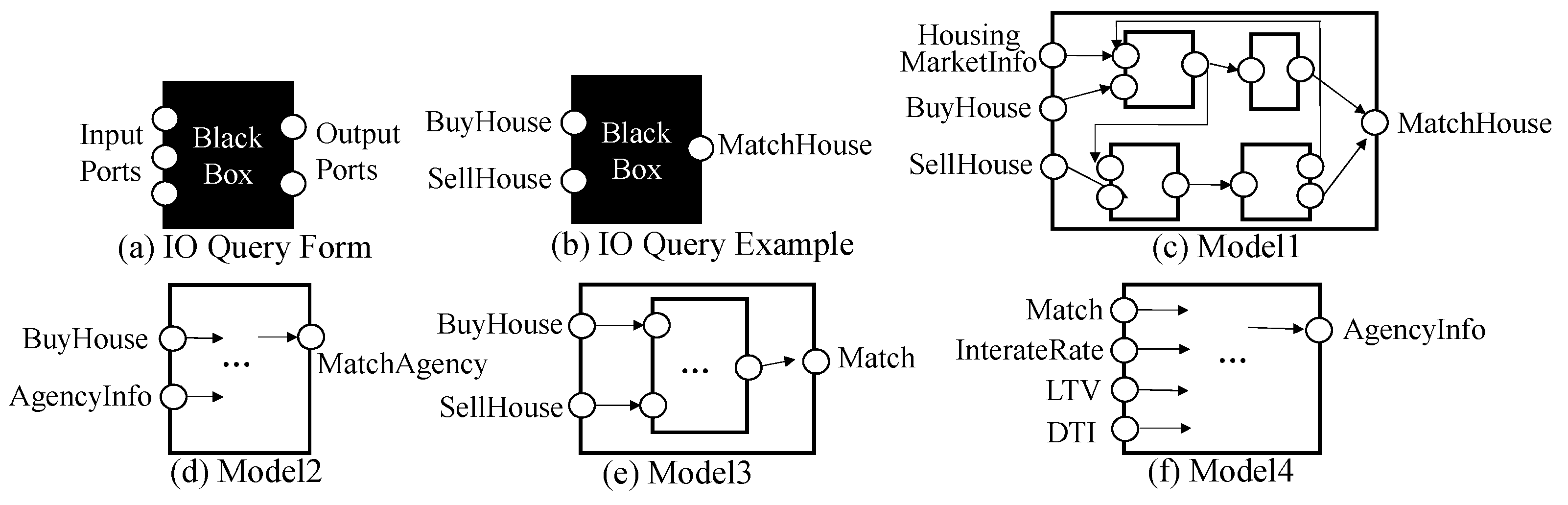
- Queries to Retrieve DEVS Models: To retrieve DEVS models that model developers want to find, we propose two types of queries, IO query and structure query.
- Effective Table Design to Retrieve DEVS models: To support efficient processing for two types of queries, we provide the basic table design and the advanced table design. In the advanced table design, an XML numbering scheme is adopted.
2. Related Work
3. Preliminary
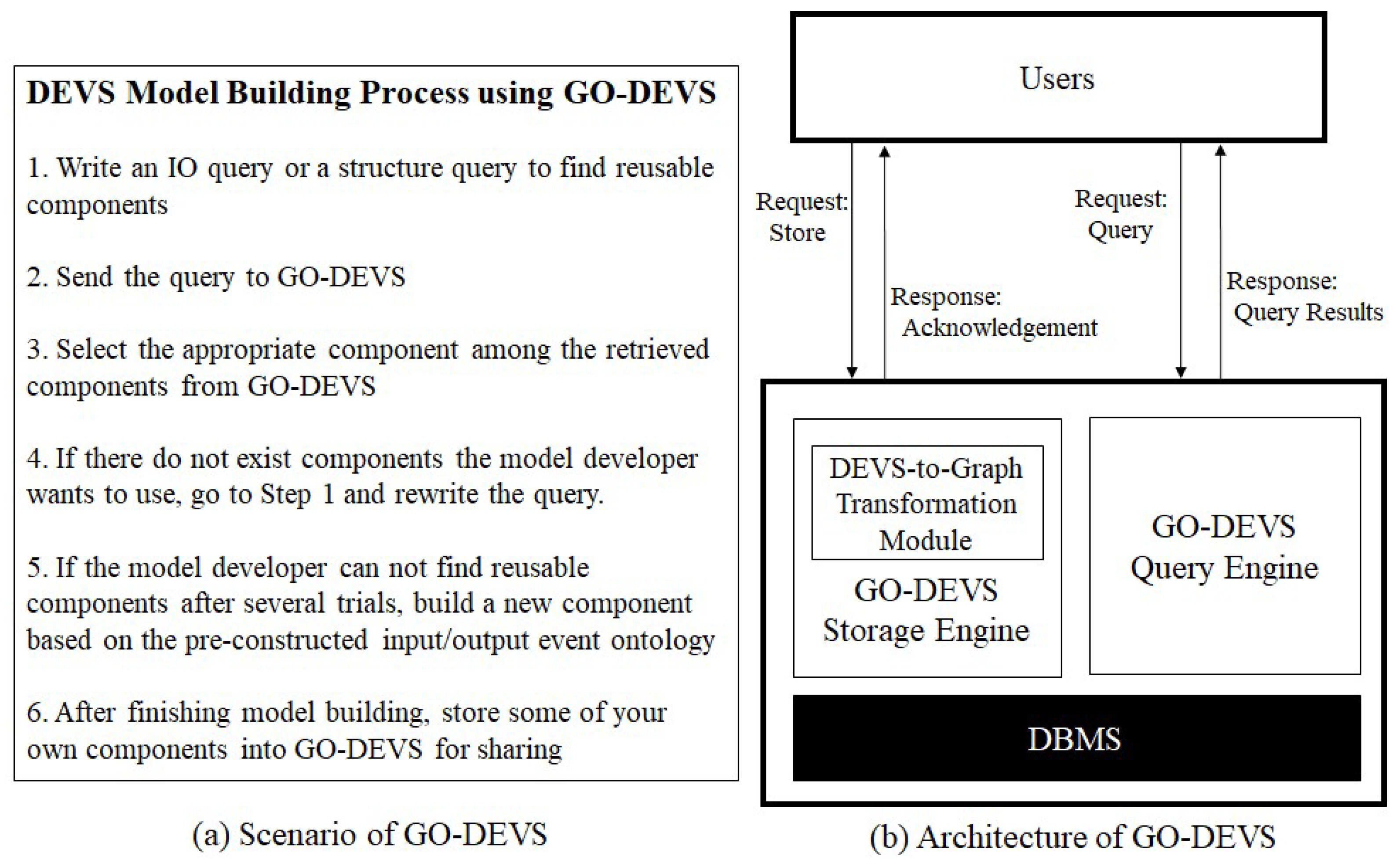
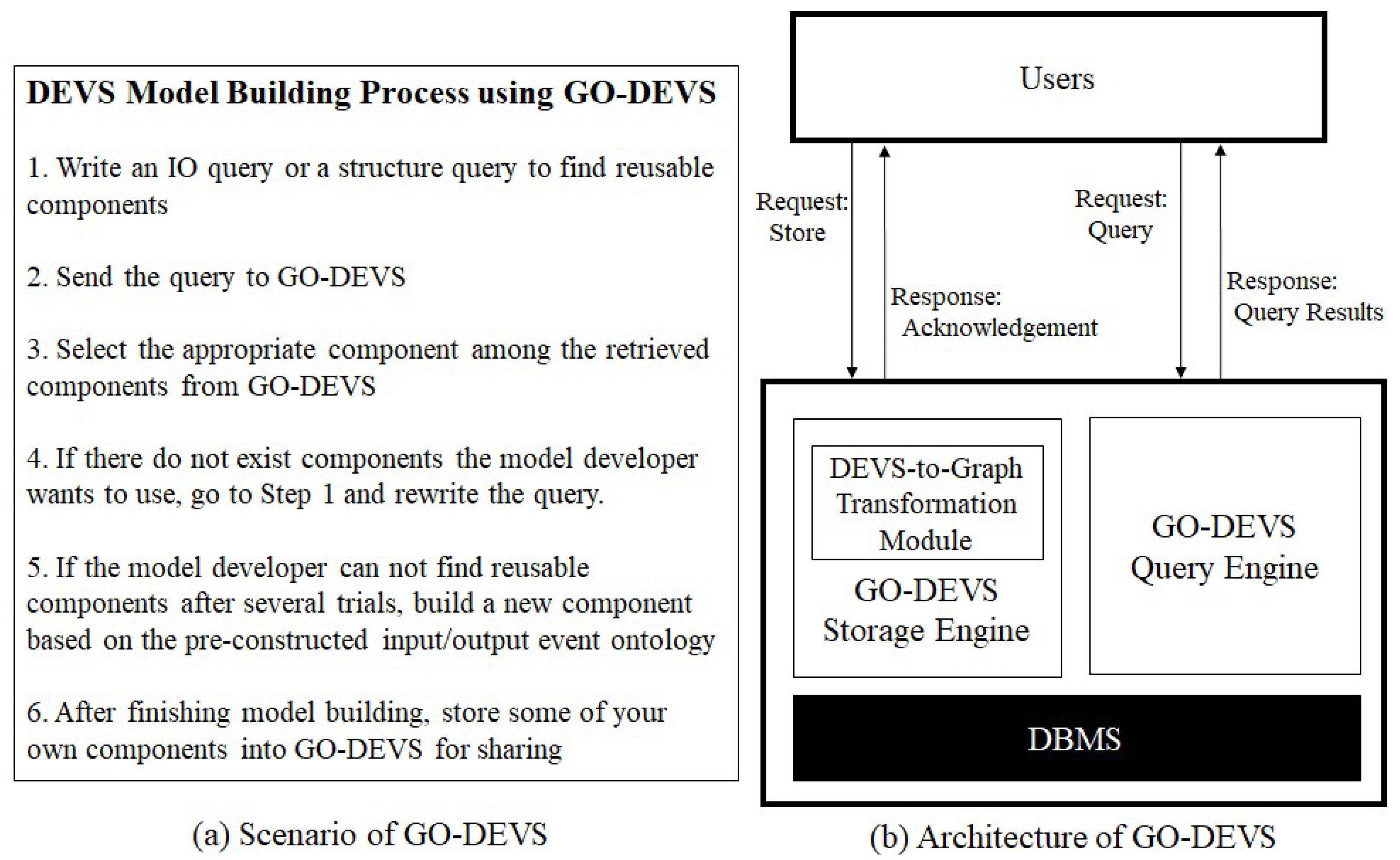
4. Scenario and Architecture of GO-DEVS
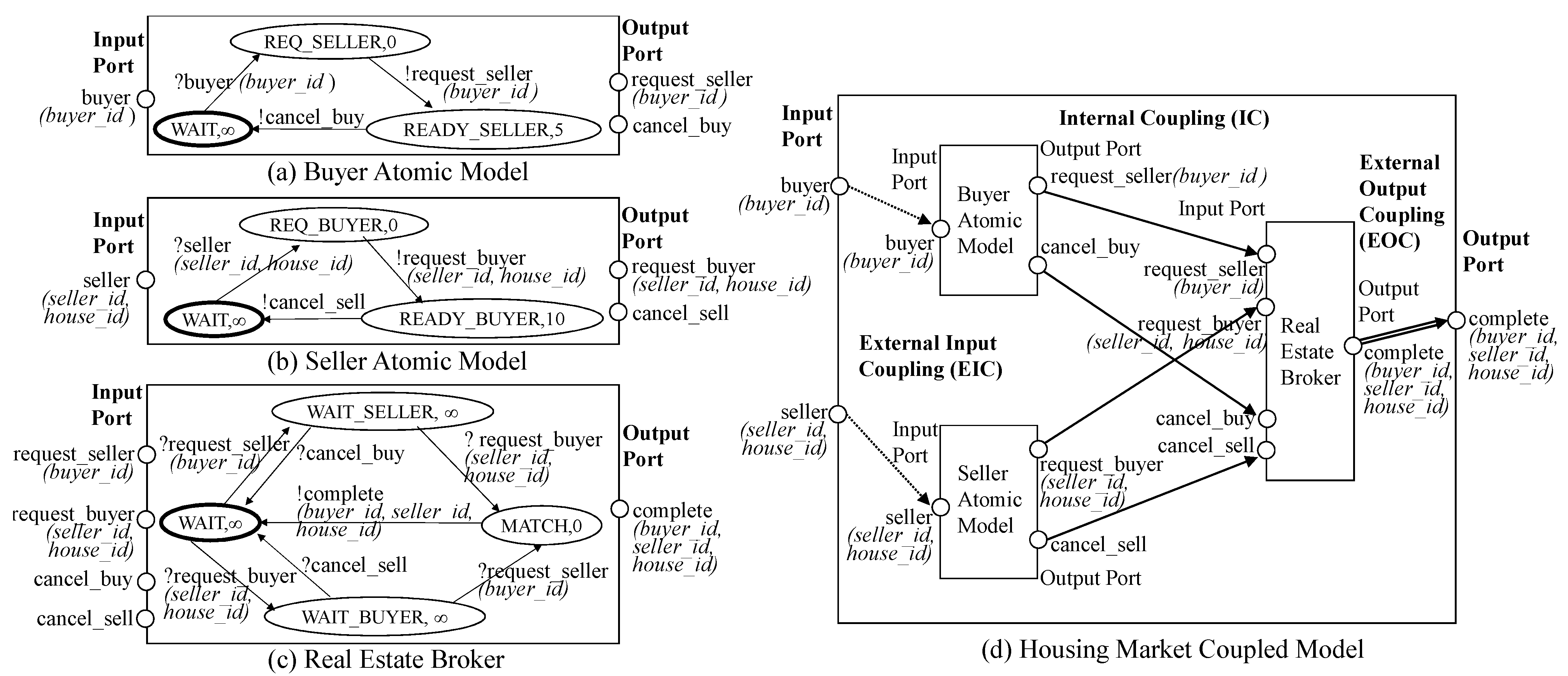
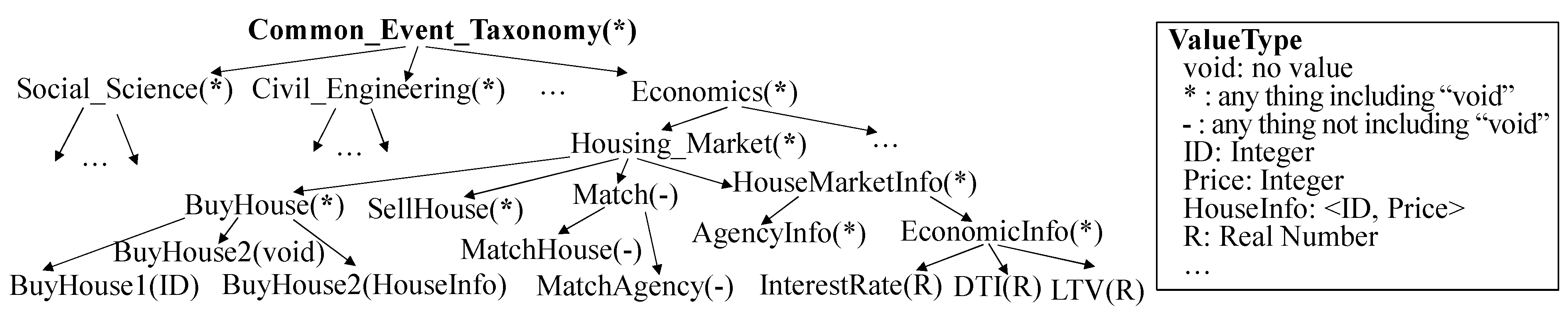
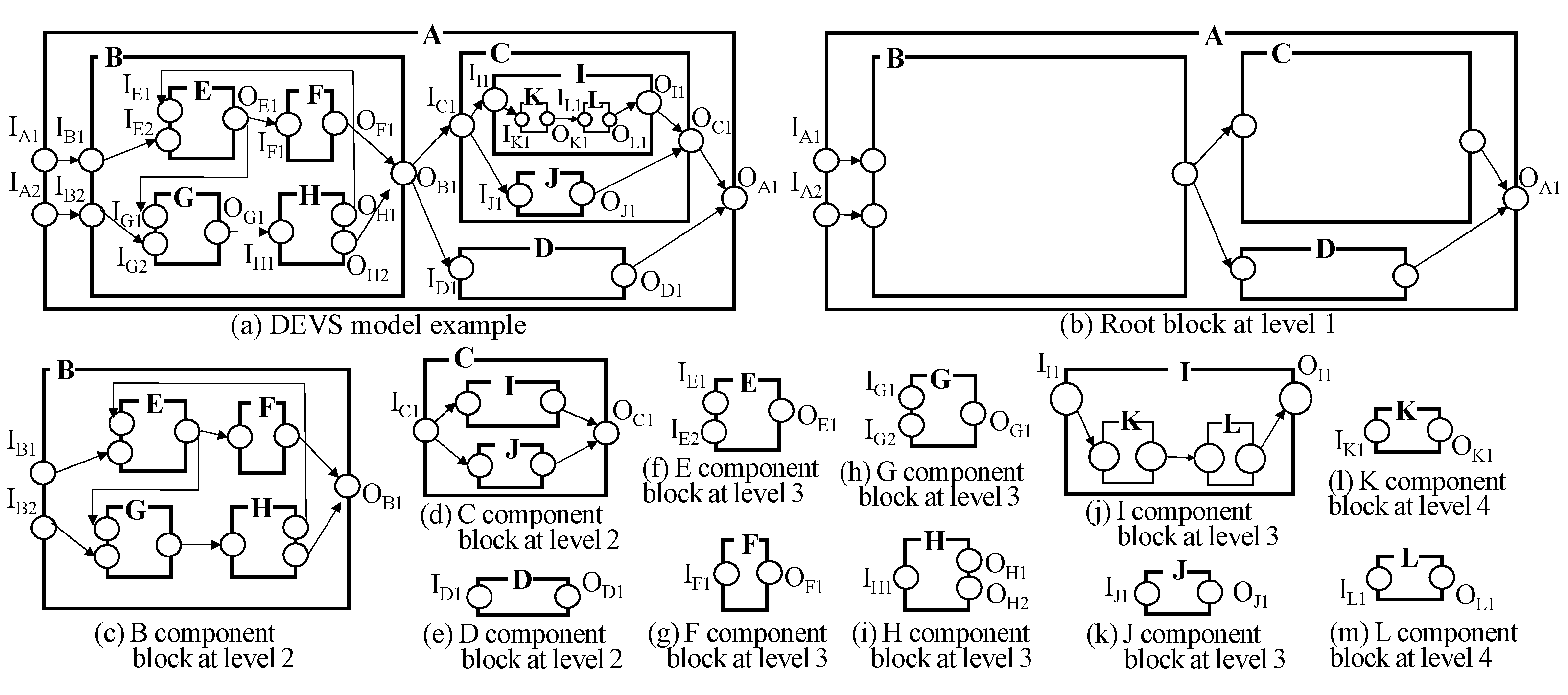
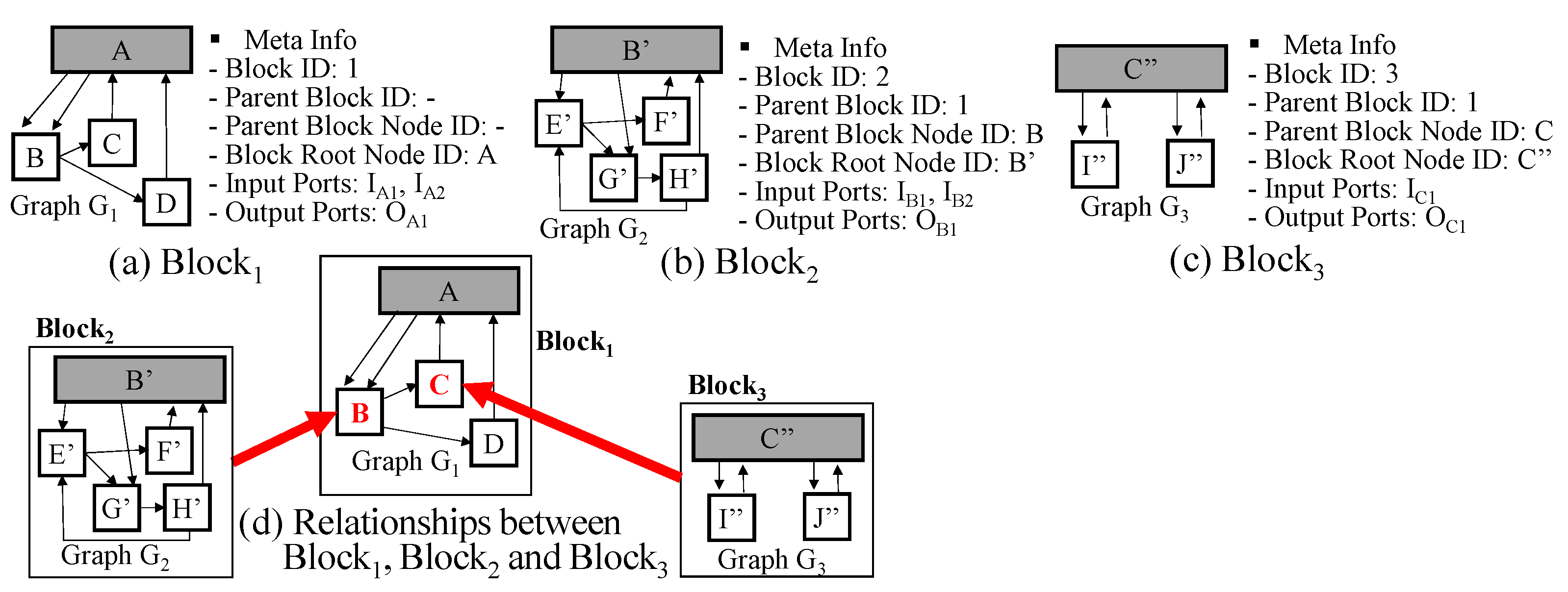
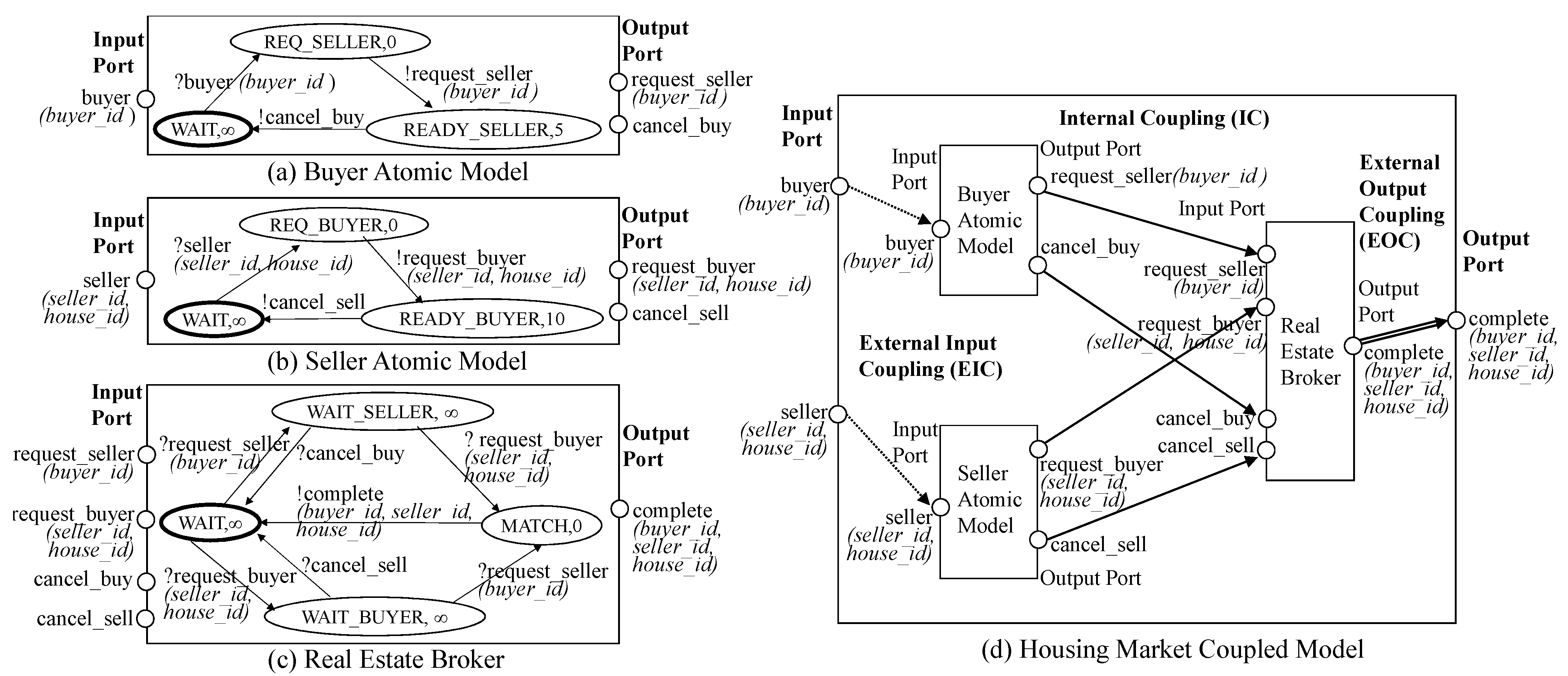
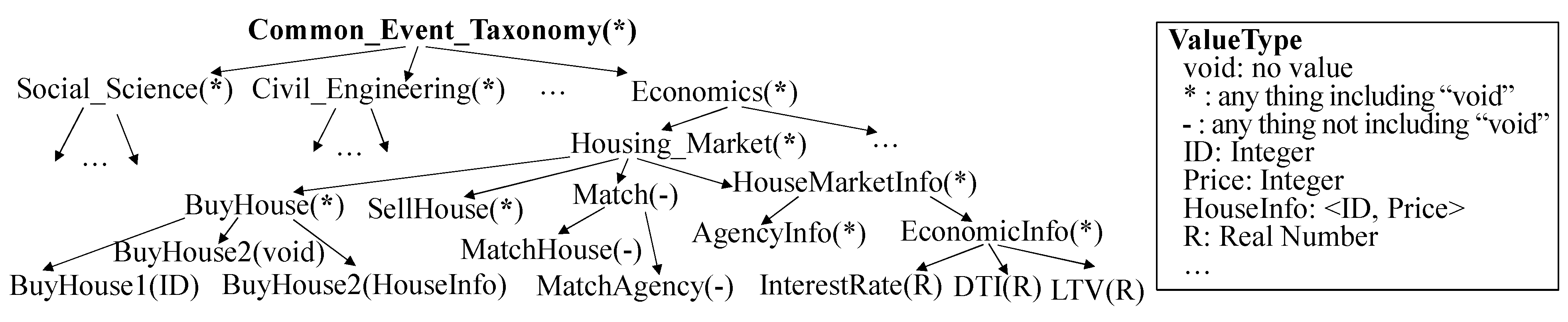
5. Ontology and Graph Representation in GO-DEVS
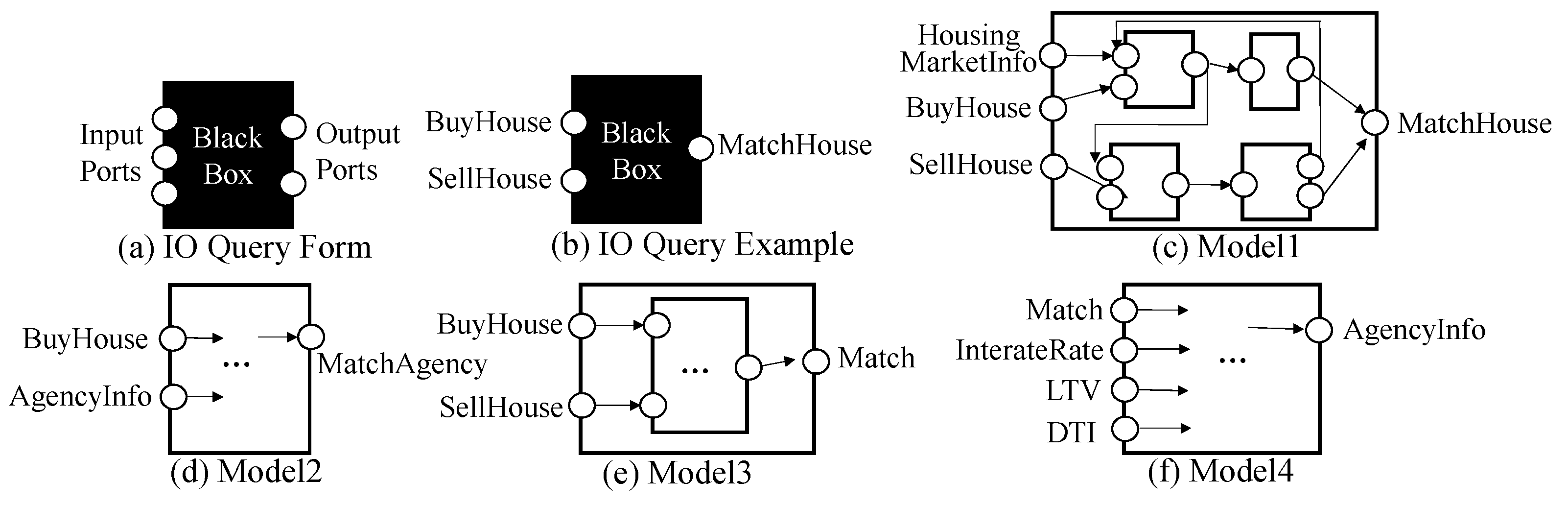
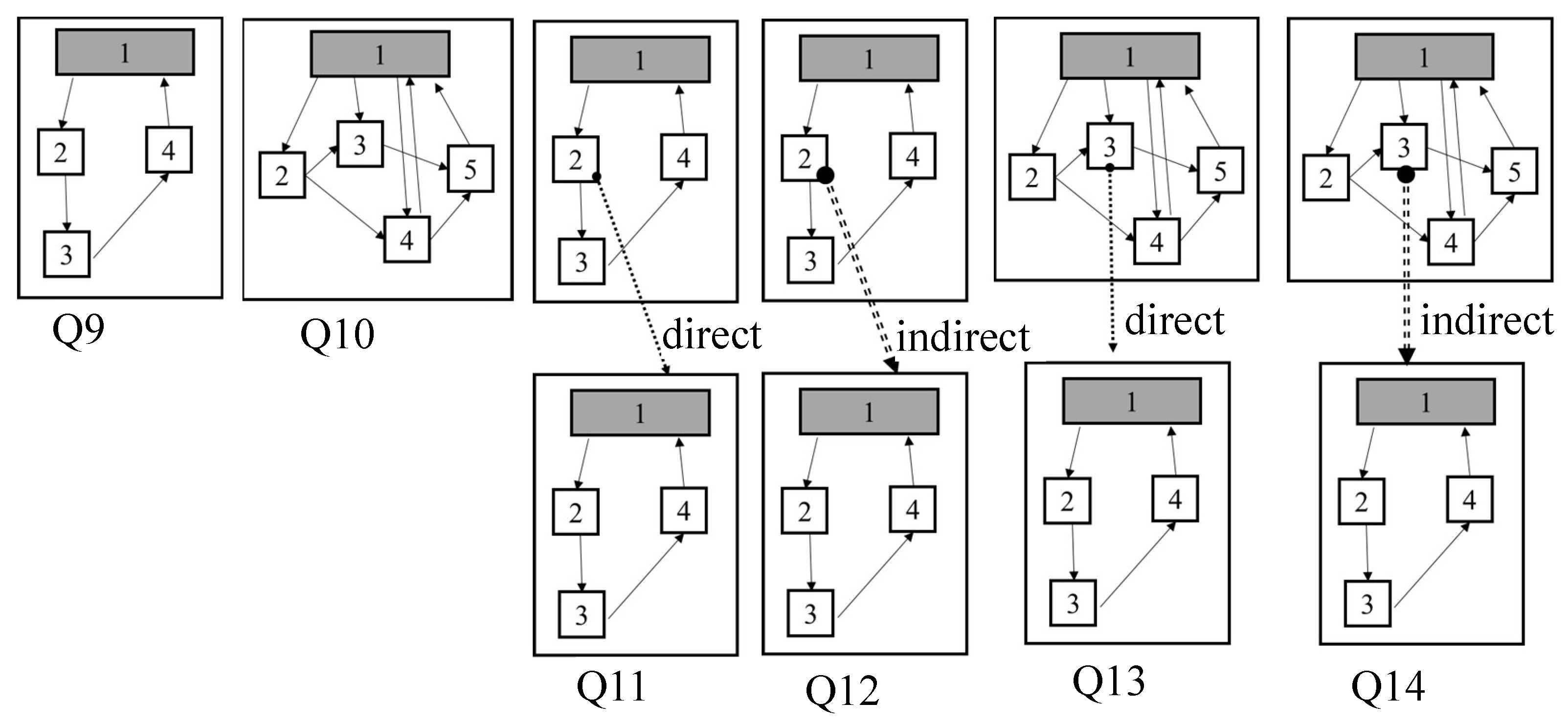
6. Queries for DEVS Model Retrieval
- (1)
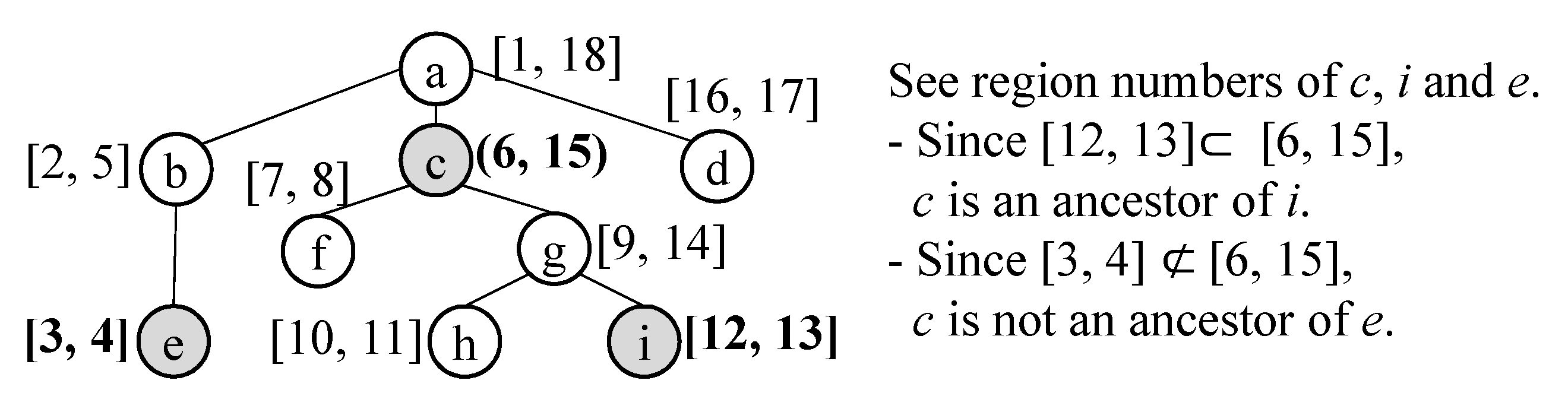
- , where is located at the same position as or the ancestor position of on the event taxonomy.
- (2)
- , where is located at the same position as or the ancestor position of on the event taxonomy.
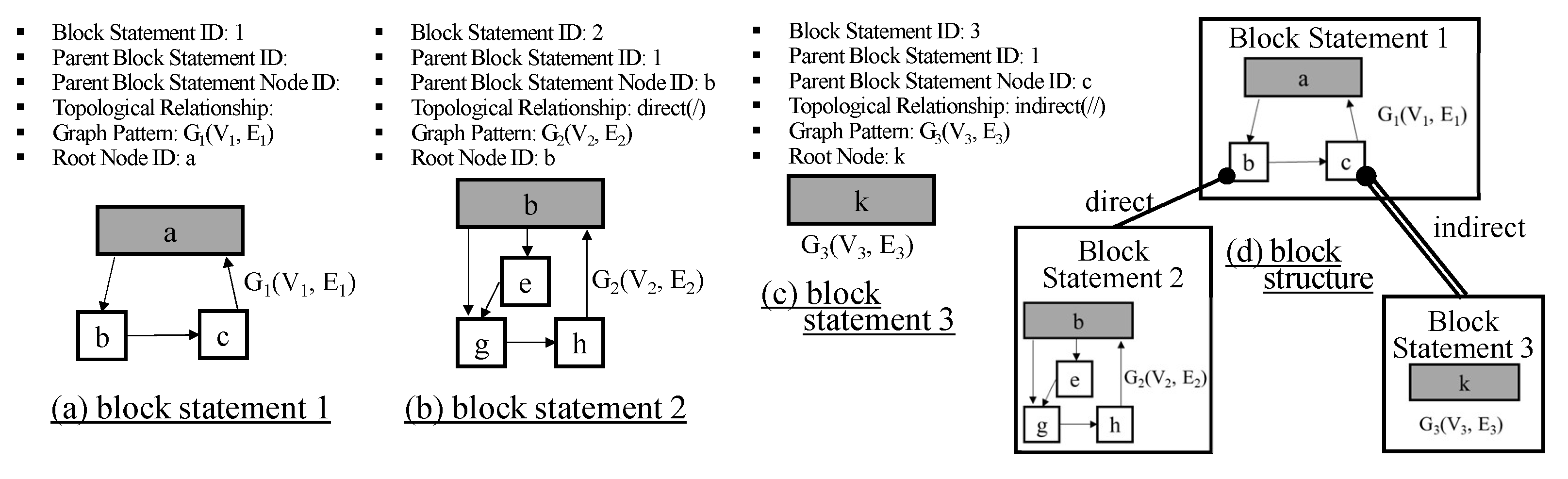
7. Storing DEVS Models in GO-DEVS
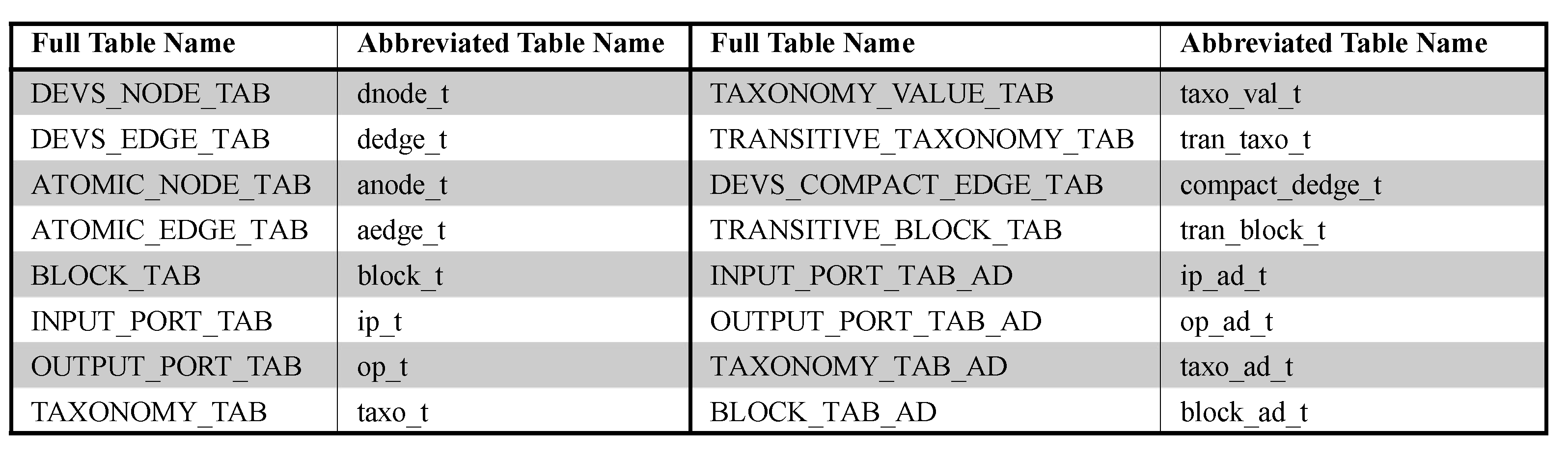
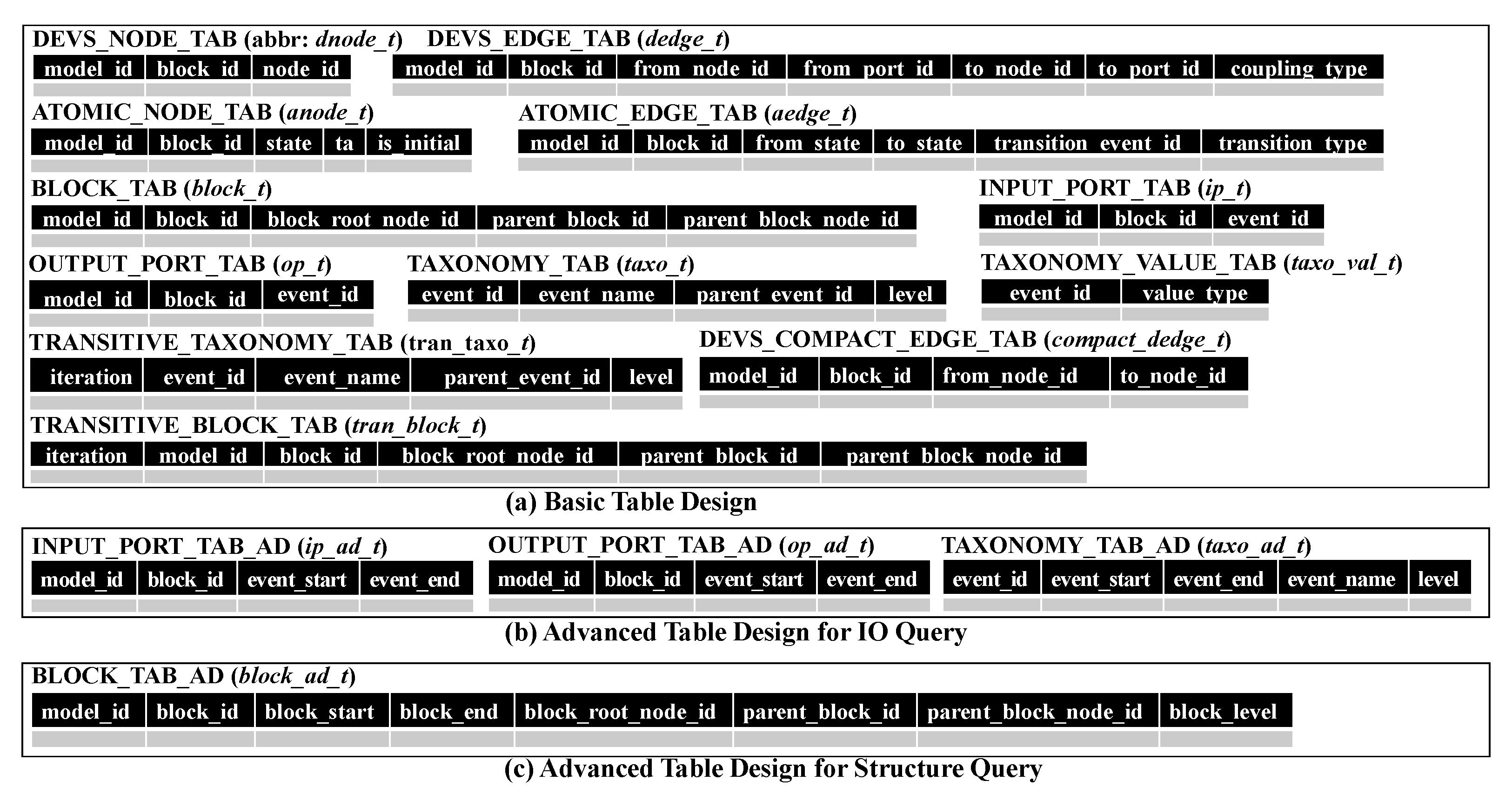
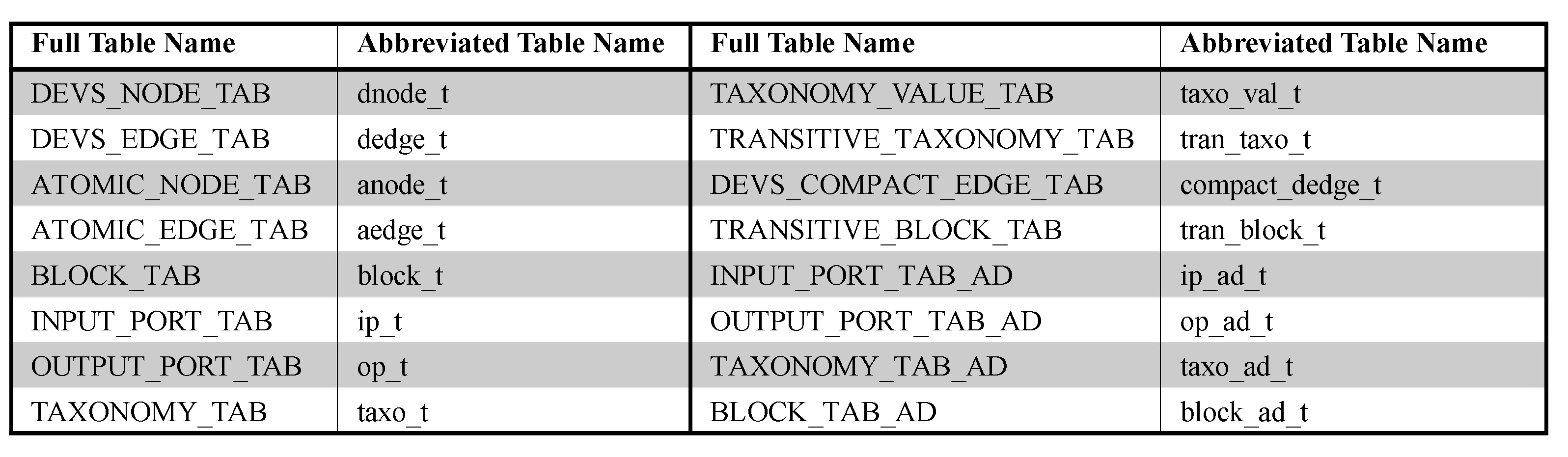
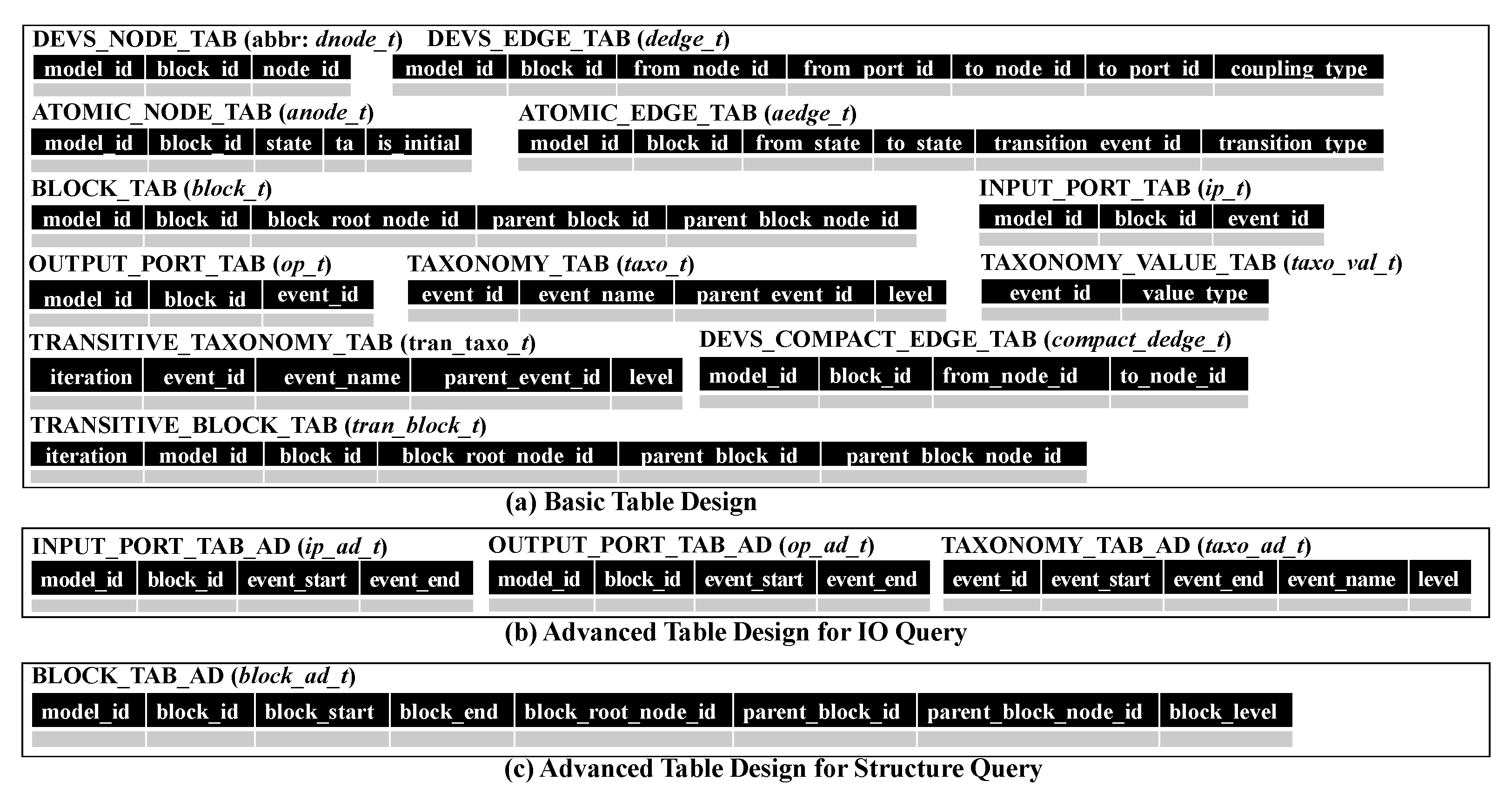
7.1. Basic Table Design
7.2. Advanced Table Design for IO Query
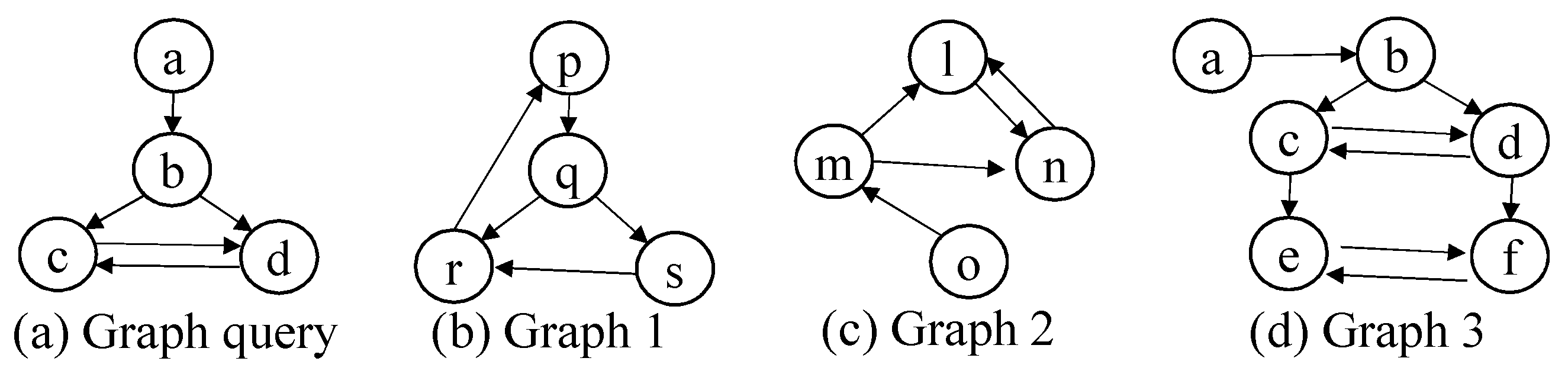
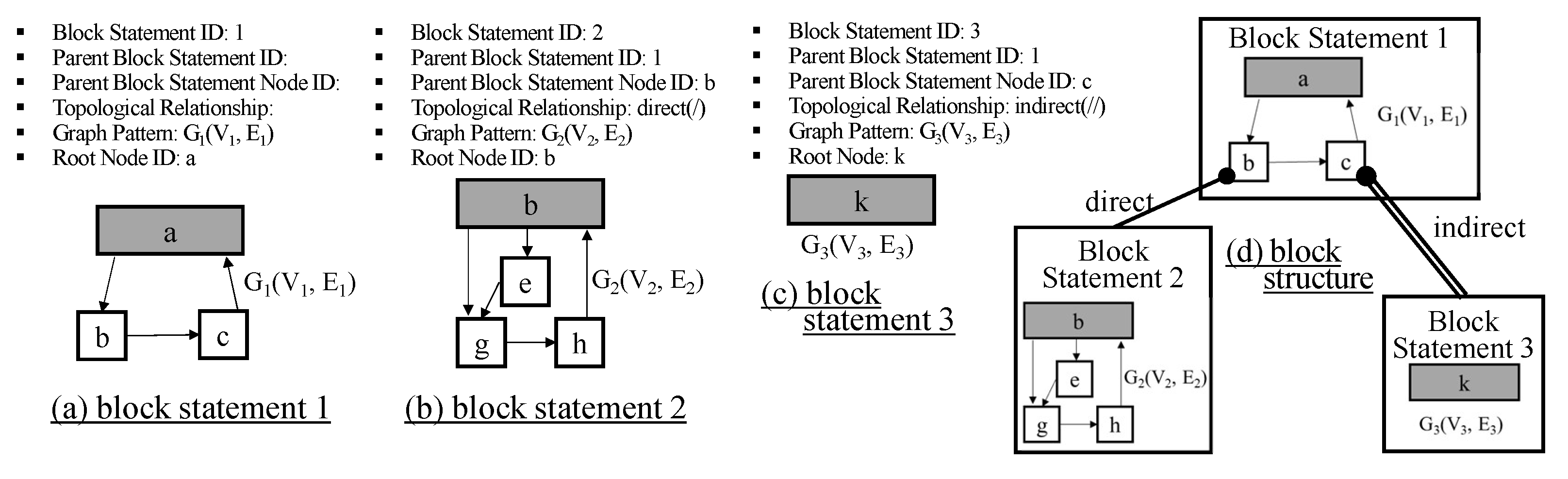
7.3. Advanced Table Design for Structure Query
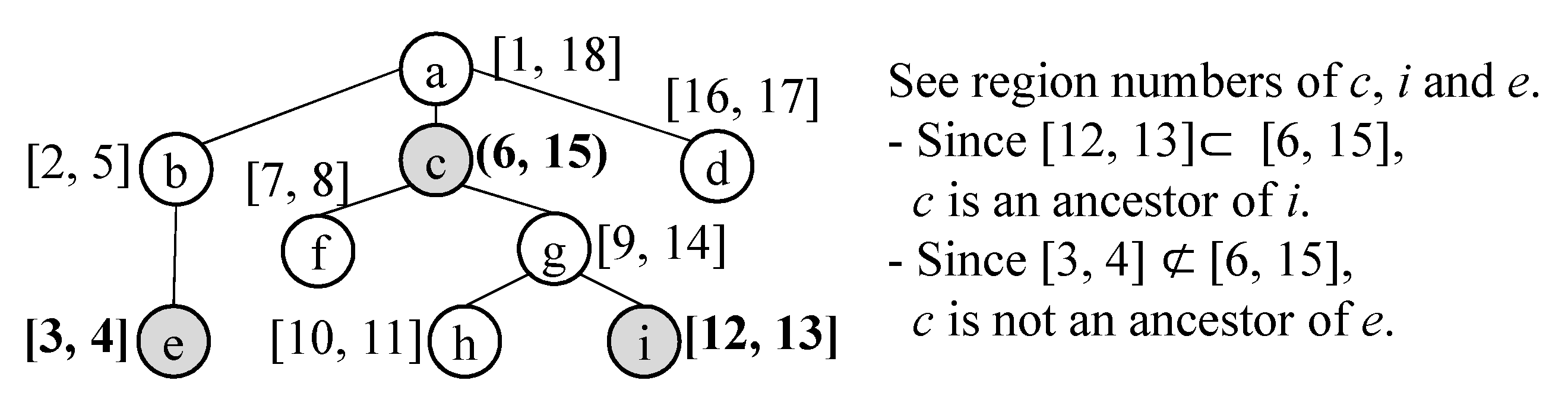
8. Processing Queries in GO-DEVS
8.1. IO Query Processing
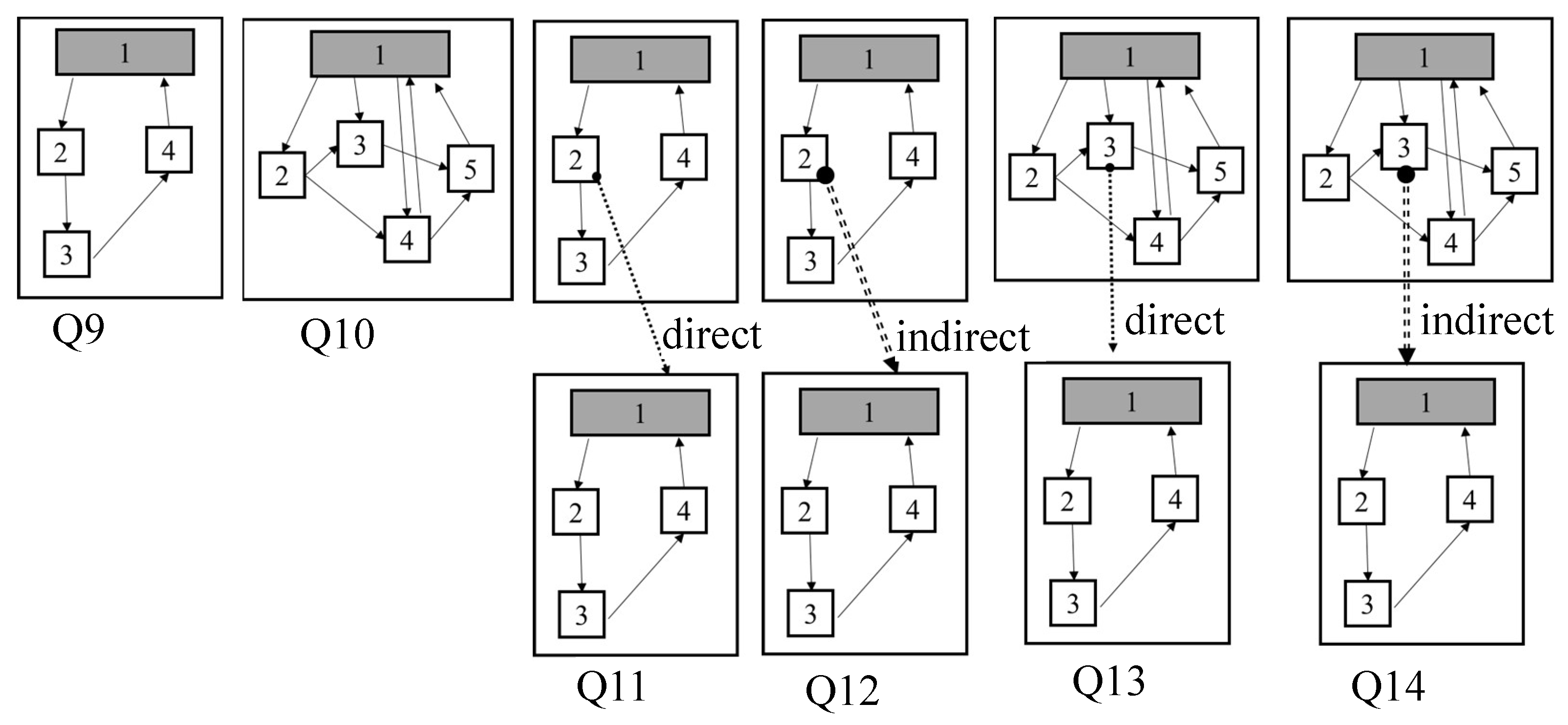
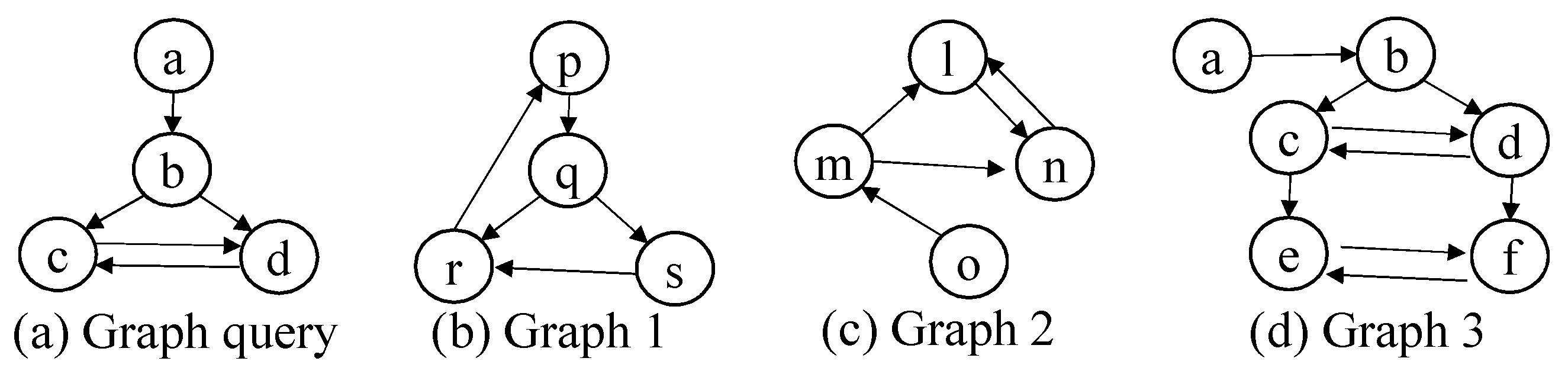
8.2. Structure Query Processing
| Algorithm 1:translateStructureQuery_BASIC() |
 |
| Algorithm 2:translateStructureQuery_ADVANCED() |
 |
| Algorithm 3:translateGraphPattern() |
 |
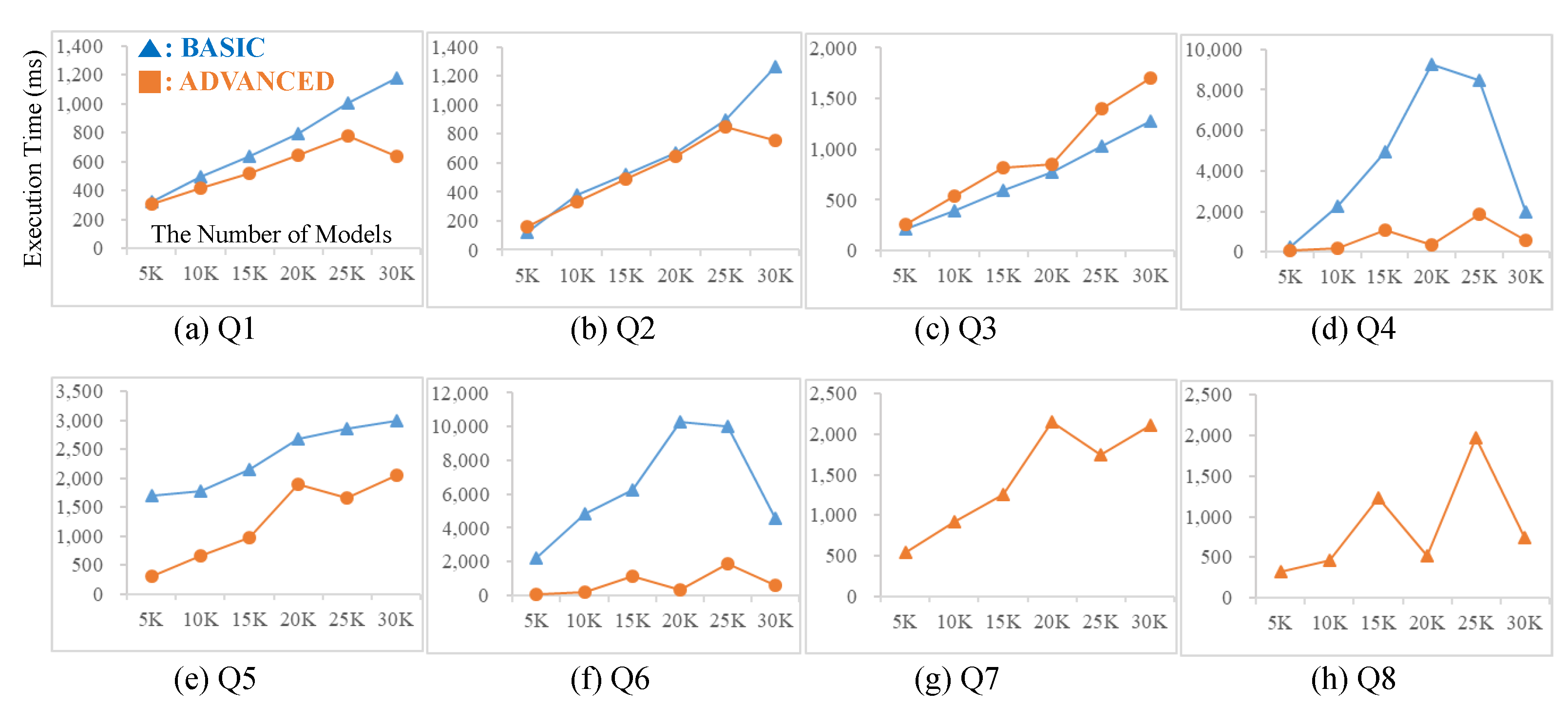
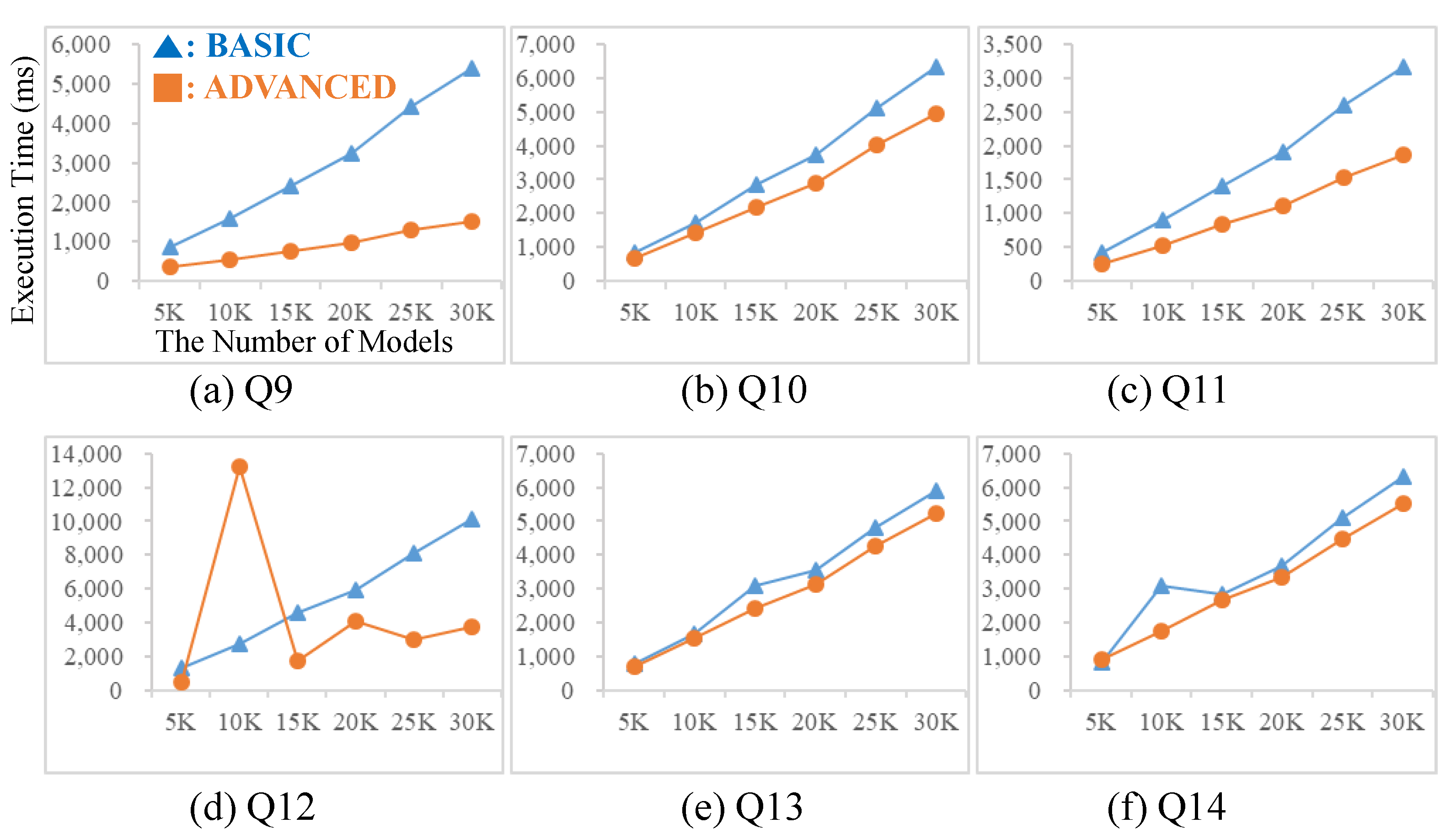
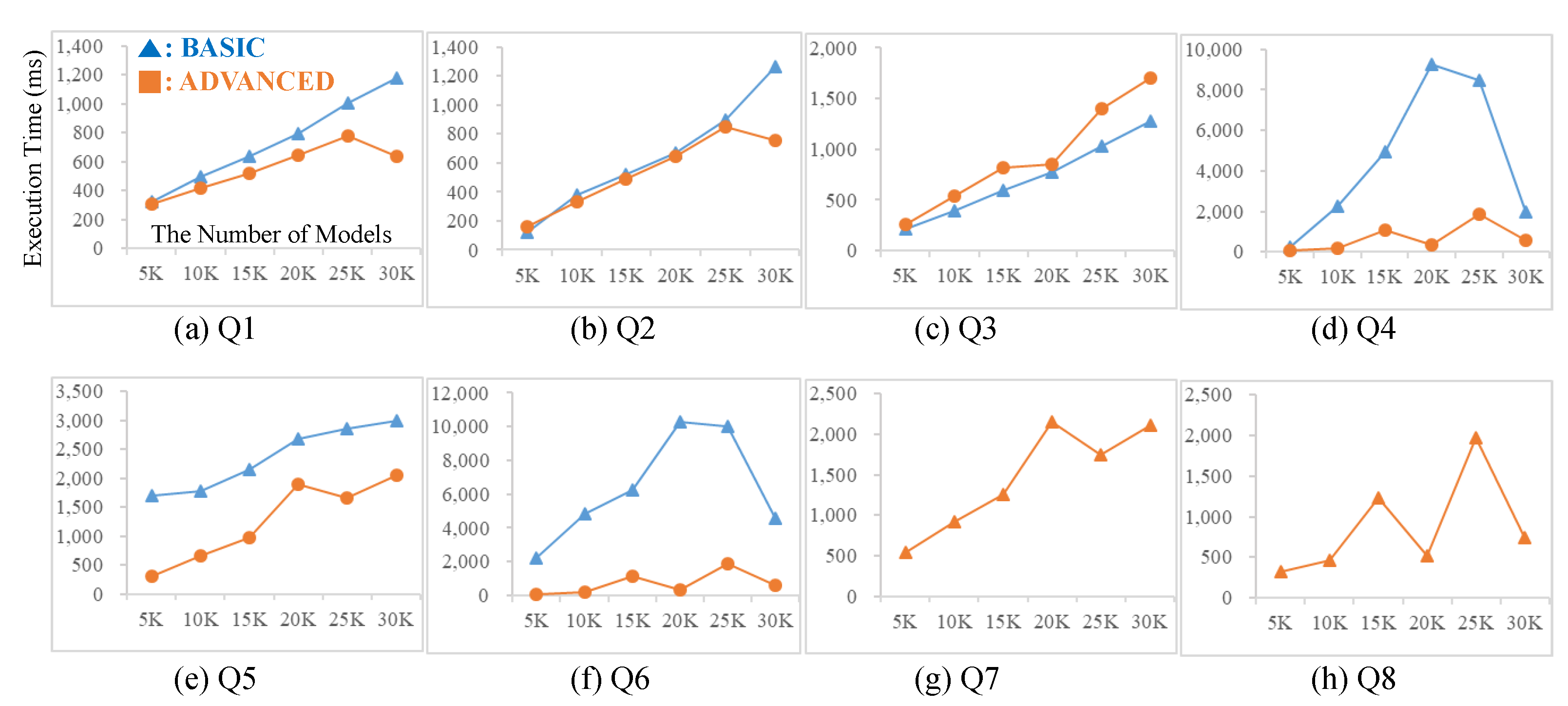
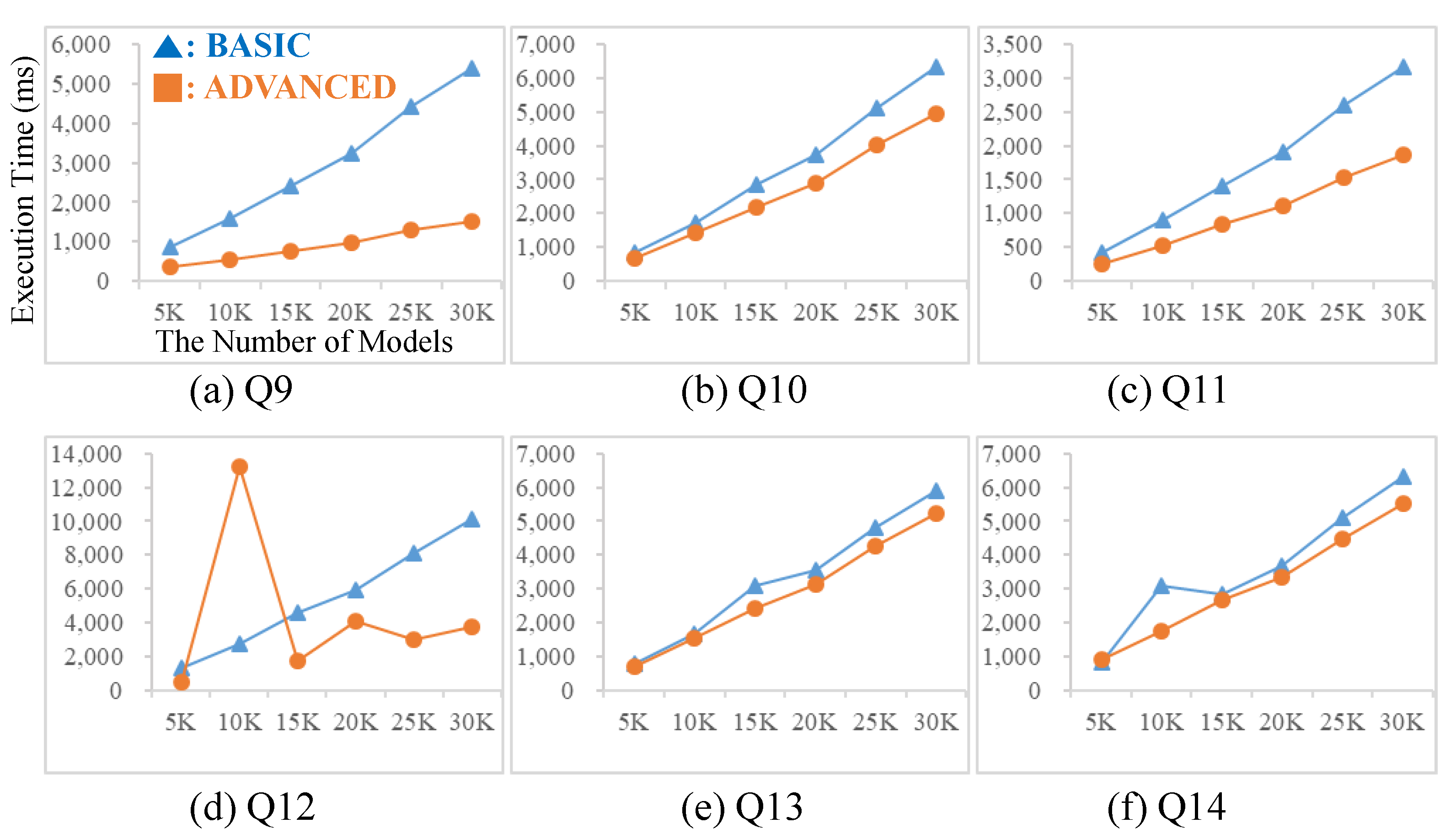
9. Experiments
9.1. Experimental Environment
9.2. Experimental Results
10. Discussion
- DEVS extensions: We developed GO-DEVS by focusing classic DEVSs but there are many DEVS extensions. To share as many models as possible, we should consider all the DEVS extensions in a model storage and retrieval system. To support them, we can consider a framework to provide both common table designs and user-defined table designs. We can extract common design concepts from a classic DEVS and various DEVS extensions. Based on the common design concepts, the classic DEVS and simple extensions can be handled. For other DEVS extensions, users must add a user-created design using tools provided by the framework.
- Integration of SES and our approach: As mentioned in Section 2, SES (System Entity Structure) was proposed for “plan-generate-evaluate” framework [2,13]. It can be used for representing the structural knowledge in hierarchical and modular systems. Even though SES can provide the structural information between parent and child components in a general way, it does not consider the relations between components at the same level. Therefore, SES and our approach need to be integrated in a systematic way. For instance, we can extend SES by adding internal structures and develop a framework to store and query extended SES data.
- Query Extensions: Even though we proposed IO and structure queries, we need to invent easy and powerful queries for model sharing. Based on the queries, various query optimization techniques must be developed to provide users with query results quickly. Additionally, we must develop a UI tool for users to input queries easily.
11. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zeigler, B.P. Theory of Modeling and Simulation; Wiley: New York, NY, USA, 1976. [Google Scholar]
- Zeigler, B.P.; Praehofer, H.; Kim, T.G. Theory of Modeling and Simulation, 2nd ed.; Academic Press: Orlando, FL, USA, 2000. [Google Scholar]
- Zeigler, B.P.; Muzy, A.; Kofman, E. Theory of Modeling and Simulation: Discrete Event & Iterative System Computational Foundations, 3rd ed.; Academic Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Hamri, M.; Driouche, N. Modeling and simulation of logic gates using devs. In Proceedings of the SIMULTECH-5th International Conference on Simulation and Modeling Methodologies, Technologies and Applications, Colmar, Alsace, France, 21–23 July 2015; pp. 212–218. [Google Scholar]
- Seo, K.-M.; Choi, C.; Kim, T.; Kim, J.H. Devs-based combat modeling for engagement-level simulation. Simulation Trans. Soc. Model. Simul. Int. 2014, 90, 759–781. [Google Scholar] [CrossRef]
- Bae, J.W.; Paik, E.; Kang, D.O.; Jung, J.; Lee, C.-H. Simulation framework for self-evolving agent-based models: A case study of housing market model. In Proceedings of the Winter Simulation Conference, Gothenburg, Sweden, 12 December 2018; pp. 1120–1131. [Google Scholar]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing. Int. J.-Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Dalle, O.; Zeigler, B.P.; Wainer, G.A. Extending devs to support multiple occurrence in component-based simulation. In Proceedings of the Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 933–941. [Google Scholar]
- Vicino, D.; Dalle, O.; Wainer, G. A data type for discretized time representation in devs. In Proceedings of the SIMUTOOLS—7th International Conference on Simulation Tools and Techniques, ICST, Lisbon, Portugal, 17–19 March 2014. [Google Scholar]
- Franceschini, R.; Bisgambiglia, P.-A.; Touraille, L.; Bisgambiglia, P.; Hill, D. A survey of modelling and simulation software frameworks using discrete event system specification. In Proceedings of the Imperial College Computing Student Workshop, London, UK, 25–26 September 2014; pp. 40–49. [Google Scholar]
- Wainer, G. Cd++: A toolkit to define discrete-event models. Softw. Pract. Exp. 2002, 32, 1261–1306. [Google Scholar] [CrossRef]
- Bolduc, J.-S.; Vangheluwe, H. A Modeling and Simulation Package for Classic Hierarchical DEVS. McGill University. Technical Report. 2002. Available online: http://atom3.cs.mcgill.ca/research/projects/DEVS/PythonDEVS/PythonDEVS.pdf (accessed on 1 October 2019).
- Zeigler, B.P.; Hammonds, P.E. Modeling & Simulation-Based Data Engineering: Introducing Pragmatics into Ontologies for Net-Centric Information Exchange; Academic Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Song, F.; Zacharewicz, G.; Chen, D. Adapting Simulation Modeling to Model-Driven Architecture for Model Requirement Verification. In Proceedings of the International Conference on Simulation and Modeling Methodologies, Technologies and Applications, Reykjavík, Iceland, 29–31 July 2013; pp. 302–309. [Google Scholar]
- Wang, H.; Park, S.; Fan, W.; Yu, P.S. Vist: A dynamic index method for querying XML data by tree structures. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 9–12 June 2003; pp. 110–121. [Google Scholar]
- Rao, P.; Moon, B. PRIX: Indexing and querying XML using prüfer sequences. In Proceedings of the 20th International Conference on Data Engineering, ICDE 2004, Boston, MA, USA, 30 March–2 April 2004; pp. 288–299. [Google Scholar]
- Yan, X.; Yu, P.S.; Han, J. Graph indexing based on discriminative frequent structure analysis. ACM Trans. Database Syst. 2005, 30, 960–993. [Google Scholar] [CrossRef]
- Cheng, J.; Ke, Y.; Ng, W.; Lu, A. Efficient query processing on graph databases. ACM Trans. Database Syst. 2009, 34, 2–48. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.-H.; Chung, C.-W. Efficient search in graph databases using cross filtering. Inf. Sci. 2014, 286, 1–18. [Google Scholar] [CrossRef]
- Ramakrishnan, R.; Gehrke, J. Database Management Systems, 2nd ed.; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Halevy, A.Y. Answering queries using views: A survey. VLDB J. 2001, 10, 270–294. [Google Scholar] [CrossRef]
- Ullmann, J.R. An Algorithm for Subgraph Isomorphism. J. Assoc. Comput. Mach. 1976, 23, 31–42. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Yan, X.; Yu, P.S.; Han, J.; Zhang, D.-Q.; Gu, X. Towards graph containment search and indexing. In Proceedings of the VLDB, Very Large Data Base Endowment, Vienna, Austria, 23–28 September 2007; pp. 926–937. [Google Scholar]
- Yan, X.; Yu, P.S.; Han, J. Substructure similarity search in graph databases. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005. [Google Scholar]
- Baek, S.G.; Kang, D.; Lee, S.; Eom, Y. Efficient graph pattern matching framework for network-based in-vehicle fault detection. J. Syst. Softw. 2018, 140, 17–31. [Google Scholar] [CrossRef]
- Zhang, C.; Naughton, J.; Dewitt, Q.L.D.; Lohman, G. On supporting containment queries in relational database management system. ACM SIGMOD Rec. 2001, 30, 425–436. [Google Scholar] [CrossRef]
- Schmidt, A.; Waas, F.; Kersten, M.L.; Carey, M.J.; Manolescu, I.; Busse, R. Xmark: A benchmark for xml data management. In Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002; pp. 974–985. [Google Scholar]
- XMark—An XML Benchmark Project. Available online: https://projects.cwi.nl/xmark/ (accessed on 1 October 2019).


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.-H.; Bae, J.W.; Paik, E. GO-DEVS: Storage and Retrieval System for DEVS Models Using Graph and Ontology Representation. Sensors 2021, 21, 6771. https://doi.org/10.3390/s21206771
Lee C-H, Bae JW, Paik E. GO-DEVS: Storage and Retrieval System for DEVS Models Using Graph and Ontology Representation. Sensors. 2021; 21(20):6771. https://doi.org/10.3390/s21206771
Chicago/Turabian StyleLee, Chun-Hee, Jang Won Bae, and Euihyun Paik. 2021. "GO-DEVS: Storage and Retrieval System for DEVS Models Using Graph and Ontology Representation" Sensors 21, no. 20: 6771. https://doi.org/10.3390/s21206771
APA StyleLee, C.-H., Bae, J. W., & Paik, E. (2021). GO-DEVS: Storage and Retrieval System for DEVS Models Using Graph and Ontology Representation. Sensors, 21(20), 6771. https://doi.org/10.3390/s21206771