
Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification

 , , , , , and
, , , , , and
Abstract
:1. Introduction
- The first is the main applied goal. Our group is developing a BCI for people with communication difficulties, locked-in syndrome and other serious difficulties in articulation. Thus, we have to focus on minimizing the contribution of verbal communication in our data.
- The second is convenience of signal processing in less noisy data. Using only silent speech we had less distortion from motor center activation obscuring our speech center data. When working with an EEG, articulation itself and other small movements such as blinking and head movements cause serious noises. In our dataset, we tried to reduce the contribution of motion to our data, assuming that we can add this kind of noise later.
2. Materials and Methods
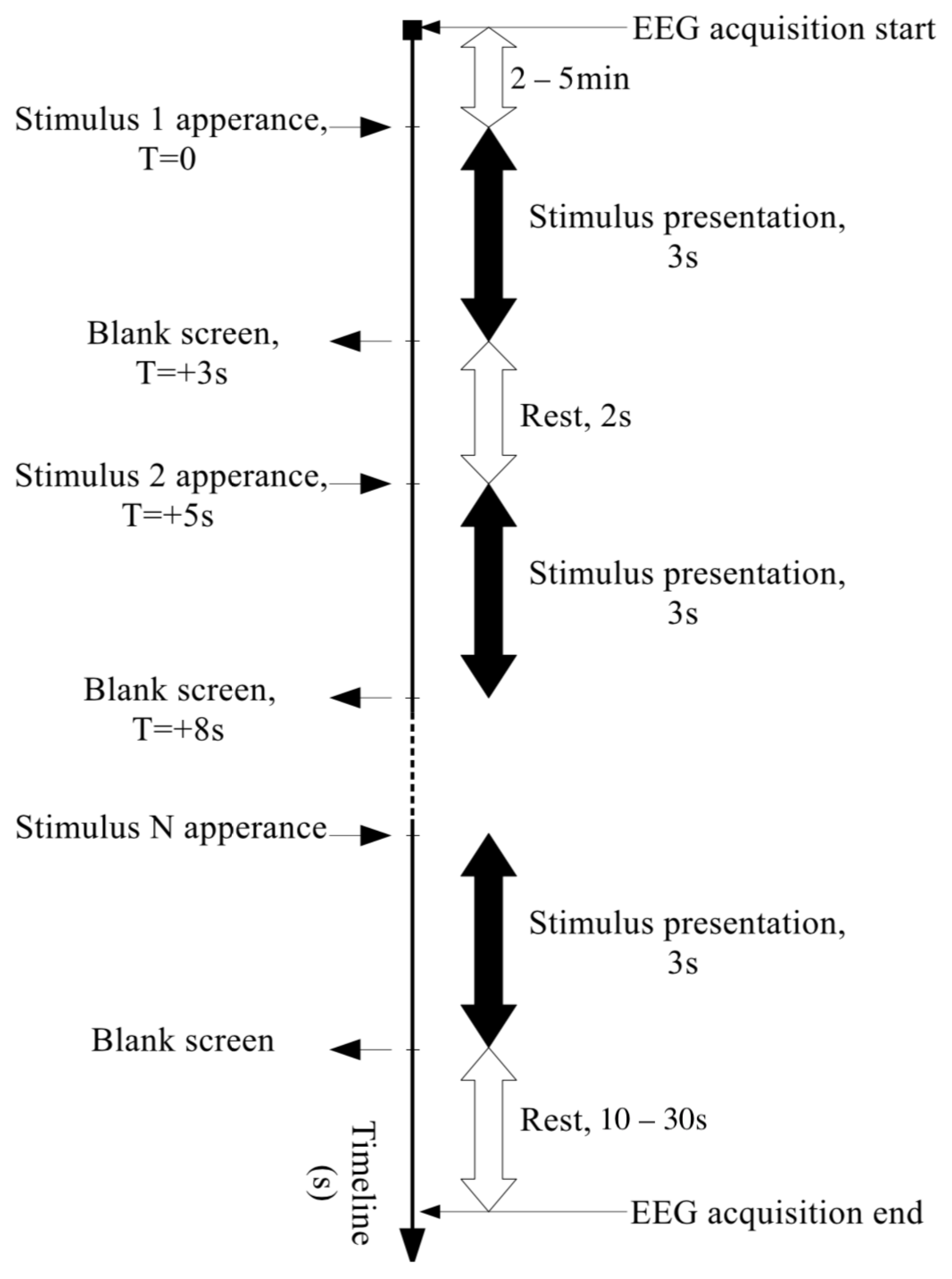
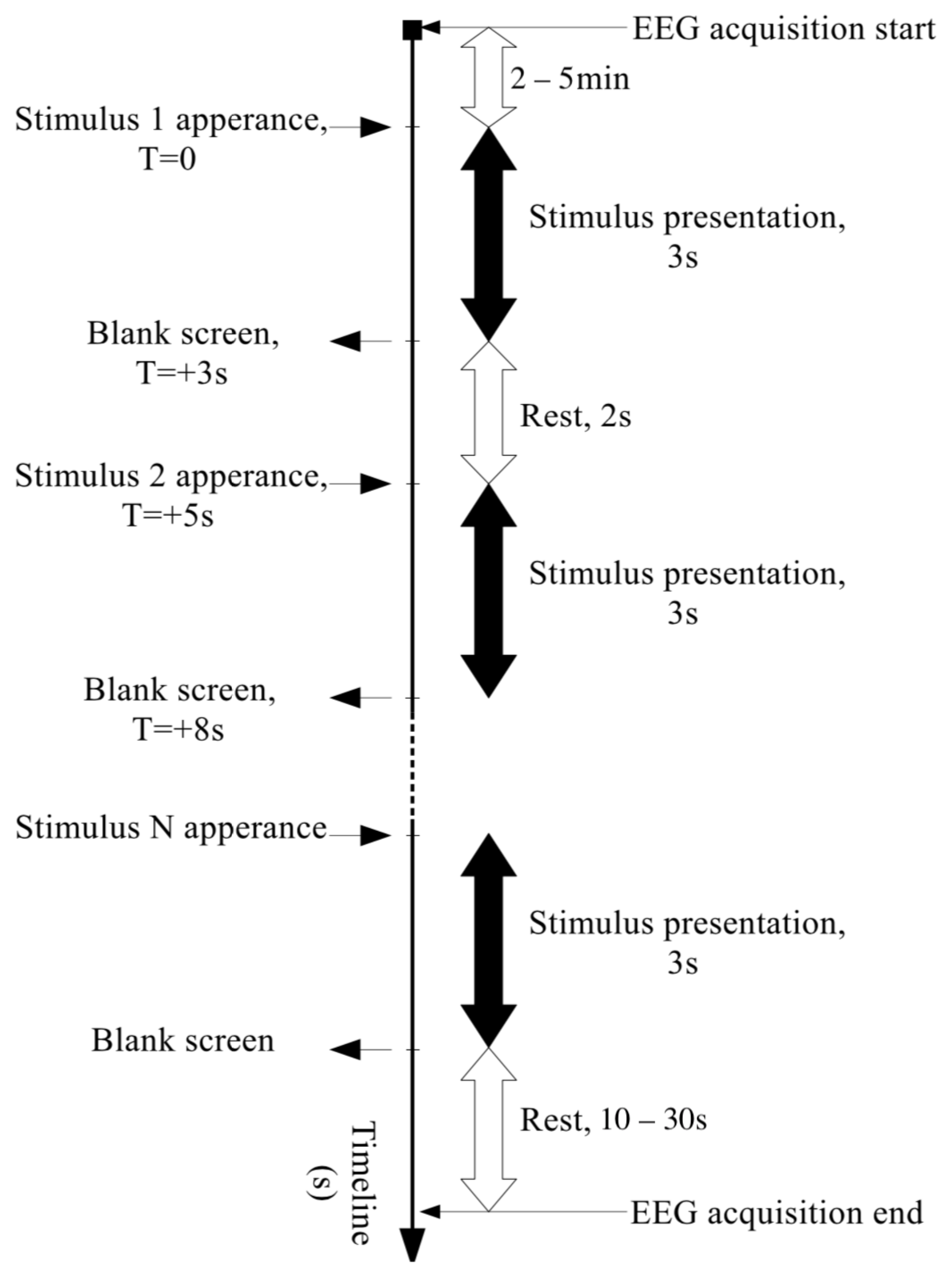
2.1. Collecting the EEG Data
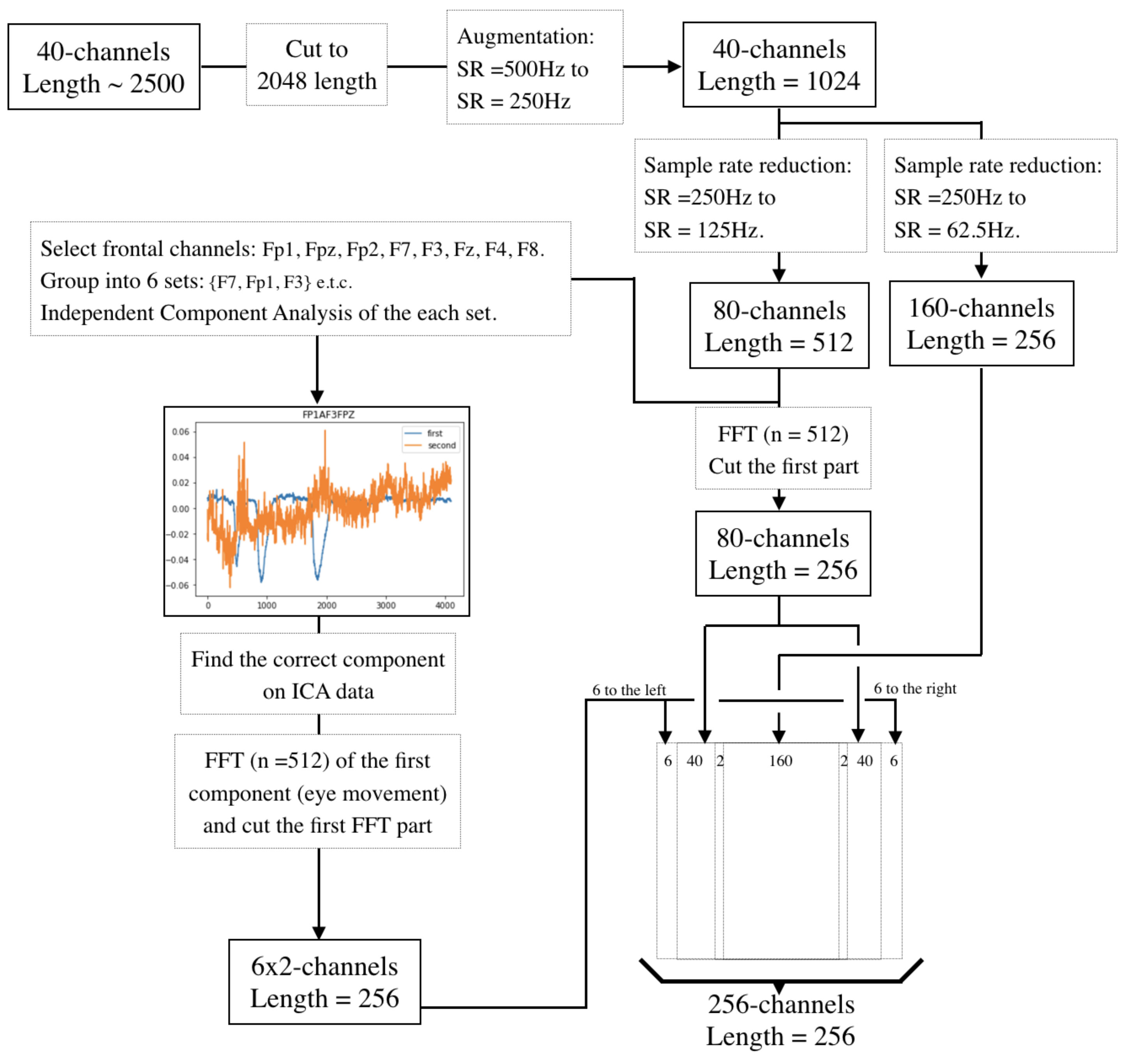
2.2. Eye Noise Filtering
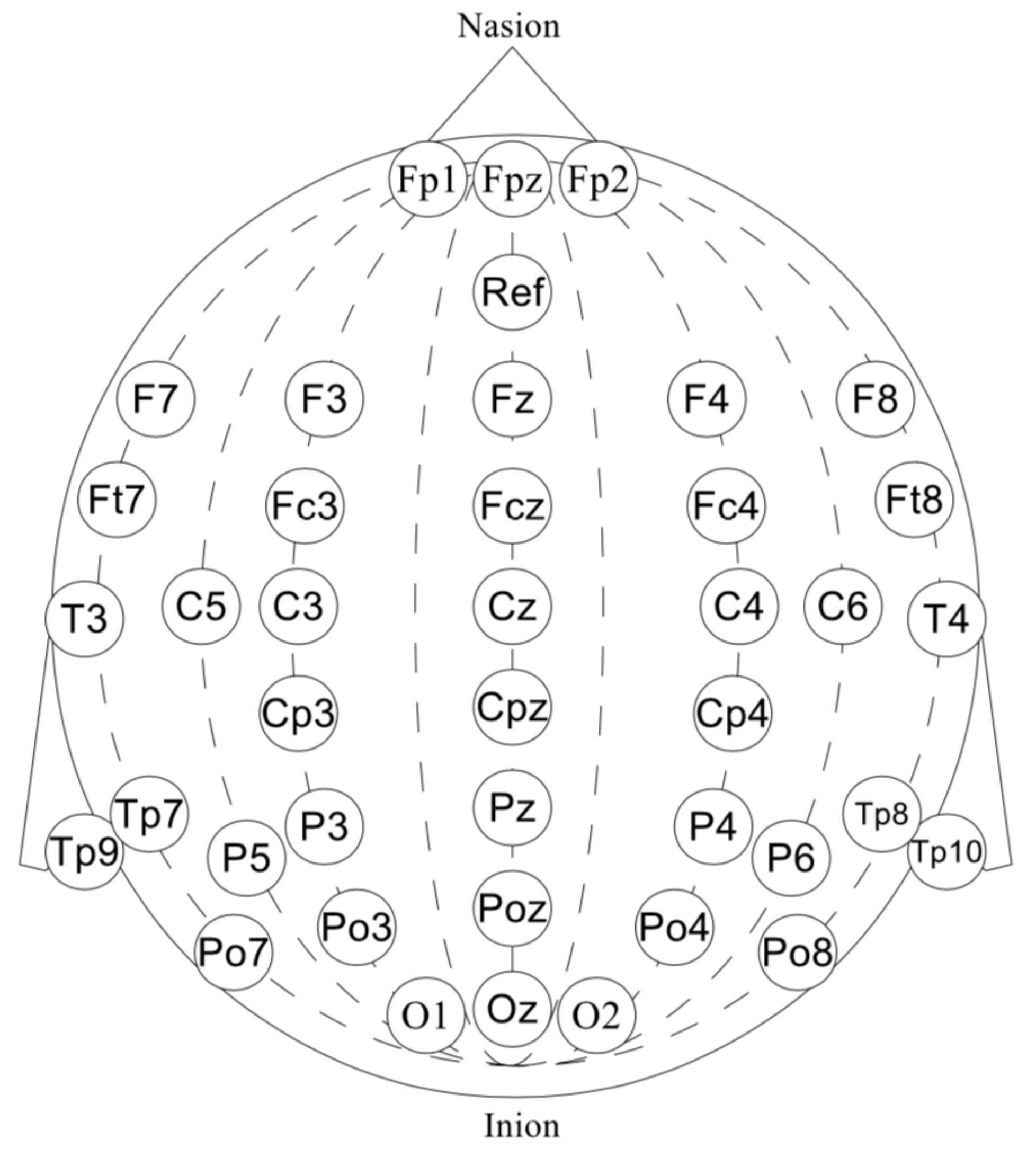
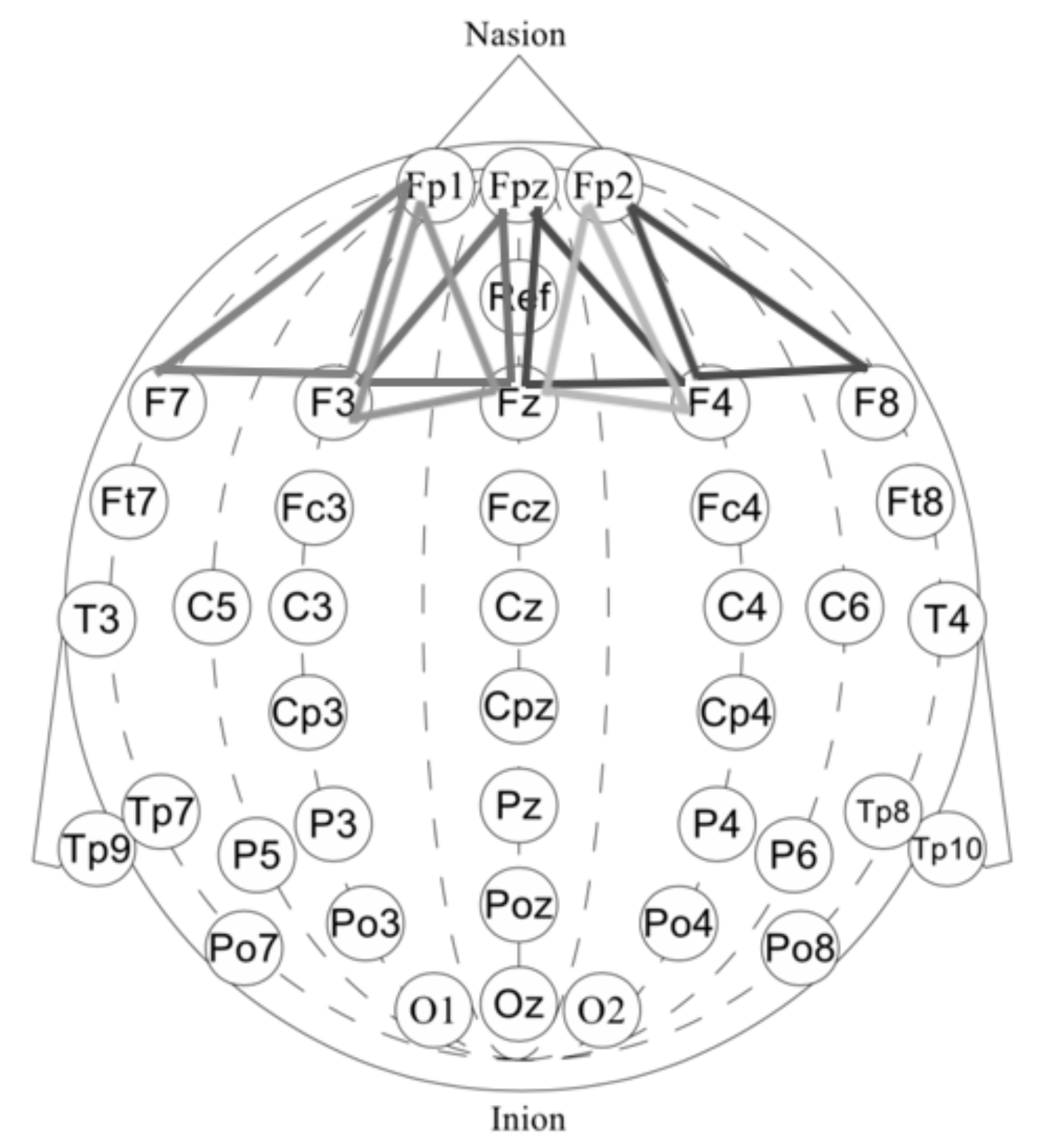
- First, we performed a morphological selection of electrodes. To identify eye noise, we chose the most eye-sensitive electrodes located in the frontal region. We grouped the frontal electrodes into four sets of three electrodes, taking into account the proximity and location to one side of the reference electrode: {‘Fpz’, ‘Fz’, ‘F3’}, {‘Fp1’, ‘F3’, ‘F7’}, {‘Fpz’, ‘Fz’, ‘F4’}, {‘Fp2’, ‘F4’, ‘F8’}. See Figure 4 for the location of the electrode groups on the head.
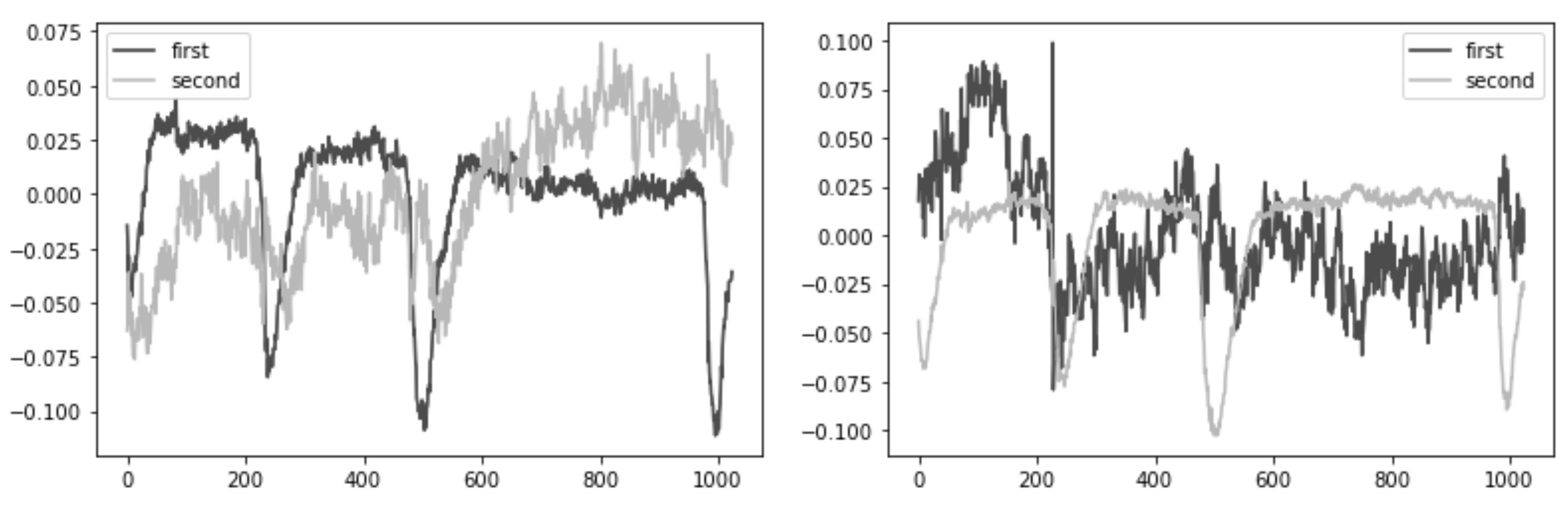
- Second, we performed an Independent Component Analysis (ICA). We used ICA on the grouped frontal electrodes to decompose a multivariate signal into independent non-Gaussian signals: eye noise and brain activity during silent speech. For each triad of the frontal electrodes ({‘Fpz’, ‘Fz’, ‘F3’}, {‘Fp1’, ‘F3’, ‘F7’}, {‘Fpz’, ‘Fz’, ‘F4’}, {‘Fp2’, ‘F4’, ‘F8’}) ICA was applied to get two components. We used the sklearn library to apply ICA to our data with the following parameters: sklearn.decomposition.FastICA . However, as you can see in the picture, the components were not always selected in the correct order (Figure 5). To select the correct component, we applied the following method.
- Third, we correctly identified and isolated the eye noise component. Separating the eye noise component required three steps as well. During the first step, we performed a Fast Fourier transform (FFT) for each component and cut the lowest 3 frequencies to remove a trend, and right after we performed an inverse Fourier transform. During the second step, the resulting two components were smoothed using the Savitsky–Galey filter with the following parameters: . During the third step, we calculated the median and maximum value for each component. Finally, we selected the component with the largest difference between the median and maximum values and considered this the eye noise component.
2.3. Dimensions Reduction and Component Analysis
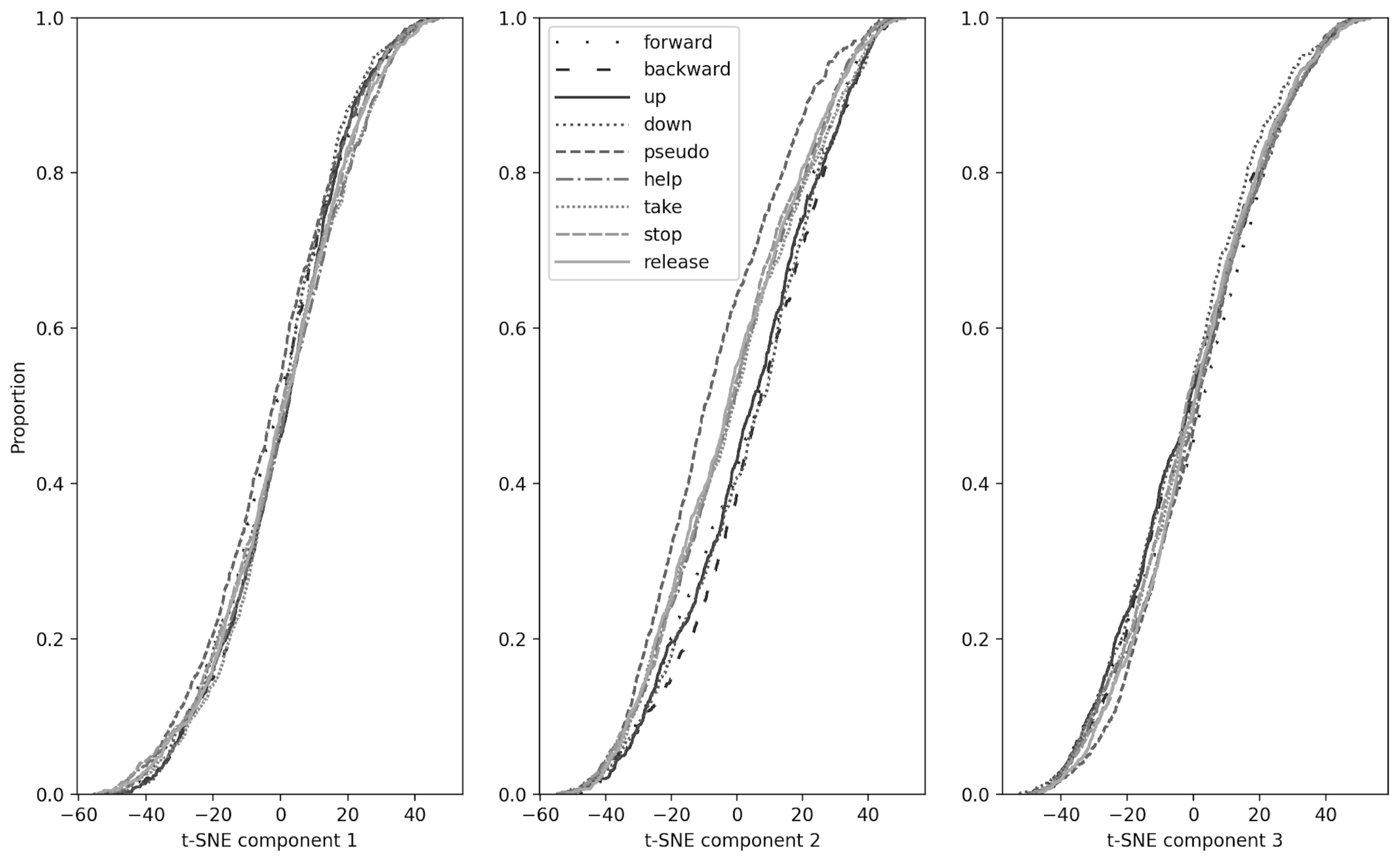
2.4. Kolmogorov–Smirnov Test
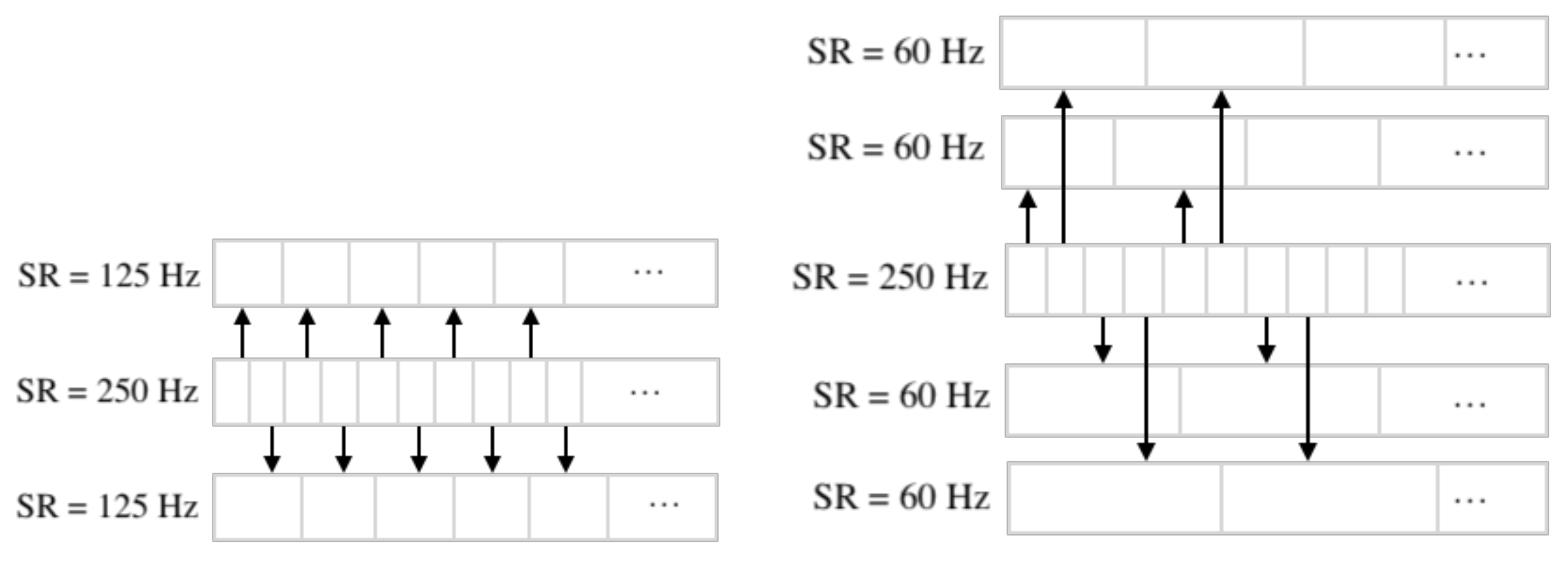
2.5. Downsampling
2.6. Separation of Electrodes into Left and Right Hemispheres
2.7. Presenting the EEG-Data as a Two-Dimensional Vector
2.8. Neural Networks
3. Results
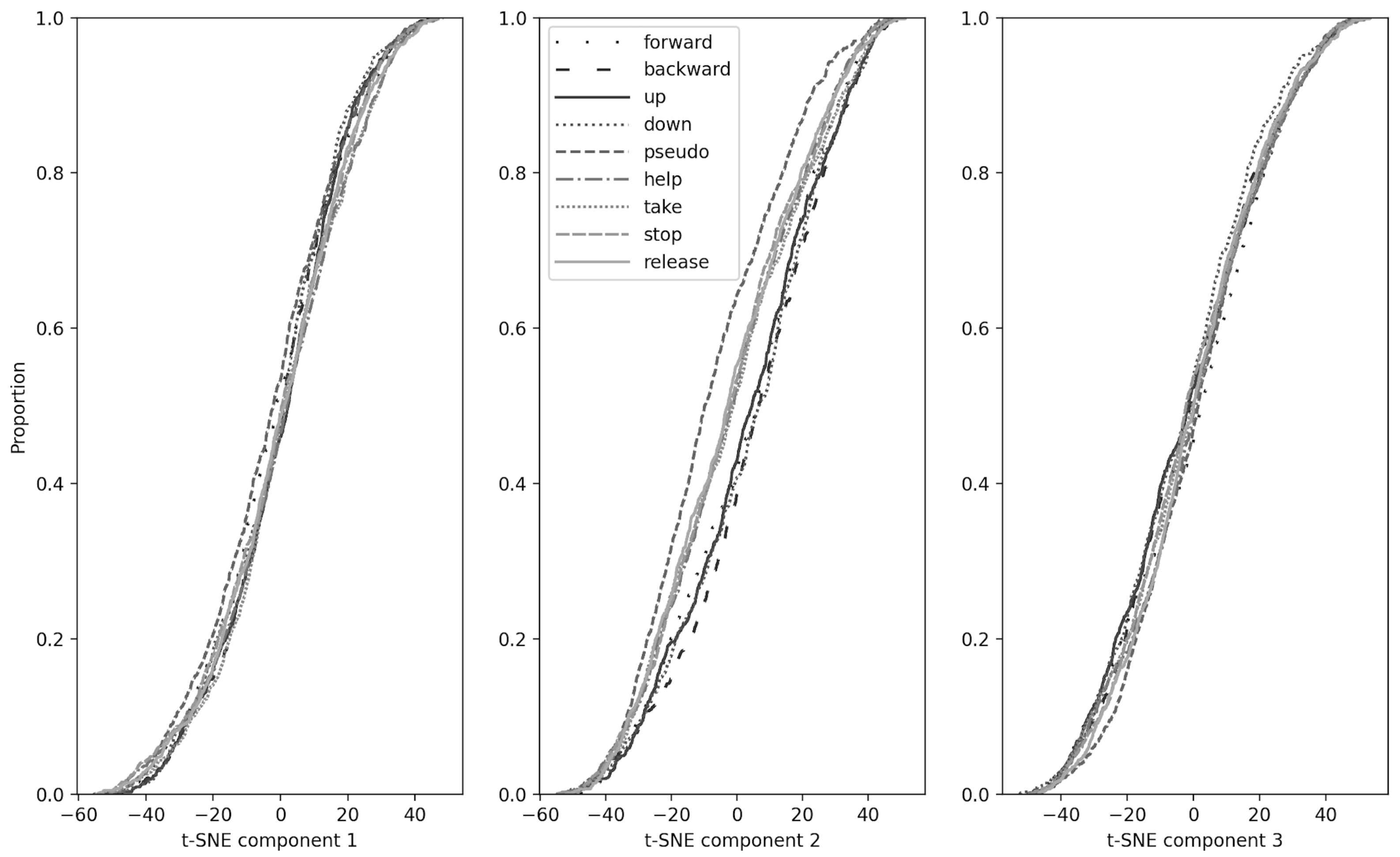
3.1. Dimensions Reduction, Component Analysis and Kolmogorov–Smirnov Test
3.2. Neural Networks Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| PJSC | Public Joint-Stock Company |
| ML | Machine Learning |
| EEG | Electroencephalography |
| BCI | Brain–computer Interface |
| ICA | Independent Component Analysis |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| PCA | Principal Component Analysis |
| CNN | Convolutional Neural Network |
| FFT | Fast Fourier Transform |
| GRU | Gated Recurrent Unit |
| SVM | Support Vector Machine |
References
- Taylor, D.M.; Stetner, M.E. Intracortical BCIs: A Brief History of Neural Timing. In Brain–Computer Interfaces; Graimann, B., Pfurtscheller, G., Allison, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 9–12. [Google Scholar]
- Wyler, A.R. Electrocorticography. In Presurgical Evaluation of Epileptics; Wieser, H.G., Elger, C.E., Eds.; Springer: Berlin/Heidelberg, Germany, 1987; pp. 9–31. [Google Scholar]
- Willett, F.R.; Avansino, D.T.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. High-performance brain-to-text communication via handwriting. Nature 2008, 593, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Biasiucci, A.; Franceschiello, B.; Murray, M.M. Electroencephalography. Curr. Biol. 2019, 29, R80–R85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rashkov, G.; Bobe, A.; Fastovets, D.; Komarova, M. Natural image reconstruction from brain waves: A novel visual BCI system with native feedback. bioRxiv 2019. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Advances in neural information processing systems. Int. J. Pattern Recognit. Artif. Intell. 1994, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- DaSalla, C.S.; Kambara, H.; Sato, M.; Koike, Y. Single-trial classification of vowel speech imagery using common spatial patterns. Neural Netw. 2009, 22, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Brigham, K.; Kumar, B. Imagined Speech Classification with EEG Signals for Silent Communication: A Preliminary Investigation into Synthetic Telepathy. In Proceedings of the 2010 4th International Conference on Bioinformatics and Biomedical Engineering, iCBBE 2010, Chengdu, China, 10–12 June 2010. [Google Scholar]
- Min, B.; Kim, J.; Park, H.J.; Lee, B. Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram. Biomed. Res. Int. 2016, 2016, 2618265. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004. [Google Scholar]
- Balaji, A.; Haldar, A.; Patil, K.; Ruthvik, T.S.; Valliappan, C.A.; Jartarkar, M.; Baths, V. EEG-based classification of bilingual unspoken speech using ANN. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017. [Google Scholar]
- Nguyen, C.H.; Karavas, G.K.; Artemiadis, P. Inferring imagined speech using EEG signals: A new approach using Riemannian manifold features. J. Neural Eng. 2018, 15, 016002. [Google Scholar] [CrossRef] [PubMed]
- Cooney, C.; Folli, R.; Coyle, D. Mel Frequency Cepstral Coefficients Enhance Imagined Speech Decoding Accuracy from EEG. In Proceedings of the 2018 29th Irish Signals and Systems Conference (ISSC), Belfast, UK, 21–22 June 2018. [Google Scholar]
- Panachakel, J.T.; Ramakrishnan, A.G.; Ananthapadmanabha, T.V. Decoding Imagined Speech using Wavelet Features and Deep Neural Networks. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019. [Google Scholar]
- Pramit, S.; Muhammad, A.-M.; Sidney, F. SPEAK YOUR MIND! Towards Imagined Speech Recognition with Hierarchical Deep Learning. arXiv 2019, arXiv:1904.04358. [Google Scholar]
- Pey, A.; Wang, D. TCNN: Temporal Convolutional Neural Network for Real-time Speech Enhancement in the Time Domain. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Oleksii, K.; Boris, G. Training Deep AutoEncoders for Collaborative Filtering. arXiv 2017, arXiv:1708.01715. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Sun, S.; Huang, R. An adaptive k-nearest neighbor algorithm. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery, Yantai, China, 11–12 August 2010. [Google Scholar]
- Zhang, D.; Li, Y.; Zhang, Z. Deep Metric Learning with Spherical Embedding. arXiv 2020, arXiv:2011.02785. [Google Scholar]
- Sereshkeh, A.R.; Trott, R.; Bricout, A.; Chau, T. EEG Classification of Covert Speech Using Regularized Neural Networks IEEE/ACM Transactions on Audio, Speech, and Language Processing. IEEE J. Sel. Top. Signal Process. 2017, 15, 37–50. [Google Scholar]
- Arnav, K.; Shreyas, K.; Pattie, M. AlterEgo: A Personalized Wearable Silent Speech Interface. In Proceedings of the 23rd International Conference on Intelligent User Interfaces (IUI ’18), Tokyo, Japan, 7–11 March 2018. [Google Scholar]
- Pawar, D.; Dhage, S. Multiclass covert speech classification using extreme learning machine. Biomed. Eng. Lett. 2020, 10, 217–226. [Google Scholar] [CrossRef] [PubMed]
- Chengaiyan, S.; Retnapandian, A.S.; Anandan, K. Identification of vowels in consonant-vowel-consonant words from speech imagery based EEG signals. Cogn. Neurodyn. 2020, 14, 1–19. [Google Scholar] [CrossRef]
- Krishna, G.; Tran, C.; Yu, J.; Tewfik, A.H. Speech Recognition with No Speech or with Noisy Speech. In Proceedings of the CASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Kapur, A.; Sarawgi, U.; Wadkins, E.; Wu, M.; Hollenstein, N.; Maes, P. Non-Invasive Silent Speech Recognition in Multiple Sclerosis with Dysphonia. Proc. Mach. Learn. Res. 2020, 116, 25–38. [Google Scholar]
- Cooney, C.; Korik, A.; Folli, R.; Coyle, D. Evaluation of Hyperparameter Optimization in Machine and Deep Learning Methods for Decoding Imagined Speech EEG. Sensors 2020, 20, 4629. [Google Scholar] [CrossRef]
- Lee, D.-Y.; Lee, M.; Lee, S.-W. Classification of Imagined Speech Using Siamese Neural Network. arXiv 2020, arXiv:2008.12487. [Google Scholar]
- Public Dataset Results—OpenNeuro. Available online: Https://openneuro.org/search/eeg (accessed on 15 May 2020).
- Zhao, S.; Rudzicz, F. Classifying phonological categories in imagined and articulated speech. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Queensland, Australia, 19–24 April 2015. [Google Scholar]
- Gautam, K.; Yan, H.; Co, T.; Mason, C.; Ahmed, H.T. State-of-the-art Speech Recognition using EEG and Towards Decoding of Speech Spectrum From EEG. arXiv 2019, arXiv:1908.05743. [Google Scholar]
- Koctúrová, M.; Juhár, J. EEG Based Voice Activity Detection. In Proceedings of the 2018 16th International Conference on Emerging eLearning Technologies and Applications (ICETA) The High Tatras, Slovakia, 15–16 November2018. [Google Scholar]
- NVX EEG Amplifiers for Teaching and Research. Available online: Https://mks.ru/product/nvx/ (accessed on 18 May 2020).
- NoeRec Software for EEG Registration. Available online: Https://mks.ru/product/neorec (accessed on 18 May 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Yan, C.; Xiao, Y.; Lei, Y.; Mikhailov, S.; Zhengkui, W. Automatic Image Captioning Based on ResNet50 and LSTM with Soft Attention. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar]
- Chigozie, N.; Winifred, I.; Anthony, G.; Stephen, M. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Data Type | Accuracy on NN Set Size | Year | |||
|---|---|---|---|---|---|---|
| Binary | 3 | 4 | > 4 | |||
| Spatial filters and support vector machines [7] | Phonemes: /a/, /u/ | 78% | - | - | - | 2009 |
| K-nearest neighbor algorithm and autoregression [8] | Syllables: /ba/, /ku/ | 61% | - | - | - | 2010 |
| Extreme learning machine with radial basis function and linear discriminant analysis [9] | Phonemes: /a/, /e/, /i/, /o/, /u/. | 72% | - | - | - | 2016 |
| Support vector machine on the Riemannian space [12] | Phonemes: /a/, /i/, /u/ | 49.2% | - | - | - | 2017 |
| Words: ’in’, ’cooperate’ | 80.1% | - | - | - | ||
| Support vector machine and neural network [11] | English words: ‘yes’, ‘no’. Hindi words: ‘haan’, ‘na’. | 75.4% | - | - | - | 2017 |
| Wavelet transform and regularized neural network [21] | Words: ‘yes’, ‘no’. | 67% | - | - | - | 2017 |
| Support vector machine [13] | Syllables: /iy/, /piy/, /tiy/, /diy/, /uw/, /m/, /n/. Words: ‘pat’, ‘pot’, ‘knew’, ‘gnaw’. | - | - | 33.33% | - | 2018 |
| Three-layer convolutional neural network on myography data [22] | Numbers 0 to 9 in English. | - | - | - | 92.01% | 2018 |
| Hierarchical conventional neural network, deep autoencoder and extreme gradient boosting [15] | Syllables: /iy/, /piy/, /tiy/, /diy/, /uw/, /m/, /n/. Words: ‘pat’, ‘pot’, ‘knew’, ‘gnaw’. | 83.42% | - | - | 66.2% | 2019 |
| Recurrent network [25] | Phonemes: /a/, /e/, /i/, /o/, /u/. | - | - | - | 98.61% | 2019 |
| Words: ‘yes’, ‘no’, ‘left’, ‘right’. | - | - | 99.38% | - | ||
| Recurrent network [24] | Words with a consonant-vowel-consonant structure. | 72% | - | - | - | 2019 |
| Kernel-based extreme learning machine [14] | Words: ‘left’, ‘right’, ‘up’, ‘down’ | 85.57% | - | 49.77% | - | 2020 |
| Five-layer convolutional neural network with the final fully connected layer [26] | 15 English sentences from 3 participants. | - | - | - | 81% | 2020 |
| Time and space convolution networks [27] | Phonemes: /a/, /e/, /i/, /o/, /u/. | - | - | - | 30% | 2020 |
| Hierarchical neural network consisting of two convolutional neural networks and the k-nearest neighbors algorithm [28] | Spanish words: ‘arriba’, ‘abajo’, ‘derecha’, ‘izquierda’, ‘adelante’, ’atrás’. | - | - | 24.97% | 31.40 ± 2.73% | 2020 |
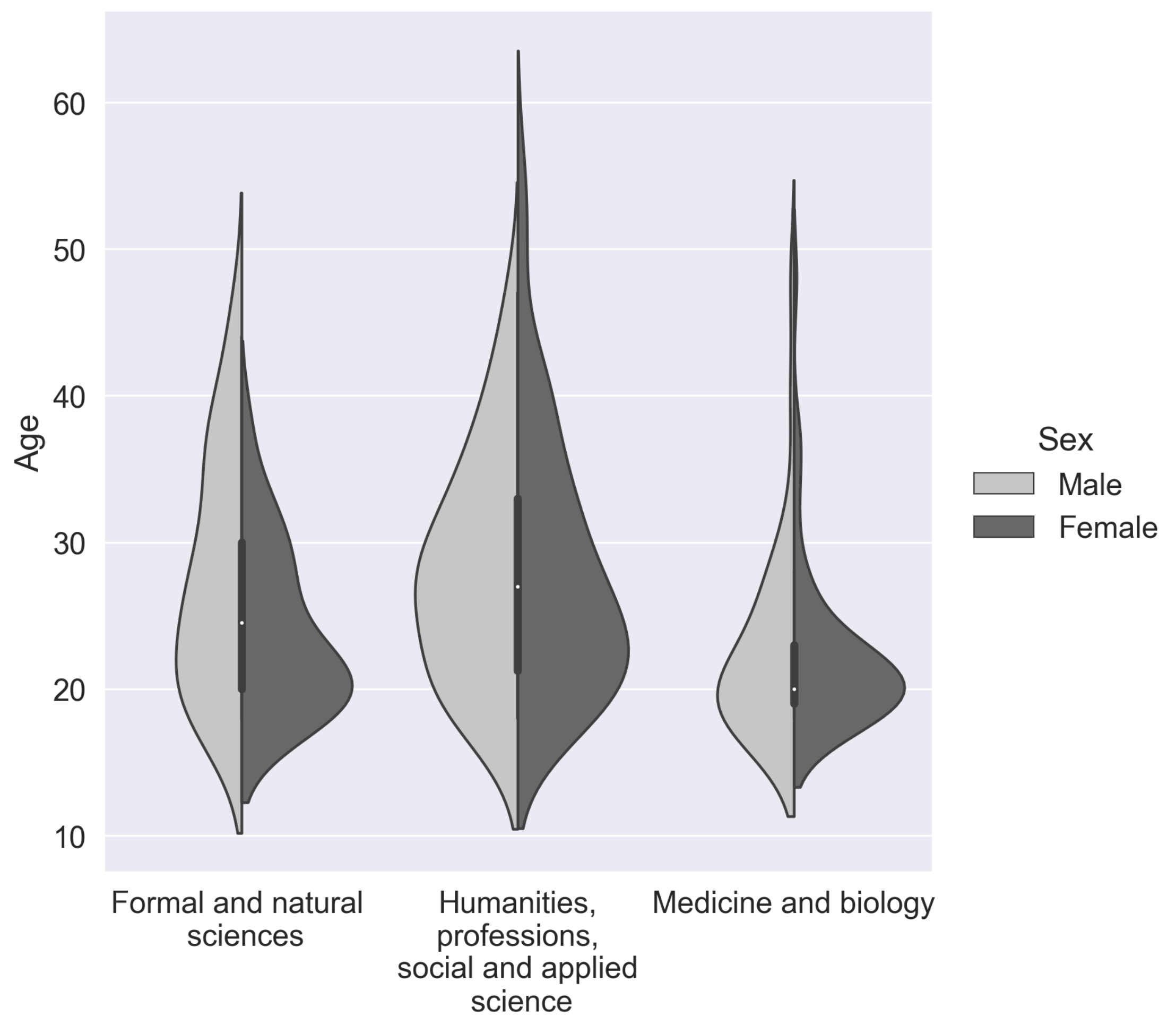
| Sex | Professional | Sample | Mean | Std | Min | Max |
|---|---|---|---|---|---|---|
| Area | Number | Age | Age | Age | ||
| Female | Formal and natural sciences | 27 | 23.8 | 5.5 | 18 | 38 |
| Female | Humanities, social and applied science | 72 | 28.0 | 8.8 | 18 | 56 |
| Female | Medicine and biology | 63 | 22.1 | 5.4 | 18 | 48 |
| Male | Formal and natural sciences | 39 | 27.6 | 8.1 | 18 | 46 |
| Male | Humanities, social and applied science | 34 | 28.1 | 7.6 | 18 | 47 |
| Male | Medicine and biology | 33 | 22.8 | 6.7 | 18 | 48 |
| Word: | ‘backward’ | ‘up’ | ‘down’ | pseudo | ‘help’ | ‘take’ | ‘stop’ | ‘release’ |
|---|---|---|---|---|---|---|---|---|
| ‘forward’ | ||||||||
| Component | 3 | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
| Statistics | 0.046 | 0.047 | 0.023 | 0.117 | 0.161 | 0.125 | 0.175 | 0.137 |
| p-value | 0.0109 | 0.009 | 0.0027 | |||||
| ‘backward’ | ||||||||
| Component | 1 | 3 | 2 | 2 | 2 | 2 | 2 | |
| Statistics | 0.056 | 0.059 | 0.059 | 0.167 | 0.13 | 0.155 | 0.14 | |
| p-value | 0.0006 | 0.0003 | ||||||
| ‘up’ | ||||||||
| Component | 2 | 2 | 2 | 2 | 2 | 2 | ||
| Statistics | 0.0269 | 0.14 | 0.142 | 0.104 | 0.144 | 0.12 | ||
| p-value | 0.00015 | |||||||
| ‘down’ | ||||||||
| Component | 2 | 2 | 2 | 2 | 2 | |||
| Statistics | 0.128 | 0.147 | 0.114 | 0.156 | 0.126 | |||
| p-value | ||||||||
| pseudo | ||||||||
| Component | 2 | 2 | 2 | 2 | ||||
| Statistics | 0.242 | 0.233 | 0.27 | 0.23 | ||||
| p-value | ||||||||
| ‘help’ | ||||||||
| Component | 3 | 1 | 3 | |||||
| Statistics | 0.063 | 0.052 | 0.095 | |||||
| p-value | 0.001 | 0.0096 | ||||||
| ‘take’ | ||||||||
| Component | 2 | 3 | ||||||
| Statistics | 0.054 | 0.074 | ||||||
| p-value | 0.0057 | |||||||
| ‘stop’ | ||||||||
| Component | 3 | |||||||
| Statistics | 0.074 | |||||||
| p-value |
| 9 Silent Words | 2 Silent Words | |||||
|---|---|---|---|---|---|---|
| Limited | Out-of-Sample | Limited | Out-of-Sample | |||
| Data | Data | Data | Data | |||
| Training | Train | Test | Test | Train | Test | Test |
| Sample | Accuracy/ | Accuracy/ | Accuracy/ | Accuracy/ | Accuracy/ | Accuracy/ |
| Cardinality | Loss | Loss | Loss | Loss | Loss | Loss |
| 1 | 91.98%/ | 84.51%/ | 10.79%/ | 100%/ | 87.92%/ | 52%/ |
| 1.52 | 1.46 | 2.26 | 0.46 | 0.37 | 0.74 | |
| 2 | 80.52%/ | 82.34%/ | 10.1%/ | 100%/ | 88.21%/ | 52.3%/ |
| 1.56 | 1.55 | 2.26 | 0.39 | 0.31 | 0.77 | |
| 32 | 74.28%/ | 18.91%/ | 13.15%/ | 70%/ | 89.5%/ | 51.4%/ |
| 1.91 | 2.18 | 2.23 | 0.43 | 0.69 | 0.84 | |
| 256 | 72.34%/ | 13.39%/ | 10.21%/ | 66.04%/ | 85.18%/ | 52.3%/ |
| 1.64 | 2.16 | 2.2 | 0.41 | 0.62 | 0.77 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vorontsova, D.; Menshikov, I.; Zubov, A.; Orlov, K.; Rikunov, P.; Zvereva, E.; Flitman, L.; Lanikin, A.; Sokolova, A.; Markov, S.; et al. Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification. Sensors 2021, 21, 6744. https://doi.org/10.3390/s21206744
Vorontsova D, Menshikov I, Zubov A, Orlov K, Rikunov P, Zvereva E, Flitman L, Lanikin A, Sokolova A, Markov S, et al. Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification. Sensors. 2021; 21(20):6744. https://doi.org/10.3390/s21206744
Chicago/Turabian StyleVorontsova, Darya, Ivan Menshikov, Aleksandr Zubov, Kirill Orlov, Peter Rikunov, Ekaterina Zvereva, Lev Flitman, Anton Lanikin, Anna Sokolova, Sergey Markov, and et al. 2021. "Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification" Sensors 21, no. 20: 6744. https://doi.org/10.3390/s21206744
APA StyleVorontsova, D., Menshikov, I., Zubov, A., Orlov, K., Rikunov, P., Zvereva, E., Flitman, L., Lanikin, A., Sokolova, A., Markov, S., & Bernadotte, A. (2021). Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification. Sensors, 21(20), 6744. https://doi.org/10.3390/s21206744