
Detection of the Deep-Sea Plankton Community in Marine Ecosystem with Underwater Robotic Platform




 , and
, and 
Abstract
:1. Introduction
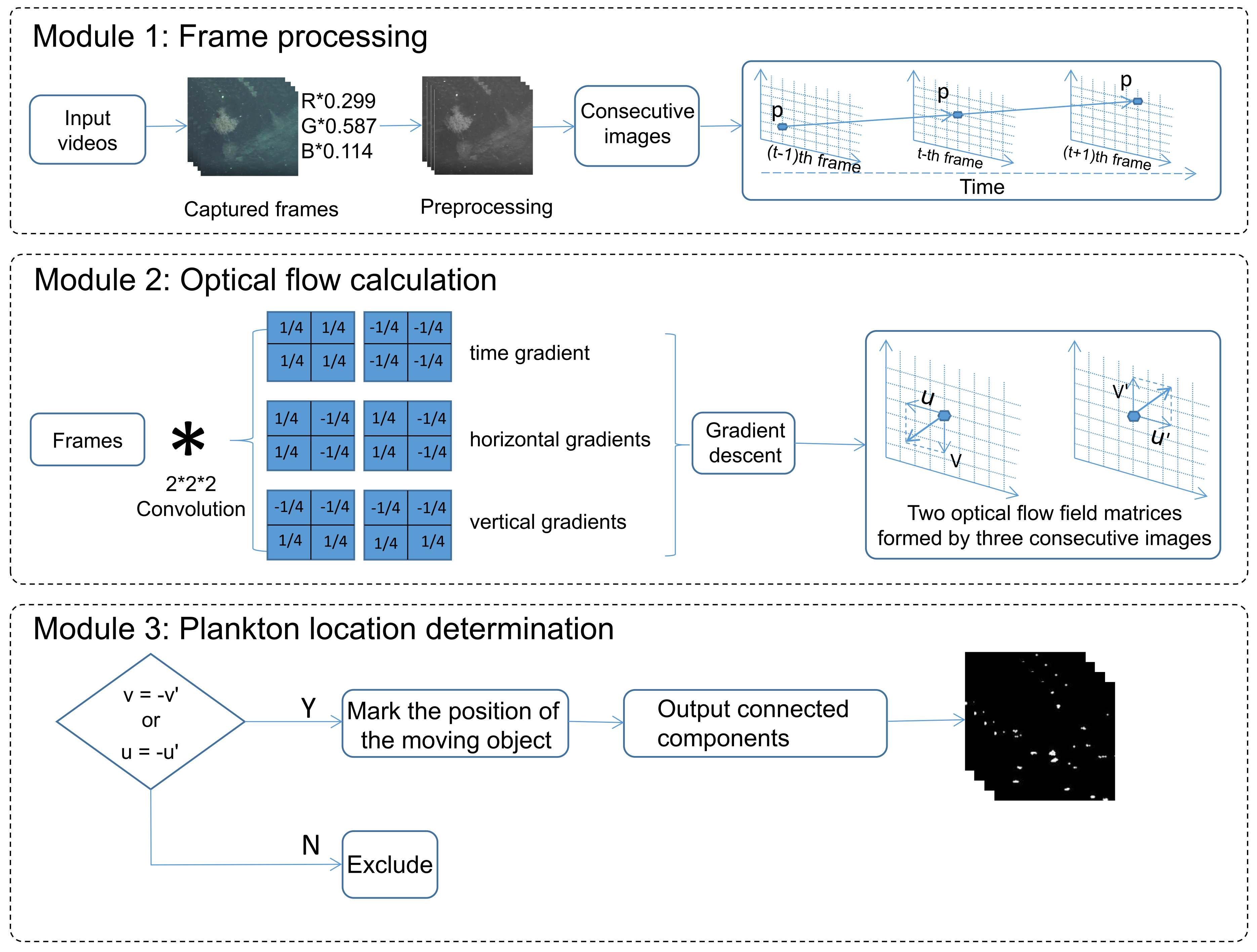
2. The Proposed Method
2.1. Principle
2.2. Proof
2.3. The Volume of Plankton
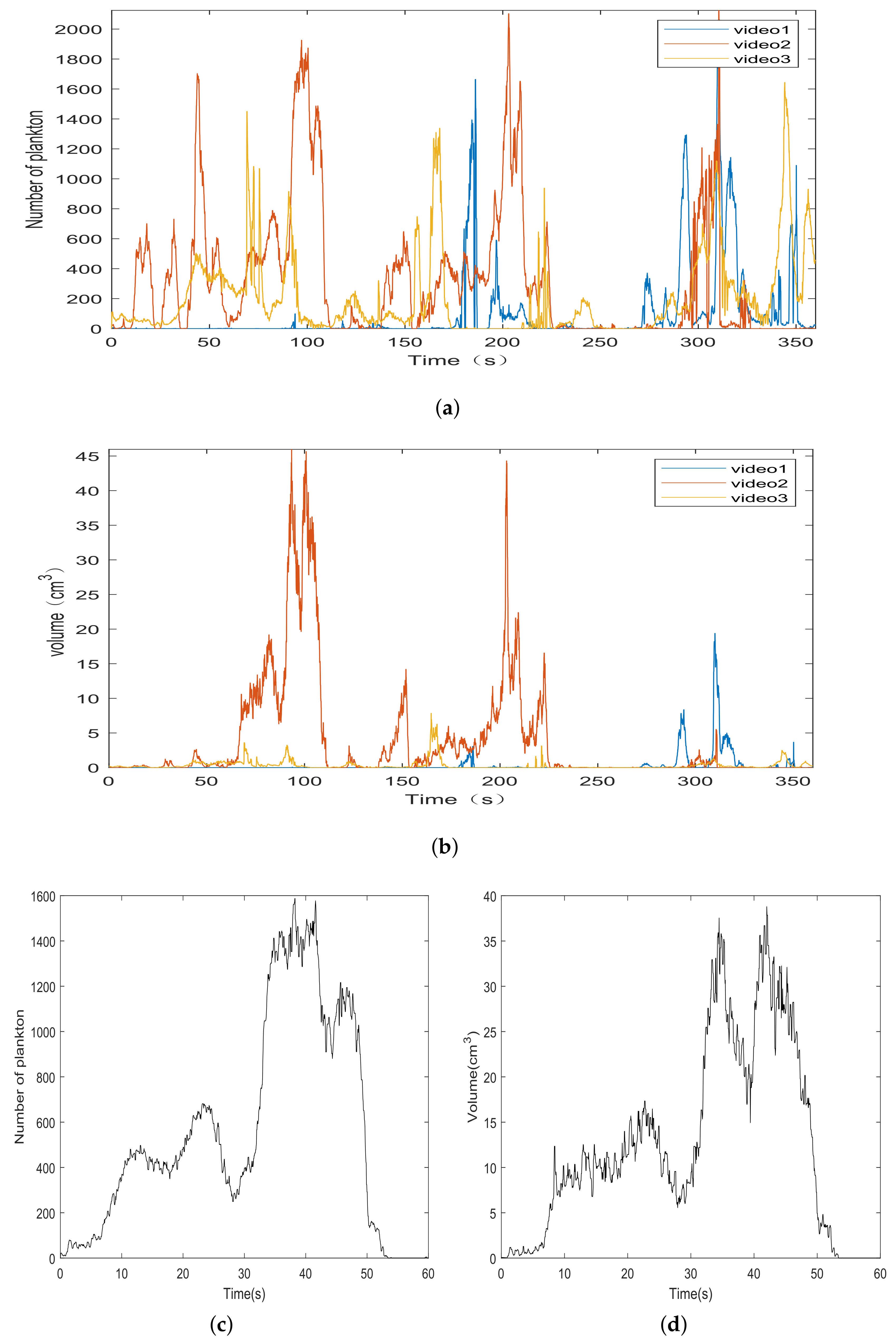
3. Experimental Results and Analysis
3.1. Number and Volume of Plankton
3.2. Comparison with Six Target Detection Methods
3.3. Discussion of Parameters
3.4. Time Complexity Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brierley, A. Plankton. Curr. Biol. 2017, 27, 478–483. [Google Scholar] [CrossRef]
- Wang, K.; Razzano, M.; Mou, X. Cyanobacterial blooms alter the relative importance of neutral and selective processes in assembling freshwater bacterioplankton community. Sci. Total Environ. 2020, 706, 135724. [Google Scholar] [CrossRef]
- Forster, D.; Qu, Z.; Pitsch, G.; Bruni, E.P.; Kammerlander, B.; Proschold, T.; Sonntag, B.; Posch, T.; Stoeck, T. Lake Ecosystem Robustness and Resilience Inferred from a Climate-Stressed Protistan Plankton Network. Microorganisms 2021, 9, 549. [Google Scholar] [CrossRef] [PubMed]
- Henrik, L.; Torkel, G.; Benni, W. Planton community structure and carbon cycling on the western coast of Greenland during the stratified summer situation. II.Heterotrophic dinoflagellates and ciliates. Aquat. Microb. Ecol. 1999, 16, 217–232. [Google Scholar]
- Lu, H.; Wang, D.; Li, J.; Li, X.; Kim, H.; Serikawa, S.; Humar, I. Conet: A cognitive ocean network. IEEE Wirel. Commun. 2019, 26, 90–96. [Google Scholar] [CrossRef] [Green Version]
- Wiebe, P.; Benfield, M. From the Hensen net toward four-dimensional biological oceanography. Prog. Oceanogr. 2003, 56, 7–136. [Google Scholar] [CrossRef]
- Yan, Y.; Ren, J.; Sun, G.; Zhao, H.; Han, J.; Li, X.; Marshall, S.; Zhan, J. Unsupervised image saliency detection with Gestalt-laws guided optimization and visual attention based refinement. Pattern Recogn. 2018, 79, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Tschannerl, J.; Ren, J.; Yuen, P.; Sun, G.; Zhao, H.; Yang, Z.; Wang, Z.; Marshall, S. MIMR-DGSA: Unsupervised hyperspectral band selection based on information theory and a modified discrete gravitational search algorithm. Inform. Fusion 2019, 51, 189–200. [Google Scholar] [CrossRef] [Green Version]
- Zabalza, J.; Ren, J.; Yang, M.; Zhang, Y.; Wang, J.; Marshall, S.; Han, J. Novel Folded-PCA for improved feature extraction and data reduction with hyperspectral imaging and SAR in remote sensing. ISPRS J. Photogramm. 2014, 93, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Tian, X.; Yang, M.; Wu, Y.; Su, H. PAC-Bayesian framework based drop-path method for 2D discriminative convolutional network pruning. Multidim. Syst. Sign. Process. 2020, 31, 793–827. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Tian, X.; Jiang, N.; Wang, D. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discrete Dyn. Nat. Soc. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Jiang, N.; Yang, M. Layer-wise learning based stochastic gradient descent method for the optimization of deep convolutional neural network. J. Intell. Fuzzy Syst. 2019, 37, 5641–5654. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Zhang, Q.; Zhang, X. Fine-grained image classification based on the combination of artificial features and deep convolutional activation features. In Proceedings of the 2017 IEEE/CIC International Conference on Communications in China, Qingdao, China, 22–24 October 2019; pp. 1–6. [Google Scholar]
- Craig, J. Distribution of Deep-Sea Bioluminescence across the Mid-Atlantic Ridge and Mediterranean Sea: Relationships with Surface Productivity, Topography and Hydrography. Ph.D. Thesis, University of Aberdeen, Aberdeen, UK, 2012. [Google Scholar]
- Craig, J.; Priede, I.G.; Aguzzi, J.; Company, J.B.; Jamieson, A.J. Abundant bioluminescent sources of low-light intensity in the deep Mediterranean Sea and North Atlantic Ocean. Mar. Biol. 2015, 162, 1637–1649. [Google Scholar] [CrossRef]
- Phillips, B.; Gruber, D.; Vasan, G.; Pieribone, V.; Sparks, J.; Roman, C. First Evidence of Bioluminescence on a "Black Smoker" Hydrothermal Chimney. Oceanography 2016, 29, 10–12. [Google Scholar] [CrossRef] [Green Version]
- Kydd, J.; Rajakaruna, H.; Briski, E.; Bailey, S. Examination of a high resolution laser optical plankton counter and FlowCAM for measuring plankton concentration and size. J. Sea Res. 2018, 133, 2–10. [Google Scholar] [CrossRef] [Green Version]
- Kocak, D.M.; Da Vitoria Lobo, N.; Widder, E.A. Computer vision techniques for quantifying, tracking, and identifying bioluminescent plankton. IEEE J. Oceanic Eng. 2002, 24, 81–95. [Google Scholar] [CrossRef]
- Mazzei, L.; Marini, S.; Craig, J.; Aguzzi, J.; Fanelli, E.; Priede, I.G. Automated Video Imaging System for Counting Deep-Sea Bioluminescence Organisms Events. In Proceedings of the 2014 ICPR Workshop on Computer Vision for Analysis of Underwater Imagery, Stockholm, Sweden, 24 August 2014; pp. 57–64. [Google Scholar]
- Schmid, M.; Cowen, R.; Robinson, K.; Luo, J.; Briseno-Avena, C.; Sponaugle, S. Prey and predator overlap at the edge of a mesoscale eddy: Fine-scale, in-situ distributions to inform our understanding of oceanographic processes. Sci. Rep. 2020, 10, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horn, B.K.P.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Iversen, M.H.; Nowald, N.; Ploug, H.; Jackson, G.A.; Fischer, G. High resolution profiles of vertical particulate organic matter export off Cape Blanc, Mauritania: Degradation processes and ballasting effects. Deep Sea Res. Part I Oceanogr. Res. Pap. 2010, 57, 771–784. [Google Scholar] [CrossRef]
- He, F.; Hu, Y.; Wang, J. Texture Detection of Aluminum Foil Based on Top-Hat Transformation and Connected Region Segmentation. Adv. Mater. Sci. Eng. 2020, 3, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Wei, H.; Peng, Q. A block-wise frame difference method for real-time video motion detection. Int. J. Adv. Robot. Syst. 2018, 15, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Shi, X.; Zhang, G.; Lv, C.; Yang, X. Measurement of 3-DOF Planar Motion of the Object Based on Image Segmentation and Matching. Nanomanuf. Metrol. 2019, 2, 124–129. [Google Scholar] [CrossRef]
- Wang, W.; Wang, W.; Yan, Y. A Scan-Line-Based Hole Filling Algorithm for Vehicle Recognition. Adv. Mater. Res. 2011, 179, 92–96. [Google Scholar] [CrossRef]
- Lu, N.; Wang, J.; Wu, Q. An optical flow and inter-frame block-based histogram correlation method for moving object detection. Int. J. Model. Identif. Control 2010, 10, 87–93. [Google Scholar] [CrossRef]
- Mohiuddin, K.; Alam, M.; Das, A.; Munna, T.; Allayear, S.; Ali, H. Haar Cascade Classifier and Lucas-Kanade Optical Flow Based Realtime Object Tracker with Custom Masking Technique. Adv. Inf. Commun. Netw. 2019, 2, 398–410. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diving Number | Date | Diving Time | Longitude | Latitude | Depth |
|---|---|---|---|---|---|
| 76 | 17 July 2014 | 8.95 h | 155.32 E–155.34 E | 15.50 N–15.52 N | 2741.88 m |
| 77 | 21 July 2014 | 10.33 h | 154.58 E–154.59 E | 15.70 N–15.72 N | 5555.68 m |
| Relevant | Nonrelevant | |
|---|---|---|
| Retrieved | True Positives (TP) | False Positives (FP) |
| Not Retrieved | False Negatives (FN) | True Negatives (TN) |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean | std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | 10 | 12 | 9 | 15 | 17 | 18 | 18 | 22 | 24 | 22 | 16.7 | 4.9 |
| Frame difference | 20 | 22 | 18 | 22 | 21 | 17 | 19 | 15 | 17 | 14 | 18.5 | 2.7 |
| Image match | 26 | 24 | 23 | 21 | 24 | 17 | 15 | 15 | 16 | 16 | 19.7 | 4.1 |
| Scan line marking | 11 | 7 | 8 | 9 | 10 | 9 | 10 | 9 | 9 | 8 | 9.0 | 1.1 |
| SD | 17 | 13 | 11 | 11 | 13 | 13 | 12 | 10 | 12 | 10 | 12.2 | 1.9 |
| LK | 17 | 14 | 13 | 13 | 13 | 13 | 12 | 11 | 11 | 10 | 12.7 | 1.8 |
| Proposed method | 16 | 14 | 12 | 12 | 12 | 11 | 12 | 10 | 11 | 10 | 12.0 | 1.7 |
| Ground-Truth | 14 | 13 | 12 | 12 | 11 | 12 | 11 | 9 | 10 | 9 | 11.3 | 1.6 |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | Precision | 0.9 | 0.85 | 0.89 | 0.73 | 0.59 | 0.61 | 0.56 | 0.36 | 0.42 | 0.41 | 0.632 |
| Recall | 0.64 | 0.92 | 0.67 | 0.92 | 0.91 | 0.92 | 0.91 | 0.89 | 1 | 1 | 0.878 | |
| 0.75 | 0.88 | 0.76 | 0.81 | 0.72 | 0.73 | 0.69 | 0.51 | 0.59 | 0.58 | 0.73 | ||
| Frame difference | Precision | 0.65 | 0.55 | 0.61 | 0.5 | 0.52 | 0.65 | 0.56 | 0.53 | 0.59 | 0.57 | 0.573 |
| Recall | 0.93 | 0.92 | 0.92 | 0.92 | 1 | 0.92 | 1 | 0.89 | 1 | 0.89 | 0.939 | |
| 0.77 | 0.69 | 0.73 | 0.65 | 0.68 | 0.76 | 0.72 | 0.66 | 0.74 | 0.69 | 0.712 | ||
| Image match | Precision | 0.54 | 0.54 | 0.49 | 0.52 | 0.46 | 0.65 | 0.67 | 0.53 | 0.56 | 0.56 | 0.552 |
| Recall | 1 | 1 | 0.92 | 0.92 | 1 | 0.92 | 0.91 | 0.89 | 0.9 | 1 | 0.946 | |
| 0.7 | 0.7 | 0.64 | 0.66 | 0.63 | 0.76 | 0.77 | 0.66 | 0.69 | 0.72 | 0.7 | ||
| Scan line marking | Precision | 0.82 | 0.86 | 0.88 | 0.78 | 0.9 | 0.89 | 0.9 | 0.89 | 0.89 | 0.88 | 0.869 |
| Recall | 0.64 | 0.46 | 58 | 0.58 | 0.82 | 0.67 | 0.82 | 0.89 | 0.8 | 0.78 | 0.704 | |
| 0.72 | 0.6 | 0.7 | 0.67 | 0.86 | 0.76 | 0.86 | 0.89 | 0.84 | 0.83 | 0.778 | ||
| SD | Precision | 0.76 | 0.92 | 0.91 | 0.91 | 0.77 | 0.85 | 0.83 | 0.8 | 0.75 | 0.8 | 0.83 |
| Recall | 0.93 | 0.92 | 0.83 | 0.83 | 0.91 | 0.92 | 0.91 | 0.89 | 0.9 | 0.89 | 0.893 | |
| 0.84 | 0.92 | 0.87 | 0.87 | 0.83 | 0.88 | 0.87 | 0.84 | 0.82 | 0.84 | 0.86 | ||
| LK | Precision | 0.76 | 0.86 | 0.85 | 0.85 | 0.85 | 0.85 | 0.83 | 0.73 | 0.82 | 0.8 | 0.82 |
| Recall | 0.93 | 0.93 | 0.92 | 0.92 | 1 | 0.92 | 0.91 | 0.89 | 0.9 | 0.89 | 0.921 | |
| 0.84 | 0.89 | 0.88 | 0.88 | 0.92 | 0.88 | 0.87 | 0.8 | 0.86 | 0.84 | 0.868 | ||
| Proposed method | Precision | 0.81 | 0.93 | 1 | 1 | 0.92 | 1 | 0.83 | 0.8 | 0.82 | 0.9 | 0.901 |
| Recall | 0.93 | 1 | 1 | 1 | 1 | 0.92 | 0.91 | 0.89 | 0.9 | 1 | 0.955 | |
| 0.87 | 0.96 | 1 | 1 | 0.96 | 0.96 | 0.87 | 0.84 | 0.86 | 0.95 | 0.927 |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean | std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | 22 | 17 | 17 | 16 | 13 | 12 | 13 | 12 | 9 | 18 | 14.9 | 3.6 |
| Frame difference | 28 | 28 | 30 | 24 | 30 | 15 | 28 | 28 | 27 | 24 | 26.2 | 4.2 |
| Image match | 22 | 22 | 25 | 26 | 31 | 27 | 32 | 28 | 31 | 24 | 26.8 | 3.5 |
| Scan line marking | 13 | 15 | 14 | 11 | 16 | 15 | 19 | 15 | 15 | 13 | 14.6 | 2.0 |
| SD | 16 | 21 | 22 | 23 | 23 | 23 | 22 | 23 | 20 | 17 | 21.0 | 2.4 |
| LK | 16 | 22 | 23 | 22 | 23 | 23 | 21 | 23 | 20 | 18 | 21.1 | 2.4 |
| Proposed method | 15 | 21 | 22 | 21 | 22 | 21 | 21 | 22 | 19 | 16 | 20.0 | 2.4 |
| Ground-Truth | 19 | 19 | 19 | 18 | 21 | 18 | 21 | 21 | 18 | 15 | 18.9 | 1.8 |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | Precision | 0.77 | 0.94 | 0.94 | 0.93 | 0.92 | 0.92 | 0.92 | 0.92 | 1 | 0.77 | 0.903 |
| Recall | 0.89 | 0.84 | 0.84 | 0.83 | 0.57 | 0.61 | 0.57 | 0.52 | 0.5 | 0.93 | 0.762 | |
| 0.83 | 0.89 | 0.89 | 0.88 | 0.7 | 0.73 | 0.7 | 0.66 | 0.67 | 0.84 | 0.827 | ||
| Frame difference | Precision | 0.64 | 0.64 | 0.6 | 0.71 | 0.65 | 0.93 | 0.71 | 0.71 | 0.59 | 0.58 | 0.676 |
| Recall | 0.95 | 0.95 | 0.95 | 0.94 | 0.95 | 0.78 | 0.95 | 0.95 | 0.88 | 0.93 | 0.923 | |
| 0.76 | 0.76 | 0.74 | 0.81 | 0.77 | 0.85 | 0.81 | 0.81 | 0.71 | 0.71 | 0.78 | ||
| Image match | Precision | 0.82 | 0.82 | 0.72 | 0.65 | 0.67 | 0.63 | 0.63 | 0.71 | 0.55 | 0.58 | 0.678 |
| Recall | 0.95 | 0.95 | 0.95 | 0.94 | 0.95 | 0.94 | 0.95 | 0.95 | 0.94 | 0.93 | 0.945 | |
| 0.88 | 0.88 | 0.82 | 0.77 | 0.79 | 0.75 | 0.76 | 0.81 | 0.69 | 0.71 | 0.789 | ||
| Scan line marking | Precision | 0.92 | 0.93 | 0.93 | 1 | 0.94 | 0.93 | 0.95 | 0.93 | 0.93 | 0.92 | 0.938 |
| Recall | 0.63 | 0.74 | 0.68 | 0.61 | 0.71 | 0.78 | 0.86 | 0.67 | 0.78 | 0.8 | 0.726 | |
| 0.75 | 0.82 | 0.79 | 0.76 | 0.81 | 0.85 | 0.9 | 0.78 | 0.85 | 0.86 | 0.82 | ||
| SD | Precision | 0.94 | 0.85 | 0.82 | 0.74 | 0.87 | 0.74 | 0.91 | 0.87 | 0.85 | 0.82 | 0.841 |
| Recall | 0.79 | 0.94 | 0.94 | 0.94 | 0.95 | 0.94 | 0.95 | 0.95 | 0.94 | 0.93 | 0.893 | |
| 0.86 | 0.89 | 0.88 | 0.83 | 0.91 | 0.83 | 0.93 | 0.91 | 0.89 | 0.87 | 0.88 | ||
| LK | Precision | 0.94 | 0.82 | 0.78 | 0.77 | 0.87 | 0.74 | 0.95 | 0.87 | 0.85 | 0.78 | 0.837 |
| Recall | 0.79 | 0.94 | 0.95 | 0.94 | 0.95 | 0.94 | 0.95 | 0.95 | 0.94 | 0.93 | 0.928 | |
| 0.86 | 0.88 | 0.86 | 0.85 | 0.91 | 0.83 | 0.95 | 0.91 | 0.89 | 0.85 | 0.88 | ||
| Proposed method | Precision | 1 | 0.85 | 0.82 | 0.86 | 0.91 | 0.81 | 0.9 | 0.91 | 0.95 | 0.94 | 0.895 |
| Recall | 0.79 | 0.95 | 0.95 | 1 | 0.95 | 0.94 | 0.9 | 0.95 | 1 | 1 | 0.943 | |
| 0.88 | 0.9 | 0.88 | 0.92 | 0.93 | 0.87 | 0.9 | 0.93 | 0.97 | 0.97 | 0.918 |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | 19 | 34 | 1 | 47 | 45 | 3 | 3 | 0 | 0 | 2 |
| Frame difference | 281 | 260 | 10 | 159 | 143 | 15 | 13 | 8 | 10 | 12 |
| Image match | 78 | 129 | 12 | 106 | 120 | 16 | 15 | 11 | 9 | 14 |
| Scan line marking | 8 | 119 | 1 | 51 | 99 | 7 | 4 | 2 | 2 | 3 |
| SD | 172 | 195 | 0 | 83 | 124 | 1 | 5 | 1 | 1 | 9 |
| LK | 163 | 190 | 0 | 86 | 121 | 1 | 5 | 1 | 1 | 10 |
| Proposed method | 94 | 105 | 0 | 71 | 89 | 1 | 7 | 1 | 1 | 5 |
| Ground-Truth | 87 | 94 | 1 | 66 | 76 | 2 | 6 | 1 | 1 | 5 |
| The Ten Frames: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-Hat | Precision | 0.95 | 0.88 | 1.00 | 0.94 | 0.89 | 0.67 | 1.00 | 0.00 | 0.00 | 1.00 | 0.733 |
| Recall | 0.21 | 0.32 | 1.00 | 0.66 | 0.53 | 1.00 | 0.50 | 0.00 | 0.00 | 0.40 | 0.462 | |
| 0.34 | 0.47 | 1.00 | 0.78 | 0.66 | 0.80 | 0.67 | 0.00 | 0.00 | 0.57 | 0.529 | ||
| Frame difference | Precision | 0.28 | 0.35 | 0.1 | 0.38 | 0.49 | 0.13 | 0.38 | 0.13 | 0.10 | 0.33 | 0.267 |
| Recall | 0.92 | 0.96 | 1.00 | 0.91 | 0.92 | 1.00 | 0.83 | 1.00 | 1.00 | 0.80 | 0.934 | |
| 0.43 | 0.51 | 0.18 | 0.54 | 0.64 | 0.23 | 0.52 | 0.23 | 0.18 | 0.47 | 0.393 | ||
| Image match | Precision | 0.90 | 0.70 | 0.08 | 0.57 | 0.58 | 0.13 | 0.33 | 0.09 | 0.11 | 0.29 | 0.378 |
| Recall | 0.80 | 0.96 | 1.00 | 0.91 | 0.92 | 1.00 | 0.83 | 1.00 | 1.00 | 0.80 | 0.922 | |
| 0.85 | 0.81 | 0.15 | 0.70 | 0.71 | 0.23 | 0.47 | 0.17 | 0.20 | 0.43 | 0.472 | ||
| Scan line marking | Precision | 0.94 | 0.73 | 1.00 | 0.88 | 0.71 | 0.29 | 1.00 | 0.50 | 0.50 | 0.67 | 0.722 |
| Recall | 0.86 | 0.93 | 1.00 | 0.68 | 0.92 | 1.00 | 0.67 | 1.00 | 1.00 | 0.40 | 0.846 | |
| 0.90 | 0.82 | 1.00 | 0.77 | 0.80 | 0.45 | 0.80 | 0.67 | 0.67 | 0.50 | 0.738 | ||
| SD | Precision | 0.47 | 0.46 | 0.00 | 0.72 | 0.57 | 1.00 | 1.00 | 1.00 | 1.00 | 0.56 | 0.678 |
| Recall | 0.93 | 0.95 | 0.00 | 0.91 | 0.93 | 0.50 | 0.83 | 1.00 | 1.00 | 1.00 | 0.805 | |
| 0.62 | 0.62 | 0.00 | 0.80 | 0.71 | 0.67 | 0.91 | 1.00 | 1.00 | 0.72 | 0.705 | ||
| LK | Precision | 0.50 | 0.47 | 0.00 | 0.72 | 0.57 | 1.00 | 1.00 | 1.00 | 1.00 | 0.50 | 0.676 |
| Recall | 0.94 | 0.95 | 0.00 | 0.94 | 0.91 | 0.50 | 0.83 | 1.00 | 1.00 | 1.00 | 0.807 | |
| 0.65 | 0.63 | 0.00 | 0.82 | 0.70 | 0.67 | 0.91 | 1.00 | 1.00 | 0.67 | 0.705 | ||
| Proposed method | Precision | 0.88 | 0.86 | 0.00 | 0.89 | 0.81 | 1.00 | 0.86 | 1.00 | 1.00 | 1.00 | 0.830 |
| Recall | 0.95 | 0.96 | 0.00 | 0.95 | 0.95 | 0.50 | 1.00 | 1.00 | 1.00 | 1.00 | 0.831 | |
| 0.91 | 0.91 | 0.00 | 0.92 | 0.87 | 0.67 | 0.92 | 1.00 | 1.00 | 1.00 | 0.820 |
| Threshold: | 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | 0.30 | 0.35 |
|---|---|---|---|---|---|---|---|
| 3 | 0.050 | 0.059 | 0.065 | 0.069 | 0.072 | 0.074 | 0.076 |
| 4 | 0.048 | 0.057 | 0.062 | 0.066 | 0.069 | 0.072 | 0.074 |
| 5 | 0.047 | 0.055 | 0.061 | 0.065 | 0.068 | 0.070 | 0.072 |
| 6 | 0.046 | 0.054 | 0.059 | 0.076 | 0.069 | 0.066 | 0.070 |
| 7 | 0.045 | 0.053 | 0.058 | 0.062 | 0.065 | 0.067 | 0.069 |
| 8 | 0.044 | 0.052 | 0.057 | 0.061 | 0.064 | 0.066 | 0.068 |
| 9 | 0.044 | 0.051 | 0.056 | 0.060 | 0.063 | 0.065 | 0.067 |
| Top-Hat | Frame Difference | Image Match | Scan Line Marking | SD | LK | Proposed Method |
|---|---|---|---|---|---|---|
| 3478 s | 176 s | 13,149 s | 4476 s | 989 s | 1070 s | 1112 s |
| A Total of 116 Plankton | Take Interval Frames from full Sequence | ||||
|---|---|---|---|---|---|
| Quantity | Precision | Recall | Calculation Time | ||
| Pixel interval sampling | 81 | 0.86 | 0.6 | 0.71 | 137 s |
| All the pixels | 30 | 0.83 | 0.23 | 0.36 | 618 s |
| A Total of 116 Plankton | Full Sequence | ||||
| Quantity | Precision | Recall | Calculation Time | ||
| Pixel interval sampling | 110 | 0.95 | 0.91 | 0.93 | 436 s |
| Full sequence | 113 | 0.97 | 0.95 | 0.96 | 1112 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Yang, M.; Ding, Z.; Zheng, Q.; Wang, D.; Kpalma, K.; Ren, J. Detection of the Deep-Sea Plankton Community in Marine Ecosystem with Underwater Robotic Platform. Sensors 2021, 21, 6720. https://doi.org/10.3390/s21206720
Wang J, Yang M, Ding Z, Zheng Q, Wang D, Kpalma K, Ren J. Detection of the Deep-Sea Plankton Community in Marine Ecosystem with Underwater Robotic Platform. Sensors. 2021; 21(20):6720. https://doi.org/10.3390/s21206720
Chicago/Turabian StyleWang, Jiaxing, Mingqiang Yang, Zhongjun Ding, Qinghe Zheng, Deqiang Wang, Kidiyo Kpalma, and Jinchang Ren. 2021. "Detection of the Deep-Sea Plankton Community in Marine Ecosystem with Underwater Robotic Platform" Sensors 21, no. 20: 6720. https://doi.org/10.3390/s21206720
APA StyleWang, J., Yang, M., Ding, Z., Zheng, Q., Wang, D., Kpalma, K., & Ren, J. (2021). Detection of the Deep-Sea Plankton Community in Marine Ecosystem with Underwater Robotic Platform. Sensors, 21(20), 6720. https://doi.org/10.3390/s21206720