An IoT-Focused Intrusion Detection System Approach Based on Preprocessing Characterization for Cybersecurity Datasets

 ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Background and Related Work
2.1. Data Threatment
2.2. Preprocessing Related Works and Network Iintrusion Detection Systems Data Preprocessing
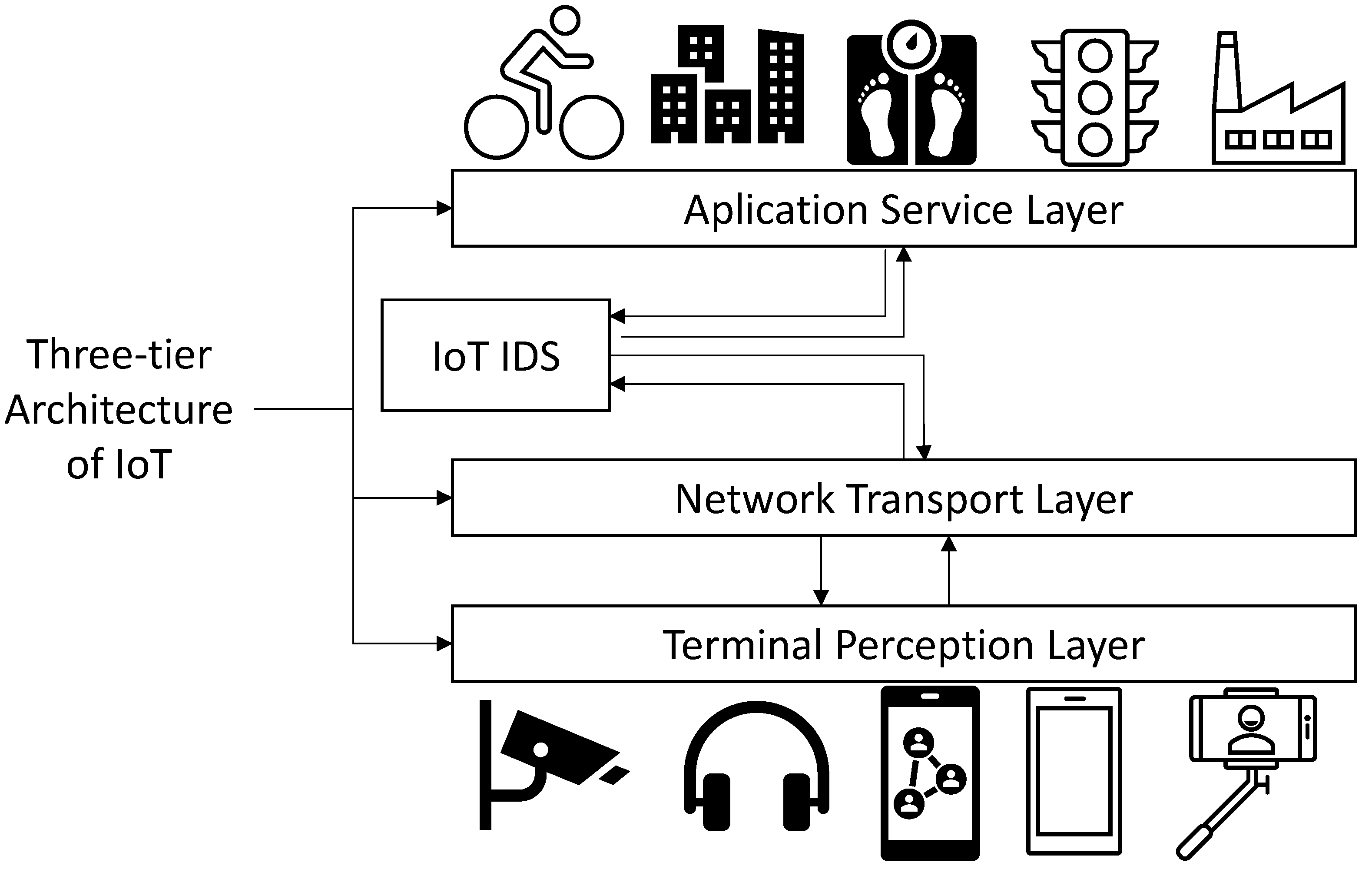
3. The Proposed Approach
3.1. Datasets under Study
3.1.1. Dataset UGR16
3.1.2. Dataset UNSW-NB15
- The basic characteristics, unlike in NSL-KDD, include the attributes that represent the protocol connections, most of them similar to the basic characteristics in NSL-KDD.
- The flow characteristics include the identifying attributes between the hosts.
- Content characteristics involve TCP/IP attributes and some http connections.
- The time characteristics contain all the attributes related to time i.e., arrival time between packets.
- Additional characteristics generated divided into two groups, i.e., general purpose to protect the service of protocols and connection characteristics.
3.1.3. Dataset NSL-KDD
- The basic characteristics include all the attributes that can be extracted from an individual TCP/IP connection.
- The content characteristics consist of some specific characteristics necessary to detect attacks that show suspicious behavior in the data portion, for example, number of failed login attempts.
- Flow characteristics include the characteristics calculated with respect to a window interval.
3.2. Data Preprocessing
3.2.1. Normalization Function
3.2.2. Standardization Function
3.3. Deep Learning Algorithm under Study
3.4. Evaluation Metrics
4. Methodology and Experimentation
4.1. Entire Set of Characteristics Evaluation
4.2. Individual Set of Characteristics Evaluation
5. Discussion
6. Conclusions and Future Lines
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Alvarez-Campana, M.; López, G.; Vázquez, E.; Villagrá, V.A.; Berrocal, J. Smart CEI Moncloa: An IoT-Based Platform for People Flow and Environmental Monitoring on a Smart University Campus. Sensors 2017, 17, 2856. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Han, H.; Wang, X.; Sun, S. Research on Artificial Intelligence Enhancing Internet of Things Security: A Survey. IEEE Access 2020, 8, 153826–153848. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and Other Botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Kumar, V.; Sinha, D.; Das, A.K.; Pandey, S.C.; Goswami, R.T. An Integrated Rule Based Intrusion Detection System: Analysis on UNSW-NB15 Data Set and the Real Time Online Dataset. Clust. Comput. 2020, 23, 1397–1418. [Google Scholar] [CrossRef]
- Zarpelão, B.B.; Miani, R.S.; Kawakani, C.T.; de Alvarenga, S.C. A Survey of Intrusion Detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar] [CrossRef]
- AL-Hawawreh, M.; Moustafa, N.; Sitnikova, E. Identification of Malicious Activities in Industrial Internet of Things Based on Deep Learning Models. J. Inf. Secur. Appl. 2018, 41, 1–11. [Google Scholar] [CrossRef]
- Shah, A.A.; Usman, N.; Waqar, J.; Saeed, H. An Efficient Machine Learning Prediction Based Model for Intrusion Detection. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 1–2 November 2019; pp. 1–6. [Google Scholar]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network Intrusion Detection for IoT Security Based on Learning Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Larriva-Novo, X.; Vega-Barbas, M.; Villagrá, V.A.; Rivera, D.; Álvarez-Campana, M.; Berrocal, J. Efficient Distributed Preprocessing Model for Machine Learning-Based Anomaly Detection over Large-Scale Cybersecurity Datasets. Appl. Sci. 2020, 10, 3430. [Google Scholar] [CrossRef]
- Bagui, S.; Nandi, D.; Bagui, S.; White, R.J. Classifying Phishing Email Using Machine Learning and Deep Learning. In Proceedings of the 2019 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Oxford, UK, 3–4 June 2019; pp. 1–2. [Google Scholar]
- Kathiresan, V.; Sumathi, P. An Efficient Clustering Algorithm Based on Z-Score Ranking Method. In Proceedings of the 2012 International Conference on Computer Communication and Informatics, Coimbatore, India, 10–12 January 2012; pp. 1–4. [Google Scholar]
- Burkov, A. The Hundred-Page Machine Learning Book; Andriy Burkov: Quebec City, QC, Canada, 2019; ISBN 1-9995795-0-X. [Google Scholar]
- Larriva-Novo, X.A.; Vega-Barbas, M.; Villagra, V.A.; Sanz Rodrigo, M. Evaluation of Cybersecurity Data Set Characteristics for Their Applicability to Neural Networks Algorithms Detecting Cybersecurity Anomalies. IEEE Access 2020, 8, 9005–9014. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. A Scheme for Generating a Dataset for Anomalous Activity Detection in IoT Networks. In Proceedings of the Advances in Artificial Intelligence; Goutte, C., Zhu, X., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 508–520. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Revathi, S.; Malathi, D.A. A Detailed Analysis on NSL-KDD Dataset Using Various Machine Learning Techniques for Intrusion Detectio. Int. J. Eng. Res. Technol. (IJERT) 2013, 2, 1848–1853. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Maciá-Fernández, G.; Camacho, J.; Magán-Carrión, R.; García-Teodoro, P.; Theron, R. UGR ‘16: A New Dataset for the Evaluation of Cyclostationarity-Based Network IDSs. Comput. Secur. 2018, 73, 411–424. [Google Scholar] [CrossRef]
- Mafarja, M.; Heidari, A.A.; Habib, M.; Faris, H.; Thaher, T.; Aljarah, I. Augmented Whale Feature Selection for IoT Attacks: Structure, Analysis and Applications. Future Gener. Comput. Syst. 2020, 112, 18–40. [Google Scholar] [CrossRef]
- Modi, C.N.; Patel, D. A Novel Hybrid-Network Intrusion Detection System (H-NIDS) in Cloud Computing. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence in Cyber Security (CICS), Singapore, 16–19 April 2013; pp. 23–30. [Google Scholar]
- Huang, J.; Li, Y.-F.; Xie, M. An Empirical Analysis of Data Preprocessing for Machine Learning-Based Software Cost Estimation. Inf. Softw. Technol. 2015, 67, 108–127. [Google Scholar] [CrossRef]
- Jo, J.-M. Effectiveness of Normalization Pre-Processing of Big Data to the Machine Learning Performance. J. Korea Inst. Electron. Commun. Sci. 2019, 14, 547–552. [Google Scholar] [CrossRef]
- Özgür, A.; Erdem, H. A Review of KDD99 Dataset Usage in Intrusion Detection and Machine Learning between 2010 and 2015. PeerJ Prepr. 2016, 4, e1954v1. [Google Scholar]
- Paulauskas, N.; Auskalnis, J. Analysis of Data Pre-Processing Influence on Intrusion Detection Using NSL-KDD Dataset. In Proceedings of the 2017 Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 27 April 2017; pp. 1–5. [Google Scholar]
- Salih, A.A.; Abdulrazaq, M.B. Combining Best Features Selection Using Three Classifiers in Intrusion Detection System. In Proceedings of the 2019 International Conference on Advanced Science and Engineering (ICOASE), Zakho-Duhok, Iraq, 2–4 April 2019; pp. 94–99. [Google Scholar]
- Lokeswari, N.; Rao, B.C. Artificial Neural Network Classifier for Intrusion Detection System in Computer Network. In Proceedings of the Second International Conference on Computer and Communication Technologies; Springer: Berlin/Heidelberg, Germany, 2016; pp. 581–591. [Google Scholar]
- Chiba, Z.; Abghour, N.; Moussaid, K.; El Omri, A.; Rida, M. A Novel Architecture Combined with Optimal Parameters for Back Propagation Neural Networks Applied to Anomaly Network Intrusion Detection. Comput. Secur. 2018, 75, 36–58. [Google Scholar] [CrossRef]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy and Survey of Intrusion Detection System Design Techniques, Network Threats and Datasets. arXiv Preprint 2018, arXiv:1806.03517. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep Learning for Cyber Security Intrusion Detection: Approaches, Datasets, and Comparative Study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- Verma, A.; Ranga, V. Machine Learning Based Intrusion Detection Systems for IoT Applications. Wirel. Pers Commun. 2020, 111, 2287–2310. [Google Scholar] [CrossRef]
- Ring, M.; Wunderlich, S.; Grüdl, D.; Landes, D.; Hotho, A. Flow-Based Benchmark Data Sets for Intrusion Detection. In Proceedings of the 16th European Conference on Cyber Warfare and Security, Ireland, Dublin, 29–30 June 2017; pp. 361–369. [Google Scholar]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep Learning Methods on Network Intrusion Detection Using NSL-KDD Dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Mulyanto, M.; Faisal, M.; Prakosa, S.W.; Leu, J.-S. Effectiveness of Focal Loss for Minority Classification in Network Intrusion Detection Systems. Symmetry 2021, 13, 4. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Montréal, QC, Canada, 31 March 2010; pp. 249–256. [Google Scholar]
- tf.keras.callbacks.EarlyStopping|TensorFlow Core v2.4.0. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping?hl=es-419 (accessed on 4 January 2021).
- Cassel, M.; Lima, F. Evaluating One-Hot Encoding Finite State Machines for SEU Reliability in SRAM-Based FPGAs. In Proceedings of the 12th IEEE International On-Line Testing Symposium (IOLTS’06), Lake Como, Italy, 10–12 July 2006; p. 6. [Google Scholar]
- Sklearn.Model_Selection.Train_Test_Split—Scikit-Learn 0.24.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html (accessed on 3 January 2021).
- Glossary of Common Terms and API Elements—Scikit-Learn 0.24.0 Documentation. Available online: https://scikit-learn.org/stable/glossary.html#term-random_state (accessed on 3 January 2021).
- Armbrust, M.; Das, T.; Torres, J.; Yavuz, B.; Zhu, S.; Xin, R.; Ghodsi, A.; Stoica, I.; Zaharia, M. Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 601–613. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Percentage |
|---|---|
| Attack | 12.82% |
| No Attack | 87.18% |
| Category | Percentage |
|---|---|
| Attack | 44.94% |
| No Attack | 55.06% |
| Category | Percentage |
|---|---|
| Attack | 46.54% |
| No Attack | 53.56% |
| Predicted Class | ||
|---|---|---|
| Actual Class | TP | FN |
| FP | TN | |
| Dataset | One-Hot Encoding | Binary Vector |
|---|---|---|
| UGR16 | protocol, flag | attack_tag |
| NSL-KDD | protol_type, service, flag, land, num_failed_login, is_host_login, is_guest_login | attack_tag |
| UNSW-NB15 | dur, proto, service | attack_tag |
| Basic Characteristics | Content Characteristics | Flow Characteristics | Accuracy |
|---|---|---|---|
| z-score | min_max_0 | z-score | 0.97923414 |
| min_max_0 | min_max_0 | z-score | 0.978567346 |
| z-score | min_max_0 | min_max_0 | 0.97694799 |
| min_max_0 | z-score | z-score | 0.974693592 |
| z-score | z-score | min_max_0 | 0.971550137 |
| min_max_0 | z-score | min_max_0 | 0.970851591 |
| min_max_0 | - | z-score | 0.970121293 |
| min_max_0 | z-score | z-score | 0.969867276 |
| z-score | z-score | min_max_0 | 0.964628183 |
| min_max_0 | z-score | - | 0.946434241 |
| Basic Characteristics. | Flow Characteristics | Content Characteristics | Direction-Based Traffic Characteristics | Accuracy |
|---|---|---|---|---|
| z-score | z-score | z-score | min_max_0 | 0.992 |
| z-score | min_max_0 | min_max_0 | min_max_0 | 0.9908 |
| z-score | - | - | - | 0.8638 |
| z-score | z-score | z-score | - | 0.8618 |
| z-score | - | 0.8349 | ||
| - | z-score | z-score | z-score | 0.7869 |
| - | z-score | z-score | - | 0.7163 |
| - | - | - | z-score | 0.6581 |
| - | z-score | - | - | 0.5775 |
| Configuration | Dataset | Basic Characteristics | Content Characteristics | Flow Characteristics | Direction-Based Traffic Characteristics | Accuracy |
|---|---|---|---|---|---|---|
| N01 | NSL-KDD | z-score | min_max_0 | z-score | 0.997 | |
| N02 | NSL-KDD | min_max_0 | min_max_0 | z-score | 0.978 | |
| N03 | NSL-KDD | z-score | z-score | z-score | 0.978 | |
| N04 | NSL-KDD | 0.95 | ||||
| N05 | UGR16 | z-score | 0.993 | |||
| N06 | UGR16 | 0.87 | ||||
| N07 | UNSW-NB15 | z-score | z-score | z-score | min_max_0 | 0.992 |
| N08 | UNSW-NB15 | min_max_0 | min_max_0 | z-score | min_max_0 | 0.990 |
| N09 | UNSW-NB15 | z-score | z-score | z-score | z-score | 0.983 |
| N10 | UNSW-NB15 | 0.55 |
| Model N01 | Model N05 | Model N07 | |||||
|---|---|---|---|---|---|---|---|
| True Label | Attack | 47.94% | 0.03% | 11.55% | 0.49% | 43.31% | 0.39% |
| No Attack | 0.36% | 51.67% | 0.14% | 87.82% | 1.18% | 55.12% | |
| Attack | No Attack | Attack | No Attack | Attack | No Attack | ||
| Predicted Label | |||||||
| Model N01 | Model N05 | Model N07 | |
|---|---|---|---|
| Precision | 0.992 | 0.988 | 0.973 |
| Recall | 0.999 | 0.959 | 0.990 |
| Research and Configuration Proposed | Preprocessing Technique | ML Model Applied | Dataset | Accuracy | ||
|---|---|---|---|---|---|---|
| Scalar | Normalization | Categorical | ||||
| N01-Model proposed | Yes | Yes | Yes | NN | NSL-KDD | 0.997 |
| N05-Model proposed | Yes | Yes | Yes | NN | UNSW-NB15 | 0.992 |
| N07-Model proposed | Yes | Yes | Yes | NN | UGR16 | 0.993 |
| Paulauskas et al. | No | Yes | No | NN | NSL-KDD | 0.99 |
| Salih et al. | No | Yes | No | NN | NSL-KDD | 0.989 |
| Lokeswari et al. | Yes | No | Yes | NN | KDD99 | 0.99 |
| Chiba et al. | Yes | Yes | No | NN | KDD99 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larriva-Novo, X.; Villagrá, V.A.; Vega-Barbas, M.; Rivera, D.; Sanz Rodrigo, M. An IoT-Focused Intrusion Detection System Approach Based on Preprocessing Characterization for Cybersecurity Datasets. Sensors 2021, 21, 656. https://doi.org/10.3390/s21020656
Larriva-Novo X, Villagrá VA, Vega-Barbas M, Rivera D, Sanz Rodrigo M. An IoT-Focused Intrusion Detection System Approach Based on Preprocessing Characterization for Cybersecurity Datasets. Sensors. 2021; 21(2):656. https://doi.org/10.3390/s21020656
Chicago/Turabian StyleLarriva-Novo, Xavier, Víctor A. Villagrá, Mario Vega-Barbas, Diego Rivera, and Mario Sanz Rodrigo. 2021. "An IoT-Focused Intrusion Detection System Approach Based on Preprocessing Characterization for Cybersecurity Datasets" Sensors 21, no. 2: 656. https://doi.org/10.3390/s21020656
APA StyleLarriva-Novo, X., Villagrá, V. A., Vega-Barbas, M., Rivera, D., & Sanz Rodrigo, M. (2021). An IoT-Focused Intrusion Detection System Approach Based on Preprocessing Characterization for Cybersecurity Datasets. Sensors, 21(2), 656. https://doi.org/10.3390/s21020656