1. Introduction
High availability (HA) [
1] is an important feature of a cloud system, where availability is the percentage of time that an application or service is available at a given time [
2,
3]. From the perspective of cloud service providers, the availability of the cloud is a factor that affects customer choice, and this is not less important than the price [
4]. For example, in February 2017, Amazon’s Simple Storage Service failed for 4 h and caused at least
$150 million in losses to customers [
5]. Therefore, in modern cloud services, there is a commitment between the service provider and the customer—that is, the Service-Level Agreements (SLAs) [
6]—and HA is one of the important items in the agreement. In other words, modern cloud computing systems must protect the liveness of services/applications running on the computing pool of the system [
7]. A common way to do this is to efficiently detect whether a system fault happens on a cloud service. Then, a corresponding fault recovery strategy is used to recover the cloud service in a short time.
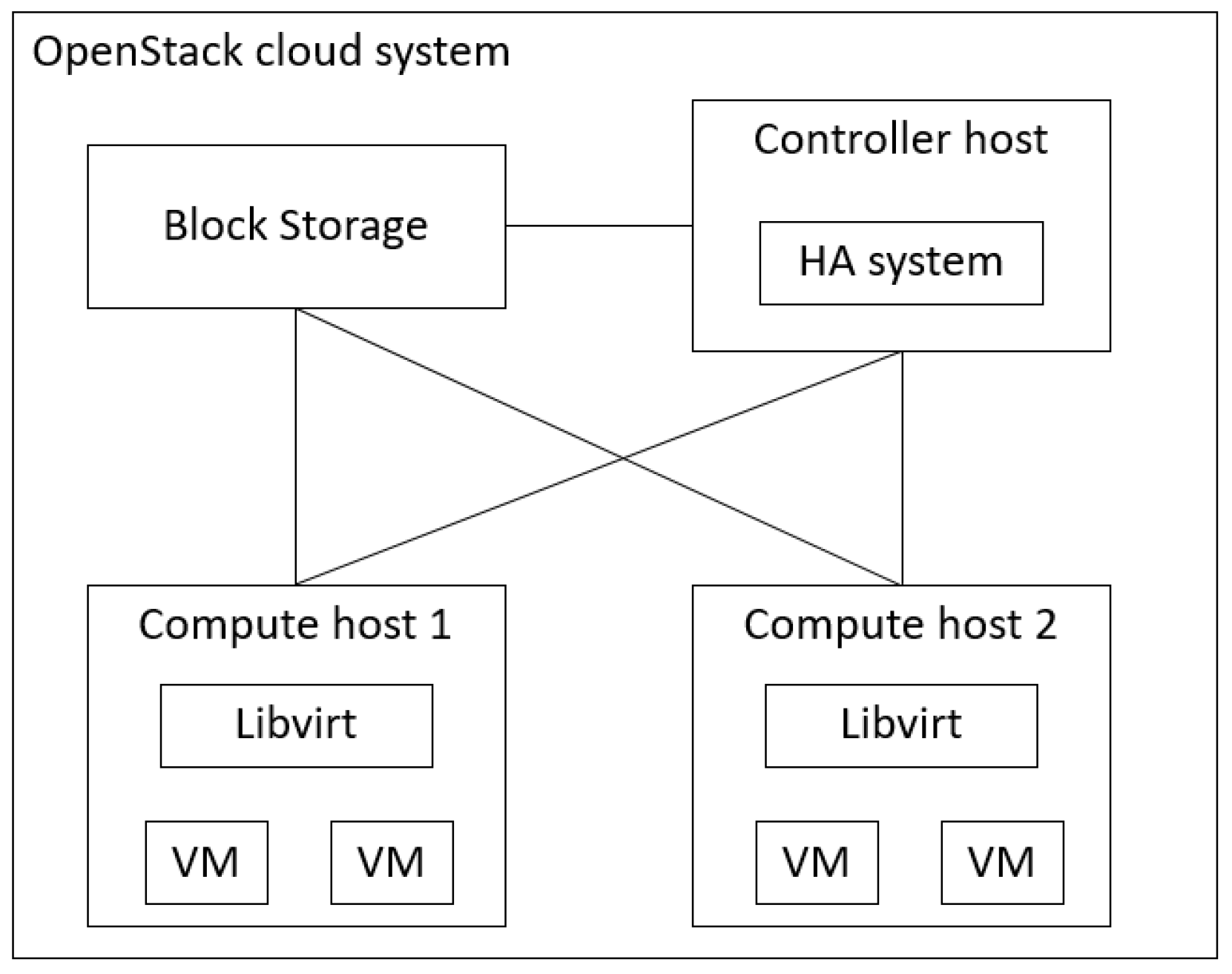
A modern cloud computing system is comprised of a controller, a computing pool (physical hosts), virtual machines (VMs), a storage system, and a network infrastructure that connects the above components [
8,
9]. A cloud service usually runs on VMs, and the VMs are placed onto the physical machines of the computing pool. In order to ensure the HA of the cloud service, many studies have presented several HA techniques [
9,
10,
11] for VM liveness detection and system fault recovery. For example, VMware vSphere [
9] uses the heartbeat of the datastore, Internet Control Message Protocol (ICMP) [
12], and VM I/O monitors to detect different types of system faults. Another HA example is presented in the paper by Tajiki et al. [
13], which addresses the issue of efficient system fault recovery and system fault prevention for fog-supported Software Defined Networks (SDN). System fault recovery is triggered by the liveness detection of Fog Nodes, while system fault prevention is achieved by regular network topology reconfiguration. The scheme reroutes the network flow to recover and prevent system faults, optimize the energy consumption of the Fog Node and the reliability of the selected path and guarantee the required quality of service level.
According to prior studies [
14,
15,
16,
17], a cloud computing system can be abstracted into multiple layers, where the functionality of the upper layer depends on that of the lower layers [
18,
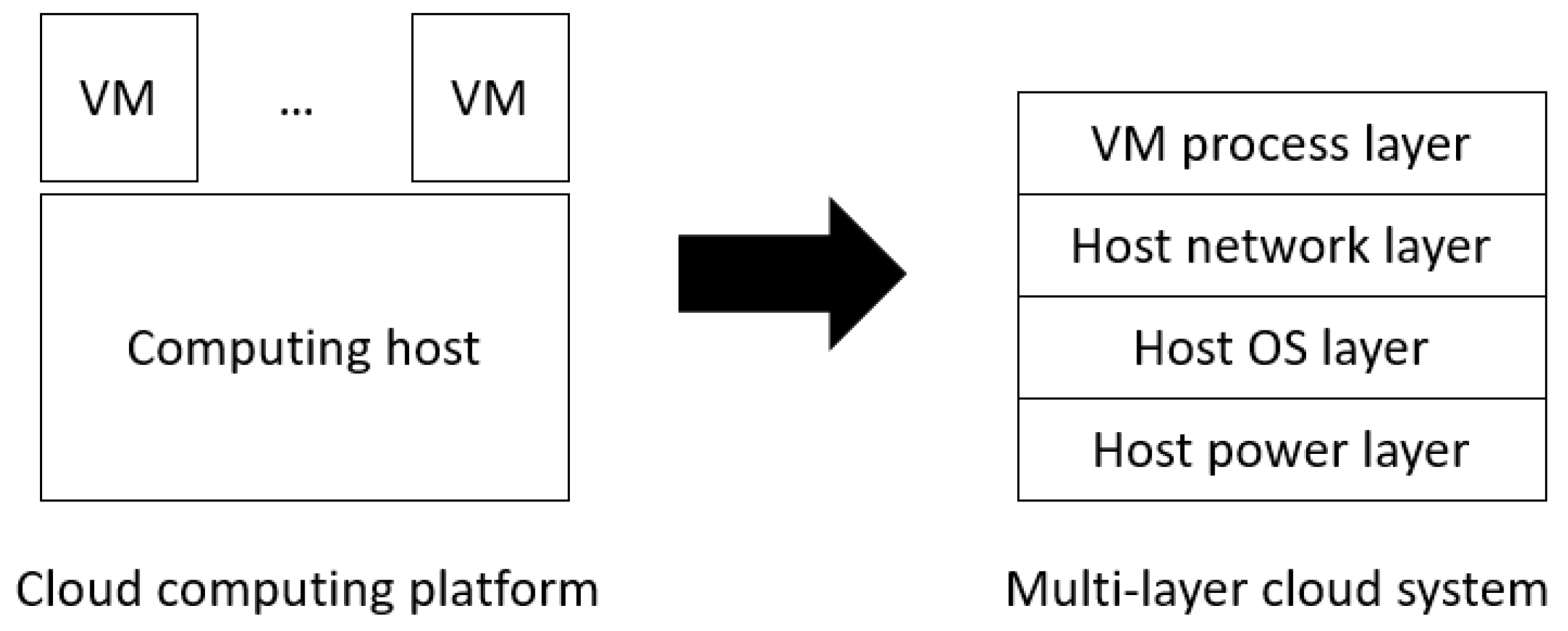
19]. For example, the host OS layer depends on the host power layer, the host network layer depends on the lower two layers, and the VM process layer depends on the lower three layers, as shown in
Figure 1. This multi-layer abstraction facilitates the use of multi-sensor-based fault detection and may reduce system downtime [
14,
15]. However, one issue remains unsolved in multi-sensor-based fault detection: a fault may occur at any sensor and consequently disable the system fault detection procedure, meaning that the HA mechanism cannot identify and recover a system fault in the cloud service. To this end, this paper proposes a multi-sensor-based HA mechanism to continuously provide system (liveness) fault detection and recovery for a protected cloud service, even if some sensors become faulty.
In the proposed approach, a sensor is installed at each layer to report the liveness of the layer. The sensors can be implemented as a hardware-assisted component such as the Intelligent Platform Management Interface (IPMI) tool [
20] or a software detection process such as an ICMP-based heartbeating component. Through these sensors, we develop the system fault detection method based on the Software-Defined High Availability Cluster (SDHAC) approach [
14] to quickly determine whether a layer is faulty and choose an efficient recovery strategy to recover the protection target. The major problem of the original HA mechanism in the SDHAC is that a sensor can fail at any time, and then the HA mechanism designed based on the fault model using all of the sensors cannot work correctly. Typically, a sensor fault can be detected by checking its return format, values, and liveness (the ability to respond to a query in a given time). When a sensor fault has been detected, we propose the use of a dynamic fault model switching method that is able to reconstruct a new fault model with
healthy sensors from the original fault model with
N sensors. The system fault detection and recovery methods are updated based on the new fault model without human intervention. As a result, the multi-layer cloud system can continue providing HA protection for a cloud service on VMs.
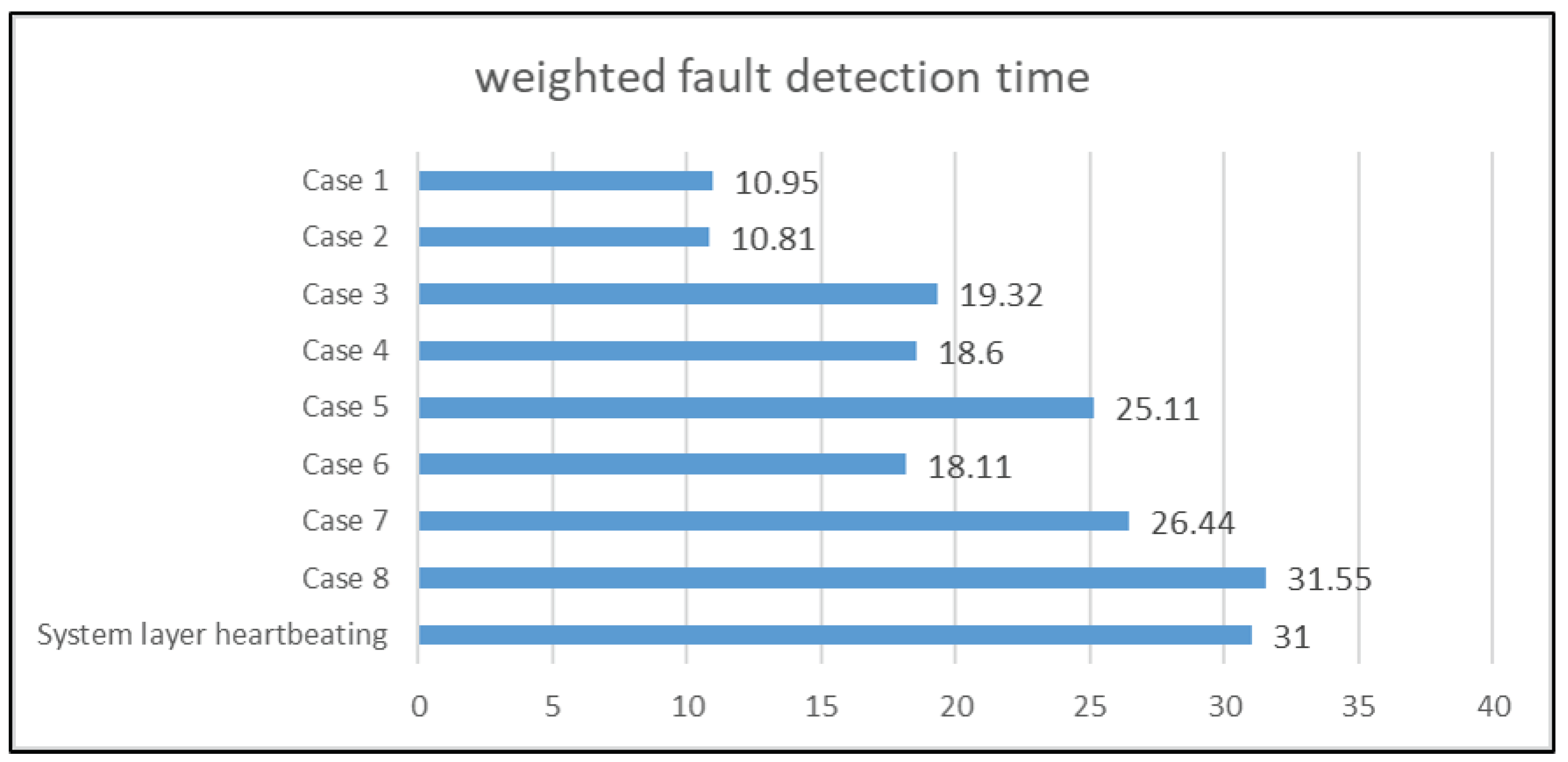
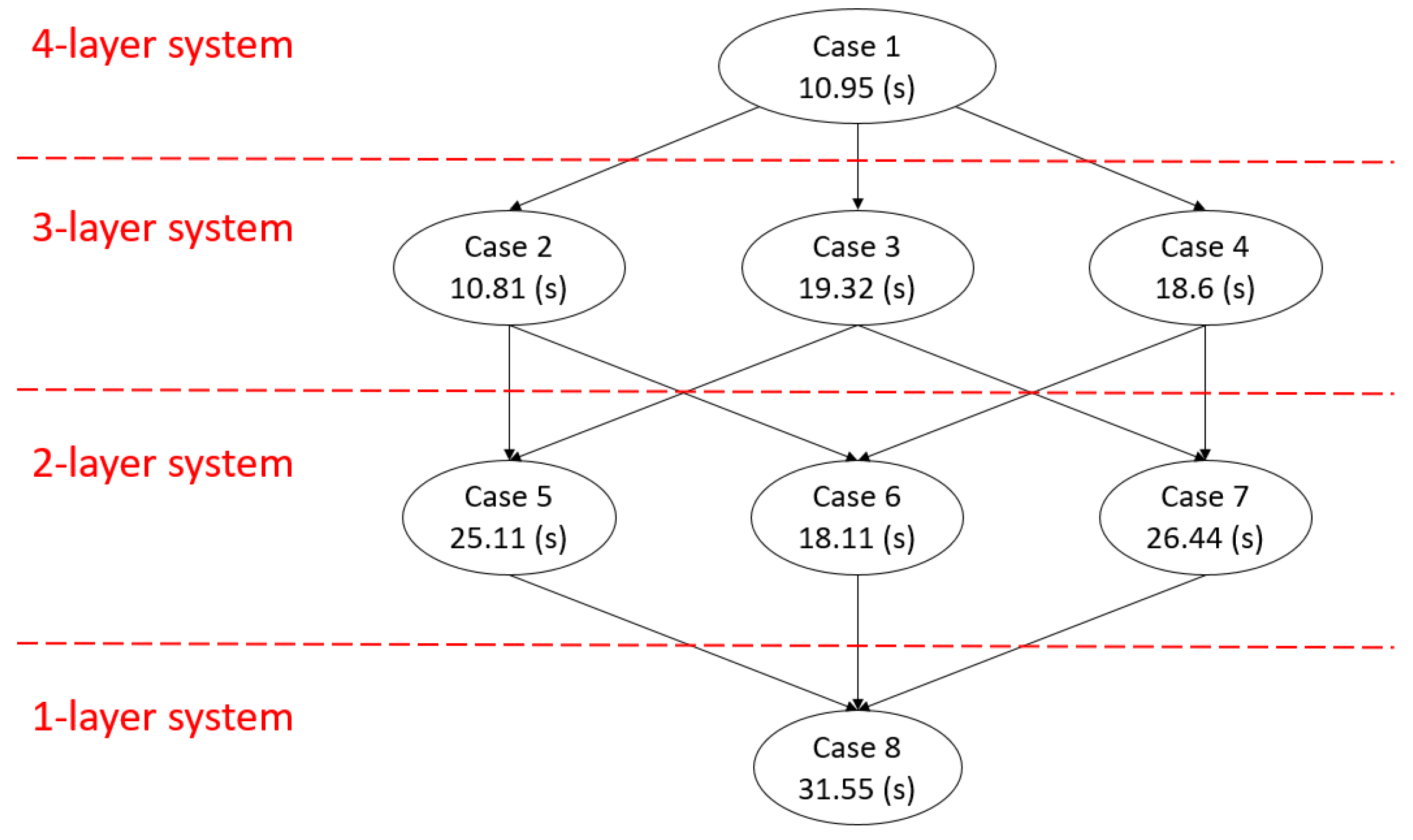
To the best of our knowledge, this study is the first to address the sensor fault issue on cloud HA. With the assumption of the liveness of the sensor at the highest layer, the proposed HA mechanism can tolerate any detectable sensor fault and continue providing HA protection for the cloud computing system. To show how a sensor fault affects the system fault detection efficiency of the proposed HA mechanism, we have conducted several experiments on a four-layer cloud computing system by injecting different kinds of sensor faults and system faults. When a sensor fault is detected, the proposed mechanism attempts to automatically reduce the four-layer fault model to a three-layer fault model and continue to provide HA protection to the system. The fault model can be further reduced to a one-layer fault model with the sensor at the highest layer. For each fault model, we injected the same set of system faults to evaluate their system fault detection efficiency. According to the experimental results, the proposed mechanism can tolerate sensor faults, and the system fault detection efficiency gradually reduces as the number of healthy sensors decreases. Although, in some cases, the weighted (system) fault detection time of the proposed mechanism increases, it is still shorter than or equal to that of the traditional system layer heartbeating [
21], which is a common system fault detection method that requires at least 30 s for system fault detection [
9].
The remainder of this paper is organized as follows.
Section 2 introduces related work.
Section 3 illustrates the proposed mechanism through examples.
Section 4 presents the experiment results and analysis.
Section 5 presents our conclusions.
3. The Proposed Mechanism
In this section, we first define the symbols used in the section. Then, we use the symbols to explain the concept of multi-layer systems and their fault models with N sensors. Consequently, we explain the proposed mechanism that can handle sensor faults with the proposed fault model reconstruction method, and then use an example to illustrate fault model reconstruction.
3.1. Symbols
Table 1 defines the symbols that are used in this section.
3.2. The Multi-Layer Cloud System
A modern cloud computing system can be abstracted into a multi-layer system. As shown in
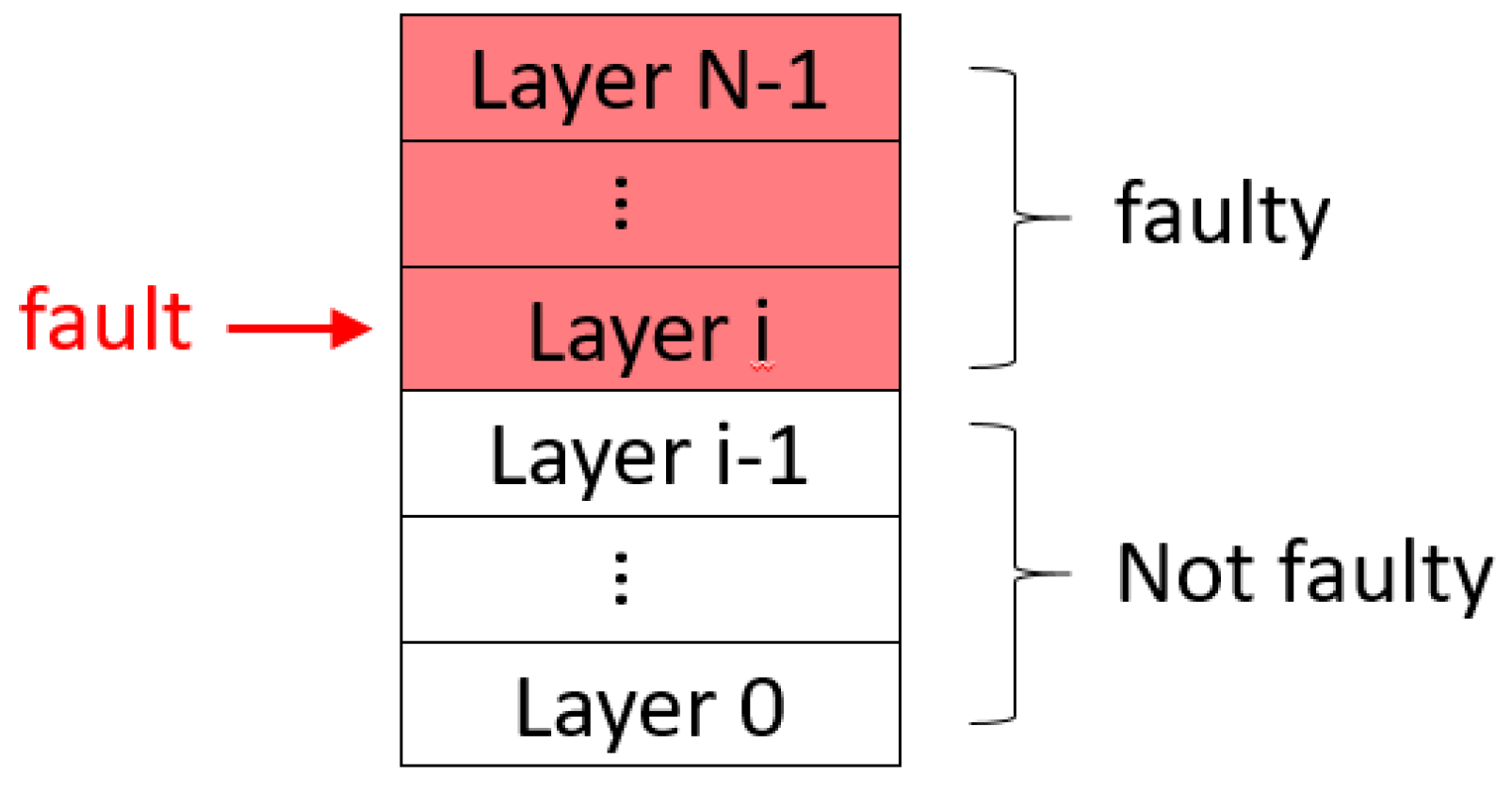
Figure 1, a cloud computing system is divided into a four-layer system, which consists of a host power layer, a host operating system (OS) layer, a host network layer, and a virtual machine (VM) process layer. As the multi-layer is an abstracted concept of the system, the system can be partitioned into N layers, depending on the property of the subcomponents of the system and the sensors used for these subcomponents, as shown in
Figure 2. In the N-layer system, we install a sensor for each layer, that is,
to
. For liveness detection, a system must be able to handle transient faults that could occur and then be recovered automatically before the system is considered not to be live. As a result, each layer has at most two kinds of faults, as described below.
In a multi-layer system, there is an important and useful property called (liveness) layer dependency. This property has been reported in several prior studies. For example, Tchana et al. [
16] indicated that the hardware layer fault can trigger faults at high layers (VM and application) in a three-layer system. Here, we propose a layer dependency property for N layers as follows.
This means that a system fault in a lower layer can result in the failure of the liveness of all upper layers, but a system fault in an upper layer cannot impede the liveness of any lower layer. For example,
Figure 2 is an N-layer system. When a system fault occurs at the layer
(0 ≤ i ≤
), all the layers above
must fail. On the contrary, all the layers below the
do not fail. An example in a real system: When the host network fails, the user cannot access the VM, but the host power and OS are still live. Similarly, the network being busy (transient fault) causes the VM to be temporarily inaccessible until the network becomes live again, and the VM will not be damaged after the network stops being busy.
3.3. Continuous Liveness Detection and Fault Recovery with Sensor Faults
In this study, we assume that the highest-layer sensor never fails. There are two reasons for this: first, the faults at the highest-layer sensor result in incomplete system fault detection, which is beyond our research scope, and second, the highest-layer sensor is usually the most robust in practical cloud systems. As liveness detection on the highest layer usually requires a long time to distinguish transient faults from permanent faults, we can use other low-layer sensors to accelerate this process. In addition, we assume that only one system fault in the cloud system occurs at a time, due to problem simplification. This means that no other system faults can occur in the same host of the computing pool until the protected target has been recovered.
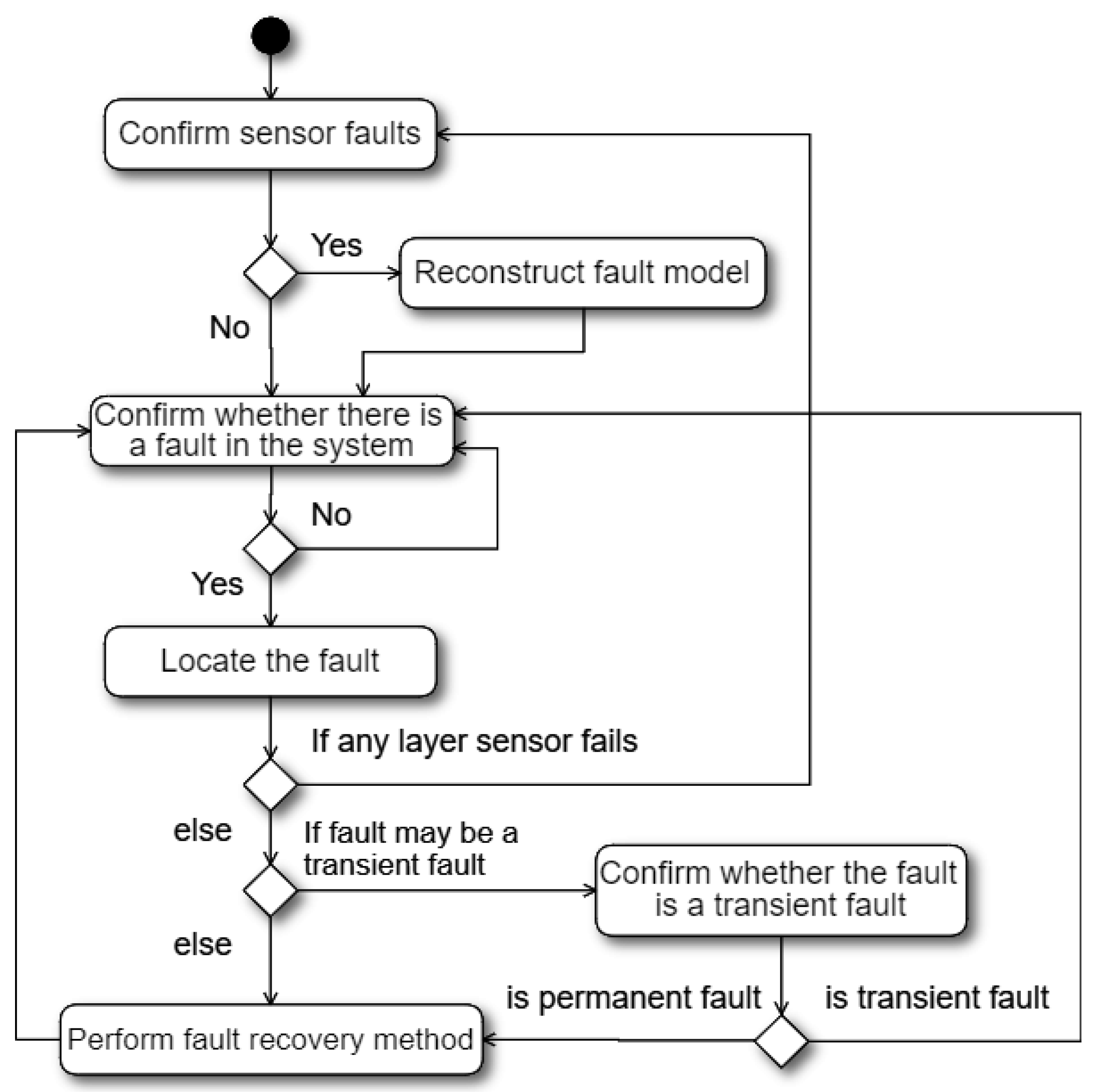
Based on the layer dependency feature of the multi-layer system, we propose a new HA mechanism based on fault model reconstruction, as shown in
Figure 3. The mechanism first checks sensor faults, and then reconstructs the fault model based on the detected sensor faults if needed. Then, the mechanism confirms whether there is a system fault in the cloud system by using the sensor of the highest layer. This is because all faults in the system can be detected by the sensor of the highest layer according to the liveness layer dependency. If the highest layer sensor detects a system fault, the mechanism will detect the remaining layers according to the fault model to find the system fault location. The common method of locating the system fault is to detect the remaining layers in order from highest to lowest until the lowest faulty layer is found, where the lowest faulty layer is the location of the root cause. If any sensor fault occurs while finding the system fault, the mechanism needs to reconstruct the fault model and then restarts the new system fault detection process based on the newly constructed fault model. The method for identifying sensor faults can be achieved by checking the return format, values, and liveness (the ability to respond to a query in a given time) of the sensor. On the contrary, if there is no sensor fault and the system fault location (the lowest faulty layer) is found, the mechanism directly checks whether the system fault location may have a transient fault according to the fault model. If the system fault location may have a transient fault, the mechanism continuously uses the sensor at the lowest faulty layer within the transient fault detection time to confirm whether the fault is transient. If the mechanism has confirmed that the system fault is a transient fault because the layer has responded to the liveness query of its layer sensor, the mechanism simply ignores the transient fault and begins the next round of system fault detection. On the contrary, if the mechanism has confirmed that the system fault is a permanent fault, the mechanism performs the corresponding fault recovery method to recover the system. After the failed system is successfully recovered, the mechanism then starts the next round of system fault detection.
3.4. Fault Model Reconstruction and Switching
The fault model reconstruction method (Algorithm 1) is described as follows.
| Algorithm 1 fault_model_reconstruction |
| Input: the faulty sensor and the corresponding layer . |
Output: a fault model.- 1:
If is the highest layer, return . - 2:
Combine the layers and into a new layer . - 3:
Use the sensor as the sensor of . - 4:
Calculate the value Tx as the maximum of and . Update to be the smallest multiple of that is larger than or equal to Tx. The total sensor detection time can be divided into a sensor response time and a transient fault detection time. - 5:
Update with . - 6:
Update with the difference between the total sensor detection time and its sensor response time. - 7:
If is larger than 0, includes transient faults. - 8:
Reuse as the recovery method of . - 9:
For , reuse the system fault detection and recovery methods of at . - 10:
For , reuse the system fault detection and recovery methods of at . - 11:
return the new fault model based on the new multi-layer system from to .
|
The concept of Algorithm 1 is to merge the layer
for which the sensor
has failed with the normal layer
, as described in Step 2. Then, the new merged layer, namely,
, needs to be updated with new system fault detection and recovery methods. In the case that
>
, the proposed HA mechanism needs to wait for a sufficient time to cover transient faults, as shown in Steps 4 to 7. Then, the mechanism directly applies the recovery method for
to the new layer
because the low-layer recovery method must guarantee the recovery of the upper layers, as shown in Step 8. Take
Figure 1 as an example: the recovery method of the host OS layer needs to consider the recovery of the protection target—the VM process—which means the above layers must be healthy after recovery. A typical solution for this case is to evacuate the VM to a healthy host. Other layers are not affected by the proposed fault model reconstruction method and can be reused, as shown in Steps 9 and 10.
To analyze the computational and space complexity, we assume that the cloud computing pool consists of
M hosts and each host has
N layers. The proposed mechanism uses sequential detection to scan whether a system fault exists at some layer, which is similar to the system fault detection method of the SDHAC [
14], and creates
K threads to perform parallel liveness detection for each host. The computational complexity of the proposed fault model reconstruction method is
, and the space complexity is
for a sensor fault; the computational complexity of the system fault detection method is
, and the space complexity is
for each system fault at the cloud system. When the number of faulty hosts is
L, only the computational complexity of the system fault detection method changes to
. Generally,
N and
L are small, and
M is much larger than
N and
L. Therefore, the computational complexity of the system fault detection method is close to
.
It is worth mentioning that the number of possible fault models is
. Although increasing
N could help the HA mechanism to achieve faster system fault detection [
14] or faster recovery [
8,
9,
14,
15], it could greatly complicate the design and implementation of the HA mechanism because more system fault detection sensors and system fault recovery methods would need to be included. As a result, N should be a small number in practice.
3.5. Example of Fault Model Reconstruction
After reconstructing the fault model, the proposed mechanism should switch the fault model and continue to detect system faults based on the new fault model. In the following, we employ a seven-layer (N = 7) system comprised of to layers as an example to explain the details of how to reconstruct the fault model.
First of all, the fault model used in this study can be shown in two important tables: the fault-symptom table [
34,
35] and the sensor information table, as shown in
Table 2 and
Table 3.
Table 2 is the fault-symptom table of the seven-layer system, which is used to list the symptoms of all system faults in the cloud system. In the fault-symptom table, the system fault location is a layer and the system fault symptom is a list. The elements in the system fault symptom list represent the results detected by all sensors from
to
when a system fault occurs, where 0 means that the sensor detects that the layer is not faulty, and 1 means that the sensor detects that the layer is faulty. For example, when a system fault occurs at
, only the detection result of
is 0; this is because all other layers except
are faulty.
Table 3 is the sensor information table, which lists the information of all sensors used in the seven-layer system. For each sensor, the table displays the sensor ID, the layer to be detected by the sensor, the value of the “Including transient faults?” column, the total sensor detection time of the layer sensor and the sensor response time of the layer sensor. The “Including transient faults?” column shows whether the layer may generate a transient fault. The total sensor detection time is the sum of the sensor response time and the transient fault detection time.
In order to facilitate the explanation of the reconstruction method of the fault model, the definition of the new layer type is given below.
According to the status of the layer sensor, the layers are divided into active layers and disabled layers. According to the liveness layer dependency, we can detect system faults in the disabled layer through the sensor of the active layer higher than the disabled layer. Therefore, we first reorganize the layer by merging the disabled layer and the higher active layer as a new layer called the combination layer.
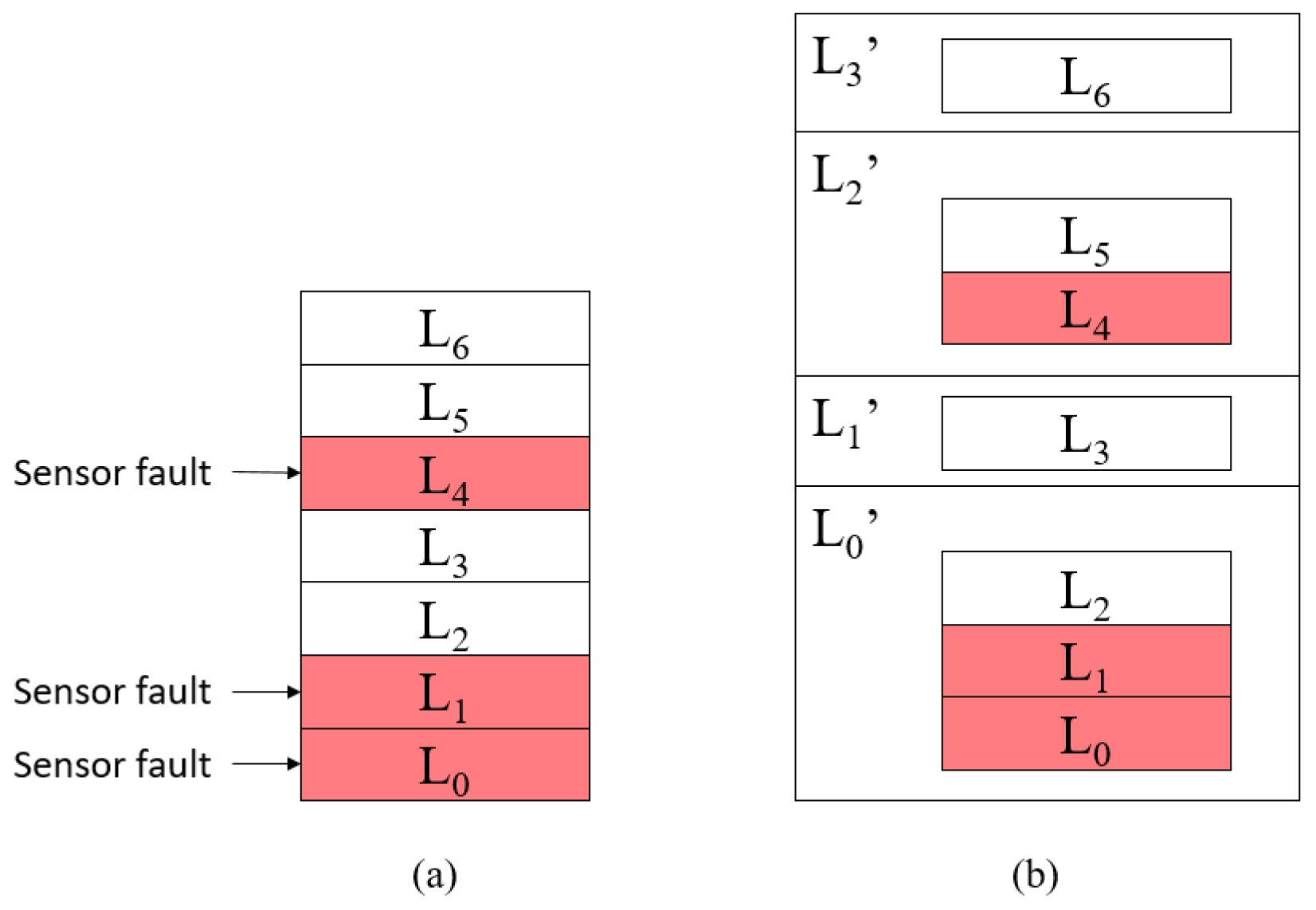
In
Figure 4,
Figure 4a is a seven-layer system in which the sensors
,
, and
have failed. Then, we merge
,
, and
into one combination layer
and merge
and
into another combination layer
based on the proposed fault model reconstruction method, one at a time. The final result is shown in
Figure 4b. Thus, we can detect the system faults of
,
, and
through
and detect the system faults of
and
through
. After that, we obtain a new layer list, which contains
,
,
, and
. This means that the seven-layer system becomes a four-layer system. Moreover, the layers in the new layer list still have liveness layer dependency.
Next, we can update the fault-symptom table based on the active sensors and liveness layer dependency, as shown in
Table 4. We use sensor
as sensor
, sensor
as sensor
, and reuse sensors
and
as sensors
and
, respectively. In
Table 4, the elements of the system fault symptom list represent the detection results of
,
,
, and
, respectively. Similarly, we must also update the sensor information table, as shown in
Table 5. We first update the sensor list, sensor ID list, and detection target list; then, we use the fault model reconstruction to obtain the corresponding fault model parameters, such as the total sensor detection time, sensor response time, the need to handle transient faults, and the recovery method. Note that the sensor information table only records the necessary parameters for system fault detection.
In order to recover the protected target, the proposed fault model reconstruction method must be able to automatically create new recovery methods for and . The new recovery method is equal to . Similarly, is equal to . Finally, the proposed fault model reconstruction method reuses and as and , respectively.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}