PHD Filter for Object Tracking in Road Traffic Applications Considering Varying Detectability




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Related Work
1.2. Contributions of the Paper
2. Theoretical Background
2.1. Random Finite Sets
2.2. PHD Filter
2.3. Problem Statement and Motivation
3. The Proposed Method
Handling Multiple Measurements in One Timestep
| Algorithm 1 Measurement clusterization. |
|
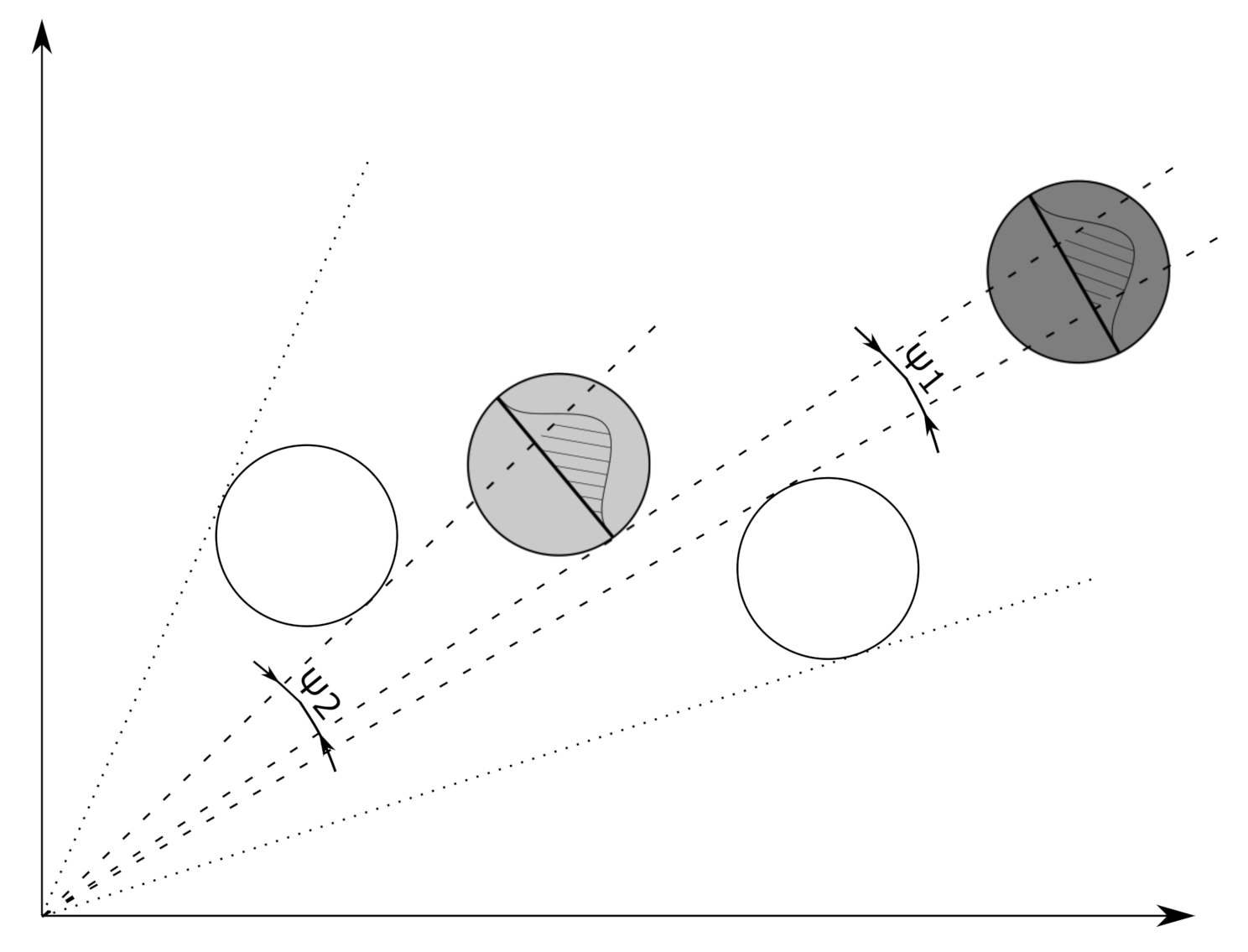
4. Occlusion Model
5. Simulation Results
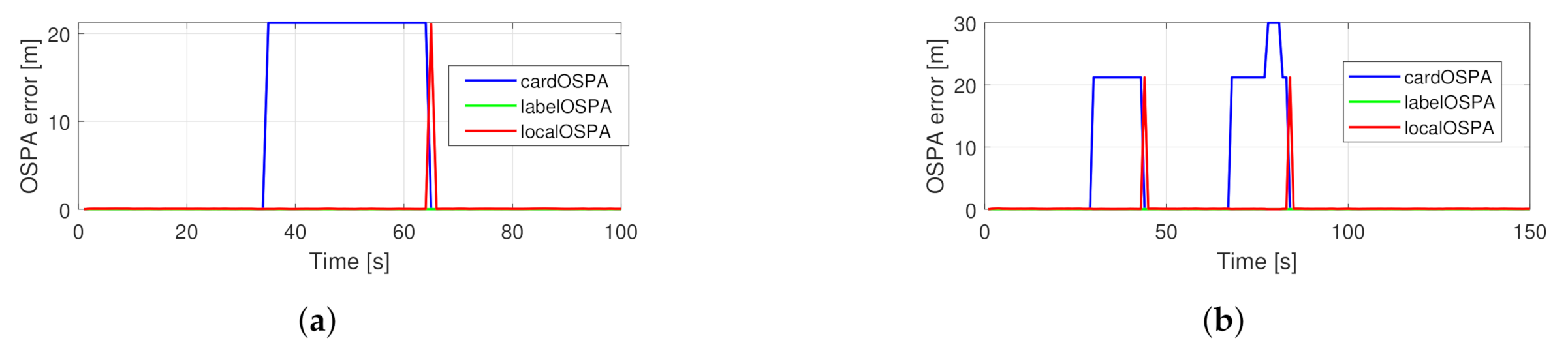
5.1. Measuring Filter Performance
5.2. Abstract Simulations
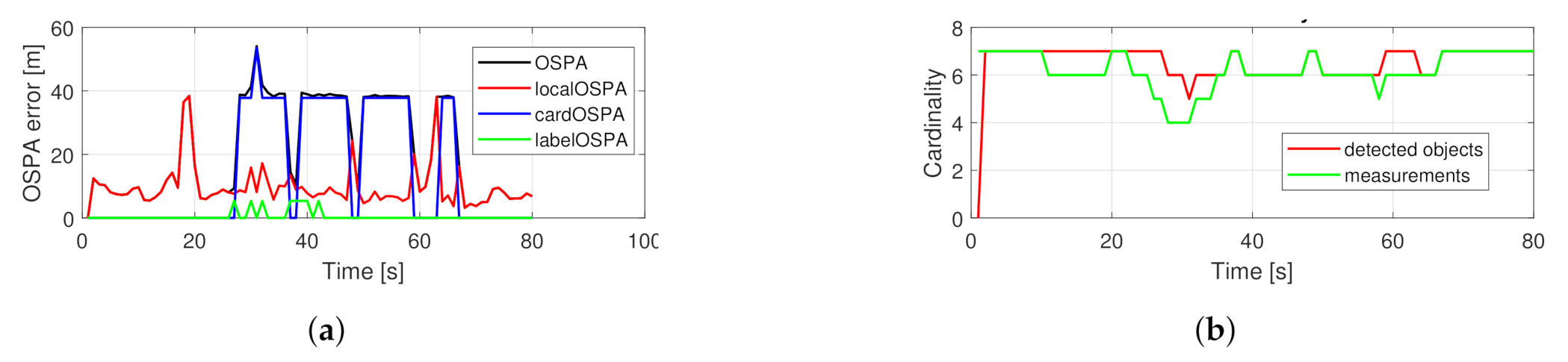
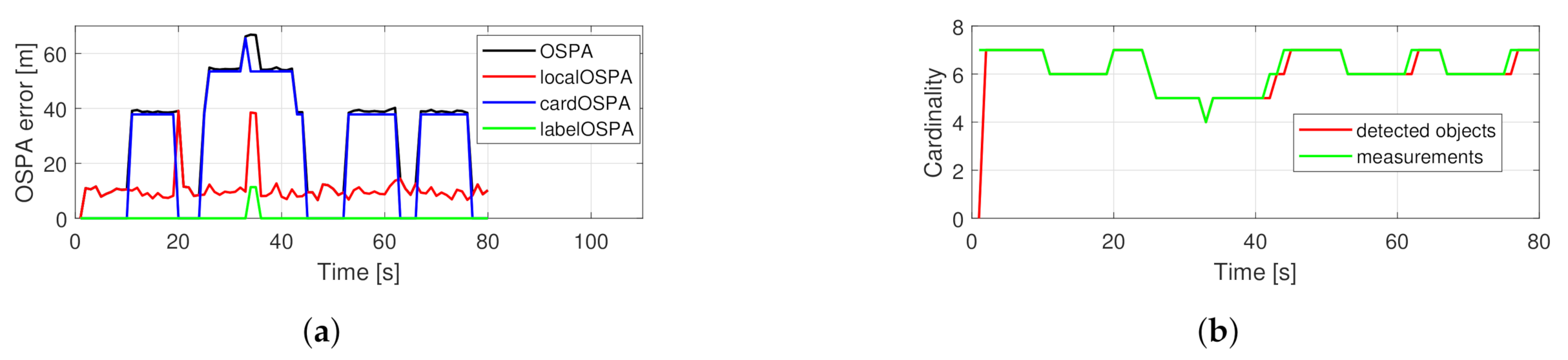
5.2.1. Crossing Trajectories
5.2.2. Random Trajectories
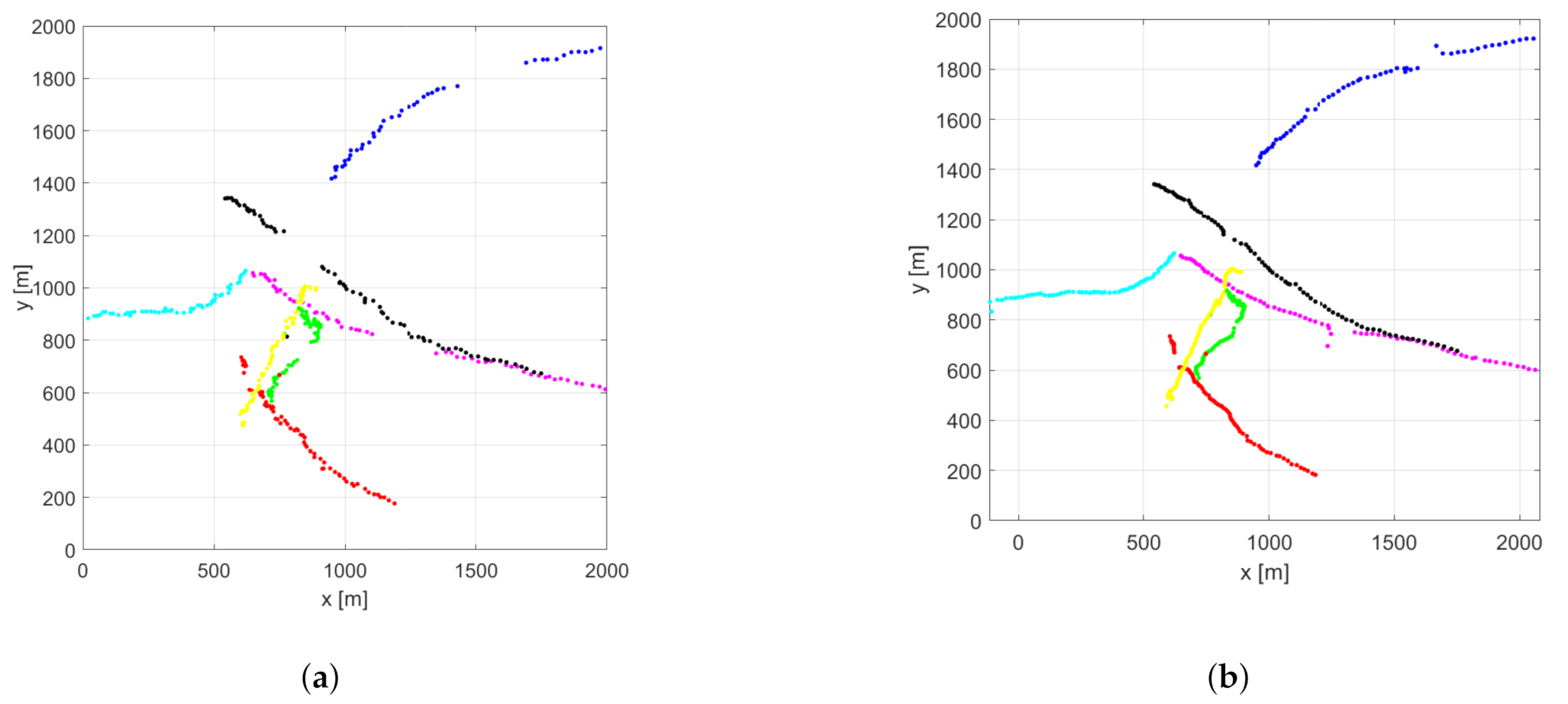
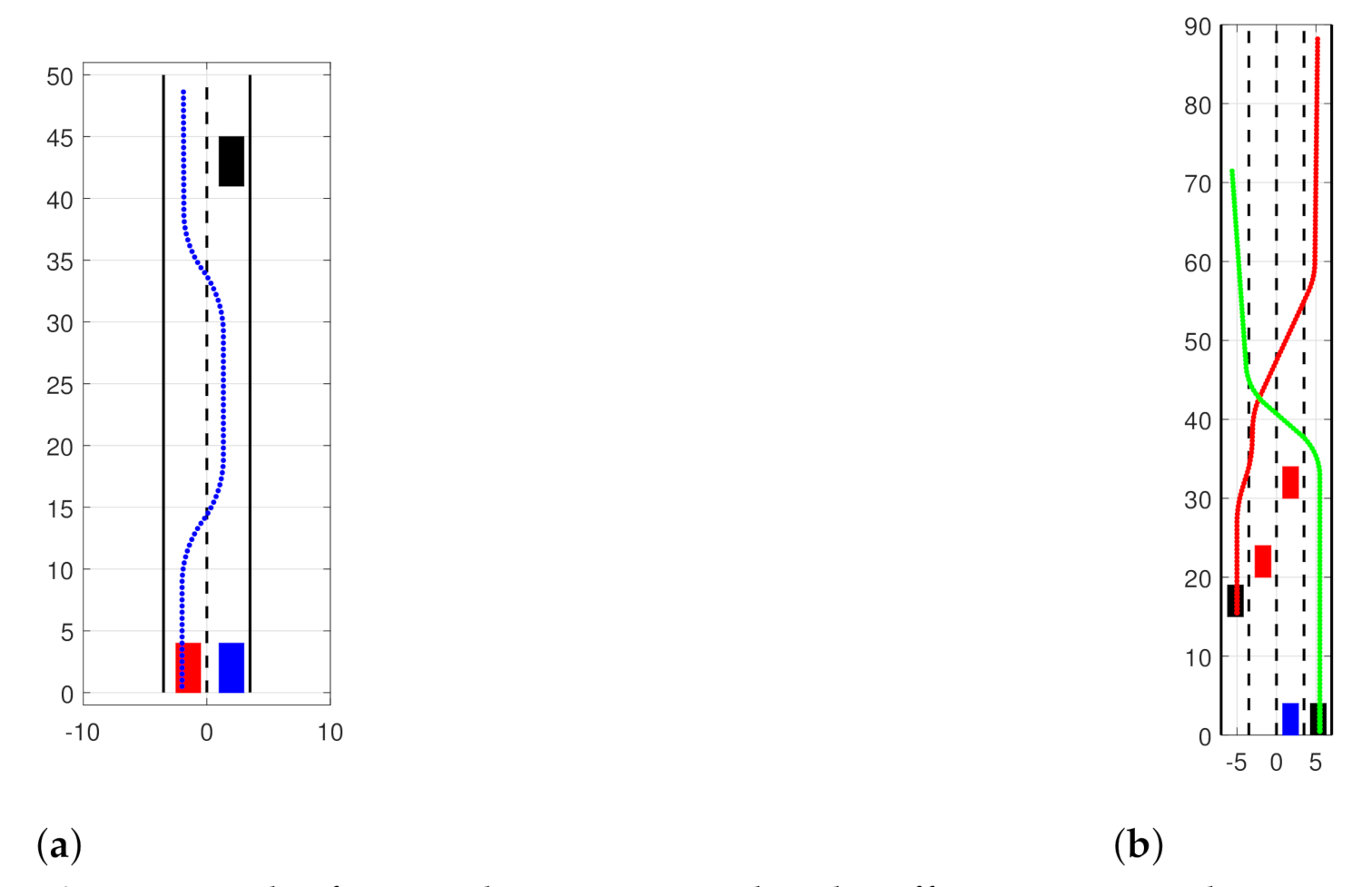
5.3. Road Traffic Simulations
6. Highway Measurements
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| probability density function | |
| CDF | cumulative distribution function |
| GM | Gaussian mixture |
| PF | particle filter |
| SMC | sequential Monte Carlo |
| FISST | finite set statistics |
| RFS | random finite set |
| PHD | probability hypothesis density |
| JPDAF | joint probabilistic data association filter |
| MHT | multiple hypothesis tracking |
| OSPA | optimal subpattern assignment |
| FOV | field of view |
References
- Zhu, H.; Yuen, K.V.; Mihaylova, L.; Leung, H. Overview of Environment Perception for Intelligent Vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2584–2601. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Mihály, A.; Baranyi, M.; Németh, B.; Gáspár, P. Tuning of look-ahead cruise control in HIL vehicle simulator. Period. Polytech. Transp. Eng. 2017, 45, 157–161. [Google Scholar] [CrossRef]
- Mihály, A.; Farkas, Z.; Gáspár, P. Multicriteria Autonomous Vehicle Control at Non-Signalized Intersections. Appl. Sci. 2020, 10, 7161. [Google Scholar] [CrossRef]
- Vo, B.N.; Mallick, M.; Bar-shalom, Y.; Coraluppi, S.; Osborne, R.; Mahler, R.; Vo, B.T. Multitarget Tracking. In Wiley Encyclopedia of Electrical and Electronics Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015; pp. 1–15. [Google Scholar] [CrossRef]
- Mahler, R.P. Multitarget Bayes Filtering via First-Order Multitarget Moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Ba-Ngu, V.; Singh, S.; Doucet, A. Sequential monte carlo implementation of the phd filter for multi-target tracking. In Proceedings of the Sixth International Conference of Information Fusion, Cairns, Australia, 8–11 July 2003; pp. 792–799. [Google Scholar] [CrossRef]
- Maehlisch, M.; Schweiger, R.; Ritter, W.; Dietmayer, K. Multisensor vehicle tracking with the probability hypothesis density filter. In Proceedings of the 9th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013. [Google Scholar] [CrossRef]
- Kalyan, B.; Lee, K.W.; Wijesoma, S.; Moratuwage, D.; Patrikalakis, N.M. A random finite set based detection and tracking using 3D LIDAR in dynamic environments. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 2288–2292. [Google Scholar] [CrossRef]
- Reuter, S.; Wilking, B.; Dietmayer, K. Methods to model the motion of extended objects in multi-object Bayes filters. In Proceedings of the 15th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 527–534. [Google Scholar]
- Zhang, M.; Fu, R.; Guo, Y.; Wang, L. Moving Object Classification Using 3D Point Cloud in Urban Traffic Environment. J. Adv. Transp. 2020, 2020. [Google Scholar] [CrossRef]
- Lin, L.; Bar-Shalom, Y.; Kirubarajan, T. Track labeling and PHD filter for multitarget tracking. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 778–793. [Google Scholar] [CrossRef]
- García, F.; Prioletti, A.; Cerri, P.; Broggi, A. PHD filter for vehicle tracking based on a monocular camera. Expert Syst. Appl. 2018, 91, 472–479. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Li, Y.; Yu, J. PHD and CPHD Algorithms Based on a Novel Detection Probability Applied in an Active Sonar Tracking System. Appl. Sci. 2017, 8, 36. [Google Scholar] [CrossRef]
- Koch, J. Bayesian approach to extended object and cluster tracking using random matrices. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 1042–1059. [Google Scholar] [CrossRef]
- Granstrom, K.; Orguner, U. A phd Filter for Tracking Multiple Extended Targets Using Random Matrices. IEEE Trans. Signal Process. 2012, 60, 5657–5671. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, L.; Wang, X.; An, W. Anti-clutter Gaussian Inverse Wishart PHD Filter for Extended Target Tracking. Sensors 2019, 19, 5140. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Gao, M. Tracking Ground Targets with a Road Constraint Using a GMPHD Filter. Sensors 2018, 18, 2723. [Google Scholar] [CrossRef] [PubMed]
- Mahler, R. PHD filters for nonstandard targets, I: Extended targets. In Proceedings of the 2009 12th International Conference on Information Fusion, Seattle, DC, USA, 6–9 July 2009; pp. 915–921. [Google Scholar]
- Tang, X.; Chen, X.; McDonald, M.; Mahler, R.; Tharmarasa, R.; Kirubarajan, T. A Multiple-Detection Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2015, 63, 2007–2019. [Google Scholar] [CrossRef]
- Erdinc, O.; Willett, P.; Bar-Shalom, Y. Probability hypothesis density filter for multitarget multisensor tracking. In Proceedings of the 7th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2005; Volume 1, pp. 146–153. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N. The para-normal Bayes multi-target filter and the spooky effect. In Proceedings of the 15th International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 173–180. [Google Scholar]
- Fränken, D.; Schmidt, M.; Ulmke, M. Spooky action at a distance in the cardinalized probability hypothesis density filter. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 1657–1664. [Google Scholar] [CrossRef]
- Hendeby, G.; Karlsson, R. Gaussian mixture PHD filtering with variable probability of detection. In Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 7–10 July 2014. [Google Scholar]
- Yazdian-Dehkordi, M.; Azimifar, Z. Refined GM-PHD tracker for tracking targets in possible subsequent missed detections. Signal Process. 2015, 116, 112–126. [Google Scholar] [CrossRef]
- Wang, S.; Bao, Q.; Chen, Z. Refined PHD Filter for Multi-Target Tracking under Low Detection Probability. Sensors 2019, 19, 2842. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Liu, H. Probability hypothesis density filter with imperfect detection probability for multi-target tracking. Optik 2016, 127, 10428–10436. [Google Scholar] [CrossRef]
- Ristic, B.; Clark, D.; Vo, B.N. Improved SMC implementation of the PHD filter. In Proceedings of the 13th Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010. [Google Scholar] [CrossRef]
- Mahler, R.P.S. Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2007; p. 856. [Google Scholar]
- Mahler, R. “Statistics 102” for Multisource-Multitarget Detection and Tracking. IEEE J. Sel. Top. Signal Process. 2013, 7, 376–389. [Google Scholar] [CrossRef]
- Ristic, B.; Beard, M.; Fantacci, C. An overview of particle methods for random finite set models. Inf. Fusion 2016, 31, 110–126. [Google Scholar] [CrossRef]
- Mahler, R.P. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2014; p. 1174. [Google Scholar]
- Ristic, B. Particle Filters for Random Set Models; Springer: New York, NY, USA, 2013; Volume 9781461463, pp. 1–174. [Google Scholar] [CrossRef]
- Li, T.; Sun, S.; Corchado, J.M.; Siyau, M.F. Random finite set-based Bayesian filters using magnitude-adaptive target birth intensity. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- Schikora, M.; Koch, W.; Streit, R.; Cremers, D. A Sequential Monte Carlo Method for Multi-target Tracking with the Intensity Filter. In Advances in Intelligent Signal Processing and Data Mining: Theory and Applications; Georgieva, P., Mihaylova, L., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 55–87. [Google Scholar] [CrossRef]
- Li, T.; Corchado, J.M.; Sun, S.; Fan, H. Multi-EAP: Extended EAP for multi-estimate extraction for SMC-PHD filter. Chin. J. Aeronaut. 2017, 30, 368–379. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Ristic, B.; Vo, B.N.; Clark, D.; Vo, B.T. A metric for performance evaluation of multi-target tracking algorithms. IEEE Trans. Signal Process. 2011, 59, 3452–3457. [Google Scholar] [CrossRef]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Törő, O.; Bécsi, T.; Gáspár, P. PHD Filter for Object Tracking in Road Traffic Applications Considering Varying Detectability. Sensors 2021, 21, 472. https://doi.org/10.3390/s21020472
Törő O, Bécsi T, Gáspár P. PHD Filter for Object Tracking in Road Traffic Applications Considering Varying Detectability. Sensors. 2021; 21(2):472. https://doi.org/10.3390/s21020472
Chicago/Turabian StyleTörő, Olivér, Tamás Bécsi, and Péter Gáspár. 2021. "PHD Filter for Object Tracking in Road Traffic Applications Considering Varying Detectability" Sensors 21, no. 2: 472. https://doi.org/10.3390/s21020472
APA StyleTörő, O., Bécsi, T., & Gáspár, P. (2021). PHD Filter for Object Tracking in Road Traffic Applications Considering Varying Detectability. Sensors, 21(2), 472. https://doi.org/10.3390/s21020472