FAR-Net: Feature-Wise Attention-Based Relation Network for Multilabel Jujube Defect Classification


Abstract
1. Introduction
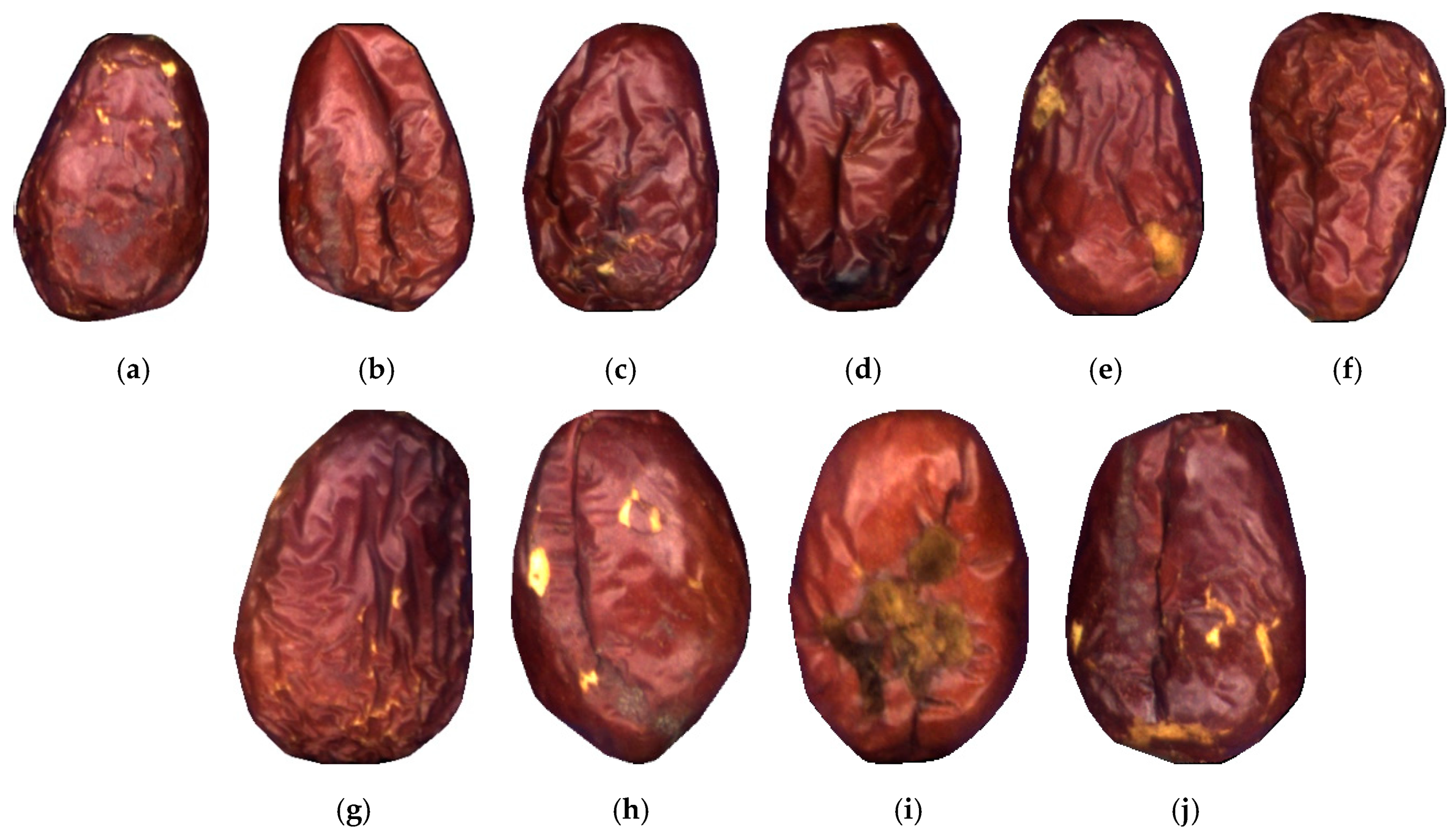
1.1. Multilabel Jujube Defect Classification
1.2. Review of the Deep Learning-Based Method for Multilabel Classification
1.2.1. CNN-Based Methods
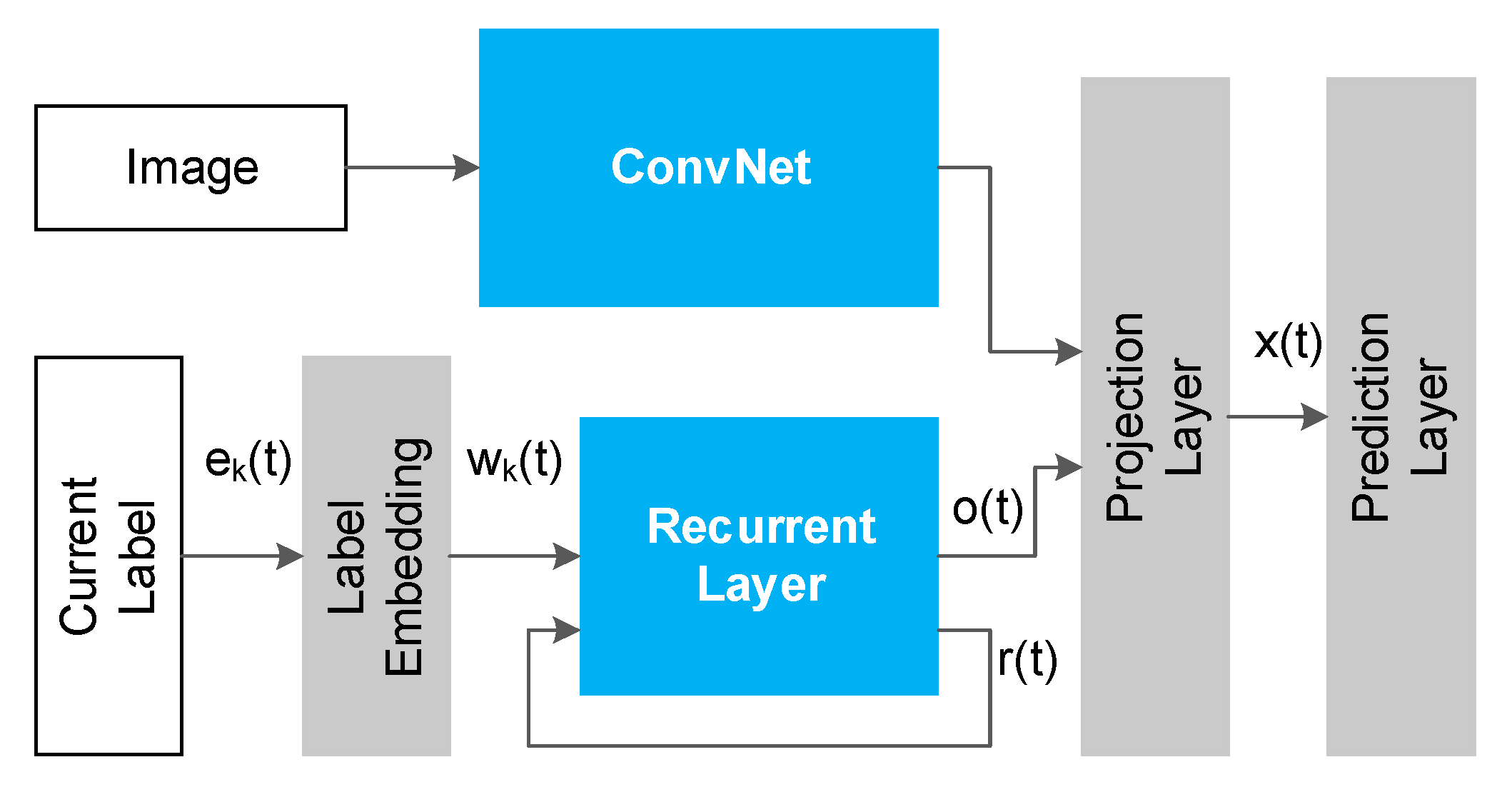
1.2.2. RNN-Based Methods
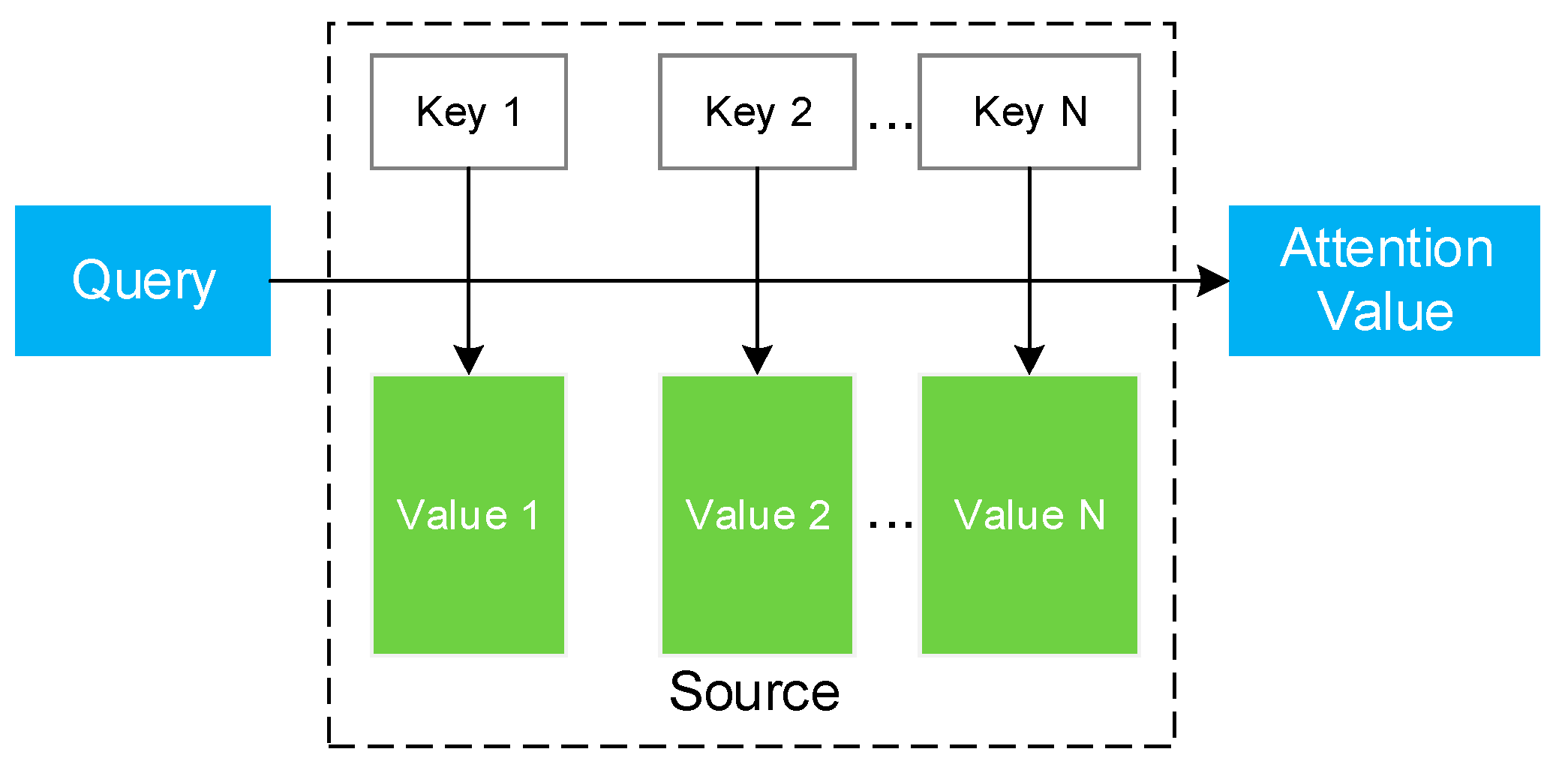
1.2.3. Attention-Based Methods
- Calculate the similarity between query and each key to obtain the corresponding weight. Commonly used similarity algorithms include the dot product:cosine similarity:multi-layer perceptron (MLP):and concatenation, etc.
- Use Softmax or other functions with similar characteristics to normalize all weights:
- The weight and the corresponding value are weighted and summed to obtain the final attention value:
2. Feature-Wise Attention-Based Relation Network
- (1)
- Reliable feature extraction. Feature extraction is the most preconditioned part in a machine vision system. Specifically in multilabel classification, the information contained in a multilabel sample is more abundant than that in a single-label sample. Therefore, a reliable feature extraction module is required to ensure that the effective knowledge about a sample is extracted completely and learned;
- (2)
- Label-wise feature aggregation. After obtaining the overall valid feature information about a multilabel sample, the label-wise aggregation of feature maps is required to learn dependencies and connections between different labels in subsequent modules.
- (3)
- Activation and deactivation of label features. As a single sample usually does not contain all kinds of defects, it is necessary to further filter the aggregated label features. That is, the feature maps corresponding to the labels that do not exist in a sample are required to be deactivated, and the remaining label features need to remain activated.
- (4)
- Comprehensive learning of the correlation among label features. Undoubtedly, this is the most conclusive module in a multilabel classification network. Whether a semantic relation between different defects can be completely learned, it determines the multilabel classification performance of a network.
2.1. Feature Extraction
- (1)
- Feature information contained in multilabel samples is more abundant and complex than that of single-label samples. Therefore, a feature extraction network needs to have sufficiently deep convolution layers and rich receptive fields.
- (2)
- Considering that a defect inspection system needs to be quickly deployed and implemented in an actual production environment, the network requires efficient training and inference performance.
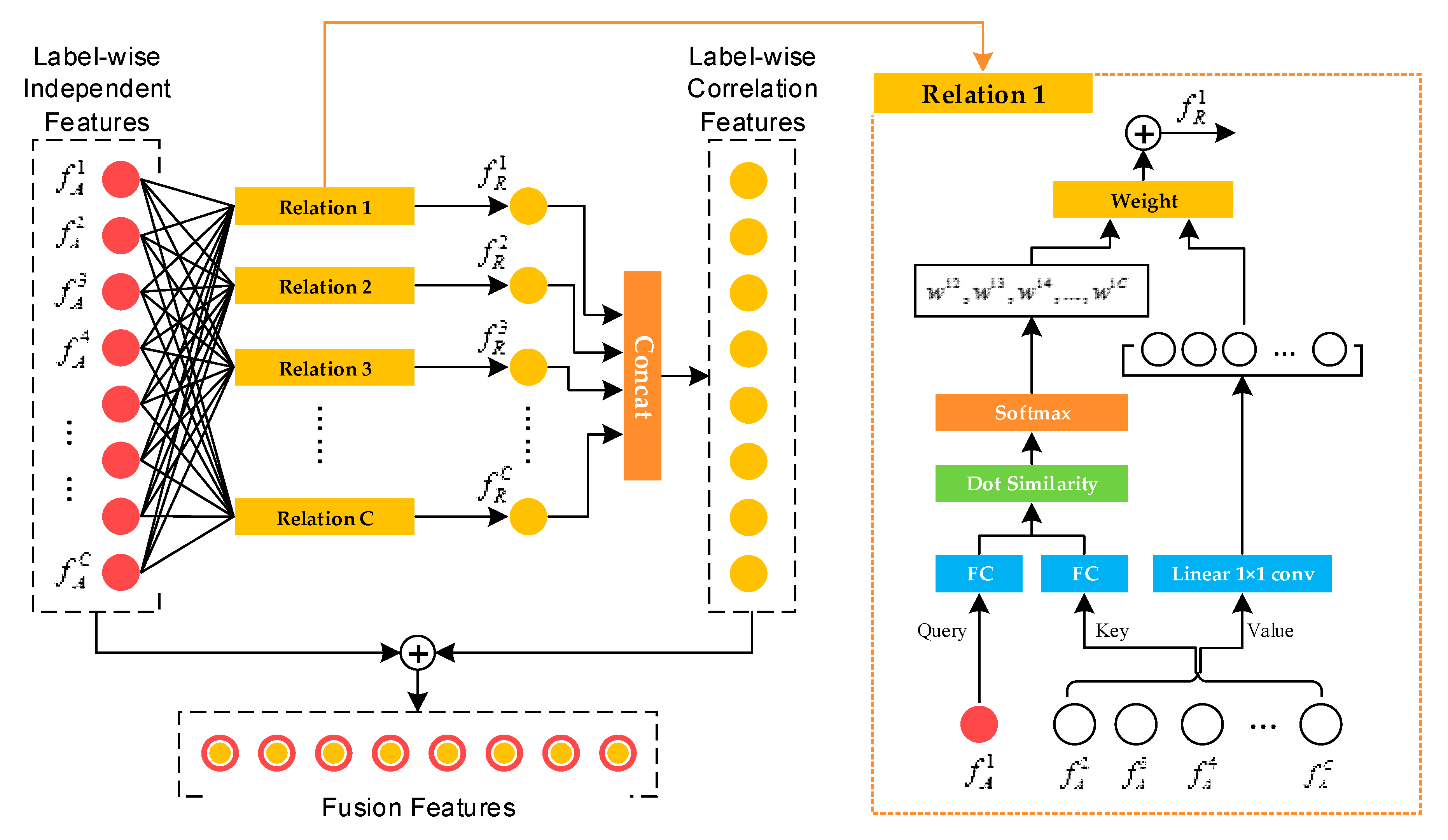
2.2. Label-Wise Feature Aggregation
2.3. Feature Activation and Deactivation
2.4. Attention-Based Relation Learning
3. Experimental Evaluation and Module Discussion
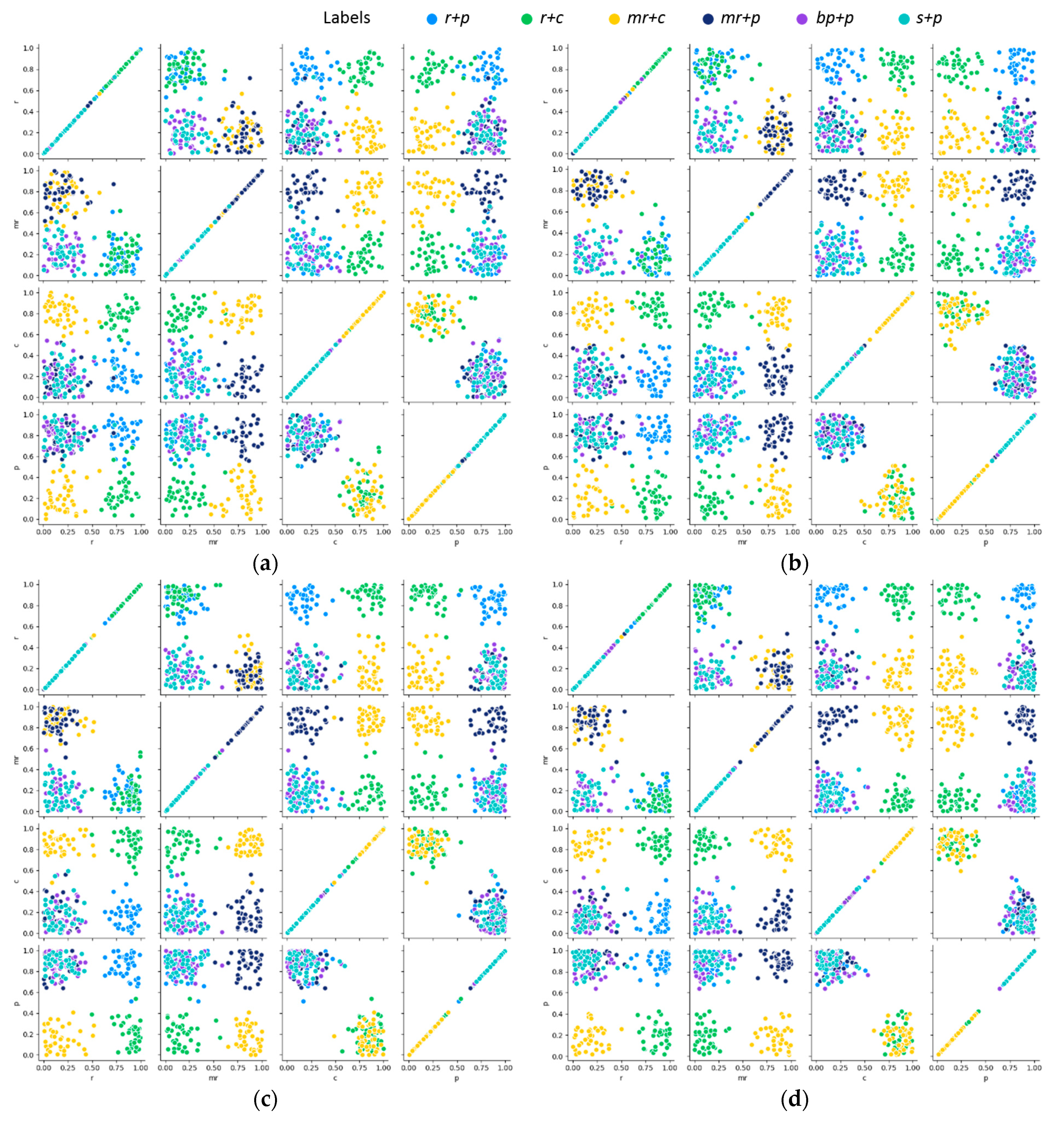
3.1. Multilabel Jujube Defect Dataset
3.2. Model Training
- (1)
- The FE module was fine-tuned on the multilabel jujube defect dataset, while the initial parameters of the model were obtained by pretraining on the ImageNet single-label dataset.
- (2)
- The parameters of the FE module were fixed, and the LFA and ADA modules were trained.
- (3)
- The parameters of the first three modules were fixed, and the ARL module was trained.
- (4)
- The overall model was fine-tuned simultaneously on the multilabel dataset.
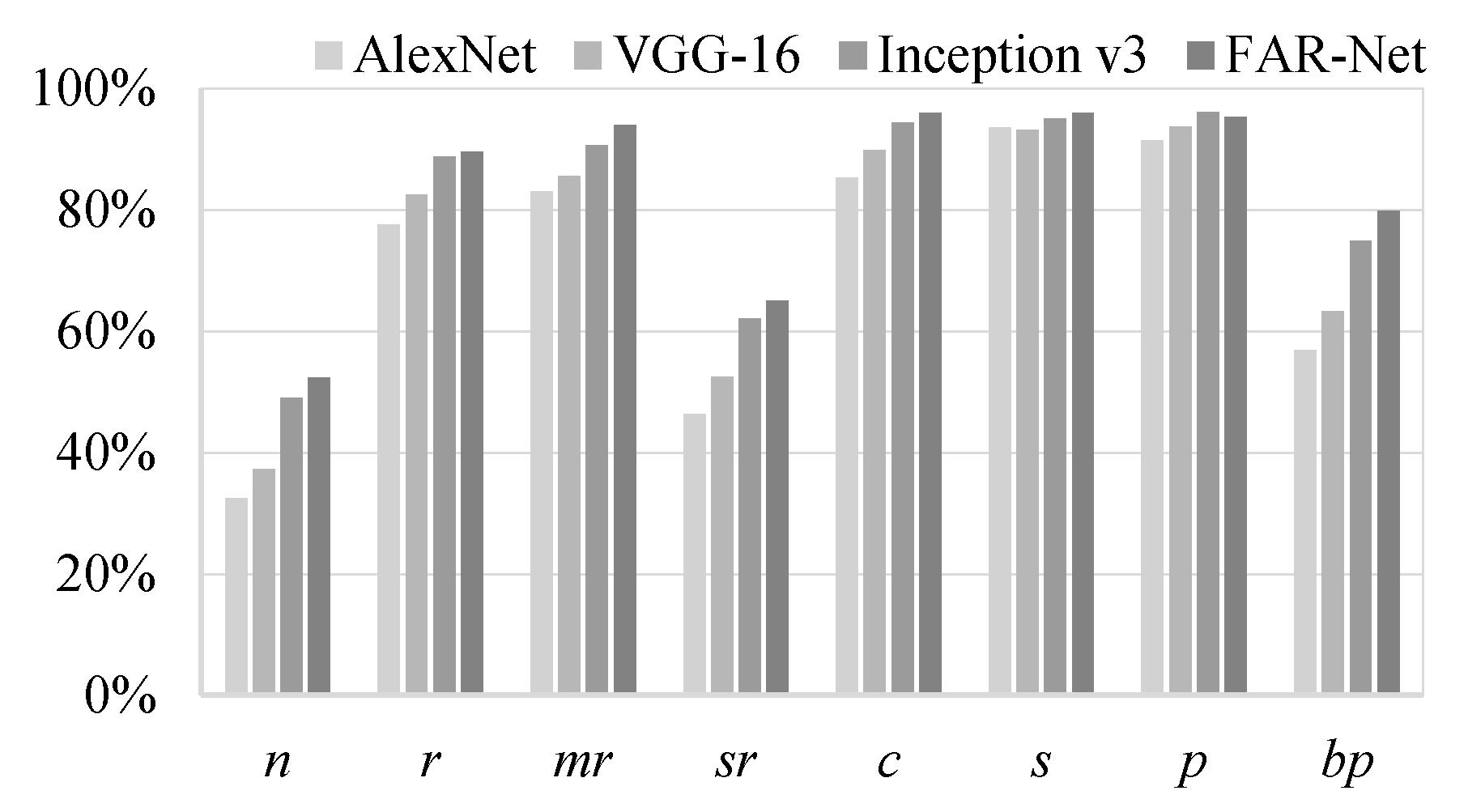
3.3. Experimental Results
3.4. Module Discussion
- (1)
- FAR-Net was equivalent to Inception v3 after removing LFA, ADA, and ARL modules. In this case, mAP was 89.25% on the multilabel jujube dataset.
- (2)
- The value of mAP reached 89.40% when the LFA and ADA modules were added, which was only 0.15% higher than that of Inception v3. This indicated that adding label feature separation only did not result in a considerable improvement in the overall classification outcome. This was because the model only extracted the label-wise independent features and did not learn the semantic correlation between labels.
- (3)
- The value of mAP achieved 90.28% when the ARL module was also added, which was 0.88% higher than that in step (2).
- (4)
- The value of mAP achieved only 89.85% when ADA module was removed, which indicated that label-wise feature aggregation is not enough for relation learning because negative responses need to be deactivated, while positive ones need to be further activated.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Jin, Y.; Yang, X.; Li, X.; Duan, X.; Sun, Y.; Liu, H. Convolutional neural network-based multilabel classification of PCB defects. J. Eng. 2018, 16, 1612–1616. [Google Scholar]
- Liu, Y. Research on Multilabel Data Classification Technology. Ph.D. Thesis, Xidian University, Xi’an, China, 2019. [Google Scholar]
- Gong, Y.; Jia, Y.; Leung, T.; Toshev, A.; Ioffe, S. Deep convolutional ranking for multilabel image annotation. arXiv 2013, arXiv:1312.4894. [Google Scholar]
- Wei, Y.; Xia, W.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. CNN: Single-label to multilabel. arXiv 2014, arXiv:1406.5726. [Google Scholar]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A Unified Framework for Multilabel Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Zhang, J.; Wu, Q.; Shen, C.; Zhang, J.; Lu, J. Multilabel image classification with regional latent semantic dependencies. IEEE Trans. Multimed. 2018, 20, 2801–2813. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, T.; Li, G.; Xu, R.; Lin, L. Multilabel Image Recognition by Recurrently Discovering Attentional Regions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 464–472. [Google Scholar]
- Chen, T.; Wang, Z.; Li, G.; Lin, L. Recurrent Attentional Reinforcement Learning for Multilabel Image Recognition. In Proceedings of the 2018 Association for the Advance of Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Heess, N.; Graves, A. Recurrent Models of Visual Attention. In Proceedings of the 2014 Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Wei, B.; Hao, K.; Gao, L.; Tang, X.S. Bio-Inspired Visual Integrated Model for Multilabel Classification of Textile Defect Images. IEEE Trans. Cogn. Dev. Syst. 2020. [Google Scholar] [CrossRef]
- Yan, Z.; Liu, W.; Wen, S.; Yang, Y. Multilabel image classification by feature attention network. IEEE Access 2019, 2019, 98005–98013. [Google Scholar] [CrossRef]
- Hua, Y.; Mou, L.; Zhu, X.X. Multilabel Aerial Image Classification using A Bidirectional Class-wise Attention Network. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Zheng, X.; Li, P.; Chu, Z.; Hu, X. A survey on multilabel data stream classification. IEEE Access 2020, 8, 1249–1275. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2818–2826. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Jiang, D. Research on Multilabel Image Classification Method Based on Deep Learning. Master’s Thesis, Hefei University of Technology, Hefei, China, 2019. [Google Scholar]
- Xu, X.; Zheng, H.; Guo, Z.; Wu, X.; Zheng, Z. SDD-CNN: Small data-driven convolution neural networks for subtle roller defect inspection. Appl. Sci. 2019, 9, 1364. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phrase | Conv1 | Conv2_x | Conv3_x | |
| Feature size | 149 × 149 × 32 | 147 × 147 × 64 | 71 × 71 × 192 | |
| Conv params | ||||
| Phrase | Conv4_x | Conv5_x | Conv6_x | Linear |
| Feature size | 35 × 35 × 288 | 17 × 17 × 768 | 8 × 8 × 2048 | 1 × 1 |
| Conv params | Avg pooling C-d FC Sigmoid |
| Sample | No. | Sample | No. | Sample | No. |
|---|---|---|---|---|---|
| n1 | 100 | r + p | 200 | r + p + mr | 20 |
| r | 80 | r + c | 200 | r + p + c | 20 |
| mr | 80 | mr + p | 200 | mr + c + p | 15 |
| sr | 80 | mr + c | 200 | bp + sr + c | 15 |
| c | 80 | bp + p | 200 | ||
| s | 80 | s + p | 200 | ||
| p | 80 | ||||
| bp | 80 | Total | 1930 |
| CPU: | Intel E3-1230 V2*2 (3.30 GHz) |
| Memory: | 16 GB DDR3 |
| GPU: | NVIDIA Tesla K20 |
| OS: | Ubuntu 16.04 LTS |
| Compiler: | Visual Studio Code with Python 2.7 |
| Momentum: | 0.9 |
| Weight decay: | 0.0005 |
| Base learning rate: | 0.001 |
| Learning rate policy: | Exponential |
| Batch size: | 16 |
| n | r | mr | sr | c | s | p | bp | mAP | |
|---|---|---|---|---|---|---|---|---|---|
| AlexNet | 95.00% | 71.73% | 67.57% | 93.68% | 70.87% | 77.86% | 81.39% | 72.88% | 78.87% |
| VGG-16 | 96.00% | 75.58% | 75.34% | 95.79% | 75.73% | 82.86% | 85.67% | 76.95% | 82.99% |
| CNN-RNN | 100.00% | 82.47% | 81.95% | 100.00% | 78.86% | 87.35% | 88.08% | 78.74% | 87.18% |
| Inception v3 | 100.00% | 83.85% | 83.50% | 100.00% | 81.94% | 90.00% | 91.98% | 82.71% | 89.25% |
| FAR-Net | 100.00% | 89.62% | 87.57% | 100.00% | 85.44% | 86.43% | 92.83% | 80.34% | 90.28% |
| Network | Micro-F1 | Macro-F1 | Testing Time (s) |
|---|---|---|---|
| AlexNet | 74.64% | 71.50% | 0.67 |
| VGG-16 | 78.67% | 76.21% | 0.81 |
| CNN-RNN | 83.04% | 81.61% | 0.93 |
| Inception v3 | 85.13% | 83.55% | 0.55 |
| FAR-Net (without ARL) | 85.35% | 84.01% | 0.61 |
| FAR-Net | 86.77% | 85.42% | 0.88 |
| Network | mAP |
|---|---|
| FAR-Net (without LFA, ADA, and ARL) | 89.25% |
| FAR-Net (without ARL) | 89.40% |
| FAR-Net (without ADA) | 89.85% |
| FAR-Net | 90.28% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zheng, H.; You, C.; Guo, Z.; Wu, X. FAR-Net: Feature-Wise Attention-Based Relation Network for Multilabel Jujube Defect Classification. Sensors 2021, 21, 392. https://doi.org/10.3390/s21020392
Xu X, Zheng H, You C, Guo Z, Wu X. FAR-Net: Feature-Wise Attention-Based Relation Network for Multilabel Jujube Defect Classification. Sensors. 2021; 21(2):392. https://doi.org/10.3390/s21020392
Chicago/Turabian StyleXu, Xiaohang, Hong Zheng, Changhui You, Zhongyuan Guo, and Xiongbin Wu. 2021. "FAR-Net: Feature-Wise Attention-Based Relation Network for Multilabel Jujube Defect Classification" Sensors 21, no. 2: 392. https://doi.org/10.3390/s21020392
APA StyleXu, X., Zheng, H., You, C., Guo, Z., & Wu, X. (2021). FAR-Net: Feature-Wise Attention-Based Relation Network for Multilabel Jujube Defect Classification. Sensors, 21(2), 392. https://doi.org/10.3390/s21020392