A Bayesian Driver Agent Model for Autonomous Vehicles System Based on Knowledge-Aware and Real-Time Data


Abstract
1. Introduction
- Sense and cognitively understand the current traffic scene situation;
- Predict the confidence and probability distribution of current driving patterns;
- Process partially observable and uncertain information.
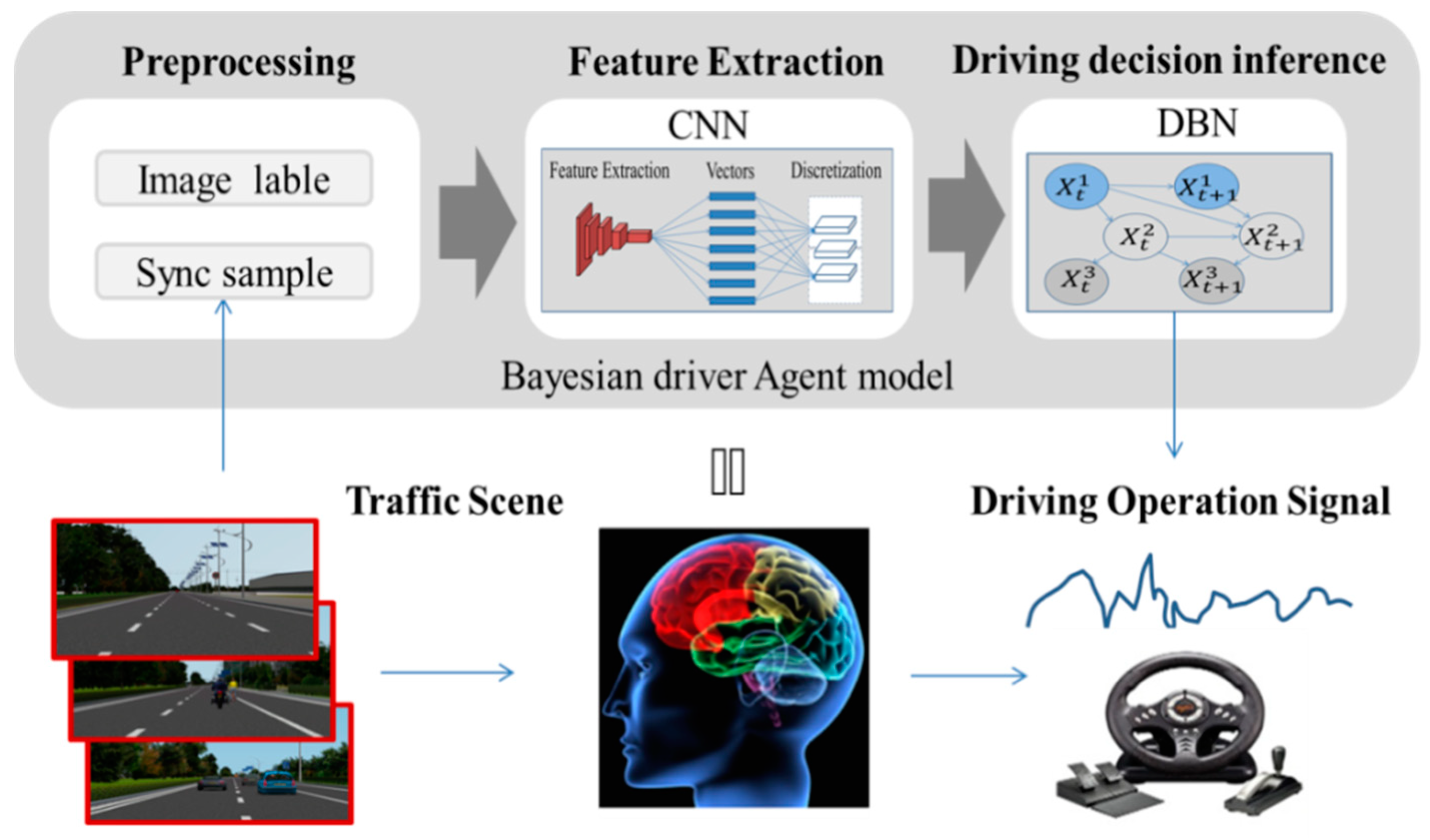
2. Approach for the Bayesian Driver Agent Model
2.1. Conventional Neural Network-Based Simulation of a Human Driver Agent’s Cognitive Functional Region
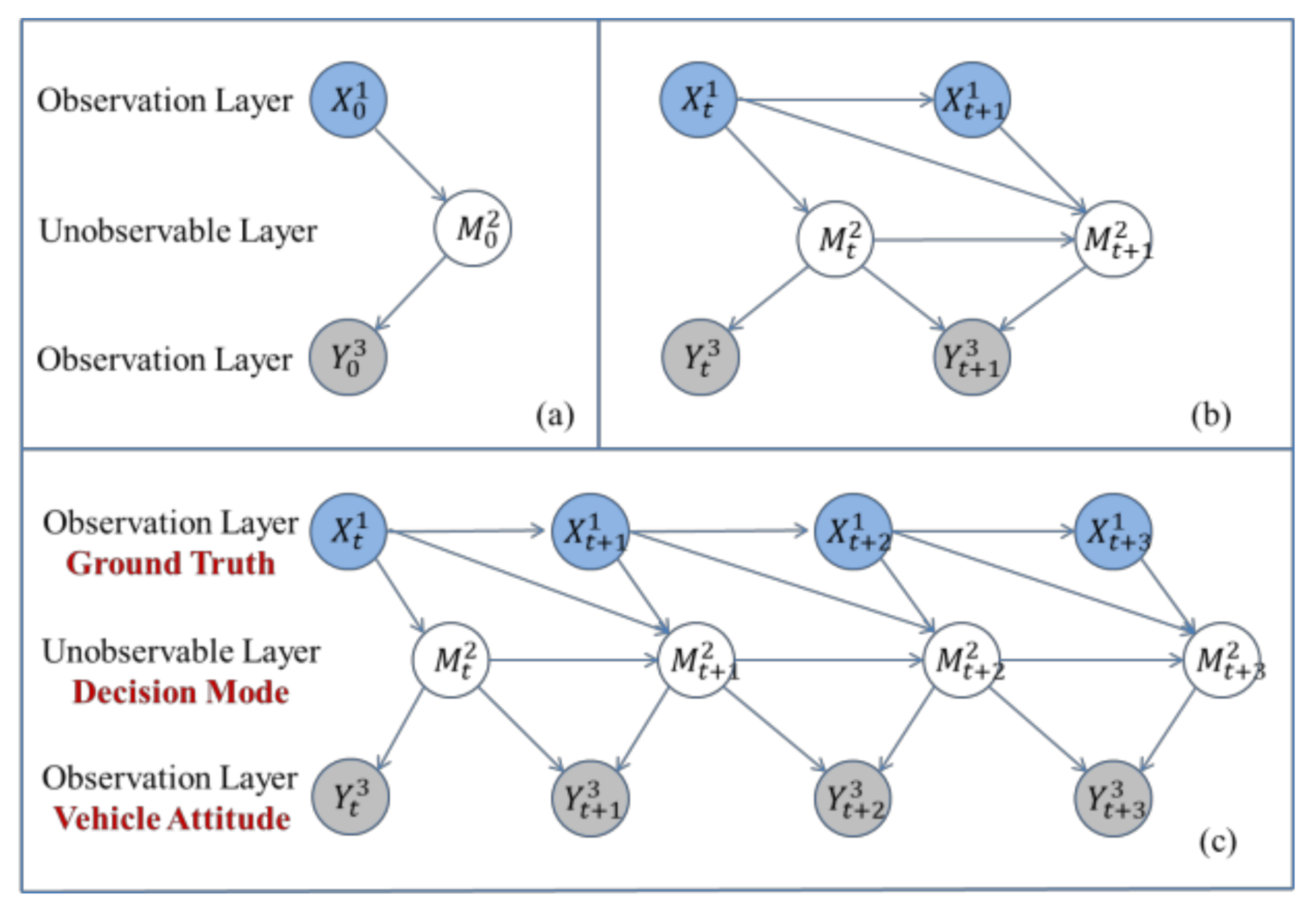
2.2. Dynamic Bayesian Network-Based Simulation of a Human Driver Agent’s Inference Functional Region
| Algorithm 1 KB-GES based on the fusion of priori knowledge |
| Input: Variable order; Experts constraints; Maximum number of parent nodes; Complete sample data. |
| Output: Optimal Bayesian network structure. |
| 1: Gboundless graph composed of nodes |
| 2: for j = 1 to n |
| 3: |
| 4: while (True) |
| 5: |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: Add an edge to G |
| 11: else |
| 12: break; |
| 13: end if |
| 14: end while |
| 15: end for |
| 16: return G |
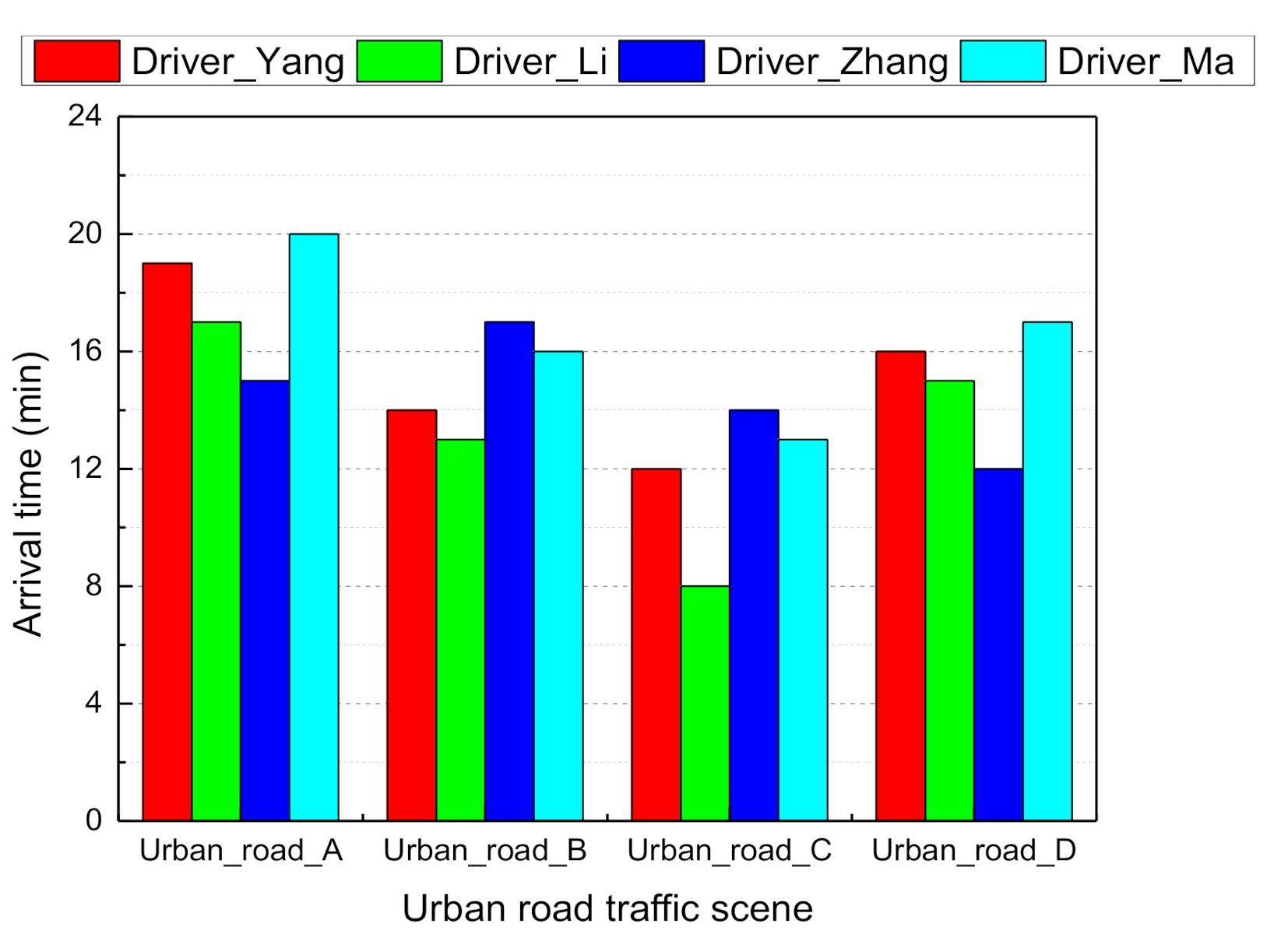
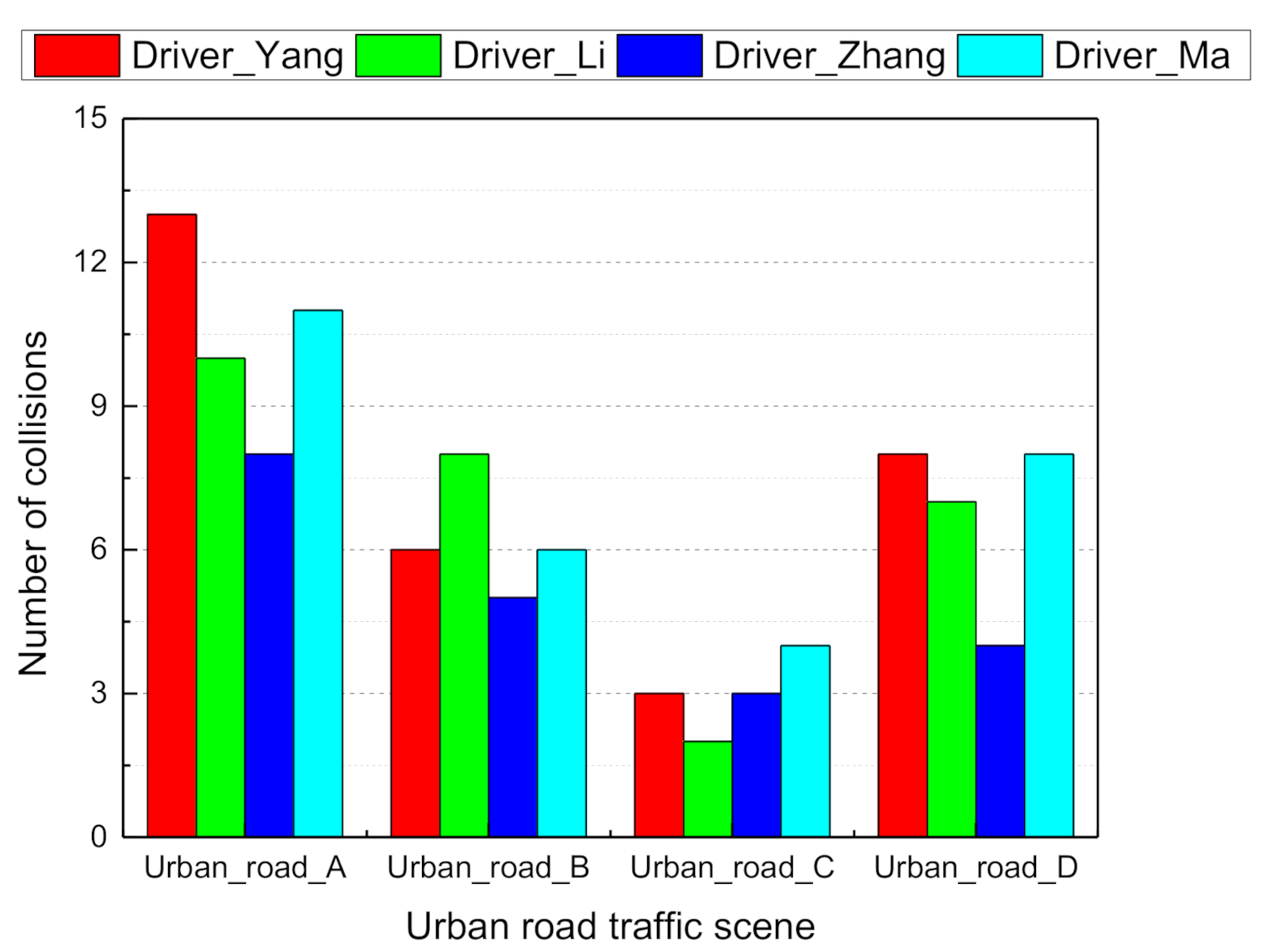
3. Experiments and Analysis of Results
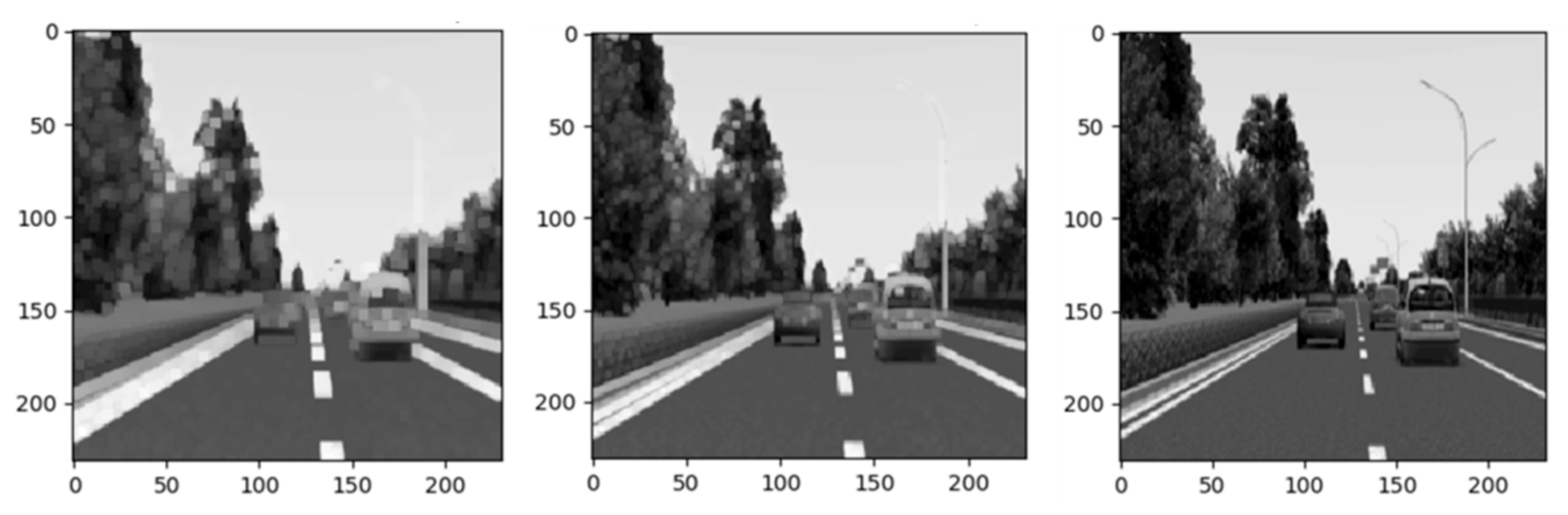
3.1. Cognitive Ability with Multi-Layer Convolutional Networks
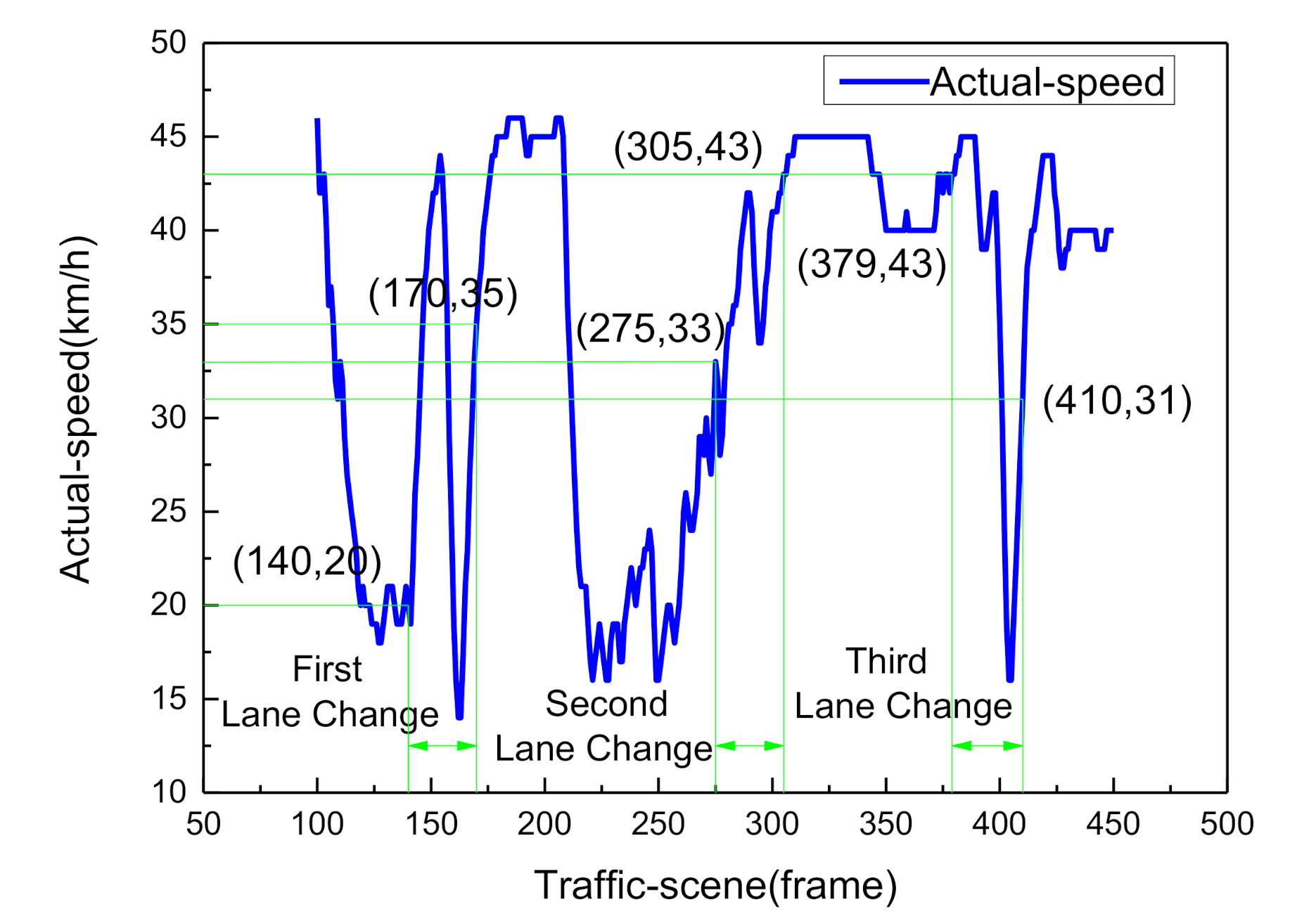
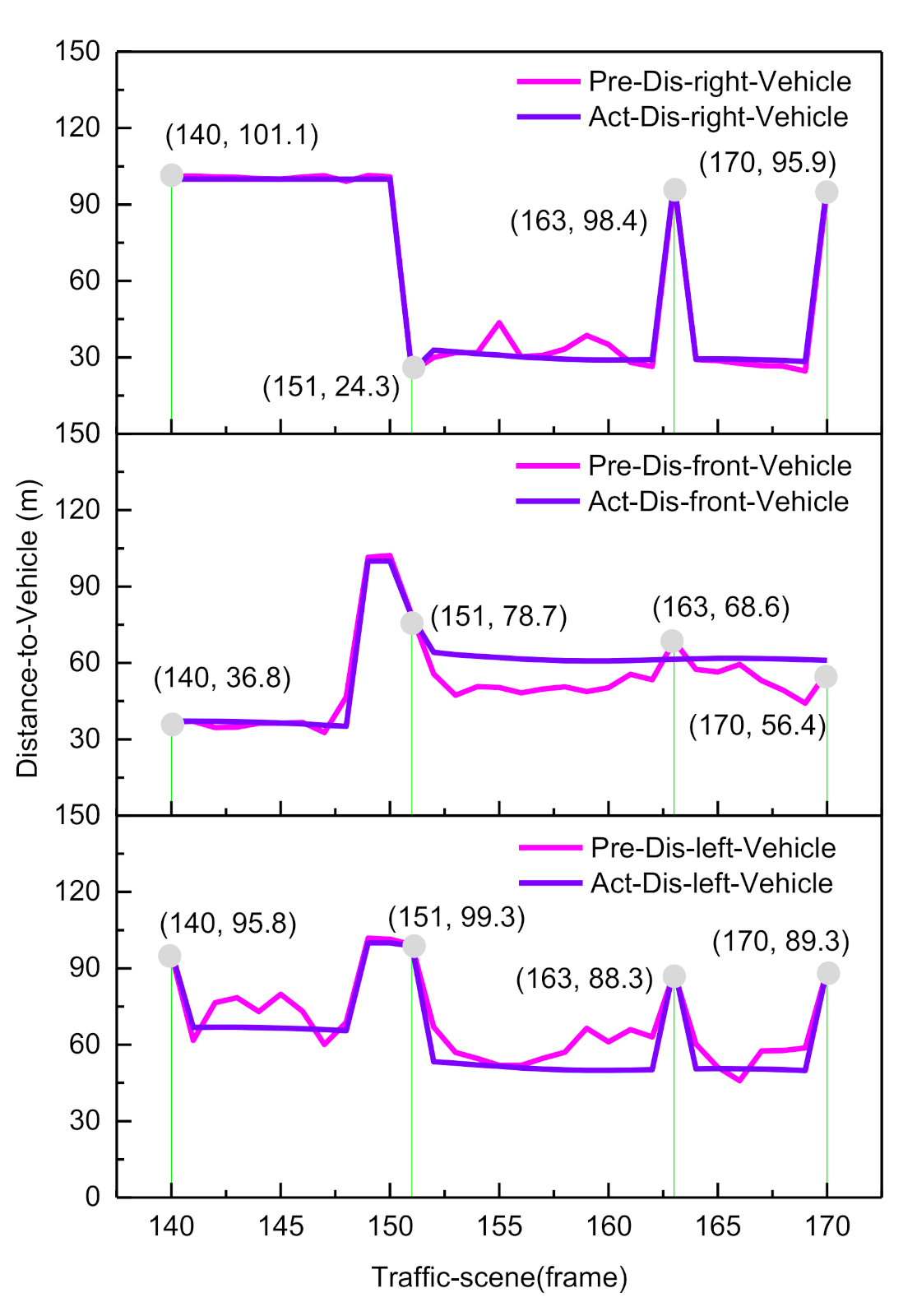
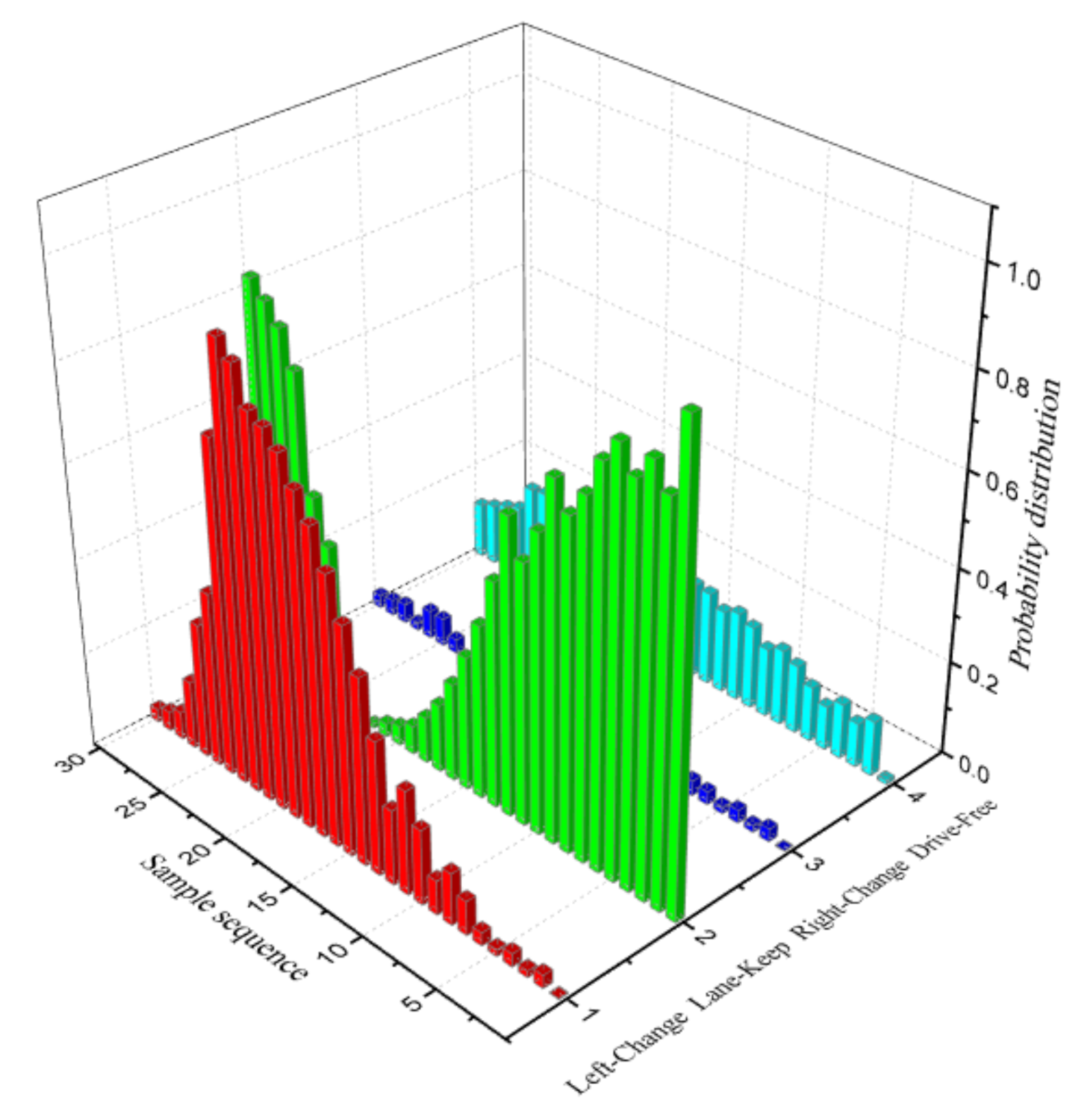
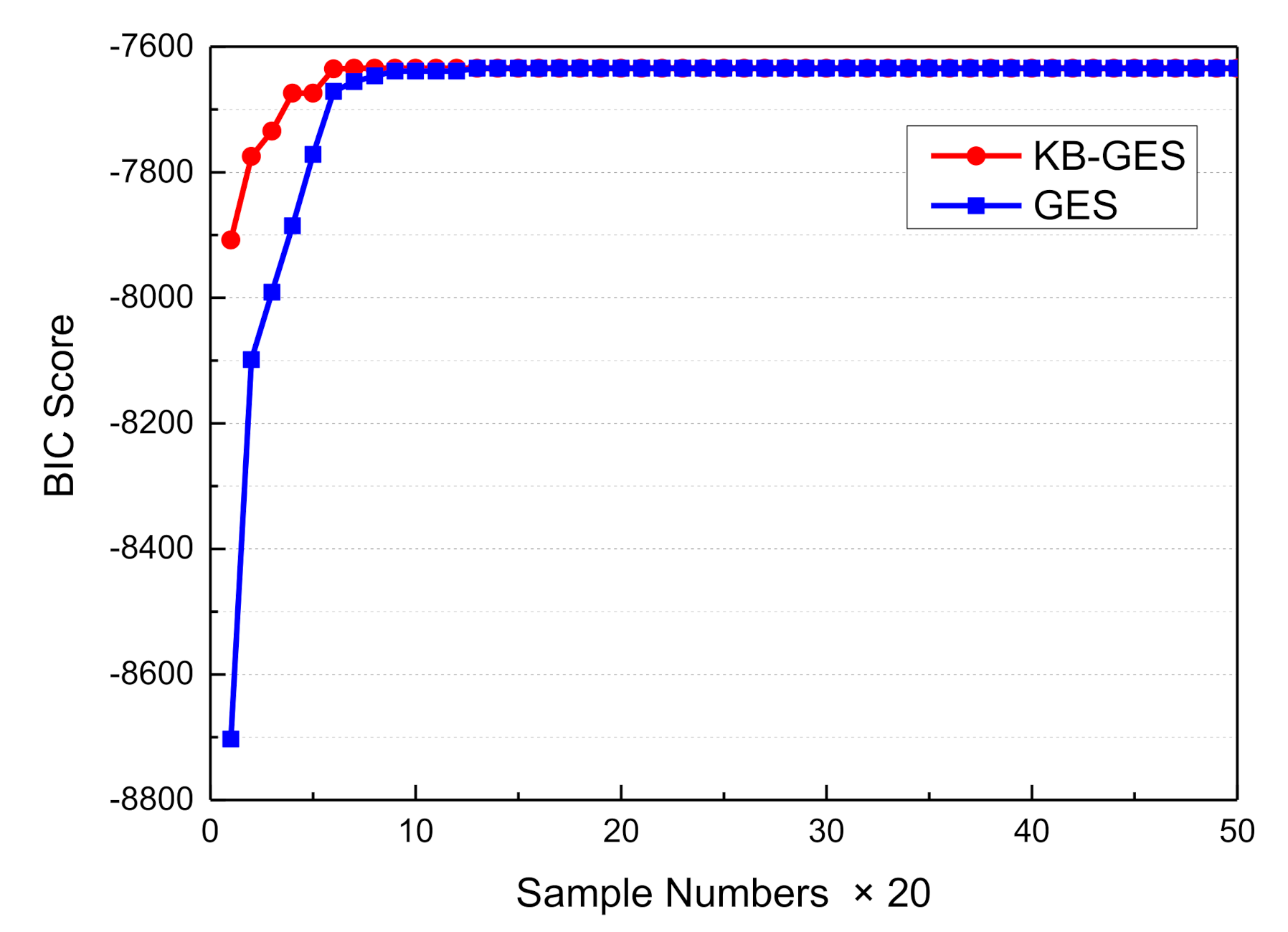
3.2. Inference Decision with Dynamic Bayesian Networks
- (a)
- A priori network structure based on expert experience
- (b)
- Structure learning from sample data using the KB-GES algorithm
| Algorithm 2 Pseudo-code of Bayesian probability programming |
| Input: Observable Evidence Information |
| Output: Decision Mode Confidence |
| Begin: |
| Preliminary Knowledge Initialization |
| While (1) |
| Ground_truth = Discretize (CNN_OutPut && Sensor_read) |
| Vehicle_attitude = Discretize (Sensor_read) |
| Drive_mode (t) = Propagate (Ground_truth && Vehicle_attitude) |
| Set_Maximum entropy principle (Drive_mode (t)) |
| End |
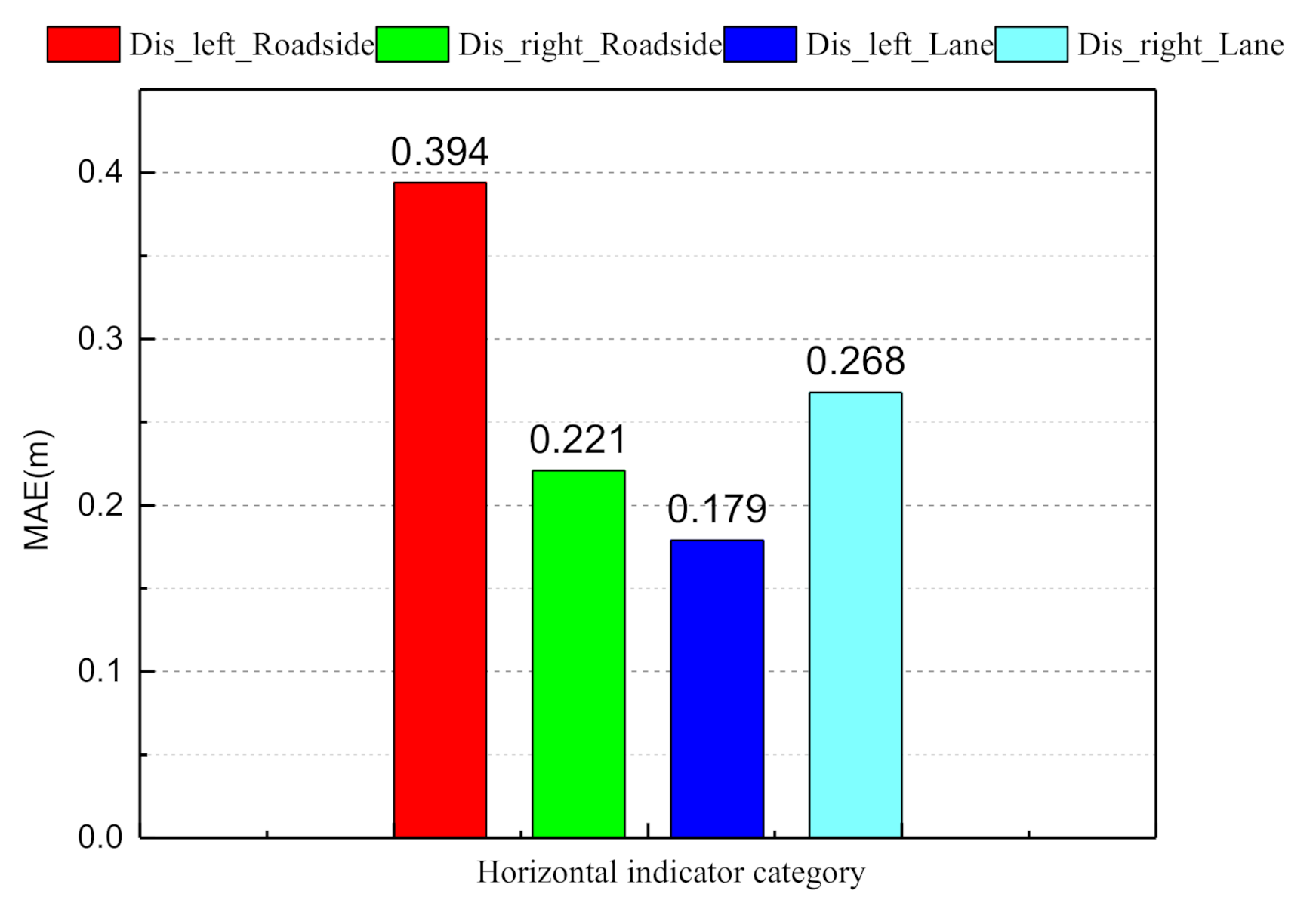
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Pomerleau, D. ALVINN: An autonomous land vehicle in a neural network. Adv. Neural Inf. Process. Syst. 1989, 1, 305–313. [Google Scholar]
- Muller, U.; Ben, J.; Cosatto, E.; Flepp, B.; Cun, Y. Off-road obstacle avoidance through end-to-end learning. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2005; pp. 739–746. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Bojarski, M.; Yeres, P.; Choromanska, A.; Choromanski, K.; Firner, B.; Jackel, L.; Muller, U. Explaining how a deep neural network trained with end-to-end learning steers a car. arXiv 2017, arXiv:1704.07911. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Eilers, M.; Möbus, C. Learning the human longitudinal control behavior with a modular hierarchical Bayesian mixture-of-behaviors model. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 540–545. [Google Scholar]
- Eilers, M.; Möbus, C. Learning the relevant percepts of modular hierarchical Bayesian driver models using a Bayesian information criterion. In Digital Human Modelling; Springer: Heidelberg, Germany, 2011; pp. 463–472. [Google Scholar]
- Xie, G.; Gao, H.; Huang, B.; Qian, L.; Wang, J. A Driving Behavior Awareness Model based on a Dynamic Bayesian Network and Distributed Genetic Algorithm. Int. J. Comput. Intell. Syst. 2018, 11, 469–482. [Google Scholar] [CrossRef]
- Eilers, M.; Möbus, C. Learning of a Bayesian autonomous driver mixture-of-behaviors (BAD-MoB) model. In Advances in Applied Digital Human Modeling; CRC Press: Boca Raton, FL, USA, 2010; pp. 436–445. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 2722–2730. [Google Scholar]
- Darlington, T.R.; Beck, J.M.; Lisberger, S.G. Neural implementation of Bayesian inference in a sensorimotor behavior. Nat. Neurosci. 2018, 21, 1442–1451. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Li, J.; Qi, G.; Li, S.; Sigman, M.; Wang, L. Statistical inference of body representation in the macaque brain. Proc. Natl. Acad. Sci. USA 2019, 116, 20151–20157. [Google Scholar] [CrossRef] [PubMed]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. Deeplanes: End-to-end lane position estimation using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27–30 June 2016; pp. 38–45. [Google Scholar]
- Chen, Y.; Zhao, D.; Lv, L.; Zhang, Q. Multi-task learning for dangerous object detection in autonomous driving. Inf. Sci. 2018, 432, 559–571. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Le Roux, N.; Bach, F. Ask the locals: Multi-way local pooling for image recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2651–2658. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Stochastic pooling for regularization of deep convolutional neural networks. In Proceedings of the 2013 International Conference on Learning Representations; ICLR: Scottsdale, AZ, USA, 2013; pp. 1–9. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2007; ISBN 0-387-68281-3. [Google Scholar]
- Cooper, G.F.; Herskovits, E. A bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning bayesian networks: The combination of knowledge and statistical data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Guo, H.; Perry, B.; Stilson, J.A.; Hsu, W.H. A genetic algorithm for tuning variable orderings in Bayesian network structure learning. In Proceedings of the 18th National Conference on Artificial Intelligence, Manhattan, KS, USA, 28 July–1 August 2002; pp. 951–952. [Google Scholar]
- Zhu, S.Y.; Chen, Z.T. Causal Discovery with Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Khosravy, M.; Gupta, N.; Marina, N.; Sethi, I.K.; Asharif, M.R. Perceptual Adaptation of Image based on Chevreul-Mach Bands Visual Phenomenon. IEEE Signal. Process. Lett. 2017, 24, 594–598. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Proceedings of the 12th International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 194–202. [Google Scholar] [CrossRef]
- Rabaseda, S.; Rakotomalala, R.; Sebban, M. Discretization of continuous attributes: A survey of methods. In Proceedings of the Second Annual Joint Conference on Information Sciences, Wrightsville Beach, NC, USA, 28 September–1 October 1995; pp. 164–166. [Google Scholar]
- Tsai, C.J.; Lee, C.I.; Yang, W.P. A discretization algorithm based on class-attribute contingency coefficient. Inf. Sci. 2008, 178, 714–731. [Google Scholar] [CrossRef]
- Henrion, M. Propagating uncertainty in Bayesian networks by probabilistic logic sampling. In Proceedings of the 4th Conference on Uncertainty in Artificial Intelligence, Minneapolis, MN, USA, 10–12 July 1988; pp. 149–163. [Google Scholar]
- Murphy, K. Dynamic Bayesian Networks: Representation, Inference and Learning. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2002. [Google Scholar]
- Mekhnacha, K.; Smail, L.; Ahuactzin, J.; Bessière, P.; Mazer, E. A Unifying Framework for Exact and Approximate Bayesian Inference. Available online: https://www.probayes.com/ (accessed on 8 December 2020).
- Koo, T.K.; Li, M.Y. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef] [PubMed]
- Fleiss, J.L.; Cohen, J. The Equivalence of Weighted Kappa and the Intraclass Correlation Coefficient As Measures of Reliability. Educ. Psychol. Meas. 2016, 33, 613–619. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Li, J.; Lu, C.; Luo, Z.; Xue, H.; Wang, C. LiDAR-Video Driving Dataset: Learning Driving Policies Effectively. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2015; Volume 2, pp. 961–970. [Google Scholar]
- Yuan, W.; Yang, M.; Li, H.; Wang, C.X.; Wang, B. End-to-end learning for high-precision lane keeping via multi-state model. Intell. Technol. CAAI Trans. 2018, 3, 185–190. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to Real Reinforcement Learning for Autonomous Driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Tan, B.; Xu, N.; Kong, B. Autonomous Driving in Reality with Reinforcement Learning and Image Translation. arXiv 2018, arXiv:1801.05299. [Google Scholar]






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Kernel Size | Stride | Tensor Size |
|---|---|---|---|
| Input Layer | Width × Height × Channels | -/- | 231 × 231 × 3 |
| Conv-1 | 11 × 11 | 4 | 56 × 56 × 96 |
| Pool-1 | 3 × 3 | 2 | 27 × 27 × 96 |
| Conv-2 | 5 × 5 | 1 | 27 × 27 × 256 |
| Pool-2 | 3 × 3 | 2 | 13 × 13 × 256 |
| Conv-3 | 3 × 3 | 1 | 13 × 13 × 384 |
| Conv-4 | 3 × 3 | 1 | 13 × 13 × 384 |
| Conv-5 | 3 × 3 | 1 | 13 × 13 × 256 |
| Pool-5 | 3 × 3 | 2 | 6 × 6 × 256 |
| FC-1 | -/- | -/- | 4096 × 1 |
| FC-2 | -/- | -/- | 4096 × 1 |
| FC-3 | -/- | -/- | 7 |
| OutPut | S member function discretization status value | ||
| Drive-Posture Description Parameter of Traffic Scenes |
|---|
| (1) Dis_front_Vehicle: Distance to the vehicle of the current lane |
| (2) Dis_right_Vehicle: Distance to the vehicle of the right lane |
| (3) Dis_left_Vehicle: Distance to the vehicle of the left lane |
| (4) Dis_left_Roadside: Distance to the left side of the road |
| (5) Dis_right_Roadside: Distance to the side of the road |
| (6) Dis_left_Lane: Distance between the left lane and left wheel |
| (7) Dis_right_Lane: Distance between the right lane and right wheel |
| Driving Decision Semantic Vector Space |
|---|
| (1) Veh_Speed: Vehicle longitudinal speed |
| (2) Veh_Acceleration: Vehicle longitudinal acceleration |
| (3) Veh_Course_Angle: angle between the axis of the vehicle body and road |
| Query Node | State Description | Discretization Value |
|---|---|---|
| Driving decision mode | Left_Lane_Change | 1 |
| Lane_Keep | 2 | |
| Right_Lane_Change | 3 | |
| Drive_Free | 4 |
| Layers of Model | Nodes of Model |
|---|---|
| Ground Truth | 1. Dis_left_Vehicle, 2. Dis_front_Vehicle, 3. Dis_right_Vehicle, 4. Dis_left_rear_Vehicle, 5. Dis_rear_Vehicle, 6. Dis_right_rear_Vehicle, 7. Dis_left_Lane, 8. Dis_left_Roadside, 9. Dis_right_Lane, 10. Dis_right_Roadside |
| Situation Evaluation | 11. ROI_front_situation, 12. ROI_rear_situation, 13. ROI_left_situation, 14. ROI_right_situation 15. Lane_Number, 16. Current_Lane |
| Driving Decision | 17. Driving_decision_mode |
| Vehicle Attitude | 18. Veh_Speed, 19. Veh_Course_Angle, 20. Veh_Acceleration |
| Intraclass Correlation | 95% Confidence Interval | F-Test One-Way ANOVA with = 0.05 | ||||||
|---|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | F-Statistic | Df1 (r-1) | Df2 (n-r) | p-Value | F-Critical One-Tail | ||
| Single measures | 0.984 | 0.972 | 0.991 | 0.144 | 1 | 120 | 0.705 | 3.920 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Xie, H.; Song, K.; Liu, H. A Bayesian Driver Agent Model for Autonomous Vehicles System Based on Knowledge-Aware and Real-Time Data. Sensors 2021, 21, 331. https://doi.org/10.3390/s21020331
Ma J, Xie H, Song K, Liu H. A Bayesian Driver Agent Model for Autonomous Vehicles System Based on Knowledge-Aware and Real-Time Data. Sensors. 2021; 21(2):331. https://doi.org/10.3390/s21020331
Chicago/Turabian StyleMa, Jichang, Hui Xie, Kang Song, and Hao Liu. 2021. "A Bayesian Driver Agent Model for Autonomous Vehicles System Based on Knowledge-Aware and Real-Time Data" Sensors 21, no. 2: 331. https://doi.org/10.3390/s21020331
APA StyleMa, J., Xie, H., Song, K., & Liu, H. (2021). A Bayesian Driver Agent Model for Autonomous Vehicles System Based on Knowledge-Aware and Real-Time Data. Sensors, 21(2), 331. https://doi.org/10.3390/s21020331