
Extended-Range Prediction Model Using NSGA-III Optimized RNN-GRU-LSTM for Driver Stress and Drowsiness



 ,
,  and
and
Abstract
:1. Introduction
1.1. Related Works
1.2. Inadequacies of Related Works
- Simulated dataset: Most works [14,15,16,17,18,19,20,21,22] implement and evaluate prediction models using simulated datasets (driving simulator). These reduce the practicality and reliability of the models because simulated datasets are comprised of data obtained from simulated environments where danger and nervousness cannot be realized.
- Time of in-advance prediction: The specific time (5, 6, 8, 30, and 60 s; e.g., the model predict the driver’s status in time t + 5 s) [16,17,18,19,20,21,22] and distinct time ranges (3–5 and 13.8–16.4 s; e.g., the model predict the driver’s status in time t + time range with certain step size) [14,15] of in-advance prediction were observed. Attributed to the individual variation in the mental and psychological status (drowsiness and stress) of the drivers, the requirements for the time range of in-advance prediction vary among drivers. For examples, some drivers may fall asleep quickly and some some may become angry easily.
1.3. Research Contributions
- The proposed NSGA-III optimized RNN-GRU-LSTM makes use of the advantages of each algorithm to achieve extended range prediction, with the algorithm achieving a 1–60 s (step size of 1 s) in-advance prediction so that it allows sufficient time (more than the reaction time of humans) to drivers from focusing back to normal driving.
- Compared with baseline models namely stand-alone RNN, stand-alone GRU, and stand-alone LSTM, the NSGA-III optimized RNN-GRU-LSTM enhances the overall accuracy by 11.2–13.6% and 10.2–12.2% for driver stress prediction and driver drowsiness prediction.
- Compared with boosting learning of multiple RNNs, multiple GRUs, and multiple LSTMs, the NSGA-III optimized RNN-GRU-LSTM enhances the overall accuracy by 6.9–12.7% and 6.9–8.7% for driver stress prediction and driver drowsiness prediction.
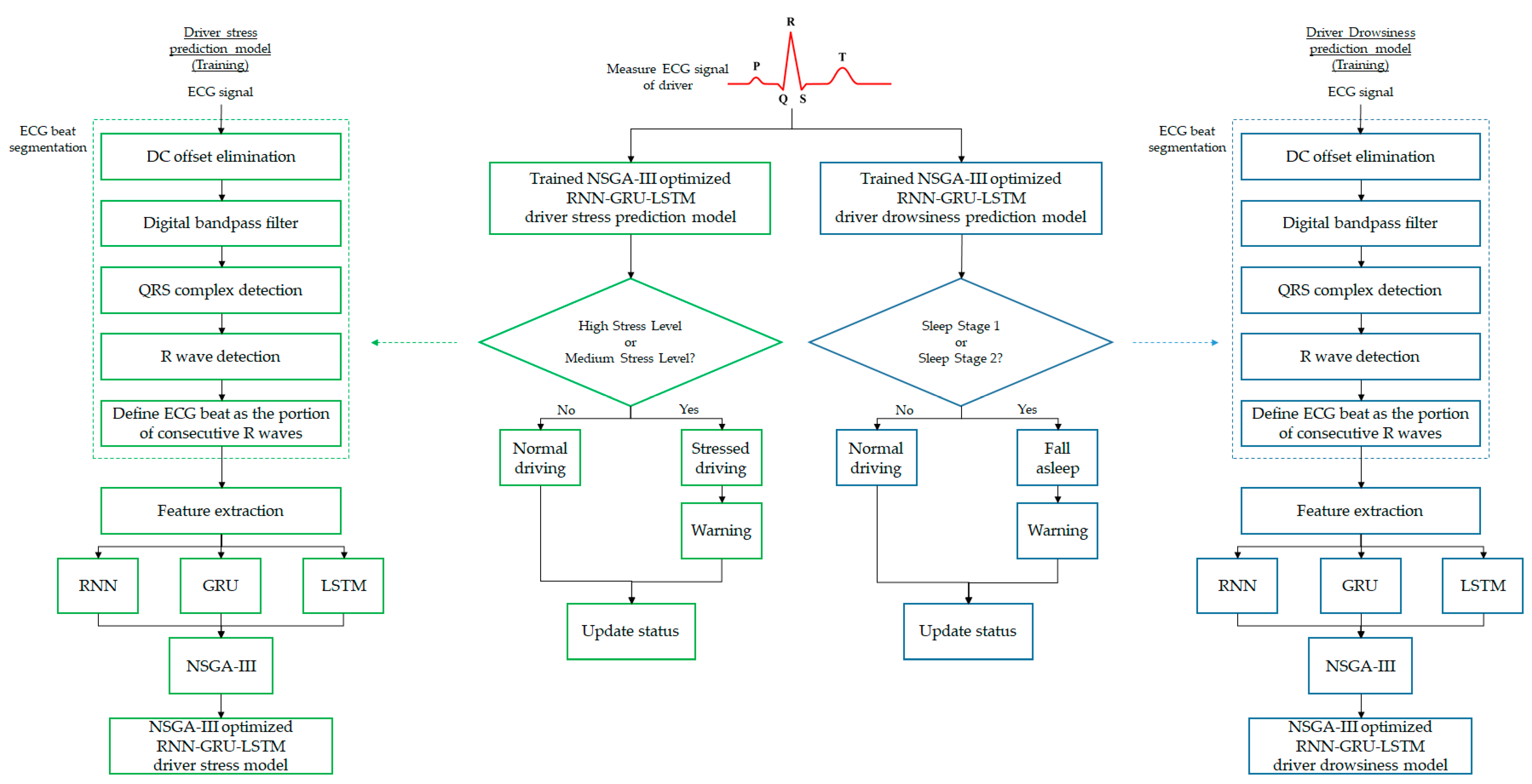
2. Methodology of Proposed NSGA-III Optimized RNN-GRU-LSTM Model
2.1. Real-world Driving Datasets
- The Stress Recognition in Automobile Drivers Database [25,26]: 18 drivers participated in a real-world driving experiment in the USA. An ECG signal was collected based on three scenarios which form three stress levels—namely, a low stress level (LSL), a medium stress level (MSL), and a high stress level (HSL). The LSL was contributed by drivers sitting at rest and closing their eyes 15 min before and after driving. Therefore, it contributed to an overall of total of 30 min. The MSL was generated between a toll at the on-ramp and preceding the off-ramp during highway driving. The HSL was conducted using the driving scenario of a winding and narrow lame in main and side streets. The MSL and HSL of the drivers contributed to 20–60 min of the record length.
- The Cyclic Alternating Pattern (CAP) Sleep Database [26,27]: This comprises 108 records of ECG signals from six sleep stages. These are: (i) normal stage; (ii) sleep stage 1; (iii) sleep stage 2; (iv) sleep stage 3; (v) sleep stage 4; and (vi) rapid eye movement stage. Based on the definitions of these stages, sleep stage 1 and sleep stage 2 are related to drowsiness and thus were selected as driver drowsiness samples.
2.2. ECG Beat Segmentation
2.3. NSGA-III Optimized RNN-GRU-LSTM Model
- RNN is less complex and requires less training time compared with GRU and LSTM. However, RNN suffers from the issue of vanishing gradient, in which the gradient between the current and previous layers keeps decaying [38,39]. This has led to the inefficiency of RNN in learning early inputs and thus supporting short-term prediction.
- Both the GRU and LSTM avoid the issue of vanishing gradient [40]. The former offers a less complex structure because individual memory cells are not included, whereas the latter has better control of memory through the use of three gates (input, forget, and output gates).
- Attributed to the advantages and disadvantages of the RNN, GRU, and LSTM algorithms, optimally merging the algorithms would enhance the performance of the prediction model compared with the stand-alone-based algorithm. The optimization problem is solved by NSGA-III because it not only enhances the diversity of the new population but also requires computing power with a small population size [41,42].
- There are some previous works adopted hybrid algorithms such as GRU and LSTM for credit card fraud detection [43], RNN and LSTM for spoken language understanding [44], RNN and GRU for state-of-charge detection for lithium-ion battery [45], and RNN, GRU, and LSTM for rumor detection in social media [46]. These support the applicability and effectiveness of merging RNN, GRU, and LSTM algorithms which takes advantages from each of the algorithm.
2.3.1. RNN Algorithm
2.3.2. GRU Algorithm
2.3.3. LSTM Algorithm
2.3.4. Optimal Design of RNN-GRU-LSTM Model Using NSGA-III
3. Results and Comparison
3.1. NSGA-III Optimized RNN-GRU-LSTM Algorithm
- The best for driver stress prediction is 93.1% for 2 s in-advance prediction, whereas that for driver drowsiness prediction is 94.2% for 1 s in-advance prediction.
- The worst for driver stress prediction is 71.2% for 60 s in-advance prediction, whereas that for driver drowsiness prediction is 75.3% for 60 s in-advance prediction.
- The overall accuracies (, , , and ) drop along with the increase in the time of the in-advance prediction. This is an expected phenomenon because more unseen information may occur when the time increases.
- The average discrepancy of −2.91% (less accurate) in the of the minority class (class 3) is found in the driver stress prediction. For driver drowsiness prediction, the average discrepancies are −1.15% and −4.92% for minority classes, class 2, and class 3, respectively. The major reason for the discrepancy is the issue of class-imbalance, which was reduced by formulating the prediction model using multi-objective optimization.
3.2. Individual RNN, GRU, and LSTM Algorithms
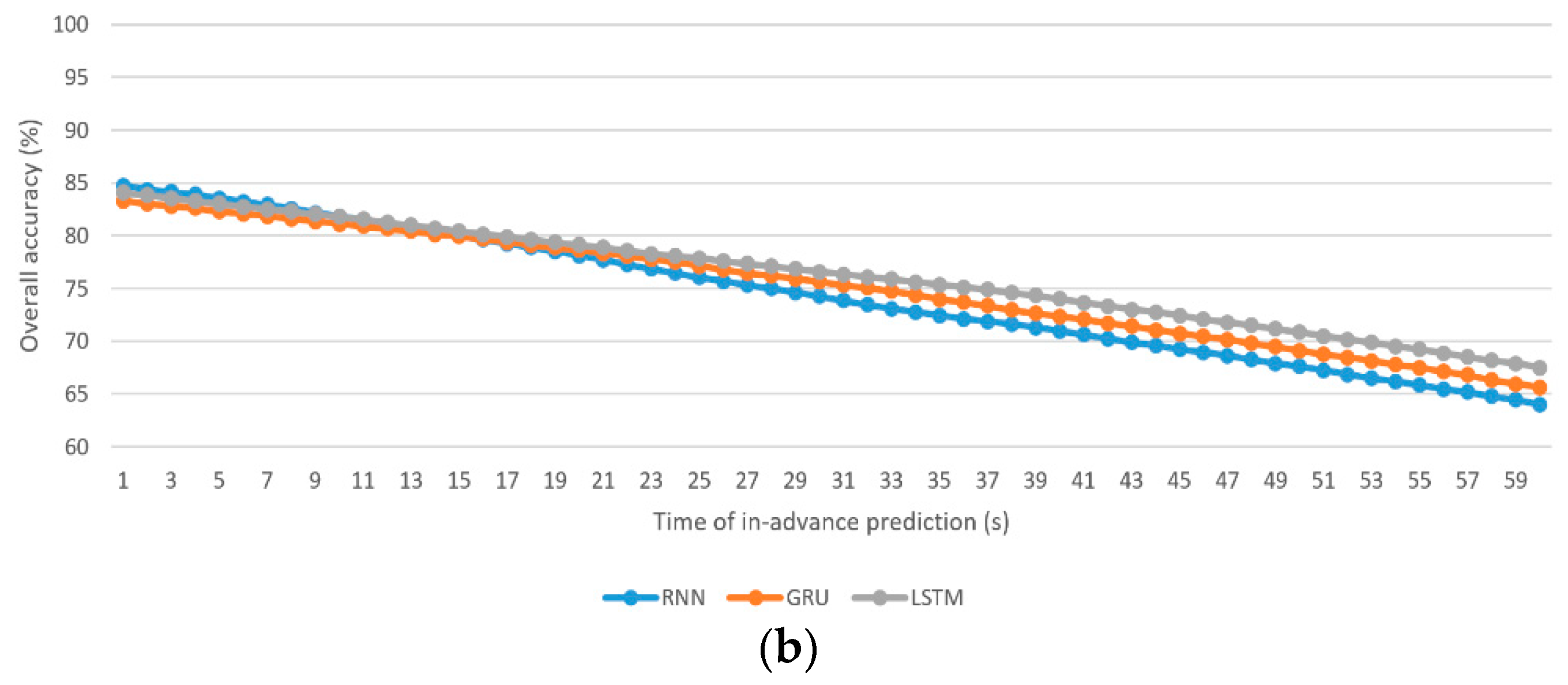
- The best using the individual RNN, GRU, and LSTM algorithms for driver stress prediction are 83%, 81.3%, and 82.2%, respectively, at 1 s in-advance prediction, whereas those for driver drowsiness prediction are 84.5%, 83.1%, and 83.9%, respectively, at 1 s in-advance prediction.
- The worst using the individual RNN, GRU, and LSTM algorithms for driver stress prediction are 60.9%, 63.7%, and 66.8%, respectively, at 60 s in-advance prediction, whereas those for driver drowsiness prediction are 63.6%, 65.5%, and 67.5%, respectively, at 60 s in-advance prediction.
- As there is more unseen information when the time of in-advance prediction increases, the overall accuracies (, , , and ) drop.
- For the driver stress prediction model, the average discrepancies are −3.12%, −3.10%, and −2.33% (less accurate) in the of the minority class (class 3) using the individual RNN, GRU, and LSTM algorithms, respectively. For the driver drowsiness prediction model, they are (−1.34%, −1.76%, −1.05%) and (−4.16%, −4.71%, −4.38%) for minority classes, class 2, and class 3, respectively.
- Driver stress prediction: The RNN algorithm performs better in short-term prediction compared with the GRU and LSTM algorithms. In terms of , the average lead is 1.31% for 1–11 s in-advance prediction compared with the GRU algorithm. Compared with the LSTM algorithm, the average lead is 0.5% for 1–9 s in-advance prediction. The rate of deterioration of with the increase in the time of in-advance prediction is more severe in the RNN algorithm, followed by the GRU and LSTM algorithms. As a result, LSTM yields a higher result for in medium-term and long-term predictions, followed by the GRU and RNN algorithms.
- Driver drowsiness prediction: Similar to driver stress prediction, the RNN algorithm is the best for short-term prediction. The average lead in is 1.63% for 1–21 s compared with the GRU algorithm. Compared with LSTM, the average lead is 0.53% for 1–10 s in-advance prediction.
3.3. Boosting Learning of Multiple RNNs, GRUs, and LSTMs Algorithms
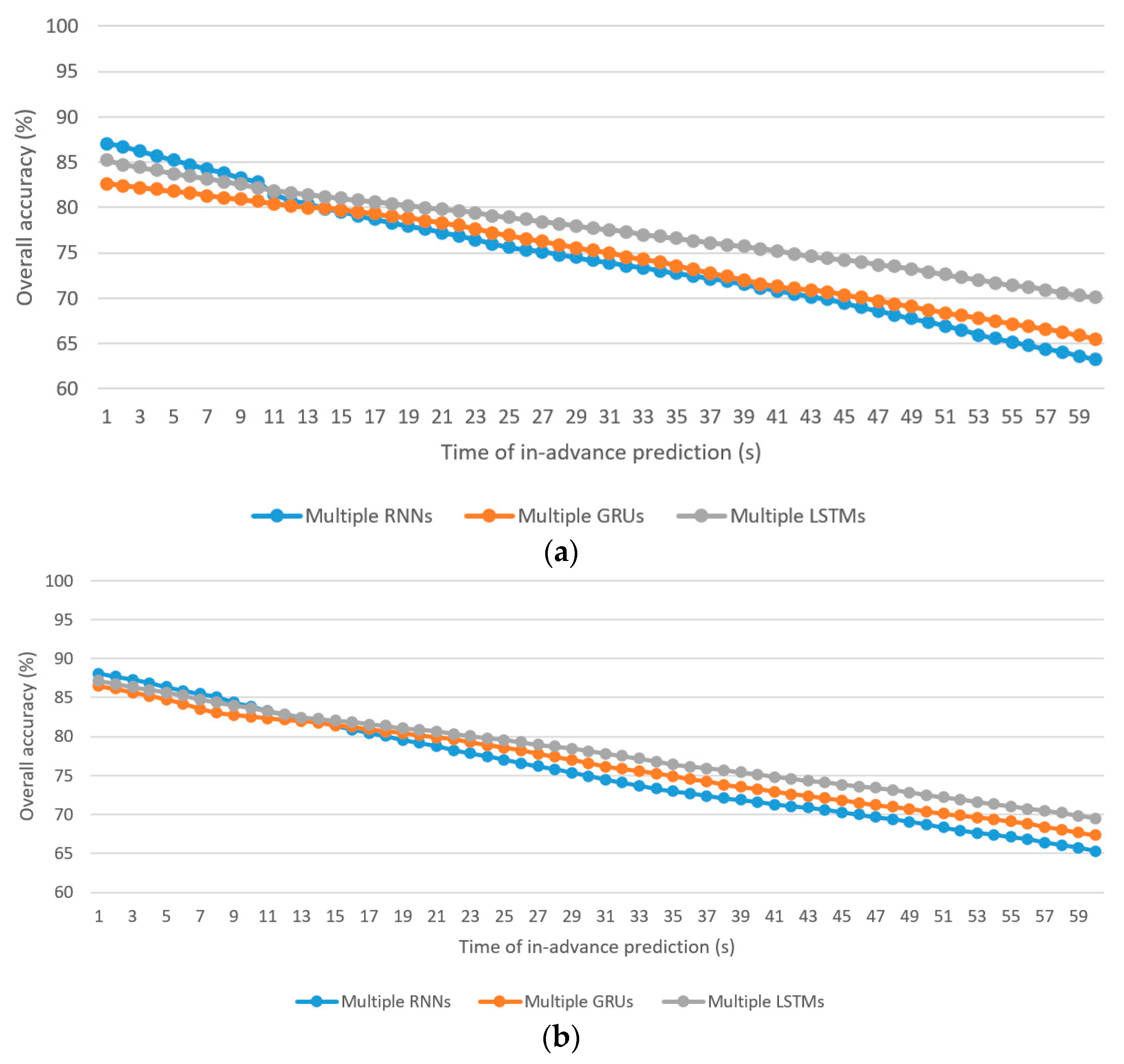
- The best using the boosting learning with multiple RNNs, GRUs, and LSTMs algorithms for driver stress prediction are 87.1%, 82.6%, and 85.2%, respectively, at 1 s in-advance prediction, whereas those for driver drowsiness prediction are 88.1%, 86.5%, and 87.2%, respectively, at 1 s in-advance prediction.
- The worst using the individual RNN, GRU, and LSTM algorithms for driver stress prediction are 63.2%, 65.5%, and 70.1%, respectively, at 60 s in-advance prediction, whereas those for driver drowsiness prediction are 65.3%, 67.3%, and 69.5%, respectively, at 60 s in-advance prediction.
- As expected, the overall accuracies (, , , and ) drop along with the increase in the time of in-advance prediction.
- For the driver stress prediction model, the average discrepancies are −2.48%, −2.57%, and −1.95% (less accurate) in the of the minority class (class 3) using multiple RNNs, GRUs, and LSTMs algorithms, respectively. For the driver drowsiness prediction model, they are (−0.42%, −0.44%, −0.48%) and (−3.01%, −2.38%, −1.98%) for minority classes, class 2, and class 3, respectively.
- Driver stress prediction: The multiple RNNs algorithm performs better in short-term prediction compared with the multiple GRUs and multiple LSTMs algorithms. In terms of , the average lead is 3.29% for 1–13 s in-advance prediction compared with the multiple GRUs algorithm. Compared with the multiple LSTMs algorithm, the average lead is 1.58% for 1–10 s in-advance prediction. The rate of deterioration of with the increase in the time of in-advance prediction is more severe in the multiple RNNs algorithm, followed by the multiple GRUs and multiple LSTMs algorithms. As a result, multiple LSTMs yield a higher result for in medium-term and long-term predictions, followed by the multiple GRUs and multiple RNNs algorithms.
- Driver drowsiness prediction: Similar to driver stress prediction, the multiple RNNs algorithm is the best for short-term prediction. The average lead in is 1.57% for 1–14 s compared with the multiple GRUs algorithm. Compared with multiple LSTMs, the average lead is 0.74% for 1–11 s in-advance prediction.
3.4. Comparison between NSGA-III Optimized RNN-GRU-LSTM Algorithm and Individual RNN, GRU, and LSTM Algorithms
3.5. Comparison between NSGA-III Optimized RNN-GRU-LSTM Algorithm and Boosting Learning of RNNs, GRUs, and LSTMs Algorithms
3.6. Comparison between NSGA-III Optimized RNN-GRU-LSTM Algorithm and Existing Works
3.6.1. In the Perspective of Driver Drowsines Prediction Model
3.6.2. In the Perspective of Driver Stress Prediction Model
3.7. Implications of the Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Rolison, J.J.; Regev, S.; Moutari, S.; Feeney, A. What are the factors that contribute to road accidents? An assessment of law enforcement views, ordinary drivers’ opinions, and road accident records. Accid. Anal. Prev. 2018, 115, 11–24. [Google Scholar] [CrossRef]
- Daniels, S.; Martensen, H.; Schoeters, A.; Van den Berghe, W.; Papadimitriou, E.; Ziakopoulos, A.; Perez, O.M. A systematic cost-benefit analysis of 29 road safety measures. Accid. Anal. Prev. 2019, 133, 105292. [Google Scholar] [CrossRef]
- Moradi, A.; Nazari, S.S.H.; Rahmani, K. Sleepiness and the risk of road traffic accidents: A systematic review and meta-analysis of previous studies. Transp. Res. Part F Traffic Psychol. Behav. 2019, 65, 620–629. [Google Scholar] [CrossRef]
- National Sleep Foundation. 2009 “Sleep in America” Poll: Summary of Findings; National Sleep Foundation: Washington, DC, USA, 2009. [Google Scholar]
- Precht, L.; Keinath, A.; Krems, J.F. Effects of driving anger on driver behavior–Results from naturalistic driving data. Transp. Res. Part F Traffic Psychol. Behav. 2017, 45, 75–92. [Google Scholar] [CrossRef]
- AAA Foundation for Traffic Safety. Prevalence of Self-Reported Aggressive Driving Behavior; AAA Foundation for Traffic Safety: Washington, DC, USA, 2016. [Google Scholar]
- Watling, C.N.; Hasan, M.M.; Larue, G.S. Sensitivity and specificity of the driver sleepiness detection methods using physiological signals: A systematic review. Accid. Anal. Prev. 2021, 150, 105900. [Google Scholar] [CrossRef] [PubMed]
- Ramzan, M.; Khan, H.U.; Awan, S.M.; Ismail, A.; Ilyas, M.; Mahmood, A. A survey on state-of-the-art drowsiness detection techniques. IEEE Access 2019, 7, 61904–61919. [Google Scholar] [CrossRef]
- Chung, W.Y.; Chong, T.W.; Lee, B.G. Methods to detect and reduce driver stress: a review. Int. J. Automot. Technol. 2019, 20, 1051–1063. [Google Scholar] [CrossRef]
- Arbabzadeh, N.; Jafari, M.; Jalayer, M.; Jiang, S.; Kharbeche, M. A hybrid approach for identifying factors affecting driver reaction time using naturalistic driving data. Transp. Res. Part C Emerg. Technol. 2019, 100, 107–124. [Google Scholar] [CrossRef]
- Chen, Y.; Lazar, M. Driving Mode Advice for Eco-driving Assistance System with Driver Reaction Delay Compensation. IEEE Trans. Circuits Syst II Express Briefs (Early Access) 2021. [Google Scholar] [CrossRef]
- Zhou, F.; Alsaid, A.; Blommer, M.; Curry, R.; Swaminathan, R.; Kochhar, D.; Lei, B. Driver fatigue transition prediction in highly automated driving using physiological features. Expert Syst. Appl. 2020, 147, 113204. [Google Scholar] [CrossRef]
- Saurav, S.; Mathur, S.; Sang, I.; Prasad, S.S.; Singh, S. Yawn Detection for Driver’s Drowsiness Prediction Using Bi-Directional LSTM with CNN Features. In Proceedings of the 11th International Conference (IHCI), Allahabad, India, 12–14 December 2019. [Google Scholar]
- Papakostas, M.; Das, K.; Abouelenien, M.; Mihalcea, R.; Burzo, M. Distracted and Drowsy Driving Modeling Using Deep Physiological Representations and Multitask Learning. Appl. Sci. 2021, 11, 88. [Google Scholar] [CrossRef]
- Lin, C.T.; Chuang, C.H.; Hung, Y.C.; Fang, C.N.; Wu, D.; Wang, Y.K. A driving performance forecasting system based on brain dynamic state analysis using 4-D convolutional neural networks. IEEE Trans. Cybern. 2020, 1–9. [Google Scholar] [CrossRef]
- Nguyen, T.; Ahn, S.; Jang, H.; Jun, S.C.; Kim, J.G. Utilization of a combined EEG/NIRS system to predict driver drowsiness. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Rastgoo, M.N.; Nakisa, B.; Maire, F.; Rakotonirainy, A.; Chandran, V. Automatic driver stress level classification using multimodal deep learning. Expert Syst. Appl. 2019, 138, 112793. [Google Scholar] [CrossRef]
- Mou, L.; Zhou, C.; Zhao, P.; Nakisa, B.; Rastgoo, M.N.; Jain, R.; Gao, W. Driver stress detection via multimodal fusion using attention-based CNN-LSTM. Expert Syst. Appl. 2021, 173, 114693. [Google Scholar] [CrossRef]
- Magana, V.C.; Munoz-Organero, M. Toward safer highways: predicting driver stress in varying conditions on habitual routes. IEEE Veh. Technol. Mag. 2017, 12, 69–76. [Google Scholar] [CrossRef]
- Alharthi, R.; Alharthi, R.; Guthier, B.; El Saddik, A. CASP: context-aware stress prediction system. Multimed. Tools Appl. 2019, 78, 9011–9031. [Google Scholar] [CrossRef]
- Bitkina, O.V.; Kim, J.; Park, J.; Park, J.; Kim, H.K. Identifying traffic context using driving stress: A longitudinal preliminary case study. Sensors 2019, 19, 2152. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Yu, X.B. An Innovative Nonintrusive Driver Assistance System for Vital Signal Monitoring. IEEE J. Biomed. Health Inform. 2014, 18, 1932–1939. [Google Scholar] [CrossRef]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. 2005, 6, 156–166. [Google Scholar] [CrossRef] [Green Version]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.H.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2003, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Terzano, M.G.; Parrino, L.; Sherieri, A.; Chervin, R.; Chokroverty, S.; Guilleminault, C.; Hirshkowitz, M.; Mahowald, M.; Moldofsky, H.; Rosa, A.; et al. Atlas, rules, and recording techniques for the scoring of cyclic alternating pattern (CAP) in human sleep. Sleep Med. 2001, 2, 537–553. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, J.; Bao, N.; Gupta, B.B.; Lv, Z. Survey on atrial fibrillation detection from a single-lead ECG wave for Internet of Medical Things. Comput. Comm. 2021, 178, 245–258. [Google Scholar] [CrossRef]
- Hesar, H.D.; Mohebbi, M. A multi rate marginalized particle extended Kalman filter for P and T wave segmentation in ECG signals. IEEE J. Biomed. Health Inform. 2018, 23, 112–122. [Google Scholar] [CrossRef] [PubMed]
- Kohler, B.U.; Hennig, C.; Orglmeister, R. The principles of software QRS detection. IEEE Eng. Med. Biol. 2002, 21, 42–57. [Google Scholar] [CrossRef]
- Chui, K.T.; Tsang, K.F.; Wu, C.K.; Hung, F.H.; Chi, H.R.; Chung, H.S.H.; Ko, K.T. Cardiovascular diseases identification using electrocardiogram health identifier based on multiple criteria decision making. Expert Syst. Appl. 2015, 42, 5684–5695. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Shahabadi, M.S.E.; Tabrizchi, H.; Rafsanjani, M.K.; Gupta, B.B.; Palmieri, F. A combination of clustering-based under-sampling with ensemble methods for solving imbalanced class problem in intelligent systems. Technol. Forecast. Soc. Chang. 2021, 169, 120796. [Google Scholar] [CrossRef]
- Soda, P. A multi-objective optimisation approach for class imbalance learning. Pattern Recognit. 2011, 44, 1801–1810. [Google Scholar] [CrossRef]
- Cai, X.; Niu, Y.; Geng, S.; Zhang, J.; Cui, Z.; Li, J.; Chen, J. An under-sampled software defect prediction method based on hybrid multi-objective cuckoo search. Concurr. Comp. Pract. Exp. 2020, 32, e5478. [Google Scholar] [CrossRef]
- Cui, Z.; Du, L.; Wang, P.; Cai, X.; Zhang, W. Malicious code detection based on CNNs and multi-objective algorithm. J. Parallel Distrib. Comput. 2019, 129, 50–58. [Google Scholar] [CrossRef]
- Chui, K.T.; Tsang, K.F.; Chi, H.R.; Ling, B.W.K.; Wu, C.K. An accurate ECG-based transportation safety drowsiness detection scheme. IEEE Trans. Ind. Informat. 2016, 12, 1438–1452. [Google Scholar] [CrossRef]
- Chen, P.C.; Hsieh, H.Y.; Su, K.W.; Sigalingging, X.K.; Chen, Y.R.; Leu, J.S. Predicting station level demand in a bike-sharing system using recurrent neural networks. IET Intell. Transp. Syst. 2020, 14, 554–561. [Google Scholar] [CrossRef]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints. IEEE Trans. Evol. Comput. 2013, 18, 577–601. [Google Scholar] [CrossRef]
- Jain, H.; Deb, K. An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part II: Handling constraints and extending to an adaptive approach. IEEE Trans. Evol. Comput. 2013, 18, 602–622. [Google Scholar] [CrossRef]
- Forough, J.; Momtazi, S. Ensemble of deep sequential models for credit card fraud detection. Appl. Soft Comp. 2021, 99, 106883. [Google Scholar] [CrossRef]
- Firdaus, M.; Bhatnagar, S.; Ekbal, A.; Bhattacharyya, P. Intent detection for spoken language understanding using a deep ensemble model. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Nanjing, China, 28–31 August 2021; pp. 629–642. [Google Scholar]
- Xiao, B.; Liu, Y.; Xiao, B. Accurate state-of-charge estimation approach for lithium-ion batteries by gated recurrent unit with ensemble optimizer. IEEE Access 2019, 7, 54192–54202. [Google Scholar] [CrossRef]
- Kotteti, C.M.M.; Dong, X.; Qian, L. Ensemble Deep Learning on Time-Series Representation of Tweets for Rumor Detection in Social Media. Appl. Sci. 2020, 10, 7541. [Google Scholar] [CrossRef]
- Wang, J. A deep learning approach for atrial fibrillation signals classification based on convolutional and modified Elman neural network. Future Gener. Comput. Syst. 2020, 102, 670–679. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Z.; Li, S. Solving time-varying system of nonlinear equations by finite-time recurrent neural networks with application to motion tracking of robot manipulators. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2210–2220. [Google Scholar] [CrossRef]
- Xu, F.; Li, Z.; Nie, Z.; Shao, H.; Guo, D. New recurrent neural network for online solution of time-dependent underdetermined linear system with bound constraint. IEEE Trans. Ind. Informat. 2019, 15, 2167–2176. [Google Scholar] [CrossRef]
- Tan, Z.; Hu, Y.; Chen, K. On the investigation of activation functions in gradient neural network for online solving linear matrix equation. Neurocomputing 2020, 413, 185–192. [Google Scholar] [CrossRef]
- Xiao, L. A finite-time convergent Zhang neural network and its application to real-time matrix square root finding. Neural Comput. Appl. 2019, 31, 793–800. [Google Scholar] [CrossRef]
- Li, W.; Wu, H.; Zhu, N.; Jiang, Y.; Tan, J.; Guo, Y. Prediction of dissolved oxygen in a fishery pond based on gated recurrent unit (GRU). Inf. Process. Agric. 2021, 8, 185–193. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- Castillo-Zúñiga, I.; Luna-Rosas, F.J.; Rodríguez-Martínez, L.C.; Muñoz-Arteaga, J.; López-Veyna, J.I.; Rodríguez-Díaz, M.A. Internet data analysis methodology for cyberterrorism vocabulary detection, combining techniques of big data analytics, NLP and semantic web. Int. J. Sem. Web Inf. Syst. 2020, 16, 69–86. [Google Scholar] [CrossRef]
- Rafati, F.; Nouhi, E.; Sabzevari, S.; Dehghan-Nayeri, N. Coping strategies of nursing students for dealing with stress in clinical setting: A qualitative study. Electron. Physician 2017, 9, 6120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spence, J.C.; Kim, Y.B.; Lamboglia, C.G.; Lindeman, C.; Mangan, A.J.; McCurdy, A.P.; Clark, M.I. Potential impact of autonomous vehicles on movement behavior: a scoping review. Am. J. Prev. Med. 2020, 58, e191–e199. [Google Scholar] [CrossRef] [PubMed]
- Fatemidokht, H.; Rafsanjani, M.K.; Gupta, B.B.; Hsu, C.H. Efficient and secure routing protocol based on artificial intelligence algorithms with UAV-assisted for vehicular Ad Hoc networks in intelligent transportation systems. IEEE Trans. Intell. Transport. Syst. 2021, 22, 4757–4769. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Lv, X.; Hou, H.; You, X.; Zhang, X.; Han, J. Distant Supervised Relation Extraction via DiSAN-2CNN on a Feature Level. Int. J. Sem. Web Inf. Syst. 2020, 16, 1–17. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep Recurrent neural network vs. support vector machine for aspect-based sentiment analysis of Arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Tanha, J.; Abdi, Y.; Samadi, N.; Razzaghi, N.; Asadpour, M. Boosting methods for multi-class imbalanced data classification: An experimental review. J. Big Data 2020, 7, 1–47. [Google Scholar] [CrossRef]
- Cheng, K.; Gao, S.; Dong, W.; Yang, X.; Wang, Q.; Yu, H. Boosting label weighted extreme learning machine for classifying multi-label imbalanced data. Neurocomputing 2020, 403, 360–370. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Classes | Sample Sizes |
|---|---|---|
| The Stress Recognition in Automobile Drivers Database [25,26] | Class 0: LSL | 40,000 |
| Class 1: MSL | 38,000 | |
| Class 2: HSL | 16,000 | |
| The Cyclic Alternating Pattern (CAP) Sleep Database [26,27] | Class 0: Normal stage | 76,000 |
| Class 1: Sleep stage 1 | 35,000 | |
| Class 2: Sleep stage 2 | 20,000 |
| Overall Accuracy | Driver Stress Prediction | Driver Drowsiness Prediction | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Minimum | Maximum | Minimum | Maximum | |||||||||
| RNN | GRU | LSTM | RNN | GRU | LSTM | RNN | GRU | LSTM | RNN | GRU | LSTM | |
| (%) | 60.9 | 63.7 | 66.8 | 83.0 | 81.3 | 82.2 | 63.6 | 65.5 | 67.5 | 84.5 | 83.1 | 83.9 |
| (%) | 61.2 | 65 | 67.7 | 83.2 | 82 | 82.8 | 63.6 | 66 | 68 | 84.9 | 83.3 | 84.2 |
| (%) | 61.3 | 63.2 | 67 | 83.6 | 81.3 | 82.4 | 64.8 | 66.2 | 68.1 | 85.3 | 83.8 | 84.6 |
| (%) | 59 | 61.6 | 64.2 | 81.3 | 79.5 | 80.2 | 61.8 | 62.7 | 64.3 | 82.5 | 81.4 | 81.8 |
| Overall Accuracy | Driver Stress Prediction | Driver Drowsiness Prediction | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Minimum | Maximum | Minimum | Maximum | |||||||||
| RNNs | GRUs | LSTMs | RNNs | GRUs | LSTMs | RNNs | GRUs | LSTMs | RNNs | GRUs | LSTMs | |
| (%) | 63.2 | 65.5 | 70.1 | 87.1 | 82.6 | 85.2 | 65.3 | 67.3 | 69.5 | 88.1 | 86.5 | 87.2 |
| (%) | 63.8 | 66 | 70.3 | 87.5 | 83.3 | 85.5 | 66.1 | 68 | 71 | 88.8 | 87 | 87.7 |
| (%) | 63.5 | 65.7 | 70.5 | 87.3 | 82.6 | 85.6 | 65 | 67 | 69 | 87.7 | 86.2 | 87 |
| (%) | 61.2 | 63.6 | 68.6 | 85.4 | 80.8 | 83.6 | 62.8 | 65.4 | 68.1 | 85.9 | 84.8 | 85.4 |
| Driver Stress Prediction | Driver Drowsiness Prediction | |||||
|---|---|---|---|---|---|---|
| RNN | GRU | LSTM | RNN | GRU | LSTM | |
| Improvement (%) | 11.2 | 13.6 | 12.3 | 10.2 | 12.2 | 11.2 |
| Driver Stress Prediction | Driver Drowsiness Prediction | |||||
|---|---|---|---|---|---|---|
| RNN | GRU | LSTM | RNN | GRU | LSTM | |
| Improvement (%) | 6.9 | 12.7 | 9.3 | 6.9 | 8.9 | 8.0 |
| Work | Nature of Dataset | Dataset | Features | Methodology | Time of In-Advance Prediction (s) | Cross-Validation | Results |
|---|---|---|---|---|---|---|---|
| [14] | Simulated | 20 participants; 10,303 samples | The percentage of time of the eyelids closure | NLAEN | 13.8–16.4 | No | Recall = 96.1%; Precision = 98.6% |
| [15] | Simulated | 18 participants; 731 drowsy and 496 normal samples | CNN extracts features from images | CNN; LSTM | 3–5 | No | Accuracy = 95% |
| [16] | Simulated | 45 participants; unspecified samples | blood volume pulse; skin temperature; skin conductance; respiration | CNN; LSTM | 8 | 5-fold | Recall = 82%; Specificity = 71%; Sensitivity = 93% |
| [17] | Simulated | 37 participants; 4680 samples | 2-D spatial information, temporal, and frequency of the EEG signal | 4-D CNN | 6 | Leave-one-subject-out | Error rate = 0.283 |
| [18] | Simulated | 11 participants; 120 samples | Image; EEG; HRV; EOG | FLDA | 5 | No | Accuracy = 79.2% |
| Proposed | Real-world | 108 participants; 76,000 normal samples, 35,000 sleep stage 1 samples, and 20,000 sleep stage 2 samples | ECG | NSGA-III optimized RNN-GRU-LSTM algorithm | 1–60 | 10-fold | Accuracy = 75.3–94.2% |
| Work | Nature of Dataset | Dataset | Features | Methodology | Time of In-Advance Prediction (s) | Cross-Validation | Results |
|---|---|---|---|---|---|---|---|
| [19] | Simulated | 27 participants; 20,160 samples | Contextual data; vehicle data; ECG | CNN; LSTM | 5 | No | Accuracy = 92.8% |
| [20] | Simulated | 27 participants; 20,160 samples | Environmental data; vehicle dynamics; eye data | CNN; LSTM; self-attention mechanism | 5 | 10-fold | Accuracy = 95.5% |
| [21] | Simulated | 3 participants; 150 normal samples and 150 stressed samples | HRV; speed and intensity of turning of vehicle | DBN | 60 | 10-fold | Specificity = 62.7–83.6%; Sensitivity = 61.7–82.3% |
| [22] | Simulated | 5 participants; unspecified samples | HRV; weather | NB | 30 | 10-fold | Accuracy = 78.3% |
| [23] | Real-world | 1 participant; 64 low stress samples and 75 high stress samples | Accelerometer; EDA; PPG | LR | 60 | 10-fold | Specificity = 86.7%; Sensitivity = 60.9% |
| Proposed | Real-world | 18 participants; 40,000 LSL samples, 38,000 MSL samples, 16,000 HSL samples | ECG | NSGA-III optimized RNN-GRU-LSTM algorithm | 1–60 | 10-fold | Accuracy = 71.2–93.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chui, K.T.; Gupta, B.B.; Liu, R.W.; Zhang, X.; Vasant, P.; Thomas, J.J. Extended-Range Prediction Model Using NSGA-III Optimized RNN-GRU-LSTM for Driver Stress and Drowsiness. Sensors 2021, 21, 6412. https://doi.org/10.3390/s21196412
Chui KT, Gupta BB, Liu RW, Zhang X, Vasant P, Thomas JJ. Extended-Range Prediction Model Using NSGA-III Optimized RNN-GRU-LSTM for Driver Stress and Drowsiness. Sensors. 2021; 21(19):6412. https://doi.org/10.3390/s21196412
Chicago/Turabian StyleChui, Kwok Tai, Brij B. Gupta, Ryan Wen Liu, Xinyu Zhang, Pandian Vasant, and J. Joshua Thomas. 2021. "Extended-Range Prediction Model Using NSGA-III Optimized RNN-GRU-LSTM for Driver Stress and Drowsiness" Sensors 21, no. 19: 6412. https://doi.org/10.3390/s21196412
APA StyleChui, K. T., Gupta, B. B., Liu, R. W., Zhang, X., Vasant, P., & Thomas, J. J. (2021). Extended-Range Prediction Model Using NSGA-III Optimized RNN-GRU-LSTM for Driver Stress and Drowsiness. Sensors, 21(19), 6412. https://doi.org/10.3390/s21196412