5.1. System Model
We define a smart home, S, as a 6-tuple where:
represents the physical space which the residents inhabit. Formally, , where , and represents a zone, e.g., a room or a specific space, located within the curtilage of the house, where activities of daily living (cooking, eating, showering, etc.) are performed. Here, we assume the existence of a set of unique locations, , where the nodes in N can reside.
is a set of physical components that enable the smart home. Effectively,
, where
C: connected devices,
M: mobile devices, and
B: backends. For
C, this represents network-connected devices such as wireless cameras and home appliances such as Internet-enabled washing machines. For
M, this typically represents smartphones (e.g., iPhone or Android) which are used for remotely controlling and managing
C. For
B, this is typically a cloud data center, but it can also be an edge device such as a dedicated home server. While
C are located inside
H, both
B and
M can be located outside
H. Here, we assume that there are a finite set
of capabilities, a binary relation
, where
means that node
n implements capability
, and a mapping function
. The
for
C were summarized earlier in
Table 1.
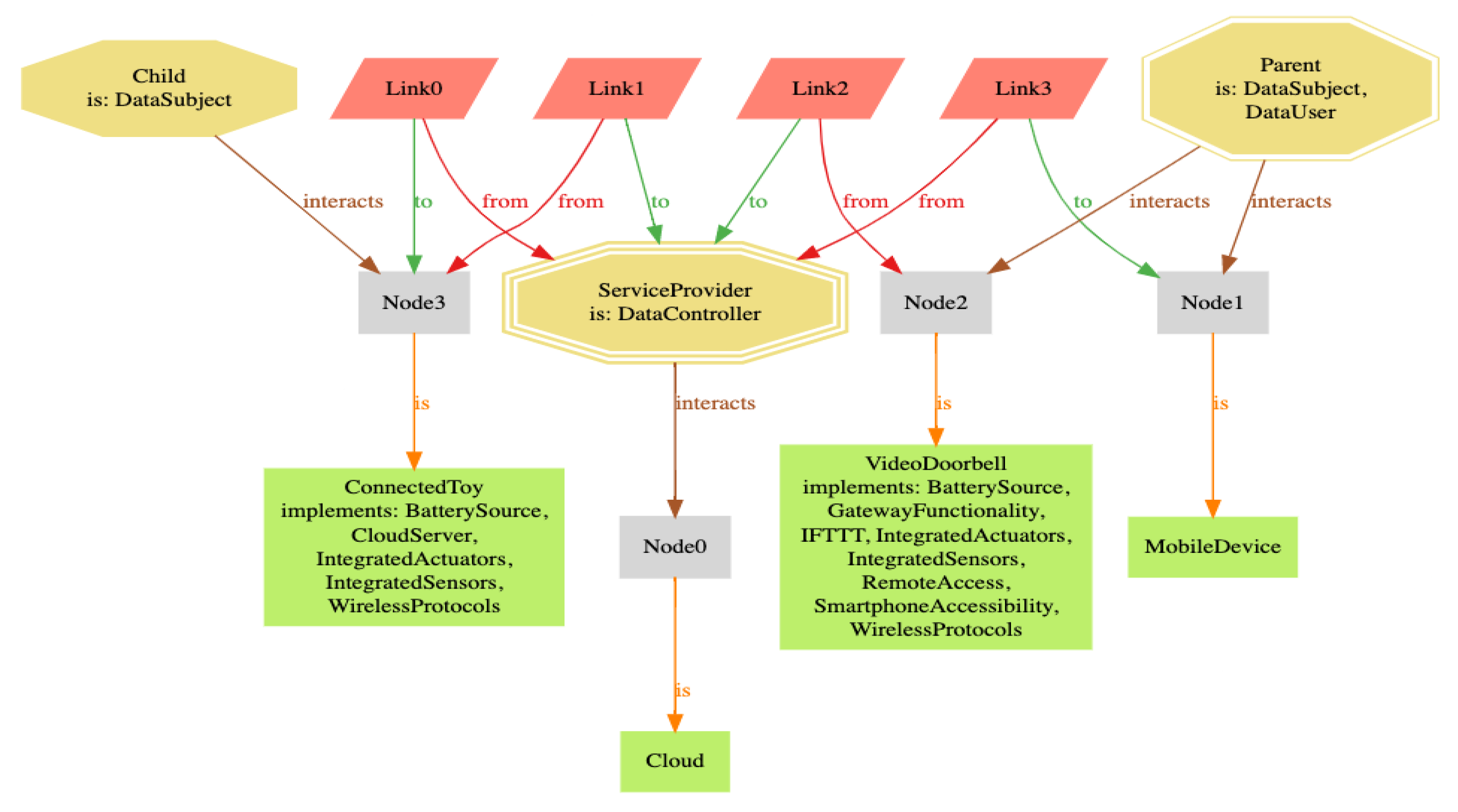
is a set of human entities interacting with the smart home. A user may interact directly with N or indirectly through services (e.g., applications) which are incorporated in N. Here, we assume that there are a set R of roles , and a ternary relation , where means that user u has a role r with respect to node n.
is a set of communication channels, i.e., physical or logical channels, interconnecting N and U, and over which D are transferred. Effectively, representing the set of data flows. Here, we assume that channels are unidirectional.
is a set of data items being collected and processed by N. Here, we assume that D is represented as a set of tuples , with the values of each attribute, except for , being metadata, and where:
- –
,
data item, representing the specific attributes that
N is collects or processes. This ranges from a specific data item, e.g., name, to more generic data types, e.g., biometric data, depending on
N [
62]. An overview of data types collected by
C is displayed in
Table 3.
- –
, data subject, representing the entity, whose data are being collected or processed. This can have possible values with: indicating that the entity represents U and indicating that the entity represents N.
- –
, data processing purpose, representing the purpose, e.g., for uniquely identifying a person, for collecting or processing .
- –
, data retention time, representing the general condition for storing with possible values with indicating there is no time constraint for the deletion of the data; indicating that the data has to be deleted after the completion of the corresponding purpose, i.e., after is attained; and indicating the actual date/time for the deletion of .
- –
, explicit identifier, is a Boolean indicating whether explicitly identifies the identity (social security number, voice, MAC address, etc.) of .
- –
, data control, representing a set of tuples () where represents a privacy-enhancing technology with possible values , and indicates the data lifecycle phase, with possible values , over which the is implemented.
is a set of rules describing the smart home configuration and operation. Based on the trigger-action programming paradigm, and similarly to the IFTTT pattern extension proposed by Nacci et al. [
63], we represent a rule as the pair–trigger and action. Trigger represents the condition, such as location, time, arrival of a specific person, or a particular property of
S, e.g.,
, for the rule to be activated. Action represents updates or invocation on the data done as a consequence of receiving a corresponding trigger. Rules can be formalized using Extended Backus–Naur form [
64] as follows:
Rule = “(“ Trigger Action ”)”.
Trigger = AtomicFormula | “(“ BinaryLogicalOp Trigger Trigger ”)”.
AtomicFormula = “(“ BinaryTermOp Parameter ”)”.
Action = “(“ Read | Write | Relay ”)”.
Read = “read” Node ParameterName [Link] | User ParameterName [Link].
Write = “write” Node Parameter [Link].
Relay = “relay” Parameter Node [Link].
BinaryLogicalOp = “AND” | “OR”.
BinaryTermOp = “=” | “!=” | “>” | “>=” | “<” | “=<”.
Parameter = ParameterName ParameterValue.
ParameterName = “:” String.
ParameterValue = “?” String.
In the grammar above, we define three actions–, , and , that transmit data between U and N. The action extracts or queries a parameter from U or N. The action stores a parameter inside N. The action forwards a parameter to a destination N. Each specified action takes an optional parameter, an instance of L, indicating the communication channel over which a parameter is read or sent to. In practice, the value of a parameter, represented as in the formal grammar, could represent concrete instances of data such as media data (e.g., video), numeral data (e.g., timestamps), and binary states (e.g., online/offline).
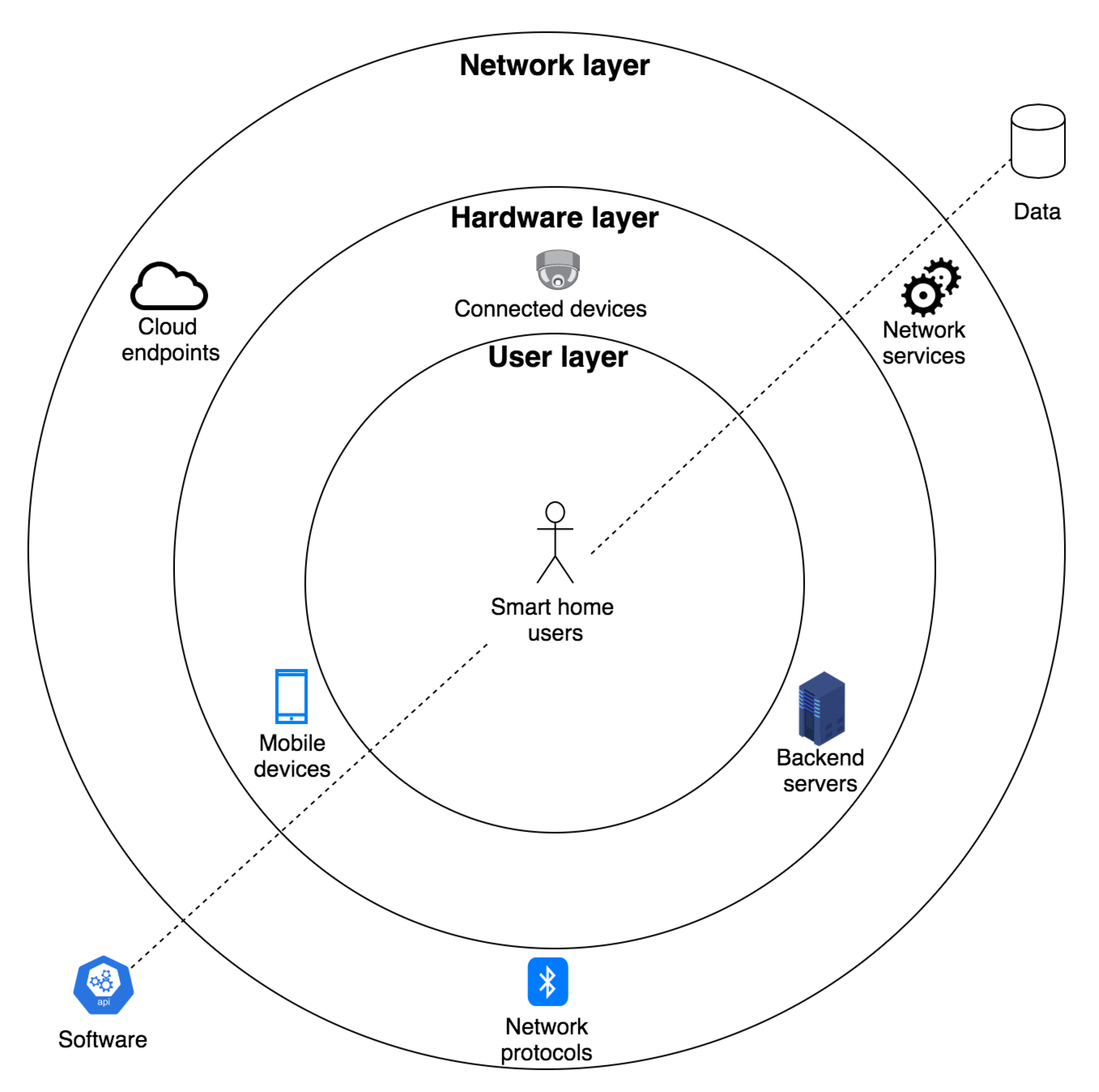
In
Figure 3, we graphically illustrate the smart home system model formalization. Effectively, the attributes of
S can be mapped to the architecture layers described in
Section 2 as follows:
N→ hardware layer,
L→ network layer, and
U→ user layer. Moreover, as discussed in
Section 2, we assume that
D is pervasive across the different architecture layers. As shown in
Section 6, we encoded the system model using Alloy [
65], a declarative formal specification language.
Definition 1 (
Data flow)
. We define a data flow as where i specifies the data sender or subject and r the data recipient, and and . Each data flow carries data items . Technically, how data flows and are interrelated in terms of data transformations are specified in P.
Definition 2 (
Data context)
. We define a data context as , consisting of a non-empty set of data flows. Effectively, represents the permissible data flows for use in a particular setting. We assume that S has a set of valid contexts, = specified by the homeowner.
For privacy risk analysis, we assume that the data contexts have been identified and labeled according to their type and sensitivity. This would allow for instance differentiating between sharing health data from a smartwatch to a doctor (e.g., represented as ) versus sharing health data with another entity, e.g., to the smart meter provider. The latter data context may be considered inappropriate by the data subject, whereas the former data context is appropriate. Identifying the data contexts is core to the CI theory of privacy.
5.2. Threat Model
Given
S, we can identify the set of possible privacy threats,
T, that can result in a privacy violation. This can be done for instance by having
S specified in a property specification language and then analyzed through a model checker [
66].
We assume that there is a global set of vulnerabilities,
V for
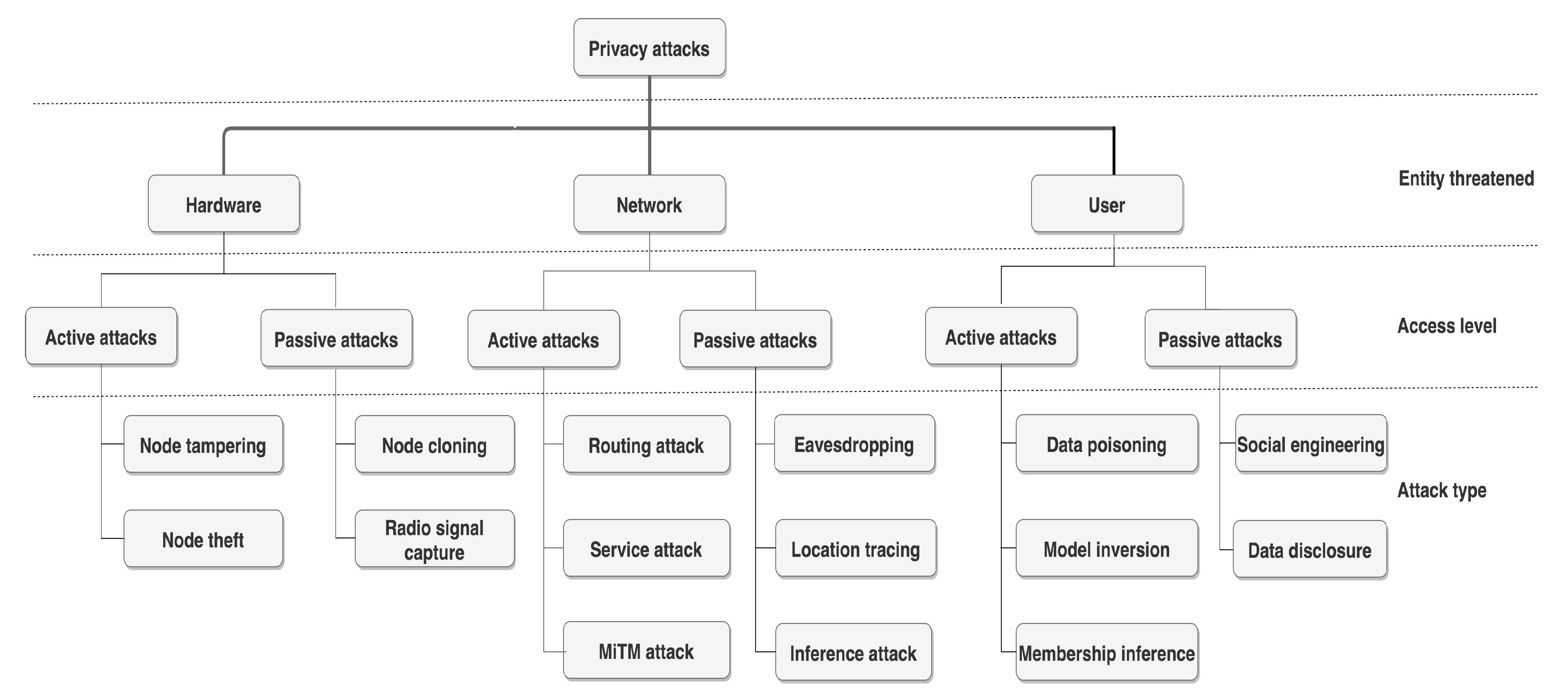
T. An attack exploits a set of vulnerabilities and when it is successful it results in the creation of a corresponding threat(s). Attacks targeting the smart home were established earlier and grouped in a taxonomy in
Section 3. In relation to the taxonomy, we assume the existence of a function,
query-taxonomy(c,al), that returns a set of attack types (e.g., service attack) from the taxonomy given
c representing the entity threatened (e.g., the network) and
representing the access level (e.g., active). We assume that
is an optional parameter.
Each
has a set of exploitability-relevant parameters,
, where
indicating the attack success likelihood (
) and attack impact (
), respectively. These are calculated through the privacy metrics described in
Section 5.3. In practice, data regarding these scores can be obtained from risk assessment studies, and using open repositories of vulnerabilities such as the Vulnerability Scoring System (CVSS) [
67] or the National Vulnerability Database (NVD) [
68].
Definition 3 (
Attack tree)
. Using the attack tree formalization proposed by Ge et al. [57] we define an attack tree, , as a 5-tuple . Here, X is a set of components which are the leaves of and Y is a set of gates which are the inner nodes of . We require and . Let denote the power set of Z. The function describes the children of each inner node in (we assume there are no cycles). The function describes the type of each gate. In Algorithm 1, we document how the threat model is created from
S. The algorithm assumes the existence of a helper function,
build-attack-tree(attack-goal, root, attack-types), that generates an
using
attack-goal as the goal of the attack,
acting as a unique name for the
root node, and
attack-types representing children nodes; and a function
that appends a subtree
to
and thus expanding
with new attack paths. Finally, we assume that the vulnerabilities of
N,
U, and
L are combined using logical
and
gates; and that the leaf nodes of
are the identified vulnerabilities. In Algorithm 1, line 7 and 8 refer to the computation of the attack success likelihood and attack impact, respectively. While the attack impact can be calculated automatically through
, as shown in line 8, it can be adjusted considering the parameters indicated in line 10. Details about these metrics are discussed in
Section 5.3.
| Algorithm 1 Computation of attack metrics for each vulnerability. |
| | Input: S:smart home, :data context set, :attack goal, :access level
|
| | Output: :attack tree
|
| 1: | |
| 2: |
) in S do |
| 3: |
Ψi,al) |
| 4: |
Ψi,attack_type.Ψi) |
| 5: |
|
| 6: |
|
| 7: |
p(discoverability) × p(reproducability) × p(exploitability) |
| 8: |
DecisionSupportSystem(P,D,SC) |
| 9: | if user-override then |
| 10: |
Norm(affected users × damage potential) |
| 11: | end if |
| 12: |
end for |
| 13: |
join(at, subtree_at.Ψi)
|
| 14: | end if |
| 15: | return at |
| 16: | end if |
Threat agent. A threat agent,
, is a person (or a group of persons) who originates attacks to achieve a goal related to the system under attack [
69]. Each
owns different skills and capabilities to achieve its objectives. Nonetheless, this is done by exploiting vulnerabilities in
S typically as a result of conducting attacks as identified in
Section 3. These vulnerabilities would allow
access to data being transmitted along
L, reading data directly from
N when stored or being processed, and obtaining it data directly from
U. Hereunder, we identify instances of malicious external threat agents targeting the smart home ordered according to their respective offensive capabilities [
70,
71,
72,
73].
Hackers. Malicious individuals, script kiddies, and employees of an organization who may be disgruntled, nosy, or whistle-blowers. This agent is typically moved by curiosity to experiment and try things out. An example of an attack conducted by a hacker is a social engineering attack (
Section 3, item 14).
Thieves. Individuals that are associated with stealing mostly for personal financial gain. This agent type is typically moved by a monetary gain, acquisition of knowledge, peer recognition, and related. An example of an attack conducted by a thieve is node theft (
Section 3, item 2).
Hacktivists. Individuals that mainly pursue a political or social agenda often related to human rights and freedom of information. Typically, hacktivists target specific organizations or industries. An example of an attack conducted by a hacktivist is a service attack (
Section 3, item 6).
Competitors and organized crime. Private criminal organizations and commercial competitors (industrial spies) that compete for revenues or resources (e.g., acquisitions). Competitors and organized crime are most likely moved by financial gains and in part by terrorism motives. An example of an attack conducted by competitors and organized crime is a routing attack (
Section 3, item 5).
Nation states. Enemy state attackers are groups of highly sophisticated individuals that are well-funded by governments and associated with a military unit. Nation states may target the home of individuals as part of digital surveillance programs and cyberespionage campaigns. An example of an attack conducted by a nation state is eavesdropping (
Section 3, item 8).
Using Rocchetto et al. [
74] work on the formal extensions to the Dolev-Yao attacker model for cyber-physical systems, we can represent the actions and rules followed by,
, and thus also the connection between
and
S as:
where:
attacker-property represents a property of
, e.g., access type (in-person, remote, in-network) with respect to
S;
system-property represents a physical or logical property of
S, e.g., connected device status (on, off);
is the action to be performed on
S, e.g., reading data from
N; and
action-result is the result of the
performed (e.g., user’s data obtained). The
attacker-property and
system-property act as preconditions to perform
. Properties can also be further combined using Horn clauses [
74]. In practice, the success of executing an action depends on the
threat agent’s power.
Threat agent power. Threat agents can exploit vulnerabilities in
S and perform different actions. We assume the threat agent power,
, to be a value, [0,1]. This value represents the agent’s overall familiarity with
S and its offensive capabilities. A high value of
, e.g.,
, is indicative of
possessing advanced knowledge of
S, e.g., in terms of the devices used, home network configuration, and residence routines, and having advanced offensive capabilities, e.g., in terms of tools (hardware and software) and skills (e.g., technical expertise in exploiting protocols, hardware, and security services), whereas a low value of
, e.g.,
, indicates the contrary. In practice,
, can also factor in other attributes, for example, the available time and monetary resources of
for performing an attack. While we assume an aggregate value for
, different attack attributes can be combined, for instance using multi-attribute utility theory [
75]. Nonetheless, a high
can be associated with nation states and competitors and organized crime, and in general a low
to hackers, thieves, and hacktivists.
5.3. Privacy Metrics
The privacy metrics help us measure the privacy risk, i.e., the risk to the data subject after an attack is performed on S. Accordingly, we develop three metrics–attack success likelihood, attack impact, and risk score, described as follows.
Attack success likelihood. This metric determines the probability of to successfully compromise a target to achieve an attack goal and thus obtain access to the data of a data subject. We assume the attack success likelihood, , to be a value, . Here, a low value of , e.g., , is indicative that it is difficult and unlikely (rare) for to access a component whereas a high value, e.g., , indicates the contrary, i.e., it is likely.
In order to populate
for the entire attack tree, we can use the aggregation rule defined by Equation (
1).
Based on the DREAD risk assessment model [
60], we adopt the risk categories of discoverability (e.g., determining how likely are the attackers to discover the vulnerability), exploitability (e.g., determining how much work is needed to implement the attack), and reproducibility (e.g., determining how reliable is the attack), for calculating
of a privacy attack. These parameters are combined as conditional probabilities in Algorithm 1. Guidelines for determining the probabilistic score for each parameter are found in
Table 4.
Some of the capabilities of N can also affect . For instance, if N implements remote access it is more likely that this allows a easier access to N. Similarly, the more capabilities N supports, the more likely it is that N is exposed to more vulnerabilities. For instance, if N implements API, IFTTT, web browser accessibility, and smartphone accessibility, this is likely to increase the discoverability of potential attacks as the attack surface of S is widened.
It is also possible to positively correlate
to
. Thus, we can evolve
into
to factor in
. In this way,
becomes jointly dependent on
S and
properties. Through
we can more realistically compute risk scenarios based on dynamic threat agent behavior (e.g., including increasing attacker resources). Using Item Response Theory [
76,
77,
78] we can combine the relation between
and
in a logistic function as follows:
Using Equation (
2) we can represent scenarios where, for example, if an attack is more difficult, the
will be lower assuming
stays the same.
Attack impact. This metric determines the potential loss to the privacy of a data subject caused when manages to successfully achieve the corresponding attack goal. We assume the attack impact, , to be a value, . Effectively, this equates to the maximum potential harm caused to the data subject when successfully compromises a target. Here, a low value, e.g., , indicates that the impact is almost negligible, whereas a high value, e.g., , is indicative that the impact is major.
In determining
, we base it on the calculation of the level of identification of the data subject and data context sensitivity. Formally, we assume the existence of a decision matrix,
, for calculating the privacy impact with
representing the
identification level and
representing the
data context sensitivity. We also assume a corresponding
lookup function,
:
, for
. While we assume that
is associated with a single data subject rather than the collective dimension—as is the typical case when conducting privacy risk analysis [
79]—we also indicate how
can be tuned for impact that affects a group of users, e.g., the entire family.
Identification level. The identification level,
, determines the extent to which a data subject can be identified from a data flow. Identification of a data subject can occur by having explicit identifiers declared in the data flow (i.e., in the corresponding
attributes), or otherwise by having quasi-identifiers that can help identify a data subject indirectly with sufficient background knowledge. Some examples of possible identifiers that can used to identify a person are: email addresses, device identifiers (e.g., MAC addresses and serial numbers), biometric identifiers, and more [
80]. We assume that,
, to be a value,
. Here, a low value indicates that explicit identity is not part of the data flow and quasi-identifying information in the data flow is unlikely to reidentify a data subject, whereas a higher value indicates the contrary and thus a possibility that reidentification of the data subject is possible. In determining whether identification data are present in a data flow, the
attribute of the corresponding data items (
) of a data flow can be inspected.
Data context sensitivity. The data context sensitivity,
, identifies the violation to privacy as perceived by the data subject in a specific context. We assume that,
, to be a value,
. Concurring with the CI theory of privacy [
81] we associate
to the intended use of the collected data. Thus, this value equates to the whole context of the data flow, instead of the individual data element. Here, a low value, indicates that the data are being used/processed in a context that is assessed by the data subject as involving a low impact (e.g., sharing energy profile of the home with the smart grid supplier), whereas a high value indicates the contrary and thus data are being used in a critical context (e.g., sharing medical data with a healthcare provider) implying that the user privacy can be at stake depending on
. The data context sensitivity may also depend on the location where a node is installed (e.g., the bathroom might be considered a more sensitive context than the kitchen room). Here, we assume the existence of an oracle that can identify the current context of a data flow, and by inspecting the smart home policy (
P) can determine whether the data flow respects the designated context or not.
Lookup function. The impact is determined by
using
Table 5 as
. In practice,
Table 5 serves as guidance and the data subject can adjust the particular weights according to their own judgement. A similar approach is followed by EPIC [
43] for building the privacy likelihood matrix. However, we also include additional suggestions to further refine the output produced by
and thus the final score for
. Based on the DREAD model [
60] we include damage potential (e.g., determining how much the attack costs to the family) and affected users (e.g., determining how many people are impacted by the attack) as potential impact factors for
. The mentioned risk factors and
were integrated earlier Algorithm 1. In Algorithm 1, the
is effectively the implementation of the lookup function and decision matrix.
For damage potential, we associate this to the monetary loss, psychological, and potentially safety harms caused by an attack, and grade this using an ordinal scale (0–5). We assume that a higher value of damage potential is associated also as to when there are vulnerable data subjects involved. Some examples of vulnerable data subjects are children, employees, and people needing special protection [
82]. The damage potential can also be calculated based on the data items (
that
N collects and processes, and the data subjects (
) corresponding to those. Leaking certain
can cause a direct threat to user privacy, for example, by revealing patterns of social life, behaviors and actions, the state of one’s body and mind, etc. [
83]. Arguably, the more of these aspects that are affected, the more likely it is for an increased damage potential. Nonetheless, if there are data controls (
) set across the different data lifecycle phases of
S then the damage potential is likely to become lower than when not set.
For affected users, we assume that this represents whether the leaked data affects one individual to multiple users, e.g., the entire family, and grade this using an ordinal scale (1–3). The affected users is also related to the smart home backend (i.e., B). For instance, if B is a cloud backend, then it is more likely that a group (2) is affected. It can also be argued that if a node (N) implements gateway functionality as a capability then arguably more users, e.g., the entire family, could be affected in case N is compromised.
In
Table 6, we display the risk factors associated with
. These factors are combined using multiplication, and thus
=
Norm(damage potential × affected users), with
being a function that normalizes the output into the range of [1–10].
In order to populate
for the entire attack tree, we can use the aggregation rule defined by Equation (
3).
Risk score. Following a common approach in computer security, we compute the privacy violation risk as the combination of likelihood of occurrence of a privacy violation and its impact. Specifically, by multiplying
with
, we come up with a quantitative score (
) representing the risk level of a smart home component. This value is indicative of the priorities that should be invested in making the smart home secure against the discovered vulnerabilities. Scores range from 0 to 10, with 10 being the most severe. In
Table 7, we provide guidelines on how the risk scores can be described.
In order to populate
for the entire attack tree, we can use Equation (
4).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}