
Dynamic Hand Gesture Recognition in In-Vehicle Environment Based on FMCW Radar and Transformer

 ,
,
Abstract
:1. Introduction
- (1)
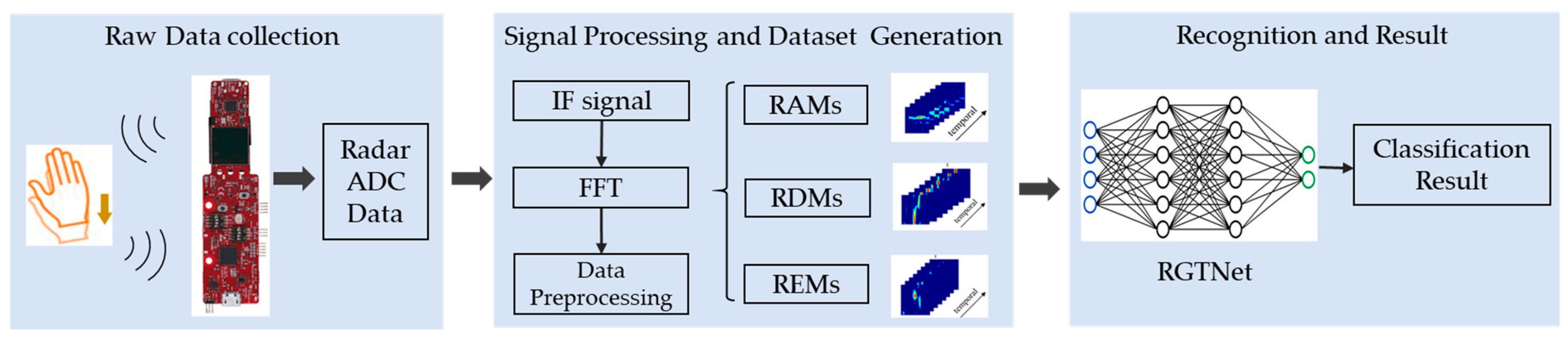
- We collected and made a gesture recognition dataset based on MMW radar in an in-vehicle environment. Based on the FMCW radar, we carried out gesture acquisition under actual driving conditions. By radar signal processing, we converted the original continuous IF signals into time-sequenced RDMs, RAMs, and REMs. Then we preprocessed the radar feature maps through ROI extraction, vibration removal algorithm, background removal algorithm and standardization to obtain cleaner data. Finally, we obtained a total of 5318 samples containing eight types of gestures. Each sample contains eight continuous frames of the processed RDMs, RAMs, and REMs.
- (2)
- We propose a transformer-based network architecture for radar gesture recognition, RGTNet. The spatial feature extraction and spatial feature fusion modules are designed to embed the input of the time-sequenced radar feature maps. We take the temporal information between frames into account by positional encoding. A transformer encoder based on VIT [32] is used to extract the deep temporal feature associations between different frames. Finally, the probability prediction is completed by the fully connected layer and softmax operation.
- (3)
- The experimental results show that our proposed method can better extract radar spatial-temporal features and get a high level of accuracy.
2. Dataset Production
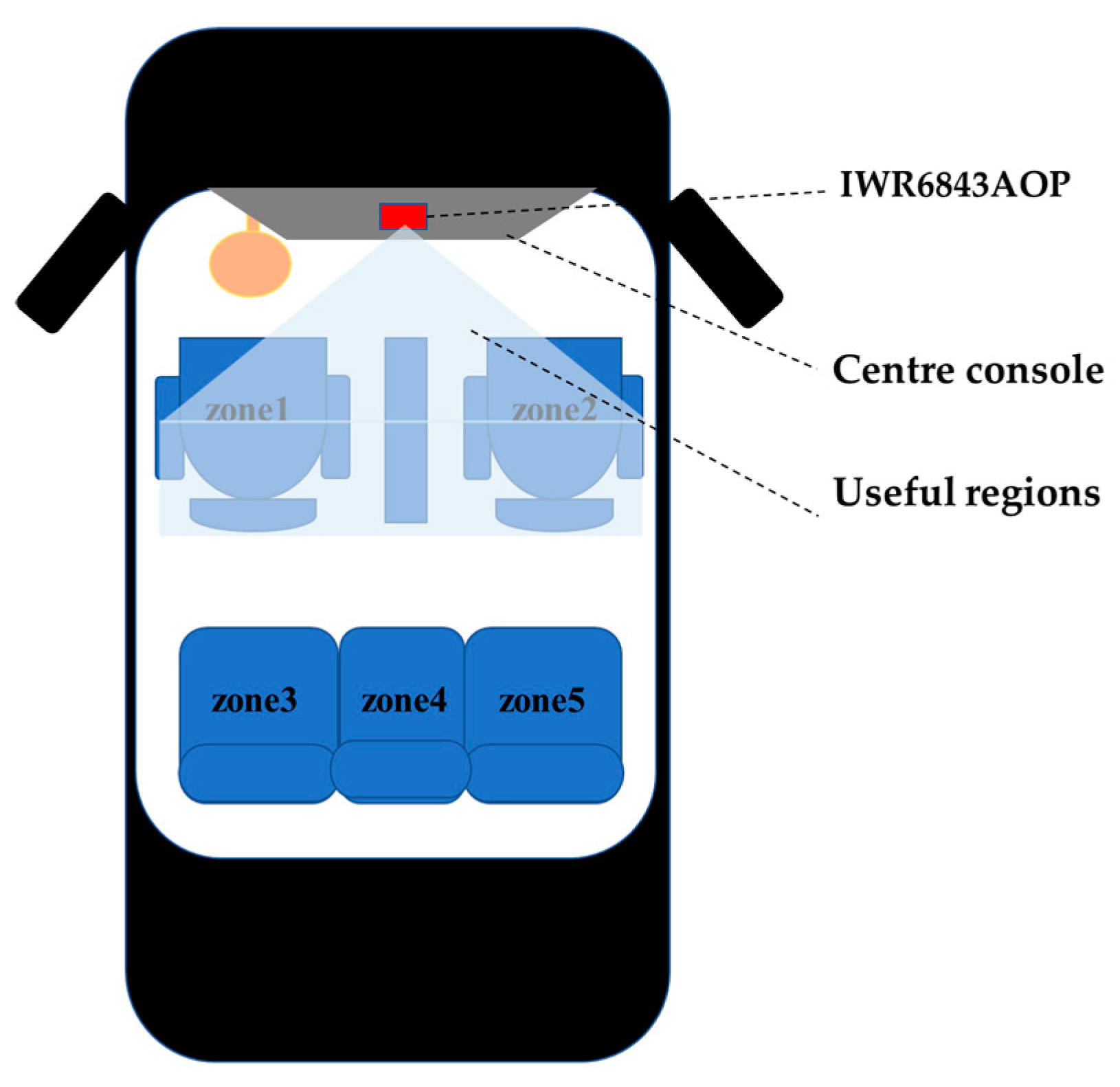
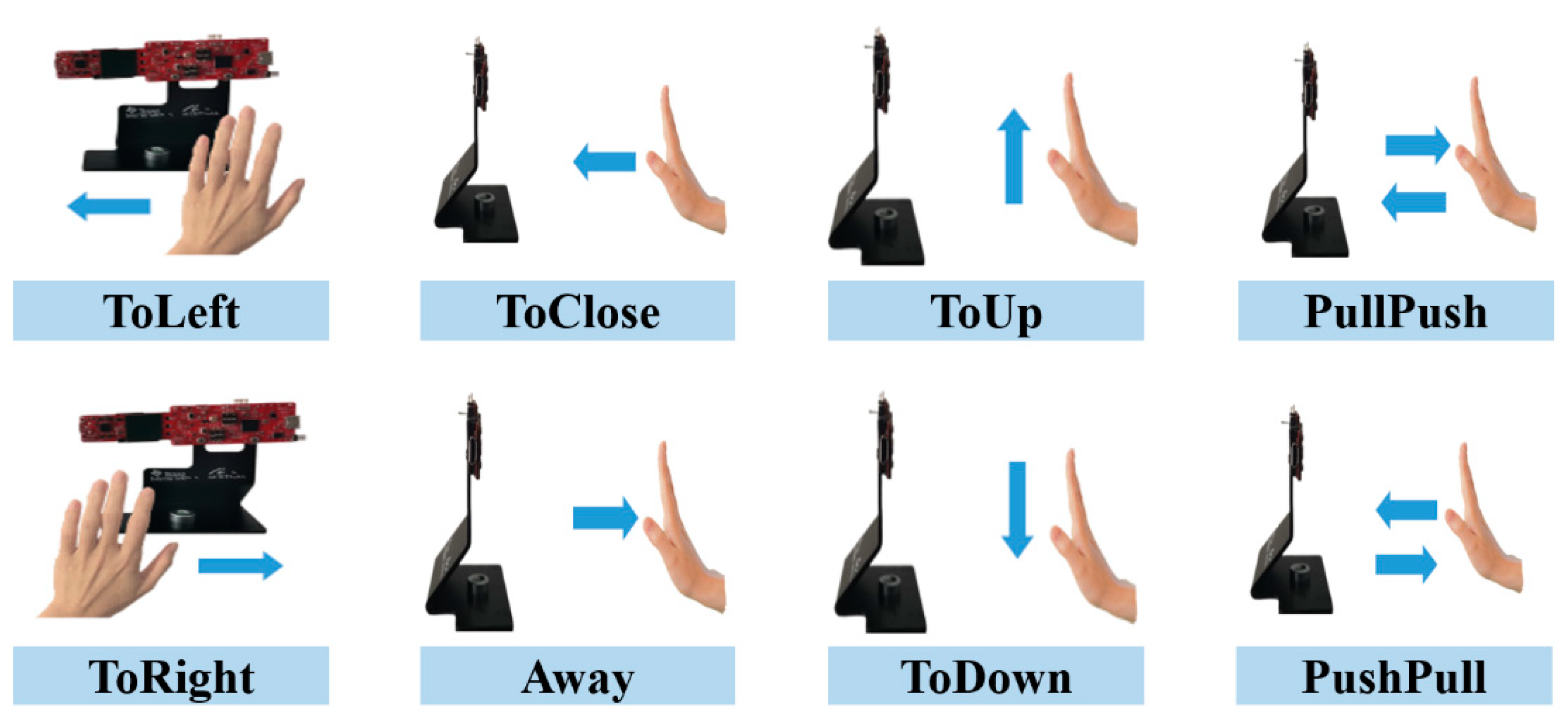
2.1. Experimental Equipment and Data Acquisition
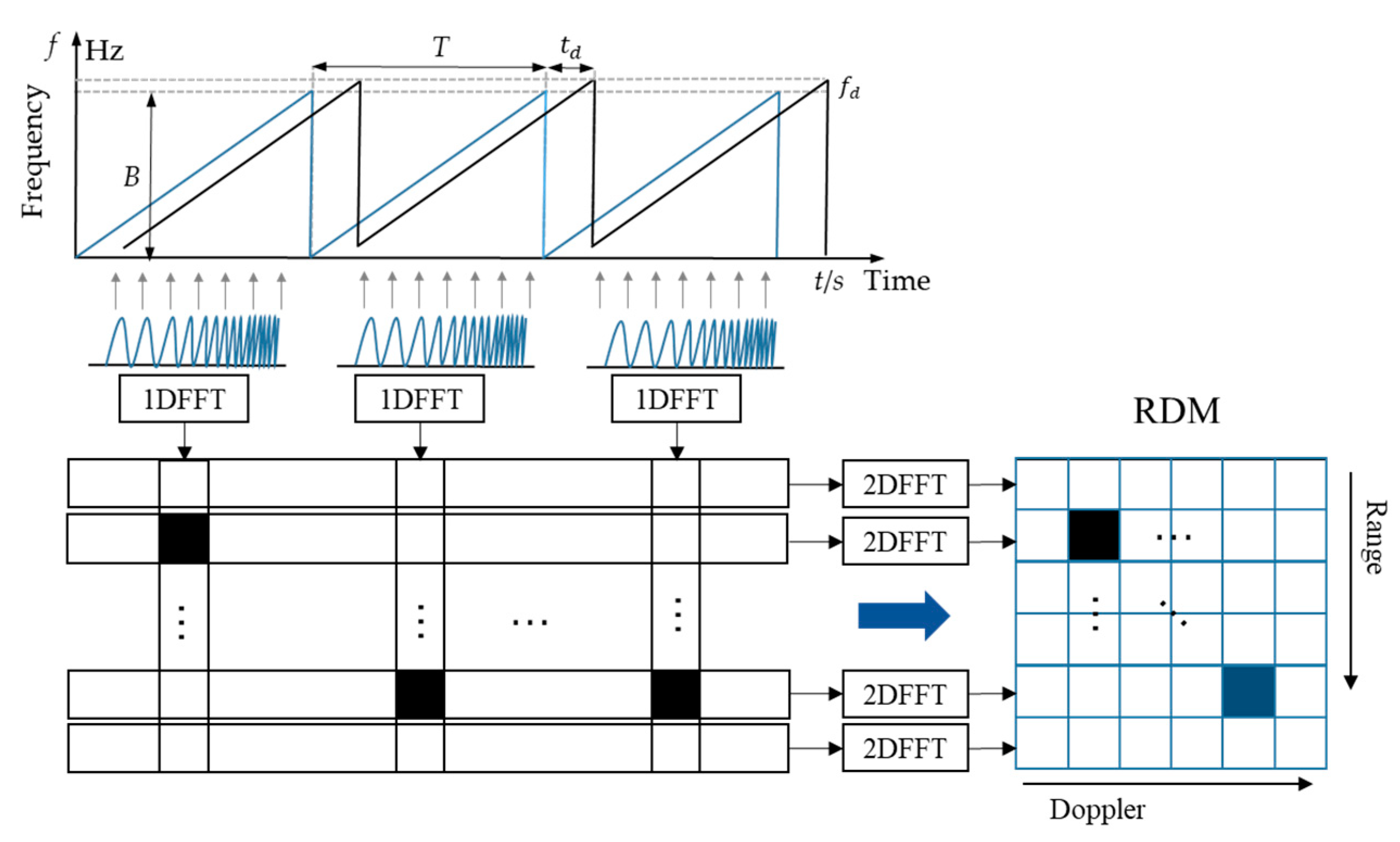
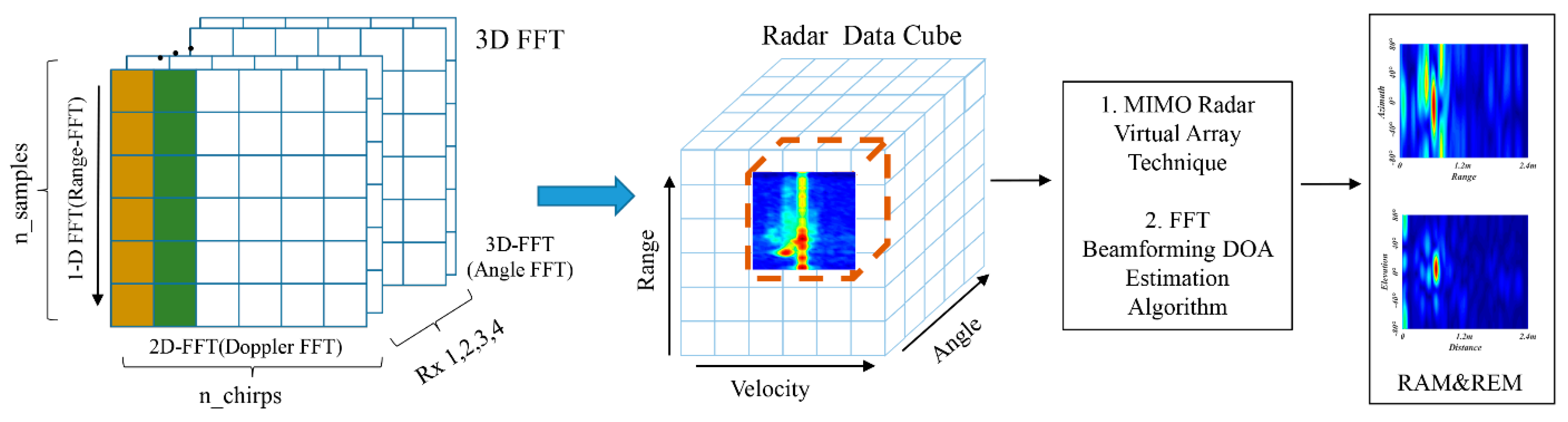
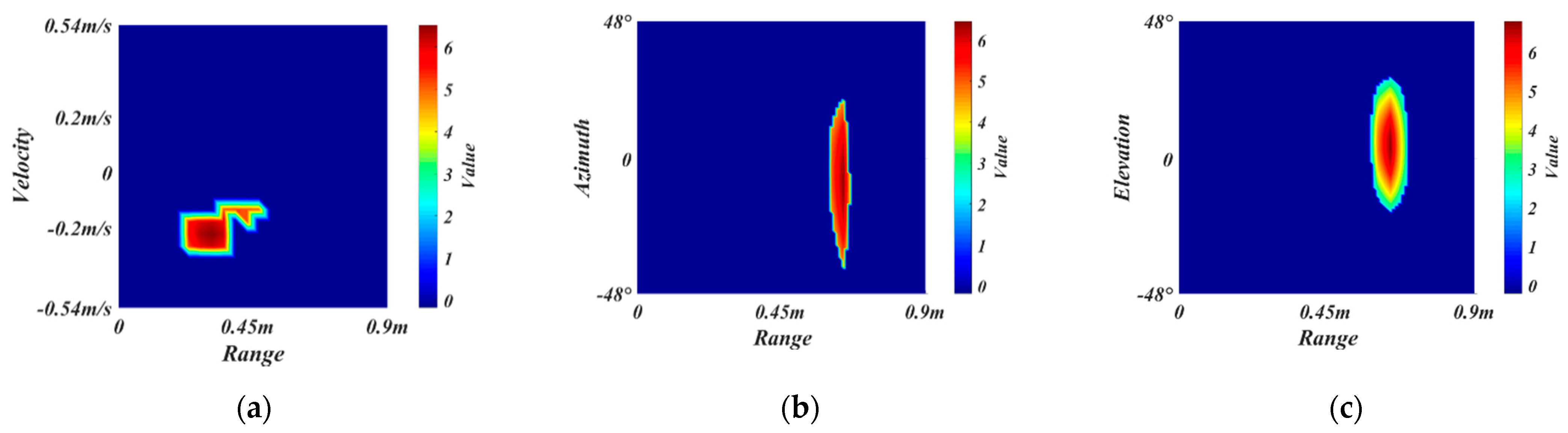
2.2. Radar Signal Processing
2.3. Data Preprocessing
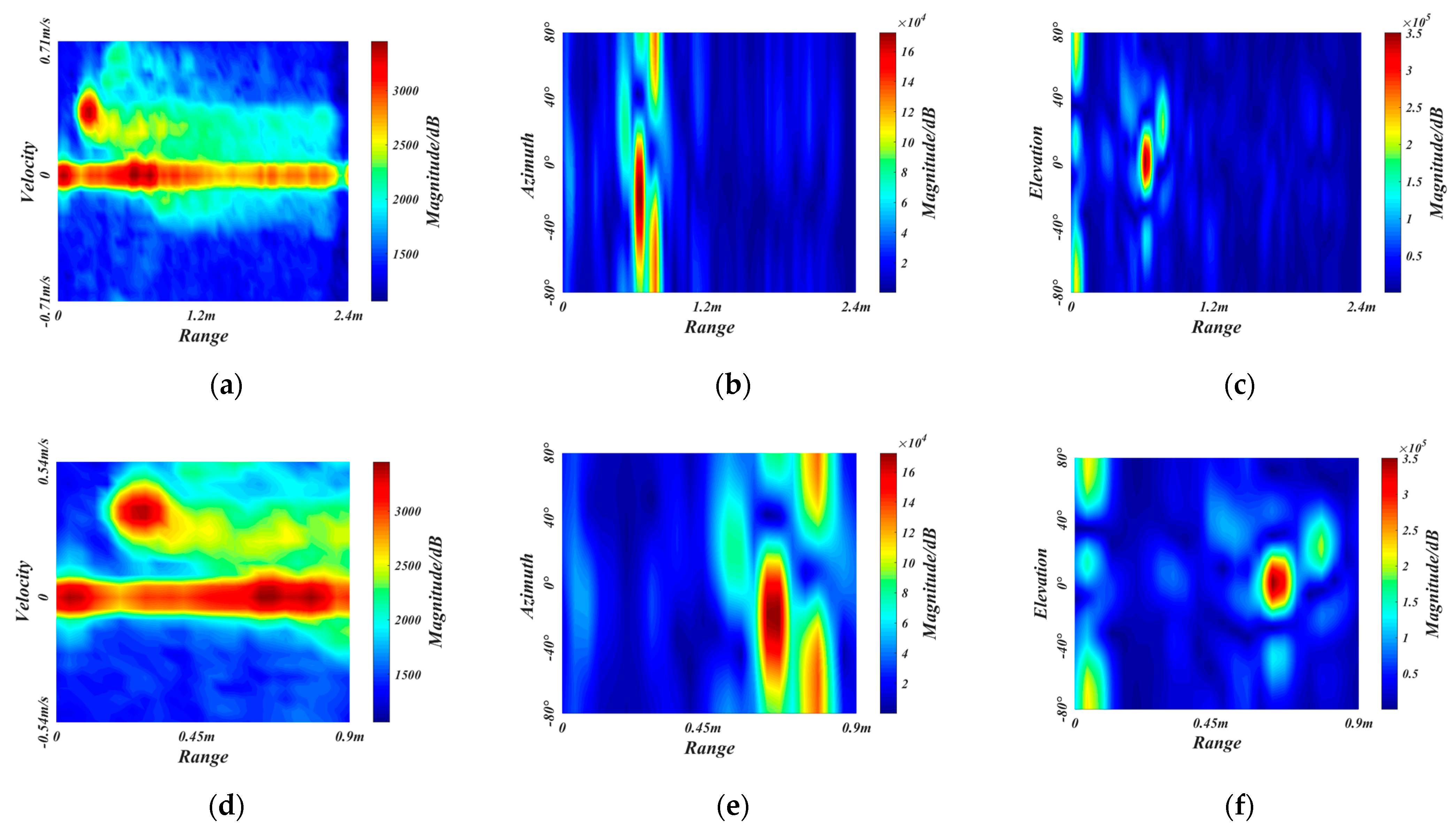
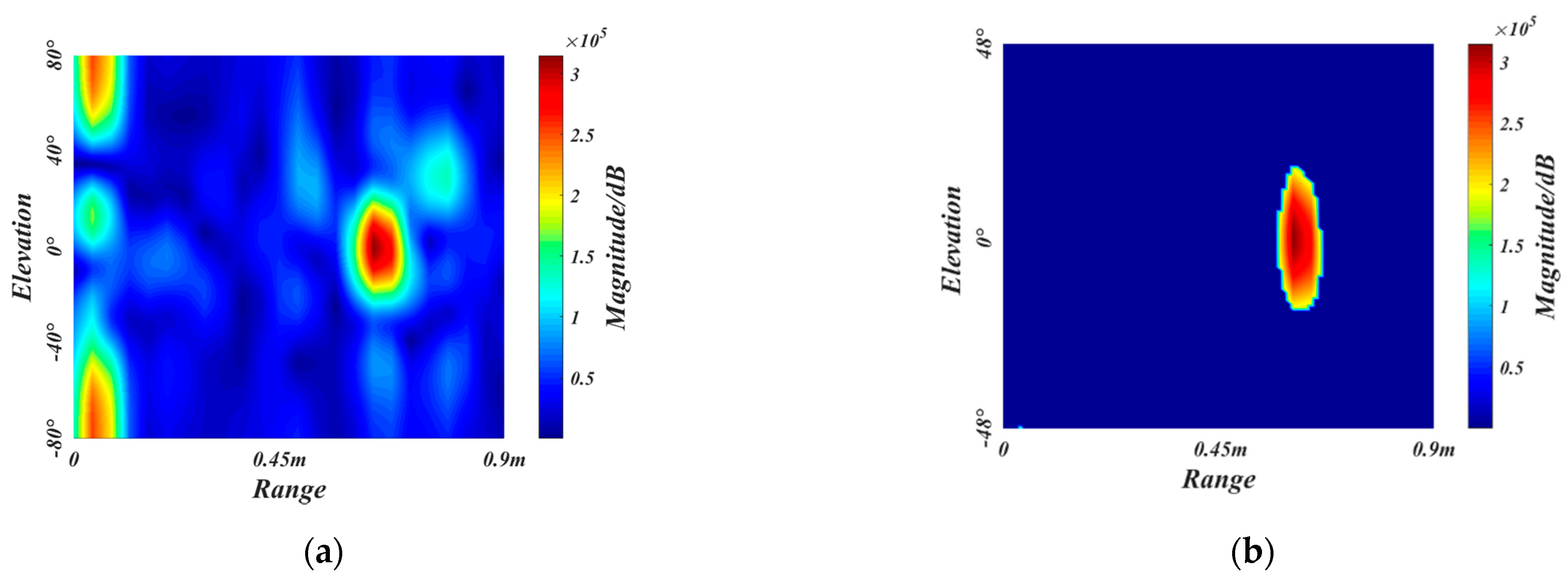
2.3.1. The ROI Extraction
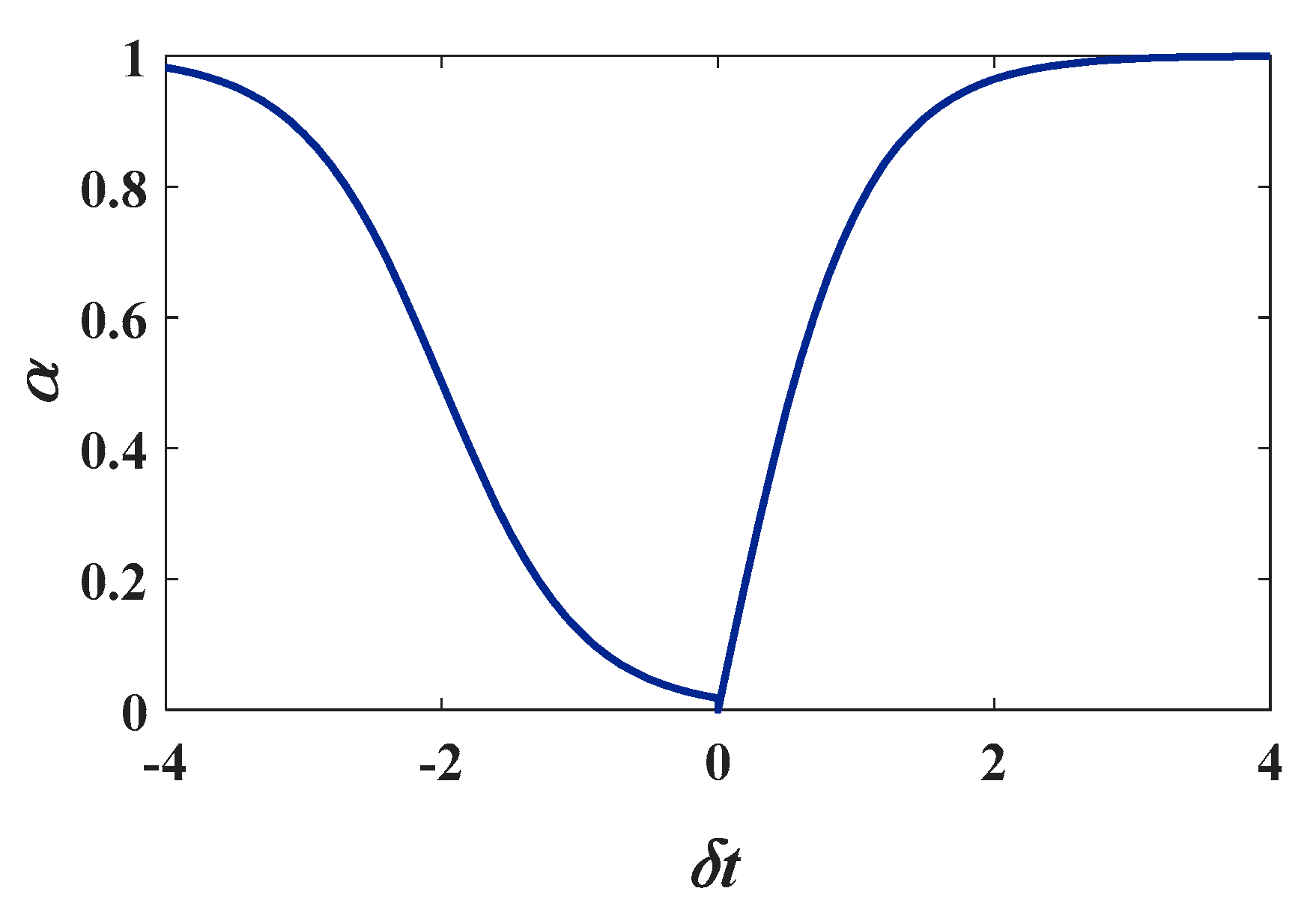
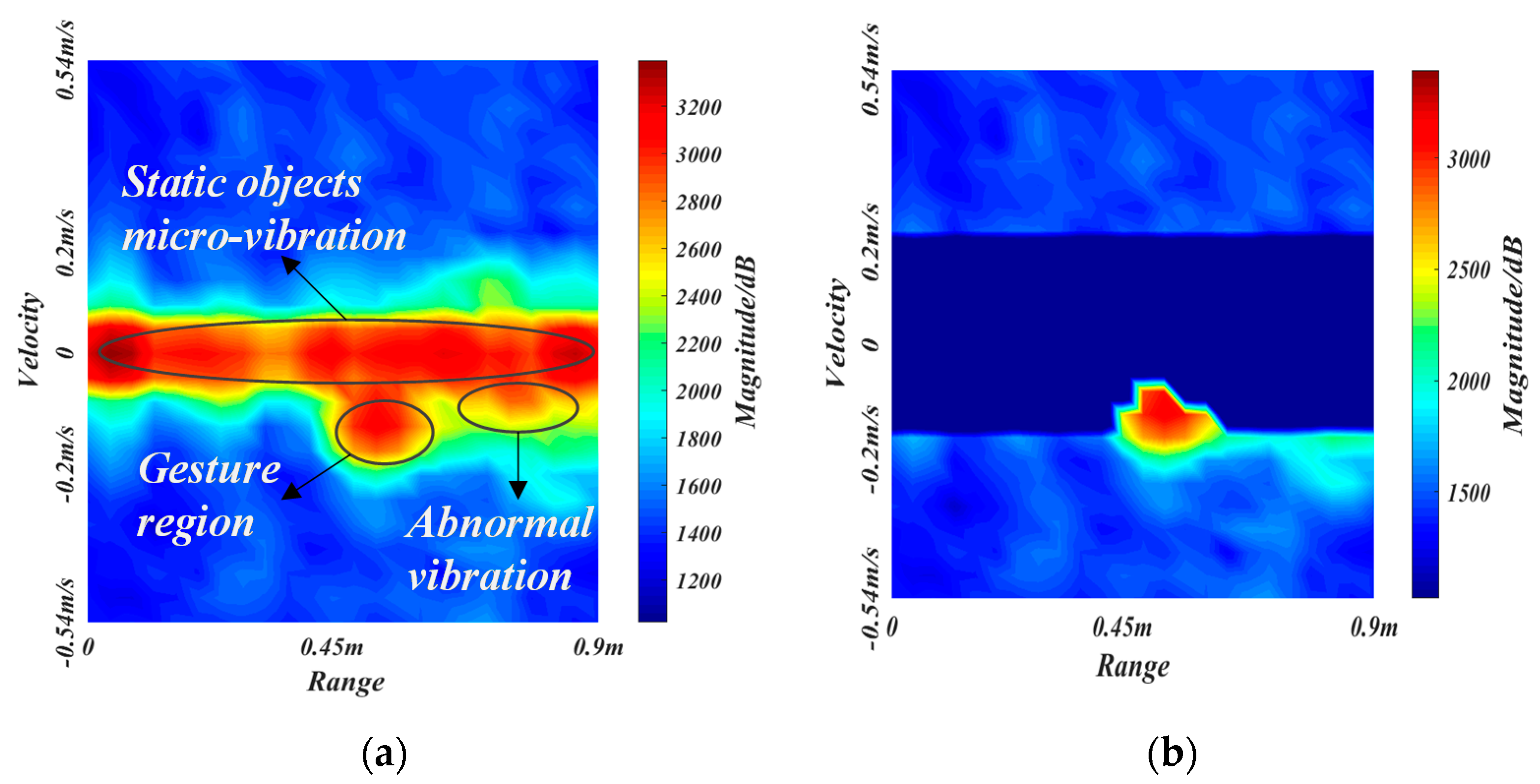
2.3.2. Vibration Removal Algorithm
2.3.3. Background Removal Algorithm
2.3.4. Standardization
3. Proposed Method
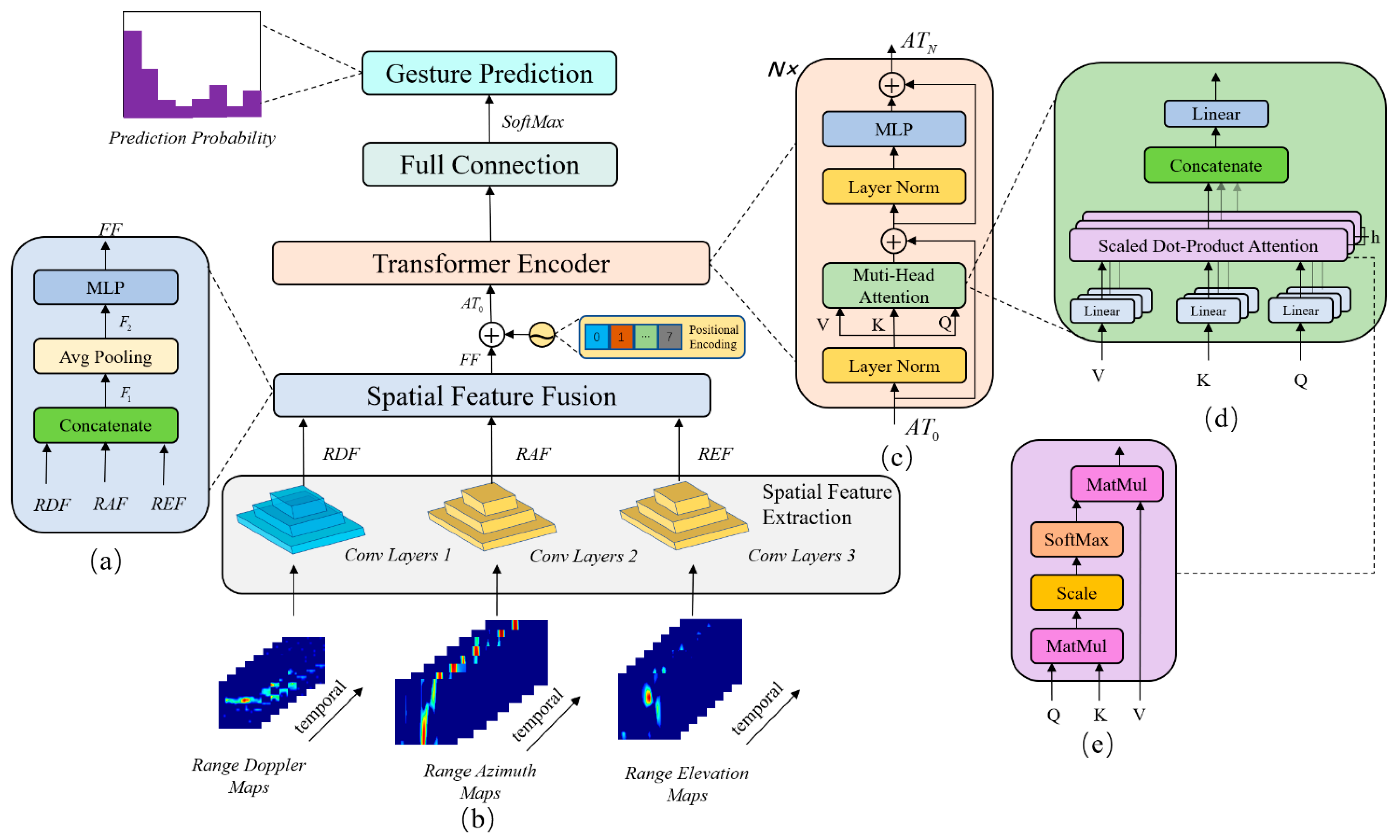
3.1. Network Architecture
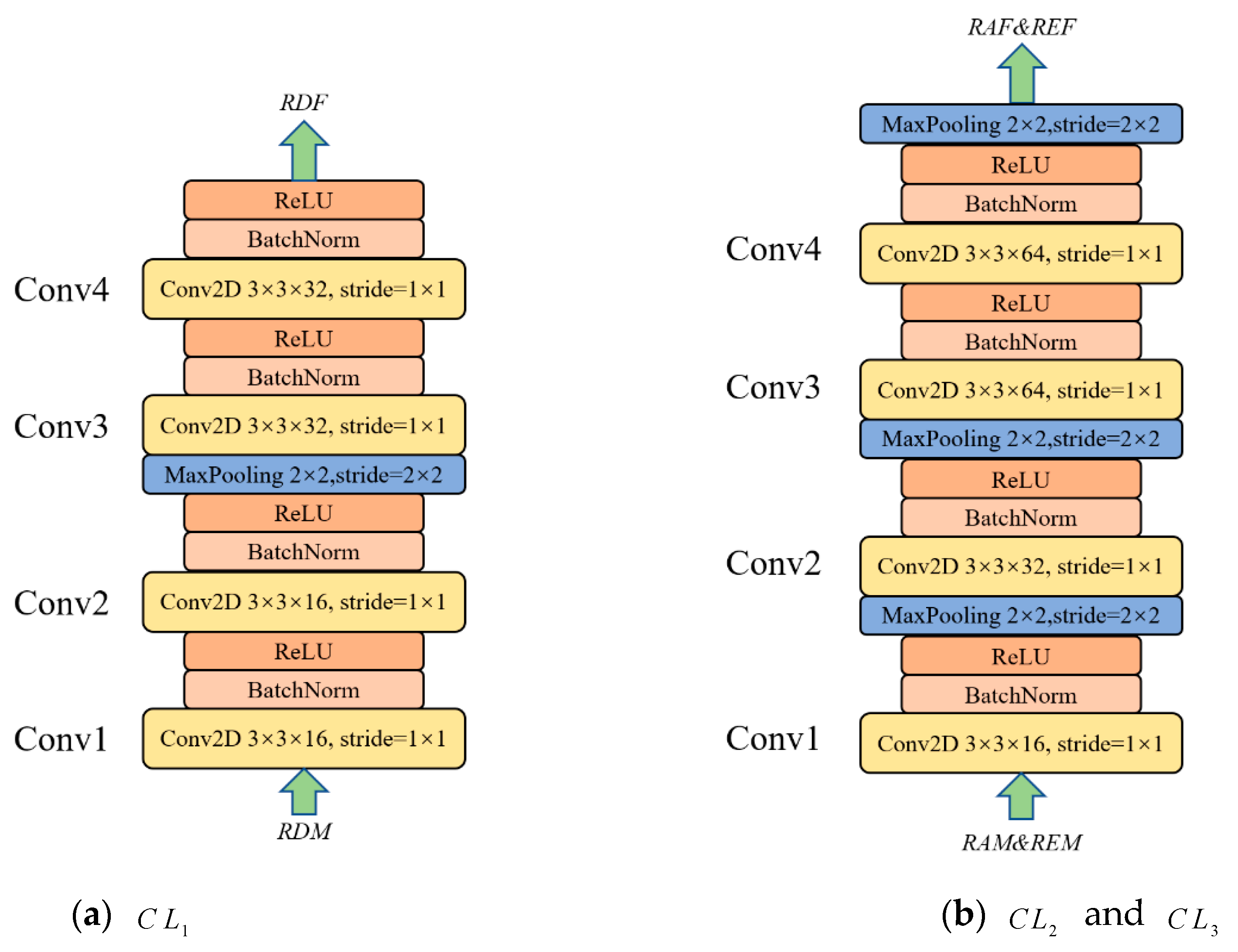
3.2. Spatial Feature Extraction
3.3. Spatial Feature Fusion
3.4. Transformer Encoder Module
3.5. Full Connection Outhead
4. Experiment
4.1. Experimental Details and Evaluation Metrics
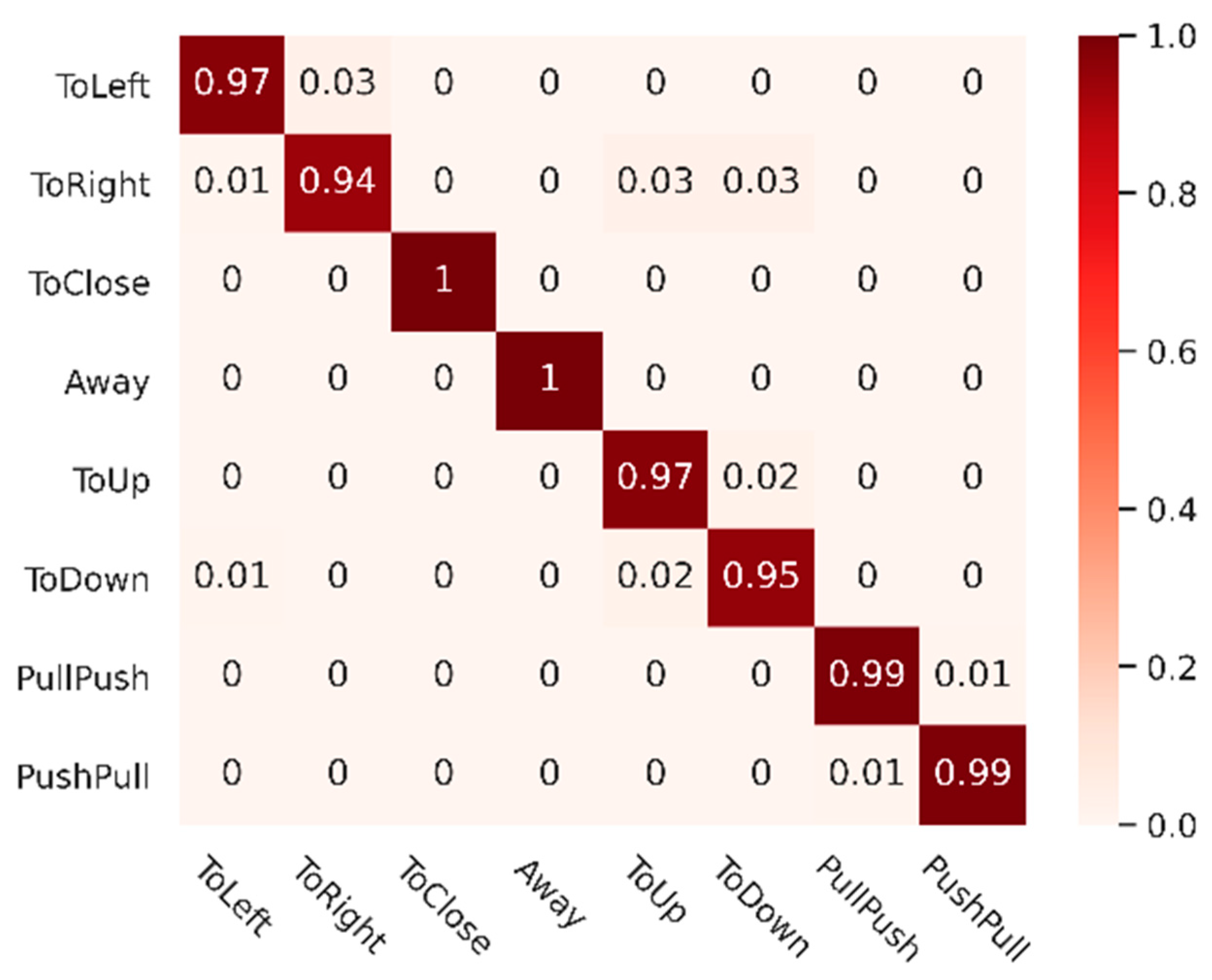
4.2. Experimental Results
5. Discussion
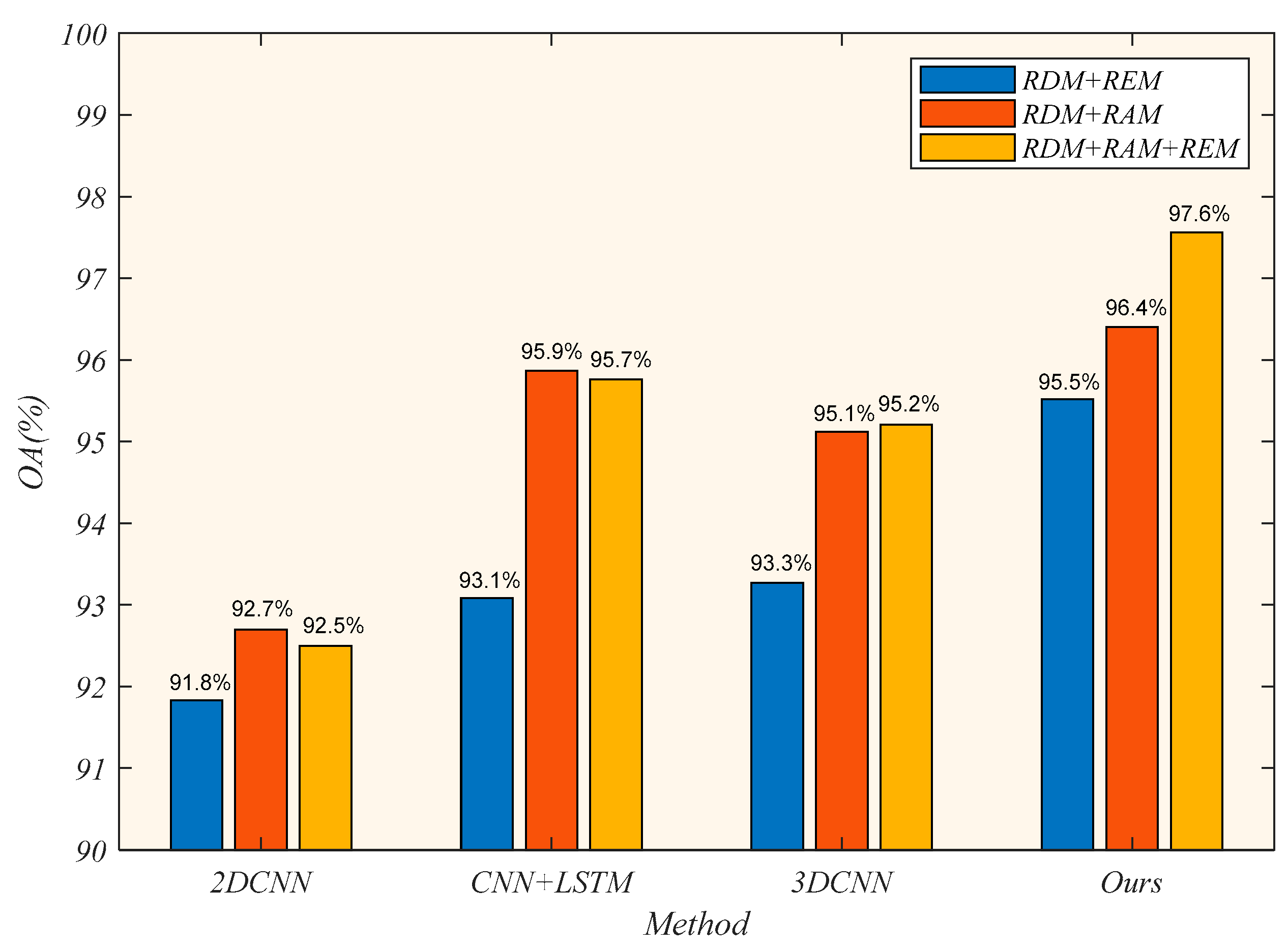
5.1. Impact of Different Input Modalities
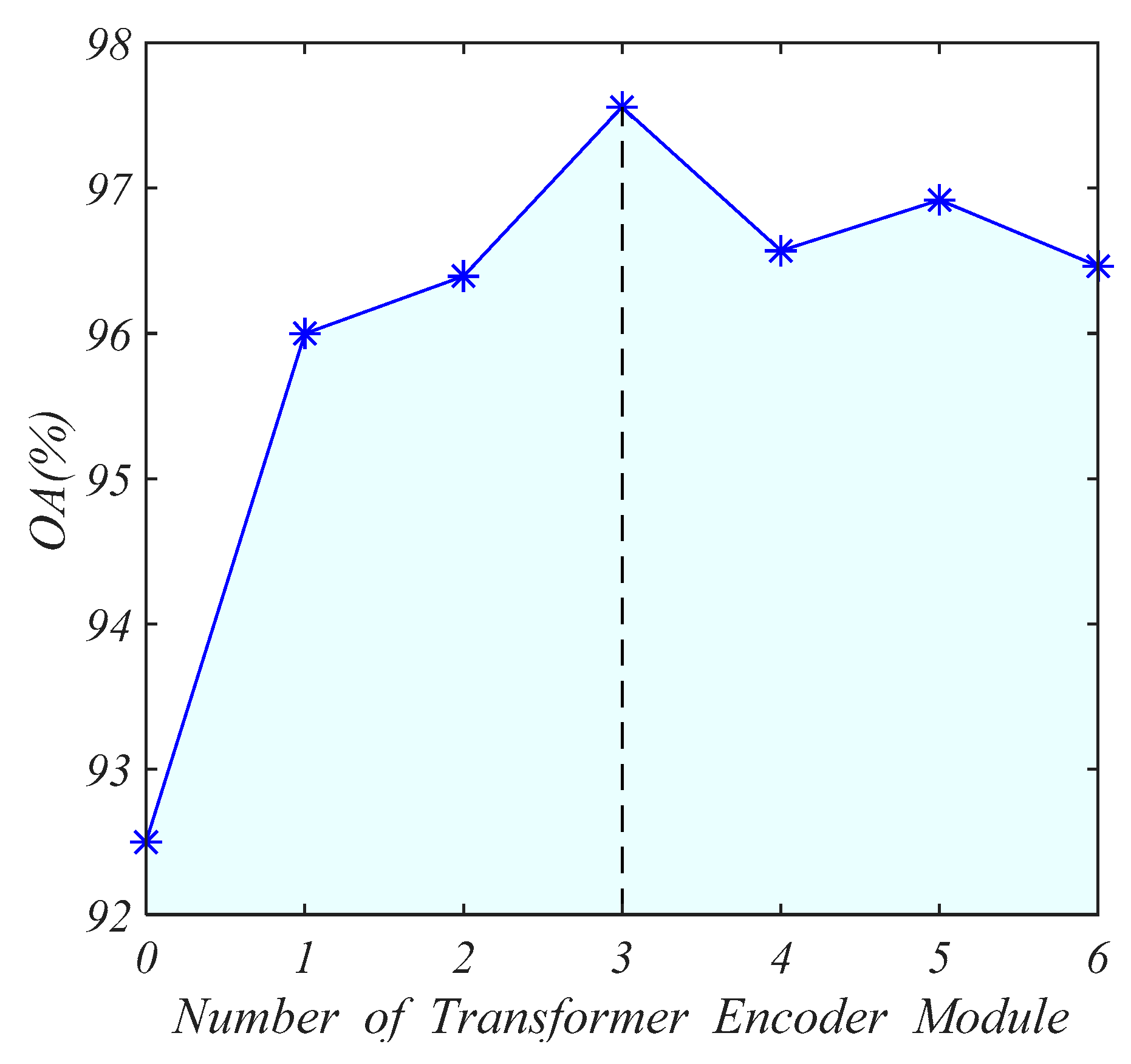
5.2. Impact of Numbers of Transformer Encoder
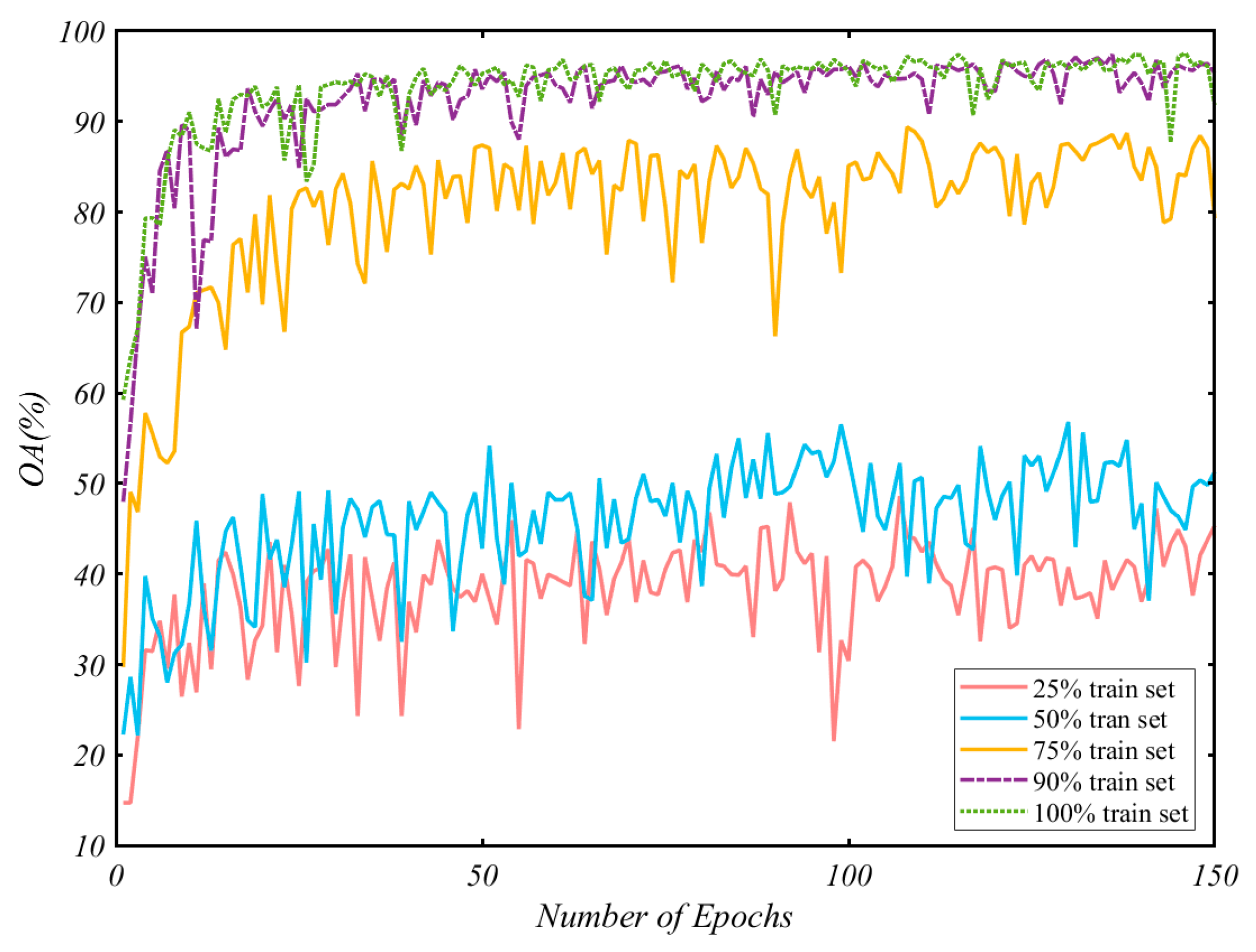
5.3. Impact of the Size of the Train Set
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gui, G.; Huang, H.; Song, Y.; Sari, H. Deep Learning for an Effective Nonorthogonal Multiple Access Scheme. IEEE Trans. Veh. Technol. 2018, 67, 8440–8450. [Google Scholar] [CrossRef]
- Yu, L.; Abuella, H.; Islam, M.Z.; O’Hara, J.F.; Crick, C.; Ekin, S. Gesture Recognition Using Reflected Visible and Infrared Lightwave Signals. IEEE Trans. Hum.-Mach. Syst. 2021, 51, 44–55. [Google Scholar] [CrossRef]
- Deng, M. Robust human gesture recognition by leveraging multi-scale feature fusion. Signal Process. Image Commun. 2020, 83, 115768. [Google Scholar] [CrossRef]
- John, V.; Umetsu, M.; Boyali, A.; Mita, S.; Imanishi, M.; Sanma, N.; Shibata, S. Real-time hand posture and gesture-based touchless automotive user interface using deep learning. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 869–874. [Google Scholar]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust Part-Based Hand Gesture Recognition Using Kinect Sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Hu, Z.; Hu, Y.; Liu, J.; Wu, B.; Han, D.; Kurfess, T. 3D separable convolutional neural network for dynamic hand gesture recognition. Neurocomputing 2018, 318, 151–161. [Google Scholar] [CrossRef]
- Dhingra, N.; Kunz, A. Res3ATN—Deep 3D Residual Attention Network for Hand Gesture Recognition in Videos. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 491–501. [Google Scholar]
- Coelho, Y.L.; Salomáo, J.M.; Kulitz, H.R. Intelligent Hand Posture Recognition System Integrated to Process Control. IEEE Lat. Am. Trans. 2017, 15, 1144–1153. [Google Scholar] [CrossRef]
- Jiang, X.; Merhi, L.-K.; Xiao, Z.G.; Menon, C. Exploration of Force Myography and surface Electromyography in hand gesture classification. Med. Eng. Phys. 2017, 41, 63–73. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Hu, R.; Zhang, X.; Chen, X. Hand Gesture Recognition based on Surface Electromyography using Convolutional Neural Network with Transfer Learning Method. IEEE J. Biomed. Health Inform. 2021, 25, 1292–1304. [Google Scholar] [CrossRef] [PubMed]
- Matsubara, T.; Morimoto, J. Bilinear Modeling of EMG Signals to Extract User-Independent Features for Multiuser Myoelectric Interface. IEEE Trans. Biomed. Eng. 2013, 60, 2205–2213. [Google Scholar] [CrossRef]
- Lu, Z.; Chen, X.; Li, Q.; Zhang, X.; Zhou, P. A Hand Gesture Recognition Framework and Wearable Gesture-Based Interaction Prototype for Mobile Devices. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 293–299. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A Framework for Hand Gesture Recognition Based on Accelerometer and EMG Sensors. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Sung-Jung, C.; Jong Koo, O.; Won-Chul, B.; Wook, C.; Eunseok, C.; Yang, J.; Joonkee, C.; Dong Yoon, K. Magic wand: A hand-drawn gesture input device in 3-D space with inertial sensors. In Proceedings of the Ninth International Workshop on Frontiers in Handwriting Recognition, Kokubunji, Japan, 26–29 October 2004; pp. 106–111. [Google Scholar]
- Moazen, D.; Sajjadi, S.A.; Nahapetian, A. AirDraw: Leveraging smart watch motion sensors for mobile human computer interactions. In Proceedings of the 2016 13th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2016; pp. 442–446. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Pulli, K. Multi-sensor system for driver’s hand-gesture recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar]
- Gao, X.; Xu, J.; Rahman, A.; Yavari, E.; Lee, A.; Lubecke, V.; Boric-Lubecke, O. Barcode based hand gesture classification using AC coupled quadrature Doppler radar. In Proceedings of the 2016 IEEE MTT-S International Microwave Symposium (IMS), San Francisco, CA, USA, 22–27 May 2016; pp. 1–4. [Google Scholar]
- Kim, Y.; Toomajian, B. Application of Doppler radar for the recognition of hand gestures using optimized deep convolutional neural networks. In Proceedings of the 2017 11th European Conference on Antennas and Propagation (EUCAP), Paris, France, 19–24 March 2017; pp. 1258–1260. [Google Scholar]
- Kim, Y.; Toomajian, B. Hand Gesture Recognition Using Micro-Doppler Signatures with Convolutional Neural Network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Smith, K.A.; Csech, C.; Murdoch, D.; Shaker, G. Gesture Recognition Using mm-Wave Sensor for Human-Car Interface. IEEE Sens Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Lien, J.; Gillian, N.; Karagozler, M.E.; Amihood, P.; Schwesig, C.; Olson, E.; Raja, H.; Poupyrev, I. Soli: Ubiquitous gesture sensing with millimeter wave radar. ACM Trans. Graph. 2016, 35, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Lei, W.; Jiang, X.; Xu, L.; Luo, J.; Xu, M.; Hou, F. Continuous Gesture Recognition Based on Time Sequence Fusion Using MIMO Radar Sensor and Deep Learning. Electronics 2020, 9, 869. [Google Scholar] [CrossRef]
- Chung, H.Y.; Chung, Y.L.; Tsai, W.F. An Efficient Hand Gesture Recognition System Based on Deep CNN. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019; pp. 853–858. [Google Scholar]
- Yu, J.; Yen, L.; Tseng, P. mmWave Radar-based Hand Gesture Recognition using Range-Angle Image. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Zhang, Z.; Tian, Z.; Zhou, M. Latern: Dynamic Continuous Hand Gesture Recognition Using FMCW Radar Sensor. IEEE Sens. J. 2018, 18, 3278–3289. [Google Scholar] [CrossRef]
- Ryu, S.-J.; Suh, J.-S.; Baek, S.-H.; Hong, S.; Kim, J.-H. Feature-Based Hand Gesture Recognition Using an FMCW Radar and its Temporal Feature Analysis. IEEE Sens. J. 2018, 18, 7593–7602. [Google Scholar] [CrossRef]
- Senigagliesi, L.; Ciattaglia, G.; De Santis, A.; Gambi, E. People Walking Classification Using Automotive Radar. Electronics 2020, 9, 588. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Ren, A.; Zhou, M.; Wang, W.; Yang, X. A Novel Detection and Recognition Method for Continuous Hand Gesture Using FMCW Radar. IEEE Access 2020, 8, 167264–167275. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P.J. Visual Transformers: Token-based Image Representation and Processing for Computer Vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Guo, M.-H.; Cai, J.-X.; Liu, Z.-N.; Mu, T.-J.; Martin, R.R.; Hu, S.-M. PCT: Point cloud transformer. Comput. Vis. Med. 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Bai, J.; Zheng, L.; Li, S.; Tan, B.; Chen, S.; Huang, L. Radar Transformer: An Object Classification Network Based on 4D MMW Imaging Radar. Sensors 2021, 21, 3854. [Google Scholar] [CrossRef] [PubMed]
- MMWAVEICBOOST and Antenna Module User’s Guide. Available online: https://www.ti.com.cn/tool/cn/IWR6843AOPEVM/ (accessed on 16 July 2020).
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; Volume 22, pp. 28–31. [Google Scholar]
- Hamsa, S.; Panthakkan, A.; Al Mansoori, S.; Alahamed, H. Automatic Vehicle Detection from Aerial Images using Cascaded Support Vector Machine and Gaussian Mixture Model. In Proceedings of the 2018 International Conference on Signal Processing and Information Security (ICSPIS), Dubai, United Arab Emirates, 7–8 November 2018; pp. 1–4. [Google Scholar]
- Lin, J., Jr.; Li, Y.-P.; Hsu, W.-C.; Lee, T.-S. Design of an FMCW radar baseband signal processing system for automotive application. SpringerPlus 2016, 5, 42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, W.; Huang, J.; He, C. A new algorithm for DOA estimation in colocated MIMO array. In Proceedings of the 2011 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 14–16 September 2011; pp. 1–4. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Start Frequency | 60 GHz |
| Bandwidth | 4 GHz |
| Frequency Slope | 100 MHz/μs |
| Chirps per frame | 96 |
| Maximum range | 2.4 m |
| Range resolution | 0.0469 m |
| Maximum angle | −80°–80° |
| Angle resolution | 29° |
| Maximum velocity | 0.7120 m/s |
| Velocity resolution | 0.0445 m/s |
| Antennas | 3 × TX, 4 × RX |
| Method | OA | ToLeft | ToRight | ToClose | Away | ToUp | ToDown | PullPush | PushPull |
|---|---|---|---|---|---|---|---|---|---|
| 2DCNN-based | 92.50% | 92.34% | 84.72% | 92.99% | 100% | 97.13% | 98.14% | 87.04% | 87.96% |
| CNN+LSTM | 95.74% | 92.79% | 94.44% | 93.46% | 99.47% | 95.69% | 94.42% | 95.83% | 99.44% |
| 3DCNN-based | 95.21% | 93.69% | 95.37% | 89.72% | 98.93% | 96.17% | 94.42% | 95.83% | 97.69% |
| Ours | 97.56% | 96.85% | 93.52% | 99.57% | 99.53% | 97.13% | 95.35% | 99.07% | 99.44% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; Bai, J.; Zhu, X.; Huang, L.; Shan, C.; Wu, Q.; Zhang, L. Dynamic Hand Gesture Recognition in In-Vehicle Environment Based on FMCW Radar and Transformer. Sensors 2021, 21, 6368. https://doi.org/10.3390/s21196368
Zheng L, Bai J, Zhu X, Huang L, Shan C, Wu Q, Zhang L. Dynamic Hand Gesture Recognition in In-Vehicle Environment Based on FMCW Radar and Transformer. Sensors. 2021; 21(19):6368. https://doi.org/10.3390/s21196368
Chicago/Turabian StyleZheng, Lianqing, Jie Bai, Xichan Zhu, Libo Huang, Chewu Shan, Qiong Wu, and Lei Zhang. 2021. "Dynamic Hand Gesture Recognition in In-Vehicle Environment Based on FMCW Radar and Transformer" Sensors 21, no. 19: 6368. https://doi.org/10.3390/s21196368
APA StyleZheng, L., Bai, J., Zhu, X., Huang, L., Shan, C., Wu, Q., & Zhang, L. (2021). Dynamic Hand Gesture Recognition in In-Vehicle Environment Based on FMCW Radar and Transformer. Sensors, 21(19), 6368. https://doi.org/10.3390/s21196368