Abstract
Image inpainting aims to fill in corrupted regions with visually realistic and semantically plausible contents. In this paper, we propose a progressive image inpainting method, which is based on a forked-then-fused decoder network. A unit called PC-RN, which is the combination of partial convolution and region normalization, serves as the basic component to construct inpainting network. The PC-RN unit can extract useful features from the valid surroundings and can suppress incompleteness-caused interference at the same time. The forked-then-fused decoder network consists of a local reception branch, a long-range attention branch, and a squeeze-and-excitation-based fusing module. Two multi-scale contextual attention modules are deployed into the long-range attention branch for adaptively borrowing features from distant spatial positions. Progressive inpainting strategy allows the attention modules to use the previously filled region to reduce the risk of allocating wrong attention. We conduct extensive experiments on three benchmark databases: Places2, Paris StreetView, and CelebA. Qualitative and quantitative results show that the proposed inpainting model is superior to state-of-the-art works. Moreover, we perform ablation studies to reveal the functionality of each module for the image inpainting task.
1. Introduction
Image inpainting, which has been a research hotspot in the computer vision community, aims to fill in corrupted regions of an image with visually realistic and semantically plausible contents [1]. Its applications include photo-editing [2,3,4], computer-aided relic restoration [5,6,7,8], de-occlusion [9,10], privacy protection [11,12,13], aesthetic assessment [14], and virtual try-on systems [15,16]. The ill-posedness of image inpainting can be distilled into the following: how to seek the most proper hypothesis for the corrupted region conditioned on the valid surroundings. In the past decade, researchers have devoted substantial efforts to this field, which can be mainly divided into three categories: diffusion-based methods [17,18,19,20], patch-based methods [21,22,23,24,25,26], and CNN (Convolutional Neural Network)-based methods [27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50].
Based on the priori knowledge that image pixels are piece-wise smooth, the diffusion-based methods [17,18,19,20] establish a variety of anisotropic PDEs (Partial Differential Equations) for modeling the process of information diffusion. Although these methods attempt to mimic the paradigm of manual inpainting, they are suitable only for the corrupted region with slender shape and homogeneous texture.
The patch-based methods [21,22,23,24,25,26], which exploit the non-local self-similarity of images, typically operate through the following steps: feature extraction, similarity calculation, candidate screening, and texture synthesis. Unfortunately, these methods focus only on the low-level features and fail to perceive the overall semantics of a given image. It is virtually impossible for the patch-based methods to create semantically meaningful contents, so that they usually suffer setbacks when dealing with the task of face completion.
Nowadays, we are witnessing all-round breakthroughs in the computer vision community, mainly caused by the deep CNNs and the powerful large-scale parallel computing devices (e.g., the graphics processing unit). In general, the CNNs are constructed as a hierarchical architecture with depth, which is conducive to capturing rich features geared towards a specific task. More interestingly, some exquisite networks, such as GAN (Generative Adversarial Network) [51] or VAE (Variational Auto-Encoder) [52], excel at creating realistic samples. Thus, the CNN-based methods [27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50] have been a recent surge of interests in the field of image inpainting. Pathak et al. [27] set up a CE (Context Encoder) network that is of a channel-wise fully connected layer in the middle. Remarkably, an adversarial mechanism, which is similar in spirit to GAN, is introduced into the learning procedure for generating visually clear fillings. Using dual discriminators, Iizuka et al. [28] developed a variant of the CE network [27], which encourages global coherence and local consistency. Yang et al. [29] proposed a multi-scale neural patch synthesis approach, in which a tailor-made loss function was designed to guide the procedures of preserving contextual structures and of generating fine-grained contents. However, although these methods have the capability to create novel contents, there still exist semantic faults or visual artifacts such as color discrepancy and texture distortion. To address these problems, advanced inpainting mechanisms in the following three aspects: specialized convolution operations [30,31,32,33], contextual attention module [34,35,36,37,38,39,40,41,42,43,44,45], and progressive inpainting strategies [46,47,48,49,50], have been studied recently.
In the first aspect, Liu et al. [30] proposed a partial CNN, which is specialized to the task of image inpainting. Therein, each partial convolution kernel acts only on the valid pixels and thus effectively resist the interference derived from the corrupted regions. After each partial convolutional layer, a vanilla rule-based operation is triggered to update the masked region with the goal of shrinking its area layer by layer. In [31], the partial convolution kernel was used to process structure and texture features, which produces multiple feature streams with different scales. Yu et al. [32] put forward a learnable dynamic feature selection mechanism, which can be viewed as a generalized version of the partial convolution. Specifically, a group of accompanying convolution kernels are configured at each layer for learning channel-wise soft-gating masks. Using the element-wise multiplication, the learned masks modulate the feature maps for adaptively filtering out the interference. Ma et al. [33] devised region-wise convolutions and deployed them into the decoder network. As its name implies, the region-wise convolution is to separate the tasks of reconstructing the valid region and inferring the corrupted region.
In the second aspect, Song et al. [34] designed a contextual attention module based on patch-swap operation. Unlike the traditional patch-based methods, their proposal not only takes feature maps as surrogates for texture propagation but also embeds the contextual attention module seamlessly into the entire learnable network. Yan et al. [35] inserted a shift-connection layer into the decoder network, which explicitly borrows contextual information from encoder’s feature map. Yu et al. [36] computed attention scores over feature maps through the convolution operations and normalized these scores by applying the softmax function. During network training, feature patches in the contextual region are weighted by the normalized attention scores for texture synthesis. This attention module [36] was adopted in a multi-task inpainting framework [37] for processing multi-modal features extracted from image, edge and gradient maps. Sagong et al. [38,39] constructed a shared encoder network for reducing the number of convolution operations and modified the means of computing the attention scores. Uddin and Jung [40] designed a global-and-local attention module and aimed to refine the inpainting-oriented features by integrating global dependency and local similarity information. In this attention module, an effective mask pruning mechanism was developed to filter out features with interference. More recently, Yu’s contextual attention module [36] has been extended to a multi-scale version in [41], to a cascaded version in [42], to a pyramid version in [43], to a locally coherent version in [44], and to a knowledge consistent version in [45].
In the third aspect, Xiong et al. [46] explicitly separated the whole inpainting task into three parts in sequence to perceive image foreground, to complete object contour, and to fill in corrupted region. Zhang et al. [47] proposed a progressive generative neural network for semantically inpainting images. Inspired by the concept of curriculum learning, they added a LSTM (Long Short-Term Memory) component [53] into the middle of U-net [54] to store and share the inpainting knowledge between multiple stages. Guo et al. [48] invented a full-resolution residual block, which learns to inpaint a local region covered by one dilation. Stacking such blocks in series helps to progressively fill in the corrupted region. Unfortunately, this method can only deal with small holes, i.e., the area up to 96 pixels in diameter. Chen and Hu [49] progressively completed the image inpainting task from the perspective of pyramid multi-resolution, in which lower-resolution inpainting is followed by higher-resolution inpainting iteratively. Zeng et al. [50] proposed to evaluate predications’ confidence during the progressive process of inpainting. The confident regions, which serve as feedback information, were encouraged to cover as large corruption as possible.
However, there still exist some problems in these advanced inpainting mechanisms. First, although the partial convolution can restrict itself to absorb information from the valid region, the frequently used fully spatial feature normalization may still introduce interference. Second, feature patches lying inside the corrupted region usually contain larger deviations. This phenomenon misleads the contextual attention module and incurs wrong attention allocation. Third, the progressive inpainting strategies, in general, employ the learnable convolution kernels to perceive the periphery of the corrupted region but neglect the contextual information outside the receptive field.
To alleviate these problems, in this paper, we propose a novel end-to-end multi-stage pipeline mainly consisting of a shared encoder network and a forked-then-fused decoder network. The encoder network aims to capture the useful information from the valid region and to block out the objectionable interference derived from the corrupted region. To this end, we design a new network unit, called PC-RN, which equips the partial convolutional layer [30] with the region-wise feature normalization [55]. The decoder network, at the beginning, forks into two branches, called local reception branch and long-range attention branch, respectively. To ensure local consistency, the former is responsible for perceiving the valid information and for reconstructing the local field around the corrupted region. To generate fine-grained details, the latter resorts to two cascaded MSCA (Multi-Scale Contextual Attention) modules, both of which basically follow the attention mechanism in [41], for flexibly borrowing features from remote spatial positions. Two feature flows are then adaptively refined through a SE (squeeze-and-excitation)-based [56] fusing module.
Our proposal is to fill in the whole corrupted region progressively. Each inpainting stage only targets a limited area of the corrupted region, thereby somewhat alleviating the problem of wrong attention allocation. Furthermore, thanks to the SE-based fusing module, each inpainting stage can comprehensively utilize the local and long-range features extracted by the double branches.
We conducted extensive experiments and comparative studies on three benchmark databases: Places2 [57], Paris StreetView [58], and CelebA [59]. To support the above claims, we visualize the feature deviations within the corrupted region and exhibit how each region contributes to the inpainting performance across the multiple stages. Additionally, qualitative and quantitative results demonstrate the effectiveness and the superiority of the proposed model compared with state-of-the-art works.
2. Our Model
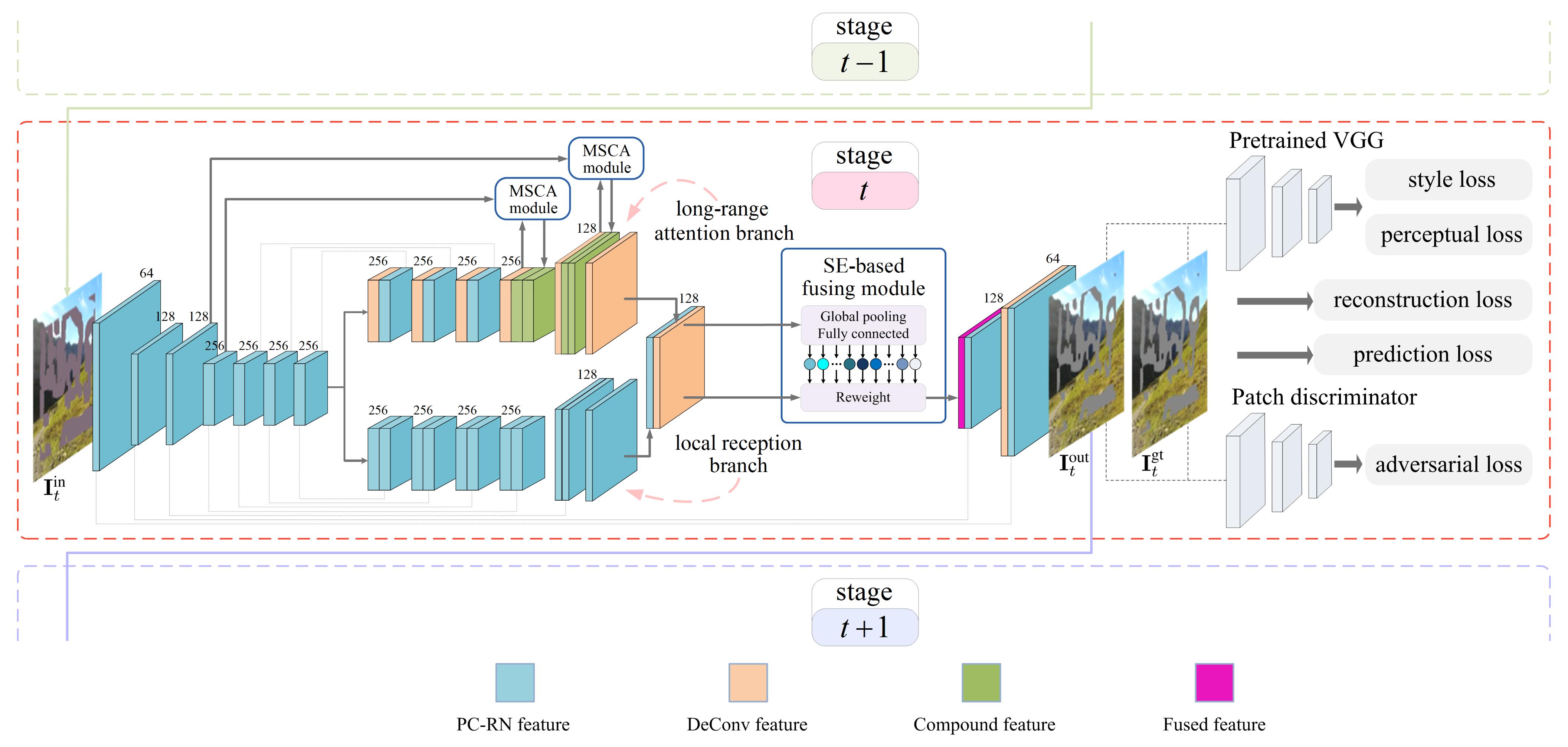
The overall architecture of the proposed inpainting network is schematically illustrated in Figure 1. Let , , and denote the input, output, and groundtruth images, respectively, at the inpainting stage. The shared encoder network captures the useful information from the valid region of . Then, the resulting feature map is fed into the forked-then-fused decoder network for image generation, yielding . Comparing with , we calculate various losses: reconstruction loss, perceptual loss, style loss, and adversarial loss, with the aid of a pre-trained VGG (Visual Geometry Group) network [60] and a patch-based discriminator network [61]. We collectively use these losses to guide the end-to-end training. The inpainting network at the inpainting stage restricts its attention to a limited area of the corrupted region. Its output image acts as the input image for the next inpainting stage, namely that . Without loss of generality, we elaborate on a single inpainting stage hereafter. The subscript t is dropped for clarity, unless explicitly needed to distinguish between multiple inpainting stages.
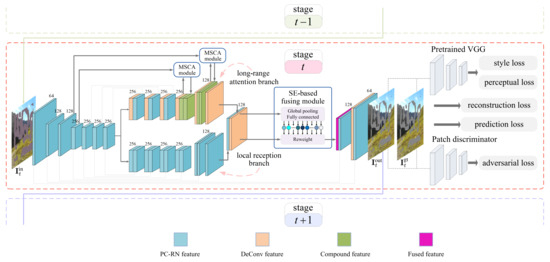
2.1. Shared Encoder Network
Unlike generic computer vision tasks, which process full information, the image inpainting task is to deal with incomplete information. Hence, how to resist the incompleteness-caused interference becomes a critical issue for the inpainting network, especially for the shallow layers. To cope with this issue, in this paper, we combine the partial convolution [30] and the region normalization [55] and take them as a basic unit, called PC-RN, to construct the inpainting network. The PC-RN unit provides an elegant way, which is immune against the interference, to process the incomplete information and paves the way for generating high-quality results. Hereafter, we give a brief introduction to the PC-RN unit.
We define as an input feature map of a PC-RN unit, where C, H, and W represent the number of channels, height, and width, respectively. Let denote a binary mask of size , which takes value 0 inside the corrupted region and 1 elsewhere. Suppose that a partial convolution kernel of size currently encompasses a local part, denoted by , of the input feature map . Correspondingly, we use to represent the local binary mask that is covered by the kernel. Let and denote the weights and biases of the kernel, respectively. Mathematically, the current partial convolution, which yields a response , can be expressed as
where ⊙ denotes Hadamard product while counts the number of 1s in . The scaling factor makes an appropriate compensation for the corrupted positions because they are absent from the calculation course of Equation (1). After each partial convolution, the local binary mask is updated as follows:
The convolved feature map, denoted by , and the updated binary mask, denoted by , are composed of and , respectively. We denote the sizes of and by and , respectively.
Feature normalization acts to standardize the mean and variance of the convolved feature map for stabilizing learning. In our proposal, such normalization is performed in a region-wise fashion. Specifically, we first properly resize to the resolution of , namely . Then, according to (the resized version) and , the feature map is partitioned into three regions, namely the valid region , the filled region , and the corrupted region . Their formal definitions are as follows:
where represents a spatial coordinate with and . Note that may become ⌀ after several PC-RN units (and several inpainting stages), meaning that all of the corrupted positions have been assigned by predictions. For each region, calculate its mean and standard deviation as follows:
where and stands for the cardinality of the set . The subscript k, of which the value lies in the interval , is the index of a channel. The notation is a prescribed small constant for numerical stability. The region-wise feature normalization can be formulated as
Finally, region-wise affine transformations based on a set of learnable parameters , where , are separately applied to the normalized feature values.
As shown in Figure 1, we set up the shared encoder network by cascading seven PC-RN units. Throughout our proposal, the partial convolution kernel is of size and has “same” mode for zero-padding. Downsampled convolution is realized by setting the stride to 2.
2.2. Forked-Then-Fused Decoder Network
The decoder network, which receives the output feature map of the encoder network, forks into the local reception branch and the long-range attention branch. Then, a SE-based fusing module adaptively refines the feature maps from the two branches. In addition to the main body of the network, extra skip connections, which concatenate two feature maps as shown in Figure 1, are added to avoid information loss during the forward pass and to mitigate the vanishing gradient problem during the backward pass.
2.2.1. Local Reception Branch
The local reception branch is expected to infer the corrupted region conditioned on the valid surroundings. In the early inpainting stages, however, the shared encoder network may fail to cover the entire corrupted region. In other words, the input to the decoder network still contains the corrupted region, namely . To prevent the interference, the PC-RN unit is reused here for constructing the six-layer local reception branch, as shown in Figure 1. The upsampled convolution is realized by setting the stride to . In the later inpainting stages, eventually becomes 0. Under this circumstance, the partial convolution and the region normalization naturally degenerate into the standard convolution and batch normalization, respectively.
2.2.2. Long-Range Attention Branch
The long-range attention branch, of which the core component is the MSCA module, aims to infer the corrupted region by borrowing features from distant spatial positions. In particular, the standard convolutions, rather than the partial convolutions, are used in this branch, with the goal of making a rough prediction for the whole corrupted region. The MSCA module operates on a pair of feature maps, denoted by and . The former represents the feature map at the -to-end layer of the shared encoder network, while the latter is the one generated by the convolutional layer of the long-range attention branch.
First, we combine with via the following form
where , taking value 0 inside the filled region and 1 elsewhere, denotes the binary mask accompanied with and . Since the standard convolution fills in the whole corrupted region at a time, the resulting feature map contains only two kinds of regions, namely the valid region and the filled region .
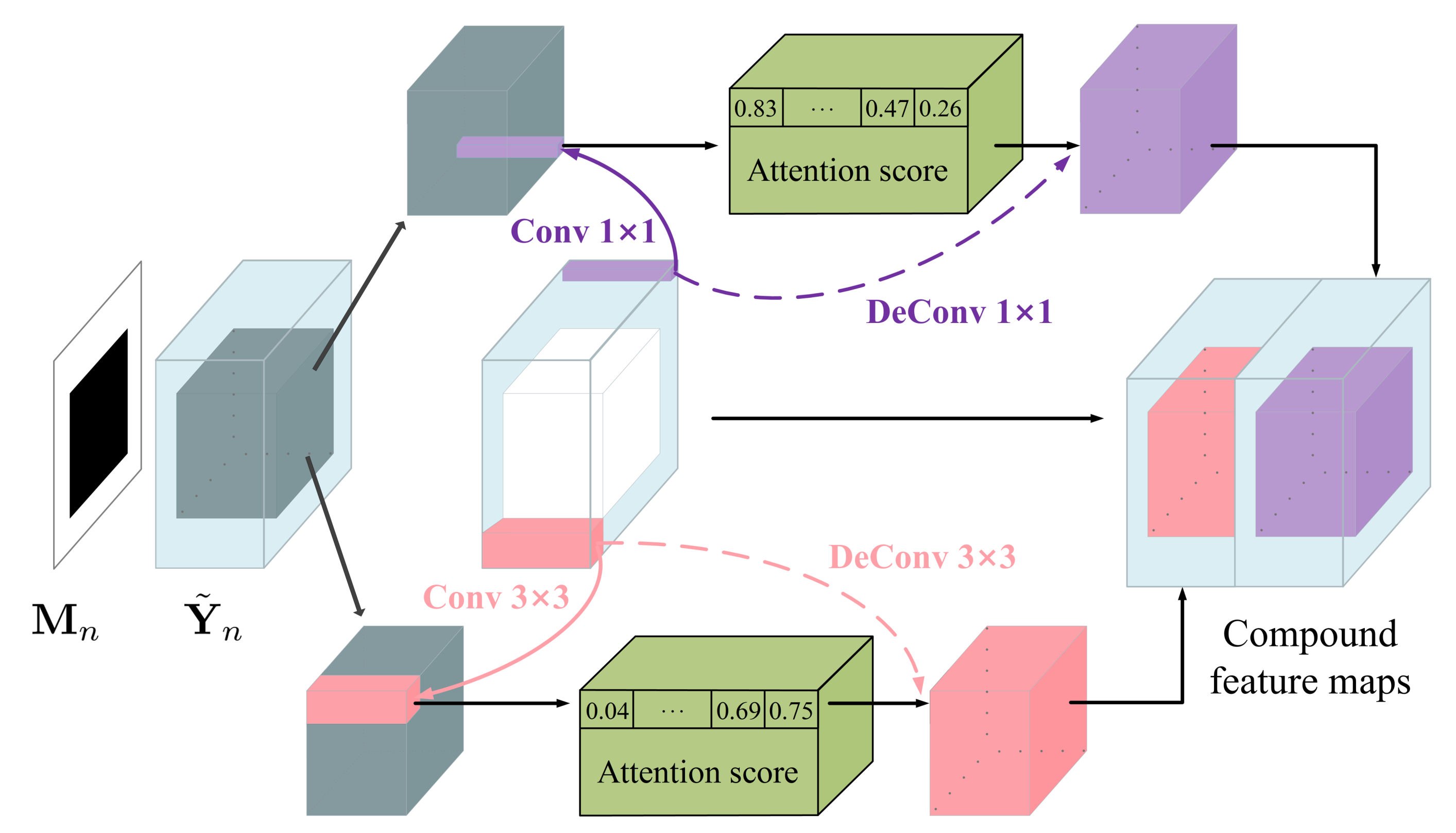
Second, as shown in Figure 2, we divide into multi-scale patches of size and and compute the inter-patch normalized inner product
where and represent the patches of centered at in the valid region and centered at in the filled region, respectively. It is worth mentioning that Equation (8) can be effectively implemented using convolution, in which serves as the kernel. We then use the softmax function to exponentiate and normalize the inter-patch similarity along the - dimension. The processed result, denoted by , is called the attention score.
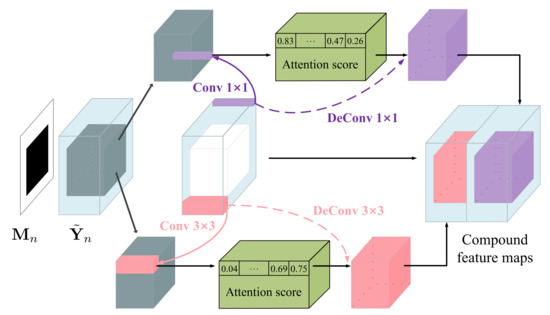
Figure 2.
The schematic illustration of the multi-scale contextual attention (MSCA) module.
Third, we reuse as the kernel and apply deconvolution to the attention score map. Such an inverse operation reconstructs the filled region, in the sense of integrating the valid patches through a weighted average way.
Finally, the filled region of is replaced by the reconstructed counterpart, yielding a new compound feature map. Inspired by [41], we also consider the multi-scale scenario, where the patch sizes are and , so that the MSCA module produces two compound feature maps, as shown in Figure 2. We concatenate and the two compound feature maps to form the output of the layer of the long-range attention branch.
Alternatively, we can propagate the attention scores over a small neighboring region along the horizontal and vertical directions. Mathematically, the horizontal version can be formulated as
where p denotes a shift lying in the interval . Analogously, the vertical version imposes the shift p on and , respectively. This trick is helpful because the neighboring region usually shares similar attention scores, and its effectiveness has been validated by [36].
It is worth noting the differences between the MSCA module and the multi-scale attention module used in [41]. First, a SE block [56] is configured in the original attention module [41] for refining the compound feature maps. By contrast, we move the SE block [56] to the fusing module (see the next section) for comprehensively refining the local and long-range features. Second, the original attention module [41] only processes the decoding feature map in a single-stage regime. Contrastively, we not only cascade two MSCA modules together for hierarchically synthesizing the inpainting-oriented features but also perform the MSCA modules in multiple inpainting stages. Consequently, for different stages, the MSCA module has different sources for synthesizing features. See the results of the ablation study in Section 3.4.4.
2.2.3. SE-Based Fusing Module
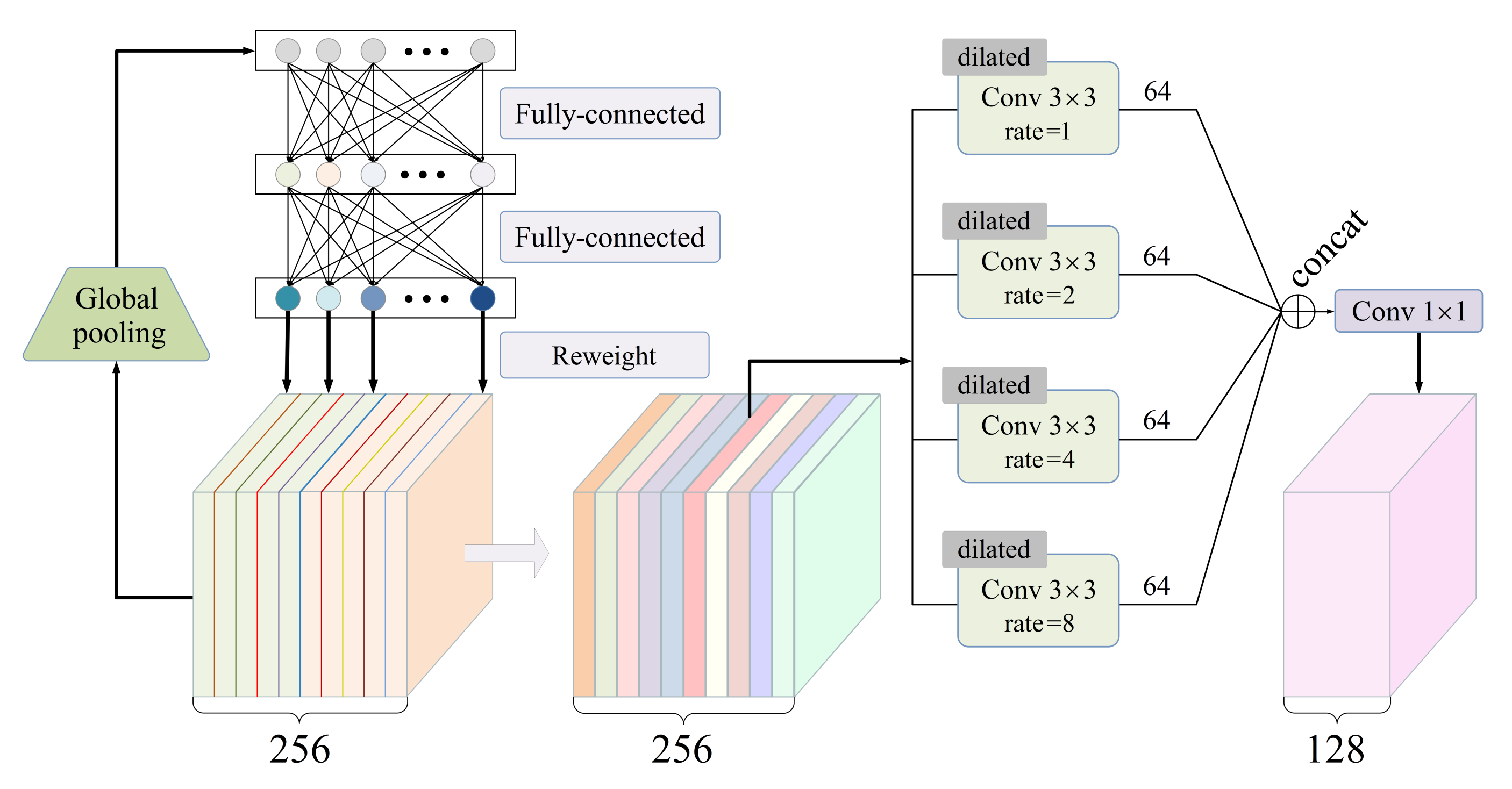
Let denote a concatenation of the two feature maps obtained from the double branches. The SE-based fusing module takes as input.
As shown in Figure 3, the SE (Squeeze-and-Excitation) [56] block processes through the following steps. First, the squeeze step applies an average-pooling operation to each channel of , with the goal of extracting a global feature vector with C elements. Second, the modulation step learns to properly transform the global feature vector into C weighting coefficients through a two-layer fully connected net. Third, the excitation step multiplies each channel of by the corresponding weighting coefficient.
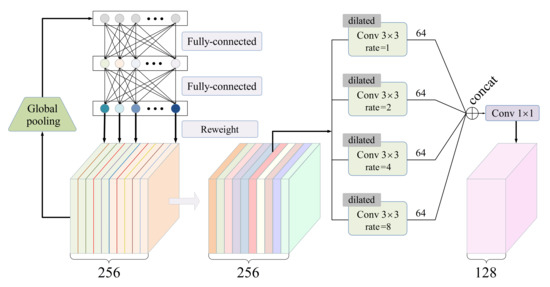
Figure 3.
The schematic illustration of the SE-based fusing module, where the number of channels C is set to 256.
Furthermore, four dilated convolutional layers with the same kernel size of , in parallel, perceive the weighted feature map. Four dilation rates are set to 1, 2, 4, and 8. This ASPP (Atrous Spatial Pyramid Pooling)-like architecture [62] allows us to capture rich features from multi-scale receptive fields. Finally, a standard convolutional layer with a kernel size of is responsible for compressing a feature map by halving the number of channels. The SE-based fusing module outputs a feature map with the size .
Note that, driven by data, all of the parameters in the SE-based fusing module are learnable and are jointly optimized together with other part of the network. Hence, this module has the capability to comprehensively refine the local and long-range features, making them more suitable for the image inpainting task.
2.3. Progressive Inpainting Strategy
The proposed network fulfills the image inpainting task in a progressive fashion, and each inpainting stage is in charge of inferring a limited area of the corrupted region by using the fused features.
Two binary masks, which share the same resolution as the input image , determines the to-be-filled region at the inpainting stage. The first one, denoted by , is called input binary mask. It takes value 0s for the corrupted region and 1s for the valid region. The second one , called output binary mask, stems from the last PC-RN unit of the shared encoder network. Here, proper upsampling is required for to ensure the consistency of resolution. According to the update rule in Equation (2), we know that takes 1s not only for the valid region but also for the filled region. Consequently, the to-be-filled region at the inpainting stage can be represented by .
Let and denote the output image of the inpainting network and the groundtruth image, respectively. At the inpainting stage, the resulting image (or the groundtruth image ) is defined as (or ). Furthermore, the inpainted results at the stage will be inherited by the next stage, in the sense that and . The total number of inpainting stages T, which is a hyper-parameter, controls the trade-off between the inpainting quality and the computational cost. We stipulate that the output binary mask is an all one-valued matrix, meaning that the corrupted region must be filled at the final inpainting stage.
The progressive inpainting strategy manages to fill in the central part of the corrupted region at the last few stages, with the aid of the inpainted results inherited from the previous stages. In other words, the progressive inpainting strategy allows the MSCA module to borrow features not only from the valid region but also from the filled region to alleviate the problem of wrong attention allocation. These claims are corroborated by the visualized results in Section 3.4.4.
2.4. Loss Function
In this paper, reconstruction loss, prediction loss, perceptual loss, style loss, and adversarial loss are collectively used to guide the network training.
The reconstruction loss measures the average error between and at the pixel level. Its definition is
where denotes the -norm of the enclosed argument.
The prediction loss, which focuses in particular on the filled region, measures the average error between the predicted pixel values and the groundtruth ones. Its definition takes the following form
The perceptual loss evaluates the inpainting quality at the semantic level. VGG19 network [60] pre-trained on the ImageNet database [63] is employed to extract the semantic features. Suppose that is the extracted feature map for a given image , where . The size of is denoted by . With these preparations, the perceptual loss can be written as
where that is of size refers to a downsampled version of . In this paper, we consider feature maps selected from the , the , and the VGG19’s convolutional layers.
Gram matrix, which expresses the correlation between channels, can be viewed as a style indicator for a given image. We define a style loss, based on the Gram matrix, to evaluate the matching degree between two images. The Gram matrix is calculated as follows:
where . In Equation (13), the notation ∘ refers to a compound operation. It first reshapes its operands into matrices of size and then performs a matrix multiplication between the reshaped operands, yielding a Gram matrix. Furthermore, the style loss is defined by
The adversarial loss quantifies the inpainting verisimilitude, with the aid of a patch-level discriminator network, as shown in Figure 1. In practice, the adversarial loss can be equivalent to a summation of two binary cross-entropy losses. That is
where D and G stand for the patch-level discriminator network and the inpainting network, respectively. The bold symbol (and ) is a patch-level label matrix in which the elements are one-valued (and zero-valued). Each element in (and ) means that the corresponding feature patch is “real” (and “fake”). The loss function computes the binary cross-entropy between and . Mathematically, its formula takes the following form:
where (and ) is the element of (and ). The adversarial loss turns the network training into a min–max optimization problem, in which G and D collaborate each other and adapt to evolve together. Spectral normalization technique [64] is used to stabilize the training of the discriminator network.
In summary, the total loss used to guide the training of the entire network is as follows:
where the weight coefficients are hyperparameters of the proposed inpainting model. They are set to 1, 3, 0.08, 150, and 0.2, respectively, under the guidance of validation set.
3. Experiments
In this section, we conduct extensive experiments and comparative studies to demonstrate the effectiveness and the superiority of the proposed inpainting model.
Source code is available at https://github.com/yabg-shuai666/Inpainting (accessed on 22 August 2021).
3.1. Experimental Setup
Three benchmark databases, namely Places2 [57], Paris StreetView [58], and CelebA [59], are commonly used in the image inpainting community. The Places2 database [57] contains more than 10 million images comprising over 400 indoor or outdoor scene categories. The Paris StreetView database [58] contains about 60 K panoramas scraped from Google Street View. Two perspective images have been carefully cropped from each panorama. These images mainly reflect building facades appearing in the modern city. The CelebA database [59] contains more than 200 K face images with large pose variations and background clutter. Images in these databases cover a variety of scenes and contents, allowing us to train an inpainting model more suitable for real-world applications.
We prepare the training set, the validation set, and the test set via the following steps. First, randomly select 50 K images from each database. Second, normalize their spatial resolutions to through appropriate cropping and scaling operations. Third, artificially fabricate the corrupted images according to the binary masks , where means the initial inpainting stage. In our experiments, we adopt the irregular binary masks prepared in [30]. Fourth, group the images into three sets: 600 images for testing, another 600 ones for validating, and the remaining ones for training.
Five image inpainting models [30,35,41,47,48], which are the representatives in specialized convolutions, contextual attention, and progressive strategies, serve as baselines for performing the comparative studies. Hereafter, these baselines are called PConv [30], Shift-net [35], MUSICAL [41], LSTM-PGN [47], and FRRN [48] for short. Unless explicitly stated, the total number of inpainting stages T is set to 4, 8, and 4, respectively, for LSTM-PGN [47], FRRN [48], and the proposed one. All of the image inpainting networks are trained by the Adam optimizer with default settings [65].
Our computing device is a workstation with a 3.20 GHz Intel Xeon W-2104 CPU and a 11GB NVIDIA GeForce RTX 2080Ti GPU. Our programming environment is PyTorch v1.2 installed on Ubuntu v18.04 operation system.
3.2. Qualitative Results
Figure 4 exhibits the qualitative results. The first column of Figure 4 lists the corrupted images, which serve as the inputs to the inpainting networks. From top to bottom, the first two images come from the Place2 [57], the middle two from the Paris StreetView [58], and the last two from the CelebA [59] databases. The irregular gray region indicates the corrupted part, and the corresponding corruption rates are 30.63%, 25.00%, 31.49%, 41.89%, 39.27%, and 38.98%, respectively. The second to seventh columns of Figure 4 display the inpainted results, in which zoomed-in details are placed at the top-left corner.

Figure 4.
Qualitative results for visual comparisons. From top to bottom, the first two images come from Places2 [57], the middle two from Paris StreetView [58], and the last two from CelebA [59]. All images are free from post-processing.
As we can see, the PConv model [30] fails to suppress the blurring and upsampling artifacts. This may be partly due to the absence of the adversarial loss and partly due to the interference introduced by the fully spatial feature normalization. Although the shift-net [35] and the MUSICAL [41] models are equipped with the contextual attention modules, they still occasionally generate the distorted structures in the filled region. This implies that allocating attention within a single stage may synthesize wrong features to some extent. The LSTM-PGN [47] and FRRN [48] models tend to fill in the hole according to surrounding colors. For example, their resulting images in the first row show that most of the filled regions share the similar hue (red) with their surroundings. This verifies that these two models [47,48] can only perceive a part of the surroundings throughout all inpainting stages. By contrast, our model successfully generates semantically reasonable and visually realistic contents with clear textures and sharper details. These qualitative comparisons demonstrate the superiority of the proposed model.
3.3. Quantitative Results
Table 1 lists the quantitative results, in which four canonical metrics, i.e., SSIM (Structural Similarity), PSNR (Peak Signal-to-Noise Ratio), FID (Fréchet Inception Distance) [66], and -norm, are used to objectively evaluate the inpainting quality. In this experiment, we consider three ranges of the corruption rates: 20–, 30–, and 40–, and correspondingly divide the test set into three groups, each of which comprises 150 test images. The values recorded in Table 1 are the average evaluation scores over 150 test images.

Table 1.
Quantitative results for numerical comparisons. The arrow “↑” (or “↓”) is intended to indicate that a higher (or lower) value is better. The best and the second best scores are highlighted by bold and underline, respectively.
As we can see, in most cases, the proposed model achieves better evaluation scores than the baselines, especially on the CelebA database [59]. For the case of low corruption rate (20–), our SSIM (PSNR) scores reach 0.901 (25.53 dB), 0.915 (28.17 dB), and 0.941 (31.10 dB) on the three databases, and their average equals 0.919 (28.27 dB). For the case of middle corruption rate (30–), our average SSIM (PSNR) score is 0.868 (25.93 dB). These evaluation scores reflect that the proposed model can fill in the hole with visually pleasing contents even when 20– pixels are unknowns. For the case of the high corruption rate (40–), although the average SSIM (PSNR) score drops down to 0.77 (23.58 dB), the principal outlines in the filled region can still be recognizable. Additionally, the proposed model behaves better in terms of FID and -norm, which jointly supports the qualitative comparisons.
Interestingly, we find that the MUSICAL model [41] usually achieves the second best performance, which just ranks below ours. This suggests that the multi-scale contextual attention mechanism is helpful for the image inpainting task, and equipping it with the progressive inpainting strategy (our main proposal) does further boost the performance.
3.4. Ablation Studies
In this section, we study how each part of the proposed model contributes to the inpainting performance from the following four perspectives: the MSCA module, the SE-based fusing module, the number of inpainting stages, and the collaborations between inpainting stages. Unless explicitly stated, the ablation studies are performed on the Places2 database [57] with the corruption rate of 30–.
3.4.1. Ablation Study on the MSCA Module
Recall that and are fed into the MSCA module. The former is the feature map at the -to-end layer of the shared encoder network, while the latter is feature map of the long-range attention branch. This ablation study is devoted to examining the influence of the position n on the inpainted results. As shown in Table 2, we consider six settings: , , , , , and , where the null set ⌀ indicates that the MSCA module is turned off.
Table 2.
Quantitative results for the ablation study on the MSCA module.
The scores in the column of are the worst, which demonstrates that the MSCA module are indeed useful for the image inpainting task. Moreover, we find that cascading two MSCA modules on the deeper layers usually outperforms the other settings. In this paper, the MSCA module is configured at the and layers of the long-range attention branch, as shown in Figure 1.
In Figure 5, we provide the qualitative results under the settings: , , and . Without the MSCA module, the predictions in the zoomed-in box look rather blurry and suffer from texture distortions. By contrast, the inpainted results in the third and fourth columns look clearer and sharper. Especially for the second example, the principal content in the shelf area has been restored successfully. These observations are consistent with the scores in Table 2.

Figure 5.
Qualitative results for the ablation study on the MSCA module. (a) Input images. (b) Resulting images for the setting . (c) Resulting images for the setting . (d) Resulting images for the setting .
3.4.2. Ablation Study on the SE-Based Fusing Module
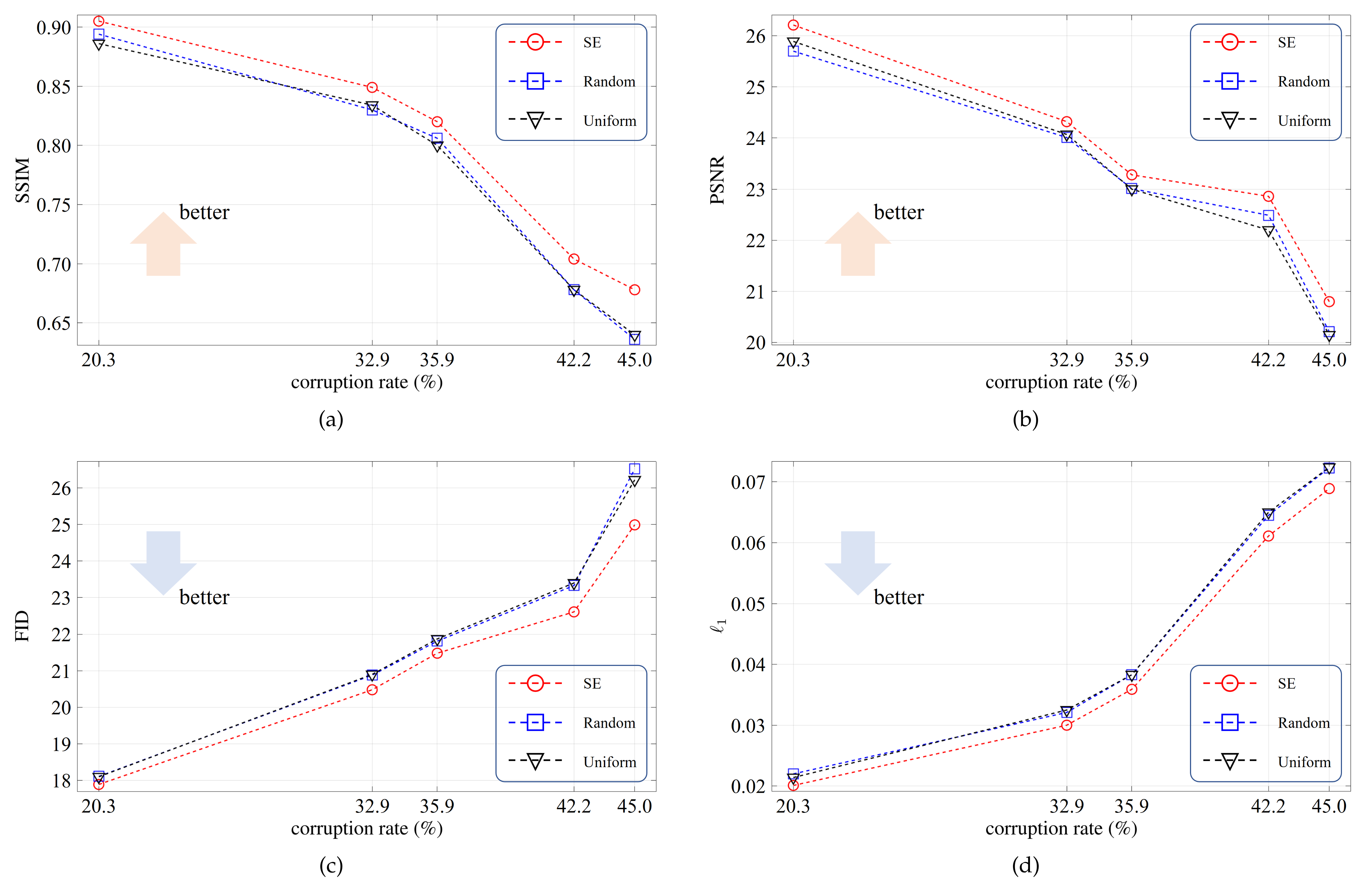
The SE-based fusing module is to refine the local and long-range features. To verify its effectiveness, in this ablation study, we consider three reweighting modes: SE, random, and uniform. The SE mode, as shown in Figure 3, means that the reweighting coefficients are generated from the learnable fully connected layers. In the random mode, the reweighting coefficients are sampled from a random distribution. In the uniform mode, the reweighting coefficients are fixed to . For convenience, all testing images are corrupted by five irregular binary masks, in which the corruption rates are , , , , and .
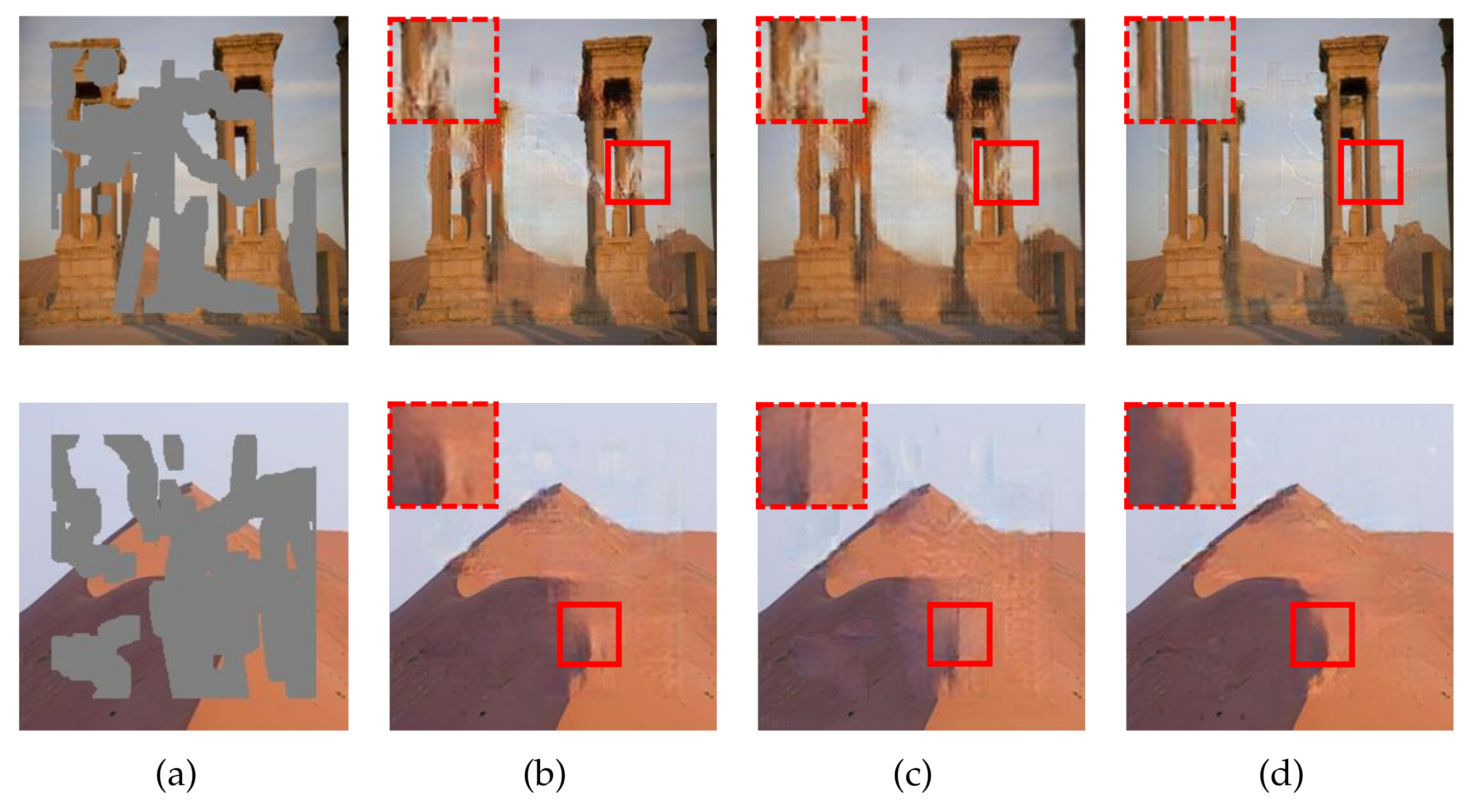
The average evaluation scores are plotted in Figure 6. As we can see, the SE mode outperforms the other two modes by clear margins, and the superiority becomes more significant for larger corruption rates. Figure 7 exhibits the resulting images for the three modes. For the first example, the SE mode completely reconstructs the pillar area while the other two modes suffer defeat. These results demonstrate that the SE-based fusing module plays a key role in comprehensively refining the two feature flows.
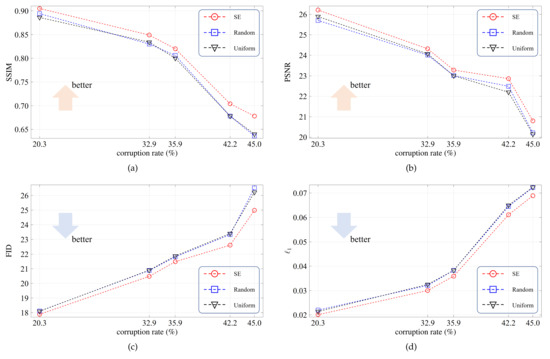
Figure 6.
Quantitative results for the ablation study on the SE-based fusing module. red(a) The SSIM scores. (b) The PSNR scores. (c) The FID scores. (d) The scores.
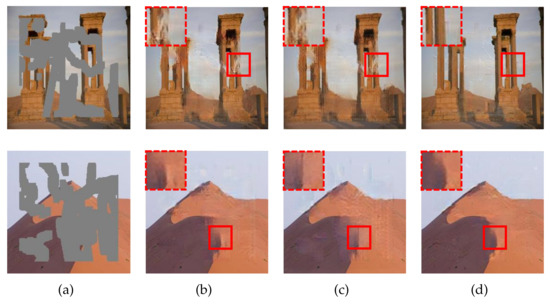
Figure 7.
Qualitative results for the ablation study on the SE-based fusing module. The corruption rates, from top to bottom, are and , respectively. (a) Input images. (b) Resulting images for the random mode. (c) Resulting images for the uniform mode. (d) Resulting images for the SE mode.
3.4.3. Ablation Study on the Number of Inpainting Stages
The total number of inpainting stages T highly affects the final inpainting performance. In this ablation study, we experimentally investigate what is the appropriate value of T. To this end, we set T to 1, 4, and 6, respectively, in the course of training. Table 3 records the evaluation scores. As expected, multiple inpainting stages, i.e., or 6, is superior to the single inpainting stage, i.e., . Comparing the last two columns of Table 3, we find that the quality gain is tiny when increasing T from 4 to 6. Based on our measurement, this tiny quality gain, however, consumes an additional 6.9G FLOPs (Floating Point Operations). In order to strike the balance between the inpainting quality and the computational cost, we recommend setting T to 4.
Table 3.
Quantitative results for the ablation study on the number of inpainting stages.
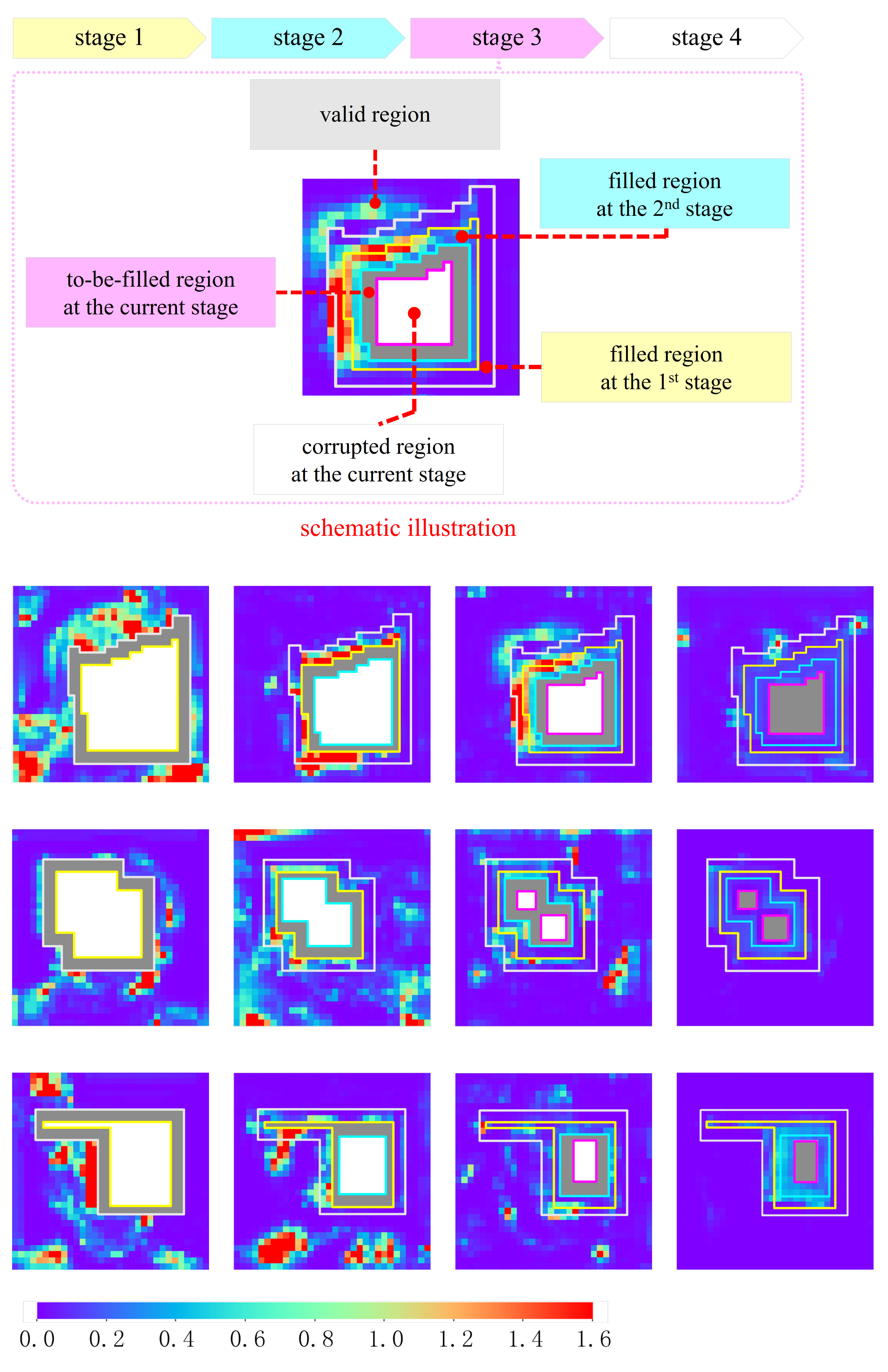
The first and third rows of Figure 8 show the resulting images, from which we find that more inpainting stages help to restore the realistic boundaries between objects. The second and fourth rows of Figure 8 visualize the feature deviations, which are obtained at the layer after the fusing module (the pink one in Figure 1) by calculating the difference between the feature maps of the input and groundtruth images. We focus on the filled region and highlight larger feature deviations in hot colors. As we can see, the second column of Figure 8 (i.e., ) contains more noticeable hot spots than the other columns. These results suggest that the designed progressive inpainting strategy is useful for the image inpainting task to reduce the feature deviations and narrow the semantic gap.

Figure 8.
Qualitative results for the ablation study on the number of inpainting stages. The corruption rates, from top to bottom, are and , respectively.
3.4.4. Ablation Study on the Collaborative Effect between Inpainting Stages
As discussed before, the filled region at the stage is regarded as the valid region at the stage. In other words, the MSCA module at the stage treats the filled region as the new source for synthesizing the inpainting-oriented features. In this ablation study, we attempt to reveal the collaborative effect between inpainting stages through two trials.
In the first trial, we visualize attention scores, which reflect how the patches in the to-be-filled region refer to the valid region. The actual calculation is the complement to the one shown in Figure 2 because the to-be-filled patches, rather than the valid patches, serve as the kernels in this trial. For simplicity, we focus only on the second MSCA module, namely the one configured at the layer of the long-range attention branch. Figure 9 shows the visualized heat map, which is obtained by summing the attention scores over the channel dimension. In the heat map, the hot and cool colors represent the high and low attention scores, respectively.
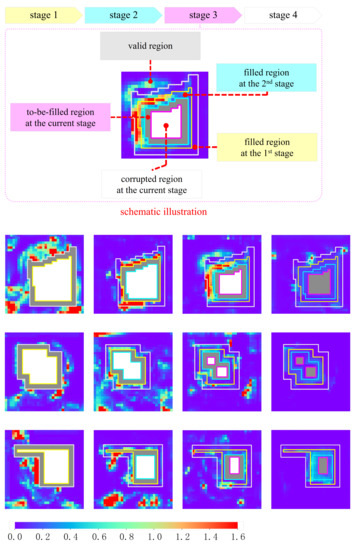
Figure 9.
Heat maps of the attention scores. A schematic illustration is shown at the top-half panel, in which four inpainting stages are demarcated by closed-loop frames depicted in colors. Three rows at the bottom-half panel exhibit the heat maps for three practical examples. Four columns, from left to right, correspond to the first, the second, the third and the fourth inpainting stages, respectively.
For the first inpainting stage, only the valid region is the source for synthesizing features, and all of the valid patches are likely to contribute to the inpainting task in a learnable way. For the other inpainting stages, the MSCA module borrows the features not only from the valid region but also from the filled ones. As we see in the first example, more hot colors are accumulated in the filled regions. This demonstrates the existence of the collaborative effect between inpainting stages.
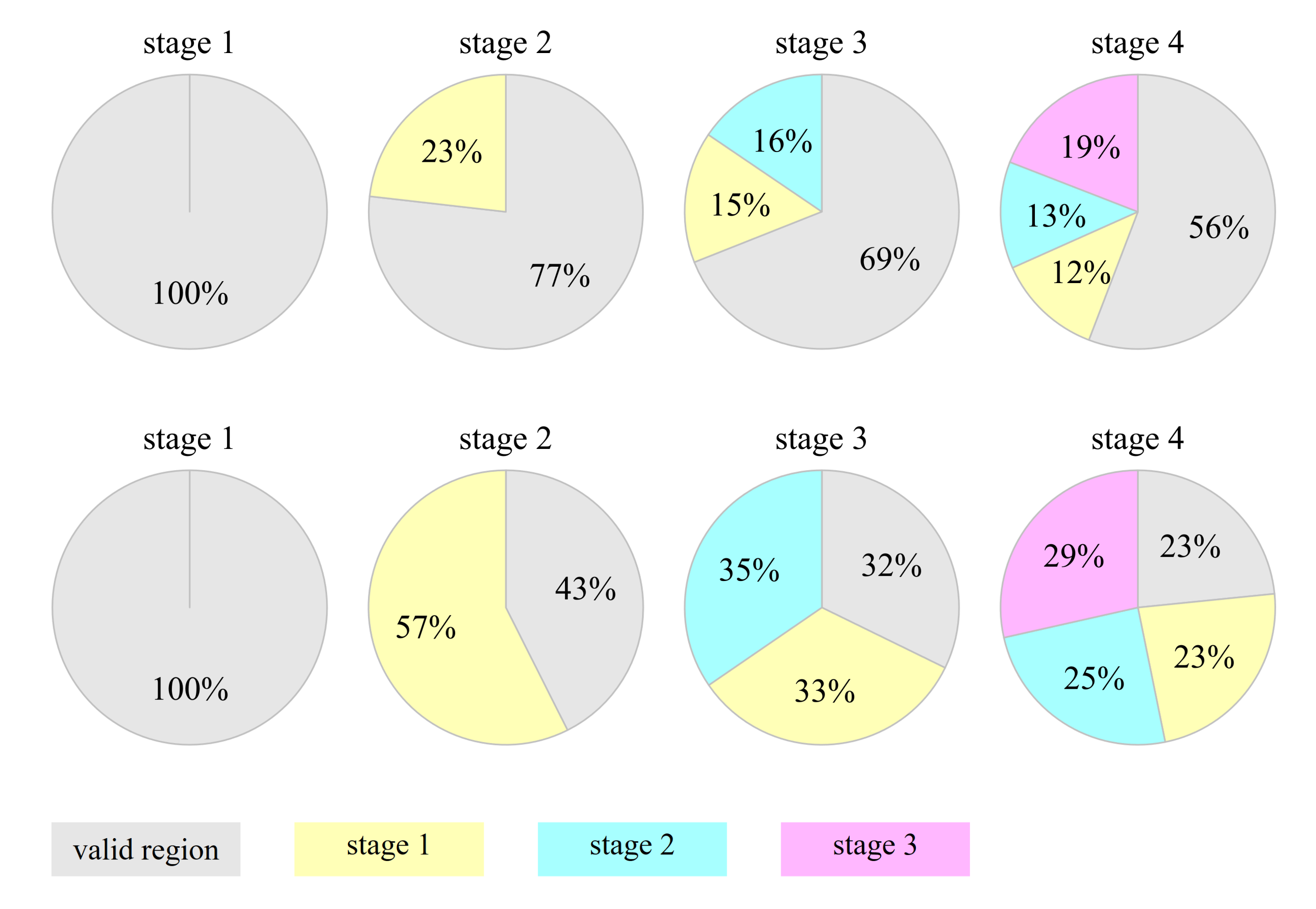
Figure 10 further shows how different regions contribute to the inpainting task at each stage. The contribution of a region is defined as the proportion of attention scores received by that region. From the first row of Figure 10, we see that, except for the first stage, all of the filled regions contribute to the inpainting task. Especially at the inpainting stage, the filled regions receive nearly half of the attention scores. Intuitively, the larger the region, the higher probability to receive the attention scores. For a fair comparison, we count the area-normalized contribution by using the attention score per unit area. From the second row of Figure 10, we see that, except for the first stage, each filled region roughly makes the same contribution the valid region. These statistical results demonstrate the usefulness of the collaborative effect between inpainting stages.
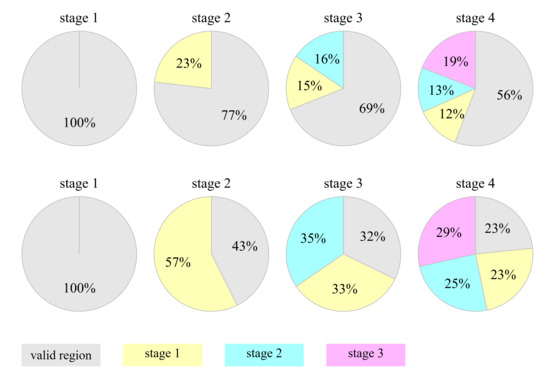
Figure 10.
Region-wise contribution at each inpainting stage. The second row corresponds to the area-normalized contribution.
In the second trial, we deliberately exclude the filled regions from the MSCA module. In doing so, only the valid region is available for the MSCA module to synthesize the features, regardless of the inpainting stage. In Figure 11, we show the resulting images for qualitative comparisons. As we see, the resulting images in Figure 11b contain observable upsampling artifacts and content deviations. For the top example, some white spots improperly appear in the black background. See the zoomed-in box for details. The reason for this is as follows. In this example, white is the dominant color in the valid region. When the filled regions are switched off, the MSCA module runs a higher risk of borrowing wrong features from the white region. By contrast, the resulting images in the last column have visually realistic and semantically plausible contents. This is because the filled regions extend the available source for synthesizing features to reduce the risk of allocating wrong attention. These results demonstrate the effectiveness of the collaborative effect between inpainting stages.

Figure 11.
Qualitative results for the ablation study on the collaborative effect between inpainting stages. The corruption rates, from top to bottom, are and , respectively. (a) Input images. (b) Resulting images when the filled regions are switched off. (c) Resulting images when the filled regions are switched on.
4. Conclusions
In this paper, we propose progressively inpainting the corrupted images based on a shared encoder network and a forked-then-fused decoder network. We design a PC-RN unit, which can perceive the valid information whilst suppressing the incompleteness-caused interference. The proposed decoder network forks into the local reception branch and the long-range attention branch (with two MSCA modules) at the beginning, and the two feature flows are adaptively refined through a SE-based fusing module. The progressive inpainting strategy has the collaborative effect in the sense that the filled region at the previous stage helps the MSCA module find matching features. We evaluate our inpainting model on three benchmark databases [57,58,59] and conduct the extensive comparative studies and ablation studies. Experimental results demonstrate the effectiveness and the superiority of the proposed model compared with the state-of-the-art works [30,35,41,47,48]. Four ablation studies reveal the functionality of each module for the inpainting task.
Author Contributions
Conceptualization, R.H. and F.H.; methodology, S.Y. and R.H.; validation, S.Y., R.H., and F.H.; data curation, S.Y.; writing, S.Y. and R.H.; visualization, S.Y.; supervision, R.H. and F.H.; funding acquisition, R.H. and F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the Fundamental Research Funds for the Central Universities (17D110408) and the National Natural Science Foundation of China (62001099 and 11972115).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Akbari, Y. Image inpainting: A review. Neural Process. Lett. 2020, 51, 2007–2028. [Google Scholar] [CrossRef] [Green Version]
- Shetty, R.; Fritz, M.; Schiele, B. Adversarial scene editing: Automatic object removal from weak supervision. Proc. Adv. Neural Inf. Process. Syst. (NIPS) 2018, 31, 7717–7727. [Google Scholar]
- Song, L.S.; Cao, J.; Song, L.X.; Hu, Y.B.; He, R. Geometry-aware face completion and editing. Proc. Assoc. Adv. Artif. Intell. (AAAI) 2019, 33, 2506–2513. [Google Scholar] [CrossRef] [Green Version]
- Xiong, H.; Wang, C.Y.; Wang, X.C.; Tao, D.C. Deep representation calibrated bayesian neural network for semantically explainable face inpainting and editing. IEEE Access 2020, 8, 13457–13466. [Google Scholar] [CrossRef]
- Cornelis, B.; Ružić, T.; Gezels, E.; Dooms, A.; Pižurica, A.; Platiša, L.; Cornelis, J.; Martens, M.; DeMey, M.; Daubechies, I. Crack detection and inpainting for virtual restoration of paintings: The case of the Ghent Altarpiece. Signal Process. 2013, 93, 605–619. [Google Scholar] [CrossRef]
- Pei, S.C.; Zeng, Y.C.; Chang, C.H. Virtual restoration of ancient Chinese paintings using color contrast enhancement and lacuna texture synthesis. IEEE Trans. Image Process. 2004, 13, 416–429. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, W.L.; Jia, Y.J. Damaged region filling and evaluation by symmetrical exemplar-based image inpainting for Thangka. EURASIP J. Image Vid. Process. 2017, 38, 1–13. [Google Scholar] [CrossRef]
- Jo, I.S.; Choi, D.B.; Park, Y.B. Chinese character image completion using a generative latent variable model. Appl. Sci. 2021, 11, 624. [Google Scholar] [CrossRef]
- Ehsani, K.; Mottaghi, R.; Farhadi, A. SeGAN: Segmenting and generating the invisible. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6144–6153. [Google Scholar]
- Yan, X.S.; Wang, F.G.G.; Liu, W.X.; Yu, Y.L.; He, S.F.; Pan, J. Visualizing the invisible: Occluded vehicle segmentation and recovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7617–7626. [Google Scholar]
- Upenik, E.; Akyazi, P.; Tuzmen, M.; Ebrahimi, T. Inpainting in omnidirectional images for privacy protection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2487–2491. [Google Scholar]
- Sun, Q.R.; Ma, L.Q.; Oh, S.J.; Gool, L.V.; Schiele, B.; Fritz, M. Natural and effective obfuscation by head inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5050–5059. [Google Scholar]
- Gong, M.G.; Liu, J.L.; Li, H.; Xie, Y.; Tang, Z.D. Disentangled representation learning for multiple attributes preserving face deidentification. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar]
- Ching, J.H.; See, J.; Wong, L.K. Learning image aesthetics by learning inpainting. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Virtual, Abu Dhabi, UAE, 25–28 October 2020; pp. 2246–2250. [Google Scholar]
- Han, X.T.; Wu, Z.X.; Huang, W.L.; Scott, M.R.; Davis, L.S. FiNet: Compatible and diverse fashion image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4480–4490. [Google Scholar]
- Yu, L.; Zhong, Y.Q.; Wang, X. Inpainting-based virtual try-on network for selective garment transfer. IEEE Access 2019, 7, 134125–134136. [Google Scholar] [CrossRef]
- Li, P.; Li, S.J.; Yao, Z.A.; Zhang, Z.J. Two anisotropic forth-order partial differential equations for image inpainting. IET Image Process. 2013, 7, 260–269. [Google Scholar] [CrossRef] [Green Version]
- Li, S.J.; Yang, X.H. Novel image inpainting algorithm based on adaptive fourth-order partial differential equation. IET Image Process. 2017, 11, 870–879. [Google Scholar] [CrossRef]
- Kumar, B.V.R.; Halim, A. A linear fourth-order PDE-based gray-scale image inpainting model. Comput. Appl. Math. 2019, 38, 6. [Google Scholar] [CrossRef]
- Halim, A.; Kumar, B.V.R. An anisotropic PDE model for image inpainting. Comput. Math. Appl. 2020, 79, 2701–2721. [Google Scholar] [CrossRef]
- Criminisi, A.; Pérez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Sun, J. Image completion approaches using the statistics of similar patches. IEEE Pattern Anal. Mach. Intell. 2014, 36, 2423–2435. [Google Scholar] [CrossRef] [PubMed]
- Buyssens, P.; Daisy, M.; Tschumperlé, D.; Lézoray, O. Exemplar-based inpainting: Technical review and new heuristics for better geometric reconstructions. IEEE Trans. Image Process. 2015, 24, 1809–1824. [Google Scholar] [CrossRef]
- Liu, X.M.; Zhai, D.M.; Zhou, J.T.; Wang, S.Q.; Zhao, D.B.; Gao, H.J. Sparsity-based image error concealment via adaptive dual dictionary learning and regularization. IEEE Trans. Image Process. 2017, 26, 782–796. [Google Scholar] [CrossRef]
- Guo, Q.; Gao, S.S.; Zhang, X.F.; Yin, Y.L.; Zhang, C.M. Patch-based image inpainting via two-stage low rank approximation. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2023–2036. [Google Scholar] [CrossRef]
- Ding, D.; Ram, S.; Rodríguez, J.J. Image inpainting using nonlocal texture matching and nonlinear filtering. IEEE Trans. Image Process. 2019, 28, 1705–1719. [Google Scholar] [CrossRef] [PubMed]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6721–6729. [Google Scholar]
- Liu, G.L.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. Proc. Eur. Conf. Comput. Vis. (ECCV) 2018, 11215, 89–105. [Google Scholar]
- Liu, H.Y.; Jiang, B.; Song, Y.B.; Huang, W.; Yang, C. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. Proc. Eur. Conf. Comput. Vis. (ECCV) 2020, 12347, 725–741. [Google Scholar]
- Yu, J.H.; Lin, Z.; Yang, J.M.; Shen, X.H.; Lu, X.; Huang, T. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4470–4479. [Google Scholar]
- Ma, Y.Q.; Liu, X.L.; Bai, S.H.; Wang, L.; He, D.L.; Liu, A.S. Coarse-to-fine image inpainting via region-wise convolutions and non-local correlation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3123–3129. [Google Scholar]
- Song, Y.H.; Yang, C.; Lin, Z.; Liu, X.F.; Huang, Q.; Li, H.; Kuo, C.C.J. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Yan, Z.Y.; Li, X.M.; Li, M.; Zuo, W.M.; Shan, S.G. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yu, J.H.; Lin, Z.; Yang, J.M.; Shen, X.H.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Yang, J.; Qi, Z.Q.; Shi, Y. Learning to incorporate structure knowledge for image inpainting. Proc. Assoc. Adv. Artif. Intell. (AAAI) 2020, 34, 12605–12612. [Google Scholar] [CrossRef]
- Sagong, M.C.; Shin, Y.G.; Kim, S.W.; Park, S.; Ko, S.J. PEPSI: Fast image inpainting with parallel decoding network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11352–11360. [Google Scholar]
- Shin, Y.G.; Sagong, M.C.; Yeo, Y.J.; Kim, S.W.; Ko, S.J. PEPSI++: Fast and lightweight network for image. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 252–265. [Google Scholar] [CrossRef] [Green Version]
- Uddin, S.M.N.; Jung, Y.J. Global and local attention-based free-form image inpainting. Sensors 2020, 20, 3204. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Li, J.Y.; Zhang, L.F.; Du, B. MUSICAL: Multi-scale image contextual attention learning for inpainting. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3748–3754. [Google Scholar]
- Wang, N.; Ma, S.H.; Li, J.Y.; Zhang, Y.P.; Zhang, L.F. Multistage attention network for image inpainting. Pattern Recognit. 2020, 106, 107448. [Google Scholar] [CrossRef]
- Zeng, Y.H.; Fu, J.L.; Chao, H.Y.; Guo, B.N. Learning pyramid-context encoder network for high-quality image inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1486–1494. [Google Scholar]
- Liu, H.Y.; Jiang, B.; Xiao, Y.; Yang, C. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4169–4178. [Google Scholar]
- Li, J.Y.; Wang, N.; Zhang, L.F.; Du, B.; Tao, D.C. Recurrent Feature Reasoning for Image Inpainting. Available online: https://openaccess.thecvf.com/content_CVPR_2020/papers/Li_Recurrent_Feature_Reasoning_for_Image_Inpainting_CVPR_2020_paper.pdf (accessed on 22 August 2021).
- Xiong, W.; Yu, J.H.; Lin, Z.; Yang, J.M.; Lu, X.; Barnes, C.; Luo, J.B. Foreground-aware image inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5833–5841. [Google Scholar]
- Zhang, H.R.; Hu, Z.Z.; Luo, C.Z.; Zuo, W.M.; Wang, M. Semantic image inpainting with progressive generative networks. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 939–1947. [Google Scholar]
- Guo, Z.Y.; Chen, Z.B.; Yu, T.; Chen, J.L.; Liu, S. Progressive image inpainting with full-resolution residual network. In Proceedings of the 26th ACM international conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2496–2504. [Google Scholar]
- Chen, Y.Z.; Hu, H.F. An improved method for semantic image inpainting with GANs: Progressive inpainting. Neural Process. Lett. 2019, 49, 1355–1367. [Google Scholar] [CrossRef]
- Zeng, Y.; Lin, Z.; Yang, J.M.; Zhang, J.M.; Shechtman, E.; Lu, H.C. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 1–17. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Proc. Adv. Neural Inf. Process. Syst. (NIPS) 2014, 2, 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. Proc. Med. Image Comput. Comput. Assist Interv. (MICCAI) 2015, 9351, 234–241. [Google Scholar]
- Yu, T.; Guo, Z.Y.; Jin, X.; Wu, S.L.; Chen, Z.B.; Li, W.P.; Zhang, Z.Z.; Liu, S. Region normalization for image inpainting. Proc. Assoc. Adv. Artif. Intell. (AAAI) 2020, 34, 12733–12740. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doersch, C.; Singh, S.; Gupta, A.; Sivic, J.; Efros, A.A. What makes Paris look like Paris. ACM Trans. Graph. 2012, 31, 101. [Google Scholar] [CrossRef]
- Liu, Z.W.; Luo, P.; Wang, X.G.; Tang, X.O. Deep learning face attributes in the wild. Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.H.; Efros, A.A. Image-to-image translation with conditional adversarial networks. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.H.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980v5. [Google Scholar]
- Hensel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Proc. Adv. Neural Inf. Process. Syst. (NIPS) 2017, 30, 6629–6640. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).