
Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors

 ,
,  , , , , , and
, , , , , and 
Abstract
:1. Introduction
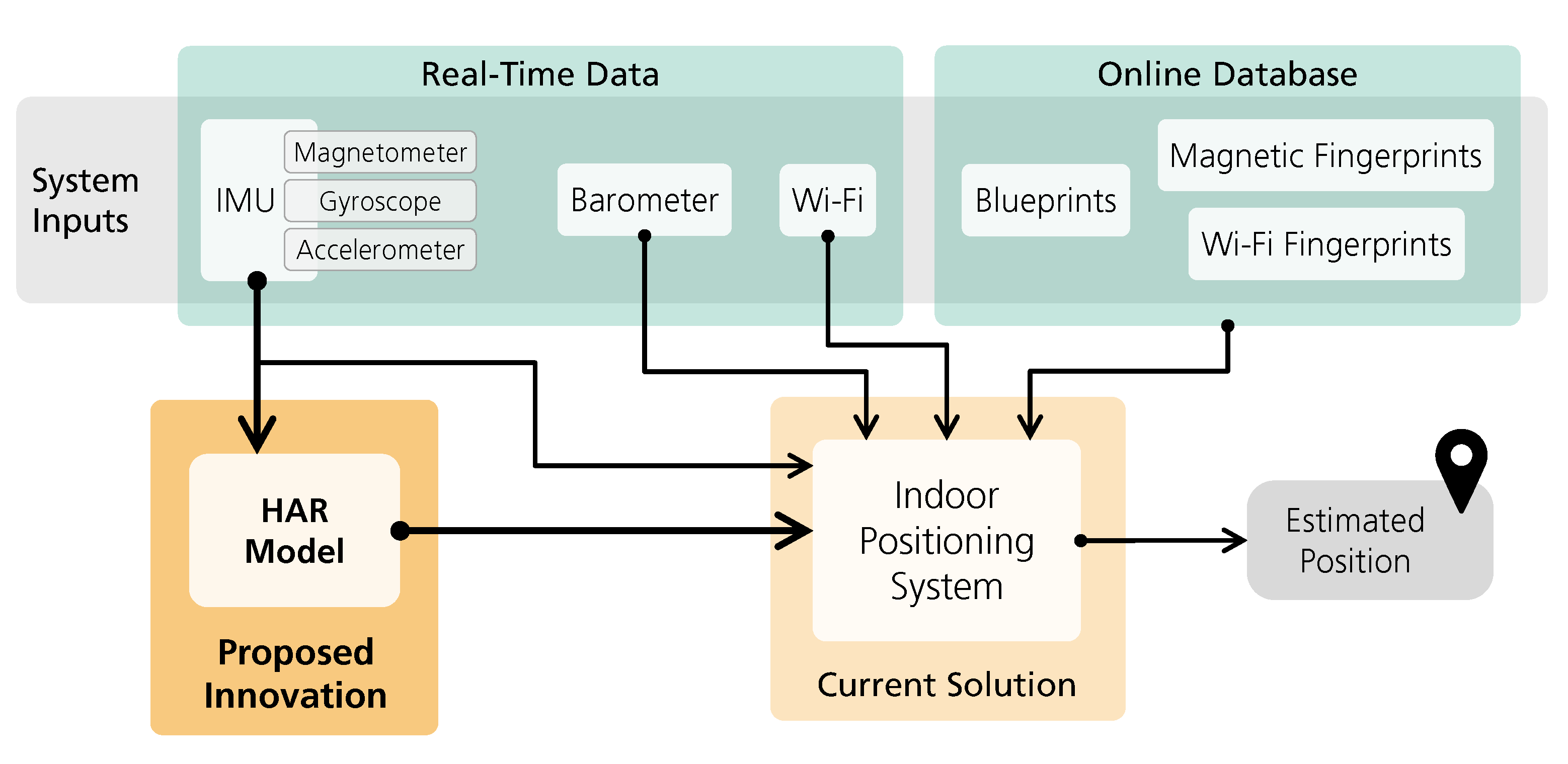
- A deep-learning framework that relies only on inertial sensors to accurately recognize nine different activities;
- The training of the HAR model using data from a vast number of different users and several different low- to high-range smartphones, increasing the model’s robustness;
- Using a human activity recognition module within an indoor positioning system, improving the overall positioning results.
2. Related Work
2.1. Traditional Machine Learning Methods for HAR
2.2. Deep-Learning Methods for HAR
2.3. Indoor Localization with HAR
3. Background: Neural Networks
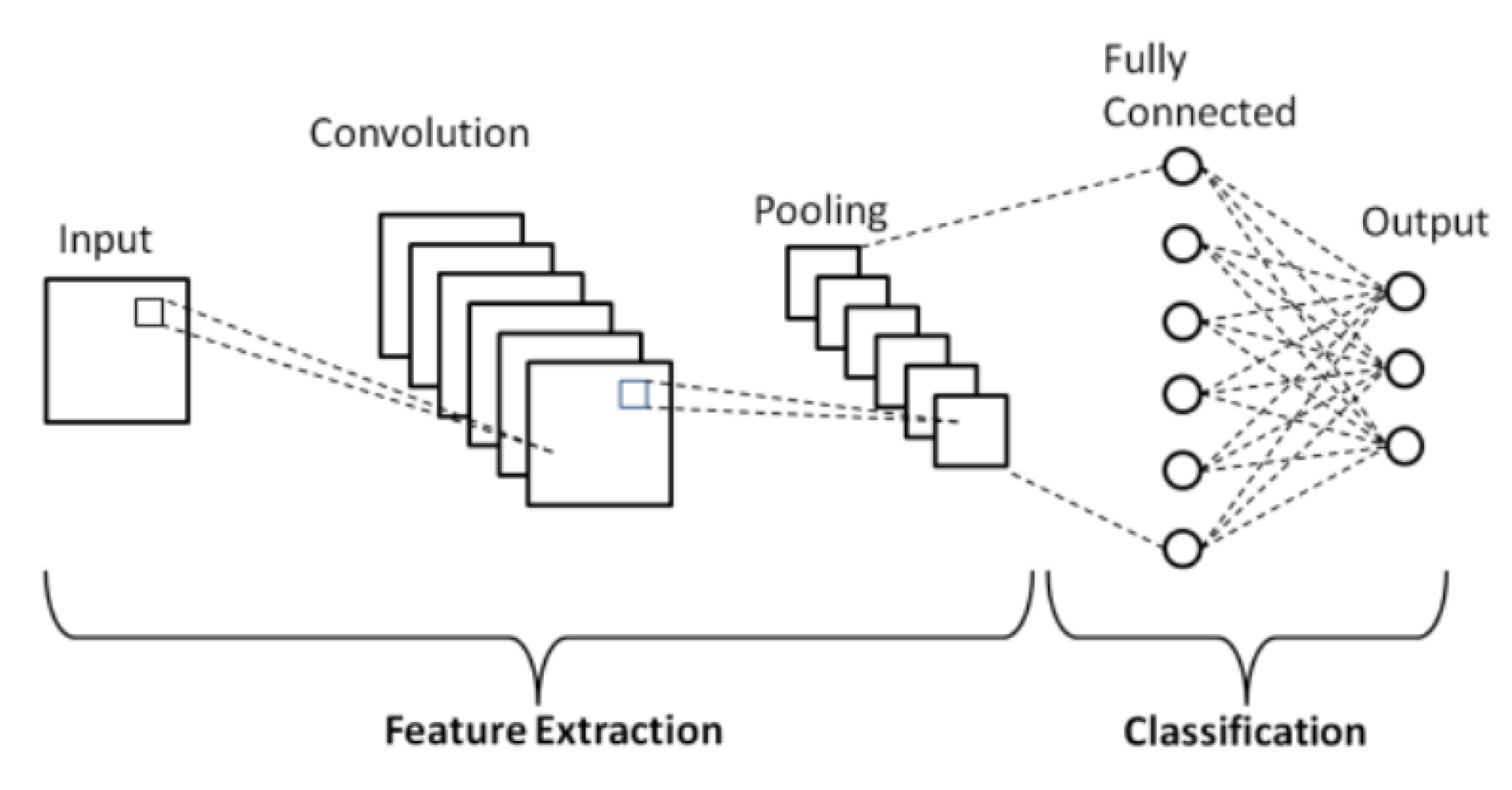
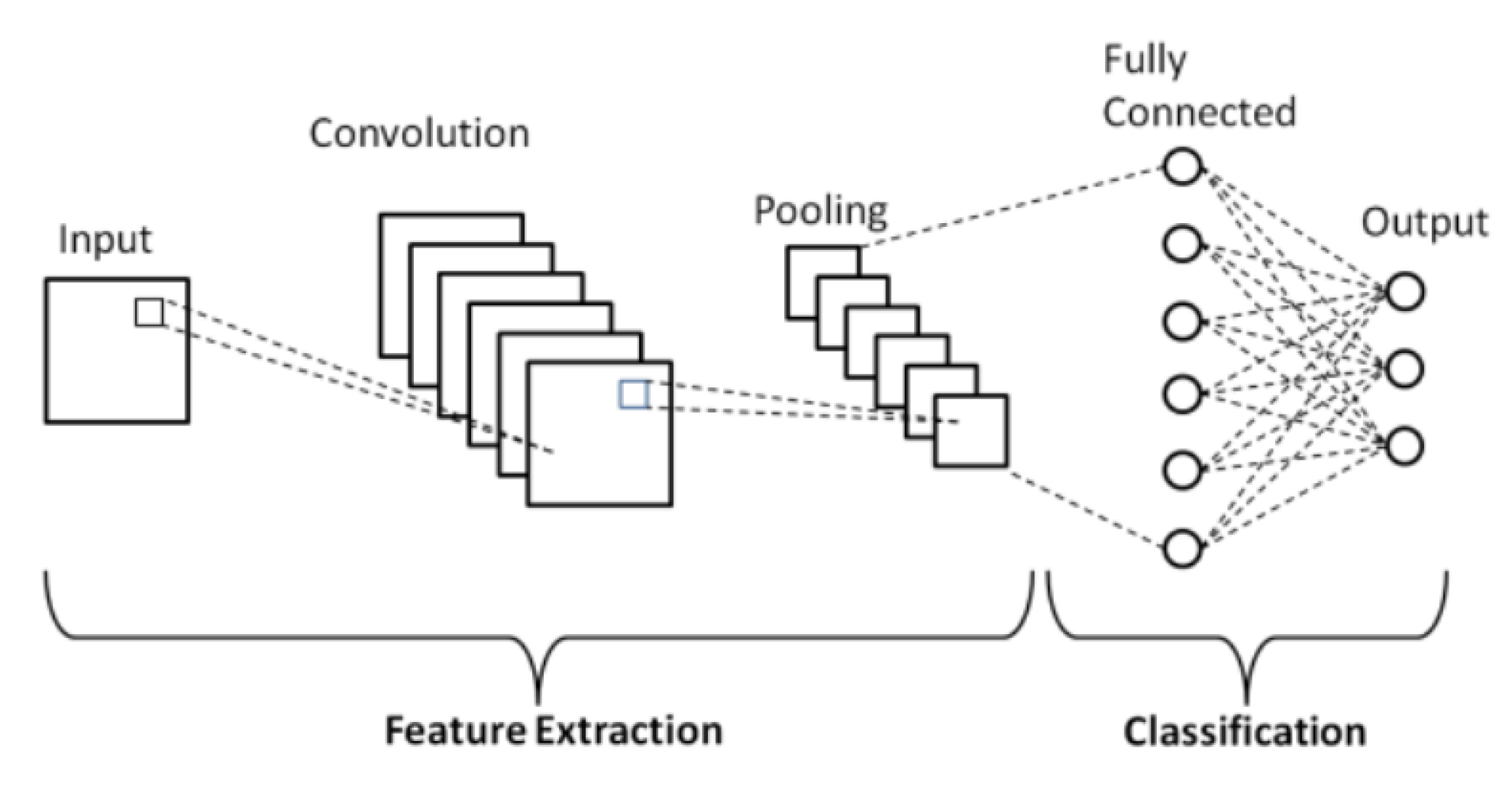
3.1. Convolution Neural Networks
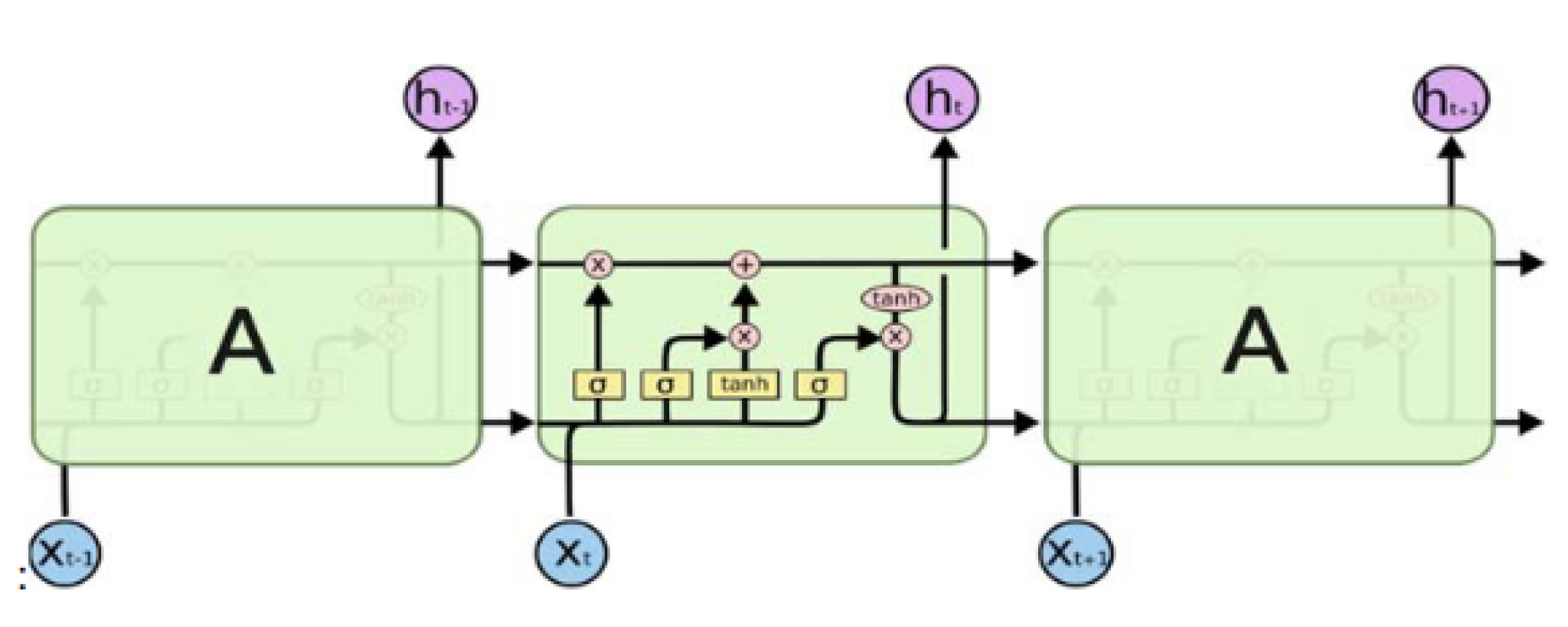
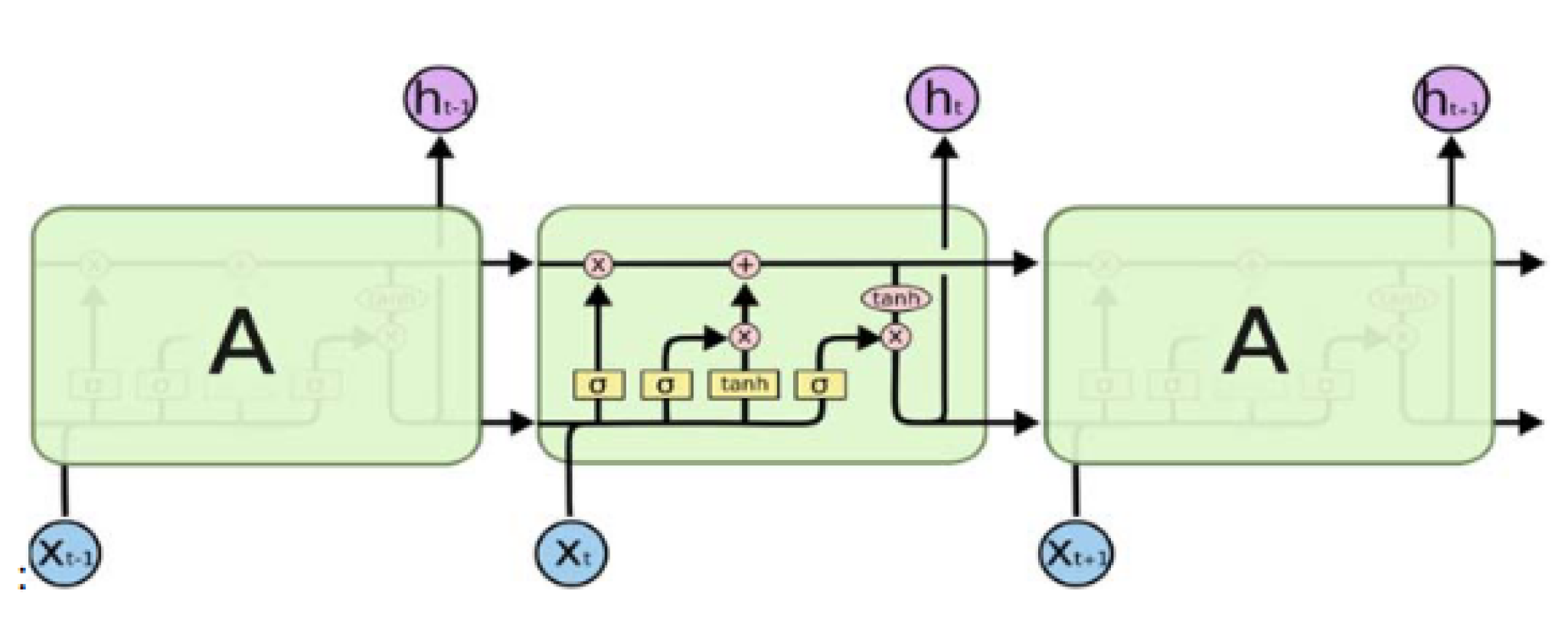
3.2. Long Short-Term Neural Networks
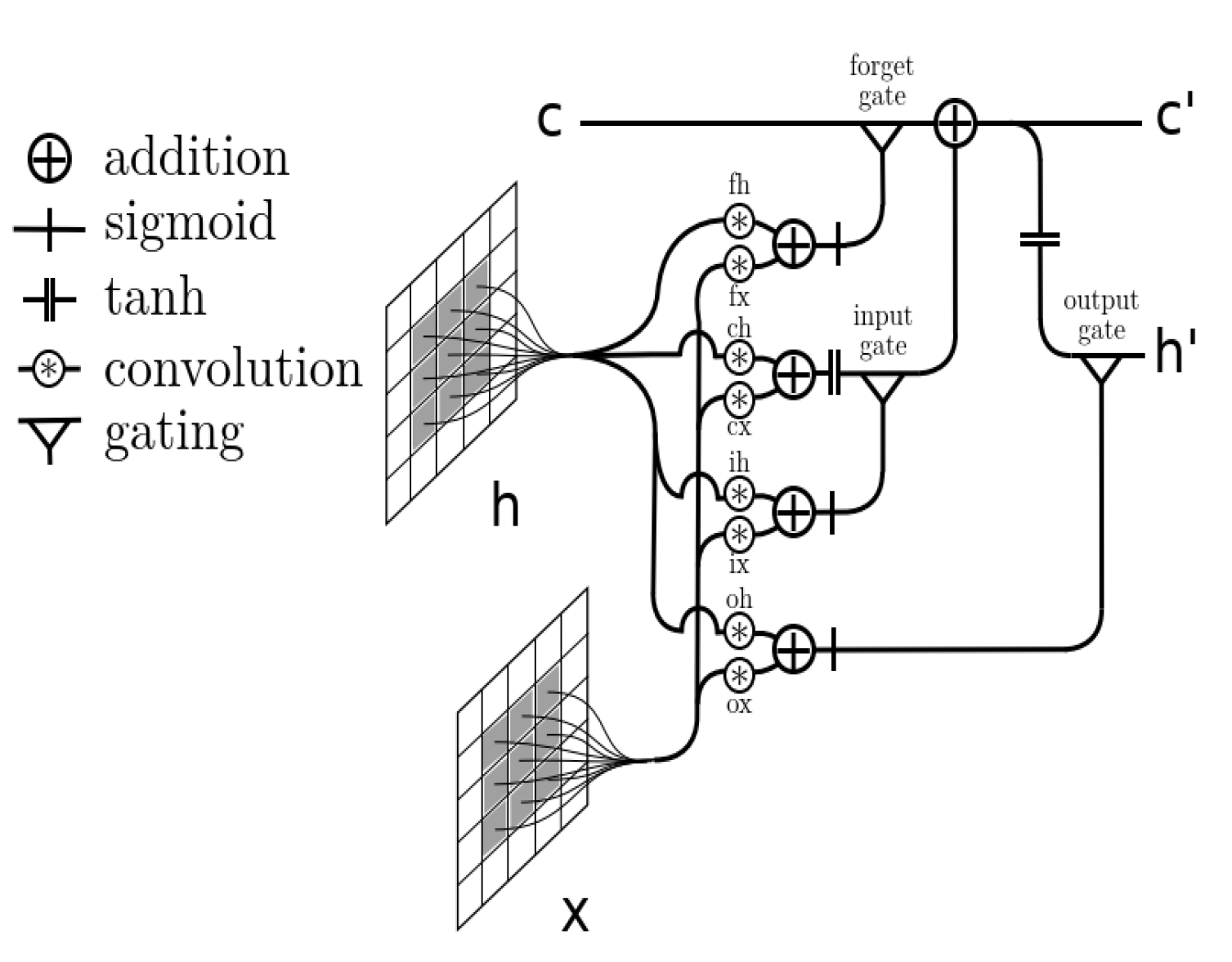
3.3. Convolution LSTM Neural Networks
4. Methodology
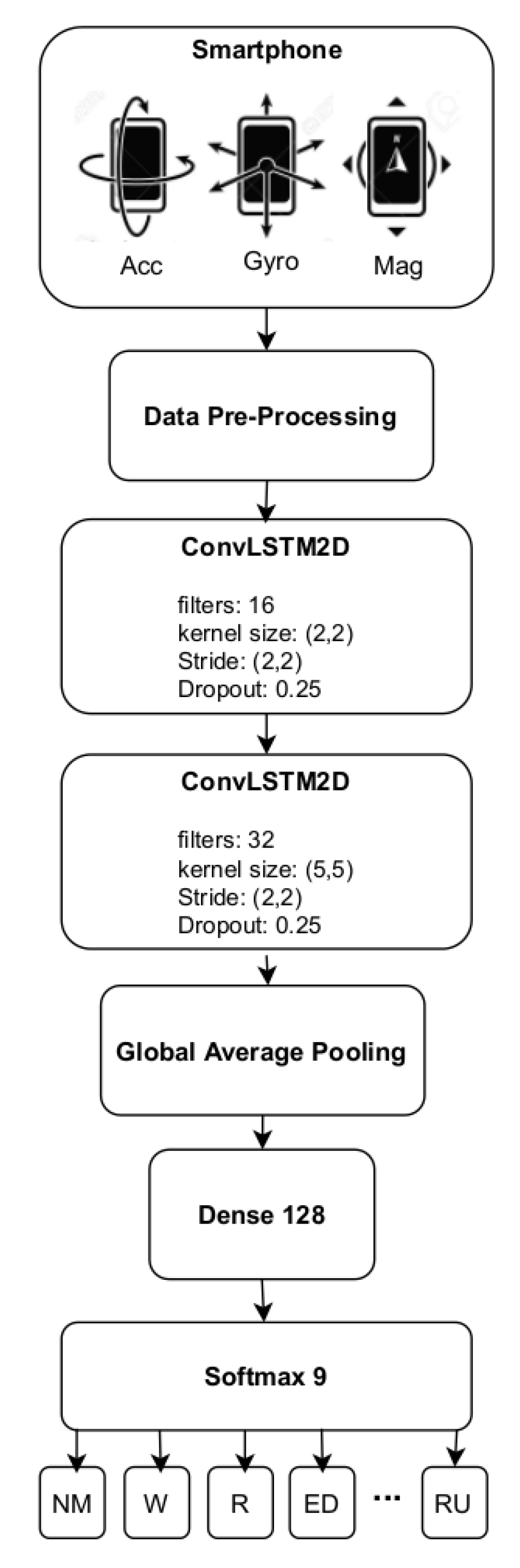
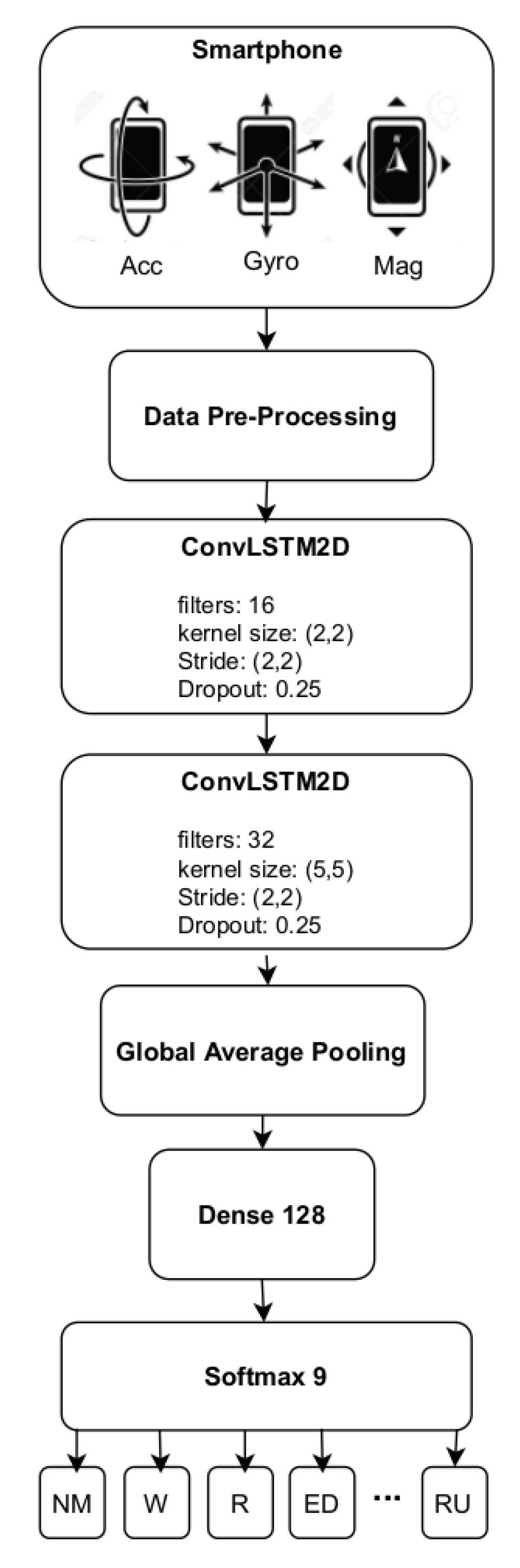
4.1. Proposed HAR Architecture
4.1.1. Data Pre-Processing
Resampling
Filtering
Segmentation
Scaling
4.1.2. Model Training and Optimization
4.2. Indoor Positioning System
4.2.1. Human Motion Tracking
4.2.2. Particle Filtering
5. Experiments and Results
5.1. Datasets
5.1.1. HAR Activities
5.1.2. HAR Dataset
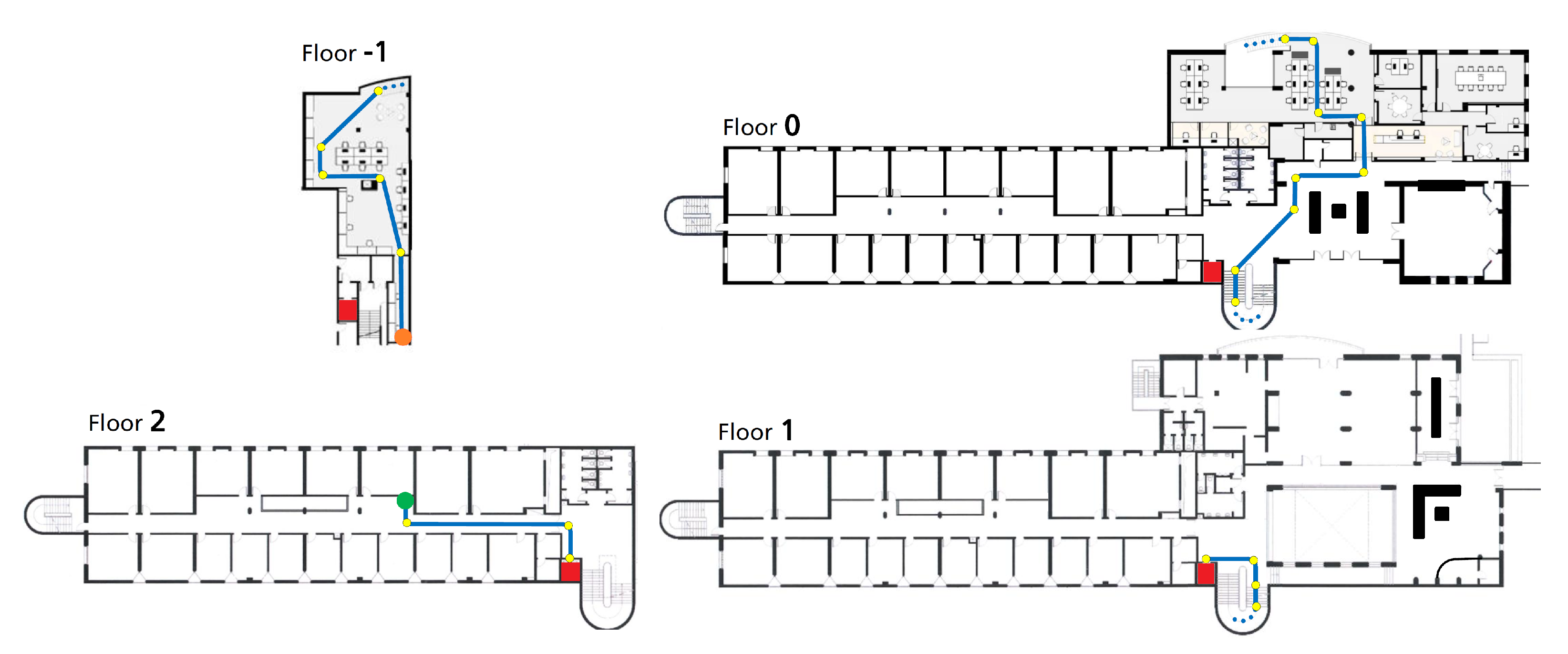
5.1.3. Indoor Location Dataset
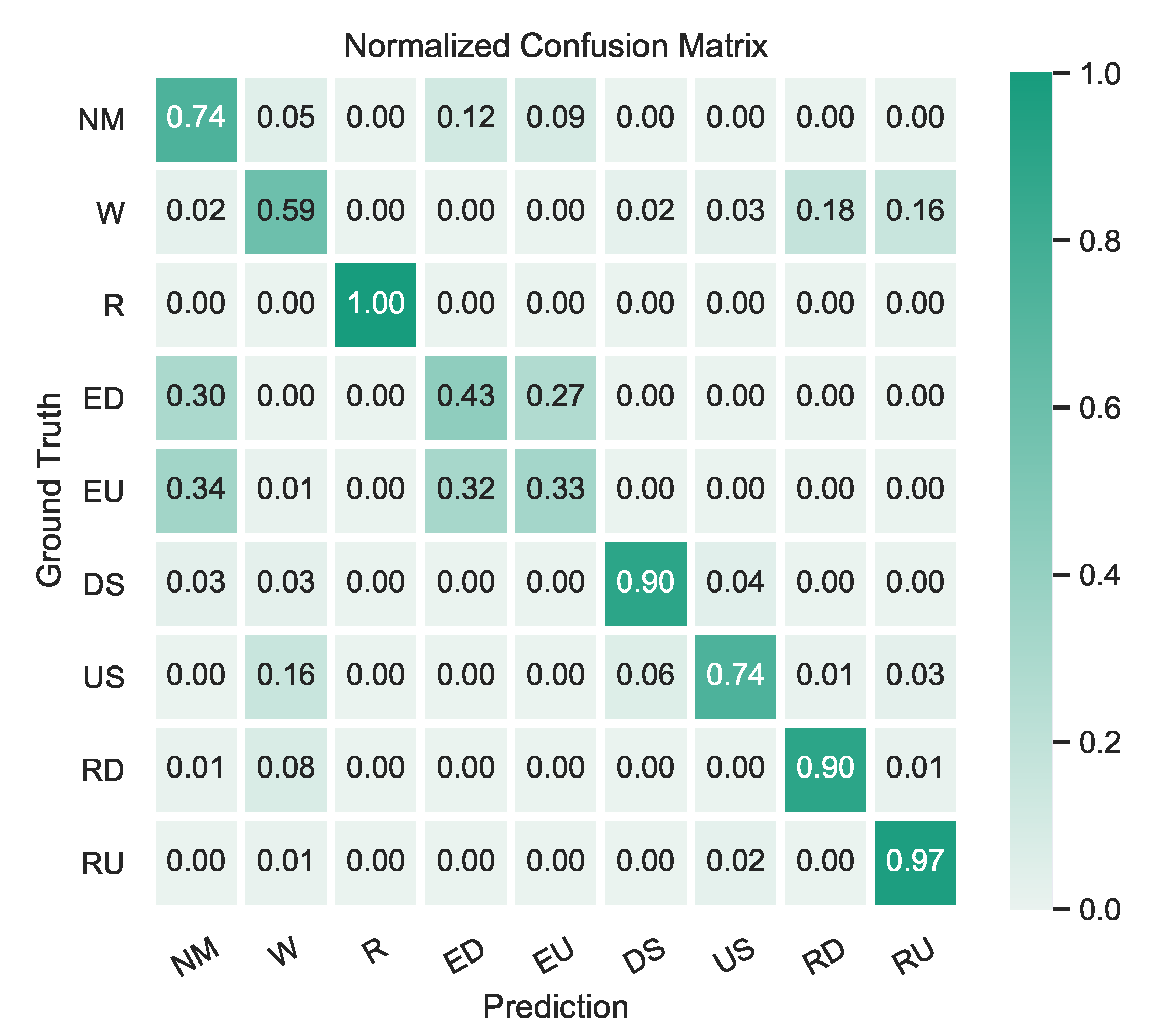
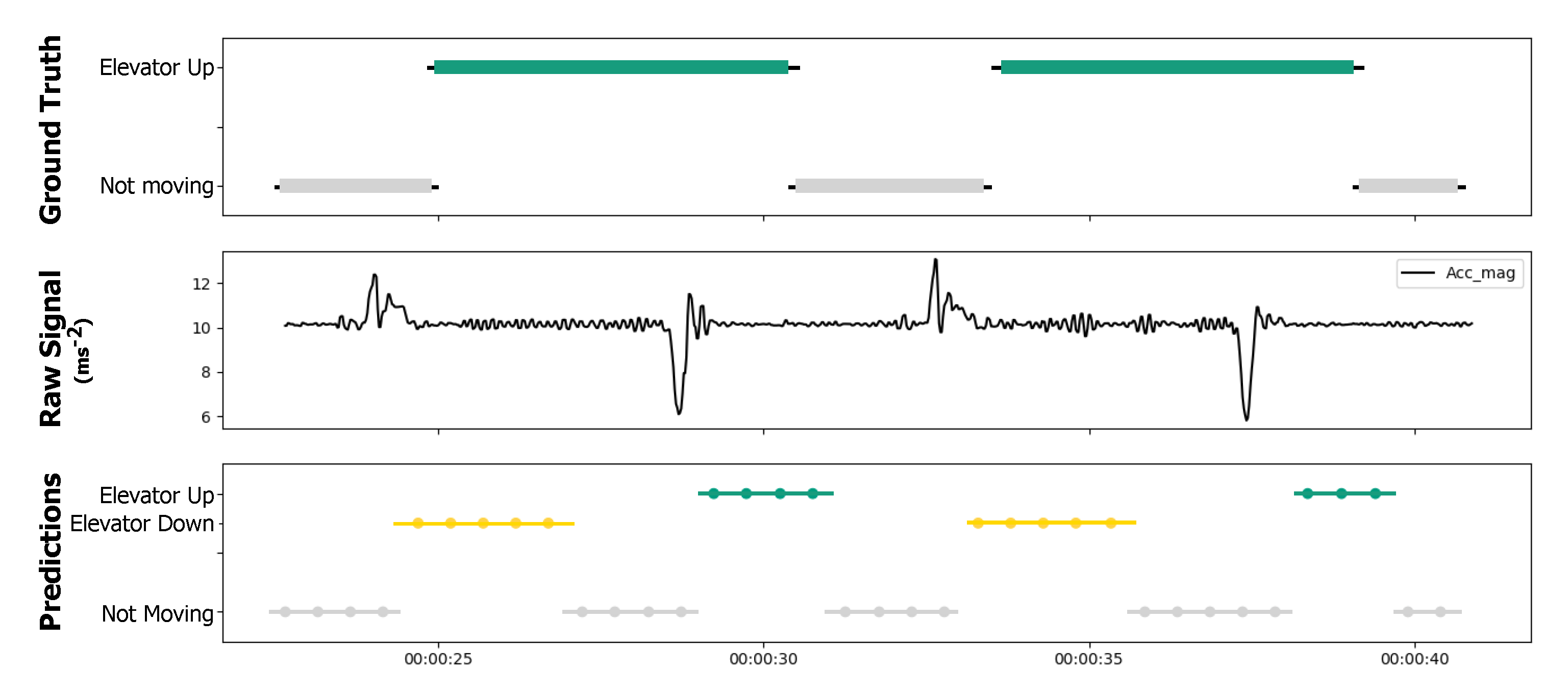
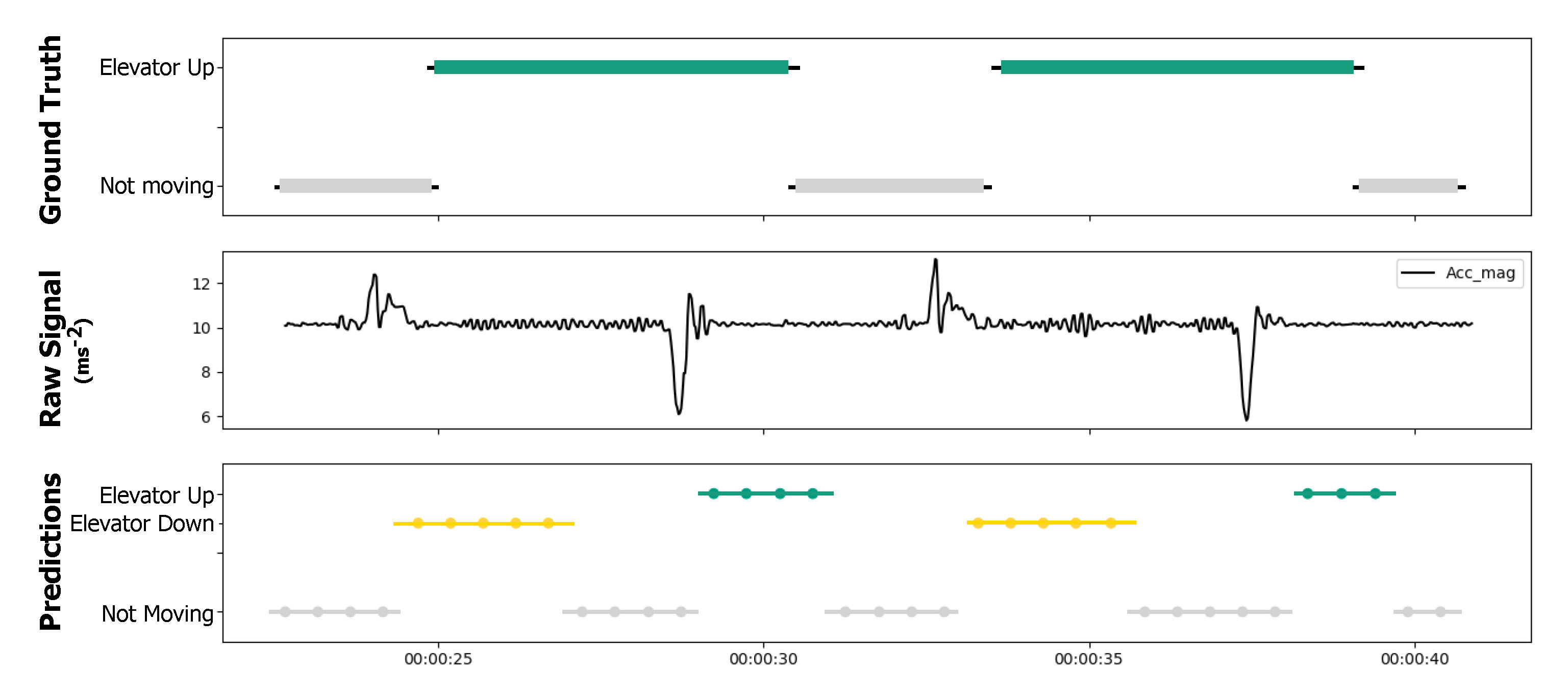
5.2. HAR Classification Performance
5.3. Indoor Localization Performance
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sousa Lima, W.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human activity recognition using inertial sensors in a smartphone: An overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [Green Version]
- Mekruksavanich, S.; Jitpattanakul, A. LSTM networks using smartphone data for sensor-based human activity recognition in smart homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Yang, J.; Li, Q. Smartphone-based activity recognition for indoor localization using a convolutional neural network. Sensors 2019, 19, 621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Almaslukh, B.; Artoli, A.M.; Al-Muhtadi, J. A robust deep learning approach for position-independent smartphone-based human activity recognition. Sensors 2018, 18, 3726. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep learning models for real-time human activity recognition with smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Guo, S.; Xiong, H.; Zheng, X.; Zhou, Y. Activity recognition and semantic description for indoor mobile localization. Sensors 2017, 17, 649. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rida, M.E.; Liu, F.; Jadi, Y.; Algawhari, A.A.A.; Askourih, A. Indoor Location Position Based on Bluetooth Signal Strength. In Proceedings of the 2nd International Conference on Information Science and Control Engineering, Shanghai, China, 24–26 April 2015; pp. 769–773. [Google Scholar]
- Guimarães, V.; Castro, L.; Carneiro, S.; Monteiro, M.; Rocha, T.; Barandas, M.; Machado, J.; Vasconcelos, M.; Gamboa, H.; Elias, D. A motion tracking solution for indoor localization using smartphones. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Madrid, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Cerón, J.D.; López, D.M. Human Activity Recognition Supported on Indoor Localization: A Systematic Review. pHealth 2018, 249, 93–101. [Google Scholar]
- Yuan, G.; Wang, Z.; Meng, F.; Yan, Q.; Xia, S. An overview of human activity recognition based on smartphone. Sens. Rev. 2019, 39, 288–306. [Google Scholar] [CrossRef]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey. IEEE Access 2020. [Google Scholar] [CrossRef] [PubMed]
- Zebin, T.; Sperrin, M.; Peek, N.; Casson, A.J. Human activity recognition from inertial sensor time-series using batch normalized deep LSTM recurrent networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 1–4. [Google Scholar]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time series feature extraction library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galván-Tejada, C.E.; López-Monteagudo, F.E.; Alonso-González, O.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Gamboa-Rosales, H.; Magallanes-Quintanar, R.; Zanella-Calzada, L.A. A Generalized Model for Indoor Location Estimation Using Environmental Sound from Human Activity Recognition. ISPRS Int. J. Geo-Inf. 2018, 7, 81. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W.; Zhang, X.; Chen, L. ALIMC: Activity Landmark-Based Indoor Mapping via Crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2774–2785. [Google Scholar] [CrossRef]
- Wang, H.; Sen, S.; Elgohary, A.; Farid, M.; Youssef, M.; Choudhury, R.R. No Need to War-Drive: Unsupervised Indoor Localization. In Proceedings of the 10th International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2012; pp. 197–210. [Google Scholar]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Conditional time series forecasting with convolutional neural networks. arXiv 2017, arXiv:1703.04691. [Google Scholar]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Phung, V.H.; Rhee, E.J. A high-accuracy model average ensemble of convolutional neural networks for classification of cloud image patches on small datasets. Appl. Sci. 2019, 9, 4500. [Google Scholar] [CrossRef] [Green Version]
- Pan, S. Coal Price Prediction based on LSTM. J. Phys. Conf. Ser. 2021, 1802, 042055. [Google Scholar] [CrossRef]
- Stollenga, M.F. Advances in Humanoid Control and Perception. Ph.D. Thesis, Università della Svizzera Italiana, Lugano, Switzerland, 2016. [Google Scholar]
- Santos, R.; Leonardo, R.; Barandas, M.; Moreira, D.; Rocha, T.; Alves, P.; Oliveira, J.P.; Gamboa, H. Crowdsourcing-based fingerprinting for indoor location in multi-storey buildings. IEEE Access 2021, 9, 31143–31160. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. Esann 2013, 3, 3. [Google Scholar]
- Wan, X. Influence of feature scaling on convergence of gradient iterative algorithm. J. Phys. Conf. Ser. 2019, 1213, 032021. [Google Scholar] [CrossRef] [Green Version]
- Leonardo, R.; Rodrigues, G.; Barandas, M.; Alves, P.; Santos, R.; Gamboa, H. Determination of the Walking Direction of a Pedestrian from Acceleration Data. In Proceedings of the 2019 International Conference on Indoor Positioning and Indoor Navigation (IPIN), IEEE, Pisa, Italy, 30 September–3 October 2019; pp. 1–6. [Google Scholar]
- Weinberg, H. Using the ADXL202 in pedometer and personal navigation applications. Analog. Devices AN-602 Appl. Note 2002, 2, 1–6. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Activity | Description |
|---|---|---|
| NW | Not Moving | The user is seated, standing, or waving their smartphone around without actually moving. |
| W | Walking | The user is walking naturally. |
| R | Running | The user is running. |
| ED | Elevator Down | The user is taking an elevator downward (one or more floors). |
| EU | Elevator Up | The user is taking an elevator upward (one or more floors). |
| DS | Down Stairs | The user is going downstairs. |
| US | Up Stairs | The user is going upstairs. |
| RD | Ramp Down | The user is going down a ramp. |
| RU | Ramp Up | The user is going up a ramp. |
| Activity ID | Number of Samples | |
|---|---|---|
| Train | Test | |
| NM | 18,590 | 1147 |
| W | 16,980 | 1512 |
| R | 605 | 76 |
| ED | 4569 | 436 |
| EU | 4639 | 434 |
| DS | 7285 | 170 |
| US | 8402 | 237 |
| RD | 7892 | 355 |
| RU | 8471 | 340 |
| Barometer | HAR | Bar + HAR | |
|---|---|---|---|
| Average Centroid Error (m) | 3.33 ± 0.07 | 2.52 ± 0.12 | 2.41 ± 0.06 |
| Correct Floor Changes (%) | 66 ± 1 | 84 ± 1 | 89 ± 1 |
| Best Particle Final Positional Error (m) | 6.19 ± 0.57 | 3.73 ± 1.10 | 2.84 ± 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreira, D.; Barandas, M.; Rocha, T.; Alves, P.; Santos, R.; Leonardo, R.; Vieira, P.; Gamboa, H. Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors. Sensors 2021, 21, 6316. https://doi.org/10.3390/s21186316
Moreira D, Barandas M, Rocha T, Alves P, Santos R, Leonardo R, Vieira P, Gamboa H. Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors. Sensors. 2021; 21(18):6316. https://doi.org/10.3390/s21186316
Chicago/Turabian StyleMoreira, Dinis, Marília Barandas, Tiago Rocha, Pedro Alves, Ricardo Santos, Ricardo Leonardo, Pedro Vieira, and Hugo Gamboa. 2021. "Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors" Sensors 21, no. 18: 6316. https://doi.org/10.3390/s21186316
APA StyleMoreira, D., Barandas, M., Rocha, T., Alves, P., Santos, R., Leonardo, R., Vieira, P., & Gamboa, H. (2021). Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors. Sensors, 21(18), 6316. https://doi.org/10.3390/s21186316