
Smart Prognostics and Health Management (SPHM) in Smart Manufacturing: An Interoperable Framework


Abstract
:1. Introduction
2. Review of Key Concepts and Trends
2.1. Overview of Maintenance Strategies
- Unplanned or reactive maintenance—typically allows for machinery to breakdown, after which it is analyzed and repaired.
- Planned or preventive maintenance—an assessment of the system is conducted at regular time intervals to determine whether any repair/replacement is necessary. It is important to note that the health of the system is not taken into consideration in establishing the time intervals.
- Predictive maintenance—a data-driven approach in which parameters concerning the health of the system are used to monitor the condition of the equipment and in determining the RUL.
2.2. Multi-Faceted Approach to PHM
- Data acquisition and preprocessing: For any predictive problem in maintenance to be solved, the availability of data is of utmost importance. IoT devices and smart sensors are typically used to acquire data in manufacturing settings. The data are recorded and evaluated in real-time as certain anomalies may be detected at an early stage by maintenance engineers or control systems. The collection of such data is extremely important as it provides vital information that helps to understand the relationships between the heterogenous components of the system. Once the data are collected, they are analyzed and preprocessed to ensure that crucial information which helps in failure detection is obtained.
- Degradation detection: Identifying that a component is degrading or that it is bound to fail is the next step once the data have been collected and prepared. Anomalies and failures can be detected using sensor readings and by other specified criteria, such as surface roughness, temperature, size of tools/equipment, etc.
- Diagnostics: Once a determination is made that a failure is occurring, understanding the cause of the failure is the next step. Failure types can be categorized to evaluate the extent of the failure, helping in finding its root causes. Operating conditions of individual components can be analyzed along with their interactions to help diagnose the cause of failures.
- Prognostics: With the ability to detect failures using diagnosing mechanisms, predictive methods are used to predict the system health to avoid potential failures. Model-based prognostics involve Physics-of-Failure (PoF) methods to assess wear and predict failure. However, such approaches are limited as even minor changes to the operations can result in poor predictive power. Data-driven approaches are becoming more common for prognostics with the use of DL and ML techniques. By using data-driven methods along with crucial information from physics-based methods, highly accurate predictions can be made about systems.
- Maintenance decisions: Based on results from the predictive methods developed, manufacturing enterprises can determine policies to be followed for maintenance planning that will help with less downtime, higher yield and a reduction in losses.
2.3. Challenges in Implementing PHM in the Industry
2.3.1. In Prognostics
- Insufficient failure data or excessive failure data may skew prediction of RUL
- Inadequate standards to assess prognostic models
- Lack of precise real-time assessment of RUL
- Uncertainty in determining accuracy and performance of prognostic models.
2.3.2. In Diagnostics
- Expertise required in diagnosis of failures
- Limitations due to lack of training and formal guidelines in authentication of diagnostic methods
- Difficulty in diagnosis due to outliers, noise in signal data and operating environment.
2.3.3. In Manufacturing
- Ability to effectively assess electronic components
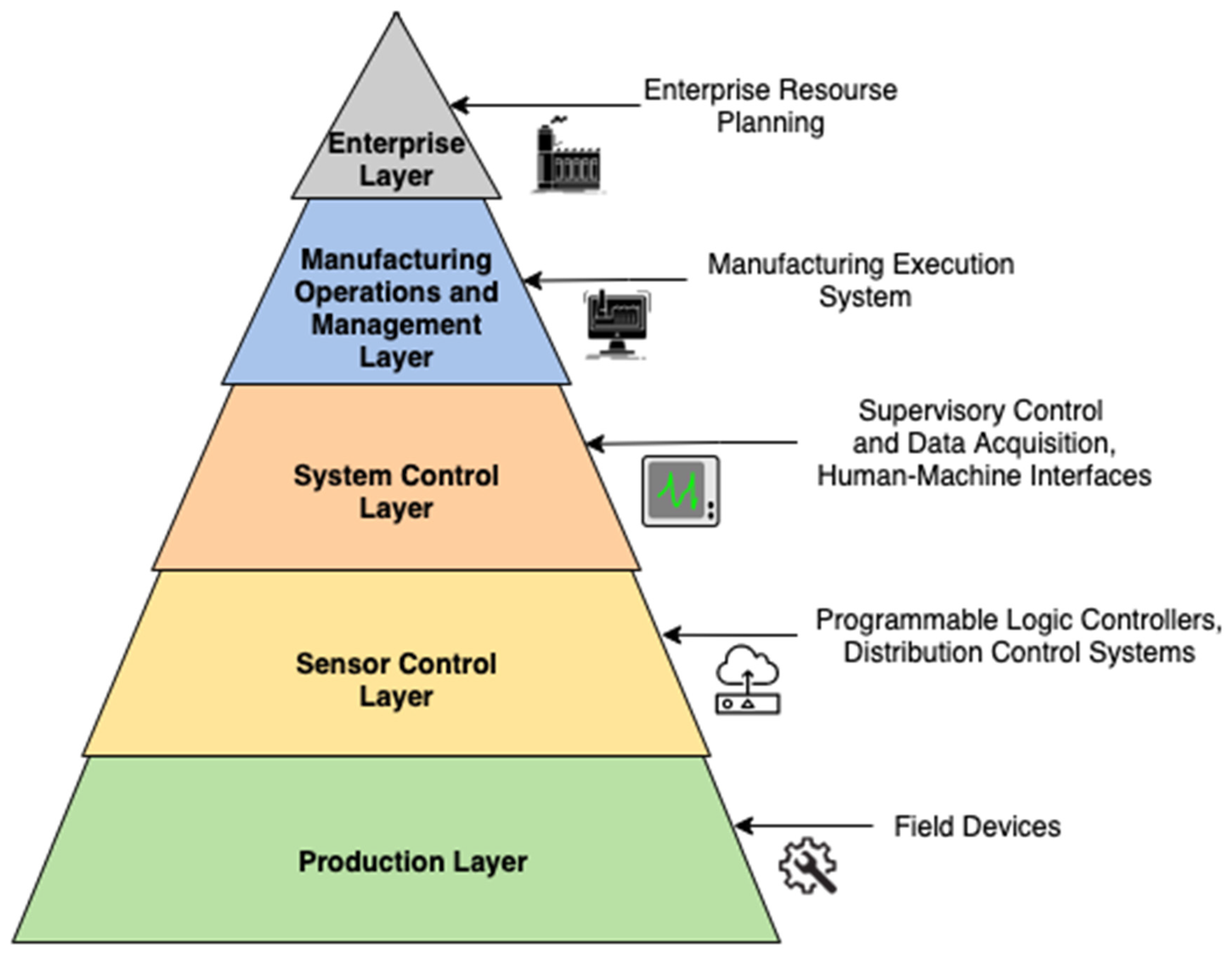
- Integration of sensors and field devices with PHM standards
- Inconsistencies in data, data formats, and interoperability of data in manufacturing facilities
- Inadequate correspondence between production planning and control units and maintenance departments
- High level of complexity and heterogeneity in manufacturing systems.
2.3.4. In Enterprises
- Proactive involvement required towards maintenance to view PHM as a cost-saving approach and not a cost-inducing one
- Enterprises with legacy machines and equipment tend to go with one of the traditional approaches to maintenance, even though PHM methods are more effective
- Securing funding for PHM projects.
2.3.5. In Human Factors
- User friendly interfaces and applications
- Collection of expert knowledge
- Improvement in outlook towards implementing changes to existing mechanisms.
2.4. Overview of Prognostics Modeling Approaches
- Lack of readily available data in a standardized format
- Insufficient failure data due to imbalance in data classes
- Lack of physics-based parameters in the data.
2.5. Current Trends in PHM Research
2.5.1. Applications of Machine Learning in PHM
2.5.2. Applications of Deep Learning in PHM
2.5.3. Health Index Construction
2.5.4. PHM Using Manufacturing Paradigms
3. Research Gap and Proposal
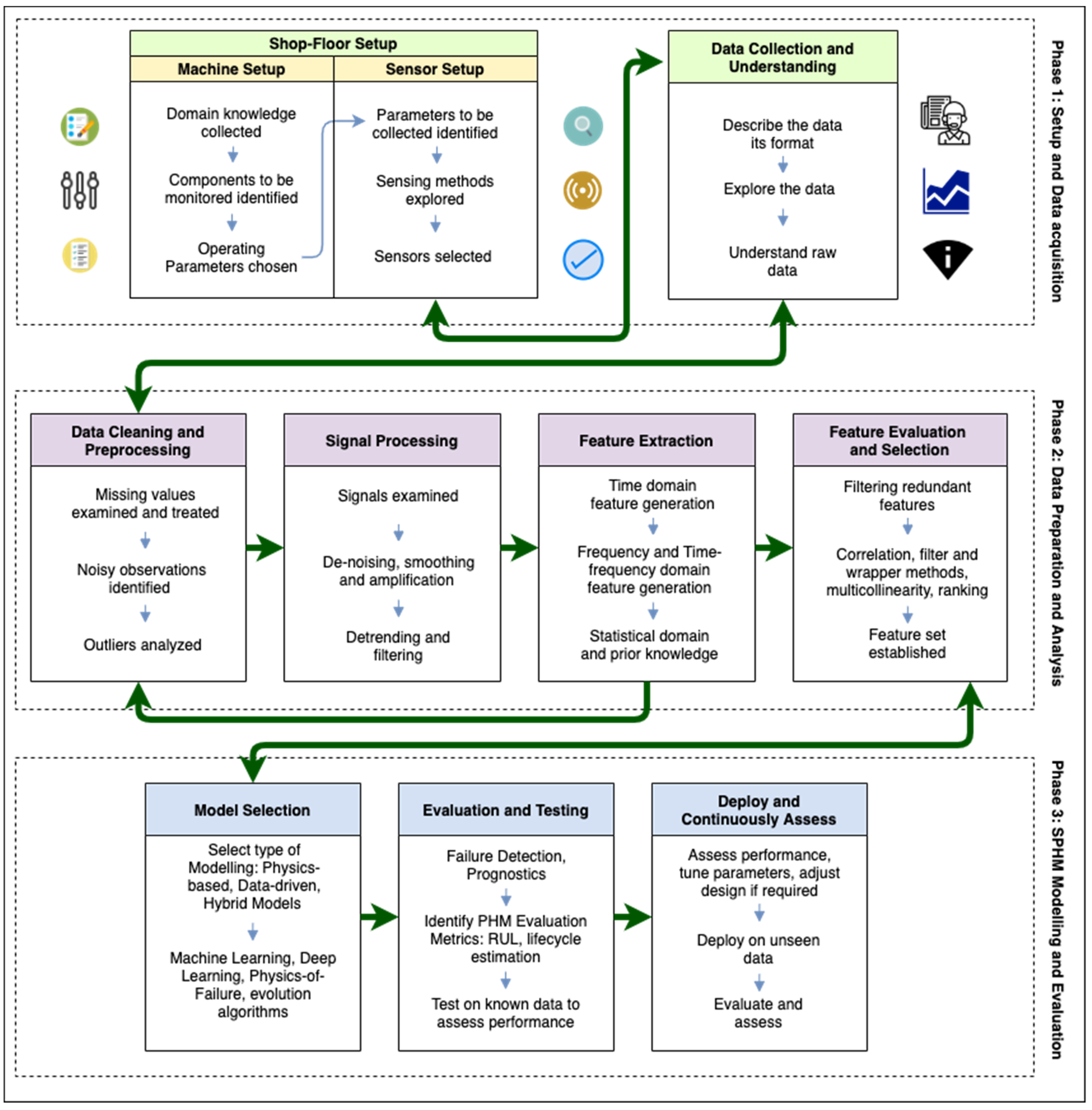
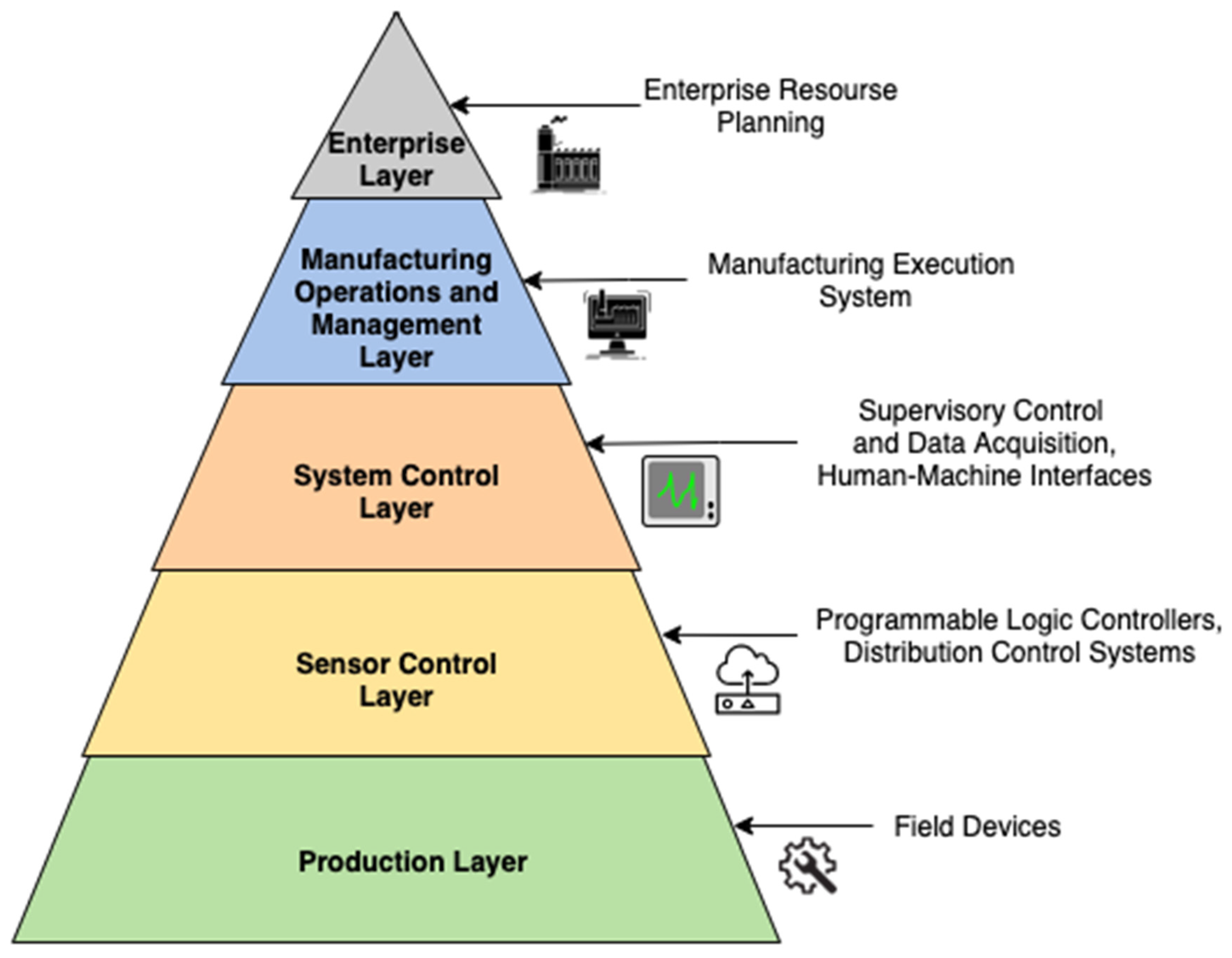
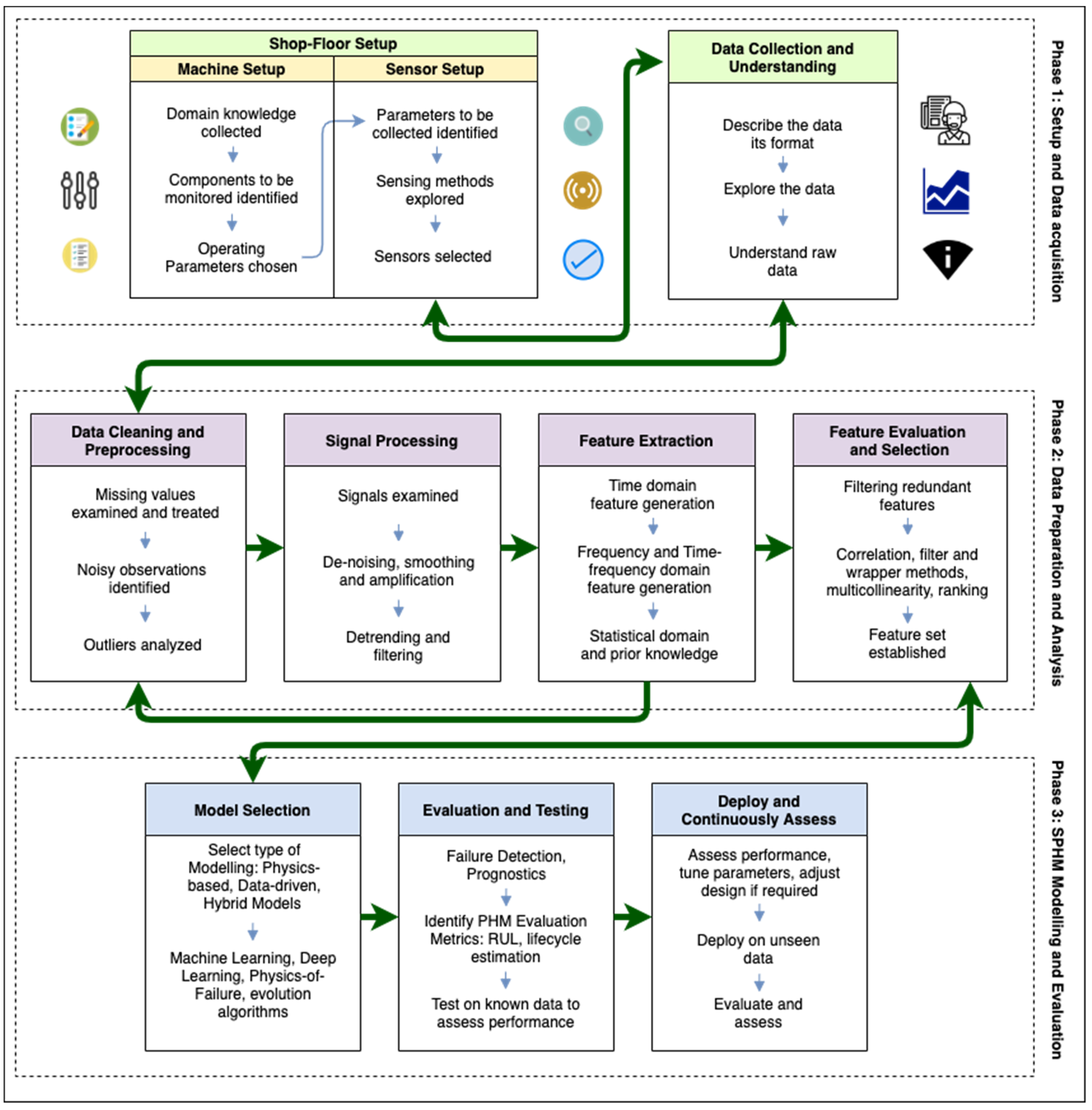
4. An Interoperable Framework for SPHM in SM
4.1. Phase 1: Setup and Data Acquisition Phase
4.1.1. Shopfloor Setup
4.1.2. Data Collection and Understanding
4.2. Phase 2: Data Preparation and Analysis
4.2.1. Data Cleaning and Preprocessing
- Min–max normalization
- 2.
- Mean normalization
- 3.
- Unit Scaling
- 4.
- Standardization
4.2.2. Signal Preprocessing
4.2.3. Feature Extraction
Time-Domain Feature Extraction
Frequency-Domain Feature Extraction
- = input signal at time ,
- = nT = n-th sampling instant, for n 0,
- = spectrum of x at frequency ,
- = sample from k-th frequency in radians per second,
- T = sampling interval in seconds,
- = 1/T = sampling rate or samples per second,
- = total number of samples in signal.
- = signal amplitude at sample,
- = DTFT of x at sample.
Time-Frequency Domain Features
4.2.4. Feature Evaluation and Selection
4.3. Phase 3: SPHM Modeling and Evaluation
5. Case Study: Milling Machine Operation
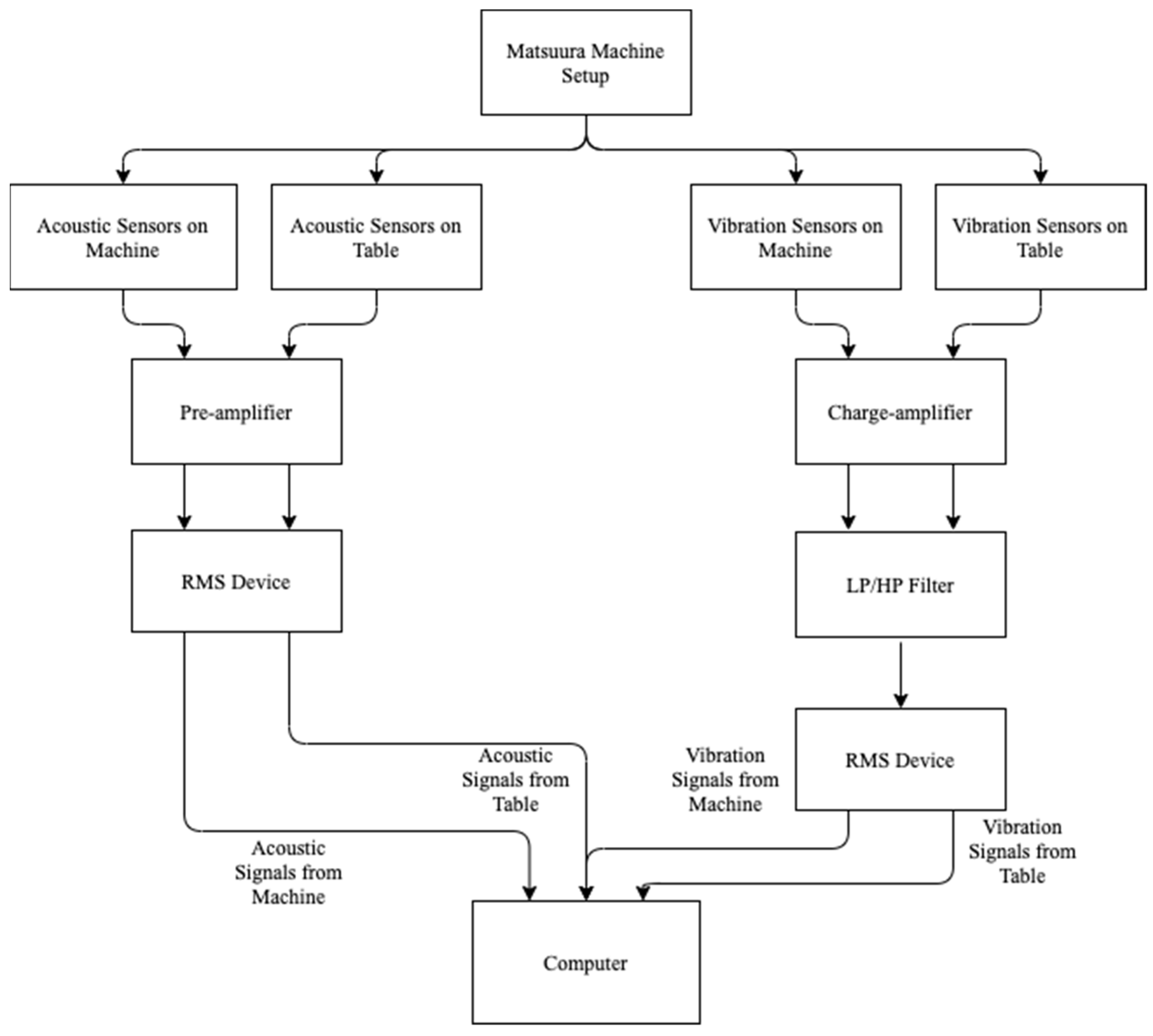
5.1. Phase 1: Milling Machine Setup and Data Acquisition
5.1.1. Milling Machine and Sensor Setup
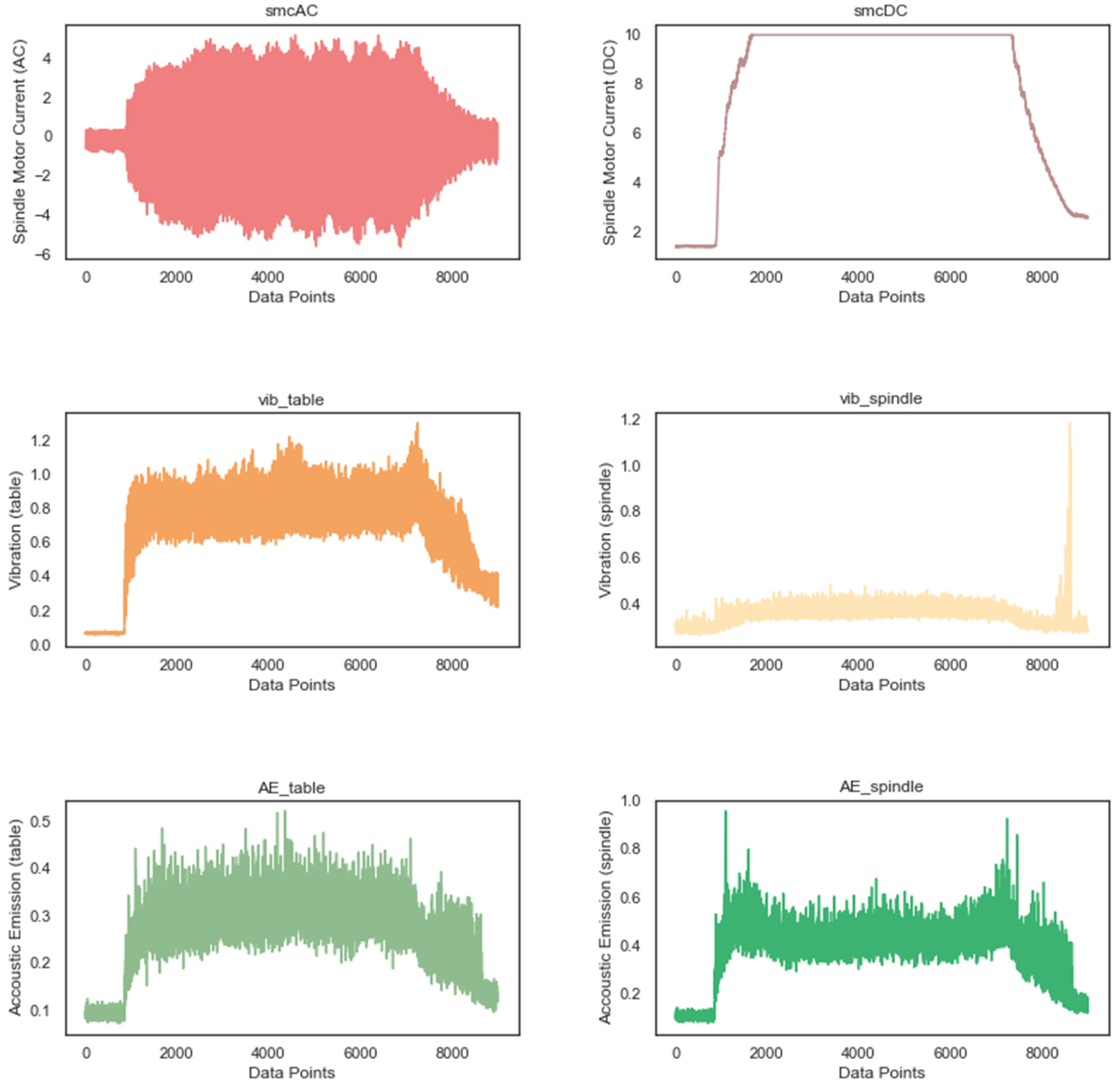
5.1.2. Data Collection and Understanding
5.2. Phase 2: Data Preparation and Analysis
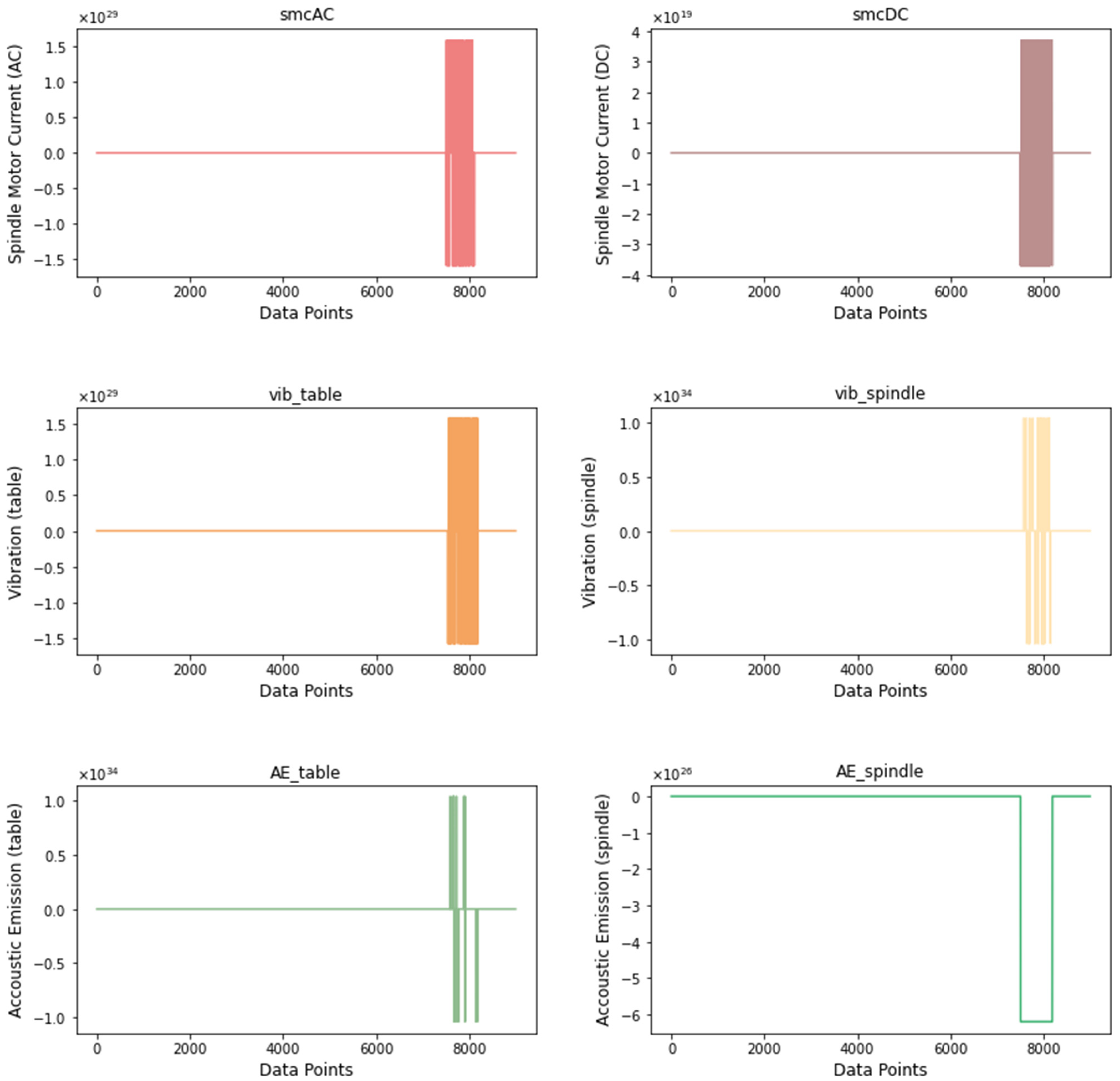
5.2.1. Data Cleaning and Preprocessing
5.2.2. Signal Preprocessing
5.2.3. Feature Extraction
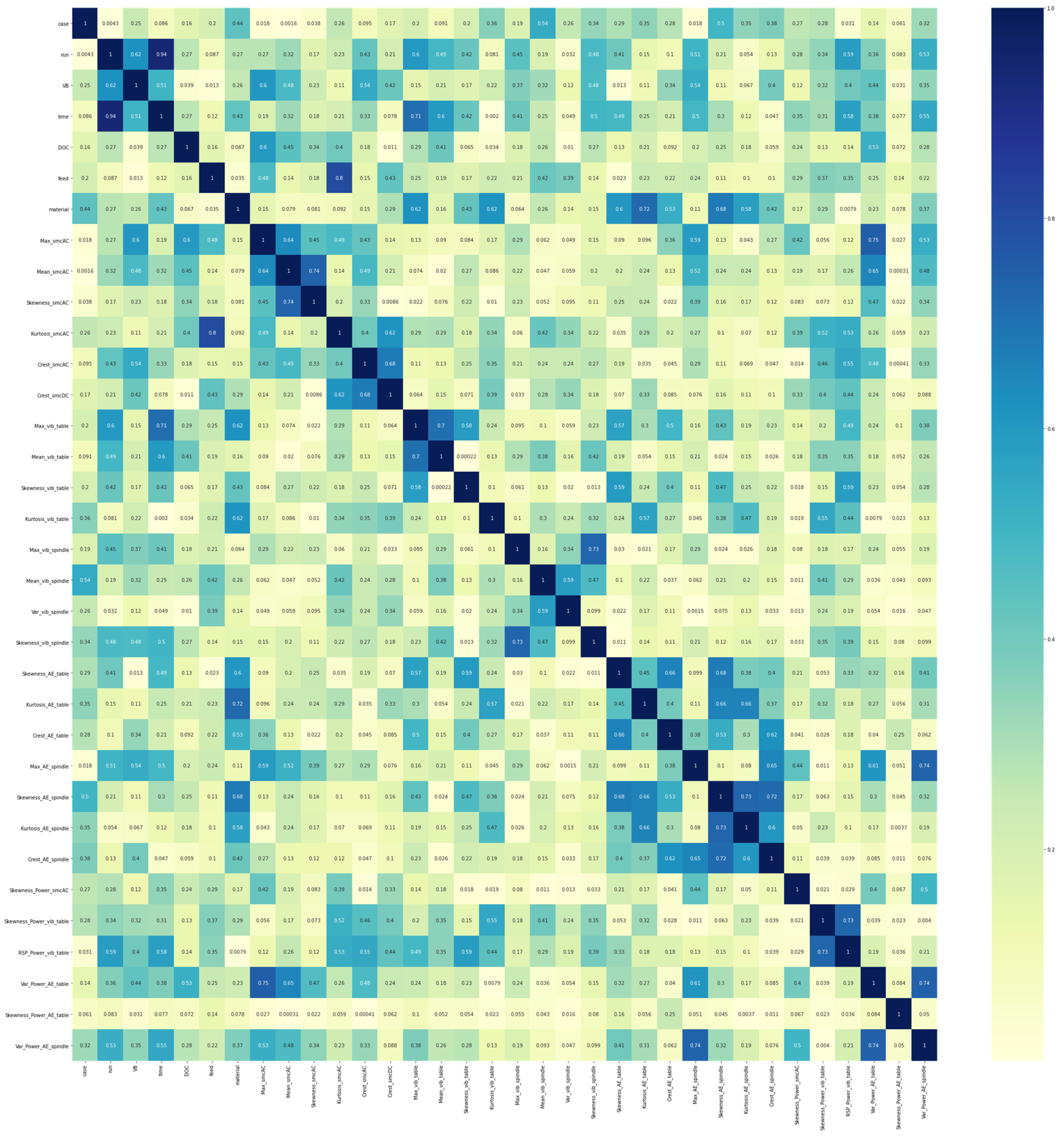
5.2.4. Feature Evaluation and Selection
6. Results
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Run | VB | Time | DOC | Feed | Material | smcAC | smcDC | vib_table | vib_spindle | AE_table | AE_spindle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 2 | 1.5 | 0.5 | 1 | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim |
| 1 | 2 | NaN | 4 | 1.5 | 0.5 | 1 | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim |
| 1 | 3 | NaN | 6 | 1.5 | 0.5 | 1 | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim |
| 1 | 4 | 0.11 | 7 | 1.5 | 0.5 | 1 | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim |
| 1 | 5 | NaN | 11 | 1.5 | 0.5 | 1 | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim | 9000 × 1 dim |


References
- Thomas, D.S.; Weiss, B. Maintenance Costs and Advanced Maintenance Techniques: Survey and Analysis. Int. J. Progn. Health Manag. 2021, 12. Available online: https://papers.phmsociety.org/index.php/ijphm/article/view/2883 (accessed on 6 May 2021). [CrossRef]
- Venkatasubramanian, V. Prognostic and diagnostic monitoring of complex systems for product lifecycle management: Challenges and opportunities. Comput. Chem. Eng. 2005, 29, 1253–1263. [Google Scholar] [CrossRef]
- Zeid, A.; Sundaram, S.; Moghaddam, M.; Kamarthi, S.; Marion, T. Interoperability in Smart Manufacturing: Research Challenges. Machines 2019, 7, 21. Available online: https://www.mdpi.com/2075-1702/7/2/21 (accessed on 11 February 2020). [CrossRef] [Green Version]
- Pintelon, L.M.; Gelders, L.F. Maintenance management decision making. Eur. J. Oper. Res. 1992, 58, 301–317. [Google Scholar] [CrossRef]
- Pinjala, S.K.; Pintelon, L.; Vereecke, A. An empirical investigation on the relationship between business and maintenance strategies. Int. J. Prod. Econ. 2006, 104, 214–229. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Atamuradov, V.; Medjaher, K.; Dersin, P.; Lamoureux, B.; Zerhouni, N. Prognostics and Health Management for Maintenance Practitioners—Review, Implementation and Tools Evaluation. Int. J. Progn. Health Manag. 2017, 8, 1–31. Available online: https://oatao.univ-toulouse.fr/19521/ (accessed on 10 June 2021).
- Vogl, G.W.; Weiss, B.A.; Helu, M. A review of diagnostic and prognostic capabilities and best practices for manufacturing. J. Intell. Manuf. 2019, 30, 79–95. [Google Scholar] [CrossRef]
- Meng, H.; Li, Y.F. A review on prognostics and health management (PHM) methods of lithium-ion batteries. Renew. Sustain. Energy Rev. 2019, 116, 109405. [Google Scholar] [CrossRef]
- Eker, O.F.; Camci, F.; Jennions, I.K. Major Challenges in Prognostics: Study on Benchmarking Prognostics Datasets. PHM Society. 2012. Available online: http://dspace.lib.cranfield.ac.uk/handle/1826/9994 (accessed on 3 January 2021).
- Elattar, H.M.; Elminir, H.K.; Riad, A.M. Prognostics: A literature review. Complex Intell. Syst. 2016, 2, 125–154. Available online: https://link.springer.com/article/10.1007/s40747-016-0019-3 (accessed on 10 June 2021). [CrossRef] [Green Version]
- Sarih, H.; Tchangani, A.P.; Medjaher, K.; Pere, E. Data preparation and preprocessing for broadcast systems monitoring in PHM framework. In Proceedings of the 6th International Conference on Control, Decision and Information Technologies, CoDIT 2019, Paris, France, 23–26 April 2019; pp. 1444–1449. [Google Scholar] [CrossRef] [Green Version]
- Cubillo, A.; Perinpanayagam, S.; Esperon-Miguez, M. A review of physics-based models in prognostics: Application to gears and bearings of rotating machinery. Adv. Mech. Eng. 2016, 8, 1–21. Available online: https://us.sagepub.com/en-us/nam/ (accessed on 17 June 2021). [CrossRef] [Green Version]
- Pecht, M.; Jie, G. Physics-of-failure-based prognostics for electronic products. Trans. Inst. Meas. Control 2009, 31, 309–322. Available online: http://tim.sagepub.com (accessed on 17 June 2021). [CrossRef]
- Lui, Y.H.; Li, M.; Downey, A.; Shen, S.; Nemani, V.P.; Ye, H.; VanElzen, C.; Jain, G.; Hu, S.; Laflamme, S.; et al. Physics-based prognostics of implantable-grade lithium-ion battery for remaining useful life prediction. J. Power Sources 2021, 485, 229327. [Google Scholar] [CrossRef]
- Bradley, D.; Ortega-Sanchez, C.; Tyrrell, A. Embryonics + immunotronics: A bio-inspired approach to fault tolerance. In Proceedings of the The Second NASA/DoD Workshop on Evolvable Hardware, Palo Alto, CA, USA, 15 July 2000; pp. 215–223. [Google Scholar]
- Dong, H.; Yang, X.; Li, A.; Xie, Z.; Zuo, Y. Bio-inspired PHM model for diagnostics of faults in power transformers using dissolved gas-in-oil data. Sensors 2019, 19, 845. Available online: www.mdpi.com/journal/sensors (accessed on 10 June 2021). [CrossRef] [PubMed] [Green Version]
- Soualhi, A.; Razik, H.; Clerc, G.; Doan, D.D. Prognosis of bearing failures using hidden markov models and the adaptive neuro-fuzzy inference system. IEEE Trans. Ind. Electron. 2014, 61, 2864–2874. [Google Scholar] [CrossRef]
- Moghaddam, M.; Chen, Q.; Deshmukh, A.V. A neuro-inspired computational model for adaptive fault diagnosis. Expert Syst. Appl. 2020, 140, 112879. [Google Scholar] [CrossRef]
- Huang, B.; Di, Y.; Jin, C.; Lee, J. Review of data-driven prognostics and health management techniques: Lessions learned from PHM data challenge competitions. Mach. Fail. Prev. Technol. 2017, 2017, 1–17. [Google Scholar]
- Jia, X.; Huang, B.; Feng, J.; Cai, H.; Lee, J. Review of PHM Data Competitions from 2008 to 2017. Annu. Conf. PHM Soc. 2018, 10. Available online: https://papers.phmsociety.org/index.php/phmconf/article/view/462 (accessed on 11 June 2021). [CrossRef]
- Huang, H.Z.; Wang, H.K.; Li, Y.F.; Zhang, L.; Liu, Z. Support vector machine based estimation of remaining useful life: Current research status and future trends. J. Mech. Sci. Technol. 2015, 29, 151–163. Available online: www.springerlink.com/content/1738-494x (accessed on 11 June 2021). [CrossRef]
- Mathew, V.; Toby, T.; Singh, V.; Rao, B.M.; Kumar, M.G. Prediction of Remaining Useful Lifetime (RUL) of turbofan engine using machine learning. In Proceedings of the IEEE International Conference on Circuits and Systems, ICCS 2017, Thiruvananthapuram, India, 20–21 December 2017; Volume 2018, pp. 306–311. [Google Scholar]
- Elforjani, M.; Shanbr, S. Prognosis of Bearing Acoustic Emission Signals Using Supervised Machine Learning. IEEE Trans. Ind. Electron. 2018, 65, 5864–5871. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, S.S.; Karvelis, P.; Georgoulas, G.; Nikolakopoulos, G. Remaining Useful Battery Life Prediction for UAVs based on Machine Learning. IFAC-PapersOnLine 2017, 50, 4727–4732. [Google Scholar] [CrossRef]
- Cho, S.; Asfour, S.; Onar, A.; Kaundinya, N. Tool breakage detection using support vector machine learning in a milling process. Int. J. Mach. Tools Manuf. 2005, 45, 241–249. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Abdelgayed, T.S.; Morsi, W.G.; Sidhu, T.S. Fault detection and classification based on co-training of semisupervised machine learning. IEEE Trans. Ind. Electron. 2017, 65, 1595–1605. [Google Scholar] [CrossRef]
- Wang, X.; Feng, H.; Fan, Y. Fault detection and classification for complex processes using semi-supervised learning algorithm. Chemom. Intell. Lab. Syst. 2015, 149, 24–32. [Google Scholar] [CrossRef]
- Yan, K.; Zhong, C.; Ji, Z.; Huang, J. Semi-supervised learning for early detection and diagnosis of various air handling unit faults. Energy Build. 2018, 181, 75–83. [Google Scholar] [CrossRef]
- Malhi, A.; Yan, R.; Gao, R.X. Prognosis of defect propagation based on recurrent neural networks. IEEE Trans. Instrum. Meas. 2011, 60, 703–711. [Google Scholar] [CrossRef]
- Heimes, F.O. Recurrent neural networks for remaining useful life estimation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar] [CrossRef]
- Palau, A.S.; Bakliwal, K.; Dhada, M.H.; Pearce, T.; Parlikad, A.K. Recurrent Neural Networks for real-time distributed collaborative prognostics. In Proceedings of the 2018 IEEE International Conference on Prognostics and Health Management, ICPHM 2018, Seattle, WA, USA, 11–13 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Gugulothu, N.; TV, V.; Malhotra, P.; Vig, L.; Agarwal, P.; Shroff, G. Predicting Remaining Useful Life using Time Series Embeddings based on Recurrent Neural Networks. arXiv 2017, arXiv:1709.01073. Available online: http://arxiv.org/abs/1709.01073 (accessed on 11 June 2021).
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, G.; Liu, Y.; Zhang, B.; Hu, C. Lithium-ion battery remaining useful life prediction with Deep Belief Network and Relevance Vector Machine. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management, ICPHM 2017, Dallas, TX, USA, 19–21 June 2017; pp. 7–13. [Google Scholar]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective Deep Belief Networks Ensemble for Remaining Useful Life Estimation in Prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2306–2318. [Google Scholar] [CrossRef]
- Liao, L.; Jin, W.; Pavel, R. Enhanced Restricted Boltzmann Machine with Prognosability Regularization for Prognostics and Health Assessment. IEEE Trans. Ind. Electron. 2016, 63, 7076–7083. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, R.; Yan, R.; Shao, S.; Chen, X. Convolutional Discriminative Feature Learning for Induction Motor Fault Diagnosis. IEEE Trans. Ind. Inform. 2017, 13, 1350–1359. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. Available online: www.mdpi.com/journal/sensors (accessed on 11 June 2021). [CrossRef] [PubMed]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Liu, R.; Meng, G.; Yang, B.; Sun, C.; Chen, X. Dislocated Time Series Convolutional Neural Architecture: An Intelligent Fault Diagnosis Approach for Electric Machine. IEEE Trans. Ind. Inform. 2017, 13, 1310–1320. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Babu, G.S.; Zhao, P.; Li, X.L. Deep convolutional neural network based regression approach for estimation of remaining useful life. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016; Volume 9642, pp. 214–228. Available online: http://www.i2r.a-star.edu.sg (accessed on 11 June 2021). [CrossRef]
- Wang, J.; Zhuang, J.; Duan, L.; Cheng, W. A multi-scale convolution neural network for featureless fault diagnosis. In Proceedings of the International Symposium on Flexible Automation, ISFA 2016, Cleveland, OH, USA, 1–3 August 2016; pp. 65–70. [Google Scholar]
- You, W.; Shen, C.; Guo, X.; Jiang, X.; Shi, J.; Zhu, Z. A hybrid technique based on convolutional neural network and support vector regression for intelligent diagnosis of rotating machinery. Adv. Mech. Eng. 2017, 9, 2017. Available online: https://us.sagepub.com/en-us/nam/ (accessed on 11 June 2021). [CrossRef] [Green Version]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP Ann. Manuf. Technol. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, X.; Zhang, W. Remaining useful life prediction based on health index similarity. Reliab. Eng. Syst. Saf. 2019, 185, 502–510. [Google Scholar] [CrossRef]
- Liu, D.; Wang, H.; Peng, Y.; Xie, W.; Liao, H. Satellite lithium-ion battery remaining cycle life prediction with novel indirect health indicator extraction. Energies 2013, 6, 3654–3668. Available online: https://www.mdpi.com/journal/energiesArticle (accessed on 11 June 2021). [CrossRef]
- Yang, F.; Habibullah, M.S.; Zhang, T.; Xu, Z.; Lim, P.; Nadarajan, S. Health index-based prognostics for remaining useful life predictions in electrical machines. IEEE Trans. Ind. Electron. 2016, 63, 2633–2644. [Google Scholar] [CrossRef]
- Xia, T.; Dong, Y.; Xiao, L.; Du, S.; Pan, E.; Xi, L. Recent advances in prognostics and health management for advanced manufacturing paradigms. Reliab. Eng. Syst. Saf. 2018, 178, 255–268. [Google Scholar] [CrossRef]
- Blecker, T.; Friedrich, G. Guest editorial: Mass customization manufacturing systems. IEEE Trans. Eng. Manag. 2007, 54, 4–11. [Google Scholar] [CrossRef]
- Jin, X.; Ni, J. Joint Production and Preventive Maintenance Strategy for Manufacturing Systems With Stochastic Demand. J. Manuf. Sci. Eng. 2013, 135. Available online: http://asmedigitalcollection.asme.org/manufacturingscience/article-pdf/135/3/031016/6261104/manu_135_3_031016.pdf (accessed on 16 August 2021). [CrossRef]
- Fitouhi, M.C.; Nourelfath, M. Integrating noncyclical preventive maintenance scheduling and production planning for multi-state systems. Reliab. Eng. Syst. Saf. 2014, 121, 175–186. [Google Scholar] [CrossRef]
- Koren, Y.; Heisel, U.; Jovane, F.; Moriwaki, T.; Pritschow, G.; Ulsoy, G.; Van Brussel, H. Reconfigurable Manufacturing Systems. CIRP Ann. 1999, 48, 527–540. [Google Scholar] [CrossRef]
- Xia, T.; Xi, L.; Pan, E.; Ni, J. Reconfiguration-oriented opportunistic maintenance policy for reconfigurable manufacturing systems. Reliab. Eng. Syst. Saf. 2017, 166, 87–98. [Google Scholar] [CrossRef]
- Zhou, J.; Djurdjanovic, D.; Ivy, J.; Ni, J. Integrated reconfiguration and age-based preventive maintenance decision making. IIE Trans. 2007, 39, 1085–1102. Available online: https://www.tandfonline.com/doi/abs/10.1080/07408170701291779 (accessed on 16 August 2021). [CrossRef]
- Koren, Y.; Gu, X.; Badurdeen, F.; Jawahir, I.S. Sustainable Living Factories for Next Generation Manufacturing. Procedia Manuf. 2018, 21, 26–36. [Google Scholar] [CrossRef]
- Gao, J.; Yao, Y.; Zhu, V.C.Y.; Sun, L.; Lin, L. Service-oriented manufacturing: A new product pattern and manufacturing paradigm. J. Intell. Manuf. 2009, 22, 435–446. Available online: https://link.springer.com/article/10.1007/s10845-009-0301-y (accessed on 16 August 2021). [CrossRef]
- Ning, D.; Huang, J.; Shen, J.; Di, D. A cloud based framework of prognostics and health management for manufacturing industry. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016. [Google Scholar] [CrossRef]
- Traini, E.; Bruno, G.; D’Antonio, G.; Lombardi, F. Machine learning framework for predictive maintenance in milling. IFAC-Pap. 2019, 52, 177–182. [Google Scholar] [CrossRef]
- Mohanraj, T.; Shankar, S.; Rajasekar, R.; Sakthivel, N.R.; Pramanik, A. Tool condition monitoring techniques in milling process-a review. J. Mater. Res. Technol. 2020, 9, 1032–1042. [Google Scholar] [CrossRef]
- Shin, I.; Lee, J.; Lee, J.Y.; Jung, K.; Kwon, D.; Youn, B.D.; Jang, H.S.; Choi, J.H. A Framework for Prognostics and Health Management Applications toward Smart Manufacturing Systems. Int. J. Precis. Eng. Manuf. Green Technol. 2018, 5, 535–554. Available online: https://link.springer.com/article/10.1007/s40684-018-0055-0 (accessed on 14 June 2021). [CrossRef]
- Wirth, R. CRISP-DM: Towards a standard process model for data mining. In Proceedings of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining, London, UK, 11–13 April 2000; pp. 29–39. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.198.5133 (accessed on 3 May 2021).
- Van Buuren, S. Flexible Imputation of Missing Data, 2nd ed.; Chapman and Hall/CRC: London, UK, 2018. [Google Scholar]
- Efron, B. Missing data, imputation, and the bootstrap. J. Am. Stat. Assoc. 1994, 89, 463–475. Available online: https://amstat.tandfonline.com/doi/abs/10.1080/01621459.1994.10476768 (accessed on 8 May 2021). [CrossRef]
- Miao, F.; Zhao, R.; Wang, X. A New Method of Denoising of Vibration Signal and Its Application. Shock Vib. 2020, 2020. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing: Estimation Theory; Prentice-Hall: Hoboken, NJ, USA, 1993; Volume 37. [Google Scholar]
- Siddhpura, A.; Paurobally, R. A review of flank wear prediction methods for tool condition monitoring in a turning process. Int. J. Adv. Manuf. Technol. 2013, 65, 371–393. Available online: https://link.springer.com/article/10.1007/s00170-012-4177-1 (accessed on 4 May 2021). [CrossRef]
- Zhang, C.; Yao, X.; Zhang, J.; Jin, H. Tool condition monitoring and remaining useful life prognostic based on awireless sensor in dry milling operations. Sensors 2016, 16, 795. [Google Scholar] [CrossRef] [Green Version]
- Caesarendra, W.; Tjahjowidodo, T. A Review of Feature Extraction Methods in Vibration-Based Condition Monitoring and Its Application for Degradation Trend Estimation of Low-Speed Slew Bearing. Machines 2017, 5, 21. Available online: https://www.mdpi.com/2075-1702/5/4/21 (accessed on 21 February 2021). [CrossRef]
- Smith, J.O. Mathematics of the Discrete Fourier Transform (DFT) with Audio Applications, 2nd ed.; Online Book. 2007. Available online: http://ccrma.stanford.edu/~jos/mdft/Fourier_Theorems_DFT.html (accessed on 20 June 2021).
- Smith, J.O. “Periodogram” Spectral Audio Signal Processing; Online Book. 2011. Available online: https://ccrma.stanford.edu/~jos/sasp/Periodogram.html (accessed on 20 June 2021).
- Zhu, Q.; Wang, Y.; Shen, G. Comparison and application of time-frequency analysis methods for nonstationary signal processing. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 175 CCIS, pp. 286–291. Available online: https://link.springer.com/chapter/10.1007/978-3-642-21783-8_47 (accessed on 20 June 2021). [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Goebel, K.; Ames, N.; Agogino, A.; Berkeley, U.C. Documentation for Mill Data Set. BEST Lab UC Berkeley 2007. Available online: http://ti.arc.nasa.gov/project/prognostic-data-repository (accessed on 20 July 2021).
- Goebel, K.F. Management of Uncertainty in Sensor Validation, Sensor Fusion, and Diagnosis of Mechanical Systems Using Soft Computing Techniques; University of California: Berkeley, CA, USA, 1996; Available online: https://www.proquest.com/docview/304224063?pq-origsite=gscholar&fromopenview=true# (accessed on 20 June 2021).
- MATLAB. MATLAB 2020; The MathWorks Inc.: Natick, MA, USA, 2021; Available online: https://nl.mathworks.com/products/matlab.html%0Ahttp://www.mathworks.com/products/matlab/ (accessed on 8 June 2021).


| Modeling Approach | Advantages | Disadvantages |
|---|---|---|
| Physics-based models |
|
|
| Data-driven models |
|
|
| Hybrid models |
|
|
| Index | Feature | Description |
|---|---|---|
| 1 | Maximum | |
| 2 | Mean | |
| 3 | Root Mean Square | |
| 4 | Variance | |
| 5 | Standard Deviation | |
| 6 | Skewness | |
| 7 | Kurtosis | |
| 8 | Peak-to-Peak | |
| 9 | Crest Factor |
| Index | Feature | Description |
|---|---|---|
| 1 | Maximum Band Power Spectrum | |
| 2 | Sum of Band Power Spectrum | |
| 3 | Mean of Band Power Spectrum | |
| 4 | Variance of Band Power Spectrum | |
| 5 | Skewness of Band Power Spectrum | |
| 6 | Kurtosis of Band Power Spectrum | |
| 7 | Relative Spectral Peak per Band |
| Feature Name | Feature Description |
|---|---|
| case | Cases from number 1 to 16 |
| run | Counting the runs in each case |
| VB | Flank wear observed in the cutting tool, not observed after each run |
| time | Time taken for each experiment, resets after completion of each case |
| DOC | Depth of Cut, kept constant in each case |
| feed | Feed, kept constant in each case |
| material | Material, kept constant in each case |
| smcAC | AC current at spindle motor |
| smcDC | DC current at spindle motor |
| vib_table | Vibration measured at table |
| vib_spindle | Vibration measured at spindle |
| AE_table | Acoustic emission measured at table |
| AE_spindle | Acoustic emission measured at spindle |
| SPHM Phase | Steps | Relevant Section | Implementation on Use-Case |
|---|---|---|---|
| Phase 1: Setup and Data Acquisition |
|
| |
|
| ||
| Phase 2: Data Preparation and Analysis |
|
| |
| |||
|
| ||
|
| ||
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sundaram, S.; Zeid, A. Smart Prognostics and Health Management (SPHM) in Smart Manufacturing: An Interoperable Framework. Sensors 2021, 21, 5994. https://doi.org/10.3390/s21185994
Sundaram S, Zeid A. Smart Prognostics and Health Management (SPHM) in Smart Manufacturing: An Interoperable Framework. Sensors. 2021; 21(18):5994. https://doi.org/10.3390/s21185994
Chicago/Turabian StyleSundaram, Sarvesh, and Abe Zeid. 2021. "Smart Prognostics and Health Management (SPHM) in Smart Manufacturing: An Interoperable Framework" Sensors 21, no. 18: 5994. https://doi.org/10.3390/s21185994
APA StyleSundaram, S., & Zeid, A. (2021). Smart Prognostics and Health Management (SPHM) in Smart Manufacturing: An Interoperable Framework. Sensors, 21(18), 5994. https://doi.org/10.3390/s21185994