
American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation



Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
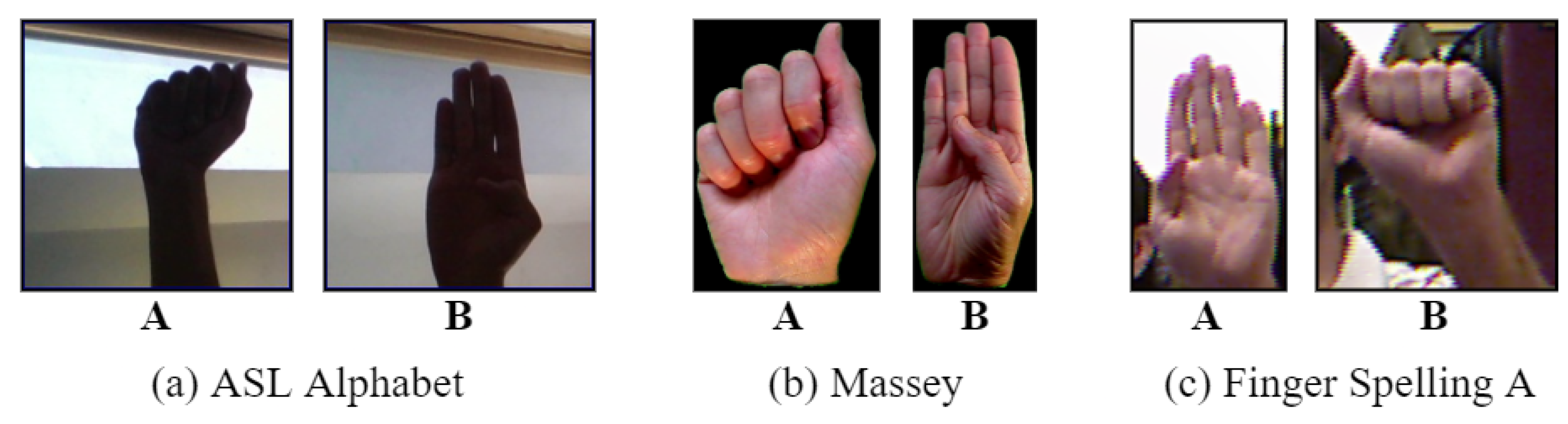
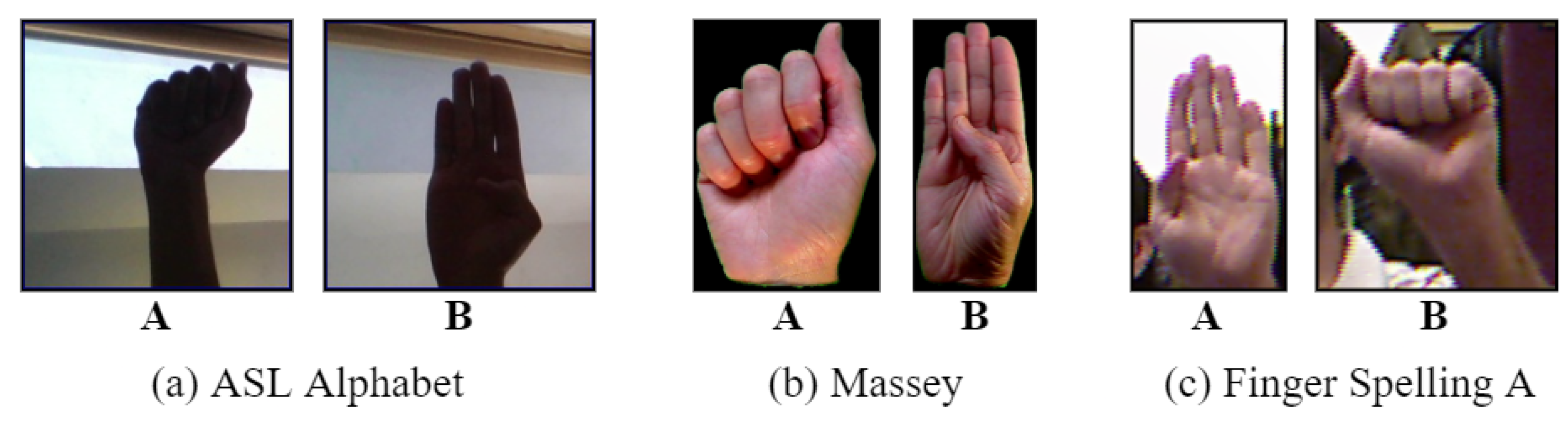
3.1. Dataset Description
3.1.1. ASL Alphabet Dataset
3.1.2. Massey Dataset
3.1.3. Finger Spelling A Dataset
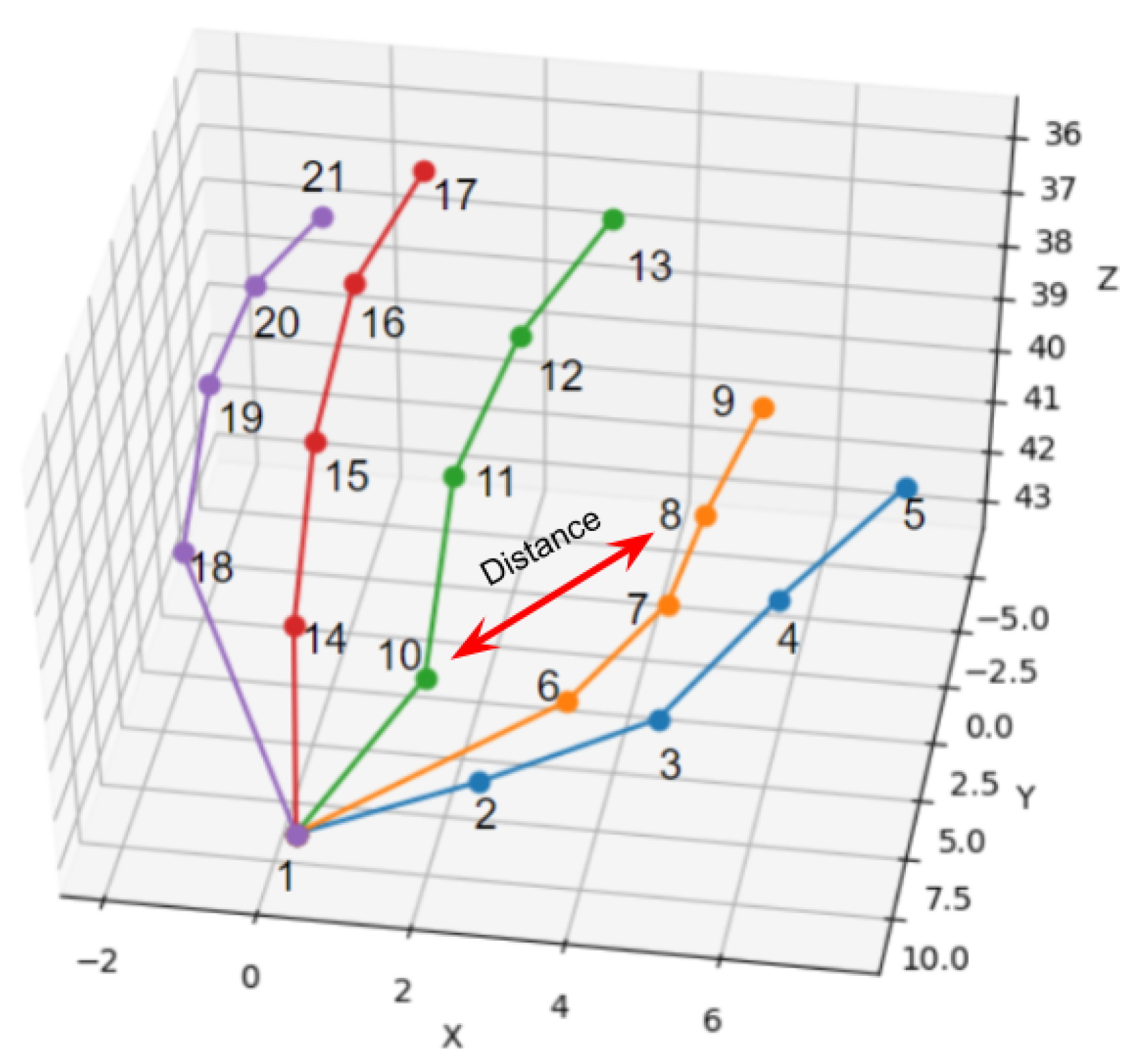
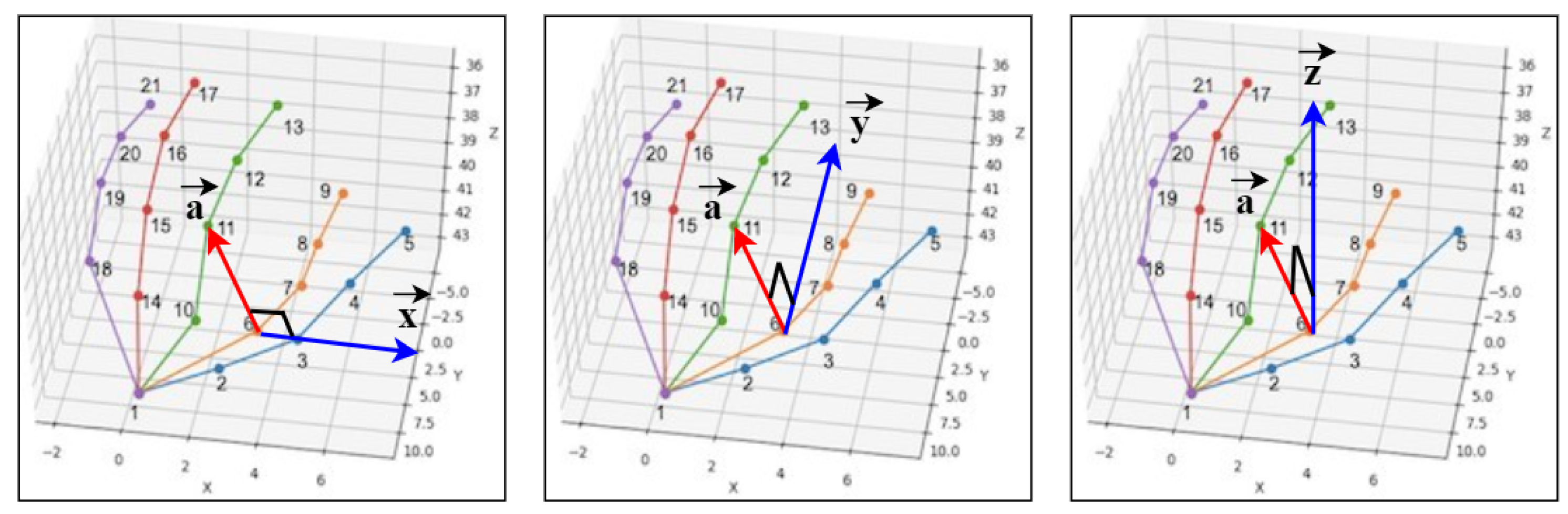
3.2. Feature Extraction
3.2.1. Hand Pose Estimation
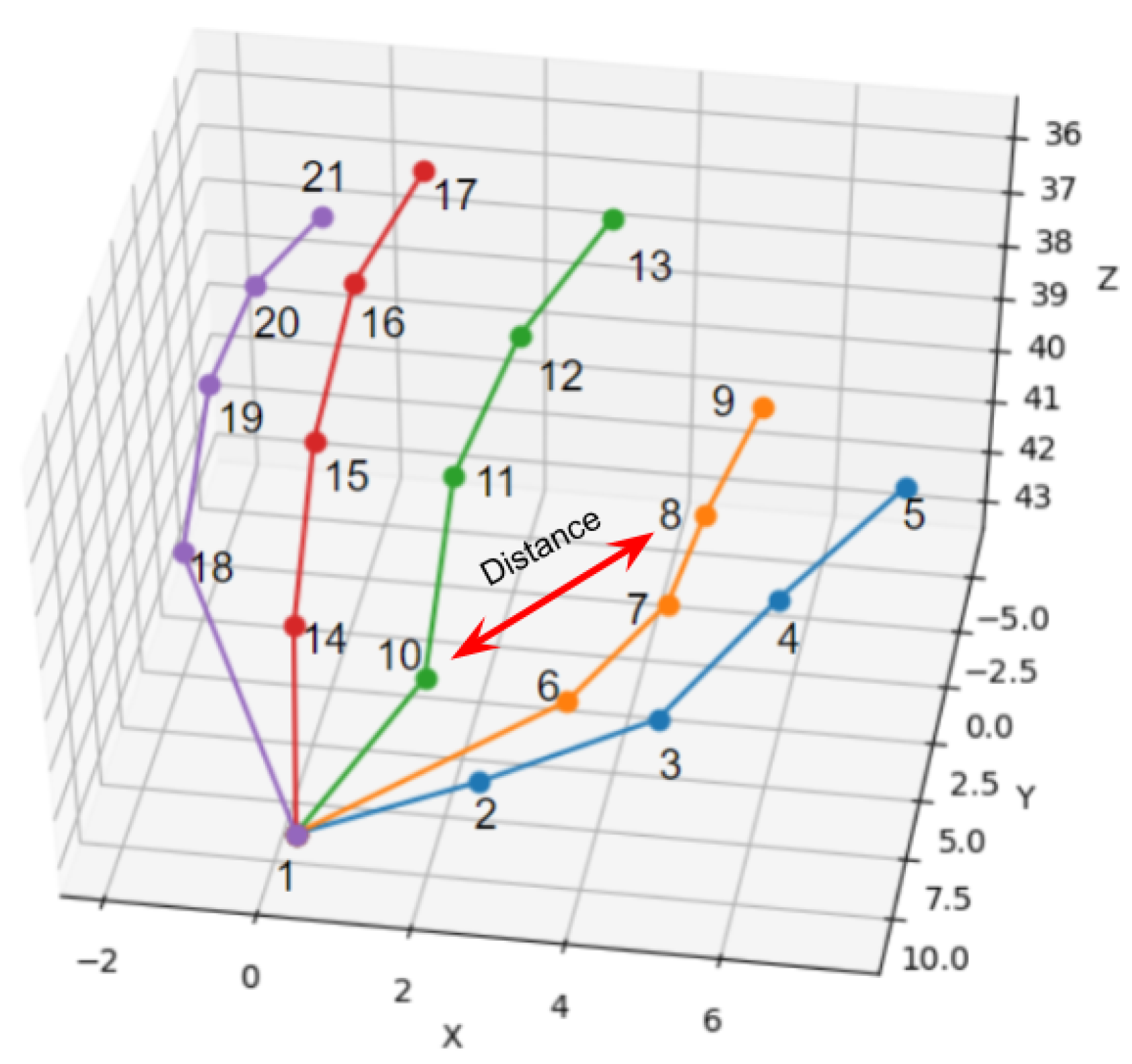
3.2.2. Distance-Based Features
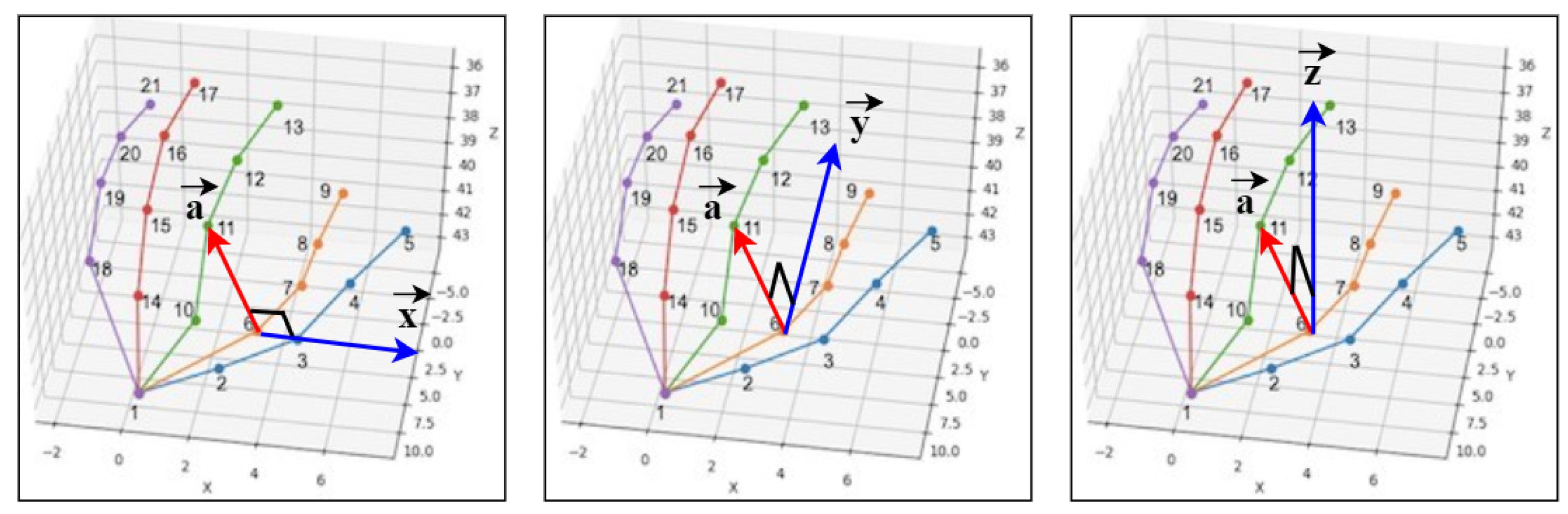
3.2.3. Angle-Based Features
3.3. Classification
3.3.1. Support Vector Machine
3.3.2. Light Gradient Boosting Machine
3.4. Experimental Settings and Evaluation Metric
4. Experimental Analysis
4.1. Parameter Turning
4.2. Results Analysis
4.3. Comparison with Previous Studies
4.4. Necessity of Distance-Based Features, Angle-Based Features, and Both
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mindess, A. Reading between the Signs: Intercultural Communication for Sign Language Interpreters; Nicholas Brealey: London, UK, 2014. [Google Scholar]
- World Health Organization. Deafness and Hearing Loss, Fact sheet N 300. 2015. Available online: http://www.who.int/mediacentre/factsheets/fs300/en (accessed on 19 July 2021).
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2019, 10, 131–153. [Google Scholar] [CrossRef]
- Lasak, J.M.; Allen, P.; McVay, T.; Lewis, D. Hearing loss: Diagnosis and management. Prim. Care Clin. Off. Pract. 2014, 41, 19–31. [Google Scholar] [CrossRef] [PubMed]
- Vos, T.; Allen, C.; Arora, M.; Barber, R.M.; Bhutta, Z.A.; Brown, A.; Carter, A.; Casey, D.C.; Charlson, F.J.; Chen, A.Z.; et al. Global, regional, and national incidence, prevalence, and years lived with disability for 310 diseases and injuries, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet 2016, 388, 1545–1602. [Google Scholar] [CrossRef] [Green Version]
- Grippo, J.; Vergel, M.; Comar, H.; Grippo, T. Mutism in children. Rev. Neurol. 2001, 32, 244–246. [Google Scholar] [PubMed]
- World Health Organization. The Global Burden of Disease: 2004 Update; World Health Organization: Geneva, Switzerland, 2008. [Google Scholar]
- Olusanya, B.O.; Neumann, K.J.; Saunders, J.E. The global burden of disabling hearing impairment: A call to action. Bull. World Health Organ. 2014, 92, 367–373. [Google Scholar] [CrossRef] [PubMed]
- Ringo, A. Understanding Deafness: Not Everyone Wants to be “Fixed”. The Atlantic, 9 August 2013. [Google Scholar]
- Sparrow, R. Defending deaf culture: The case of cochlear implants. J. Political Philos. 2005, 13, 135–152. [Google Scholar] [CrossRef]
- Chouhan, T.; Panse, A.; Voona, A.K.; Sameer, S. Smart glove with gesture recognition ability for the hearing and speech impaired. In Proceedings of the 2014 IEEE Global Humanitarian Technology Conference-South Asia Satellite (GHTC-SAS), Trivandrum, India, 26–27 September 2014; pp. 105–110. [Google Scholar]
- Assaleh, K.; Shanableh, T.; Zourob, M. Low complexity classification system for glove-based arabic sign language recognition. In International Conference on Neural Information Processing; Springer: Berin/Heidelberg, Germany, 2012; pp. 262–268. [Google Scholar]
- Shukor, A.Z.; Miskon, M.F.; Jamaluddin, M.H.; Bin Ali, F.; Asyraf, M.F.; Bin Bahar, M.B. A new data glove approach for Malaysian sign language detection. Procedia Comput. Sci. 2015, 76, 60–67. [Google Scholar] [CrossRef] [Green Version]
- Mohandes, M.; A-Buraiky, S.; Halawani, T.; Al-Baiyat, S. Automation of the Arabic sign language recognition. In Proceedings of the 2004 International Conference on Information and Communication Technologies: From Theory to Applications, Damascus, Syria, 23 April 2004; pp. 479–480. [Google Scholar]
- Hongo, H.; Ohya, M.; Yasumoto, M.; Niwa, Y.; Yamamoto, K. Focus of attention for face and hand gesture recognition using multiple cameras. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 156–161. [Google Scholar]
- Zhang, H.; Wang, Y.; Deng, C. Application of gesture recognition based on simulated annealing BP neural network. In Proceedings of the 2011 International Conference on Electronic & Mechanical Engineering and Information Technology, Harbin, China, 12–14 August 2011; Volume 1, pp. 178–181. [Google Scholar]
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and EMG sensors. In IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans; IEEE: New York, NY, USA, 2011; Volume 41, pp. 1064–1076. [Google Scholar]
- Almeida, S.G.M.; Guimarães, F.G.; Ramírez, J.A. Feature extraction in Brazilian Sign Language Recognition based on phonological structure and using RGB-D sensors. Expert Syst. Appl. 2014, 41, 7259–7271. [Google Scholar] [CrossRef]
- Lai, K.; Konrad, J.; Ishwar, P. A gesture-driven computer interface using Kinect. In Proceedings of the 2012 IEEE Southwest Symposium on Image Analysis and Interpretation, Santa Fe, NM, USA, 22–24 April 2012; pp. 185–188. [Google Scholar]
- Chuan, C.H.; Regina, E.; Guardino, C. American sign language recognition using leap motion sensor. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–6 December 2014; pp. 541–544. [Google Scholar]
- Hoshino, K. Dexterous robot hand control with data glove by human imitation. IEICE Trans. Inf. Syst. 2006, 89, 1820–1825. [Google Scholar] [CrossRef]
- Elakkiya, R. Machine learning based sign language recognition: A review and its research frontier. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 7205–7224. [Google Scholar] [CrossRef]
- Sandjaja, I.N.; Marcos, N. Sign language number recognition. In Proceedings of the 2009 Fifth International Joint Conference on INC, IMS and IDC, Seoul, Korea, 25–27 August 2009; pp. 1503–1508. [Google Scholar]
- Ong, C.; Lim, I.; Lu, J.; Ng, C.; Ong, T. Sign-language recognition through gesture & movement analysis (SIGMA). In Mechatronics and Machine Vision in Practice 3; Springer: Berlin/Heidelberg, Germany, 2018; pp. 235–245. [Google Scholar]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. Mediapipe hands: On-device real-time hand tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Multi-modal deep hand sign language recognition in still images using restricted Boltzmann machine. Entropy 2018, 20, 809. [Google Scholar] [CrossRef] [Green Version]
- Sandler, W.; Lillo-Martin, D. Sign Language and Linguistic Universals; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Mitchell, R.E.; Young, T.A.; Bachelda, B.; Karchmer, M.A. How many people use ASL in the United States? Why estimates need updating. Sign Lang. Stud. 2006, 6, 306–335. [Google Scholar] [CrossRef]
- Yanay, T.; Shmueli, E. Air-writing recognition using smart-bands. Pervasive Mob. Comput. 2020, 66, 101183. [Google Scholar] [CrossRef]
- Murata, T.; Shin, J. Hand gesture and character recognition based on kinect sensor. Int. J. Distrib. Sens. Netw. 2014, 10, 278460. [Google Scholar] [CrossRef]
- Sonoda, T.; Muraoka, Y. A letter input system based on handwriting gestures. Electron. Commun. Jpn. Part III Fundam. Electron. Sci. 2006, 89, 53–64. [Google Scholar] [CrossRef]
- Khari, M.; Garg, A.K.; Crespo, R.G.; Verdú, E. Gesture Recognition of RGB and RGB-D Static Images Using Convolutional Neural Networks. Int. J. Interact. Multim. Artif. Intell. 2019, 5, 22–27. [Google Scholar] [CrossRef]
- Dong, C.; Leu, M.C.; Yin, Z. American sign language alphabet recognition using microsoft kinect. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–52. [Google Scholar]
- Das, A.; Gawde, S.; Suratwala, K.; Kalbande, D. Sign language recognition using deep learning on custom processed static gesture images. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET), Mumbai, India, 5 January 2018; pp. 1–6. [Google Scholar]
- Bird, J.J.; Ekárt, A.; Faria, D.R. British sign language recognition via late fusion of computer vision and leap motion with transfer learning to american sign language. Sensors 2020, 20, 5151. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of American sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Tao, W.; Lai, Z.H.; Leu, M.C.; Yin, Z. American sign language alphabet recognition using leap motion controller. In Proceedings of the 2018 Institute of Industrial and Systems Engineers Annual Conference (IISE 2018), Orlando, FL, USA, 19–22 May 2018. [Google Scholar]
- Chong, T.W.; Lee, B.G. American sign language recognition using leap motion controller with machine learning approach. Sensors 2018, 18, 3554. [Google Scholar] [CrossRef] [Green Version]
- Tolentino, L.K.S.; Juan, R.O.S.; Thio-ac, A.C.; Pamahoy, M.A.B.; Forteza, J.R.R.; Garcia, X.J.O. Static sign language recognition using deep learning. Int. J. Mach. Learn. Comput. 2019, 9, 821–827. [Google Scholar] [CrossRef]
- Kasukurthi, N.; Rokad, B.; Bidani, S.; Dennisan, D. American Sign Language Alphabet Recognition using Deep Learning. arXiv 2019, arXiv:1905.05487. [Google Scholar]
- Kapuściński, T.; Warchoł, D. Hand Posture Recognition Using Skeletal Data and Distance Descriptor. Appl. Sci. 2020, 10, 2132. [Google Scholar] [CrossRef] [Green Version]
- Kolivand, H.; Joudaki, S.; Sunar, M.S.; Tully, D. A new framework for sign language alphabet hand posture recognition using geometrical features through artificial neural network (part 1). Neural Comput. Appl. 2021, 33, 4945–4963. [Google Scholar] [CrossRef]
- Rivera-Acosta, M.; Ortega-Cisneros, S.; Rivera, J.; Sandoval-Ibarra, F. American sign language alphabet recognition using a neuromorphic sensor and an artificial neural network. Sensors 2017, 17, 2176. [Google Scholar] [CrossRef] [Green Version]
- Tao, W.; Leu, M.C.; Yin, Z. American Sign Language alphabet recognition using Convolutional Neural Networks with multiview augmentation and inference fusion. Eng. Appl. Artif. Intell. 2018, 76, 202–213. [Google Scholar] [CrossRef]
- Valli, C.; Lucas, C. Linguistics of American sign language: An introduction; Gallaudet University Press: Washington, DC, USA, 2000. [Google Scholar]
- Kaggle. ASL Alphabet. Available online: https://www.kaggle.com/grassknoted/asl-alphabet (accessed on 19 July 2021).
- Barczak, A.; Reyes, N.; Abastillas, M.; Piccio, A.; Susnjak, T. A new 2D static hand gesture colour image dataset for ASL gestures. Res. Lett. Inf. Math. Sci. 2011, 15, 12–20. [Google Scholar]
- Pugeault, N.; Bowden, R. Spelling it out: Real-time ASL fingerspelling recognition. In Proceedings of the 2011 IEEE International conference on computer vision workshops (ICCV workshops), Barcelona, Spain, 6–13 November 2011; pp. 1114–1119. [Google Scholar]
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Sklearn.Svm.SVC — Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html (accessed on 19 July 2021).
- Garcia, B.; Viesca, S.A. Real-time American sign language recognition with convolutional neural networks. Convolutional Neural Netw. Vis. Recognit. 2016, 2, 225–232. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Classifier | Recognition Rate |
|---|---|---|---|
| [29] | Smart Bands | KNN with DTW | 89.20% |
| [29] | Smart Bands | CNN | 83.20% |
| [30] | Kinect | DP Matching | 98.90% |
| [31] | Video Camera | DP Matching | 75.00% |
| [32] | Kinect | VGG19 | 94.80% |
| [33] | Kinect | Random Forest | 90.00% |
| [34] | Direct Images | InceptionV3 | 90.00% |
| [26] | Images from Massey Dataset | RBM | 99.31% |
| [26] | Images from Finger Spelling A Dataset | RBM | 97.56% |
| [26] | Images from NYU Dataset | RBM | 90.01% |
| [26] | Images from ASL Fingerspelling Dataset of Surrey University | RBM | 98.13% |
| [35] | Leap Motion Camera | ANN | 94.44% |
| [36] | Leap Motion in Virtual Reality Environment | HMC | 86.10% |
| [37] | Leap Motion Controller | CNN | 80.10% |
| [38] | Leap Motion Controller | SVM | 72.79% |
| [38] | Leap Motion Controller | DNN | 88.79% |
| [39] | Skin Color Modeling | CNN | 93.67% |
| [40] | Direct Images | DNN with Squeezenet | 83.28% |
| [41] | Skeletal Data and Distance Descriptor | TreeBag & NN | 90.70% |
| [42] | Geometrical Features | ANN | 96.78% |
| [43] | Neuromorphic Sensor | ANN | 79.58% |
| [44] | Multiview Augmentation & Inference Fusion | CNN | 93.00% |
| Starting Joint Number | Set of Two Joint Numbers for Measuring Distance by Considering Starting Joint Number as a First Joint Number | Number of Distance-Based Features |
|---|---|---|
| 1 | {(1,3), (1,4), (1,6), (1,7), (1,8), (1,10), (1,11), (1,12), (1,14), (1,15), (1,16), (1,18), (1,19), (1,20), (1,21)} | 15 |
| 2 | {(2,4), (2,5), (2,6), (2,7), (2,8), (2,9), (2,10), (2,11), (2,12), (2,13), (2,14), (2,15), (2,16), (2,17), (2,18), (2,19), (2,20), (2,21)} | 18 |
| 3 | {(3,5), (3,6), (3,7), (3,8), (3,9), (3,10), (3,11), (3,12), (3,13), (3,14), (3,15), (3,16), (3,17), (3,18), (3,19), (3,20), (3,21)} | 17 |
| 4 | {(4,6), (4,7), (4,8), (4,9), (4,10), (4,11), (4,12), (4,13), (4,14), (4,15), (4,16), (4,17), (4,18), (4,19), (4,20), (4,21)} | 16 |
| 5 | {(5,6), (5,7), (5,8), (5,9), (5,10), (5,11), (5,12), (5,13), (5,14), (5,15), (5,16), (5,17), (5,18), (5,19), (5,20), (5,21)} | 16 |
| 6 | {(6,8), (6,9), (6,10), (6,11), (6,12), (6,13), (6,14), (6,15), (6,16), (6,17), (6,18), (6,19), (6,20), (6,21)} | 14 |
| 7 | {(7,9), (7,10), (7,11), (7,12), (7,13), (7,14), (7,15), (7,16), (7,17), (7,18), (7,19), (7,20), (7,21)} | 13 |
| 8 | {(8,10), (8,11), (8,12), (8,13), (8,14), (8,15), (8,16), (8,17), (8,18), (8,19), (8,20), (8,21)} | 12 |
| 9 | {(9,10), (9,11), (9,12), (9,13), (9,14), (9,15), (9,16), (9,17), (9,18), (9,19), (9,20), (9,21)} | 12 |
| 10 | {(10,12), (10,13), (10,14), (10,15), (10,16), (10,17), (10,18), (10,19), (10,20), (10,21)} | 10 |
| 11 | {(11,13), (11,14), (11,15), (11,16), (11,17), (11,18), (11,19), (11,20), (11,21)} | 9 |
| 12 | {(12,14), (12,15), (12,16), (12,17), (12,18), (12,19), (12,20), (12,21)} | 8 |
| 13 | {(13,14), (13,15), (13,16), (13,17), (13,18), (13,19), (13,20), (13,21)} | 8 |
| 14 | {(14,16), (14,17), (14,18), (14,19), (14,20), (14,21)} | 6 |
| 15 | {(15,17), (15,18), (15,19), (15,20), (15,21)} | 5 |
| 16 | {(16,18), (16,19), (16,20), (16,21)} | 4 |
| 17 | {(17,18), (17,19), (17,20), (17,21)} | 4 |
| 18 | {(18,20), (18,21)} | 2 |
| 19 | {(19,21)} | 1 |
| 20 | {} | 0 |
| 21 | {} | 0 |
| Starting Joint Number | Set of Vectors Formed by Taking Starting Joint Number as First Point and Other Joints as Second Points | Number of Angle-Based Features |
|---|---|---|
| 1 | {, , , , , , , , , , | |
| , , , , , , , , } | ||
| 2 | {, , , , , , , , , | |
| , , , , , , , , } | ||
| 3 | {, , , , , , , , , | |
| , , , , , , , } | ||
| 4 | {, , , , , , , , | |
| , , , , , , , } | ||
| 5 | {, , , , , , , , | |
| , , , , , , } | ||
| 6 | {, , , , , , , | |
| , , , , , , } | ||
| 7 | {, , , , , , , | |
| , , , , , } | ||
| 8 | {, , , , , , | |
| , , , , , } | ||
| 9 | {, , , , , | |
| , , , , , } | ||
| 10 | {, , , , , | |
| , , , , } | ||
| 11 | {, , , , | |
| , , , , } | ||
| 12 | {, , , , | |
| , , , } | ||
| 13 | {, , , , , , , } | |
| 14 | {, , , , , , } | |
| 15 | {, , , , , } | |
| 16 | {, , , , } | |
| 17 | {, , , } | |
| 18 | {, , } | |
| 19 | {, } | |
| 20 | {} | |
| 21 | {} | 0 |
| Parameter Name | Used Values for Grid Search |
|---|---|
| C | 0.1, 1, 10, 100, 1000 |
| gamma | scale *, 0.001, 0.0001 |
| Dataset | Parameter | All Distance | All Angle | Both Distance and |
|---|---|---|---|---|
| Features | Features | Angle Features | ||
| ASL Alphabet | C | 1000 | 1000 | 1000 |
| gamma | 0.001 | 0.001 | scale | |
| Massey | C | 100 | 1000 | 1000 |
| gamma | 0.01 | scale | 0.0001 | |
| Finger Spelling A | C | 1000 | 1000 | 1000 |
| gamma | 0.001 | 0.001 | scale |
| Parameter Name | Used Values for Grid Search |
|---|---|
| number of leaves | 5, 10, 25, 50, 75, 100, 500, 1000 |
| learning rate | 0.1, 0.01, 0.001, 0.0001, 0.00001 |
| minimum child samples | 5, 10, 25, 50, 100, 500, 1000 |
| number of estimators | 10–250 |
| Dataset | Parameter | All Distance | All Angle | Both Distance and |
|---|---|---|---|---|
| Features | Features | Angle Features | ||
| ASL Alphabet | No. of leaves | 100 | 100 | 100 |
| learning rate | 0.1 | 0.1 | 0.1 | |
| min. child samples | 25 | 25 | 25 | |
| No. of estimators | 12 | 13 | 14 | |
| Massey | No. of leaves | 50 | 50 | 50 |
| learning rate | 0.1 | 0.1 | 0.1 | |
| min. child samples | 25 | 25 | 25 | |
| No. of estimators | 86 | 82 | 200 | |
| Finger Spelling A | No. of leaves | 100 | 100 | 100 |
| learning rate | 0.1 | 0.1 | 0.1 | |
| min. child samples | 25 | 25 | 25 | |
| No. of estimators | 44 | 42 | 40 |
| Classifier | Dataset | All Distance | All Angle | Both Distance and |
|---|---|---|---|---|
| Features (190) | Features (630) | Angle Features (820) | ||
| SVM | ASL Alphabet | 81.20% | 87.06% | 87.60% |
| Massey | 98.56% | 99.23% | 99.39% | |
| Finger Spelling A | 96.97% | 97.63% | 98.45% | |
| Light GBM | ASL Alphabet | 79.11% | 86.01% | 86.12% |
| Massey | 96.51% | 97.25% | 97.80% | |
| Finger Spelling A | 94.50% | 96.06% | 96.71% |
| Dataset | Samples | Avg. HPET | Avg. FET | PTPS | RFPS | Req. Memory |
|---|---|---|---|---|---|---|
| Massey | 1815 | 0.011 | 0.003 | 0.014 | 71 | 4.04 MB |
| Finger Spelling A | 65,774 | 0.01 | 0.002 | 0.015 | 66 | 47.97 MB |
| ASL Alphabet | 780,000 | 0.011 | 0.002 | 0.016 | 62 | 115.14 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors 2021, 21, 5856. https://doi.org/10.3390/s21175856
Shin J, Matsuoka A, Hasan MAM, Srizon AY. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors. 2021; 21(17):5856. https://doi.org/10.3390/s21175856
Chicago/Turabian StyleShin, Jungpil, Akitaka Matsuoka, Md. Al Mehedi Hasan, and Azmain Yakin Srizon. 2021. "American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation" Sensors 21, no. 17: 5856. https://doi.org/10.3390/s21175856
APA StyleShin, J., Matsuoka, A., Hasan, M. A. M., & Srizon, A. Y. (2021). American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors, 21(17), 5856. https://doi.org/10.3390/s21175856