
CAPformer: Pedestrian Crossing Action Prediction Using Transformer

 ,
,  ,
,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
1.1. Context
1.2. Motivation
2. Related Work
2.1. JAAD
2.2. TITAN and STIP
2.3. PIE
2.4. PePScenes
2.5. Benchmark
3. Proposed Approach
3.1. Problem Formulation
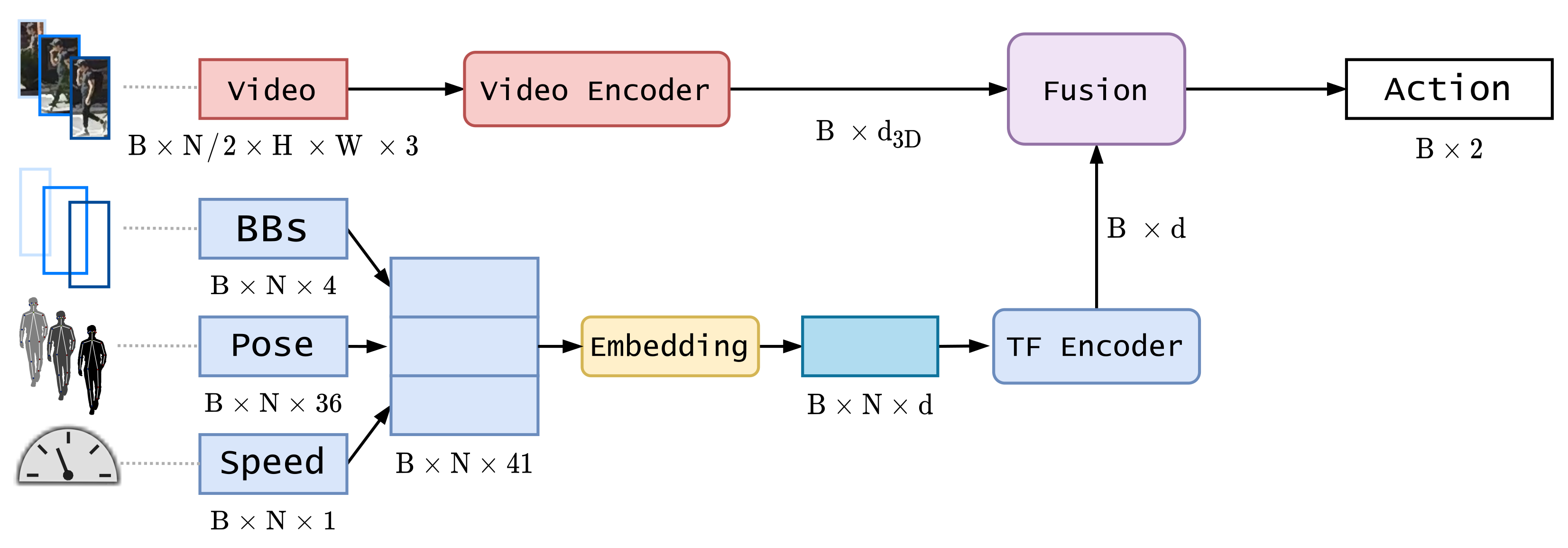
3.2. System Description
3.2.1. Video Encoder Branch
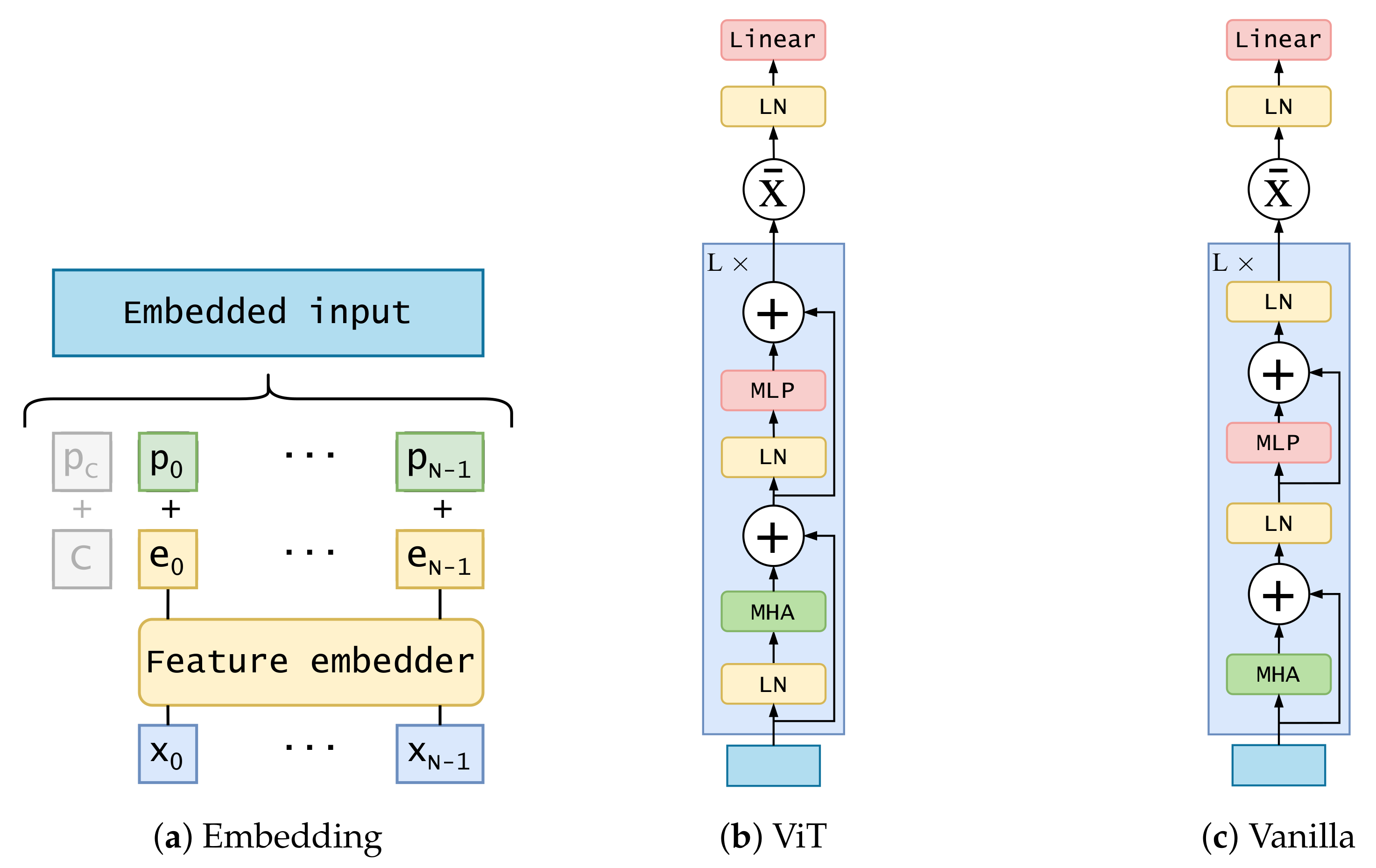
3.2.2. Kinematics Encoder Branch
- ViT encoder: similar to the one proposed in [34] for image classification. It applies a layer normalization on the embedded input before forwarding it into a multi-head attention layer. Its output is added to the original embedded input through a residual connection. After that, another layer normalization is applied and forwarded to a multi-layer perceptron composed of two linear layers with a Gaussian error linear units (GELU) activation between them. After another residual connection, the output of the layer is used as input for the next layer. The L layer’s output is summarized and the resulting vector is forwarded through a layer normalization and a simple feed-forward layer. Dropout is applied through all the processes, after every feed-forward layer, except for the last one. The diagram of this architecture is shown in Figure 2b;
- Vanilla transformer encoder: using the original proposed encoder in [7]. The main difference with the previous one is the application of layer normalization. Instead of applying it to embedded input, it is applied to the output of the second residual connection. The diagram of this architecture is shown in Figure 2c. Another difference is the usage of ReLU activation instead of GELU in the multi-layer perceptron.
3.2.3. Feature Fusion Block
- Concatenation through fully connected: The output of the video encoder is concatenated with the output of the kinematics encoder. This is forwarded through a multi-layer perceptron with one hidden layer, dropout regularization, and a ReLU activation. The output dimension of this layer corresponds to the number of classes;
3.3. Training
3.3.1. Datasets
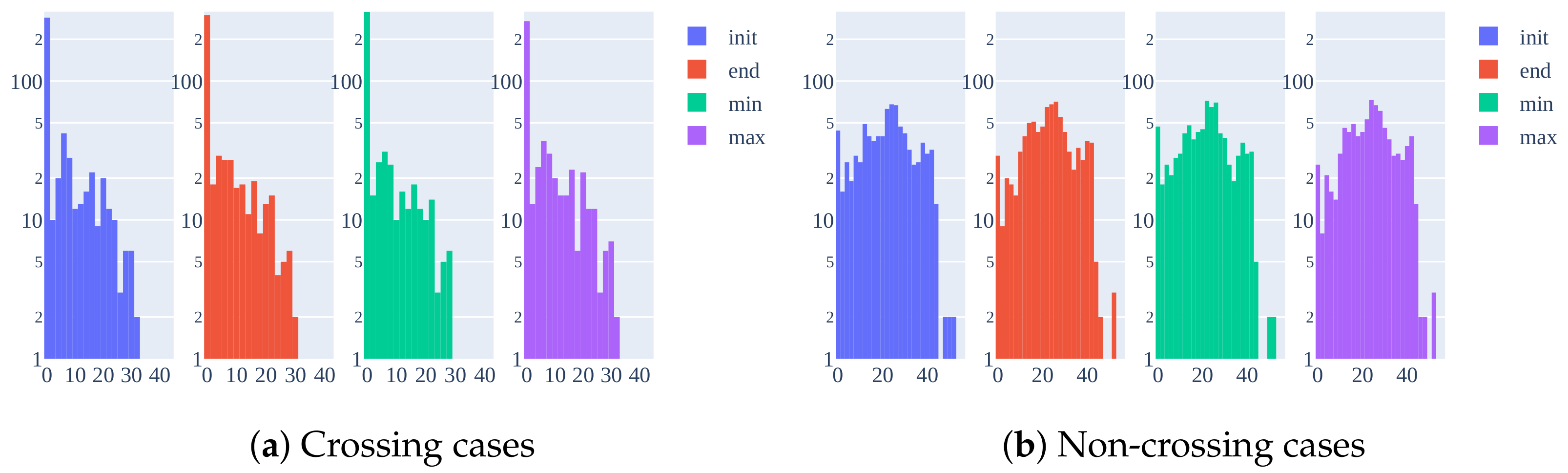
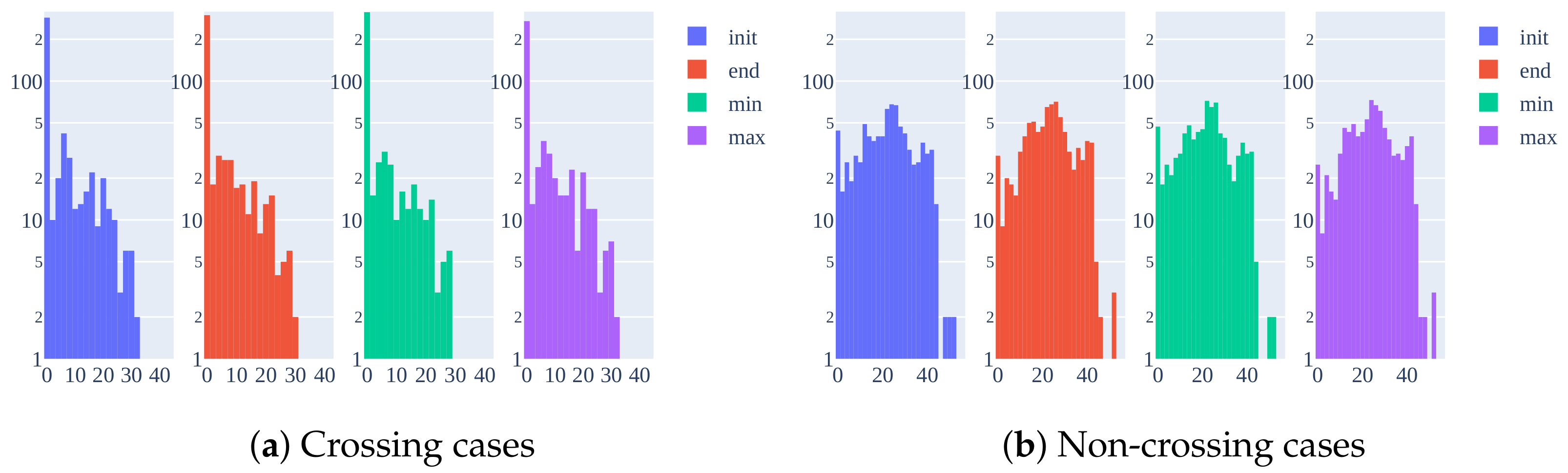
- JAAD [9]: This dataset is composed of 346 short clips (only 323 are used, excluding low resolution and adverse weather or night ones) recorded in several countries using different cameras. Two variants of the annotations are used in the benchmark: and . includes only pedestrians with behavioral annotations: 495 crossing and 191 non-crossing, giving rise to 374 non-crossing and 1760 crossing samples. comprises the entire set of pedestrians in the sequences, adding 2100 non-crossing pedestrian far from the road, resulting in 6853 non-crossing and 1760 crossing sequence samples. The sequence samples from pedestrian tracks are extracted using a sliding window approach with an of overlap between them. Bounding boxes are manually annotated and provided for each pedestrian track. However, ego-vehicle state information is not measured, and the only related annotation is the categorical ego-vehicle state. Since this annotation is not used in the original results in the benchmark, we decided not to include it in our ranking process;
- PIE [26]: This dataset is composed of a continuous recording session in Toronto, Canada, spanning 6 hours during the day in clear weather. In addition to bounding boxes, as in the case of JAAD, PIE provides real measurements of the ego-vehicle state, obtained using an On-Board Diagnostics (OBD) sensor. As in the case of the benchmark, we decided to include this information as input for some of the trained models in both experiments and the ranking process. It contains 512 crossing and 1322 non-crossing pedestrians, which leads to 3576 non-crossing and 1194 crossing samples, using an overlap of .
3.3.2. Loss
3.3.3. Optimizer
3.3.4. Hardware and Software Details
4. Experimental Setup
4.1. Data Ablation Study
4.1.1. Bounding Boxes Image Cropping Strategies
4.1.2. Bounding Box Coordinates Preprocessing
- Center coordinates and height: we obtain the center coordinates of the bounding box and its height. We did not include the width to avoid redundancy, as we include it as a measure related to the distance between ego-vehicle and pedestrian;
- Center coordinates and height including speed: in addition to the above features, we include the speed of change of center coordinates and height.
4.1.3. Pose Keypoints Missing Data
4.1.4. Ego-Vehicle Speed Controversy
4.1.5. Input Features Combinations
4.1.6. Data Augmentation Applied
- Horizontal flip: apply a random horizontal flip on the image plane;
- Roll rotation: apply a roll rotation of the 3D sequence, which is equivalent to applying a 2D rotation on each image in the sequence;
- Color jittering: apply a random change in brightness, contrast, saturation, and hue of the input sequence.
4.1.7. Combined Datasets Training
4.2. Model Ablation Study
4.2.1. Pre-Trained Backbones
4.2.2. Different Transformer Encoders
4.3. Benchmark
- Multi-stream RNN (MultiRNN) [44]: Two stream architecture which combines two RNN streams, one for odometry prediction (includes a CNN encoder for including visual features) and the other for bounding box prediction. Instead of predicting future bounding boxes, it is modified to predict the future pedestrian crossing action;
- C3D [45]: 3D convolutional model which combines 3D convolutional layers and 3D max-pooling layers. It uses only the pedestrian bounding box cropped regions from RGB video sequences as input data;
- Inflated 3D (I3D) [41]: 3D convolutional model based on 2D CNN inflation, where filters and pooling kernels are expanded into 3D. It uses as input optical flow sequence information, extracted from pedestrian bounding box cropped regions;
- PCPA [8]: best performing model in the benchmark. Multi-branch model with four branches. The first branch is based on C3D network and encodes input RGB video sequence extracted by cropping pedestrian bounding boxes. The other three branches consist of RNNs. The information is fussed using attention at the temporal level and the branch (modality) level.
- Query, key and value size is the same ;
- Number of self-attention heads ;
- Number of transformer encoders ;
- Multi-layer perceptron hidden layer dimension ;
- Dropout rate, applied after embedding and the MLP block .
4.4. Model Hyperparameters
- PIE dataset used for training;
- Batch size of 16 samples;
- Local box warp used as the pre-processing for bounding boxes crops;
- TimeSformer used as backbone, pre-trained on SSv2 and fine-tuned. The output vector size of 1024;
- Fusion strategy: concatenation;
- Input sequence length ;
- Learning rate with value for the fusion and kinematic encoder and for the video backbone;
- Input image dimension of ;
- Weight decay of .
4.5. Metrics
5. Results
5.1. Preprocessing
5.1.1. Image Input Nature and Size
5.1.2. Bounding Box Coordinates Preprocessing
5.1.3. Different Combinations of Input Features
5.1.4. Data Augmentation
5.2. Combined Datasets Training
5.3. Different Encoder Strategies
5.4. Benchmark
5.5. Qualitative Results
6. Discussion
7. Conclusions and Future Work
- Train and test models in a combination of different available behavior datasets and analyze it in an unrelated scenario to see its generalization capabilities;
- Research deeper in the usage of data augmentation techniques in the training of multi-branch models;
- Consider the development of virtual scenarios to include more crossing cases and fight data imbalance;
- Explore new features from datasets, such as labeled information from the environment (e.g., the relative relationship between vehicles, crosswalk position, traffic signals). These new features will be 2D or 3D, depending on the availability of datasets in the literature;
- Experimentation with different data cleaning strategies in training time, applying a maximum occlusion level, pedestrian minimum size, etc.;
- Simulate real case scenario to find new weaknesses and strengths in available models.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Adminaité-Fodor, D.; Jost, G. Safer Roads, Safer Cities: How to Improve Urban Road Safety in The EU; Technical Report; European Transport Safety Council: Brussels, Belgium, 2019. [Google Scholar]
- European New Car Assessment Programme (Euro NCAP) Test Protocol-AEB VRU Systems; Technical Report; Euro NCAP: Leuven, Belgium, 2020.
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; Arras, K.O. Human motion trajectory prediction: A survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Pedestrian Action Anticipation Using Contextual Feature Fusion in Stacked RNNs. arXiv 2020, arXiv:2005.06582. [Google Scholar]
- Zhu, Y.; Li, X.; Liu, C.; Zolfaghari, M.; Xiong, Y.; Wu, C.; Zhang, Z.; Tighe, J.; Manmatha, R.; Li, M. A Comprehensive Study of Deep Video Action Recognition. arXiv 2020, arXiv:2012.06567. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Kotseruba, I.; Rasouli, A.; Tsotsos, J.K. Benchmark for Evaluating Pedestrian Action Prediction. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), 5–9 January 2021; pp. 1258–1268. [Google Scholar]
- Rasouli, A.; Tsotsos, J.K. Joint Attention in Driver-Pedestrian Interaction: From Theory to Practice. arXiv 2018, arXiv:1802.02522. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are They Going to Cross? A Benchmark Dataset and Baseline for Pedestrian Crosswalk Behavior. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar] [CrossRef]
- Fang, Z.; López, A.M. Is the Pedestrian going to Cross? Answering by 2D Pose Estimation. arXiv 2018, arXiv:1807.10580. [Google Scholar]
- Gesnouin, J.; Pechberti, S.; Bresson, G.; Stanciulescu, B.; Moutarde, F. Predicting Intentions of Pedestrians from 2D Skeletal Pose Sequences with a Representation-Focused Multi-Branch Deep Learning Network. Algorithms 2020, 13, 331. [Google Scholar] [CrossRef]
- Cadena, P.R.G.; Yang, M.; Qian, Y.; Wang, C. Pedestrian Graph: Pedestrian Crossing Prediction Based on 2D Pose Estimation and Graph Convolutional Networks. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference, ITSC, Auckland, New Zealand, 27–30 October 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 2000–2005. [Google Scholar] [CrossRef]
- Ait Bouhsain, S.; Alahi, A. Pedestrian Intention Prediction: A Multi-Task Perspective. Technical Report. arXiv 2020, arXiv:2010.10270v1. [Google Scholar]
- Lorenzo, J.; Parra, I.; Wirth, F.; Stiller, C.; Llorca, D.F.; Sotelo, M.A. RNN-based Pedestrian Crossing Prediction using Activity and Pose-related Features. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 19 October–13 November 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 1801–1806. [Google Scholar] [CrossRef]
- Ghori, O.; MacKowiak, R.; Bautista, M.; Beuter, N.; Drumond, L.; DIego, F.; Ommer, B.B. Learning to Forecast Pedestrian Intention from Pose Dynamics. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1277–1284. [Google Scholar] [CrossRef]
- Ranga, A.; Giruzzi, F.; Bhanushali, J.; Wirbel, E.; Pérez, P.; Vu, T.H.; Perrotton, X. VRUNet: Multi-Task Learning Model for Intent Prediction of Vulnerable Road Users. IS T Int. Symp. Electron. Imaging Sci. Technol. 2020, 2020. [Google Scholar] [CrossRef]
- Pop, D.O.; Rogozan, A.; Chatelain, C.; Nashashibi, F.; Bensrhair, A. Multi-Task Deep Learning for Pedestrian Detection, Action Recognition and Time to Cross Prediction. IEEE Access 2019, 7, 149318–149327. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Real-time Intent Prediction of Pedestrians for Autonomous Ground Vehicles via Spatio-Temporal DenseNet. arXiv 2019, arXiv:1904.09862. [Google Scholar]
- Yang, B.; Zhan, W.; Wang, P.; Chan, C.; Cai, Y.; Wang, N. Crossing or Not? Context-Based Recognition of Pedestrian Crossing Intention in the Urban Environment. IEEE Trans. Intell. Transp. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Piccoli, F.; Balakrishnan, R.; Perez, M.J.; Sachdeo, M.; Nunez, C.; Tang, M.; Andreasson, K.; Bjurek, K.; Raj, R.D.; Davidsson, E.; et al. FuSSI-Net: Fusion of Spatio-temporal Skeletons for Intention Prediction Network. arXiv 2020, arXiv:2005.07796. [Google Scholar]
- Gujjar, P.; Vaughan, R. Classifying pedestrian actions in advance using predicted video of urban driving scenes. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 2097–2103. [Google Scholar] [CrossRef]
- Chaabane, M.; Trabelsi, A.; Blanchard, N.; Beveridge, R. Looking ahead: Anticipating pedestrians crossing with future frames prediction. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, WACV, Snowmass, CO, USA, 1–5 March 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 2286–2295. [Google Scholar] [CrossRef]
- Malla, S.; Dariush, B.; Choi, C. TITAN: Future Forecast using Action Priors. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14–19 June 2020; pp. 11183–11193. [Google Scholar]
- Liu, B.; Adeli, E.; Cao, Z.; Lee, K.H.; Shenoi, A.; Gaidon, A.; Niebles, J.C. Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction. IEEE Robot. Autom. Lett. 2020, 5, 3485–3492. [Google Scholar] [CrossRef] [Green Version]
- Rasouli, A.; Kotseruba, I.; Kunic, T.; Tsotsos, J.K. PIE: A Large-Scale Dataset and Models for Pedestrian Intention Estimation and Trajectory Prediction. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6261–6270. [Google Scholar]
- Rasouli, A.; Yau, T.; Lakner, P.; Malekmohammadi, S.; Rohani, M.; Luo, J. PePScenes: A Novel Dataset and Baseline for Pedestrian Action Prediction in 3D. arXiv 2020, arXiv:2012.07773. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Yau, T.; Malekmohammadi, S.; Rasouli, A.; Lakner, P.; Rohani, M.; Luo, J. Graph-SIM: A Graph-based Spatiotemporal Interaction Modelling for Pedestrian Action Prediction. arXiv 2020, arXiv:2012.02148. [Google Scholar]
- Yang, D.; Zhang, H.; Yurtsever, E.; Redmill, K.; Özgüner, Ü. Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention. arXiv 2021, arXiv:2104.05485. [Google Scholar]
- Fan, L.; Buch, S.; Wang, G.; Cao, R.; Zhu, Y.; Niebles, J.C.; Fei-Fei, L. RubiksNet: Learnable 3D-Shift for Efficient Video Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the International Conference on Machine Learning (ICML), 18–24 July 2021.
- Khan, S.; Naseer, M.; Hayat, M.; Waqas Zamir, S.; Shahbaz Khan, F.; Shah, M. Transformers in Vision: A Survey. arXiv 2021, arXiv:2101.01169. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT), San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:cs.LG/1711.05101. [Google Scholar]
- Falcon, WA, e.a. PyTorch Lightning. GitHub. 2019. Available online: https://github.com/PyTorchLightning/pytorch-lightning (accessed on 15 August 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32 (NeurIPS); Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; pp. 8024–8035. [Google Scholar]
- Biewald, L. Experiment Tracking with Weights and Biases. 2020. Available online: wandb.com (accessed on 15 August 2021).
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzyńska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. arXiv 2017, arXiv:cs.CV/1706.04261. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv 2018, arXiv:cs.CV/1705.07750. [Google Scholar]
- Miech, A.; Zhukov, D.; Alayrac, J.B.; Tapaswi, M.; Laptev, I.; Sivic, J. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2630–2640. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A Short Note about Kinetics-600. arXiv 2018, arXiv:cs.CV/1808.01340. [Google Scholar]
- Bhattacharyya, A.; Fritz, M.; Schiele, B. Long-Term On-Board Prediction of People in Traffic Scenes under Uncertainty. arXiv 2018, arXiv:cs.CV/1711.09026. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning (CoRL), Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]


| 0.325 | 0.325 | 0.325 |
| (a) b | (b) b | (c) b |

| 0.24 | 0.24 | 0.24 | 0.24 |
| (a) b | (b) b | (c) b | (d) b |
| 0.49 | 0.49 |
| (a) b | (b) b |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of ann. fr. | Diff. Weather | Diff. Loc. | Ego-Veh. Mot. | |||
|---|---|---|---|---|---|---|
| JAAD | 75 K | 495 | 2291 | Yes | Yes | No |
| PIE | 293 K | 512 | 1322 | No | No | Yes |
| F1 | P | R | AUC | |
|---|---|---|---|---|
| box | ||||
| box warp | ||||
| context | ||||
| surround |
| F1 | P | R | AUC | |
|---|---|---|---|---|
| Mode | F1 | P | R | AUC |
|---|---|---|---|---|
| Only image | ||||
| Input | F1 | P | R | AUC | |||
|---|---|---|---|---|---|---|---|
| I | B | P | S | ||||
| 🗸 | |||||||
| 🗸 | 🗸 | ||||||
| 🗸 | 🗸 | 🗸 | |||||
| 🗸 | 🗸 | ||||||
| 🗸 | |||||||
| 🗸 | 🗸 | ||||||
| 🗸 | 🗸 | 🗸 | |||||
| 🗸 | 🗸 | 🗸 | 🗸 | ||||
| 🗸 | 🗸 | 🗸 | |||||
| 🗸 | 🗸 | ||||||
| 🗸 | 🗸 | 🗸 | |||||
| 🗸 | 🗸 | ||||||
| 🗸 | |||||||
| 🗸 | 🗸 | ||||||
| 🗸 | |||||||
| Augm. | Input | F1 | P | R | AUC |
|---|---|---|---|---|---|
| − | I | ||||
| I+B | |||||
| C | I | ||||
| I+B | |||||
| F | I | ||||
| I+B | |||||
| F+R+C | I | ||||
| I+B | |||||
| R | I | ||||
| I+B |
| Train | Test | F1 | P | R | AUC |
|---|---|---|---|---|---|
| P+J | P | ||||
| J | |||||
| P | P | ||||
| J |
| F1 | P | R | AUC | ||
|---|---|---|---|---|---|
| − | − | ||||
| ViT [34] | mean | ||||
| flat | |||||
| Vanilla [7] | mean | ||||
| flat |
| Model | Backbone | Fusion | Input | PIE | |||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | AUC | F1 | AUC | F1 | AUC | ||||
| Ours | TimeSformer | M | I,B,S | 0.761 | 0.844 | 0.763 | 0.545 | 0.557 | 0.728 |
| C | 0.779 | 0.853 | 0.743 | 0.552 | 0.514 | 0.701 | |||
| RubiksNet | M | 0.749 | 0.839 | 0.752 | 0.589 | 0.630 | 0.782 | ||
| C | 0.738 | 0.828 | 0.691 | 0.549 | 0.618 | 0.778 | |||
| C3D | M,T | I,B | 0.750 | 0.851 | 0.615 | 0.577 | 0.614 | 0.802 | |
| C3D | – | I | 0.520 | 0.670 | 0.750 | 0.510 | 0.650 | 0.810 | |
| MultiRNN | GRU | – | B, S * | 0.710 | 0.800 | 0.740 | 0.500 | 0.580 | 0.790 |
| I3D | – | O | 0.720 | 0.830 | 0.750 | 0.510 | 0.630 | 0.800 | |
| PCPA | C3D | C | I,B,S,P | 0.730 | 0.830 | 0.630 | 0.480 | 0.580 | 0.800 |
| M | 0.750 | 0.840 | 0.680 | 0.490 | 0.620 | 0.830 | |||
| T | 0.770 | 0.860 | 0.710 | 0.480 | 0.620 | 0.790 | |||
| M,T | 0.770 | 0.860 | 0.710 | 0.500 | 0.680 | 0.860 | |||
| 0.735 | 0.834 | 0.630 | 0.484 | 0.530 | 0.779 | ||||
| I,B | 0.723 | 0.820 | 0.613 | 0.486 | 0.522 | 0.780 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lorenzo, J.; Alonso, I.P.; Izquierdo, R.; Ballardini, A.L.; Saz, Á.H.; Llorca, D.F.; Sotelo, M.Á. CAPformer: Pedestrian Crossing Action Prediction Using Transformer. Sensors 2021, 21, 5694. https://doi.org/10.3390/s21175694
Lorenzo J, Alonso IP, Izquierdo R, Ballardini AL, Saz ÁH, Llorca DF, Sotelo MÁ. CAPformer: Pedestrian Crossing Action Prediction Using Transformer. Sensors. 2021; 21(17):5694. https://doi.org/10.3390/s21175694
Chicago/Turabian StyleLorenzo, Javier, Ignacio Parra Alonso, Rubén Izquierdo, Augusto Luis Ballardini, Álvaro Hernández Saz, David Fernández Llorca, and Miguel Ángel Sotelo. 2021. "CAPformer: Pedestrian Crossing Action Prediction Using Transformer" Sensors 21, no. 17: 5694. https://doi.org/10.3390/s21175694
APA StyleLorenzo, J., Alonso, I. P., Izquierdo, R., Ballardini, A. L., Saz, Á. H., Llorca, D. F., & Sotelo, M. Á. (2021). CAPformer: Pedestrian Crossing Action Prediction Using Transformer. Sensors, 21(17), 5694. https://doi.org/10.3390/s21175694