
Urban Intersection Classification: A Comparative Analysis

 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Related WorkWord
2.1. LSTM
2.2. GAN
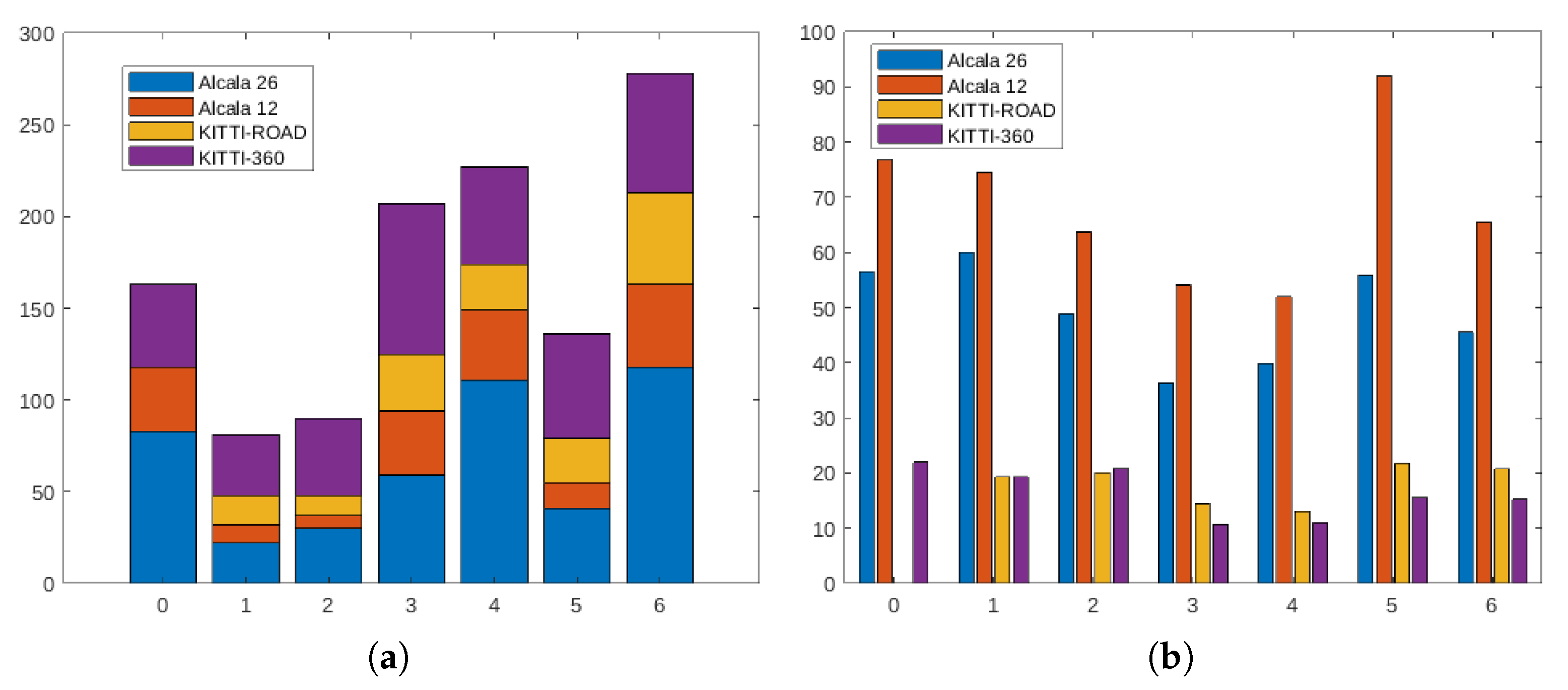
3. Dataset
4. Technical Approach
4.1. RGB Baseline
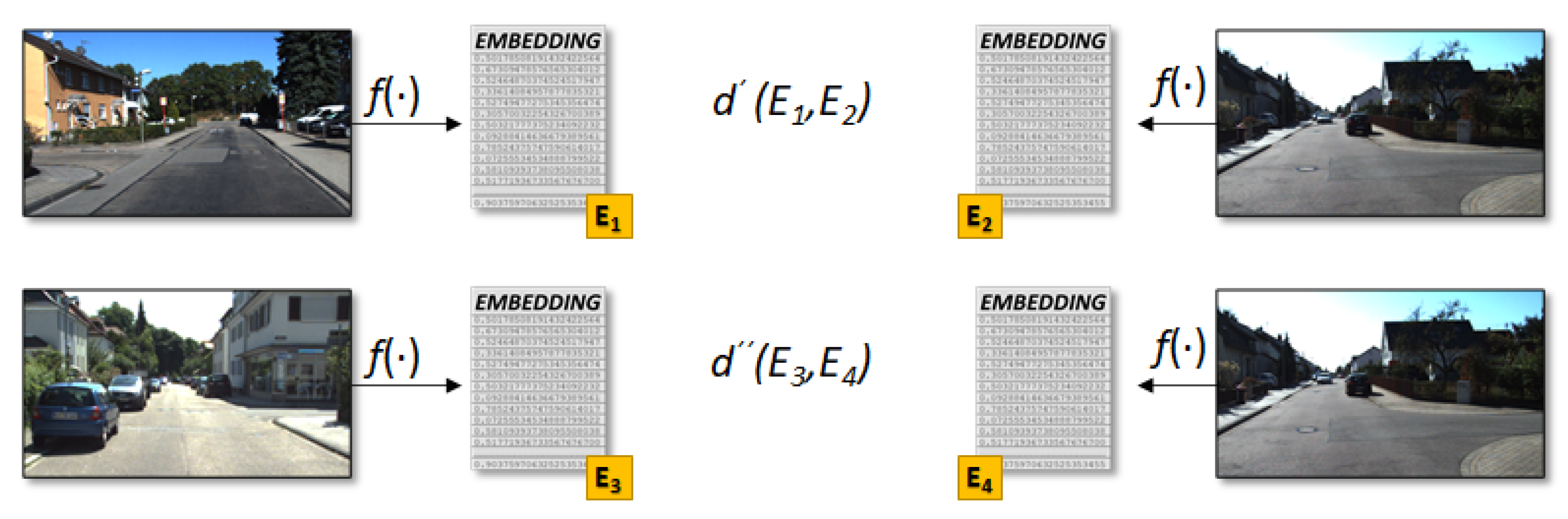
4.2. Metric Learning
Triplet Scheme
4.3. RGB Metric
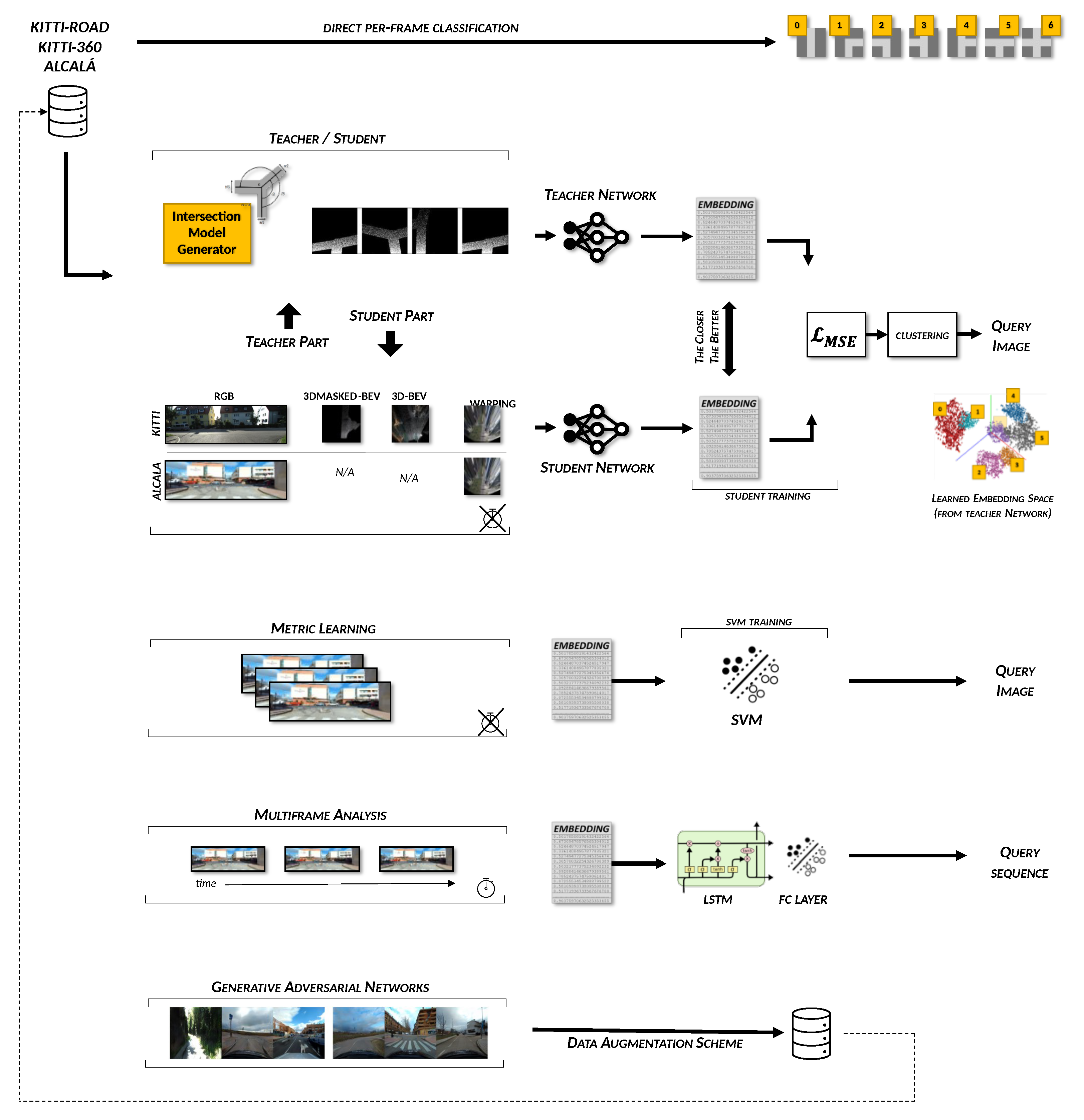
4.4. Teacher/Student and the Intersection Model
4.4.1. The Intersection Model
4.4.2. RGB Pre-Processing
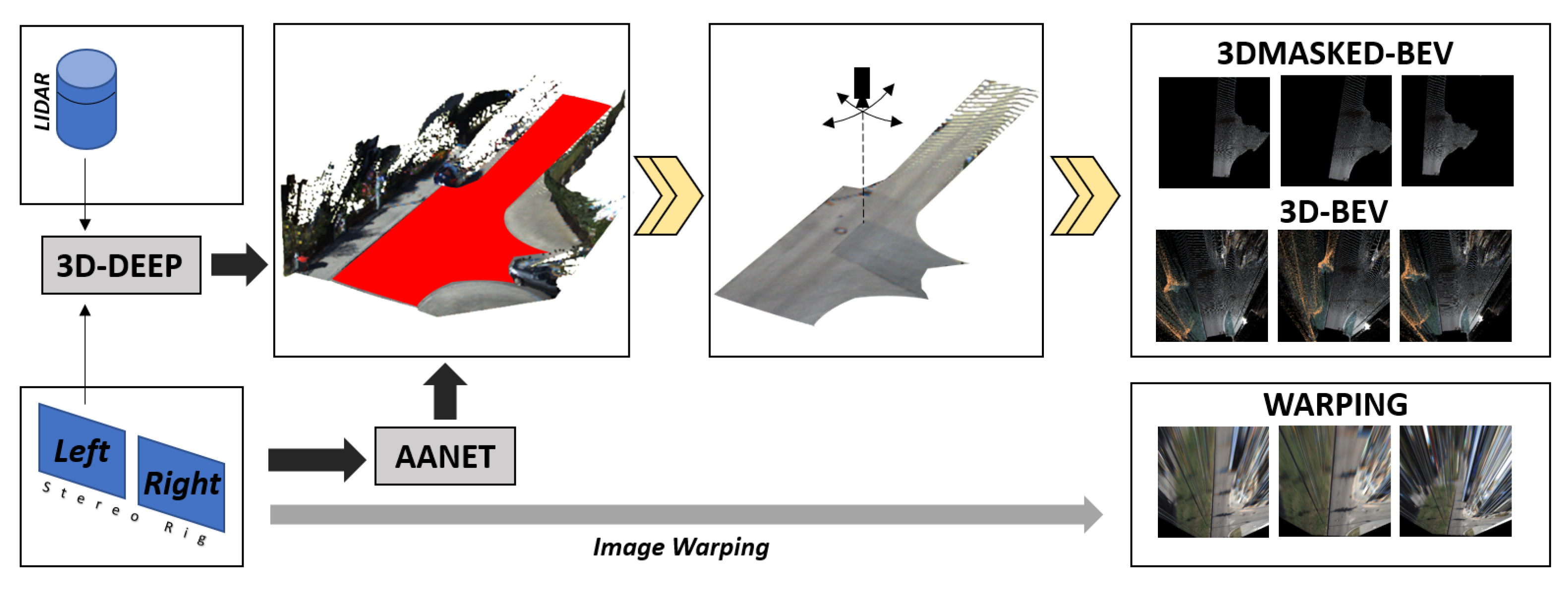
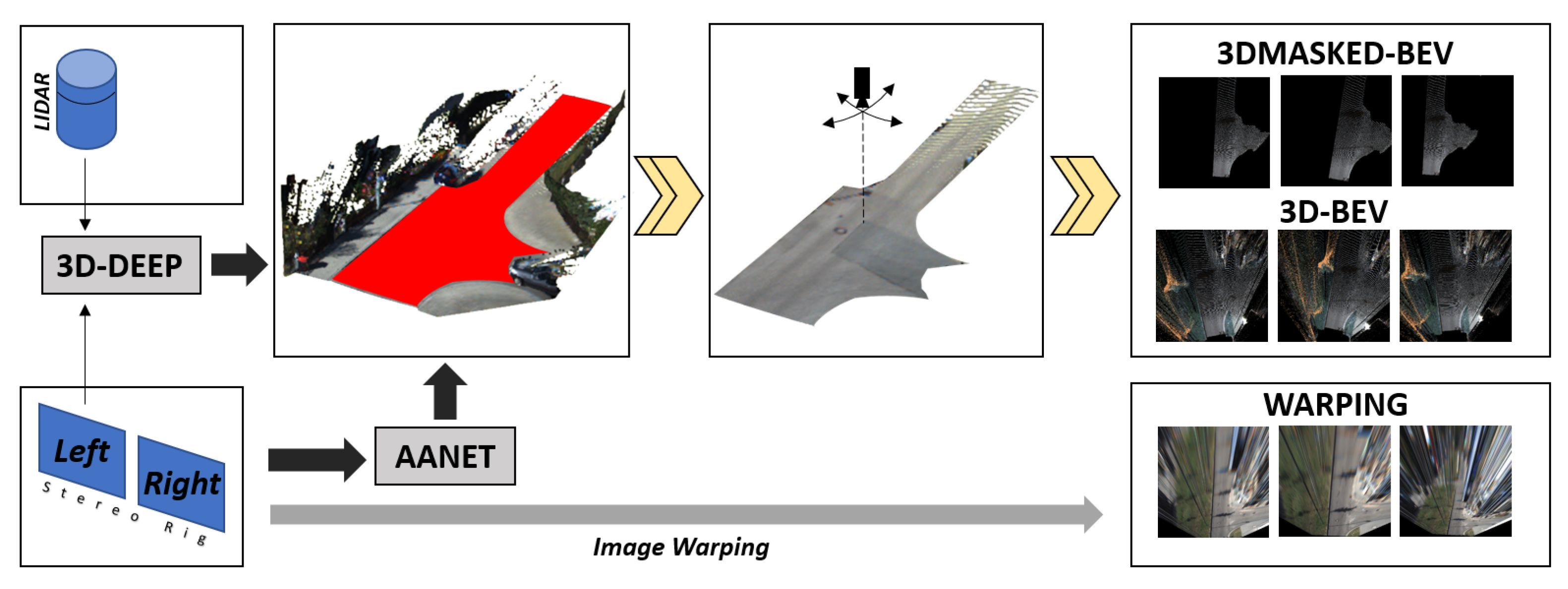
- 3D-Generated Bird’s Eye Views (3D-BEVs): this first transformation, applicable only to datasets that provides stereo camera configurations, creates a BEV representation of the scene using a 3D-reconstruction process; it is the most accurate 2D plan view that can be generated from images, as no distortions are introduced in this procedure. The effect of the virtual camera can be seen in the center box of Figure 10. We used the work in [53] to generate the depth image that, in turn, allowed us to create a 3D representation and then the desired 2D image. Please note that having a 3D representation allows us to change the virtual camera position retaining the scene’s consistency and simultaneously acting as a data augmentation methodology.
- Masked 3D-Generated Bird’s Eye Views (3DMASKED-BEVs): for this second transformation, we extended the previous pipeline by including the results in [54], to remove the 3D points that do not belong to the road surface and thus generate an image containing only road pixels. The main insight here is to evaluate whether the classification may benefit from less cluttered yet pre-segmented images. For this purpose, we combined the previous depth-image to the generated road-mask before creating the 2D view. The downside with this variation is that the approach in [54] only works with LiDAR data.
- Warping with Homographies (WARPINGs): this last transform tries to overcome the limitation of stereo and LiDARs availability at the cost of introducing distortions in the generated images. We applied standard computer vision techniques to create a homography between the RGB image and the desired 2D image. As homographies are only defined for flat surfaces, but common roads do always have at least slight deformations, this image transformation introduces distortions to the final image, as depicted in the warping images in Figure 10. Moreover, as we used fixed homographies, the actual attitude of the vehicle introduces similar distortion effects as the vehicle moves along its route. Nevertheless, as we have more than one frame-per-intersections in our videos, we can conceive this effect as a data augmentation scheme, as the same intersection visually appears different across successive frames. Please notice that this scheme is equivalent to the one proposed for the RGB-Baseline described in Section 4.1.
4.4.3. Applying the Teacher–Student Paradigm
4.4.4. Training Details
4.5. Multi-Frame Analysis or Schemes
4.5.1. Recurrent Neural Networks
4.5.2. Video Classification Networks
4.6. Artificial Data-Augmentation: GAN
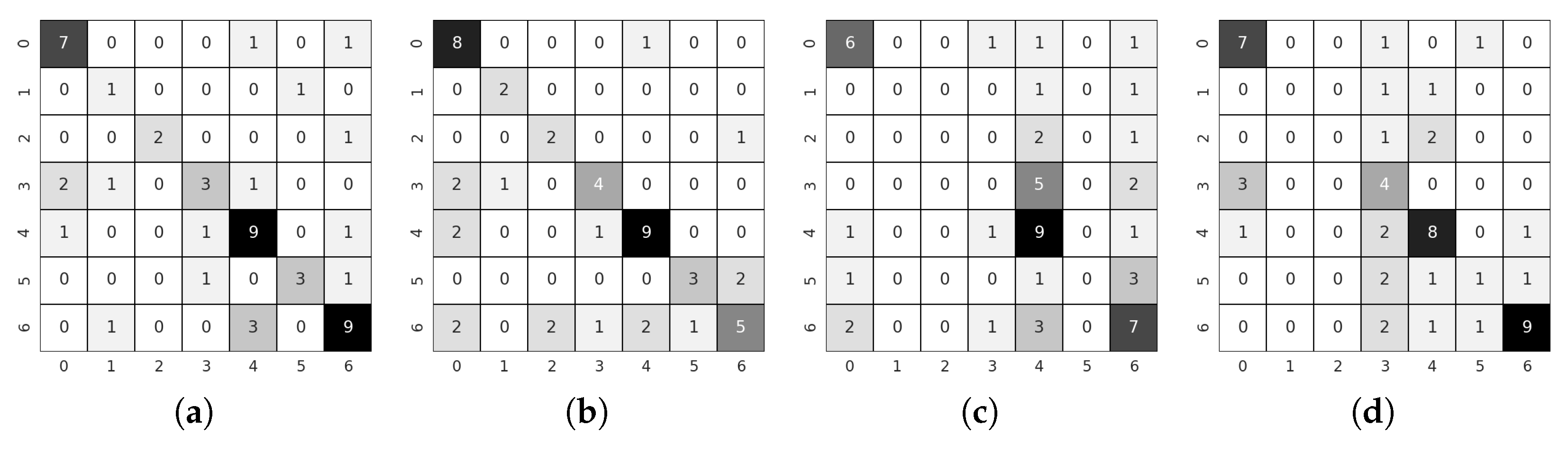
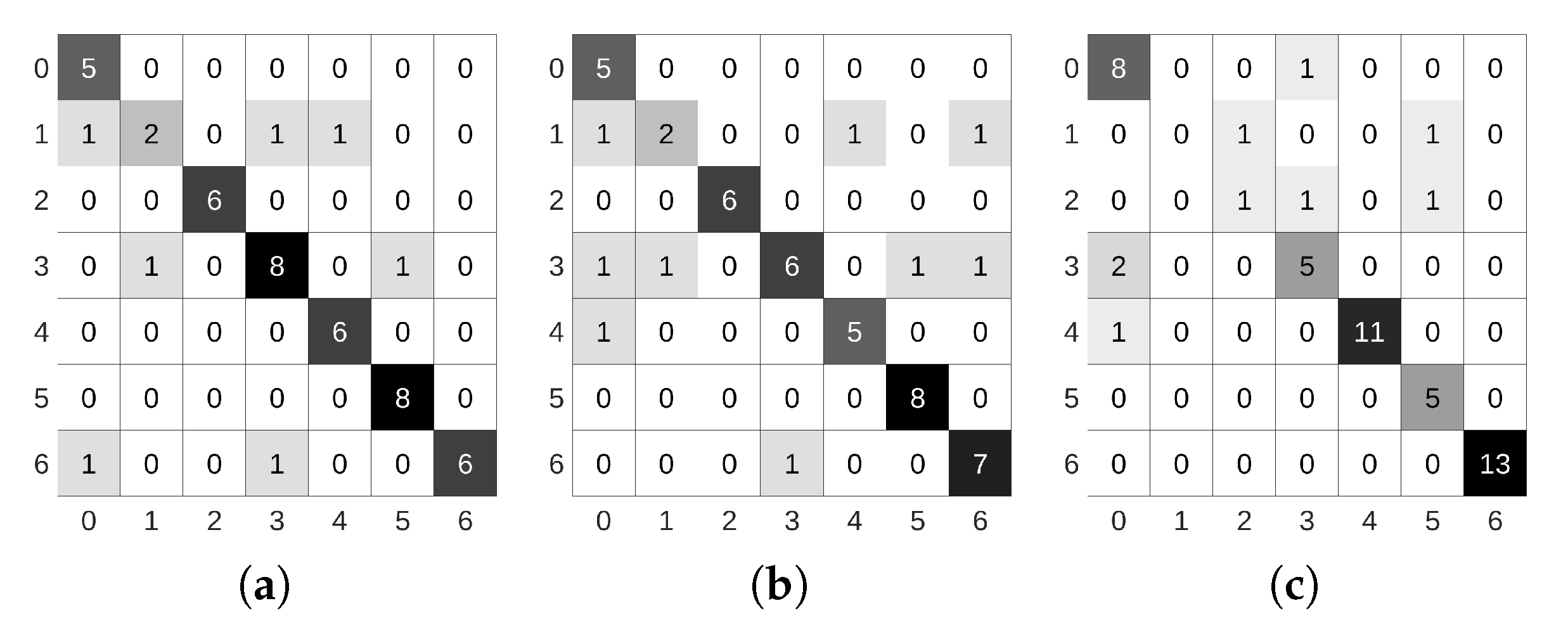
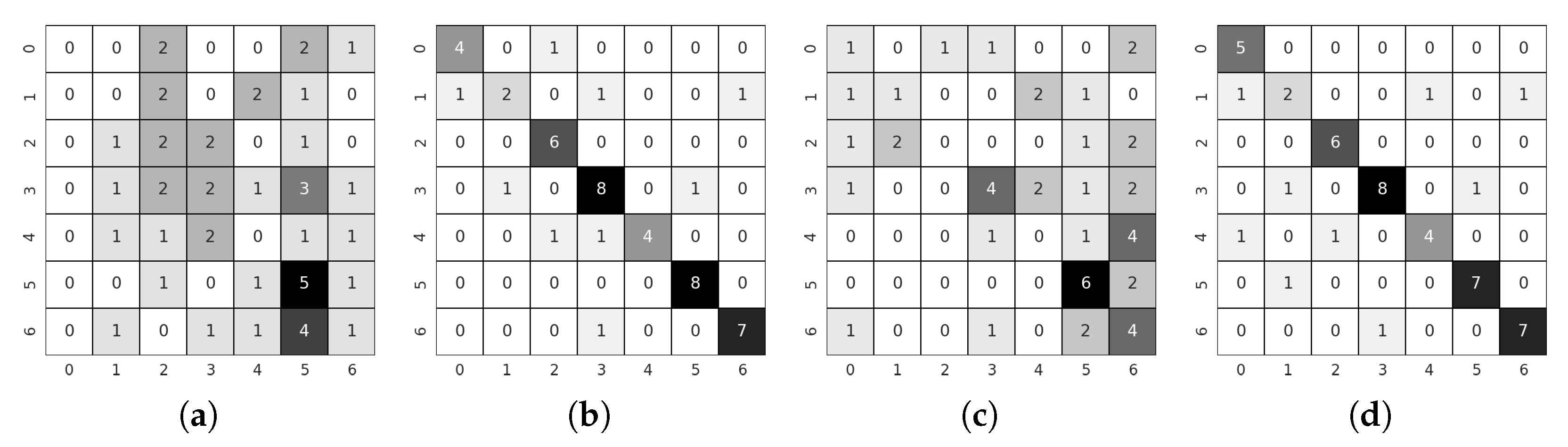
5. Experimental Results
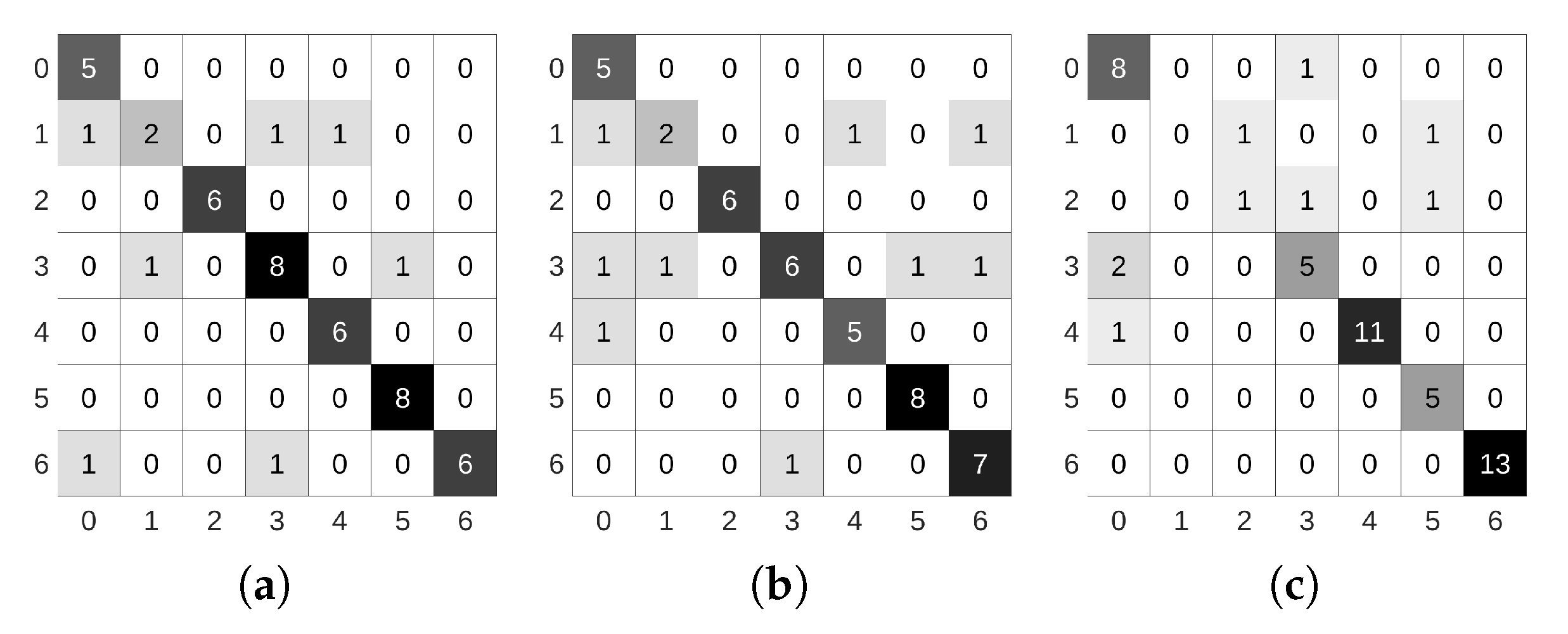
5.1. Teacher Training
5.2. Student Training
- Learning Rate: max: 0.01 min: 2.5 ×
- Optimizer: adamW, adam, rmsprop, sgd, ASGD, Adamax
- Loss Function: SmoothL1, L1, MSE
- Batch Size: 8, 16, 34, 64, 128
- first, how the different data transformations exposed in Section 4.4.2 affect the results in the Teacher/Student paradigm and the possible benefits;
- second, whether the use of the Teacher/Student paradigm substantially improves results over the direct classification of the data;
- third, if the data recording methodology and the camera angle are critical points in obtaining good results; and
- fourth, whether the inclusion of new architectures in training produces a significant variation in the results obtained.
5.3. Metric Learning Training Phase
- first, whether the new comprehensive way of calculating batch losses helps to alleviate the problems detected in the previous paradigm with the lack of images and
- second, once the lack of images is solved, the usefulness of the data transformations and the improvement over the direct classification can be verified again.
- Learning Rate: max: 0.01 min: 2.5 × 10
- Optimizer: adamW, adam, rmsprop, sgd, ASGD, Adamax
- Distance Function: SNR, Cosine Distance, Pairwise
- Batch Size: 8, 16, 34, 64, 128
- Margin: max: 5.0 min: 0.5 q: 0.5
- Miner: All, Hard
5.4. Multi-Frame Scheme Results
- first, we check if the temporal integration helps achieving our goal of classifying intersections and
- second evaluate whether this new approach offers more light on the previous results.
- Learning Rate: max: 0.01 min: 2.5 × 10
- Optimizer: adamW, adam, rmsprop, sgd, ASGD, Adamax
- Loss Function: Cross Entropy, Focal
- Batch Size: 16, 34, 64
- FC dropout: max: 0.5 min: 0.1 q: 0.1
- LSTM dropout: max: 0.5 min: 0.1 q: 0.1
- LSTM hidden layer: 256, 128, 64, 32, 16, 8
- LSTM layers: 1, 2
5.5. GAN Related Results
5.6. Pytorchvideo
- First, how the video-analysis networks handle both RGB and MBEVs images, comparing their performances with respect to the learning schemes proposed in this research. This test was executed using the KITTI360 and KITTI360-masked imagery.
- Second, how different frame rates affect the classification capabilities. For this second test, we used the Alcalá-1 sequence, subsampling the original 30 fps to 6 and 15 fps. These experiments could not have been performed with the KITTI sequences due to the dataset low frame rate. Please notice that all the actions datasets originally used with these networks share the same length, which is not realistic with videos containing intersection approaches due to different speeds of the vehicle while approaching a generic intersection.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- European Commission Road Safety Key Figures 2020. Available online: https://ec.europa.eu/transport/road_safety/sites/roadsafety/files/pdf/scoreboard_2020.pdf (accessed on 21 May 2021).
- European Union Annual Accident Report 2018. Available online: https://ec.europa.eu/transport/road_safety/specialist/observatory/statistics/annual_accident_report_archive_en (accessed on 21 May 2021).
- Fatality and Injury Reporting System Tool of, U.S. National Highway Traffic Safety Administration. Available online: https://cdan.dot.gov/query (accessed on 21 May 2021).
- European Union Report on Mobility and Transportation: ITS & Vulnerable Road Users. Available online: https://ec.europa.eu/transport/themes/its/road/action_plan/its_and_vulnerable_road_users_en (accessed on 3 September 2021).
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The ApolloScape Dataset for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chang, M.F.; Lambert, J.W.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Houston, J.; Zuidhof, G.; Bergamini, L.; Ye, Y.; Jain, A.; Omari, S.; Iglovikov, V.; Ondruska, P. One Thousand and One Hours: Self-driving Motion Prediction Dataset. arXiv 2020, arXiv:2006.14480. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- PandaSet (2020) PandaSet Dataset. Available online: https://scale.com/open-datasets/pandaset (accessed on 21 May 2021).
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Kiefel, M.; Sun, M.T.; Geiger, A. Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Ki, Y.; Lee, D. A Traffic Accident Recording and Reporting Model at Intersections. IEEE Trans. Intell. Transp. Syst. 2007, 8, 188–194. [Google Scholar] [CrossRef]
- Golembiewski, G.; Chandler, B.E. Intersection Safety: A Manual for Local Rural Road Owners; Technical Report; United States Federal Highway Administration Office of Safety: Washington, DC, USA, 2011.
- Kushner, T.R.; Puri, S. Progress in road intersection detection for autonomous vehicle navigation. In Mobile Robots II. International Society for Optics and Photonics; SPIE: Cambridge, CA, USA, 1987; Volume 852, pp. 19–24. [Google Scholar]
- Geiger, A. Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms; KIT Scientific Publishing: Karlsruhe, Germany, 2013; Volume 25. [Google Scholar]
- An, J.; Choi, B.; Sim, K.B.; Kim, E. Novel intersection type recognition for autonomous vehicles using a multi-layer laser scanner. Sensors 2016, 16, 1123. [Google Scholar] [CrossRef] [Green Version]
- Ballardini, A.L.; Cattaneo, D.; Fontana, S.; Sorrenti, D.G. An online probabilistic road intersection detector. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Habermann, D.; Vido, C.E.; Osório, F.S.; Ramos, F. Road junction detection from 3d point clouds. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4934–4940. [Google Scholar]
- Baumann, U.; Huang, Y.Y.; Gläser, C.; Herman, M.; Banzhaf, H.; Zöllner, J.M. Classifying road intersections using transfer-learning on a deep neural network. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 683–690. [Google Scholar]
- Bhatt, D.; Sodhi, D.; Pal, A.; Balasubramanian, V.; Krishna, M. Have i reached the intersection: A deep learning-based approach for intersection detection from monocular cameras. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4495–4500. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Koji, T.; Kanji, T. Deep intersection classification using first and third person views. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 454–459. [Google Scholar]
- Xu, P.; Davoine, F.; Bordes, J.B.; Zhao, H.; Denœux, T. Multimodal information fusion for urban scene understanding. Mach. Vis. Appl. 2016, 27, 331–349. [Google Scholar] [CrossRef] [Green Version]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. arXiv 2015, arXiv:1411.4555. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. arXiv 2016, arXiv:1411.4389. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. arXiv 2015, arXiv:1503.08909. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Sandfort, V.; Yan, K.; Pickhardt, P.; Summers, R. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef] [PubMed]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data Augmentation Generative Adversarial Networks. arXiv 2018, arXiv:1711.04340. [Google Scholar]
- Wu, E.; Wu, K.; Cox, D.; Lotter, W. Conditional Infilling GANs for Data Augmentation in Mammogram Classification. In Image Analysis for Moving Organ, Breast, and Thoracic Images; Stoyanov, D., Taylor, Z., Kainz, B., Maicas, G., Beichel, R.R., Martel, A., Maier-Hein, L., Bhatia, K., Vercauteren, T., Oktay, O., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Bowles, C.; Gunn, R.; Hammers, A.; Rueckert, D. GANsfer Learning: Combining labelled and unlabelled data for GAN based data augmentation. arXiv 2018, arXiv:1811.10669. [Google Scholar]
- Li, C.L.; Zaheer, M.; Zhang, Y.; Poczos, B.; Salakhutdinov, R. Point Cloud GAN. arXiv 2018, arXiv:1810.05795. [Google Scholar]
- Gadelha, M.; Rai, A.; Maji, S.; Wang, R. Inferring 3D Shapes from Image Collections using Adversarial Networks. arXiv 2019, arXiv:1906.04910. [Google Scholar] [CrossRef]
- Saito, M.; Matsumoto, E.; Saito, S. Temporal Generative Adversarial Nets with Singular Value Clipping. arXiv 2017, arXiv:1611.06624. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2019, arXiv:1812.04948. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. arXiv 2020, arXiv:1912.04958. [Google Scholar]
- Gal, R.; Cohen, D.; Bermano, A.; Cohen-Or, D. SWAGAN: A Style-based Wavelet-driven Generative Model. arXiv 2021, arXiv:2102.06108. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. arXiv 2020, arXiv:2006.06676. [Google Scholar]
- Ballardini, A.L.; Hernández, A.; Sotelo, M.A. Model Guided Road Intersection Classification. arXiv 2021, arXiv:2104.12417. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Bellet, A.; Habrard, A.; Sebban, M. A Survey on Metric Learning for Feature Vectors and Structured Data. arXiv 2014, arXiv:1306.6709. [Google Scholar]
- Musgrave, K.; Belongie, S.; Lim, S.N. PyTorch Metric Learning. arXiv 2020, arXiv:2008.09164. [Google Scholar]
- Yuan, T.; Deng, W.; Tang, J.; Tang, Y.; Chen, B. Signal-to-noise ratio: A robust distance metric for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4815–4824. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Musgrave, K.; Belongie, S.; Lim, S.N. A metric learning reality check. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 681–699. [Google Scholar]
- Ballardini, A.L.; Cattaneo, D.; Sorrenti, D.G. Visual Localization at Intersections with Digital Maps. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Xu, H.; Zhang, J. AANet: Adaptive Aggregation Network for Efficient Stereo Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1959–1968. [Google Scholar]
- Hernández, A.; Woo, S.; Corrales, H.; Parra, I.; Kim, E.; Llorca, D.F.; Sotelo, M.A. 3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns for road scene interpretation. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 892–898. [Google Scholar] [CrossRef]
- Cattaneo, D.; Vaghi, M.; Fontana, S.; Ballardini, A.L.; Sorrenti, D.G. Global visual localization in LiDAR-maps through shared 2D-3D embedding space. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2020; pp. 4365–4371. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. Advances in Neural Information Processing Systems, Autodiff Workshop. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 21 May 2021).
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 203–213. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. arXiv 2016, arXiv:1604.01753. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2020. [Google Scholar] [CrossRef] [PubMed]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5843–5851. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; Li, Y.; Xiong, B.; Lo, W.Y.; Feichtenhofer, C. PySlowFast. 2020. Available online: https://github.com/facebookresearch/slowfast (accessed on 21 May 2021).
- Biewald, L. Experiment Tracking with Weights and Biases. 2020. Software. Available online: wandb.com (accessed on 21 May 2021).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Alcalá-1 (jan26) | 4693 | 1321 | 1467 | 2144 | 4429 | 2291 | 5374 |
| Alcalá-2 (feb12) | 2686 | 745 | 446 | 1893 | 1973 | 1287 | 2948 |
| KITTI-ROAD | ✗ | 308 | 21 | 452 | 52 | 523 | 1035 |
| KITTI-360 | 1190 | 711 | 999 | 1040 | 706 | 1048 | 1129 |
| Total | 8569 | 3085 | 2933 | 5529 | 7160 | 5149 | 10,486 |
| Learning Scheme | Key Features |
|---|---|
| Baseline | End-to-End Classification |
| Standard RGB image classification method | |
| Metric Learning | Learning to classify by using distances between |
| embedding vectors | |
| Teacher/Student | Two networks are sequentially trained |
| metric learning can also be applied | |
| LSTM | These networks are well suited to process time series data |
| PyTorchVideo | Deep Learning library for video understanding research |
| ResNet | VGG | MobileNet-V3 | Inception | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| version | version | version | Version | ||||||||||
| 18 | 34 | 50 | 101 | 152 | 11 | 13 | 16 | Large | Small | v3 | |||
| KITTI-ROAD | RGB | Validation | 0.69 | 0.71 | 0.69 | 0.72 | 0.70 | 0.58 | 0.74 | 0.73 | 0.66 | 0.69 | 0.65 |
| Test | - | - | - | - | - | - | 0.53 | - | - | - | - | ||
| Warping | Validation | 0.60 | 0.67 | 0.70 | 0.68 | 0.60 | 0.60 | 0.63 | 0.61 | 0.65 | 0.60 | 0.67 | |
| Test | - | - | 0.62 | - | - | - | - | - | - | - | - | ||
| KITTI-360 | RGB | Validation | 0.83 | 0.82 | 0.77 | 0.81 | 0.81 | 0.80 | 0.84 | 0.81 | 0.82 | 0.73 | 0.87 |
| Test | - | - | - | - | - | - | - | - | - | - | 0.78 | ||
| Warping | Validation | 0.81 | 0.78 | 0.83 | 0.84 | 0.80 | 0.81 | 0.80 | 0.82 | 0.83 | 0.80 | 0.87 | |
| Test | - | - | - | - | - | - | - | - | - | - | 0.70 | ||
| ALCALÁ | RGB | Validation | 0.82 | 0.87 | 0.85 | 0.86 | 0.80 | 0.74 | 0.86 | 0.85 | 0.89 | 0.80 | 0.89 |
| Test | - | - | - | - | - | - | - | - | - | - | 0.94 | ||
| Warping | Validation | 0.88 | 0.91 | 0.82 | 0.90 | 0.88 | 0.85 | 0.89 | 0.85 | 0.91 | 0.87 | 0.91 | |
| Test | - | - | - | - | - | - | - | - | 0.92 | - | - | ||
| ResNet | VGG | MobileNet-V3 | Inception | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Version | Version | Version | Version | ||||||||||
| 18 | 34 | 50 | 101 | 152 | 11 | 13 | 16 | Large | Small | v3 | |||
| KITTI-ROAD | RGB | Validation | 0.51 | 0.50 | 0.53 | 0.50 | 0.57 | 0.66 | 0.70 | 0.71 | 0.75 | 0.71 | 0.57 |
| Test | - | - | - | - | - | - | - | - | 0.64 | - | - | ||
| Warping | Validation | 0.47 | 0.58 | 0.70 | 0.59 | 0.52 | 0.61 | 0.63 | 0.66 | 0.66 | 0.64 | 0.57 | |
| Test | - | - | 0.61 | - | - | - | - | - | - | - | - | ||
| 3D-Images | Validation | 0.45 | 0.55 | 0.65 | 0.67 | 0.58 | 0.56 | 0.62 | 0.60 | 0.60 | 0.62 | 0.46 | |
| Test | - | - | - | 0.64 | - | - | - | - | - | - | - | ||
| 3D-Masked | Validation | 0.64 | 0.71 | 0.72 | 0.71 | 0.71 | 0.70 | 0.72 | 0.72 | 0.73 | 0.72 | 0.69 | |
| Test | - | - | - | - | - | - | - | - | 0.71 | - | - | ||
| KITTI-360 | RGB | Validation | 0.60 | 0.65 | 0.79 | 0.79 | 0.83 | 0.73 | 0.82 | 0.86 | 0.8 | 0.79 | 0.60 |
| Test | - | - | - | - | - | - | - | 0.75 | - | - | - | ||
| Warping | Validation | 0.63 | 0.61 | 0.69 | 0.8 | 0.63 | 0.85 | 0.79 | 0.83 | 0.82 | 0.73 | 0.70 | |
| Test | - | - | - | - | - | 0.73 | - | - | - | - | - | ||
| 3D-Images | Validation | 0.51 | 0.65 | 0.71 | 0.75 | 0.65 | 0.61 | 0.68 | 0.59 | 0.79 | 0.73 | 0.57 | |
| Test | - | - | - | - | - | - | - | - | 0.73 | - | - | ||
| 3D-Masked | Validation | 0.65 | 0.61 | 0.76 | 0.78 | 0.79 | 0.74 | 0.77 | 0.78 | 0.78 | 0.76 | 0.78 | |
| Test | - | - | - | - | 0.67 | - | - | - | - | - | |||
| ALCALÁ | RGB | Validation | 0.76 | 0.49 | 0.88 | 0.88 | 0.86 | 0.82 | 0.90 | 0.87 | 0.88 | 0.77 | 0.81 |
| Test | - | - | - | - | - | - | 0.96 | - | - | - | - | ||
| Warping | Validation | 0.88 | 0.87 | 0.88 | 0.87 | 0.91 | 0.88 | 0.90 | 0.80 | 0.90 | 0.88 | 0.90 | |
| Test | - | - | - | - | 0.90 | - | - | - | - | - | - | ||
| ResNet | VGG | MobileNet-V3 | Inception | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Version | Version | Version | Version | ||||||||||
| 18 | 34 | 50 | 101 | 152 | 11 | 13 | 16 | Large | Small | v3 | |||
| KITTI-ROAD | RGB | Validation | 0.50 | 0.37 | 0.52 | 0.44 | 0.54 | 0.41 | 0.42 | 0.45 | 0.48 | 0.51 | 0.34 |
| Test | - | - | - | - | 0.56 | - | - | - | - | - | - | ||
| Warping | Validation | 0.62 | 0.47 | 0.40 | 0.35 | 0.46 | 0.37 | 0.41 | 0.35 | 0.47 | 0.56 | 0.38 | |
| Test | 0.60 | - | - | - | - | - | - | - | - | - | - | ||
| 3D-Images | Validation | 0.49 | 0.48 | 0.41 | 0.43 | 0.47 | 0.29 | 0.32 | 0.30 | 0.44 | 0.40 | 0.36 | |
| Test | 0.47 | - | - | - | - | - | - | - | - | - | - | ||
| 3D-Masked | Validation | 0.65 | 0.51 | 0.51 | 0.50 | 0.45 | 0.46 | 0.52 | 0.41 | 0.49 | 0.54 | 0.59 | |
| Test | 0.72 | - | - | - | - | - | - | - | - | - | - | ||
| KITTI-360 | RGB | Validation | 0.32 | 0.64 | 0.64 | 0.59 | 0.74 | 0.59 | 0.23 | 0.25 | 0.55 | 0.53 | 0.72 |
| Test | - | - | - | - | 0.69 | - | - | - | - | - | - | ||
| Warping | Validation | 0.63 | 0.65 | 0.31 | 0.42 | 0.38 | 0.65 | 0.31 | 0.60 | 0.64 | 0.41 | 0.44 | |
| Test | - | 0.78 | - | - | - | - | - | - | - | - | - | ||
| 3D-Images | Validation | 0.57 | 0.53 | 0.29 | 0.40 | 0.62 | 0.36 | 0.42 | 0.33 | 0.67 | 0.56 | 0.60 | |
| Test | - | - | - | - | - | - | - | - | 0.73 | - | - | ||
| 3D-Masked | Validation | 0.65 | 0.61 | 0.76 | 0.78 | 0.79 | 0.74 | 0.77 | 0.78 | 0.78 | 0.76 | 0.78 | |
| Test | - | - | - | - | 0.81 | - | - | - | - | - | |||
| ALCALÁ | RGB | Validation | 0.72 | 0.78 | 0.83 | 0.75 | 0.50 | 0.80 | 0.45 | 0.84 | 0.70 | 0.60 | 0.40 |
| Test | - | - | - | - | - | - | - | 0.94 | - | - | - | ||
| Warping | Validation | 0.74 | 0.81 | 0.72 | 0.52 | 0.81 | 0.71 | 0.77 | 0.59 | 0.84 | 0.83 | 0.82 | |
| Test | - | - | - | - | - | - | - | - | 0.91 | - | - | ||
| KITTI ROAD | KITTI-360 | Alcalá | ||||
|---|---|---|---|---|---|---|
| Validation | Test | Validation | Test | Validation | Test | |
| RGB | 0.69 | 0.55 | 0.90 | 0.85 | 0.85 | 0.84 |
| Warping | 0.82 | 0.45 | 0.82 | 0.73 | 0.91 | 0.92 |
| 3D-Images | 0.88 | 0.65 | 0.84 | 0.79 | - | - |
| 3D-Masked | 0.90 | 0.70 | 0.89 | 0.81 | - | - |
| Warped | RGB | |||||||
|---|---|---|---|---|---|---|---|---|
| Teacher/Student | Metric Learning | Teacher/Student | Metric Learning | |||||
| Validation | Test | Validation | Test | Validation | Test | Validation | Test | |
| ALL | 0.890 | 0.894 | 0.901 | 0.872 | 0.885 | 0.894 | 0.893 | 0.817 |
| ALL AUGMENTED (GAN) | 0.932 | 0.935 | 0.920 | 0.928 | 0.876 | 0.935 | 0.882 | 0.935 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ballardini, A.L.; Hernández Saz, Á.; Carrasco Limeros, S.; Lorenzo, J.; Parra Alonso, I.; Hernández Parra, N.; García Daza, I.; Sotelo, M.Á. Urban Intersection Classification: A Comparative Analysis. Sensors 2021, 21, 6269. https://doi.org/10.3390/s21186269
Ballardini AL, Hernández Saz Á, Carrasco Limeros S, Lorenzo J, Parra Alonso I, Hernández Parra N, García Daza I, Sotelo MÁ. Urban Intersection Classification: A Comparative Analysis. Sensors. 2021; 21(18):6269. https://doi.org/10.3390/s21186269
Chicago/Turabian StyleBallardini, Augusto Luis, Álvaro Hernández Saz, Sandra Carrasco Limeros, Javier Lorenzo, Ignacio Parra Alonso, Noelia Hernández Parra, Iván García Daza, and Miguel Ángel Sotelo. 2021. "Urban Intersection Classification: A Comparative Analysis" Sensors 21, no. 18: 6269. https://doi.org/10.3390/s21186269
APA StyleBallardini, A. L., Hernández Saz, Á., Carrasco Limeros, S., Lorenzo, J., Parra Alonso, I., Hernández Parra, N., García Daza, I., & Sotelo, M. Á. (2021). Urban Intersection Classification: A Comparative Analysis. Sensors, 21(18), 6269. https://doi.org/10.3390/s21186269