
Using an Internet of Behaviours to Study How Air Pollution Can Affect People’s Activities of Daily Living: A Case Study of Beijing, China

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- (1)
- We propose a methodology to better understand the link between environmental changes such as air pollution and citizens’ activities of daily life. It can help government and businesses to understand better the actual effect not the presumed effect of air pollution on the pattern of daily activities of citizens;
- (2)
- This opens up a new perspective for understanding and exploring the interaction between PM2.5 and in more general air pollution and people’s physical behaviour.
- (3)
- This can not only reveal the subtle impact of PM2.5/air pollution on human ADL but can also monitor the indirect impact of PM2.5/air pollution on some human-based business activities, e.g., restaurants. This is challenging to do because different data sets, such as air pollution, human movement, location contexts, etc., with different temporal and spatial characteristics, need to be acquired and fused. Human activities can be complex to characterise. Individual human behaviour in a crowd needs to be identified. Human behaviour is affected by a range of environmental factors, some of which may not be observable, that need to be correlated.
2. Related Works
3. Data and Pre-Processing
3.1. Data Introduction
3.1.1. Call Detail Record (CDR)
3.1.2. Air Pollution
3.2. Data Collection and Accuracy Analysis
3.3. Data Pre-Processing
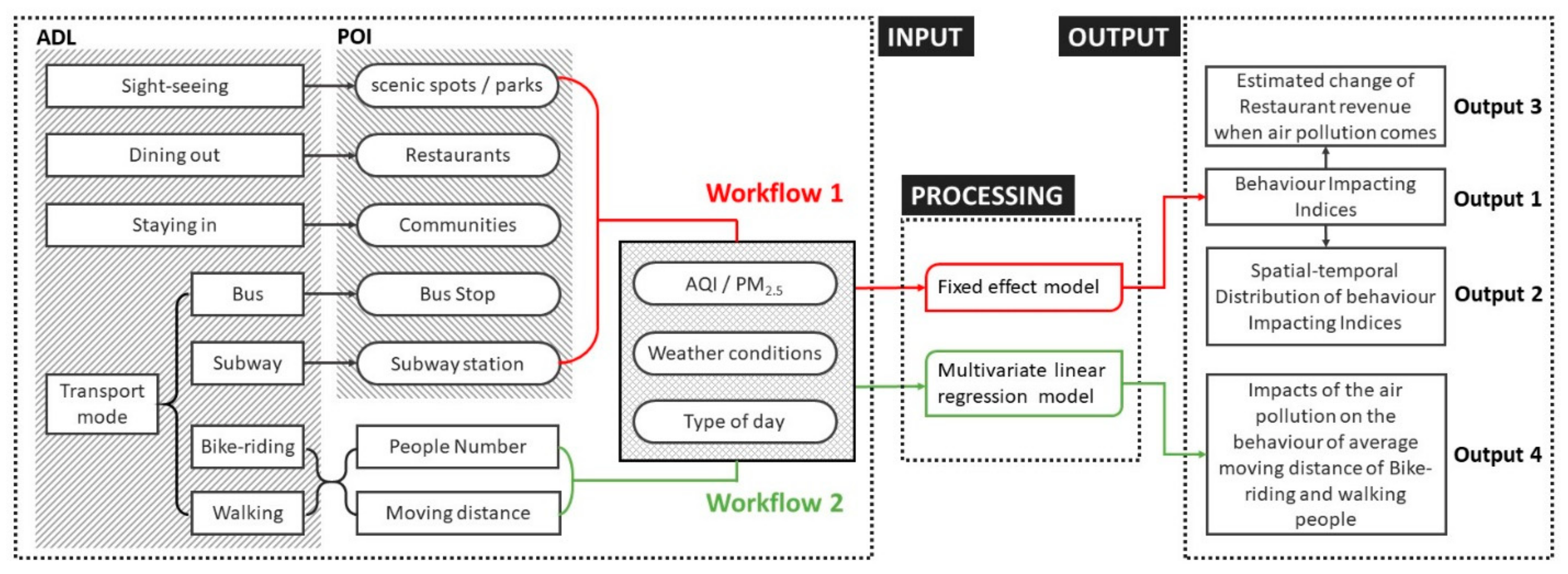
4. Methodology
4.1. Overview
4.2. Workflow 1
4.2.1. Input Module: Data Preparation and Input Set Up
4.2.2. Processing Module, Output 1: Fixed Effect Model (FEM)
4.2.3. Output 2: Spatial-Temporal Distribution of Behaviour Impacting Indices
4.2.4. Output 3: Estimating the Revenue Change
4.3. Workflow 2
4.3.1. Input Module: Walking and Cycling People Data
4.3.2. Processing Module: Multivariate Linear Regression Model
4.3.3. Output 4: Average Distance Changing of Walking and Cycling People
5. Results and Discussion
5.1. Spatial-Temporal Dataset Description
5.2. Output 1: Fixed Effect Model Results
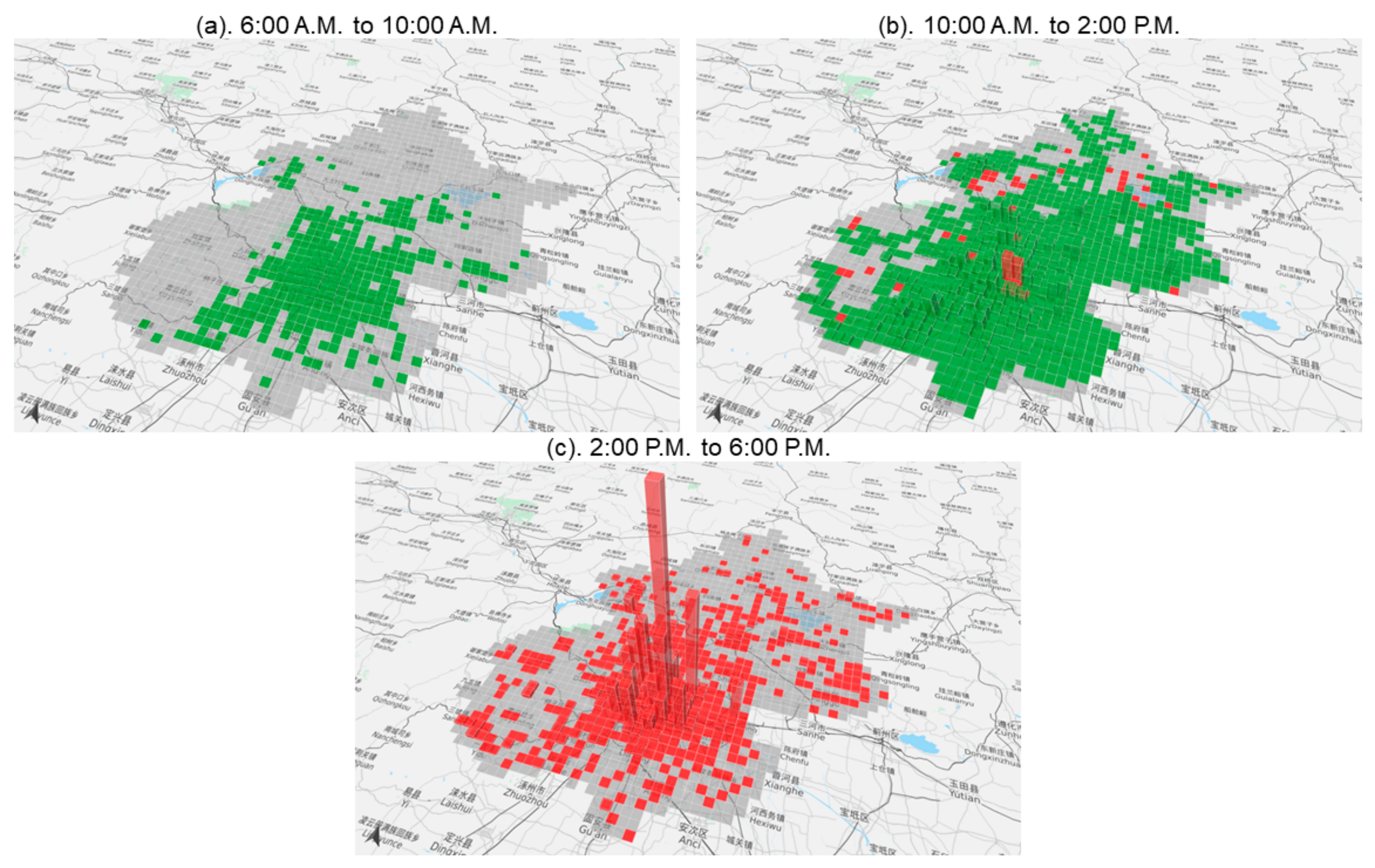
5.3. Output 2: Spatial-Temporal Behaviour Impacting Indices of Air Pollution on ADLs
5.4. Output 3: Restaurant Business Loss Estimation Due to Air
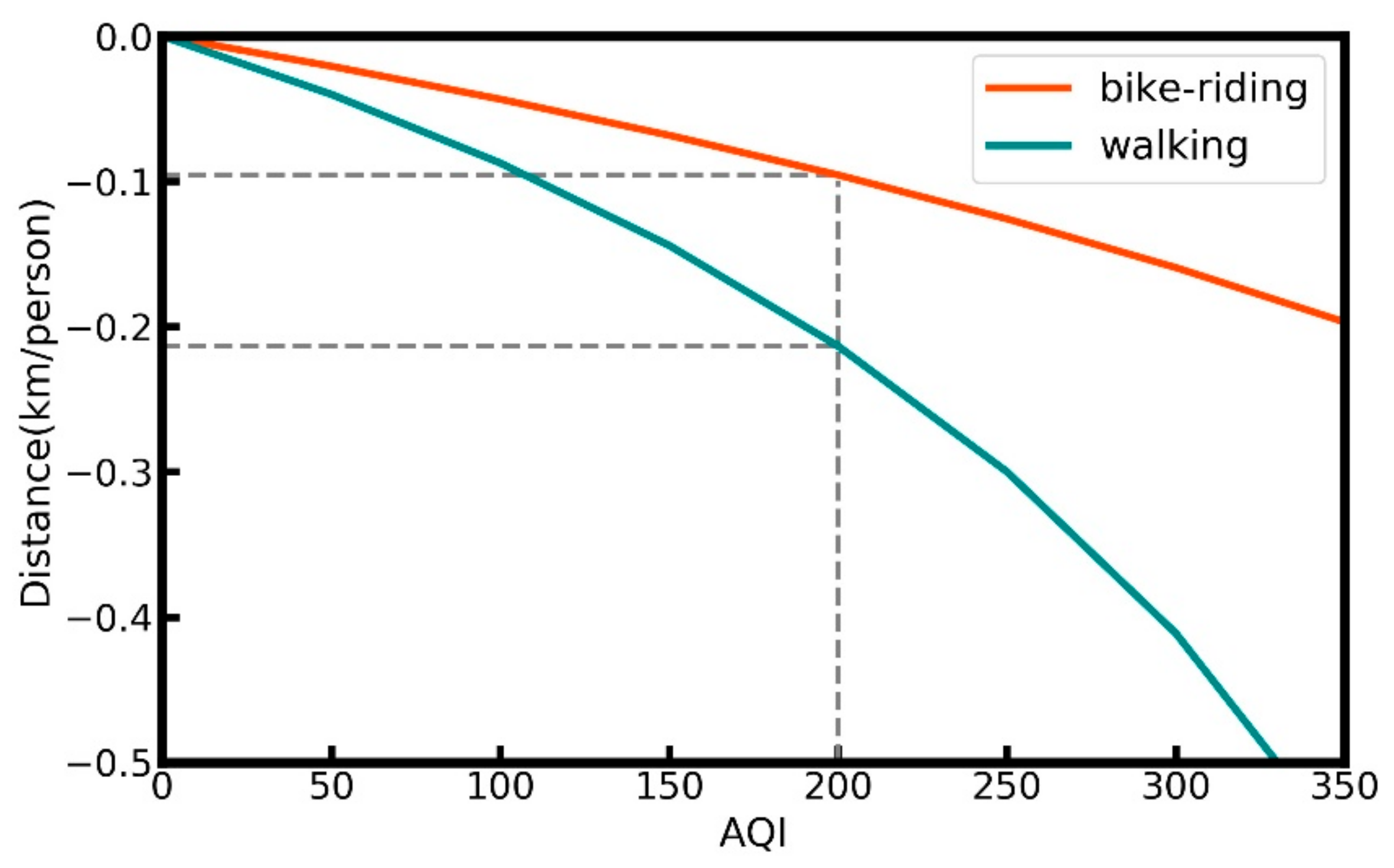
5.5. Output 4: Changes in the Average Distance Travelled by People Walking and Cycling
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Additional Description of Datasets
Appendix A.1. Additional Materials for CDR Dataset Description

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Name | Description |
|---|---|---|
| 1 | Timestamp | Interactive time of users and base station |
| 2 | CI | Corresponding base station’ identity |
| 3 | IMSI | The encrypted ID of users |
| ID | Name | Description |
|---|---|---|
| 1 | CI | Unique ID of the base station |
| 2 | Lat, Lon | Latitude and longitude of the base station location |

Appendix A.2. Error Analysis When Estimating Mobile Phone Users’ Density Distributions
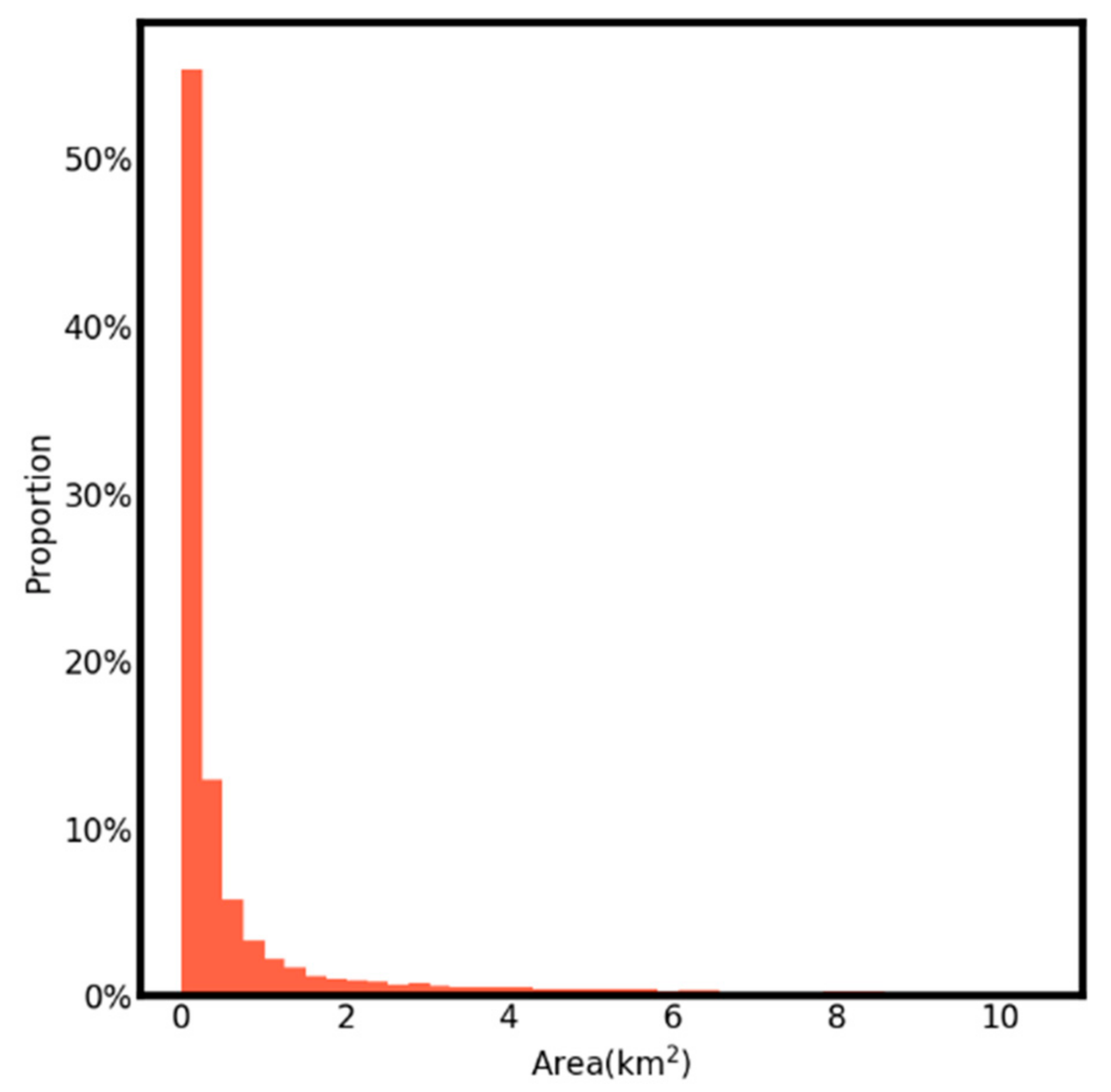
Appendix A.3. Error Control Solution When Estimating Mobile Phone Users’ Density Distributions

Appendix A.4. Description of Other Datasets
Appendix A.4.1. Additional Materials for Air Quality Datasets
| AQI | PM2.5 | PM10 | SO2 | O3 | NO2 | CO | |
|---|---|---|---|---|---|---|---|
| Mean concentration (μg/m3) | / | 107.929 | 133.959 | 32.307 | 39.289 | 53.460 | 1.698 |
| % hours when it is the primary pollutant | / | 64.29% | 18.65% | 0.00% | 1.79% | 15.48% | 0.00% |
| Whether it is easily perceived | / | YES | YES | YES | NO | NO | NO |
| Correlation between it and PM2.5 | 0.625 *** | / | 0.703 *** | 0.760 *** | -0.626 *** | 0.723 *** | 0.832 *** |
- HJ 655-2013 (China): Technical Specifications for Installation and Acceptance of Ambient Air Quality Continuous Automated Monitoring System for PM10 and PM2.5
- HJ 653-2013 (China): Specifications and Test Procedures for Ambient Air Quality Continuous Automated Monitoring System for PM10 and PM2.5
- HJ 93-2013 (China): Specifications and Test Procedures for PM10 and PM2.5 Sampler
| PM | Sensor | Range | Resolution | CTRM | EDR | PoM | Specification |
|---|---|---|---|---|---|---|---|
| PM2.5 | PM2.5 Sampler | 0~10,000 μg/m3 | 0.1 μg/m3 | Coef. ≥ 0.93 | ≥85% | ≤15% | (1) HJ 655-2013 (2) HJ 653-2013 (3) HJ 93-2013 |
| PM10 | PM10 Sampler | 0~10,000 μg/m3 | 0.1 μg/m3 | Coef. ≥ 0.95 | ≥85% | ≤10% |
- HJ 193-2013 (China): Technical Specifications for Installation and Acceptance of Ambient air Quality Continuous Automated Monitoring System for SO2, NO2, O3 and CO
- HJ 654-2013 (China): Specifications and Test Procedures for Ambient Air Quality Continuous Automated Monitoring System for SO2, NO2, O3 and CO
| Pollution | Sensor | Measure Method | Range | Resolution | Indication Error | Specification |
|---|---|---|---|---|---|---|
| SO2 | SO2 Analyzer | Ultraviolet Fluorescent method | 0~500 ppb | 0.1 μg/m3 | ±2%F.S. | (1) HJ 193-2013 (2) HJ 654-2013 |
| O3 | O3 Analyzer | Ultraviolet Absorbance method | 0~500 ppb | 0.1 μg/m3 | ±4%F.S. | |
| NO2 | NO2 Analyzer | Chemiluminescence Detection method | 0~500 ppb | 0.1 μg/m3 | ±2%F.S. | |
| CO | CO Analyzer | Non-dispersive Infrared Absorption method, Gas Filter Correlation Infrared Absorption method | 0~50 ppm | 0.1 mg/m3 | ±2%F.S. |
Appendix A.4.2. Weather Conditions
- GB/T 35221-2017 (China): Specification for surface meteorological observation—General
- GB/T 35226-2017 (China): Specification for surface meteorological observation—Air temperature and humidity
- GB/T 35227-2017 (China): Specification for surface meteorological observation—Wind direction and wind speed
- GB/T 35222-2017 (China): Specification for surface meteorological observation—Cloud
- GB/T 35228-2017 (China): Specification for surface meteorological observation—Precipitation
- GB/T 35229-2017 (China): Specification for surface meteorological observation—Snow depth and snow pressure
| Weather Condition | Sensor | Range | Resolution | Accuracy | Specification |
|---|---|---|---|---|---|
| Temperature | Thermometer | −50~50 °C | 0.1 °C | ±0.2 °C | GB/T 35226-2017 |
| Wind | Wind Speed Sensor | 0~60 m/s | 0.1 m/s | ±(0.5 m/s + 0.03 v) | GB/T 35227-2017 |
| Cloud Amount | - | 0~100% | - | - | GB/T 35222-2017 |
| Precipitation (Rain) | Tipping-Bucket Rain Gauge, Weighing Precipitation Sensor | ≤4 mm/min | 0.1 mm | ±0.4 mm (≤10 mm), ±4% (>10 mm) | GB/T 35228-2017 |
| Snow (depth) | Automatic Snow Depth Observation Instrument, Ultrasonic or Laser Sensors | 0~2000 mm | 1 mm | ±10 mm | GB/T 35229-2017 |
- (1)
- POI
- (2)
- Building distribution
Appendix B. An Additional Strategy (S2) for the Eating out ADL
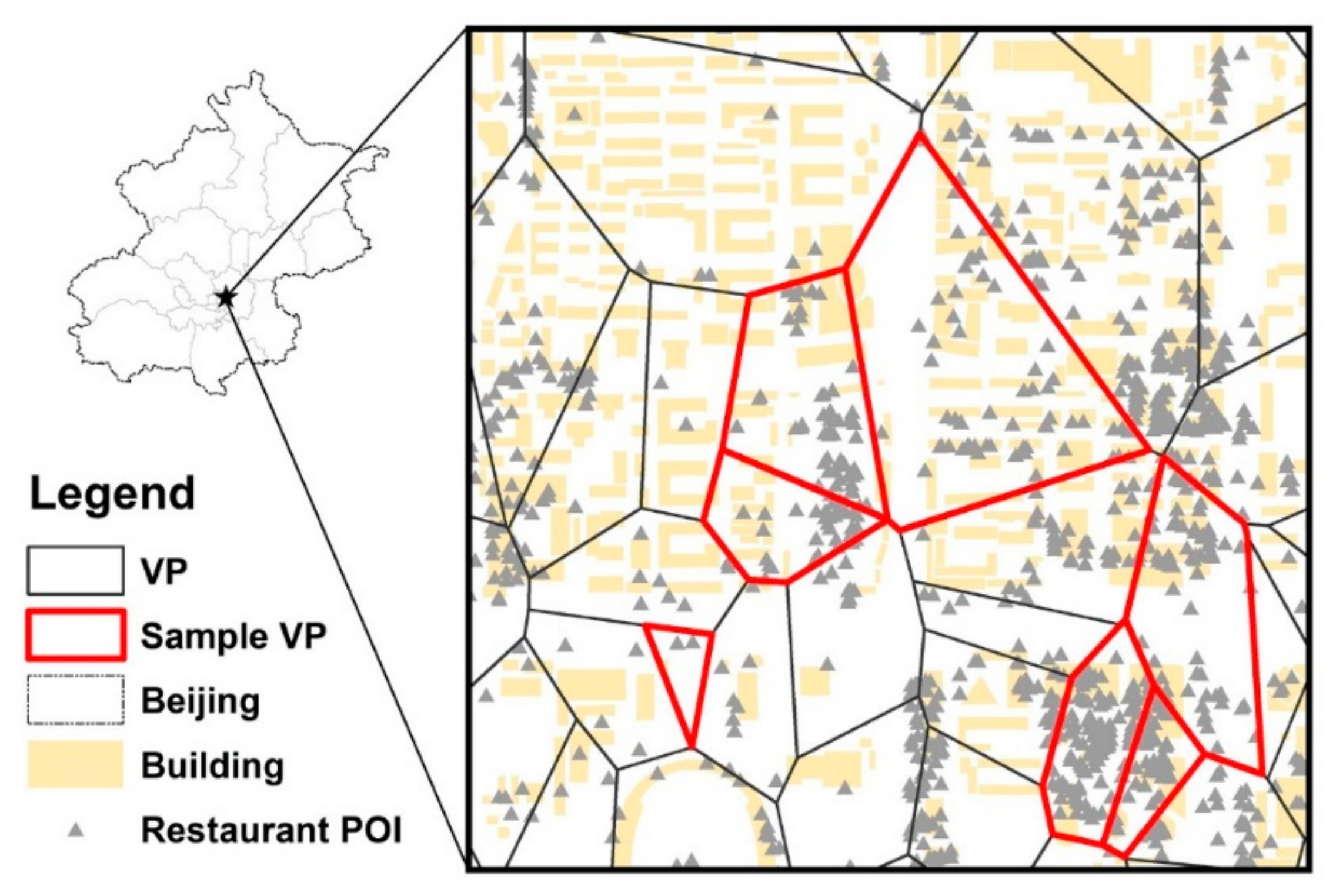
Appendix C. Additional Materials for Results
Appendix C.1. Spatial-Temporal Distributions for Key Datasets
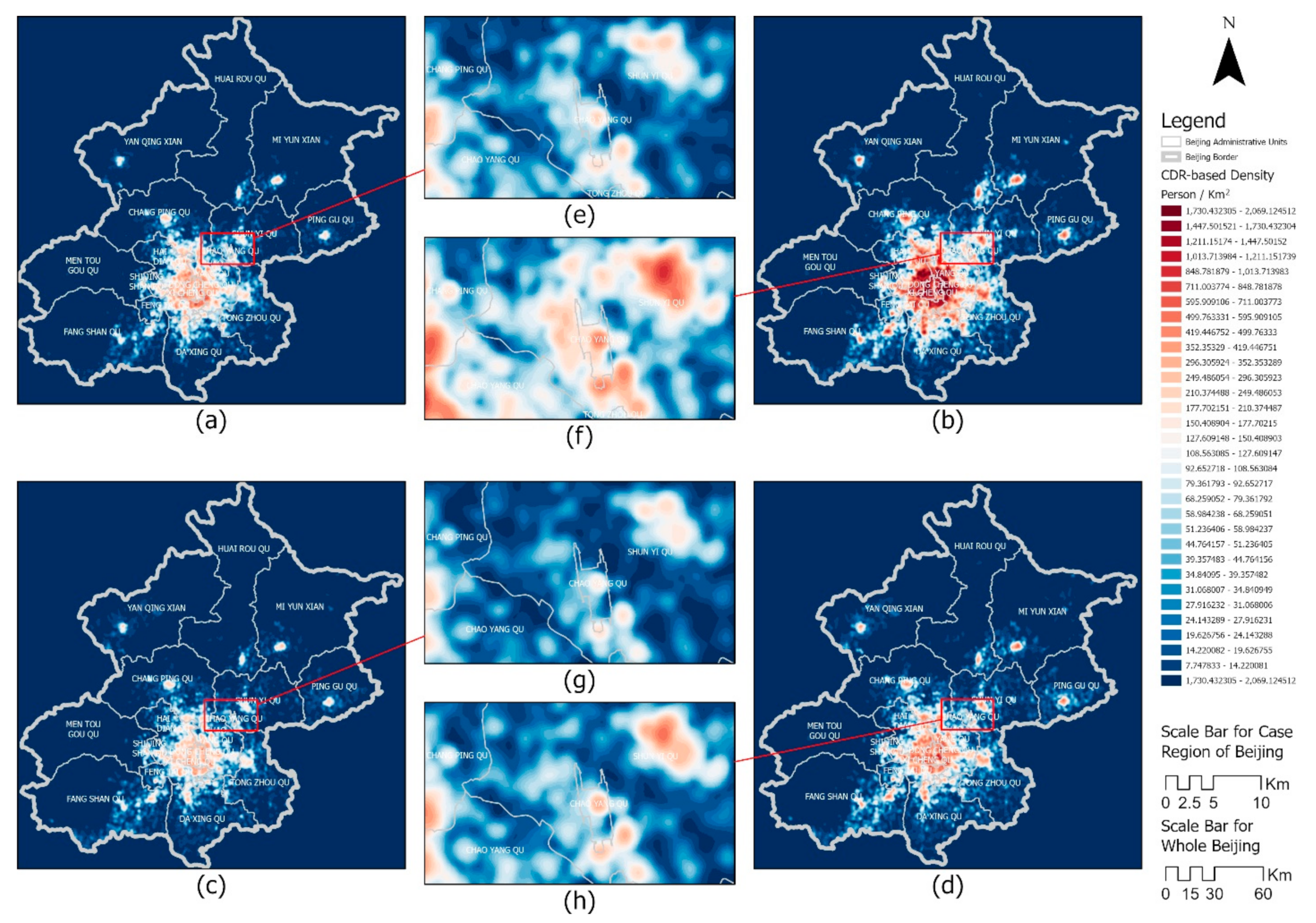
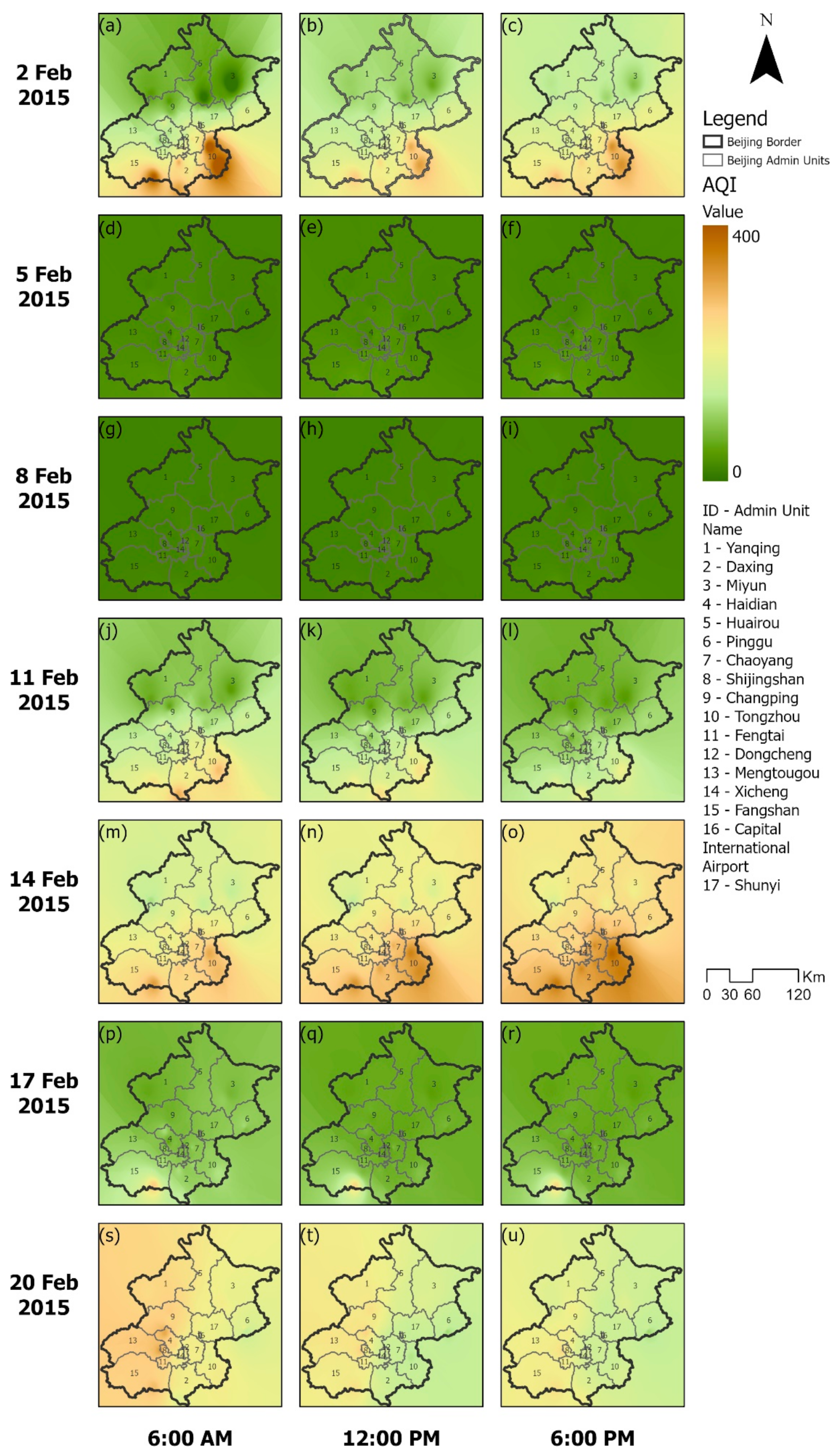
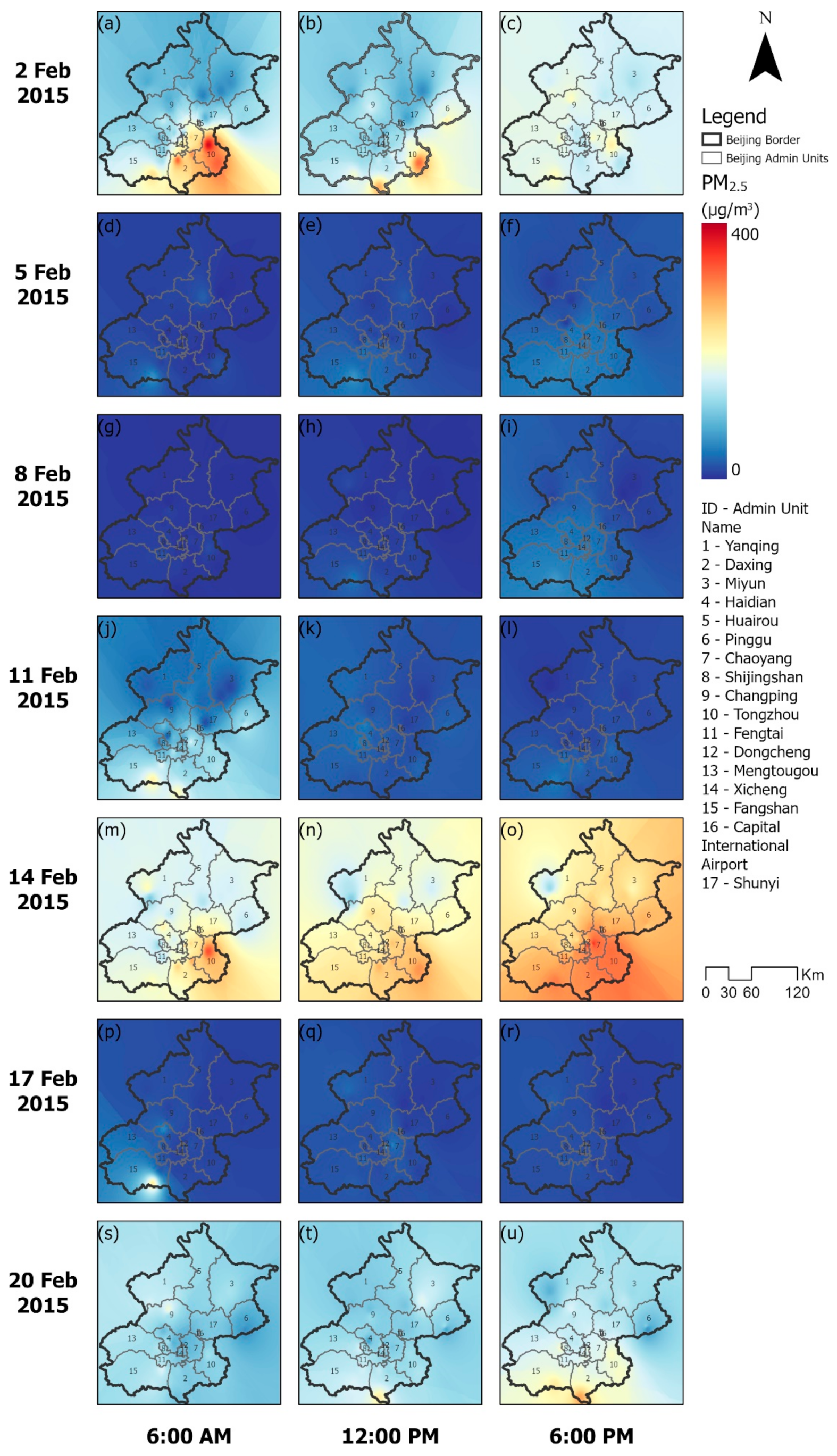
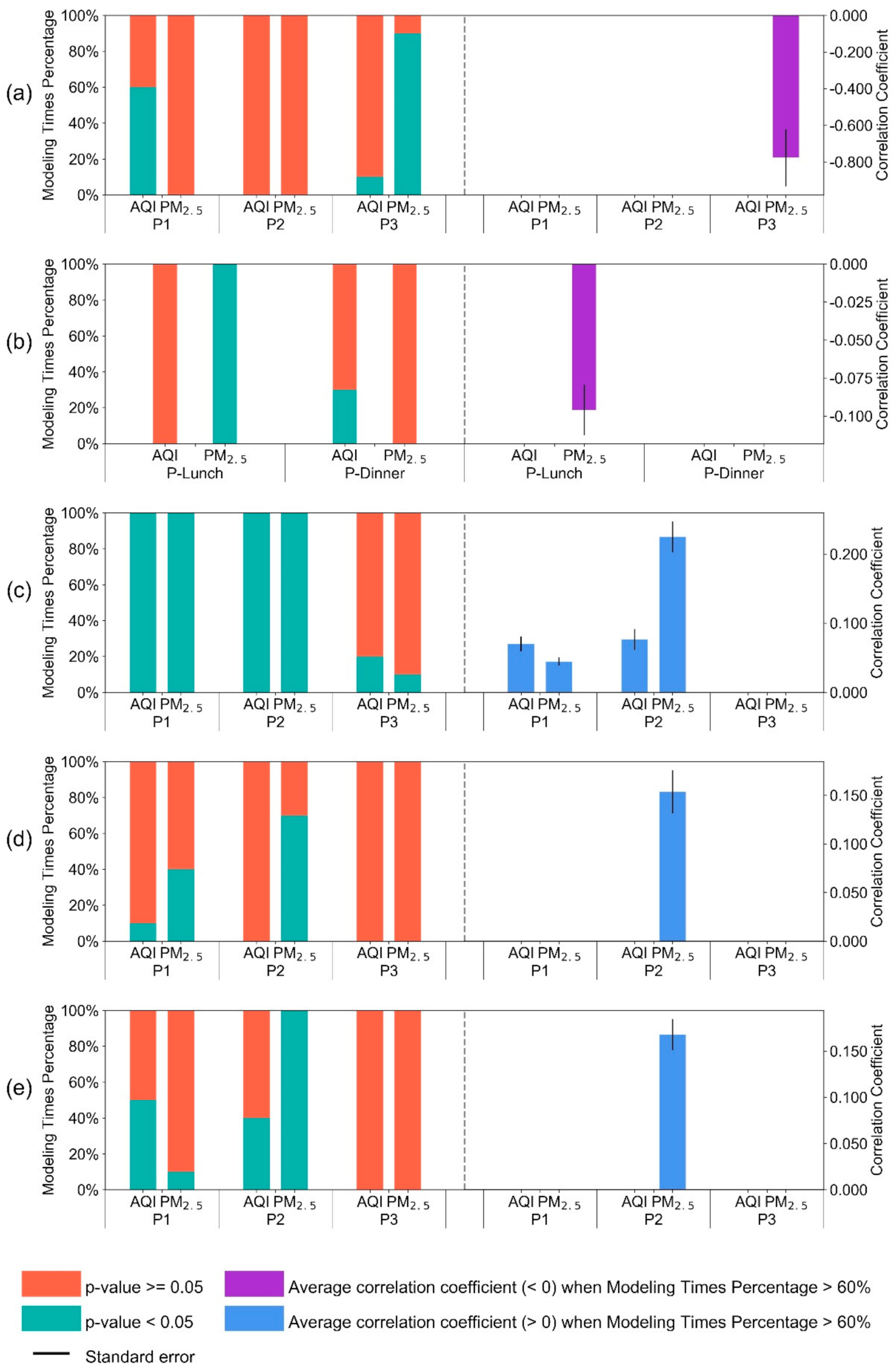
Appendix C.2. The Results of FEM Regressions
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Times | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| 1 | 0.0741 *** (0.001) | 0.0215 (0.117) | 0.0005 (0.988) | −0.0006 (0.988) | 0.0854 (0.63) | −0.6276 *** (0.001) |
| 2 | 0.0289 (0.057) | 0.0067 (0.554) | −0.0065 (0.848) | −0.0153 (0.693) | 0.1172 (0.512) | −0.9823 *** (0) |
| 3 | 0.0551 ** (0.006) | −0.0011 (0.93) | −0.0113 (0.752) | −0.0462 (0.262) | −0.0747 (0.719) | −0.8426 *** (0) |
| 4 | 0.0402 * (0.039) | 0.0001 (0.991) | −0.0102 (0.781) | −0.0082 (0.83) | 0.1253 (0.555) | −0.5164 (0.056) |
| 5 | 0.0296 (0.105) | −0.0073 (0.568) | 0.0192 (0.56) | 0.0084 (0.804) | 0.2183 (0.284) | −0.5702 * (0.043) |
| 6 | 0.0511 * (0.023) | 0.0138 (0.297) | −0.0065 (0.858) | 0.0314 (0.402) | 0.1038 (0.623) | −0.7019 ** (0.003) |
| 7 | 0.0428 * (0.017) | 0.0067 (0.615) | −0.0026 (0.942) | −0.0149 (0.723) | 0.3725 * (0.034) | −0.6325 ** (0.004) |
| 8 | 0.0276 (0.146) | −0.0051 (0.678) | −0.0112 (0.735) | −0.0183 (0.603) | 0.1539 (0.382) | −0.7492 ** (0.002) |
| 9 | 0.0301 (0.076) | −0.0043 (0.732) | 0.0142( 0.627) | −0.0014 (0.966) | −0.0336 (0.874) | −0.9454 *** (0.001) |
| 10 | 0.0596 *** (0.001) | 0.0111 (0.415) | 0.0237 (0.501) | −0.0056 (0.889) | 0.0243 (0.887) | −0.9433 *** (0) |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | |
|---|---|---|---|---|
| Times | Period Lunch | Period Lunch | Period Dinner | Period Dinner |
| 1 | 0.0023 (0.94) | −0.0946 *** (0) | 0.4986 * (0.022) | −0.1509 (0.647) |
| 2 | 0.0167 (0.528) | −0.0733 *** (0) | 0.3937 (0.086) | 0.4015 (0.251) |
| 3 | 0.0278 (0.366) | −0.1149 *** (0) | 0.527 * (0.031) | 0.2915 (0.398) |
| 4 | 0.0305 (0.311) | −0.0857 *** (0) | 0.3457 (0.199) | 0.4059 (0.303) |
| 5 | −0.0303 (0.223) | −0.1288 *** (0) | 0.45 (0.065) | 0.1942 (0.548) |
| 6 | 0.0115 (0.7) | −0.0859 *** (0) | 0.2361 (0.363) | −0.3118 (0.391) |
| 7 | 0.0041 (0.862) | −0.1055 *** (0) | 0.3577 (0.126) | 0.2314 (0.519) |
| 8 | −0.0067 (0.769) | −0.0943 *** (0) | 0.5685 * (0.012) | 0.2882 (0.412) |
| 9 | 0.0097 (0.728) | −0.0824 *** (0) | 0.2516 (0.268) | −0.0278 (0.932) |
| 10 | 0.0037(0.89) | −0.0947 ***(0) | 0.4027(0.058) | 0.1461(0.644) |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Times | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| 1 | 0.0667 * (0.014) | 0.0411 ** (0.002) | 0.0742 ** (0.005) | 0.2097 *** (0) | 0.4271 (0.2) | 0.0218 (0.967) |
| 2 | 0.0643 * (0.014) | 0.0435 ** (0.001) | 0.0726 ** (0.004) | 0.2099 *** (0) | 0.0996 (0.737) | −0.8888 * (0.032) |
| 3 | 0.0694 ** (0.009) | 0.0452 *** (0) | 0.0453 * (0.034) | 0.2119 *** (0) | 0.3369 (0.273) | −0.1589 (0.716) |
| 4 | 0.0748 ** (0.007) | 0.0469 *** (0.001) | 0.0923 *** (0.001) | 0.2553 *** (0) | −0.005 (0.987) | −0.4784 (0.267) |
| 5 | 0.0675 ** (0.01) | 0.0466 *** (0.001) | 0.0896 *** (0.001) | 0.2431 *** (0) | 0.3581 (0.247) | −0.1621 (0.688) |
| 6 | 0.061 ** (0.008) | 0.0352 ** (0.008) | 0.0771 ** (0.002) | 0.2109 *** (0) | 0.4108 (0.255) | −0.6785 (0.143) |
| 7 | 0.0963 *** (0.001) | 0.0489 *** (0.001) | 0.0838 *** (0.001) | 0.2181 *** (0) | 0.6312 * (0.043) | −0.5569 (0.162) |
| 8 | 0.0743 ** (0.002) | 0.0559 *** (0) | 0.0853 *** (0.001) | 0.2267 *** (0) | 0.2482 (0.419) | −0.6419 (0.139) |
| 9 | 0.0562 * (0.04) | 0.039 ** (0.008) | 0.0566 * (0.015) | 0.1986 *** (0) | 0.1134 (0.625) | −0.5035 (0.128) |
| 10 | 0.071 ** (0.008) | 0.0441 *** (0.001) | 0.0868 *** (0.001) | 0.2655 *** (0) | 0.5811 * (0.03) | −0.4768 (0.237) |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Times | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| 1 | 0.0271 (0.298) | 0.0353 ** (0.007) | −0.0231 (0.43) | 0.197 *** (0) | 0.5775 (0.399) | 0.0459 (0.954) |
| 2 | 0.0319 (0.262) | 0.0246 (0.235) | 0.0002 (0.997) | 0.0996 (0.18) | 0.1527 (0.744) | −0.2459 (0.746) |
| 3 | 0.0405 (0.148) | 0.0249 (0.14) | 0.0244 (0.564) | 0.134 * (0.021) | 0.0236 (0.958) | −0.5818 (0.428) |
| 4 | 0.026 (0.233) | 0.0209 (0.229) | −0.0175 (0.648) | 0.1333 * (0.013) | 0.5704 (0.335) | −0.0521 (0.931) |
| 5 | 0.0329 (0.195) | 0.0378 * (0.018) | −0.011 (0.736) | 0.1571 *** (0.001) | −0.3182 (0.518) | −0.6631 (0.348) |
| 6 | 0.0815 * (0.011) | 0.0437 * (0.028) | −0.0069 (0.834) | 0.1378 ** (0.01) | −0.3302 (0.579) | −0.6254 (0.446) |
| 7 | 0.0206 (0.542) | 0.0072 (0.752) | 0.0054 (0.883) | 0.1078 (0.066) | 0.033 (0.956) | −0.8677 (0.276) |
| 8 | 0.0273 (0.316) | 0.0299 (0.137) | 0.0095 (0.807) | 0.161 *** (0.001) | 0.0735 (0.925) | −1.2288 (0.199) |
| 9 | 0.0364 (0.166) | 0.0394 * (0.039) | 0.0441 (0.17) | 0.1548 ** (0.002) | −0.4657 (0.408) | −1.0819 (0.256) |
| 10 | 0.0406 (0.112) | 0.0339 (0.073) | −0.0193 (0.607) | 0.0894 (0.171) | 0.6506 (0.309) | 0.0991 (0.907) |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Times | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| 1 | 0.0399 * (0.046) | 0.0117 (0.525) | 0.0948 ** (0.001) | 0.1623 *** (0) | −0.2442 (0.793) | −1.0232 (0.466) |
| 2 | 0.0521 * (0.032) | 0.0304 (0.076) | 0.0376 (0.112) | 0.1408 *** (0.001) | −0.7651 (0.109) | −0.5469 (0.444) |
| 3 | 0.0112 (0.628) | −0.0325 (0.082) | 0.0581 * (0.021) | 0.1575 *** (0) | 0.6758 (0.329) | 0.4968 (0.654) |
| 4 | 0.0439 * (0.041) | 0.0321 * (0.042) | 0.0367 (0.086) | 0.1616 *** (0) | −0.4887 (0.371) | −0.2133 (0.776) |
| 5 | 0.0651 *** (0.008) | 0.0341 (0.057) | 0.0159 (0.482) | 0.1752 *** (0) | 0.2509 (0.65) | −0.872 (0.185) |
| 6 | 0.0146 (0.469) | −0.0079 (0.652) | 0.0307 (0.208) | 0.161 *** (0) | 0.1355 (0.827) | 0.8016 (0.263) |
| 7 | 0.0479 * (0.022) | −0.0045 (0.824) | 0.0491 (0.095) | 0.1653 *** (0) | 0.3038 (0.671) | 0.1252 (0.897) |
| 8 | 0.0049 (0.825) | 0.0094 (0.563) | 0.0394 (0.105) | 0.2048 *** (0) | 0.5727 (0.345) | 0.9211 (0.263) |
| 9 | 0.0342 (0.142) | 0.0132 (0.475) | 0.0617 * (0.027) | 0.18 *** (0) | −0.6704 (0.354) | −1.2534 (0.162) |
| 10 | 0.0431 (0.061) | 0.0177 (0.298) | 0.0746 * (0.011) | 0.1702 *** (0) | −0.0914 (0.881) | 0.2375 (0.722) |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Dependent variables | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| AQI | 0.0570 *** | 0.00195 | 0.0744 | |||
| (0.0145) | (0.0242) | (0.1343) | ||||
| PM2.5 | 0.00949 | −0.00784 | −0.794 *** | |||
| (0.0093) | (0.0269) | (0.1658) | ||||
| Weather variables | ||||||
| TEMP | 2.264 | 2.446 | 206.5 *** | 201.9 *** | 100.5 ** | −19.3 |
| (2.3320) | (2.1031) | (18.3392) | (23.3036) | (31.1725) | (20.4207) | |
| (TEMP)2 | −0.0769 ** | −0.0754 ** | −2.701 *** | −2.642 *** | −2.227 *** | 0.19 |
| (0.0254) | (0.0229) | (0.2376) | (0.2982) | (0.6226) | (0.4093) | |
| WIND | 2.534 *** | 2.790 *** | 15.58 *** | 15.56 *** | 54.01 *** | 15.93 * |
| (0.2617) | (0.2194) | (0.9970) | (0.9738) | (5.7752) | (7.4903) | |
| CLOUD | 7.730 *** | 8.616 *** | −21.49 *** | −21.31 *** | 0 | 0 |
| (0.8331) | (0.7992) | (1.5167) | (1.3588) | − | − | |
| Constant | 402.6 *** | 398.0 *** | −3436 *** | −3346 *** | −632.4 | 1088.0 *** |
| (52.2414) | (47.5121) | (351.9851) | (450.4228) | (416.5775) | (298.0420) | |
| POI fixed effects | YES | YES | YES | YES | YES | YES |
| Type of day fixed effects | YES | YES | YES | YES | YES | YES |
| N | 4000 | 4000 | 4000 | 4000 | 2200 | 2200 |
| R2 | 0.4525 | 0.452 | 0.277 | 0.277 | 0.3775 | 0.3795 |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | |
|---|---|---|---|---|
| Dependent variables | Lunch | Lunch | Dinner | Dinner |
| AQI | 0.00374 | 0.620 *** | ||
| (0.0198) | (0.1661) | |||
| PM2.5 | −0.0994 *** | 0.391 | ||
| (0.0144) | (0.2482) | |||
| Weather variables | ||||
| TEMP | −376.0 *** | −378.7 *** | −244.8 *** | −210.0 *** |
| (15.8275) | (16.0107) | (17.3950) | (29.7944) | |
| (TEMP)2 | 4.711 *** | 4.748 *** | 6.258 *** | 5.588 *** |
| (0.1979) | (0.1999) | (0.4188) | (0.6805) | |
| WIND | 23.60 *** | 23.57 *** | 93.60 *** | 89.30 *** |
| (1.4692) | (1.4384) | (5.6235) | (5.6046) | |
| CLOUD | −41.08 *** | −38.94 *** | 0 | 0 |
| (2.8149) | (2.6028) | − | − | |
| Constant | 7867.2 *** | 7926.1 *** | 2564.5 *** | 2177.8 *** |
| (301.4089) | (306.0135) | (156.5763) | (341.0804) | |
| POI fixed effects | YES | YES | YES | YES |
| Type of day fixed effects | YES | YES | YES | YES |
| N | 3780 | 3780 | 2268 | 2268 |
| R2 | 0.5421 | 0.5425 | 0.6658 | 0.6655 |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Dependent variables | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| AQI | 0.0614 *** | 0.0704 *** | 0.375 | |||
| (0.0175) | (0.0171) | (0.2090) | ||||
| PM2.5 | 0.0393 *** | 0.225 *** | −0.403 | |||
| (0.0091) | (0.0144) | (0.2895) | ||||
| Weather variables | ||||||
| TEMP | 14.22 *** | 13.35 *** | 342.6 *** | 451.4 *** | 240.5 *** | 114.0 ** |
| (1.7454) | (1.6242) | (29.4455) | (34.5974) | (44.3278) | (37.9603) | |
| (TEMP)2 | −0.217 *** | −0.206 *** | −4.424 *** | −5.799 *** | −5.067 *** | −2.511 ** |
| (0.0192) | (0.0179) | (0.3826) | (0.4478) | (0.8937) | (0.7672) | |
| WIND | 2.656 *** | 2.996 *** | 19.01 *** | 19.78 *** | 93.94 *** | 66.43 *** |
| (0.2548) | (0.2106) | (1.3030) | (1.3243) | (8.8098) | (15.2918) | |
| CLOUD | 12.40 *** | 12.00 *** | −18.56 *** | −22.73 *** | 0 | 0 |
| (1.0094) | (1.0000) | (1.3265) | (1.3514) | − | − | |
| Constant | 279.9 *** | 296.8 *** | −5923 *** | −8050 *** | −2277.7 *** | −528.7 |
| (40.8030) | (38.2207) | (562.706) | (664.212) | (591.1757) | (549.7147) | |
| POI fixed effects | YES | YES | YES | YES | YES | YES |
| Type of day fixed effects | YES | YES | YES | YES | YES | YES |
| N | 4000 | 4000 | 4000 | 4000 | 2200 | 2200 |
| R2 | 0.5943 | 0.5943 | 0.4793 | 0.4814 | 0.5618 | 0.5618 |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Dependent variables | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| AQI | 0.036 | 0.0142 | 0.17 | |||
| (0.0193) | (0.0263) | (0.3953) | ||||
| PM2.5 | 0.0217 | 0.147 *** | −0.342 | |||
| (0.0136) | (0.0383) | (0.5427) | ||||
| Weather variables | ||||||
| TEMP | 5.526 | 5.049 | 296.6 *** | 373.7 *** | 190.8 * | 112 |
| (3.9977) | (3.6908) | (31.9462) | (38.7465) | (82.4009) | (68.1898) | |
| (TEMP)2 | −0.129 ** | −0.123 ** | −3.832 *** | −4.808 *** | −4.059 * | −2.469 |
| (0.0433) | (0.0402) | (0.4170) | (0.4995) | (1.6581) | (1.3709) | |
| WIND | 3.668 *** | 3.860 *** | 18.86 *** | 19.31 *** | 83.43 *** | 63.88 ** |
| (0.4218) | (0.3523) | (1.6356) | (1.6282) | (12.6869) | (24.2800) | |
| CLOUD | 12.28 *** | 12.11 *** | −22.85 *** | −25.77 *** | 0 | 0 |
| (1.2568) | (1.0827) | (2.1693) | (1.9706) | − | − | |
| Constant | 522.5 *** | 532.0 *** | −5028.9 *** | −6535.0 *** | −1620.6 | −517.1 |
| (88.3302) | (81.8273) | (609.2183) | (745.6948) | (1100) | (996.0337) | |
| POI fixed effects | YES | YES | YES | YES | YES | YES |
| Type of day fixed effects | YES | YES | YES | YES | YES | YES |
| N | 1980 | 1980 | 1980 | 1980 | 1089 | 1089 |
| R2 | 0.5687 | 0.5686 | 0.4249 | 0.426 | 0.5603 | 0.5603 |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | (v—AQI) | (vi—PM2.5) | |
|---|---|---|---|---|---|---|
| Dependent variables | Period1 | Period1 | Period2 | Period2 | Period3 | Period3 |
| AQI | 0.031 | 0.0567 ** | −0.00762 | |||
| (0.0159) | (0.0184) | (0.4551) | ||||
| PM2.5 | 0.00557 | 0.167 *** | −0.18 | |||
| (0.0127) | (0.0272) | (0.6530) | ||||
| Weather variables | ||||||
| TEMP | 10.44 ** | 10.53 ** | 333.8 *** | 411.8 *** | 183.4 | 161.1 |
| (3.3324) | (3.1121) | (42.0320) | (48.6495) | (93.7985) | (81.4032) | |
| (TEMP)2 | −0.186 *** | −0.185 *** | −4.306 *** | −5.291 *** | −3.935 * | −3.486 * |
| (0.0346) | (0.0325) | (0.5481) | (0.6306) | (1.8950) | (1.6519) | |
| WIND | 3.938 *** | 4.072 *** | 20.71 *** | 21.30 *** | 89.90 *** | 82.09 ** |
| (0.3957) | (0.3453) | (1.9061) | (1.9226) | (14.7067) | (30.4025) | |
| CLOUD | 13.99 *** | 14.47 *** | −26.44 *** | −29.32 *** | 0 | 0 |
| (1.2415) | (1.1751) | (2.7577) | (2.5480) | − | − | |
| Constant | 472.7 *** | 470.3 *** | −5656.0 *** | −7181.8 *** | −1374.6 | −1049.3 |
| (78.7130) | (73.8032) | (800.5169) | (931.2908) | (1200) | (1200) | |
| POI fixed effects | YES | YES | YES | YES | YES | YES |
| Type of day fixed effects | YES | YES | YES | YES | YES | YES |
| N | 1960 | 1960 | 1960 | 1960 | 1078 | 1078 |
| R2 | 0.5725 | 0.5725 | 0.4474 | 0.4482 | 0.55 | 0.55 |
Appendix C.3. The Results of the Mutilative Linear Regression
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | |
|---|---|---|---|---|
| Number | Number | Distance | Distance | |
| AQI | −19.54 * | −7.271 * | ||
| (8.6284) | (3.5220) | |||
| PM2.5 | −2.839 | −1.015 | ||
| (6.5185) | (2.7622) | |||
| TEMP | 255.9 | −37.73 | 116.7 | −3.994 |
| (277.4387) | (292.0201) | (123.4601) | (128.0484) | |
| (TEMP)2 | −6.352 | −2.794 | −2.831 | −1.403 |
| (3.5965) | (3.8598) | (1.6012) | (1.6949) | |
| WIND | 124.4 | 95.25 | 56.04 * | 44.06 |
| (62.5282) | (63.9672) | (27.6811) | (28.0982) | |
| CLOUD | −1147.5 ** | −830.4 | −497.8 * | −360.2 |
| (425.6531) | (505.6191) | (192.2372) | (226.7534) | |
| Constant | 7563.8 | 9745.2 | 2855.4 | 3988 |
| (5700) | (5700) | (2500) | (2500) | |
| Type of day controls | YES | YES | YES | YES |
| Hour controls | YES | YES | YES | YES |
| N | 73 | 73 | 73 | 73 |
| R2 | 0.3971 | 0.3983 | 0.3838 | 0.3989 |
| (i—AQI) | (ii—PM2.5) | (iii—AQI) | (iv—PM2.5) | |
|---|---|---|---|---|
| Number | Number | Distance | Distance | |
| AQI | −7.466 * | −1.201 * | ||
| (3.3690) | (0.5445) | |||
| PM2.5 | −0.661 | −0.207 | ||
| (2.3764) | (0.4006) | |||
| TEMP | 30.77 | −35.41 | 7.162 | −3.113 |
| (84.8118) | (90.3629) | (14.7112) | (15.6714) | |
| (TEMP)2 | −1.202 | −0.343 | −0.23 | −0.103 |
| (1.1018) | (1.1933) | (0.1909) | (0.2069) | |
| WIND | 25.21 | 22.78 | 5.529 | 5.127 |
| (19.4659) | (20.3324) | (3.3585) | (3.5008) | |
| CLOUD | −360.4 ** | −293.3 | −59.49 ** | −44.84 |
| (126.2527) | (151.0873) | (22.0692) | (26.2204) | |
| Constant | 3506.3 | 3132.2 | 542.1 | 506.2 |
| (1800) | (1800) | (309.7733) | (316.8005) | |
| Type of day controls | YES | YES | YES | YES |
| Hour controls | YES | YES | YES | YES |
| N | 73 | 73 | 73 | 73 |
| R2 | 0.4087 | 0.3661 | 0.404 | 0.3682 |
| Number of People | Distance of Movement | |||
|---|---|---|---|---|
| AQI | PM2.5 | AQI | PM2.5 | |
| Walk | 1.818 | 1.778 | 1.889 | 1.818 |
| (0.423) | (0.394) | (0.415) | (0.391) | |
| Riding bike | 1.929 | 1.856 | 1.893 | 1.838 |
| (0.404) | (0.376) | (0.397) | (0.372) | |
References
- Chen, X.; Lu, W. Identifying factors influencing demolition waste generation in Hong Kong. J. Clean. Prod. 2017, 141, 799–811. [Google Scholar] [CrossRef] [Green Version]
- Lu, W.; Chen, X.; Peng, Y.; Shen, L. Benchmarking construction waste management performance using big data. Resour. Conserv. Recycl. 2015, 105, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Wirahadikusumah, R.D.; Ario, D. A readiness assessment model for Indonesian contractors in implementing sustainability principles. Int. J. Constr. Manag. 2015, 15, 126–136. [Google Scholar] [CrossRef]
- Shen, L.; Shuai, C.; Jiao, L.; Tan, Y.; Song, X. Dynamic sustainability performance during urbanization process between BRICS countries. Habitat Int. 2017, 60, 19–33. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, M.; Yang, X.; Yuan, X. Public awareness and willingness to pay for tackling smog pollution in China: A case study. J. Clean. Prod. 2016, 112, 1627–1634. [Google Scholar] [CrossRef]
- Ebenstein, A.; Fan, M.; Greenstone, M.; He, G.; Zhou, M. New evidence on the impact of sustained exposure to air pollution on life expectancy from China’s Huai River Policy. Proc. Natl. Acad. Sci. USA 2017, 114, 10384–10389. [Google Scholar] [CrossRef] [Green Version]
- Chang, T.Y.; Zivin, J.G.; Gross, T.; Neidell, M. The effect of pollution on worker productivity: Evidence from call center workers in China. Am. Econ. J. Appl. Econ. 2019, 11, 151–172. [Google Scholar] [CrossRef] [Green Version]
- Currie, J.; Zivin, J.G.; Mullins, J.; Neidell, M. What do we know about short-and long-term effects of early-life exposure to pollution? Annu. Rev. Resour. Econ. 2014, 6, 217–247. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Wang, J.; Sun, C.; Zhang, X.; Kahn, M.E. Air pollution lowers Chinese urbanites’ expressed happiness on social media. Nat. Hum. Behav. 2019, 3, 237. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, C.; Liu, H.; Zheng, S. The role of public information in increasing homebuyers’ willingness-to-pay for green housing: Evidence from Beijing. Ecol. Econ. 2016, 129, 40–49. [Google Scholar] [CrossRef]
- Zhang, J.; Mu, Q. Air pollution and defensive expenditures: Evidence from particulate-filtering facemasks. J. Environ. Econ. Manag. 2018, 92, 517–536. [Google Scholar] [CrossRef]
- Mlinac, M.E.; Feng, M.C. Assessment of activities of daily living, self-care, and independence. Arch. Clin. Neuropsychol. 2016, 31, 506–516. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Rui, X.; Poslad, S.; Song, X.; Fan, Y.; Wu, B. A method for the estimation of finely-grained temporal spatial human population density distributions based on cell phone call detail records. Remote Sens. 2020, 12, 2572. [Google Scholar] [CrossRef]
- Razak, M.A.W.A.; Othman, N.; Nazir, N.N.M. Connecting people with nature: Urban park and human well-being. Procedia-Soc. Behav. Sci. 2016, 222, 476–484. [Google Scholar] [CrossRef] [Green Version]
- Stokols, D. Translating social ecological theory into guidelines for community health promotion. Am. J. Health Promot. 1996, 10, 282–298. [Google Scholar] [CrossRef] [Green Version]
- De Freitas, C. Weather and place-based human behavior: Recreational preferences and sensitivity. Int. J. Biometeorol. 2015, 59, 55–63. [Google Scholar] [CrossRef]
- Liu, B.; Huangfu, Y.; Lima, N.; Jobson, B.; Kirk, M.; O’Keeffe, P.; Pressley, S.; Walden, V.; Lamb, B.; Cook, D.; et al. Analyzing the relationship between human behavior and indoor air quality. J. Sens. Actuator Netw. 2017, 6, 13. [Google Scholar]
- Jiang, Y.; Huang, G.; Fisher, B. Air quality, human behavior and urban park visit: A case study in Beijing. J. Clean. Prod. 2019, 240, 118000. [Google Scholar] [CrossRef]
- Toubes, D.; Araújo-Vila, N.; Fraiz-Brea, J.A. Influence of Weather on the Behaviour of Tourists in a Beach Destination. Atmosphere 2020, 11, 121. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Li, S.; Li, P.; Liu, J.; Long, K. How does air pollution influence cycling behaviour? Evidence from Beijing. Transp. Res. Part D Transp. Environ. 2018, 63, 826–838. [Google Scholar] [CrossRef]
- Hu, L.; Zhu, L.; Xu, Y.; Lyu, J.; Imm, K.; Yang, L. Relationship between air quality and outdoor exercise behavior in China: A novel mobile-based study. Int. J. Behav. Med. 2017, 24, 520–527. [Google Scholar] [CrossRef]
- Wooldridge, J.M. Econometric Analysis of Cross Section and Panel Data; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Laird, N.M.; Ware, J.H. Random-effects models for longitudinal data. Biometrics 1982, 32, 963–974. [Google Scholar] [CrossRef]
- Gao, R.; Ma, H.; Ma, H.; Li, J. Impacts of Different Air Pollutants on Dining-Out Activities and Satisfaction of Urban and Suburban Residents. Sustainability 2020, 12, 2746. [Google Scholar] [CrossRef] [Green Version]
- Siqi, Z.; Xiaonan, Z.; Zhida, S.; Cong, S. Influence of air pollution on urban residents’ outdoor activity: Empirical study based on dining-out data from the Dianping website. J. Tsinghua Univ. 2016, 56, 89–96. [Google Scholar]
- Berk, R.A. An introduction to sample selection bias in sociological data. Am. Sociol. Rev. 1983, 48, 386–398. [Google Scholar] [CrossRef]
- Zhang, G.; Rui, X.; Poslad, S.; Song, X.; Fan, Y.; Ma, Z. Large-Scale, Fine-Grained, Spatial, and Temporal Analysis, and Prediction of Mobile Phone Users’ Distributions Based upon a Convolution Long Short-Term Model. Sensors 2019, 19, 2156. [Google Scholar] [CrossRef] [Green Version]
- Keele, L.; Titiunik, R. Natural experiments based on geography. Political Sci. Res. Methods 2016, 4, 65–95. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Gong, S.; Yu, Y.; Yu, L.; Wu, Y.; Mao, H.; Song, C.; Zhao, S.; Liu, H.; Li, X.; et al. Air pollution characteristics and their relation to meteorological conditions during 2014–2015 in major Chinese cities. Environ. Pollut. 2017, 223, 484–496. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: Oxforshire, UK, 2018. [Google Scholar]
- Philip, G.; Watson, D.F. A precise method for determining contoured surfaces. APPEA J. 2018, 22, 205–212. [Google Scholar] [CrossRef]
- Granger, C.W.; Newbold, P.; Econom, J. Spurious regressions in econometrics. In A Companion to Theoretical Econometrics; Blackwell Publisher: Hoboken, NJ, USA, 2001; pp. 557–561. [Google Scholar]
- Im, K.S.; Pesaran, M.H.; Shin, Y. Testing for unit roots in heterogeneous panels. J. Econom. 2003, 115, 53–74. [Google Scholar] [CrossRef]
- Harris, R.D.; Tzavalis, E. Inference for unit roots in dynamic panels where the time dimension is fixed. J. Econom. 1999, 91, 201–226. [Google Scholar] [CrossRef]
- Xiaoyu, X. Analysis on Spatial Distribution Pattern of Beijing Restaurants based on Open Source Big Data. J. Geo-Inf. Sci. 2019, 21, 215–255. [Google Scholar]
- Ljung, G.M.; Box, G.E. The likelihood function of stationary autoregressive-moving average models. Biometrika 1979, 66, 265–270. [Google Scholar] [CrossRef]
- Prais, S.J.; Winsten, C.B. Trend Estimators and Serial Correlation; Discussion Paper; Unpublished Cowles Commission: Chicago, IL, USA, 1954. [Google Scholar]
- Wang, H.; Calabrese, F.; di Lorenzo, G.; Ratti, C. Transportation Mode Inference from Anonymized and Aggregated Mobile Phone Call Detail Records. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Madeira Island, Portugal, 19–22 September 2010; pp. 318–323. [Google Scholar]
- Wang, X.; Dong, H.; Zhou, Y.; Liu, K.; Jia, L.; Qin, Y. Travel Distance Characteristics Analysis Using Call Detail Record Data. In Proceedings of the 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 3485–3489. [Google Scholar]
- Bwambale, A.; Choudhury, C.; Hess, S. Modelling long-distance route choice using mobile phone call detail record data: A case study of Senegal. Transp. A Transp. Sci. 2019, 15, 1543–1568. [Google Scholar] [CrossRef]
- Cherry, C.R.; He, M. Alternative Methods of Measuring Operating Speed of Electric and Traditional Bikes in China—Implications for Travel Demand Models. J. East. Asia Soc. Transp. Stud. 2010, 8, 1424–1436. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Z.; Hong, J.; Han, D.; Zhao, L. Research on Characteristics of Pedestrian Traffic and Simulation in the Underground Transfer Hub in Beijing. In Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea, 24–26 November 2009; pp. 1352–1357. [Google Scholar]
- Laumbach, R.; Meng, Q.; Kipen, H. What can individuals do to reduce personal health risks from air pollution? J. Thorac. Dis. 2015, 7, 96. [Google Scholar]
- Jie, W.J.H.; Haitao, J.; Fengjun, J. Investigating spatiotemporal patterns of passenger flows in the Beijing metro system from smart card data. Prog. Geogr. 2018, 37, 397–406. [Google Scholar]
- Barwick, P.J.; Li, S.; Rao, D.; Zahur, N.B. The Morbidity Cost of Air Pollution: Evidence from Consumer Spending in China; National Bureau of Economic Research: Cambridge, MA, USA, 2018. [Google Scholar]
- Cohen, A.J.; Anderson, H.; Ostro, B.; Pandey, K.; Krzyzanowski, M.; Kunzli, N.; Gutschmidt, K.; Pope, A.; Romieu, I.; Samet, J.; et al. The global burden of disease due to outdoor air pollution. J. Toxicol. Environ. Health Part A 2005, 68, 1301–1307. [Google Scholar] [CrossRef] [PubMed]
- Ren, L.; Yang, W.; Bai, Z. Characteristics of major air pollutants in China. In Ambient Air Pollution and Health Impact in China; Springer: Berlin/Heidelberg, Germany, 2017; pp. 7–26. [Google Scholar]
- Zhang, Y.-L.; Cao, F. Fine particulate matter (PM 2.5) in China at a city level. Sci. Rep. 2015, 5, 14884. [Google Scholar] [CrossRef] [Green Version]
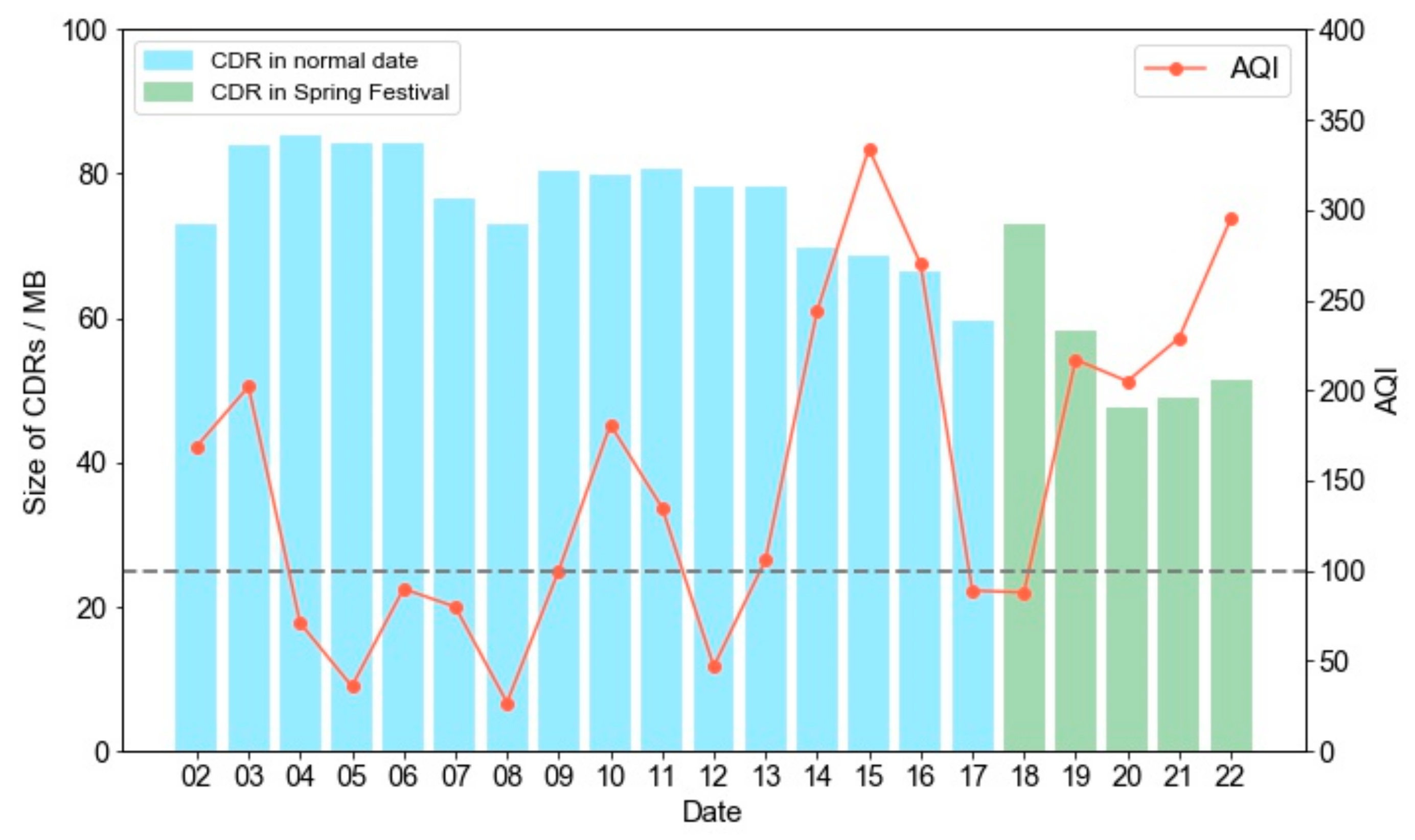
| ADL Category | Time (Minutes) | Percentage | If Is LD-ADL |
|---|---|---|---|
| Total | 1440 | . | - |
| 1. Personal Physiologically Necessary Activities | 713 | 49.51% | - |
| Sleeping | 559 | 38.82% | YES |
| Personal Hygiene Care | 50 | 3.47% | NO |
| Meals or Other Diet | 104 | 7.22% | YES |
| 2. Paid Labour | 264 | 18.33% | - |
| Employment Work | 177 | 12.29% | NO |
| Family Production and Business Activities | 87 | 6.04% | NO |
| 3. Unpaid Work | 162 | 11.25% | - |
| Housework | 86 | 5.97% | YES |
| Accompanying and Caring for Family | 53 | 3.68% | NO |
| Purchase Goods or Services (including Medical Treatment) | 21 | 1.46% | NO |
| Charitable Activities | 3 | 0.21% | NO |
| 4. Personal Discretionary Activity | 236 | 16.39% | - |
| Fitness Exercise | 31 | 2.15% | YES |
| Listening to Radio or Music | 6 | 0.42% | NO |
| Watching TV | 100 | 6.94% | YES |
| Reading Books, Newspapers and Periodicals | 9 | 0.63% | NO |
| Leisure and Entertainment | 65 | 4.51% | NO |
| Social Interaction | 24 | 1.67% | NO |
| 5. Learning and Training | 27 | 1.88% | NO |
| 6. Transportation | 38 | 2.64% | YES |
| Other: Use the Internet | 162 | 11.25% | NO |
| Abbreviation | Explanation | Abbreviation | Explanation |
|---|---|---|---|
| ADL | Activities of daily living | MEP | Ministry of Environmental Protection |
| AQ | Air quality | MPUD | Mobile phone users’ density |
| AQI | Air quality index | NCDC | National Climatic Data Centre |
| CAR | Change in average revenue | NOAA | National Oceanic and Atmospheric Administration |
| CDR | Call Detail Record | OLS | Ordinary Least Squares |
| CI | Cell Identity | P1 | Period 1 |
| CNAAQS | Chinese National Ambient Air Quality Standard | P2 | Period 2 |
| CNY | Chinese Yuan | P3 | Period 3 |
| CSV | Comma-Separated Values | PCC | Per Capita Consumption |
| CTRM | Comparison Test of Reference Method | P-Dinner | Period dinner |
| EDR | Effective Data Rate | P-Lunch | Period lunch |
| EPE | Empty-positive-empty | PM | Particulate Matter |
| EPN | Empty-positive-negative | PNN | positive-negative-negative |
| FEM | Fixed Effect Model | POI | Point of Interest |
| GIS | Geographic Information Science | PoM | Parallelism of Monitors |
| GSM | Global System for Mobile Communication | PURT | Panel Unit Root Test |
| HT | Harris-Tzavalis | S1 | Strategy 1 |
| IDW | Inverse Distance Weighting | S2 | Strategy 2 |
| IMSI | International Mobile Subscriber Identification Number | SIM | Subscriber Identity Module |
| IoB | Internet of Behaviours | SPSA | Specific place with a specific activity |
| IoT | Internet of Things | TEOM | Tapered Element Oscillating Microbalance |
| IPS | Im-Pesaran-Shin | UWB | Ultra Wide Band |
| KDE | Kernel Density Estimation | VP | Voronoi polygon |
| LD-ADL | Location-driven ADL |
| Author(s) | Detected ADL(s) | Data Collection | Analysis Method | Limitation(s) |
|---|---|---|---|---|
| De Freitas [16] | Beach user behaviour | Questionnaire survey | Two-dimensional regression analysis | Single ADL; Traditional survey method |
| Lin et al. [17] | Stay in behaviours of elder people | Multi-sensors | Traditional machine learning methods | Single ADL; Small spatial scale; |
| Jiang et al. [18] | Maximum number of park visits | On-line and off-line survey | Quantile regression analysis | Single ADL; Small spatial scale; cannot consider unobservable variables |
| R-Toubes et al. [19] | Tourist number on beaches | Webcam images in combination with real-time weather | Pearson relatsionship anaylsis | Single ADL; Small spatial scale; cannot consider unobservable variables |
| Zhao et al. [20] | Cycling behaviour | Survey in various locations during different periods | Conceptualize the relationship via perceptions | Single ADL; Small spatial scale; cannot consider unobservable variables |
| Hu et al. [21] | Outdoor exercise (running, biking, and walking) | APP Tulipsport users’ data | Multivariate analyses of variance | Too few samples; cannot consider unobservable variables |
| Gao et al. [24]; Zheng et al. [25] | Dining-out activities | Third-party website (dianping.com), (accessed on 26 July 2021) | FEMs | Data objectivity and model robustness have not been tested |
| Dataset | Sensor | Range | Resolution | Accuracy |
|---|---|---|---|---|
| PM2.5 | PM2.5 | 0~10,000 μg/m3 | 0.1 μg/m3 | ≥85% |
| PM10 | PM10 | 0~10,000 μg/m3 | 0.1 μg/m3 | ≥85% |
| SO2 | SO2 | 0~500 ppb | 0.1 μg/m3 | ±2%F.S. |
| O3 | O3 | 0~500 ppb | 0.1 μg/m3 | ±4%F.S. |
| NO2 | NO2 | 0~500 ppb | 0.1 μg/m3 | ±2%F.S. |
| CO | CO | 0~50 ppm | 0.1 mg/m3 | ±2%F.S. |
| Temperature | Thermometer | −50~50 °C | 0.1 °C | ±0.2 °C |
| Wind | Wind Speed | 0~60 m/s | 0.1 m/s | ±(0.5 m/s + 0.03 v) |
| Cloud Amount | - | 0~100% | - | - |
| Precipitation (Rain) | Tipping-Bucket Rain Gauge, Weighing Precipitation | ≤4 mm/min | 0.1mm | ±0.4 mm (≤10 mm), ±4% (>10 mm) |
| Snow (depth) | Automatic Snow Depth Observation Instrument, Ultrasonic or Laser Sensors | 0~2000 mm | 1 mm | ±10 mm |
| Variable | Definition | Obs. | Mean | Std. |
|---|---|---|---|---|
| Mobile phone users’ density (MPUD) variables (Person/Km2) | ||||
| Sightseeing | MPUD for the sampled sightseeing POIs | 92,232 | 529.287 | 469.586 |
| Eating out | MPUD for the sampled restaurant POIs | 95,256 | 519.974 | 440.782 |
| Stay in | MPUD for the sampled house POIs | 100,593 | 539.684 | 452.293 |
| Bus Stop | MPUD for the sampled bus stop POIs | 49,811 | 562.951 | 418.586 |
| Subway Station | MPUD for the sampled underground station POIs | 49,310 | 620.532 | 509.309 |
| Sources: CDR data is from China Mobile Limited Company (Beijing Branch), POI dataset is from AutoNavi Software Limited Company. | ||||
| Pollution variables | ||||
| AQI | Hourly air quality index | 17,640 | 153.025 | 93.099 |
| PM2.5 | Hourly PM2.5 concentration (μg/m3) | 17,640 | 107.929 | 89.774 |
| Source: Ministry of Environmental Protection of the People’s Republic of China | ||||
| Weather variables | ||||
| TEMP | Mean temperature of the site in Beijing (°F) | 504 | 34.381 | 8.642 |
| WIND | Mean wind speed of the site in Beijing (m/s) | 504 | 6.871 | 5.412 |
| CLOUD | Cloud coverage score (0 to 3), 3 = full, 0 = none | 504 | 0.325 | 0.741 |
| RAIN | One-hour liquid precipitation of the site (inches) | 504 | 0 | 0 |
| SNOW | One-hour snow depth of the site (inches) | 504 | 0 | 0 |
| Source: Daily weather data are collected from the National Oceanic and Atmospheric Administration | ||||
| Type of day variables | ||||
| Spring Festival | 1 = today is in Spring Festival Holiday, 0 = otherwise | - | - | - |
| Weekend | 1 = today is weekend, 0 = otherwise | - | - | - |
| Valentine’s Day | 1 = today is Valentine’s Day, 0 = otherwise | - | - | - |
| Source: None | ||||
| Number of People | Distance of Movement | |||
|---|---|---|---|---|
| AQI | PM2.5 | AQI | PM2.5 | |
| Walk | −7.466 * | −0.661 | −1.201 * | −0.207 |
| (0.031) | (0.782) | (0.032) | (0.608) | |
| Riding bike | −19.540 * | −2.839 | −7.271 * | −1.015 |
| (0.028) | (0.665) | (0.044) | (0.715) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Poslad, S.; Rui, X.; Yu, G.; Fan, Y.; Song, X.; Li, R. Using an Internet of Behaviours to Study How Air Pollution Can Affect People’s Activities of Daily Living: A Case Study of Beijing, China. Sensors 2021, 21, 5569. https://doi.org/10.3390/s21165569
Zhang G, Poslad S, Rui X, Yu G, Fan Y, Song X, Li R. Using an Internet of Behaviours to Study How Air Pollution Can Affect People’s Activities of Daily Living: A Case Study of Beijing, China. Sensors. 2021; 21(16):5569. https://doi.org/10.3390/s21165569
Chicago/Turabian StyleZhang, Guangyuan, Stefan Poslad, Xiaoping Rui, Guangxia Yu, Yonglei Fan, Xianfeng Song, and Runkui Li. 2021. "Using an Internet of Behaviours to Study How Air Pollution Can Affect People’s Activities of Daily Living: A Case Study of Beijing, China" Sensors 21, no. 16: 5569. https://doi.org/10.3390/s21165569
APA StyleZhang, G., Poslad, S., Rui, X., Yu, G., Fan, Y., Song, X., & Li, R. (2021). Using an Internet of Behaviours to Study How Air Pollution Can Affect People’s Activities of Daily Living: A Case Study of Beijing, China. Sensors, 21(16), 5569. https://doi.org/10.3390/s21165569