2.1. Content Generation Algorithms
The virtual environment developed is interactively explored from a first-person perspective. All geometrical components of the streets are generated as the user encounters them. The scene and roads are generated using pseudo-infinite virtual objects in real-time [
14]. A pseudo-irregular number generator is utilized with an integer derived from buildings, trees, and roads. The road plan is made by consolidating randomly generated geometries in an iterative interaction to foster intersections with sharp bends.
PCG’s critical property describes the entity as a sequence of generation instructions rather than static block information. The boundaries set in the algorithm allow the generation of occasions with differing qualities.
In a PCG, mathematical and texture data are not determined in the ordinary sense. Instead, details are abstracted into an algorithm with few details. The parameters in the algorithm are adjusted according to a specific behavior, i.e., the number of PCG segments. PCG enables capturing the essence of an entity without explicitly bounding it inside the present reality limit. By fluctuating boundaries, we could deliver a broad scope of results not restricted to the original model’s limitations.
To generate the terrain, we isolated it into square cells on a 2-D matrix where every cell addresses an intermediary for its procedurally produced content. The cells are orchestrated in square loops around the camera’s position situated at the middle. Cells are tried for possible permeability before their substance is produced. Every cell in our virtual scene contains buildings, roads, and trees. The point dictates the possible permeability between the cell and the viewing direction and the camera’s distance. In our execution, only the substance of cells situated inside a 120 survey point and a distance of [loops × cell-size] are considered apparent.
The street’s appearance was determined by a single thirty-two-bit pseudo-random number generator (PRNG) seed [
15]. The random number sequence creates streets with buildings, trees, and road layouts through the vertexes and height values. Comparative initial groupings of arbitrary numbers for comparable seeds were found with the irregular number generator. Comparative arrangements of numbers could bring about comparable formats. The terrain types are stored in a macro-matrix grid, which is utilized to make customized height maps.
If the vertex being analyzed is mapped to a macro-matrix location described as a green area with trees, a pedestrian crossing, buildings, or roads with traffic lights, then the algorithm assigns a height value required by that vertex to create the height. PRNGs produce a sequence of random numbers that are two-dimensional polygons with an initial seed value. When initialized with the same seed, indistinguishable groupings of numbers are delivered.
The subsequent virtual items have their stature and width characterized by the most extreme size of marked integers. The macro-matrix has (i, j) segments that address a few vertices in the virtual world. The terrain height generation uses parametric functions that inform the height value of each vertex. The functions are seeded with the point location in the world. Consequently, the function can describe all the height information globally with no limitation concerning its size. The processing time is identified with the user’s view as the functions employ the point information to calculate its height value.
Simplex noise (SN) stochastic functions are integrated to generate a pseudo-random gradient vector at each lattice point of the terrain, and the pseudo-random gradients determine its behavior between lattice points and interpolate a smooth function between the points. The method comprises making a lattice of irregular slopes, the dot products of which are then interpolated to acquire values between the grids [
16]. Each corner of the SN containing
P has a unit length random gradient vector
where
G is the pseudo-random gradient function and
c is one of the
corners of the SN.
The scalar item is found between the inclination vector
and the gradient slopes
to acquire a scalar value of
. In SN, each
esteem is increased by a radially symmetric lessening function to obtain a weighted scalar worth. Each
will be duplicated by weight
addressing each corner’s distance to
P. In an execution made by Gustavson [
17];
where
and
are the distances in the
x and
y directions between each
c and
P. Only the
c corners influence a point found inside a given Simplex, as other vertices in the Simplex matrix will disintegrate to zero preceding arriving at the current Simplex. Each edge of the Simplex is at an equivalent distance. The qualities are, as of this point, weighted depending on their connection to
P to lessen the need to introduce. The outcome is the summation of weighted qualities for each
corner of the current SN.
Rare examples are generally portrayed in the recurrence area, and a sign is controlled by indicating the plentifulness and stage for each recurrence [
18]. Four-dimensional SN was used in this examination because of its low computational intricacies, low number of augmentations, low spot items, and scale-capacity for higher measurements [
19,
20]. SN execution utilized numerical organize changes and slope commotions to produce smooth and constant capacities without sharp edges.
Most VR games currently developed reuse the same assets when rendering the VR environment with NPCs and assets [
21]. We used machine learning to generate 3D models employing a class of deep learning algorithms to address this shortfall and to ensure the cycling (user) did not become overly familiar with the environment being encountered. The objects were validated via the machine learning model and rendered via the Unity Game Engine.
The algorithm improved continuously by receiving feedback from the output mesh after every iteration. We used a UV map to use machine learning to optimize the game engine performance and avoid a lag when rendering objects. A standard map for the objects was created, and textures were applied on top of a base mesh and vertices of landmarks through the baking process. The algorithm generated new content based on provided examples as a draft for the designer to polish and finish the drafted content afterward.
PCG was fused with machine-learned models (PCGML) to generate VR content. The models were trained on existing VR contents [
22]. PCGML is a technique for creating different content and replicating designed content to provide the player with infinite and unique gameplay variations. PCGML autonomously generates game artifacts at the time of generation. PCGML techniques were organized through two dimensions: Data Representation and Training Method. Data Representation is the underlying representation of the data used for training and generation. The machine learning technique was utilized for training the model. PCGML uses the created set of representative artifacts (NPCs, and objects in the scene) in the target domain as a model for the generator, and then the algorithm generates new content in this style.
2.3. CHP-VR Simulator Procedure
The participants were invited (individually) to attend a laboratory that included the CHP-VR simulator set-up. On arrival, a demonstration of the equipment was provided. The stationary bicycle’s saddle and bar handle height was adjusted to suit the rider’s position, and the participant was made familiar with the bicycle gearing. It was clarified that the participant should cycle at a leisurely and comfortable speed, adhering to the cycling rules outlined in the Highway Code. Following the fitting and calibration of the head-mounted display (HMD), the participants completed an initial 3-minute practice trial. Following familiarization, a break was provided, and initial feedback about comfort was verified.
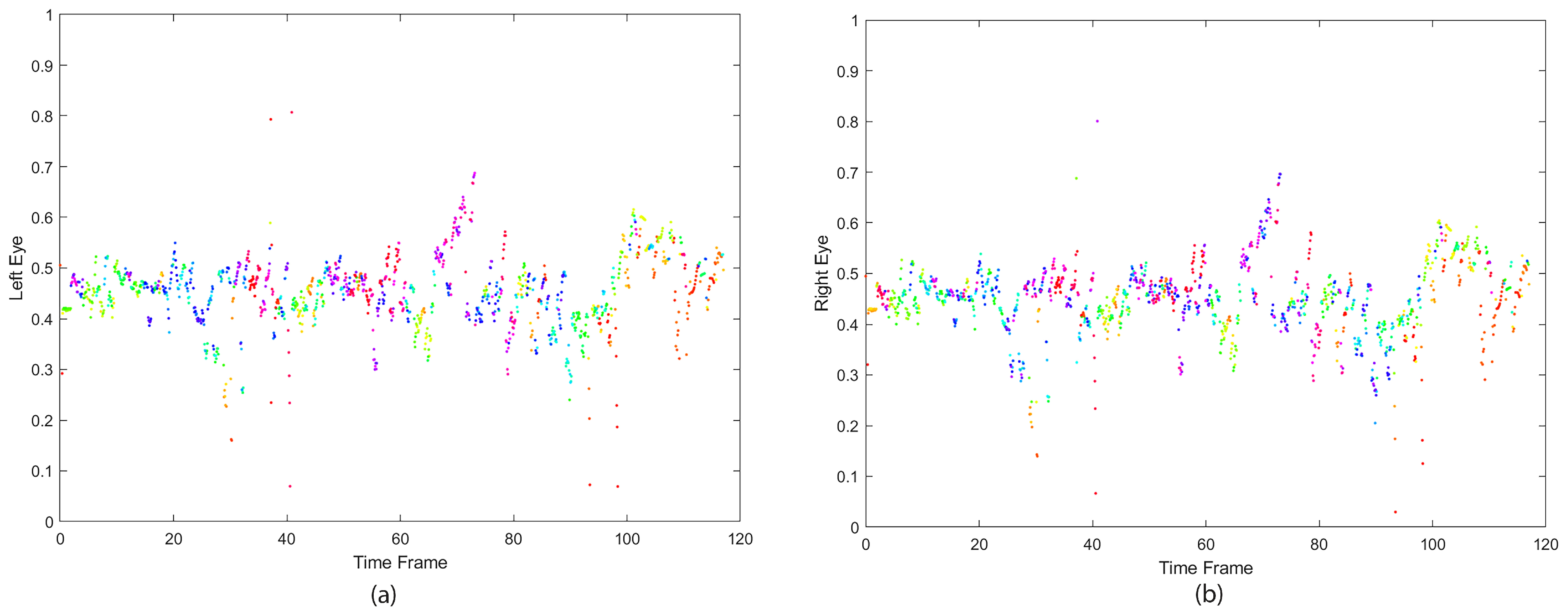
Participants were asked to cycle for five minutes in the VR environment (observing the Highway Code) within the second trial. VR visual search behavior (eye fixation and orientation) was recorded throughout the trial while the players anticipated (through speed adjustments and steering) other road users’ activities and the associated risks. The collected eye data incorporated the monocular pupillary distance (PD); the distance measured in millimeters between the centers of the pupils of the eyes [
23]. Monocular PD refers to the distance between each eye and the bridge of the nose [
24].
HMD calibration started at the center of the screen, where the right and left eyes’ positions on the screen have an average distance equal to PD (mm). The adult’s average PD is estimated to be in the range of [54–74] (mm), while children’s PD range is [43–58] mm. The player’s PD was measured through the HMD’s initial calibration before starting the trial.
Figure 1 displays a player’s left and right eye positions while incorporating the PD.
2.3.1. FOVE VR Headset
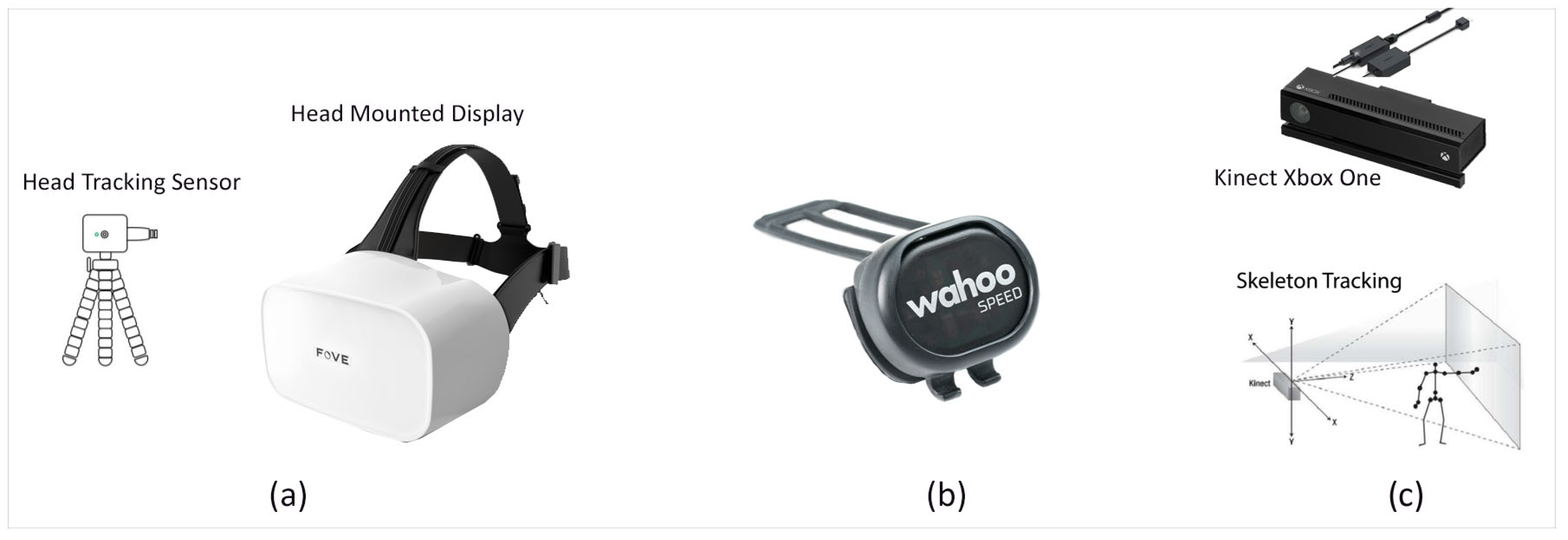
A FOVE HMD was used to develop the VR illustrated in
Figure 2a. It was equipped with a position-tracking camera that recognizes the LED lights situated under the head-mounted cover with Inertial Measurement Units (IMU) and infrared (IR)-based framework eye-following sensors. The headset had a (90–100
) field of view (FOV), which gives a high-quality view experience. The HMD had a head position tracking sampling rate of 100 Hz. The showcase outline rate was 70 Hz, and the eye-following sensor had a 140–180 Hz sampling rate (120 fps). We positioned the position-following camera within three meters from the player while navigating the virtual environment. Adaptation of the VR headset enabled us to track and trace the player’s eyes position whilst interacting with the virtual assets and to determine the time to react to and avoid hazards.
2.3.2. Wahoo RPM Cycling Speed
A low profile and wireless Wahoo RPM Speed Sensor was used to track the player’s cycling speed and transfer it to the virtual reality environment via a Bluetooth Smart system (
https://uk.wahoofitness.com/devices/bike-sensors, accessed on 10 December 2017), (
Figure 2b). The sensor uses a three-axis accelerometer to determine the wheel’s rotation, obtains a reference for the distance, and computes the wheel size. The sensor starts with self-calibration and enables the player to move forward in the scene based on the pedaling speed.
2.3.3. Microsoft Kinect
The Kinect V2 device consists of an infrared laser-based IR emitter and a colored (RGB: red green blue) camera. It detected the position and orientation of 25 individual joints of the player and transferred it to the virtual reality environment displayed in
Figure 2c. Body position was determined in a two-stage process; (I) computing a depth map and (II) inferring the participant’s body position. The depth map is constructed by analyzing a speckle pattern of infrared laser light [
25]. Body parts are inferred using a randomized decision forest learned from over one million training examples [
26].
Kinect provided us with approximately seventy skeleton joints (the body’s main joints and hand joints) and sixty frames per second (fps). The skeleton tracking is illustrated in
Figure 3a by colored cubes showing the players’ main body joints. The static bike steering operation in real-time is transferred via the skeleton tracking system. This facilitates a braking system in the virtual world and maneuvering toward left, right, or straight ahead. Images in the right lower side of
Figure 3 show players pictured while cycling on the static bike and wearing the VR headset collected via the Kinect.
2.4. Gaze Behavior in VR versus In Situ
To address presence by involvement [
27], the current project compared the allocation of selective visual attention in the VR environment to an in situ environment. Evidence from perception-action coupling in the sports environment suggests that behavior, and consequently performance, in video-based experimental paradigms is distinct from in situ situations [
28]. Furthermore, experimental task constraints influence the direction of visual attention; reduced perception–action coupling changes the direction of visual attention from the vision for action (control of movement) to the vision for perception (prediction of intention), [
9]. After participating in the CHP-VR simulator, the participants’ visual search behavior was collected when cycling outdoors in situ; the experiment aimed to compare gaze behavior while cycling in an in situ environment to a VR environment.
In Situ Procedure
The participants were asked to cycle both in the VR and in situ environments (on the road). For familiarity [
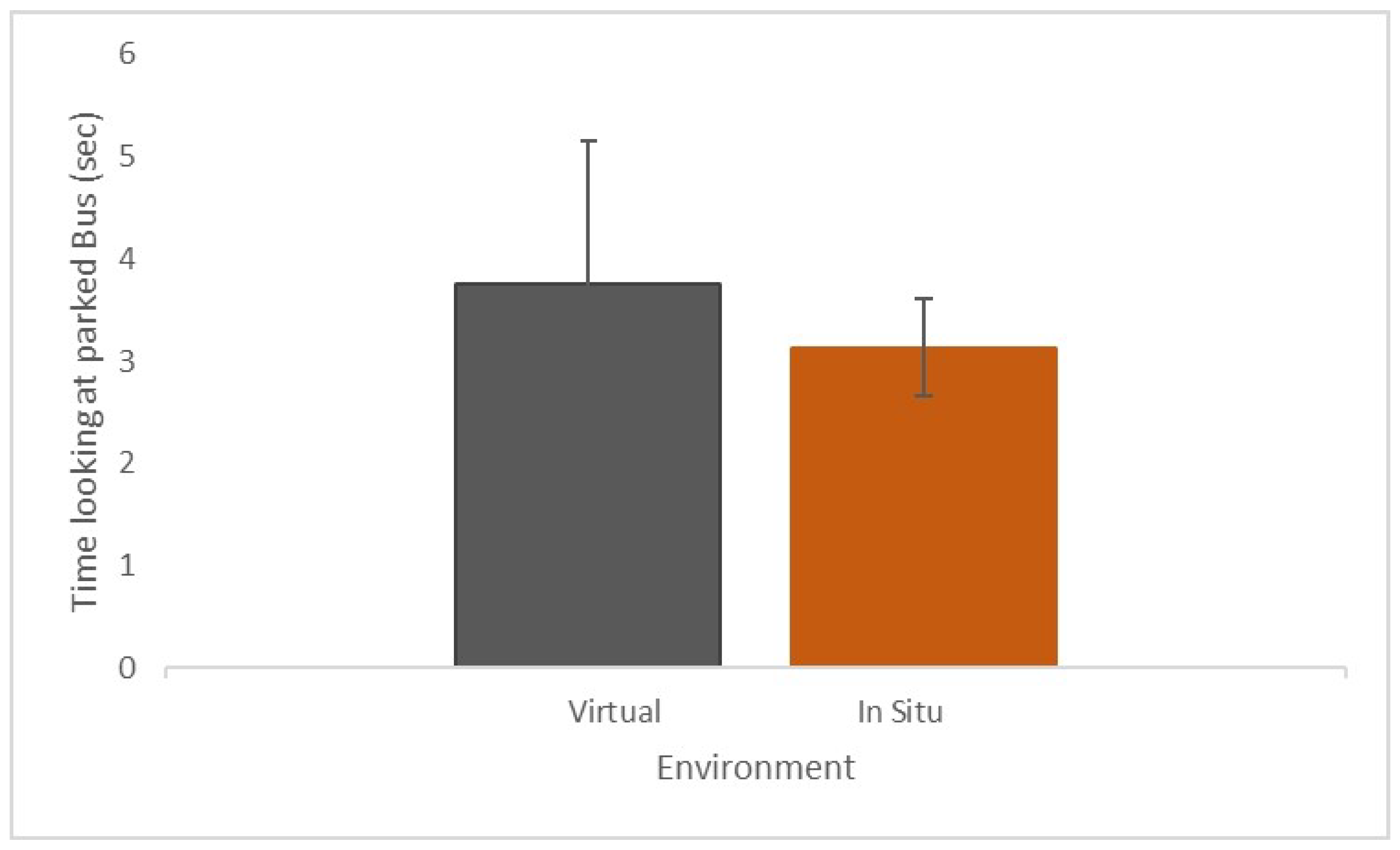
29], for in situ testing, the participants were allowed to use their own bikes. In situ testing took place in daylight hours. Before commencing the ride, the route selection, procedures, and instructions (i.e., where to start and finish) were provided to participants. The selected route was a straight road in the center of Cambridge (UK). Next to the road’s left side was a park, and on the right side, a row of houses. The road was characterized by a selection of bus bays on the left of the route (i.e., in the direction of the traveling cyclist, see
Figure 4a).
The participants were asked to cycle as they would typically, and throughout the entire trial, a research assistant followed the participant on a bicycle at a safe distance. The participant was required to wear a bicycle helmet to participate. A portable eye tracker was used to measure gaze behavior in on-road cycling. The SMI mobile eye gaze registration system (IviewETG, SensoMotoric Instruments Inc., Teltow, Germany, Ver. 1.0) consists of a pair of lightweight glasses with two infrared eye cameras and an HD scene camera. The SMI eye tracker measures the binocular direction of gaze via corneal reflection and the dark pupil principle. The center of the eye’s relative position concerning the scene camera is used to determine the direction of gaze in the environment with a frequency of 30 Hz and a spatial resolution of 0.1 and gaze position accuracy of 0.5.
The glasses were connected to a laptop (Lenovo X220, Thinkpad, Lenovo Group Limited, Beijing, China) stored in a backpack worn by the participant. The eye cameras have a gaze tracking range of 80 horizontally and 60 vertically where the high definition (HD) scene camera (1280 × 960 pixel, 24 Hz) has a tracking range of 60 horizontally and 46 vertically. The data were collected with Iview ETG software (Ver. 2.0, SMI, Teltow, Germany), and a three-point calibration in the sagittal plane at a five-meter distance from the participant was completed before the trial started. Following completion of the cycling route, the calibration of the eye tracker was checked.
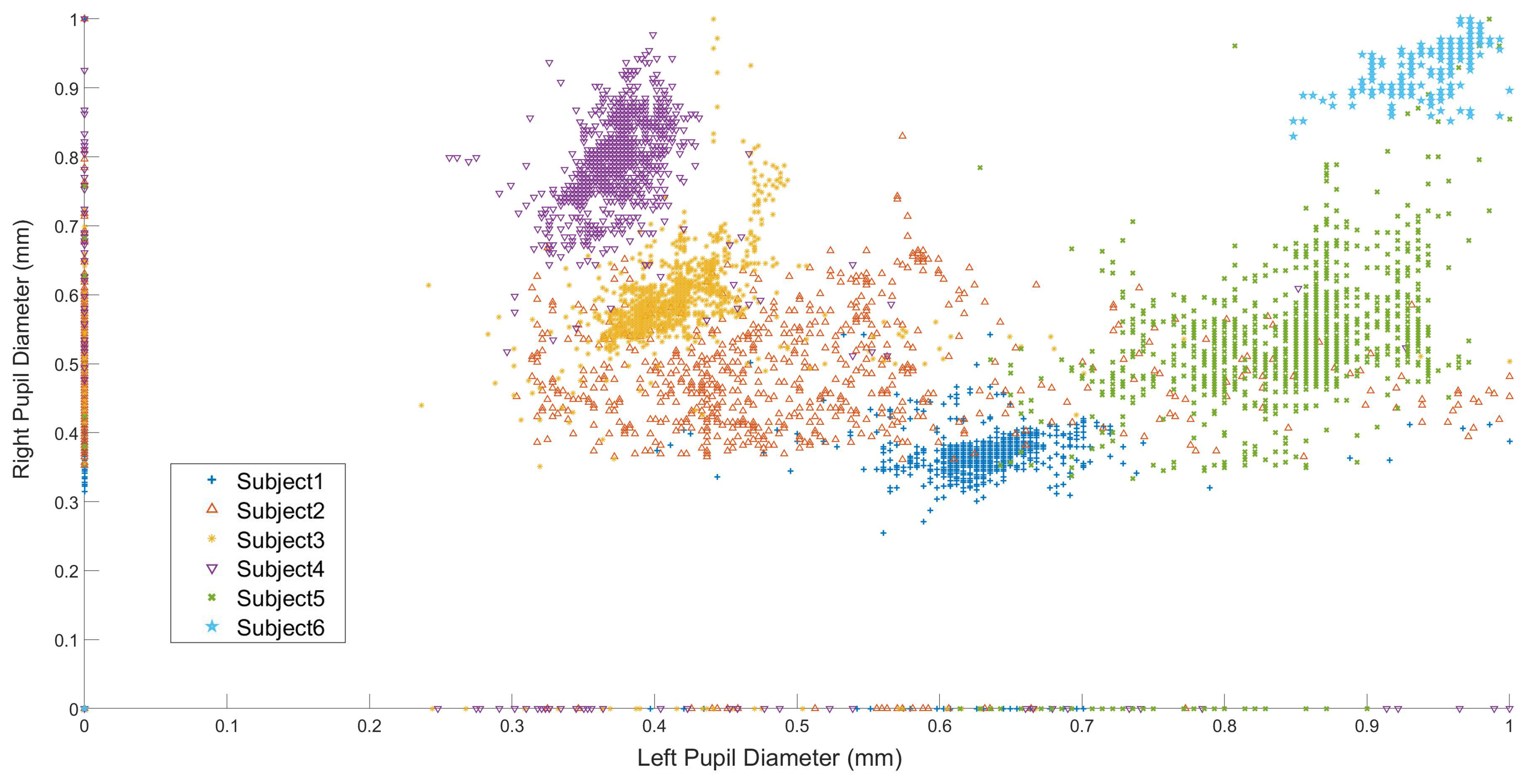
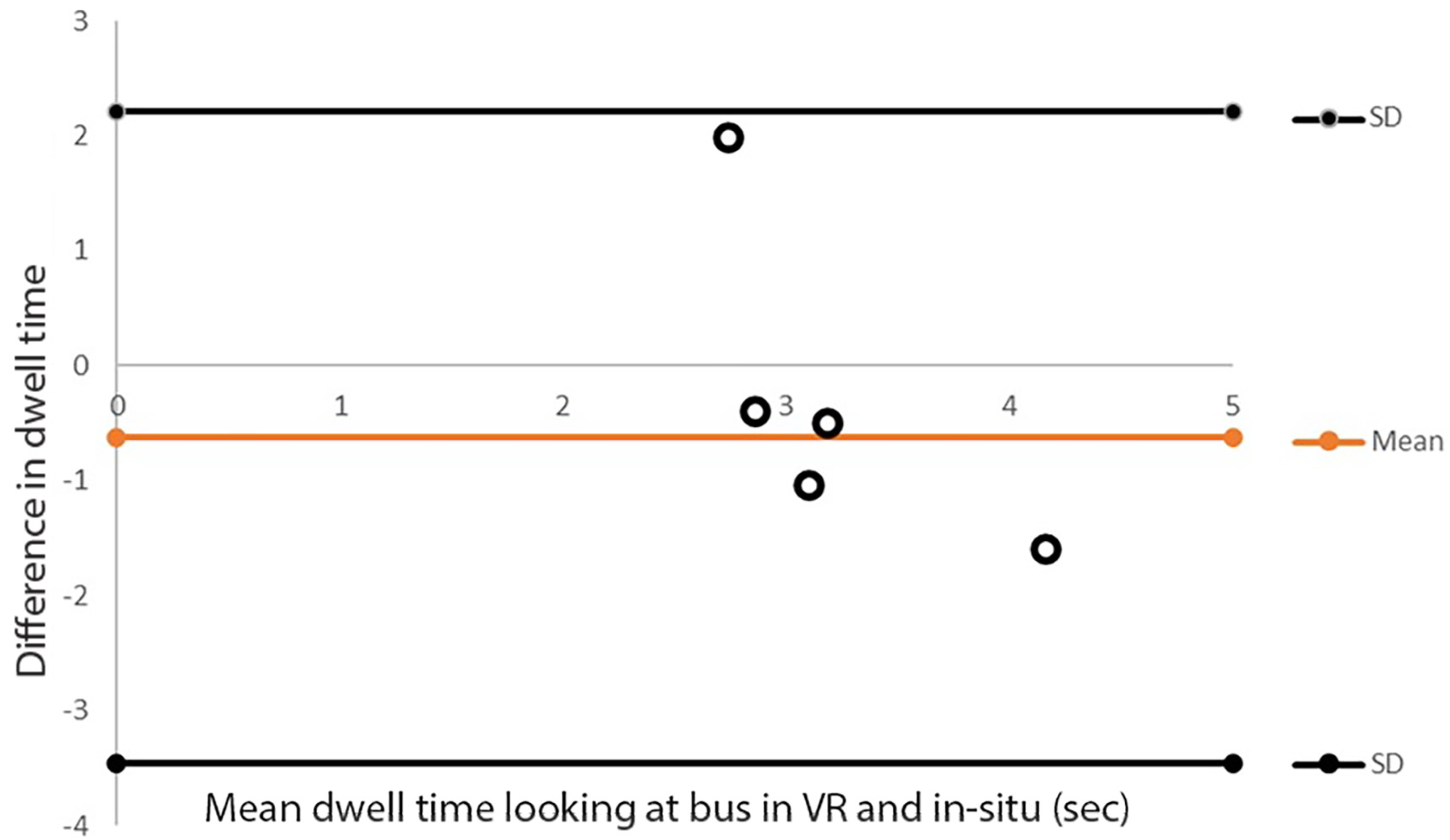
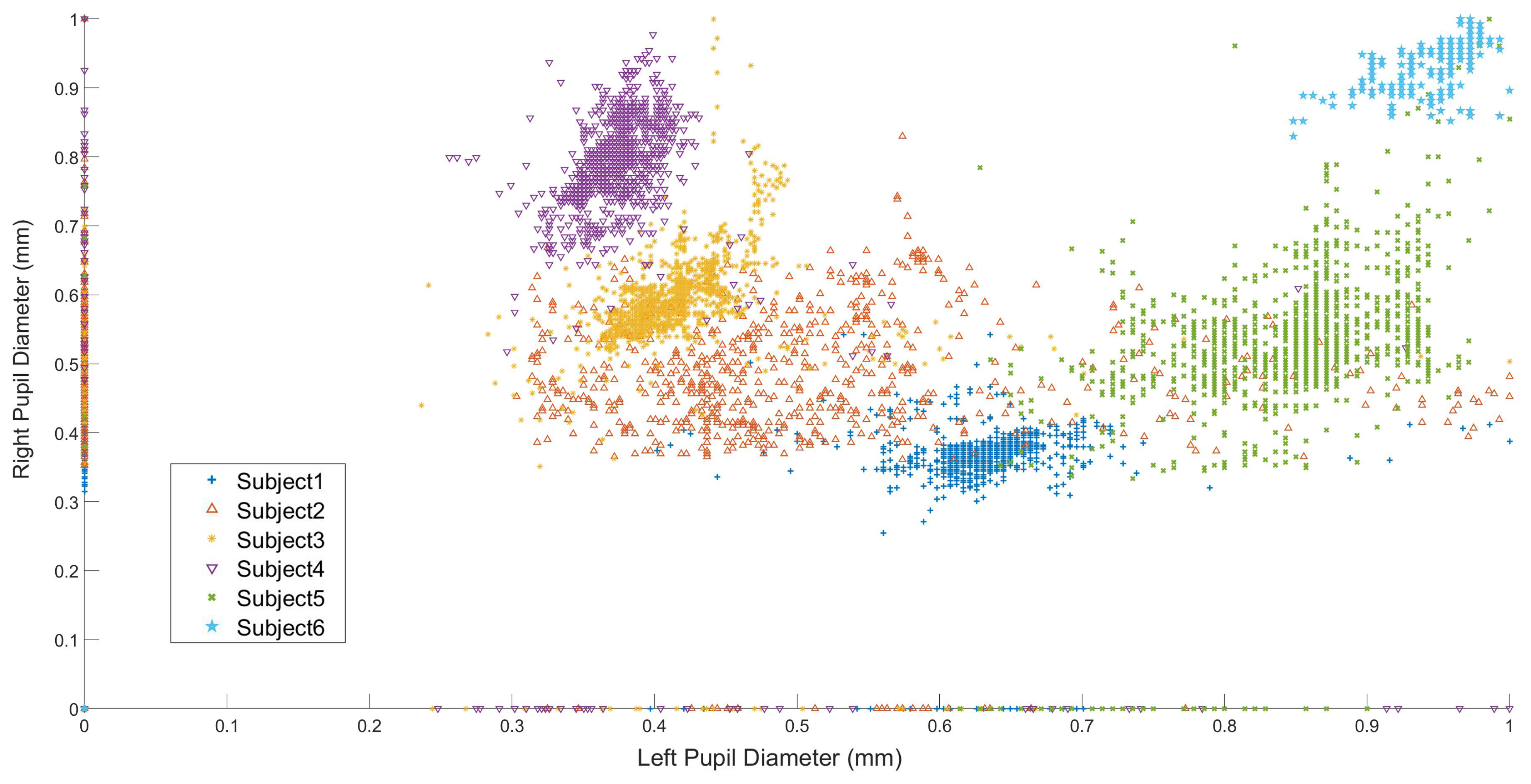
Figure 5 shows the participant’s normalized left and right eye pupil diameter size variation in situ while passing the bus. As illustrated in the
Figure 6, subjects 2 (
Figure 6b) and 5 (
Figure 6e) had the most significant alteration in pupil diameter, while subjects 1 (
Figure 6a), 3 (
Figure 6c), 4 (
Figure 6d), and 6 (
Figure 6f) had a limited range of change.
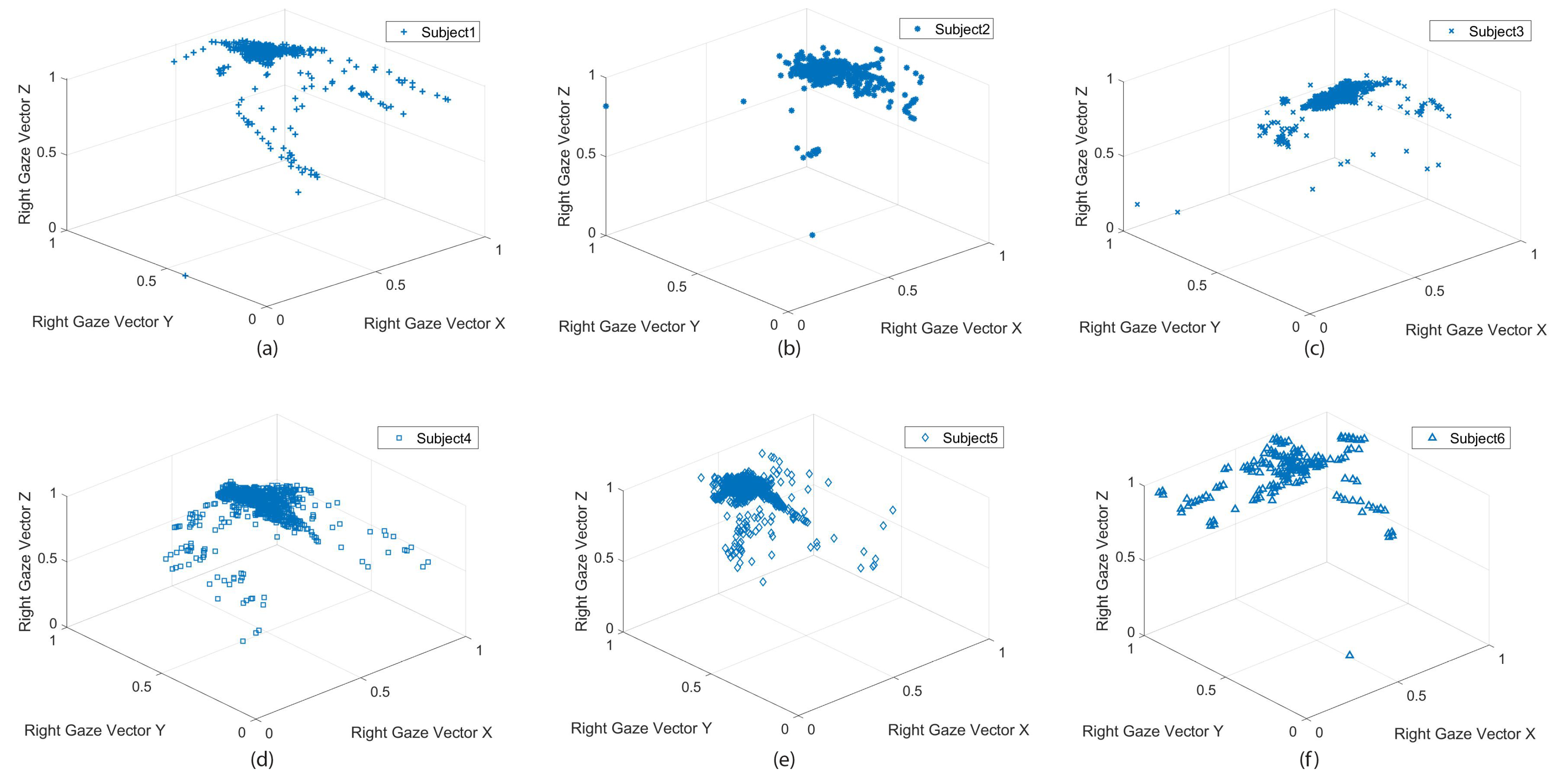
Figure 6 shows the subjects’ gaze vector and the visual search behavior in situ. The participants had different visual exploration performances although the trial’s conditions were the same. Some participants’ focus was more on the road ahead with an occasional visual search
Figure 6b,c,e In contrast, others kept directing attention to objects and circumstances around them while cycling—a more comprehensive visual search span;
Figure 6a,d,f.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}